
C H A P T E R 6
Design Principles
There are two ways of constructing a software design. One way is to make it so simple that there are obviously no deficiencies. And the other way is to make it so complicated that there are no obvious deficiencies.
— C. A. R. Hoare
One way to look at software problems is with a model that divides the problems into two different layers:
- “Wicked” problems fall in the upper layer. These are problems that typically come from domains outside of computer science (e.g. biology, business, meteorology, sociology, political science, etc.). These types of problems tend to be open-ended, ill-defined, and large in the sense that they require much work. For example, pretty much any kind of a web commerce application is a wicked problem. Horst W. J. Rittel and Melvin M. Webber, in a 1973 paper on social policy,1 gave a definition for and a set of characteristics used to recognize a wicked problem that we'll look at later in this chapter.
- “Tame” problems fall in the lower layer. These problems tend to cut across other problem domains; they tend to be more well defined and small. Sorting and searching are great examples of tame problems. Small and well-defined don't mean “easy” however. Tame problems can be very complicated and difficult to solve. It's just that they are clearly defined and you know when you have a solution. These are the kinds of problems that provide computer scientists with foundations in terms of data structures and algorithms for the wicked problems we solve from other problem domains.
According to Rittel and Webber, a wicked problem is one for which the requirements are completely known only after the problem is solved, or for which the requirements and solution evolve over time. It turns out this describes most of the “interesting” problems in software development. Recently, Jeff Conklin has revised Rittel and Webber's description of a wicked problem and provided a more succinct list of the characteristics of wicked problems.2 To paraphrase:
__________
1 Rittel, H. W. J. and M. M. Webber. “Dilemmas in a General Theory of Planning.” Policy Sciences 4(2): 155-169. (1973)
- A wicked problem is not understood until after the creation of a solution. Another way of saying this is that the problem is defined and solved at the same time.3
- Wicked problems have no stopping rule; that is, you can create incremental solutions to the problem, but there's nothing that tells you that you've found the correct and final solution.
- Solutions to wicked problems are not right or wrong; they are better or worse, or good-enough or not-good-enough.
- Every wicked problem is essentially novel and unique. Because of the “wickedness” of the problem, even if you have a similar problem next week, you basically have to start over again because the requirements will be different enough and the solution will still be elusive.
- Every solution to a wicked problem is a ‘one shot operation’. See number 4 above.
- Wicked problems have no given alternative solutions. That is, there is no small finite set of solutions from which to choose.
Wicked problems crop up all over the place. For example, creating a word processing program is a wicked problem. You may think that you know what a word processor needs to do – insert text, cut and paste, handle paragraphs, print. But this list of features is only one person's list. As soon as you “finish” your word processor and release it, you'll be inundated with new feature requests: spell checking, footnotes, multiple columns, support for different fonts, colors, styles, and the list goes on. The word processing program is essentially never done – at least not until you release the last version and end-of-life the product.
Word processing is actually a pretty obvious wicked problem. Others might include problems where you don't really know if you can solve the problem at the start. Expert systems require a user interface, an inference engine, a set of rules, and a database of domain information. For a particular domain, it's not at all certain at the beginning that you can create the rules that the inference engine will use to reach conclusions and recommendations. So you have to iterate through different rule sets, send out the next version and see how well it performs. Then you do it again, adding and modifying rules. You don't really know if the solution is correct until you're done. Now that's a wicked problem.
Conklin and Rittel and Webber say that when faced with a large, complicated problem (a wicked one), that traditional cognitive studies indicate most people will follow a linear problem solving approach, working top-down from the problem to the solution. This is equivalent to the traditional waterfall model described in Chapter 24. Figure 6-1 shows this linear approach.
__________
2 Conklin, J. Dialogue Mapping: Building Shared Understanding of Wicked Problems. (New York, NY: John Wiley & Sons, 2005.)
3 DeGrace, P. and L. H. Stahl Wicked Problems, Righteous Solutions : A Catalogue of Modern Software Engineering Paradigms. (Englewood Cliffs, NJ: Yourdon Press, 1990.)
4 Conklin, J. Wicked Problems and Social Complexity. Retrieved from http://cognexus.org/wpf/wickedproblems.pdf on 8 September 2009. Paper last updated October, 2008.
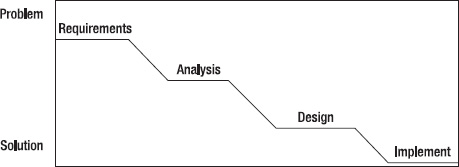
Figure 6-1. Linear problem-solving approach
Instead of this linear, waterfall approach, real wicked problem solvers tend to use an approach that swings from requirements analysis to solution modeling and back until the problem solution is good enough. Conklin calls this an opportunity-driven or opportunistic approach because the designers are looking for any opportunity to make progress toward the solution.5 Instead of the traditional waterfall picture in Figure 601, the opportunity-driven approach looks like Figure 6-2.
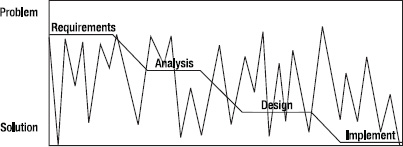
Figure 6-2. The opportunity-driven development approach
In this figure, the jagged line indicates the designer's work moving from the problem to a solution prototype and back again, slowly evolving both the requirements understanding and the solution iteration and converging on an implementation that is good enough to release. As an example, let's take a quick look at a web application.
Say that a not-for-profit organization keeps a list of activities for youth in your home county. The list is updated regularly and is distributed to libraries around the county. Currently, the list is kept on a spreadsheet and is distributed in hard copy in a three-ring binder. The not-for-profit wants to put all its data online and make it accessible over the web. It also wants to be able to update the data via the same web site. Simple, you say. It's just a web application with an HTML front-end and a database back end. Not a problem.
Ah, but this is really a wicked problem in disguise. First of all, the customer has no idea what they want the web page(s) to look like. So whatever you give them the first time will not be precisely what they want; the problem won't be understood completely until you are done. Secondly, as you develop prototypes, they will want more features – so the problem has no stopping rule. And finally, as time goes on the not-for-profit will want new features, so there is no “right” answer, there is only a “good enough” answer. Very wicked.
__________
5 Conklin, J. (2008)
Conklin also provides a list of characteristics of “tame” problems, ones for which you can easily and reliably find a solution. “A tame problem:
- has a well-defined and stable problem statement;
- has a definite stopping point, i.e., when the solution is reached;
- has a solution which can be objectively evaluated as right or wrong;
- belongs to a class of similar problems which are all solved in the same similar way;
- has solutions which can be easily tried and abandoned; and
- comes with a limited set of alternative solutions.”
A terrific example of a tame problem is sorting a list of data values.
- The problem is easily and clearly stated – sort this list into ascending order using this function to compare data elements.
- Sorting has a definite stopping point – the list is sorted.
- The result of a sort can be objectively evaluated (the list is either sorted correctly, or it isn't.)
- Sorting belongs to a class of similar problems that are all solved in the same way. Sorting integers, is similar to sorting strings, is similar to sorting database records using a key and so on.
- Sorting has solutions that can easily be tried and abandoned.
- Finally, sorting has a limited set of alternative solutions; sorting by comparison has a set of known algorithms and a theoretical lower bound.
What does this have to do with design principles, you ask? Well, realizing that most of the larger software problems we'll encounter have a certain amount of “wickedness” built into them influences how we think about design issues, how we approach the design of a solution to a large, ill-formed problem, and gives us some insight into the design process. It also lets us abandon the waterfall model with a clear conscience and pushes us to look for unifying heuristics that we can apply to design problems. In this chapter we'll discuss overall principles for design that we'll then expand upon in the chapters ahead.
The Design Process
Design is messy. Even if you completely understand the problem requirements (it's a tame problem), you typically have many alternatives to consider when you're designing a software solution. You'll also usually make lots of mistakes before you come up with a solution that works. As we saw in Figure 6-2, your design will change as you understand the problem better over time. This gives the appearance of messiness and disorganization, but really, you're making progress.
Design is about tradeoffs and priorities. Most software projects are time-limited, so you usually won't be able to implement all the features that the customer wants. You have to figure out the subset that will give the customer the most bang in the time you have available. So you have to prioritize the requirements and trade off one subset for another.
Design is heuristic. For the overwhelming majority of projects there is no set of cut and dried rules that says, “First we design component X using technique Y. Then we design component Z using technique W.” Software just doesn't work that way. Software design is done using a set of ever-changing heuristics (rules of thumb) that each designer acquires over the course of a career. Over time good designers learn more heuristics and patterns (see Chapter 11) that allow them to quickly get through the easy bits of a design and get to the heart of the wickedness of the problem. The best thing you can do is to sit at the feet of a master designer and learn the heuristics.
Designs evolve. Finally, good designers recognize that for any problem, tame or wicked, the requirements will change over time. This will then cascade into changes in your design. And so your design will evolve over time. This is particularly true across product releases and new feature additions. The trick here is to create a software architecture (Chapter 5) that is amenable to change with limited effect on the downstream design and code.
Desirable Design Characteristics (Things Your Design Should Favor)
Regardless of the size of your project or what process you use to do your design, there are a number of desirable characteristics that every software design should have. These are the principles you should adhere to as you consider your design. Your design doesn't necessarily need to exhibit all of these characteristics, but having a majority of them will certainly make your software easier to write, understand, and use.
- Fitness of purpose. Your design must work, and work correctly in the sense that it must satisfy the requirements you've been given within the constraints of the platform on which your software will be running. Don't add new requirements as you go – the customer will do that for you.
- Separation of concerns. Related closely to modularity, this principle says you should separate out functional pieces of your design cleanly in order to facilitate ease of maintenance and simplicity. Modularity is good.
- Simplicity. Keep your design as simple as possible. This will let others understand what you're up to. If you find a place that can be simplified, do it! If simplifying your design means adding more modules or classes to your design, that's okay. Simplicity also applies to interfaces between modules or classes. Simple interfaces allow others to see the data and control flow in your design. In agile methodologies, this idea of simplicity is kept in front of you all the time. Most agile techniques have a rule that says if you're working on part of a program and you have an opportunity to simplify it (called refactoring in agile-speak) do it right then. Keep you design and your code as simple as possible at all times.
- Ease of maintenance. A simple, understandable design is amenable to change. The first kind of change you'll encounter is fixing errors. Errors occur at all phases of the development process, requirements, analysis, design, coding, and testing. The more coherent and easy to understand your design is, the easier it will be to isolate and fix errors.
- Loose coupling. When you are separating your design into either modules or in object-oriented design, into classes, the degree to which the classes depend on each other is called coupling. Tightly coupled modules may share data or procedures. This means that a change in one module is much more likely to lead to a required change in the other module. This increases the maintenance burden and makes the modules more likely to contain errors. Loosely coupled modules, on the other hand, are connected solely by their interfaces. Any data they both need must be passed between procedures or methods via an interface. Loosely coupled modules hide the details of how they perform operations from other modules, sharing only their interfaces. This lightens the maintenance burden because a change to how one class is implemented will not likely affect how another class operates as long as the interface is invariant. So changes are isolated and errors are much less likely to propagate.
- High cohesion. The complement of loose coupling is high cohesion. Cohesion within a module is the degree to which the module is self-contained with regards both to the data it holds and the operations that act on the data. A class that has high cohesion pretty much has all the data it needs defined within the class template and all the operations that are allowed on the data are defined within the class as well. So any object that is instantiated from the class template is very independent and just communicates with other objects via its published interface.
- Extensibility. An outgrowth of simplicity and coupling is the ability to add new features to the design easily. This is extensibility. One of the features of wicked software problems is that they're never really finished. So after every release of a product, the next thing that happens is the customer asks for new features. The easier it is to add new features, the cleaner your design is.
- Portability. While not high on the list, keeping in mind that your software may need to be ported to another platform (or two or three) is a desirable characteristic. There are a lot of issues involved with porting software, including, operating system issues, hardware architecture, and user interface issues. This is particularly true for web applications.
Design Heuristics
Speaking of heuristics, here's a short list of good, time-tested heuristics. The list is clearly not exhaustive and it's pretty idiosyncratic, but it's a list you can use time and again. Think about them and try some of them during your next design exercise. We will come back to all of these heuristics in much more detail in later chapters.
Find real world objects to model. Alan Davis6 and Richard Fairley7 call this “intellectual distance.” It's how far your design is from a real world object. The heuristic here is to try to find real world objects that are close to things you want to model in your program. Keeping the real world object in mind as you are designing your program helps keep your design closer to the problem. Fairley's advice is to minimize the intellectual distance between the real world object and your model of it.
__________
6 Davis, A. M. 201 Principles of Software Development. (New York, NY: McGraw-Hill, 1995).
7 Fairley, R. E. Software Engineering Concepts. (New York, NY: McGraw-Hill, 1985.)
Abstraction is key. Whether you're doing object-oriented design and you are creating interfaces and abstract classes, or whether you're doing a more traditional layered design, you want to use abstraction. Abstraction means being lazy. You put off what you need to do by pushing it higher in the design hierarchy (more abstraction) or pushing it further down (more details). Abstraction is a key element of managing the complexity of a large problem. By abstracting away the details you can see the kernel of the real problem.
Information hiding is your friend. Information hiding is the concept that you isolate information – both data and behavior – in your program so that you can isolate errors and isolate changes; you also only allow access to the information via a well-defined interface. A fundamental part of object-oriented design is encapsulation, a concept that derives from information hiding. You hide the details of a class away and only allow communication and modification of data via a public interface. This means that your implementation can change, but as long as the interface is consistent and constant, nothing else in your program need change. If you're not doing object-oriented design, think libraries for hiding behavior and structures (structs in C and C++) for hiding state.
Keep your design modular. Breaking your design up into semi-independent pieces has many advantages. It keeps the design manageable in your head; you can just think about one part at a time and leave the others as black boxes. It takes advantage of information hiding and encapsulation. It isolates changes. It helps with extensibility and maintainability. Modularity is just a good thing. Do it.
Identify the parts of your design that are likely to change. If you make the assumption that there will be changes in your requirements, then there will likely be changes in your design as well. If you identify those areas of your design that are likely to change, you can separate them, thus mitigating the impact of any changes you need to make. What things are likely to change? Well, it depends on your application, doesn't it? Business rules can change (think tax rules or accounting practices), user interfaces can change, hardware can change, and so on. The point here is to anticipate the change and to divide up your design so that the necessary changes are contained.
Use loose coupling. Use interfaces and abstract classes. Along with modularity, information hiding, and change, using loose coupling will make your design easier to understand and to change as time goes along. Loose coupling says that you should minimize the dependencies of one class (or module) on another. This is so that a change in one module won't cause changes in other modules. If the implementation of a module is hidden and only the interface exposed, you can swap out implementations as long as you keep the interface constant. So you implement loose coupling by using well-defined interfaces between modules, and in an object-oriented design, using abstract classes and interfaces to connect classes.
Use your knapsack full of common design patterns. Robert Glass8 describes great software designers as having “…a large set of standard patterns” that they carry around with them and apply to their designs. This is what design experience is all about. Doing design over and over again and learning from the experience. In Susan Lammer's book Programmers at Work,9 Butler Lampson says, “Most of the time, a new program is a refinement, extension, generalization, or improvement of an existing program. It's really unusual to do something that's completely new….” That's what design patterns are: they're descriptions of things you've already done that you can apply to a new problem. Voila!
Adhere to the Principle of One Right Place. In his book Programming on Purpose: Essays on Software Design, P.J. Plauger says, “My major concern here is the Principle of One Right Place – there should be One Right Place to look for any nontrivial piece of code, and One Right Place to make a likely maintenance change.”10 Your design should adhere to the Principle of One Right Place; debugging and maintenance will be much easier.
__________
8 Glass, R. L. Software Creativity 2.0. Atlanta, GA, developer.*. (2006)
9 Lammers, S. Programmers At Work. (Redmond, WA: Microsoft Press, 1986.)
Use diagrams as a design language. I'm a visual learner. For me, a picture really is worth a thousand or so words. As I design and code I'm constantly drawing diagrams so I can visualize how my program is going to hang together, which classes or modules will be talking to each other, what data is dependent on what function, where do the return values go, what is the sequence of events. This type of visualization can settle the design in your head and it can point out errors or possible complications in the design. Whiteboards or paper are cheap; enjoy!
Designers and Creativity
Don't think that design is cut and dried or that formal process rules can be imposed to crank out software designs. It's not like that at all. While there are formal restrictions and constraints on your design that are imposed by the problem, the problem domain, and the target platform, the process of reaching the design itself need not be formal. It is at bottom a creative activity. Bill Curtis, in a 1987 empirical study of software designers came up with a process that seems to be what most of the designers followed:11
- Understand the problem.
- Decompose the problem into goals and objects.
- Select and compose plans to solve the problem.
- Implement the plans.
- Reflect on the design product and process.
Frankly, this is a pretty general list and doesn't really tell us all we'd need for software design. Curtis, however, then went deeper in #3 on his list, “select and compose plans,” and found that his designers used the following steps
- Build a mental model of a proposed solution.
- Mentally execute the model to see if it solves the problem – make up input and simulate the model in your head.
- If what you get is not correct, then change the model to remove the errors and go back to step 2 to simulate again.
- When your sample input produces the correct output, select some more input values and go back and do steps 2 and 3 again.
- When you've done this enough times (you'll know because you're experienced) then you've got a good model and you can stop.12
__________
10 Plauger, P. J. Programming on Purpose : Essays on Software Design. Englewood Cliffs, NJ: PTR Prentice Hall, 1993.)
11 Curtis, B., R. Guindon, et al. Empirical Studies of the Design Process: Papers for the Second Workshop on Empirical Studies of Programmers. Austin, TX, MCC. (1987)
This deeper technique makes the cognitive and the iterative aspects of design clear and obvious. We see that design is fundamentally a function of the mind, and is idiosyncratic and depends on things about the designer that are outside the process itself.
John Nestor, in a report to the Software Engineering Institute came up with a list of what are some common characteristics of great designers.
Great designers
- have a large set of standard patterns;
- have experienced failing projects;
- have mastery of development tools;
- have an impulse towards simplicity;
- can anticipate change;
- can view things from the user's perspective; and
- can deal with complexity.13
Conclusion
So at the end of the chapter, what have we learned about software design?
Design is ad hoc, heuristic, and messy. It fundamentally uses a trial-and-error and heuristic process and that process is the natural one to use for software design. There are a number of well-known heuristics that any good designer should employ.
Design depends on understanding of prior design problems and solutions. Designers need some knowledge of the problem domain. More importantly, they need knowledge of design and patterns of good designs. They need to have a knapsack of these design patterns that they can use to approach new problems. The solutions are tried and true. The problems are new but they contain elements of problems that have already been solved. The patterns are malleable templates that can be applied to those elements of the new problem that match the pattern's requirements.
Design is iterative. Requirements change, and so must your design. Even if you have a stable set of requirements, your understanding of the requirements changes as you progress through the design activity and so you'll go back and change the design to reflect this deeper, better understanding. The iterative process clarifies and simplifies your design at each step.
Design is a cognitive activity. You're not writing code at this point, so you don't need a machine. Your head and maybe a pencil and paper or a whiteboard are all you need to do design. As Dijkstra says, “We must not forget that it is not our business to make programs; it is our business to design classes of computations that will display a desired behavior.”14
__________
12 Glass, R. L. Software Creativity 2.0. Atlanta, GA, developer.*. (2006)
13 Glass, R. L. (2006)
Design is opportunistic. Glass sums up his discussion of design with “The unperturbed design process is opportunistic – that is, rather than proceed in an orderly process, good designers follow an erratic pattern dictated by their minds, pursuing opportunities rather than an orderly progression.”15
All the characteristics above argue against a rigid, plan-driven design process and for a creative, flexible way of doing design. This brings us back to the first topic in this chapter – design is just wicked.
And finally:
A designer can mull over complicated designs for months. Then suddenly the simple, elegant, beautiful solution occurs to him. When it happens to you, it feels as if God is talking! And maybe He is.
—Leo Frankowski (in The Cross-Time Engineer)
References
Conklin, J. Dialogue Mapping: Building Shared Understanding of Wicked Problems. (New York, NY: John Wiley & Sons, 2005.)
Conklin, J. Wicked Problems and Social Complexity. Retrieved from http://cognexus.org/wpf/wickedproblems.pdf on 8 September 2009. Paper last updated October, 2008.
Curtis, B., R. Guindon, et al. Empirical Studies of the Design Process: Papers for the Second Workshop on Empirical Studies of Programmers. Austin, TX, MCC. (1987)
Davis, A. M. 201 Principles of Software Development. (New York, NY: McGraw-Hill, 1995).
DeGrace, P. and L. H. Stahl Wicked Problems, Righteous Solutions : A Catalogue of Modern Software Engineering Paradigms. (Englewood Cliffs, NJ: Yourdon Press, 1990.)
Dijkstra, E. "The Humble Programmer." CACM 15(10): 859-866. (1972)
Fairley, R. E. Software Engineering Concepts. (New York, NY: McGraw-Hill, 1985.)
Glass, R. L. Software Creativity 2.0. Atlanta, GA, developer.*. (2006)
Lammers, S. Programmers At Work. (Redmond, WA: Microsoft Press, 1986.)
McConnell, S. Code Complete 2. (Redmond, WA: Microsoft Press, 2004.)
Parnas, D. “On the Criteria to be Used in Decomposing Systems into Modules.” CACM 15(12): 1053-1058. (1972)
Plauger, P. J. Programming on Purpose : Essays on Software Design. Englewood Cliffs, NJ: PTR Prentice Hall, 1993.)
Rittel, H. W. J. and M. M. Webber. “Dilemmas in a General Theory of Planning.” Policy Sciences 4(2): 155-169. (1973)
__________
14 Dijkstra, E. “The Humble Programmer.” CACM 15(10): 859-866. (1972)
15 Glass, R. L. (2006)