
Appendix. Python 3
In December 2008, Python 3.0 was released—a major update to the Python language that breaks backwards compatibility with Python 2 in a number of critical areas. A fairly complete survey of the changes made to Python 3 can be found in the “What’s New in Python 3.0” document available at http://docs.python.org/3.0/whatsnew/3.0.html. In some sense, the first 26 chapters of this book can be viewed as the polar opposite of the “What’s New” document. That is, all of the material covered so far has focused on features that are shared by both Python 2 and Python 3. This includes all of the standard library modules, major language features, and examples. Aside from a few minor naming differences and the fact that print() is a function, no unique Python 3 features have been described.
The main focus of this appendix is to describe new features to the Python language that are only available in version 3 as well as some important differences to keep in mind if you are going to migrate existing code. At the end of this appendix, some porting strategies and use of the 2to3 code conversion tool is described.
Who Should Be Using Python 3?
Before going any further, it is important to address the question of who should be using the Python 3.0 release. Within the Python community, it has always been known that the transition to Python 3 would not happen overnight and that the Python 2 branch would continue to be maintained for some time (years) into the future. So, as of this writing, there is no urgent need to drop Python 2 code. I suspect that huge amounts of Python 2 code will continue to be in development when the 5th edition of this book is written years from now.
A major problem facing Python 3.0 concerns the compatibility of third-party libraries. Much of Python’s power comes from its large variety of frameworks and libraries. However, unless these libraries are explicitly ported to Python 3, they are almost certain not to work. This problem is amplified by the fact that many libraries depend upon other libraries that depend on yet more libraries. As of this writing (2009), there are major libraries and frameworks for Python that haven’t even been ported to Python 2.4, let alone 2.6 or 3.0. So, if you are using Python with the intention of running third-party code, you are better off sticking with Python 2 for now. If you’ve picked up this book and it’s the year 2012, then hopefully the situation will have improved.
Although Python 3 cleans up a lot of minor warts in the language, it is unclear if Python 3 is currently a wise choice for new users just trying to learn the basics. Almost all existing documentation, tutorials, cookbooks, and examples assume Python 2 and use coding conventions that are incompatible. Needless to say, someone is not going to have a positive learning experience if everything appears to be broken. Even the official documentation is not entirely up-to-date with Python 3 coding requirements; while writing this book, the author submitted numerous bug reports concerning documentation errors and omissions.
Finally, even though Python 3.0 is described as the latest and greatest, it suffers from numerous performance and behavioral problems. For example, the I/O system in the initial release exhibits truly horrific and unacceptable runtime performance. The separation of bytes and Unicode is also not without problem. Even some of the built-in library modules are broken due to changes related to I/O and string handling. Obviously these issues will improve with time as more programmers stress-test the release. However, in the opinion of this author, Python 3.0 is really only suitable for experimental use by seasoned Python veterans. If you’re looking for stability and production quality code, stick with Python 2 until some of the kinks have had time to be worked out of the Python 3 series.
New Language Features
This section outlines some features of Python 3 that are not supported in Python 2.
Source Code Encoding and Identifiers
Python 3 assumes that source code is encoded as UTF-8. In addition, the rules on what characters are legal in an identifier have been relaxed. Specifically, identifiers can contain any valid Unicode character with a code point of U+0080 or greater. For example:
![]()
Just because you can use such characters in your source code doesn’t mean that it’s a good idea. Not all editors, terminals, or development tools are equally adept at Unicode handling. Plus, it is extremely annoying to force programmers to type awkward key sequences for characters not visibly present on a standard keyboard (not to mention the fact that it might make some of the gray-bearded hackers in the office tell everyone another amusing APL story). So, it’s probably better to reserve the use of Unicode characters for comments and string literals.
Set Literals
A set of items can now be defined by enclosing a collection of values in braces { items }. For example:
days = { 'Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun' }
This syntax is the same as using the set() function:
days = set(['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun'])
Set and Dictionary Comprehensions
The syntax { expr for x in s if conditional } is a set comprehension. It applies an operation to all of the elements of a set s and can be used in a similar manner as list comprehensions. For example:
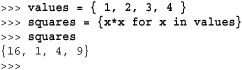
The syntax { kexpr:vexpr for k, v in s if condition } is a dictionary comprehension. It applies an operation to all of the keys and values in sequence s of (key, value) tuples and returns a dictionary. The keys of the new dictionary are described by an expression kexpr, and the values are described by the expression vexpr. This can be viewed as a more powerful version of the dict() function.
To illustrate, suppose you had a file of stock prices 'prices.dat' like this:
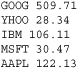
Here is a program that reads this file into a dictionary mapping stock names to price using a dictionary comprehension:
![]()
Here is an example that converts all of the keys of the prices dictionary to lowercase:
d = {sym.lower():price for sym,price in prices.items()}
Here is an example that creates a dictionary of prices for stocks over $100.00:
![]()
Extended Iterable Unpacking
In Python 2, items in an iterable can be unpacked into variables using syntax such as the following:
![]()
In order for this unpacking to work, the number of variables and items to be unpacked must exactly match.
In Python 3, you can use a wildcard variable to only unpack some of the items in a sequence, placing any remaining values in a list. For example:
![]()
In these examples, the variable prefixed by a * receives all of the extra values and places them in a list. The list may be empty if there are no extra items. One use of this feature is in looping over lists of tuples (or sequences) where the tuples may have differing sizes. For example:

No more than one starred variable can appear in any expansion.
Nonlocal Variables
Inner functions can modify variables in outer functions by using the nonlocal declaration. For example:

In Python 2, inner functions can read variables in outer functions but cannot modify them. The nonlocal declaration enables this.
Function Annotations
The arguments and return value of functions can be annotated with arbitrary values. For example:
![]()
The function attribute _ _annotations_ _ is a dictionary mapping argument names to the annotation values. The special 'return' key is mapped to the return value annotation. For example:
![]()
The interpreter does not attach any significance to these annotations. In fact, they can be any values whatsoever. However, it is expected that type information will be most useful in the future. For example, you could write this:
![]()
Annotations are not limited to single values. An annotation can be any valid Python expression. For variable positional and keyword arguments, the same syntax applies. For example:
![]()
Again, it is important to emphasize that Python does not attach any significance to annotations. The intended use is in third-party libraries and frameworks that may want to use them for various applications involving metaprogramming. Examples include, but are not limited to, static analysis tools, documentation, testing, function overloading, marshalling, remote procedure call, IDEs, contracts, etc. Here is an example of a decorator function that enforces assertions on function arguments and return values:

Here is an example of code that uses the previous decorator:
Following is some sample output of using the function:

Keyword-Only Arguments
Functions can specify keyword-only arguments. This is indicated by defining extra parameters after the first starred parameter. For example:
![]()
When calling this function, the strict parameter can only be specified as a keyword. For example:
a = foo(1, strict=True)
Any additional positional arguments would just be placed in args and not used to set the value of strict. If you don’t want to accept a variable number of arguments but want keyword-only arguments, use a bare * in the parameter list. For example:
![]()
Here is an example of usage:
![]()
Ellipsis as an Expression
The Ellipsis object (...) can now appear as an expression. This allows it to be placed in containers and assigned to variables. For example:

The interpretation of the ellipsis is still left up to the application that uses it. This feature allows the ... to be used as an interesting piece of syntax in libraries and frameworks (for example, to indicate a wild-card, continuation, or some similar concept).
Chained Exceptions
Exceptions can now be chained together. Essentially this is a way for the current exception to carry information about the previous exception. The from qualifier is used with the raise statement to explicitly chain exceptions. For example:

When the SyntaxError exception is raised, a traceback message such as the following will be generated—showing both exceptions:

Exception objects have a _ _cause_ _ attribute, which is set to the previous exception. Use of the from qualifier with raise sets this attribute.
A more subtle example of exception chaining involves exceptions raised within another exception handler. For example:

If you try this in Python 2, you only get an exception related to the NameError in error(). In Python 3, the previous exception being handled is chained with the result. For example, you get this message:

For implicit chaining, the _ _context_ _ attribute of an exception instance e contains a reference to previous exception.
Improved super()
The super() function, used to look up methods in base classes, can be used without any arguments in Python 3. For example:
![]()
In Python 2, you had to use super(C,self).bar(). The old syntax is still supported but is significantly more clunky.
Advanced Metaclasses
In Python 2, you can define metaclasses that alter the behavior of classes. A subtle facet of the implementation is that the processing carried out by a metaclass only occurs after the body of a class has executed. That is, the interpreter executes the entire body of a class and populates a dictionary. Once the dictionary has been populated, the dictionary is passed to the metaclass constructor (after the body of the class has executed).
In Python 3, metaclasses can additionally carry out extra work before the class body executes. This is done by defining a special class method called _ _prepare_ _(cls, name, bases, **kwargs) in the metaclass. This method must return a dictionary as a result. This dictionary is what gets populated as the body of the class definition executes. Here is an example that outlines the basic procedure:

Python 3 uses an alternative syntax for specifying a metaclass. For example, to define a class that uses MyMeta, you use this:

If you run the following code, you will see the following output that illustrates the control flow:

The additional keyword arguments on the _ _prepare_ _() method of the metaclass are passed from keyword arguments used in the bases list of a class statement. For example, the statement class Foo(metaclass=MyMeta,spam=42,blah="Hello") passes the keyword arguments spam and blah to MyMeta._ _prepare_ _(). This convention can be used to pass arbitrary configuration information to a metaclass.
To perform any kind of useful processing with the new _ _prepare_ _() method of metaclasses, you generally have the method return a customized dictionary object. For example, if you wanted to perform special processing as a class is defined, you define a class that inherits from dict and reimplements the _ _setitem_ _() method to capture assignments to the class dictionary. The following example illustrates this by defining a metaclass that reports errors if any method or class variable is multiply defined.

If you apply this metaclass to another class definition, it will report an error if any method is redefined. For example:

Common Pitfalls
If you are migrating from Python 2 to 3, be aware that Python 3 is more than just new syntax and language features. Major parts of the core language and library have been reworked in ways that are sometimes subtle. There are aspects of Python 3 that may seem like bugs to a Python 2 programmer. In other cases, things that used to be “easy” in Python 2 are now forbidden.
This section outlines some of the most major pitfalls that are likely to be encountered by Python 2 programmers making the switch.
Text Versus Bytes
Python 3 makes a very strict distinction between text strings (characters) and binary data (bytes). A literal such as "hello" represents a text string stored as Unicode, whereas b"hello" represents a string of bytes (containing ASCII letters in this case).
Under no circumstances can the str and bytes type be mixed in Python 3. For example, if you try to concatenate strings and bytes together, you will get a TypeError exception. This differs from Python 2 where byte strings would be automatically coerced into Unicode as needed.
To convert a text string s into bytes, you must use s.encode(encoding). For example, s.encode('utf-8') converts s into a UTF-8 encoded byte string. To convert a byte string t back into text, you must use t.decode(encoding). You can view the encode() and decode() methods as a kind of “type cast” between strings and bytes.
Keeping a clean separation between text and bytes is ultimately a good thing—the rules for mixing string types in Python 2 were obscure and difficult to understand at best. However, one consequence of the Python 3 approach is that byte strings are much more restricted in their ability to actually behave like “text.” Although there are the standard string methods like split() and replace(), other aspects of byte strings are not the same as in Python 2. For instance, if you print a byte string, you simply get its repr() output with quotes such as b'contents'. Similarly, none of the string formatting operations (%, .format()) work. For example:
![]()
The loss of text-like behavior with bytes is a potential pitfall for system programmers. Despite the invasion of Unicode, there are many cases where one actually does want to work with and manipulate byte-oriented data such as ASCII. You might be inclined to use the bytes type to avoid all of the overhead and complexity of Unicode. However, this will actually make everything related to byte-oriented text handling more difficult. Here is an example that illustrates the potential problems:
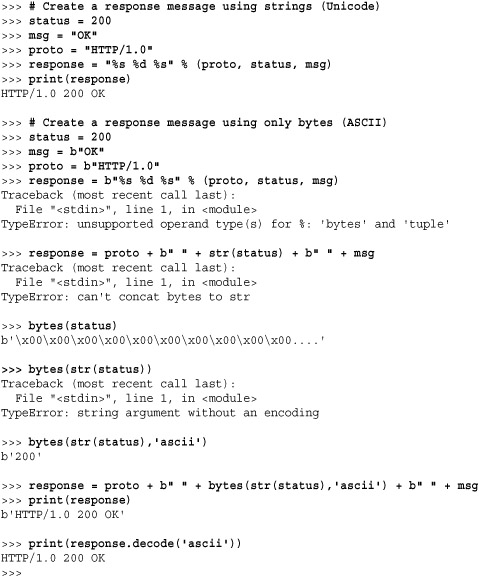
In the example, you can see how Python 3 is strictly enforcing the text/bytes separation. Even operations that seem like they should be simple, such as converting an integer into ASCII characters, are much more complicated with bytes.
The bottom line is that if you’re performing any kind of text-based processing or formatting, you are probably always better off using standard text strings. If you need to obtain a byte-string after the completion of such processing, you can use s.encode('latin-1') to convert from Unicode.
The text/bytes distinction is somewhat more subtle when working with various library modules. Some libraries work equally well with text or bytes, while some forbid bytes altogether. In other cases, the behavior is different depending on what kind of input is received. For example, the os.listdir(dirname) function only returns filenames that can be successfully decoded as Unicode if dirname is a string. If dirname is a byte string, then all filenames are returned as byte strings.
New I/O System
Python 3 implements an entirely new I/O system, the details of which are described in the io module section of Chapter 19, “Operating System Services.” The new I/O system also reflects the strong distinction between text and binary data present with strings.
If you are performing any kind of I/O with text, Python 3 forces you to open files in “text mode” and to supply an optional encoding if you want anything other than the default (usually UTF-8). If you are performing I/O with binary data, you must open files in “binary mode” and use byte strings. A common source of errors is passing output data to a file or I/O stream opened in the wrong mode. For example:

Sockets, pipes, and other kinds of I/O channels should always be assumed to be in binary mode. One potential problem with network code in particular is that many network protocols involve text-based request/response processing (e.g., HTTP, SMTP, FTP, etc.). Given that sockets are binary, this mix of binary I/O and text processing can lead to some of the problems related to mixing text and bytes that were described in the previous section. You’ll need to be careful.
print() and exec() Functions
The print and exec statements from Python 2 are now functions. Use of the print() function compared to its Python 2 counterpart is as follows:
![]()
The fact that print() is a function that means you can replace it with an alternative definition if you want.
exec() is also now a function, but its behavior in Python 3 is subtly different than in Python 2. For example, consider this code:
![]()
In Python 2, calling foo() will print the number '42'. In Python 3, you get a NameError exception with the variable a being undefined. What has happened here is that exec(), as a function, only operates on the dictionaries returned by the globals() and locals() functions. However, the dictionary returned by locals() is actually a copy of the local variables. The assignment made in the exec() function is merely modifying this copy of the locals, not the local variables themselves. Here is one workaround:
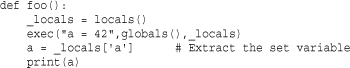
As a general rule, don’t expect Python 3 to support the same degree of “magic” that was possible using exec(), eval(), and execfile() in Python 2. In fact, execfile() is gone entirely (you can emulate its functionality by passing an open file-like object to exec()).
Use of Iterators and Views
Python 3 makes much greater use of iterators and generators than Python 2. Built-in functions such as zip(), map(), and range() that used to return lists now return iterables. If you need to make a list from the result, use the list() function.
Python 3 takes a slightly different approach to extracting key and value information from a dictionary. In Python 2, you could use methods such as d.keys(), d.values(), or d.items() to obtain lists of keys, values, or key/value pairs, respectively. In Python 3, these methods return so-called view objects. For example:
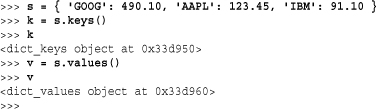
These objects support iteration so if you want to view the contents, you can use a for loop. For example:

View objects are always tied back to the dictionary from which they were created. A subtle aspect of this is that if the underlying dictionary changes, the items produced by the view change as well. For example:

Should it be necessary to build a list of dictionary keys or values, simply use the list() function—for example, list(s.keys()).
Integers and Integer Division
Python 3 no longer has an int type for 32-bit integers and a separate long type for long integers. The int type now represents an integer of arbitrary precision (the internal details of which are not exposed to the user).
In addition, integer division now always produces a floating-point result. For example, 3/5 is 0.6, not 0. The conversion to a float applies even if the result would have been an integer. For example, 8/2 is 4.0, not 4.
Comparisons
Python 3 is much more strict about how values are compared. In Python 2, it is the case that any two objects can be compared even if it doesn’t make sense. For example:
![]()
In Python 3, this results in a TypeError. For example:

This change is minor, but it means that in Python 3, you have to be much more careful about making sure data is of appropriate types. For example, if you use the sort() method of a list, all of the items in the list must be compatible with the < operator, or you get an error. In Python 2, the operation would be silently carried out anyways with a usually meaningless result.
Iterators and Generators
Python 3 has made a slight change to the iterator protocol. Instead of calling _ _iter_ _() and the next() method to perform iteration, the next() method has been renamed to _ _next_ _(). Most users will be unaffected by this change except if you have written code that manually iterates over an iterable or if you have defined your own custom iterator objects. You will need to make sure you change the name of the next() method in your classes. Use the built-in next() function to invoke the next() or _ _next_ _() method of an iterator in a portable manner.
File Names, Arguments, and Environment Variables
In Python 3, filenames, command-line arguments in sys.argv, and environment variables in os.environ may or may not be treated as Unicode depending on local settings. The only problem is that the usage of Unicode within the operating system environment is not entirely universal. For example, on many systems it may be technically possible to specify filenames, command-line options, and environment variables that are just a raw sequence of bytes that don’t correspond to a valid Unicode encoding. Although these situations might be rare in practice, it may be of some concern for programming using Python to perform tasks related to systems administration. As previously noted, supplying file and directory names as byte strings will fix many of the problems. For example, os.listdir(b'/foo').
Library Reorganization
Python 3 reorganizes and changes the names of several parts of the standard library, most notably modules related to networking and Internet data formats. In addition, a wide variety of legacy modules have been dropped from the library (e.g., gopherlib, rfc822, and so on).
It is now standard practice to use lowercase names for modules. Several modules such as ConfigParser, Queue, and SocketServer have been renamed to configparser, queue, and socketserver, respectively. You should try to follow similar conventions in your own code.
Packages have been created to reorganize code that was formerly contained in disparate modules—for example, the http package containing all the module used to write HTTP servers, the html package has modules for parsing HTML, the xmlrpc package has modules for XML-RPC, and so forth.
As for deprecated modules, this book has been careful to only document modules that are in current use with Python 2.6 and Python 3.0. If you are working with existing Python 2 code and see it using a module not documented here, there is a good chance that the module has been deprecated in favor of something more modern. Just as an example, Python 3 doesn’t have the popen2 module commonly used in Python 2 to launch subprocesses. Instead, you should use the subprocess module.
Absolute Imports
Related to library reorganization, all import statements appearing in submodules of a package use absolute names. This is covered in more detailed in Chapter 8, “Modules, Packages, and Distribution,” but suppose you have a package organized like this:

If the file spam.py uses the statement import bar, you get an ImportError exception even though bar.py is located in the same directory. To load this submodule, spam.py either needs to use import foo.bar or a package relative import such as from . import bar.
This differs from Python 2 where import always checks the current directory for a match before moving onto checking other directories in sys.path.
Code Migration and 2to3
Converting code from Python 2 to Python 3 is a delicate topic. Just to be absolutely clear, there are no magic imports, flags, environment variables, or tools that will enable Python 3 to run an arbitrary Python 2 program. However, there are some very specific steps that can be taken to migrate code, each of which is now described.
Porting Code to Python 2.6
It is recommended that anyone porting code to Python 3 first port to Python 2.6. Python 2.6 is not only backwards-compatible with Python 2.5, but it also supports a subset of new features found in Python 3. Examples include advanced string formatting, the new exception syntax, byte literals, I/O library, and abstract base classes. Thus, a Python 2 program can start to take advantage of useful Python 3 features now even if it is not yet ready to make the full migration.
The other reason to port to Python 2.6 is that Python 2.6 issues warning messages for deprecated features if you run it with the -3 command-line option. For example:

Using these warning messages as a guide, you should take great care to make sure that your program runs warning-free on Python 2.6 before moving forward with a Python 3 port.
Providing Test Coverage
Python has useful testing modules including doctest and unittest. Make sure your application has thorough test coverage before attempting a Python 3 port. If your program has not had any tests to this point, now would be a good time to start. You will want to make sure your tests cover as much as possible and that all tests pass without any warning messages when run on Python 2.6.
Using the 2to3 Tool
Python 3 includes a tool called 2to3 that can assist with code migration from Python 2.6 to Python 3. This tool is normally found in the Tools/scripts directory of the Python source distribution and is also installed in the same directory as the python3.0 binary on most systems. It is a command-line tool that would normally run from a UNIX or Windows command shell.
As an example, consider the following program that contains a number of deprecated features.

To run 2to3 on this program, type “2to3 example.py”. For example:

As output, 2to3 will identify parts of the program that it considers to be problematic and that might need to be changed. These are shown as context-diffs in the output. Although we have used 2to3 on a single file, if you give it the name of a directory, it recursively looks for all Python files contained in the directory structure and generates a report for everything.
By default, 2to3 does not actually fix any of the source code it scans—it merely reports parts of the code that might need to be changed. A challenge faced by 2to3 is that it often only has incomplete information. For example, consider the spam() function in the example code. This function calls a method d.has_key(). For dictionaries, has_key() has been removed in favor of the in operator. 2to3 reports this change, but without more information, it is not clear if spam() is actually manipulating a dictionary or not. It might be the case that d is some other kind of object (a database perhaps) that happens to provide a has_key() method, but where using the in operator would fail. Another problematic area for 2to3 is in the handling of byte strings and Unicode. Given that Python 2 would automatically promote byte strings to Unicode, it is somewhat common to see code that carelessly mixes the two string types together. Unfortunately, 2to3 is unable to sort all of this out. This is one reason why it’s important to have good unit test coverage. Of course, all of this depends on the application.
As an option, 2to3 can be instructed to fix selected incompatibilities. First, a list of “fixers” can be obtained by typing 2to3 -l. For example:

Using names from this list, you can see what a selected fix would actually change by simply typing “2to3 -f fixname filename”. If you want to apply multiple fixes, just specify each one with a separate -f option. If you actually want to apply the fix to a source file, add the -w option as in 2to3 -f fixname -w filename. Here is an example:

If you look at example.py after this operation, you will find that xrange() has been changed to range() and that no other changes have been made. A backup of the original example.py file is found in example.py.bak.
A counterpart to the -f option is the -x option. If you use 2to3 -x fixname filename, it will run all of the fixers except for the ones you listed with the -x option.
Although it is possible to instruct 2to3 to fix everything and to overwrite all of your files, this is probably something best avoided in practice. Keep in mind that code translation is an inexact science and that 2to3 is not always going to do the “right thing.” It is always better to approach code migration in a methodical calculated manner as opposed to crossing your fingers and hoping that it all just magically “works.”
2to3 has a couple of additional options that may be useful. The -v option enables a verbose mode that prints additional information that might be useful for debugging. The -p option tells 2to3 that you are already using the print statement as a function in your code and that it shouldn’t be converted (enabled by the from _ _future_ _ import print_statement statement).
A Practical Porting Strategy
Here is a practical strategy for porting Python 2 code to Python 3. Again, it is better to approach migration in a methodical manner as opposed to doing everything at once.
1. Make sure your code has an adequate unit testing suite and that all tests pass under Python 2.
2. Port your code and testing suite to Python 2.6 and make sure that all tests still pass.
3. Turn on the -3 option to Python 2.6. Address all warning messages and make sure your program runs and passes all tests without any warning messages. If you’ve done this correctly, chances are that your code will still work with Python 2.5 and maybe even earlier releases. You’re really just cleaning out some of the cruft that’s accumulated in your program.
4. Make a backup of your code (this goes without saying).
5. Port the unit testing suite to Python 3 and make sure that the testing environment itself is working. The individual unit tests themselves will fail (because you haven’t yet ported any code). However, a properly written test suite should be able to deal with test failures without having an internal crash of the test software itself.
6. Convert the program itself to Python 3 using 2to3. Run the unit testing suite on the resulting code and fix all of the issues that arise. There are varying strategies for doing this. If you’re feeling lucky, you can always tell 2to3 to just fix everything and see what happens. If you’re more cautious, you might start by having 2to3 fix the really obvious things (print, except statements, xrange(), library module names, etc.) and then proceed in a more piecemeal manner with the remaining issues.
By the end of this process, your code should pass all unit tests and operate in the same manner as before.
In theory, it is possible to structure code in a way so that it both runs in Python 2.6 and automatically translates to Python 3 without any user intervention. However, this will require very careful adherence to modern Python coding conventions—at the very least you will absolutely need to make sure there are no warnings in Python 2.6. If the automatic translation process requires very specific use of 2to3 (such as running only a selected set of fixers), you should probably write a shell script that automatically carries out the required operations as opposed to requiring users to run 2to3 on their own.
Simultaneous Python 2 and Python 3 Support
A final question concerning Python 3 migration is whether or not it’s possible to have a single code base that works unmodified on Python 2 and Python 3. Although this is possible in certain cases, the resulting code runs the risk of becoming a contorted mess. For instance, you will have to avoid all print statements and make sure all except clauses never take any exception values (extracting them from sys.exc_info() instead). Other Python features can’t be made to work at all. For example, due to syntax differences, there is no possible way to use metaclasses in a way that would be portable between Python 2 and Python 3.
Thus, if you’re maintaining code that must work on Python 2 and 3, your best bet is to make sure your code is as clean as possible and runs under Python 2.6, make sure you have a unit testing suite, and try to develop a set of 2to3 fixes to make automatic translation possible.
One case where it might make sense to have a single code base is with unit testing. A test suite that operates without modification on Python 2.6 and Python 3 could be useful in verifying the correct behavior of the application after being translated by 2to3.
Participate
As an open-source project, Python continues to be developed with the contributions of its users. For Python 3, especially, it is critically to report bugs, performance problems, and other issues. To report a bug, go to http://bugs.python.org. Don’t be shy—your feedback makes Python better for everyone.