
Chapter 5. External Ranking Factors
In Chapter 4 we covered internal ranking factors, which are elements over which you have absolute control, such as adding appropriate keywords on your pages and using a consistent linking site structure to ensure easy navigation. In this chapter we will cover external ranking factors, which are factors that do not depend entirely on you and, in some cases, in which you have no say at all.
When I talk about external ranking factors, I am talking about many different things, including the number of external inbound links, user behavior patterns, website performance, website age, and so forth.
There are many different external ranking factors. Each factor will be in its own context with its own set of rules. In cases where you can sway these factors in your favor, you want to take full advantage by being proactive.
I will reference several scripts in this chapter, including the mymonitor.pl script, which appears in its entirety in Appendix A. By the end of this chapter, you will have an overall picture of the most important external ranking factors.
External Links
External links are also known as backlinks, inbound links, and referral links. According to Wikipedia, backlinks are defined as follows:
Backlinks (or back-links (UK)) are incoming links to a website or web page. In the search engine optimization (SEO) world, the number of backlinks is one indication of the popularity or importance of that website or page (though other measures, such as PageRank, are likely to be more important). Outside of SEO, the backlinks of a webpage may be of significant personal, cultural or semantic interest: they indicate who is paying attention to that page.
Know Your Referrers
As your website gains in popularity, managing external inbound links will become a necessity. It is important to know who is linking to your site, especially if you are in an industry where reputation is paramount. Although you can certainly create a rigorous “terms of service” page—accessible via a link in the page footer of all pages—not all webmasters will abide by these rules.
To see who is linking to your site, you can use Google’s link:
command:
link:yourdomain.com
The effectiveness of this command has decreased somewhat over the years as Google’s algorithm has changed. Recently, Google added similar, albeit limited, functionality in its Webmaster Tools that allows website owners to see their website’s backlinks. Although this can be very useful information, it does not say much about your competitors’ backlinks.
Utilizing Yahoo! Site Explorer
To augment Google’s link:
command, you can utilize Yahoo!’s Site Explorer
tool, which can provide similar functionality. Although it
is still possible to write a scraper script to pick up Yahoo!’s
results, being able to get a clean text file may be more than
sufficient for smaller sites.
With Yahoo! Site Explorer, you can export the first 1,000 backlinks to a file in Tab Separated Value (TSV) format just by clicking on the TSV link, as shown in Figure 5-1.
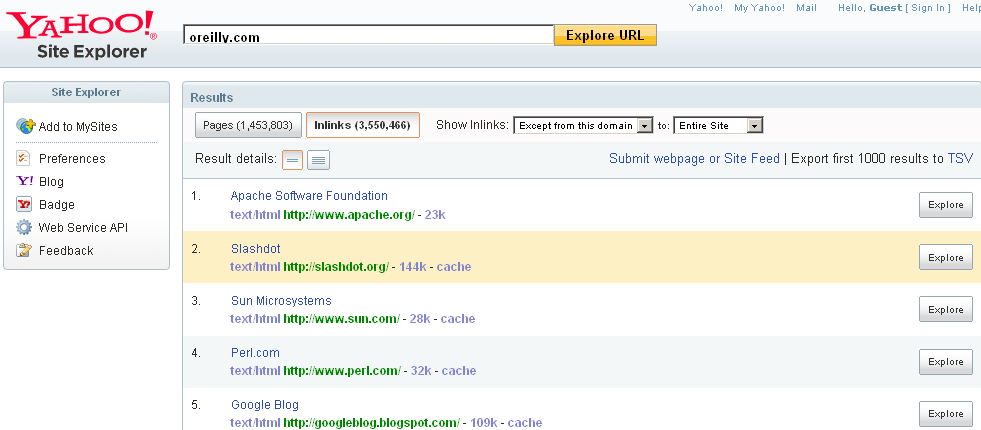
After downloading the TSV file, you can parse the 1,000 links to see the link anchor text in each destination page. You can also sign up with Yahoo! to get its API to extract the same data.
Parsing the TSV file
Before you parse the TSV file, you need to understand its format. The following fragment shows the first four lines of the TSV file downloaded in Figure 5-1:
List of inlinks to the site oreilly.com
TITLE URL SIZE FORMAT
Apache Software Foundation http://www.apache.org/ 22809 text/html
Slashdot http://slashdot.org/ 144476 text/html
...The preceding code contains four fields: Title, URL, Size, and Format. The one we are really interested
in is the URL field. We can
scrape each URL while recording the link anchor text. This is
exactly what the inlinksAnalysis.pl Perl script does.
Please refer to Appendix A for more
details.
Running the script is straightforward:
perl inlinksAnalysis.pl oreilly.com_inlinks.txt oreilly.com
The first parameter represents the name of the file saved from Yahoo! Site Explorer, and the second parameter reflects the name of the domain we are analyzing. Running the script for the Oreilly.com domain produces a text report that, at the time of this writing, appears as follows:
http://radar.oreilly.com/, 260, "O'Reilly Radar" http://www.oreilly.com/, 108, "O'Reilly Media" http://www.oreilly.com, 105, "Oreilly Logo" http://oreilly.com/, 103, "O'Reilly Media" http://jobs.oreilly.com/, 69, "Jobs" http://press.oreilly.com/, 68, "Press Room" http://en.oreilly.com/webexny2008/public/content/home, 66, "Web 2.0 Expo" http://toc.oreilly.com/, 66, "Tools of Change for Publishing" http://academic.oreilly.com/, 66, "Academic Solutions" http://oreilly.com/feeds/, 66, "RSS Feeds" http://oreilly.com/contact.html, 66, "Contacts" http://oreilly.com/terms/, 66, "Terms of Service" http://oreilly.com/oreilly/author/intro.csp, 66, "Writing for O'Reilly" http://digitalmedia.oreilly.com/, 65, "Digital Media" http://ignite.oreilly.com/, 64, "Ignite" . . .
The report is sorted in descending order and is truncated to the first 20 lines of output. The most popular URLs appear at the top of the report. In this example, http://radar.oreilly.com was the most popular link from the 1,000 referring URLs.
Companies such as O’Reilly Media can take full advantage of having so many highly popular websites. This is especially the case in promoting new products or services on new domains or subdomains, as O’Reilly is now in full control of providing self-serving external links to its new websites.
Links from highly popular sites such as Wikipedia.org, Oreilly.com, and NYTimes.com are an indication of trust from those sites to the sites receiving the vote. Search engines are increasingly relying heavily on trust, as evidenced by their search results’ bias.
You can find backlinks in other ways as well. Google’s
link: command and Yahoo!’s Site
Explorer are just two quick ways.
Quantity and Quality of External Links
Having more external inbound links is something to be desired. If these links can be quality links with a lot of link juice, that’s even better. For best results, try to acquire inbound links from sites or pages with high PageRank values. As a rule of thumb, backlinks with a minimum PageRank value of 4 yield the best results.
As long as those links are not from link farms or other link schemes, you should be in good shape. The more backlinks you acquire from high-PageRank sites, the better.
Backlinks say a lot about a website’s popularity. You can think of backlinks as votes for your link or URL. This is what search engines consider in their rankings as well. The benefit is multifold, as you will be receiving traffic from your backlinks as well as from the search engines.
Speed of backlink accumulation
How fast are you accumulating backlinks? This can become a negative ranking factor if your site is found to be using an unethical linking scheme.
If all your backlinks are using the same anchor text, search engines may view this as suspicious activity, which might trigger a manual inspection by the search engines and a delisting of your site. Let’s say your site had 20 backlinks yesterday, and today you suddenly have more than 100,000. Wouldn’t that look suspicious?
Topical link relevance
It is important for backlinks to contain relevant anchor text. Here are some examples of good and bad anchor text:
<!--Good--> <a target=_new href="http://yoursite.com/basketball>Learn about Basketball</a> <a target=_new href="http://yoursite.com/basketball>Talk about Basketball at www.yoursite.com</a> <--Bad--> <a target=_new href="http://yoursite.com/basketball">Click Here</a> <a target=_new href="http://yoursite.com/basketball"> http://yoursite.com</a> <a target=_new href="http://yoursite.com/basketball">more..</a> <a href="http://yoursite.com/basketball"><img src="http://www.somesite.net/pic1.jpg"></a>
The good examples use relevant text in the links. The bad examples, although they use the same destination URL, do not use relevant text. Ideally, the referring sites should also be talking about the same subject matter. At the very least, the referring page should be on the same topic.
Backlinks from expert sites and the Hilltop Algorithm
For good or bad, search engines have given certain websites a biased advantage over all other sites for most of the popular keywords. The basis of this practice stems from a popular ranking algorithm developed at the University of Toronto, called the Hilltop Algorithm.
The creators of the Hilltop Algorithm define it as follows:
...a novel ranking scheme for broad queries that places the most authoritative pages on the query topic at the top of the ranking. Our algorithm operates on a special index of “expert documents.” These are a subset of the pages on the WWW identified as directories of links to non-affiliated sources on specific topics. Results are ranked based on the match between the query and relevant descriptive text for hyperlinks on expert pages pointing to a given result page.
At the time of this writing, in a search for the keyword hilltop algorithm, Google’s search results look like Figure 5-2.
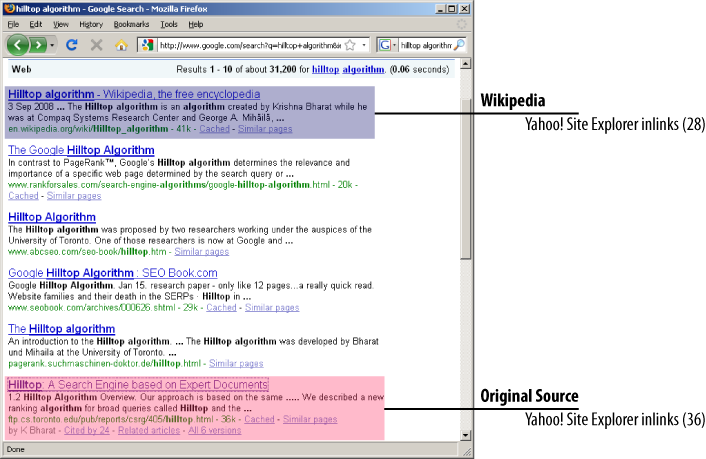
In this example, the Wikipedia search result came in ahead on Google, as it did on Yahoo! and Bing. Now, if we open the Wikipedia result, we don’t really see much except for the definition. So a single-paragraph page with a ton of useless Wikipedia links gets a PageRank value of 5 and the first spot on Google. Meanwhile, all other search results on the first page contain much more information on the given keywords.
Google at least showed one page from the University of Toronto in its top 10 results—unlike Yahoo! and Bing. This is because the Wikipedia page contains the exact same link from the University of Toronto!
This should speak volumes about the importance of backlinks from expert sites. The pattern of Wikipedia importance is repeated countless times, so get a link on Wikipedia if you can!
Backlinks from .edu and .gov domains
When Matt Cutts (Google search quality engineer) was asked about the extra ranking boost from inbound links originating from .edu and .gov TLDs, he responded as follows:
This is a common misconception—you don’t get any PageRank boost from having an .edu link or .gov link automatically.
Although Google denies that .edu and .gov links get a PageRank boost, you can easily construe that the domain extension does matter in some sense. When Google flat out denies something, it is almost always because it is not true. But when Google is cagey about something, you need to beware. Most people believe that .edu and .gov links are more valuable than others because those sites typically have strong PageRank and therefore more link juice. It is doubtful that Google actually gives these sites greater weight simply because of the TLD extension. When your site has a link from an .edu or .gov link, it says a great deal about the site’s trust and authority.
It is very hard to get an .edu or .gov domain. Only one registrar today has permission to grant .edu domains: EDUCAUSE, a nonprofit organization that won the right to be the sole registrar of all .edu domains in 2001. Not everyone can get an .edu domain, and .edu domains are not transferable. Eligibility requirements are very strict (http://net.educause.edu/edudomain/):
Eligibility for a .edu domain name is limited to U.S. postsecondary institutions that are institutionally accredited, i.e., the entire institution and not just particular programs, by agencies on the U.S. Department of Education’s list of Nationally Recognized Accrediting Agencies. These include both “Regional Institutional Accrediting Agencies” and “National Institutional and Specialized Accrediting Bodies” recognized by the U.S. Department of Education.
The situation is similar for .gov TLDs; these domains can be registered only at http://www.dotgov.gov (see http://bit.ly/1givpb):
To maintain domain name integrity, eligibility is limited to qualified government organizations and programs. Having a managed domain name such as .gov assures your customers that they are accessing an official government site.
Attaining links from TLDs such as .edu and .gov is valuable provided that the referring page is on the same topic as the recipient page. Historically, very little spam has originated from these domains. The added value of these links is that they tend to change very little over time, and age is an important off-page ranking factor, as we’ll discuss later in this chapter.
In some countries, there are strict regulations in terms of domain name assignments for ccTLDs. Country-specific TLDs, especially expansive TLDs, are believed to carry more clout, as spammy sites are usually those of cheap TLDs such as .com or .info.
Other places where domain extensions matter are in localized searches. The benefit of country-specific TLDs can also be augmented by ensuring that web servers hosting the domain are using IPs from the same region. If the question is whether to pursue getting some inbound links from these foreign TLDs, the answer is almost always yes.
Backlinks from directories
Traditionally, specialized web directories carried more authority than regular sites. Google and others have relied on directories not just in terms of ranking factors, but also in using directory descriptions as their own descriptions in search results. Directories are considered similar to other “expert” sites such as Wikipedia.
Be careful which directory you choose to use for your site, as not all are created equal. Check the PageRank of each directory to determine whether it is worth having your listing there. The higher the PageRank is, the better. Also ensure that these directories are passing link juice.
Age of backlinks
The age of the backlinks conveys a message of trust, and therefore a perceived link quality. A new backlink on a page that is constantly changing is not as beneficial as an old backlink on the same page.
In some cases, new backlinks exhibit a state of “purgatory” before they attain trust. In other words, the real benefit of new backlinks takes time to propagate. You have to start somewhere, so build your links for their future benefits.
Relative page position
Backlinks found closer to the top of an HTML page are perceived as being more important than those found farther down the page.
This makes sense from a website usability perspective as well. Links found on long scrolling pages are much more likely to do better if they are found at the top of the page.
Be careful with this, though. With some simple CSS, links rendered at the top of a page in a typical web browser can easily be placed at the bottom of the actual (physical) HTML file.
Broken Outbound Links
Although site updates and migrations are part of your website life cycle, broken links can be a significant cause of lost visitors, especially if your site is not being updated on a regular basis. How you handle broken links, or 404 errors, is important both from the human visitor’s perspective and from the web spider’s perspective.
In this section, we will focus on outbound links. We view broken links as an external factor because some or all of the broken links on a page worked at some point.
Broken links can say a lot about someone’s website. Many broken links on a site could be interpreted in the wrong way. Search engines could perceive the website as having been abandoned, and will remove it from their indexes. Two scenarios can cause broken links: old link references and invalid link references.
Old link references occur when sites linking to your site have not updated their links. This can happen if you decide to change your website’s pages without informing your referral sites. This will, of course, produce 404 errors to anyone clicking on these referral links. This situation will look bad on your website and on the referrer sites, since they have not updated their links.
Erroneous link references refer to sloppy coding, such as when your links are pointing to misspelled documents which do not exist. For all intents and purposes, pages resulting in server errors can also be interpreted as broken links as they are not the intended result.
Handling Broken Links
There really is no excuse for having broken links on your website. Many tools are available for checking your site for broken links. One such tool, linkchecker.pl, is available in Appendix A.
Running linkchecker.pl
You can run linkchecker.pl with the following code:
> perl linkchecker.pl http://www.somedomain.com > somedomain.csv
Depending on the size of the site, it can take anywhere from a few seconds to several hours to check the site for broken links. If you have a really large site, you may want to partition this activity into several smaller checks. After the script is finished, you can open the report file in Excel. Figure 5-3 shows sample output.
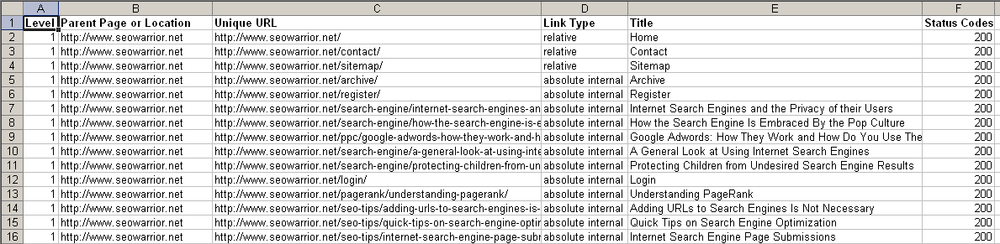
The spreadsheet in Figure 5-3 shows the following columns:
“Level” (represents a depth from 1 to 4)
“Parent Page or Location” (represents the parent HTML page)
“Unique URL” (URL not found on parent levels)
“Link Type” (can be inbound, outbound, absolute, or relative)
“Title” (text used in the title tag)
“Status Codes” (HTTP status codes)
Simply inspect the spreadsheet for 404 status codes to find your broken links, whether they happen to be internal or external. You may also want to inspect 500 status codes, as they indicate server errors.
User Behavior Patterns
Once they are perfected, user behavior patterns may be the greatest ranking method for all of the major search engines. Google is clearly the front-runner in this arena, as it has already unleashed a powerful array of tools for formulating, disseminating, and analyzing user patterns.
Although user behavior patterns can be a great help to search engines, they do come at a price: privacy. Everything you do can be used by search engines in user behavior analysis. For instance, Google is pushing the envelope to such an extent that it claims it can provide personalized search results.
In the opinion of some, personalized results can never truly be provided, as too many unknown variables are at stake. Theoretically speaking, for personalized search to really function, Google or others would have to store a separate, unique searchable index for every single person using their service. That’s about 8 billion indexes. Even Google cannot handle this sort of storage.
But there is another side to this argument: Google does not need everyone to use Google Analytics, Webmaster Central, and the Google Toolbar to get a fairly accurate assessment of a particular website or of the search patterns of the masses.
Analyzing the Search Engine Query Interface
In this section, we will take on the role of a search engine and examine what we can learn about behavior patterns.
First point of contact: the search form
We can learn a lot about a visitor as soon as he arrives on our home page. First, we know his IP address. Using his IP address we can pinpoint his geographic location. Based on his geographic location, we can create a customized index based on the patterns of previous visitors from the same geographic location.
We can also record cases in which another link referred the visitor to our home page. Depending on his Internet service provider and his assigned IP range, we can be so precise that we can pinpoint his city or town location!
In addition to IP and referrer values, we can also learn a great deal of additional information, including browser version, associated (installed) browser software, operating system version, current screen resolution, whether the visitor’s browser cookies are enabled, the speed of his Internet connection, and more. That’s a lot of information already, and the visitor has not even clicked on the Search button!
Interactions with SERPs
Once the visitor clicks on the Search button, things start to get more interesting. First, the visitor is telling the search engine what he is looking for. The search engine responds with a results page based on the current index for the specific region the visitor is coming from. Between the time that the results page shows up and the time the visitor clicks on a specific search result, many things can be recorded, including:
The time it took to click on the first result (not necessarily the first SERP result)
The time it took to click on other results (if any)
Whether the visitor clicked on subsequent SERPs
Which result in the SERPs the visitor clicked on first, second, and so on
The time between clicks on several results
The CTR for a specific result
As you can see, we can learn many things from a single visitor. But the picture becomes much clearer when we combine these stats with those from thousands or even millions of other visitors. With more data available, it becomes easier to spot patterns. Just using a small sample of visitor data is often enough to approximate which links are popular and which are not so useful.
For example, say that for a particular keyword, most visitors clicked on the third result, immediately followed by the sixth result. This could indicate that the third result did not contain good or sufficient information for this keyword, as visitors kept coming back to inspect the sixth result. It could also say that other results shown on the SERPs were not enticing enough for visitors to click on.
As another example, say that visitors clicked on the first result and then came back 10 minutes later to click on the fourth result. This could signify that visitors liked the information in the first result but chose to research further by clicking on the fourth result.
Now let’s consider CTR, which is the number of times a specific result is clicked on in relation to the total number of times it is shown. A high CTR is something all webmasters want for their URLs. A low CTR could signal to search engines that the result is not interesting or relevant.
Search engines can also gather information on multiple search queries, especially if they were all performed through the same browser window in the same session. These sorts of search queries can indicate keyword correlation. Although such information is already empowering search engines, it is not perfect. There are ways to make it better or more accurate.
Google Analytics
With the pretext of aiding webmasters, Google can now collect data from websites just like web server logs can. Although the Analytics platform certainly provides many helpful tools, some webmasters choose to stay away from it due to data privacy concerns.
Anytime a Google Analytics tracking code is inserted into a page of a website, Google records who is visiting the site. With this sort of information, Google Analytics could be used to do all sorts of things, including being used as a critical part of the overall Google ranking algorithm. Only Google knows whether this does occur.
It is also easy to see why every search engine would want to know these sorts of stats. We will discuss the Google Analytics platform in more detail in Chapter 7. Alternatives to Google Analytics include Webtrends Analytics and SiteCatalyst.
Google Toolbar
Microsoft’s CEO, Steve Ballmer, was recently quoted as saying the following:
Why is that (Google) toolbar there? Do you think it is there to help you? No. It is there to report data about everything you do on your PC.
Google has acknowledged that when the advanced toolbar features are turned on, every visit to every page is sent to Google, which then sends the PageRank value back to the toolbar.
This sort of information can have profound benefits for Google. First, it can help Google learn various user patterns. In addition, it can help Google learn about so-called personalized searches. Finally, Internet Explorer preinstalled with the Google Toolbar can help improve Google’s ranking algorithms.
It’s easy to verify that the Google Toolbar does send statistics
to Google. The following is sample output from the Windows netstat
command when browsing a typical site:
Proto Local Address Foreign Address State TCP seowarrior:2071 gw-in-f100.google.com:http ESTABLISHED TCP seowarrior:2072 qb-in-f104.google.com:http ESTABLISHED TCP seowarrior:2073 qb-in-f147.google.com:http ESTABLISHED TCP seowarrior:2074 qb-in-f100.google.com:http ESTABLISHED TCP seowarrior:4916 qb-in-f104.google.com:http CLOSE_WAIT
Examining the TCP packets when browsing http://www.google.com in Internet Explorer reveals the following information:
//Request to Google GET /search?client=navclient-auto&iqrn=ql7B&orig=0BKqM&ie=UTF-8& oe=UTF-8&features=Rank:&q=info:http%3a%2f%2fwww.google.com%2f& googleip=O;72.14.205.103;78&ch=78804486762 HTTP/1.1 User-Agent: Mozilla/4.0 (compatible; GoogleToolbar 5.0.2124.4372; Windows XP 5.1; MSIE 7.0.5730.13) Host: toolbarqueries.google.com Connection: Keep-Alive Cache-Control: no-cache Cookie: PREF=ID=54ac8de29fa2745f:TB=5:LD=en:CR=2:TM=1234724889: LM=1234753499:S=AgFeyxE1VD2Rr5i0; NID=20=GoJF_PXD5UZ_I5wdy6Lz4kMcwo9DsywL5Y4rrrE46cNTWpvVdt7ePFkHNe2t 5qIG8CPJrZfkq0dvKvGgVC1rO0rn0WhtNhe8PR7YpKjMQonnuAtYrIvEbSl-gPgqBSFw //First Google Response HTTP/1.1 200 OK Cache-Control: private, max-age=0 Date: Tue, 24 Feb 2009 08:38:19 GMT Expires: −1 Content-Type: text/html; charset=UTF-8 Server: gws Transfer-Encoding: chunked //Second Google Response c Rank_1:2:10 0
The Google Toolbar initiates the request to toolbarqueries.google.com, which then sends a couple of packet replies. The first one simply sends the HTTP header information, and the second one contains the PageRank part that is consumed by the Google Toolbar.
In this case, the last three lines are part of a separate TCP packet, which is Google’s response indicating the PageRank value of 10 for http://www.google.com; and so on for any other links you enter in your web browser running the Google Toolbar.
User Behavior Lessons
It is inevitable that search engines will continue to evolve. User behavior patterns are becoming a powerful ally to search engines. With these advances, the importance of relevant content increases exponentially.
Without relevant content, it is too easy for search engines to weed out unpopular or useless sites. If they cannot do this algorithmically, they can certainly fill the void with more precise user behavior data obtained from their external tools and platforms.
Website Performance and Website Age
We will close this chapter with a discussion of two other important external ranking factors: website performance and website age.
Website Performance
There is an unwritten law on the Internet that states that every page must load within the first four seconds; otherwise, people will start to get impatient and leave before the page loads. You must take this into consideration. It is important not only from a usability perspective, but also from the sense that web spiders will learn of your website performance.
Monitoring website performance
If you are on a dedicated server, you may already have access to website monitoring tools and insight into your website performance. If your website is on a shared host, chances are that all the websites sharing that host are competing for a slice of the available CPU pie.
Every serious website owner needs to proactively monitor his website’s performance, as poor performance can have adverse web crawling and indexing effects. You can monitor a website with a relatively simple Perl script. One such script is mymonitor.pl, which you can find in Appendix A. Running the script is as simple as:
perl mymonitor.pl http://www.somedomain.net/somelink.html
The script records the elapsed time it takes to download the supplied URL while writing to several text files. Each line of these text files is formatted in the following way:
mm-dd-yyyy hh:mm:ss;10;15;20;[actual elapsed time]
Example text file content looks like this:
12-6-2009 6:0:4;10;15;20;3.25447 12-6-2009 6:5:3;10;15;20;1.654549 12-6-2009 6:10:2;10;15;20;1.765499 12-6-2009 6:15:9;10;15;20;8.2816
Numbers 10, 15, and 20 represent markers in seconds for easier viewing on a chart. Several free graphics packages are available on the market. Plotting our data with amCharts’ charting Flash demo version software yields a graph similar to Figure 5-4.
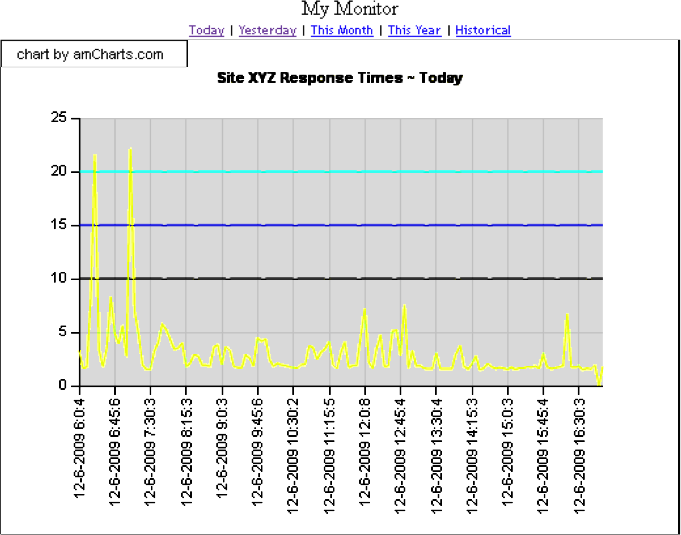
Figure 5-4 illustrates degraded performance from about 6:00 a.m. to 7:30 a.m. Knowing such information is valuable, as it can provide clues for further analysis. The last thing left to do is to automate the process of running the script. If you are on a Linux system, you can simply set up a crontab job. To run the script every five minutes, you could set up your crontab as follows:
#Run test every 5 minutes */5 6-22 * * * perl mymonitor.pl http://www.domain.net/link1.html
The preceding crontab entry would run every five minutes between 7:00 a.m. and 11:00 p.m. every day. This is only one link, and nobody is preventing you from setting up several links to track. Also note that you could use the Windows Task Scheduler to set up the script-running schedule.
Website Age
New websites tend to exhibit more ranking fluctuations than their older counterparts. The Google Dance refers to the index update of the Google search engine. It can affect any domain at any time. Today, Google index updates occur more frequently than they have in the past. It is relatively easy to check website age by simply using online Whois tools.
Domain registration years
A longer registration period suggests a serious domain owner, whereas short registrations such as single-year registrations could be interpreted as suspicious. This is of no surprise, as most search engine spam tends to come from short-lived domains.
Expired domains
Google recently confirmed that expired domains, when renewed, are essentially treated as new domains. In other words, if an expired domain had a high PageRank, that PageRank will be wasted if the domain is allowed to expire before someone else buys it.
Plan for long-term benefits
Domains that have existed for a long time carry an age trust factor. New pages added to these domains tend to get higher rankings more quickly. As we discussed, older domains convey authority and are given much more leeway than newer ones. If your domain is new and relevant, focus on the daily activities of your business while building compelling and relevant content—and plan for the long term.
Summary
In this chapter, we covered the most important external ranking factors. Be proactive and check your outbound links. Beware of user patterns becoming increasingly prevalent as key ranking factors. Create enticing content and stay away from spammy shortcuts. And always make sure you check your website performance regularly.