
C H A P T E R 10
Object-Oriented Design Principles
Devotion to the facts will always give the pleasures of recognition; adherence to the rules of design, the pleasures of order and certainty.
—Kenneth Clark
How can I qualify my faith in the inviolability of the design principles? Their virtue is demonstrated. They work.
—Edgar Whitney
Now that we’ve spent some time looking at object-oriented analysis and design, let's recapitulate some of what we’ve already seen and add some more pithy prose. First, let's talk about some common design characteristics.
First, designs have a purpose. They describe how something will work in a context, using the requirements (lists of features, user stories, and use cases) to define the context. Second, designs must have enough information in them so that someone can implement them. You need enough details in the design so that someone can come after you and implement the program correctly. Next, there are different styles of design, just like there are different types of house architectures. The type of design you want depends on what it is you’re being required to build. It depends on the context (see, we’re back to context); if you’re an architect, you’ll design a different kind of house at the sea shore than you will in the mountains. Finally, designs can be expressed at different levels of detail. When building a house, the framing carpenter needs one level of detail, the electrician and plumber another, and the finish carpenter yet another.
There are a number of rules of thumb about object-oriented design that have evolved over the last few decades. These design principles act as guidelines for you the designer to abide by so that your design ends up being a good one, easy to implement, easy to maintain, and one that does just what your customer wants. We’ve looked at several of them already in previous chapters, and here I’ve pulled out ten fundamental design principles of object-oriented design that are likely to be the most useful to you as you become that designer extraordinaire. I’ll list them here and then explain them and give examples in the rest of the chapter.
Our List of Fundamental Object-Oriented Design Principles
Here are the ten fundamental principles:
- Encapsulate things in your design that are likely to change.
- Code to an interface rather than to an implementation.
- The Open-Closed Principle (OCP): Classes should be open for extension and closed for modification.
- The Don’t Repeat Yourself Principle (DRY): Avoid duplicate code. Whenever you find common behavior in two or more places, look to abstract that behavior into a class and then reuse that behavior in the common concrete classes. Satisfy one requirement in one place in your code.
- The Single Responsibility Principle (SRP): Every object in your system should have a single responsibility, and all the objects services should be focused on carrying out that responsibility. Another way of saying this is that a cohesive class does one thing well and doesn’t try to do anything else. This implies that higher cohesion is better. It also means that each class in your program should have only one reason to change.
- The Liskov Substitution Principle (LSP): Subtypes must be substitutable for their base types. (in other words, inheritance should be well designed and well behaved.)
- The Dependency Inversion Principle (DIP): Don’t depend on concrete classes; depend on abstractions.
- The Interface Segregation Principle (ISP): Clients shouldn’t have to depend on interfaces they don’t use.
- The Principle of Least Knowledge (PLK) (also known as the Law of Demeter): Talk only to your immediate friends.
- The Principle of Loose Coupling: Objects that interact should be loosely coupled with well-defined interfaces.
As you probably notice, there’s some overlap here, and one or more of the design principles may depend on others. That’s okay. It’s the fundamentals that count. Let’s go through these one at a time.
Encapsulate Things in Your Design That Are Likely to Change
This first principle means to protect your classes from unnecessary change by separating the features and methods of a class that remain relatively constant throughout the program from those that will change. By separating the two types of features, we isolate the parts that will change a lot into a separate class (or classes) that we can depend on changing, and we increase our flexibility and ease of change. We also leave the stable parts of our design alone, so that we just need to implement them once and test them once. (Well, you hope.) This protects the stable parts of the design from any unnecessary changes.
Let's create a very simple class Violinist. Figure 10-1 is a class diagram for the Violinist class.
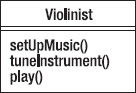
Figure 10-1. A Violinist
Notice that the setUpMusic() and tuneInstrument() methods are pretty stable. But what about the play() method? It turns out that there are several different types of playing styles for violins – classical, bluegrass, and Celtic, just to name three. So that means that the play() method will vary, depending on the playing style. Because we have a behavior that will change depending on the playing style, maybe we should abstract that behavior out and encapsulate it in another class? If we do that, then we get something like Figure 10-2.
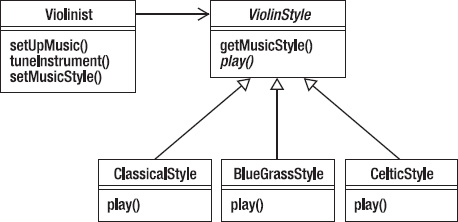
Figure 10-2. Violinist and playing styles
Notice that we’re using association between the Violinist class and the ViolinStyle abstract class. This allows Violinist to use the concrete classes that inherit the abstract method from the abstract ViolinStyle class. We’ve abstracted out and encapsulated the play() method – which will vary – in a separate class so that we can isolate any changes we want to make to the playing style from the other stable behaviors in Violinist.
Code to an Interface Rather Than to an Implementation
The normal response to this design principle is, “Huh? What does that mean?” Well, here’s the idea. This principle – like many of the principles in this chapter - has to do with inheritance and how you use it in your program. Say you have a program that will model different types of geometric shapes in two dimensions. We’ll have a class Point that will represent a single point in 2D, and we’ll have an interface named Shape that will abstract out a couple of things that all shapes have in common – areas and perimeters. (okay, circles and ellipses call it circumference; bear with me.) So here’s what we’ve got (see Figure 10-3).
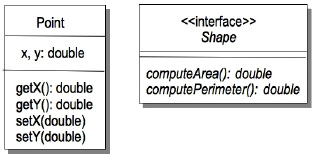
Figure 10-3. A simple Point class and the common Shape Interface
If we want to create concrete classes of some different shapes, we’ll implement the Shape interface. This means that the concrete classes must implement each of the abstract methods in the Shape interface. See Figure 10-4.

Figure 10-4. Rectangle, Circle, and Triangle all implement Shape
So now we’ve got a number of classes that represent different geometric shapes. How do we use them? Say we’re writing an application that will manipulate a geometric shape. We can do this in two different ways. First, we can write a separate application for each geometric shape. See Figure 10-5.
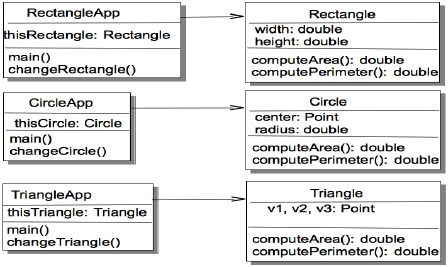
Figure 10-5. Using the geometric objects.
What’s wrong with these apps? Well, we’ve got three different applications doing the same thing. If we want to add another shape, say a rhombus, we’d have to write two new classes, the Rhombus class, which implements the Shape interface, and a new RhombusApp class. Yuk! This is inefficient. We’ve coded to the implementation of the geometric shape rather than coding to the interface itself.
So how do we fix this? The thing to realize is that the interface is the top of a class hierarchy of all the classes that implement the interface. As such it’s a class type and we can use it to help us implement polymorphism in our program. In this case, since we have some number of geometric shapes that implement the Shape interface we can create an array of Shapes that we can fill up with different types of shapes and then iterate through. In Java we’ll use the List collection type to hold our shapes:
import java.util.*;
/**
* ShapeTest - test the Shape interface implementations.
*
* @author fred
* @version 1.0
*/
public class ShapeTest
{
public static void main(String [] args)
{
List<Shape> figures = new ArrayList<Shape>();
figures.add(new Rectangle(10, 20));
figures.add(new Circle(10));
Point p1 = new Point(0.0, 0.0);
Point p2 = new Point(5.0, 1.0);
Point p3 = new Point(2.0, 8.0);
figures.add(new Triangle(p1, p2, p3));
Iterator<Shape> iter = figures.iterator();
while (iter.hasNext()) {
Shape nxt = iter.next();
System.out.printf("area = %8.4f perimeter = %8.4f
",
nxt.computeArea(), nxt.computePerimeter());
}
}
}
So when you code to the interface, your program becomes easier to extend and modify. Your program will work with all the interface’s subclasses seamlessly.
As an aside, the principles above let you know that you should be constantly reviewing your design. Changing your design will force your code to change because of the need to refactor. Your design is iterative. Pride kills good design; don’t be afraid to revisit your design decisions. (Hey! Maybe that’s another design principle!)
The Open-Closed Principle (OCP)
Classes should be open for extension and closed for modification.1
Find the behavior that does not vary and abstract that behavior up into a super/base class. That locks the base code away from modification but all subclasses will inherit that behavior. You are encapsulating the behavior that varies in the subclasses (those classes that extend the base class) and closing the base class from modification. The bottom line here is that in your well-designed code, you add new features not by modifying existing code (it’s closed for modification), but by adding new code (it’s open for extension).
The BankAccount class example that we did in the previous chapter is a classic example of the Open-Closed Principle at work. In that example, we abstracted all the personal information into the abstract BankAccount class, closed it from modification and then extended that class into the different types of bank accounts. In this situation it is very easy to add new types of bank accounts just by extending the BankAccount class again. We avoid duplication of code, and we preserve the integrity of the BankAccount properties. See Figure 10-6.
___________________
1 Larman, C. “Protected Variation: The Importance of Being Closed.” IEEE Software 18(3): 89-91. 2001.
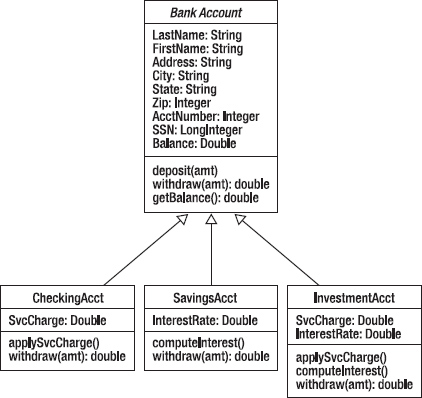
Figure 10-6. The classic BankAccount example for OCP
For example, in the BankAccount class we define the withdraw() method that allows a customer to withdraw funds from an account. But the way in which withdrawals occur can differ in each of the extended account classes. While the withdraw() method is closed for modification in the BankAccount class it can be overridden in the subclasses to implement the specific rules for that type of account and thus extend the power of the method. It’s closed for modification but open for extension.
The Open-Closed Principle doesn’t have to be limited to inheritance either. If you have several private methods in a class, those methods are closed for modification, but if you then create one or more public methods that use the private methods, you’ve opened up the possibility of extending those private methods by adding functionality in the public methods. Think outside the box – er, class.
Don’t Repeat Yourself Principle (DRY)
Avoid duplicate code by abstracting out things that are common and placing those things in a single location.2
DRY is the motherhood and apple pie design principle. It’s been handed down ever since developers started thinking about better ways to write programs. Go back and look at Chapters 6 and 7 if you don’t believe me. With DRY you have each piece of information and each behavior in a single place in the design. Ideally you have one requirement in one place. This means that you should create your design so that there is one logical place where a requirement is implemented. Then if you have to change the requirement you have only one place to look to make the change. You also remove duplicate code and replace it with method calls. If you are duplicating code, you are duplicating behavior.
___________________
2 Hunt, A. and D. Thomas. The Pragmatic Programmer: From Journeyman to Master. (Boston, MA: Addison-Wesley, 2000.)
DRY doesn’t have to apply just to your code either. It’s always a good idea to comb your feature list and requirements for duplications. Rewriting requirements to avoid duplicating features in the code will make your code much easier to maintain.
Consider the final version of the B4++ bird feeder that we discussed in the last chapter. The last thing we worked on was adding a song identifier to the feeder so that the feeding doors would open and close automatically. But let's look at the two use cases we ended up with (see Table 10-1).
Table 10-1. The Song Identifier Use Case and Its Alternate
| Main Path | Alternate Path |
| 1. Alice hears or sees birds at the bird feeder. | 1.1 The songbird identifier hears birdsong. |
| 2. Alice determines that they are not songbirds. | 2.1 The songbird identifier recognizes the song as from an unwanted bird. |
| 3. Alice presses the remote control button. | 3.1 The song bird identifier sends a message to the feeding doors to close. |
| 4. The feeding doors close. | |
| 5. The birds give up and fly away. | 5.1 The songbird identifier hears birdsong. 5.2 The songbird identifier recognizes the song as from a songbird. |
| 6. Alice presses the remote control button. | 6.1 The songbird identifier sends a message to the feeding doors to open. |
| 7. The feeding doors open again. |
Notice that we’re opening and closing the feeding doors in two different places, via the remote control and via the song identifier. But if you think about it, regardless of where we request the doors to be open or closed, they always open and close in the same way. So this is a classic opportunity to abstract out the open and close door behavior and put them in a single place, say the FeedingDoor class. DRY at work!
The Single Responsibility Principle (SRP)
This principle says that a class should have one, and only one, reason to change.3
Here’s an example of the overlap between these design principles that was mentioned above: SRP, the first principle about encapsulation, and DRY all say similar, but slightly different things. Encapsulation is about abstracting behavior and putting things in your design that are likely to change in the same place. DRY is about avoiding duplicating code by putting identical behaviors in the same place. SRP is about designing your classes so that each does just one thing, and does it very well.
Every object should have a single responsibility and all the object’s services are targeted towards carrying out that responsibility. Each class should have only one reason to change. Put simply, this means to beware of having your class try to do too many things.
As an example, let's say we’re writing the embedded code for a mobile phone. After months (really) of discussions with the marketing folks, our first cut at a MobilePhone class looks like Figure 10-7.

Figure 10-7. A very busy MobilePhone class
This class seems to incorporate a lot of what we would want a mobile phone to do, but it violates the SRP in several different ways. This class is not trying to do a single thing, it is trying to do way too many things – make and receive phone calls (who does that, anyway?), create, send, and receive text messages, create, send and receive pictures, browse the Internet. The class doesn’t have a single responsibility. It has many. But we don’t want a single class to be impacted by these completely different forces. We don’t want to modify the MobilePhone class every time the picture format is changed, or every time the browser changes. Rather, we want to separate these functions out into different classes so that they can change independently of each other. So how do we recognize the things that should move out of this class, and how do we recognize the things that should stay? Have a look at Figure 10-8.
___________________
3 McLaughlin, Brett D., et. al., Head First Object-Oriented Analysis & Design. (Sebastopol, CA: O’Reilly Media, Inc., 2007.)
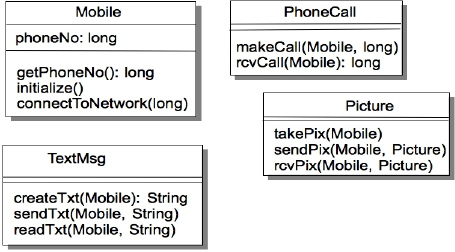
Figure 10-8. Mobile phone classes each with a single responsibility
In this example, we ask the question, “What does the mobile phone do (to itself)?” as opposed to, “What services are offered by the mobile phone?” By asking questions like this, we can start to separate out the responsibilities of the objects in the design. In this case, we can see that the phone itself can get its own phone number, initialize itself, and connect itself to the mobile phone network. The services offered, on the other hand, are really independent of the actual mobile phone, and so can be separated out into PhoneCall, TextMsg, and Picture classes. So we divide up the initial one class into four separate classes, each with a single responsibility. This way we can change any of the four classes without affecting the others. We’ve simplified the design (although we’ve got more classes), and made it easier to extend and modify. Is that a great principle, or what?
Liskov Substitution Principle (LSP)
Subclasses must be substitutable for their base class..4 This principle says that inheritance should be well designed and well behaved. In any case a user should be able to instantiate an object as a subclass and use all the base class functionality invisibly.
In order to illustrate the LSP, most books give an example that violates the Substitution Principle and say, “don’t do that.” Why should we be any different? One of the best and canonical examples of violating the Liskov Substitution Principle is the Rectangle/Square example. The example itself is all over the Internet; Robert Martin gives a great variation on this example in his book Agile Software Development, Principles, Patterns, and Practices,5 and we’ll follow his version of the example. Here it is in Java.
___________________
4 Wintour, Damien. “The Liskov Substitution Principle.” 1988. Downloaded on September 14, 2010 from www.necessaryandsufficient.net/2008/09/design-guidelines-part3-the-liskov-substitutionprinciple/.
Say you have a class Rectangle that represents the geometric shape of a rectangle:
/**
* class Rectangle.
*/
public class Rectangle
{
private double width;
private double height;
/**
* Constructor for objects of class Rectangle
*/
public Rectangle(double width, double height){
this.width = width;
this.height = height;
}
public void setWidth(double width){
this.width = width;
}
public void setHeight(double height) {
this.height = height;
}
public double getHeight() {
return this.height;
}
public double getWidth() {
return this.width;
}
}
And, of course, one of your users wants to have the ability to manipulate squares as well as rectangles. You, being the bright math student you are, already know that squares are just a special case of rectangles; in other words a Square IS-A Rectangle. Being a great object-oriented designer as well, you know all about inheritance. So you create a Square class that inherits from Rectangle.
/**
* class Square
*/
public class Square extends Rectangle
{
/**
* Constructor for objects of class Square
*/
public Square(double side) {
super(side, side);
}
public void setSide(double side) {
super.setWidth(side);
super.setHeight(side);
}
public double getSide() {
return super.getWidth();
}
}
___________________
5 Martin, R. C. Agile Software Development: Principles, Patterns, and Practices. (Upper Saddle River, NJ: Prentice Hall, 2003.)
Well, this seems to be okay. Notice that because the width and height of a Square are the same, we couldn’t run the risk of changing them individually, so setSide() uses setWidth() and setHeight() to set both for the sides of a Square. No big deal, right?
Well, if we have a function like:
void myFunc(Rectangle r, double newWidth) {
r.setWidth(newWidth);
}
and we pass myFunc() a Rectangle object, it works just fine, changing the width of the Rectangle. But what if we pass myFunc() a Square object? Well, it turns out that in Java the same thing happens as before, but that’s wrong. It violates the integrity of the Square object by just changing its width without changing its height as well. So we’ve violated the LSP here and the Square can not substitute for a Rectangle without changing the behavior of the Square. The LSP says that the subclass (Square) should be able to substitute for the superclass (Rectangle), but it doesn’t in this case.
Now we can get around this. We can override the Rectangle class’ setWidth() and setHeight() methods in Square like this:
public void setWidth(double w) {
super.setWidth(w);
super.setHeight(w);
}
public void setHeight(double h) {
super.setWidth(h);
super.setHeight(h);
}
These will both work and we’ll get the right answers and preserve the invariants of the Square object, but where’s the point in that? If we have to override a bunch of methods we’ve inherited, then what’s the point of using inheritance to begin with? That’s what the LSP is all about: getting the behavior of derived classes right and thus getting inheritance right. If we think of the base class as being a contract that we adhere to (remember the Open-Closed Principle?), then the LSP is saying that you must adhere to the contract even for derived classes. Oh, by the way, this works in Java because Java public methods are all virtual methods, and are thus able to be overridden. If we had defined setWidth() and setHeight() in Rectangle with a final keyword or if they had been private, then we couldn’t have overridden them.
In this example, while a square is mathematically a specialized type of rectangle and one where the invariants related to rectangles still hold, that mathematical definition just doesn't work in Java. In this case you don’t want to have Square be a subclass of Rectangle; inheritance doesn't work for you in this case, because you think about rectangles having two different kinds of sides – length and width - and squares having only one kind of side. So if a Square class inherits from a Rectangle class the image of what a Square is versus what a Rectangle is gets in the way of the code. Inheritance is just the wrong thing to use here.
How can you tell when you’re likely to be violating the Liskov Substitution Principle? Indications that you’re violating LSP include:
- A subclass doesn’t keep all the external observable behavior of its super class.
- A subclass modifies, rather than extends, the external observable behavior of its super class.
- A subclass throws exceptions in an effort to hide certain behavior defined in its super class.
- A subclass that overrides a virtual method defined in its super class using an empty implementation in order to hide certain behavior defined in its super class.
- Method overriding in derived classes is the biggest cause of LSP violations.6
Sometimes inheritance just isn’t the right thing to do. Luckily, you’re not screwed here. You’ve got options.
It turns out there are other ways to share the behavior and attributes of other classes. The three most common are delegation, composition, and aggregation.
Delegation – it’s what every manager should do. Give away work and let someone else do it. If you want to use the behaviors in another class but you don’t want to change that behavior consider using delegation instead of inheritance. Delegation says to give responsibility for the behavior to another class; this creates an association between the classes. Association in this sense means that the classes are related to each other, usually through an attribute or a set of related methods. Delegation has a great side benefit. It shields your objects from any implementation changes in other objects in your program; you’re not using inheritance, so encapsulation protects you.7 Let's show a bit of how delegation works with an example.
When last we left Alice and Bob and their B4++, Alice was tired of using the remote to open and close the feeding doors to keep away the non-song birds. So they’d requested yet another new feature – an automatic song identifier. With the song identifier the B4++ itself would recognize songbird songs and open the doors, and keep them closed for all other birds. We can think of this in a couple of ways.
The BirdFeeder class, because of the Single Responsibility Principle, shouldn’t do the identification of bird songs, but it should know what songs are allowed. We’ll need a new class, SongIdentifier, that will do the actual song identification. We’ll also need a Song object that contains a birdsong. Figure 10-9 shows what we’ve got so far.
___________________
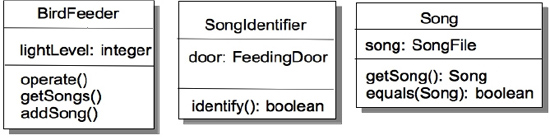
Figure 10-9. A first cut at the song identifier feature
Now, the BirdFeeder knows about birdsong and keeps a list of the allowed songs for the feeder. The SongIdentifier has the single job of identifying a given song. Now, there are two ways that this can happen. The first is that the SongIdentifier class can do the work itself in the identify() method. That would mean that SongIdentifier would need an equals() method in order to do the comparison between two songs (the allowed song from the door, and the song that the new B4++ hardware just sent to us). The second way of identifying songs is for the Song class to do it itself, using its own equals() method. Which should we choose?
Well, if we do all the identification in the SongIdentifier class, that means that any time anything changes in a Song, that we’ll have to change both the Song class and the SongIdentifier class. This doesn’t sound optimal. But! If we delegate the song comparison work to the Song class, then the SongIdentifier’s identify() method could just take a Song as an input parameter and call that method and we’ve isolated any Song changes to just the Song class. Figure 10-10 shows the revised class diagrams.
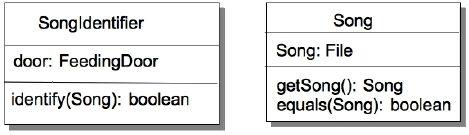
Figure 10-10. Simplifying SongIdentifier and Song
And our corresponding code might look like:
public class SongIdentifier {
private BirdFeeder feeder;
private FeedingDoor door;
public SongIdentifier(BirdFeeder feeder) {
this.door = feeder.getDoor();
}
public void identify(Song song) {
List<Song> songs = feeder.getSongs();
Iterator<Song> song_iter = songs.iterator();
while (song_iter.hasNext()) {
Song nxtSong = song_iter.next();
if (nxtSong.equals(song)) {
door.open();
return;
}
}
door.close();
}
}
public class Song {
private File song;
public Song(File song) {
this.song = song;
}
public File getSong() {
return this.song;
}
public boolean equals(Object newSong) {
if (newSong instanceof Song) {
Song newSong2 = (Song) newSong;
if (this.song.equals(newSong2.song)) {
return true;
}
}
return false;
}
}
In this implementation, if we change anything with regards to a Song, then the only changes we make will be in the Song class, and SongIdentifier is insulated from those changes. The behavior of the Song class doesn’t change, although how it implements that behavior might. SongIdentifier doesn’t care how the behavior is implemented, as long as it is always the same behavior. BirdFeeder has delegated the work of handling birdsong to the SongIdentifier class and SongIdentifier has delegated the work of comparing songs to the Song class, all without using inheritance. What a concept.
Delegation allows you to give away the responsibility for a behavior to another class and not have to worry about changing the behavior in your class. You can count on the behavior in the delegated class not changing. But sometimes you will want to use an entire set of behaviors simultaneously, and delegation doesn’t work for that. Instead, if you want to have your program use that set of behaviors you need to use composition. We use composition to assemble behaviors from other classes.
Say that you’re putting together a space-based role playing game (RPG), Space Rangers. One of the things you’ll model in your game is the spaceships themselves. Spaceships will have lots of different characteristics. For example, there are different types of ships, shuttles, traders, fighters, freighters, capital ships. Each ship will also have different characteristics, weapons, shields, cargo capacity, number of crew, and so on. But what will all the ships have in common?
Well, if you want to create a generic Ship class, it will be hard to gather all these things together in a single Ship superclass so you can create subclasses for things like Shuttle, Fighter, Freighter, and the like. They are all just too different. This seems to imply that inheritance isn’t the way to go here. So back to our question – what do all the ships have in common?
We can say that all the Ships in Space Rangers have just two things in common – a ship type, and a set of properties that relate to that ship type. This gets us to our first class diagram, shown in Figure 10-11.

Figure 10-11. What do all Spaceships have in common?
This allows us to store the space ship type and a map of the various properties for an instance of a ship. It means we can then develop the properties independently from the ships and then different ships can share similar properties. For example, all ships can have weapons, but they can have different ones with different characteristics. This leads us to develop a weapons interface that we can then use to implement particular classes. We get to use these weapons in our SpaceShip by using composition. Remember that composition allows us to use an entire family of behaviors that we can be guaranteed won’t change. See Figure 10-12.
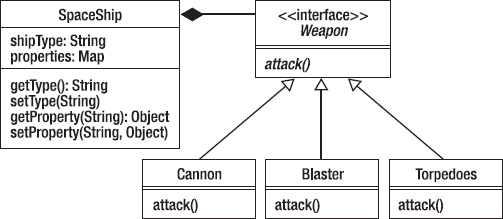
Figure 10-12. Using composition to allow the SpaceShip to use Weapons
Remember that the open triangle in the UML diagram means inheritance (or in the case of an interface, it means implements). The closed diamond in UML means composition. So in this design we can add several weapons to our properties Map and each weapon can have different characteristics, but all of them exhibit the same behavior. Isn’t composition grand?
You should also note that in composition the component objects (Weapons) become part of a larger object (SpaceShip) and when the larger object goes away (you get blown up), so do the components. The object that is composed of other behaviors owns those behaviors. When that object is destroyed, so are all of its behaviors. The behaviors in a composition don’t exist outside of the composition itself. When your SpaceShip is blown up, so are all your weapons.
Of course, sometimes you want to put together a set of objects and behaviors in such a way that when one of them is removed, the others continue in existence. That’s what aggregation is all about. If the behaviors need to persist, then you must aggregate. Aggregation is when one class is used as a part of another class, but still exists outside of that other class. If the object does make sense existing on its own, then use aggregation, otherwise use composition. For example, a library is an example of aggregation. Each book makes sense on its own, but the aggregation of them all is a library. The key is to show an instance where it makes sense to use a component outside a composition implying that it should have a separate existence.
In Space Rangers, we can have Pilot objects in addition to SpaceShip objects. A Pilot can also carry weapons. Different ones, of course; Pilots probably don’t carry Cannon objects with them! Say a Pilot is carrying around a HandBlaster, so in object-oriented speak he’s using the behaviors of the HandBlaster. If the Pilot is accidentally crushed by a mad SpaceCow, is the weapon destroyed along with the Pilot? Probably not, hence the need for a mechanism where the HandBlaster can be used by a Pilot but has an existence outside of the Pilot class. Ta, da! Aggregation!
So we’ve seen three different mechanisms that allow objects to use the behaviors of other objects, none of which require inheritance. As it’s said in OOA&D, “If you favor delegation, composition, and aggregation over inheritance your software will usually be more flexible and easier to maintain, extend and reuse.”8
The Dependency Inversion Principle (DIP)
Robert C. Martin introduced the Dependency Inversion Principle in his C++ Report and later in his classic book “Agile Software Development.”9 In his book, Martin defined the DIP as
- High-level modules should not depend on low-level modules. Both should depend on abstraction.
- Abstractions should not depend on details. Details should depend on abstractions.
The simple version of this is: don’t depend on concrete classes; depend on abstractions. Martin’s contention is that object-oriented design is the inverse of traditional structured design. In structured design as we saw in Chapter 7, one either works from the top-down, pushing details and design decisions as low in the hierarchy of software layers as possible. Or one works from the bottom-up, designing low-level details first, and later putting together a set of low-level functions into a single higher-level abstraction. In both these cases, the higher level software depends on decisions that are made at the lower levels, including interface and behavioral decisions.
Martin contends that for object-oriented design that this is backward. The Dependency Inversion Principle implies that higher-level (more abstract) design levels should create an interface that lower (more concrete) levels should code to. This will mean that as long as the lower level – concrete – classes code to the interface of the upper level abstraction that the upper level classes are safe. As Martin puts it, “The modules that contain the high-level business rules should take precedence over, and be independent of, the modules that contain the implementation details. High-level modules simply should not depend on low-level modules in any way.”
___________________
Here’s a simple example. Traditionally, in structured design we write many programs with the general format of:
11. Get input data from somewhere.
12. Process the data.
13. Write the data to somewhere else.
In this example, the Processor uses the Collector to get data, it then packages the data and uses the Writer to write the data to, say, a database. If we draw this out, we get something that looks like Figure 10-13.
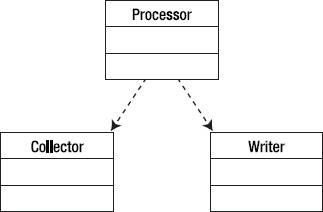
Figure 10-13. A traditional input-process-output model
One problem with this implementation is that the Processor must create and use the Writer whose interface and parameter types it must know in order to write correctly. This means that the Processor must be written to a concrete implementation of a Writer and so must be re-written if we want to change what kind of Writer we want. Say the first implementation writes to a File, if we then want to write to a printer, or a database, we need to change Processor every time. This is not very reusable. So the Dependency Inversion Principle says that the Processor should be coded to an interface (we abstract Processor) and then the interface is implemented in separate concrete classes for each type of Writer destination. The resulting design looks like Figure 10-14.
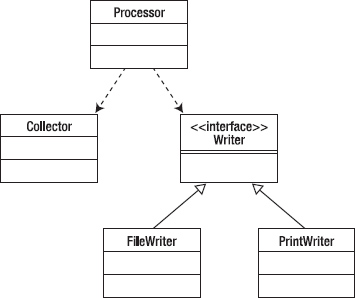
Figure 10-14. Using an interface to allow different writer implementations
In this way, different writers can be added and as long as they adhere to the interface, Processor never needs to change. Note that the DIP is closely related to Principle #2, Code to an Interface.
The Interface Segregation Principle (ISP)
Clients shouldn’t have to depend on interfaces they don’t use. In particular, they shouldn’t have to depend on methods they don’t use.10
We’ve talked a lot about interfaces in this chapter. Coding to interfaces, using interfaces to abstract out common details, and so on. We use interfaces to make our code more flexible and maintainable. So overall, interfaces are a great thing, right? Well, young Skywalker, you must beware of interfaces as well.
One of the greatest temptations with respect to interfaces is to make them bigger. If an interface is good, then a bigger interface must be better, right? After all, you can then use the interface is way more objects and the user just has to not implement certain methods that they don’t need. Ack! By doing that you are ruining the cohesion of your interface. By “generalizing” an interface too much you are moving away from that single lightning bolt of a set of methods that are all closely related to each other to a jumble of methods that say hello to each other in passing. Remember cohesion is good. Your applications should be cohesive and the classes and interfaces they depend on should also be cohesive.
You make your interfaces less cohesive, and begin to violate the Interface Segregation Principle when you start adding new methods to your interface because one of the subclasses that implements the interface needs it – and others do not. So what’s the answer here? How do we keep our interfaces cohesive and still make them useful for a range of objects?
The answer is: make more interfaces. The Interface Segregation Principle implies that instead of adding new methods that are only appropriate to one or a few implementation classes, that you make a new interface. You divide your bloated interface into two or more smaller, more cohesive interfaces. That way, new classes can just implement the interfaces that they need and not implement ones that they don’t.
___________________
The Principle of Least Knowledge (PLK)
(Also known as the Law of Demeter). Talk only to your immediate friends.11
The complement to strong cohesion in an application is loose coupling. That’s what the Principle of Least Knowledge is all about. It says that classes should collaborate indirectly with as few other classes as possible.12 Here’s an example.
You’ve got a computer system in your car – we all do these days. Say you’re writing an application that graphs temperature data in the car. There are a number of sensors that provide temperature data and that are part of a family of sensors in the car’s engine. Your program should select a sensor, gather and plot its temperature data. (This example is derived from one found in Hunt).13 Part of your program might look like:
public void plotTemperature(Sensor theSensor) {
double temp = theSensor.getSensorData().getOilData().getTemp();
…
}
This will likely work – once. But now you’ve coupled your temperature plotting method to the Sensor, SensorData, and OilSensor classes. Which means that a change to any one of them could affect your plotTemperature() method and cause you to have to refactor your code. Not good.
This is what the PLK urges you to avoid. Instead of linking your method to a hierarchy and having to traverse the hierarchy to get the service you’re looking for, just ask for the data directly
public void plotTemperature(double theSensor) {
...
}
...
plotTemperature(aSensor.getTemp());
Yup, we had to add a method to the Sensor class to get the temperature for us, but that’s a small price to pay for cleaning up the mess (and the possible errors) above. Now your class is just collaborating directly with one class, and letting that class take care of the others. Of course, your Sensor class will do the same thing with SensorData, and so on.
This leads us to a corollary to the PLK – keep dependencies to a minimum. This is the crux of loose coupling. By interacting with only a few other classes, you make your class more flexible and less likely to contain errors.
___________________
12 Lieberherr, K., I. Holland, et al. Object-Oriented Programming: An Objective Sense of Style. OOPSLA ’88, Association for Computing Machinery, 1988.
Class Design Guidelines for Fun and Enjoyment
Finally, just so we shouldn’t exit the chapter without yet another list, we present a list of 24 class design guidelines. These guidelines are somewhat more specific than the general design guidelines that we have described above, but they are handy to have around. Cut them out and burn them into your brain.
These 24 class design guidelines are taken from Davis14 and McConnell.15
- Present a consistent level of abstraction in the class interface.
- Be sure you understand what abstraction the class is implementing.
- Move unrelated information to a different class (ISP).
- Beware of erosion of the class’s interface when you are making changes. (ISP).
- Don’t add public members that are inconsistent with the interface abstraction.
- Minimize accessibility of classes and members (OCP).
- Don’t expose member data in public.
- Avoid putting private implementation details into the class’s interface.
- Avoid putting methods into the public interface.
- Watch for coupling that’s too tight (PLK).
- Try to implement “has a” relations through containment within a class (SRP).
- Implement “is a” relations through inheritance (LSP).
- Only inherit if the derived class is a more specific version of the base class.
- Be sure to inherit only what you want to inherit (LSP).
- Move common interfaces, data, and operations as high in the inheritance hierarchy as possible (DRY).
- Be suspicious of classes of which there is only one instance.
- Be suspicious of base classes that only have a single derived class.
- Avoid deep inheritance trees (LSP).
- Keep the number of methods in a class as small as possible.
- Minimize indirect method calls to other classes (PLK).
- Initialize all member data in all constructors, if possible.
- Eliminate data-only classes.
- Eliminate operation-only classes.
- Oh, and be careful out there.… (OK, I added this one.)
___________________
14 Davis, A. M. 201 Principles of Software Development. (New York, NY: McGraw-Hill, Inc., 1995.)
15 McConnell, Steve, Code Complete, 2nd Edition. (Redmond, WA: Microsoft Press, 2004.)
Conclusion
In this chapter we examined a number of rules of thumb about object-oriented design that have evolved over the last few decades. These design principles act as guidelines for you the designer to abide by so that your design ends up being a good one, easy to implement, easy to maintain, and one that does just what your customer wants. Importantly, these design principles give guidance when you're feeling your way from features to design. They talk about ways to examine and implement the important object-oriented principles of inheritance, encapsulation, polymorphism, and abstraction. They also reinforce basic design principles like cohesion and coupling. Burn these principles into your brain, OO designer.
References
Davis, A. M. 201 Principles of Software Development. (New York, NY: McGraw-Hill, Inc., 1995.)
Hunt, A. and D. Thomas. The Pragmatic Programmer: From Journeyman to Master. (Boston, MA: Addison-Wesley, 2000.)
Larman, C. “Protected Variation: The Importance of Being Closed.” IEEE Software 18(3): 89-91. 2001.
Lieberherr, K., I. Holland, et al. Object-Oriented Programming: An Objective Sense of Style. OOPSLA ’88, Association for Computing Machinery, 1988.
Martin, R. C. Agile Software Development: Principles, Patterns, and Practices. (Upper Saddle River, NJ: Prentice Hall, 2003.)
McConnell, Steve, Code Complete, 2nd Edition. (Redmond, WA: Microsoft Press, 2004.)
McLaughlin, Brett D., et. al., Head First Object-Oriented Analysis & Design. (Sebastopol, CA: O’Reilly Media, Inc., 2007.)
Wintour, Damien. “The Liskov Substitution Principle.” 1988. Downloaded on September 14, 2010 from www.necessaryandsufficient.net/2008/09/design-guidelines-part3-the-liskov-substitution-principle/.