
Critical Success Factors
The success of a DRP depends on several critical success factors (CSFs). A CSF is an element necessary for the plan’s success. For example, any organization has several CSFs that must be successful to ensure the success of the organization. Similarly, DRPs have CSFs. Without these factors included in the DRP, it has less chance to succeed.
Elements that are critical to the success of a DRP include:
- Management support
- Knowledge and authority for DRP developers
- Identification of primary concerns, such as RTOs and alternate location needs
- A disaster recovery budget
The following sections explore these disaster recovery plan CSFs in more depth.
What Management Must Provide
Like risk management and security plans, DRPs require the support of management. Some support can be as simple as publicly endorsing the plan, whereas other support can be much more material, such as providing funds.
Management support doesn’t guarantee success of a DRP because other elements are also necessary, but, without management’s support, a DRP is likely to fail. If management doesn’t support the DRP, others within the organization won’t support it either.
Resources
The primary resource that management provides is personnel, who are needed to create, test, and update the DRP. They can be in-house employees or outside consultants who are specialists in disaster recovery.
Financial support from management is also necessary. For example, if the company needs an alternate location, one will be secured only with financial support. If backups are needed, funding will be necessary to purchase backup tapes or other backup media.
Leadership
Management must also provide leadership to support any DRP. Leaders understand the importance of the DRP and know that its success can be achieved only with combined teamwork. Leaders help disaster recovery and business continuity teams recognize the value of the DRP.
 TIP
TIP
Being a boss and being a leader are not the same thing. The boss has a position of authority and directs people to complete tasks. People complete the tasks for the boss because they are told to do so. On the other hand, the leader influences others to achieve a common goal and excel in their performance. The leader has, or at least understands, the overall vision and helps others see how they can contribute to its success. People complete the tasks for the leader because they share the vision with the leader. Management helps teams identify project priorities, or the MBCO. For example, if a DRP includes several DRPs, management helps identify which ones are more important than others, in other words, MBCOs. If a single DRP has several objectives, management can help the authors identify priorities within the DRP. More resources will be given to the highest priorities in a DRP.
Management must also lead by example. If management wants others to support the requirements of the DRP, it must support the DRP. If management wants others to give the DRP their time and attention, then operational level managers must provide their time and attention to it when needed.
All of this translates into support. When management supports the efforts of the disaster recovery team, the overall disaster recovery process has a much better chance of succeeding.
What DRP Developers Need
The developers of the DRP need some specific knowledge and authority to succeed. Any system subject matter expert (SME) can’t just be tasked with and expected to be able to write a DRP. Neither can some disaster recovery experts be expected to be able to write a DRP.
Instead, personnel with combined skills are needed. The DRP developers need to have an understanding of disaster recovery and how the organization functions. They can often work with individual SMEs to identify specific steps for systems.
Knowledge of Disaster Recovery
The DRP team must have an understanding of disaster recovery in general and specifically what a BIA is, what a BCP is, and how a DRP fits in with a BIA and a BCP.
As a reminder, the BIA identifies the critical systems and prioritizes them. The BCP includes both BIAs and DRPs. DRPs provide details to restore specific systems. Some DRPs address system recovery of CBFs immediately after a disruption. Other DRPs address system recovery of all business functions after a disaster has passed.
The DRP developer must understand the purpose of the DRP and how it fits in the overall BCP. If not, the DRP lacks focus. The relationship between different risk management concepts such as BIA, DRP, and BCP is shown in FIGURE 14-1.
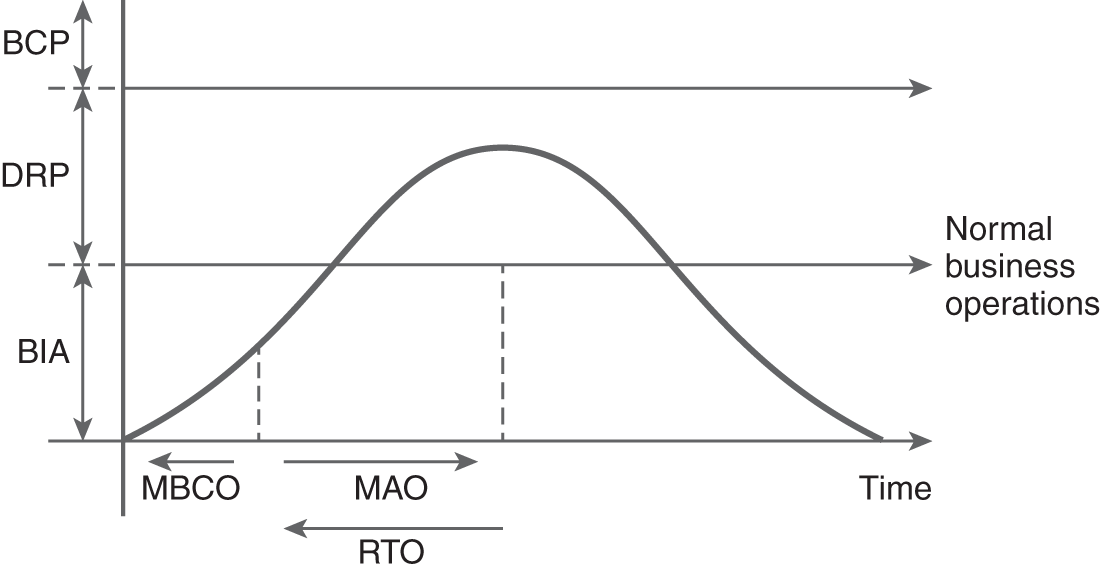
FIGURE 14-1 Risk management: BIA, DRP, and BCP.
Knowledge of How the Organization Functions
Understanding how the organization functions is critical to writing an effective DRP. For example, the DRP for a military base will be much different from the DRP for a small business. The military base would require some support 24 hours a day, seven days a week, whereas the small business may require support only from 9:00 to 5:00, Monday through Friday.
TIP
Many companies hire outside consultants to help with the development of DRPs and BCPs. These consultants can work with management and the SMEs to ensure that the DRPs meet the needs of the organization.
In addition to the operating hours, any organization has specific processes in place that the DRP developer needs to understand, and some of them are critical. Either the DRP supports these processes or the DRP can assume that they will remain operational. Other processes are not critical and should not be relied on for the DRP.
For example, one organization may have both uninterruptible power supplies (UPSs) and generators in place. These units provide continuous power to critical systems even if commercial power is lost. The DRP may include steps to ensure that fuel is on hand to last a specific amount of time when a disaster occurs.
Another organization may use cloud computing for some CBFs, such as data services. If so, service level agreements (SLAs) will be in place to ensure that a third-party vendor keeps these operational, so the DRP doesn’t need to address these services.
Authority
DRP developers need some authority when creating the DRP. For example, a DRP developer needs to gather data before writing the DRP. This is especially true if the developer is not an SME. To succeed, the DRP developer needs authority to interview experts who understand the systems.
If the DRP crosses departmental lines, the DRP author needs to make decisions that can affect multiple departments. With this in mind, the DRP author needs management support to make the initial decisions.
Primary Concerns
The DRP should address several primary concerns, and the DRP developer should have a clear idea of what they are before writing the DRP. One important concern is RTOs, which identify the critical nature of the DRP. Some systems need to be restored almost immediately, whereas others can be offline for days before they are recovered.
Having knowledge about required off-site resources is also important. At a minimum, a copy of backups needs to be stored off-site. The DRP may also address the use of alternate locations for operations. All of these topics are explored in other sections in this chapter.
Recovery Time Objectives
The RTOs identify when a system must be recovered and is derived from the MAO identified in the BIA. Outages longer than the MAO will have a significant negative effect on the organization, which means that, if the outage isn’t resolved within the RTO, it will impact the mission.
An MAO could be 60 minutes, 24 hours, or something different. However, this number drives the RTO. For example, if the MAO is 60 minutes, the DRP needs to be written to meet an RTO of less than 60 minutes. If the MAO is 24 hours, the RTO needs to be less than 24 hours.
Knowing this information helps amplify the importance of a BIA. If a DRP is being written before a BIA has been developed, extra steps will need to be taken. Without a BIA, the MAO will be unknown, and the correct RTO will not be determinable. Instead, extra steps will need to be taken to determine the MAO, and then the RTO will need to be identified and the DRP written.
Off-Site Data Storage, Backup, and Recovery
Performing backups of critical data is an integral part of any recovery plan because inevitably data will be lost. If the data can’t be restored, the result can be catastrophic to the organization.
Backup plans are often included as a part of the DRP and are derived from backup policies. The backup policy identifies details, such as what data should be backed up and how long the backup data should be kept. The backup plan identifies the steps to take to back up and restore the data.
Backups are primarily focused on data. However, in some situations, programs may need to be backed up. For example, if the organization develops applications, their backups must be available. Naturally, the source code should be kept secure, but backups will also be needed of this source code.
Another critical element of backups is ensuring that copies of backups are stored off-site. Not all the backups should be stored in the same location as the servers. If a fire destroys the building, it destroys the servers and all the backups, whereas, if copies of backups are stored in a separate location, they can always be used to restore the data even if a fire completely destroys the building.
Traditional backups don’t always need to be performed to ensure copies of the data are available. Other technical processes can be used too. For example, database applications, such as Oracle and Microsoft SQL Server, support data replication.
FIGURE 14-2 shows that users access a primary database server for data and that this primary server is also replicating data to a secondary server, which has up-to-date data each time replication occurs. If the primary server fails, the secondary server can be brought online to take over for the primary server. How often replication occurs can also be controlled, which ensures that the RTO for the system can be met.

FIGURE 14-2 Data backups from data replication.
The following two terms identify different types of redundant transfers, which are often used as part of an overall disaster recovery plan:
- Electronic vaulting—This method transfers the backup data to an off-site location over wide area network (WAN) links or tunnels through the Internet.
- Remote journaling—This method starts with full copies of the data at the remote location and then sends a log of the changes from the primary location to the secondary location. These changes are applied as a batch to the secondary location. After they have been applied, the secondary location is up to date.
Slight variations of remote journaling are possible with databases. These variations include database mirroring and database shadowing techniques.
TIP
Several methods of replicating data from one database server to another are available. Mirrored servers can be created, and both of them can be online; standby servers can be created with one online and the other offline to accept the replicated data; and complex replication models can be created with distributors, publishers, and subscribers.
Alternate Locations
Many companies need to ensure that their businesses stay in operation even if a significant disruption occurs. For example, businesses working along the San Andreas fault in California have an almost constant threat of an earthquake. If an earthquake hits, the business may not be able to function in the same location.
One or more alternate locations need to be identified if an organization must continue to operate even if a major disaster occurs. These alternate locations can be in different buildings, different cities, or even different states, which depends on the type of disaster being prepared for. For example, if a fire destroys a building, an alternate location in the same city will work, but, if an earthquake is being prepared for, an alternate location in a different city or possibly in a different state would be needed.
Four types of alternate locations are available: cold sites, warm sites, hot sites, and mobile sites. Each site must have the capability to host the critical data and programs of the primary location. However, each site has different costs and initial capabilities. As an introduction, TABLE 14-1 provides an overview of cold-, warm-, hot-, and mobile-site capabilities.
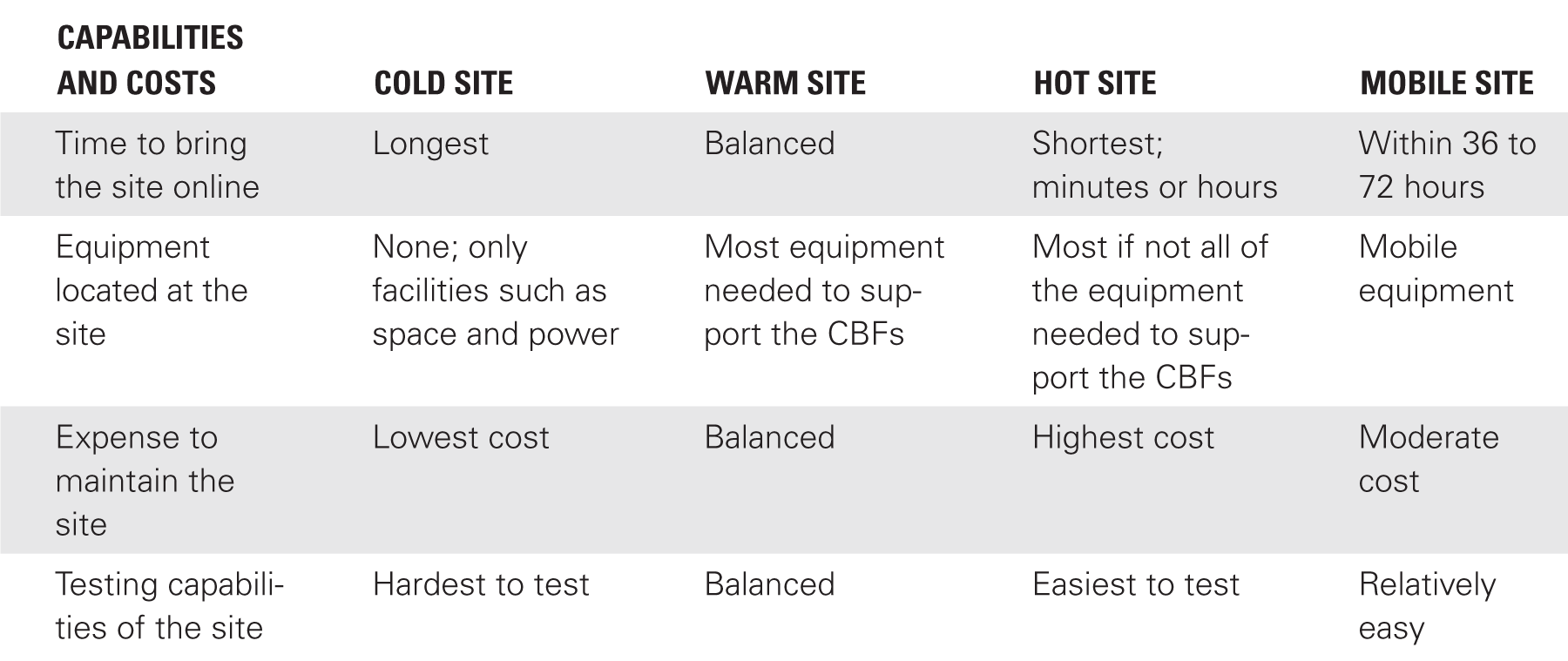
Cold Site. A cold site is an available building that has electricity, running water, and restrooms but none of the equipment, data, or applications needed for critical operations. It may have raised floors if needed to support a server environment.
For example, an organization could rent space in a different building to prepare for a major disaster. If a disaster occurs, they would move the equipment and data to this location and set up the CBFs there. Obviously, it would take a lot of work to move and set up the equipment.
Cold sites are inexpensive to maintain because they are just empty buildings. However, it is difficult and costly to test a cold site.
 NOTE
NOTE
When renting space in a different building for a cold site, it’s important to ensure this space isn’t rented to others. For example, some businesses rent out available space to two or more organizations. When a disaster hits, several organizations might try to move into the same space.
Hot Site. A hot site includes all the equipment and data necessary to take over business functions. A hot site will be able to assume operations within hours and sometimes within minutes. It usually has personnel at the location 24 hours a day, seven days a week.
Hot sites are expensive to maintain. However, some newer technologies make them a little easier to manage. Cloud computing and virtualization are two newer technologies that are sometimes used with hot sites. Cloud computing is a general term for anything that involves hosting services over a public network, such as the Internet.
TIP
Organizations often contract with third-party vendors to provide services via cloud computing. The organization doesn’t need to manage the service; rather it has an SLA with the vendor that provides the service.
As shown in FIGURE 14-3, several services are hosted using cloud computing. Each of these services is accessible over the Internet, so the physical location of the services doesn’t matter. As long as users are able to access the Internet, they are able to access the services.

FIGURE 14-3 Cloud computing.
This can be useful for hot sites. For example, if critical operations need to be managed from a regional office instead of from headquarters, the transfer can be almost seamless. Both locations already have access to the critical services. The only thing that may need to be moved to the regional office is personnel.
Virtualization is another technology that can be useful for hot sites. Several virtual servers can be hosted on a network within a single physical server. Each virtual server runs on the network just as if it’s a physical server.
In FIGURE 14-4, SRV1 is the physical server, and it is hosting four servers named SRV2, SRV3, SRV4, and SRV5. All five servers operate as if they are on the network as separate servers. SRV1 would have more resources than a typical server because it would have multiple processors, a significant amount of random access memory (RAM), and fast hard drives. Administrators would allocate some of these resources to each virtual server.
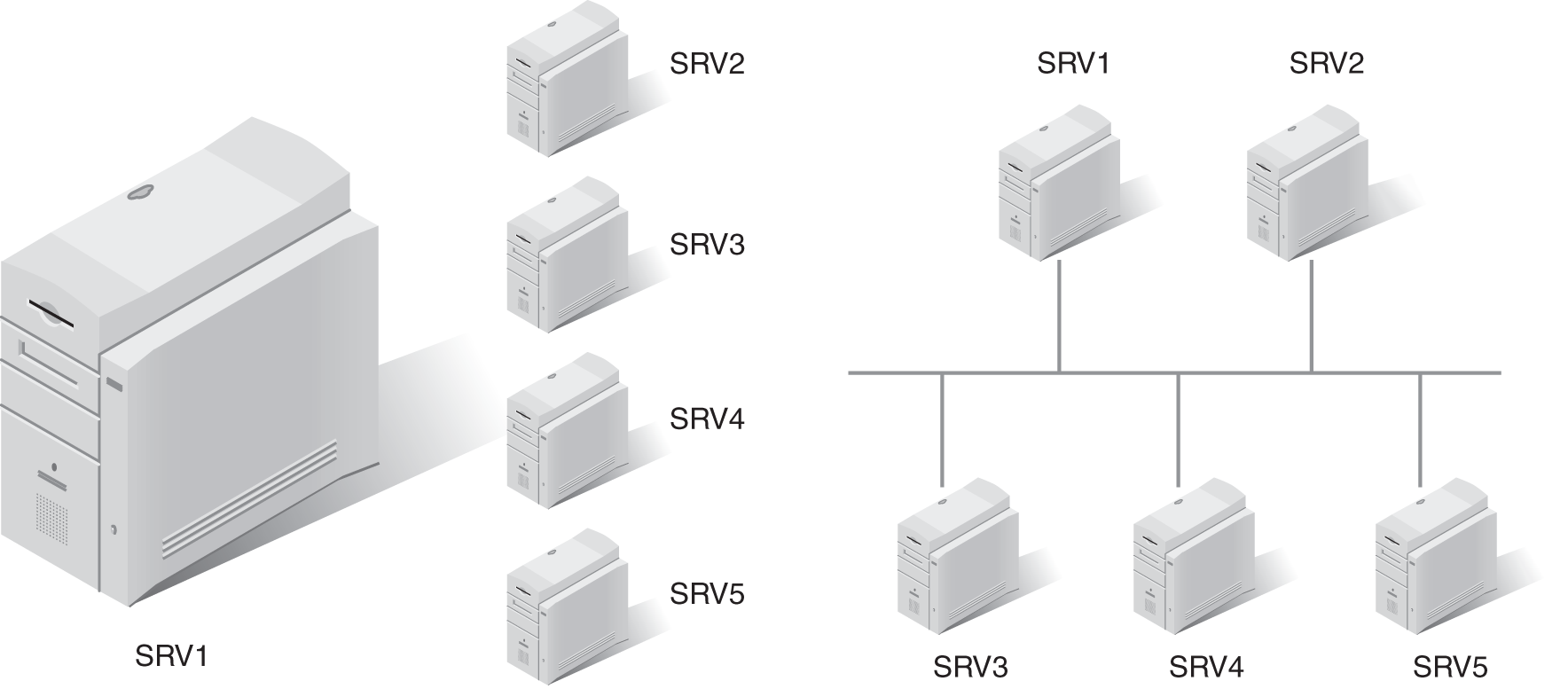
FIGURE 14-4 One physical server hosting four virtual servers.
Once a virtual server has been created, it can easily be moved from one physical server to another. The virtual server consists of a group of files stored on the physical server. Admittedly, these files are quite large. However, the virtual server can be shut down, the files copied to another physical server, and the virtual server started there.
Virtual server files can be transferred over a WAN link if the bandwidth is adequate. If not, a high-capacity universal serial bus (USB) drive is an option. Just copy the virtual server files to the USB drive, plug it in to a new physical server, and copy the files to the physical server. The process of copying these files varies depending on the virtualization software. For example, in Microsoft’s Hyper-V, the files are exported from the original server and then imported into the new server.
Virtual servers also require less facility support. If four servers are being hosted on a single physical server, not as much physical space is needed as would be necessary for five servers. Additionally, this single physical server draws less power and requires less air-conditioning than five physical servers.
Warm Site. A warm site is a compromise between a cold and a hot site. It includes most or all of the equipment needed, but data is not usually kept up to date. The equipment is maintained in an operational state. If a disaster occurs, the systems are updated with current data and brought online.
Warm sites are often fully functioning sites for noncritical business functions. When a disaster occurs, noncritical functions stop, and the site is used for critical business functions.
One of the main benefits of the warm site is that management is able to match the desired cost with an acceptable amount of time for an outage, which means that, if a longer MAO is acceptable, management can balance the costs to match the desired amount of time it will take to bring the warm site online.
Mobile Site. A mobile site can be set up in an outside space close to an impacted site. One of the advantages of a mobile site is that it can be put in place between 36 and 72 hours. However, it has some disadvantages. The recovery time is usually longer than for a hot site, access to the impacted facility can be difficult, and transporting mobile-site equipment can be a challenge.
Redundant Backup Site. Another option is to outsource the data recovery site. Instead of maintaining the alternate location, the company can contract with a third-party vendor to host its data and services in a redundant backup site. If a disaster occurs, the critical services can be switched over to the alternate location, which often has a minimal impact on operations.
Fully redundant backup sites have the ability to host all the data and services, and they can be used as both the primary and secondary environments. In this scenario, all of the data and services are outsourced to the third-party vendor’s primary location. If a disaster occurs, the vendor is responsible for switching over to the secondary environment.
User Access. Users must have access to data and services if the operations are moved to an alternate location. In this situation, what is needed for them to have access depends on how they are using the data and services.
If users access services over the Internet, then the alternate location must include Internet access with the required bandwidth. However, users may normally access the services internally or via private WAN links. If this is the case, then the alternate location must have the capacity to get the data to the users, which may require additional WAN links.
Management Access. Management may also need access to data and services during the disaster, and, in many instances, management represents just another user. If users have access, then management also has access.
However, in some instances, management may have specific needs, such as for time-sensitive data. For example, if the end of the fiscal year is close, certain data must be accessible to management for reporting requirements. These specific management needs must be identified. When they are addressed, the DRP can meet them.
Customer Access. Customers must have the access they require. Customer access needs vary from one organization to another depending on how customers normally access the organization’s network and what customer expectations are during a disaster.
For example, with a local bank, the majority of banking may be done at the bank’s location. However, more and more customers use online banking today. If a disaster hits, customers can use the online site for many of their banking needs. The DRP should ensure that the bank’s website continues to function even if a major disruption affects the physical location of the bank.
Today, many organizations have websites, and most of them outsource their website hosting, which means that the website isn’t hosted on a server at the organization’s location. Instead, organizations rent space on a web server, and the hosting provider hosts the website. In this example, the hosting provider is responsible for disaster recovery.
However, this doesn’t mean that the website shouldn’t be considered. What if a disaster affected the website hosting provider? How would this situation affect the organization? Low-cost hosting providers often don’t have significant disaster recovery processes in place, and both minor and major disruptions take down websites on a regular basis.
Disaster Recovery Financial Budget
The last CSF to consider for a DRP is money. A DRP cannot be successfully developed and implemented without a budget because money is necessary to pay for preparation and executing a DRP if a disaster strikes.
There are several costs to consider when preparing for disasters. These include:
- Backups—Although most operating systems include backup software, it usually does only the basics. Most organizations purchase third-party backup software that is easier to use and has more capabilities. Additionally, backup media, such as multiple backup tapes, can be expensive. The cost increases when larger amounts of data need to be backed up.
- Alternate locations—Any type of alternate location costs additional money. As mentioned previously, hot sites are the most expensive, whereas cold sites are the least expensive. The site that is chosen depends on several factors, including the available budget.
- Fuel costs during a disaster—If an organization needs to be able to generate power for extended periods, someone must purchase fuel for the generators. The BCP identifies assumptions, such as how long critical operations need to function without outside support, such as commercial power. This information helps determine how much fuel to purchase.
- Food and water during a disaster—If personnel need to support the systems during the disaster, they need food and water. The amount needed depends on how many people will stay at the location and how many days they are expected to stay.
- Emergency funds right after a disaster—Funds are often needed right after a disaster for unforeseen circumstances. The budget should include funding for these expenses if needed. Additionally, these funds need to be accessible when the disaster hits.
In addition to establishing the budget, the people who can release the funds need to be identified, which is especially true for any monies needed during and immediately after the disaster. These people can be identified in the DRP or the BCP.