
Chapter 4
Introduction to Operating System Concepts
In Chapter 2, we saw the hardware of the computer. In order to facilitate communication between the user and the hardware, computer systems use an operating system. This chapter introduces numerous operating system concepts, many of which are referenced in later chapters of this book. Specifically, the roles of process management, resource management, user interface, protection, and security are introduced here so that later examinations can concentrate on how to utilize them in Windows and Linux operating systems. Operating system concepts of interrupts, the context switch, the booting process, and the administrator account are also introduced. The chapter concludes with the steps required for operating system installation for Windows 7 and Linux Red Hat.
The learning objectives of this chapter are to
- Describe the roles of the operating system.
- Compare the graphical user interface and the command line interface.
- Differentiate between the forms of process management.
- Discuss the interrupt and the context switch.
- Describe virtual memory.
- Discuss the issues involved in resource management: synchronization and deadlock.
- Describe the boot process and system initialization.
- Provide step-by-step instructions on Windows 7 and Linux Red Hat installation.
What Is an Operating System?
At its most simple description, an operating system (OS) is a program. Its primary task is to allow a computer user to easily access the hardware and software of a computer system. Beyond this, we might say that an OS is required to maintain the computer’s environment.
An OS is about control and convenience. The OS supports control in that it allows the user to control the actions of the software, and through the software, to control (or access) hardware. The OS supports convenience in that it provides access in an easy-to-use manner. Early OSs were not easy to use but today’s OSs use a graphical user interface (GUI), and commands can be issued by dragging, pointing, clicking, and double clicking with the mouse. In some OSs such as Linux and Unix, there are two ways to issue commands: through the GUI and by typing in commands at a command line prompt. In actuality, both Windows and Mac OS also have command line prompts available, but most users never bother with them. Linux and Unix users, however, will often prefer the command line over the GUI.
Some Useful Terms
In earlier chapters, we already introduced the components of any computer system. Let us revisit those definitions, with new details added as needed. We also introduce some OS terms.
Hardware
The physical components of the computer. We can break these components into two categories: internal components and peripheral devices. The internal components are predominantly situated on the motherboard, a piece of plastic or fiberglass that connects the devices together. On the motherboard are a number of sockets for chips and expansion cards. One chip is the CPU, other chips make up memory. The CPU is the processor; it is the component in the computer that executes a program. The CPU performs what is known as the fetch–execute cycle, fetching each program instruction, one at a time from memory, and executing it in the CPU. There are several forms of memory: cache (SRAM), DRAM, and ROM. Cache is fast memory, DRAM is slow memory, but cache is usually far more expensive than DRAM so our computers have a little cache and a lot of DRAM. ROM is read-only memory and is only used to store a few important programs that never change (like the boot program). Connecting the devices together is the bus. The bus allows information to move from one component to another. The expansion slots allow us to plug in expansion cards, which either are peripheral devices themselves (e.g., wireless MODEM card) or connect to peripheral devices through ports at the back of the computer. Some of the more important peripheral devices are the hard disk drive, the keyboard, the mouse, and the monitor. It is likely that you will also have an optical disk drive, a wireless MODEM (or possibly a network card), a sound card, and external speakers, and possibly a printer.
Software
The programs that the computer runs, referred to as software to differentiate them from the physical components of the computer (hardware). Software exists only as electrical current flowing through the computer (or as magnetic charges stored on disk). Software is typically classified as either applications software (programs that we run to accomplish some task) or systems software (programs that the computer runs to maintain its environment). We will primarily explore systems software in this text. In both Linux and Windows, the OS is composed of many small programs. For instance, in Linux, there are programs called ls, rm, cd, and so forth, which are executed when you issue the commands at the command line. These programs are also called by some of the GUI tools such as the file manager. If you look at the Linux directories /bin, /usr/bin, /sbin, and /usr/sbin, you will find a lot of the OS programs. Many users will rarely interact directly with the OS by calling these programs. If you look at directories such as /usr/local/bin, you will find some of the applications software. Applications software includes word processors, spreadsheets, internet browsers, and computer games. In Windows, you find the application software under the Program Files directory and the OS under the Windows directory.
All software is written in a computer programming language such as Java or C++. The program written by a human is called the source program or source code. Java and C++ look something like English combined with math symbols. The computer does not understand source code. Therefore, a programmer must run a translation program called a compiler. The compiler takes the source code and translates it into machine language. The machine language version is an executable program. There is another class of language translators known as an interpreter. The interpreter is a little different in that it combines the translation of the code with the execution of the code, so that running an interpreted program takes more time. As this is far less efficient, we tend to use the interpreted approach on smaller programs, such as shell scripts, web browser scripts, and webserver scripts. As an IT student, you will primarily write code that will be interpreted. Scripting languages include the Bash shell scripting language, PHP, Perl, JavaScript, Python, and Ruby.
Computer System
A collection of computer hardware, software, user(s) and network. Our OS is in reality a collection of software components. We might divide those components into four categories, described below.
Kernel
The core of the OS; we differentiate this portion from other parts that are added on by users: shells, device drivers, utilities. The kernel will include the programs that perform the primary OS tasks: process management, resource management, memory management, file management, protection, and security (these are explored in the next section).
Device Drivers
Programs that are specific interfaces between the OS running your computer and a piece of hardware. You install a device driver for each new piece of hardware that you add to your computer system. The drivers are usually packaged with the hardware or available for download over the Internet. Many common drivers are already part of the OS, only requiring installation. Rarer drivers may require loading off of CD or over the Internet.
Shell
An interface for the user, often personalized for that given user. The shell provides access to the kernel. For instance, a GUI shell will translate mouse motions into calls to kernel routines (e.g., open a file, start a program, move a file). Linux and Unix have command-line shells as well that may include line editing commands (such as using control+e to move to the end of the line, or control+b to back up one position). Popular GUI shells in Linux/Unix include CDE, Gnome, and KDE, and popular text-based shells in Linux/Unix include bash (Bourne-again shell), ksh (Korn shell), and C shell (csh). The text-based shells include the command-line interpreter, a history, environment variables, and aliases. We cover the Bash shell in detail in Chapter 9.
Utility Programs
Software that helps manage and fine-tune the hardware, OS, and applications software. Utilities greatly range in function and can include file utilities (such as Window’s Windows Explorer program), antiviral software, file compression/uncompression, and disk defragmentation.
Virtual Machines
A software emulator is a program that emulates another OS, that is, it allows your computer to act like it is a different computer. This, in turn, allows a user to run software that is not native to or compiled for his/her computer, but for another platform. A Macintosh user, for instance, might use a Windows emulator to run Windows software on a Macintosh.
Today, we tend to use virtual machines (VMs) rather than stand-alone emulators. A VM is software that pretends to be hardware. By installing a different OS within the VM, a user then has the ability to run software for that different OSs platform in their computer that would not otherwise be able to run that software.
However, the use of VMs gives considerably more flexibility than merely providing a platform for software emulation. Consider these uses of a VM.
- Have an environment that is secure in that downloaded software cannot influence or impact your physical computer
- Have an environment to explore different platforms in case you are interested in purchasing different OSs or different types of computer hardware
- Have an environment where you can issue administrator commands and yet have no worry that you may harm a physical computer—if you make a mistake, delete the VM and create a new one!
- Have an environment where multiple users could access it to support collaboration
- Have an environment that could be accessed remotely
There are different types of VMs. The Java Virtual Machine (JVM) exists in web browsers to execute Java code. VM software, such as VirtualBox (from Sun) and vSphere (from VMWare), provide users the ability to extend their computer hardware to support multiple OSs in a safe environment.
OS Tasks
The OS is basically a computer system manager. It is in charge of the user interface, process and resource management, memory management, file management, protection, and security.
User Interface
The GUI allows a user to control the computer by using the mouse and pointing and clicking at objects on the screen (icons, menus, buttons, etc.). Each OS offers a different “feel”. For instance, Mac OS has a standard set of menus always listed along the top of the desktop and each application software adds to the menu selections. In Windows 7, there is no desktop level menu selection, but instead each software title has its own set of menus. Linux GUIs include Gnome and KDE. Each of these OSs provides desktop icons for shortcuts and each window has minimize, maximize, and close buttons. Additionally, each of these interfaces is based on the idea of “point and click”. The mouse is used to position the cursor, and the mouse buttons are used to specify operations through single clicking, double clicking, and dragging. Cell phones and tablets, based on touch screens, have a gesture-based interface where movements include such operations as swipe, tap, pinch, and reverse pinch. Windows 8 is being marketed as following the touch screen approach rather than the point-and-click.
The GUI is a much simpler way to control the computer than by issuing commands via the command line. The command line in most OSs* runs in a shell. A shell is merely a part of the OS that permits users to enter information through which the user can command the OS kernel. The shell contains a text interpreter—it interprets entered text to pass along proper commands to the OS kernel. As an example, a Linux user may type in a command like:
find ~ -name ‘core*’ -exec rm {} ;
This instruction executes the Linux find command to locate, in this user’s home directory, anything with a name that starts with core, and then executes the rm command on any such files found. In other words, this command finds and deletes all files starting with the letters “core” found in the user’s home directory. Specifically, the instruction works as follows:
- The command is find which receives several parameters to specify how find should operate.
- ~/ specifies where find should look (the user’s home directory).
- -name ‘core*’ are a pair, indicating that the name of the file sought will contain the letters “core” followed by anything (the * is a wildcard character).
- -exec indicates that any file found should have the instruction that follows executed on it.
- rm is the deletion operation, {} indicates the found file.
- ; ends the instruction.
Many OS command line interpreters (such as DOS, which is available in the Windows OS) are far more simplistic. Linux is favored by some computer users because of the ability to express very complex instructions. You will study the Bash interpreter in Chapter 9, where you will learn more about how the command line interpreter works.
Process Management
The main task of any computer is to run programs. A program being executed by the computer is called a process. The reason to differentiate between program and process is that a program is a static entity, whereas a process is an active entity. The process has a status. Its status might include “running” (process is currently being executed by the CPU), “waiting” (process is waiting for input or output, or waiting to be loaded into memory), or “ready” (process is loaded into memory but not currently being executed by the CPU). The process also has specific data stored in memory, cache, and registers. These data change over time and from execution to execution. Thus, the process is dynamic.
A computer might run a single process at a time, or multiple processes in some form of overlapped (concurrent) fashion. The OS is in charge of starting a process, watching as it executes, handling interrupting situations (explained below) and input/output (I/O) operations, handling multiple process interaction, and terminating processes.
An interrupt is a situation where the CPU is interrupted from its fetch–execute cycle. As discussed in Chapter 2, the CPU continuously fetches, decodes, and executes instructions from memory. Left to itself, the CPU would do this indefinitely. However, there are times when the CPU’s attention needs to be shifted from the current process to another process (including the OS) or to address a piece of hardware. Therefore, at the end of each fetch–execute cycle, the CPU examines the interrupt flag (part of the status flags register) to see if anyone has raised an interrupt. An interrupt signal can come from hardware or from software.
If an interrupt arises, the CPU handles the interrupt as follows. First, it saves what it was doing. This requires taking the values of the various registers and saving them to memory. Second, the CPU identifies the type of interrupt raised. This requires the CPU to determine which device raised the interrupt, or if the interrupt was caused by software. Third, the CPU switches to execution of the OS. Specifically, the CPU begins executing an interrupt handler. The OS will have an interrupt handler (a set of code) for each type of interrupt. See Table 4.1 for a list of types of interrupts. The CPU then resumes the fetch–execute cycle, but now is executing the OS interrupt handler. Upon completion of executing the interrupt handler, which will have taken care of the interrupting situation, the CPU restores the register values saved to memory. This “refreshes” the interrupted process. The CPU then resumes the fetch–execute cycle, but now it is continuing with the process it has previously been executing, as if it had never stopped. The interruption may have taken just a few machine cycles or seconds to minutes if the interruption involves the user. For instance, if the interruption was caused by a “disk not in drive”, then the user has to physically insert a disk. The interruption would only be resolved once the user has acted.
Types of Interrupts
|
Device |
Reason(s) for Interrupt |
|
Disk drive |
File not found Disk not in drive Disk not formatted |
|
Keyboard |
User enters keystroke User presses ctrl+alt+del |
|
Mouse |
Mouse moved Mouse button pressed or depressed |
|
Network/MODEM |
Message arrives |
|
Printer |
Paper jam Printer out of paper Printout complete |
|
Program |
Run time error (e.g., divide by 0, bad user input) Requires communication with another program |
|
Timer |
Timer elapses |
OSs will implement process management in different ways. The simplest approach is to use single tasking where a process starts, executes, and terminates with no other processes running. This is not a very satisfactory use of computer resources however, nor do users typically want to be limited to running one program at a time. Various forms of concurrent processing exist. Concurrency means that processes are executed in some overlapped fashion. These include multiprogramming, multitasking (or time sharing as it was originally called), multithreading, and multiprocessing. What each of these have in common is that the OS permits multiple processes to be in some state of execution. With the exception of multiprocessing (which uses multiple CPUs), there is only one CPU so that only one process can be executing at any moment in time. The others wait. How long they wait, why they are waiting, and where they wait differs to some extent based on the type of process management.
We will explore various forms of process management in the next section. However, before proceeding, we must first introduce multitasking as it is referenced later in this section. In multitasking, there are two or more processes running. The CPU only executes one process at any one time, but switches off between all of the running processes quickly. So, for instance, the CPU might execute a few thousand machine cycles each on process 0, and then process 1, and then process 2, and then return to process 0. A timer is used to time how long each process is executed. When the timer elapses, it interrupts the CPU and the OS then is invoked to force a switch between processes. The timer is reset and the CPU continues with the next process.
Scheduling
If we want the computer to do anything other than single processing—that is, running one program until it completes and then moving on to the next user task, the OS will have to perform scheduling. There are several types of scheduling. For instance, in multitasking, when the timer elapses, the CPU switches from the current process to another. Which one? Typically, the OS uses a round-robin scheduler. If there are several processes running, they will be placed into a queue. The processes then are given attention by the CPU in the order that they reside in the queue. When the processor has executed some number of instructions on the last process in the queue, it resumes with the first process in the queue. That is, the queue is a “wrap-around” queue, thus the term round-robin. The OS is also in charge of deciding which processes should be loaded into memory at any time. Only processes present in memory will be placed in the queue. Commonly today, all processes are loaded upon demand, but low priority processes may be removed from the ready queue and memory and reside in a waiting queue. Finally, the user can also specify that a process should be run. This can be done by selecting, for instance, the process from the tab at the bottom of the desktop. This forces a process to move from the background to the foreground. We will consider scheduling in more detail in the next section, as well as in Chapter 11.
Memory Management
Because main memory is smaller in size than the size of the software we typically want to run, the OS is in charge of moving chunks of programs and data into and out of memory as needed. Every program (along with its data) is divided into fixed-sized blocks called pages. Before a program can be executed, the OS copies the program’s “image” into swap space and loads some of its pages into memory. The “image” is the executable program code along with the memory space that makes up the data that the program will access. Swap space is a reserved area of the hard disk. Now, as the process runs, only the needed pages are loaded into memory. This keeps each program’s memory utilization down so that memory can retain more programs. If each program were to be loaded into memory in its entirety, memory would fill quickly and limit the number of programs that could fit.
The use of swap space to back up memory gives the user an illusion that there is more main memory than there actually is. This is called virtual memory. Figure 4.1 demonstrates virtual memory with two processes (A and B), each of which currently have pages loaded into main memory and the remainder of the processes are stored in swap space. The unmapped pages refer to pages that have not yet been loaded into memory. Swapped out pages are pages that had at one time been in memory but were removed in order to accommodate newer pages.
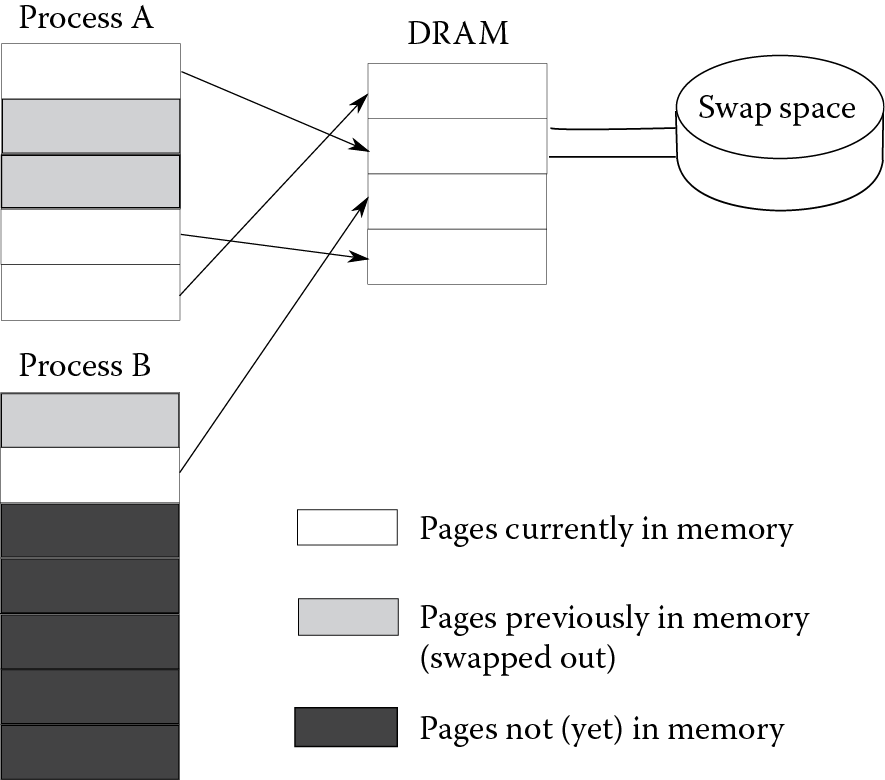
When the CPU generates a memory address (for instance, to fetch an instruction or a datum), that address must be translated from its logical (or virtual) address into a physical address. In order to perform that translation, the OS maintains a page table for every process. This table denotes for every page of the process, if it is currently in memory and if so, where. Figure 4.2 shows what the page tables would look like for the two processes in Figure 4.1. Process A has three pages currently loaded into memory at locations 0, 1, and 3 (these locations are referred to as frames) and process B has one page currently loaded into memory at location 2. The valid column is a bit that indicates if the page is currently in memory (valid bit set to 1) or not.
Process A page table
|
Page |
Frame |
Valid |
|
0 |
1 |
T |
|
1 |
– |
F |
|
2 |
– |
F |
|
3 |
3 |
T |
|
4 |
0 |
T |
Process B page table
|
Page |
Frame |
Valid |
|
0 |
– |
F |
|
1 |
2 |
T |
|
2 |
– |
F |
|
3 |
– |
F |
|
4 |
– |
F |
|
5 |
– |
F |
|
6 |
– |
F |
Example page tables for processes in Figure 4.1 .
If a referenced page is not currently in memory, a page fault is generated that causes an interrupt. The OS gets involved at this point to perform swapping. First, the OS locates an available frame to use in memory. If there are no available frames, then the OS must select a page to discard. If the page has been modified, then it must first be saved back to swap space. Once a frame is available, the OS then loads the new page from swap space into that frame in memory. The OS modifies the page table to indicate the location of the new page (and if a page has been removed from memory). Finally, the OS allows the CPU to resume the current process.
As swap space is stored on hard disk, any paging (swapping) involves hard disk access. Because the hard disk response time is so much slower than memory response time, any swapping will slow down the execution of a program. Therefore, swapping is to be avoided as much as possible. If the discarded page had to be written back to swap space first, this increases the swap time even more.
Another factor requiring memory management is that processes generate addresses for data accesses (loads and stores). What is to prevent a process from generating an address of a section of memory that does not contain data of that process? A situation where a process generates an address of another process’ memory space is called a memory violation. This can happen through the use of pointers, for instance, in programming languages such as C and C++. A memory violation should result in termination of the process, although in C++, a programmer could also handle this situation through an exception handler, which is an interrupt handler written by the programmer and included with the current program.
Resource Management
Aside from memory and the CPU, there are many other resources available including the file system, access to the network, and the use of other devices. The OS maintains a table of all active processes and the resources that each process is currently using or wants to use. Most resources can only be accessed in a mutually exclusive way. That is, once a process starts using a resource, no other process can use the resource until the first process frees it up. Once freed, the OS can decide which process next gets to access the resource.
There are many reasons for mutual exclusion, but consider this situation. A file stores your checking account balance. Let us assume it is currently $1000. Now, imagine that you and your significant other enter the bank, stand in line, and each of you is helped by different tellers at the same time. You both ask to deduct the $1000. At the same time, both tellers access the data and both find there is $1000 available. Sad that you are closing out the account, they both enter the transaction, again at the same time. Both of the tellers’ computers access the same shared disk file, the one storing your account information. Simultaneously, both programs read the value ($1000), determine that it is greater than or equal to the amount you are withdrawing, and reset the value to $0. You and your significant other each walk out with $1000, and the balance has been reduced to $0. Although there was only $1000 to begin with, you now have $2000! This is good news for you, but very bad news for the bank. To prevent such a situation from happening, we enforce mutually exclusive access to any shared resource.
Access to any shared datum must be synchronized whether the datum is shared via a computer network or is shared between two processes running concurrently on the same computer. If one process starts to access the datum, no other process should be allowed to access it until the first process completes its access and frees up the resource. The OS must handle interprocess synchronization to ensure mutually exclusive access to resources. Returning to our bank teller example, synchronization to the shared checking account datum would work like this. The OS would receive two requests for access to the shared file. The OS would select one of the two processes to grant access to. The other would be forced to wait. Thus, while one teller is allowed to perform the database operation to deduct $1000, the other would have to wait. Once the first teller is done, the resource becomes freed, and the second teller can now access the file. Unfortunately, the second teller would find the balance is $0 rather than $1000 and not hand out any money. Therefore, you and your significant other will only walk away with $1000.
Aside from keeping track of the open resources, the OS also handles deadlock. A simple version of deadlock is illustrated in Figure 4.3. The OS is multitasking between processes P0 and P1, and there are (at least) two available resources, R0 and R1.

P0 runs for a while, then requests access to R0.
The OS determines that no other process is using R0, so grants the request.
P0 continues until the timer elapses and the OS switches to P1.
P1 runs for a while, then requests access to R1.
The OS determines that no other process is using R1, so grants the request.
P1 continues until the timer elapses and the OS switches to P0.
P0 continues to use R0 but now also requests R1.
The OS determines that R1 is currently in use by P1 and moves P0 to a waiting queue, and switches to P1.
P1 continues to use R1 but now also requests R0.
The OS determines that R0 is currently in use by P0 and moves P1 to a waiting queue.
The OS is ready to execute a process but both running processes, P0 and P1, are in waiting queues. Furthermore, neither P0 nor P1 can start running again until the resource it is waiting for (R1 and R0, respectively) becomes available. But since each process is holding onto the resource that the other needs, and each is waiting, there will never be a time when the resource becomes available to allow either process to start up again, thus deadlock.
To deal with deadlock, some OSs check to see if a deadlock might arise before granting any request. This tends to be overcautious and not used by most OSs. Other OSs spend some time every once in a while to see if a deadlock has arisen. If so, one or more of the deadlocked processes are arbitrarily killed off, freeing up their resources and allowing the other process(es) to continue. The killed-off processes are restarted at some random time in the future. Yet other OSs do not deal with deadlock at all. It is up to the user to decide if a deadlock has arisen and take proper action!
File System Management
The primary task of early OSs was to offer users the ability to access and manipulate the file system (the name MS-DOS stands for Microsoft Disk Operating System, and the commands almost entirely dealt with the disk file system). Typical commands in file management are to open a file, move a file, rename a file, delete a file, print a file, and create, move, rename, and delete directories (folders). Today, these capabilities are found in file manager programs such as Windows Explorer. Although these commands can be performed through dragging, clicking, etc., they are also available from the command line. In Unix/Linux, file system commands include cd, ls, mv, cp, rm, mkdir, rmdir, and lp. In DOS, file system commands include cd, dir, move, copy, del, mkdir, rmdir, and print. There are a wide variety of additional Unix/Linux commands that allow a system administrator to manipulate the file system as a whole by mounting new devices or relocating where those devices will be accessed from in the file space, as well as checking out the integrity of files (for instance, after a file is left open and the system is rebooted).
Behind the scenes, the OS manages file access. When a user submits a command such as to move a file or open a file, whether directly from the command line or from some software, the user is in actuality submitting a request. The OS now takes over. First, the OS must ensure that the user has access rights for the requested file. Second, the OS must locate the file. Although users will specify file locations, those locations are the file’s logical location in the file system. Such a specification will include the disk partition and the directory of the file (e.g., C:UsersFoxrMy DocumentsCIT 130). However, as will be discussed in Chapter 5, files are broken up into smaller units. The OS must identify the portion of the file desired, and its physical location. The OS must map the logical location into a physical location, which is made up of the disk surface and location on the surface. Finally, the OS must initiate the communication with the disk drive to perform the requested operation.
Protection and Security
Most computers these days are a part of a larger network of computers where there may be shared files, access to the network, or some other shared resource. Additionally, multiple users may share the same computer. The files stored both locally and over the network must be protected so that a user does not accidentally (or maliciously) overwrite, alter, or inappropriately use another user’s files. Protection ensures that a user is not abusing the system—not using someone else’s files, not misusing system resources, etc. Security extends protection across a network.
A common mechanism for protection and security is to provide user accounts. Each user will have a user name and authentication mechanism (most commonly, a password). Once the OS has established who the user is, the user is then able to access resources and files that the user has the right to access. These will include shared files (files that other users have indicated are accessible) and their own files. Unix and Linux use a fairly simplistic approach by placing every user into a group. Files can be read, written, and executed, and a file’s accessibility can be controlled to provide different rights to the file’s owner, the file’s group, and the rest of the world. For instance, you might create a file that is readable/writable/executable by yourself, readable/executable by anyone in your group, and executable by the world. We discuss user accounts, groups, and access control methods in Chapter 6.
Forms of Process Management
The various ways in which OSs will execute programs are
- Single tasking
- Batch
- Multiprogramming
- Multitasking
- Multithreaded
- Multiprocessing
A single tasking system, the oldest and simplest, merely executes one program until it concludes and then switches back to the OS to wait for the user to request another program to execute. MS-DOS was such an OS. All programs were executed in the order that they were requested. If the running process required attention, such as a lengthy input or output operation, the CPU would idle until the user or I/O device responded. This is very inefficient. It can also be frustrating for users who want to do more than one thing at a time. Aside from early PCs, the earliest mainframe computers were also single tasking.
A batch processing system is similar to a single tasking system except that there is a queue (waiting line) for processes. The main distinction here is that a batch processing system has more than a single user. Therefore, users may submit their programs for execution at any time. Upon submitting a program request, the process is added to a queue. When the processor finishes with one process, the OS is invoked to decide which of the waiting processes to bring to the CPU next. Some form of scheduling is needed to decide which process gets selected next. Scheduling algorithms include a priority scheme, shortest job first, and first come first serve. For the priority scheme, processes are each given a priority depending on the user’s status (e.g., administration, faculty, graduate student, undergraduate student). Based on the scheduling algorithm, the load on the machine, and where your process is placed in the queue, you could find yourself waiting minutes, hours, or even days before your program executes! In shortest job first, the OS attempts to estimate the amount of CPU time each process will require and selects the process that will take the least amount of time. Statistically, this keeps the average waiting time to a minimum although it might seem unfair to users who have time-consuming processes. First come first serve is the traditional scheme for any queue, whether in the computer or as found in a bank. This scheme, also known as FIFO (first-in, first-out), is fair but not necessarily efficient.
Another distinction between a single tasking system and a batch processing system is that the batch processing system has no interactivity with the user. In single tasking, if I/O is required, the process pauses while the computer waits for the input or output to complete. But in batch processing, all input must be submitted at the time that the user submits the process. Since batch processing was most commonly used in the first three computer generations, input typically was entered by punch cards or stored on magnetic tape. Similarly, all output would be handled “offline”, being sent to magnetic tape or printer. Obviously, without interactivity, many types of processes would function very differently than we are used to. For instance, a computer game would require that all user moves be specified before the game started, and a word processor would require that all edit and formatting changes to be specified before the word processor started. Therefore, batch processing has limitations. Instead, batch processing was commonly used for such tasks as computing payroll or taxes, or doing mathematical computations.
Notice that in batch processing, like in single tasking, only one process executes at a time, including the OS. The OS would not be invoked when a new process was requested by a user. What then would happen when a user submits a new process request? A separate batch queuing system was in charge of receiving new user submissions and adding them to the appropriate queue.
Although batch processing was common on computers in the first through third generation, running on mainframe and minicomputers, you can still find some batch processing today. For instance, in Unix and Linux, there are scheduling commands such as cron and at, and in Windows, the job scheduler program is available. Programs scheduled will run uninterrupted in that they run without user intervention, although they may run in some multitasking mode.
In a batch processing system, the input is made available when the process begins execution through some source such as punch cards or a file on magnetic tape or disk. A single tasking system, on the other hand, might obtain input directly from the user through keyboard or some other device. Introducing the user (human) into the process greatly slows down processing. Why? Because a human is so much slower at entering information than a disk drive, tape drive, or punch card reader (even though the punch card reader is very slow). Similarly, waiting on output could slow down processing even if output is handled offline. The speed of the magnetic tape, disk, or printer is far slower than that of the CPU. A single tasking system then has a significant inefficiency—input and output slows down processing. This is also true of batch processing even though batch processing is not as significantly impacted because there is no human in the processing loop.
A multiprogramming system is similar to a batch system except that, if the current process requires I/O, then that process is moved to another queue (an I/O waiting queue), and the OS selects another process to execute. When the original process finishes with its I/O, it is resumed and the replacement process is moved back into a queue. In this way, lengthy I/O does not cause the CPU to remain idle, and so the system is far more efficient. The idea of surrendering the CPU to perform I/O is referred to as cooperative multitasking. We will revisit this idea below.
There are several different uses for queues in multiprogramming, so we need to draw a distinction between them. There is the ready queue (the queue of processes waiting for the CPU), I/O queues (one for each I/O device), and the waiting queue (the queue of processes that have been requested to be run, but have not yet been moved into the ready queue). The reason that there is a waiting queue is that those processes in the ready queue are already loaded into memory. Because memory is limited in size, there may be processes requested by users that cannot fit, and so they sit in the waiting queue until there is room in the ready queue. There will be room in the ready queue if a process ends and exits that queue, or if many processes have been moved from the ready queue to I/O queues.
The multiprogramming system requires an additional mechanism known as a context switch. A context switch is merely the CPU switching from one process to another. We examined this briefly earlier. Let us take a closer look. In order to switch processes, the CPU must first save the current process’ status and retrieve the next process’ status. Figure 4.4 provides a snapshot of a computer to illustrate the context switch. At this point, process P3 is being executed by the CPU. The PC register stores the address in memory of the next instruction of P3, the IR stores the current instruction of P3, the SP stores the top of P3’s run-time stack in memory, the flags store the status of the last instruction executed, and the data registers store relevant data for P3. The context switch requires that these values be stored to memory. Then, P3 is moved to the appropriate I/O queue in memory, moving process P7 up to the front of the ready queue. Finally, the CPU must restore P7’s status, going to memory and retrieving the stored register values for P7. Now, the PC will store the address in memory of P7’s next instruction, the IR will store P7’s current instruction, the SP will store the top of P7’s run-time stack, the flags will store the status of P7’s last executed instruction, and the data registers will store the data last used by P7. The CPU resumes its fetch–execute cycle, but now on P7 rather than P3. This continues until either P3 is ready to resume or P7 requires I/O or terminates. In the former case, a context switch occurs in which P3 is restored and P7 moved back in the queue, and in the latter cases, the CPU switches from P7 to P0.
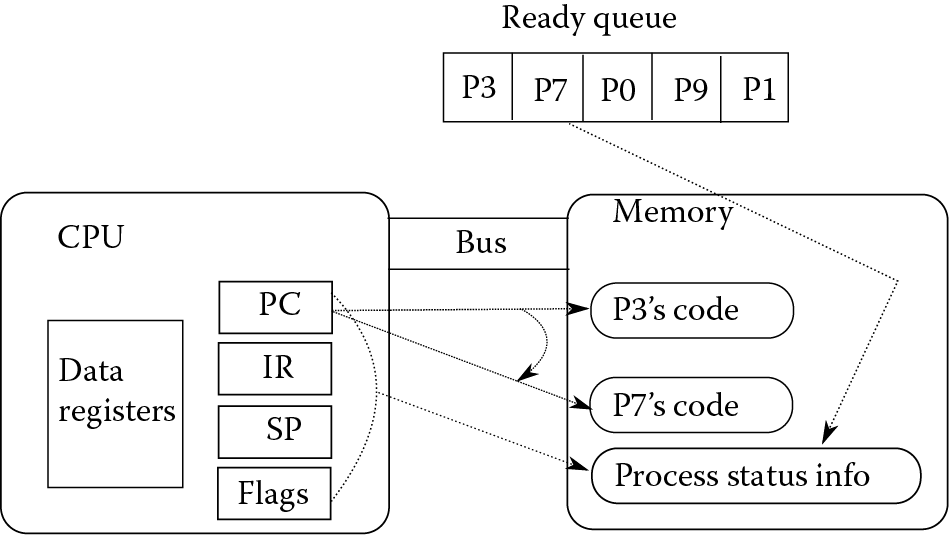
As the context switch requires saving and restoring the context of two processes, it is not instantaneous, but rather is somewhat time consuming. The CPU idles during the switch. Most computers store process status in main memory. Therefore, the context switch requires several, perhaps a dozen to two dozen, memory operations. These are slow compared to CPU speed. If the context switch can store and restore from cache, so much the better. However, some high-performance computers use extra sets of registers for the context switch. This provides the fastest response and thus keeps the CPU idle during the least amount of time. However, in spite of the CPU idle time caused by the context switch, using the context switch in multiprogramming is still far more efficient than letting the CPU idle during an input or output operation.
Multitasking takes the idea of multiprogramming one step further. In multiprogramming, a process is only suspended (forced to wait) when it needs I/O, thus causing the CPU to switch to another process. But in multitasking, a timer is used to count the number of clock cycles that have elapsed since the last context switch started this process. The timer is set to some initial value (say 10,000). With each new clock cycle, the timer is decremented. Once it reaches 0, the timer interrupts the CPU to force it to switch to another process. Figure 4.5, which is a variation of Figure 4.4, demonstrates the context switch as being forced by the timer. The suspending process gets moved to the end of the ready queue and must wait its turn. This may sound like a tremendous penalty for a process, but in fact since modern processors are so fast, a suspended process only waits a few milliseconds at most before it is moved back to the CPU. In multitasking systems, humans will not even notice that a process has been suspended and then resumed because human response time is greater than the millisecond range. Therefore, although the computer appears to be executing several programs simultaneously with multitasking, the truth is that the computer is executed the processes in a concurrent, or overlapping, fashion.
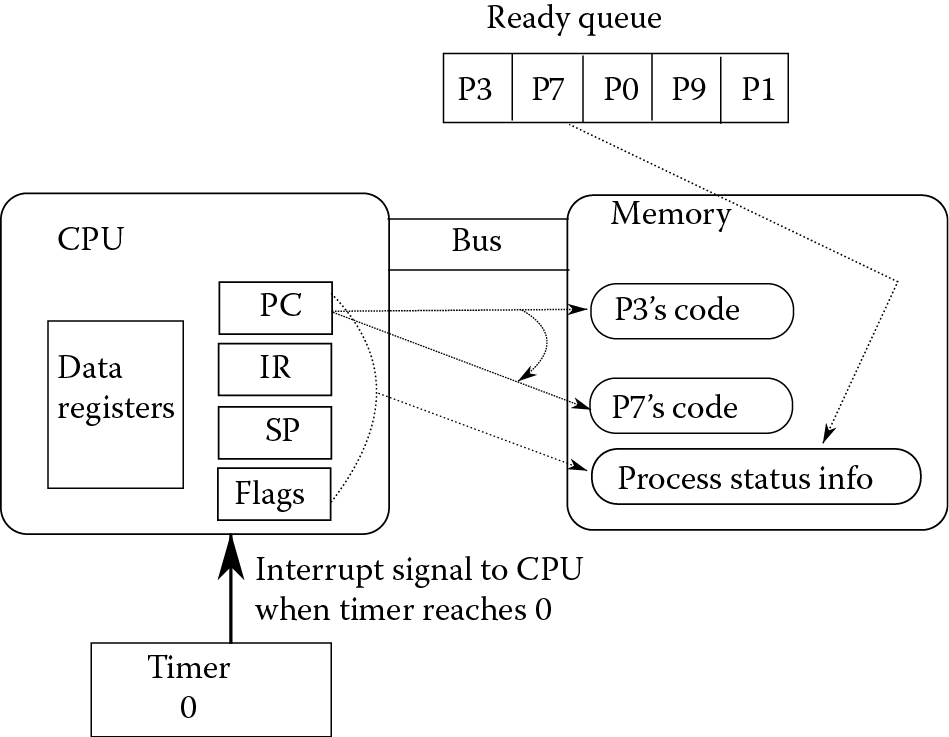
In multitasking, we see two mechanisms by which the CPU will move from one process to another: because the current process is requesting some form of I/O or because the timer has elapsed on this process. Multitasking is more properly considered to be cooperative multitasking when the process voluntarily gives up the CPU. This happens in multiprogramming when the process requires I/O. In the case of the timer causing a context switch, this form of multitasking is called competitive multitasking, or preemptive multitasking. In this case, the process is forced to give up the CPU.
There are other reasons why a process might move itself to another queue or back to the end of the ready queue. One such reason is forced upon a process by the user who moves the process from the foreground to the background. We use the term foreground to denote processes that are either immediately available for user input or currently part of the ready queue. Background processes “sit in the background”. This means that the user is not interacting with them, or is currently waiting until they have another chance at gaining access to the processor. In Windows, for instance, the foreground process is the one whose tab has been selected, the one “on top” of the other windows as they appear in the desktop. In Linux, the same is true of GUI processes. From the command line, a process is in the foreground unless it has been executed using the & command. This is covered in more detail in Process Execution in Chapter 11.
Another reason that a process may voluntarily surrender the CPU has to do with waiting for a rendezvous. A rendezvous occurs when one process is waiting on some information (output, shared datum) from another process. Yet another reason for a process to surrender the CPU is that the process has a low priority and other, higher priority processes are waiting.
The original idea behind multitasking was called time sharing. In time sharing, the process would give up the CPU on its own. It was only later, when OSs began implementing competitive multitasking, that the term time sharing was dropped. Time sharing was first implemented on mainframes in 1957 but was not regularly used until the third generation. By the fourth generation, it was commonplace in mainframes but not in personal computers until the 1980s. In fact, PC Windows OSs before Windows 95 and Mac OS before OS X performed cooperative, but not competitive, multitasking.
Multitasking uses a round-robin scheduling routine. This means that all processes in the ready queue are given their own time with the CPU. The CPU moves on from one process to the next as time elapses. The timer is then reset. Although this is a very fair approach, a user may want one specific process to have more CPU attention than others. To accomplish this, the user can specify a priority for any or every process. Typically, all processes start with the same priority. We will examine setting and changing process priorities in Chapter 11.
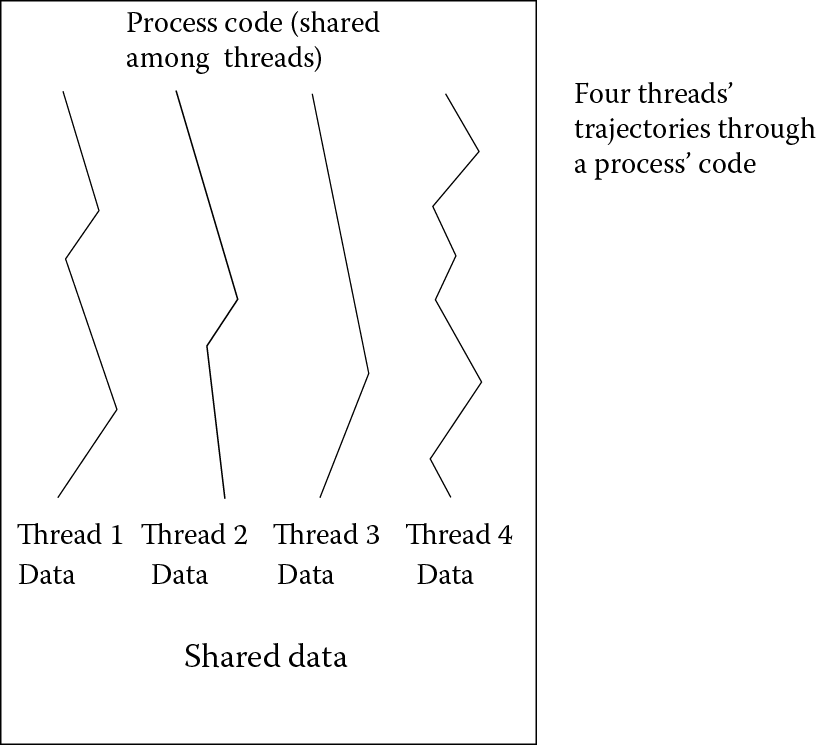
Today, processes can contain multiple running parts, called threads. A thread shares the same resources as another thread. The shared resources are typical shared program code stored in memory, although they can also share data, register values, and status. What differentiates one thread from another is that they will also have their own data. For instance, you might run a Firefox web browser with several open tabs or windows. You are running a single process (Firefox) where each tab or window is its own thread. The only difference between each tab or window is its data. As the threads are of the same program, the OS is running one process but multiple threads. A multitasking system that can switch off between processes and between threads of the same process is known as a multithreaded OS. See Figure 4.6, which illustrates a process of four threads. Each thread makes its own way through the code, and although the four threads share some data, they each have their own separate data as well.
Threads serve another purpose in programming. With threads in a process, the threads can control their and other threads’ availabilities. Consider a process that contains two threads. One thread produces values for a memory buffer. The other consumes values from the buffer. In multithreading, the processor switches off between threads. However, the consumer thread cannot proceed if the buffer is currently empty. This is because there is nothing to consume. Therefore, the consumer thread can force itself to wait until the producer thread signifies that a new datum has become available. On the other hand, the producer thread may force itself to wait if the buffer is full, until the consumer signals that it has consumed something. The two threads can “meet up” at a rendezvous. By forcing themselves to wait, the threads in this example use cooperative multitasking (multithreading) in that they voluntarily give up the processor, as opposed to being forced to surrender the processor when the timer elapses.
Going one step further than the rendezvous, it is important that two threads or processes do not try to access a shared datum at the same time. Consider what might happen if thread 1 is attempting to access the shared buffer and the thread is interrupted by a context switch. It has already copied the next buffer item, but has not had a chance to reset the buffer to indicate that the particular item is now “consumed”. Now, thread 2 is resumed and it attempts to place a datum in the buffer only to find that the buffer is full. It is not actually full because one item has been consumed. Therefore, access to the buffer by thread 2 causes the thread to wait when it should not. Another situation is when the two threads share the same datum. Recall our banking example from earlier in the chapter motivating the use of mutual exclusive access. For threads, again, access to the shared datum must be mutually exclusive. Now, we consider the same example using threads. Thread 1 reads the checking account balance of $1000. Thread 1 is ready to deduct $1000 from it, but is interrupted by the timer. Thread 2 reads the checking account balance, $1000, deducts $1000 from it and stores the new value back, $0. Switching back to thread 1, it has an out-of-date value, $1000. It deducts $1000, stores $0 back. The result is that the value is set to $0, but two different threads deducted $1000. This would corrupt the data.
To ensure proper access to any shared data, the OS must maintain proper synchronization. Synchronization requires that the process or thread is not interrupted while accessing a datum, or that the datum is not accessible once one process or thread has begun accessing it until it has been freed. Multiprogramming, multitasking, and multithreading require synchronization.
The advantage of the multithreaded OS over the multitasking OS is that context switching between threads is faster and more efficient than switching between processes. The reason for this is that the context switch requires fewer operations to store the current thread and restore the next thread than it does to store and restore processes. Imagine, referring back to Figure 4.5, that process P7’s code has been moved out of memory and back to virtual memory (swap space). A context switch between P3 and P7 would be somewhat disastrous as the OS would not only have to store P3’s status and restore P7’s status, but also would have to load some pages of P7 from disk to memory. This will not happen when switching between threads. Assume that P3 and P7 are threads of the same process. The context switch between them requires far less effort and therefore is much quicker.
Most computers, up until recently, were known as single-processor systems. That is, they had only a single CPU. With one CPU, only one process or thread could be actively executing at any time. In multiprogramming, multitasking, and multithreading, several processes (or threads) could be active, but the CPU would only be executing one at any given time. Thus, concurrent execution was possible using any of these modes of process execution, but not true parallel processing. In multiprocessing, a computer has more than one CPU. If a computer, for instance, had two processors, it could execute two processes or threads simultaneously, one per processor. Today, most computers are being produced with multiple processors.
The more traditional form of multiprocessor system was one that contained more than one CPU chip. Such computers were expensive and few personal computers were multiprocessor systems. However, with the continued miniaturization seen over the past decade, enough space has been made available in a single CPU to accommodate multiple cores. Thus, modern processors are referred to as dual or quad core processors. Each core is, in effect, a processor; it has its own ALU (arithmetic/logic unit), control unit, registers, and cache. The only thing it shares with the other processors on the chip are the pins that attach the entire set of cores to the computer’s system bus.
Parallel processing presents an opportunity and a challenge. The opportunity is to execute multiple processes simultaneously. For instance, one core might execute a web browser process while another might execute an entertainment program such as a video or mp3 player. The challenge, however, is to ensure that each core is being used as much as possible. If the user is only running one process, could that process somehow be distributed to the multiple cores such that each core executes a separate portion of the process? This requires a different mindset when writing program code. A programmer may try to separate the logic of the program from the computer graphics routines. In this way, one core might execute the logic and the other core the computer graphics routines. The idea of distributing the processing over multiple processors is known as parallel programming, and it remains one of the greater challenges open to programmers today.
We wrap up this section by comparing some of the approaches to process management described in this section. Imagine that you want to run three programs called p1, p2, p3. We will see how they run on a single tasking system, batch system, multiprogramming system, and multitasking system.
In single tasking, p1 is executed until it completes, and then p2 is run, and then p3 is run. This is not very satisfying for the user because you are unable to do multiple things at a time (for instance, you might be editing a paper, searching the Internet for some references, and answering email—you do not do them simultaneously, as you do not have them all running at the same time). You cannot copy and paste from one program to another either, because one program completes before the next starts.
In batch processing, the execution of the three processes is almost identical to single tasking. There are two changes. First, since batch processing foregoes any interaction with the user, all input must be supplied with the program and any output is performed only after execution concludes. Second, a separate processing system might be used to schedule the three processes as they are added to a waiting queue. Scheduling might be first come first serve, priority, shortest job first, or some other form.
In multiprogramming, the computer would run p1 until either p1 terminated or p1 needed to perform I/O. At this point, the OS would move p1 to a waiting queue and start p2. Now p2 will run until either p2 needs I/O, p2 terminates, or p1 is ready to resume. If p2 needs I/O or terminates, then the OS would start p3. If p1 becomes ready, p1 is resumed and p2 is forced to wait. Whereas in multiprogramming, input and output can be done on demand, as opposed to batch, multiprogramming may not give the user the appearance of interaction with the computer as processes are forced to wait their turn with the CPU and I/O devices.
In multitasking, we truly get an overlapped execution so that the user cannot tell that the CPU is switching between processes. For multitasking, the process works like this:
- Load p1, p2, p3 into memory (or as much of each process as needed)
- Repeat
- Start (or resume) p1 and set the timer to a system preset amount (say 10,000 cycles)
- Decrement the timer after each machine cycle
- When the timer reaches 0, invoke the OS
- The OS performs a context switch between p1 and p2
- The context switch requires saving p1’s status and register values and restoring p2’s status and register values, possibly also updating memory as needed
- Repeat with p2
- Repeat with p3
- Until all processes terminate
If any of p1, p2, and p3 were threads of the same process, then multithreading would be nearly identical to multitasking except that the context switch would be less time consuming.
Booting and System Initialization
Main memory is volatile, that is, it requires a constant power supply to retain its contents. Shut off the power and main memory becomes empty (all of its contents become 0s). After shutting the computer down, memory is empty. The next time you turn on the computer, memory remains empty. This is important because, in order to use the computer, you need to have the OS loaded into memory and running. The OS is the program that will allow us to load and run other programs. This presents a paradoxical situation: how can we get the OS loaded and running when it is the OS that takes care of loading and running programs for us and the OS is not in memory when we first turn the computer on? We need a special, one-time process, called booting.†
The boot process operates as follows:
- The CPU initializes itself (initializes its registers) and sends out control signals to various components in the computer system.
- The basic I/O system (BIOS) performs a power-on self-test (POST) where it checks memory and tests devices for responses. It may also perform such tasks as to set the system clock, enable or disable various hardware components, and communicate with disk controllers.
- The hard disk controllers (SCSI first, then IDE) are signaled to initialize themselves, other devices are tested, network card, USB, etc.
- BIOS determines where the OS is stored. This is usually done by testing each of these devices in a preset order looking for the OS until it is found: floppy disk, CD-ROM, first disk drive, second disk drive, or network.
- If your computer has multiple OSs, then a boot loader program is run to determine which OS to load and run. Two programs used to dual boot in Windows and Linux are GRUB (Grand Unified Boot loader) and LILO (Linux Loader).
- The OS kernel is loaded from disk into memory. The kernel represents the portions of the OS that must be in memory to use the computer, or the core components of the OS.
- At this point, control moves from the boot program to the OS kernel, which then runs initialization scripts to finish the boot process. Initialization scripts are exactly what they sound like, shell scripts that, when run, initialize various aspects of the OS.
- (a) Linux begins by running the program init. Its primary job is to start the OS in a particular run-level, such as text-only, text-with-network, graphics, or graphics-with-network. Once the level has been selected, the program runs other scripts such as the rc.sysinit script. This script, based on the run level, starts up various services. For instance, if the system starts in a level with network availability, then the network services must be started.
- (b) In Windows, one of the decisions is whether to start the OS in safe mode or full user mode. Safe mode is a diagnostic mode primarily used so that a system administrator can remove malicious software without that software making copies of itself or moving itself. Another task of initialization is to determine if a secure login is necessary and if so, bring up a log in window. One of the last steps of initialization is to start up a user-specific shell based on who logged in.
The boot process is a program. However, it cannot reside in RAM since, when the computer is turned on, RAM is empty. Since the boot process does not change, we will store it in ROM, which is nonvolatile since its contents are permanently fixed into place. However, since ROM tends to be expensive, and since portions of the boot process need to be flexible, we can store portions of the boot program, such as the boot loader program and parts of the BIOS, on hard disk.
Administrator Account
In order to perform system-oriented operations, most OSs have a set of privileged instructions. For instance, to create new user accounts, test for security holes, and manipulate system files you must have administrator access. Most OSs have two types of accounts, user accounts, and administrator accounts.‡ The administrator account is sometimes referred to as root or superuser. The administrator account comes with an administrator password that only a few should know to prevent the casual user from logging in as administrator and doing something that should not be done.
In Windows, the account is called Administrator. To switch to Administrator, you must log in as Administrator, entering the proper password. In Linux, the account is called root. To change to the root, you use the su command (switch user). Typically, su is used to change from one user account to another by saying su username. The OS then requires the password for username. If you do su without the username, then you are requesting to change to root. Because you can run su from the command line prompt, you do not have to log out. In fact, you can open numerous windows, some of which are controlled as you, the user, and some as root.
The administrator account is the owner for all of the system software and some of the applications software. In Linux, an ls –l (long listing) of directories such as /sbin, /bin, /usr/bin, and /usr/sbin will demonstrate that many of the programs and files are owned by root. In many cases, root is the only user that can access them. In other cases, root is the only user that can write to or execute them but others can view them. For instance, you must be root to run useradd and userdel so that only the system administrator(s) can add and delete user accounts. The root account in Linux is also peculiar in that root’s home directory is not in the same partition as the users’ home directories. User home directories are typically under /home/username, whereas root is under /root.
As an IT person, you should always be aware of when you are logged in as an administrator and when you are not. In Linux, you can differentiate between the two by looking at the prompt in the command line. The root prompt in Linux is typically # and the user prompt is typically $ (unless you alter it). You can also find out who you are in Linux by using the command whoami. You might wonder why it is important to remember who you are, but you do not want to issue certain commands as root casually. For instance, if you are a user and you want to delete all of the files in a directory, including any subdirectories, you might switch to that directory and issue rm –rf *. This means “remove all files recursively without asking permission”. By “recursively” deleting files, it also deletes all subdirectories and their files and subdirectories. If you are in the wrong directory, the OS will probably tell you that it is not able to comply because you do not own the files. But if you are in the wrong directory AND you are root, then the OS performs the deletion and now you have deleted the wrong files by mistake. You may think that you will have no trouble remembering who you are, but in fact there will be situations where you will log into one window as root and another as yourself in order to change OS settings (as root) and test those changes out (as a normal user).
Installing an OS
When you purchase most computers today, they have a preinstalled OS. Some users may wish to install a different OS, or because of such situations as computer virus infections, deleted files, or obsolete OSs, a user may wish to reinstall or upgrade an OS. In addition, adding an OS does not necessarily mean that the current OS must be replaced or deleted.
A user may install several OSs, each in its own disk partition, and use some boot loading program such as GRUB, LILO, and BOOTMGR. When the computer first boots, the four hardware initialization steps (See the section Booting and System Initialization) are performed. Step 5 is the execution of the bootloader program, which provides a prompt for the user to select the OS to boot into. Once selected, the boot process loads the selected OS, which is then initialized, and now the user is able to use the computer in the selected OS. To change OSs, the user must shut down the current OS and reboot to reach the bootloader program. Loading multiple OSs onto a computer can lead to difficulties especially when upgrading one of the OSs or attempting to repartition the hard drive. Another way to have access to multiple OSs is to use VMs. The VM is in essence a self-contained environment into which you can install an OS. The VM itself is stored as data on the hard disk until it is executed. Therefore, the VM only takes up disk space. If your computer has an older processor, it is possible that executing a VM will greatly slow down your computer, but with modern multicore processors available, VMs can run effectively and efficiently. This also allows you to have two (or more) OSs open and running at the same time, just by moving in and out of the VM’s window. With VM software, you can create multiple VMs and run any or all of them at the same time.
The remainder of this section discusses how to install two OSs, Red Hat Linux (specifically, CentOS 5.5), and Windows 7. It is recommended that if you attempt either installation, that you do so from within a VM. There are commercial and free VM software products available such as VMWare’s VMWare Client, VMWare Player, VMWare Server, and vSphere, and Sun’s VirtualBox (or VBox).
Installing Windows
To install Windows 7, you start by inserting a Windows 7 CD into your optical drive and then booting the computer. As your computer is set up to boot to an OS on hard disk, unless your computer has no prior OS, you will have to interrupt the normal boot process. This is done, when booting, by pressing the F12 function key.§ It is best to press the key over and over until you see your computer respond to it. This takes you to the boot options, which is a list of different devices that can be booted from. Your choices are typically hard disk, optical disk, network, USB device, and possibly floppy disk. Select the optical disk. The optical disk will be accessed and the installation process begins.
In a few moments, you will be presented with the first of several Windows 7 installation dialogs. The typical installation requires only selecting the default (or recommended) settings and clicking on Next with each window. Early on, you will be asked to select the language to install (e.g., English), time and currency format, and input/keyboard type (e.g., US). Then, you will be prompted to click on the Install Now button (this will be your only option to proceed). You will be asked to accept the licensing terms.
You are then given options for a custom installation or an upgrade. You would select upgrade if you already had a version of Windows 7 installed and were looking to upgrade the system. This might be the case, for instance, if your Windows 7 were partially damaged or years out of date. The custom installation does not retain any previous files, settings, or programs, whereas upgrade retains them all. The custom installation can also allow you to change disks and partitioning of disks. You are then asked where windows should be installed. If you have only a single hard disk drive, there is no choice to make.
From this point, the installer will run for a while without interruption or need for user input (perhaps 10 to 20 minutes depending on the speed of your optical drive and processor). During this time, Windows will reboot several times. When prompted again, you will be asked to create an initial account and name your computer. The default name for the computer is merely the account name you entered followed by –PC. For instance, if you specify the name Zappa, then the computer would default to Zappa-PC. You can, of course, change the default name. The next window has you finish the account information by providing an initial password for the account along with a “hint” in case you are prone to forgetting the password. This initial account will allow the user to immediately begin using the computer without requiring that an Administrator create an account.
Before proceeding, Windows now requests a product key. This is a code that is probably on the CD packaging. The key will be a combination of letters and numbers and be 25 characters long. This ensures that your version of Windows is authorized and not pirated.
The next step is for Windows to perform automated updates. Although this step is optional, it is highly useful. It allows your installation to obtain the most recent patches of the Windows 7 OS. Without this step, you would be limited to installing the version of the OS as it existed when the CD was manufactured. If you choose to skip this step, Windows would install the updates at a later time, for instance, the first time you attempt to shut down your computer.
After updates are installed, you set the time zone and have the option of adjusting the date and time. Finally, you are asked to specify the computer’s current location, which is in essence selecting a network for your computer to attempt to connect to. Your options are Home network, Work network, and Public network. This is an option that you can reset at a later time. Once selected, your computer will try to connect to the network. Finally, your desktop is prepared and the OS initializes into user mode. You are ready to go!
Although you are now ready to use your computer, Windows booted with settings that were established by the Windows programmers. At this point, if you wish to make changes to your desktop, you should do so through the Control Panel. You may, for instance, change the style of windows, the desktop background, the color settings used, the resolution of the screen, and the size of the desktop icons. You can also specify which programs should be pinned to the taskbar that runs along the bottom of the desktop, and those that should appear at the top of the programs menu. You should also ensure that your network firewall is running.
Installing Windows 7 is easy and not very time consuming. From start to finish, the entire installation should take less than an hour, perhaps as little as 30 minutes.
Installing Linux
Similar to Windows 7, installing Red Hat Linux can be done through CD. Here, we assume that you have a CentOS 5.5 installation CD. The installation is more involved than with Windows and requires an understanding of concepts such as disk partitioning (disk partitions are described in Chapter 5).
Upon booting from the installation CD, you will be presented with a screen that has several installation options such as testing the media (not really necessary unless you have created the install CD on your own) and setting the default language.
Now you reach the disk partitioning step. In a new install, it is likely that the hard disk is not partitioned and you will have to specify the partitions. If you are installing Linux on a machine with an existing OS, you will have to be careful to partition a free disk. Note that this does not necessarily require two or more hard disk drives. The “free disk” is a logical designation and may be a partition that is not part of the other OS. If partitions already exist that you want to remove, you must select “Remove Linux partitions on selected drives and create default layout” and select the “Review and modify partitioning layout” checkbox.
Here, you must specify the partitions of your Linux disk. You will want to have different partitions for each of the root partition, the swap space, and the user directories. You may want a finer group of partitions by, for instance, having a partition for /var and for /usr; otherwise, these directories will be placed under root. For each partition, you must select the mount point (the directory) or the file system (for swap), the size of the partition, and whether the partition should be fixed in size, or fill the remaining space available. As an example, you might partition your Linux disk as follows:
- Mount Point: select /(root), size of 4000 (i.e., is 4 GB), fixed size
- Mount Point: select /var, size of 1000, fixed size
- File System Type: swap (do not select a Mount Point), size of 1000, fixed size
- Mount Point: select /home, fill to maximum allowable size
At this next screen, you will be asked for a boot loader. GRUB is the default and should be selected and installed on the main hard disk, which is probably /dev/sda1. For network devices, you need to specify how an IP address is to be generated. The most common technique is to have it assigned by a server through DHCP. The last question is to select your time zone.
You are asked to specify the root password of the system. This password will be used by the system administrator every time a system administration chore is required such as creating an account or installing software. You want to use a password that you will not forget.
At the next screen, you can specify what software should automatically be installed with CentOS. Desktop—Gnome should already be selected. You may select other software at this point, or Customize Later. The installation is ready to begin. This process usually takes 5 to 10 minutes. When done, you will be prompted to reboot the system. Once rebooted, you finalize the installation process. This includes setting up the initial firewall settings (the defaults will probably be sufficient) and whether you want to enforce SELinux (security enhanced). Again, the default (enforcing) is best. You are able to set the date and time. Finally, you are asked to create an initial user account, much like with Windows. This account is required so that, as a user, you can log into the GUI. It is not recommended that you ever log in to the GUI as root. Unlike Windows, you do not have to reboot at this point to start using the system; instead, you are taken to a log in window and able to proceed from there by logging in under the user account just created.
Further Reading
As with computer organization, OS is a required topic in computer science. There are a number of texts, primarily senior-level or graduate reading. Such texts often discuss OS tasks such as process management, resource management, and memory management. In addition, some highlight various OSs. The following texts target computer science students, but the IT student could also benefit from any of these texts to better understand the implementation issues involved in designing OSs.
- Elmasri, R., Carrick, A., and Levine, D. Operating Systems: A Spiral Approach. New York: McGraw Hill, 2009.
- Garrido, J. and Schlesinger, R. Principles of Modern Operating Systems. Sudbury, MA: Jones and Bartlett, 2007.
- Silberschatz, A., Galvin, P., and Gagne, G. Operating System Concepts. Hoboken, NJ: Wiley & Sons, 2008.
- Stallings, W. Operating Systems: Internals and Design Principles. Upper Saddle River, NJ: Prentice Hall, 2011.
- Tanenbaum, A. Modern Operating Systems. Upper Saddle River, NJ: Prentice Hall, 2007.
For the IT student, texts specific to Linux, Windows, Unix, and Mac OS will be essential. These texts typically cover how to use or administer the OS rather than the theory and concepts underlying OSs. Texts range from “for dummies” introductory level texts to advanced texts for system administrators and programmers. A few select texts are listed here for each OS. Many of these texts also describe how to install the given OS.
- Adelstein, T. and Lubanovic, B. Linux System Administration. Sebastopol, CA: O’Reilly Media, 2007.
- Bott, E., Siechert, C., and Stinson, C. Windows 7 Inside Out. Redmond, WA: Microsoft Press, 2009.
- Elboth, D. The Linux Book. Upper Saddle River, NJ: Prentice Hall, 2001.
- Frisch, E. Essential System Administration. Cambridge, MA: O’Reilly, 2002.
- Fox, T. Red Hat Enterprise Linux 5 Administration Unleashed. Indianapolis, IN: Sams, 2007.
- Helmke, M. Ubuntu Unleashed. Indianapolis, IN: Sams, 2012.
- Hill, B., Burger, C., Jesse, J., and Bacon, J. The Official Ubuntu Book. Upper Saddle River, NJ: Prentice Hall, 2008.
- Kelby, S. The Mac OS X Leopard Book. Berkeley, CA: Peachpit, 2008.
- Nemeth, E., Snyder, G., Hein, T., and Whaley, B. Unix and Linux System Administration Handbook. Upper Saddle River, NJ: Prentice Hall, 2010.
- Russinovich, M., Solomon, D., and Ionescu, A. Windows Internal. Redmond, WA: Microsoft Press, 2009.
- Sarwar, S. and Koretsky, R. Unix: The Textbook. Boston, MA: Addison Wesley, 2004.
- Sobell, M. A Practical Guide to Linux Commands, Editors, and Shell Programming. Upper Saddle River, NJ: Prentice Hall, 2009.
- Wells, N. The Complete Guide to Linux System Administration. Boston, MA: Thomson Course Technology, 2005.
- Wrightson, K. and Merino, J., Introduction to Unix. California: Richard D. Irwin, 2003.
There are also thousands of websites set up by users and developers, and many are worth exploring.
Virtualization and VMs are becoming a very hot topic although the topic is too advanced for this text. Books again range from “for dummies” books to texts on cloud computing. Three references are listed here:
- Golden, B. Virtualization for Dummies. Hoboken, NJ: Wiley and Sons, 2007.
- Hess, K., and Newman, A. Practical Virtualization Solutions. Upper Saddle River, NJ: Prentice Hall, 2010.
- Kusnetzky, D. Virtualization: A Manager’s Guide. Massachusetts: O’Reilly, 2011.
Review Terms
Terminology from this chapter
Background Initialization
Batch Initialization script
BIOS Interactivity
Booting Interrupt
Boot Loader Interrupt handler
Command line I/O queue
Competitive multitasking Kernel
Concurrent processing Memory management
Context switch Memory violation
Cooperative multitasking Multiprocessing
Deadlock Multiprogramming
Device driver Multitasking
File system management Multithreading
Foreground Mutually exclusive
Nonvolatile memory Security
Page Shell
Page fault Single tasking
Page table Swap space
Process Swapping
Process management Synchronization
Process status Thread
Program Timer
Protection User account
Queue User interface
Ready queue Utility program
Rendezvous Virtual machine
Resource management Virtual memory
Root Volatile memory
Root account Waiting queue
Round-robin scheduling
Review Questions
- In what way does the OS support convenient access for a user?
- What does the OS help a user control?
- What components of an operating system are always in memory?
- Why might a user prefer to use a command line for input over a GUI?
- What types of status can a process have?
- What is an interrupt and when might one arise?
- What types of situations might cause a disk drive to raise an interrupt? The keyboard?
- Why might a USB flash drive raise an interrupt?
- Aside from hardware, programs can raise interrupts. Provide some examples of why a program might raise an interrupt. Note: if you are familiar with a programming language such as C++ or Java, an interrupt can trigger an exception handler. This might help you more fully answer this question.
- When does the CPU check for an interrupt? What does the CPU do immediately before handling an interrupt?
- In virtual memory, what is swapped into and out of memory? Where is virtual memory stored?
- Given the following page table for some process, X, which of X’s pages are currently in memory and which are currently not in memory? Where would you look for page 4? For page 5?
Process X Page Table
Page
Memory Frame
Valid Bit
0
12
1
1
3
1
2
–
0
3
–
0
4
9
1
5
–
0
6
–
0
7
2
1
- What happens if a memory request is of a page that is not currently in memory?
- Why is swapping a slow process?
- If a resource’s access is not synchronized, what could happen to the resource?
- If a resource does not require mutually exclusive access, can it be involved in a deadlock?
- Assume a deadlock has arisen between processes P0 and P1. What has to happen before either process can continue?
- If a deadlock arises, what are the choices for the user?
- What is the difference between the OS roles of protection and security?
- What is the difference between single tasking and batch processing?
- What is the difference between batch processing and multiprogramming?
- What is the difference between multiprogramming and multitasking?
- What is the difference between multitasking and multithreading?
- What is the difference between competitive and cooperative multitasking?
- Why might you use shortest job first as a scheduling algorithm?
- What is the difference between placing a process in the waiting queue versus the ready queue?
- What does the CPU do during a context switch?
- What changes when a context switch occurs?
- Why are context switches more efficient between threads than processes?
- What is the difference between a process in the foreground and a process in the background?
- What are the steps of a boot process?
- Why is the boot program (at least in part) stored in ROM instead of RAM or the hard disk?
- What is BIOS and what does it do?
- What is an initialization script? Provide an example of what an initialization script does.
- Why should a system administrator log in to a computer running a GUI environment as his/herself and then switch to the administrator account instead of logging in directly as the administrator?
Discussion Questions
- Are you a fan of entering OS commands via the command line instead of using a GUI? Explain why or why not.
- What are the advantages and disadvantages of using the command line interface for an ordinary end user? What are the advantages and disadvantages of using the command line interface for a system administrator?
- Are you more likely to use the command line in Windows or Linux, both, or neither? Why?
- As an end user, how can an understanding of concepts such as virtual memory, process management, deadlock, protection, and security help you?
- Identify specific situations in which understand operating system concepts will be essential for a system administrator.
- Consider a computer without an interrupt system. In such a system, if a program is caught doing something that you do not want it to (e.g., an infinite loop), you would not be able to stop it by closing the window or typing control-c or control-alt-delete. What other things would your computer not do if it did not have an interrupt system?
- As a user, do you need to understand concepts such as a context switch, cooperative multitasking, competitive multitasking, and multithreading? Explain.
- As a system administrator, do you need to understand concepts such as a context switch, cooperative multitasking, competitive multitasking, and multithreading? Explain.
- As a system administrator, do you need to understand concepts of threads, synchronization, and rendezvous? Explain.
- Rebooting a computer starts the operating system in a fresh environment. However, booting can be time consuming. If you are a Windows user, how often do you reboot? How often would you prefer to reboot? Under what circumstances do you reboot your computer?
- You are planning on purchasing a new computer. In general, you have two choices of platform, Mac or Windows. You can also install other operating systems. For instance, it is common to install Linux so that your computer can dual boot to either Windows or Linux. Alternatively, you could wipe the disk and install Linux. How would you decide which of these to do? (Mac, Windows, dual boot, Linux, other?)
* What is the plural of OS? There are several options, I chose OSs out of convenience, but some people dislike that because OSS stands for Open Source Software. Other people advocate OSes, OS’s, and operating systems. For a discussion, see http://weblogs.mozillazine.org/gerv/archives/007925.html.
† The term booting comes from the word bootstrapping, which describes how one can pull himself up by his own bootstraps, like a fireman when he gets up in the middle of the night in response to a fire alarm. The term itself is attributed to the tales of Baron Munchhausen.
‡ There are some operating systems that have more than two levels of accounts. In the MULTICS operating system for instance, there are eight levels of access, with each higher level gaining more access rights.
§ The actual function key may differ depending on your particular manufacturer. Instructions appear during system booting to tell you which function key(s) to use.