
3
A Software Testing Lifecycle
Testing is the process of executing a software product on sample input data and analyzing its output. Unlike other engineering products, which are usually fault-free, software products are prone to be faulty, due to an accumulation of faults in all the phases of their lifecycle (faulty specifications, faulty design, faulty implementation, etc.). Also, unlike other engineering products, where faults arise as a result of product wear and/or decay, the faults that arise in software products are design faults, which are delivered with the new product.
3.1 A SOFTWARE ENGINEERING LIFECYCLE
The simplest model of a software product lifecycle views the process of developing and evolving the product as a set of phases proceeding sequentially from a requirements analysis phase to a product operation and maintenance phase. While this process model is widely believed to be simplistic, and not to reflect the true nature of software development and evolution, we adopt it nevertheless as a convenient abstraction. If nothing else, this process model enables us to situate software testing activities in their proper context within the software engineering lifecycle. For the sake of argument, we adopt the following sequence of phases:
- Feasibility Analysis: Feasibility analysis is the phase when the economic and technical feasibility of the development project is assessed, and a determination is made of whether to proceed with the development project, within a given budget, schedule, and technological means.
- Requirements Analysis: The phase of requirements analysis is the most difficult of the software lifecycle, at the same time as it is the most fateful phase, in terms of determining the fate of the project (its success or failure, its scope, its cost, its value to users, etc.). Whereas a naïve view may understand this phase as consisting of a user dictating user requirements and a software engineer who is carefully taking notes, the reality of this phase is typically much more complex: The requirements engineer (a software engineering specializing in analyzing requirements) must conduct a vast data gathering operation that consists in the following steps: identifying system stakeholders; gathering relevant domain knowledge (pertaining to the application domain of the system); identifying relevant outside requirements (relevant laws of nature, applicable regulations, relevant standards, etc.); collecting requirements from all relevant stakeholders (system end users, system operators, system custodians, system managers, etc.); documenting the requirements; identifying possible ambiguities, gaps, inconsistencies; resolving/negotiating inconsistencies; specifying the functional and nonfunctional requirements of the system; and finally validating the requirements specification for completeness (all relevant requirements are captured) and minimality (all captured requirements are relevant). As we shall see in Chapter 5, validating a specification has much in common with testing a program.
- Product Architecture: The phase of product architecture consists in determining the broad structure of the product, including a specification of the main components of the architecture, along with a specification of the coordination and communication mechanisms between the components, as well as decisions pertaining to how the system will be deployed, how it will be distributed, how data will be shared, and so on. The architecture is usually evaluated by the extent to which it supports relevant operational attributes (see Chapter 2).
- Product Design: In the product design phase, system designers make system-wide design decisions pertaining to data structures, data representation, and algorithms, and decompose the software product into small units to be developed independently by programmers. This phase is verified by ensuring that if all the units perform as specified, then the overall system performs as specified.
- Programming: The phase of programming can be carried out by a large number of programmers working independently (ideally, at least), and developing program units from unit specifications. This phase is verified by means of Unit Testing, where each unit is tested against the specification that it was developed to satisfy.
- System Integration: Once all the units have been developed, the system is put together according to its design and tested to ensure that it meets its system wide specification. This is referred to as Integration Testing, as it tests the integration of the units into the overall system. This phase takes usually a significant portion of the project’s budget and schedule. This phase can also be used to carry out another form of testing: Reliability Testing, where fault removal is accompanied by an evolving estimate of reliability growth, until a target reliability is reached; this differs from integration testing in that its focus is not on finding faults, but on improving reliability (hence targeting those faults that have the greatest negative impact on reliability).
- Delivery: Once the system has gone through integration testing and has been deemed to be ready for delivery, it is delivered to the customer, in an operation that includes Acceptance Testing. Like integration testing, acceptance testing is a system-wide test. But whereas integration testing is focused on finding faults, acceptance testing is focused on showing their absence, or at least highlighting their sparsity. This phase can also be used to carry out another form of testing: Certification Testing, whose goal is to certify (or not) that the product meets some quality standard; this differs from acceptance testing in that the goal is not to make a particular customer happy, but rather to satisfy a generic quality standard.
- Operations and Maintenance: If during the operation phase, the software product fails, or the software requirements change, then a maintenance operation is initiated to alter the software product accordingly. Upon the completion of the maintenance operation, the software system must be tested; but given that the maintenance operation may involve only a limited portion of the source code, or only limited aspects of system functionality, it may be advantageous to focus the testing effort to those portions of the code that have been modified, or those functional aspects that are part of the altered requirements; this is called Regression Testing.
Figure 3.1 illustrates this lifecycle, and highlights the testing activities that take place therein. Each phase of this lifecycle concludes with a verification and validation step, intended to ensure that the deliverable that is produced in the phase is sufficiently trustworthy to serve as a launchpad for the next phase. Strictly speaking, validation ensures that the specification is valid (in the sense that it record all the valid requirements, and nothing but the valid requirements), whereas verification ensures that the product is correct with respect to the specification; hence, in theory, validation is used at the end of the requirements specification phase, and verification is used in all subsequent phases (see Fig. 3.2 for a summary illustration). But in practice, it is a good idea to maintain a healthy suspicion of the specification throughout the lifecycle, to test it at every opportunity (we will explore means to this end in subsequent chapters), and be prepared to adjust it as necessary.
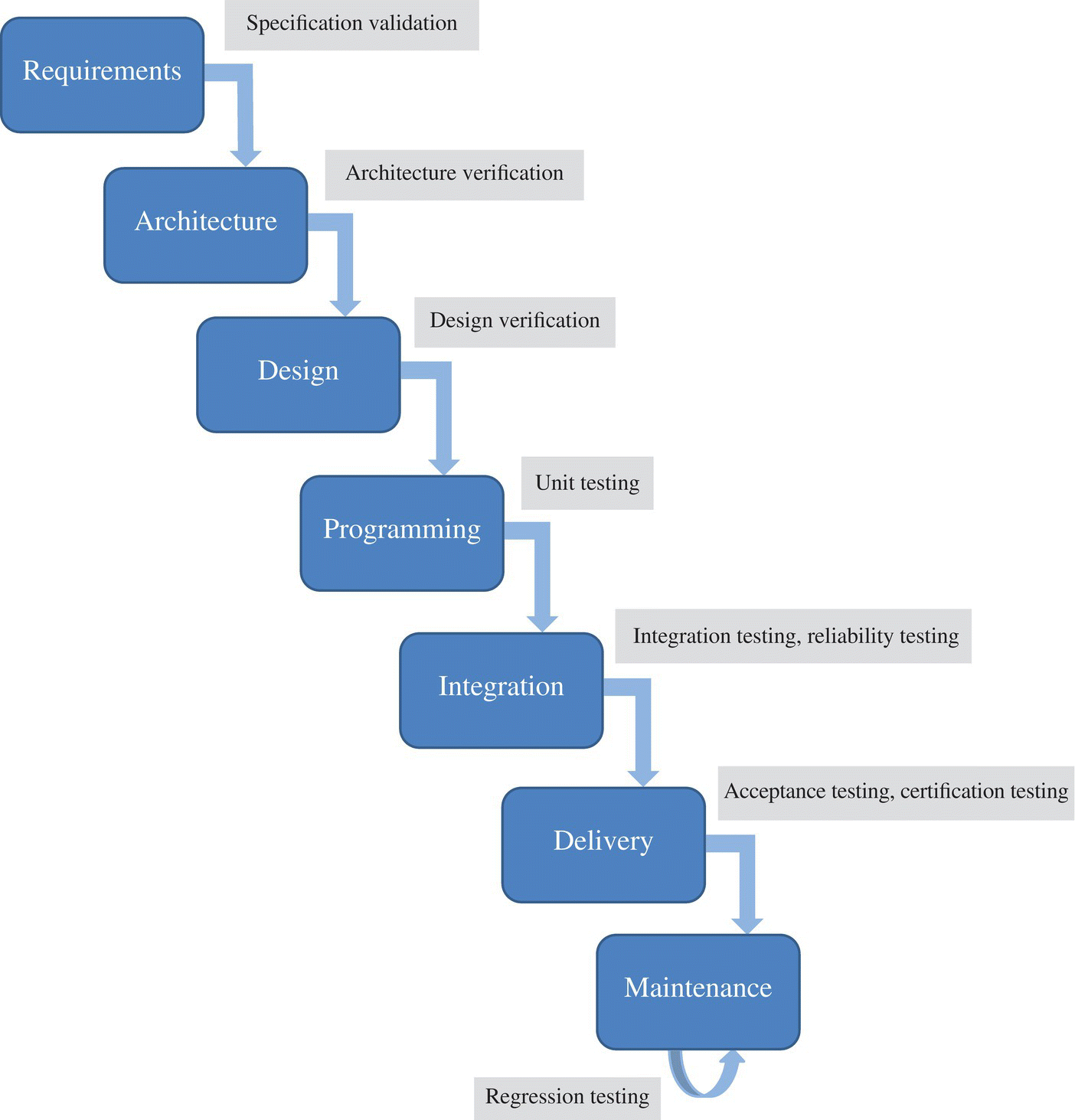
Figure 3.1 A reference software lifecycle.
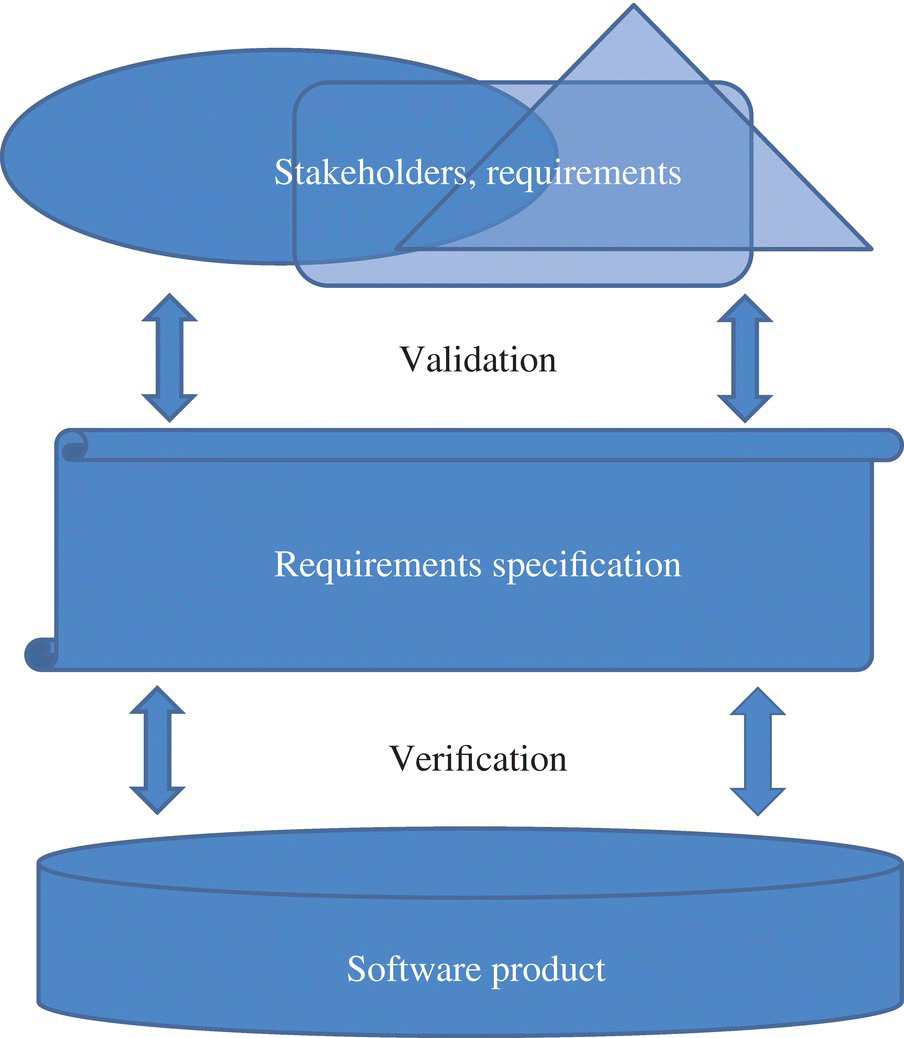
Figure 3.2 Verification and validation.
As Figure 3.2 shows, it is much harder to ascertain specification validation than it is to ascertain program verification, for the following reasons:
- Assuming the requirements specification is written in a formal notation, the verification step consists in checking a relationship between two formal documents (the specification and the program); as hard as this may be, it is a well-defined property between two formal artifacts. By contrast, validation involves a formal artifact (the specification) and a heterogeneous collection of requirements and facts from diverse sources.
- Because verification involves a well-defined property between two well defined artifacts, it is a systematic, repeatable, possibly automatable operation.
- Because validation involves interaction with multiple stakeholders, it is an informal process that is neither repeatable nor automatable. Its success depends on the competence, cooperation and dependability of several human actors.
In addition to this chronological decomposition of the lifecycle into phases, we can also consider an organizational decomposition the lifecycle into activities, where each activity represents a particular aspect of the software project carried out by a specialized team. A typical set of activities includes the following:
- Requirements Analysis
- Software Design
- Programming
- Test Planning
- Configuration Management and Quality Assurance
- Verification and Validation
- Manuals
- Project Management
So that a complete view of the lifecycle is given by a two-dimensional table that shows phases and activities; in principle, all activities are active at all phases, though to different degrees.
3.2 A SOFTWARE TESTING LIFECYCLE
So far, we have seen many testing processes, including unit testing, integration testing, reliability testing, acceptance testing, certification testing, and regression testing. We will review other forms of testing in the next chapter. While they may differ in many ways, these forms of testing all follow a generic process, which includes the following phases:
- Preparing a Test Environment: With the possible exception of regression testing, which takes place during the operations and maintenance, most testing happens in a development environment rather than its actual operating environment. Hence, it is incumbent on the test engineer to create a test environment that mimics the operational environment as faithfully as possible. This may be a nontrivial task, involving such steps as simulating the operational environment; creating stubs for missing parts of the operational environment; and simulating workload conditions by creating fictitious demands on the system.
- Generating Test Data: Ideally, to test a program, we would like to execute it on all possible inputs or combinations of inputs or combinations of inputs and internal states (if the program carries an internal state), and observe its behavior under these circumstances. Unfortunately, that is totally unrealistic for all but the most trivial programs. Hence, the challenge for the program tester is to find a set of test data that is small enough to be feasible, yet large enough to be representative. What do we mean by representative: we mean that if the program executes successfully on the test data, then we can be fairly confident that it would execute successfully on any input data (or more generally any configuration of input data and internal state). Quantitatively, if we let S be the set of all possible configurations of inputs and internal states, and D the subset of S that includes all the configurations on which the program was tested successfully; and if we let σ and δ be, respectively, the events “the program runs successfully on all elements of S” and “the program runs successfully on all elements of D,” then we want the conditional probability Π(σ | δ) to be as close to 1.0 as possible. This, in general, is a very difficult problem; hence Dijkstra’s often-cited quote that “testing can be used to prove the presence of faults, never their absence.” While one can hardly argue with this premise, we will see in later chapters that while testing cannot be used to prove a program correct, it can be used to establish lesser goals, that are useful nevertheless, such as: to estimate the reliability of a program; to estimate the fault density of the program; to certify that the reliability of a program exceeds a required threshold; or, if used in conjunction with fault diagnosis and removal, to enhance the reliability of a program.
In practice, test data is generated by means of what is called a test selection criterion. This is a condition that characterizes elements of S that are in D. It is not difficult to generate a test selection criterion that produces a small set D; what is very difficult is to generate a test selection criterion that is representative of S (a much harder case to make). The generation of a test selection criterion is one of the most important attributes of software testing; it is also a very difficult decision to make, as we discuss in Part III of the book, and the aspect of software testing that has mobilized the greatest share of researcher attention. Selecting what data to run the product on determines the fate of the test process, in the sense that it affects the extent to which the test achieves its goal. We can identify three broad categories of test selection criteria, which are as follows:
- Functional criteria of test data selection: These criteria consist in generating test data by inspecting the specification of the software product; the goal of these criteria is to exercise all the functionalities and services that the product is supposed to deliver.
- Structural criteria of test data selection: These criteria consist in generating test data by inspecting the source code of the product; the goal of these criteria is to exercise all the components of the product.
- Random test data selection: These criteria consist in generating test data randomly over all of S (the combination of the input space and the internal state space); but this is usually done according to a specific usage pattern. In practice, the combined configurations of inputs and internal states are not equally likely to occur; some may be more likely to occur than others; in order for this type of selection criterion to be effective, we need to have a probability distribution function over S that quantifies the likelihood of occurrence of any element of S in normal usage. By adhering to the same probability distribution during the testing phase, we ensure that whatever behavior is observed during the testing phase is likely to arise during field usage; another advantage of this approach is that test data can be generated automatically (using random data generators), so that a software product can be tested on much more inputs than if test data were generated by hand.
- Generating an Oracle: Whenever we test a software product, we need an oracle, that is, an agent that tells us, for each execution, whether the software product behaved correctly or not. The most obvious candidate for an oracle is the specification that the software product is meant to satisfy; and the safest way to implement an oracle is to write a certified Boolean function that takes as input the test data and the output of the program and rules on whether the observed input/output behavior satisfies the specification. But there are several situations where this ideal solution is impractical, or unnecessary, which are as follows:
- First, the specification may be so complex that writing a Boolean function to test it is difficult and/or error-prone; if the Boolean function that represents the oracle is more complex than the program under test, then this solution defeats the purpose of the test, and may in fact mislead us into the wrong conclusions and actions.
- Second, it may be unnecessary to test the program against all the clauses of the specification: we may be interested in testing safety properties of the software product, in which case the oracle will only reflect safety critical requirements; or we may verify the correctness of the program against some aspects of the specification using alternative means (e.g., static analysis).
- Third, the process of storing the test data prior to each test and executing the oracle after each test may be prohibitively expensive in terms of computer resources, compelling us to consider more cost-effective options.
- Fourth, there are cases where we want to use an oracle that is in fact stronger (more demanding) than the specification: when the goal of the test is to find faults, it is not sufficient to know that the program satisfies the specification; rather it is necessary to check that the program computes the exact function that the designers intended it to compute; any deviation from this function may be an indication of a fault in the program.
- Generating a Termination Condition: Any test process aims to achieve a goal: For example, unit testing aims to diagnose faults in the program unit before integrating it into the project’s configuration; integration testing aims to diagnose faults in the design of the system or the specifications in the system’s unit; reliability testing aims to estimate the reliability of the software product, or to remove enough faults from the system to raise its reliability beyond a required threshold; acceptance testing aims to establish the dependability of the software product to the satisfaction of the customer (or to the terms of the development contract); and so on. The Termination Condition of a test is the condition that characterizes the achievement of the goal, that is, the condition that we test to know that we have achieved the goal of the test, hence we can terminate the test.
- Producing a Test Driver: The test driver is the process whereby the program is executed on the selected test data, its output is tested against the selected test oracle, and a course of action is defined for the case of a successful test and the case of an unsuccessful test, until the condition of termination is realized. If test data is generated automatically (e.g., using random test data generation, or by reading from a predefined test data repository), and if the termination condition can be checked on the fly (e.g., generating a predefined number of test data samples, or exhausting a file of test data), and if the analysis of the test outcome can be done off-line, then the test driver can be automated. A generic pattern for such a test driver may be as follows:
void function testdriver(){statetype state, initstate;while (! testTermination()){generateTest(state); initstate=state;Program(state); // candidate program// modifies stateif (oracle(initstate, state)){successfultest(initstate);}else{unsuccessfultest(initstate);}}cout << “test report”;}At each iteration, the driver generates a new test data sample, stores it into variable
initstate, then lets the program under test run, modifying the current state but keeping the initial state intact. Then, the test oracle is called to check the execution of the program on the current test data sample, and depending on the outcome of the test, takes some action; if the test is successful, it may record the initial state on which the test was successful, or simply increment a counter recording the number of successful tests; if the test is unsuccessful it may write a failure report on some file intended for the analysis of the test outcome. - Executing the Test: This phase consists merely of executing, whether by hand or automatically, the test driver that is defined in the previous phase.
- Analyzing Test Outcome: The whole test would be in vain if we did not have a phase in which we analyze the outcome of the test and draw the conclusion that is called for, depending on the goal of the test. If the goal of the test is to find faults, then this phase consists in analyzing the outcome of the test to identify faults and remove them; if the goal of the test is to judge acceptance, then this phase consists in determining whether the product can be deemed acceptable; if the goal of the test is to estimate reliability, then this phase consists in computing the estimated reliability on the basis of the observed successes and failures of the program under test; and so on.
The process of executing the test varies according to the type of test, but broadly follows the process depicted in Figure 3.3. There are instances where the test loop exits whenever an unsuccessful execution is encountered; in such cases, the fault that may have caused the failure of the program is diagnosed, then removed, and the test resumes by reentering the loop. In other instances, an unsuccessful test does not disrupt the loop, but does cause a record to be stored to document the circumstances of the failure. These cases will be explored in Chapter 7, when we discuss a taxonomy of testing methods.
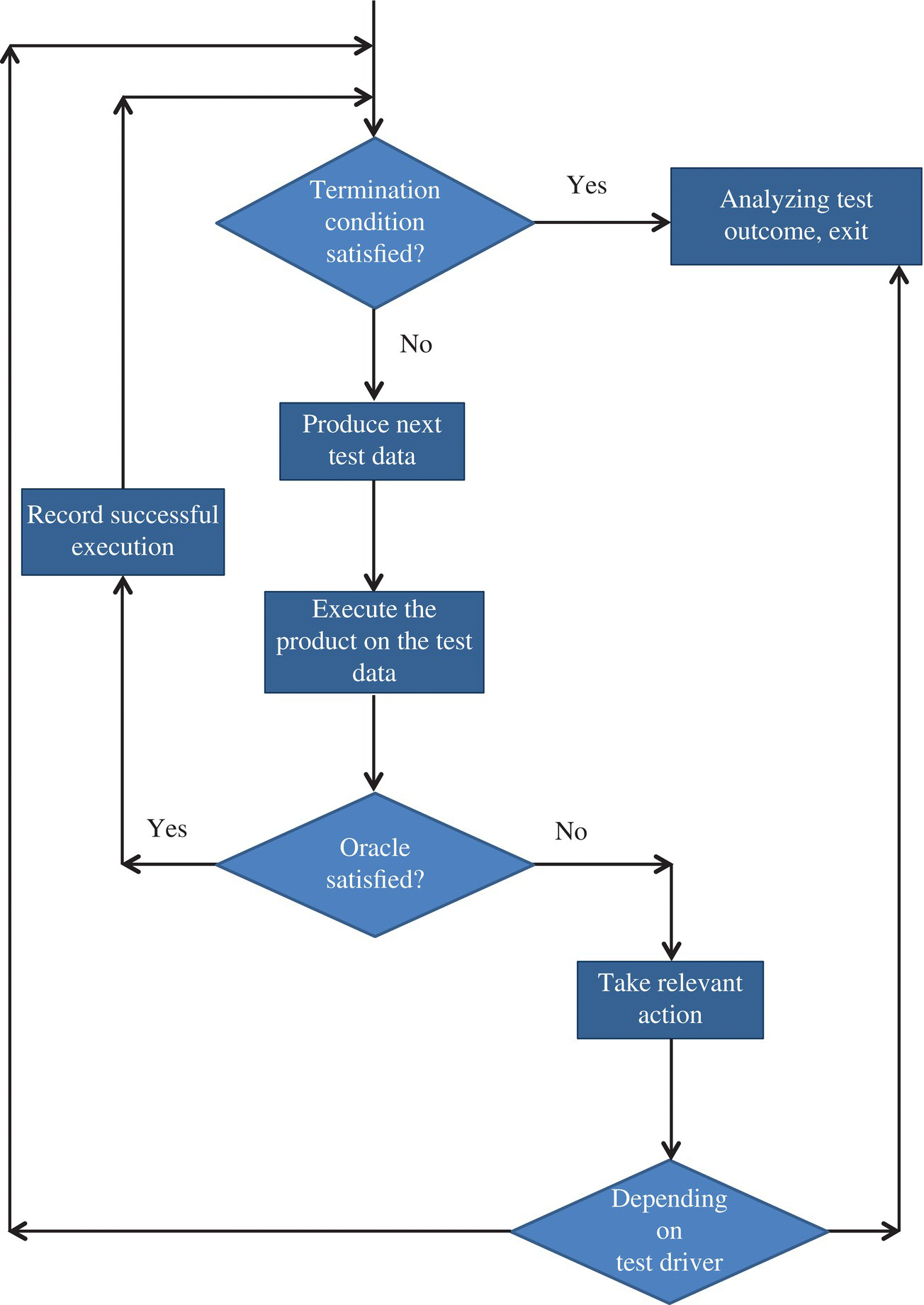
Figure 3.3 A generic testing lifecycle.
3.3 THE V-MODEL OF SOFTWARE TESTING
Even though testing is usually thought of as a single phase, the last phase, of the software lifecycle, it is actually best viewed as an activity that proceeds concurrently through all the phases of the lifecycle, from start to finish. The following model, called the V-model, illustrates the nature of testing as an ongoing activity through the software lifecycle, and shows how testing can be planned step by step as the lifecycle proceeds; it superimposes, in effect, the software lifecycle with the testing lifecycle. We discuss later how each pair of phases connected by a horizontal arrow in the Figure 3.4 are related to each other: generally, the phase on the left branch of the V prepares the corresponding phase on the right branch; and the latter tests the validity of the former.
- It is possible to start planning for acceptance testing as soon as the phase of requirements analysis and software specification is complete. Indeed, the software specifications that emerge from this phase can be used to prepare the test oracle, and can also be used to derive, if not actual test data, at least the criteria for selecting test data, and the standards of thoroughness that acceptance testing must meet. On the other hand, acceptance testing checks the final software product against the specifications that were derived in the phase of requirements analysis and software specification.
- Whereas acceptance testing is a service to the end user, system testing is a service to the development team. Whereas the goal of acceptance testing is to show that the software behaves according to its specifications within the parameters of the agreement between the developer and the user, the goal of system testing is to find as many faults as possible prior to acceptance testing (if there are any faults, we want them to show up at system testing rather than acceptance testing). Planning for system testing can start as soon as the software architecture is drawn, when we have some idea about what function the software system fulfills, and how it operates; this information affects test data generation and oracle design.
- Whereas system testing tests the software system as a monolith, by considering its external behavior and its global specification, integration testing tests a specific attribute of the software product, namely, the ability of the system components to interact according to the design of the system. Accordingly, test data has to be targeted to exercise component interactions, and the test oracle focuses on whether the exercised interactions are consistent with the intent of the designer.
- Unit testing focuses on testing individual modules against module specifications generated as part of the system design. Test data may be generated in such a way as to cover all aspects of the specification, or all structural features of the unit.
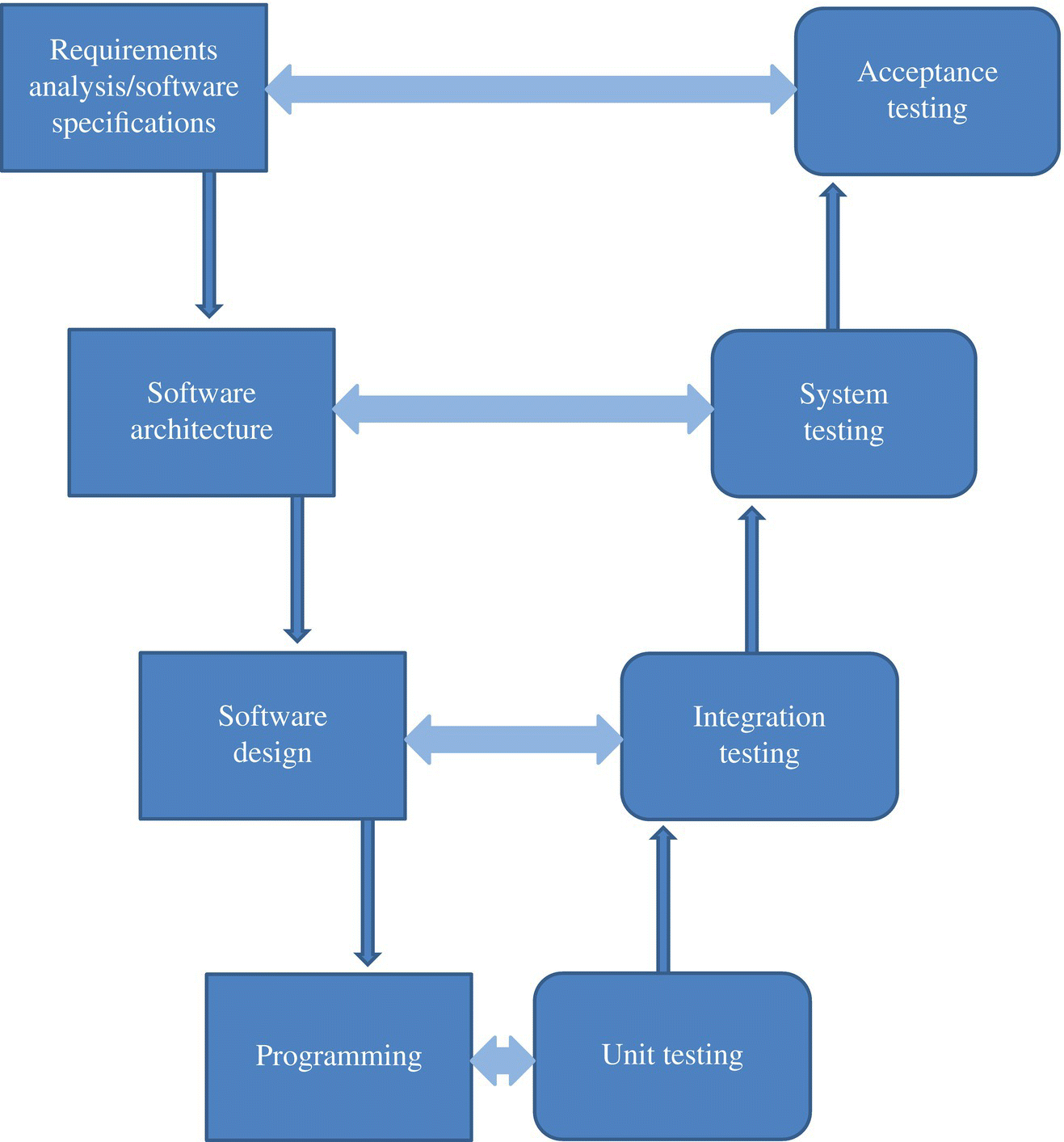
Figure 3.4 The V-model of software testing.
3.4 CHAPTER SUMMARY
In this chapter, we have reviewed two broad lifecycles, which are as follows:
- The lifecycle of software development and maintenance, focusing in particular on the various forms of testing that take place along this lifecycle, including unit testing, integration testing, system testing, reliability testing, acceptance testing, certification testing, and regression testing.
- The lifecycle of software testing, as a sequence of phases that include preparing a test environment, generating test data, generating a test oracle, generating a termination criterion, generating a test driver, executing the test, and analyzing the outcome of the test.
3.5 BIBLIOGRAPHIC NOTES
Though there are several sources that discuss software lifecycles, the ideas presented in this chapter are most influenced by Boehm (1981), most notably his view of the software lifecycle as a two-dimensional structure that decomposes the software development process into a chronological dimension (phases) and an organizational dimension (activities). The V-model is inspired from Culbertson et al. (2002). Other examples of lifecycle models can be found in Black (2007), Kaner et al. (1999), and Kit (1995).