
Chapter 10. Sitemaps
The concept of website Sitemaps is not new. In the early days of the Internet, having a Sitemap was as important as it is today, but in those days, Sitemaps were primarily intended for human visitors; that they also were helping search engine crawlers was just a side benefit. HTML Sitemaps are the organized collection of site links and their associated descriptions. Use of HTML Sitemaps was and still is one of the “nuts and bolts” of SEO, and they are still the most popular Sitemap type.
Over the years, search engines realized the benefit of Sitemaps. Google jumped on this concept in 2005 with the creation of its own Google Sitemap Protocol. Shortly after, Yahoo!, Microsoft, Ask, and IBM jumped on the bandwagon. During 2006, Google Sitemaps Protocol was renamed XML Sitemap Protocol, to acknowledge its “universal” acceptance. The work of these joint efforts is now under the auspices of Sitemaps.org.
The premise of using XML Sitemap Protocol was that it would help search engines index content faster while providing ways to improve their existing crawling algorithms. Using XML Sitemap Protocol does not guarantee anything in terms of better page rankings. Furthermore, use of XML Sitemap Protocol is not mandatory for all sites. In other words, a website will not be penalized if it is not using XML Sitemaps.
This chapter covers several different Sitemap types, including plain-text URL listings, HTML, XML, RSS/Atom, video, and mobile Sitemaps. Not all search engines treat Sitemaps the same, nor do they provide the same Sitemap services.
Understanding Sitemaps
Sitemaps are divided into two broad categories: those created for human users and those specifically created for search engine crawlers. Ultimately, both of these categories are equally important.
Why Use Sitemaps?
It is important to use Sitemaps because they help your visitors quickly get to the information they need, and they help web spiders find your site’s links.
There is no universal Sitemap rule that you can apply to every site. Understanding different Sitemap options should help you identify the right type for each situation. The following subsections discuss some of the reasons for using Sitemaps.
Crawl augmentation
Although web spiders are continuously improving, they are far from perfect. Search engines have no problems admitting this. Here is what Google says about crawl augmentation:
Submitting a Sitemap helps you make sure Google knows about the URLs on your site. It can be especially helpful if your content is not easily discoverable by our crawler (such as pages accessible only through a form). It is not, however, a guarantee that those URLs will be crawled or indexed. We use information from Sitemaps to augment our usual crawl and discovery processes.
Poor linking site structure
Not all sites are created equal. Sites with poor linking structures tend to index poorly. Orphan pages, deep links, and search engine traps are culprits of poor site indexing. The use of Sitemaps can alleviate these situations, at least temporarily, to give you enough time to fix the root of the problem.
Crawling frequency
One of the biggest benefits of using Sitemaps is in timely crawls or recrawls of your site (or just specific pages). XML Sitemap documents let you tell crawlers how often they should read each page.
Sites using Sitemaps tend to be crawled faster on Yahoo! and Google. It takes Google and Yahoo! minutes to respond to Sitemap submissions or resubmissions. This can be very helpful for news sites, e-commerce sites, blogs, and any other sites that are constantly updating or adding new content.
Content ownership
Many malicious web scraper sites are lurking around the Internet. Having search engines index your content as soon as it is posted can be an important way to ensure that search engines are aware of the original content owner. In this way, a copycat site does not get the credit for your content. Granted, it is still possible for search engines to confuse the origins of a content source.
Page priority
As you will see later in this chapter, XML Sitemap Protocol allows webmasters to assign a specific priority value for each URL in the XML Sitemap file. Giving search engines suggestions about the importance of each page is empowering—depending on how each search engine treats this value.
Large sites
Using Sitemaps for large sites is important. Sites carrying tens of thousands (or millions) of pages typically suffer in indexing due to deep linking problems. Sites with this many documents use multiple Sitemaps to break up the different categories of content.
History of changes
If all your links are contained in your Sitemaps, this could be a way to provide a history of your site’s links. This is the case if your site is storing your Sitemaps in the code versioning control. This information can help you analyze changes in page rankings, the size of indexed documents, and more.
HTML Sitemaps
Creating HTML Sitemaps can be straightforward for small sites. You can build HTML Sitemaps using a simple text editor such as Notepad. For larger sites, it may make more sense to use automated tools that will help you gather all your links. Google suggests the following:
Offer a site map to your users with links that point to the important parts of your site. If the site map is larger than 100 or so links, you may want to break the site map into separate pages.
HTML Sitemap Generators
If your site has hundreds or thousands of links, Sitemap generation tools will help you to create multipage Sitemaps. Some of the tools available for this on the Internet include:
Most Internet websites are small. Typically, a small business website would have only a few links, and all the pages would have links to each other. Having a Sitemap in those cases is still valuable, as most sites on the Internet are not designed by professionals, nor do they knowingly employ SEO.
When creating your HTML Sitemap, you should describe all of the links. A link with no description (using its own URL value as the link anchor text) provides very little value. Just placing the URLs without providing any context is plain lazy.
You can automate HTML Sitemap creation for large sites, as long
as all your web pages are using unique <title> tags.
One such GNU General Public License (GPL) tool that can utilize
<title> tags in place of link
anchor text is Daniel Naber’s tree.pl script, which you can download from
his website.
Creating a custom HTML Sitemap generator
It doesn’t take much effort to create your own custom generator. You could start with the following Perl code fragment:
use HTML::TagParser; @files=`find . /home/site -type f -name "*.html"`; $baseurl='http://www.somedomain.com/'; foreach $file (@files) { if($file =~ /^//) { $filetmp = `cat $file`; $html = HTML::TagParser->new( "$filetmp" ); $elem = $html->getElementsByTagName( "title" ); print "<a href='" . $baseurl . getFileName($file)."'>" . $elem->innerText() . "</a><br> "; } } sub getFileName { $takeout='/home/site/public_html/'; $name=shift; @nametmp = split(/$takeout/, $name); $name = $nametmp[1]; $name =~ s/^s+//; $name =~ s/s+$//; return $name; }
This code fragment utilizes three system commands:
Let’s suppose your directory and file structure are as follows:
$ ls -laR .: drwxrwxrwx+ 3 john None 0 Dec 27 14:53 public_html -rw-r--r-- 1 john None 635 Dec 27 15:42 sitemap.pl ./public_html: -rwxrwxrwx 1 john None 85 Dec 27 15:27 page1.html -rwxrwxrwx 1 john None 78 Dec 27 14:39 page2.html -rwxrwxrwx 1 john None 76 Dec 27 14:39 page3.html -rwxrwxrwx 1 john None 75 Dec 27 14:40 page4.html drwxrwxrwx+ 2 john None 0 Dec 27 14:54 sectionX ./public_html/sectionX: -rwxrwxrwx 1 john None 77 Dec 27 14:44 page5.html
Running the script would produce the following:
$ perl sitemap.pl
<a href='http://www.somedomain.com/page1.html'>Company Home Page</a>
<br><a href='http://www.somedomain.com/page2.html'>Contact Us</a><br>
<a href='http://www.somedomain.com/page3.html'>Services</a><br>
<a href='http://www.somedomain.com/page4.html'>Sitemap</a><br>
<a href='http://www.somedomain.com/sectionX/page5.html'>Service X</a>
<br>You could pipe this output to an HTML file that you could then reorganize in your HTML editor to create the final sitemap.html file. Note that the name of the HTML Sitemap file is arbitrary and that this code will work on sites that do not require URL rewriting. To handle sites with enabled URL rewriting, you need to take another approach that involves the use of the HTTP protocol and the design of a web spider script.
XML Sitemaps
Although XML Sitemaps are written only for web spiders, they are easy to create. They are collections of links with their respective (optional) attributes formatted according to the XML schema.
At the time of this writing, XML Sitemap Protocol is at version 0.9 (as signified by its schema version). You must save each XML Sitemap file using the UTF-8 encoding format. Other rules apply as well. If you are familiar with XML, these rules should be easy to understand.
XML Sitemap Format
Each link in an XML Sitemap can have up to four attributes. The first
attribute, loc, is the URL location and is mandatory. The rest of the
attributes are optional and include lastmod, changefreq, and priority. Here is an example Sitemap file
with a single link:
<?xml version='1.0' encoding='UTF-8'?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.sitemaps.org/schemas/sitemap/0.9
http://www.sitemaps.org/schemas/sitemap/0.9/sitemap.xsd">
<url>
<loc>http://mydomain.com/</loc>
<lastmod>2010-01-01</lastmod>
<changefreq>weekly</changefreq>
<priority>0.5</priority>
</url>
</urlset>In this example, we can see the XML file header which describes the rules that this XML document is bound to. Note that the XML header would need to change only if you wanted to support the upgraded schema.
The next (bolded) section represents a single URL entry enclosed
by <url> tags.
Within this block we see all of the possible attributes. Each
attribute is bound by specific rules. The following subsections go
into more details regarding each attribute.
Understanding <loc>
The loc attribute
tag represents the actual URL or link value. Several
rules govern the use of loc.
According to Sitemaps.org:
...as with all XML files, any data values (including URLs) must use entity escape codes...all URLs (including the URL of your Sitemap) must be URL-escaped and encoded for readability by the web server on which they are located.... Please check to make sure that your URLs follow the RFC-3986 standard for URIs, the RFC-3987 standard for IRIs, and the XML standard.
All url tag values must use entity escape codes for certain characters. Table 10-1 provides a summary of entity escape
codes.
Most popular blog and CMS products on the market have already updated their code bases to support automated creation of XML Sitemaps. Here is an example of a URL that would need to be rewritten:
| http://www.mydomain.com/store?prodid=10& |
The properly escaped version would be:
<loc>http://www.mydomain.com/store?prodid=10&</loc>
Note that the http part is
mandatory. Also note that the URL should not be longer than 2,048
characters, as this is a known URL length limit for some of the
server platforms.
Understanding <lastmod>
As its name implies, the lastmod attribute tag represents the time and date when a
particular link was last modified. This is an optional attribute but
a very powerful one, as you can use it as a signal to the incoming
search engine crawlers that this document or page may need to be
crawled again.
The lastmod attribute tag
has two data value formats. You can use the short form without the
time part and the long form with the full date and time.
Furthermore, the lastmod
attribute tag needs to be in the W3C datetime format, as described
at http://www.w3.org/TR/NOTE-datetime. The
following fragment is an example of both formats:
...
<lastmod>2010-01-01</lastmod>
...
<lastmod>2010-01-01T09:00:15-05:00</lastmod>
...The first example indicates a last modification date of January 1, 2010. The second example indicates the same date as well as a time of 9:15 a.m. (U.S. Eastern Standard Time).
Understanding <changefreq>
The changefreq attribute
represents a hint as to how often a particular link
might change. It does not have to be 100% accurate; search engines
will not penalize you if the changefreq attribute is not accurate. The
changefreq attribute is an
optional attribute tag with a range of values, including:
...
<changefreq>always</changefreq>
...
<changefreq>hourly</changefreq>
...
<changefreq>daily</changefreq>
...
<changefreq>weekly</changefreq>
...
<changefreq>monthly</changefreq>
...
<changefreq>yearly</changefreq>
...
<changefreq>never</changefreq>
...According to Sitemaps.org, you should use the
always value when a particular
page changes on every access, and you should use the never value for archived pages. Note that
web spiders could recrawl all your URLs in your Sitemap at any time,
regardless of the changefreq
settings.
Understanding <priority>
The priority attribute
tag is perhaps the most important of all the optional
link attributes. Its values range from 0.0 to 1.0. The median or
default value for any page is signified by a value of 0.5.
The higher the priority
value, the higher the likelihood of that page being crawled. Using a
priority value of 1.0 for all URLs is counterproductive and
does not influence ranking or crawling benefits. The priority value is only a strong
suggestion. It does not have any correlation with the corresponding
page rank.
XML Sitemap Example
Now that you understand the basic syntax of XML Sitemaps, let’s look at a small example with multiple links:
<?xml version='1.0' encoding='UTF-8'?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.sitemaps.org/schemas/sitemap/0.9
http://www.sitemaps.org/schemas/sitemap/0.9/sitemap.xsd">
<url>
<loc>http://www.mydomain.com/</loc>
</url>
<url>
<loc>http://www.mydomain.com/shop.do?item=74&</loc>
<priority>0.5</priority>
</url>
<url>
<loc>http://www.mydomain.com/services.html</loc>
<lastmod>2010-11-23</lastmod>
</url>
<url>
<loc>http://mydomain.com/dailyonsaleproducts.html</loc>
<changefreq>daily</changefreq>
<priority>1.0</priority>
</url>
<url>
<loc>http://mydomain.com/aboutus.html</loc>
<lastmod>2009-01-01</lastmod>
<changefreq>monthly</changefreq>
<priority>0.6</priority>
</url>
...
</urlset>The first URL is that of the main home page. In this part, we
are using only the <loc>
tag and no optional tags. The second URL is an example
of the online store product page with the escaped ampersand character.
The priority of this page is set to normal (0.5).
The third URL is for a page called dailyonsaleproducts.html. As the filename
suggests, this URL is using the daily indicator for its <changefreq>
tag. In addition, the priority is set to 1.0 to indicate the highest
importance.
The last example is that of the aboutus.html page. All optional tags are used to indicate the last date of modification, the monthly change frequency, and a slightly higher page priority.
Why Use XML Sitemaps?
You should use XML Sitemaps to promote faster crawling and indexing of your site. Doing a bit of math along with making some assumptions can help us see the bigger picture. Let’s suppose we have three websites, each with a different number of pages or documents:
- Site A
100 pages, 1 second average per-page crawler retrieval time
- Site B
10,000 pages, 1.2 seconds average per-page crawler retrieval time
- Site C
1 million pages, 1.5 seconds average per-page crawler retrieval time
Now suppose you changed one of the pages on all three sites. Here is the worst-case scenario (modified page crawled last) of retrieving this page by a web crawler:
- Site A
100 pages × 1 second = 100 seconds (1.67 minutes)
- Site B
10,000 pages × 1.2 seconds = 12,000 seconds (3.3 hours)
- Site C
1 million pages × 1.5 seconds = 1.5 million seconds (17.4 days)
When you consider that web crawlers typically do not crawl entire sites all in one shot, it could take a lot longer before the modified page is crawled. This example clearly shows that big sites are prime candidates for using XML Sitemaps.
XML Sitemap Auto-Discovery
As we discussed in Chapter 9, XML Sitemaps are now discovered within robots.txt. You can have multiple XML Sitemap files defined. The relative order of appearance does not matter. The following is an example of a robots.txt file utilizing two XML Sitemaps:
1 Sitemap: http://www.mydomain.com/sitemap1.xml 2 3 User-agent: * 4 Disallow: /cgi-bin/ 5 6 Sitemap: http://www.mydomain.com/sitemap2.xml 7 8 User-agent: Googlebot-Image 9 Disallow: /images/
In this example, we have two Sitemap declarations alongside other robots.txt entries. They are shown on lines 1 and 6. They would be crawled by all search engine crawlers supporting REP.
Multiple XML Sitemaps
Let’s suppose you have a large site composed of several key hotspots with the following URL structure:
http://www.mydomain.com/presidentsblog/ http://www.mydomain.com/products/ http://www.mydomain.com/services/ http://www.mydomain.com/news/ http://www.mydomain.com/pressreleases/ http://www.mydomain.com/support/ http://www.mydomain.com/downloads/
Instead of combining all these Sitemaps into one big Sitemap, XML Sitemap Protocol allows us to deal with this situation more elegantly with the use of the XML Sitemap Index file. Using our current example, we would have the following Sitemap files:
http://www.mydomain.com/presidentsblog/sitemap.xml http://www.mydomain.com/products/sitemap.xml http://www.mydomain.com/services/sitemap.xml http://www.mydomain.com/news/sitemap.xml http://www.mydomain.com/pressreleases/sitemap.xml http://www.mydomain.com/support/sitemap.xml http://www.mydomain.com/downloads/sitemap.xml
Creating the XML Sitemap Index file is similar to creating XML Sitemap files. Here is an XML Sitemap Index file that we could use to represent XML Sitemap files:
<?xml version='1.0' encoding='UTF-8'?>
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.sitemaps.org/schemas/sitemap/0.9
http://www.sitemaps.org/schemas/sitemap/0.9/siteindex.xsd">
<sitemap>
<loc>http://www.mydomain.com/presidentsblog/sitemap.xml</loc>
<lastmod>2010-01-01T09:00:15-05:00</lastmod>
</sitemap>
<sitemap>
<loc>http://www.mydomain.com/products/sitemap.xml</loc>
<lastmod>2010-01-01</lastmod>
</sitemap>
<sitemap>
<loc>http://www.mydomain.com/services/sitemap.xml</loc>
<lastmod>2010-01-01</lastmod>
</sitemap>
<sitemap>
<loc>http://www.mydomain.com/news/sitemap.xml</loc>
<lastmod>2010-01-01</lastmod>
</sitemap>
<sitemap>
<loc>http://www.mydomain.com/pressreleases/sitemap.xml</loc>
</sitemap>
<sitemap>
<loc>http://www.mydomain.com/support/sitemap.xml</loc>
</sitemap>
<sitemap>
<loc>http://www.mydomain.com/downloads/sitemap.xml</loc>
</sitemap>
</sitemapindex>XML Sitemap Index files have the single optional tag, <lastmod>. The <lastmod> tag tells the crawler the date when a particular Sitemap
was modified. XML Sitemap Index files have similar rules to XML
Sitemap files. For more information on XML Sitemap Index files, visit
http://www.sitemaps.org/.
Sitemap Location and Naming
XML Sitemaps can refer only to files in the folder in which they are placed, or files located in any child folders of that folder. For example, a Sitemap corresponding to a URL location of http://www.mydomain.com/sales/sitemap.xml can refer only to URLs starting with http://www.mydomain.com/sales/.
You are also allowed to host Sitemaps on different domains. For
this to work, you need to prove the ownership of the domain hosting
the Sitemap. For example, let’s say DomainA.com hosts a Sitemap for
DomainB.com. The location of the Sitemap is
http://domainA.com/sitemapDomainB.xml. All that
is required is for DomainB.com to place this URL anywhere within its
robots.txt file, using
the Sitemap
directive.
Although your XML Sitemap can have arbitrary names, the recommended name is sitemap.xml. Many people choose to name their XML Sitemaps another name. This is to prevent rogue site scrapers from easily obtaining most, if not all, of the URLs for the site.
XML Sitemap Limitations
The use of XML Sitemaps has some limitations. For instance, an XML Sitemap file can have no more than 50,000 links. In this case, creating multiple Sitemaps is useful. You may also want to create an XML Sitemap Index file to indicate all of your XML Sitemaps. The XML Sitemap Index file can contain up to 1,000 XML Sitemaps. If you do the math, that is a maximum of 50 million URLs. Recently, Bing introduced enhanced support for large Sitemaps. See http://bit.ly/K99mQ for more information.
In addition to the URL limitation, each XML Sitemap should be less than 10 MB in size. Sometimes the Sitemap size limit will be reached before the URL limit. If that is the case, you can compress the XML Sitemap by using gzip. Here is an example of using compressed XML Sitemaps within the XML Sitemap Index file:
<?xml version='1.0' encoding='UTF-8'?>
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.sitemaps.org/schemas/sitemap/0.9
http://www.sitemaps.org/schemas/sitemap/0.9/siteindex.xsd">
<sitemap>
<loc>http://www.mydomain.com/sitemap1.xml.gz</loc>
</sitemap>
...
<sitemap>
<loc>http://www.mydomain.com/sitemap1000.xml.gz</loc>
</sitemap>
</sitemapindex>You can also submit compressed XML Sitemaps (or XML Sitemap
Index files) via robots.txt,
using the Sitemap directive.
XML Sitemap Generators
Creating XML Sitemap generators is straightforward for sites with intelligent (basic) linking structures. If you are reasonably sure that a text browser can reach each page of your site, you can write a crawler script to go through your site to create the XML Sitemap.
If you do not have the time to create a script, many XML Sitemap generators (both free and paid) are available. Table 10-2 lists some of the available tools for creating XML Sitemaps.
The bigger your site is, the more it makes sense to use XML Sitemap generators. No auto-generated Sitemap is perfect. Manual intervention is almost always necessary—if you care about the little details. If your site has dynamic links or search engine traps, no automated tool will be able to create a full Sitemap using the HTTP protocol method.
XML Sitemap Validators
There is no point in hosting XML Sitemaps without knowing that they pass validation. Google provides an interface via Google Webmaster Tools to submit XML Sitemaps. Visit the following link when troubleshooting your XML Sitemap validation problems with Google Webmaster Tools:
| http://www.google.com/support/webmasters/bin/answer.py?hl=en&answer=35738 |
Although Google’s response is relatively quick, it is not quick enough if you want to see validation results immediately. In this case, you may want to use one of the online validators listed in Table 10-3.
XML Sitemap Submissions
You can let search engines know of your XML Sitemaps in three ways. For instance,
some search engines allow you to submit Sitemaps through
their sites if you have an account with them (an example is Google).
The second way is to use the ping method. The third way is to use robots.txt along with the
embedded Sitemap directive
(we discussed this in Chapter 9).
When using the ping method, you can also submit your Sitemaps using
your web browser.
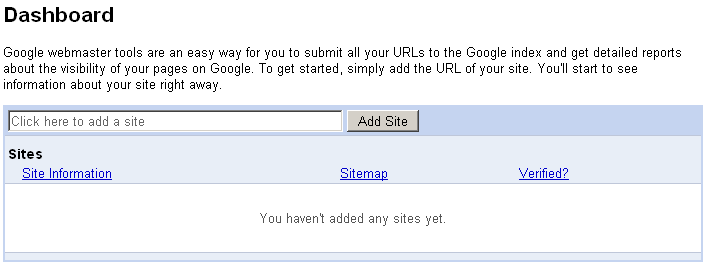
Using Google Webmaster Tools to submit Sitemaps
Before you can submit your Sitemaps to Google, you need to register for a Google account. You can do this at https://www.google.com/accounts/NewAccount. To activate your account, you will need to respond to Google’s confirmation email. Once you click on the confirmation link, your account should be ready. When you log in, you will be presented with a Dashboard page. Figure 10-1 shows the pertinent part of the Dashboard page.
Next, you need to add your site’s URL. After you do that, Google will ask you to verify the ownership of your site. Figure 10-2 shows the portion of the screen requesting your site’s ownership verification.
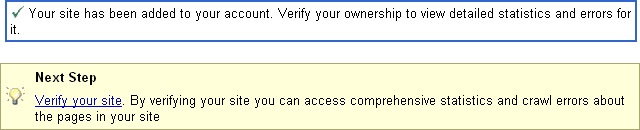
As of this writing, Google allows for two types of verifications. The first method is by using the Google-generated HTML file (which you must place in your web root). The second method is by placing the Google-generated meta tag in your website’s index file, such as index.html. Most people prefer using the first method.
Once your site verification is complete, you can click on the Sitemaps menu link to add your Sitemap(s) to Google. Figure 10-3 shows the Sitemaps section of Google Webmaster Tools.
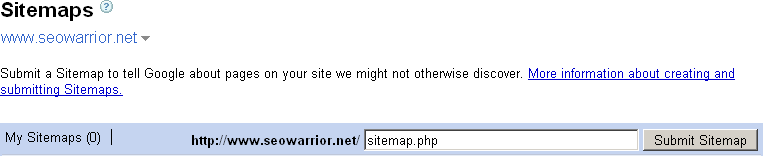
Simply point Google to your Sitemap location and click the Submit Sitemap button. Figure 10-3 shows an example of adding a Sitemap called sitemap.php to the http://www.seowarrior.net domain. After you click on the Submit Sitemap button, Google provides a confirmation, as shown in Figure 10-4.

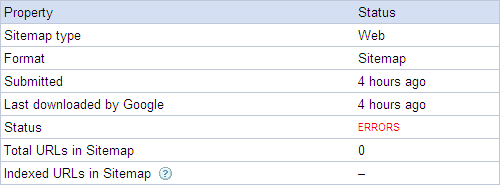
Typically, it takes only a few minutes for Google to crawl your Sitemap. Come back in about an hour and check your Sitemap status. If Google cannot process your Sitemap (for whatever reason), it will provide you with an indication of a faulty Sitemap. Figure 10-5 shows an example report indicating errors.
The Sitemap validation report in Figure 10-5 shows pertinent data, including the Sitemap type, its format, the time of the Sitemap submission, the time it was last downloaded, the Sitemap status (whether it is valid or not), the total number of URLs found, and the number of indexed URLs.
Using the ping method to submit Sitemaps
Google, Yahoo!, and Ask already have a public HTTP ping interface for submitting Sitemaps. The following fragment shows how to submit the Sitemap found at http://www.mydomain.com to all three search engines:
Google http://www.google.com/webmasters/sitemaps/ping?sitemap=http://www. mydomain.com/sitemap.xml Yahoo! http://search.yahooapis.com/SiteExplorerService/V1/ping?sitemap= http://www.mydomain.com/sitemap.xml Ask.com http://submissions.ask.com/ping?sitemap=http%3A//www.mydomain.com/ sitemap.xml
Submitting your website’s Sitemap is easy with your web browser. Simply browse to the full ping URL and you are done. After you enter this URL in your web browser’s address bar, Google’s success response is as follows (at the time of this writing):
Sitemap Notification Received Your Sitemap has been successfully added to our list of Sitemaps to crawl. If this is the first time you are notifying Google about this Sitemap, please add it via http://www.google.com/webmasters/tools/ so you can track its status. Please note that we do not add all submitted URLs to our index, and we cannot make any predictions or guarantees about when or if they will appear.
This is merely an acknowledgment that your submission was
received. It does not indicate anything about the validity of the
Sitemap. Note that in all three interfaces there is a sitemap URL parameter. You can also
automate these submissions by writing a small script.
Automating ping submissions
Google makes a specific point of not sending more than a single ping per hour. You can automate these pings using a small PHP script, as shown in the following fragment:
<? $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, 'http://www.google.com/webmasters/sitemaps/ping?sitemap= http://www.mydomain.com/sitemap.xml'), curl_setopt($ch, CURLOPT_HEADER, 1); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); $response = curl_exec($ch); curl_close($ch); $logFile = "googleping.txt"; $fileHandle = fopen($logFile, 'a'), fwrite($fileHandle, $response); ?>
This PHP script would ping Google servers, letting them know of any changes to your Sitemap. Furthermore, the script appends the returned message (including the HTTP header) to a logfile (googleping.txt). This return data should look similar to the following fragment:
HTTP/1.1 200 OK Content-Type: text/html; charset=UTF-8 Expires: Tue, 28 Apr 2009 04:21:06 GMT Date: Tue, 28 Apr 2009 04:21:06 GMT Cache-Control: private, max-age=0 X-Content-Type-Options: nosniff Content-Length: 1274 Server: GFE/2.0 <html> <meta http-equiv="content-type" content="text/html; charset=UTF-8"> <head> <title>Google Webmaster Tools - Sitemap Notification Received</title> <!-- some JavaScript code removed from this section for simplicity --> </head> <body><h2>Sitemap Notification Received</h2> <br> Your Sitemap has been successfully added to our list of Sitemaps to crawl. If this is the first time you are notifying Google about this Sitemap, please add it via <a href="http://www.google.com/webmasters/tools/"> http://www.google.com/webmasters/tools/</a> so you can track its status. Please note that we do not add all submitted URLs to our index, and we cannot make any predictions or guarantees about when or if they will appear. </body> </html>
If you know how often your content is changing, you can also set up a crontab job (or a Windows scheduled task) to call your PHP script at known time intervals. You can further extend the script by sending email alerts when the HTTP response code is not 200, or by initiating ping retries for all other HTTP response codes.
Utilizing Other Sitemap Types
Many other Sitemap types exist. These include pure text, news, RSS (and Atom), mobile, and video Sitemaps. We cover all of these types in the following subsections.
Pure Text (URL Listing) Sitemaps
In this format, each URL is listed on a separate line, with up to 50,000 URLs in a single (UTF-8) text file. Here is an example:
http://www.mydomain.com/services.html http://www.mydomain.com/products.html ... http://www.mydomain.com/support/downloads.html
This approach is the simplest way to create Sitemaps, especially if you were not going to use any of the optional XML Sitemap attributes. For more information, refer to the Google Webmaster Tools website.
Yahoo! supports the same format. However, the name of the Sitemap file must be urllist.txt (or urllist.txt.gz if compressed). So, if you are using robots.txt as a way to let search engine crawlers know of your text file Sitemap, use this name for all search engines. Otherwise, you will have duplicate Sitemaps for non-Yahoo! search engines.
News Sitemaps
You should use news Sitemaps (another Google XML Sitemap extension) when describing news articles. Articles up to three days old should appear in news Sitemaps. Otherwise, they will be ignored. Here is one article example:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
xmlns:news="http://www.google.com/schemas/sitemap-news/0.9">
<url>
<loc>http://mydomain.com/article012388.html</loc>
<news:news>
<news:publication_date>2009-01-01T06:06:36-05:00
</news:publication_date>
<news:keywords>New Year's Eve, New York, Los Angeles, Boston, US,
Europe, Asia, Africa, World</news:keywords>
</news:news>
</url>
</urlset>Note the use of the <news:keywords> tag. This tag can be
helpful if and when Google indexes this news article. Examples of news
Sitemaps include:
RSS and Atom Sitemaps
Google and Yahoo! support news feed formats including RSS 0.9, RSS 1.0, RSS 2.0, Atom 0.3, and Atom 1.0. Although RSS and Atom feeds are great channels of communication, they are not particularly useful as Sitemaps, as they usually contain only the last few articles from your site.
Mobile Sitemaps
Google supports mobile content including XHTML (WAP 2.0), WML (WAP 1.2), and cHTML (iMode) markup languages. Yahoo! offers a similar type of support for mobile devices. Creating mobile Sitemaps is similar to creating other XML Sitemaps. Here is an example:
<?xml version="1.0" encoding="UTF-8" ?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
xmlns:mobile="http://www.google.com/schemas/sitemap-mobile/1.0">
<url>
<loc>http://m.mydomain.com/story08245.html</loc>
<mobile:mobile/>
</url>
...
<url>
<loc>http://m.mydomain.com/wml/games</loc>
<lastmod>2010-01-01</lastmod>
<mobile:mobile />
</url>
</urlset>All URLs listed in a mobile Sitemap must be specifically designed for mobile devices in one of the acceptable formats. For more information about mobile Sitemaps, visit http://bit.ly/2rBIHc.
Video Sitemaps
Video Sitemaps are yet another extension of XML Sitemap Protocol. Video Sitemaps can be helpful if your videos show up in Google SERPs. The following fragment shows a basic video Sitemap with one example video:
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
xmlns:video="http://www.google.com/schemas/sitemap-video/1.1">
<url>
<loc>http://mydomain.com/article23423.html</loc>
<video:video>
<video:content_loc>http://mydomain.com/videos/article23423.flv
</video:content_loc>
</video:video>
</url>
</urlset>For simplicity reasons, just one video is listed with only the
single optional tag of <video:content_loc>. You can use many
other optional tags to further classify videos. For more information
on all the optional video tags, visit http://bit.ly/3QnO3j.
Summary
Sitemaps come in many different forms. Often, using HTML Sitemaps with Sitemaps created around XML Sitemaps Protocol is the ideal choice. HTML Sitemaps address the specific needs of your website visitors, whereas XML Sitemaps talk directly to search engine spiders. XML Sitemaps offer benefits to webmasters as well as search engines. Webmasters enjoy faster site crawls while search engine spiders get to augment their natural crawls—often discovering new pages not discovered by conventional natural crawls. There are other mutual benefits, including the ability for search engines to provide fresh URLs faster in their search results.
Smaller sites with infrequent site updates can do fine with only HTML Sitemaps. Larger sites carrying thousands of pages will see great value in using XML Sitemap types. With the convergence of search engine support of XML Sitemap Protocol (as defined at Sitemaps.org), using XML Sitemaps makes sense as more and more search engines come on board.
Using mobile, video, and news Sitemaps provides additional opportunities for SEO practitioners to consider. With search engines continuously enhancing their search capabilities with mixed (media-enriched) results, search engines are sending a strong message to site owners to spice up their sites with rich media content.