
![]()
Considering Data Access Strategies
At this point in the process of covering the topic of database design, we have designed and implemented the database, devised effective security and indexing strategies, implemented concurrency controls, organized the database(s) into a manageable package and taken care of all of the other bits and pieces that go along with the task of creating a database. The next logical step is to decide on the data-access strategy and how best to implement and distribute data-centric business logic. Of course, in reality, design is not really a linear process, as performance tuning and indexing require a test plan, and data access is going to require that tools and some form of UI has been designed and that tools have been chosen to get an idea of how the data is going to be accessed. In this chapter I will take a rather brief look at some data access concerns and provide pros and cons of different methods…in other words opinions, technically-based opinions nevertheless.
Regardless of whether your application is a good, old-fashioned, client-server application, a multi-tier web application, uses an object relational mapper, or uses some new application pattern that hasn’t been yet been created, data must be stored in and retrieved from tables. Therefore, most of the advice presented in this chapter will be relevant regardless of the type of application you’re building. One way or another, you are going to have to build some interface between the data and the applications that use them. At minimum I will point out some of the pros and cons of the methods you will be using.
The really “good” arguments tend to get started about the topics in this chapter. Take every squabble to decide whether or not to use surrogate keys as primary keys, add to it all of the discussions about whether or not to use triggers in the application, and then multiply that by the number of managers it takes to screw in a light bulb, which I calculate as about 3.5. That is about how many times I have argued with a system implementer to decide whether stored procedures were a good idea.
![]() Note The number of managers required to screw in a light bulb, depending on the size of the organization, would generally be a minimum of three or four: one manager to manage the person who notices the burnt out bulb, the manager of building services, and the shift manager of the person who actually changes light bulbs. Sometimes, the manager of the two managers might have to get involved to actually make things happen, so figure about three and a half.
Note The number of managers required to screw in a light bulb, depending on the size of the organization, would generally be a minimum of three or four: one manager to manage the person who notices the burnt out bulb, the manager of building services, and the shift manager of the person who actually changes light bulbs. Sometimes, the manager of the two managers might have to get involved to actually make things happen, so figure about three and a half.
In this chapter, I will present a number of opinions on how to use stored procedures, ad hoc SQL , and the CLR. Each of these opinions is based on years of experience working with SQL Server technologies, but I am not so set in my ways that I cannot see the point of the people on the other side of any fence—anyone whose mind cannot be changed is no longer learning. So if you disagree with this chapter, feel free to e-mail me at [email protected] ; you won’t hurt my feelings and we will both probably end up learning something in the process.
In this chapter, I am going to discuss the following topics:
- Using ad hoc SQL: Formulating queries in the application’s presentation and manipulation layer (typically functional code stored in objects, such as .NET or Java, and run on a server or a client machine).
- Using stored procedures: Creating an interface between the presentation/manipulation layer and the data layer of the application. Note that views and functions, as well as procedures, also form part of this data-access interface. You can use all three of these object types.
- Using CLR in T-SQL : In this section, I will present some basic opinions on the usage of the CLR within the realm of T-SQL.
Each section will analyze some of the pros and cons of each approach, in terms of flexibility, security, performance, and so on. Along the way, I’ll offer some personal opinions on optimal architecture and give advice on how best to implement both types of access.
![]() Note You may also be thinking that another thing I might discuss is object-relational mapping tools, like Hibernate, Spring, or even the ADO.NET Entity Framework. In the end, however, these tools are really using ad hoc access, in that they are generating SQL on the fly. For the sake of this book, they should be lumped into the ad hoc group, unless they are used with stored procedures (which is pretty rare).
Note You may also be thinking that another thing I might discuss is object-relational mapping tools, like Hibernate, Spring, or even the ADO.NET Entity Framework. In the end, however, these tools are really using ad hoc access, in that they are generating SQL on the fly. For the sake of this book, they should be lumped into the ad hoc group, unless they are used with stored procedures (which is pretty rare).
The most difficult part of a discussion of this sort is that the actual arguments that go on are not so much about right and wrong, but rather the question of which method is easier to program and maintain. SQL Server and Visual Studio .NET give you lots of handy-dandy tools to build your applications, mapping objects to data, and as the years pass, this becomes even truer with the Entity Framework and many of the object relational mapping tools out there.
The problem is that these tools don’t always take enough advantage of SQL Server’s best practices to build applications in their most common form of usage. Doing things in a best practice manner would mean doing a lot of coding manually, without the ease of automated tools to help you. Some organizations do this manual work with great results, but such work is rarely going to be popular with developers who have never hit the wall of having to support an application that is extremely hard to optimize once the system is in production.
A point that I really should make clear is that I feel that the choice of data-access strategy shouldn’t be linked to the methods used for data validation nor should it be linked to whether you use (or how much you use) check constraints, triggers, and such. If you have read the entire book, you should be kind of tired of hearing how much I feel that you should do every possible data validation on the SQL Server data that can be done without making a maintenance nightmare. Fundamental data rules that are cast in stone should be done on the database server in constraints and triggers at all times so that these rules can be trusted by the user (for example, an ETL process). On the other hand, procedures or client code is going to be used to enforce a lot of the same rules, plus all of the mutable business rules too, but in either situation, non-data tier rules can be easily circumvented by using a different access path. Even database rules can be circumvented using bulk loading operations, so be careful there too.
![]() Note While I stand by all of the concepts and opinions in this entire book (typos not withstanding), I definitely do not suggest that your educational journey end here. Please read other people’s work, try out everything, and form your own opinions. If some day you end up writing a competitive book to mine, the worst thing that happens is that people have another resource to turn to.
Note While I stand by all of the concepts and opinions in this entire book (typos not withstanding), I definitely do not suggest that your educational journey end here. Please read other people’s work, try out everything, and form your own opinions. If some day you end up writing a competitive book to mine, the worst thing that happens is that people have another resource to turn to.
Ad Hoc SQL
Ad hoc SQL is sometimes referred to as “straight SQL” and generally refers to the formulation of SELECT, INSERT, UPDATE, and DELETE statements (as well as any others) in the client. These statements are then sent to SQL Server either individually or in batches of multiple statements to be syntax checked, compiled, optimized (producing a plan), and executed. SQL Server may use a cached plan from a previous execution, but it will have to pretty much exactly match the text of one call to another to do so, the only difference can be some parameterization of literals, which we will discuss a little later in the chapter.
I will make no distinction between ad hoc calls that are generated manually and those that use a middleware setup like LINQ: from SQL Server’s standpoint, a string of characters is sent to the server and interpreted at runtime. So whether your method of generating these statements is good or poor is of no concern to me in this discussion, as long as the SQL generated is well formed and protected from users’ malicious actions. (For example, injection attacks are generally the biggest offender. The reason I don’t care where the ad hoc statements come from is that the advantages and disadvantages for the database support professionals are pretty much the same, and in fact, statements generated from a middleware tool can be worse, because you may not be able to change the format or makeup of the statements, leaving you with no easy way to tune statements, even if you can modify the source code.
Sending queries as strings of text is the way that most tools tend to converse with SQL Server, and is, for example, how SQL Server Management Studio does all of its interaction with the server metadata. If you have never used Profiler to watch the SQL that any of management and development tools uses, you should; just don’t use it as your guide for building your OLTP system. It is, however, a good way to learn where some bits of metadata that you can’t figure out come from.
There’s no question that users will perform some ad hoc queries against your system, especially when you simply want to write a query and execute it just once. However, the more pertinent question is: should you be using ad hoc SQL when building the permanent interface to an OLTP system’s data?
![]() Note This topic doesn’t include ad hoc SQL statements executed from stored procedures (commonly called dynamic SQL), which I’ll discuss in the section "Stored Procedures."
Note This topic doesn’t include ad hoc SQL statements executed from stored procedures (commonly called dynamic SQL), which I’ll discuss in the section "Stored Procedures."
Advantages
Using uncompiled ad hoc SQL has the following advantages over building compiled stored procedures:
- Runtime control over queries : Queries are built at runtime, without having to know every possible query that might be executed. This can lead to better performance as queries can be formed at runtime; you can retrieve only necessary data for SELECT queries or modify data that’s changed for UPDATE operations.
- Flexibility over shared plans and parameterization: Because you have control over the queries, you can more easily build queries at runtime that use the same plans and even can be parameterized as desired, based on the situation.
Runtime Control over Queries
Unlike stored procedures, which are prebuilt and stored in the SQL Server system tables, ad hoc SQL is formed at the time it’s needed: at runtime. Hence, it doesn’t suffer from some of the inflexible requirements of stored procedures. For example, say you want to build a user interface to a list of customers. You can add several columns to the SELECT clause, based on the tables listed in the FROM clause. It’s simple to build a list of columns into the user interface that the user can use to customize his or her own list. Then the program can issue the list request with only the columns in the SELECT list that are requested by the user. Because some columns might be large and contain quite a bit of data, it’s better to send back only the columns that the user really desires instead of also including a bunch of columns the user doesn’t care about.
For instance, consider that you have the following table to document contacts to prospective customers (it’s barebones for this example). In each query, you might return the primary key but show or not show it to the user based on whether the primary key is implemented as a surrogate or natural key—it isn’t important to our example either way. You can create this table in any database you like. In the sample code, I’ve created a database named architectureChapter.
CREATE SCHEMA sales;
GO
CREATE TABLE sales.contact
(
contactId int CONSTRAINT PKsales_contact PRIMARY KEY,
firstName varchar(30),
lastName varchar(30),
companyName varchar(100),
salesLevelId int, --real table would implement as a foreign key
contactNotes varchar(max),
CONSTRAINT AKsales_contact UNIQUE (firstName, lastName, companyName)
);
--a few rows to show some output from queries
INSERT INTO sales.contact
(contactId, firstName, lastname, companyName, saleslevelId, contactNotes)
VALUES( 1,'Drue','Karry','SeeBeeEss',1,
REPLICATE ('Blah…',10) + 'Called and discussed new ideas'),
( 2,'Jon','Rettre','Daughter Inc',2,
REPLICATE ('Yada…',10) + 'Called, but he had passed on'),
One user might want to see the person’s name and the company, plus the end of the contactNotes, in his or her view of the data:
SELECT contactId, firstName, lastName, companyName,
RIGHT(contactNotes,30) AS notesEnd
FROM sales.contact;
So something like:
| contactId | firstName | lastName | companyName | notesEnd |
| --------- | --------- | -------- | ------------ | ------------------------------ |
| 1 | Drue | Karry | SeeBeeEss | Called and discussed new ideas |
| 2 | Jon | Rettre | Daughter Inc | ..Called, but he had passed on |
Another user might want (or need) to see less:
SELECT contactId, firstName, lastName, companyName
FROM sales.contact;
Which returns:
| contactId | firstName | lastName | companyName |
| --------- | -------- | -------- | ------------ |
| 1 | Drue | Karry | SeeBeeEss |
| 2 | Jon | Rettre | Daughter Inc |
And yet another may want to see all columns in the table, plus maybe some additional information. Allowing the user to choose the columns for output can be useful. Consider how the file-listing dialog works in Windows, as shown in Figure 13-1.
Figure 13-1. The Windows file-listing dialog
You can see as many or as few of the attributes of a file in the list as you like, based on some metadata you set on the directory. This is a useful method of letting the users choose what they want to see. Let’s take this one step further. Consider that the contact table is then related to a table that tells us if a contact has purchased something:
CREATE TABLE sales.purchase
(
purchaseId int CONSTRAINT PKsales_purchase PRIMARY KEY,
amount numeric(10,2),
purchaseDate date,
contactId int
CONSTRAINT FKsales_contact$hasPurchasesIn$sales_purchase
REFERENCES sales.contact(contactId)
);
INSERT INTO sales.purchase(purchaseId, amount, purchaseDate, contactId)
VALUES (1,100.00,'2012-05-12',1),(2,200.00,'2012-05-10',1),
(3,100.00,'2012-05-12',2),(4,300.00,'2012-05-12',1),
(5,100.00,'2012-04-11',1),(6,5500.00,'2012-05-14',2),
(7,100.00,'2012-04-01',1),(8,1020.00,'2012-06-03',2);
Now consider that you want to calculate the sales totals and dates for the contact and add these columns to the allowed pool of choices. By tailoring the output when transmitting the results of the query back to the user, you can save bandwidth, CPU, and disk I/O. As I’ve stressed, values such as this should usually be calculated rather than stored, especially when working on an OLTP system.
In this case, consider the following two possibilities. If the user asks for a sales summary column, the client will send the whole query:
SELECT contact.contactId, contact.firstName, contact.lastName,
sales.yearToDateSales, sales.lastSaleDate
FROM sales.contact AS contact
LEFT OUTER JOIN
(SELECT contactId,
SUM(amount) AS yearToDateSales,
MAX(purchaseDate) AS lastSaleDate
FROM sales.purchase
WHERE purchaseDate >= --the first day of the current year
DATEADD(day, 0, DATEDIFF(day, 0, SYSDATETIME() )
- DATEPART(dayofYear,SYSDATETIME() ) + 1)
GROUP BY contactId) AS sales
ON contact.contactId = sales.contactId
WHERE contact.lastName Like 'Rett%';
Which returns:
| contactId | firstName | lastName | yearToDateSales | lastSaleDate |
| ---------- | --------- | -------- | --------------- | ------------ |
| 2 | Jon | Rettre | 6620.00 | 2012-06-03 |
If the user doesn’t ask for a sales summary column, the client will send only the bolded query:
SELECT contact.contactId, contact.firstName, contact.lastName
-- ,sales.yearToDateSales, sales.lastSaleDate
FROM sales.contact AS contact
--LEFT OUTER JOIN
-- (SELECT contactId,
-- SUM(amount) AS yearToDateSales,
-- MAX(purchaseDate) AS lastSaleDate
-- FROM sales.purchase
-- WHERE purchaseDate >= --the first day of the current year
-- DATEADD(Day, 0, DATEDIFF(Day, 0, SYSDATETIME() )
-- -DATEPART(dayofyear,SYSDATETIME() ) + 1)
-- GROUP by contactId) AS sales
-- ON contact.contactId = sales.contactId
WHERE contact.lastName Like 'Karr%';
Which only returns:
contactId firstName lastName
---------- --------- ---------
1 Drue Karry
Not wasting the resources to do calculations that aren’t needed can save a lot of system resources if the aggregates in the derived table were very costly to execute
In the same vein, when using ad hoc calls, it’s trivial (from a SQL standpoint) to build UPDATE statements that include only the columns that have changed in the set lists, rather than updating all columns, as can be necessary for a stored procedure. For example, take the customer columns from earlier: customerId, name, and number. You could just update all columns:
UPDATE sales.contact
SET firstName = 'Drew',
lastName = 'Carey',
salesLevelId = 1, --no change
companyName = 'CBS',
contactNotes = 'Blah…Blah…Blah…Blah…Blah…Blah…Blah…Blah…Blah…'
+ 'Blah…Called and discussed new ideas' --no change
WHERE contactId = 1;
But what if only the firstName and lastName columns change? What if the company column is part of an index, and it has data validations that take three seconds to execute? How do you deal with varchar(max) columns (or other long types)? Say the notes columns for contactId = 1 contain 3 MB each. Execution could take far more time than is desirable if the application passes the entire value back and forth each time. Using ad hoc SQL, to update the firstName column only, you can simply execute the following code:
UPDATE sales.contact
SET firstName = 'John',
lastName = 'Ritter'
WHERE contactId = 1;
Some of this can be done with dynamic SQL calls built into the stored procedure, but it’s far easier to know if data changed right at the source where the data is being edited, rather than having to check the data beforehand. For example, you could have every data-bound control implement a “data changed” property, and perform a column update only when the original value doesn’t match the value currently displayed. In a stored-procedure-only architecture, having multiple update procedures is not necessarily out of the question, particularly when it is very costly to modify a given column.
One place where using ad hoc SQL can produce more reasonable code is in the area of optional parameters. Say that, in your query to the sales.contact table, your UI allowed you to filter on either firstName, lastName, or both. For example, take the following code to filter on both firstName and lastName:
SELECT firstName, lastName, companyName
FROM sales.contact
WHERE firstName Like 'J%'
AND lastName Like 'R%';
What if the user only needed to filter by last name? Sending the '%' wildcard for firstName can cause code to perform less than adequately, especially when the query is parameterized. (I’ll cover query parameterization in the next section, “Performance.”)
SELECT firstName, lastName, companyName
FROM sales.contact
WHERE firstName LIKE '%'
AND lastName LIKE 'Carey%';
If you think this looks like a very silly query to execute, you are right. If you were writing this query, you would write the more logical version of this query, without the superfluous condition:
SELECT firstName, lastName, companyName
FROM sales.contact
WHERE lastName LIKE 'Carey%';
This doesn’t require any difficult coding. Just remove one of the criteria from the WHERE clause, and the optimizer needn’t consider the other. What if you want to OR the criteria instead? Simply build the query with OR instead of AND. This kind of flexibility is one of the biggest positives to using ad hoc SQL calls.
![]() Note The ability to change the statement programmatically does sort of play to the downside of any dynamically built statement, as now, with just two parameters, we have three possible variants of the statement to be used, so we have to consider performance for all three when we are building our test cases.
Note The ability to change the statement programmatically does sort of play to the downside of any dynamically built statement, as now, with just two parameters, we have three possible variants of the statement to be used, so we have to consider performance for all three when we are building our test cases.
For a stored procedure, you might need to write code that functionally works in a manner such as the following:
IF @firstNameValue <> '%'
SELECT firstName, lastName, companyName
FROM sales.contact
WHERE firstName LIKE @firstNameValue
AND lastName LIKE @lastNameValue;
ELSE
SELECT firstName, lastName, companyName
FROM sales.contact
WHERE lastName LIKE @lastNameValue;
Or do something messy like this in your WHERE clause so if there is any value passed in it uses it, or uses '%' otherwise:
WHERE Firstname Like isnull(nullif(ltrim(@FirstNamevalue) +'%','%'),Firstname)
and Lastname Like isnull(nullif(ltrim(@LastNamevalue) +'%','%'),Lastname)
Unfortunately though, this often does not optimize very well because the optimizer has a hard time optimizing for factors that can change based on different values of a variable—leading to the need for the branching solution mentioned previously to optimize for specific parameter cases. A better way to do this with stored procedures might be to create two stored procedures—one with the first query and another with the second query—especially if you need extremely high performance access to the data. You’d change this to the following code:
IF @firstNameValue <> '%'
EXECUTE sales.contact$get @firstNameValue, @lastNameValue;
ELSE
EXECUTE sales.contact$getLastOnly @lastNameValue;
You can do some of this kind of ad hoc SQL writing using dynamic SQL in stored procedures. However, you might have to do a good bit of these sorts of IF blocks to arrive at which parameters aren’t applicable in various datatypes. Because you know which parameters are applicable, due to knowing what the user filled in, it can be far easier to handle this situation using ad hoc SQL. Getting this kind of flexibility is the main reason that I use an ad hoc SQL call in an application (usually embedded in a stored procedure): you can omit parts of queries that don’t make sense in some cases, and it’s easier to avoid executing unnecessary code.
Flexibility over Shared Plans and Parameterization
Queries formed at runtime, using proper techniques, can actually be better for performance in many ways than using stored procedures. Because you have control over the queries, you can more easily build queries at runtime that use the same plans, and even can be parameterized as desired, based on the situation.
This is not to say that it is the most favorable way of implementing parameterization. (If you want to know the whole picture you have to read the whole section on ad hoc and stored procedures.) However, the fact is that ad hoc access tends to get a bad reputation for something that Microsoft fixed several versions back. In the following sections, Shared Execution Plans and Parameterization, I will take a look at the good points and the caveats you will deal with when building ad hoc queries and executing them on the server.
The age-old reason that people used stored procedures was because the query processor cached their plans. Every time you executed a procedure, you didn’t have to decide the best way to execute the query. As of SQL Server 7.0 (which, was released in 1998!), cached plans were extended to include ad hoc SQL. However, the standard for what can be cached is pretty strict. For two calls to the server to use the same plan, the statements that are sent must be identical, except possibly for the literal values in search arguments. Identical means identical; add a comment, change the case, or even add a space character, and the plan will no longer match. SQL Server can build query plans that have parameters, which allow plan reuse by subsequent calls. However, overall, stored procedures are better when it comes to using cached plans for performance, primarily because the matching and parameterization are easier for the optimizer to do, since it can be done by object_id, rather than having to match larger blobs of text.
A fairly major caveat is that for ad hoc queries to use the same plan, they must be exactly the same, other than any values that can be parameterized. For example, consider the following two queries. (I’m using AdventureWorks2012 tables for this example, as that database has a nice amount of data to work with.)
SELECT address.AddressLine1, address.AddressLine2,
address.City, state.StateProvinceCode, address.PostalCode
FROM Person.address as address
JOIN Person.StateProvince as state
on address.StateProvinceID = state.StateProvinceID
WHERE address.addressLine1 = '1, rue Pierre-Demoulin';
Next, run the following query. See whether you can spot the difference between the two queries.
SELECT address.AddressLine1, address.AddressLine2,
address.City, state.StateProvinceCode, address.PostalCode
FROM Person.Address AS address
JOIN Person.StateProvince AS state
on address.StateProvinceID = state.StateProvinceID
WHERE address.AddressLine1 = '1, rue Pierre-Demoulin';
These queries can’t share plans because the AS in the first query’s FROM clause is lowercase (FROM Person.Address as address); but in the second, it’s uppercase. Using the sys.dm_exec_query_stats dynamic management view, you can see that the case difference does cause two plans by running:
SELECT *
FROM (SELECT execution_count,
SUBSTRING(st.text, (qs.statement_start_offset/2)+1,
((CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(st.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2) + 1) AS statement_text
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS st
) AS queryStats
WHERE queryStats.statement_text LIKE 'SELECT address.AddressLine1%';
This SELECT statement will return at least two rows; one for each query you have just executed. (It could be more depending on whether or not you have executed the statement in this statement more than two times). Hence, trying to use some method to make sure that every query sent that is essentially the same query is formatted the same is important: queries must use the same format, capitalization, and so forth.
Parameterization
The next performance query plan topic to discuss is parameterization. When a query is parameterized, only one version of the plan is needed to service many queries. Stored procedures are parameterized in all cases, but SQL Server does parameterize ad hoc SQL statements. By default, the optimizer doesn’t parameterize most queries, and caches most plans as straight text, unless the query is “simple.” For example, it can only reference a single table (search for “Forced Parameterization” in Books Online for the complete details). When the query meets the strict requirements, it changes each literal it finds in the query string into a parameter. The next time the query is executed with different literal values, the same plan can be used. For example, take this simpler form of the previous query:
SELECT address.AddressLine1, address.AddressLine2
FROM Person.Address AS address
WHERE address.AddressLine1 = '1, rue Pierre-Demoulin';
The plan (from using showplan_text on in the manner we introduced in Chapter 10 “Basic Index Usage Patterns”) is as follows:
|--Index Seek(OBJECT:([AdventureWorks2012].[Person].[Address].|
IX_Address_AddressLine1_AddressLine2_City_StateProvinceID_PostalCode] AS [address]),
SEEK:([address].[AddressLine1]=CONVERT_IMPLICIT(nvarchar(4000),[@1],0)) ORDERED FORWARD)
The value of N'1, rue Pierre-Demoulin' has been changed to @1 (which is in bold in the plan), and the value is filled in from the literal at execute time. However, try executing this query that accesses two tables:
SELECT address.AddressLine1, address.AddressLine2,
address.City, state.StateProvinceCode, address.PostalCode
FROM Person.Address AS address
JOIN Person.StateProvince AS state
ON address.StateProvinceID = state.StateProvinceID
WHERE address.AddressLine1 ='1, rue Pierre-Demoulin';
The plan won’t recognize the literal and parameterize it:
|--Nested Loops(Inner Join, OUTER REFERENCES:([address].[StateProvinceID])) |--Index Seek(OBJECT:([AdventureWorks].[Person].[Address]. [IX_Address_AddressLine1_AddressLine2_City_StateProvinceID_PostalCode] AS [address]),SEEK:([address].[AddressLine1]=N'1, rue Pierre-Demoulin') ORDERED FORWARD) |--Clustered Index Seek(OBJECT:([AdventureWorks2008].[Person].[StateProvince]. [PK_StateProvince_StateProvinceID] AS [state]), SEEK:([state].[StateProvinceID]=[AdventureWorks].[Person]. [Address].[StateProvinceID] as [address].[StateProvinceID]) ORDERED FORWARD)
Note that the literal (bolded in this plan) from the query is still in the plan, rather than a parameter. Both plans are cached, but the first one can be used regardless of the literal value included in the WHERE clause. In the second, the plan won’t be reused unless the precise literal value of N'1, rue Pierre-Demoulin' is passed in.
If you want the optimizer to be more liberal in parameterizing queries, you can use the ALTER DATABASE command to force the optimizer to parameterize:
ALTER DATABASE AdventureWorks2012
SET PARAMETERIZATION FORCED;
Try the plan of the query with the join. It now has replaced the N'1, rue Pierre-Demoulin' with CONVERT_IMPLICIT(nvarchar(4000),[@0],0) . Now the query processor can reuse this plan no matter what the value for the literal is. This can be a costly operation in comparison to normal, text-only plans, so not every system should use this setting. However, if your system is running the same, reasonably complex-looking queries over and over, this can be a wonderful setting to avoid the need to pay for the query optimization.
|--Nested Loops(Inner Join, OUTER REFERENCES:([address].[StateProvinceID]))
|--Index Seek(OBJECT:([AdventureWorks2012].[Person].[Address].
[IX_Address_AddressLine1_AddressLine2_City_StateProvinceID_PostalCode]
AS [address]),
SEEK:([address].[AddressLine1]= CONVERT_IMPLICIT(nvarchar(4000),[@0],0))
ORDERED FORWARD)
|--Clustered Index Seek(OBJECT:([AdventureWorks2012].[Person].[StateProvince].
[PK_StateProvince_StateProvinceID] AS [state]),
SEEK:([state].[StateProvinceID]=[AdventureWorks2012].[Person].
[Address].[StateProvinceID] as [address].[StateProvinceID]
Not every query will be parameterized when forced parameterization is enabled. For example, change the equality to a LIKE condition:
SELECT address.AddressLine1, address.AddressLine2,
address.City, state.StateProvinceCode, address.PostalCode
FROM Person.Address AS address
JOIN Person.StateProvince AS state
ON address.StateProvinceID = state.StateProvinceID
WHERE address.AddressLine1 Like '1, rue Pierre-Demoulin';
The plan will contains the literal, rather than the parameter, because it cannot parameterize the second and third arguments of the LIKE operator (the arguments are arg1 LIKE arg2 [ESCAPE arg3]).
|--Nested Loops(Inner Join, OUTER REFERENCES:([address].[StateProvinceID]))
|--Index Seek(OBJECT:([AdventureWorks2012].[Person].[Address].
[IX_Address_AddressLine1_AddressLine2_City_StateProvinceID_PostalCode]
AS [address]),
SEEK:([address].[AddressLine1] >= N'1, rue Pierre-Demoulin'
AND [address].[AddressLine1] <= N'1, ru …(cut off in view)
|--Clustered Index Seek(OBJECT:([AdventureWorks2012].[Person].[StateProvince].
[PK_StateProvince_StateProvinceID] AS [state]),
SEEK:([state].[StateProvinceID]=[AdventureWorks2012].[Person].
[Address].[StateProvinceID] AS [address].[StateProvinceID]
If you change the query to end with WHERE '1, rue Pierre-Demoulin' Like address.AddressLine1, it would be parameterized, but that construct is rarely what is desired.
For your applications, another method is to use parameterized calls from the data access layer. Basically using ADO.NET, this would entail using T-SQL variables in your query strings, and then using a SqlCommand object and its Parameters collection. The plan that will be created from SQL parameterized on the client will in turn be parameterized in the plan that is saved.
The myth that performance is definitely worse with ad hoc calls is just not quite true (certainly after 7.0). Performance can actually be less of a worry than you might have been led to believe when using ad hoc calls to the SQL Server in your applications. However, don’t stop reading here. While performance may not suffer tremendously, performance tuning is one of the pitfalls, since once you have compiled that query into your application, changing the query is never as easy as it might seem during the development cycle.
So far, we have just executed queries directly, but there is a better method when building your interfaces that allows you to parameterize queries in a very safe manner. Using sp_executeSQL , you can fashion your SQL statement using variables to parameterize the query:
DECLARE @AddressLine1 nvarchar(60) = '1, rue Pierre-Demoulin',
@Query nvarchar(500),
@Parameters nvarchar(500)
SET @Query= N'SELECT address.AddressLine1, address.AddressLine2,address.City,
state.StateProvinceCode, address.PostalCode
FROM Person.Address AS address
JOIN Person.StateProvince AS state
ON address.StateProvinceID = state.StateProvinceID
WHERE address.AddressLine1 Like @AddressLine1';
SET @Parameters = N'@AddressLine1 nvarchar(60)';
EXECUTE sp_executesql @Query, @Parameters, @AddressLine1 = @AddressLine1;
Using sp_executesql is generally considered the safest way to parameterize queries because it does a good job of parameterizing the query and helps avoid issues like SQL injection attacks, which I will cover later in this chapter.
Finally, if you know you need to reuse the query multiple times, you can compile it and save the plan for reuse. This is generally useful if you are going to have to call the same object over and over, Instead of sp_executesql, use sp_prepare to prepare the plan; only this time you won’t use the actual value:
DECLARE @Query nvarchar(500),
@Parameters nvarchar(500),
@Handle int
SET @Query= N'SELECT address.AddressLine1, address.AddressLine2,address.City,
state.StateProvinceCode, address.PostalCode
FROM Person.Address AS address
JOIN Person.StateProvince AS state
ON address.StateProvinceID = state.StateProvinceID
WHERE address.AddressLine1 Like @AddressLine1';
SET @Parameters = N'@AddressLine1 nvarchar(60)';
EXECUTE sp_prepare @Handle output, @Parameters, @Query;
SELECT @handle;
That batch will return a value that corresponds to the prepared plan, in my case it was 1. This value is you handle to the plan that you can use with sp_execute on the same connection only. All you need to execute the query is the parameter values and the sp_execute statement, and you can use and reuse the plan as needed:
DECLARE @AddressLine1 nvarchar(60) = '1, rue Pierre-Demoulin';
EXECUTE sp_execute 1, @AddressLine1;
SET @AddressLine1 = '6387 Scenic Avenue';
EXECUTE sp_execute 1, @AddressLine1;
You can unprepare the statement using sp_unprepare and the handle number. It is fairly rare that anyone will manually execute sp_prepare and sp_execute, but it is very frequently built into engines that are built to manage ad hoc access for you. It can be good for performance, but it is a pain for troubleshooting because you have to decode what the handle 1 actually represents. You can release the plan using sp_unprepare with a parameter of the handle.
What you end up with is pretty much the same as a procedure for performance, but it has to be done every time you run your app, and it is scoped to a connection, not shared on all connections. The better solution for parameterizing complex statements is a stored procedure. Generally, the only way this makes sense as a best practice is when you cannot use procedures, perhaps because of your tool choice or using a third-party application. Why? Well, the fact is with stored procedures, the query code is stored on the server and is a layer of encapsulation that reduces coupling; but more on that in the stored procedure section.
Pitfalls
I’m glad you didn’t stop reading at the end of the previous section, because although I have covered the good points of using ad hoc SQL, there are the following significant pitfalls, as well:
- Low cohesion, high coupling
- Batches of statements
- Security issues
- SQL injection
- Performance-tuning difficulties
The number-one pitfall of using ad hoc SQL as your interface relates to what you learned back in Programming 101: strive for high cohesion, low coupling. Cohesion means that the different parts of the system work together to form a meaningful unit. This is a good thing, as you don’t want to include lots of irrelevant code in the system, or be all over the place. On the other hand, coupling refers to how connected the different parts of a system are to one another. It’s considered bad when a change in one part of a system breaks other parts of a system. (If you aren’t too familiar with these terms, I suggest you go to www.wikipedia.org and search for these terms. You should build all the code you create with these concepts in mind.)
When issuing T-SQL statements directly from the application, the structures in the database are tied directly to the client interface. This sounds perfectly normal and acceptable at the beginning of a project, but it means that any change in database structure might require a change in the user interface. This makes making small changes to the system just as costly as large ones, because a full testing cycle is required.
![]() Note When I started this section, I told you that I wouldn’t make any distinction between toolsets used. This is still true. Whether you use a horribly, manually coded system or the best object-relational mapping system, the fact that the application tier knows and is built specifically with knowledge of the base structure of the database is an example of the application and data tiers being highly coupled. Though stored procedures are similarly inflexible, they are stored with the data, allowing the disparate systems to be decoupled: the code on the database tier can be structurally dependent on the objects in the same tier without completely sacrificing your loose coupling.
Note When I started this section, I told you that I wouldn’t make any distinction between toolsets used. This is still true. Whether you use a horribly, manually coded system or the best object-relational mapping system, the fact that the application tier knows and is built specifically with knowledge of the base structure of the database is an example of the application and data tiers being highly coupled. Though stored procedures are similarly inflexible, they are stored with the data, allowing the disparate systems to be decoupled: the code on the database tier can be structurally dependent on the objects in the same tier without completely sacrificing your loose coupling.
For example, consider that you’ve created an employee table, and you’re storing the employee’s spouse’s name, as shown in Figure 13-2.

Figure 13-2. An employee table
Now, some new regulation requires that you have to include the ability to have more than one spouse, which necessitates a new table, as shown in Figure 13-3.
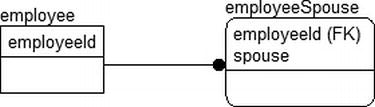
Figure 13-3. Adding the ability to have more than one spouse
The user interface must immediately be morphed to deal with this case, or at the least, you need to add some code to abstract this new way of storing data. In a scenario such as this, where the condition is quite rare (certainly most everyone will have zero or one spouse), a likely solution would be simply to encapsulate the one spouse into the employee table via a view, change the name of the object the non-data tier accesses, and the existing UI would still work. Then you can add support for the atypical case with some sort of otherSpouse functionality that would be used if the employee had more than one spouse. The original UI would continue to work, but a new form would be built for the case where COUNT(spouse) > 1.
Batches of More Than One Statement
A major problem with ad hoc SQL access is that when you need to do multiple commands and treat them as a single operation, it becomes increasingly more difficult to build the mechanisms in the application code to execute multiple statements as a batch, particularly when you need to group statements together in a transaction. When you have only individual statements, it’s easy to manage ad hoc SQL for the most part. Some queries can get mighty complicated and difficult, but generally speaking, things pretty much work great when you have single statements per transaction. However, as complexity rises in the things you need to accomplish in a transaction, things get tougher. What about the case where you have 20 rows to insert, update, and/or delete at one time and all in one transaction?
Two different things usually occur in this case. The first way to deal with this situation is to start a transaction using functional code. For the most part, as discussed in Chapter 10, the best practice was stated as never to let transactions span batches, and you should minimize starting transactions using an ADO.NET object (or something like it). This isn’t a hard and fast rule, as it’s usually fine to do this with a middle-tier object that requires no user interaction. However, if something occurs during the execution of the object, you can still leave open connections and transactions to the server.
The second way to deal with this is to build a batching mechanism for batching SQL calls. Implementing the first method is self explanatory, but the second is to build a code-wrapping mechanism, such as the following:
BEGIN TRY
BEGIN TRANSACTION;
<-- statements go here
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
ROLLBACK TRANSACTION;
THROW 50000, '<describe what happened>',1;
END CATCH
For example, if you wanted to send a new invoice and line items, the application code would need to build a batch such as in the following code. Each of the SET @Action = … and INSERT statements would be put into the batch by the application with the rest being boilerplate code that is repeatable:
SET NOCOUNT ON;
BEGIN TRY
BEGIN TRANSACTION;
DECLARE @Action nvarchar(200);
SET @Action = 'Invoice Insert';
INSERT invoice (columns) values (values);
SET @Action = 'First InvoiceLineItem Insert';
INSERT invoiceLineItem (columns) values (values);
SET @Action = 'Second InvoiceLineItem Insert';
INSERT invoiceLineItem (columns) values (values);
SET @Action = 'Third InvoiceLineItem Insert';
INSERT invoiceLineItem (columns) values (values);
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
ROLLBACK TRANSACTION;
DECLARE @Msg nvarchar(4000);
SET @Msg = @Action + ': Error was: ' + CAST(ERROR_NUMBER() as varchar(10)) + ':' +
ERROR_MESSAGE ();
THROW 50000, @Msg,1 ;
END CATCH
Executing multiple statements in a transaction is done on the server and the transaction either completes or not. There’s no chance that you’ll end up with a transaction swinging in the wind, ready to block the next user who needs to access the locked row (even in a table scan for unrelated items). A downside is that it does stop you from using any interim values from your statements (without some really tricky coding/forethought), but starting transactions outside of the batch you commit them is asking for blocking and locking due to longer batch times.
Starting the transaction outside of the server using application code is likely easier, but building this sort of batching interface is always the preferred way to go. First, it’s better for concurrency, because only one batch needs to be executed instead of many little ones. Second, the execution of this batch won’t have to wait on communications back and forth from the server before sending the next command. It’s all there and happens in the single batch of statements.
![]() Note The problem I have run into in almost all cases was that building a batch of multiple SQL statements is a very unnatural thing for the object oriented code to do. The way the code is generally set up is more one table to one object, where the invoice and invoiceLineItem objects have the responsibility of saving themselves. It is a lot easier to code, but too often issues come up in the execution of multiple statements and then the connection gets left open and other connections get blocked behind the locks that are left open due because of the open transaction.
Note The problem I have run into in almost all cases was that building a batch of multiple SQL statements is a very unnatural thing for the object oriented code to do. The way the code is generally set up is more one table to one object, where the invoice and invoiceLineItem objects have the responsibility of saving themselves. It is a lot easier to code, but too often issues come up in the execution of multiple statements and then the connection gets left open and other connections get blocked behind the locks that are left open due because of the open transaction.
Security is one of the biggest downsides to using ad hoc access. For a user to use his or her own Windows login to access the server, you have to grant too many rights to the system, whereas with stored procedures, you can simply give access to the stored procedures. Using ad hoc T-SQL, you have to go with one of three possible security patterns, each with their own downsides:
- Use one login for the application: This, of course, means that you have to code your own security system rather than using what SQL Server gives you. This even includes some form of login and password for application access, as well as individual object access.
- Use application roles: This is slightly better: while you have to implement security in your code since all application users will have the same database security, at the very least, you can let SQL server handle the data access via normal logins and passwords (probably using Windows authentication). Using application roles can be better way to give a user multiple sets of permissions as having only the one password for users to log in with usually avoids the mass of sticky notes embossed in bold letters all around the office: payroll system ID: fred, password: fredsisawesome!
- Give the user direct access to the tables, or possibly views: This unfortunately opens up your tables to users who discover the magical world of Management Studio, where they can open a table and immediately start editing it without any of those pesky UI data checks or business rules that only exist in your data access layer that I warned you about.
Usually, almost all applications follow the first of the three methods. Building your own security mechanisms is just considered a part of the process, and just about as often, it is considered part of the user interface’s responsibilities. At the very least, by not giving all users direct access to the tables, the likelihood of them mucking around in the tables editing data all willy-nilly is greatly minimized. With procedures, you can give the users access to stored procedures, which are not natural for them to use and certainly would not allow them to accidentally delete data from a table.
The other issues security-wise are basically performance related. SQL Server must evaluate security for every object as it’s used, rather than once at the object level for stored procedures—that is, if the owner of the procedure owns all objects. This isn’t generally a big issue, but as your need for greater concurrency increases, everything becomes an issue!
![]() Caution If you use the single-application login method, make sure not to use an account with system administration or database owner privileges. Doing so opens up your application to programmers making mistakes, and if you miss something that allows SQL injection attacks, which I describe in the next section, you could be in a world of hurt.
Caution If you use the single-application login method, make sure not to use an account with system administration or database owner privileges. Doing so opens up your application to programmers making mistakes, and if you miss something that allows SQL injection attacks, which I describe in the next section, you could be in a world of hurt.
A big issue with ad hoc query being hacked by a SQL injection attack. Unless you (and/or your toolset) program your ad hoc SQL intelligently and/or (mostly and) use the parameterizing methods we discussed earlier in this section on ad hoc SQL, a user could inject something such as the following:
' + char(13) + char(10) + ';SHUTDOWN WITH NOWAIT;' + '--'
In this case, the command might just shut down the server if the user has rights, but you can probably see far greater attack possibilities. I’ll discuss more about injection attacks and how to avoid them in the “Stored Procedures” section. When using ad hoc SQL, you must be careful to avoid these types of issues for every call.
A SQL injection attack is not terribly hard to beat, but the fact is, for any use enterable text where you don’t use some form of parameterization, you have to make sure to escape any single quote characters that a user passes in. For general text entry, like a name, commonly if the user passes in a string like “O'Malley”, you know to change this to 'O''Malley'. For example, consider the following batch, where the resulting query will fail. (I have to escape the single quote in the literal to allow the query to execute.)
DECLARE @value varchar(30) = 'O''Malley';
SELECT 'SELECT '''+ @value + '''';
EXECUTE ('SELECT '''+ @value + ''''),
This will return:
SELECT 'O'Malley'
Msg 105, Level 15, State 1, Line 1
Unclosed quotation mark after the character string ''.
This is a very common problem that arises, and all too often the result is that the user learns not to enter a single quote in the query parameter value. But you can make sure this doesn’t occur by changing all single quotes in the value to double single quotes, like in the DECLARE @value statement:
DECLARE @value varchar(30) = 'O''Malley', @query nvarchar(300);
SELECT @query = 'SELECT ' + QUOTENAME(@value,''''),
SELECT @query;
EXECUTE (@query );
This returns:
SELECT 'O''Malley'
------------------
O'Malley
Now, if someone tries to put a single quote, semicolon, and some other statement in the value, it doesn’t matter; it will always be treated as a literal string:
DECLARE @value varchar(30) = 'O''; SELECT ''badness',
@query nvarchar(300);
SELECT @query = 'SELECT ' + QUOTENAME(@value,''''),
SELECT @query;
EXECUTE (@query );
The query is now, followed by the return:
SELECT 'O''; SELECT ''badness'
------------------------------
O'; SELECT 'badness
However, what isn’t quite so obvious is that you have to do this for every single string, even if the string value could never legally (due to application and constraints) have a single quote in it. If you don’t double up on the quotes, the person could put in a single quote and then a string of SQL commands—this is where you get hit by the injection attack. And as I said before, the safest method of avoiding injection issues is to always parameterize your queries; though it is very hard to use a variable query conditions using the parameterized method, losing some of the value of using ad hoc SQL.
DECLARE @value varchar(30) = 'O''; SELECT ''badness',
@query nvarchar(300),
@parameters nvarchar(200) = N'@value varchar(30)';
SELECT @query = 'SELECT ' + QUOTENAME(@value,''''),
SELECT @query;
EXECUTE sp_executesql @Query, @Parameters, @value = @value;
If you employ ad hoc SQL in your applications, I strongly suggest you do more reading on the subject of SQL injection, and then go in and look at the places where SQL commands can be sent to the server to make sure you are covered. SQL injection is especially dangerous if the accounts being used by your application have too much power because you didn’t set up particularly granular security.
Note that if all of this talk of parameterization sounds complicated, it kind of is. Generally there are two ways that parameterization happens well. Either by building a framework that forces you to follow the correct pattern (as do most object-relational tools, thought they often force (or at least lead) you into sub-optimal patterns of execution, like dealing with every statement separately without transactions.) The second way is stored procedures. Stored procedures parameterize in a manner that is impervious to SQL injection (except, when you use dynamic SQL, which, as I will discuss later, is subject to the same issues as ad hoc access from any client.)
Difficulty Tuning for Performance
Performance tuning is generally far more difficult when having to deal with ad hoc requests, for a few reasons:
- Unknown queries: The application can be programmed to send any query it wants, in any way. Unless very extensive testing is done, slow or dangerous scenarios can slip through. With procedures, you have a tidy catalog of possible queries that might be executed. Of course, this concern can be mitigated by having a single module where SQL code can be created and a method to list all possible queries that the application layer can execute (however, that takes more discipline than most organizations have.).
- Often requires people from multiple teams: It may seem silly, but when something is running slower, it is always blamed on SQL Server first. With ad hoc calls, the best thing that the database administrator can do is use a profiler to capture the query that is executed, see if an index could help, and call for a programmer, leading to the issue in the next bullet.
- Recompile required for changing queries: If you want to add a tip to a query to use an index, a rebuild and a redeploy are required. For stored procedures, you’d simply modify the query without the client knowing.
These reasons seem small during the development phase, but often they’re the real killers for tuning, especially when you get a third-party application and its developers have implemented a dumb query that you could easily optimize, but since the code is hard coded in the application, modification of the query isn’t possible (not that this regularly happens; no, not at all; nudge, nudge, wink, wink).
SQL Server 2005 gave us plan guides (and there are some improvements in their usability in later versions) that can be used to force a plan for queries, ad hoc calls, and procedures when you have troublesome queries that don’t optimize naturally, but the fact is, going in and editing a query to tune is far easier than using plan guides.
Stored Procedures
Stored procedures are compiled batches of SQL code that can be parameterized to allow for easy reuse. The basic structure of stored procedures follows. (See SQL Server Books Online at http://msdn.microsoft.com/en-us/library/ms130214.aspx for a complete reference.)
CREATE PROCEDURE <procedureName>
[(
@parameter1 <datatype> [ = <defaultvalue> [OUTPUT]]
@parameter2 <datatype> [ = <defaultvalue> [OUTPUT]]
…
@parameterN <datatype> [ = <defaultvalue> [OUTPUT]]
)]
AS
<T-SQL statements> | <CLR Assembly reference>
There isn’t much more to it. You can put any statements that could have been sent as ad hoc calls to the server into a stored procedure and call them as a reusable unit. You can return an integer value from the procedure by using the RETURN statement, or return almost any datatype by declaring the parameter as an output parameter other than text or image, though you should be using (max) datatypes instead because they will not likely exist in the version after 2012. (You can also not return a table valued parameter.) After the AS, you can execute any T-SQL commands you need to, using the parameters like variables.
The following is an example of a basic procedure to retrieve rows from a table (continuing to use the AdventureWorks2012 tables for these examples):
CREATE PROCEDURE Person.Address$select
(
@addressLine1 nvarchar(120) = '%',
@city nvarchar(60) = '%',
@state nchar(3) = '___', --special because it is a char column
@postalCode nvarchar(8) = '%'
) AS
--simple procedure to execute a single query
SELECT address.AddressLine1, address.AddressLine2,
address.City, state.StateProvinceCode, address.PostalCode
FROM Person.Address as address
JOIN Person.StateProvince as state
ON address.StateProvinceID = state.StateProvinceID
WHERE address.AddressLine1 Like @addressLine1
AND address.City Like @city
AND state.StateProvinceCode Like @state
AND address.PostalCode Like @postalCode;
Now instead of having the client programs formulate a query by knowing the table structures, the client can simply issue a command, knowing a procedure name and the parameters. Clients can choose from four possible criteria to select the addresses they want. For example, they’d use the following if they want to find people in London:
Person.Address$select @city = 'London';
Or they could use the other parameters:
Person.Address$select @postalCode = '98%', @addressLine1 = '%Hilltop%';
The client doesn’t know whether the database or the code is well built or even if it’s horribly designed. Originally our state value might have been a part of the address table but changed to its own table when we realized that it was necessary to store more information about a state than a simple code. The same might be true for the city, the postalCode, and so on. Often, the tasks the client needs to do won’t change based on the database structures, so why should the client need to know the database structures?
For much greater detail about how to write stored procedures and good T-SQL, consider the books Pro T-SQL 2008 Programmer’s Guide by Michael Coles (Apress, 2008); Inside Microsoft SQL Server 2008: T-SQL Programming (Pro-Developer) by Itzik Ben-Gan, et al. (Microsoft Press, 2009); or search for “stored procedures” in Books Online. In this section, I’ll look at some of the characteristics of using stored procedures as our only interface between client and data. I’ll discuss the following topics:
- Encapsulation : Limits client knowledge of the database structure by providing a simple interface for known operations
- Dynamic procedures: Gives the best of both worlds, allowing for ad hoc–style code without giving ad hoc access to the database
- Security : Provides a well-formed interface for known operations that allows you to apply security only to this interface and disallow other access to the database
- Performance: Allows for efficient parameterization of any query, as well as tweaks to the performance of any query, without changes to the client interface
- Pitfalls: Drawbacks associated with the stored-procedure–access architecture
To me, encapsulation is the primary reason for using stored procedures, and it’s the leading reason behind all the other topics that I’ll discuss. When talking about encapsulation, the idea is to hide the working details from processes that have no need to know about the details. Encapsulation is a large part of the desired “low coupling” of our code that I discussed in the pitfalls of ad hoc access. Some software is going to have to be coupled to the data structures, of course, but locating that code with the structures makes it easier to manage. Plus, the people who generally manage the SQL Server code on the server are not the same people who manage the compiled code.
For example, when we coded the person.address$select procedure, it’s unimportant to the client how the procedure was coded. We could have built it based on a view and selected from it, or the procedure could call 16 different stored procedures to improve performance for different parameter combinations. We could even have used the dreaded cursor version that you find in some production systems:
--pseudocode:
CREATE PROCEDURE person.address$select
…
Create temp table;
Declare cursor for (select all rows from the address table);
Fetch first row;
While not end of cursor (@@fetch_status)
Begin
Check columns for a match to parameters;
If match, put into temp table;
Fetch next row;
End;
SELECT * FROM temp table;
This would be horrible, horrible code to be sure. I didn’t give real code so it wouldn’t be confused for a positive example and imitated. (Somebody would end up blaming me, though definitely not you!) However, it certainly could be built to return correct data and possibly could even be fast enough for smaller data sets. Even better, when the client executes the following code, they get the same result, regardless of the internal code:
Person.Address$select @city = 'london';
What makes procedures great is that you can rewrite the guts of the procedure using the server’s native language without any concern for breaking any client code. This means that anything can change, including table structures, column names, and coding method (cursor, join, and so on), and no client code need change as long as the inputs and outputs stay the same.
The only caveat to this is that you can get some metadata about procedures only when they are written using compiled SQL without conditionals (if condition select … else select…). For example, using sp_describe_first_result_set you can metadata about what the procedure we wrote earlier returns:
EXECUTE sp_describe_first_result_set
N'Person.Address$select @postalCode = ''98%'', @addressLine1 = ''%Hilltop%'';'
This returns metadata about what will be returned (this is just a small amount of what is returned):
| column_ordinal | name | system_type_name |
| -------------- | ----------------- | ---------------- |
| 1 | AddressLine1 | nvarchar(60) |
| 2 | AddressLine2 | nvarchar(60) |
| 3 | City | nvarchar(30) |
| 4 | StateProvinceCode | nchar(3) |
| 5 | PostalCode | nvarchar(15) |
For poorly formed procedures, (even if it returns what appears to be the exact same result set, you will not be as able to get the metadata from the procedure. For example, consider the following procedure:
CREATE PROCEDURE test (@value int = 1)
AS
IF @value = 1
SELECT 'FRED' AS name;
ELSE
SELECT 200 AS name;
If you run the procedure with 1 for the parameter, it will return FRED, for any other value, it will return 200. Both are named “name”, but they are not the same type. So checking the result set:
EXECUTE sp_describe_first_result_set N'test'
Returns this (actually quite) excellent error message:
Msg 11512, Level 16, State 1, Procedure sp_describe_first_result_set, Line 1
The metadata could not be determined because the statement 'SELECT 'FRED' as name;' in procedure 'test' is not compatible with the statement 'SELECT 200 as name;' in procedure 'test'.
This concept of having easy access to the code may seem like an insignificant consideration, especially if you generally only work with limited sized sets of data. The problem is, as data set sizes fluctuate, the types of queries that will work often vary greatly. When you start dealing with increasing orders of magnitude in the number of rows in your tables, queries that seemed just fine somewhere at ten thousand rows start to fail to produce the kinds of performance that you need, so you have to tweak the queries to get results in an amount of time that users won’t complain to your boss about. I will cover more about performance tuning in a later section.
![]() Note Some of the benefits of building your objects in the way that I describe can also be achieved by building a solid middle-tier architecture with a data layer that is flexible enough to deal with change. However, I will always argue that it is easier to build your data access layer in the T-SQL code that is built specifically for data access. Unfortunately, it doesn’t solve the code ownership issues (functional versus relational programmers) nor does it solve the issue with performance-tuning the code.
Note Some of the benefits of building your objects in the way that I describe can also be achieved by building a solid middle-tier architecture with a data layer that is flexible enough to deal with change. However, I will always argue that it is easier to build your data access layer in the T-SQL code that is built specifically for data access. Unfortunately, it doesn’t solve the code ownership issues (functional versus relational programmers) nor does it solve the issue with performance-tuning the code.
Dynamic Procedures
You can dynamically create and execute code in a stored procedure, just like you can from the front end. Often, this is necessary when it’s just too hard to get a good query using the rigid requirements of precompiled stored procedures. For example, say you need a procedure that needs a lot of optional parameters. It can be easier to include only parameters where the user passes in a value and let the compilation be done at execution time, especially if the procedure isn’t used all that often. The same parameter sets will get their own plan saved in the plan cache anyhow, just like for typical ad hoc SQL.
Clearly, some of the problems of straight ad hoc SQL pertain here as well, most notably SQL injection. You must always make sure that no input users can enter can allow them to return their own results, allowing them to poke around your system without anyone knowing. As mentioned before, a common way to avoid this sort of thing is always to check the parameter values and immediately double up the single quotes so that the caller can’t inject malicious code where it shouldn’t be.
Make sure that any parameters that don’t need quotes (such as numbers) are placed into the correct datatype. If you use a string value for a number, you can insert things such as 'novalue' and check for it in your code, but another user could put in the injection attack value and be in like Flynn. For example, take the sample procedure from earlier, and let’s turn it into the most obvious version of a dynamic SQL statement in a stored procedure:
ALTER PROCEDURE Person.Address$select
(
@addressLine1 nvarchar(120) = '%',
@city nvarchar(60) = '%',
@state nchar(3) = '___',
@postalCode nvarchar(50) = '%'
) AS
BEGIN
DECLARE @query varchar(max);
SET @query =
'SELECT address.AddressLine1, address.AddressLine2,
address.City, state.StateProvinceCode, address.PostalCode
FROM Person.Address AS address
join Person.StateProvince AS state
on address.StateProvinceID = state.StateProvinceID
WHERE address.City LIKE ''' + @city + '''
AND state.StateProvinceCode Like ''' + @state + '''
AND address.PostalCode Like ''' + @postalCode + '''
--this param is last because it is largest
--to make the example
--easier as this column is very large
AND address.AddressLine1 Like ''' + @addressLine1 + '''';
SELECT @query; --just for testing purposes
EXECUTE (@query);
END;
There are two problems with this version of the procedure. The first is that you don’t get the full benefit, because in the final query you can end up with useless parameters used as search arguments that make using indexes more difficult, which is one of the main reasons I use dynamic procedures. I’ll fix that in the next version of the procedure, but the most important problem is the injection attack. For example, let’s assume that the user who’s running the application has dbo powers or rights to sysusers . The user executes the following statement:
EXECUTE Person.Address$select
@addressLine1 = '∼''select name from sysusers--';
This returns three result sets: the two (including the test SELECT) from before plus a list of all of the users in the AdventureWorks2012 database. No rows will be returned to the proper result sets, because no address lines happen to be equal to '∼', but the list of users is not a good thing because with some work, a decent hacker could probably figure out how to use a UNION and get back the users as part of the normal result set.
The easy way to correct this is to use the quotename() function to make sure that all values that need to be surrounded by single quotes are formatted in such a way that no matter what a user sends to the parameter, it cannot cause a problem. Note that if you programmatically chose columns that you ought to use the quotename() function to insert the bracket around the name. SELECT quotename('FRED') would return [FRED].
In the next code block, I will change the procedure to safely deal with invalid quote characters, plus instead of just blindly using the parameters, if the parameter value is the same as the default, I will leave off the values from the WHERE clause. Note that using sp_executeSQL and parameterizing will not be possible if you want to do a variable WHERE or JOIN clause , so you have to take care to avoid SQL injection in the query itself.
ALTER PROCEDURE Person.Address$select
(
@addressLine1 nvarchar(120) = '%',
@city nvarchar(60) = '%',
@state nchar(3) = '___',
@postalCode nvarchar(50) = '%'
) AS
BEGIN
DECLARE @query varchar(max);
SET @query =
'SELECT address.AddressLine1, address.AddressLine2,
address.City, state.StateProvinceCode, address.PostalCode
FROM Person.Address AS address
join Person.StateProvince AS state
on address.StateProvinceID = state.StateProvinceID
WHERE 1=1';
IF @city <> '%'
SET @query = @query + ' AND address.City Like ' + quotename(@city,''''),
IF @state <> '___'
SET @query = @query + ' AND state.StateProvinceCode Like ' + quotename(@state,''''),
IF @postalCode <> '%'
SET @query = @query + ' AND address.City Like ' + quotename(@city,''''),
IF @addressLine1 <> '%'
SET @query = @query + ' AND address.AddressLine1 LIKE ' +
quotename(@addressLine1,''''),
SELECT @query;
EXECUTE (@query);
END;
Now you might get a much better plan, especially if there are several useful indexes on the table. That’s because SQL Server can make the determination of what indexes to use at runtime based on the parameters needed, rather than using a single stored plan for every possible combination of parameters. You also don’t have to worry about injection attacks, because it’s impossible to put something into any parameter that will be anything other than a search argument, and that will execute any code other than what you expect. Basically this version of a stored procedure is the answer to the flexibility of using ad hoc SQL, though it is a bit messier to write. However, it is located right on the server where it can be tweaked as necessary.
Try executing the evil version of the query, and look at the WHERE clause it fashions:
WHERE 1=1
AND address.AddressLine1 Like '∼''select name from sysusers--'
The query that is formed, when executed will now just return two result sets (one for the query and one for the results), and no rows for the executed query. This is because you are looking for rows where address.addressLine1 is like ∼'select name from sysusers--. While not being exactly impossible, this is certainly very, very unlikely.
I should also note that in versions of SQL Server before 2005, using dynamic SQL procedures would break the security chain, and you’d have to grant a lot of extra rights to objects just used in a stored procedure. This little fact was enough to make using dynamic SQL not a best practice for SQL Server 2000 and earlier versions. However, in SQL Server 2005 you no longer had to grant these extra rights, as I’ll explain in the next section. (Hint: you can EXECUTE AS someone else.)
Security
My second most favorite reason for using stored-procedure access is security. You can grant access to just the stored procedure, instead of giving users the rights to all the different resources used by the stored procedure. Granting rights to all the objects in the database gives them the ability to open Management Studio and do the same things (and more) that the application allows them to do. This is rarely the desired effect, as an untrained user let loose on base tables can wreak havoc on the data. (“Oooh, I should change that. Oooh, I should delete that row. Hey, weren’t there more rows in this table before?”) I should note that if the database is properly designed, users can’t violate core structural business rules, but they can circumvent business rules in the middle tier and can execute poorly formed queries that chew up important resources.
![]() Note In general, it is best to keep your users away from the power tools like Management Studio and keep them in a sandbox where even if they have advanced powers (like because they are CEO) they cannot accidentally see too much (and particularly modify and/or delete) data that they shouldn’t. Provide tools that hold user’s hands and keep them from shooting off their big toe (or really any toe for that matter).
Note In general, it is best to keep your users away from the power tools like Management Studio and keep them in a sandbox where even if they have advanced powers (like because they are CEO) they cannot accidentally see too much (and particularly modify and/or delete) data that they shouldn’t. Provide tools that hold user’s hands and keep them from shooting off their big toe (or really any toe for that matter).
With stored procedures, you have a far clearer surface area of a set of stored procedures on which to manage security at pretty much any granularity desired, rather than tables, columns, groups of rows (row-level security), and actions (SELECT, UPDATE, INSERT, DELETE), so you can give rights to just a single operation, in a single way. For example, the question of whether users should be able to delete a contact is wide open, but should they be able to delete their own contacts? Sure, so give them rights to execute deletePersonalContact (meaning a contact that the user owned). Making this choice easy would be based on how well you name your procedures. I use a naming convention of <tablename | subject area>$<action>. For example, to delete a contact, the procedure might be contact$delete , if users were allowed to delete any contact. How you name objects is completely a personal choice, as long as you follow a standard that is meaningful to you and others.
As discussed back in the ad hoc section, a lot of architects simply avoid this issue altogether by letting objects connect to the database as a single user (or being forced into this by political pressure, either way), and let the application handle security. That can be an adequate method of implementing security, and the security implications of this are the same for stored procedures or ad hoc usage. Using stored procedures still clarifies what you can or cannot apply security to.
In SQL Server 2005, the EXECUTE AS clause was added on the procedure declaration. In versions before SQL Server 2005, if a different user owned any object in the procedure (or function, view, or trigger), the caller of the procedure had to have explicit rights to the resource. This was particularly annoying when having to do some small dynamic SQL operation in a procedure, as discussed in the previous section.
The EXECUTE AS clause gives the programmer of the procedure the ability to build procedures where the procedure caller has the same rights in the procedure code as the owner of the procedure—or if permissions have been granted, the same rights as any user or login in the system.
For example, consider that you need to do a dynamic SQL call to a table. (In reality, it ought to be more complex, like needing to use a sensitive resource.) First, create a test user:
CREATE USER fred WITHOUT LOGIN;
Next, create a simple stored procedure:
CREATE PROCEDURE dbo.testChaining
AS
EXECUTE ('SELECT CustomerID, StoreID, AccountNumber
FROM Sales.Customer'),
GO
GRANT EXECUTE ON testChaining TO fred;
Now execute the procedure (changing your security context to be this user):
EXECUTE AS user = 'fred';
EXECUTE dbo.testChaining;
REVERT;
You’re greeted with the following error:
Msg 229, Level 14, State 5, Line 1
SELECT permission denied on object 'Customer', database 'AdventureWorks', schema 'Sales'.
You could grant rights to the user directly to the object, but this gives users more usage than just from this procedure, which is probably not desirable. Now change the procedure to EXECUTE AS SELF:
ALTER PROCEDURE dbo.testChaining
WITH EXECUTE AS SELF
AS
EXECUTE ('SELECT CustomerID, StoreId, AccountNumber
FROM Sales.Customer'),
![]() Note If you have restored this database from the web, you may get an error message: Msg 15517, Cannot execute as the database principal because the principal "dbo" does not exist, this type of principal cannot be impersonated, or you do not have permission. This will occur if your database owner’s sid is not correct for the instance you are working on. Use: ALTER AUTHORIZATION ON DATABASE::AdventureWorks2012 to SA to set the owner to the SA account. Determine database owner using query: SELECT SUSER_SNAME(owner_sid) FROM sys.databases WHERE name = 'Adventureworks2012';
Note If you have restored this database from the web, you may get an error message: Msg 15517, Cannot execute as the database principal because the principal "dbo" does not exist, this type of principal cannot be impersonated, or you do not have permission. This will occur if your database owner’s sid is not correct for the instance you are working on. Use: ALTER AUTHORIZATION ON DATABASE::AdventureWorks2012 to SA to set the owner to the SA account. Determine database owner using query: SELECT SUSER_SNAME(owner_sid) FROM sys.databases WHERE name = 'Adventureworks2012';
Now, go back to the context of user Fred and try again. Just like when Fred had access directly, you get back data. You use SELF to set the context the same as the principal creating the procedure. OWNER is usually the same as SELF, and you can only specify a single user in the database (it can’t be a group).
Warning: the EXECUTE AS clause can be abused if you are not extremely careful. Consider the following query, which is obviously a gross exaggeration of what you might hope to see but not beyond possibility:
CREATE PROCEDURE dbo.doAnything
(
@query nvarchar(4000)
)
WITH EXECUTE AS SELF
AS
EXECUTE (@query);
This procedure gives the person that has access to execute it full access to the database. Bear in mind that any query can be executed (DROP TABLE? Sure, why not?), easily allowing improper code to be executed on the database. Now, consider a little math problem; add the following items:
- EXECUTE AS SELF
- Client executing code as the database owner (a very bad, yet very typical practice)
- The code for dbo.doAnything
- An injection-susceptible procedure, with a parameter that can hold approximately 120 characters (the length of the dbo.doAnything procedure plus punctuation to create it)
What do you get? If you guessed no danger at all, please e-mail me your Social Security number, address, and a major credit card number. If you realize that the only one that you really have control over is the fourth one and that hackers, once the dbo.doAnything procedure was created, could execute any code they wanted as the owner of the database, you get the gold star. So be careful to block code open to injection.
![]() Tip I am not suggesting that you should avoid the EXECUTE
AS setting completely, just that its use must be scrutinized a bit more than the average stored procedure along the lines of when a #temp table is used. Why was EXECUTE
AS used? Is the use proper? You must be careful to understand that in the wrong hands this command can be harmful to security.
Tip I am not suggesting that you should avoid the EXECUTE
AS setting completely, just that its use must be scrutinized a bit more than the average stored procedure along the lines of when a #temp table is used. Why was EXECUTE
AS used? Is the use proper? You must be careful to understand that in the wrong hands this command can be harmful to security.
Performance
There are a couple of reasons why stored procedures are great for performance:
- Parameterization of complex plans is controlled by you at design time rather than controlled by the optimizer at compile time.
- You can performance-tune your queries without making invasive program changes.
Parameterization of Complex Plans
Stored procedures, unlike ad hoc SQL, always have parameterized plans for maximum reuse of the plans. This lets you avoid the cost of recompilation, as well as the advanced costs of looking for parameters in the code. Any literals are always literal, and any variable is always a parameter. This can lead to some performance issues as well, as occasionally the plan for a stored procedure that gets picked by the optimizer might not be as good of a plan as might be picked for an ad hoc procedure.
The interesting thing here is that, although you can save the plan of a single query with ad hoc calls, with procedures you can save the plan for a large number of statements. With all the join types, possible tables, indexes, view text expansions, and so on, optimizing a query is a nontrivial task that might take quite a few milliseconds. Now, admittedly, when building a single-user application, you might say, “Who cares?” However, as user counts go up, the amount of time begins to add up. With stored procedures, this has to be done only once. (Or perhaps a bit more frequently; SQL Server can create multiple copies of the plan if the procedure is heavily used.)
Stored procedure parameterization uses the variables that you pass the first time the procedure is called to create the best plan. This process is known as parameter sniffing. This is fine and dandy, except when you have a situation where you have some values that will work nicely for a query but others that work pitifully. Two different values that are being searched for can end up creating two different plans. Often, this is where you might pass in a value that tells the query that there are no values, and SQL Server uses that value to build the plan. When you pass in a real value, it takes far too long to execute. Using WITH RECOMPILE at the object level or the RECOMPILE statement-level hint can avoid the problems of parameter sniffing, but then you have to wait for the plan to be created for each execute, which can be costly. It’s possible to branch the code out to allow for both cases, but this can get costly if you have a couple of different scenarios to deal with. In still other cases, you can use an OPTIMIZE FOR to optimize for the common case when there are parameter values that produce less than adequate results, although presumably results that you can live with, not a plan that takes an hour or more to execute what normally takes milliseconds.
In some cases, the plan gets stale because of changes in the data, or even changes in the structure of the table. In stored procedures, SQL Server can recompile only the single statement in the plan that needs recompiled. While managing compilation and re-compilation can seem a bit complicated, there are a few caveats but they are very few and far between. You have several ways to manage the parameterization and you have direct access to the code to change it. For the person who has to deal with parameter issues, or really any sort of tuning issues, our next topic is about tuning procedures without changing the procedure’s public interface. You can use the tricks mentioned to fix the performance issue without the client’s knowledge.
Fine-Tuning Without Program Changes
Even if you didn’t have the performance capabilities of parameterization for stored procedures (say every query in your procedure was forced to do dynamic SQL), the ability to fine-tune the queries in the stored procedure without making any changes to the client code is of incredible value. Of course, this is the value of encapsulation, but again, fine-tuning is such an important thing.
Often, a third-party system is purchased that doesn’t use stored procedures. If you’re a support person for this type of application, you know that there’s little you can do other than to add an index here and there.
“But,” you’re probably thinking, “shouldn’t the third party have planned for all possible cases?” Sure they should, because while the performance characteristics of a system with 10 rows might turn out to be identical to one with 10,000, there is the outlier, like the organization that pumped 10 million new rows per day into that system that was only expected to do 10,000 per day. The fact is, SQL Server is built to operate on a large variety of hardware in a large variety of conditions. A system running on a one-processor laptop with its slow disk subsystem behaves exactly like a RAID 10 system with 20 high-speed, 32 GB, solid-state drives, right? (Another gold star if you just said something witty about how dumb that sounded.)
The answer is no. In general, the performance characteristics of database systems vary wildly based on usage characteristics, hardware, and data sizing issues. By using stored procedures, it’s possible to tweak how queries are written, as the needs change from small dataset to massive dataset. For example, I’ve seen many not so perfect queries that ran great with 10,000 rows, but when the needs grew to millions of rows, the queries ran for hours. Rewriting the queries using proper query techniques, or sometimes using temporary tables gave performance that was several orders of magnitude better. And I have had the converse be true, where I have removed temporary tables and consolidated queries into a single statement to get better performance. The user of the procedures did not even know.
This ability to fine-tune without program changes is very important. Particularly as a corporate developer, when the system is running slow and you identify the query or procedure causing the issue, fixing it can be either a one-hour task or a one-week task. If the problem is a procedure, you can modify, test, and distribute the one piece of code. Even following all of the rules of proper code management, your modify/test/distribute cycle can be a very fast operation. However, if application code has to be modified, you have to coordinate multiple groups (DBAs and programmers, at least) and discuss the problem and the code has to be rewritten and tested (for many more permutations of parameters and settings than for the one procedure).
For smaller organizations, it can be overly expensive to get a really good test area, so if the code doesn’t work quite right in production, you can tune it easily then. Tuning a procedure is easy, even modification procedures, you can just execute the code in a transaction and roll it back. Keep changing the code until satisfied, compile the code in the production database, and move on to the next problem. (This is not best practice, but it is something I have to do from time to time.)
Pitfalls
So far, everything has been all sunshine and lollipops for using stored procedures, but this isn’t always the case. We need to consider the following pitfalls:
- The high initial effort to create procedures can be prohibitive.
- It isn’t always easy to implement optional parameters in searches in an optimum manner.
- It’s more difficult to affect only certain columns in an operation.
Another pitfall, which I won’t cover in detail here, is cross-platform coding. If you’re going to build a data layer that needs to be portable to different platforms such as Oracle or MySQL, this need for cross-platform coding can complicate your effort, although it can still be worthwhile in some cases.
Of all the pros and cons, initial effort is most often the straw that breaks the camel’s proverbial back in the argument for or against stored procedures. Pretty much every time I’ve failed to get stored procedure access established as the method of access, this is the reason given. There are many tools out there that can map a database to objects or screens to reduce development time. The problem is that they suffer from some or all of the issues discussed in the ad hoc SQL pitfalls.
It’s an indefensible stance that writing lots of stored procedures takes less time up front—quite often, it takes quite a bit more time for initial development. Writing stored procedures is definitely an extra step in the process of getting an application up and running.
An extra step takes extra time, and extra time means extra money. You see where this is going, because people like activities where they see results, not infrastructure. When a charismatic programmer comes in and promises results, it can be hard to back up claims that stored procedures are certainly the best way to go. The best defenses are knowing the pros and cons and, especially, understanding the application development infrastructure you’ll be dealing with.
Difficulty Supporting Optional Parameters in Searches
I already mentioned something similar to optional parameters earlier when talking about dynamic SQL. In those examples, all of the parameters used simple LIKE parameters with character strings. But what about integer values? Or numeric ones? As mentioned earlier in the ad hoc sections, a possible solution is to pass NULL into the variable values by doing something along the lines of the following code:
WHERE (integerColumn = @integerColumn or @integerColumn is null)
AND (numericColumn = @numericColumn or @numericColumn is null)
AND (characterColumn Like @characterColumn);
Generally speaking, it’s possible to come up with some scheme along these lines to implement optional parameters alongside the rigid needs of procedures in stored procedures. Note too that using NULL as your get everything parameter value means it is then hard to get only NULL values. For character strings you can use LIKE '%'. You can even use additional parameters to state: @returnAllTypeFlag to return all rows of a certain type.
It isn’t possible to come up with a scheme, especially a scheme that can be optimized. However, you can always fall back on using dynamic SQL for these types of queries using optional parameters, just like I did in the ad hoc section. One thing that can help this process is to add the WITH RECOMPILE clause to the stored-procedure declaration. This tells the procedure to create a new plan for every execution of the procedure.
Although I try to avoid dynamic SQL because of the coding complexity and maintenance difficulties, if the set of columns you need to deal with is large, dynamic SQL can be the best way to deal with the situation. Using dynamically built stored procedures is generally the same speed as using ad hoc access from the client, so the benefits from encapsulation still exist.
Difficulty Affecting Only Certain Columns in an Operation
When you’re coding stored procedures without dynamic SQL, the code you’ll write is going to be pretty rigid. If you want to write a stored procedure to modify a row in the table created earlier in the chapter—sales.contact —you’d write something along the lines of this skeleton procedure (back in the architectureChapter database):
CREATE PROCEDURE sales.contact$update
(
@contactId int,
@firstName varchar(30),
@lastName varchar(30),
@companyName varchar(100),
@salesLevelId int,
@personalNotes varchar(max),
@contactNotes varchar(max)
)
AS
DECLARE @entryTrancount int = @@trancount;
BEGIN TRY
UPDATE sales.contact
SET firstName = @firstName,
lastName = @lastName,
companyName = @companyName,
salesLevelId = @salesLevelId,
personalNotes = @personalNotes,
contactNotes = @contactNotes
WHERE contactId = @contactId;
END TRY
BEGIN CATCH
IF @@trancount > 0
ROLLBACK TRANSACTION;
DECLARE @ERRORmessage nvarchar(4000)
SET @ERRORmessage = 'Error occurred in procedure ''' +
object_name(@@procid) + ''', Original Message: '''
+ ERROR_MESSAGE() + '''';
THROW 50000,@ERRORmessage,1;
END CATCH
A procedure such as this is fine most of the time, because it usually isn’t a big performance concern just to pass all values and modify those values, even setting them to the same value and revalidating. However, in some cases, validating every column can be a performance issue because not every validation is the same as the next.
For example, say that the salesLevelId column was a very important column for the corporate sales process. And it needed to validate in the sales data if the customer could, in fact, actually be that level. A trigger might be created to do that validation, and it could take a relatively large amount of time. Note that when the average operation takes 1 millisecond, 100 milliseconds can actually be “a long time.” It is all relative to what else is taking place and how many times a minute things are occurring. You could easily turn this into a dynamic SQL procedure, though since you don’t know if the value of salesLevel has changed, you will have to check that first:
ALTER PROCEDURE sales.contact$update
(
@contactId int,
@firstName varchar(30),
@lastName varchar(30),
@companyName varchar(100),
@salesLevelId int,
@personalNotes varchar(max),
@contactNotes varchar(max)
)
WITH EXECUTE AS SELF
AS
DECLARE @entryTrancount int = @@trancount;
BEGIN TRY
--declare variable to use to tell whether to include the
DECLARE @salesOrderIdChangedFlag bit =
CASE WHEN (SELECT salesLevelId
FROM sales.contact
WHERE contactId = @contactId) =
@salesLevelId
THEN 0 ELSE 1 END;
DECLARE @query nvarchar(max);
SET @query = '
UPDATE sales.contact
SET firstName = ' + quoteName(@firstName,'''') + ',
lastName = ' + quoteName(@lastName,'''') + ',
companyName = ' + quoteName(@companyName, '''') + ',
'+ case when @salesOrderIdChangedFlag = 1 then
'salesLevelId = ' + quoteName(@salesLevelId, '''') + ',
' else '' end + 'personalNotes = ' + quoteName(@personalNotes,
'''') + ',
contactNotes = ' + quoteName(@contactNotes,'''') + '
WHERE contactId = ' + cast(@contactId as varchar(10)) ;
EXECUTE (@query);
END TRY
BEGIN CATCH
IF @@trancount > 0
ROLLBACK TRANSACTION;
DECLARE @ERRORmessage nvarchar(4000)
SET @ERRORmessage = 'Error occurred in procedure ''' +
object_name(@@procid) + ''', Original Message: '''
+ ERROR_MESSAGE() + '''';
THROW 50000,@ERRORmessage,1;
END CATCH
This is a pretty simple example, and as you can see the code is already getting pretty darn ugly. Of course, the advantage of encapsulation is still intact, since the user will be able to do exactly the same operation as before with no change to the public interface, but the code is immediately less manageable at the module level.
An alternative you might consider would be an INSTEAD OF trigger to conditionally do the update on the column in question if the inserted and deleted columns don’t match:
CREATE TRIGGER sales.contact$insteadOfUpdate
ON sales.contact
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
SET ROWCOUNT 0; --in case the client has modified the rowcount
--use inserted for insert or update trigger, deleted for update or delete trigger
--count instead of @@rowcount due to merge behavior that sets @@rowcount to a number
--that is equal to number of merged rows, not rows being checked in trigger
DECLARE @msg varchar(2000), --used to hold the error message
--use inserted for insert or update trigger, deleted for update or delete trigger
--count instead of @@rowcount due to merge behavior that sets @@rowcount to a number
--that is equal to number of merged rows, not rows being checked in trigger
@rowsAffected int = (SELECT COUNT(*) FROM inserted);
-- @rowsAffected int = (SELECT COUNT(*) FROM deleted);
--no need to continue on if no rows affected
IF @rowsAffected = 0 RETURN;
BEGIN TRY
--[validation blocks]
--[modification blocks]
--<perform action>
UPDATE contact
SET firstName = inserted.firstName,
lastName = inserted.lastName,
companyName = inserted.companyName,
personalNotes = inserted.personalNotes,
contactNotes = inserted.contactNotes
FROM sales.contact AS contact
JOIN inserted
on inserted.contactId = contact.contactId
IF UPDATE(salesLevelId) --this column requires heavy validation
--only want to update if necessary
UPDATE contact
SET salesLevelId = inserted.salesLevelId
FROM sales.contact AS contact
JOIN inserted
ON inserted.contactId = contact.contactId
--this correlated subquery checks for rows that have changed
WHERE EXISTS (SELECT *
FROM deleted
WHERE deleted.contactId =
inserted.contactId
AND deleted. salesLevelId <>
inserted. salesLevelId)
END TRY
BEGIN CATCH
IF @@trancount > 0
ROLLBACK TRANSACTION;
THROW;
END CATCH
END;
This is a lot of code, but it’s simple. This is one of the rare uses of INSTEAD OF triggers, but it’s pretty simple to follow. Just update the simple columns and not the “high cost” columns, unless it has changed. The point of this is to note that the more encapsulated you get from the client, the more you can do in your code to modify the code to your needs. The stored procedure layer can be treated as a set of modules that return a set of data, save the state of some data, and so forth, without the client needing to know anything about the structure of anything other than the parameters and tabular data streams that are to be returned.
All Things Considered…What Do I Choose?
If the opinions in the previous two sections were not enough (and they weren’t), this section lays out my opinions on what is good and bad about using ad hoc SQL and stored procedures. As Oscar Wilde was quoted as saying, “It is only about things that do not interest one that one can give a really unbiased opinion, which is no doubt the reason why an unbiased opinion is always absolutely valueless.” This is a topic that I care about, and I have firm feelings about what is right and wrong. Of course, it is also true that many viable, profitable, and stable systems don’t follow any of these opinions. That said, let’s recap the pros and cons I have given for the different approaches. The pros of using ad hoc SQL are as follows:
- It gives a great deal of flexibility over the code, as the code can be generated right at runtime, based on metadata, or even the user’s desires. The modification statement can only update column values that have changed.
- It can give adequate or even i mproved performance by only caching and parameterizing obviously matching queries. It also can be much easier to tailor queries in which you have wildly varying parameter and join needs.
- It’s fast. If the programmer can write a SQL statement or use an API that does, there’s less overhead learning about how to write stored procedures.
The cons are as follows:
- Your client code and database structures are tightly coupled, and when any little thing changes (column name, type, etc for example) in the database, it often requires making a change to the client code, requiring greater costs in deploying changes.
- Tying multiple statements together can be cumbersome, especially when transactions are required.
- API-generated queries often are not optimal, causing performance and especially maintenance issues when the database administrator has to optimize queries that cannot be easily modified.
- Performance-tuning database calls can be much harder to do, because modifying a statement, even to add a query hint, requires a recompile.
For stored procedure access, the pros are as follows:
- The encapsulation of database code reduces what the user interface needs to know about the implemented database structures. If they need to change, often you can change the structures and tweak a procedure, and the client needn’t know.
- You can easily manage security at the procedure level, with no need whatsoever to grant rights to base tables. This way, users don’t have to have rights to any physical tables.
- You have the ability to do dynamic SQL in your procedures. In SQL Server 2005 and later, you can do this without the need to grant rights to objects using EXECUTE AS.
- Performance is improved, due to the parameterizing of all plans (unless otherwise specified).
- Performance tuning is made far simpler, due to the ability to tune a procedure without the client knowing the difference.
The cons for stored-procedure access are as follows:
- The rigid code of precompiled stored procedures can make coding them difficult.
- You can’t effectively vary the columns affected by any T-SQL statement.
- There’s a larger initial effort required to create the procedures.
With no outside influence other than this list of pros and cons and experience, I can state without hesitation that stored procedures are the way to go, if for no other reason other than the encapsulation angle. By separating the database code from the client code, you get an effective separation of data-manipulation code from presentation code. But “no outside influence” is a pipe dream, as developers will have their own ideas, and to be realistic, I am obviously open to the value of using an ORM type tool that encapsulates a lot of the work of application building as well, keeping in mind that development costs are dwarfed by maintenance costs when you consider a system outage means users aren’t producing, but still getting paid.
Keep in mind that I’m not suggesting that all code that works with data should be in stored procedures. Too often when stored procedures are used as the complete data interface, the people doing the programming have a tendency to start putting all sorts of procedural code in the procedures, making them hard to write and hard to maintain. The next step is moaning that procedures are terrible, slow, and inflexible. This is often one of the sticking points between the two different opinions on how to do things. More or less, what’s called for when building a user interface is to build stored procedures that replace T-SQL statements that you would have built in an ad hoc manner, using T-SQL control of flow language at a minimum. Several types of code act on data that shouldn’t be in stored procedures or T-SQL:
- Mutable business logic and rules : T-SQL is a rigid language that can be difficult to work with. Even writing CLR SQL Server objects (covered in the next section of this chapter) is unwieldy in comparison to building an adequate business layer in your application.
- Formatting data : When you want to present a value in some format, it’s best to leave this to the presentation layer or user interface of the application. You should use SQL Server primarily to do set-based operations using basic DML, and have as little of the T-SQL control of flow language as possible.
Probably the biggest drawback to using procedures in earlier versions of SQL Server was eliminated in 2005 in the EXECUTE AS clause on the procedure creation. By carefully using the EXECUTE AS clause, you can change the security context of the executor of a procedure when the ownership chain is broken. So, in any places where a dynamic call is needed, you can make a dynamic call, and it will look to the user exactly as a normal precompiled stored procedure would—again, making sure to avoid the very dangerous SQL Injection errors that are far too common.
I don’t want to sound as if any system largely based on ad hoc SQL is permanently flawed and just a festering pile of the smelly bits of an orangutan. Many systems have been built on letting the application handle all the code, especially when tools are built that need to run on multiple platforms. This kind of access is exactly what SQL-based servers were originally designed for, so it isn’t going to hurt anything. At worst, you’re simply not using one of the advanced features that SQL Server gives you in stored procedures.
The one thing that often tips the scales to using ad hoc access is time. The initial effort required to build stored procedures is going to be increased over just using ad hoc SQL generated from a mapping layer. In fact, for every system I’ve been involved with where our access plan was to use ad hoc SQL, the primary factor was time: “It takes too long to build the procedures,” or “it takes too long to develop code to access the stored procedures.” Or even, “The tool we are using doesn’t support stored procedures.” All this inevitably swings to the statement that “The DBA is being too rigid. Why do we want to…?”
These responses are a large part of why this section of the chapter needed to be written. It’s never good to state that the ad hoc SQL is just plain wrong, because that’s clearly not true. The issue is which is better, and stored procedures greatly tip the scale, at least until outside forces and developer talents are brought in.
Many world-class and mission-critical corporate applications have been created using T-SQL and SQL Server, so why integrate SQL Server with the CLR? The fact is, integrating the CLR provides a host of benefits to developers and DBAs that wasn’t possible or wasn’t easy with SQL Server 2000 and earlier. It also opens up a plethora of questions about the applicability of this still reasonably new technology.
In the last two sections, I approached the topic of stored procedures and ad hoc access to data, but as of SQL Server 2005, there’s another interesting architectural option to consider. Beyond using T-SQL to code objects, you can use a .NET language to write your objects to run not in interpreted manner that T-SQL objects do but rather in what is known as the SQLCLR, which is a SQL version of the CLR that is used as the platform for the .NET languages to build objects that can be leveraged by SQL Server just like T-SQL objects.
Using the SQLCLR, Microsoft provides a choice in how to program objects by using the enhanced programming architecture of the CLR for SQL Server objects. By hosting the CLR inside SQL Server, developers and DBAs can develop SQL Server objects using any .NET-compatible language, such as C# or Visual Basic. This opens up an entire new world of possibilities for programming SQL Server objects and makes the integration of the CLR one of the most powerful new development features of SQL Server.
Back when the CLR was introduced to us database types, it was probably the most feared new feature of SQL Server. As adoption of SQL Server versions 2005 and greater are almost completely the norm now, use of the CLR still may be the problem we suspected, but the fact is, properly built objects written in the CLR need to follow many of the same principals as T-SQL and the CLR can be very useful when you need it.
Microsoft chose to host the CLR inside SQL Server for many reasons; some of the most important motivations follow:
- Rich language support : .NET integration allows developers and DBAs to use any .NET—compatible language for coding SQL Server objects. This includes such popular languages as C# and VB.NET.
- Complex procedural logic and computations : T-SQL is great at set-based logic, but .NET languages are superior for procedural/iterative code. .NET languages have enhanced looping constructs that are more flexible and perform far better than T-SQL. You can more easily factor .NET code into functions, and it has much better error handling than T-SQL. T-SQL has some computational commands, but .NET has a much larger selection of computational commands. Most important for complex code, .NET ultimately compiles into native code while T-SQL is an interpreted language. This can result in huge performance wins for .NET code.
- String manipulation, complex statistical calculations, custom encryption , and so on: As discussed earlier, heavy computational requirements such as string manipulation, complex statistical calculations, and custom encryption algorithms that don’t use the native SQL Server encryption fare better with .NET than with T-SQL in terms of both performance and flexibility.
- .NET Framework classes : The .NET Framework provides a wealth of functionality within its many classes, including classes for data access, file access, registry access, network functions, XML, string manipulation, diagnostics, regular expressions, arrays, and encryption.
- Leveraging existing skills: Developers familiar with .NET can be productive immediately in coding SQL Server objects. Familiarity with languages such as C# and VB.NET, as well as being familiar with the .NET Framework is of great value. Microsoft has made the server-side data-access model in ADO.NET similar to the client-side model, using many of the same classes to ease the transition. This is a double-edged sword, as it’s necessary to determine where using .NET inside SQL Server provides an advantage over using T-SQL. I’ll consider this topic further throughout this section.
- Easier and safer substitute for extended stored procedures : You can write extended stored procedures in C++ to provide additional functionality to SQL Server. This ability necessitates an experienced developer fluent in C++ and able to handle the risk of writing code that can crash the SQL Server engine. Stored procedures written in .NET that extend SQL Server’s functionality can operate in a managed environment, which eliminates the risk of code crashing SQL Server and allows developers to pick the .NET language with which they’re most comfortable.
- New SQL Server objects and functionality : If you want to create user-defined aggregates or user-defined types (UDTs) that extend the SQL Server type system, .NET is your only choice. You can’t create these objects with T-SQL. There’s also some functionality only available to .NET code that allows for streaming table-valued functions.
- Integration with Visual Studio : Visual Studio is the premier development environment from Microsoft for developing .NET code. This environment has many productivity enhancements for developers. The Professional and higher versions also include a new SQL Server project, with code templates for developing SQL Server objects with .NET. These templates significantly ease the development of .NET SQL Server objects. Visual Studio .NET also makes it easier to debug and deploy .NET SQL Server objects.
However, while these are all good reasons for the concept of mixing the two platforms, it isn’t as if the CLR objects and T-SQL objects are equivalent. As such, it is important to consider the reasons that you might choose the CLR over T-SQL, and vice versa, when building objects. The inclusion of the CLR inside SQL Server offers an excellent enabling technology that brings with it power, flexibility, and design choices. And of course, as we DBA types are cautious people, there’s a concern that the CLR is unnecessary and will be misused by developers. Although any technology has the possibility of misuse, you shouldn’t dismiss the SQLCLR without consideration as to where it can be leveraged as an effective tool to improve your database designs.
What really makes using the CLR for T-SQL objects is that in some cases, T-SQL just does not provide native access to the type of coding you need without looping and doing all sorts of machinations. In T-SQL it is the SQL queries and smooth handling of data that make it a wonderful language to work with. In almost every case, if you can fashion a SQL query to do the work you need, T-SQL will be your best bet. However, once you have to start using cursors and/or T-SQL control of flow language (for example, looping through the characters of a string or through rows in a table) performance will suffer mightily. This is because T-SQL is an interpreted language. In a well-thought-out T-SQL object, you may have a few non-SQL statements, variable declarations, and so on. Your statements will not execute as fast as they could in a CLR object, but the difference will often just be milliseconds if not microseconds.
The real difference comes if you start to perform looping operations, as the numbers of operations grow fast and really start to cost. In the CLR, the code is compiled and runs very fast. For example, I needed to get the maximum time that a row had been modified from a join of multiple tables. There were three ways to get that information. The first method is to issue a correlated subquery in the SELECT clause. I will demonstrate the query using several columns from the Sales Order Header and Customer tables in the AdventureWorks2012:
SELECT SalesOrderHeader.SalesOrderID,
(SELECT MAX(DateValue)
FROM (SELECT SalesOrderHeader.OrderDate AS DateValue
UNION ALL
SELECT SalesOrderHeader.DueDate AS DateValue
UNION ALL
SELECT SalesOrderHeader.ModifiedDate AS DateValue
UNION ALL
SELECT Customer.ModifiedDate as DateValue) AS dates
) AS lastUpdateTime
FROM Sales.SalesOrderHeader
JOIN Sales.Customer
ON Customer.CustomerID = SalesOrderHeader.CustomerID;
Yes, Oracle users will probably note that this subquery performs the task that their GREATEST function will (or so I have been told many times). The approach in this query is a very good approach, and works adequately for most cases, but it is not necessarily the fastest way to answer the question that I’ve posed. A second, and a far more natural, approach for most programmers is to build a T-SQL scalar user-defined function:
CREATE FUNCTION dbo.date$getGreatest
(
@date1 datetime,
@date2 datetime,
@date3 datetime = NULL,
@date4 datetime = NULL
)
RETURNS datetime
AS
BEGIN
RETURN (SELECT MAX(dateValue)
FROM ( SELECT @date1 AS dateValue
UNION ALL
SELECT @date2
UNION ALL
SELECT @date3
UNION ALL
SELECT @date4 ) AS dates);
END;
Now to use this, you can code the solution in the following manner:
SELECT SalesOrderHeader.SalesOrderID,
dbo.date$getGreatest (SalesOrderHeader.OrderDate,
SalesOrderHeader.DueDate,
SalesOrderHeader.ModifiedDate,
Customer.ModifiedDate) AS lastUpdateTime
FROM Sales.SalesOrderHeader
JOIN Sales.Customer
ON Customer.CustomerID = SalesOrderHeader.CustomerID;
This is a pretty decent approach, though it is actually slower to execute than the native T-SQL approach in the tests I have run, as there is some overhead in using user-defined functions, and since the algorithm is the same, you are merely costing yourself. The third method is to employ a CLR user-defined function. The function I will create is pretty basic and uses what is really a brute force algorithm:
<SqlFunction(IsDeterministic:=True, DataAccess:=DataAccessKind.None, _
Name:="date$getMax_CLR", _
IsPrecise:=True)> _
Public Shared Function MaxDate(ByVal inputDate1 As SqlDateTime, _
ByVal inputDate2 As SqlDateTime, _
ByVal inputDate3 As SqlDateTime, _
ByVal inputDate4 As SqlDateTime _
) As SqlDateTime
Dim outputDate As SqlDateTime
If inputDate2 > inputDate1 Then outputDate = inputDate2
Else outputDate = inputDate1
If inputDate3 > outputDate Then outputDate = inputDate3
If inputDate4 > outputDate Then outputDate = inputDate4
Return New SqlDateTime(outputDate.Value)
End Function
Generally, I just let VS .NET build and deploy the object into tempdb for me and script it out to distribute to other databases. (I have included this VB script in the downloads in a .vb file. If you want to build it yourself you will use SQL Data Tools. I have also included the T-SQL binary representations in the download for those who just want to build the object and execute it, though other than the binary representation it will seem very much like the T-SQL versions. In both cases, you will need to enable CLR using sp_configure setting 'clr enabled').
For cases where the number of data parameters is great (ten or so in my testing on moderate, enterprise-level hardware), the CLR version will execute several times faster than either of the other versions. This is very true in most cases where you have to do some very functional-like logic, rather than using set-based logic.
After deploying, you the call you make still looks just like normal T-SQL (the first execution may take a bit longer due to the just in time compiler needing to compile the binaries the first time):
SELECT SalesOrderHeader.SalesOrderID,
dbo.date$getMax_CLR (SalesOrderHeader.OrderDate,
SalesOrderHeader.DueDate,
SalesOrderHeader.ModifiedDate,
Customer.ModifiedDate) as lastUpdateTime
FROM Sales.SalesOrderHeader
JOIN Sales.Customer
ON Customer.CustomerID = SalesOrderHeader.CustomerID;
Ignoring for a moment the performance factors, some problems are just easier to solve using the CLR, and the solution is just as good, if not better than using T-SQL. For example, to get a value from a comma-delimited list in T-SQL requires either a looping operation or the use of techniques requiring a Numbers table (as introduced in Chapter 12). This technique is slightly difficult to follow and is too large to reproduce here as an illustration.
However, in .NET, getting a comma-delimited value from a list is a built-in operation:
Dim tokens() As String = Strings.Split(s.ToString(), delimiter.ToString(), _
-1, CompareMethod.Text)
'return string at array position specified by parameter
If tokenNumber > 0 AndAlso tokens.Length >= tokenNumber.Value Then
Return tokens(tokenNumber.Value - 1).Trim()
In this section, I have probably made the CLR implementation sound completely like sunshine and puppy dogs. For some usages, particularly functions that don’t access data other than what is in parameters, it certainly can be that way. Sometimes, however, the sun burns you, and the puppy dog bites you and messes up your new carpet. The fact is, the CLR is not bad in and of itself but it must be treated with the respect it needs. It is definitely not a replacement for T-SQL. It is a complementary technology that can be used to help you do some of the things that T-SQL does not necessarily do well.
The basic thing to remember is that while the CLR offers some great value, T-SQL is the language on which most all of your objects should be based. A good practice is to continue writing your routines using T-SQL until you find that it is just too difficult or slow to get done using T-SQL; then try the CLR.
In the next two sections, I will cover the guidelines for choosing either T-SQL or the CLR.
Let’s get one thing straight: T-SQL isn’t going away anytime soon. On the contrary, it’s being enhanced, along with the addition of the CLR. Much of the same code that you wrote today with T-SQL back in SQL Server 7 or 2000 is still best done the same way with SQL Server 2005, 2008, 2012, and most likely going on for many versions of SQL Server. If your routines primarily access data, I would first consider using T-SQL. The CLR is a complementary technology that will allow you to optimize some situations that could not be optimized well enough using T-SQL.
The exception to this guideline of using T-SQL for SQL Server routines that access data is if the routine contains a significant amount of conditional logic, looping constructs, and/or complex procedural code that isn’t suited to set-based programming. What’s a significant amount? You must review that on a case-by-case basis. It is also important to ask yourself, “Is this task even something that should be done in the data layer, or is the design perhaps suboptimal and a different application layer should be doing the work?”
If there are performance gains or the routine is much easier to code and maintain when using the CLR, it’s worth considering that approach instead of T-SQL. T-SQL is the best tool for set-based logic and should be your first consideration if your routine calls for set-based functionality (which should be the case for most code you write). I suggest avoiding rewriting your T-SQL routines in the CLR unless there’s a definite benefit. If you are rewriting routines, do so only after trying a T-SQL option and asking in the newsgroups and forums if there is a better way to do it. T-SQL is a very powerful language that can do amazing things if you understand it. But if you have loops or algorithms that can’t be done easily, the CLR is there to get you compiled and ready to go.
Keep in mind that T-SQL is constantly being enhanced with a tremendous leap in functionality. In SQL Server 2012 they have added vastly improved windowing functions, query paging extensions, and quite a lot of new functions to handle tasks that are unnatural in relational code. In 2008, they added such features as MERGE, table parameters, and row constructors; and in 2005, we got CTEs (which gave us recursive queries), the ability to PIVOT data, new TRY-CATCH syntax for improved error handling, and other features that we can now take advantage of. If there are new T-SQL features you can use to make code faster, easier to write, and/or easier to maintain, you should consider this approach before trying to write the equivalent functionality in a CLR language.
![]() Note Truthfully, if T-SQL is used correctly with a well designed database, almost all of your code will fit nicely into T-SQL code with only a function or two possibly needing to be created using the CLR.
Note Truthfully, if T-SQL is used correctly with a well designed database, almost all of your code will fit nicely into T-SQL code with only a function or two possibly needing to be created using the CLR.
Guidelines for Choosing a CLR Object
The integration of the CLR is an enabling technology. It’s not best suited for all occasions, but it has some advantages over T-SQL that merit consideration. As we’ve discussed, CLR objects compile to native code, and is better suited to complex logic and CPU-intensive code than T-SQL. One of the best scenarios for the CLR approach to code is writing scalar functions that don’t need to access data. Typically, these will perform an order (or orders) of magnitude faster than their T-SQL counterparts. CLR user-defined functions can take advantage of the rich support of the .NET Framework, which includes optimized classes for functions such as string manipulation, regular expressions, and math functions. In addition to CLR scalar functions, streaming table-valued functions is another great use of the CLR. This allows you to expose arbitrary data structures—such as the file system or registry—as rowsets, and allows the query processor to understand the data.
The next two scenarios where the CLR can be useful are user-defined aggregates and CLR based UDTs. You can only write user-defined aggregates with .NET. They allow a developer to perform any aggregate such as SUM or COUNT that SQL Server doesn’t already do. Complex statistical aggregations would be a good example. I’ve already discussed .NET UDTs. These have a definite benefit when used to extend the type system with additional primitives such as point, SSN, and date (without time) types. As I discussed in Chapter 6, you shouldn’t use .NET UDTs to define business objects in the database.
This section provides a brief discussion of each of the different types of objects you can create with the CLR. You’ll also find additional discussion about the merits (or disadvantages) of using the CLR for each type.
You can build any of the following types of objects using the CLR:
- User-defined functions
- Stored procedures
- Triggers
- User-defined aggregates
- User-defined types
When the CLR was added to SQL Server, using it would have been worth the effort had it allowed you only to implement user-defined functions. Scalar user-defined functions that are highly computational are the sweet spot of coding SQL Server objects with CLR, particularly when you have more than a statement or two executing such functions. In fact, functions are the only type of objects that I have personally created and used using the CLR. I have seen some reasonable uses of several others, but they are generally fringe use cases. Those functions have been a tremendous tool for improving performance of several key portions of the systems I have worked with.
You can make both table value and scalar functions, and they will often be many times faster than corresponding T-SQL objects when there is no need for data other than what you pass in via parameters. CLR functions that have to query data via SQL become cumbersome to program, and usually coding them in T-SQL will simply be easier. Examples of functions that I have built using the CLR include:
- Date functions: Especially those for getting time zone information
- Comparison functions: For comparing several values to one another, like the date$getMax function shown earlier, though with more like thirty parameters instead of four.
- Calculation functions: Performing math functions or building a custom, soundex-style function for comparing strings and so forth.
Of all of the CLR object types, the user-defined functions are definitely the ones that you should consider using to replace your T-SQL objects, particularly when you are not interacting with data in SQL.
As a replacement for extended stored procedures, .NET stored procedures provide a safe and relatively easy means to extend the functionality of SQL Server. Examples of extended stored procedures include xp_sendmail, xp_cmdshell, and xp_regread. Traditionally, extended stored procedures required writing code in a language such as C++ and ran in-process with the sqlservr.exe process. CLR stored procedures have the same capabilities as traditional, extended stored procedures, but they’re easier to code and run in the safer environment of managed code. Of course, the more external resources that you access, the less safe your CLR object will be. The fact is that extended stored procedures were very often a dangerous choice, no matter how many resources you used outside of SQL server.
Another means of extending SQL Server was using the extended stored procedures beginning with sp_OA%. These used OLE automation to allow you to access COM objects that could be used to do things that T-SQL was unable to accomplish on its own. These objects were always slow and often unreliable and the CLR is an admirable replacement for the sp_OA% procedures and COM objects. You can use the .NET Framework classes to perform the same functionality as COM objects can.
If you are iterating through a set (perhaps using a cursor) performing some row-wise logic, you might try using CLR and the SqlDataReader class as it can be faster than using cursors. That said, it’s best to start with T-SQL for your stored procedures that access SQL Server data, since there is very little that you cannot do using setwise manipulations, especially using ROW_NUMBER and the other ranking functions.
If performance of the stored procedure becomes a factor and there’s lots of necessary procedural and computational logic within the stored procedure, experimenting with rewriting the stored procedure using CLR might be worthwhile. Quite often, if you find yourself doing too much in T-SQL code, you might be doing too much in the data layer, and perhaps you should move the procedural and computational logic away from the database to the middle tier and use the T-SQL stored procedure(s) primarily for data-access routines.
If you choose to use triggers in your database architecture, they’re almost the exclusive domain of T-SQL. I felt this when I first heard of CLR triggers, and I feel this now. There is really not a good mainstream scenario where CLR triggers are going to be better than a well written T-SQL trigger. For any complex validation that might be done in a trigger, a better option is probably to use a CLR scalar function and call it from within a T-SQL trigger. Perhaps if there’s significant procedural logic in a trigger, .NET would be a better choice than T-SQL, but just hearing the phrase “significant procedural logic in a trigger” makes me shudder a bit.
Be careful when using complex triggers. Almost any complex activity in a trigger is probably a cause for moving to use some form of queue where the trigger pushes rows off to some layer that operates asynchronously from the current transaction.
User-defined aggregates are a feature that have been desired for many years, and in 2005, with the introduction of the CLR, we were finally able to create our own aggregate functions. SQL Server already includes the most commonly used aggregate functions such as SUM, COUNT, and AVG. There might be a time when your particular business needs a special type of aggregate, or you need a complex statistical aggregate not supplied out of the box by SQL Server. Aggregates you create are not limited to numeric values either. An aggregate that I’ve always wanted is one similar to Sybase’s List() aggregate that concatenates a list of strings in a column, separating them by commas.
In the code download for this book, you will find the code for the following aggregate function, called string$list (I also include the assembly in the T-SQL code for those of you who are purists who think procedural code is for other people!). Once the function’s code is compiled and loaded into SQL server, you can do something like the following:
SELECT dbo.string$list(name) as names
FROM (VALUES('Name'),('Name2'),('Name3')) AS Names (name)
This will return:
----------------------------
Name, Name2, Name3
In informal testing, running code like this using a custom aggregate can give an order of magnitude performance improvement over the T-SQL alternatives of using XML or over any trick you can do with variables and concatenation. A good part of the reason that the CLR version runs faster is that the T-SQL version is going to run a query for each group of values desired, while the CLR version is simply aggregating the products returned from the single query, using techniques that are natural to the SQL engine.
Versions of Visual Studio 2005 Professional and higher have included a SQL Server project and template that includes the stub for the functions that must be included as part of the contract for coding a .NET user-defined aggregate. For each aggregate, you must implement the Init, Accumulate, Merge, and Terminate functions. Besides the obvious performance benefit, there’s also the flexibility benefit of being able to use such an aggregate with any column of any table. That is definitely unlike the T-SQL options where you need to hard-code which column and table are being aggregated.
![]() Note As of SQL Server 2008, you can pass more than one parameter to your aggregate function, allowing you to perform far more interesting aggregations involving multiple values from each individual row returned by a query.
Note As of SQL Server 2008, you can pass more than one parameter to your aggregate function, allowing you to perform far more interesting aggregations involving multiple values from each individual row returned by a query.
Microsoft has built several types into SQL Server 2008 using the CLR. These are the hierarchyId and the spatial types. The fact is, though, that you should hesitate to base all of your datatypes on CLR types. The intrinsic, built-in datatypes will suffice for nearly every situation you will find, but if you have a need for a richer type with some complex handling, they are definitely available.
The largest downside to the CLR UDTs is that in order to get the full experience using the types, you will need to have the client set up to use them. To access the properties and methods of a UDT on the client and take full advantage of the new datatype, each client must have a copy of the UDT available in an assembly accessible by the client. If the code for a UDT is updated on SQL Server, the UDT class that’s registered on each client that makes use of the UDT should be kept in sync with the server version to avoid any data problems. If the client does not have the UDT class available (like when you return the value of a column based on a UDT in Management Studio), the value will be returned as a hexadecimal value, unless you use the .ToString method on the type (which is a requirement for building a type). All in all, I generally steer clear of user defined types in pretty much all cases, because the management costs is typically way higher than the payoff.
Best Practices
The first half of the chapter discussed the two primary methods of architecting a SQL Server application, either by using stored procedures as the primary interface, or by using ad hoc calls built outside the server. Either is acceptable, but in my opinion the best way to go is to use stored procedures as much as possible. There are a few reasons:
- As precompiled batches of SQL statements that are known at design and implementation time, you get a great interface to the database that encapsulates the details of the database from the caller.
- They can be a performance boost, primarily because tuning is on a known set of queries, and not just on any query that the programmer might have written that slips by untested (not even maliciously; it could just be a bit of functionality that only gets used “occasionally”).
- They allow you to define a consistent interface for security that lets you give users access to a table in one situation but not in another. Plus, if procedures are consistently named, giving access to database resources is far easier.
However, not every system is written using stored procedures. Ad hoc access can serve to build a fine system as well. You certainly can build a flexible architecture, but it can also lead to harder-to-maintain code that ends up with the client tools being tightly coupled with the database structures. At the very least, if you balk at the use of procedures, make sure to architect in a manner that makes tuning your queries reasonable without full regression testing of the application.
I wish I could give you definitive best practices, but there are so many possibilities, and either method has pros and cons. (Plus, there would be a mob with torches and pitchforks at my door, no matter how I said things must be done.) This topic will continue to be hotly contested, and rightly so. In each of the last few releases of SQL Server, Microsoft has continued to improve the use of ad hoc SQL, but it’s still considered a best practice to use stored procedures if you can. I realize that in a large percentage of systems that are created, stored procedures are only used when there’s a compelling reason to do so (like some complex SQL, or perhaps to batch together statements for a transaction).
Whether or not you decide to use stored-procedure access or use ad hoc calls instead, you’ll probably want to code some objects for use in the database. Introduced in SQL Server 2005, there’s another interesting decision to make regarding what language and technology to use when building several of these database objects. The best practices for the CLR usage are a bit more clear-cut:
- User-defined functions: When there’s no data access, the CLR is almost always a better way to build user-defined functions; though the management issues usually make them a last choice unless there is a pressing performance issue. When data access is required, it will be dependent on the types of operations being done in the function, but most data access functions would be best at least done initially in T-SQL.
- Stored procedures: For typical data-oriented stored procedures, T-SQL is usually the best course of action. On the other hand, when using the CLR, it’s far easier and much safer to create replacements for extended stored procedures (procedures typically named xp_) that do more than simply touch data.
- User-defined types: For the most part, the advice here is to avoid them, unless you have a compelling reason to use them. For example, you might need complex datatypes that have operations defined between them (such as calculating the distance between two points) that can be encapsulated into the type. The client needs the datatype installed to get a natural interface; otherwise the clunky .NET-like methods need to be used (they aren’t SQL-like).
- User-defined aggregates: You can only create these types of objects using .NET. User-defined aggregates allow for some interesting capabilities for operating on groups of data, like the example of a string aggregation.
- Triggers: There seems to be little reason to use triggers built into a CLR language. Triggers are about data manipulation. Even with DDL triggers, the primary goal is usually to insert data into a table to make note of a situation.
Summary
In this chapter full of opinions, what’s clear is that SQL Server has continued to increase the number of options for writing code that accesses data. I’ve covered two topics that you need to consider when architecting your relational database applications using SQL Server. Designing the structure of the database is (reasonably) easy enough. Follow the principles set out by normalization to ensure that you have limited, if any, redundancy of data and limited anomalies when you modify or create data. On the other hand, once you have the database architected from an internal standpoint, you have to write code to access this data, and this is where you have a couple of seemingly difficult choices.
The case for using stored procedures is compelling (at least to many SQL architects), but it isn’t a definite. Many programmers use ad hoc T-SQL calls to access SQL Server (including those made from middleware tools), and this isn’t ever likely to change completely. This topic is frequently debated in blogs, forums, newsgroups, and church picnics with little budge from either side. I strongly suggest stored procedures for the reasons laid out in this chapter, but I do concede that it isn’t the only way.
I then introduced the CLR features, and presented a few examples and even more opinions about how and when to use them. I dare say that some of the opinions concerning the CLR in this chapter might shift a little over time, but so far, it remains the case that the CLR is going to be most valuable as a tool to supercharge parts of queries, especially in places where T-SQL was poor because it was interpreted at runtime, rather than compiled. Usually this isn’t a problem, because decent T-SQL usually has few procedural statements, and all the real work is done in set-based SQL statements.
The primary thing to take from this chapter is that lots of tools are provided to access the data in your databases. Use them wisely, and your results will be excellent. Use them poorly, and your results will be poor. Hopefully this advice will be of value to you, but as you were warned at the start of the chapter, a good amount of this chapter was opinion.
Last, the decision about the data-access method (i.e., ad hoc SQL code versus stored procedures and how much to use the CLR) should be chosen for a given project up front, when considering high-level design. For the sake of consistency, I would hope that the decision would be enforced across all components of the application(s). Nothing is worse than having to figure out the application as you dig into it.
![]() Note A resource that I want to point out for further reading after this chapter is by Erland Sommarskog. His web site (
www.sommarskog.se
) contains a plethora of information regarding many of the topics I have covered in this chapter—and in far deeper detail. I would consider most of what I have said the introductory-level course, while his papers are nearly graduate-level courses in the topics he covers.
Note A resource that I want to point out for further reading after this chapter is by Erland Sommarskog. His web site (
www.sommarskog.se
) contains a plethora of information regarding many of the topics I have covered in this chapter—and in far deeper detail. I would consider most of what I have said the introductory-level course, while his papers are nearly graduate-level courses in the topics he covers.