
Chapter 2. Search Engine Primer
It is vital for you to understand—even if at only a basic level—how search engines work, as they are not all created equal, nor do they produce identical search engine results pages (SERPs). Website owners need to carefully examine which search engines they want to target. The current leader in the search engine marketplace is, of course, Google.
When performing SEO, it is important to target specific search engines. You cannot possibly target every search engine that exists. If you are in the Western parts of the world, your choices boil down to Google, Yahoo!, and Bing. According to comScore’s June 2009 press release for U.S. searches (http://bit.ly/sLQfX):
Google Sites led the U.S. core search market in June with 65.0 percent of the searches conducted, followed by Yahoo! Sites (19.6 percent), and Microsoft Sites (8.4 percent). Ask Network captured 3.9 percent of the search market, followed by AOL LLC with 3.1 percent.
Google is even more dominant in Europe, with approximately 80% of search engine market share. However, in Asia the situation is a bit different. comScore’s press release for the Asia–Pacific region for July 2008 states the following:
“Although Google leads the Asia–Pacific search market, powerhouse Chinese search engine Baidu.com follows closely on its heels with only a 6-percent difference separating the two,” said Will Hodgman, comScore executive vice president for the Asia–Pacific region. “It will be interesting to watch Google and Baidu compete for the top spot in the region and the loyalty of the growing Asian population.”
According to comScore, in the Asia–Pacific region Google is running neck-and-neck with Baidu. It will be interesting to watch how this situation develops in the coming months and years, as currently Baidu is eating away at Google’s market share.
Another regional search engine powerhouse is Yandex, which owns more than 60% of Russia’s search engine market share. Although it is hard to dispute Google’s world dominance in terms of world searches, take these numbers with a grain of salt, as some search engines may be inflating their numbers.
Search Engines That Matter Today: Google
If you focus your design on Google’s webmaster guidelines, chances are your website will also do well across all of the other (important) search engines. Google’s rise from its humble beginnings to what it is today is nothing short of phenomenal.
Google was created by Larry Page and Sergey Brin at Stanford University. In many ways, Google was similar to most of the other major search engines, but its interface did not look like much, consisting of a simple form and search button. This simplicity, so different from portal-like search engine sites, was a welcome relief for many.
Over the years, Google evolved into the multiproduct company it is today, providing many other applications including Google Earth, Google Moon, Google Products, AdWords, Google Android (operating system), Google Toolbar, Google Chrome (web browser), and Google Analytics, a very comprehensive web analytics tool for webmasters. In 2008, the company even launched its own standards-compliant browser, Chrome, into what some feel was an already saturated market.
Designing your website around Google makes sense. The Google search network (search properties powered by Google’s search algorithms) has 65% of the market share, according to comScore’s June 2009 report.
Google’s home page has not changed much over the years. Its default search interface mode is Web, and you can change this to Images, Maps, Shopping, or Gmail, among others. What have changed greatly are Google’s results pages, mostly with the addition of ads and supplementary search results.
In the years ahead, Google will be hard to beat, as it is many steps ahead of its competition. Google is using many of its own or acquired tools and services to retain its grip on the search engine market.
Granted, Google’s competitors are watching it. It is also clear that Google is not standing still in its pursuit to maintain and increase its search engine market share dominance. This is evident in its acquisition of YouTube.com and others.
According to comScore’s press release for July 2008, YouTube drew 5 billion online video views in the United States:
In July, Google Sites once again ranked as the top U.S. video property with more than 5 billion videos viewed (representing a 44 percent share of the online video market), with YouTube.com accounting for more than 98 percent of all videos viewed at the property. Fox Interactive Media ranked second with 446 million videos (3.9 percent), followed by Microsoft Sites with 282 million (2.5 percent) and Yahoo! Sites with 269 million (2.4 percent). Hulu ranked eighth with 119 million videos, representing 1 percent of all videos viewed.
In late 2006, Google made a deal with MySpace to provide search and ad services to MySpace users. Currently, with more than 100 million users and still growing, MySpace is one of the two biggest social networking websites.
Some additional notable Google offerings include:
To see even more Google products and services, visit http://www.google.com/options/ and http://en.wikipedia.org/wiki/List_of_Google_products.
Yahoo!
Founded by Jerry Yang and David Filo, Yahoo! emerged in the clumsy form of http://akebono.stanford.edu/yahoo (this URL no longer exists, but you can read about Yahoo!’s history in more detail at http://docs.yahoo.com/info/misc/history.html). For the longest time, Yahoo! leveraged the search services of other companies. This included its acquisition of Inktomi technology. This changed in 2004, when it dropped Google as its search provider in favor of using its own acquired technology.
Yahoo! was Google’s biggest rival for many years. What sets Yahoo! apart from Google is its interface. When you go to the Yahoo! website, you actually see a web portal with all kinds of information. Many people see this design as cluttered, with too much competing superfluous information. Once you get to Yahoo!’s search results pages, things start to look similar to Google and Bing.
In 2008, Microsoft made a failed attempt to buy Yahoo!, which responded by forming an advertising relationship with Google. That changed in July 2009, when Yahoo! reached an agreement with Microsoft to use Bing as its search engine provider while focusing more heavily on the content delivery and advertising business.
As of this writing, Yahoo! is still using its own technology to provide its search results. It will take some time before Microsoft and Yahoo! are able to merge their systems. Today, Yahoo!’s main attraction is in its textual and video news aggregations, sports scores, and email services. Yahoo! is a strong brand, and the Yahoo! Directory continues to be one of the most popular paid web directories on the Internet.
Its search home page, http://search.yahoo.com, shows top link tabs that are similar to Google’s and Bing’s. Web is the default search mode; additional tabs include Images, Video, Local, Shopping, and More.
Popular tools owned by Yahoo! include:
Bing
Microsoft Bing is the successor to Microsoft Live Search, which failed to gain substantial market traction. Bing is also struggling to cut into Google’s market share, but it has made some inroads thus far. Moreover, with Microsoft’s 10-year agreement with Yahoo!, Bing will see a boost in its search user base by absorbing Yahoo!’s search traffic.
It may be a long time before the majority of people switch to Bing, if they ever do. The fact is that for many people, the word Google is synonymous with the term search engine. Google is even commonly used as a verb, as in “I’ll Google it.”
At the time of this writing, Microsoft is investing heavily in marketing Bing, spending tens of millions of dollars on Bing campaigns. Over the next few years, the general anticipation is that Microsoft will battle it out with Google for the top spot in the search engine market space. Microsoft did this with Netscape in the browser wars; there is no reason to believe it will not attempt to do the same thing with Google.
The Bing search interface is similar to any other search engine. Bing inherited the same (top) tabs from its predecessor, including Web, Images, Videos, News, Maps, and More.
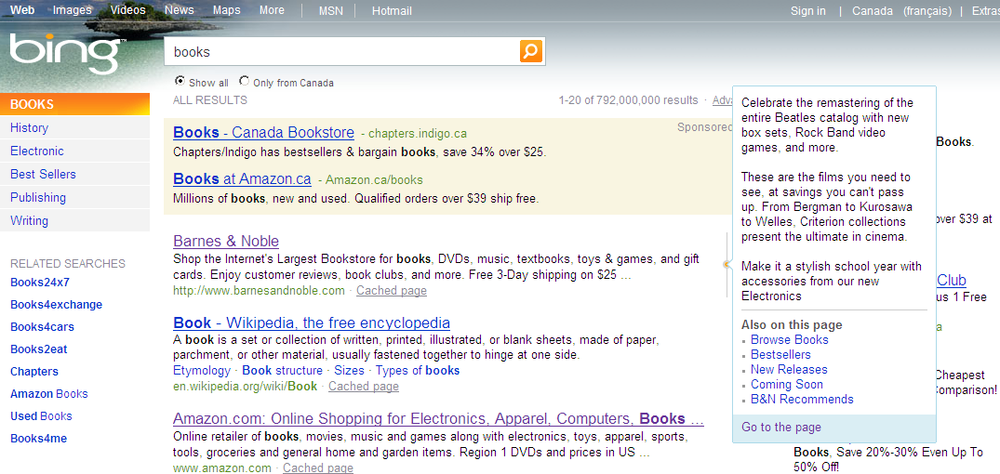
Where it differs is in its search results. Figure 2-1 shows the Bing interface. The left side of Bing’s search results page is called the Explorer pane. Within the Explorer pane, you are presented with results categories (quick tabs) if your particular search query has related search categories.
To the right of the Explorer pane are the actual search results, which are now more centered on the page when compared to Google’s search results. Every search result is also accompanied by a Quick Preview pane. Bing will select additional text from the URL to show in this pane. The intent is to help searchers see more information about the destination URL before they click on the search result.
Types of Search Engines and Web Directories
Many search engines exist on the Internet. How do you make sense out of all the offerings? The following subsections go into detail regarding several different types and groups of search engines, including primary, secondary, regional, topical, web spider (based), meta, and hybrid search engines.
First-Tier Search Engines
Google, Yahoo!, and Bing are considered first-tier, or primary, search engines, as they own most of the search engine market share in the Western parts of the world. These search engines usually scour the entire Web, and in the process create very large index databases.
For all intents and purposes (and if you reside in the Western world), primary search engines are the only ones you should really care about, as most of your visitors will have come from these search engine sources.
Second-Tier Search Engines
Secondary or second-tier search engines are lesser known or not as popular as first-tier search engines. They may provide value similar to that of the most popular search engines, but they simply cannot compete with them, or they may be new. You will obviously not be spending much of your time optimizing your sites for these types of search engines.
With Google, Yahoo!, and Microsoft holding most of the search market share, there is very little incentive to optimize for any other search engine. The ROI is just not there to warrant the additional work.
Regional Search Engines
Although Google may be the top dog in North America and Europe, it is not necessarily so in other parts of the world. The extent of your involvement with regional search engines will depend entirely on your target audience. For a list of regional or country-specific search engines, visit the following URLs:
Topical (Vertical) Search Engines
Topical search engines are focused on a specific topic. Topical search engines are also referred to as specialty search engines. Topics can be anything, including art, business, academia, literature, people, medicine, music, science, and sports, among others. Here are some of the most popular topical search engines on the Internet today:
Visit http://bit.ly/19yvsU for more examples of topical search engines.
Web Spider–Based Search Engines
Web spider–based search engines employ an automated program, the web spider, to create their index databases. In addition to Google, Yahoo!, and Microsoft, this class of search engine includes:
Hybrid Search Engines
Some search engines today contain their own web directories. The basic idea of hybrid search engines is the unification of a variety of results, including organic spidered results, directory results, news results, and product results.
Google has adopted this blended (SERP) model, calling it Universal Search. Yahoo! does the same thing once you get to its search results page. The premise of Blended Search results is that the multiple types of results complement each other, and ultimately provide the web visitor with more complete, relevant search results. This is illustrated in Figure 2-2.
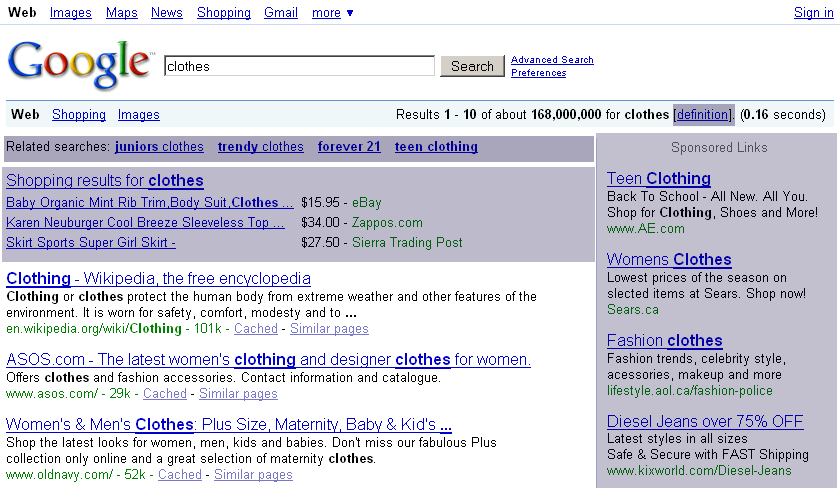
In Figure 2-2, you can see how the Google SERP looks for the keyword clothes. On the righthand side of the screen you can see the Sponsored Links section. Similarly, at the top of the screen are shopping results, and just below those are organic results from website owners who have done their SEO homework.
If you do some further research on popular search terms, you will realize that extremely popular keywords usually produce SERPs with only the big players, such as Amazon, Wikipedia, and YouTube, showing up on the top of the first page of Google and others.
Meta Search Engines
If you search for an identical term on various spider-based search engines, chances are you will get different search engine results. The basic premise of meta search engines is to aggregate these search results from many different crawler-based search engines, thereby improving the quality of the search results.
The other benefit is that web users need to visit only one meta search engine instead of multiple spider-based search engines. Meta search engines (theoretically) will save you time in getting to the search engine results you need.
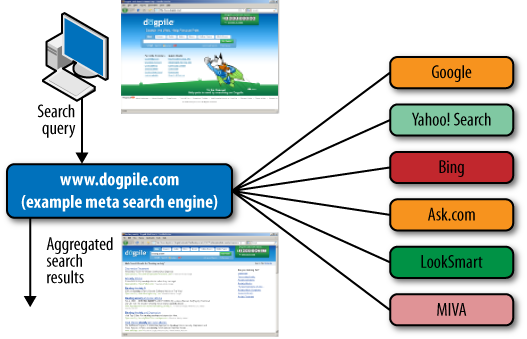
As shown in Figure 2-3, Dogpile.com compiles its results from several sources, including Google, Bing, Ask.com, and LookSmart. One thing to note about meta search engines is that aside from caching frequently used queries for performance purposes, they usually do not hold an index database of their own.
Dogpile.com is not the only meta search engine. There are many others, including Vivisimo.com, Kartoo.com, and Mamma.com.
Web Directories
Web directories are not search engines in the typical sense; they are collections of links that have been organized by humans. The advantage of web directories over typical search engines is that all the links are (usually) reviewed by human editors for quality, relevance, and suitability before being posted online. Make no mistake: some web directories are completely automated. You should avoid these types of directories.
The most famous web directory, Open Directory Project, boasts 4,576,062 URLs in its listings at the time of this writing. Most web directories, including Dmoz.org, can also be searched.
Not all web directories are free. Some require yearly or one-time listing fees. One such directory is Yahoo!. Currently, you must pay a $299 yearly fee to be listed on Yahoo!.
Here is a list of additional web directories:
For the longest time, Google stated that it would view listings on web directories as a good thing. Many directories lost their ability to pass on link juice in Google’s crackdown on paid (automated garbage) directories.
Google rewards human-edited directories, although it does not want to see paid directories that are auto-generated with no human editing. Before you decide to put a link on a web directory, ensure that the benefit will be there. See Chapter 12 for more details.
Search Engine Anatomy
When I talk about important search engines, I am really talking about the “big three”: Google, Bing, and Yahoo! Search. At the time of this writing, all of these search engines are using their own search technologies.
Web spider–based search engines usually comprise three key components: the so-called web spider, a search or query interface, and underlying indexing software (an algorithm) that determines rankings for particular search keywords or phrases.
Spiders, Robots, Bots, and Crawlers
The terms spider, robot, bot, and crawler represent the same thing: automated programs designed to traverse the Internet with the goal of providing to their respective search engine the ability to index as many websites, and their associated web documents, as possible.
Not all spiders are “good.” Rogue web spiders come and go as they please, and can scrape your content from areas you want to block. Good, obedient spiders conform to Robots Exclusion Protocol (REP), which we will discuss in Chapter 9.
Web spiders in general, just like regular users, can be tracked in your web server logs or your web analytics software. For more information on web server logs, see Chapters 6 and 7.
Web spiders crawl not only web pages, but also many other files, including robots.txt, sitemap.xml, and so forth. There are many web spiders. For a list of known web spiders, see http://www.user-agents.org/.
These spiders visit websites randomly. Depending on the freshness and size of your website’s content, these visits can be seldom or very frequent. Also, web spiders don’t visit a site only once. After they crawl a website for the first time, web spiders will continue visiting the site to detect any content changes, additions, or modifications.
Googlebot is Google’s web spider. Googlebot signatures (or traces) can originate from a number of different IPs. You can obtain web spider IPs by visiting http://www.iplists.com/.
A typical Googlebot request looks similar to the following HTTP header fragment:
GET / HTTP/1.1 Host: www.yourdomain.com Connection: Keep-alive Accept: */* From: googlebot(at)googlebot.com User-Agent: Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) Accept-Encoding: gzip,deflate
In this example, Googlebot has made a request for the index or root document of the www.yourdomain.com domain. Googlebot supports web server compression. Web server compression allows for faster file transmissions and should be used whenever possible.
Yahoo!’s web crawler is called Slurp, and the Bing spider is called MSNBot; they both exhibit similar behavior. Your job is to make their lives easier by feeding them properly optimized web content and ensuring that they can find everything you need them to find.
Web spider technology is not perfect. Sometimes web spiders will not be able to see the entirety of your website (referred to as a search engine trap). Other times you may want to prohibit them from crawling certain parts of your website, which you can do in your robots.txt file and via REP.
With the introduction of different (document type) indexing capabilities, Google and others are now using specialized spiders to handle media, syndication, and other content types.
You may want to block the indexing of your images and media files. Many times, malicious web users or even bloggers can create direct HTML references to your media files, thereby wasting your website’s bandwidth and perhaps adversely affecting your website’s performance.
In the beginning, search engines could handle only a limited range of indexing possibilities. This is no longer the case. Web spiders have evolved to such an extent that they can index many different document types. Web pages or HTML pages are only one subset of web documents. Table 2-1 lists the file indexing capabilities of Googlebot.
File type(s) | Description |
Adobe Portable Document Format | |
PS | Adobe PostScript |
RSS, ATOM | Syndication feeds |
DWF | Autodesk Design Web Format |
KML, KMZ | Google Earth |
WK1, WK2, WK3, WK4, WK5, WKI, WKS, WKU | Lotus 1-2-3 |
LWP | Lotus WordPro |
MW | MacWrite |
XLS | Microsoft Excel |
PPT | Microsoft PowerPoint |
DOC | Microsoft Word |
WKS, WPS, WDB | Microsoft Works |
WRI | Microsoft Write |
ODT | Open Document Format |
RTF | Rich Text Format |
SWF | Shockwave Flash |
ANS, TXT | Text files |
WML, WAP | Wireless Markup Language |
JSP, ASP, and PHP files are indexed in the same way as any HTML document. Usually, the process of indexing non-HTML documents is to extract all text prior to indexing.
Search engine web page viewer
Have you ever wondered how your web pages look to search engines? If you strip out all of the HTML, JavaScript, and CSS fragments on a web page, you will get the bare text. This is pretty much what a typical search engine would do before indexing your web pages. You can find the spider viewer script in Appendix A.
That code listing contains two distinct fragments. The top part of the code is mostly HTML. The bottom part of the code is mostly PHP. Once rendered in the web browser, the PHP code will show a small text field where you can enter a particular URL.
A few seconds after this form is submitted, you should see the “spider” view of your URL. Figure 2-4 shows the output of running this PHP script on the O’Reilly website.

This script can be useful for all websites, especially those that use a lot of graphics and media files. It should give you some insight as to what the search engine crawlers will see.
You can also use text browsers. One such tool, SEO Text Browser, is available at http://www.domaintools.com. You can navigate websites using text links as in the early web browsers.
The Search (or Query) Interface
The search or query interface is your door to the SERPs. Each search engine may have a slightly different interface. Nonetheless, each one will present you with the search form and a SERP with relevant links.
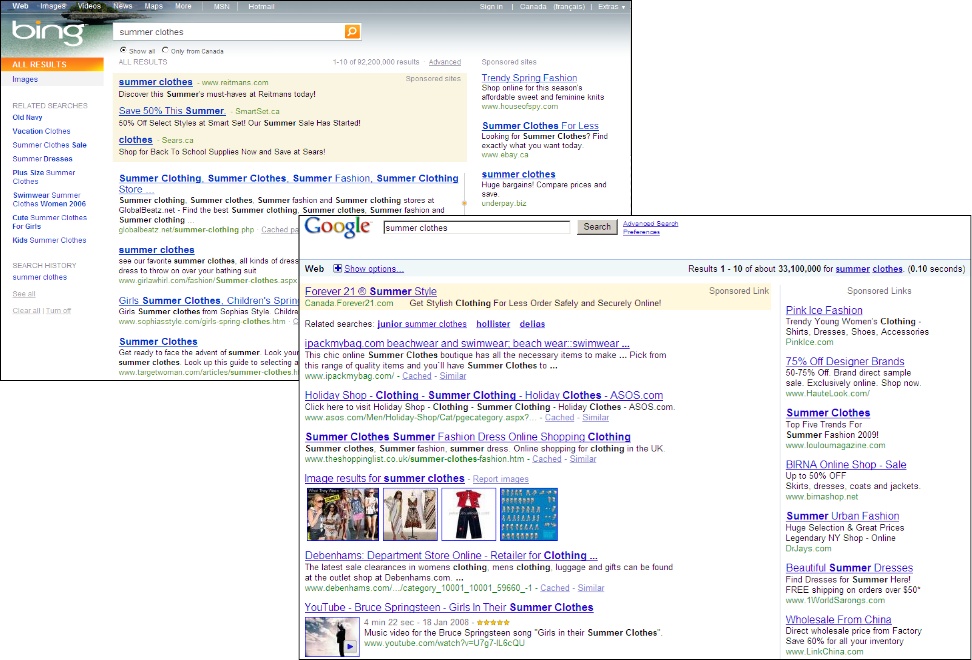
If the search term is popular, chances are you will see a lot of ads posted alongside or even mixed in with the organic search results. Each search engine uses different search ranking algorithms. Accordingly, the search results on one search engine will likely be different from the search results on another search engine, even for identical keywords. For example, searching for summer clothes on Google and Bing produces the results pages shown in Figure 2-5.
Search engines are not perfect, and sometimes you will get spam result links that are completely irrelevant to what you are looking for. At those times, it might take some “keyword massaging” to get to the relevant links.
Search Engine Indexing
Google and others are indexing more pages than ever. Many of the modern search engines now boast upward of a few billion indexed documents. Here is how Wikipedia describes the process of search engine indexing:
Search engine indexing collects, parses, and stores data to facilitate fast and accurate information retrieval. Index design incorporates interdisciplinary concepts from linguistics, cognitive psychology, mathematics, informatics, physics and computer science. An alternate name for the process in the context of search engines designed to find web pages on the Internet is Web indexing.
Although web spiders do their best to obtain as many documents as possible for search engines to index, not all documents get indexed. Search engine indexing is closely tied to the associated search engine algorithms. The search engine indexing formula is a highly secretive and intriguing concept to most SEO enthusiasts.
Search engine indexing is not an entirely automated process. Websites that are considered to be practicing various unethical (spamming) techniques are often manually removed and banned. On the other end of the spectrum, certain websites may receive a ranking boost based on their ownership or brand.
Although Google and others will continue to provide guidelines and tutorials on how to optimize websites, they will never share their proprietary indexing technologies. This is understandable, as it is the foundation of their search business.
Search Engine Rankings
Search engine rankings are determined by search engine algorithms. When search engine algorithms change, search engine rankings change. It is a well-known fact that Google and others are continually modifying their secretive search engine algorithms and thus their SERP rankings.
Some of these modifications have been so profound that listings of many websites disappeared from the SERPs literally overnight. Keeping track of web page or site rankings is one of the most common activities of any SEO practitioner. The driving force behind algorithm changes is almost always the following:
Improvements in search results quality
Penalization of signature search engine spam activities
Search engine algorithms are based on a system of positive and negative weights or ranking factors as designed by the search engine’s engineers or architects. One of Google’s search engine algorithms is called PageRank. You can view Google PageRank by installing the Google Toolbar. To quote Wikipedia:
PageRank is a link analysis algorithm that assigns a numerical weighting to each element of a hyperlinked set of documents, such as the World Wide Web, with the purpose of “measuring” its relative importance within the set. The algorithm may be applied to any collection of entities with reciprocal quotations and references. The numerical weight that it assigns to any given element E is also called the PageRank of E and denoted by PR(E).
The PageRank (or PR) is Google’s measurement of how important or popular a particular web page is, on a scale of 1 to 10, with 10 implying the most importance or highest popularity. You can also think of the PR value as an aggregate vote of all pages linking to a particular page.
You can visualize PageRank by looking at Figure 2-6, which illustrates the basic concept of PageRank. The figure is based on a slideshow created by Google search quality engineer Matt Cutts, which you can find at http://bit.ly/13a6qu. The numbers used in the diagram are for illustrative purposes only.
Examining Figure 2-6, you can observe how the PageRank flows from page to page. If you look at the top-left page, you can see that it has a score of 100. This page has several inbound links, all of which contribute to this score.
This same page has two outbound links. The two recipient pages split the link juice value, each receiving 50 points. The top-right page also contains two outbound links, each carrying a value of 26.5 to their destination page. Note that this page also received 3 points from the lower-left page.
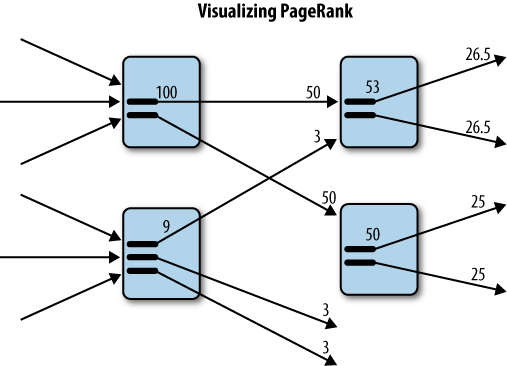
There are two key factors behind the inner workings of PageRank: the number of inbound links and the quality of those links. This means you should not obsess over getting the highest number of inbound links. Instead, focus on the quality of the inbound links. If you have the most interesting content, links will come—naturally.
Summary
Monitoring search engine market share news can be helpful in pursuing sound SEO choices. Although new search engines will continue to crop up from time to time, SEO activities need only focus on a select few primary search engines: Google, Bing, and Yahoo!. If your site needs to rank well in the Asia–Pacific region, you may also want to consider a regional search engine such as Baidu or Yandex.
After examining the big players, you learned about the different types of search engines, including first tier, second tier, regional, topical (vertical), web spider (based), meta, and hybrid search engines.
We also talked about the different web directories before turning our attention to search engine anatomy. In that section, we explored different web spiders, the search engine query interface, and search engine algorithms. We also created a spider viewer script. At the end of this chapter, we covered Google’s PageRank in more detail.