
C H A P T E R 28
![]()
Spice Your Content Up With Tasty Semantics
It used to be that search engines had to guess which parts of a page to show to make your site look relevant and attractive in their search results. Now Drupal gives you the tools to clearly express what meaning your content carries, thus helping other applications on the Web to truly understand your site and reuse your content in potentially useful and attractive ways (see Figure 28–1).

Figure 28–1. Drupal offers the tools to clearly express your content.
Thanks to the semantic markup used on this recipe page, it shows up in a Google search for Thai mango salad with a picture and the rating users on the site gave it. When your web site's pages provide information in ways that machines can understand, Google can give selected pieces of information (such as the picture and the rating) a privileged place in its presentation of the search engine results page (SERP).
With Drupal 7, you can easily add semantic markup to your pages. The ways to do this through your site's user interface will be covered in the RDF UI section. The challenge and promise of the growing Semantic Web are much greater, however, and Drupal 7 is set to play an important role helping you both navigate and build this information-rich future.
Information Overload
The Web contains more than 20 billion publicly available pages, to which one can add 900 billion deep pages1 (password-protected pages or dynamic pages generated after a search). If you combine all the personal computers, data servers, and other devices connected to the Web, the online storage capacity is estimated to be above 600 exabytes (that's 600 billion gigabytes). Together with the fact that memory is cheap and an ever growing number of users are joining the Web, the amount of information we, as humans, process on a daily basis is skyrocketing. It's crucial to understand that without the help of the machines, we won't be able to digest this information overload.
_________
1 LLRX, “Deep Web Research 2007,” www.llrx.com/features/deepweb2007.htm, 2006.
But aren't we already using machines today to surf the Web? Yes, we are, but we're not using them to the best of their ability;you still need a human reader in order to understand the structure and content of most web pages. Search engines like Google, Yahoo!, and Bing are constantly harvesting pages on the Web and mirroring them into their server farms in order to achieve very fast search results for end users. But there's something broken here. All the search engines have access to are HTML pages or plain text in PDF files. RSS feeds provide more structured information in the form of XML, but it is limited to title, date, and content; it can't express the type of item (news, blog post, user profile, item for sale, event), nor can it express the amount of reviews, the image, or the price.
It is fairly trivial for the human brain to identify the various bits of information on a page and guess what type of information it is reading: text, date, or image. The same goes for the relationship between the elements of the page and what they refer to. (Is this the name of the author who wrote the page or the topic of the page?) These exercises are much more challenging for machines as they lack the ability to infer this sort of knowledge from contextual clues that we, as humans, use throughout our day-to-day lives.
In other words, a machine visiting a web site will mostly see plain text that links to other pages or images. Experts have to run many complex algorithms to attempt to reverse engineer the process used to put the page together. A very simple, resource-intensive example is to find dates in a page using regular expressions by searching for slash-separated digits. With a date like 08/07/10, how could a machine guess whether the date is July 8th or August 7th when even an English reader and an American reader would read this date differently? Machines need a clear, non-ambiguous way to interpret this information.
The same thing goes for words. What would a machine infer when coming across the word “apple?” Many terms in the English language have several meanings and nuances. The Semantic Web is a set of tools and standards designed to tackle these issues by adding a layer of semantics on top of the Web that we know today. It's important to understand that the Semantic Web is not trying to replace the existing Web, but rather enhance its content with clues for machines to understand context, as if a Web chef was adding spices to blend content in order to make it more tasty and meaningful for machines.
The Semantic Web has had increasing real world impact over the years and was recently adopted by the big players on the Web. Among all the Semantic Web standards, RDFa (RDF in attributes) is the one that has seen the largest adoption. In 2008, Yahoo! Search Monkey initiated the trend by supporting RDFa-enabled pages. Google followed with its Rich Snippets a year later. In April 2010, Facebook announced they were using RDFa as part of the Open Graph protocol, which has since been deployed on millions of web pages. You have probably come across RDFa-enhanced web sites without even knowing it: the White House, O'Reilly, Best Buy, The New York Times. And you can also add most Drupal 7 sites to that list.
THE RESOURCE DESCRIPTION FRAMEWORK
_________
2 W3C, “Linked Data,” www.w3.org/DesignIssues/LinkedData, 2006.
3 XMLNS, “FOAF Vocabulary Specification 0.98”, http://xmlns.com/foaf/spec/, 2010
4 W3C, “CURIE Syntax 1.0: A syntax for expressing Compact URIs,” www.w3.org/TR/curie/, 2010.
How Did We Get There?
Any source of data tends to be made available on the Internet so that it can be shared, reused in accordance with the license of the site, and mashed up with other data. Content management systems like Drupal help people to produce content online. Whether it's via self-hosted web sites, software as a service (SaaS), or free platforms (such as Facebook, Twitter, MySpace, or Gmail), ordinary users of the Web have many ways to produce content online.
From the 140 character update on Twitter to the four paragraph blog post to the one hundred page PDF documentation, all these pieces of information land on the Web in one form or another. Some are public; others are behind firewalls or password-protected. Much of this content ends up being visible as HTML, although other formats exist, like text files, PDF documents, and images. Some of this data results directly from the content the user has put on the Web (content, ideas, thoughts) but there is also a lot of metadata surrounding this user input, like the date it was entered, the number of page visits, or the number of comments the page has received.
Navigating the Web and contributing to it has become very easy with the wide adoption of the browsers like Mozilla Firefox and Google Chrome; these browsers are now available on a variety of platforms such as desktop computers, laptops, tablets, and mobile devices. E-mail clients are another means to publish content on the Web; mailing lists are a good example.
Decentralized Dataspaces
When Sir Tim Berners-Lee created the World Wide Web in 1990, he envisioned a globally distributed information space in which everyone was free to say anything about anything without having to deal with heavy bureaucratic procedures, corporate policies, or any form of centralized control authority. Most importantly, this information space was to remain free and open for every single person: you may have to pay your local Internet Service Provider (ISP) for the service to get access to this information space, but once you're connected to it, you're free to do what you want. Each user can own her dataspace and can claim what she thinks is true, share her ideas with the rest of the world, and link to other people's dataspaces in agreement or disagreement.
Web applications such as Drupal empower Internet users to build their own dataspace, create content, and link it to other dataspaces. The collection of all these dataspaces is what is commonly called the Web, built on top of the Internet infrastructure that has been developing since the 1960s.
Linking Data at the Global Web Scale
Before you dive into the details of Drupal and RDF, it's important to understand another aspect of the Semantic Web and how it allows you to address information beyond the boundaries of your web site. Most applications store their data using the concept of foreign keys, which allows them to address each data item in their database and find the data relating to each data item easily across tables. This works well on a closed system where it is easy to enforce constraints on these foreign keys, such as making each identifier unique. This does not work on a global scale because each site on the Web does not rely on a centralized authority for assigning identifiers.
While my user ID on my personal site is 1, it does not mean I have the same user ID on all sites on the Web. On drupal.org, my user ID is 52142 and on groups.drupal.org it's 3258. Likewise, my username on identi.ca is “scor” but on twitter this username was already taken so I had to choose the username “scorlosquet” instead. The bottom line is that talking about plain IDs or usernames does not mean anything in a totally distributed system such as the World Wide Web and is ambiguous at best!
To work around this, RDF uses URIs (Uniform Resource Identifiers) as a means to name and address resources on the Internet. URIs look much like URLs, starting with http:// or https://. So instead of referring to a user as an integer, RDF will use strings of the form “http://drupal.org/user/52142”. With that, we can claim things like http://drupal.org/user/52142 and http://groups.drupal.org/user/3258 are two user profile pages of the same person. With URIs, each web site can own its dedicated namespace and create as many resources as needed without having to consult with anyone else. Drupal typically will assign an ID to each user and build their URI as http://sitename/user/{userid}; ditto for nodes, taxonomy terms, etc. This path can be customized using URL aliases; Drupal will ensure that each URL alias points to a unique resource on your site and thus avoid any ambiguity.
Now that you've seen the importance of URIs, you can move along and see in what context they are useful. You've learned that a username is meaningless on the Web without some kind of namespace, such as the web site to which it belongs. Beyond this use case, think of the problem of ambiguity when talking about concepts, such as tagging a blog post with “apple.” You're back to using a string for identifying a potentially ambiguous concept, and like the username case, this is something RDF can help you with. You could host your concepts yourself on your namespace, but for common concepts like “name” or all the countries in the world, it makes more sense to use a somewhat agreed upon centralized repository.
Wikipedia5 contains a huge amount of information about objects, concepts, famous people, cities, countries, organizations, etc. Each entry has a URI on Wikipedia that displays some information about the topic at hand. Talking about “apple” can mean either the fruit or the company. If you were instead using URIs, you could easily get rid of any ambiguity; http://en.wikipedia.org/wiki/Apple is about the fruit and http://en.wikipedia.org/wiki/Apple_Inc describes the company. Making this distinction might not be necessary for humans who understand from the context which meaning was intended, but it's crucial for machines. The more sites that use the same identifiers, the easier it is for machines to make cross references to infer whether a set of posts is talking about the same topic or not.
_________
5 Wikipedia (http://en.wikipedia.org/) is an online multilingual encyclopedia composed of more than 17 millions articles. Dbpedia (http://dbpedia.org/) is a separate project aiming at extracting structured information from Wikipedia and making it available online as RDF. With DBpedia it becomes possible to run complex queries against Wikipedia content and to reuse this data more easily within RDF applications.
Do You See What I Mean?
Drupal offers a user-friendly interface to produce HTML. When submitting data, Drupal will typically store it in the database and then process it to build the HTML output. Drupal knows exactly from which tables and columns the data should be pulled; when building the page, it knows what corresponds to the title of the page, the date it was created, and its main content. It knows the current version of the node and can pull it from the right database record. However, once it has put together the page as HTML, all this structure is lost; the actual data is laid out on the page properly and formatted for the human eye, but the semantics have been lost.
The first versions of HTML were not designed to make this structure explicit to machines, but imagine if HTML tags offered a way to specify what type of data the tag contains and how it related to other pieces of information on the page or on other pages of the Web? This is what a recent World Wide Web consortium working group addressed in the “RDFa in XHTML” W3C Recommendation,6 released in October 2008.
RDFa, or How HTML Can Be Augmented with Semantics
From a web developer perspective, RDFa is no more than a few XHTML attributes that can be added to web pages in order to explicitly state the semantics of the data contained in the HTML tags (see Figure 28–2). The RDFa markup does not change the way the page is rendered in a web browser; it looks just the same to the user. However, the difference is visible to any RDFa-capable software reading the page because it can understand the semantic markup.
Web browsers can then enhance the user experience depending on the type of data the page contains: some browser extensions can, for example, provide additional functionalities based on the RDFa markup contained in the page. Search engines typically also make great use of this data, as it allows them to better understand the information at hand and display it accordingly in search results; it's easy to extract the title, the date, and an image for the page, which can drastically improve the visibility in search results and aid the search engine optimization (SEO) of a given site. The price, ratings, and the number of reviews are also relevant elements that can drive more traffic to an e-commerce site. Yahoo! has reported up to 15 percent increase in click-through rate due to RDFa (www.slideshare.net/NickCox/ses-chicago-2009-searchmonkey).
_________
6 W3C, “RDFa in XHTML: Syntax and Processing,” www.w3.org/TR/rdfa-syntax/, 2008.

Figure 28–2. By adding a few simple XHTML attributes to existing HTML tags, RDFa enriches the content of a webpage with machine-readable hints.
The RDFa processing model relies on a DOM traversal technique where each DOM element is visited, starting from the document object and making its way to each child element in a recursive manner. RDFa is best explained with some basic examples. Remember that RDFa is all about adding attributes to existing XHTML markup. First of all, some adjustments need to be made to the top of the XHTML template so that they are compliant with the RDFa specification.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML+RDFa 1.0//EN"
"http://www.w3.org/MarkUp/DTD/xhtml-rdfa-1.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" version="XHTML+RDFa 1.0" dir="ltr">
<head profile="http://www.w3.org/1999/xhtml/vocab">
Secondly, let's set some prefixes so you can use the CURIE syntax discussed in the section on RDF. This is done in the HTML tag using the syntax xmlns:prefix="http://somenamespace.org/". For FOAF, it would be
xmlns:foaf=http://xmlns.com/foaf/0.1/
Drupal 7 takes care of all of the above and includes a set of commonly used namespaces. Modules can declare additional prefixes and namespaces.
You are now all set to start using RDFa markup in your HTML document. To denote the attributes in HTML, we'll prefix them with an at sign (@). The RDFa attributes are @about, @content, @datatype, @href, @property, @rel, @rev, @resource, @src, and @typeof. Each RDFa attribute will have an effect on how RDF statements are built from the structure and the content of the HTML document. You might recognize some of these attributes (rel, href, or src), and you will soon see what role they play in RDFa and how RDFa can reuse existing attribute values.
The attributes @property, @rel, and @rev specify the verb of an RDF statement. To understand how they work, it's best to look at the following examples:
<h1 property="dc:title">Joe's homepage</h1>
<div rel="sioc:has_creator"><a href="/user/9">John Smith</a></div>
dc:title and sioc:has_creator are two different RDF verbs that specify the title and the author of a page. In the first example, the @property forces the object of the RDF statement to be a string. In the second example, the @rel is used instead of @property in order to force the object of the statement to be a URI pointing to the author page; in other words, it's a resource as opposed to a simple string. Doing so allows the markup to include much more information about the author than if it was just a string. The author resource can include not only his name, but his bio and links to his other articles, allowing for content discovery.
An exhaustive description of RDFa is beyond the scope of this chapter, so please consult the RDFa primer at www.w3.org/TR/xhtml-rdfa-primer/ for a more detailed understanding of how RDFa markup is processed. See also these excellent articles on RDFa published in the A List Apart Magazine:
www.alistapart.com/articles/introduction-to-rdfa/
www.alistapart.com/articles/introduction-to-rdfa-ii/
RDFa, Microformats andMicrodata
RDFa is not the only syntax for adding semantics to HTML. Microformats (microformats.org)were the first syntax to see a wide adoption by the web developer community. However, Microformats were never standardized and due to its design, the development of its vocabularies (hCard, vCard, etc.) was centralized and limited to one organization. RDFa, on the other hand, can be freely extended due to the nature of RDF: external vocabularies can be combined and custom domain-specific vocabularies can be built when needed. RDFa also benefits from all the work that has been put into the Semantic Web stack in the last decade. Many tools are available for parsing, storing, and querying RDF data. Most notably SPARQL en.wikipedia.org/wiki/SPARQL, the RDF querying language similar to SQL for relational databases, allows running queries over data federated from any RDF source.
RDFa has been a W3C standard since 2008 and has been adopted by many prominent companies on the Web such as Google, Facebook, BBC, and Best Buy. Recent research from Yahoo! shows that RDFa saw an explosive growth in 2010 and is the fastest growing data markup format (http://tripletalk.wordpress.com/2011/01/25/rdfa-deployment-across-the-web). Microdata (www.whatwg.org/specs/web-apps/current-work/multipage/links.html#microdata) is a new syntax part of the HTML5 specification, which is still under development at the time of this writing. Microdata shares more in common with RDFa than microformats, such as the use of URIs to allow for extensibility. Microdata and HTML5 were still too new during the development phase of Drupal 7, and the more established RDFa standard was more promising and a better fit to Drupal's native XHTML output. While version 1.0 of RDFa is only valid with XHTML markup, the upcoming RDFa 1.1 will allow RDFa in both XHTML5 and HTML5. See the HTML+RDFa 1.1 draft document at http://dev.w3.org/html5/rdfa/. RDFa 1.1 also includes feedback from the microformats and the microdata communities, allowing for a simpler syntax and more use cases. Given that RDFa 1.1 is backward compatible with Drupal 7 RDFa 1.0 markup, expect to see RDFa-enabled HTML5 pages soon on Drupal 7. Join the conversation on HTML5 in Drupal at http://groups.drupal.org/html5.
Drupal 7 and the Semantic Web
You might have already noticed an rdf folder while browsing Drupal 7's modules directory or seen it on the Modules page in the administration interface. If you have installed the standard profile, this module will be already enabled (see Figure 28–3).
Figure 28–3. Make sure the RDF module is enabled by visiting the Modules page in the administration section of your site.
All the work of the RDF module happens behind the scene. In fact, it does not include any user interface and only provides an API for other modules to use (much like the Field module). Many modules in core leverage the RDF module, including Node, Comment, User, Taxonomy, Forum, Blog, and Tracker.
The RDF module does essentially two things: it describes the data structure of a Drupal site in terms of RDF mappings (which relates a Drupal field to one or more RDF terms) and then takes these mappings and inserts them into the HTML output in the form of RDFa attributes. The RDF module takes advantage of the new concepts of entities, bundles, and fields introduced in Drupal 7. Let's have a closer look at the lifecycle of these RDF mappings.
Starting at the higher level, entity types such as node have a set of attributes like title or date that can be mapped to an RDF property. Whenever this value is output in HTML, this RDF property can be added to the HTML, so that agents looking at this HTML from an outside point of view can still understand a piece of data's origin and significance. A very simple example of a node whose title is “My trip to Belgium” would then be output to HTML as
<h2 property="dc:title">My trip to Belgium</h2>
Note the extra property attribute that is added to the wrapping h2 tag, indicating clearly the title of the node. Aside from the attributes of an entity type, a special kind of mapping exists for the actual type of an entity. This might sound redundant from a Drupal standpoint, but remember that the RDF mappings are there to help external applications that do not know anything about the internal structure of your web site.
The entity type is yet another element of information that gets lost and does not appear clearly in the HTML, but the RDF module offers a chance to solve this with the rdftype key of the RDF mapping structure (see Listing 28–1). This RDF-type mapping will appear accordingly in the page in the form of RDFa.
Listing 28–1. RDF Mapping Structure for the User Entity Type as Defined in user.module
/**
* Implements hook_rdf_mapping().
*/
function user_rdf_mapping() {
return array(
array(
'type' => 'user',
'bundle' => RDF_DEFAULT_BUNDLE,
'mapping' => array(
'rdftype' => array('sioc:UserAccount'),
'name' => array(
'predicates' => array('foaf:name'),
),
'homepage' => array(
'predicates' => array('foaf:page'),
'type' => 'rel',
),
),
),
);
}
The second level of the RDF mapping lifecycle happens with the content types and other bundles (see Chapter 18). Entity types never get instantiated as such; they first go through a level of specialization to become bundles, where they can get other optional features such as revisions, comments, taxonomy, and most importantly, fields. An entity type with a small set of attributes can suddenly be extended with a customizable set of fields depending on the needs of the site administrator. Fields can be attached to bundles via the Field user interface that is part of Drupal 7 core.
The same can be done programmatically, such as in the Drupal 7 standard profile. Nodes are the ideal use case for understanding the concept of a bundle: when installing Drupal 7 with the standard profile, you will find two predefined content types: Article and Basic Page, which are simply two bundles of the node entity type. While these two content types share some attributes such as title and date, they have a different set of fields. For example, Basic Page has a title and a body, while Article comes with some additional fields: tags and image. Each bundle will inherit the RDF mapping structure of its parent entity type.
This is very convenient in the case of nodes where some attributes are common to all bundles and are unlikely to change (such as the title and date). Similarly to the way the RDF mappings are defined for each entity, they can be defined for each bundle when necessary. Most of the time, because each bundle inherits the entity type RDF mapping structure, it is only necessary to specify the RDF mappings for the fields specific to a bundle, as shown in Listing 28–2. Note how only the RDF mappings for the specific fields need to be specified.
Listing 28–2. RDF Mapping Structure for the Article Bundle as Specified in the Standard Installation Profile
array(
'type' => 'node',
'bundle' => 'article',
'mapping' => array(
'field_image' => array(
'predicates' => array('og:image', 'rdfs:seeAlso'),
'type' => 'rel',
),
'field_tags' => array(
'predicates' => array('dc:subject'),
'type' => 'rel',
),
),
),
Note that the RDF mapping structure for the bundle and entity type are similar, the only difference being that an RDF mapping structure affecting an entity type must specify RDF_DEFAULT_BUNDLE as the value for the bundle key. By contrast, an RDF mapping structure for a bundle should explicitly state what bundle the mapping is for.
Understanding the Structure of RDF Mappings
An RDF mapping is a nested associative array defining a relation between Drupal's internal attributes and meaningful RDF predicates, which are designed to be understood by and interoperate with external applications. A mapping structure contains three required keys. The type and bundle keys refer respectively to the entity type and the bundle to which the RDF mappings pertain. The third key, mapping, lists the Drupal attributes that should be mapped to RDF.
Besides the special rdftype key that was described earlier, the other keys refer to either Drupal custom attributes (title, date, author) or to fields defined by the core Field module. Each item contains an array listing the RDF predicates of this attribute in the predicates key. This is sufficient when dealing with a string value (such as the title of a node or the name of a user in Listing 28–1). But when dealing with attributes that refer to some other resource with a URI (link, image, or another entity), the developer should specify a type for a mapping element. This type indicates the direction of the relation between the two resources with regards to the RDF predicate used.
In most cases, type =>rel is what's required; the rel relationship indicates that the parent HTML element is the subject. For instance,
<div>Lora is interested in <a rel="foaf:interest" href="http://drupal.org">Drupal</a></div>
states that the user Lora is interested in Drupal.
The rev value can be used when a reverse relation is needed, like so:
<div about="http://drupal.org">Drupal is interesting to <a rev="foaf:interest"
href="user/5">Lora</a></div>
This nuance in direction is inherited from the RDF model, which is based on directed graphs. It is generally easier to use the rel type; few developers will need to use the reverse type. Thus, the rel type for any non-string linkage is all you need to bear in mind.
Going back to Listing 28–2, the Drupal 7 standard installation profile maps the field_image of the article bundle to the og:image RDF predicate. In other words, it links each article node to its image via the og:image directed relation. This relation is automatically reflected in the form of RDFa inside the HTML output of the page, clearly helping any application such as a search engine understand what image is associated with an article. The same thing goes for the field_tags field mapping element, which makes an explicit semantic relation between an article and the subjects it covers via the dc:subject predicate. Once these relations have been established in the RDF mapping structure, the RDF module will take care of adding them where they need to be in the HTML markup; the developer does not need to worry about placing the RDFa elements.
Working with RDF Mapping Structures
Drupal developers have basically two options for working with RDF mappings. Module developers who create their own entity types and bundles are encouraged to use hook_rdf_mapping() in order to associate RDF predicates with their attributes. Drupal core modules should be used for reference (namely Node, User, Comment, and Taxonomy).
Secondly, in keeping with Drupal's traditions of extensibility and flexibility, the RDF module also provides API functions to alter the RDF mappings defined by the modules. This is what the standard installation profile uses in order to add RDF mappings to the image and tag fields upon installation, right after creating these fields and attaching them to the article bundle via the Field API. All RDF mappings defined with these CRUD functions are stored in the database. The CRUD functions rdf_mapping_load(), rdf_mapping_save(), and rdf_mapping_delete() can be used to specify the RDF mappings of new bundles and fields, as well as alter existing RDF mappings that have been saved to the database on module installation and are not alterable without the CRUD API. Listing 28–3 is an example of altering some of the mappings of the article content type. Note that only the RDF mappings of the fields to change need to be specified.
Listing 28–3. PHP Code Example to Alter Some RDF Mappings
$article_rdf_mappings = array(
'type' => 'node',
'bundle' => 'article',
'mapping' => array(
'field_image' => array(
'predicates' => array('og:image', 'rdfs:seeAlso'),
'type' => 'rel',
),
'field_tags' => array(
'predicates' => array('dc:subject'),
'type' => 'rel',
),
),
);
rdf_mapping_save($article_rdf_mappings);
RDF Vocabularies in Drupal 7
As you saw earlier, many schemas already exist on the Web, and some of them are quite well understood by applications like search engines. The major vocabularies that Drupal 7 uses are as follows:
- Dublin Core caters to online media such as generic documents, news articles, or date of publications. See the Dublin Core specification at
http://dublincore.org/documents/dcmi-terms/. - Friend of a Friend (FOAF) describes the relationships between people, as well as their name, address, picture, location, and their social web attributes like e-mail, home page, OpenID, or interests. FOAF also contains some broader terms to define documents, organizations, groups and their members, and projects. See the FOAF specification at
http://xmlns.com/foaf/spec/. - Semantically-Interlinked Online Communities (SIOC) is used to model the connections between the content created online and the users who create this content. It can describe several channels of discussion such as forums, blogs, polls, and news in general. See the SIOC specification at
http://rdfs.org/sioc/spec/. - Simple Knowledge Organization System (SKOS) tailors the representation and sharing of knowledge organization systems like thesauri, taxonomies, subject heading systems, and classification schemes. It is a good match to Drupal taxonomies for both controlled vocabularies and free tags. See the SKOS specification at
www.w3.org/TR/skos-reference/.
Figure 28–4 depicts how these vocabularies are used natively in Drupal 7.
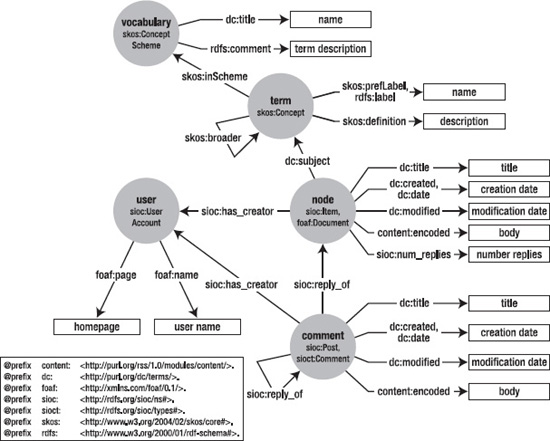
Figure 28–4. Default RDF mappings as defined in Drupal 7
Modules can add new namespaces and their associated prefix by implementing hook_rdf_namespaces(). The snippet in Listing 28-4 adds the WGS84 Geo Positioning namespace to Drupal, which will be serialized along with the other namespaces defined by the other modules in the HTMl output. The prefix “geo” can then be used when defining the RDF mappings using the WGS84 Geo Positioning vocabulary.
Listing 28–4. RDF Mapping Structure for the User Entity Type as Defined in user.module
function mymodule_rdf_namespaces() {
return array(
'geo' => 'http://www.w3.org/2003/01/geo/wgs84_pos#',
);
}
Using RDF Beyond Drupal Core with the Contributed Modules
The previous sections only addressed what Drupal 7 core APIs enable, but there are more functionalities that the contributed modules space offers. The following are a few contributed projects that extend Drupal 7's RDF capabilities. These projects are evolving fast, so please check their description on their project page to get up to date information on what they do.
The RDF Extensions project downloadable at http://drupal.org/project/rdfx offers a set of useful modules to directly interact with the Drupal 7 core RDF module. Site administrators who prefer a user interface to writing code will use the RDF UI module to alter the RDF mappings, as illustrated on Figure 28–5. This package also offers more RDF serialization formats such as RDF/XML, N-Triples, and Turtle.
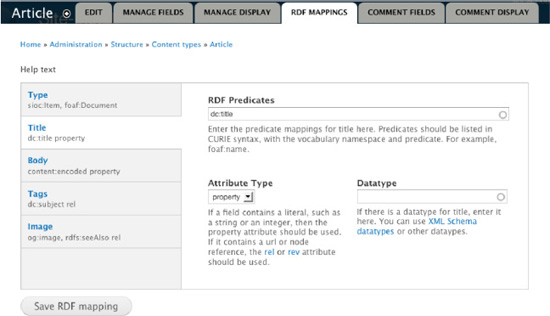
Figure 28–5. The RDF Extensions user interface allows site administrators to edit the RDF mappings without writing code.
The SPARQL project can turn your Drupal site into a SPARQL endpoint by indexing all its RDF data. Site administrators can also register external endpoints that other modules can use to get their data from. The SPARQL package also exposes an API for other modules to run SPARQL queries on the fly without having to worry about setting up a SPARQL endpoint locally. Download SPARQL at http://drupal.org/project/sparql.
SPARQL Views is a query plug-in for Views 3 allowing you to bring data from SPARQL endpoints into Views. Download SPARQL Views at http://drupal.org/project/sparql_views.
The Examples project includes a module showing some examples of RDF mappings. Download Examples at http://drupal.org/project/examples.
Summary
In this chapter, you learned about the Resource Description Framework, an abstract data model used to describe information and make statements about Web resources in the form of subject-verb-object expressions. You've also seen how RDF can be embedded directly into XHTML and HTML5 in order to annotate the bits of information it contains, making it easier for machines to understand the content at hand, which in turn helps Internet users to find the information they need.
You've seen how Drupal 7 makes use of RDF in its internal data modeling via the RDF mappings and how this structured information is surfaced during the rendering of HTML. Many of the RDF mappings are set by default for generic content types; for example, blogs and articles include the author, the tags, and the comments. More complex or domain-specific sites can make use of Drupal's RDF mapping API to add new vocabularies and choose the appropriate mappings for their data.
![]() Tip Semantic web technology is hot. Set your machine to read
Tip Semantic web technology is hot. Set your machine to read dgd7.org/semantic for the Drupal community's take on new developments.