
10
Target Tracking Using Probabilistic Data Association-Based Techniques with Applications to Sonar, Radar, and EO Sensors
T. Kirubarajan and Yaakov Bar-Shalom
CONTENTS
10.2 Probabilistic Data Association
10.2.5 State and Covariance Update
10.2.7 Probabilistic Data Association
10.3 Low Observable TMA Using the ML-PDA Approach with Features
10.3.1 Amplitude Information Feature
10.3.3 Maximum Likelihood Estimator Combined with PDA: The ML-PDA
10.3.4 Cramér–Rao Lower Bound for the Estimate
10.4 IMMPDAF for Tracking Maneuvering Targets
10.4.3.1 Probabilistic Data Association
10.4.3.2 IMM Estimator Combined with PDA Technique
10.4.3.3 Models in the IMM Estimator
10.5 Flexible-Window ML-PDA Estimator for Tracking Low Observable Targets
10.5.2 Formulation of ML-PDA Estimator
10.5.2.2 Maximum Likelihood-Probabilistic Data Association Estimator
10.1 Introduction
In tracking targets with less-than-unity probability of detection in the presence of false alarms (FA) (clutter), data association—deciding which of the received multiple measurements to use to update each track—is crucial. A number of algorithms have been developed to solve this problem.1, 2, 3 and 4 Two simple solutions are the strongest neighbor filter (SNF) and the nearest neighbor filter (NNF). In the SNF, the signal with the highest intensity among the validated measurements (in a gate) is used for track update and the others are discarded. In the NNF, the measurement closest to the predicted measurement is used. Although these simple techniques work reasonably well with benign targets in sparse scenarios, they begin to fail as the FA rate increases or with low observable (LO) (low probability of target detection) maneuvering targets.5,6 Instead of using only one measurement among the received ones and discarding the others, an alternative approach is to use all of the validated measurements with different weights (probabilities), known as probabilistic data association (PDA).3 The standard PDA and its numerous improved versions have been shown to be very effective in tracking a single target in clutter.6,7
Data association becomes more difficult with multiple targets where the tracks compete for measurements. Here, in addition to a track validating multiple measurements as in the single target case, a measurement itself can be validated by multiple tracks (i.e., contention occurs among tracks for measurements). Many algorithms exist to handle this contention. The joint probabilistic data association (JPDA) algorithm is used to track multiple targets by evaluating the measurement-to-track association probabilities and combining them to find the state estimate.3 The multiple-hypothesis tracking (MHT) is a more powerful (but much more complex) algorithm that handles the multitarget tracking problem by evaluating the likelihood that there is a target given a sequence of measurements.4 In the tracking benchmark problem8 designed to compare the performance of different algorithms for tracking highly maneuvering targets in the presence of electronic countermeasures (ECM), the PDA-based estimator, in conjunction with the interacting multiple model (IMM) estimator, yielded one of the best solutions. Its performance was comparable to that of the MHT algorithm.6,9
This chapter presents an overview of the PDA technique and its application for different target-tracking scenarios. Section 10.2 summarizes the PDA technique. Section 10.3 describes the use of the PDA technique for tracking LO targets with passive sonar measurements. This target motion analysis (TMA) is an application of the PDA technique, in conjunction with the maximum likelihood (ML) approach for target motion parameter estimation via a batch procedure. Section 10.4 presents the use of the PDA technique for tracking highly maneuvering targets and for radar resource management. It illustrates the application of the PDA technique for recursive state estimation using the IMM estimator with probabilistic data association filter (IMMPDAF). Section 10.5 presents a state-of-the-art sliding-window (which can also expand and contract) parameter estimator using the PDA approach for tracking the state of a maneuvering target using measurements from an electrooptical (EO) sensor. This, while still a batch procedure, offers the flexibility of varying the batches depending on the estimation results.
10.2 Probabilistic Data Association
The PDA algorithm calculates in real time the probability that each validated measurement is attributable to the target of interest. This probabilistic (Bayesian) information is used in a tracking filter, the PDA filter (PDAF), which accounts for the measurement origin uncertainty.
10.2.1 Assumptions
The following assumptions are made to obtain the recursive PDAF state estimator (tracker)
There is only one target of interest whose state evolves according to a dynamic equation driven by process noise.
The track has been initialized.
The past information about the target is summarized approximately by
p[x(k)|Zk+1]=N[x(k);ˆx(k|k−1),P(k|k−1)](10.1)
where N[k(k);ˆx(k|k−1),P(k|k−1)]
At each time, a validation region as in Ref. 3 are set up (Equation 10.4).
Among the possibly several validated measurements, at most one of them can be target-originated—if the target was detected and the corresponding measurement fell into the validation region.
The remaining measurements are assumed to be FA or clutter and are modeled as independent identically distributed (iid) measurements with uniform spatial distribution.
The target detections occur independently over time with known probability PD.
These assumptions enable a state estimation scheme to be obtained, which is almost as simple as the Kalman filter, but much more effective in clutter.
10.2.2 PDAF Approach
The PDAF approach uses a decomposition of the estimation with respect to the origin of each element of the latest set of validated measurements, denoted as
Z(k)={zi(k)}m(k)i=1(10.2)
where zi(k) is the ith validated measurement and m(k) is the number of measurements in the validation region at time k.
The cumulative set (sequence) of measurements* is
Zk={Z(j)}kj=1(10.3)
10.2.3 Measurement Validation
From the Gaussian assumption (Equation 10.1), the validation region is the elliptical region
V(k,γ)={Z:[z−ˆz(k|k−1)]′S(k)−1[z−ˆz(k|k−1)]≤γ}(10.4)
where γ is the gate threshold and
S(k)=H(k)P(k|k−1)H(k)′+R(k)(10.5)
is the covariance of the innovation corresponding to the true measurement. The volume of the validation region (Equation 10.4) is
V(k)=cnz|γS(k)|1/2=cnzγnz/2|S(k)|1/2(10.6)
where the coefficient cnz depends on the dimension of the measurement (it is the volume of the nz-dimensional unit hypersphere: c1 = 2, c2 = π, c3 = 4π/3, etc.).
10.2.4 State Estimation
In view of the assumptions listed, the association events
θi(k)={{Zi(k) is the target-originated measurement}i=1,...,m(k){none of the measurements is target originated}i=0(10.7)
are mutually exclusive and exhaustive for m(k) ≥ 1.
Using the total probability theorem10 with regard to the events given in Equation 10.7, the conditional mean of the state at time k can be written as
ˆx(k|k)=E[x(k)Zk]=m(k)Σi=0 E[x(k)|θi(k),Zk]P{θi(k)|Zk}=m(k)Σi=0ˆxi(k|k)βi(k) (10.8)
where ˆxi(k|k)
βi(k)Δ=P{θi(k)|Zk}(10.9)
is the conditional probability of this event—the association probability, obtained from the PDA procedure presented in Section 10.2.7.
The estimate conditioned on measurement i being correct is
ˆxi(k|k)=ˆx(k|k−1)+W(k)vi(k)i=1,...,m(k)(10.10)
where the corresponding innovation is
vi(k)=zi(k)−ˆz(k|k−1)(10.11)
The gain W(k) is the same as in the standard filter
W(k)=P(k|k−1)H(k)′S(k)−1(10.12)
because conditioned on θi(k), there is no measurement origin uncertainty.
For i = 0 (i.e., if none of the measurements is correct) or m(k) = 0 (i.e., there is no validated measurement)
ˆx0(k|k)=ˆx(k|k−1)(10.13)
10.2.5 State and Covariance Update
Combining Equations 10.10 and 10.13 with Equation 10.8 yields the state update equation of the PDAF
ˆx(k|k)=ˆx(k|k−1)+W(k)v(k)(10.14)
where the combined innovation is
v(k)=m(k)Σi=1βi(k)vi(k)(10.15)
The covariance associated with the updated state is
P(k|k)=β0(k)P(k|k−1)+[1−β0(k)]Pc(k|k−1)+˜P(k)(10.16)
where the covariance of the state updated with the correct measurement is3
Pc(k|k)=P(k|k−1)−W(k)S(k)W(k)′(10.17)
and the spread of the innovations term (similar to the spread of the means term in a mixture)10 is
˜P(k)Δ=W(k)[m(k)Σi=1βi(k)vi(k)vi(k)′−v(k)v(k)′]W(k)′(10.18)
10.2.6 Prediction Equations
The prediction of the state and measurement to k + 1 is done as in the standard filter, that is,
ˆx(k+1|k)=F(k)ˆx(k|k)(10.19)
ˆz(k+1|k)=H(k+1)ˆx(k+1|k)(10.20)
The covariance of the predicted state is, similarly,
P(k+1|k)=F(k)P(k|k)F(k)′+Q(k)(10.21)
where P(k|k) is given by Equation 10.16.
The innovation covariance (for the correct measurement) is, again, as in the standard filter
S(k+1)=H(k+1)P(k+1|k)H(k+1)′+R(k+1)(10.22)
10.2.7 Probabilistic Data Association
To evaluate the association probabilities, the conditioning is broken down into the past data Zk–1 and the latest data Z(k). A probabilistic inference can be made on both the number of measurements in the validation region (from the clutter density, if known) and on their location, expressed as
βi(k)=P{θi(k)|Zk}=P{θi(k)|Z(k),m(k),Zk−1}(10.23)
Using Bayes’ formula, the Equation 10.23 is rewritten as
βi(k)=1cp[Z(k)|θi(k),m(k),Zk−1]p{θi(k)|m(k),Zk−1}i=0,...,m(k)(10.24)
The joint density of the validated measurements conditioned on θi(k), i ≠ 0, is the product of
The (assumed) Gaussian pdf of the correct (target-originated) measurements
The pdf of the incorrect measurements, which are assumed to be uniform in the validation region whose volume V(k) is given in Equation 10.6
The pdf of the correct measurement (with the PG factor that accounts for restricting the normal density to the validation gate) is
p[zi(k)|θi(k),m(k),Zk−1]=P−1GN[zi(k);z(k|k−1),S(k)]=P−1GN[vi(k);0,S(k)](10.25)
The pdf from Equation 10.24 is then
p[Z(k)|θi(k),m(k),Zk−1]={V(k)−m(k)+1P−1GN[vi(k);0,S(k)]}(10.26)
The probabilities of the association events conditioned only on the number of validated measurements are
p[Z(k)|θi(k),m(k),Zk−1]={V(k)−m(k)+1P−1GN[vi(k);0,S(k)]i=1,...,m(k)V(k)−m(k)i=0(10.27)
where µF(m) is the probability mass function (pmf) of the number of false measurements (FA or clutter) in the validation region.
Two models can be used for the pmf µF(m) in a volume of interest V
A Poisson model with a certain spacial density λ
μF(m)=e−λV(λV)mm!(10.28)
μF(m)=e−λV(λV)mm!(10.28) A diffuse prior model3
μF(m)=μF(m−1)=δ(10.29)
μF(m)=μF(m−1)=δ(10.29)
where the constant δ is irrelevant since it cancels out.
Using the (parametric) Poisson model in Equation 10.27 yields
γi[m(k)]={PDPG[PDPGm(k)+(1−PDPG)λV(k)]−1i=1,...,m(k)(1−PDPF)λV(k)[PDPGm(k)+(1−PDPG)λV(k)]−1i=0(10.30)
The (nonparametric) diffuse prior (Equation 10.29) yields
γi[m(k)]={1m(k)PDPGi=1,...,m(k)(1−PDPG)i=0(10.31)
The nonparametric model (Equation 10.31) can be obtained from Equation 10.30 by setting
λ=m(k)V(k)(10.32)
that is, replacing the Poisson parameter with the sample spatial density of the validated measurements. The volume V(k) of the elliptical (i.e., Gaussian-based) validation region is given in Equation 10.6.
10.2.8 Parametric PDA
Using Equations 10.30 and 10.26 with the explicit expression of the Gaussian pdf in Equation 10.24 yields, after some cancellations, the final equations of the parametric PDA with the Poisson clutter model
βi(k)={eib+Σm(k)j=1eji=1,...,m(k)bb+Σm(k)j=1eji=0(10.33)
where
eiΔ=e−(1/2)vi(k)′S(k)−1vi(k)(10.34)
bΔ=λ|2πS(k)|1/21−PDPGPD(10.35)
Equation (10.35) can be rewritten as
b=(2πλ)nz/2 λV(k)c−1nz1−PDPGPD(10.36)
10.2.9 Nonparametric PDA
The nonparametric PDA is the same as the parametric PDA except for replacing λV(k) in Equation 10.36 by m(k)—this obviates the need to know λ.
10.3 Low Observable TMA Using the ML-PDA Approach with Features
This section considers the problem of TMA—estimation of the trajectory parameters of a constant velocity target—with a passive sonar, which does not provide full target position measurements. The methodology presented here applies equally to any target motion characterized by a deterministic equation, in which case the initial conditions (a finite dimensional parameter vector) characterize in full the entire motion. In this case the (batch) ML parameter estimation can be used; this method is more powerful than state estimation when the target motion is deterministic (it does not have to be linear). Furthermore, the ML-PDA approach makes no approximation, unlike the PDAF in Equation 10.1.
10.3.1 Amplitude Information Feature
The standard TMA consists of estimating the target’s position and its constant velocity from bearings-only (wideband sonar) measurements corrupted by noise.10 Narrowband passive sonar tracking, where frequency measurements are also available, has been studied.11 The advantages of narrowband sonar are that it does not require a maneuver of the platform for observability, and it greatly enhances the accuracy of the estimates. However, not all passive sonars have frequency information available. In both cases, the intensity of the signal at the output of the signal processor, which is referred to as measurement amplitude or amplitude information (AI), is used implicitly to determine whether there is a valid measurement. This is usually done by comparing it with the detection threshold, which is a design parameter.
This section shows that the measurement amplitude carries valuable information and that its use in the estimation process increases the observability even though the AI cannot be correlated to the target state directly. Also, superior global convergence properties are obtained.
The pdf of the envelope detector output (i.e., the AI) a when the signal is due to noise only is denoted as p0(a) and the corresponding pdf when the signal originated from the target is p1(a). If the signal-to-noise ratio (SNR—this is the SNR in a resolution cell, to be denoted later as SNRc) is d, the density functions of noise-only and target-originated measurements can be written as
p0(a)=a exp(−a22)a≥0(10.37)
p1(a)=a1+dexp(−a22(1+d))a≥0(10.38)
respectively. This is a Rayleigh fading amplitude (Swerling I) model believed to be the most appropriate for shallow water passive sonar.
A suitable threshold, denoted by τ, is used to declare a detection. The probability of detection and the probability of FA are denoted by PD and PFA, respectively. Both PD and PFA can be evaluated from the pdfs of the measurements. Clearly, to increase PD, the threshold τ must be lowered; however, this also increases PFA. Therefore, depending on the SNR, τ must be selected to satisfy two conflicting requirements.*
The density functions given above correspond to the signal at the envelope detector output. Those corresponding to the output of the threshold detector are
ρτ0(a)=1PFAp0(a)=1PFAa exp(−a22)a>τ(10.39)
ρτ1(a)=1PDp1(a)=1PDa1+da exp(−a22(1+d))a>τ(10.40)
where ρτ0(a)
ρ=pτ1(a)pτ0(a)(10.41)
10.3.2 Target Models
Assume that n sets of measurements, made at times t = t1, t2, …, tn, are available.
For bearings-only estimation, the target motion is defined by the four-dimensional parameter vector
x≡[ξ(t0),η(t0),˙ξ,˙η](10.42)
where ξ(t0) and η(t0) are the distances of the target in the east and north directions, respectively, from the origin at the reference time t0. The corresponding velocities, assumed constant, are ˙ξ
The state of the platform at ti (i = 1, …, n) is defined by
xp(ti)≡[ξp(ti),ηp(ti),˙ξp(ti),˙ηp(ti)]′(10.43)
The relative position components in the east and north directions of the target with respect to the platform at ti are defined by rξ(ti, x) and rη(ti, x), respectively. Similarly, vξ(ti, x) and vη(ti, x) define the relative velocity components. The true bearing of the target from the platform at ti is given by
θi(x)Δ=tan−1[rξ(ti,x)rη(ti,x)](10.44)
The range of possible bearing measurements is
UθΔ=[θ1,θ2]⊂[0,2π](10.45)
The set of measurements at ti is denoted by
Z(i)Δ={zj(i)}mij=1(10.46)
where mi is the number of measurements at ti, and the pair of bearing and amplitude measurements zj(i), is defined by
zj(i)Δ=[βijaij]′(10.47)
The cumulative set of measurements during the entire period is
ZnΔ={Z(i)}ni=1(10.48)
The following additional assumptions about the statistical characteristics of the measurements are also made:11
The measurements at two different sampling instants are conditionally independent, that is,
p[Z(i1),Z(i2)|x]=p[Z(i1)|x]p[Z(i2)|x]∀i1≠i2(10.49)
p[Z(i1),Z(i2)|x]=p[Z(i1)|x]p[Z(i2)|x]∀i1≠i2(10.49) where p[·] is the pdf.
A measurement that originated from the target at a particular sampling instant is received by the sensor only once during the corresponding scan with probability PD and is corrupted by zero-mean Gaussian noise of known variance. That is,
βij=θi(x)+∈ij(10.50)
βij=θi(x)+∈ij(10.50) where ∈ij∼N[0,σ2θ]
∈ij∼N[0,σ2θ] is the bearing measurement noise. Owing to the presence of false measurements, the index of the true measurement is not known.The false bearing measurements are distributed uniformly in the surveillance region, that is,
βij∼U[θ1,θ2](10.51)
βij∼U[θ1,θ2](10.51) The number of false measurements at a sampling instant is generated according to Poisson law with a known expected number of false measurements in the surveillance region. This is determined by the detection threshold at the sensor (exact equations are given in Section 10.3.5).
For narrowband sonar (with frequency measurements) the target motion model is defined by the five-dimensional vector
x≡[ξ(t1),η(t1),˙ξ,˙η,γ](10.52)
where γ is the unknown emitted frequency assumed constant. Owing to the relative motion between the target and platform at ti, this frequency will be Doppler shifted at the platform. The (noise-free) shifted frequency, denoted by γi(x), is given by
γi(x)=γ[1−vξ(ti,x)sin θi(x)+vn(ti,x)cos θi(x)c](10.53)
where c is the velocity of sound in the medium. If the bandwidth of the signal processor in the sonar is [Ω1, Ω2], the measurements can lie anywhere within this range. As in the case of bearing measurements, we assume that an operator is able to select a frequency subregion [Γ1, Γ2] for scanning. In addition to the bearing surveillance region given in Equation 10.45, the region for frequency is defined as
UγΔ=[Γ1,Γ2]⊂[Ω1,Ω2](10.54)
The noisy frequency measurements are denoted by fi and the measurement vector is
zj(i)Δ=[βij,fij,aij]′(10.55)
As for the statistical assumptions, those related to the conditional independence of measurements (assumption 1) and the number of false measurements (assumption 4) are still valid. The equations relating the number of FA in the surveillance region to detection threshold are given in Section 10.3.5.
The noisy bearing measurements satisfy Equation 10.50 and the noisy frequency measurements fij satisfy
fij=γi(x)+vij(10.56)
where vij∼N[0,σ2γ]
It is also assumed that these two measurement noise components are conditionally independent. That is,
p(∈ij,vij|x)=p(∈ij|x)p(vij|x)(10.57)
The measurements resulting from noise only are assumed to be uniformly distributed in the entire surveillance region.
10.3.3 Maximum Likelihood Estimator Combined with PDA: The ML-PDA
In this section, we present the derivation and implementation of the ML estimator combined with the PDA technique for both bearings-only tracking and narrowband sonar tracking. If there are mi detections at ti, one has the following mutually exclusive and exhaustive events:3
εj(i)Δ={{measurement zj(i) is from the target}j=1,...,mi{all measurements are false}j=0(10.58)
The pdf of the measurements corresponding to the above events can be written as
p[Z(i)|ej(i),x]={u1−mi p(βij)ρijmiΠj=1pτ0(aij)j=1,...,miu−mimiΠj=1pτ0(aij)j=0(10.59)
where u = Uθ is the area of the surveillance region.
Using the total probability theorem, the likelihood function of the set of measurements at ti can be expressed as
p[Z(i)|x]=u−mi(1−PD)miΠj=1pτ0(aij)μF(mi)+u1−miPDμF(mi−1)mimiΠj=1pτ0(aij)miΣj=1p(bij)ρij=u−mi(1−PD)miΠj=1pτ0(aij)μF(mi)+u1−miPDμF(mi−1)mimiΠj=1pτ0(aij)⋅miΣj=11√2πσθexp(−12[βij−θi(x)σθ]2)ρij(10.60)
µF (mi) is the Poisson pmf of the number of false measurements at ti. Dividing the above by p[Z(i)|ε0(i), x] yields the dimensionless likelihood ratio Φi[Z(i), x] at ti. Then
Φi[Z(i),x]=p[Z(i),x]p[Z(i) | ε0(i),x]=(1−PD)+PDλmiΣj=11√2πσθρij exp(−12[βij−θi(x)σθ]2)(10.61)
where λ is the expected number of FA per unit area. Alternately, the log-likelihood ratio at ti can be defined as
ϕi[Z(i),x]=ln[(1−PD)+PDλmiΣj=11√2πσθρij exp(−12[βij−θi(x)σθ]2)](10.62)
Using conditional independence of measurements, the likelihood function of the entire set of measurements can be written in terms of the individual likelihood functions as
p[Zn|x]=nΠi=1p[Z(i)|x](10.63)
Then the dimensionless likelihood ratio for the entire data is given by
Φ[Zn,x]=nΠi=1Φi[Z(i),x](10.64)
From the above, the total log-likelihood ratio Φi[Z(i), x]ti can be expressed as
Φ[Zn,x]=nΣi=1ln[(1−PD)+PDλmiΣj=11√2πσθρij exp(−12[βij−θi(x)σθ]2)](10.65)
The maximum likelihood estimate (MLE) is obtained by finding the state x=ˆx
Arguments similar to those given earlier can be used to derive the MLE when frequency measurements are also available. Defining εj(i) as in Equation 10.58, the pdf of the measurements is
p[Z(i)|εj(i),x]={u1−mip(βij)p(fij)pijmiΠj=1pτ0(aij)j=1,....,miu−mimiΠj=1pτ0(aij)j=0(10.66)
where u = Uθ Uγ is the volume of the surveillance region.
After some lengthy manipulations, the total log-likelihood function is obtained as
Φ[Zn,x]=Σ ln[(1−PD)+PDλmiΣj=1ρij2πσθσγexp(−12[βij−θi(x)σθ]2−12[fij−γi(x)σγ]2)](10.67)
For narrowband sonar, the MLE is found by maximizing Equation 10.67.
This section demonstrated the essence of the use of the PDA—all the measurements are accounted for and the likelihood function is evaluated using the total probability theorem, similar to Equation 10.8. However, since Equation 10.67 is exact (for the parameter estimation formulation), there is no need for the approximation in Equation 10.1, which is necessary in the PDAF for state estimation.
The same ML-PDA approach is applicable to the estimation of the trajectory of an exoatmospheric ballistic missile.12,13 The modification of this fixed-batch ML-PDA estimator to a flexible (sliding/expanding/contracting) procedure is discussed in Section 10.5 and demonstrated with an actual EO data example.
10.3.4 Cramér–Rao Lower Bound for the Estimate
For an unbiased estimate, the Cramér–Rao lower bound (CRLB) is given by
E{(x−ˆx)(x−ˆx)′}≥J−1(10.68)
where J is the Fisher information matrix (FIM) given by
J=E{[∇x ln p(Zn|x)][∇x ln p(Zn|x)]′} |x=xtrue(10.69)
Only in simulations will the true value of the state parameter be available. In practice CRLB is evaluated at the estimate.
As expounded in Ref. 14, the FIM J is given in the present ML-PDA approach for the bearings-only case, wideband sonar, by
J=q2(PD,λvg,g)nΣi=11σ2θ[∇xθi(x)][∇xθi(x)]′(10.70)
where q2(PD, λvg, g) is the information reduction factor that accounts for the loss of information resulting from the presence of false measurements and less-than-unity probability of detection,3 and the expected number of FA per unit volume is denoted by λ.
In deriving Equation 10.70, only the bearing measurements that fall within the validation region
Vig(x)Δ={βij:|βij−θi(x)σθ|≤g}(10.71)
at ti were considered. The validation region volume (g-sigma region), vg, is given by
vg=2σθg(10.72)
The information reduction factor q2(PD, λvg, g) for the present two-dimensional measurement situation (bearing and amplitude) is given by
q2(PD,λvg,g)=11+d√2π∞Σm=1μf(m−1)(gPFA)m−1I2(m,PD,g)(10.73)
where I2(m, PD, g) is a 2m-fold integral given in Ref. 14 where numerical values of q2(PD, λvg, g) for different combinations of PD and λvg are also presented. The derivation of the integral is based on Bar-Shalom and Li.3 In this implementation, g = 5 was selected. Knowing PD and λvg, PFA can be determined by using
λvg=PFAvgVc(10.74)
where Vc is the resolution cell volume of the signal processor (discussed in more detail in Section 10.3.5). Finally, d, the SNR, can be calculated from PD and λvg.
The rationale for the term information reduction factor follows from the fact that the FIM for zero FA probability and unity target detection probability, J0, is given by Ref. 10.
J0=nΣi=11σ2θ[∇xθi(x)][∇xθi(x)]′(10.75)
Equations 10.70 and 10.75 clearly show that q2(PD, λvg, g), which is always less than or equal to unity, represents the loss of information due to clutter.
For narrowband sonar (bearing and frequency measurements), the FIM is given by
J=q2(PD,λvg,g)nΣi=1{1σ2θ[∇xθi(x)][∇xθi(x)]′+1σ2θ[∇xγi(x)][∇xγi(x)]′}(10.76)
where q2(PD, λvg, g) for this three-dimensional measurement (bearing, frequency, and amplitude) case is evaluated14 using
q2(PD,λvg,g)=11+dΣ2m−1μF(m−1)(g2PFA)m−1I2(m,PD,g)(10.77)
The expression for I2(m, PD, g) and the numerical values for q2(PD, λvg, g) are also given by Kirubarajan and Bar-Shalom.14
For narrowband sonar, the validation region is defined by
Vig(x)Δ={(βij,fij):[βij−θi(x)σθ]2+[fij−θi(x)σγ]2}≤g2(10.78)
and the volume of the validation region, vg, is
vg=σθσγg2(10.79)
10.3.5 Results
Both the bearings-only and the narrowband sonar problems with AI were implemented to track a target moving at constant velocity. The results for the narrowband case are given in the following text, accompanied by a discussion of the advantages of using AI by comparing the performances of the estimators with and without AI.
In narrowband signal processing, different bands in the frequency domain are defined by an appropriate cell resolution and a center frequency about which these bands are located. The received signal is sampled and filtered in these bands before applying FFT and beamforming. Then the angle of arrival is estimated using a suitable algorithm.15 As explained earlier, the received signal is registered as a valid measurement only if it exceeds the threshold τ. The threshold value, together with the SNR, determines the probability of detection and the probability of FA.
The signal processor was assumed to consist of the frequency band (500 Hz, 1000 Hz) with a 2048-point FFT. This results in a frequency cell whose size is given by
Cγ=5002048≈0.25 Hz(10.80)
Regarding azimuth measurements, the sonar is assumed to have 60 equal beams, resulting in an azimuth cell Cθ with size
Cθ=180°60=3.0°(10.81)
Assuming uniform distribution in a cell, the frequency and azimuth measurement standard deviations are given by*
σγ=0.25√12=0.0722 Hz(10.82)
σθ=3.0√12=0.866°(10.83)
The SNRc in a cell† was taken as 6.1 dB and PD = 0.5. The estimator is not very sensitive to an incorrect PD. This is verified by running the estimator with an incorrect PD on the data generated with a different PD. Differences up to 0.15 are tolerated by the estimator. The corresponding SNR in a 1 Hz bandwidth SNR1 is 0.1 dB. These values give
τ=2.64(10.84)
PFA=0.306(10.85)
From PFA, the expected number of FA per unit volume, denoted by λ, can be calculated using
PFA=λCθCγ(10.86)
Substituting the values for Cθ and λ gives
λ=0.03063.0×0.25=0.0407/deg⋅Hz(10.87)
The surveillance regions for azimuth and frequency, denoted by Uθ and Uγ, respectively, are taken as
Uθ=[−20°,20°](10.88)
Uγ=[747 Hz,753 Hz](10.89)
The expected number of FA in the entire surveillance region and that in the validation gate Vg can be calculated. These values are 9.8 and 0.2, respectively, where the validation gate is restricted to g = 5. These values mean that, for every true measurement that originated from the target, there are about 10 FA that exceed the threshold.
The estimated tracks were validated using the hypothesis testing procedure described in Ref. 14. The track acceptance test was carried out with a miss probability of 5%.
To check the performance of the estimator, simulations were carried out with clutter only (i.e., without a target) and also with a target present; measurements were generated accordingly. Simulations were done in batches of 100 runs.
When there was no target, irrespective of the initial guess, the estimated track was always rejected. This corroborates the accuracy of the validation algorithm given by Kirubarajan and Bar-Shalom.14
For the set of simulations with a target, the following scenario was selected: the target moves at a speed of 10 m/s heading west and 5 m/s heading north starting from (5,000 m, 35,000 m). The signal frequency is 750 Hz. The target parameter is x = [5,000 m, 35,000 m, −10 m/s, 5 m/s, 750 Hz]. The motion of the platform consisted of two velocity legs in the northwest direction during the first half, and in the northeast direction during the second half of the simulation period with a constant speed of 7.1 m/s. Measurements were taken at regular intervals of 30 s. The observation period was 900 s. Figure 10.1 shows the scenario including the target true trajectory (solid line), platform trajectory (dashed line), and the 95% probability regions of the position estimates at the initial and final sampling instants based on the CRLB (Equation 10.76). The initial and the final positions of the trajectories are marked by I and F, respectively. The purpose of the probability region is to verify the validity of the CRLB as the actual parameter estimate covariance matrix from a number of Monte Carlo runs.4

FIGURE 10.1
Estimated tracks from 100 runs for narrowband sonar with amplitude information.
TABLE 10.1
Results of 100 Monte Carlo Runs for Narrowband Sonar with AI (SNRc = 6.1 dB)

Figure 10.1 shows the 100 tracks formed from the estimates. Note that in all but 6 runs (i.e., 94 runs) the estimated trajectory endpoints fall in the corresponding 95% uncertainty ellipses.
Table 10.1 gives the numerical results from 100 runs. Here ˉx
∈xΔ=(x−ˆx)′J(x−ˆx)(10.90)
where ˉx
10.4 IMMPDAF for Tracking Maneuvering Targets
Target tracking is a problem that has been well studied and documented. Some specific problems of interest in the single-target, single-sensor case are tracking maneuvering targets,10 tracking in the presence of clutter,3 and ECM. In addition to these tracking issues, a complete tracking system for a sophisticated electronically steered antenna radar has to consider radar scheduling, waveform selection, and detection threshold selection.
Although many researchers have worked on these issues and many algorithms are available, there had been no standard problem comparing the performances of the various algorithms. Rectifying this, the first benchmark problem16 was developed, focusing only on tracking a maneuvering target and pointing/scheduling phased array radar. Of all the algorithms considered for this problem, the IMM estimator yielded the best performance.17 The second benchmark problem9 included FA and ECM—specifically, a standoff jammer (SOJ) and range gate pull off (RGPO)—as well as several possible radar waveforms (from which the resource allocator has to select one at every revisit time). Preliminary results for this problem showed that the IMM and MHT algorithms were the best solutions.6,9 For the problem considered, the MHT algorithm yielded similar results as the IMMPDAF modules;3 although the MHT algorithm was one to two orders of magnitude costlier computationally (as many as 40 hypotheses were needed*). The benchmark problem of Ref. 18 was upgraded in Ref. 8 for the radar resource allocator/manager to select the operating constant FA rate (CFAR), and included the effects of the SOJ on the direction of arrival (DOA) measurements; also the SOJ power was increased to present a more challenging benchmark problem. Although in Ref. 18 the primary performance criterion for the tracking algorithm was minimization of radar energy, the primary performance was changed in Ref. 8 to minimization of a weighted combination of radar time and energy.
This section presents the IMMPDAF technique for automatic track formation, maintenance, and termination. The coordinate selection for tracking and radar scheduling/pointing, and the models used for mode-matched filtering (the modules inside the IMM estimator) are also discussed. These cover the target tracking aspects of the solution to the benchmark problem. These are based on the benchmark problem tracking and sensor resource management.6,8
10.4.1 Coordinate Selection
For target tracking in track-dwell mode of the radar, the number of detections at scan k (time tk) is denoted by mk. The mth detection report ˉζm(tk)
¯ςm (tk)=[tk,rm,bm,em,ρm,σbm,σem]′(10.91)
where the overbar indicates that this is in the radar’s spherical coordinate system.
The AI is used only to declare detections and select the radar waveform for the next scan. Since the use of AI, for example, as in Ref. 17, can be counterproductive in discounting RGPO measurements, which generally have higher SNR than target-originated measurements, AI is not utilized in the estimation process itself. Using the AI would require a separate model for the RGPO intensity, which cannot be estimated in real time due to its short duration and variability.17
For target tracking, the measurements are converted from spherical coordinates to Cartesian coordinates, and then the IMMPDAF is used on these converted measurements. This conversion avoids the use of extended Kalman filters and makes the problem linear.4 The converted measurement report ζm(tk) corresponding to ˉζm(tk)
ςm(tk)=[tk,xm,ym,zm,ρm,Rm](10.92)
where xm, ym, zm, and Rm are the three position measurements in the Cartesian frame and their covariance matrix, respectively. The converted values are
xm=rm cos(bm)cos(em)(10.93)
ym=rm sin(bm)cos(em)(10.94)
zm=rm sin(em)(10.95)
Rm=Tm⋅diag[(σrk)2,(σbm),(σem)2]⋅T′m(10.96)
where σrk
Tm=[cos(bm)cos(em)−rmsin(bm)cos(em)−rmcos(bm)cos(em)sin(bm)cos(em)rmcos(bm)cos(em)−rmsin(bm)cos(em)sin(em)0rmcos(em)](10.97)
For the scenarios considered here, this transformation is practically unbiased and there is no need for the debiasing procedure of Ref. 4.
10.4.2 Track Formation
In the presence of FA, track formation is crucial. Incorrect track initiation will result in target loss. In Ref. 3, an automatic track formation/deletion algorithm in the presence of clutter is presented based on the IMM algorithm. In the present benchmark problem, a noisy measurement corresponding to the target of interest is given in the first scan.* Forming new tracks for each validated measurement (based on a velocity gate) at subsequent scans, as suggested in Ref. 3 and as implemented in Ref. 6, is expensive in terms of both radar energy and computational load. In this implementation, track formation is simplified and handled as follows.
Scan 1 (t = 0 s): As defined by the benchmark problem, there is only one (target-originated, noisy) measurement. The position component of this measurement is used as the starting point for the estimated track.
Scan 2 (t = 0.1 s): The beam is pointed at the location of the first measurement. This yields, possibly, more than one measurement and these measurements are gated using the maximum possible velocity of the targets to avoid the formation of impossible tracks. This validation region volume, which is centered on the initial measurement, is given by
Vxyz=[2(˙xmaxδ2+3√Rxm2)][2(˙ymaxδ2+3√Rym2)][2(˙zmaxδ2+3√Rzm2)](10.98)
where δ2 = 0.1 s is the sampling interval and ˙xmax δ2
The measurement in the first scan and the measurement with the highest SNR in the second scan are used to form a track with the two-point initialization technique.10 The track splitting used in Refs 3 and 6 was found unnecessary—the strongest validated measurement was adequate. This technique yields the position and velocity estimates and the associated covariance matrices in all three coordinates.
Scan 3 (t = 0.2 s): The pointing direction for the radar is given by the predicted position at t = 0.2 s using the estimates at scan 2. An IMMPDA filter with three models discussed in the sequel is initialized with the estimates and covariance matrices obtained at the second scan. The acceleration component for the third-order model is assumed zero with variance (amax)2, where amax = 70 m/s2 is the maximum expected acceleration of the target.
From scan 3 onward, the track is maintained using the IMMPDAF as described in Section 10.4.3. To maintain a high SNR for the target-originated measurement during track formation, a high-energy waveform is used. Also, scan 3 dwells are used to ensure target detection. This simplified approach cannot be used if the target-originated measurement is not given at the first scan. In that case, the track formation technique in Ref. 3 can be used.
Immediate revisit with sampling interval 0.1 s is carried out during track formation because the initial velocity of the target is not known—in the first scan only the position is measured and there is no a priori velocity. This means that in the second scan the radar must be pointed at the first scan position, assuming zero velocity. Waiting longer to obtain the second measurement could result in the loss of the target-originated measurement due to incorrect pointing. Also, to make the IMM mode probabilities converge to the correct values as quickly as possible, the target is revisited at a high rate.
10.4.3 Track Maintenance
The true state of the target at tk is
x(tk)=[x(tk)˙x(tk)¨x(tk)y(tk)˙y(tk)¨y(tk)z(tk)˙z(tk)¨z(tk)]′
where x(tk ), y(tk ), and z(tk ) are the positions, ˙x(tk)
Assuming that the target motion is linear in the Cartesian coordinate system, the true state of the target can be written as
x(tk)=F(δk)x(tk−1)+Γ(δk)v(tk−1)(10.99)
and the target-originated measurement is related to the state according to
z(tk)=Hx(tk)+w(tk)(10.100)
where δk = t – tk−1. The white Gaussian noise sequences v(tk) and w(tk) are independent and their covariances are Q(δk) and R(tk), respectively.
With the assumptions from Equations 10.99 and 10.100, the predicted state ˆx(t−k)
ˆx(t−k)=F(δk)+ˆx(tk−1)(10.101)
and the predicted measurement is
ˆz(t−k)=Hˆx(t−k)(10.102)
with associated innovation covariance
S(tk)=HP(t−k)H′+R(tk)(10.103)
where P(t−k)
10.4.3.1 Probabilistic Data Association
During track maintenance, each measurement at scan tk is validated against the established track. This is achieved by setting up a validation region centered around the predicted measurement at t−k
[z(tk)−ˆz(t−k)]′S(tk)−1[z(tk)−ˆz(t−k)]≤γ(10.104)
where S(tk ) is the expected covariance of the innovation corresponding to the correct measurement and γ = 16 (0.9989 probability mass3) is the gate size. The appropriate covariance matrix for Equation 10.104 is discussed later in this section.
The set of measurements validated for the track at tk is
Z(k)={zm(tk),m=1,2,...,mk}(10.105)
where mk is the number of measurements validated and associated with the track. Also, the cumulative set of validated measurements up to and including scan k is denoted by zk1
With these mk validated measurements at tk, one has the following mutually exclusive and exhaustive events:
εm(tk)Δ={{measurement zm(tk) is from the target}m=1,...,mk{all measurements are false}m=0(10.106)
Using the nonparametric version of the PDAF,4 the validated measurements are associated probabilistically to the track. The combined target state estimate is obtained as
ˆx(tk)=mkΣm=0 βm(tk)ˆxm(tk)(10.107)
where βm(tk) is the probability that the mth validated measurement is correct and ˆxm(tk)
ˆxm(tk)=ˆx(t−k)+Wm(tk)vm(tk)m=1,2,...,mk(10.108)
where Wm(tk ) is the filter gain and vm(tk)=zm(tk)−ˆzm(t−k)
Wm(tk)=P(t−k)H′[HP(t−k)H′+Rm(tk)]−1Δ=P(t−k)H′Sm(tk)−1(10.109)
where Rm(tk) depends on the observed SNR for measurement m.8
The association event probabilities βm(tk) are given by
βm(tk)=P{εm(tk)|zk1}(10.110)
={e(m)b+Σmkj=1e(j)m=1,2,...,mkbb+Σmkj=1e(j)m=0(10.111)
where
e(m)=N[vm(tk);0,Sm(tk)](10.112)
b=mk1−PDPDV(tk)(10.113)
and PD is the probability of detection of a target-originated measurement. The probability that a target-originated measurement, if detected, falls within the validation gate is assumed to be unity. Also, N[v; 0, S] denotes the normal pdf with argument v, mean zero, and covariance matrix S. The common validation volume V(tk ) is the union of the validation volumes Vm(tk ) used to validate the individual measurements associated with the target V(tk ) and is given by
Vm(tk)=γnz/2Vnz|Sm(tk)|1/2(10.114)
where Vnz is the volume of the unit hypersphere of dimension nz, based on the dimension of the measurement z. For the three-dimensional position measurements Vnz = 4π/3.3
The state estimate is updated as
ˆx(tk)=ˆx(t−k)+mkΣm=1 βm(tk)Wm(tk)vm(tk)(10.115)
and the associated covariance matrix is updated as
P(tk)=P(t−k)−mkΣm=1 βm(tk)Wm(tk)Sm(tk)Wm(tk)′+˜P(tk)(10.116)
where
P(t−k)=F(δk)P(tk−1)F(δk)′+Γ(δk)Q(δk)Γ(δk)′(10.117)
is the predicted state covariance and the term
˜P(tk)=mkΣm=1 βm(tk)[Wm(tk)vm(tk)][Wm(tk)vm(tk)]′−[mkΣm=1 βm(tk)Wm(tk)vm(tk)][mkΣm=1 βm(tk)Wm(tk)vm(tk)]′(10.118)
is analogous to the spread of the innovations in the standard PDA.3 Monopulse processing results in different accuracies (standard deviations) for different measurements within the same dwell. This accounts for the difference in the preceding equations from the standard PDA, where the measurement accuracies are assumed to be the same for all of the validated measurements.
To initialize the filter at k = 3, the following estimates are used:10
x(t2)=[ˆx(t2)˙ˆx(t2)¨ˆx(t2)ˆy(t2)˙ˆy(t2)¨ˆy(t2)ˆz(t2)˙ˆz(t2)¨ˆz(t2)]=[zxh(t2)zxh(t2)−zx(t1)δ20zyh(t2)zyh(t2)−zy(t1)δ20zzh(t2)zzh(t2)−zz(t1)δ20](10.119)
where h is the index corresponding to the validated measurement with the highest SNR in the second scan, and the superscripts x, y, and z denote the components in the corresponding directions, respectively. The associated covariance matrix can be derived10 using the measurement covariance Rh and the maximum target acceleration amax. If the two-point differencing results in a velocity component that exceeds the corresponding maximum speed, it is replaced by that speed. Similarly, the covariance terms corresponding to the velocity components are upper bounded by the corresponding maximum values.
10.4.3.2 IMM Estimator Combined with PDA Technique
In the IMM estimator it is assumed that at any time the target trajectory evolves according to one of a finite number of models, which differ in their noise levels and structures.10 By probabilistically combining the estimates of the filters, typically Kalman, matched to these modes, an overall estimate is found. In the IMMPDAF the Kalman filter is replaced with the PDAF (given in Section 10.4.3.1 for mode-conditioned filtering of the states), which handles the data association.
Let r be the number of mode-matched filters used, M(tk) the index of the mode in effect in the semiopen interval (tk–1, tk) and µj(tk) be the probability that mode j (j = 1, 2, …, r) is in effect in this interval. Thus,
μj(tk)=P{M(tk)=j|Zk1}(10.120)
The mode transition probability is defined as
pij=P{M(tk)=j|M(tk−1)=i}(10.121)
The state estimates and their covariance matrix at tk conditioned on the jth mode are denoted by ˆxj(tk)
The steps of the IMMPDAF are as follows.3
Step 1: Mode interaction or mixing. The mode-conditioned state estimate and the associated covariances from the previous iteration are mixed to obtain the initial condition for the mode-matched filters. The initial condition in cycle k for the PDAF matched to the jth mode is computed using
ˆx0j(tk−1)=rΣi=1ˆxi(tk−1)μi|j(tk−1)(10.122)
where
μi|j(tk−1)=P{M(tk−1)=i|M(tk−1)=j,Zk−11}=pijμi(tk−1)Σrl=1pljμl(tk−1)i,j=1,2,...,r(10.123)
are the mixing probabilities. The covariance matrix associated with Equation 10.122 is given by
P0j(tk−1)=rΣi=1μi|j(tk−1){Pi(tk−1)+[ˆxi(tk)−ˆx0j(tk−1)][ˆxi(tk)−ˆx0j(tk−1)]′}(10.124)
Step 2: Mode-conditioned filtering. A PDAF is used for each mode to calculate the mode-conditioned state estimates and covariances. In addition, we evaluate the likelihood function Λj(tk) of each mode at tk using the Gaussian-uniform mixture:
Λj(tk)Δ=p[Z(k)|M(tk)=j,Zk−11]=V(tk)−ml(1−PD)+V(tk)1−mkPDmkmkΣm=1ej(m)(10.125)
=PDV(tk)1−mkmk(b+mkΣm=1ej(m))(10.126)
where ej(m) is defined in Equation 10.112 and b in Equation 10.113. Note that the likelihood function, as a pdf, has a physical dimension that depends on mk. Since ratios of these likelihood functions are to be calculated, they all must have the same dimension, that is, the same mk. Thus, a common validation region (Equation 10.104) is vital for all the models in the IMMPDAF. Typically, the “largest” innovation covariance matrix corresponding to “noisiest” model covers the others and, therefore, this can be used in Equations 10.104 and 10.114.
Step 3: Mode update. The mode probabilities are updated based on the likelihood of each mode using
μj(tk)=Λj(tk)Σrl=1 pljμl(tk−1)Σrl=1 Σrl=1Λi(tk)pljμl(tk−1)(10.127)
Step 4: State combination. The mode-conditioned estimates and covariances are combined to find the overall estimate ˆx(tk)
ˆx(tk)=rΣj=1μj(tk)ˆx(tk)(10.128)
P(tk)=rΣj=1μj(tk){Pj(tk)+[ˆxj(tk)−ˆx(tk)][ˆxj(tk)−ˆx(tk)]′}(10.129)
10.4.3.3 Models in the IMM Estimator
The selection of the model structures and their parameters is one of the critical aspects of the implementation of IMMPDAF. Designing a good set of filters requires a priori knowledge about the target motion, usually in the form of maximum accelerations and sojourn times in various motion modes.10 The tracks considered in the benchmark problem span a wide variety of motion modes—from benign constant velocity motions to maneuvers up to 7g. To handle all possible motion modes and to handle automatic track formation and termination, the following models are used.
Benign motion model (M1). This second-order model with low noise level (to be given later) has a probability of target detection PD given by the target’s expected SNR and corresponds to the nonmaneuvering intervals of the target trajectory. For this model the process noise is, typically, assumed to model air turbulence.
Maneuver model (M2). This second-order model with high noise level corresponds to ongoing maneuvers. For this white noise acceleration model, the process noise standard deviation σv2 is obtained using
σv2=αamax(10.130)
where amax is the maximum acceleration in the corresponding modes and 0.5 < α ≤ 1.10
Maneuver detection model (M3). This is a third-order (Wiener process acceleration) model with high noise level. For highly maneuvering targets, like military attack aircraft, this model is useful for detecting the onset and termination of maneuvers. For civilian air traffic surveillance,19 this model is not necessary.
For a Wiener process acceleration model, the standard deviation σv3 is chosen using
σv3=min{βΔaδ,amax}(10.131)
where ∆a is the maximum acceleration increment per unit time (jerk), δ the sampling interval, and 0.5 < α ≤ 1.3
For the targets under consideration, amax = 70 m/s2 and ∆a = 35 m/s3. Using these values, the process noise standard deviations were taken as
σv1=3m/s2(for nonmaneuvering intervals)σv2=35m/s2(for maneuvering intervals)σv3=min{35δ,70}(for maneuver start/termination)
In addition to the process noise levels, the elements of the Markov chain transition matrix between the modes, defined in Equation 10.121, are also design parameters. Their selection depends on the sojourn time in each motion mode. The transition probability depends on the expected sojourn time via
τi=δ1−pii(10.132)
where τi is the expected sojourn time of the ith mode, pii the probability of transition from ith mode to the same mode, and δ the sampling interval.10
For the above models, pii, I = 1, 2, 3 are calculated using
pii=min{ui,max(li,1−δτi)}(10.133)
li = 0.1 and ui = 0.9 are the lower and upper limits, respectively, for the ith model transition probability.
The expected sojourn times of 15, 4, and 2 s, are assumed for modes M1, M2, and M3, respectively. The selection of the off-diagonal elements of the Markov transition matrix depends on the switching characteristics among the various modes and is done as follows:
p12=0.1(1−p11)p13=0.9(1−p11)p21=0.1(1−p22)p23=0.9(1−p22)p31=0.3(1−p33)p32=0.7(1−p33)
The x, y, and z components of target dynamics are uncoupled, and the same process noise is used in each coordinate.
10.4.4 Track Termination
According to the benchmark problem, a track is declared lost if the estimation error is greater than the two-way beam width in angles or 1.5 range gates in range. In addition to this problem-specific criterion, the IMMPDAF declares (on its own) track loss if the track is not updated for 100 s. Alternatively, one can include a “no target” model,3 which is useful for automatic track termination, in the IMM mode set. In a more general tracking problem, where the true target state is not known, the “no target” mode probability or the track update interval would serve as the criterion for track termination, and the IMMPDAF would provide a unified framework for track formation, maintenance, and termination.
10.4.5 Simulation Results
This section presents the simulation results obtained using the algorithms described earlier. The computational requirements and root-mean-square errors (RMSE) are given.
The tracking algorithm using the IMMPDAF is tested on the following six benchmark tracks (the tracking algorithm does not know the type of the target under track—the parameters are selected to handle any target):
Target 1: A large military cargo aircraft with maneuvers up to 3g
Target 2: A Learjet or commercial aircraft that is smaller and more maneuverable than target 1 with maneuvers up to 4g
TABLE 10.2
Performance of IMMPDAF in the Presence of False Alarms, Range Gate Pull Off, and the Standoff Jammer

Target 3: A high-speed medium bomber with maneuvers up to 4g
Target 4: Another medium bomber with good maneuverability up to 6g
Targets 5 and 6: Fighter or attack aircraft with very high maneuverability up to 7g
In Table 10.2, the performance measures and their averages of the IMMPDAF (in the presence of FA, RGPO, and SOJ6,8) are given. The averages are obtained by adding the corresponding performance metrics of the six targets (with those of target 1 added twice) and dividing the sum by 7. In the table, the maneuver density is the percentage of the total time that the target acceleration exceeds 0.5g. The average floating point operation (FLOP) count per second was obtained by dividing the total number of FLOPs by the target track length. This is the computational requirement for target and jammer tracking, neutralizing techniques for ECM, and adaptive parameter selection for the estimator, that is, it excludes the computational load for radar emulation.
The average FLOP requirement is 25 kFLOPS, which can be compared with the FLOP rate of 78 MFLOPS of a Pentium® processor running at 133 MHz. (The FLOP count is obtained using the built-in MATLAB function flops. Note that these counts, which are given in terms of thousands of floating point operations per second [kFLOPS] or millions of floating point operations per second [MFLOPS], are rather pessimistic—the actual FLOP requirement would be considerably lower.) Thus, the real-time implementation of the complete tracking system is possible. With the average revisit interval of 2.5 s, the FLOP requirement of the IMMPDAF is 62.5 kFLOP/radar cycle. With the revisit time calculations taking about the same amount of computation as a cycle of the IMMPDAF, but running at half the rate of the Kalman filter (which runs at constant rate), the IMMPDAF with adaptive revisit time is about 10 times costlier computationally than a Kalman filter. Owing to its ability to save radar resources, which are much more expensive than computational resources, the IMMPDAF is a viable alternative to the Kalman filter, which is the standard “workhorse” in many current tracking systems. (Some systems still use the α – β filter as their “work mule.”)
10.5 Flexible-Window ML-PDA Estimator for Tracking Low Observable Targets
One difficulty with the ML-PDA approach of Section 10.3, which uses a set of scans of measurements as a batch, is the incorporation of noninformative scans when the target is not present in the surveillance region for some consecutive scans. For example, if the target appears within the surveillance region of the sensor after the first few scans, the estimator can be misled by the pure clutter in those scans—the earlier scans contain no relevant information, and the incorporation of these into the estimator not only increases the amount of processing (without adding any more information), but also results in less accurate estimates or even track rejection. Also, a target could disappear from the surveillance region for a while during tracking and reappear sometime later. Again, these intervening scans contain little or no information about the target and can potentially mislead the tracker.
In addition, the standard ML-PDA estimator assumes that the target SNR, the target velocity, and the density of FA over the entire tracking period remain constant. In practice, this may not be the case, and then the standard ML-PDA estimator will not yield the desired results. For example, the average target SNR may vary significantly as the target gets closer to or moves away from the sensor. In addition, the target might change its course and speed intermittently over time. For EO sensors, depending on the time of the day and weather, the number of FA may vary as well.
Because of these concerns, an estimator capable of handling time-varying SNR (with online adaptation), FA density, and slowly evolving course and speed is needed. Although a recursive estimator like the IMMPDA is a candidate, to operate under low SNR conditions in heavy clutter, a batch estimator is still preferred. In this section, the above-mentioned problems are addressed by introducing an estimator that uses the ML-PDA with AI adaptively in a sliding-window fashion,20 rather than using all the measurements in a single batch as the standard ML-PDA estimator does.14 The initial time and the length of this sliding window are adjusted adaptively based on the information content in the measurements in the window. Thus, scans with little or no information content are eliminated and the window is moved over to scans with “informative” measurements.
This algorithm is also effective when the target is temporarily lost and reappears later. In contrast, recursive algorithms will diverge in this situation and may require an expensive track reinitiation. The standard batch estimator will be oblivious to the disappearance and may lose the whole track. This section demonstrates the performance of the adaptive sliding-window ML-PDA estimator on a real scenario with heavy clutter for tracking a fast-moving aircraft using an EO sensor.
10.5.1 Scenario
The adaptive ML-PDA algorithm was tested on an actual scenario consisting of 78 frames of long wave infrared (LWIR) IR data collected during the Laptex data collection, which occurred in July 1996 at Crete, Greece. The sequence contains a single target—a fast-moving Mirage F1 fighter jet. The 920 × 480 pixel frames taken at a rate of 1 Hz were registered to compensate for frame-to-frame line-of-sight (LOS) jitter. Figure 10.2 shows the last frame in the Mirage F1 sequence.
A sample detection list for the Mirage F1 sequence obtained at the end of preprocessing is shown in Figure 10.3. Each “×” in the figure represents a detection above the threshold.
10.5.2 Formulation of ML-PDA Estimator
This section describes the target models used by the estimator in the tracking algorithm and the statistical assumptions made by the algorithm. The ML-PDA estimator for these models is introduced, and the CRLB for the estimator and the hypothesis test used to validate the track are presented.

FIGURE 10.2
The last frame in the Mirage F1 sequence.

FIGURE 10.3
Detection list corresponding to the frame in Figure 10.2.
10.5.2.1 Target Models
The ML-PDA tracking algorithm is used on the detection lists after the data preprocessing phase. It is assumed that there are n detection lists obtained at t = t1, t2, …, tn. The ith detection list, where 1 ≤ i ≤ n, consists of mi detections at pixel positions (xij, yij) along the X and Y directions. In addition to locations, the signal strength or amplitude, aij, of the jth detection in the ith list, where 1 ≤ j ≤ m, is also known. Thus, assuming constant velocity over a number of scans, the problem can be formulated as a two-dimensional scenario in space with the target motion defined by the four-dimensional vector
x≡[ξ(t0),η(t0),˙ξ,˙η](10.134)
where ξ(t0) and η(t0) are the horizontal and vertical pixel positions of the target, respectively, from the origin at the reference time t0. The corresponding velocities along these directions are assumed constant at ˙ξ(t0)
The set of measurements in list i at time ti is denoted by
Z(i)={zj(i)}mij=1(10.135)
where mi is the number of measurements at ti. The measurement vector zj(i) is denoted by
zj(i)Δ=[xij,yij,aij]′(10.136)
where xij and yij are observed X and Y positions, respectively.
The cumulative set of measurements made in scans t1 through tn is given by
Zn={Z(i)ni=1}(10.137)
A measurement can either originate from a true target or from a spurious source. In the former case, each measurement is assumed to have been received only once in each scan with a detection probability PD and to have been corrupted by zero-mean additive Gaussian noise of known variance, that is,
xij=ξ(ti)+∈ij(10.138)
yij=η(ti)+vij(10.139)
where ∈ij and vij are the zero-mean Gaussian noise components with variances σ21
Thus, the joint pdf of the position components of zij is given by
p(zij)=12πσ1σ2exp(−12[xij−ξ(ti)σ1]2−12[yij−η(ti)σ2]2)(10.140)
The FA are assumed to be distributed uniformly in the surveillance region and their number at any sampling instant obeys the Poisson pmf
μF(mi)=(λU)mi e−λUmi!(10.141)
where U is the area of surveillance and λ the expected number of FA per unit of this area. Kirubarajan and Bar-Shalom14 have shown that the performance of the ML-PDA estimator can be improved by using AI of the received signal in the estimation process itself, in addition to thresholding. After the signal has been passed through the matched filter, an envelope detector can be used to obtain the amplitude of the signal. The noise at the matched filter is assumed to be narrowband Gaussian. When this is fed through the envelope detector, the output is Rayleigh distributed. Given the detection threshold, τ, the probability of detection PD and the probability of FA PFA are
PDΔ=P(the target-oriented measurement exceeds the threshold τ)(10.142)
and
PFAΔ=P(a measurement caused by noise only exceeds the threshold τ)(10.143)
where P(⋅) is the probability of an event.
The pdfs at the output of the threshold detector, which corresponds to signals from the target and FA are denoted by pτ1(a)
ρ=pτ1(a)pτ0(a)=PFAPD(1+d)exp(a2d1(1+d))(10.144)
where τ is the detection threshold.
10.5.2.2 Maximum Likelihood-Probabilistic Data Association Estimator
This section focuses on the ML estimator combined with the PDA approach. If there are mi detections at ti, one has the following mutually exclusive and exhaustive events:3
εj(i)Δ={{measurement zj(i) is from the target}j=1,...,m{all measurements are false}j=0(10.145)
The pdf of the measurements corresponding to the above events can be written as3
p[Z(i)|εj(i),x]={U1−mip(zij)ρijmiΠj=1pτ0(aij)j=1,...,miU1−mimiΠj=1pτ0(aij)j=0(10.146)
Using the total probability theorem,
p[Z(i)|x]=miΣj=0p[Z(i)|εj(i),x]p[εj(i),x]=miΣj=0p[Z(i)|εj(i),x]p[εj(i)](10.147)
the above can be written explicitly as
p[Z(i)|x]=U−mi(1−PD)miΠj=1pτ0(aij)μF(mi)+U1−miPDμF(mi−1)mimiΠj=1pτ0(aij)miΣj=1p(zij)ρij=U−mi(1−PD)miΠj=1pτ0(aij)μF(mi)+U1−miPDμF(mi−1)2πσ1σ2mimiΠj=1pτ0(aij)⋅miΣj=1ρij exp(−12[xij−ξ(ti)σ1]2−12[yij−η(ti)σ2]2)(10.148)
To obtain the likelihood ratio, Φ[Z(i), x], at ti, divide Equation 10.148 by p[Z(i)|ε0(i), x]
Φ[Z(i),x]=p[Z(i),x]p[Z(i)|ε0(i),x]=(1−PD)+PD2πλσ1σ2Σρij exp(−12[xij−ξ(ti)σ1]2−12[yij−η(ti)σ2]2)(10.149)
Assuming that measurements at different sampling instants are conditionally independent, that is,
p[Zn|x]=Π p[Z(i)|x](10.150)
the total likelihood ratio3 for the entire data set is given by
Φ[Zn,x]=nΠi=1Φi[Z(i),x](10.151)
Then, the total log-likelihood ratio Φ[Zn, x], expressed in terms of the individual log-likelihood ratios ϕ[Z(i), x] at sampling time instants ti, becomes
φ[Zn,x]=nΣi=1φi[Z(i),x]=Σ ln[(1−PD)+PD2πλσ1σ2miΣj=1ρij exp(−12[xij−ξ(ti)σ1]2−12[yij−η(ti)σ2]2)](10.152)
The MLE is obtained by finding the vector x=ˆx
10.5.3 Adaptive ML-PDA
Often, the measurement process begins before the target becomes visible—that is, the target enters the surveillance region of the sensor some time after the sensor started to record measurements. In addition, the target may disappear from the surveillance region for a certain period of time before reappearing. During these periods of blackout, the received measurements are purely noise-only, and the scans of data contain no information about the target under track. Incorporating these scans into a tracker reduces its accuracy and efficiency. Thus, detecting and rejecting these scans is important to ensure the fidelity of the estimator. This subsection presents a method that uses the ML-PDA algorithm in a sliding-window fashion. In this case, the algorithm uses only a subset of the data at a time rather than all of the frames at once, to eliminate the use of scans that have no target. The initial time and the length of the sliding window are adjusted adaptively based on the information content of the data—the smallest window, and thus the fewest number of scans, required to identify the target is determined online and adapted over time.
The key steps in the adaptive ML-PDA estimator are as follows:
Start with a window of minimum size.
Run the ML-PDA estimator within this window and carry out the validation test on the estimates.
If the estimate is accepted (i.e., if the test is passed), and if the window is of minimum size, accept the window. The next window is the present window advanced by one scan. Go to step 2.
If the estimate is accepted, and if the window is greater than minimum size, try a shorter window by removing the initial scan. Go to step 2 and accept the window only if estimates are better than those from the previous window.
If the test fails and if the window is of minimum size, increase the window length to include one more scan of measurements and, thus, increase the information content in the window. Go to step 2.
If the test fails and if the window is greater than minimum size, eliminate the first scan, which could contain pure noise only. Go to step 2.
Stop when all scans are used.
The algorithm is described as follows. To specify the exact steps in the estimator, the following variables are defined:
W = current window length
Wmin = minimum window length
Z(ti) = scan (set) of measurements at time ti
With these definitions, the algorithm is
BEGIN PROCEDURE Adaptive ML-PDA estimator (Wmin, Z(t1), Z(tn))
i = 1—Initialize the window at the first scan.
W = Wmin—Initially, use a window of minimum size.
WHILE (i + W < n)—Repeat until the last scan at tn.
Do grid search for initial estimates by numerical search on
Z(ti), Z(ti+1),…, Z(ti+W)
Apply ML-PDA estimator on the measurements in Z(ti), Z(ti+1),…, Z(ti+W)
Validate the estimates
IF the estimates are rejected
IF (W > Wmin)—Check if we can reduce the window size.
i = i + 1—Eliminate the initial scan that might be due to noise only.
ELSEIF (W = Wmin)
W = W + 1—Expand window size to include an additional scan.
ENDIF
ENDIF
IF the estimates are accepted
IF (W > Wmin)—Check if we can reduce the window size.
Try a shorter window by removing the initial scan and
check if estimates are better, i = i + 1
ENDIF
IF estimates for shorter window are NOT better OR (W = Wmin)
Accept estimates and try next window, i = i + 1
ENDIF
ENDIF
END WHILE
END PROCEDURE
To illustrate the adaptive algorithm, consider a scenario where a sensor records 10 scans of measurements over a surveillance region. The target, however, appears in this region (i.e., its intensity exceeds the threshold) only after the second scan (i.e., from the third scan onward). This case is illustrated in Figure 10.4. The first two scans are useless because they contain only noise.
Consider the smallest window size required for a detection to be 5. Then the algorithm will evolve as shown in Figure 10.5. First, for the sake of illustration, assume that a single “noisy” scan present in the data set is sufficient to cause the MLE to fail the hypothesis test for track acceptance. The algorithm tries to expand the window to include an additional scan if a track detection is not made. This is done because an additional scan of data may bring enough additional information to detect the target track. The algorithm next tries to cut down the window size by removing the initial scans. This is done to check whether a better estimate can be obtained without this scan. If this initial scan is noise-only, then it degrades the accuracy of the estimate. If a better estimate is found (i.e., a more accurate estimate) without this scan, the latter is eliminated. Thus, as in the above-mentioned example, the algorithm expands at the front (most recent scan used) and contracts at the rear end of the window to find the best window that produces the strongest detection, on the basis of the validation test.
10.5.4 Results
10.5.4.1 Estimation Results
The Mirage F1 data set consists of 78 scans or frames of LWIR IR data. The target appears late in this scenario and moves toward the sensor. There are about 600 detections per frame. In this implementation the parameters shown in Table 10.3 were chosen.

FIGURE 10.4
Scenario with a target being present for only a partial time during observation.

FIGURE 10.5
Adaptive ML-PDA algorithm applied to the scenario illustrated in Section 10.5.3.
TABLE 10.3
Parameters Used in the ML-PDA Algorithm for the Mirage F1 Jet

The choice of these parameters is as follows:
σ1 and σ2 are, as in Equation 10.140, the standard deviations along the horizontal and vertical axes, respectively. The value of 1.25 for both variables models the results of the preprocessing.
The minimum window size, Wmin, was chosen to be 10. The algorithm will expand this window if a target is not detected in 10 frames. Initially a shorter window was used, but the estimates appeared to be unstable. Therefore, fewer than 10 scans are assumed to be ineffective at producing an accurate estimate.
The initial target SNR, d0, was chosen as 9.5 dB because the average SNR of all the detections over the frames is approximately 9.0 dB. However, in most frames, random spikes were noted. In the first frame, where a target is unlikely to be present, a single spike of 15.0 dB is noted. These spikes, however, cannot and should not be modeled as the target SNR.
A constant probability of detection (PDC) of .70 was chosen. A value that is too high would bring down the detection threshold and increase PFA
α is the parameter used to update the estimated target SNR with an α filter. A high value is chosen for the purpose of detecting a distant target that approaches the sensor over time and to account for the presence of occasional spikes of noise. Thus, the estimated SNR is less dependent on a detection that could originate from a noisy source and, thus, set the bar too high for future detections.
πm is the miss probability.
ˉν
ν¯ and ˉσνσ¯ν are used in the multipass approach of the optimization algorithm.11,14The number of passes K in the multipass approach of the optimization algorithm was chosen as 4.
Figure 10.6 further clarifies the detection process by depicting the windows where the target has been detected.
From the above results, note the following.
The first detection uses 22 scans and occurs at scan 28. This occurs because the initial scans have low-information content as the target appears late in the frame of surveillance. The IMM-MHT algorithm22 required 38 scans for a detection, whereas the IMMPDA23 required 39 scans. Some spurious detections were noticed at earlier scans, but these were rejected.
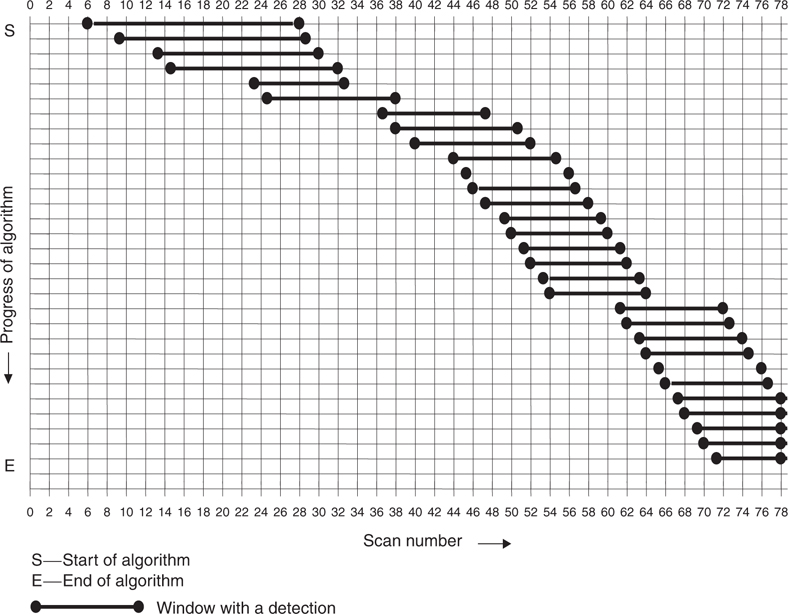
FIGURE 10.6
Progress of the algorithm showing windows with detections.
The next few detection windows produce similar target estimates. This is because a large number of scans repeat themselves in these windows.
After the initial detections, there is a “jump” in the scan number at which a detection is made. In addition, the estimates, particularly the velocity estimates, deteriorate. This could indicate that either the target has suddenly disappeared (became less visible) from the region of surveillance or the target made a maneuver.
From scan 44 onward, the algorithm stabilizes for several next windows. At scan 52, however, there is another jump in detection windows. This is also followed by a drop in the estimated target SNR, as explained above. This, however, indicates that the algorithm can adjust itself and restart after a target has become suddenly invisible. Recursive algorithms will diverge in this case.
From scan 54 onward, the algorithm stabilizes, as indicated by the estimates. Also, a detection is made for every increasing window because the target has come closer to the sensor and, thus, is more visible. This is noted by the sharp rise in the estimated target SNR after scan 54.
The above results provide an understanding of the target’s behavior. The results suggest that the Mirage F1 fighter jet appears late in the area of surveillance and moves toward the sensor. However, initially it remains quite invisible and possibly undergoes maneuvers. As it approaches the sensor, it becomes more and more visible and, thus, easier to detect.
10.5.4.2 Computational Load
The adaptive ML-PDA tracker took 442 s, including the time for data input/output, on a Pentium III processor running at 550 MHz to process the 78 scans of the Mirage F1 data. This translates into about 5.67 s/frame (or 5.67 s running time for one-second interval data), including input/output time. A more efficient implementation on a dedicated processor can easily make the algorithm real-time capable on a similar processor. Also, by parallelizing the initial grid search, which required more than 90% of the time, the adaptive ML-PDA estimator can be made even more efficient.
10.6 Summary
This chapter presented the use of the PDA technique for different tracking problems. Specifically, the PDA approach was used for parameter estimation as well as recursive state estimation. As an example of parameter estimation, track formation of a LO target using a nonlinear ML estimator in conjunction with the PDA technique with passive (sonar) measurements was presented. The use of the PDA technique in conjunction with the IMM estimator, resulting in the IMMPDAF, was presented as an example of recursive estimation on a radar-tracking problem in the presence of ECM. Also presented was an adaptive sliding-window PDA-based estimator that retains the advantages of the batch (parameter) estimator while being capable of tracking the motion of maneuvering targets. This was illustrated on an EO surveillance problem. These applications demonstrate the usefulness of the PDA approach for a wide variety of real tracking problems.
References
1. Bar-Shalom, Y. (Ed.), Multitarget-Multisensor Tracking: Advanced Applications, Vol. I, Artech House Inc., Dedham, MA, 1990. Reprinted by YBS Publishing, 1998.
2. Bar-Shalom, Y. (Ed.), Multitarget-Multisensor Tracking: Applications and Advances, Vol. II, Artech House Inc., Dedham, MA, 1992. Reprinted by YBS Publishing, 1998.
3. Bar-Shalom, Y. and Li, X. R., Multitarget-Multisensor Tracking: Principles and Techniques, YBS Publishing, Storrs, CT, 1995.
4. Blackman, S. S. and Popoli, R., Design and Analysis of Modern Tracking Systems, Artech House Inc., Dedham, MA, 1999.
5. Feo, M., Graziano, A., Miglioli, R., and Farina, A., IMMJPDA vs. MHT and Kalman filter with NN correlation: Performance comparison, IEE Proceedings on Radar, Sonar and Navigation (Part F), 144(2), 49–56, 1997.
6. Kirubarajan, T., Bar-Shalom, Y., Blair, W. D., and Watson, G. A., IMMPDA solution to benchmark for radar resource allocation and tracking in the presence of ECM, IEEE Transactions on Aerospace and Electronic Systems, 34(3), 1023–1036, 1998.
7. Lerro, D. and Bar-Shalom, Y., Interacting multiple model tracking with target amplitude feature, IEEE Transactions on Aerospace and Electronic Systems, AES-29(2), 494–509, 1993.
8. Blair, W. D., Watson, G. A., Kirubarajan, T., and Bar-Shalom, Y., Benchmark for radar resource allocation and tracking in the presence of ECM, IEEE Transactions on Aerospace and Electronic Systems, 34(3), 1015–1022, 1998.
9. Blackman, S. S., Dempster, R. J., Busch, M. T., and Popoli, R. F., IMM/MHT solution to radar benchmark tracking problem, IEEE Transactions on Aerospace and Electronic Systems, 35(2), 730–738, 1999.
10. Bar-Shalom, Y. and Li, X. R., Estimation and Tracking: Principles, Techniques and Software, Artech House Inc., Dedham, MA, 1993. Reprinted by YBS Publishing, 1998.
11. Jauffret, C. and Bar-Shalom, Y., Track formation with bearing and frequency measurements in clutter, IEEE Transactions on Aerospace and Electronic Systems, AES-26, 999–1010, 1990.
12. Kirubarajan, T., Wang, Y., and Bar-Shalom, Y., Passive ranging of a low observable ballistic missile in a gravitational field using a single sensor, Proceedings of the 2nd International Conference on Information Fusion, July 1999.
13. Sivananthan, S., Kirubarajan, T., and Bar-Shalom, Y., A radar power multiplier algorithm for acquisition of LO ballistic missiles using an ESA radar, Proceedings of the IEEE Aerospace Conference, March 1999.
14. Kirubarajan, T. and Bar-Shalom, Y., Target motion analysis in clutter for passive sonar using amplitude information, IEEE Transactions on Aerospace and Electronic Systems, 32(4), 1367–1384, 1996.
15. Nielsen, R. O., Sonar Signal Processing, Artech House Inc., Boston, MA, 1991.
16. Blair, W. D., Watson, G. A., Hoffman, S. A., and Gentry, G. L., Benchmark problem for beam pointing control of phased array radar against maneuvering targets, Proceedings of the American Control Conference, June 1995.
17. Blair, W. D. and Watson, G. A., IMM lgorithm for solution to benchmark problem for tracking maneuvering targets, Proceedings of SPIE Acquisition, Tracking and Pointing Conference, April 1994.
18. Blair, W. D., Watson, G. A., Hoffman, S. A., and Gentry, G. L., Benchmark problem for beam pointing control of phased array radar against maneuvering targets in the presence of ECM and false alarms, Proceedings of the American Control Conference, June 1995.
19. Yeddanapudi, M., Bar-Shalom, Y., and Pattipati, K. R., IMM estimation for multitarget-multisensor air traffic surveillance, Proceedings of IEEE, 85(1), 80–96, 1997.
20. Chummun, M. R., Kirubarajan, T., and Bar-Shalom, Y., An adaptive early-detection ML-PDA estimator for LO targets with EO sensors, Proceedings of SPIE Conference on Signal and Data Processing of Small Targets, 4048, 345–356, April 2000.
21. Press, W. H., Teukolsky, S. A., Vetterling, W. T., and Flannery, B. P., Numerical Recipes in C, Cambridge University Press, Cambridge, U.K., 1992.
22. Roszkowski, S. H., Common database for tracker comparison, Proceedings of SPIE Conference on Signal and Data Processing of Small Targets, 3373, 95–102, April 1998.
23. Lerro, D. and Bar-Shalom, Y., IR Target detection and clutter reduction using the interacting multiple model estimator, Proceedings of SPIE Conference on Signal and Data Processing of Small Targets, 3373, April 1998.
* When the running index is a time argument, a sequence exists; otherwise it is a set where the order is not relevant. The context should indicate which is the case.
* For other probabilistic models of the detection process, different SNR values correspond to the same PD, PFA pair. Compared to the Rician model receiver operating characteristic (ROC) curve, the Rayleigh model ROC curve requires a higher SNR for the same pair (PD, PFA), that is, the Rayleigh model considered here is pessimistic.
* The “uniform” factor corresponds to the worst case. In practice, σπ and σγ are functions of the 3 dB bandwidth and the SNR.
† The commonly used SNR, designated here as SNR1, is signal strength divided by the noise power in a 1 Hz bandwidth. SNRc is signal strength divided by the noise power in a resolution cell. The relationship between them, for Cγ = 0.25 Hz is SNRc = SNR1–6 dB. SNRc is believed to be the more meaningful SNR because it determines the ROC curve.
* The more recent IMM-MHT (as opposed to Kalman filter-based MHT) requires six to eight hypotheses.
* Assuming that this is a search pulse without (monopulse) split-beam processing, the angular errors are uniformly distributed in the beam.