
Chapter 14
Programming
IT administrators will often have to write shell scripts to support the systems that they maintain. This chapter introduces the programming task. For those unfamiliar with programming, this chapter covers more than just shell scripting. First, the chapter reviews the types of programming languages, which were first introduced in Chapter 7. Next, the chapter describes, through numerous examples, the types of programming language instructions found in most programming languages: input and output instructions, assignment statements, selection statements, iteration statements, subroutines. With this introduction, the chapter then turns to scripting in both the Bash interpreter language and DOS, accompanied by numerous examples.
The learning objectives of this chapter are to
- Describe the differences between high level language and low level programming.
- Discuss the evolution of programming languages with an examination of innovations in programming.
- Introduce the types of programming language instructions.
- Introduce through examples programming in both the Bash shell and DOS languages.
In this chapter, we look at programming and will examine how to write shell scripts in both the Bash shell and DOS.
Types of Languages
The only types of programs that a computer can execute are those written in the computer’s machine language. Machine language consists of instructions, written in binary, that directly reference the computer processor’s instruction set. Writing programs in machine language is extremely challenging. Fortunately though, programmers have long avoided writing programs directly in machine language because of the availability of language translators. A language translator is a program that takes one program as input, and creates a machine language program as output. Each language translator is tailored to translate from one specific language to the machine language of a given processor. For instance, one translator would be used to translate a C program for a Windows computer and another would be used to translate a C program for a Sun workstation. Similarly, different translator programs would be required to translate programs written in COBOL (COmmon Business-Oriented Language), Ada, or FORTRAN.
There are three types of language translators, each for a different class of programming language. These classes of languages are assembly languages, high level compiled languages, and high level interpreted languages. The translators for these three types of languages are called assemblers, compilers, and interpreters, respectively.
Assembly languages were developed in the 1950s as a means to avoid using machine language. Although it is easier to write a program in assembly language than in a machine language, most programmers avoid assembly languages as they are nearly as challenging as machine language programming. Consider a simple C instruction
for(i=0;i<n;i++)
a[i]=a[i]+1;
which iterates through n array locations, incrementing each one. In assembly (or machine) language, this simple instruction would comprise several to a few dozen individual instructions. Once better languages arose, the use of assembly language programming was limited to programmers who were developing programs that required the most efficient executable code possible (such as with early computer games). Today, almost no one writes assembly language programs because of the superiority of high level programming languages.
High level programming languages arose because of the awkwardness of writing in machine or assembly language. To illustrate the difference, see Figure 14.1. In this figure, a program is represented in three languages: machine language (for a fictitious computer called MARIE), assembly language (again, in MARIE), and the C high level programming language. Notice that the C code is far more concise. This is because many tasks, such as computing a value (e.g., a = b – 1) require several steps in machine and assembly languages but only one in a high level language. Also notice that every assembly language instruction has an equivalent machine language instruction, which is why those two programs are of equal size.
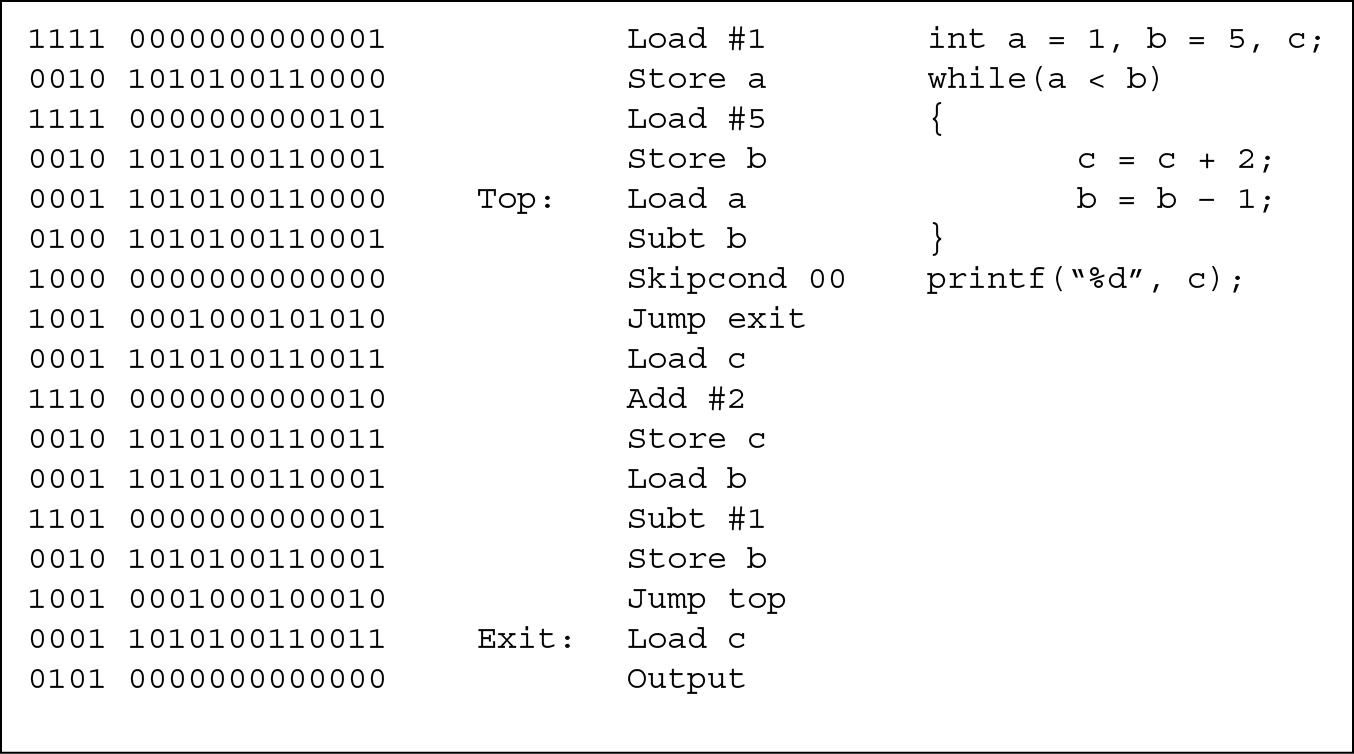
A simple program written in machine language (leftmost column), assembly language (center column), and C (rightmost column).
High level programming languages come in one of two types, compiled languages and interpreted languages. In both cases, the language translator must translate the program from the high level language to machine language. In a compiled language, the language translator, called a compiler, translates the entire program at one time, creating an executable program, which can be run at a later time. In an interpreted language, the program code is written in an interpreted environment. The interpreter takes the most recently entered instruction, translates it into machine language, and executes it. This allows the programmer to experiment while developing code. For example, if the programmer is unsure what a particular instruction might do, the programmer can enter the instruction and test it. If it does not do what was desired, the programmer then tries again. The interpreted programming process is quite different from the compiled programming process as it is more experimental in nature and developing a program can be done in a piecemeal manner. Compiled programming often requires that the entire program be written before any of it can be compiled and tested.
Most of the high level languages fell into the compiled category until recently. Scripting languages are interpreted, and more and more programmers are using scripting languages. Although interpreted programming sounds like the easier and better approach, there is a large disadvantage to interpreted programming. Once a program is compiled, the chore of language translation is over with and therefore, executing the program only requires execution time, not additional translation time. To execute an interpreted program, every instruction is translated first and then executed. This causes execution time to be lengthier than over a similarly compiled program. However, many modern interpreted languages have optional compilers so that, once complete, the program can be compiled if desired.
Another issue that arises between compiled and interpreted programming is that of software testing. Most language compilers will find many types of errors at the time a program is being compiled. These are known as syntax errors. As a programmer (particularly, a software engineer), one would not want to release software that contains errors. One type of error that would be caught by a compiler is a type mismatch error. In this type of error, the program attempts to store a type of value in a variable that should not be able to store that type, or an instruction might try to perform an operation on a variable that does not permit that type of operation. Two simple examples are trying to store a fractional value with a decimal point into an integer variable and trying to perform multiplication on a string variable. These errors are caught by the compiler at the time the program is compiled. In an interpreted program, the program is not translated until it is executed and so the interpreter would only catch the error at run-time (a run-time error), when it is too late to avoid the problem. The user, running the interpreted program, may be left to wonder why the program did not run correctly.
A run-time error is one that arises during program execution. The run-time error occurs because the computer could literally not accomplish the task at hand. A common form of run-time error is an arithmetic overload. This happens when a computation results in a value too large to place in to the designated memory location. Another type of run-time error arises when the user inputs an inappropriate value, for instance, entering a name when a number is asked for.
The type mismatch error described above is one that can be caught by a compiler. But if the language does not require compilation, the error is only caught when the particular instruction is executed, and so it happens at run time.
A third class of error is a logical error. This type of error arises because the programmer’s logic is incorrect. This might be something as trivial as subtracting two numbers when the programmer intended to add two numbers. It can also arise as a result of a very complicated code because the programmer was unable to track all of the possible outcomes.
Let us consider an example that illustrates how challenging it is to identify a logical error from the code. The following code excerpt is from C (or C++ or Java).
int x = 5;
float y;
y = 1/x;
The code first declares two variables, an integer x and a floating point (real) y. The variable x is initialized with the number 5. The third instruction computes 1/x and stores the result in y. The result should be the value 1/5 (0.2) stored in y. This should not be a problem for the computer since y is a float, which means it can store a value with a decimal point (unlike x). However, the problem with this instruction is that, in C, C++, and Java, if the numerator and the denominator are both integers, the division is an integer division. This means that the quotient is an integer as well. Dividing 1 by 5 yields the value 0 with a remainder of 1/5. The integer quotient is 0. So y = 1/x; results in y = 0. Since y is a float, the value is converted from 0 to 0.0. Thus, y becomes 0.0 instead of 0.2! Logical errors plague nearly every programmer.
A Brief Examination of High Level Programming Languages
Programming languages, like computer hardware and operating systems, have their own history. Here, we take a brief look at the evolution of programming languages, concentrating primarily on the more popular high level languages of the past 50 years.
The earliest languages were native machine languages. Such a language would look utterly alien to us because the instructions would comprise only 1s and 0s of binary, or perhaps the instructions and data would be converted into octal or hexadecimal representations for somewhat easier readability. In any event, no one has used machine language for decades, with the exception of students studying computer science or computer engineering. By the mid 1950s, assembly languages were being introduced. As with machine languages, assembly languages are very challenging.
Starting in the late 1950s, programmers began developing compilers. Compilers are language translators that translate high level programming languages into machine language. The development of compilers was hand in hand with the development of the first high level programming languages. The earliest high level language, FORTRAN (FORmula TRANslator) was an attempt to allow programmers who were dealing with mathematical and scientific computation a means to express a program as a series of mathematical formulas (thus the name of the language) along with input and output statements. Most programmers were skeptical that a compiler could produce efficient code, but once it was shown that compilers could generate machine language code that was as efficient as, or more efficient than, that produced by humans, FORTRAN became very popular.
FORTRAN, being the first high level language, contained many features found in assembly language and did not contain many features that would be found in later languages. One example is FORTRAN’s reliance on implicit variable typing. Rather than requiring that the programmer declare variables by type, the type of a variable would be based on the variable’s name. A variable with a name starting with any letter from I to N would be an integer and any other variable would be a real (a number with a decimal point). Additionally, FORTRAN did not contain a character type so you could not store strings, only numbers. Variable names were limited to six characters in length. You could not, therefore, name a variable income_tax.
FORTRAN did not have a useful if-statement, relying instead on the use of GO TO statements (a type of unconditional branching instruction). Unconditional branches are used extensively in machine and assembly language programming. In FORTRAN, the GO TO permits the programmer to transfer control of the program from any location to another. We will examine an example of this later in this section. Because of the GO TO rather than a useful if-statement, FORTRAN code would contain logic that was far more complex (or convoluted) than was necessary. In spite of its drawbacks, FORTRAN became extremely popular for scientific programming because it was a vast improvement over assembly and machine language.
As FORTRAN was being developed, the Department of Defense began working with business programmers to produce a business-oriented programming language, COBOL (COmmon Business-Oriented Language). Whereas FORTRAN often looked much like mathematical notation, COBOL was expressed in English sentences and paragraphs, although the words that made up the sentences had to be legal COBOL statements, written in legal COBOL syntax. The idea behind a COBOL program was to write small routines, each would be its own paragraph. Routines would invoke other routines. The program’s data would be described in detail, assuming that data would come from a database and output would be placed in another database. Thus, much of COBOL programming was the movement and processing of data, including simple mathematical calculations and sorting. COBOL was released a couple of years after FORTRAN and became as successful as FORTRAN, although in COBOL’s case, it was successful in business programming.
COBOL also lacked many features found in later languages. One major drawback was that all variables were global variables. Programs are generally divided into a number of smaller routines, sometimes referred to as procedures, functions, or methods. Each routine has its own memory space and variables. In this way, a program can manipulate its local variables without concern that other routines can alter them. Global variables violate this idea because a variable known in one location of the program, or one routine, is known throughout the program. Making a change to the variable in one routine may have unexpected consequences in other routines.
COBOL suffered from other problems. Early COBOL did not include the notion of an array. There was no parameter passing in early COBOL (in part because all variables were global variables). Like FORTRAN, COBOL had a reliance on unconditional branching instructions. Additionally, COBOL was limited with respect to its computational abilities. COBOL did, however, introduce two very important concepts. The first was the notion of structured data, now referred to as data structures, and the second was the ability to store character strings. Data structures allow the programmer to define variables that are composed of different types of data. For instance, we might define a Student record that consists of a student’s name, major, GPA, total credit hours earned, and current courses being taken. The different types of data would be represented using a variety of data types: strings, reals, integers.
Researchers in artificial intelligence began developing their own languages in the late 1950s and early 1960s. The researchers called for language features unavailable in either FORTRAN or COBOL: handling lists of symbols, recursion and dynamic memory allocation. Although several languages were initially developed, it was LISP—the LISt Processing language—that caught on. In addition to the above-mentioned features that made LISP appealing, LISP was an interpreted language. By being an interpreted language, programmers could experiment and test out code while developing programs and therefore programs could be written in a piecemeal fashion. LISP was very innovative and continued to be used, in different forms, through the 1990s.
Following on from these three languages, the language ALGOL (ALGOrithmic Language) was an attempt to merge the best features of FORTRAN, COBOL, and LISP into a new language. ALGOL ultimately gained more popularity in Europe than it did in the United States, and its use was limited compared to the other languages, eventually leading to ALGOL’s demise. However, ALGOL would play a significant role as newer languages would be developed.
In the 1960s, programming languages were being developed for many different application areas. New languages were also developed to replace older languages or to provide facilities that older languages did not include. Some notable languages of the early 1960s were PL/I, a language developed by IBM to contain the best features of FORTRAN, COBOL, and ALGOL while also introducing new concepts such as exception handling; SIMULA, a language to develop simulations; SNOBOL (StriNg Oriented and SymBOlic Language), a string matching language; and BCPL, an early version of C.
By the late 1960s, programmers realized that these early languages relied too heavily on unconditional branching statements. In many languages, the statement was called a GO TO (or goto). The unconditional branch would allow the programmer to specify that the program could jump from its current location to anywhere else in the program.
As an example, consider a program that happens to be 10 pages in length. On page 1, there are four instructions followed by a GO TO that branches to an instruction on page 3. At that point, there are five instructions followed by an if–then–else statement. The then clause has a GO TO statement that branches to an instruction on page 6, and the else clause has a GO TO statement that branches to an instruction on page 8. On page 6, there are three instructions followed by a GO TO statement to page 2. On page 8, there are five instructions followed by an if–then statement. The then clause has a GO TO statement that branches to page 1. And so forth. Attempting to understand the program requires tracing through it. Tracing through a program with GO TO statements leads to confusion. The trace might begin to resemble a pile of spaghetti. Thus, unconditional branching instructions can create what has been dubbed spaghetti code.
Early FORTRAN used an if-statement that was based around GO TO statements. The basic form of the statement is If (arithmetic expression) line number1, line number2, line number3. If the arithmetic expression evaluates to a negative value, GO TO line number1, else if the arithmetic expression equals zero, GO TO line number2, otherwise GO TO line number3. See Figure 14.2, which illustrates spaghetti code that is all too easily produced in FORTRAN. The second instruction is an example of FORTRAN’s if-statement, which computes I–J and if negative, branches to line 10, if zero, branches to line 20, otherwise branches to line 30.

Assuming I = 5, J = 15, and K = –1, can you trace through the code in Figure 14.2 to see what instructions are executed and in what order? If your answer is no, this may be because of the awkwardness of tracing through code that uses GO TO statements to such an extent.
Programmers who were developing newer languages decided that the unconditional branch was too unstructured. Their solution was to develop more structured control statements. This led to the development of conditional iteration statements (e.g., while loops), counting loops (for-loops), and nested if–then–else statements. Two languages that embraced the concept of structured programming were developed as an offshoot of ALGOL: C and Pascal. For more than 15 years, these two languages would be used extensively in programming (C) and education (Pascal). Developed in the early 1980s, Ada would take on features of both languages, incorporate features found in a variety of other languages, introduce new features, and become the language used exclusively by the U.S. government for decades.
In 1980, a new concept in programming came about, object-oriented programming. Developed originally in one of the variants of Simula, the first object-oriented programming language was Smalltalk, which was the result of a student’s dissertation research. The idea was that data structures could model real-world objects (whether physical objects such as a car or abstract objects such as an operating system window). A program could consist of objects that would communicate with each other. For example, if one were to program a desktop object and several window objects, the desktop might send messages to a window to close itself, to move itself, to shrink itself, or to resize itself. The object would be specified in a class definition that described both the data structure of the object and all of the code needed to handle the messages that other objects might pass to it. Programming changed from the idea of program subroutines calling each other to program objects sending messages to each other.
In the late 1980s, C was upgraded to C++ and LISP was upgraded to Common Lisp, the two newer languages being object-oriented. Ada was later enhanced to Ada 95. And then, based on C++, Java was developed. Java, at the time, was a unique language in that it was both compiled and interpreted. This is discussed in more detail later. With the immense popularity of both C++ and Java, nearly all languages since the 1990s have been object-oriented.Another concept introduced during this period was that of visual programming. In a visual programming language, GUI programs could be created easily by using a drag-and-drop method to develop the GUI itself, and then program the “behind-the-scenes” code to handle operations when the user interacts with the GUI components. For example, a GUI might contain two buttons and a text bar. The programmer creates the GUI by simply inserting the buttons and text bar onto a blank panel. Then, the programmer must implement the actions that should occur when the buttons are clicked on or when text is entered into the text bar.
The 1990s saw the beginning of the privatization of the Internet. Companies were allowed to sell individuals the ability to access the Internet from their homes or offices. With this and the advent of the World Wide Web, a new concept in programming was pioneered. Previously, to run a program on your computer, you would have to obtain a compiled version. The programmer might have to find a compiler for every platform so that the software could be made available on every platform. If a programmer wrote a C++ program, the programmer would have to compile the program for Windows, for Macintosh, for Sun workstations, for Intel-based Linux, for IBM mainframes, and so forth. Not only would this require the programmer to obtain several different compilers, it might also require that the programmer modify the code before using each compiler because compilers might expect slightly different syntax.
When developing the Java programming language, the inventors tried something new. A Java compiler would translate the Java program into an intermediate language that they called byte code. Byte code would not run on a computer because it was not machine language itself. But byte code would be independent of each platform. The compiler would produce one byte code program no matter which platform the program was intended to run on. Next, the inventors of Java implemented a number of Java Virtual Machines (JVM), one per platform. The JVM’s responsibility would be to take, one by one, each byte code instruction of the program, convert it to the platform’s machine language, and execute it. Thus, the JVM is an interpreter. Earlier, it was stated that interpreting a program is far less efficient than compiling a program, which is true. However, interpreting byte code can be done nearly as efficiently as running a compiled program because byte code is already a partially translated program instruction. Thus, this combination of compilation and interpretation of a program is nearly as efficient as running an already compiled program. The advantage of the Java approach is that of portability; a program compiled by the Java compiler can run on any platform that has a JVM. JVMs have been implemented in nearly all web browsers, so Java is a language commonly used to implement programs that run within web browsers (such programs are often called applets).
The desire for platform-independent programs has continued to increase over time with the increased popularity of the Internet. Today, Microsoft’s .net (“dot net”) programming platform permits a similar approach to Java’s byte codes in that code is compiled into byte code and then can be interpreted. .Net programming languages include C# (a variation of C++ and Java), ASP (active server pages), Visual Basic (a visual programming language), C++, and a variant of Java called J++. The .Net platform goes beyond the platform-independent nature of Java in that code written in one language of the platform can be used by code written in another one of the languages. In this way, a program no longer has to be written in a single language but instead could be composed of individual classes written in a number of these languages.
It is unknown what new features will be added to languages in the future, or where the future of programming will take us with respect to new languages. But to many in computer science, a long-term goal is to program computers to understand natural languages. A natural language is a language that humans use to communicate with each other. If a computer could understand English, then a programmer would not have to worry about writing code within any single programming language, nor would a computer user have to learn the syntax behind operating system commands such as Linux and DOS. Natural languages, however, are rife with ambiguity, so programming a computer to understand a natural language remains a very challenging problem.
Types of Instructions
Program code, no matter what language, comprises the same types of instructions. These types of instructions are described in this section along with examples in a variety of languages.
Input and Output Instructions
Input is the process of obtaining values from input devices (or files) and storing the values in variables in memory. Output is the process of sending literal values and values from variables to output devices (or to files).
Some languages have two separate sets of I/O statements: those that use standard input (keyboard) and output (monitor) and those that use files. Other languages require that the input or output statement specify the source/destination device. In C, C++, and Java, for example, there are different statements for standard input, standard output, file input, and file output. In FORTRAN and Pascal, the input and output statements default to standard input and output but can be overridden to specify a file. In addition, some languages use different I/O statements for different data types. In Ada, there are different input statements for strings, for integers, for reals, and so forth. Most languages allow multiple variables to be input or output in a single statement.
Figure 14.3 demonstrates file input instructions from four languages: FORTRAN, C, Java, and Pascal. In each case, the code inputs three data—x, y, and z (an integer and two real or floating point numbers)—from the text file input.dat. Each set of code requires more than just the input instruction itself.
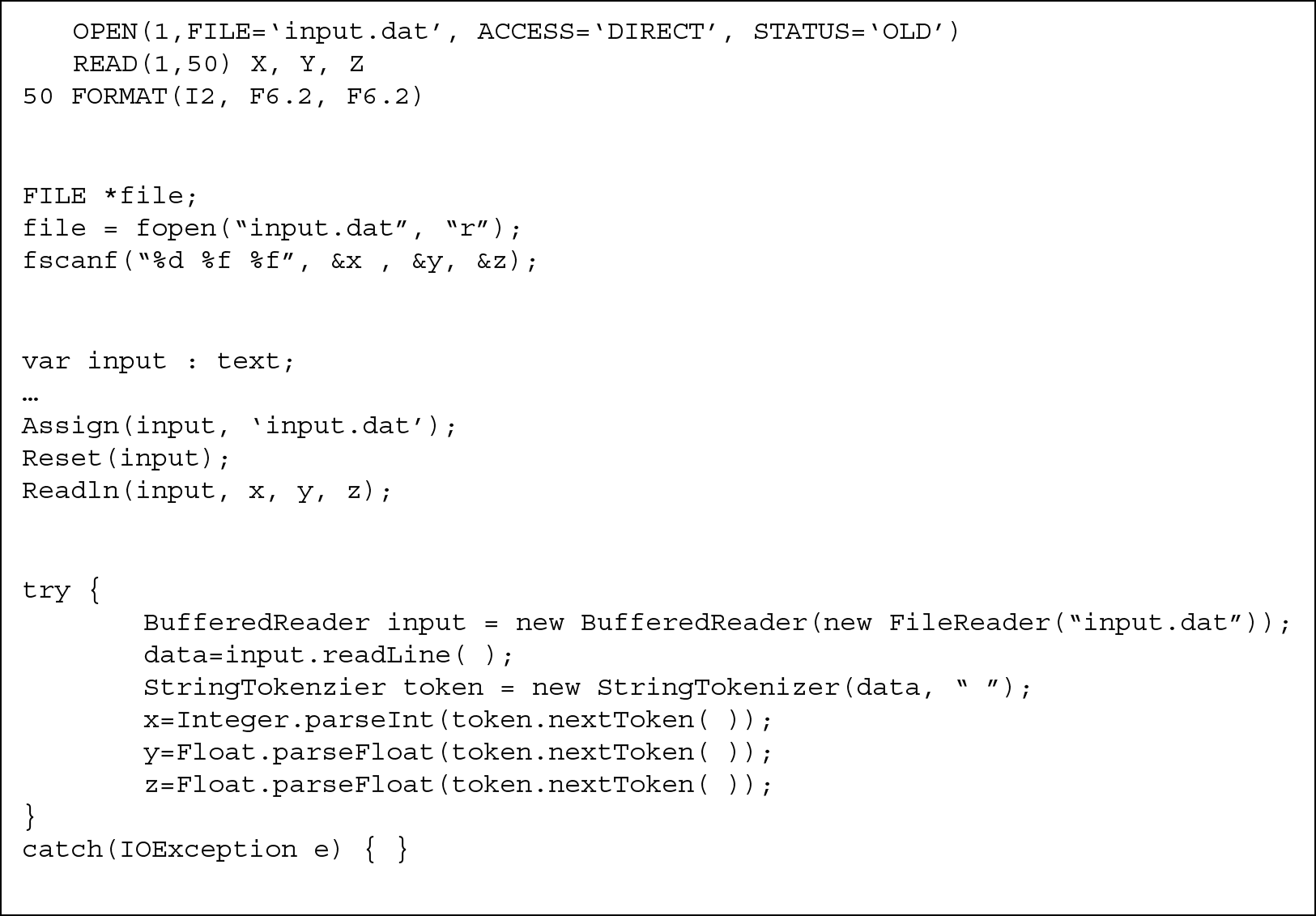
The FORTRAN code first requires an OPEN statement to open the text file for input. The file is given the designator 1, which is used in the input statement, READ. The READ statement is fairly straightforward although the (1, 50) refer to the file designator and the FORMAT line, respectively. The FORMAT statement describes how the input should be interpreted. In this case, the first two characters are treated as an integer (I) and the next six characters are treated as a floating point (real) number with two digits to the right of the decimal point (F6.2) followed by another float with the same format.
In the case of C, the first statement declares a variable to be of type FILE. Next, the file is opened with the fopen statement. The “r” indicates that the file should be read from but not written to. The notation “%d %f %f” indicates that the input should be treated as a decimal value (integer) and two floating point values. The & symbol used in C before the variables in the scanf statement is required because of how C passes parameters to its functions.
In Pascal, the textfile must be declared as type text. Next, the text variable is assigned the name of the file and opened. Finally, the values are input. Pascal, the least powerful of these four languages, is the simplest. In fact, Pascal was created with simplicity in mind.
In Java, any input must be handled by what is known as an exception handler. This is done through the try-catch block (although Java gives you other mechanisms for handling this). Next, a variable of type BufferedReader is needed to perform the input. Input from BufferedReader is handled as one lengthy string. The string must then be broken up into the component parts (the three numbers). The string tokenizer does this. Additionally, the results of the tokenizer are strings, which must be converted into numeric values through the parse statements. If an exception arises while attempting to perform input, the catch block is executed, but here, the catch block does nothing.
Assignment Statements
The assignment statement stores a value in a variable. The variable is on the left-hand side of the statement, and the value is on the right-hand side of the statement. Separating the two parts is an assignment operator. The typical form of assignment operator is either = or : = (Pascal and Ada). The right-hand side value does not have to be a literal value but is often some form of expression. There are three common forms of expressions: arithmetic, relational, and Boolean. The arithmetic expression comprises numeric values, variables, and arithmetic operators, such as a * b – 3. In this case, a and b are variables presumably storing numeric values. Arithmetic operators are +, –, *, /, and modulo (division yielding the remainder), often denoted using %. Relational expressions use relational operators (less than, equal to, greater than, greater than or equal to, equal to, etc.) to compare values. Boolean expressions use AND, OR, NOT, XOR. There can also be string expressions using such string functions as concatenation, and function calls that return values, such as sqrt(y) to obtain the square root of y. Function calls are discussed in Subroutines and Subroutine Calls.
Since the equal sign (=) is often used for assignment, what symbol do languages use to test for equality (i.e., “does a equal b”)? We usually use the equal sign in mathematics. Should a programming language use the same symbol for two purposes? If so, this not only might confuse the programmer, but it will confuse the compiler as well. Instead, languages use two different sets of symbols for assignment and equality. Table 14.1 provides a comparison in several languages. It also shows what the “not equal” operator is. Notice that PL/I is the only language that uses = for both assignment and equality.
Assignment and Equality Operators in Several Languages
|
Language |
Assignment Operator |
Equality Operator |
Not Equal Operator |
|
Ada |
: = |
= |
/= |
|
C/C++/Java, Python, Ruby |
= |
= = (2 equal signs) |
! = |
|
COBOL |
assign |
Equals (or =) |
Is not equal to (or NOT =) |
|
FORTRAN |
= |
.EQ. |
.NE. |
|
Pascal |
: = |
= |
<> |
|
Perl |
= |
eq (strings), = = (numbers) |
ne (strings), ! = (numbers) |
|
PL/I |
= |
= |
<> |
The assignment statement in most languages assigns a single variable a value. Some languages, however, allow multiple assignments in one instruction. In C, for instance, x = y = z = 0; sets all three variables to 0. In Python, you can assign multiple variables by separating them on the left-hand side with commas, as in x, y = 5, x + 1, which assigns x to the value 5, and then assigns y to the value of x+1 (or 6). This shortcut can reduce the number of instructions in a program but may make the program less readable. C also has shortcut operators. These include the use of ++ to increment a variable, as in x++, which is the same as x = x + 1, and + =, which allows us to write x+ = y instead of x = x + y. C also permits assignments within the expression part of an assignment statement. The statement a = (b = 5) * c; is two assignment statements in one. First, b is set equal to 5, and then a is set equal to b * c using b’s new value.
If the language is compiled and variables are declared, then the compiler can test for type mismatches. This type of error will arise if the right-hand side of the assignment statement generates a value that is not compatible with the variable on the left-hand side. For example, if x is an integer variable, then the assignment statement x = 3.1415 * y will yield a type mismatch error because the right-hand side involves a real (floating point) number. This is true no matter what type y is.
Selection Statements
Conditions are expressions that evaluate to true or false. Conditions are used in programs to determine what the program should do next. They are used in two types of statements, selection statements and iteration (or loop) statements (covered in Iteration Statements). The idea behind a condition is that the value stored in one or more variables is compared. Comparisons can be based on relational operators and can also use Boolean operators and arithmetic operators. For instance, a condition might test to see if x is greater than y, or x > y. Another condition might test if x equals y or x equals z. Different languages use different symbols for the relational operators (less than, greater than, equal to, etc.) and the Boolean operators (and, or, not).
A selection statement decides whether a series of instructions should be executed or skipped based on the evaluation of a condition. This type of statement is often called an if–then statement (or just an if statement). In the if–then statement, if the condition is true, the then portion of the statement (usually called the then clause) is executed. If the condition is false, the then clause is skipped.
In an if–then–else statement, if the condition is true the then clause is executed, and if the condition is false the else clause is executed. You would use an if–then statement if you only wanted code to execute when a condition is true. This is sometimes called a one-way selection. You would use an if–then–else statement if you wanted code to execute no matter what the condition turned out to be. This is sometimes called a two-way selection.
Figure 14.4 provides example code in three languages: Pascal, C, and FORTRAN IV (an early version of FORTRAN). Each example is of the same logical problem, adding 1 to x if x is equal to y or x is equal to z, and subtracting 1 from x otherwise. The Pascal code is the easiest to understand. In C, two equal signs make up the “equality” operator and two vertical bars (||) make up the OR operator. The FORTRAN code, which relies on GO TO statements, is less intuitive. Read through the code and see if you can understand it. You might notice that in C, the word “then” is omitted and the condition is placed inside of parentheses.

The if–then–else statement selects between two sets of code, a “one thing or the other” situation. What if there were more than just the two possible sets of code to select between? Most languages allow the then-clause and the else-clause to contain if–then and if–then–else statements. This creates what is called a nested if–then–else statement. Figure 14.5 shows an example in Pascal, demonstrating how to determine which letter grade to assign based on the student’s numeric grade. We use the typical 90/80/70/60 breakdown. Based on the condition that matches, the code assigns the variable letter one of the following values: ‘A’, ‘B’, ‘C’, ‘D’, or ‘F’.

Notice that the last statement does not require an if. The idea is that if the first condition is true, then the first then clause executes and the entire nested statement ends; otherwise, the first else clause executes. That else clause contains an if–then–else statement. For that second condition, if it is true, then the second then clause executes and the statement ends; otherwise, the second else clause executes. That else clause also contains an if–then–else statement. If that clause’s condition (the third condition) is true, then the third then clause executes and the statement ends; otherwise, the third else clause executes. The third else clause contains yet another if–then–else statement. If that fourth condition is true, then the fourth then clause executes and the statement ends; otherwise, the final else clause executes.
A couple of other comments are worth mentioning here. The indentation provided above helps make the code more readable, but does not impact the code’s accuracy or performance. That is, all of the tabs inserted are ignored by the computer. Also, capitalization is unimportant. Finally, you might notice that the entire set of code contains a single semicolon at the end. One difference between Pascal and C, C++, and Java is the use of semicolons to end statements. In Pascal, only one is used, to end the entire structure.
Notice in the above examples that the then and else clauses consisted of single operations. For instance, in the example shown in Figure 14.4, each clause did one thing: increment x or decrement x. It is just as often the case that the clause will contain multiple instructions. In Pascal, for instance, you might have code like this:
If x > = y
Then x: = z;
y: = 0;
q : = x + y;
Indentation and other white space is ignored, so how does the compiler know when the then clause ends? That is, is q : = x + y; part of the then clause? In fact, it is not, and neither is y : = 0; even though the spacing implies that it is. In languages such as Pascal and C, the compiler only expects a clause to have a single instruction. If you want to specify multiple instructions, you must place them into a block. A block denotes a collection of instructions that should be treated as one. This allows you to have multiple instructions in a then or else clause. In Pascal, a block is denoted using the words begin and end, whereas in C, the block is denoted using the symbols {and}. The correct Pascal and C versions of the above if–then statement are shown below. You might notice that y : = 0 does not end with a semicolon. Pascal semicolon rules are somewhat complicated.
If x > = y Then if (x > = y) {
Begin x = z;
x : = z; y = 0;
y : = 0 }
End; q = x + y;
q : = x + y;
In some languages such as Ada, an explicit endif ends the statement. In early FORTRAN instead, you denoted the end of clauses through GO TO statements. We will see the block return when we get to iteration statements and in Subroutines and Subroutine Calls. Below is the same code from above but this time written in Python. Python is a unique language in that indentation does matter. Notice how we do not need the block indicators (begin and end or {and}) but instead, the indentation indicates that both instructions after if x > = y: are part of the then clause. Without the indentation for the last statement, it means that it is not a part of the then clause.
If x > = y:
x = z
y = 0
q = x + y
Let us look at another example of a nested if–else statement, this time in C. You will see that there are three different clauses that can execute based on the values of x, y, and z. Given values for x, y, and z, you should be able to determine which of the three clauses executes. For instance, if x = 5, y = 3, and z = 0, which clause would execute?
if(x > 0)
if(y > 0)
…//clause 1
else if(z > 0)
…//clause 2
else …//clause 3
Clause 1 will execute if x > 0 and y > 0. Clause 2 will execute if x > 0, y < = 0, and z > 0 (if x < = 0, we never reach the second if-statement and therefore we never reach the else if-statement, and if y > 0, we never reach the else if-statement). When does clause 3 execute? That is, is the last else clause paired with the condition (z > 0) or the condition (x > 0)? It is not paired with (y > 0) because the else if statement contains the else clause for that condition.
In this example code, it is unclear if the last else is associated with the first if or the third if. This is a situation known as a dangling else. If we were to use block notation, we could easily resolve this as one of the following:
if(x > 0) { if(x > 0)
if(y > 0) if(y > 0) {
…//clause 1 …//clause 1
} else if(z > 0)
else if(z > 0) …//clause 2
…//clause 2 }
else …//clause 3 else …//clause 3
In the code on the left, the last else goes with the second if statement (y > 0) and in the code on the right, the last else goes with the first if statement (x > 0). However, in C, we do not need to use the block notation because, by default, any dangling else clause is always associated with the most recent condition. So clause 3 executes if x > 0 and y < = 0 and z < = 0. If we did not want the default to apply (the case on the right above), we would then use the block notation. Different languages have different rules regarding dangling else statements. By the way, if x = 5, y = 3, and z = 0, clause 3 will execute.
There are other forms of multiple selection statements. In Pascal, they are called case statements. In C and Java, they are called switch statements. We will not cover them here although you would see them in any introductory programming course.
Language Barriers
As described in Types of Instructions, all programming languages have the same types of programming language instructions: input, output, assignment, selection, iteration, subroutines. If this is true, then should you not be able to solve a given problem in any language? And if so, then why are there so many different programming languages? It seems unreasonable to have dozens, hundreds or thousands of languages when one will do!
Early in the history of computers, languages offered different features. COBOL, for instance, allowed you to structure your data very precisely, whereas ALGOL introduced useful control statements and LISP provided for both symbolic processing and recursion. But if you could write a program to solve a problem in any language, what exactly were the differences? The differences were a matter of convenience. For instance, you could not write recursive code in FORTRAN or COBOL. If the problem were to call for recursion, you could still solve it in FORTRAN or COBOL, but it would be far more challenging because your program would have to mimic the aspects of recursion that were required.
Even today, we see differences in the advantages and disadvantages of the various programming languages that lead some people to use one and other people to use another. These features include how safe a language is, whether the language can be interpreted, if the language produces byte code, and even what the language looks like. To a C++ or Java programmer, for instance, Python is very unusual because it uses indentation rather than blocks denoted with {} symbols.
Iteration Statements
There are times when a set of code should be performed multiple times. Let us consider as an example that you want to write a payroll program that will perform payroll operations. The program needs to input an employee’s data, compute the employee’s pay and taxes, output the results, and maintain totals throughout. You might think to write the program as a straight line of code that performs the input steps, the computations, and the outputs, and then ends. This would compute one employee’s pay. You would not want to run the program one time per employee because it would be annoying to keep rerunning the program. Additionally, you would not be able to compute the totals of all employees. Instead, you would write the “straight line code” and place it inside of an iteration statement. The iteration statement is used to repeat a set of code.
There are two general forms of iteration statement. The conditional, or logical, loop repeats the code while the condition evaluates to true. The counting loop (often known as a for-loop) iterates a number of times based on either a starting and ending point (for instance, 1 to 10) or the values stored in a list. The reason that counting loops are sometimes called for-loops is that most languages use the reserved word for to indicate that it is a counting loop. The following examples are of Pascal code. First, we see a logical loop.
While x > y
begin
…
end;
In the preceding loop, the condition is x > y. This means that the loop will continue to execute while x remains greater than y. Notice the use of the begin…end block. As with if–then and if–then–else statements, if the while loop’s code (known as the loop body) consists of more than one instruction, the use of a block is required. In the above loop, once y is no longer less than x, the loop terminates and the program continues with the next instruction after the end statement. In C, the same loop would look like this:
while (x > y) {
…
}
The for-loop can be used in one of two ways. First, the loop iterates through a series of values denoted as the starting value and the terminating value by units called the step size. For instance, we might specify a loop from 1 to 11 by 2s (the loop would iterate by counting 1, 3, 5, 7, 9, 11). Second, the loop iterates through a list. For instance, if a variable stored a list of values, say x = {1, 10, 25, 39, 44}, the loop would iterate five times, once per value in the list. In either case, the loop contains a loop index. This variable stores the value that is currently being iterated over. In the counting loop, the index would take on each value of 1, 3, 5, 7, 9, 11, and in the list loop, it would take on each value of the list (1, 10, 25, 39, 44).
The loop below is a counting loop. The loop index I takes on the value of 1 during the first iteration, 2 during the second iteration, 3 during the third, and so forth until it reaches 10, its final iteration.
for I : = 1 to 10 do
begin
…
end;
The loop index can be referenced in the loop body. You might use this value as part of a computation. The following code not only iterates from 1 to 10, but adds the current loop index to a running sum. This code then sums up the values from 1 to 10 (i.e., it computes 1 + 2 + 3 + … + 10). This is known as a summation loop.
Sum := 0;
For I := 1 to 10 do
Sum := Sum + I;
Notice that we did not need to place the loop body inside of begin…end statements because the loop body consists of a single instruction. The same code is given below in C. The C for-loop looks odd in comparison to the relatively simple Pascal for loop. In C, the first clause in the parentheses initializes any loop index(es), the second contains the terminating condition, and the third clause performs the step increment or decrement of the index.
sum = 0;
for(i=0;i<=10;i=i+1)
sum = sum + i;
C actually provides a number of shortcuts. One of which is the statement i++, which can be used in place of i = i + 1. Another is sum +=i, which can be used in place of sum = sum + i. The following is a for-loop (just the loop statement, not the loop body) that will iterate downward instead of upward. for (i = 10; i > 0; i--). One difference between C and Pascal is that C can vary its step size (for instance, iterating by 2s or 5s), whereas Pascal can only iterate upward or downward by ones.
Some languages offer multiple forms of both conditional and counting loops. C and Java have both while loops and do–while loops. The difference between them is where the condition is tested. In the while loop, the condition is tested before entering the loop body, whereas in the do–while loop, the condition is tested after executing the loop body. Although this may seem like the same thing, the do–while loop tests the condition after executing the loop body so that the loop body is executed at least one time. If a while loop’s condition is initially false, then the loop body does not execute at all. Here is an example that compares two loops in C.
while(x > 0)
x = x/2;
do {
x = x/2;
} while (x > 0);
Assume in both of these loops above that x is an integer initially equal to –1. In the first loop, the condition is initially false and so the loop body (x = x/2) never executes. Thus, x remains –1. In the second loop, the loop body executes one time because the condition is not checked until after the loop body executes, so x is changed from –1 to 0 (the value –1/2 cannot be stored in an integer, so instead x gets the value 0). The loop then terminates because x is not greater than 0.
Newer languages often forego the counting loop in favor of an iterator loop. This version of a counting loop iterates over a list rather than over a sequence of values. For example, if you have a list, 1, 5, 10, 19, then the loop will iterate four times, once for each of the four values in the list. Python is an example where the for-loop iterates over a list. You can use this type of loop to simulate a counting loop by iterating over a range from 1 to the upper limit by stating range(1, 100). C++ and Java originally only had the counting form of for loop but today have both counting and iterator loops.
One last comment regarding conditional loops is that the loop body should contain instructions that manipulate at least one of the variables used in the loop’s condition. Consider the following code in C.
while(x > y)
x = x + 1;
If x is initially greater than y, the loop body will be executed. However, because x starts at a value larger than y, repeatedly adding to x will never make x become less than or equal to y, and the result is that the loop will never terminate. This is known as an infinite loop. In order to ensure that you do not have an infinite loop, you have to make sure that there is code in the loop body that changes some value in the condition so that, eventually, the condition can become false. Consider the following C code.
while(x > 0)
printf(“%d ”, x); //print out x
x = x – 1;
This loop looks like it will count down from whatever x starts at to 0, printing out each value. But because the loop body contains two instructions, we need to place them inside a block using the {} symbols. Unfortunately, the compiler examines this code and decides that the statement x = x – 1; exists outside of (or after) the loop. Therefore, the while loop only performs the printf output statement. The result is that, if x is greater than 0 to begin with, the printf executes and the condition is tested again. Since the printf did not alter x, it is still greater than 0 and the printf executes again. This repeats, over and over again and never stops (until the user forces the program to abort). The reason for this infinite loop is a logical error, the programmer’s logic was not correct. To fix this problem, the loop should be as follows.
while(x > y) {
printf(“%d ”, x); //print out x
x = x – 1;
}
Infinite loops are often a problem for programmers, even those with extensive experience. This type of logical error is often difficult to detect, and the programmer only discovers the error when testing the program and finding that it seems to “hang”. In this case, a loop never terminates so the program does not advance on to the next step.
Recall from earlier that Python does not use special block designators such as begin…end and {…}. Instead, indentation is used. So in this case, the infinite loop from earlier would probably not occur because the indentation would resolve it.
Subroutines and Subroutine Calls
A subroutine is a set of code separate from the code that might invoke it. A subroutine call invokes the subroutine. The subroutine might be part of your program, or it might be part of another program or some independent piece of code made available through a library of subroutines. Most programmers will write programs as a series of subroutines. In this way, designing, writing, and debugging a program is simplified because the programmer need only concentrate on one subroutine at a time. The concept is known as modular programming where the modules are relatively small and independent chunks of code.
What follows is a brief example of two subroutines written in C. In C, subroutines are called functions. The function main is always the first to execute in a program. Here, main will execute its first printf (output) statement and then call the function foo. The function foo will output its own statement and terminate. When foo terminates, main resumes from the point immediately after the call to foo, which is the last printf statement. The function main then terminates and the program is over.
void foo() {
printf(“are we in foo? Yes!”);
}
void main() {
printf(“Hello world. We are about to enter foo.”);
foo();
printf(“We have now returned from foo.”);
}
The output of this program is as follows:
Hello world. We are about to enter foo.
are we in foo? Yes!
We have now returned from foo.
Obviously, there is no reason to write this program in two functions; we could have instead written all three printf statements in main. However, most programs are too complicated to write in a single function.
In the preceding example, the function call is foo(). The parentheses provide a means of communicating between the calling function (main) and the called function (foo). This communication comes in the form of variables and values. We call them parameters. For instance, if a function will compute the square root of a value, we must tell the function what value we want the square root of. If the function is called sqrt, we might call the function using notation such as sqrt(5) to compute the square root of 5, or sqrt(x) to compute the square root of the value stored in variable x. What follows is an example of passing a parameter in a function in C. The function computes a value (the reciprocal of the parameter) and outputs the result.
void determineReciprocal(float x) {
if(x==0)
printf(“There is no reciprocal of 0”);
else printf(“The reciprocal is %f”, 1.0/x);
}
Here, the function is passed a float value. The function will output a different message for each different parameter. For instance, what does it output if x = 1.0? What if x = 10.0? What if x = 0?
Special Purpose Instructions
These might include invocations of the operating system, string operations, computer graphics routines, random number operations, and error handling routines.
Aside from the list of executable instructions above, some programming languages also require explicit variable declarations. In languages such as Pascal, C, and Java, variables require being typed, that is, declared a specific type of value, which they then remain as during the course of the program. In JavaScript, although variables must be declared by name, you do not type them. In Figure 14.6, three variables, x, y, and z, are declared in three languages: Pascal (top), C (center) and JavaScript (bottom). In C, int means integer and float is the same as Pascal’s real (a number with a decimal point).

Some languages allow you to define your own types. In Ada, you can declare a type to be a subset of another type. For example, we might define the type Grades to be a subset of integers with an allowable range of 0..100. In this way, a variable of type Integer is any integer where a variable of type Grade is an integer within the range 0 to 100. In Java, types are known as classes.
What’s in a Name?
Most early programming languages were named by acronyms that explained the language (e.g., FORTRAN, COBOL, ALGOL, LISP). Today, language names are more creative. Here are some of the more intriguing ones.
- Axum
- BeanShell
- Blue
- Boo
- Boomerang
- Caml
- Chef
- Cola
- EASY
- Fancy
- Go
- Groovy
- Joy
- Lua
- Nice
- Oxygene
- Pure
- Rust
- Scratch
- Shakespeare
- Squeak
- ZZ T-oop
Scripting Languages
As a system administrator, it is important that you understand programming because you will often have to write scripts. A script is an interpreted program. Scripts are often fairly short (as compared to applications or systems software). But in spite of not having to write code for large-scale applications, a system administrator must still understand the commands of a programming language as presented.
Types of Instructions
Popular scripting languages today include shell scripting languages (like the Bash scripting language and DOS) as well as more complete and complex programming languages such as Python, Ruby, Perl, and PHP. Here, we will concentrate on the Bash Shell and DOS languages only. We will specifically examine the language features described in Types of Instructions, and see numerous examples. As this is not a programming text, these sections only introduce shell scripting.
Some of the code that you can place into a shell script is the same as the commands that you use at the command line. In Linux, for example, a script can contain cd, ls, rm, echo, and so forth. And similarly, commands that you will see in the next two subsections can also be typed at the command line. However, there are some differences. A script can receive parameters making the script more powerful.
Bash Shell Language
Shell scripts are stored in text files. These files must be both readable and executable. It is best to set such files with 745 or 755 permission. To execute a script named foo, you would type ./foo. This implies that your working directory stores the file foo. All Bash shell scripts should start with the following line, which alerts the Bash interpreter to execute: #!/bin/bash.
Variables in Bash scripts are handled the same way as from the command line. You can assign a variable a value using an assignment statement of the form VAR=VALUE.* The value on the right-hand side must be a string, a literal number, or the value computed from an integer-based arithmetic expression. If the string has spaces, enclose the entire string in “” marks. We look at integer-based arithmetic expressions below. To access the value in a variable, precede the variable’s name with a $. Some examples follow.
X=0
Y=“Hi there”
NAME=Frank
Z=$X
MESSAGE=“$Y $NAME”
X contains the value 0, Y the string “Hi there”, and NAME the string “Frank” even though no quote marks were used in the assignment statement. Z obtains the value currently stored in X, 0. MESSAGE obtains the string of the value stored in Y (Hi there), a space, and the value stored in NAME (Frank), or “Hi there Frank”.
An integer-based operation is tricky because, if it has variable values, it must be enclosed in peculiar syntax: $(()). For example, to set Z to be X + 5, you would use Z = $((X + 5)), and to increment X, you would use X = $((X + 1)). The legal operators for arithmetic expressions are +, –, *, /, and % (% performs the modulo operation, i.e., it provides the remainder of a division). The division operation (/) operates only on integers and returns an integer quotient. For example, if X = 5 and Y = 2, then Z = $((X/Y)) results in Z being set to 2, not 2.5. The operation Z = $((X%Y)) results in Z being set to 1 because 5/2 is 2 with a remainder of 1.
The output statement is echo. You saw this earlier in the textbook. The echo statement contains a list of items to be output. This list can contain variables, literal values, and Linux commands. If you place this list ‘’, the output is provided literally (i.e., variable values are not returned, instead you get the names of the variables). For example, if NAME = Frank and AGE = 53, then
echo $NAME is $AGE
provides the output
Frank is 53
but the instruction
echo ‘$NAME is $AGE’
provides the output
$NAME is $AGE.
You can also place your output within “”, which provides the same result as having no quote marks. In most cases, the “” can be omitted in an echo statement. However, consider the following two echo statements:
echo $NAME is $AGE
echo “$NAME is $AGE”
The first echo statement contains three arguments (parameters), whereas the second echo statement only contains one. In addition, the use of “” suppresses Bash’ file name expansion. For instance, echo * will result in Bash first expanding * to be all items in the local directory, and then echo will output them, so echo * is the same as ls or ls *. However, echo “*” will literally output * as the file name expansion does not occur.
You can use echo to combine the output of a literal message with the output of another Linux command. For instance, if you wished to output “the date and time are” along with the current date/time, you can combine the echo statement and the date operation. However, to keep echo from outputting the word “date” literally, you must indicate that Bash should execute the date command. This is accomplished using the back quote marks, ` `. For instance, the statement
echo the date is date
will literally output “the date is date”. However, the statement
echo the date is `date`
causes Linux to execute the date command and then insert its output into the echo statement. The result would look like this: “the date is Thu Mar 29 10:35:32 EDT 2012”.
Input is accomplished through the read statement. This statement must always be followed by a variable name. For instance, “read NAME” would be used to obtain an input from the user and place the entered value into the variable NAME. When a script with an input statement is executed, a read statement will result in the cursor blinking on a blank line. Since the user may not know what is going on, or what the program is expecting, it is important to precede any read statement with a prompting statement. A prompt is simply an output statement that instructs the user on what to do. The following example would prompt the user for their name, input the value, and then provide a personalized output statement. Notice that the variable NAME in the input statement is not preceded with $, whereas the $ is used in the output statement.
echo Enter your name
read NAME
echo Hello $NAME, nice to meet you!
The user may enter anything in the read statement. For instance, they might enter their name, or another string entirely, or even a number. Nothing in the code above prevents this. If the input has a space in it, no special mechanism is required in the code, unlike an assignment statement such as NAME=“Frank Zappa”, which requires that the string be placed in quote marks. If the user were to enter Frank Zappa for the above code, the output would be as expected, “Hello Frank Zappa, nice to meet you!”.
At this point, we will put together everything we have seen. The following script will compute the average of four values. Notice the use of parentheses in the two assignment statements. Recall that to perform an arithmetic operation that contains variables, you use the notation $((…)). However, in this case, since we want to sum num1, num2, num3, and num4 before performing the division or mod operation, we place that summation in another layer of parens. Without the parens, the division (num4/4) is performed before the additions.
#!/bin/bash
echo Please input your first number
read num1
echo Please input your second number
read num2
echo Please input your third number
read num3
echo Please input your fourth number
read num4
quotient = $(((num1+num2+num3+num4)/4))
remainder = $(((num1+num2+num3+num4)%4))
echo The average is $quotient with a remainder of $remainder/4
The conditional statement in Bash has very peculiar syntax. Because of this, it is often challenging for introductory scripters to get their scripts running correctly. Make sure you stick to the syntax. The form of the statement is “if [condition]; then action(s); fi”. The semicolons must be positioned where they are shown here. Furthermore, there must be spaces between the various components of the if statement as shown. Finally, the word “fi” must end your if statement. The actions are individual statements, separated by semicolons. For instance, you might have assignment statements, input statements, output statements, and even nested if-statements.
The conditional statement requires a condition. There are two common forms of the condition:
- variable comparison value
- filetest filename
In the former case, the variable’s name is preceded by a $. The comparisons are one of == or ! = for string comparisons, or one of –eq, -ne, -gt, -lt, -ge, -lt for numeric comparisons (equal to, not equal to, greater than, less than, greater than or equal to, less than or equal to). The value maybe a literal value, another variable (whose name is again preceded by $), or an arithmetic expression.
The second case is a filetest condition followed by a filename. A filetest is one of –d (item is a directory), –e (file exists), –f (file exists and is a regular file), –h (item is a symbolic link), –r (file exists and is readable), –w (file exists and is writable), and –x (file exists and is executable). The filetest may be preceded by the symbol ! to indicate that the condition should be negated. That is, the test –r foo.txt asks if foo.txt is readable, whereas ! –r foo.txt asks if foo.txt is not readable. Some example conditions follow. Notice the blank spaces between each part of the condition. Without these blank spaces, your script will generate an error and not execute.
[$NAME == “Frank”]
[$X –gt $Y]
[$X –eq 0]
[$STUDENT1 ! = $STUDENT2]
[-x $FILENAME]
[! –r $FILE2]
A complete example is shown below. In this if–then statement, the variable $NAME is tested against the value “Frank”, and if they are equal, the instruction both outputs the message “Hi Frank” and adds 1 to the variable X. The fi at the end states that this ends the if-statement.
if [$NAME == “Frank”]; then echo Hi Frank; $X=$((X+1)); fi
In some cases, a condition requires more than one comparison, combined with a Boolean AND or OR. For example, to test to see if a variable’s value lies between two other values, you would have to test the variable against both values. If we want to see if the value stored in the variable X is between 0 and 100, we would test $X –ge 0 AND $X –le 100. The syntax becomes even more peculiar in this case. Such a conditional is called a compound conditional and requires an additional set of [] around the entire condition. The symbols used for AND and OR are the same as are used in C and Java, && for AND, and || for OR. To test X between 0 and 100, we would use the following: [[$X –ge 0 && $X –le 100]].
An else clause can be added to the if-statement, in which case the word “else” appears after the action(s) in the then clause, followed by the else clause action(s). The “fi” appears only after the else clause. Below are three examples. Notice that the second example really makes no sense because there are no floating point computations in Linux, so the operation $((1/X)) would not provide a true reciprocal.
if [$X –gt $Y]; then Y=0;
else X=0;
fi
if [$X –ne 0]; then Y=$((1/X)); echo The reciprocal of $X is $Y;
else echo Cannot compute the reciprocal of 0;
fi
if [$NAME == “Frank”]; then echo “Hi Frank”; X=$((X+1));
else echo Who?; X=0;
fi
Note that you do not have to place the else clause or the fi statement on separate lines, they are written this way here for readability purposes.
There is also a nested if–then–else statement, where the “else if” is written as elif. The structure looks like this:
if [condition];
then
action(s);
elif [condition]
then
action(s);
elif [condition]
then
action(s);
…
else
action(s);
fi
If you refer back to Figure 14.5, there is an if–then–else statement in Pascal. The equivalent statement in Bash is shown in Figure 14.7.

There are two types of loops available in the Bash scripting language. The for-loop is an iterator loop that will iterate over a list. The list can consist of one of several things. First, it can be an enumerated list of values. Second, it can be a list that was supplied to the script as a list of parameters (this is discussed later in this section). Third, it can be a list generated by globbing, that is, file name expansion.
The basic form of the Bash for loop is:
for variable in list; do statement(s); done
Here, variable is the loop index. The loop index takes on each value in the list, one at a time. The loop index can then be referenced in the statements in your loop body. For instance,
for I in 1 2 3 4 5; do echo $I; done
will output each of 1, 2, 3, 4, and 5 on separate lines, one per loop iteration.
The for loop is primarily used for two purposes. The first is to iterate through the items in a directory, taking advantage of globbing. The second is to iterate through parameters in order to process them. Again, we will hold off on looking at parameters until later in this section. The following loop is an example of using globbing. In this case, the loop is merely performing a long listing on each item in the current directory. This could more easily be accomplished using ls –l *.*.
for file in *.*; do ls –l $file; done
Globbing in a for loop becomes more useful when we place an if–then statement in the loop body, where the if–then statement’s condition tests the file using one of the filetest conditions. The following for loop example examines every text file in the directory and outputs those that are executable.
for file in *.txt; do
if [-x $file];
then echo $file;
fi
done
The indentation is not necessary, but adds readability. This loop iterates through all .txt files in the current directory and displays the file names of those files that are executable.
The other type of loop is a conditional loop. This loop is similar to the while loop of C. You specify a condition, and while that condition remains true, the loop body is executed. The syntax for the Bash while loop is:
while [condition]; do statement(s); done
Recall that a while loop can be an infinite loop. Therefore, it is critical that the loop body contain code that will alter the condition from being true to false at some point. One common use of a while loop is to provide user interaction that controls the number of loop iterations. For instance, we might want to perform some process on a list of filenames. We could ask the user to input the file name. In order to control whether the loop continues or not, we could ask the user to enter a special keyword to exit, such as “quit”. In this case, “quit” would be called a sentinel value. The following script repeatedly asks the user for file names, outputs those files that are both readable and writable, and exits the loop once the user enters “quit”. The if–then statement counts the number of times the condition is true for a summary output at the end of the code.
#!/bin/bash
COUNT=0
echo Enter a filename, quit to exit
read FILENAME
while [$FILENAME ! = quit]; do
if [[–r $FILENAME && –w $FILENAME]];
then ls –l $FILENAME; COUNT=$((COUNT+1));
fi
echo Enter a filename, quit to exit
read FILENAME
done
echo There were $COUNT files that were both readable and writable
Notice in the previous example that two instructions appeared both before the loop and at the end of the loop. Why do you suppose the echo and read statements had to appear in both locations? Consider what would happen if we omitted the two statements from before the loop. When the loop condition is reached, $FILENAME returns no value, so the loop is never entered. Therefore, we must provide an initial value to filename. If we omitted the echo and read from inside of the loop, then whatever file name you entered initially remains in the variable FILENAME. Thus, the while loop’s condition is always true and we have an infinite loop!
You would tend to use a while loop when either you wanted to perform some task on a number of user inputs, waiting for the user to enter a value that indicates an exiting condition (like the word quit), or when you wanted to do a series of computations that should halt when you reached a limit. The former case is illustrated in the previous code. The following example computes the powers of 2 less than 1000, and outputs the first one found to be greater than or equal to 1000.
#/bin/bash
VALUE=1
while [$VALUE –lt 1000];
do
VALUE=$((VALUE*2));
done
echo The first power of two greater than 1000 is $VALUE
Bash scripts can be passed parameters. These are entered at the command line prompt after the script name. A script is executed using the notation ./script <enter>. Parameters can be added before the <enter>, as in ./script 5 10 15 <enter>. The parameters can then be used in your script as if they were variables, initialized with the values provided by the user. There are three different ways to reference parameters. First, $# stores the number of parameters provided. This can be used in an if statement to determine if the user has provided the proper number of parameters. Second, each individual parameter is accessed using $1, $2, $3, and so forth. If you are expecting two parameters, you would access them as $1 and $2. Finally, $@ returns the entire list of parameters. You would use $@ in a for loop as the list. The following script outputs the larger of two parameters. If the user does not specify exactly two parameters, an error message is provided instead.
#!/bin/bash
if [$# -ne 2];
then echo This script requires two parameters;
elif [$1 –gt $2];
then echo Your first parameter is larger;
else echo Your second parameter is larger;
fi
The following script expects a list of file names. If no such list is provided, that is, if $# is 0, it outputs an error message. Otherwise, it iterates through the list and tests each file for executable status and provides a long listing of all of those files that are executable. Notice that this script has an if–then–else statement where the else clause has a for loop and the for loop has an if–then statement. Because of the two if–then statements in the script, there is a need for two fi statements.
#/!bin/bash
if [$# -eq 0]; then
echo No parameters provided, cannot continue;
else
for FILE in $@; do
if [-x $FILE]; then
ls –l $FILE;
fi
done
fi
Let us conclude with a script that will expect a list of numbers provided as parameters. The script will compute and output the average of the list. Assuming that the script is called avg, you might invoke it from the command line by typing
./avg 10 381 56 18 266 531
#!/bin/bash
if [$# -eq 0]; then echo No parameters, cannot compute average;
else
SUM=0;
for NUMBER in $@; do
SUM=$((SUM+NUMBER));
done
AVERAGE=$((SUM/$#));
echo The average of the $# values is $AVERAGE;
fi
Notice in this example that all of the numbers input were specified at the time the user executed the script. What if we want to input the values from the keyboard (using the read command)? How would it differ? This problem is left to an exercise in the review section. However, here are some hints. You would use a while loop. Let us assume all numbers entered will be positive. The condition for the while loop would be [$NUMBER –gt 0] so that, once the user input a 0 or negative number, the while loop would terminate. You would have to add both an echo statement (to prompt the user) and read statement before and in the while loop to get the first input, and to get each successive input.
One last comment on Bash shell scripting. The use of the semicolon can be very confusing. In general, you do not need it if all of your instructions are placed on separate lines. This requires moving the words such as “then”, “do”, and “else” onto separate lines. The above script could also be rewritten as follows:
#!/bin/bash
if [$# -eq 0]
then
echo No parameters, cannot compute average
else
SUM = 0
for NUMBER in $@
do
SUM=$((SUM+NUMBER))
done
AVERAGE=$((SUM/$#))
echo The average of the $# values is $AVERAGE
fi
As an introductory shell scripter though, it is always safe to add the semicolons.
MS-DOS
In this section, we examine the commands and syntax specific to MS-DOS. You should read The Bash Shell Language before reading this section as some of the concepts such as loops will not be repeated here. Instead, it is assumed that you will already know the concepts so that we can limit our discussion to the commands, syntax, and examples.
As with the Bash language, DOS allows variables, which can store strings and integer numbers. There are three types of variables: parameters that are provided from the command line when the script is executed, environment variables (defined by the operating system or the user), and for-loop index variables. Parameters are denoted using %n, where n is the number of the parameter. That is, the first parameter is %1, the second is %2, up through %9 for the ninth parameter. Although you are not limited to nine parameters, using more parameters is tricky (it is not as simple as referencing %10, %11, and so on). Environment variables appear with the notation %name% (with the exception of numeric values, see the examples that follow). For-loop variables appear with the notation %name.
To assign a variable a value, the assignment statement uses the word set, as in “set x = hello”. To assign a variable a value stored in another variable, use the notation “set x =%y%”. The percent signs around the variable name tell the interpreter to return the variable’s value; otherwise, the interpreter literally uses the name, for example, “set x = y” would set x to store the value “y”, not the value stored in the variable y. However, this differs if we are dealing with arithmetic values as described in the next paragraph.
By default, values in variables are treated as strings, even if the values contain digits. Consider the following two instructions
set a=5
set b=%a%+1
seem to store the value 6 in the variable b. But instead, the instructions store the string 5 + 1 in b. This is because the items on the right-hand side of the equal sign are treated as strings by default and therefore the notation %a%+1 is considered to be a string concatenation operation by combining the value stored in a with the string “+1”. To override this default behavior, you have to specify /a in the set statement to treat the expression as an arithmetic operation rather than a string concatenation. Thus, the second statement should be “set /a b =%a%+1”, which would properly set b to 6. For arithmetic statements like this, you can omit the percent signs from around variables, so “set /a b = a+1” will accomplish the same thing.
Input uses the set command as well, with two slight variations. First, the parameter /p is used to indicate that the set statement will prompt the user. Second, the right-hand side of the equal sign will no longer be a value or expression, but instead will be a prompting message that will be output before the input. If you omit the right-hand side, the user only sees a blinking cursor. The following example illustrates how to use input.
set /p first=Enter your first name
set /p middle=Enter your middle initial
set /p last=Enter your last name
set full=%first% %middle% %last%
Notice that spaces are inserted between each variable in the last set statement so that the concatenation of the three strings has spaces between them, as in Frank V Zappa.
Output statements in DOS use the echo command, similar to Linux. Output statements will combine literal values and variables. To differentiate whether you want a literal value, say Hello, or the value stored in a variable, you must place the variable’s name inside of percent signs. Assuming that the variable name stores Frank Zappa, the statement “echo hello name” will literally output “hello name”, whereas “echo hello %name%” will output “hello Frank Zappa”.
A DOS script is set up to output each executable statement as it executes. In order to “turn this feature off”, you need to add @echo off. To send output to a file rather than the screen, add “> filename” in your echo statement to write to the file and “>> filename” to append to the file. For example, assuming again that name stores Frank Zappa. The following three output statements show how to output a greeting message to the screen, to the file greetings.txt and to append to the file greetings.txt.
echo hello %name%
echo hello %name% > greetings.txt
echo hello %name% >> greetings.txt
The if-statement permits three types of conditions. You can test the error level as provided by the last executed program, compare two variables/values, and test if a file exists. For each of these types of conditions, you can precede the condition with the word not. Comparison are equ (=), neq (not equal), lss (<), leq (< =), gtr (>), and geq (>=) for numeric comparisons and = = for strings. The if-statement has an optional else clause. The entire if-statement (including the optional else clause) must appear on a single line of the script, thus it limits the amount of actions that the then clause or else clause can perform. If you use the optional else, place both the then clause and the else clause inside of (). The word “then” is omitted, as it is in C. Here are some examples of if-statements.
If errorlevel 0 echo Previous program executed correctly
If %x% gtr 5 (echo X is greater than 5) else (echo X is not greater than 5)
If %x% lss 0 set/a x = 0-%x%
If not %name% = = Frank (echo I do not know you)
If Exist c:usersfoxrfoo.txt del c:usersfoxrfoo.txt
DOS contains a for-loop but no while loop. The for-loop is an iterator loop like Linux’s for-loop. It only iterates over a list of values. The format is as follows:
for options %var in (list) do command
The following example will sum up the values in the list. It uses no options in the for loop.
for %i in (1 2 3) do set /a sum=sum+%i
Aside from providing a list to iterate over, you can specify a command such as dir so that the for-loop iterates over the result from the dir command. To do this, you must include the option /f in the for-loop. For example, the following will output the items found when performing a dir command, one at a time.
for /f %file in (‘dir’) do echo %file
Unfortunately, combining the for-loop with the (‘dir’) command may not work as expected because the dir command provides several columns’ worth of items, and the echo statement only picks up on the first item (column) of each line (which is the date of the last modification). The command dir /b gives you just the item names themselves. To modify the above instruction, you would specify
for /f %file in (‘dir /b’) do echo %file
As with Linux, DOS commands can be placed in DOS shell scripts. This includes such commands as del (delete), move, copy, ren (rename), dir, type (similar to Linux’ cat), print (send to a printer), rmdir, mkdir, cd, and cls (clear screen). So you might write scripts, for instance, to test files in the file system, and delete, rename, or move them if they exist or have certain attributes.
Further Reading
- Blum, R. and Bresnahan, C. Linux Command Line and Shell Scripting Bible. New Jersey: Wiley and Sons, 2011.
- Dietel, P. and Dietel, H. C++: How to Program. Upper Saddle River, NJ: Prentice Hall, 2011.
- Glass, R. In the Beginning: Personal Recollections of Software Pioneers. New Jersey: Wiley and Sons, 1997.
- Kelley, A. and Pohl, I. A Book on C: Programming in C. Reading, MA: Addison Wesley, 1998.
- Kernighan, B. and Ritchie, D. The C Programming Language. Englewood Cliffs, NJ: Prentice Hall, 1988.
- Liang, Y. Introduction to Java Programming. Boston, MA: Pearson, 2013.
- Mitchell, J. Concepts in Programming Languages. UK: Cambridge, Cambridge University Press, 2003.
- Newham, C. Learning the bash Shell: Unix Shell Programming. Massachusetts: O’Reilly, 2005.
- Reddy, R., and Ziegler, C. FORTRAN 77 with 90: Applications for Scientists and Engineers, St. Paul, MN: West Publishing, 1994.
- Robbins, A. and Beebe, N. Classic Shell Scripting. Massachusetts: O’Reilly, 2005.
- Sebesta, R. Concepts of Programming Languages. Boston, MA: Pearson, 2012.
- Tucker, A. and Noonan, R. Programming Languages: Principles and Paradigms. New York: McGraw Hill, 2002.
- Venit, S., and Subramanian, P. Spotlight on Structured Programming with Turbo Pascal. Eagan, MN: West Publishing, 1992.
- Webber, A. Modern Programming Languages: A Practical Introduction. Wilsonville, OR: Franklin, Beedle and Associates, 2003.
- Weitzer, M. and Ruff, L. Understanding and Using MS-DOS/PC DOS. St. Paul, MN: West Publishing, 1986.
Review Terms
Terms introduced in this chapter:
Ada LISP
ALGOL Logical error
Assembler Loop body
Assembly language Loop index
Assignment statement Machine language
Byte code Modular programming
COBOL Object-oriented programming
Compiler Output statement
Condition Parameter
Conditional loop Pascal
Counting loop PL/I
Done (Linux) Portability
Dot net (.net) Read (Linux)
Echo (Linux and DOS) Run-time error
Elif (Linux) Scripting language
Else clause Selection statement
Fi (Linux) Sentinel value
FORTRAN Set (DOS)
GO TO Spaghetti code
High-level language Syntax error
Infinite loop Subroutine
Input statement Subroutine call
Interpreter Then clause
Iteration Type mismatch
Iterator loop Unconditional branch
Java virtual machine Variable declaration
Language translator Visual programming
Review Questions
- In what ways are high level programming languages easier to use than machine language and assembly language?
- What is the difference between a compiled language and an interpreted language?
- Name three improvements to high level programming languages between the first language, FORTRAN, and today.
- What is spaghetti code and what type of programming language instruction creates spaghetti code?
- What is the difference between a conditional loop and a counting loop?
- What is the difference between a counting loop and an iterator loop?
- You have a high level language program written in the language C. You want to be able to run the program on three different platforms. What do you need to do? If your program were written in Java, what would differ in how you would get the program to run?
- For each of these languages, explain why it was created (what its purpose was): FORTRAN, COBOL, LISP, PL/I, Simula, SNOBOL.
- What significant change occurred with the creation of Pascal and C?
- What significant change occurred with the creation of Smalltalk?
- What is the .Net platform?
Review Problems
- Write a Linux script that will receive two parameters and output whether the two parameters are the same or not.
- Rewrite #1 so that, in addition, the script will output an error message if exactly two parameters were not provided.
- Rewrite #1 as a DOS script assuming the two parameters are strings.
- Rewrite #3 assuming the two parameters are numbers.
- Write a DOS script that will test the last program for error level 0 and output an ok message if the error level was 0 and an error message if the error level was not 0.
- Write a Linux script that will receive a directory name as a parameter and will output all of the subdirectories found in that directory.
- Write a DOS script that will receive a directory name as a parameter and will output all items found in that directory.
- Write a Linux script that will compute the average of a list of values that are input, one at a time from the keyboard, until the user ends the input with a 0 or negative number. Hint: use a while loop and the read statement.
- If you have successfully solved #8, what would happen if you did not have the read statement before the while loop? What would happen if you did not have the read statement inside of the while loop?
- Recall that you can use regular Linux commands in a Linux script. Write a Linux script that will iterate through the current directory and delete any regular file that is not readable. This requires the use of rm –f and the filename. If your loop index is called file, the command might look like rm –f $file. Rewrite your program to use rm –i instead of –f. What is the difference?
Discussion Questions
- In your own words, explain the problem with unconditional branches (e.g., the GO TO statement in FORTRAN). How did structured programming solve this problem?
- Examine various code segments provided in Types of Instructions. Just in looking at the code, which language is easiest to understand, FORTRAN, C, Pascal, or Java? Which language is most difficult to understand? Explain why you feel this way.
- As a computer user, is there any value in understanding how to write computer programs? If so, explain why.
- As a system administrator, would you prefer to write code in the bash scripting language, Python, Ruby, C, Java, or other language? Explain.
* Note that variable names do not need to be written in upper-case letters. I will use upper-case letters to easily distinguish a variable from an instruction.