
9. Race Conditions
“O let not Time deceive you,
You cannot conquer Time.
In the burrows of the Nightmare
Where Justice naked is,
Time watches from the shadow
And coughs when you would kiss.”
—W. H. AUDEN
“AS I WALKED OUT ONE EVENING”
Race conditions are among the most common classes of bugs found in deployed software. They are only possible in environments in which there are multiple threads or processes occurring at once that may potentially interact (or some other form of asynchronous processing, such as with UNIX signals). People who have experience with multithread programming have almost certainly had to deal with race conditions, regardless of whether they know the term. Race conditions are a horrible problem because a program that seems to work fine may still harbor them. They are very hard to detect, especially if you’re not looking for them. They are often difficult to fix, even when you are aware of their existence. Race conditions are one of the few places where a seemingly deterministic program can behave in a seriously nondeterministic way. In a world where multithreading, multiprocessing, and distributed computing are becoming more and more prevalent, race conditions will continue to become a bigger and bigger problem.
Most of the time, race conditions present robustness problems. However, there are plenty of times when race conditions have security implications. In this chapter we explore race conditions and their security ramifications. It turns out that file system accesses are subject to security-related race conditions far more often than people tend to suspect.
What Is a Race Condition?
Let’s say that Alice and Bob work at the same company. Through e-mail, they decide to meet for lunch, agreeing to meet in the lobby at noon. However, they do not agree on whether they mean the lobby for their office or the building lobby several floors below. At 12:15, Alice is standing in the company lobby by the elevators, waiting for Bob. Then it occurs to her that Bob may be waiting for her in the building lobby, on the first floor. Her strategy for finding Bob is to take the elevators down to the first floor, and check to see if Bob is there.
If Bob is there, all is well. If he isn’t, can Alice conclude that Bob is either late or has stood her up? No. Bob could have been sitting in the lobby, waiting for Alice. At some point, it could have occurred to him that Alice may be waiting upstairs, at which point he took an elevator up to check. If Alice and Bob were both on an elevator at the same time, unless it is the same elevator, they will pass each other during their ride.
When Bob and Alice each assume that the other one is in the other place and is staying put and both take the elevator, they have been bitten by a race condition. A race condition occurs when an assumption needs to hold true for a period of time, but actually may not. Whether it does is a matter of exact timing. In every race condition there is a window of vulnerability. That is, there is a period of time when violating the assumption leads to incorrect behavior. In the case of Alice and Bob, the window of vulnerability is approximately twice the length of an elevator ride. Alice can step on the elevator up until the point where Bob’s elevator is about to arrive and still miss him. Bob can step on to the elevator up until the point that Alice’s elevator is about to arrive. We could imagine the door to Alice’s elevator opening just as Bob’s door shuts. When the assumption is broken, leading to unexpected behavior, then the race condition has been exploited.
When it comes to computer programs, windows of vulnerability can be large, but often they are small. For example, consider the following Java servlet:
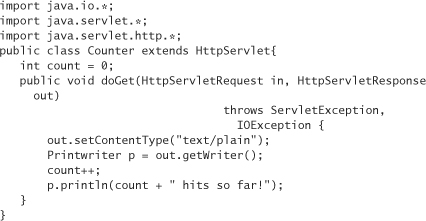
This tiny piece of code may look straightforward and correct to most people, but it has a race condition in it, because Java servlets are multithreaded. The programmer has implicitly assumed that the variable count is the same when printed as it is after the previous line of code sets its value. This isn’t necessarily the case. Let’s say that Alice and Bob both hit this servlet at nearly the same time. Alice is first; the variable count becomes 1. Bob causes count to be changed to 2, before println in Alice’s thread runs. The result is that Alice and Bob both see 2, when Alice should have seen 1. In this example, the window of vulnerability isn’t very large. It is, at most, a fraction of a second.
Even if we move the increment of the counter into the expression in which we print, there is no guarantee that it solves our problem. That is, the following change isn’t going to fix the problem:
p.println(++count + " hits so far!");
The reason is that the call to println takes time, as does the evaluation of the argument. The amount of time may seem really small, maybe a few dozen instructions. However, this isn’t always the case. In a multithread system, threads usually run for a fraction of a second, then wait for a short time while other threads get the chance to run. It could be the case that a thread increments the counter, and then must wait to evaluate the argument and run println. While that thread waits, some other thread may also increment the counter.
It is true that the window of vulnerability is very small. In practice, this means the bug may show up infrequently, if ever. If our servlet isn’t receiving several hits per second, then it is likely never to be a problem. This alludes to one of the reasons why race conditions can be so frustrating: When they manifest themselves, reproducing the problem can be almost impossible. Race conditions tend not to show up in highly controlled test environments. If you don’t have any clue where to begin looking for a problem, you may never find it. The same sorts of issues hold true even when the window of opportunity is bigger.
In real-world examples, an attacker with control over machine resources can increase the odds of exploiting a race condition by slowing down the machine. Another factor is that race conditions with security implications generally only need to be exploited once. That is, an attacker can automate code that repeatedly tries to exploit the race condition, and just wait for it to succeed. If the odds are one in a million that the attacker will be able to exploit the race condition, then it may not take too long to do so with an automated tool.
In general, the way to fix a race condition is to reduce the window of vulnerability to zero by making sure that all assumptions hold for however long they need to hold. The main strategy for doing this is to make the relevant code atomic with respect to relevant data. By atomic, we mean that all the relevant code executes as if the operation is a single unit, when nothing can occur while the operation is executing. What’s happening with race conditions is that a programmer assumes (usually implicitly) that certain operations happen atomically, when in reality they do not. When we must make that assumption, then we need to find a way to make the operation atomic. When we don’t have to make the assumption, we can code the algorithm differently.
To make an operation atomic, we usually use locking primitives, especially in multithread applications. For example, one way to fix our Java servlet would be to use the object lock on the servlet by using the synchronized keyword. The synchronized keyword prevents multiple threads from running code in the same object that is governed by the synchronized keyword. For example, if we have ten synchronized methods in a Java class, only one thread can be running any of those methods at any given time. The JVM implementation is responsible for enforcing the semantics of the synchronized keyword.
Here’s a fixed version of the counter servlet:

The problem with this solution is that it can have a significant impact on efficiency. In this particular case, we have made it so that only one thread can run our servlet at a time, because doGet is the entry point. If the servlet is incredibly popular, or if the servlet takes a long time to run, this solution won’t work very well. People will have to wait to get their chance inside the servlet, potentially for a long time. The solution is to keep the code we need to be atomic (often called a critical section) as small as possible [Silberschatz, 1999]. In Java, we can apply the synchronized keyword to blocks of code. For example, the following is a much better solution to our servlet problem:
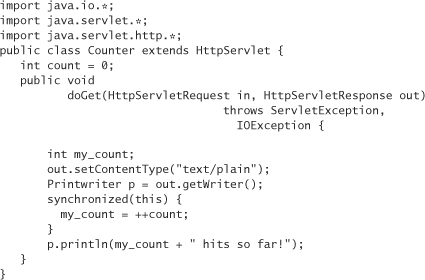
We could just put the call to println inside the synchronized block, and avoid the use of a temporary variable. However, println is a method call, which is somewhat expensive in and of itself. There’s no need for it to be in the block, so we may as well remove it, to make our critical section finish as quickly as possible.
As we have seen, race conditions may be possible whenever two or more operations occur and one of the latter operations depends on the first. In the interval between events, an attacker may be able to force something to happen, changing the behavior of the system in ways not anticipated by the developer. Making this all work as an attacker requires a security-critical context, and explicit attention to timing and knowledge of the assumptions a developer may have made.
The term race condition implies a race going on between the attacker and the developer. In fact, the attacker must “race” to invalidate assumptions about the system that the programmer may have made in the interval between operations. A successful attack involves a quick-and-dirty change to the situation in a way that has not been anticipated.
Time-of-Check, Time-of-Use
Not every race condition occurs in threaded programs. Any time that there are multiple threads of execution at once, race conditions are possible, regardless of whether they are really simultaneous as in a distributed system, such as on a single-processor multitasking machine. Therefore, multiple processes on a single machine can have race conditions between them when they operate on data that may be shared. What kinds of data may be shared? Although some systems allow you to share memory between processes, all systems allow processes to share files. File-based race conditions are the most notorious in terms of security-critical race conditions.
Note that this kind of race condition is primarily a problem on UNIX machines, mostly because local access is usually required. Much of the time, if an attacker can remotely break into a Windows machine, the attacker already has all the access necessary for whatever nefarious ends the attacker has in mind. Also, many Windows machines are not really multiuser machines. Nonetheless, this does not make security-critical, file-based race conditions impossible on a Windows machine, and you should still watch out for them. The Windows API for opening files makes these kinds of race conditions much more difficult, but they are still possible.1
1. Windows definitely eliminates most file-related race conditions. First, Windows encourages use of handles instead of continually referring to files as symbolic strings. Second, permissions checks are often combined with the call to get a file handle. However, sloppy programming can still produce a file-based race condition.
Most file-based race conditions that are security hazards follow a common formula. There is a check on some property of the file that precedes the use of that file. The check needs to be valid at the time of use for proper behavior, but may not be. (Recall the elevator problem.) Such flaws are called time-of-check, time-of-use flaws, often abbreviated TOCTOU. In the canonical example, a program running setuid root is asked to write a file owned by the user running the program. The root user can write to any file it wants, so the program must take care not to write to anything unless the actual user has permission to do so. The preferred way to solve this problem is to set the EUID to the UID running the program. However, programmers commonly use the call access in an attempt to get the same results:

The access call checks whether the real UID has permissions for a particular check, and returns 0 if it does. A text editor that needs to run as root for some reason may do this. In this case, the attacker can create a file that is malicious, such as a bogus /etc/passwd. It’s then just a matter of exploiting the race condition to install it.
The window of vulnerability here is the time it takes to call fopen and have it open a file, after having called access(). If an attacker can replace a valid file to which the attacker has permissions to write with a file owned by root, all within that time window, then the root file will be overwritten. The easiest way to do this is by using a symbolic link, which creates a file that acts very much like any other file, except that it “points to” some other file. The attacker creates a dummy file with his permissions, and then creates a symbolic link to it:
$ touch dummy
$ ln –s dummy pointer
$
Now, the attacker tells the program to open the file pointer. The attacker’s goal is to perform a command such as the following within the window of vulnerability:
$ rm pointer; ln –s /etc/passwd pointer
If successful, the program will overwrite the system password file. The attacker will have a better chance of success if using a C program that makes system calls directly rather than using the shell. To make the job easy, the attacker would write a program that fires up the editor, performs these commands, checks to see if the real password file was overwritten, and repeats the attack until successful. Problems like this are unfortunately common. A well-known, similar problem in old versions of xterm provides a classic example.
When it comes to exploitable file system race conditions, there are a few things that should be true. Usually, the attacker must have access to the local machine, legitimate or not. Also, the program with the race condition needs to be running with an EUID of root. The program must have this EUID for the period of time over which the race condition exists. Otherwise, the attacker will not be able to obtain root privileges, only the privileges he already has. There is no sense in running a race for your own privilege!
Broken passwd
Let’s look at a historic case of a TOCTOU problem (introduced in [Bishop, 1996]): a broken version of the passwd command on SunOS and HP/UX machines. The UNIX utility program passwd allows someone to change a password entry, usually their own. In this particular version of the program, passwd took the name of a password file to manipulate as one of its parameters. The broken version of passwd works as follows when the user inputs a passwd file to use:
passwd step 1. Open the password file and read it in, retrieving the entry for the user running the program.
passwd step 2. Create and open a temporary file called ptmp in the same directory as the password file.
passwd step 3. Open the password file again, copying the unchanged contents into ptmp, while updating modified information.
passwd step 4. Close both the password file and ptmp, then rename ptmp to be the password file.
Let’s pretend we’re the attacker, and that we can “step” the activities of passwd at will (causing it to wait for us in between steps while we modify the file system). Of course, in practice, we need to automate our attack, and run it multiple times in parallel with the passwd process until we hit just the right interleaving.
In this attack, we are going to overwrite some other user’s .rhosts file so that we can log in as that user. We could just as easily write over the system password file. We’ll also use symbolic linking on a directory level, instead of a file level.
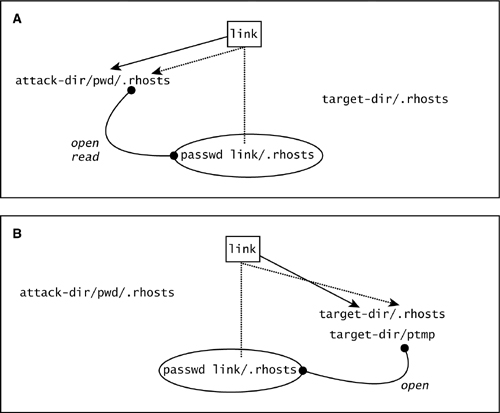
Figure 9-1A shows the state of the file system just before our attack begins. Note that we’re running our attack in our own directory, attack-dir, within which we’ll create a subdirectory pwd and the file .rhosts. We also need to fill the .rhosts file with valid information (a simulated password file entry with a blank password). And finally, we run passwd itself.
Figure 9-1 (A) The state of the system after step 1 of the passwd race condition. (B) The state of the system after step 2 of the passwd race condition.
Here’s how to do this in a generic UNIX shell:

passwd step 1. Open and read the password file (link/.rhosts) to retrieve the entry for the user running the program. Just after step 1, passwd will have opened and read the file we created (link/.rhosts). The system is now in a situation similar to what is shown in Figure 9-1A. Before step 2 runs, we need to change link quickly to point to target-dir. This is the part that must happen with exactly the right timing. (In our pretend version of the attack, remember that we have control over what happens when.) Change the link as follows: rm link; ln –s target-dir link (target-dir actually has to be specified relative to the root directory, but we’ll ignore that detail in our simplified example).
passwd step 2. Create and open a temporary file called ptmp in the same directory as the password file (link/.rhosts). Note that passwd is now using a different location to write out the file ptmp. It ends up creating a file in target-dir called ptmp, because link now points to target-dir. Now quickly, before step 3 happens, we need to change the link to point back to our directory as follows: rm link; ln –s pwd link. We need to do this because the passwd file is going to be looking for an entry in it with our UID. If we’re attacking the system password file, we wouldn’t have to go through this step (see Figure 9-1B).
passwd step 3. Open the password file (link/.rhosts in attack-dir) again and copy the contents of ptmp while updating the changed information. Note that the file ptmp has not yet been closed, so it is still the file that lives in target-dir. This means that the .rhosts file is being read from our pwd directory and is being copied to the temporary file in target-dir. See Figure 9-2A.
Figure 9-2 (A) The state of the system after step 3 of the passwd race condition. (B) The state of the system after step 4 of the passwd race condition.
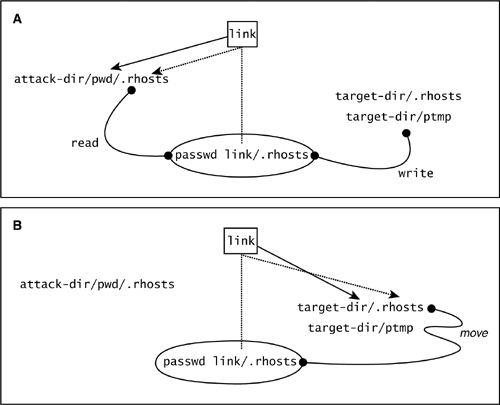
Finally, once again, we need to change link quickly to point to the target-dir: rm link; ln –s target-dir link. We do this so that when passwd performs step 4, its version of link points to target-dir again.
passwd step 4. Close both the password file and ptmp, then rename ptmp to be the password file. After all this work, our attack will have written a new .rhosts file into target-dir. This allows us to log in to the target’s account with no password (remember all those ::::’s?) and become the user who owns target-dir. Note that we can do this for target-dir equivalent to root; meaning, that if we choose the right target, we can win complete control over the machine. See Figure 9-2B.
Clearly, timing is everything in this attack. The directory pointed to through link must be pointed at precisely the right place in every stage of the attack. Getting this to happen is not always possible. In a real version of this attack we create a program to do all of the renaming and hope that our script interleaves in exactly the way described earlier with the passwd process. We do have one huge advantage in getting this to happen, though. We can run passwd as many times as we want and attack it over and over again in an automated fashion until the attack is successful.
Avoiding TOCTOU Problems
One thing you should do to help avoid TOCTOU problems is to avoid any file system call that takes a filename for an input, instead of a file handle or a file descriptor. By dealing with file descriptors or file pointers, we ensure that the file on which we are operating does not change behind our back after we first start dealing with it. Instead of doing a stat() on a file before opening it, open the file and then do an fstat() on the resulting file descriptor. Sometimes there is no reasonable alternative to a call, whether it is a check or use (and some calls can be both). In such cases, you can still use the call, but you must do so carefully. We detail a technique for doing so in the next section.
Additionally, you should avoid doing your own access checking on files. Leave that to the underlying file system. This means that you should never use the access() call. Instead, set the EUID and the EGID to the appropriate user, drop any extra group privileges by calling setgroups(0,0);.
Also, when opening arbitrary files, we recommend that you start by using open() and then using fdopen to create a FILE object once you’re sure you have the proper file. To be sure you have the proper file, we recommend the following approach:
1. lstat() the file before opening it, saving the stat structure. Note that this may be susceptible to a race condition if we perform no other checks.
2. Perform an open().
3. fstat() the file descriptor returned by the open() call, saving the stat structure.
4. Compare three fields in the two stat structures to be sure they are equivalent: st_mode, st_ino and st_dev. If these comparisons are successful, then we know the lstat() call happened on the file we ultimately opened. Moreover, we know that we did not follow a symbolic link (which is why we used lstat() instead of stat()).
If the file does not exist, lstat() says so, but an attacker may be able to place a file there where there isn’t one, before you perform the open(). To thwart this problem, pass the O_CREAT and O_EXCL flags to open(), which causes the open to fail if the file cannot be created.
As an example of these techniques, here is some code that shows how to open a file safely in a way that simulates fopen’s w+ mode. That is, the file should be created if it doesn’t exist. If it does exist, then it will be truncated:

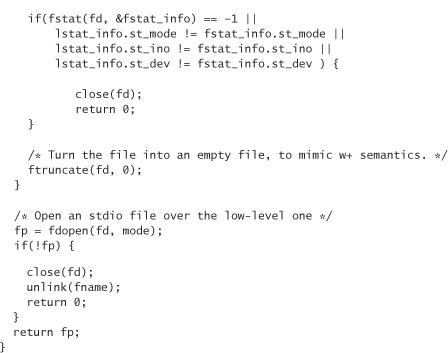
Note in the previous code that we truncate the file ourselves, and only after ensuring that it is safe to do so.
Secure File Access
In the previous two chapters we talked a lot about what can go wrong when using the file system. Primarily, we’re worried about being lazy when it comes to performing access control, and we’re worried about race conditions to which we may be susceptible. It would be nice to be able to manipulate files in a way that is guaranteed to be secure. In the previous section we discussed a way of avoiding TOCTOU problems when we can deal directly with file descriptors, and perform checks on open files, instead of on symbolic filenames. Unfortunately, this technique isn’t always something you can use, because many common calls do not have alternatives that operate on a file descriptor, including link(), mkdir(), mknod(), rmdir(), symlink(), unmount(), unlink(), and utime().
The best solution is to keep files on which we would like to operate in their own directory, where the directory is only accessible by the UID of the program performing file operations. In this way, even when using symbolic names, attackers are not able to exploit a race condition, unless they already have the proper UID (which would make exploiting a race condition pointless).
To accomplish this goal, we need to make sure that an attacker cannot modify any of the parent directories. The way to do this is to create the directory, chdir() into it, then walk up the directory tree until we get to the root, checking to make sure that the entry is not a link, and making sure that only root or the user in question can modify the directory. Therefore, we need to check the owning UID and owning GID every step of the way.
The following code takes a directory name and determines whether the specified directory is “safe” in terms of using calls that would otherwise be susceptible to race conditions. In standard C style, it returns 0 on success (in other words, if the directory can be considered safe). The user passes in a path, as well as the UID that should be considered “trusted” (usually geteuid() if not running as root). The root UID is implicitly trusted. If any parent directory has bad permissions, giving others more access to the directory than necessary (in other words, if the write or execute permissions are granted to anyone other than the owner), then safe_dir fails:
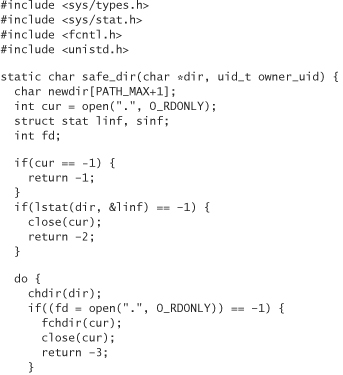

The previous code is a bit more draconian than it strictly needs to be, because we could allow for appropriate group permissions on the directory if the owning GID is the only nonroot user with access to that GID. This technique is simpler and less error prone. In particular, it protects against new members being added to a group by a system administrator who doesn’t fully understand the implications.
Once we’ve created this directory, and assured ourselves it cannot fall under the control of an attacker, we will want to populate it with files. To create a new file in this directory, we should chdir() into the directory, then double check to make sure the file and the directory are valid. When that’s done, we open the file, preferably using a locking technique appropriate to the environment. Opening an existing file should be done the same way, except that you should check appropriate attributes of the preexisting file for safety’s sake.
What about securely deleting files? If you’re not using the secure directory approach, you often cannot delete a file securely. The reason is that the only way to tell the operating system to remove a file, the unlink() call, takes a filename, not a file descriptor or a file pointer. Therefore, it is highly susceptible to race conditions. However, if you’re using the secure directory approach, deleting a file with unlink() is safe because it is impossible for an attacker to create a symbolic link in the secure directory. Again, be sure to chdir() into the secure directory before performing this operation.
Avoiding a race condition is only one aspect of secure file deletion. What if the contents of the files we are deleting are important enough that we wish to protect them after they are deleted? Usually, “deleting” a file means removing a file system entry that points to a file. The file still exists somewhere, at least until it gets overwritten. Unfortunately, the file also exists even after it gets overwritten. Disk technology is such that even files that have been overwritten can be recovered, given the right equipment and know-how. Some researchers claim that if you want to delete a file securely you should first overwrite it seven times. The first time, overwrite it with all ones, the second time with all zeros. Then, overwrite it with an alternating pattern of ones and zeros. Finally, overwrite the file four times with random data from a cryptographically secure source (see Chapter 10).
Unfortunately, this technique probably isn’t good enough. It is widely believed that the US government has disk recovery technology that can stop this scheme. If you are really paranoid, then we recommend you implement Peter Gutmann’s 35-pass scheme as a bare minimum [Gutmann, 1996]. An implementation of this technique can be found on this book’s companion Web site.
Of course, anyone who gives you a maximum number of times to write over data is misleading you. No one knows how many times you should do it. If you want to take no chances at all, then you need to ensure that the bits of interest are never written to disk. How do you store files on the disk? Do so with encryption, of course. Decrypt them directly into memory. However, you also need to ensure that the memory in which the files are placed is never swapped to disk. You can use the mlock() call to do this (discussed in Chapter 13), or mount a ramdisk to your file system. Additionally, note that it becomes important to protect the encryption key, which is quite difficult. It should never reach a disk itself. When not in use, it should exist only in the user’s head.
Temporary Files
Creating temporary files in a shared space such as /tmp is common practice. Temporary files are susceptible to the same potential problems that regular files are, with the added issue that a smart attacker may be able to guess the filename (see Chapter 10 for problems with generating data that cannot be guessed). To alleviate the situation, most C libraries2 provide calls to generate temporary files. Unfortunately, many of these calls are themselves insecure.
2. Here we’re talking about the default library that comes with the compiler or machine.
We recommend the following strategy for creating a secure temporary file, especially if you must create one in a shared directory for some reason:
1. Pick a prefix for your filename. For example, /tmp/my_app.
2. Generate at least 64 bits of high-quality randomness from a cryptographically secure source (see Chapter 10).
3. base64 encode the random bits (see Chapter 11).
4. Concatenate the prefix with the encoded random data.
5. Set umask appropriately (0066 is usually good).
6. Use fopen() to create the file, opening it in the proper mode.
7. Unless the file is on a disk mounted off the network (which is not recommended), delete the file immediately using unlink(). Don’t worry, the file does not go away until you close it.
8. Perform reads, writes, and seeks on the file as necessary.
9. Finally, close the file.
Never close and reopen the file if it lives in a directory that may be susceptible to a race condition. If you absolutely must close and reopen such a file, then you should be sure to use a secure directory, just as we recommend with regular files.
File Locking
One good primitive to have in our toolbox is a technique for locking files, so we don’t accidentally create a race condition. Note, however, that file locking on most operating systems is discretionary, and not mandatory, meaning that file locks are only enforced by convention, and can be circumvented. If you need to make sure that unwanted processes do not circumvent locking conventions, then you need to make sure that your file (and any lock files you may use) are in a directory that cannot be accessed by potential attackers. Only then can you be sure that no one malicious is circumventing your file locking.
At a high level, performing file locking seems really easy. We can just use the open() call, and pass in the O_EXCL flag, which asks for exclusive access to the file. When that flag is used, the call to open() only succeeds when the file is not in use. Unfortunately, this call does not behave properly if the file we are trying to open lives on a remote NFS-mounted file system running version 1 or version 2 of NFS. This is because the NFS protocol did not begin to support O_EXCL until version 3. Unfortunately, most NFS servers still use version 2 of the protocol. In such environments, calls to open() are susceptible to a race condition. Multiple processes living on the network can capture the lock locally, even though it is not actually exclusive.
Therefore, we should not use open() for file locking if we may be running in an environment with NFS. Of course, you should probably avoid NFS-mounted drives for any security-critical applications, because NFS versions prior to version 3 send data over the network in the clear, and are subject to attack. Even in NFS version 3 (which is not widely used at the time of this writing), encryption is only an option. Nevertheless, it would be nice to have a locking scheme that would work in such an environment. We can do so by using a lock file. The Linux manual page for open(2) tells us how to do so:
The solution for performing atomic file locking using a lockfile is to create a unique file on the same fs (e.g., incorporating hostname and pid), use link(2) to make a link to the lockfile. If link() returns 0, the lock is successful. Otherwise, use stat(2) on the unique file to check if its link count has increased to 2, in which case the lock is also successful.
Of course, when we wait for a lock to be released, we risk waiting forever. In particular, sometimes programs crash after locking a file, without ever unlocking the file, leading to a classic case of deadlock. Therefore, we’d like to be able to “steal” a lock, grabbing it, even though some other process holds it. Unfortunately, “stealing” a lock subjects us to a possible race condition. The more we steal locks, the more likely it is that we’ll end up corrupting data by writing to a file at the same time that some other process does, by not giving processes enough time to make use of their lock. If we wait a long time before stealing a lock, however, we may see unacceptable delays. The proper value for a timeout depends on your application.
On this book’s companion Web site, we provide example code for file locking that behaves properly in NFS environments.
Other Race Conditions
Security-critical race conditions do not only occur in file accesses. They show up frequently in other kinds of complex systems. For example, consider a payment system for e-commerce that uses multiple back-end databases for the sake of efficiency. The databases each contain account information for users, which needs to stay in sync. Consider an attacker with a $100 credit. After the credit is spent, all copies of the database need to be updated, so the attacker can’t connect to a different database and spend $100 more.
The way that this is done in many applications is by sending data from one server to the others when one server performs an update of data. Or, perhaps we could just send a request to lock a particular row until the databases are less busy and can synchronize. Such a lock would require all requests for the particular row to go to the database that handled the original request.
The problem with this solution is that after an attacker spends his money, there is a small time window during which the attacker can connect to other databases and spend the same money a second time. In this case, some sort of locking mechanism needs to be in place. One possible solution would be to use an additional database not used by the normal customer that is responsible for keeping track of which database has current information on a particular user.
As another example, let’s examine the Java 2 system—in particular, the interplay between policy (set ultimately by the user of a Java program) and the program itself. A Java 2 developer is at liberty to request access to particular system resources. (Note that some of this access is likely to be potentially dangerous.) A Java 2 user is at liberty to deny or allow access based on the level of trust in the identity of the code (who signed it and where it came from).
The Java 2 security model is much more sophisticated than the security model found in original versions of Java. At the core, security is still directly reliant on type safety and mediated access to potentially dangerous operating system activities. But the black-and-white “sandbox” of the early Java days based on assigning complete trust or complete skepticism is now flexibly tunable in Java 2. A sophisticated user can set policy in such a way that certain kinds of code are allowed very specific access to particular system resources.
Such power, of course, comes at a price. Setting Java 2 policy is tedious and difficult, so much so that sophisticated use of the Java 2 security model has not been widely adopted.
One of the problems with Java 2 policy is that policy in its default form (although flexible before it is instantiated) is static once it gets set. The JVM, which enforces the policy through stack inspection and other means, reads a policy file and instantiates it as a set of objects when it starts to run. This policy cannot be changed on the fly. The only way to change Java 2 policy is to restart the JVM.
Security researchers have begun to suggest ways in which policy may be reset during the execution of a particular JVM. Here is where we get back around to race conditions.
One problem with setting policy on the fly is that Java is a multithread environment. What this means is that more than one process or subprocess is often interweaved as the JVM does its work. This is the property that allows Java to play a sound file at the same time it displays a video of dancing pigs on your favorite Web site! But a multiprocess environment is, by its very nature, susceptible to race conditions.
One early research prototype suggested a way of updating policy on the fly as a JVM runs. Unfortunately, the designers forgot about race conditions. The system presented a straightforward way of removing old policy and installing new policy, but there was a central assumption lurking behind the scenes of which attackers could take advantage. The unstated idea was that nothing could happen between the policy deletion operation and the policy creation operation. This assumption is not easy to guarantee in a multithread system like Java. The design was quite susceptible to a race condition attack, and needed to be fixed.
Conclusion
Concurrent programs are incredibly difficult to debug. Race conditions are just the most security-relevant type of concurrency problem. We recommend that you stay away from multithread systems when a single thread will do. Nonetheless, when you are working on a system that makes use of time-critical multiprocessing, don’t forget the race condition! Design defensively, and think carefully about the assumptions that you’re making between operations.