
4. On Open Source and Closed Source
“Today’s security woes are not dominated
by the existence of bugs that might be discovered
by open-source developers studying system source code.”
—FRED SCHNEIDER
The technical side of business places lots of emphasis on keeping secrets—design documents are not published, code is treated as a trade secret, and sometimes algorithms themselves are kept secret. Software is often the mechanism used to keep secrets out of reach of attackers and competitors, so it is not surprising that the approach taken makes a great deal of difference. In the first part of this chapter we discuss the implications of trying to keep things secret in your software.
There are a lot of good reasons for keeping secrets. Most companies have intellectual property to protect, often including algorithms built right into the software being sold to customers. Companies also have cryptographic keys that must remain private to retain their utility. Despite popular trends toward openness, including the open-source movement, most software companies still embrace secrecy when it comes to their computer programs. The problem is, secrecy is often used as a crutch and may not be effective.
Probably the most popular way to keep secrets in code is to hide the source and release only an executable version in machine code. Not releasing source code certainly helps keep hackers from trivially stealing your secrets. However, doing so is not nearly as effective as many people believe. There are plenty of problems with this technique (often labeled security by obscurity), but the main problem stems from a false belief that code compiled into binary remains secret just because the source is not available. This is wrong. Simply put, if your code runs, determined people can eventually find out exactly what it is doing, especially if your code is compiled to Java byte code, which is particularly easy to reverse engineer.
The flip side of the security-by-obscurity coin involves releasing source code and counting on the open-source community to help you make things more secure. Unfortunately, open source is less of a security panacea than many people may think. The second part of this chapter is devoted to a discussion of open source and security.
Security by Obscurity
Hackers don’t always need to be able to look at any code (binary or source) to find security vulnerabilities. Often, controlled observation of program behavior suffices. In the worst cases, symptoms of a security problem are noticed during the course of normal use.
As an example, consider a problem discovered in Netscape Communicator’s security near the end of 1999. This particular problem affected users of Netscape mail who chose to save their POP (Post Office Protocol) mail password using the mail client. In this case, a “feature” placed in Netscape for the convenience of users turned out to introduce a large security problem.
Obviously, saving a user’s mail password means storing it somewhere permanent. The question is, where and how is the information stored? This is the sort of question that potential attackers pose all the time.
Clearly, Netscape’s programmers needed to take care that casual users (including attackers) could not read the password directly off the disk, while at the same time providing access to the password for the program that must use it in the POP protocol. In an attempt to solve this problem, Netscape’s makers attempted to encrypt the password before storing it, making it unreadable (in theory anyway). The programmers chose a “password encryption algorithm” that they believed was good enough, considering that the source code wasn’t to be made available. (Of course, most of the source was eventually made available in the form of Mozilla, but the password-storing code we’re focusing on here did not show up in the release.) Unfortunately, the algorithm that made its way into Netscape Communicator was seriously flawed.
As it turns out, on Windows machines the “encrypted” password is stored in the registry. A relevant software security tip for Windows programmers is always to assume that people on machines you don’t control can read any entries you put in the registry! If you choose to store something there, make sure it is protected with strong cryptography.
While experimenting with a simple program designed to find passwords hidden with ExclusiveOr (XOR) (that is, passwords XOR-ed against a simple pattern of ones and zeros), a couple of researchers (Tim Hollebeek and John Viega) noticed that similar plaintext versions of Netscape mail passwords stored in the registry tended to look similar to each other in “encrypted” form. This sort of thing is usually a sign of bad cryptography. With good cryptography, a one-character change to the password affects at least half the bits in the encrypted version. In this case, no such change was observed.
From this point, systematic changes to a few hundred test passwords revealed a pattern in the way the “encrypted” version changed. By looking carefully for patterns, enough information was ultimately gathered to construct (or, rather, to reconstruct) an algorithm that behaved in exactly the same way as Netscape Communicator’s encryption routine. All this was accomplished without ever having to see any actual code.
Given a copy of the “encryption” algorithm, it was easy to come up with a little program that decrypted actual Netscape POP passwords. The encryption algorithm used in the product was a poor one, developed in-house and apparently without the help of a cryptographer. By comparison with any algorithm an actual cryptographer would endorse, the Netscape Communicator algorithm was laughable.
In this case, perhaps Netscape felt that their algorithm was good enough because it was never published and was thus “secret.” That is, they were relying on security by obscurity. When it comes to cryptography though, this is a bad idea. Good cryptographic algorithms remain good even if other people know exactly what they do, and bad algorithms will be broken even if the algorithm is never directly published. It all comes down to math.
Consider the Enigma machine built by the Axis Powers during World War II. Cryptographers, including Alan Turing, were able to figure out everything about the German cryptographic algorithm by observing encoded messages. The Allies never got to take apart an actual Enigma machine until after the code was completely broken (and by then, they didn’t need one).
Even the algorithms once considered good by World War II standards are considered lousy by today’s. In fact, some ciphers considered unbreakable by the people who broke the German Enigma can today be broken easily using modern cryptanalysis techniques. In the end, it takes a real expert in cryptography to have any hope of designing a reasonably good algorithm. The people responsible for the Netscape algorithm were not good cryptographers. The question is why Netscape chose not to use a “real” cryptographic algorithm like the Data Encryption Standard (DES).
It turned out that a very similar Netscape POP password encryption algorithm had been broken nearly a year before the problem was rediscovered. In fact, similar problems had cropped up in 1996 (discovered by Alex Robinson) and 1998 (by Wojtek Kaniewski). Flaws in the original algorithm were clearly pointed out to Netscape, and in the newer version, Netscape had “fixed” the problem by changing the algorithm. The fix should have involved switching to a real algorithm. Instead, Netscape chose to make superficial changes to their fundamentally flawed algorithm, making it only slightly more complex. Once again, however, Netscape should not have relied on security by obscurity; instead, they should have turned to professional cryptographers.1
1. Note that an attacker may still be able to get at a password easily after it is decrypted. If the POP traffic is unencrypted, as is usually the case (although security-conscious people use POP over SSL), then the job of the attacker is quite easy, despite any attempt to hide the password.
The moral of our story is simple: Some malicious hackers get curious and begin to explore any time they see any anomaly while using your software. Any hint at the presence of a vulnerability is enough. For example, a simple program crash can often be a sign of an exploitable vulnerability. Of course, hackers do not have to be passive about their exploration. People interested in breaking your software will prod it with inputs you may not have been expecting, hoping to see behavior that indicates a security problem. In fact, our simple example here only begins to scratch the surface of the lengths to which attackers go to break client code (see Chapter 15).
One common technique is to feed very long inputs to a program wherever input can be accepted. This sort of test often causes a program crash. If the crash affects the machine in a particular well-defined way, then the hacker may have found an exploitable buffer overflow condition (see Chapter 7). Usually an attacker does not have to look directly at your software to know that a problem exists. If you’re using Windows, the output of Dr. Watson is all that is necessary (clicking on the More Details button in the Windows 98 program crash dialog is also sufficient). From there, an attacker can intelligently construct inputs to your program to glean more information, ultimately producing an exploit—and all this without ever having looked at your code.
Serious security problems are found this way all the time. For example, a recent buffer overflow in Microsoft Outlook was uncovered in exactly this manner, and the company eEye found a handful of bugs in Microsoft’s IIS (Internet Information Server) Web server using the same technique. The take-home message here is always to be security conscious when writing code, even if you are not going to show the code to anyone. Attackers can often infer what your code does by examining its behavior.
Reverse Engineering
Many people assume that code compiled into binary form is sufficiently well protected against attackers and competitors. This is untrue. Although potential bad guys may not have access to your original source code, they do in fact have all they need to carry out a sophisticated analysis.
Some hackers can read machine code, but even that is not a necessary skill. It is very easy to acquire and use reverse-engineering tools that can turn standard machine code into something much easier to digest, such as assembly or, in many cases, C source code.
Disassemblers are a mature technology. Most debugging environments, in fact, come with excellent disassemblers. A disassembler takes some machine code and translates it into the equivalent assembly. It is true that assembly loses much of the high-level information that makes C code easy to read. For example, looping constructs in C are usually converted to counters and jump statements, which are nowhere near as easy to understand as the original code. Still, a few good hackers can read and comprehend assembly as easily as most C programmers can read and comprehend C code. For most people, understanding assembly is a much slower process than understanding C, but all it takes is time. All the information regarding what your program does is there for the potential attacker to see. This means that enough effort can reveal any secret you try to hide in your code.
Decompilers make an attacker’s life even easier than disassemblers because they are designed to turn machine code directly into code in some high-level language such as C or Java. Decompilers are not as mature a technology as disassemblers though. They often work, but sometimes they are unable to convert constructs into high-level code, especially if the machine code was handwritten in assembly, and not some high-level language.
Machine code that is targeted to high-level machines is more likely to be understood fairly easily after it comes out the end of a reverse-engineering tool. For example, programs that run on the JVM can often be brought back to something very much similar to the original source code with a reverse-engineering tool, because little information gets thrown away in the process of compiling a Java program from source. On the other hand, C programs produced by decompilers do not often look the same as the originals because much information tends to get thrown away. Decompilation performance can be enhanced if the programmer compiled with debugging options enabled.
In general, you should always code defensively, assuming that an attacker will finagle access to your source code. Always keep in mind that looking at binary code is usually just as good as having the source in hand.
Code Obfuscation
Often it may well be impossible to keep from putting a secret somewhere in your code. For example, consider the case of the Netscape POP password. Even if Netscape had used a “real” encryption algorithm such as DES, a secret key would still have been required to carry out the encryption and decryption. Such a key needs to remain completely secret, otherwise the security of the password can easily be compromised. Moving the key to some file on a disk is not sufficient, because the code still keeps a secret: the location of the key, instead of the key itself.
In these cases, there is no absolute way to protect your secrets from people who have access to the binaries. Keep this in mind when you are writing client software: Attackers can read your client and modify it however they want! If you are able to use a client/server architecture, try to unload secrets onto the server, where they have a better chance of being kept.
Sometimes this is not a feasible technique. Netscape is not willing to save POP passwords on some central server (and people would probably get very upset if they decided to do so, because that sort of move could easily be interpreted as an invasion of privacy). Not to mention that in this particular case it would just move the problem: How do you prove your identity to get the password off the POP server? Why, by using another password!
In these cases, the best a programmer can do is to try to raise the bar as high as possible. The general idea, called code obfuscation, is to transform the code in such a way that it becomes more difficult for the attacker to read and understand. Sometimes obfuscation will break reverse-engineering tools (usually decompilers, but rarely disassemblers).
One common form of obfuscation is to rename all the variables in your code to arbitrary names.2 This obfuscation is not very effective though. It turns out not to raise the anti-attacker bar very high. Code obfuscation is a relatively uncharted area. Not much work has been done in identifying program transformations. Most of the transformations that have been identified are not very good. That is, they don’t provide much of a hurdle, or can be quite easily undone. A few of the existing obfuscating transformations can raise the bar significantly, but they usually need to be applied in bulk. Unfortunately, currently available tools for automatic code obfuscation do not perform these kinds of transformations. Instead, they perform only simple obfuscations, which are easily overcome by a skilled attacker. We discuss code obfuscation in more detail in Chapter 15.
2. This is most commonly done in languages like Java, in which symbol stripping isn’t possible, or in files that are dynamically linked and need to keep symbols.
Security for Shrink-Wrapped Software
If you use shrink-wrapped software in your product, you are not likely to have access to the source code. Keep in mind the problems we have discussed here. Some people like to believe that shrink-wrapped software is secure because no one can get the source (usually), or because the vendor says it’s secure. But neither of these arguments hold much water. Keep the risks in mind when your design calls for use of shrink-wrapped software.
Security by Obscurity Is No Panacea
There is nothing wrong with not providing the source to your application. There is something to be said for not making it trivially easy for others to make changes to a proprietary program, or to steal your algorithms. From a straight security perspective, source availability can sometimes make a difference, especially if people bother to look at your code for vulnerabilities, and report any that they find to you. However, just like security by obscurity has its fallacies (the main one being, “Because it’s compiled, it will stay secret”), so does security by source availability (or security by open source). In particular, we find that users tend not to look for security vulnerabilities, even if the source is available. If your program is commercial in any way, the odds are even lower that your users will find security problems for you.
In general, you should base your decision on providing source code on business factors, not security considerations. Do not use source availability, or the lack thereof, as an excuse to convince yourself that you’ve been duly diligent when it comes to security.
The Flip Side: Open-Source Software
Proponents of open source claim that security is one of the big advantages of “open sourcing” a piece of software. Many people seem to believe that releasing open-source software magically removes all security problems from the source code in question. In reality, open sourcing your software can sometimes help, but is no cure-all. And you should definitely not rely on it as your sole means of ensuring security. In fact, open sourcing software comes with a number of security downsides.
Is the “Many-Eyeballs Phenomenon” Real?
The main benefit of open-source software as it relates to security is what has been called the many-eyeballs phenomenon: Letting more developers scrutinize your code makes it more likely that bugs, especially security-related bugs, are found and repaired in a timely manner. One formulation that Eric Raymond has coined “Linus’ Law” is, “given enough eyeballs, all bugs are shallow,” which is obviously untrue (but is a useful hyperbole) [Raymond 2001].
Certainly, this phenomenon can help you find problems in your code that you otherwise may not have found. However, there is no guarantee that it will find any security problems in your code (assuming there are some to be found), much less all of them. Nor does open sourcing guarantee that the security problems that are found are reported.
The open-source model does provide some economic incentive for others to review your code. Note that some of these incentives go away if you release code, but don’t make it free software.
One incentive is that people who find your software useful and wish to make changes may take a look at your code. If you provide the source code as if it were under a glass case—“Look, but don’t touch”—you’re not likely to get these people scrutinizing your code. If your code has pretty much every feature everyone ever thought of, or if you add every feature everyone ever suggests, you’ll get fewer people hacking the code. If people look at your code for a few seconds, but your code looks like a big tangled mess, you’ll get fewer eyeballs on it as well. In fact, if you do anything at all that makes it hard for the average open-source user to adapt your code, you’re likely to get a lot fewer eyeballs than you could get otherwise.
There is a second economic incentive for people to review your code. Some people may have critical need of your code, and will expend resources to check your code to make sure it meets their needs. In terms of security, the hope is that companies needing high levels of security assurance will spend money to make sure the code they use is secure, instead of just trusting it blindly. This incentive is, of course, present in any open-code software, whether open source or commercial.
A final incentive is personal gain. Sometimes people may explicitly wish to find security problems in your software, perhaps because they want to build a name for themselves or because they want to create a new attack.
Because of the economic incentives, people often trust that projects that are open source are likely to have received scrutiny, and are therefore secure. When developers write open source software, they usually believe that people are diligently checking the security of their code, and, for this reason, come to believe it is becoming more and more secure over time. Unfortunately, this bad reasoning causes people to spend less time worrying about security in the first place. (Sounds suspiciously like a penetrate-and-patch problem, doesn’t it?)
There are several reasons that the economic incentives for people to help make an open source project secure don’t always work. First, the largest economic incentive of all in open source is for people to make changes to your code when they find something they’d like to change. Notice that this incentive doesn’t get you free security audits by people who know what they’re doing. What it does get you is eyeballs looking at the parts of your code people want to adapt. Often, it’s only a small part of your code.
Plus, people generally aren’t thinking about security when they’re looking at or modifying your code, just as most developers don’t really think much about security when they’re writing code in the first place. Generally speaking, developers have become adept at ignoring security up front and trying to bolt it on as an afterthought when they’re done. People looking to make functionality changes in your code don’t often have security on their agenda. We’ve often come across programmers who know very well why strcpy is dangerous, yet write code using strcpy without thinking about the implications because it’s easier to code that way. At some point these developers usually decide to go back through their code when they’re done to secure it. Often, however, they forget to change some things they should have done properly in the first place.
In truth, most developers don’t know much about security. Many developers know a little bit about buffer overflows. They know a small handful of functions that should be avoided, for example. But a majority of these developers don’t understand buffer overflows enough to avoid problems beyond not using the handful of dangerous calls with which they’re familiar. When it comes to flaws other than buffer overflows, things are much worse. For example, it is common for developers to use cryptography but to misapply it in ways that destroy the security of a system. It is also common for developers to add subtle information leaks to their programs accidentally. Most technologists wouldn’t know there was a problem if they were staring right at it. This goes for open-source and non–open-source developers alike.
As a mundane example of the problem, let’s look at something that requires far less specialized knowledge than software security. Here’s some code from Andrew Koenig’s book C Traps and Pitfalls [Koenig 1988]:
![]()
This code won’t work in the way the programmer intended; the loop will never exit. The code should read c == ' ' not c = ' '. However, none of the many code-savvy reviewers who read his book noticed the problem—people who were supposed to be looking for technical deficiencies in the book. Koenig says that thousands of people saw the error before the first person noticed it. This kind of problem seems obvious once pointed out, but it is very easy to gloss over.
When one author (Viega) examined an open-source payment system used by nearly every Dutch bank, he saw them build a nice input abstraction that allowed them to encrypt network data and to avoid buffer overflows, in theory. In practice, the generic input function was called improperly once, allowing an attacker not only to “overflow” the buffer, but also to bypass all the cryptography. We hope that at least one of the banks had thought to audit the software (banks are usually the paranoid type). Although this error was subtle, it wasn’t too complex at the surface. However, determining whether the problem in calling a function was actually an exploitable buffer overflow took almost a full day, because the buffer had to be traced through a cryptographic algorithm. For a while, it looked as if, although you could send a buffer that was too large and crash the program, you couldn’t run code because it would get “decrypted” with an unknown key, mangling it beyond use. Careful inspection eventually proved otherwise, but it required a lot of effort.
The end result is that even if you get many eyeballs looking at your software (How many software projects will get the large number of developers that the Linux project has?), they’re not likely to help much, despite the conventional wisdom that says otherwise. Few developers have the know-how or the incentive to perform reasonable security auditing on your code. The only people who have that incentive are those who care a lot about security and need your product audited for their own use, those who get paid lots of money to audit software for a living, and those who want to find bugs for personal reasons such as fame and glory.
Economic factors work against open-source vendors who may wish to raise the level of security in a given software package. The problem comes in justifying a significant investment in raising the level of assurance. Any problems that are discovered and fixed must, as part of the tenets of many kinds of open-source licensing, be reflected in everyone’s source base, diluting the return on investment for the investing vendor. Plus, assurance and risk management are not incremental activities, and constantly evolving code bases (a common occurrence in open-source projects) thus require continuous assurance investment. Economics does not appear to be on the side of security through open source.
Even some of the most widely scrutinized pieces of open source software have had significant bugs that lay undetected for years, despite numerous scrutinizing eyes. For example, 1999 and 2000 saw the discovery of at least six critical security bugs in wu-ftpd (www.wu-ftpd.org), most of which had long existed but had never been found. This code had been examined many times previously both by security experts and by members of the cracker community, but if anyone had previously discovered the problem, no one told the world. Some of these problems are believed to have lain undiscovered for more than ten years.
In fact, the wu-ftpd code was previously used as a case study for a number of vulnerability detection techniques. FIST, a dynamic vulnerability detection tool based on fault injection, was able to identify the code as potentially exploitable more than a year before the exploit was released [Ghosh, 1998]. However, before the exploit was publicized, the security-savvy developers of FIST believed, based on their inspection of the code, that they had detected an unexploitable condition.
In code with any reasonable complexity, finding bugs can be very difficult. The wu-ftpd source is not even 8,000 lines of code, but it was easy for several bugs to stay hidden in that small space over long periods of time.
Why Vulnerability Detection Is Hard
Many of the problems found in wu-ftpd during 1999 and 2000 were simple buffer overflow conditions. How is it that so many people could miss these problems? (In fact, how do we know that they did?) It turns out that determining whether an individual use of a particular function is dangerous can sometimes be difficult. That’s because not every use of a dangerous function is inherently dangerous.
Consider the case of buffer overflows. There are a large number of functions in the C standard library that should be avoided because they often lead to buffer overflow problems (see Chapter 7). However, most of these functions can be used in a safe way. For example, strcpy is one of the most notorious of all dangerous library functions. The following code is a dangerous use of strcpy:

If the name of the program is more than 255 characters (not counting the terminating null character), the buffer program_name overflows. On most architectures, the overflow can be manipulated to give a malicious user a command prompt with the privileges of the program. Therefore, if your program has administrator privileges (in other words, it is setuid root on a UNIX system, or is run by a root user with attacker-supplied inputs), a bug of this nature could be leveraged to give an attacker administrative access to your machine.
A simple modification renders the previous code example harmless:
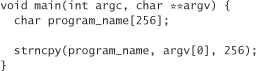
This call to strncpy copies from argv[0] into program_name, just like a regular strcpy. However, it never copies more than 256 characters. Of course, this code has other problems because it leaves the string unterminated!
In both of these examples, it is quite easy to determine whether a problem exists. But in more complex code, doing so is often far more difficult. If we see strcpy somewhere in the source code, and the length of the string is checked immediately before use, then we can be pretty sure that there will not be a problem if the check is written correctly. But what if there is no such immediately obvious check? Perhaps the programmer omitted the check, or perhaps it exists elsewhere in the program. For a complex program such as wu-ftpd, following the program logic backward through all possible paths that reach a given location can be difficult. Often, such a call looks okay, but turns out to be exploitable because of subtle interactions between widely separated sections of code.
Certainly, it is preferable to choose “safe” versions of standard library functions, when they are available. For example, snprintf is a “safe” version of sprintf, but it is not available on every platform. However, even these calls can be misused. For example, strncpy is preferable to strcpy for security, but it is not completely immune to buffer overflow errors. Consider the following code fragment:
strncpy (dst, src, n);
If, by some error, n is larger than the size of dst when this code executes, a buffer overflow condition is still possible.
All this serves to show why finding security bugs in source code is not always as straightforward as some people may believe. Nevertheless, simple code scanning tools (see Chapter 6) are certainly useful, and are amenable to use by the open-source movement.
Other Worries
Of course, code scanning tools can be used by bad guys too. This points out other problems with relying on the outside world to debug security-critical code. One worry is that a hacker may find the vulnerability and keep the information private, using it only for unsavory purposes. Thankfully, many people in the hacker community have good intentions. They enjoy breaking things, but they do so to increase everyone’s awareness of security concerns. Such hackers are likely to contact you when they break your program. When they do, be sure to fix the problem and distribute a repair as soon as possible, because hackers tend to believe in full disclosure.
Full disclosure means that hackers publicly disseminate information about your security problem, usually including a program that can be used to exploit it (sometimes even remotely). The rationale behind full disclosure should be very familiar. Full disclosure encourages people to make sure their software is more secure, and it also helps keep the user community educated. Whether you choose to release your source code, you should not get upset when a hacker contacts you, because he or she is only trying to help you improve your product.
You do, of course, need to worry about malicious hackers who find bugs and don’t tell you about them, or malicious hackers who attempt to blackmail you when they find an error. Although most hackers have ethics, and would not do such things, there are plenty of exceptions to the rule.
On Publishing Cryptographic Algorithms
Many open-source security advocates point to cryptography to support their claim that publishing source code is a good idea from a security perspective. Most cryptographers believe that publishing a cryptographic algorithm is an essential part of the independent review and validation process. The reasoning goes that the strength of a cryptographic algorithm is derived from its strong mathematics, not from keeping the algorithm secret. Plus, external review is essential, because cryptography is complicated and it is easy to make a subtle mistake. The published algorithm approach has proved most useful and prudent.
Software security is not cryptography. Although architectural review and source code review should certainly be a part of any software development process, it is not clear that publishing source code leads to benefits similar to those enjoyed by the cryptographic community.
Both in cryptography and software security, what really matters is how much expertise and diversity of experience gets invested in your work. Even in cryptography, some algorithms that are trade secrets have maintained reasonable reputations, partially because of the long track record of the inventors and partially because enough outside experts were brought in to review the work (we’re thinking of algorithms from RSA Security in particular, although some of their algorithms have been broken once they were revealed).
Two More Open-Source Fallacies
The claim that open source leads to better security appears to be based on at least two more fallacies that go beyond confusion over the many-eyeballs phenomenon. We call these fallacies the Microsoft fallacy and the Java fallacy.
The Microsoft Fallacy
The Microsoft fallacy is based on the following logic:
1. Microsoft makes bad software.
2. Microsoft software is closed source.
3. Therefore all closed-source software is bad.
Without getting into the value judgment stated in premise 1 (full disclosure: we wrote this book using Microsoft Word), it is clear that this argument holds little water. Neither availability of source code nor cost and ownership of software have anything to do with software’s inherent goodness. Plenty of open-source software is bad. Plenty of closed-source software is good.
Because Microsoft appears to be vilified by many software professionals, the Microsoft fallacy appeals to raw emotions. Nevertheless, it is not logical and should be abandoned as a supporting argument for open source.
The Microsoft fallacy is an important one to discuss, because many people claim that open source is good because source code analysis is good. Note that this is a simple confusion of issues. Of course source code analysis is an important and useful tool for building secure software, but applying such techniques does not rely on advocating the open-source model! There is nothing to stop Microsoft from using source code analysis as part of their software development process. In fact, they do!
The Java Fallacy
The Java fallacy can be stated as follows: If we keep fixing the holes in a given piece of software, eventually the software will be completely secure.
Open source proponents interested in security implicitly assume that software is not a moving target. One lesson we can learn from the Java security field is that software is an evolving and dynamic thing. Because the target moves so quickly, it is incorrect to assume that patching holes eventually results in something secure.
Part of the reason we wrote this book is to get past the penetrate-and-patch approach to security. The problem is, building secure software is not easy.
From February 1996 to December 2001, more than 19 serious security problems were discovered in implementations of Java. As discussed in [McGraw, 1999], a flurry of security problems historically accompanies a major release of Java. Java 2, arguably one of the most secure commercially viable platforms available, illustrates that a moving target does not become “more secure” over time. In fact, until you “fill up” all the holes, your program is always insecure. Worse, you’ll never know when or if your stuff becomes secure, because it’s impossible to prove that something of interesting complexity is secure.
There is no substitute for proper design and analysis when it comes to building secure software. Even Java has fallen prey both to design problems (especially in the class-loading system) and to simple implementation errors.
An Example: GNU Mailman Security
We stated earlier that if you do anything at all that makes it hard for the average open source user to work on your code, you’ll end up with fewer people involved in your project (and thus fewer eyeballs). One example to consider is the GNU Mailman project, an open-source mailing list management package originally written by one of us (Viega).
Mailman is written in Python, which is nowhere near as popular as C. A large number of people who say they would have liked to help with the development ended up not helping because they didn’t want to have to learn Python to do so. Nonetheless, the GNU Mailman project still managed to get plenty of developers hacking the code and submitting patches. The problem is, many of them didn’t seem to care about security.
The GNU Mailman project shows that the community is currently way too trusting when it comes to security. Everyone seems to assume that everyone else has done the proper auditing, when in fact nobody has. Mailman has been used at an impressive number of places during the past several years to run mailing lists (especially considering how much market penetration Majordomo had five years ago).
But for three years, Mailman had a handful of obvious and glaring security problems in the code. (Note that the code was written before we knew or cared much about security!) These problems were of the type that any person armed with grep and a single iota of security knowledge would have found in seconds. Even though we had thousands and thousands of installs during that time period, no one reported a thing.
We first realized there were problems as we started to learn more about security. And in this case, we can state in no uncertain terms that the many-eyeballs phenomenon failed for Mailman. (We can point to plenty of other examples where it also failed. Recall wu-ftpd.) The horrible thing here is that the problems in Mailman persisted for four years, despite being packaged in products you’d expect to be security conscious, such as the Red Hat Secure Web Server product. Some people may think that Red Hat would have expended some energy auditing software before including it in a product with “secure” in the name, but they didn’t. And we’re not really surprised at all, because it is way too easy to assume that a given subsystem does its job well with respect to security, when it doesn’t.
The people most likely to look at your product and find security problems are those who care a lot about security. Even if it looks like the incentive is there for a company to spend money to audit code they plan to use (say, the Red Hat people), this generally doesn’t happen. We think this is because it’s too easy to believe other people have already addressed the problem. Why reinvent the wheel? Why do somebody else’s job? Although there are groups, including the OpenBSD developers, who try to be as thorough as possible on as much software as possible, you should definitely wonder whether the bulk of the experts auditing your code wear black hats or white ones.
Even if you do get the right kind of people doing the right kinds of things, you may end up having security problems that you never hear about. Security problems are often incredibly subtle, and may span large parts of a source tree. It is not uncommon for two or three features to be spread throughout the program, none of which constitutes a security problem when examined in isolation, but when taken together can create a security breach. As a result, doing security reviews of source code tends to be complex and tedious to the point of boredom. To do a code review, you are forced to look at a lot of code, and understand it all well. Many experts don’t like to do these kinds of reviews, and a bored expert is likely to miss things as well.
By the way, people often don’t care about fixing problems, even when they know they’re there. Even when our problems in Mailman were identified, it took a while to fix them, because security was not the most immediate concern of the core development team.
Marcus Ranum reports similar data to our Mailman example from his association with the widely used firewall tool kit (www.fwtk.org). Interestingly, this famous piece of open-source code was created for and widely used by security people (who contributed to the project). This is more clear evidence that the many-eyeballs phenomenon is not as effective as people think.
More Evidence: Trojan Horses
Open-source evangelists make big claims about security. For example, we’ve heard strongly worded claims from Eric Raymond himself that the many-eyeballs phenomenon prevents Trojan horses from being introduced in open-source software. He points to the “TCP wrappers” Trojan horse from early 1999 as supporting evidence. According to him, if you put a Trojan horse in open-source software, it will never endure. We think this evidence only supports the theory that the most obvious problems are likely to be found quickly when the source code is around. The TCP wrappers Trojan horse was no poster child for stealthy Trojan horses. The code was glaringly out of place, and obviously put there only for malicious purposes. By analogy, we think the TCP wrappers Trojan horse is like what you would have if the original Trojan horse had come with a sign hanging around its wooden neck that said, Pay no attention to the army hidden in my belly!
The Trojan horse tested to see whether the client connection was coming from the remote port 421. If it was, then TCP wrappers would spawn a shell. The source code for spawning a shell is one line. It’s really obvious what’s going on, considering that TCP wrappers would never need to launch a shell, especially one that is interactive for the remote connection.
Well-crafted Trojan horses are quite different. They look like ordinary bugs with security implications, and are very subtle. Take, for example, wu-ftpd. Who is to say that one of the numerous buffer overflows found in 1999 was not a Trojan horse introduced years ago when the distribution site was hacked? Steve Bellovin once mentioned a pair of subtle bugs (found in a system that had not yet been shipped) that individually was not an issue, but added together and combined with a particular (common) system configuration option formed a complex security hole. Both bugs were introduced by the same programmer. What made this particularly interesting was that the audit that found the hole had been instigated when the programmer in question was arrested for hacking (for which he later pleaded guilty)! Bellovin was never sure whether they were added intentionally or not [Bellovin, personal communication, December 2001].
To Open Source or Not to Open Source
Open sourcing your software may make it more likely that any security problems in your code will be found, but whether the problems are found by good guys or bad guys is another matter. Even when good guys find a problem, bad guys can still exploit the problem for a long time, because informing users and getting them to upgrade is a much slower process than the distribution of exploits in the hacker community. For example, a bug in the very popular Cold Fusion server that was found in December 1998 continued to make news headlines for years. Although the severity of the bug was not realized until April 1999, attacks based on this bug were still being reported at an astounding rate in mid July 1999. Some of the sites being attacked were even warned of the vulnerability months in advance, and did not take enough precautionary measures. See Chapter 1 for more about this trend.
In any case, you’re certain not to gain much from the many-eyeballs phenomenon if you don’t release your code, because it is likely that the vast majority of the people who analyze your program for security problems have nefarious motives, and probably won’t end up sharing their discoveries with you. By taking away the source code, you make your program much harder for people to analyze, and thus make it less likely that anyone will help you improve your product.
There are other factors that make open-source software less effective than it could be. One problem is that the source code that people end up auditing may not map at all to the binary people are using. For example, let’s say that someone were to break into the site of the person who maintains the Red Hat Package Manager (RPM) for Samba, and change the release scripts to add a Trojan horse into the source before compilation any time the RPM is rebuilt (or perhaps they add a Trojan horse to some of the commands used in the build process to do the same thing). The script could easily remove the Trojan horse from the source once the build is complete. How likely do you think it is that the package maintainer will notice the problem? Integrity checkers may be able to help with some of these problems. Tripwire [Kim, 1993] is a well-known integrity checker that is still freely available in some form (http://www.tripwire.com). There are others, such as Osiris (http://www.shmoo.com/osiris/).
Another Security Lesson from Buffer Overflows
The single most pernicious problem in computer security today is the buffer overflow. Open sourcing software has definitely helped uncover quite a few of these problems. In fact, it is likely that open source can help pick off the most obvious security problems, and do it quickly. But it is not exactly clear how many security problems in popular open-source software are hit-you-in-the-face obvious, especially in newer software. Generally, developers of popular packages have seen enough to know that they need to be slightly diligent, and they tend to program defensively enough to avoid common classes of bugs. Running an automated code-scanning tool and correcting any potential problems it reports is pretty easy. This strategy generally cleans up the super-obvious bugs, but what about the subtle security problems?
The fact is that despite the open-source movement, buffer overflows still account for more than 50% of all CERT security advisories, year after year. The open source movement hasn’t made buffer overflows an obsolete problem. We argue that in the case of buffer overflows, there are solutions to the problem that work far better than open sourcing. Here’s one: Choose the right programming language. Modern programming languages never have buffer overflow problems because the language obviates them! Much of the low-hanging malicious hacker fruit can be removed by choosing a language like Java or Python instead of C. By comparison, open source on its own is far less effective.
Beating the Drum
Not to be too repetitive, but the best way to minimize the risk of adding security flaws to your program is to educate yourself thoroughly in building secure software, and to design your application with security in mind from the very beginning.
Consider security as an important concern when you’re thinking about the requirements of your application. For example, can you write your program in a language other than C or C++? These two languages are full of ways that the average programmer can add security bugs to a program without even knowing it. Unless you are fully aware of such security concerns and you don’t mind tracking them while you hammer out code, use another language.
Java is a good choice because it is very C-like, but was designed with security in mind from the beginning (mostly concerning itself with securing mobile code). For all the security FUD surrounding Java, it is significantly more difficult to mess things up in Java (resulting in insecure code) than it is in C. However, Java is still a relatively young and complex language. There are potential bugs in the language platform a hacker could attack instead, at least using mobile code attacks.
When a security problem with your software is identified, your user community is best served if you notify them as soon as a repaired version is available. One good way is to have an e-mail distribution list for the sole purpose of announcing security bugs. But, you need to make it as easy as humanly possible for people to join this list, so that you can warn as much of your user base as possible when there is a problem. You should put a prominent notice in your software, with easy instructions, such as the following:
SECURITY NOTICE: This program currently contains no known security problems. If a security problem that could affect you is found, we’d like to tell you about it. If you’d like to receive notification if such a situation does occur, send an e-mail to [email protected]. We will not use your e-mail address for any other purpose than to notify you of important security information.
Additional outside eyes are always useful for getting a fresh perspective on your code. Think about open sourcing your software. If many people do audit your software for security on their own, you will probably have more secure software to show for it in the long run. But make sure that you get as many trusted eyes as possible to examine your code before you publicly release the source. It is a whole lot easier to limit the scope of a problem if you catch it before you ship your software!
Conclusion
We should emphasize that this chapter isn’t about open code versus closed code, or even about open source versus non-free software. There are a number of benefits to open-source software, and we think there is probably some value from a security point of view in having the source code available for all to scrutinize. Open-source software has the potential to be more secure than closed, proprietary systems, precisely because of the many-eyeballs phenomenon, but only in a more perfect world.
Nonetheless, we believe that the benefits that open source provides in terms of security are vastly overstated today, largely because there isn’t as much high-quality auditing as you might suspect, and because many security problems are much more difficult to find than many people seem to think.
Open sourcing your software may help improve your security, but there are associated downsides you must be aware of if you’re going to see real benefits. In the end, open sourcing your software makes an excellent supplement to solid development practices and prerelease source-level audits, but it is most definitely not a substitute. You should make your decision on providing source code based on business factors, not security considerations. Don’t use the source availability, or lack thereof, as a crutch to convince yourself that you’ve been duly diligent when it comes to security.