
7
A Software Testing Taxonomy
7.1 THE TROUBLE WITH HYPHENATED TESTING
When reading about software testing, we often encounter types of testing that include such samples as black box testing, white box testing, unit testing, system testing, regression testing, mutation testing, stress testing, and so on. The trouble with this list is that the qualifiers that we put before testing refer to different attributes of the testing activity: depending on the case, they may refer to a test data selection criterion, or to the scale of the asset under test, or to the assumptions of the test activity, or to the product attribute being tested, and so on. The purpose of this chapter is to classify software testing activities in a systematic manner, using orthogonal dimensions; like all classifications schemes, ours aims to capture in a simple abstraction a potentially complex set of related attributes. A software testing activity can be characterized by a number of interdependent attributes; in order to build an orthogonal classification scheme, we must select a set of independent attributes that is sufficiently small so that its elements are indeed independent, yet sufficiently large to cover all classes of interest. In Section 7.2, we introduce this classification scheme, by identifying the set of attributes that we use for the purpose of classification, along with the secondary attributes that depend on these. In Section 7.3, we consider a number of important testing activities, analyze how they can be projected on our classification scheme, and discuss what inferred attributes they have by virtue of their classification.
7.2 A CLASSIFICATION SCHEME
While all testing activities consist in executing a software product on selected input data, observing its outputs and analyzing the outcome of the experiment, there is a wide variance in how testing is conducted, depending, broadly, on the goal of the test, the asset under test, the circumstances of the test, and the assumptions being made about the product and its environment. We identify four independent attributes of a software testing activity, and seven dependent attributes. We refer to the first set as primary attributes and refer to the second set as secondary attributes.
- The primary attributes of a software testing activity are as follows:
- Scale: This refers to the scale of the product under test, and can be a module, a subsystem, a system, and so on.
- Goal: There is a wide range of reasons why one may want to test a program, including finding faults, estimating the number of faults, estimating the reliability of the product, improving the reliability of the product, certifying that the product exceeds some reliability threshold, and so on.
- Property: While testing is most often used to check functional properties of software assets and systems, it may also be used to assess their average performance, their performance under stress, their robustness, and so on.
- Method: This attribute refers to the method that is used to generate test data and can, broadly, take three possible values; one may choose test data by considering the specifications (to cover all services, all functions, all circumstances) or by considering the software product (to exercise all components, all interfaces, all data flows, all control flows, etc.) or by random data generation, possibly adhering to a usage pattern (defined by a probability distribution).
- Once these primary attributes are selected, a number of secondary attributes fall in place in a nearly deterministic manner. We identify the following secondary attributes:
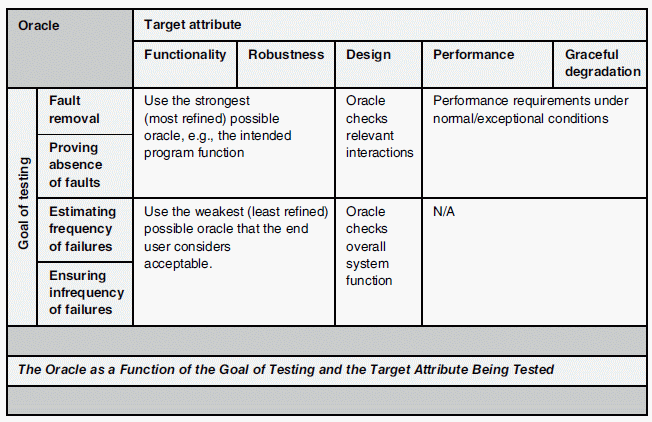
- Oracle: The oracle of a test is the agent that determines, for each execution, whether the outcome of the execution is consistent with the correctness of the product under test. The oracle of a test depends first and foremost on the property that we want to prove: while most typically we want to test the functional properties of a program, we may also want to test some operational attribute; clearly, the oracle depends on this choice. Also, for a given property, the oracle depends on the goal that we want to achieve through the test; the more ambitious the goal, the stronger the oracle.
- Test life cycle: The life cycle of a test is the set of phases that the test has to proceed through. As such, the life cycle depends, of course, on goal of the test; it also depends on the property being tested and on the method being deployed to generate test data.
- Test assumptions: Each test makes assumptions about the product, what may or may not be at fault, and to what extent the test environment mimics the operating environment of the software product.
- Test completion: Test completion is the condition under which the test activity is deemed to have achieved its goal. Of course, this attribute depends heavily on what the goal is, and consequently on what product property is being tested.
- Required artifacts: To plan and conduct a test, one may need any combination of the source code, the executable code, the specification of the product, the intended function of the product, the intended properties of the product, the design documentation of the product, the test data, and so on. This is heavily dependent on the goal of the test, the property being tested, and the test data generation method.
- Stakeholders: Different testing activities throughout the software life cycle involve different stakeholders/ participants, such as developers, designers, specifiers, users, verification and validation teams, quality assurance teams, and so on. This attribute depends on the goal of the test as well as the scale of the software product, and the phase of the software life cycle where the test takes place.
- Test environment: The environment of a test is the set of interfaces that the product under test interacts with as it executes. A software product may be tested in a variety of environments, depending on the scale of the product and the phase of the life cycle: the development environment, the operating environment, or a simulation of the operating environment.
- Position in the life cycle: Each phase of the software life cycle lends itself to a verification step, which can be carried out through testing. The position in the life cycle affects the scale of the asset to be tested, and thereby affects all the other primary attributes (goal, property, and method).
In Sections 7.2.1 and 7.2.2, we review in turn the primary then the secondary attributes, by discussing what values each attribute may take, and any dependencies that each value entails.
7.2.1 Primary Attributes
We consider four primary attributes: the scale, the goal, the property, and the method. We review these in turn in the following:
- The Scale: We consider three possible values for this attribute:
- A unit: This represents a programming unit that implements a data abstraction or a functional abstraction. As such, it can be a class in an object-oriented language, the implementation of an abstract data type, or a routine.
- A subsystem: This represents a component in an integrated software system. To test such a component in a credible manner, we may have to run the whole system and observe the behavior of this particular component within the system. This situation arises in the context of maintenance, for example, where we may change a component and then test the whole system to check whether the changes are satisfactory, and whether the new subsystem works smoothly within the overall system.
- A system: This represents a complete autonomous software system.
- The Goal: This is perhaps the most important attribute of a test. The values it may take include the following:
- Finding and removing faults: The most common goal of software testing is to observe the behavior of the program on test data, and to diagnose and remove faults whenever the program fails to satisfy its specification.
- Proving the absence of faults/certifying compliance with quality standards: While in practice it is virtually impossible to test a program on all possible combinations of inputs and configurations, this possibility cannot be excluded in theory. Also, we can imagine cases where the set of possible input data is small, or cases where we can design a test data D such that if the program runs successfully on D, then it runs successfully on all the input space S.
- Estimating fault density: Software testing can be used to estimate the fault density of a product, as will be discussed in Chapter 13. This is done by seeding faults, then running a test to compute how many seeded faults have been recovered and how many unseeded faults have been uncovered; fault density can then be estimated by interpolation.
- Estimating the frequency of failures: While the previous goals are concerned with faults, this and the next goal are concerned with failures instead; there is a sound rationale for focusing on failures rather than faults, because it is better to reason about observable/relevant effects than about hypothetical causes. To pursue this goal, we run the software product under conditions that simulate its operational environment, and estimate its failure rate; the estimate is reliable only to the extent that the test environment is a faithful reflection of the operating environment, and that the test data reflects, in its distribution, the usage pattern of the software product. It is only under such conditions that the failure rate observed during testing can be borne out during field usage. We identify three possible instances of this goal, depending on whether we want to estimate the reliability, the safety, or the security of the product:
- Estimating reliability
- Estimating safety
- Estimating security
We get one instance or another, depending on the oracle that we use for the test: To estimate reliability, we use the functional specifications of the software product; to estimate safety, we use the safety-critical requirements of the product; to estimate security, we use the security requirements of the product.
- Ensuring the infrequency of failures: As an alternative to proving the absence of faults, we may want to prove that faults are not causing frequent failures; after all, a program may have faults and still be reliable, or more generally experience infrequent failure. Also, as an alternative to estimating the frequency of failures, we may simply establish that the frequency of failure is lower than a required threshold. Whereas estimating the frequency of failure is a mere analytical process, that analyzes the product as it is, ensuring the infrequency of failures may involve diagnosing and removing faults until the frequency of failures of the software product is deemed to be lower than the mandated threshold. As we argued in the last item, in order for the estimate of the failure rate to be reliable, the software product must be tested in an environment that mimics its operating environment, and the test data must be distributed according to the usage pattern of the product in the field. Also, this goal admits three instances, depending on what oracle is used in the test:
- Certifying reliability
- Certifying security
- Certifying safety
We get one instance or another, depending on the oracle that we use for the test.
- Method: Given a limited amount of resources (time, manpower, and budget), we cannot run the software product on the set S of all possible input data; as a substitute, we want to run the software product on a set of test data, say D (a subset of S), that is large enough to help us achieve our goal, yet small enough to minimize costs. The test data generation method is the process that enables us to derive set D according to our goal; the criterion that we use to derive D from S depends on the goal of the test, as follows:
- If the goal of the test is to diagnose and remove faults, then D should cause the maximum number of failures, that is, uncover/sensitize the maximum number of faults.
- If the goal of the test is to prove correctness, then D should be chosen in such a way that if the program runs successfully on D, we can be reasonably confident (or assured) that it runs successfully on all of S.
- If the goal of the test is to estimate the product’s failure rate or to ensure that the product’s failure rate exceeds a mandated threshold, then D must be a representative sample of the usage pattern of the product.
Test data generation methods are usually divided into three broad families:
- Structural methods, which generate test data by analyzing the structure of the software product and targeting the data in such a way as to exercise relevant components of the product.
- Functional methods, which generate test data by analyzing the specification of the software product or its intended function, and targeting the data in such a way as to exercise all the services or functionalities that are part of the specification or intended function.
- Random, with respect to a usage pattern. This method generates test data in such a way as to simulate the conditions of usage of the software product in its operating environment.
It is possible to map the goal of the test to the test data generation method in a nearly deterministic manner, as shown in the following table:
| Method | Structural | Functional | Random |
| Goal | |||
| Finding and removing faults | √ | ||
| Proving the absence of faults | √ | ||
| Estimating the frequency of failure | √ | ||
| Ensuring the infrequency of failure | √ | ||
| Estimating fault density | √ | ||
Target Attribute: Most typically, one tests a software product to affect or estimate some functional quality of the product, such as correctness, reliability, safety, security, and so on; but as the following list indicates, one may also be interested in testing the product for a broad range of attributes.
- Functionality: Testing a software product for functional properties such as correctness, reliability, safety, security, and so on is the most common form of testing, and is the default option is all our discussions.
- Robustness: Whereas correctness mandates that the software product behaves according to the specification for all inputs in the specified domain, robustness further mandates that the program behaves reasonably (whatever that means: we can all recognize unreasonable program behavior when we see it) outside of the specification domain, that is, on inputs or situations for which the specification made no provisions.
- Design and structure: In integration testing, the focus of the test is on ensuring that the parts of the software system interact with each other as provided by the design; here the attribute we want to test or ensure is the proper realization of the design.
- Performance: We may want to test a software product for the purpose of empirically analyzing its performance under normal usage conditions (e.g., normal workload).
- Graceful degradation: In the same way that we distinguish between correctness (functional behavior for normal inputs) and robustness (functional behavior for exceptional or unplanned inputs), we distinguish between performance (operational behavior under normal workloads) and graceful degradation (operational behavior under excessive workloads). To test a software product for graceful degradation, we operate it under excessive workloads and observe whether its performance decreases in a continuous, acceptable manner.
In Section 7.2.2, we review the secondary attributes and discuss how they are affected by the choices made for the primary attributes reviewed in this section.
7.2.2 Secondary Attributes
We consider the secondary attributes listed earlier and review the set of values that are available for each attribute, as well as how these values are impacted by the primary attributes.
The Oracle: If the target attribute of the test is an operational attribute, such as the response time of the product under normal workloads, or under exceptional workloads, then the oracle takes the form of an operational condition (a response time, or a function plotting the response time as a function of the workload). If the target attribute of the test is functional, then the oracle depends on whether the goal of the test is to find faults or to certify failure freedom. The following table highlights these dependencies.
The Test Life Cycle: Whereas in Chapter 3 we have presented a generic test lifecycle, we can imagine three variations thereof, which we present in the following text:
- A sequential life cycle, which proceeds sequentially through three successive phases of test data generation, test execution, and test outcome analysis. An algorithmic representation of this cycle may look like this
{testDataGeneration(D); // D: test data set;
T=empty; // T: reportwhile (not empty(D))
{d=removeFrom(D);
d’=P(d);
if (not(oracle(d,d’)) {add(d,T;}}analyze(T);}
In this cycle, the phases of test data generation, test execution, and test analysis take place sequentially.
- A semisequential life cycle, where the execution of tests pauses whenever a failure is observed; this life cycle may be adopted if we want to remove faults as the test progresses. An algorithmic representation of this cycle may look like this:
{testDataGeneration(D); // D: test data set; while (not empty(D)) {repeat {d=removeFrom(D); d’=P(d);} until not(oracle(d,d’)); offLineAnalysis(d); // fault diagnosis and removal } } - An iterative life cycle, which integrates the test data generation into the iteration. An algorithmic representation of this cycle may look like this:
{while (not completeTest()){d=generateTestData();d’=P(d);if (oracle(d,d’)) {successfulTest(d);}else {unsuccessfulTest(d);}}}
The following table shows how the value of this attribute may depend on the primary attributes of goal and method.

Test Assumptions: A test can be characterized by the assumptions it makes about the product under test and/or about the environment in which it runs. As such, this attribute can take three values, depending on the scale of the product being tested, as shown in the following table.
| Assumptions | Scale | |||
| Unit | Subsystem | System | ||
| Test assumption | The oracle/specification of the unit is not in question. Only the unit’s correctness is. | Only the targeted subsystem is in question, not the remainder of the system. | The test environment mimics the product’s operating environment. | |
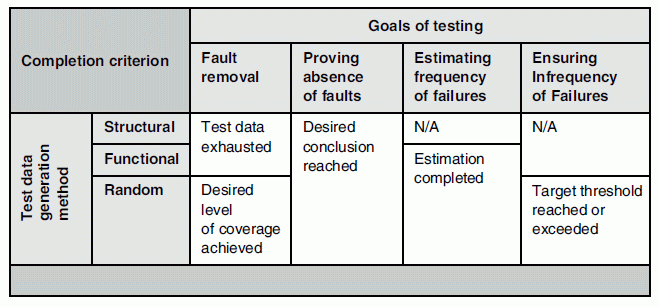
Test Completion: Test completion is the condition under which the test activity is deemed to achieve its goal. Such conditions are as follows:
- The software product has passed the certification standard.
- The software product has performed to the satisfaction of the user.
- It is felt that all relevant faults have been diagnosed and removed.
- The reliability of the software product has been estimated.
- The reliability of the software product has grown beyond the required threshold.
- The test data generated for the test have been exhausted, and so on.
The following table illustrates how this attribute depends on the goal of the test and the test data generation method.
Required Artifacts: Many artifacts may be needed to conduct a test, including any combination of the following artifacts:
- The source code
- The executable code
- The product specification
- The product’s intended function
- The product’s design
- The signature of the software product (i.e., a specification of its input space)
- The usage pattern of the software product (i.e., a probability distribution over its input space)
- The test data generated for the test
This attribute depends on virtually all four primary attributes; for the sake of parsimony, we only show its dependence on the goal of testing and on the test data generation method.
| Artifacts | Goals of testing | ||||
| Fault removal | Proving absence of faults | Estimating frequency of failures | Ensuring infrequency of failures | ||
| Test data generation method | Structural | Source + Executable + Function |
|||
| Functional | Executable + Specification + Function |
Executable + Specification |
Source + Function + Specification + Signature + Usage pattern |
||
| Random | Executable + Function + Signature + Usage pattern |
Executable + Signature + Usage pattern |
Source + Specification + Signature + Usage pattern |
||
Stakeholders: A stakeholder in a test is a party that has a role in the execution of the test, or has a role in the production of the software asset being tested, or has a stake in the outcome of the test. Possible stakeholders include the product developer, the product specifier, the product user, the quality assurance team, the verification and validation team, the configuration management team, and so on. The following table shows how this attribute depends on the goal of the test and the scale of the asset.
| Stakeholders | Goals of testing | ||||||
| Fault removal | Proving absence of faults | Estimating frequency of failures | Ensuring infrequency of failures | ||||
| Scale | Unit | Unit developer | Unit developer, CM/QA team | ||||
| Subsystem (maintenance) | Subsystem developer, maintenance engineer | Subsystem developer, maintenance engineer, CM/QA team | |||||
| System | Verification and validation team Design team | Specifier team, design team, and end users | |||||
Test Environment: The environment of a test is the set of interfaces that the product under test interacts with as it executes. The following table shows the different values that this attribute may take, depending on the goal of the test and the scale of the software product under test.
| Test Environment | Goals of testing | ||||||||
| Fault removal | Proving absence of faults | Estimating frequency of failures | Ensuring infrequency of failures | ||||||
| Scale | Unit | Development environment | Project configuration | ||||||
| Subsystem (maintenance) | Software system | ||||||||
| System | Development environment | Operating environment | Simulated operating environment | ||||||
Position in the Life Cycle: As we have seen in Chapter 3, several phases of the software life cycle include a testing activity. The software activity at each phase can be characterized by primary attributes; the following table shows how the goal of testing and the scale of the product under test determine the phase at which each test activity takes place.
| Position in the Lifecycle | Goals of testing | ||||||
| Fault removal | Proving absence of faults | Estimating frequency of failures | Ensuring infrequency of failures | ||||
| Scale | Unit | Unit testing | Adding the asset into the project configuration | ||||
| Subsystem (maintenance) | Maintenance | Regression testing | |||||
| System | Integration testing | Acceptance testing | Reliability estimation | Reliability growth | |||
7.3 TESTING TAXONOMY
In this section, we consider a number of different test activities, analyze them, and discuss to what extent the classification scheme presented in this chapter enables us to characterize them in a meaningful manner.
7.3.1 Unit-Level Testing
We distinguish between two types of unit-level testing:
- Unit-Level Fault Removal: This test is carried out by the unit’s developer as part of the coding and unit testing phase of the software life cycle; its purpose is to detect, isolate, and remove faults as part of the development life cycle.
- Unit-Level Certification: This test is carried out by the configuration management/quality assurance team for the purpose of ensuring that the unit under test meets the quality standards mandated for the project.
The following table illustrates how these two tests differ from each other, by comparing and contrasting their attributes.
| Attributes | Unit-level fault removal | Unit-level certification | |
| Primary attributes | Scale | Unit (module, routine, function) | Unit (module, routine, function) |
| Goal | Finding and removing faults | Certifying compliance with project-wide quality standards | |
| Property | Functionality | Functionality | |
| Method | Structural (attempting to sensitize and expose as many faults as possible) | Functional (attempting to exercise as many functional aspects as possible) | |
| Secondary attributes | Oracle | The function that the unit is designed to compute | The specification that the unit is designed to satisfy |
| Test life cycle | Semisequential | Sequential (generate test data, run the unit on the test data, and record outcomes, rule on certification) | |
| Test assumptions | The intended function is not in question (the correctness of the unit is) | The unit specification is not in question (the correctness of the unit is) | |
| Completion criterion | Confidence that most egregious faults have been removed | Confidence that the unit has passed/ or has failed the certification standard | |
| Required artifacts | Executable code + Source code + test environment + Intended function |
Executable code + test environment + Unit specification |
|
| Test stakeholders | Unit developer | Unit developer + Configuration management/quality Assurance team |
|
| Test environment | Simulated environment | Existing (evolving) system+ Simulated environment | |
| Position in the SW life cycle | During the programming phase | Concludes the programming phase for each individual unit | |
7.3.2 System-Level Testing
We consider three system-level tests:
- Integration test, which arises at the end of the programming phase, when programming units that have been developed, tested, and filed into the product configuration are combined according to the product design to produce an integrated product.
- Reliability test, which arises as the end of the software development project, prior to product delivery, to evaluate the reliability of the product (and eventually, ascertain that the product reliability exceeds the product’s required reliability).
- Acceptance test, which is conducted jointly by the development team and the user team to check that the software product meets its requirements.
Even though these tests are all at the same scale (system-wide), they differ from each other in significant ways, as we see in the table below.
| Attributes | Integration test | Reliability test | Acceptance test | |
| Primary attributes | Scale | System | System | System |
| Goal | Find and remove design faults (dealing with inter-component coordination) | Assess the reliability of the product | Check whether the system meets its requirements to the satisfaction of the user | |
| Property | Design | Functionality | Functionality | |
| Method | Structural | Functional (compatible with usage pattern) | Functional (as per user requirements) | |
| Secondary attributes | Oracle | System function | System Specification (or subspecification with respect to which we want to estimate reliability) | System specification |
| Test life cycle | Semisequential | Iterative | Sequential | |
| Test assumptions | Units are not in question; only system design is | Test environment mimics operating environment | Test environment mimics operating environment | |
| Completion criterion | All relevant interactions exercised, all possible faults removed | Reliability adequately estimated/ or reliability requirement met | Contractual obligation met | |
| Required artifacts | Executable code + source code + design documentation + expected function |
Executable code + usage pattern +Relevant specification |
Executable code + contractual requirements |
|
| Test stakeholders | Product designers | Product designers + verification and validation |
Requirements engineers + user representative + managers |
|
| Test environment | Development environment | Operating environment (or simulation thereof) | Operating environment (or simulation thereof) | |
| Position in the SW life cycle | Integration | Prior to delivery | At delivery | |
7.4 EXERCISES
- 7.1. Consider the software product that operates an automatic teller machine at a bank, and let S be the input space of the product:
- Define set S, assuming that each query to the automatic teller takes the form of an identification sequence (including a card ID followed by a PIN), followed by a query to the card database to authenticate the customer, followed (in case of successful identification) by a customer query (account balance, cash withdrawal, cash deposit, check deposit), followed by a query to the account database (to perform the requested operation), followed by an actuation of the cash dispenser (if the customer requests a withdrawal and it is approved), or followed by an actuation of the deposit unit (that accepts cash or checks) and updates the accounts database accordingly.
- Using empirical knowledge of how automated teller machines are usually used, define the usage pattern of the software product as a probability distribution over S.
- Write a program that generates random test data according to the probability distribution you have computed in Question (b).
- 7.2. Regression testing takes place at the end of any maintenance operation. You are asked to characterize the activity of regression testing in the context of corrective maintenance, that is, maintenance that aims to correct a fault in a software product.
- 7.3. Regression testing takes place at the end of any maintenance operation. You are asked to characterize the activity of regression testing in the context of adaptive maintenance, that is, maintenance that aims to accommodate a change in the requirements of a software product.
- 7.4. Naik and Tripathy (2008 ) discuss the following types of tests:
- Functionality
- Robustness
- Interoperability
- Performance
- Scalability
- Stress
- Load and stability
- Regression
- Documentation
- Regulatory
- Characterize these types of test using the classification scheme proposed in this chapter.
7.5 BIBLIOGRAPHIC NOTES
Alternative classification schemes for software testing can be found in the following references: Culbertson et al. (2002); Mathur (2008); Naik and Tripathy (2008); Perry (2002).