
Chapter 15
Information
The textbook has primarily emphasized technology. In this chapter, the focus turns to the information side of IT. Specifically, the chapter examines the types of information that organizations store and utilize along with the software that supports information processing. The chapter then examines information security and assurance: the ability of an organization to ensure that their information is protected. Toward that end, the chapter describes numerous forms of attacks that an organization must protect against, along with technological methods of security information. The chapter examines hardware solutions such as RAID storage and software solutions including encryption. The chapter ends with a look at legislation created to help protect the information technology and individuals’ privacy.
The learning objectives of this chapter are to
- Discuss the various forms that information comes in with an introduction to the Data–Information–Knowledge–Wisdom hierarchy.
- Describe the use of databases, database management systems, and data warehouses.
- Introduce the field of information security and assurance and the processes used in risk analysis.
- Discuss the threats to information and solutions in safeguarding information.
- Describe encryption technologies.
- Introduce U.S. legislation that facilitates the use of information and protects individuals privacy.
Up to this point of the textbook, we have concentrated mostly on the technology side of information technology (IT). We have viewed computer hardware, software, operating systems, programming, and some of the underlying theories behind their uses and functions. In this chapter, we look at the other side of IT, information.
What Is Information?
Information is often defined as processed data. That is, raw data are the input and information is the output of some process. In fact, more generically, we should think of information as any form of interpreted data. The data can be organized, manipulated, filtered, sorted, and used for computation. The information is then presented to humans in support of decision making. We might view data and information as a spectrum that ranges from raw data, which corresponds to accumulated, but unorganized findings, to intellectual property, which includes such human produced artifacts as formulas and recipes, books and other forms of literature, plans and designs, as well as computer programs and strategies.
From an IT perspective, however, although information is often the end result of IT processes, we need to consider more concretely the following issues:
- How the information should be stored
- How (or if) the information should be transmitted
- What processes we want to use on the data to transform it into information
- How the information should be viewed/visualized
- What the requirements for assuring the accuracy of the data and information are
- What the requirements for assuring the accessibility and security of the data and information are
Information itself is not the desired end result of information processing. Researchers in Information Science have developed the “DIKW Hierarchy”. This hierarchy defines the transition of data to information to knowledge to wisdom. Each level of the hierarchy is defined in terms of the previous level.
Data are the input directly received by the human (or computer). Data typically are thought of as signals. For a human, this might be the signals received by the senses (sight, sound, smell, taste, feel). For a computer, data might be the values entered by the user when running an application, although in today’s computing, data might also be received through camera, microphone, bar code reader, sensor, or pen tablet, to name but a few. The input is generally not usable until it has been converted into a relevant form. For a computer, that would be a binary representation.
In the hierarchy, information is the next level. Information is often defined in the hierarchy as having been inferred from data. The term inferred (or inference) means that one or more processes have been applied to the data to transform it into a more useful form. Implicit in any process applied is that the resulting information is more structured and more relevant than the data by itself. The idea here is that data tend to be too low level for humans to make use of directly. A list of numbers, for instance, may not itself be useful in decision making, whereas the same list of numbers processed through statistical analysis may provide for us the mean, median, standard deviation, and variance, which could then tell us something more significant.
Knowledge is a more vague concept than either information or data. Knowledge is sometimes defined as information that has been put to use. In other cases, knowledge is a synthesis of several different sources of information. One way to think of knowledge is that it is information placed into a context, perhaps the result of experience gained from using information. Additionally, we might think of knowledge as being refined information such that the user of the knowledge is able to call forth only relevant portions of information when needed. As an example, one may learn how to solve algebraic problems by studying algebraic laws. The laws represent information, whereas the practice of selecting the proper law to apply in a given situation is knowledge.
Finally, wisdom provides a social setting to knowledge. Some refer to wisdom as an understanding of “why”—whether this is “why things happened the way they did” or “why people do what they do”. Wisdom can only come by having both knowledge and experience. Knowledge, on the other hand, can be learned from others who have it. Wisdom is the ultimate goal for a human in that it improves the person’s ability to function in the modern world and to make informed decisions that take into account beliefs and values.
In some cases, the term understanding is added to the hierarchy. Typically, understanding, if inserted, will be placed between knowledge and wisdom. Others believe that understanding is a part of wisdom (or is required for both the knowledge and wisdom levels).
In the following section, we focus on data and one of its most common storage forms, the database. We also examine data warehouses and the applications utilized on data warehouses. We then focus on two primary areas of concern in IT: information assurance and information security. Among our solutions to the various concerns will be risk management, disaster planning, computer security, and encryption. We end this chapter with a look at relevant legislation that deals with the use of IT.
Data and Databases
Information takes on many different forms. It can be information written in texts. It can be oral communications between people or groups. It can also be thoughts that have yet to be conveyed to others. However, in IT, information is stored in a computer and so must be represented in a way that a computer can store and process. Aside from requiring a binary form of storage, we also want to organize the information in a useful manner. That is, we want the information stored to model some real-world equivalent. Commonly, information is organized as records and stored in databases.
A database is an organized collection of data. We create, manipulate, and access the data in a database through some form of database management system (DBMS). DBMSs include Microsoft Access, SQL and its variations (MySQL, Microsoft SQL, PostgreSQL, etc.), and Oracle, to name a few.
The typical organizing principle of a database is that of the relation. A relation describes the relationship between individual records, where each record is divided into attribute values. For instance, a relation might consist of student records. For each student, there is a first name, a last name, a student ID, a major, a minor (optional), and a GPA (Grade Point Average).
The relation itself is often presented as a table (see Table 15.1). Rows of the table represent records: individuals of interest whether they are people, objects, or concepts (for instance, a record might describe a customer, an automobile, or a college course). Formally, the records (rows) are called tuples. All records of the relation share the same attributes. These are called fields, and they make up the columns of the relation. Typically, a field will store a type of data such as a number, a string, a date, a yes/no (or true/false) value, and within the type there may be subtypes, for instance, a number might be a long integer, short integer, real number, or dollar amount.
Example Database Relation
|
Student ID |
First Name |
Last Name |
Major |
Minor |
GPA |
|
11151631 |
George |
Duke |
MUS |
PHY |
3.676 |
|
10857134 |
Mike |
Keneally |
MUS |
CHE |
2.131 |
|
19756311 |
Ian |
Underwood |
MUS |
HIS |
3.801 |
|
18566131 |
Ruth |
Underwood |
MUS |
MAT |
3.516 |
|
18371513 |
Frank |
Zappa |
MUS |
2.571 |
In Table 15.1, we see a student academic relation. In this relation, student records contain six fields: student ID, first name, last name, major, minor, and GPA. Each of the entries is a string (text that can combine letters, punctuation marks, and digits) except for GPA, which is a real number. Student ID could be a number, but we tend to use numbers for data that could be used in some arithmetic operation. Since we will not be adding or multiplying student IDs, we will store them as strings.
The fields of a relation might have restrictions placed on the values that can be stored. GPA, for instance, should be within the range 0.000–4.000. We might restrict the values under Major and Minor to correspond to a list of legal majors and minors for the university. Notice for one record in the relation in Table 15.1 that there is no value for Minor. We might require that all records have a Major but not a Minor.
Given a relation, we might wish to query the database for some information such as “show me all students who are CIT majors”, “show me all students who are CIT majors with a GPA > = 3.0”, “show me all students who are CIT majors or CSC major with a GPA > = 3.0”. These types of queries are known as restrictions. The result of such a query is a list of those records in the relation that fit the given criteria. That is, we restrict the relation to a subset based on the given criteria. We can also refer to this type of operation as filtering or searching.
Queries return data from the database although they do not have to be restrictions. That is, they do not have to restrict the records returned. A projection is another form of query that returns all of the records from the relation, but only select attributes or fields. For instance, we could project the relation from Table 15.1 to provide just the first and last names.
Another operation on a relation is to sort the records based on some field(s). For instance, the records in Table 15.1 are sorted in ascending order by last name followed by first name (thus, Ian Underwood precedes Ruth Underwood).
We could also perform insert operations (add a record), update operations (modify one or more attributes of one or more records), and delete operations (delete one or more records). By using some filtering criteria with the update or delete, we are able to modify or remove all records that fit some criteria. For instance, being a generous teacher, I might decide that all CIT majors should have a higher GPA, so an update operation may specify that GPA = GPA * 1.1 where Major = “CIT”. That is, for each record whose Major is “CIT”, update the GPA field to be GPA * 1.1.
A database will consist of a group of relations, many of which have overlapping parts. In this way, information can be drawn from multiple relations at a time. For instance, we might have another student relation that consists of student contact information. So, the relation presented in Table 15.1 might be called the student scholastic information, whereas the student contact information might look like that shown in Table 15.2.
Another Database Relation
|
Student ID |
Address |
City |
State |
Zip |
Phone |
|
10857134 |
8511 N. Pine St |
Erlanger |
KY |
41011 |
(859) 555-1234 |
|
11151631 |
315 Sycamore Dr |
Cincinnati |
OH |
45215 |
(513) 555-2341 |
|
18371513 |
32 East 21st Apt C |
Columbus |
OH |
43212 |
(614) 555-5511 |
|
18566131 |
191 Canyon Lane |
Los Angeles |
CA |
91315 |
(413) 555-1111 |
|
19756311 |
32 East 21st Apt C |
Columbus |
OH |
43212 |
(614) 555-5511 |
Given the two relations, we can now use another database query called a join. A join withdraws information from multiple relations. For instance, we can join the two relations from Table 15.1 and Table 15.2 to obtain all student records, providing their student ID, first and last names, majors, minors, GPA addresses, and phone numbers.
We can combine joins with restrictions and/or projections. For instance, a join and projection could provide the phone numbers and first and last names of all students. A join and a restriction could provide all records of students who are CIT majors who live in OH. Combining all three operations could, for instance, yield the first and last names of all CIT majors who live in OH.
There are additional operations available on a database. These include set operations of union, intersection, and difference. Union combines all records from the relations specified. Intersection retrieves only records that exist in both (or all) relations specified. Difference returns those records that are not in both (or all) relations specified.
Notice that data in the various relations can have repeated attribute values. For instance, there are three students from OH, two students with the last name of Underwood, and five students who are Music majors. For a database to work, at least one of the attributes (field) has to contain unique values. This field is known as the unique identifier or the primary key. In the case of both relations in Table 15.1 and Table 15.2, the unique identifier is the student ID.
The DBMS will use the unique identifier to match records in different relations when using a join operation. For instance, if our query asks for the phone numbers of students with a GPA ≥ 3.0, the DBMS must first search the scholastic information for records whose GPA matches the criteria, and then withdraw the phone numbers from the contact relation. To identify the students between the relations, the unique identifier is used. Also notice that the records in Table 15.2 are ordered by the student ID (as opposed to last name as the records are ordered in the relation from Table 15.1).
The relational database is only one format for database organization, although it is by far the most common form. Since the 1980s, research has explored other forms of databases. A few of the more interesting formats are listed here.
- Active database—responds to events that arise either within or external to the database, as opposed to a static relational database that only responds to queries and other database operations.
- Cloud database—as described in Chapter 12, the cloud represents a network-based storage and processing facility, so the cloud database is simply a database that exists (is stored) within a cloud and thus is accessible remotely.
- Distributed database—a database that is not stored solely within one location. This form of database will overlap the cloud and network databases and quite likely the parallel database.
- Document database—a database whose records are documents and which performs information retrieval based on perhaps less structured queries (such as keyword queries as entered in a search engine). Document databases are often found in libraries, and search engines such as Google could be considered a document database.
- Embedded database—the database and the DBMS are part of a larger application that uses the database. One example is a medical diagnostic expert system that contains several components: a natural language interface, a knowledge base, a reasoner, and a patient records database.
- Hierarchical database—a database in which data are modeled using parent–child relationships. Records are broken up so that one part of a record is in one location in the database, and another part is in a different branch. For instance, an employee database might, at the highest level, list all of the employees. A child relation could then contain for a given employee information about that employee’s position (e.g., pay level, responsibilities) and another child relation might include information about that employee’s projects.
- Hypermedia database—the database comprises records connected together by hypermedia links. The World Wide Web can be thought of as a hypermedia database where the “records” are documents. This is not a traditional database in that the records are not organized in any particular fashion, and the relations are not an organized collection of records.
- Multidimensional database—a database relation is usually thought of as a table: a two-dimensional representation. The multidimensional database stores relations that consist of more than two dimensions. Such a relation might organize data so that the third dimension represents a change in time. For instance, we might have a group of relations like that of Table 15.1, where each relation represents the students enrolled in a particular semester. Although we could combine all of these relations together and add a semester field, the three-dimensional relation provides us with a more intelligent way to view the data because it contains a more sensible organization.
- Network database—this is not the same as a distributed database; instead, the term network conveys a collection of data that are linked together like a directed graph (using the mathematical notion of a graph). The network database is somewhat similar to the hierarchical database.
- Object-oriented database—rather than defining objects as records placed into varying relations, an object’s data are collected into a single entity. Additionally, following on from object-oriented programming, the object is encapsulated with operations defined to access and manipulate the data stored within the object. In essence, this is a combination of databases and object-oriented programming.
- Parallel database—this is a database operated upon by multiple processors in parallel. To ensure that data are not corrupted (for instance, changed by one processor while another processor is using the same data), synchronization must be implemented on the data.
- Spatial or temporal database—a database that stores spatial information, temporal information, or both. Consider, for instance, medical records that contain patient records as sequences of events. Specialized queries can be used to view the sequences. Did event 1 occur before event 2? Or did they overlap or correspond to the same period? The spatial database includes the ability to query about two- and three-dimensional interactions.
A database is a collection of records organized in some fashion. The relational database uses relations. As listed above, other organizations include object-oriented, hierarchical, hypermedia, network, spatial, and temporal. A database can consist of a few records or millions. The larger the collection of data, the more critical the organization be clearly understood and represented. As databases grow in their size and complexity, we tend to view the database as not merely a collection of data, but a collection of databases. A collection of organized databases is called a data warehouse. The typical data warehouse uses an ETL process.
- Extract data—data comes from various sources, these sources must be identified, understood and tapped.
- Transform data—given that the data come from different sources, it is likely that the data are not organized using the same collection of attributes. Therefore, the data must be transformed to fit the model(s) of the data warehouse. This will include altering data to relations or objects (or whichever format is preferred), recognizing the unique identifier(s), and selecting the appropriate attributes (fields).
- Load data—into the storage facility, that is, the transformed data must be stored in the database using the appropriate representation format.
For a business, the data for the data warehouse might come from any number of sources. These include:
- Enterprise resource planning systems
- Supply chain management systems
- Marketing and public relations reports
- Sales records
- Purchasing and inventory records
- Direct input from customers (e.g., input from a web form or a survey)
- Human relations records
- Budget planning
- Ongoing project reports
- General accounting data
Once collected and transformed, the data are stored in the data warehouse. Now, the data can be utilized. There are any number of methods that can be applied, and the processed results can be stored back into the warehouse to further advance the knowledge of the organization as described below. These methods are sometimes called data marts—the means by which users obtain data or information out of the warehouse.
Data warehousing operations range from simple database management operations to more sophisticated analysis and statistical algorithms. In terms of the traditional DBMS, a user might examine purchasing, inventory, sales, and budget data to generate predicted manpower requirements. Or, sales and public relations records might help determine which products should be emphasized through future marketing strategies.
In OLAP (Online Analytical Processing), data are processed through a suite of analysis software tools. You might think of OLAP as sitting on top of the DBMS so that the user can retrieve data from the database and analyze the data without having to separate the DBMS operations from the more advanced analysis operations. OLAP operations include slicing, dicing, drilling down (or up), rolling-up, and pivoting the data.
Slicing creates a subset of the data by reducing the data from multiple dimensions to one dimension. For instance, if we think of the data in our database as being in three dimensions, slicing would create a one-dimensional view of the data. Dicing is the same as slicing except that the result can be in multiple dimensions, but still obtaining a subset of the data. For instance, a dice might limit a three-dimensional collection of data into a smaller three dimensional collection of data by discarding certain records and fields.
Drilling up and down merely shifts the view of the data. Drilling down provides more detail, drilling up provides summarized data. Rolling up is similar to drilling up in that it summarizes data, but in doing so, it collapses the data from multiple items (possible over more than one dimension) into a single value. As an example, all HR records might be collapsed into a single datum such as the number of current employees, or a single vector that represents the number of employees in each position (e.g., management, technical, support).
Finally, a pivot rotates data to view the data from a different perspective. Consider a database that contains product sales information by year and by country. If the typical view of the data is by product, we might instead want to pivot all of the data so that our view first shows us each year. The pivot then reorganizes the data from a new perspective. We could also pivot these data by country of sale instead.
Figure 15.1 illustrates, abstractly, the ideas behind slicing, dicing, and pivoting. Here, we have a collection of data. Perhaps each layer (or plane) of the original data represents a database relation from a different year. For example, the top layer might be customer records from 2012, the next layer might be customer records from 2011, and the bottom two layers are from 2010 and 2009, respectively. A slice might be an examination of one full layer, say that of 2010. A dice might be a subset in multiple dimensions, for instance, restricting the data to years 2012, 2011, and 2010, records of those customers from Ohio, and fields of only last name, amount spent, and total number of visits. The pivot might reorganize the data so that, rather than first breaking the data year by year, the data are first broken down state by state, and then year by year.
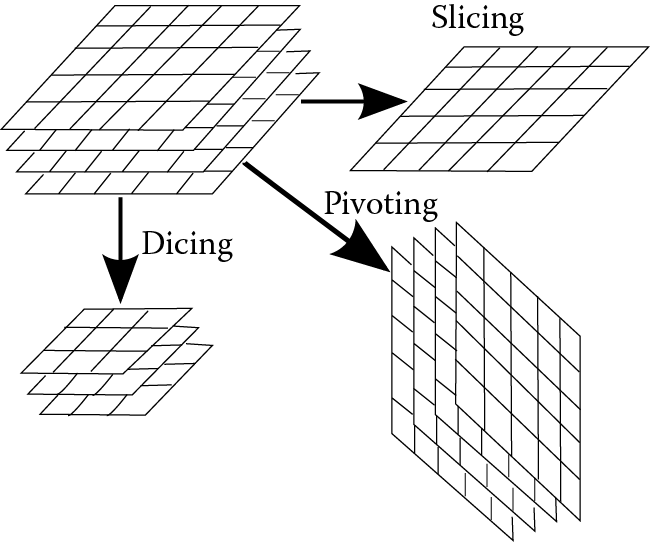
OLAP analysis has existed since the 1960s. Today, however, OLAP becomes more important than ever because the data warehouse is far too large to obtain useful responses from mere database operations.
Another suite of tools that can be applied to a data warehouse is data mining. Unlike OLAP, data mining is a fairly recent idea, dating back to the 1990s as an offshoot of artificial intelligence research. In data mining, the idea is to use a number of various statistical operations on a collection of data and see if the results are meaningful. Unlike OLAP, which is driven by the human, data mining attempts somewhat random explorations of the data. There is no way to know in advance if the results will be worthwhile. There are a number of different algorithms applied in data mining. Here, we look at a few of the most common techniques.
In clustering, data are grouped together along some, but not all, of the dimensions (fields). If you select fields wisely, you might find that the data clump together into a few different groups. If you can then identify the meaning of each clump, you have learned something about your data. In Figure 15.2, you can see that data have been clustered using two dimensions. For instance, if these data consist of patient records, we might have organized them by age and weight. Based on proximity, we have identified three clusters, with two outlying data. One of the outlying data might belong to cluster 2, the other might belong to cluster 3, or perhaps the two data belong to their own cluster. Perhaps cluster 2 indicates those patients, based on age and weight, who are more susceptible to a specific disease.
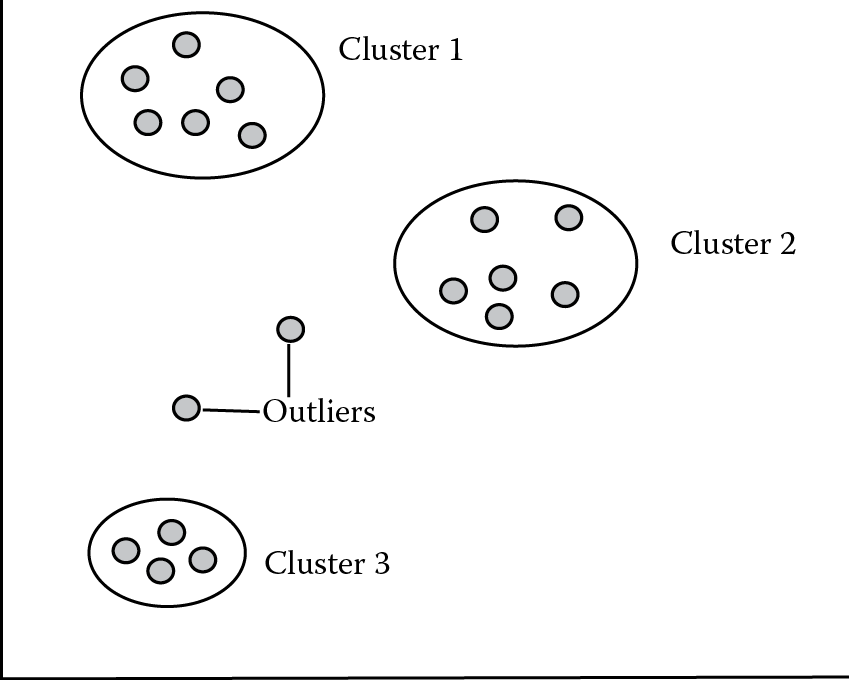
In order to identify clusters automatically, the computer determines distances between individual records. It finds a center among groups and then adds other data elements one by one by determining which cluster it comes closest to.
In forming clusters, we might find that our original selection of fields did not give us any useful groupings. For instance, if we chose weight and height instead of weight and age, we might not have identified any useful characteristics. Imagine that we want to identify patients who might be particularly susceptible to type 2 diabetes. Fields such as age, height, and income level would probably be useless. However, weight (or at least body mass index), ethnicity, and degree of job stress might find more meaningful clusters.
This leads to a problem. Whereas age, height, weight, and even income are easy enough to graph, how do we graph job stress and ethnicity? We must find a way to convert data from categories into numeric values.
Clustering is a very common data analysis technique, but as implied here, there are problems. Computationally, we might need to try to cluster over a variety of different combinations of fields before we find any useful clusters. As the number of fields increase, the number of combinations increases exponentially. For instance, with 10 fields, there are 1024 different combinations that we might try, but with 20 fields, the number of combinations increases to more than 1 million!
A variation of clustering is to identify nearest neighbors. A nearest neighbor is the datum that lies closest in proximity as computed by some mathematical equation (such as the Euclidean distance formula).* The nearest neighbor algorithm can be used in clustering to position records and identify clusters by those whose distance is less than some preset amount. The k-nearest neighbor algorithm computes distances along k of the fields. The selection of which k is another computationally intensive problem. For instance, if there are 10 fields and k = 6, we might want to try using all combinations of six fields out of 10 to determine a nearest neighbor.
Association rule learning searches data for relationships that might be of interest, and provides them as if–then types of rules. For instance, in analyzing 10,000 grocery store receipts, we find that 4000 of the receipts show that someone bought peanut butter, and 3600 of those 4000 receipts show that the person also bought bread. This becomes a rule:
if customer buys peanut butter then they buy bread
The rule also has a frequency of 90% (3600 out of 4000). The frequency describes how often the rule was true. The frequency, however, did not tell us how useful the rule might be. Consider that we find 12 people (out of 10,000) bought sushi and all of those 12 people also bought white wine. Even though the frequency is very high (100%), the rule is not very useful.
We can use the association rule to help us make decisions such as in marketing and sales. We might, for instance, decide to move the peanut butter into the bread aisle, and we might decide to put on a sale to promote the two products by saying “buy bread and get a jar of peanut butter for 25% off”. The result of association rule learning, like clustering, may or may not be of value. The sushi rule would probably not convince us to do anything special about sushi and wine. Or, imagine another rule that tells us that people who buy wine do not typically also buy beer. Is there any value in knowing this correlation? The advantage of association rule learning is that we can provide the receipt data to the data mining tool and let it find rules for us. We might tell the tool to only return rules whose frequency is greater than 80%. Then, it is up to management to decide how to use the rules.
Another product of data mining is a decision tree. A decision tree is a tree structure that contains database fields as nodes such as age, sex, and income. The branches of the tree represent different possible values of the fields. For instance, if a node has the field sex, it will have two branches, one for male and one for female (a third branch is possible if the datum for sex is not known or available). For a field such as age, rather than providing a branch for every possible value, values are grouped together. So, for instance, there might be a branch for adolescent ages (0 to 12 years old), a branch for teenage years, a branch for young adults (e.g., 20 to 32), a branch for middle age (e.g., 33 to 58), and a branch for retirement age (e.g., 59 and older). The leaf nodes of the decision tree represent the decisions that we want to make. The decision tree then represents a process of making a decision by following the proper branches of the tree.
Data Mining to the Rescue
Data mining is now a tool of business in that it can help management make decisions and predictions. However, data mining has been found to be useful far beyond profits. Here are a few interesting uses of data mining.
The Minnesota Intrusion Detection System analyzes massive amounts of data pertaining to network traffic to find anomalies that could be intrusions of various types into computer systems. Experiments on more than 40,000 computers at the University of Minnesota have uncovered numerous break-in attempts and worms.
In Bioinformatics, data mining is regularly used to help sift through literally billions of pieces of data pertaining to the human genome. Recent applications have led to improved disease diagnoses and treatment optimizations and better gene interaction modeling. In addition, BioStorm combines data mining and web information to track possible pandemic and bioterrorist incidents.
The National Security Agency has used data mining on more than approximately 1.9 trillion telephone records looking for links between known terrorists and citizens. Other data mining techniques have been used to create the Dark Web, a group of tools and links to websites of suspected terrorist organizations.
Law enforcement agencies are using data mining to identify possible crime hot spots in their cities, to predict where future crimes are likely to occur, and to track down criminals from previous crimes.
Search engines and recommender sites regularly use data mining to find links of interest based on your input queries. Google and Amazon are both pioneers in data mining.
Figure 15.3 provides a common example for a decision tree. Given banking decisions of previous loans granted or not granted, we want to automate the process. In this case, we construct the decision tree from records of customers given their income level, whether they have current debt or not, and if they have collateral. For our tree, these three fields represent our nodes (indicated in the figure with boxes). Branches are annotated with the possible values for each field. We have broken down income level into four possible values, “< 25K”, “25K...35K”, “35K…45K”, and “>45K”. The other two fields, current debt and collateral, have yes/no responses. The leaf nodes represent loan decisions made in the past. These nodes are indicated with ovals. For example, a person who has no current debt and an income of more than $45,000 has no risk, whereas a person whose income is less than $25,000 should not be given a loan under any circumstances. A person whose income is between $25,000 and $35,000 and has no debt will still need collateral to receive a loan, but even then is considered a high risk.

Decision trees can be automatically generated from database data. However, as implied in the previous example, if a field has more than just a few values (e.g., age, income), then the data should first be segmented. This can be done by a human or the data mining algorithm. In either event, decision tree generating algorithms are also computationally intensive because the algorithm must decide which fields to use in the decision tree (sex and age were not used in the tree in Figure 15.3) and the order that the fields are applied. Given a database relation of 10 fields, there are 1024 different combinations that the fields can be used, not to mention millions of potential orderings of fields (from top to bottom in the tree).
Today, data warehouses are a very common way to organize and utilize data for large organizations. Data warehousing is utilized by corporations, financial institutions, universities, hospitals and health care providers, telecommunications companies, the airline industry, the intelligence community, and many government agencies. Along with cloud computing (introduced in Chapter 12), data warehousing denotes a shift in the scale of IT in support of what many are now calling “Big Data”.
This discussion of databases and data warehouses lacks one important characteristic. Although databases and data warehouses are stored using IT, they actually are classified as forms of information systems. What is the difference? An information system is a system that stores and permits the processing of information (and data). However, the idea of an information system is neutral to technology. Although it is true that nearly all information systems today are stored by computer and utilize software to process the information, it does not have to be this way. An information system might be a card catalog system of a library stored on 3 × 5 index cards, or a database of a company’s inventory stored by paper in a filing cabinet. In fact, the term information system has existed for a lot longer than computers. Aside from databases and data warehouses, people often view expert systems and decision support systems, geographic information systems, and enterprise systems as forms of information system. The term information technology describes technology infrastructure, which itself might support information systems but could also support many other types of systems such as telecommunications systems, sensor networks, and distributed processing to name but a few, which are distinct from information systems. We briefly examine information systems as a career option in Chapter 16.
Information Assurance and Security
Information assurance and information security are often described together as information assurance and security (IAS). In this section, we introduce the concepts behind IAS. We leave some of the details of information security to the section Threats and Solutions. The IAS model combines the three components of IT—communications, hardware, and software—with the information utilized by the three components. Focusing on how information is utilized, IAS proscribes three goals, commonly referred to as CIA: confidentiality, integrity, and availability.
Confidentiality requires that data be kept secure so that they are not accidentally provided to unauthorized individuals and cannot be obtained by unauthorized users. Confidentiality goes beyond security mechanisms as it deals with policy issues of who is an authorized user of the data, how data should be kept and stored, and privacy policies. As an example, we discussed earlier in the chapter the need for a unique identifier. An organization may have a policy that employee records will use social security numbers as unique identifiers. However, such a policy violates the employee’s freedom to protect their social security number (which should only be made available for payroll purposes).
Additionally, security mechanisms must go far beyond those that protect against unauthorized access over computer network. For instance, confidentiality must ensure that either sensitive data are not available on laptop computers, or that those laptop computers should not be accessible to unauthorized individuals. A theft of a laptop should not violate the confidentiality of the organization.
Integrity requires that data are correct. This requires at a minimum three different efforts. First, data gathering must include a component that ensures the accuracy of the collected data. Second, data must be entered into the system accurately. But most importantly, data modification must be tracked. That is, once data are in a database, changes to that data must leave behind a record or trace to indicate who made the change, when the change was made, and what the change was. This permits auditing of the data and the ability to roll the data back if necessary. Furthermore, if a datum is being used by one individual, the datum should be secure from being altered by another. A lack of proper data synchronization could easily lead to corrupt data, as has been discussed previously in this text.
Finally, availability requires that information is available when needed. This seems like an obvious requirement, but it conflicts to some extent with both confidentiality and integrity. We would assume that most organizations will make their information available in a networked fashion so that users can obtain the data from computers positioned all over the organization, including remote access from off-site locations. To maintain confidentiality, proper security measures must then be taken including secure forms of login, encryption/decryption, and proper access controls (e.g., file permissions). Additionally, if one user is accessing some data, to maintain integrity, other users are shut out of accessing that data, thus limiting their availability. To promote integrity, timely backups of data need to be made, but typically during the time that files are being backed up, they are not available. An additional complication for availability is any computer downtime, caused when doing computer upgrades, power outages, hardware failures, or denial of service attacks.
Y2K
Data integrity is a worthy goal, but what about the integrity of the software? There have been numerous software blunders but probably none more well known than Y2K itself. What is Y2K, and why did it happen?
Back in the 1960s and 1970s, it was common for programmers to try to save as much memory space as possible in their programs because computers had very limited main memory sizes. One way to save space was to limit the space used to store a year. Rather than storing a four-digit number, they would usually store years as two-digit numbers. So, for instance, January 31, 1969 would be stored as 01, 31, and 69. No one realized that this would be a problem until around 1997.
With the year 2000 approaching, programmers began to realize that any logic that involved comparing the current year to some target year could suddenly be incorrect. Consider the following piece of code that would determine whether a person was old enough to vote:
If (currentyear – birthyear >= 18) …
Now let us see what happens if you were born in 1993 and it is currently 2013. Using four-digit years, we have:
If (2013 – 1993 >= 18) …
This is true. So the code works correctly. But now let us see what happens with two-digit years:
If (13 – 93 >= 18) …
This is false. Even though you are old enough to vote, you cannot!
Y2K was a significant threat to our society because it could potentially prevent people from receiving their social security checks, cause banking software to compute the wrong interest, and even prevent students from graduating! But no one knew the true extent of the problem and we would not know until January 2000. Would missile silos suddenly launch their missiles? Would power companies automatically shut down electricity to their customers? Would medical equipment malfunction? Would planes fall out of the sky or air traffic control equipment shut down?
So programmers had to modify all of the code to change two-digit years to four. In the United States alone, this effort cost more than $100 billion!
Two additional areas that are proscribed by some, but not all, in IAS are authenticity and non-repudiation. These are particularly important in e-commerce situations. Authenticity ensures that the data, information, or resource is genuine. This allows a valid transaction to take place (whether in person or over the Internet). Authenticity is most commonly implemented by security certificates or other form of digital signature. We examine these in more detail in Threats and Solutions. Non-repudiation is a legal obligation to follow through on a contract between two parties. In e-commerce, this would mean that the customer is obligated to pay for the transaction and the business is obligated to perform the service or provide the object purchased. As these two areas only affect businesses, they are not acknowledged as core IAS principles by everyone.
IAS is concerned primarily with the protection of IT. IAS combines a number of practices that define an organization’s information assets, the vulnerabilities of those assets, the threats that can damage those assets, and the policies to protect the assets. The end result of this analysis, known as strategic risk analysis, is security policies that are translated into mechanisms to support information security. We will focus on the risk management process.
To perform risk management, the organization must first have goals. These goals are utilized in several phases of risk management. Goals are often only stated at a very high level such as “the organization will provide high-quality service to members of the community with integrity and responsiveness”. Goals may be prioritized as some goals may conflict with others. For instance, a goal of being responsive to customers may conflict with a goal to ensure the integrity of data as the former requires a quick response, whereas the latter requires that data be scrutinized before use.
Now the organization must perform a risk assessment. The first step in a risk assessment is to identify the organization’s information assets. These are physical assets (e.g., computers, computer network, people), intellectual property (ideas, products), and information (gathered and processed data). Aside from identifying assets, these can be categorized by type (e.g., hardware, process, personnel) and prioritized by their importance to the organization.
In the case of information, security classifications are sometimes applied. A business might use such categories as “public”, “sensitive”, “private”, and “confidential” to describe the data that they have gathered on their clients. Public information might include names and addresses (since this information is available through the phone book). Sensitive information might include telephone numbers and e-mail addresses. Although this is not public information, it is information that will not be considered a threat to a person’s privacy if others were to learn of it. Private information is information that could be a threat if disclosed to others such as social security and credit card numbers, or health and education information. This information is often protected from disclosure by federal legislation. Finally, confidential information consists of information that an organization will keep secret, such as patentable information and business plans. The government goes beyond these four categories with a group of classified tags such as confidential, secret, and top secret.
The next step in risk assessment is to identify vulnerabilities of each asset. Vulnerabilities will vary between assets, but many assets will share vulnerabilities based on their categorized type. For instance, imagine in risk assessment, that the three types of assets are managers, technical staff, and clerical staff. These are all people, and some of their vulnerabilities will be the same. Any person might be recruited away to another organization by a higher paying salary, and any person might be vulnerable to social engineering attacks (covered in Threats and Solutions). Similarly, most hardware items will share certain vulnerabilities such as being vulnerable to power outage and damage from power surge, but not all hardware will have vulnerabilities from unauthorized access because some hardware may not be networked.
Once vulnerabilities are identified, risk assessment continues with threats. That is, given a vulnerability, what are the possible ways that vulnerability can be exploited? As stated in the previous paragraph, a person may be vulnerable to a social engineering attack. However, such an attack on someone with access to confidential files is a far greater threat than an attack on someone without such access. Similarly, unauthorized access to a file server storing confidential data is a far greater threat than unauthorized access to a printer or a laptop computer that is only used for presentation graphics.
With the risk assessment completed, the organization moves forward by determining how to handle each risk. Risks, like goals, must be prioritized. Here, the organizational goals can help determine the priorities of the risks. For instance, one organizational goal might be to “recruit the best and brightest employees”, but a goal of “high quality service” is of greater importance. Thus, risks that threaten the “service” goal would have a higher priority than risks that threaten the “employee” goal.
In prioritizing risks, risk management may identify that some risks are acceptable. It might, for instance, be an acceptable risk that employees be recruited away to other organizations. However, some risks may be identified that can critically damage the organization such as attacks to the organization’s web portal (e.g., denial of services) that result in a loss of business for some length of time. The risks, in turn, require the creation of policies that will reduce the threats. Policies must then be enacted. Policies might involve specific areas of the organization such a hiring practices for human resources, management practices for mid-level management, and technical solutions implemented by IT personnel.
Once the risk management plan is implemented, it must be monitored. For instance, after 6 months have elapsed, various personnel may examine the results. Such an examination or self-study of the organization could result in identifying areas of the plan that are not working adequately. Thus, the risk management process is iterative and ongoing. The time between examinations will be based on several criteria. Initially, iterations may last only a few months until the risk management plan is working well. Iterations may then last months to years depending on how often new assets, vulnerabilities, and threats may arise.
A risk management plan may include a wide variety of responses. Responses can vary from physical actions to IT operations to the establishment of new procedures. Physical actions might include, for instance, installing cameras, sensors, and fire alarms; locking mechanisms on computers; and hiring additional staff for monitor or guard duty. IT operations are discussed in the next section such as firewalls. New procedures might include hiring processes, policies on IT usage and access control, management of information assets, maintenance, and upgrade schedules.
One other component of a risk management plan is a disaster recovery plan. A disaster recovery plan is a plan of action for the organization in response to a disaster that impacts the organization to the point that it has lost functionality. There are several different types of disasters, and a recovery plan might cover all (or multiple) types of disasters, or there may be a unique recovery plan for each type of disaster. Disasters can be natural, based on severe weather such as tornados, hurricanes, earthquakes, and floods. Disasters can be man-made but accidental such as a fire, an infrastructure collapse (e.g., a floor that collapses within the building), a power outage that lasts days, or a chemical spill. Disasters can also be man-made but purposeful such as a terrorist attack or act of war. Here are examples of the latter two categories. The power outage that hit the East Coast in 2008 was deemed accidental, yet the outage lasted several days for some communities. And, of course, on September 11, 2001, terrorists crashed four planes in New York City, Washington, DC, and Pennsylvania, causing a great deal of confusion and leading to airline shutdowns for several days.
A disaster recovery plan should address three things. First, preventive measures are needed in an attempt to avoid a disaster. For instance, a fire alarm and sprinkler system might help prevent fires from spreading and damaging IT and infrastructure. Proper procedures when dealing with chemical spills might include how to handle an evacuation including how to quickly shut down any IT resources or how to hand off IT processing capabilities to another site. Simple preventative measures should include the use of uninterrupted power supplies and surge protectors to ensure that computers can be shut down properly when the power has gone out, and to protect against surges of electricity that could otherwise damage computers. Second, there needs to be some thought to how to detect a disaster situation in progress. Obviously, a tornado or a hurricane will be noticeable, but a power surge may not be easily detected. Finally, the disaster recovery plan must address how to recover from the disaster itself.
Focusing on IT, the best approaches for preparing for and handling disasters are these. First, regular and timely backups of all data should be made. Furthermore, the backed up data should be held off-site. Redundancy should be used in disk storage as much as possible. This is discussed in more detail in the next section. Simple measures such as uninterrupted power supplies and surge protectors on the hardware side, and strong password policies and antiviral software should always be used. Monitoring of equipment (for instance, with cameras) and logging personnel who have access to equipment that stores sensitive data are also useful actions. And, of course, fire prevention in the form of fire alarms, fire extinguishers, fire evacuation plans, and even fire suppression foam are all possible.
Preparation is only one portion of the disaster recovery plan. Recovery is the other half. Actions include restoring backed up data, having spare IT equipment (or the ability to quickly replace damaged or destroyed equipment) and having backup services ready to go are just some of the possible options. In many large organizations, IT is distributed across more than one site so that a disaster at one site does not damage the entire organization. During a disaster, the other site(s) pick up the load. Recovery requires bringing the original site back up and transferring data and processes back to that site.
The risk management plan is often put together by management. But it is critical for any organization that relies on IT to include IT personnel in the process. It is most likely the case that management will not have an understanding of all of the vulnerabilities and threats to the technology itself. Additionally, as new threats arise fairly often, it is important to get timely input. Do not be surprised if you are asked to be involved in risk management at times of your career.
Threats and Solutions
Information security must protect at its core the data/information of the organization. However, surrounding the data are several layers. These are the operating system, the applications software, the computer and its resources, the network, and the users. Each of these layers has different threats, and each will have its own forms of security. As some threats occur at multiple levels, we will address the threats rather than the layers. However, information security is not complete without protecting every layer.
Social engineering is a threat that targets users. The idea is that a user is a weak link in that he or she can be tricked, and often fairly easily. A simple example of a social engineering attack works like this. You receive a phone call at home one evening. The voice identifies itself as IT and says that because of a server failure, they need your password to recreate your account. Without your password, all of your data may be lost. You tell them your password. Now they can break into your account because they are not IT but in fact someone with malicious intent.
Social engineering has been used to successfully obtain people’s passwords, bank account numbers, credit card numbers, social security numbers, PIN (personal identification number) values, and other confidential information. Social engineering can be much more subtle than a phone call. In a social setting, you are far more likely to divulge information that a clever hacker could then use to break your password. For instance, knowing that you love your pet cats, someone may try to obtain your cats’ names to see if you are using any of them as your password. Many people will use a loved one’s name followed by a digit for a password.
A variation on social engineering is to trick a user by faking information electronically. Phishing involves e-mails to people to redirect them to a website to perform some operation. The website, however, is not what it seems. For instance, someone might mock up a website to make it look like a credit card company’s site. Now an e-mail is sent to some of the credit card company customers informing them that they need to log into their accounts or else the accounts will be closed. The link enclosed in the e-mail, however, directs them to the mocked up website. The user clicks on the link and is taken to the phony website. There, the user enters secure information (passwords, credit card number, etc.) but unknowingly, this information is made available to the wrong person.
Another class of threat attacks the computer system itself whether the attack targets the network, application software, or operating system. This class includes protocol attacks, software exploits, intrusion, and insider attacks. In a protocol attack, one attempts to obtain access to a computer system by exploiting a weakness or flaw in a protocol. There are, for instance, known security problems in TCP/IP (Transmission Control Protocol/Internet Protocol). One approach is called TCP Hijacking, in which an attacker spoofs a host computer in a network using the host computer’s IP address, essentially cutting that host off from its network.
Many forms of protocol attacks are used as a form of reconnaissance in order to obtain information about a computer network, as a prelude to the actual attack. An ICMP (Internet Control Message Protocol) attack might use the ping program to find out the IP addresses of various hosts in a computer network. Once an attacker has discovered the IP addresses, other forms of attack might be launched. A smurf attack combines IP spoofing and an ICMP (ping) attack where the attacker spoofs another device’s IP address to appear to be a part of the network. Thus, the attacker is able to get around some of the security mechanisms that might defeat a normal ICMP attack.
Software exploits vary depending on the software in question. Two very popular forms of exploits are SQL injections and buffer overflows. In the SQL injection, an attacker issues an SQL command to a web server as part of the URL. The web server, which can accept queries as part of the URL, is not expecting an SQL command. A query in a URL follows a “?” and includes a field and a value, such as www.mysite.com/products.php?productid = 1. In this case, the web page products.php most likely accesses a database to retrieve the entry productid = 1. An SQL injection can follow the query to operate on that database. For instance, the modified URL www.mysite.com/products.php?product = 1; DROP TABLE products would issue the SQL command DROP TABLE products, which would delete the relation from the database. If not protected against, the web server might pass the SQL command onto the database. This SQL command could potentially do anything to the database from returning secure records to deleting records to changing the values in the records.
The buffer overflow is perhaps one of the oldest forms of software exploit and is well known so that software engineers should be able to protect against this when they write software. However, that is not always the case, and many pieces of software are still susceptible to this attack. A buffer is merely a variable (typically an array) that stores a collection of values. The buffer is of limited size. If the software does not ensure that insertions into the buffer are limited to its size, then it is possible to insert into the buffer a sufficient amount so that the memory locations after the array are filled as well. Since memory stores both data and code, one could attempt to overflow a buffer with malicious code. Once stored in memory, the processor could potentially execute this code and thus perform the operations inserted by the attacker.
White Hat versus Black Hat
The term hacker conveys three different meanings:
- Someone who hacks code, that is, a programmer
- A computer hobbyist
- Someone who attempts to break into computer systems
Historically, the hacker has been a person who creates software as a means of protest. For instance, early hackers often broke into computer-operated telephone systems to place free long distance calls. They were sometimes called phreakers.
In order to differentiate the more traditional use of hacker, a programmer, with the derogatory use of someone who tries to break into computer systems, the term cracker has been coined. The cracker attempts to crack computer security. But even with this definition, we need to differentiate between those who do this for malicious purposes from those who do it either as a challenge or as an attempt to discover security flaws so that the security can be improved.
The former case is now referred to as a black hat hacker (or just a black hat). Such a person violates security in order to commit crime or terrorism.
The latter case of an individual breaking security systems without malicious intent is referred to as a white hat hacker (or just a white hat). However, even for a white hat, the action of breaking computer security is still unethical.
As a case in point, the organization of crackers who call themselves Anonymous purport to violate various organization’s computer systems as a means of protest. They have attacked the Vatican in protest over the Catholic church’s lack of response to child abuse claims. They have attacked sites run by the Justice Department, the Recording Industry Association of America, and Motion Picture Association of America to protest antipiracy legislature. And they attacked the sites of PayPal, MasterCard, and Visa when those companies froze assets of Wikileaks. Although touting that these attacks are a form of protest, they can also be viewed as vigilante operations violating numerous international laws.
Intrusion and other forms of active attacks commonly revolve around first gaining unauthorized access into the computer system. To gain entrance, the attacker must attempt to find a security hole in the operating system or network, or obtain access by using someone else’s account. To do so, the attacker will have to know a user’s account name and password.
As stated above, there are social engineering and phishing means of obtaining passwords. Other ways to obtain passwords include writing a program that continually attempts to log in to a user’s account by trying every word of the dictionary. Another approach is to simply spy on a person to learn the person’s password, perhaps by watching the person type it in. Or, if a person is known to write passwords down, then you can look around their computer for the password if you have access to that person’s office. You might even find the password written on a post-it note stuck to the computer monitor!
Another means of obtaining a password is through packet sniffing. Here, the attacker examines message traffic coming from your computer, for instance e-mail messages. It is possible (although hopefully unlikely) that a user might e-mail a password to someone else or to him/herself.
Aside from guessing people’s passwords, there are other weaknesses in operating systems that can be exploited to gain entrance to the system. The Unix operating system used to have a flaw with the telnet program that could allow someone to log into the Unix system without using a password at all. Once inside, the intruder then can unleash their attack. The active attack could potentially do anything from deleting data files, copying data files, and altering data files to leaving behind malicious code of some kind or creating a backdoor account (a hidden account that allows the attacker to log in at any time).
An even simpler approach to breaking through the security of an IT system is through an inside job. If you know someone who has authorized access and either can be bribed or influenced, then it is possible that the attacker can delete, copy, or alter files, insert malware, or otherwise learn about the nature of the computer system through the person. This is perhaps one of the weakest links in any computer system because the people are granted access in part because they are being trusted. That trust, if violated, can cause more significant problems than any form of intrusion.
Malware is one of the worst types of attacks perpetrated on individual users. The original form of malware was called a Trojan horse. The Trojan horse pretends to be one piece of software but is in fact another. Imagine that you download an application that you think will be very useful to you. However, the software, while pretending to be that application, actually performs malicious operations on your file system. A variation of the Trojan horse is the computer virus. The main differences are that the virus hides inside another, executable, file, and has the ability to replicate itself so that it can copy itself from one computer to another through a floppy disk (back when we used them), flash drive, or e-mail attachment.
Still other forms of malware are network worms that attack computer networks (see, e.g., Morris’ Internet worm discussed in Chapter 12) and spyware. Spyware is often downloaded unknown to the user when accessing websites. The spyware might spy on your browsing behavior at a minimum, or report back to a website sensitive information such as a credit card number that you entered into a web form. Still another form of malware will hijack some of your software. For instance, it might redirect your DNS information to go to a different DNS, which rather than responding with correct IP addresses provides phony addresses that always take your web browser to the wrong location(s).
One final form of attack that is common today, particularly to websites, is the denial of service attack. In the denial of service attack, one or more attackers attempts to flood a server with so many incoming messages that the server is unable to handle normal business. One of the simplest ways to perform a denial of service attack is to submit thousands or millions (or more) HTTP requests. However, this only increases the traffic; it does not necessarily restrict the server from responding to all requests over time. A UDP attack can replace the content of a UDP packet (defined in Chapter 12) with other content, inserted by the attacker. The new content might require that the server perform some time-consuming operation. By performing UDP flooding, large servers can essentially be shut down. Other forms of denial of service utilize the TCP/IP handshaking protocol, these are known as TCP SYN and TCP ACK flood attacks.
The above discussion is by no means a complete list of the types of attacks that have been tried. And, of course, new types of attacks are being thought of every year. What we need, to promote information security, are protection mechanisms to limit these threats to acceptable risks. Solutions are brought in from several different approaches.
First, the organization’s users must be educated. By learning about social engineering, phishing, and forms of spying, the users can learn how to protect their passwords. Additionally, IT policies must ensure that users only use strong passwords, and change their passwords often.
In some cases, organizations use a different approach than the password, which is sometimes referred to as “what you know”. Instead, two other approaches are “what you have” and “who you are”. In the former case, the access process includes possession of some kind of key. The most common form of key is a key card (swipe card). Perhaps this can be used along with a password so that you must physically possess the key and know the password to log in. In the latter case, the “who you are” constitutes some physical aspect that cannot be reproduced. Biometrics are used here; whether in the form of a fingerprint, voice identification match, or even a lip print, the metric cannot be duplicated.
Next, we need to ensure that the user gains access only to the resources that the user should be able to access. This involves access control. Part of the IT policy or the risk management plan must include a mechanism whereby a user is given access rights. Those rights should include the files that the user is expected to access while not including any files that the user should not be accessing. Access rights are usually implemented in the operating system by some access control list mechanism (see Chapter 6 for a discussion on this). In Windows and Linux, access control is restricted to file and directory access per user using either lists (Windows, Security Enhanced Linux) or the 9-bit rwxrwxrwx scheme (Linux).
Many advanced DBMS use role-based access control. In such a system, roles are defined that include a list of access methods. For instance, the supervisor may be given full access to all data, whereas managers are given access to their department’s data. A data analyst may only be given read access to specific relations. Once roles are defined, individuals are assigned to roles. One person may have different roles allowing the person to have a collection of access rights.
Most of the other forms of attack target the computer system. Protection will be a combination of technologies that protect against unauthorized access and other forms of intrusion, denial of service attacks, software exploits, and malware. Solutions include the firewall to prevent certain types of messages from coming into or out of the network, antiviral software to seek out malware, and intrusion detection software. Resolving software exploits require first identifying the exploits and then modification of the source code of the software. If the software is a commercial product or open source, usually once the exploit is found, an update is released to fix it within a few days to a few weeks. Denial of service attacks and intrusions are greater challenges, and the IT staff must be continually on guard against these.
Two types of threats arise when communicating secure information over the Internet whether this involves filling out a web form or sending information by e-mail. First, Internet communications are handled with regular text. If someone can intercept the messages, the secure information is open to read. Second, the sender must be assured that the recipient is who they say they are, that is, the recipient should be authenticated. To resolve the former problem, encryption can be used. To resolve the second problem, we might use a third party to verify the authenticity of the recipient. To handle both of these solutions, we turn to digital signatures and certificates.
The idea behind a certificate or digital signature is that a user (organization, website) creates a sign to indicate who they are. This is just data and might include for instance an e-mail signature, a picture, or a name. Next, the data are put together into a file. Encryption technology (covered in the next section) is used to generate a key. The key and the data are sent to a certificate authority. This is a company whose job is to ensure that the user is who they claim to be and to place their stamp of approval on the data file. The result is a signed certificate or digital signature. The signed document is both the authentication proof and the encryption information needed for the sender to send secure information without concern of that information being intercepted and accessed.
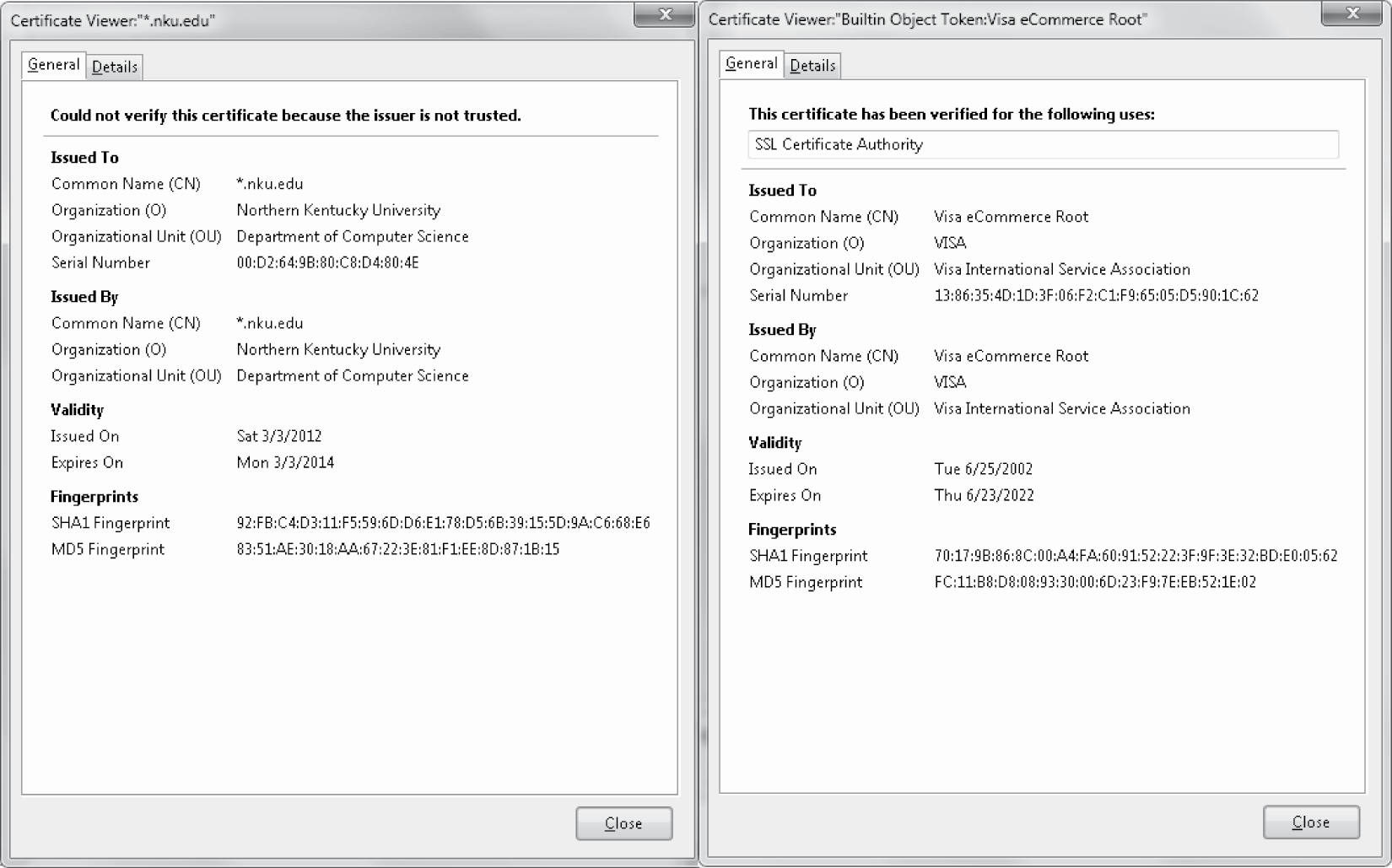
If a user receives a certificate or signature that is out of date, not signed, or whose data do not match the user’s claimed identity, then the recipient is warned that the person may not be whom they claim. Figure 15.4 shows two certificates. The one on the left is from a university and is self-signed. You might notice near the top of this certificate the statement “Could not verify this certificate because the issuer is not trusted.” This indicates that the site that uses the certificate did not bother to have a certificate authority sign their certificate. Any user who receives the certificate is warned that doing business with that site may be risky because they are not authenticated. Fortunately, the certificate is not used to obtain secure information so that a user would not risk anything substantial. The certificate on the right side of the figure is from Visa and is signed by SSL Certificate Authority, thus the site can be trusted.
Information security attempts to ensure the confidentiality, integrity, and availability of information when it is stored, processed, and transmitted (across a network). The approaches listed above primarily target the transmission of information by network and processing of information. We have to use another solution to ensure proper storage: redundancy. Redundancy provides a means so that data are available even when storage devices are damaged or offline. There are two common approaches to promote redundancy. The first is through backups of the file system. The second is through redundant storage, particularly RAID.
Backups date back to the earliest computer systems. A backup is merely a copy of a collection of data. Backups used to be stored onto magnetic tape. Backup tapes would be stored in separate rooms to ensure that if anything damaged the computer system, the tapes should be protected. Thus, the data would be easily available for restoration if needed. Ironically, many of the tapes used for data storage dating back to the 1950s have long degraded, and the data have been lost.
Floppy disks and optical disks eventually replaced tape for backup purposes. However, with the low cost of hard disk storage today, many users will back up their file system to an external hard disk, or use cloud storage. Backups can either be of the entire file system, or of those portions of the file system that have been modified since the last backup. In the latter case, this is known as an incremental backup. Operating systems can be set up to perform backups automatically. As part of the risk management plan, a backup policy is required.
RAID stands for redundant array of independent disks (alternatively, the “I” can also stand for inexpensive). The idea behind RAID is to provide a single storage device (usually in the form of a cabinet) that contains multiple coordinated hard disks. Disk files are divided into blocks as usual, but a block is itself dividing into stripes. A disk block is then stored to one or more disk surfaces depending on the size of the stripe. A large stripe will use few disks simultaneously whereas small stripes will use many disks simultaneously. Thus, the stripe size determines how independent the disks are. For instance, if a disk block is spread across every disk surface, then access to the disk block is much faster because all disk drives are accessed simultaneously and thus each surface requires less time to access the bits stored there. On the other hand, if a RAID cabinet were to use say eight separate disk drives and a stripe is spread across just two drives, then the RAID cabinet could potentially be used by four users simultaneously.
Although the “independent” aspect of RAID helps improve disk access time, the real reason for using RAID is the “redundancy”. By having multiple drives available, data can be copied so that, if a disk sector were to go bad on one disk drive, the information might be duplicated elsewhere in the cabinet. That is, the redundant data could be used to restore data lost due to bad sectors. Redundancy typically takes on one of three forms. First, there is the mirror format in which one set of disks is duplicated across another set of disks. In such a case, half of the disk space is used for redundancy. Although this provides the greatest amount of redundancy, it also is the most expensive because you lose half of the total disk space, serving as a backup. Two other approaches are to use parity bits (covered in Chapter 3) and Hamming codes for redundancy. Both parity bits and Hamming codes provide a degree of redundancy so that recovery is possible from minimal damage but not from large-scale damage. The advantage of these forms of redundancy is that the amount of storage required for the redundancy information is far less than half of the disk space, which makes these forms cheaper than the mirror solution.
RAID technology has now been in existence since 1987 and is commonplace for large organizations. It is less likely that individual users will invest in RAID cabinets because they are more expensive. RAID itself consists of different levels. Each RAID level offers different advantages, disadvantages, and costs. RAID levels are identified by numbers where a larger number does not necessarily mean a better level of RAID. Here is a brief look at the RAID levels.
RAID 0 offers no redundancy, only the independent access by using multiple drives and stripes. RAID 1, on the other hand, is the mirror format where exactly half of the disks are used as a mirror. Thus, RAID 0 and RAID 1 offer completely opposite spectrums of redundancy and cost: RAID 0, which uses all disk space for the files, is the cheapest but offers no redundancy. RAID 1, which uses half of the disk space for redundancy, is the most expensive but offers the most redundancy. RAID 2 uses Hamming codes for redundancy and uses the smallest possible stripe sizes. RAID 3 uses parity bits for redundancy and the smallest possible stripes sizes. Hamming codes are complex and time consuming to compute. In addition, RAID 2 requires a large number of disks to be successful. For these reasons, RAID 2 is not used.
RAID 4, like RAID 3, uses parity bits. But unlike RAID 3, RAID 4 uses large stripe sizes. In RAID 4, all of the parity bits are stored on the same drive. Because of this, RAID 4 does not permit independent access. For instance, if two processes attempted to access the disk drive at the same time, although the two accesses might be two separate stripes on two different disk drives, both accesses would collide when also accessing the single drive containing the parity information. For this reason, RAID 4 is unused. RAID 5 is the same as RAID 4 except that parity information is distributed across drives. In this way, two processes could potentially access two different disk blocks simultaneously, assuming that the blocks and their parity information were all on different disk drives. RAID 6 is the same as RAID 5 except that the parity information is duplicated and distributed across the disks for additional redundancy and independence.
In Figure 15.5, RAID 4, 5, and 6 are illustrated. In RAID 4, all parity data are on one and only one drive. This drive would become a bottleneck for independent accesses. In RAID 5, the parity data are equally distributed among all drives so that it is likely that multiple disk operations can occur simultaneously. In RAID 6, parity data are duplicated and distributed so that not only is the redundancy increased, but the chance of simultaneous access is increased. You will notice that RAID 6 has at least one additional disk drive and so is more expensive than either of RAID 4 or RAID 5 but offers more redundancy and possibly improved access.

More recently, hybrid RAID levels have come out that combine levels 0 and 1, known as RAID 0+1 or RAID 10, and those that combine 3 and 5, called RAID 53. With backups and/or RAID cabinets, we can ensure the redundancy of our files and therefore ensure availability and integrity of storage. However, this does not resolve the issue of confidentiality. In order to support this requirement, we want to add one more technology to our solution: encryption. Through encryption, not only can we ensure that data are held confidential, but we can also transmit it over an open communication medium such as the Internet without fear of it being intercepted and understood. Since encryption is a complex topic, we will present it in the next section.
Cryptography
Cryptography is the science behind placing information into a code so that it can be securely communicated. Encryption is the process of converting the original message into a code, and decryption is the process of converting the encrypted message back into the original message. The key to encryption is to make sure that the encrypted message, even if intercepted, cannot be understood.
The use of codes has existed for centuries. In the past, codes, or what is sometimes called classic encryption, were largely performed by pencil and paper. A message was written in code, sent by courier, and the recipient would decode it. If the courier was intercepted (or was not trustworthy), the message could not be read because it was in code.
A simple code merely replaces letters of the alphabet with other letters. For instance, a rotation code moves each letter down in the alphabet by some distance. In rotation+1, an ‘a’ becomes a ‘b’, a ‘b’ becomes a ‘c’, and so forth, and a ‘z’ wraps around to an ‘a’. During World War II, both German and Allied scientists constructed computing devices in an attempt to break the other sides’ codes. Today, strong encryption techniques are used because any other form of encryption can be easily broken by modern computers.
There are two general forms of cryptography used today: symmetric key and asymmetric key. Both forms of encryption are based on the idea that there is a key, a mathematical function, that will manipulate the message from an unencrypted form into an encrypted form, and from an encrypted form back into the unencrypted form. In symmetric-key encryption, the same key is used for both encryption and decryption. This form of encryption is useful only if the message (or file) is not intended for others, or if the recipients can be given the key. So, for instance, you might use this form of encryption to store a file such that no one else can view the file’s contents. You would not share the key with others because that would let others view the file.
Consider the case of e-commerce on the Internet. You want to transmit your credit card number from your web browser to a company’s web server so that they can charge you for a purchase (well, you may not “want” to transmit the number, but you do want to make the purchase). The company you are doing business with wants you to trust them, so they use an encryption algorithm to encrypt your credit card number before it is transmitted. To do this, your web browser must have the key. However, if they provide your web browser with the key, you can also obtain the key. If you have the key, you could potentially intercept other messages to their server and break the encryption, thus obtaining other customers’ credit card numbers.
Therefore, for e-commerce, we do not want to use symmetric-key encryption. In its place, we move on to asymmetric-key encryption. In this form of encryption, the original organization generates a key. This is the private key. Now, using the private key, they can create a public key. The public key can be freely shared with anyone. Given the public key, you can encrypt a message. However, you are unable to use the public key to decrypt a message. The organization retains the private key to themselves so that they can decrypt incoming messages. We usually refer to symmetric-key encryption as private key encryption because it only uses one key, a private (or secret) key. Asymmetric-key encryption is often called public key encryption, using two keys, a private key and a public key. Both of these forms of encryption are illustrated in Figure 15.6.
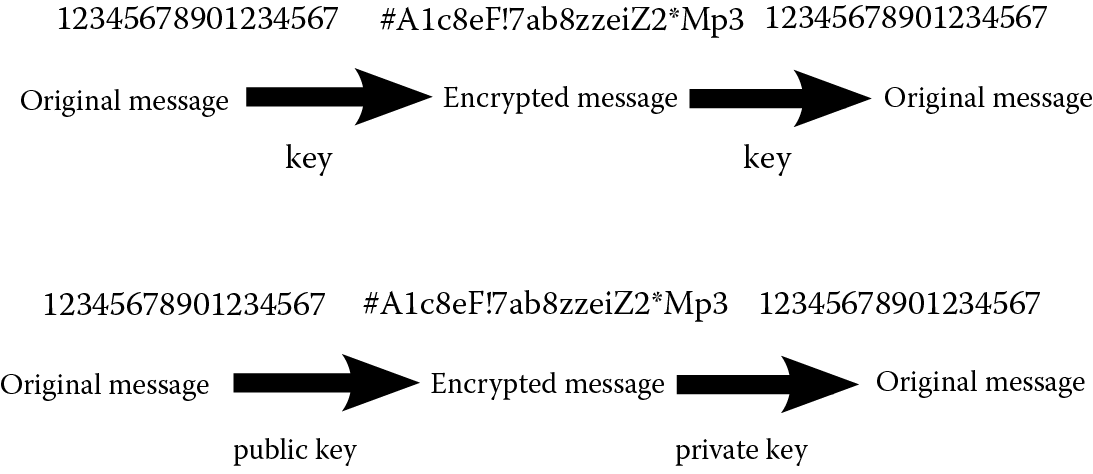
Both public and private key encryption use the notation of a block. The block is merely a sequence of some number of characters—in the case of computers, we will use a sequence of bits. So, we take some n bits of the message that we want to transmit and convert those n bits using the key. We do this for each n-bit sequence of the block, putting together a new message. The recipient similarly decomposes the received message into n-bit blocks, decrypting each block. As a simple example, let us assume the message is “Hello”. In ASCII, this message would consist of five 8-bit sequences (we add a 0 to the 7-bit ASCII character to make each character take up 1 byte). This gives us: 01001000 01100101 01101100 01101100 01101111. Now we take these 40 bits and divide them up into n-bit sequences. For our example, we will use n = 13. This gives us instead four sequences of bits: 0100100001100 1010110110001 1011000110111 1. Because the last sequence is only a single bit, we will pad it with 0s to become 1000000000000.
The key will treat each block as a binary number. It will apply some mathematical operation(s) to the binary number to transform it into a different number. One approach is to use a list of integer numbers, for instance, 1, 2, 5, 9, 19, 41, 88, 181, 370, 743, 1501, 3003, 6081. Since there are 13 integer numbers, we will add each of these integer numbers together if the corresponding bit in the 13-bit sequence is a 1. For instance, for 0100100001100, we will add 2, 19, 743, and 1501 together (because the only 1 bits in the block are the second, fifth, 10th and 11th, and 2, 19, 743, and 1501 are the second, fifth, 10th, and 11th in the sequence). The sum is 2265. So, our key has transformed 0100100001100 into 2265, which we convert back into binary to transmit.
Notice that our sequence of 13 integer numbers is not only in increasing order, but for any number, it is greater than the sum of all numbers that precede it. For instance, 88 > 41 + 19 + 9 + 5 + 2 + 1. This is crucial to being able to easily decrypt our number. To decrypt a number requires only finding the largest number in our key less than or equal to the number, subtracting that value, and then repeating until we reach 0. So, to decrypt 2265, we do the following:
Largest value < = 2265: 1501. 2265 – 1501 = 764.
Largest value < = 764: 743. 764 – 743 = 21.
Largest value < = 21: 19. 21 – 19 = 2.
Largest value < = 2: 2. 2 – 2 = 0. Done.
So we have decrypted 2265 into 1501, 743, 19, and 2, or the binary value 0100100001100.
For public key encryption, we have to apply some additional mathematics. First, we use the original list of numbers (our private key) to generate a public key. The public key numbers will not have the same property of increasingly additive. For instance, the public key might be 642, 1284, 899, 1156, 643, 901, 1032, 652, 1818, 940, 2266, 552, 723. The numbers in our public key are our private key numbers having been transformed using two additional values, some large prime numbers.
We can hand out our public key to anyone. Given the public key, the same process is used to compute a sum given a binary block. For our previous binary block (0100100001100), we add up the corresponding numbers in the public key rather than the private key. These numbers, again corresponding to the second, fifth, 10th, and 11th numbers, are 1284, 643, 940, and 2266. This sum is 5133. Instead of transmitting 2265, we transmit 5133. Using the public key, 5133 is very difficult to decrypt because our public key numbers do not have that same increasing, additive property. In fact, since the numbers are not in this order, to decrypt a number requires trying all possible combinations of values in our public key. There are 213 different combinations of these 13 numbers. For instance, we might try the first public key number by itself, 642. That is not equal to 5133, so we can now try the first two numbers, 642 + 1284. That is not equal to 5133 so we next try the first and third numbers, 642 + 899. This is still not 5133, so now we try the first three numbers, 642 + 1284 + 899. Ultimately, we may have to try all 213 different combinations before we hit on the proper solution.
You might recall from Chapter 3 that 213 equals 8192. For a human, trying all of these combinations to decrypt the one number, 5133, would take quite a while. A computer, however, would be able to try all 8192 combinations in far less than a second. For this reason, our strongest encryption technologies today use blocks of at least 200 bits instead of something as short at 13 bits. With 200 bits, it would require testing at least 2200 different combinations in order to decrypt our number. This value, 2200, is an enormous number. It is greater than 1,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000!
If our encrypted value is so difficult to decrypt, how does the recipient decrypt it? Remember that the recipient has the private key. We have to transform the received number first by applying the two prime numbers. This would convert 5133 into 2265. And now we use our private key to easily and quickly decrypt the number. Whether the key uses block sizes of 13 or 200, decryption takes almost no time at all.
Not explained above is the use of the prime numbers to create the public key and to transform the received numbers. We apply a mathematical operation known as a hash function. A hash function maps a large series of values into a smaller range. Hash functions have long been used to create hash tables, a form of data storage in memory for quick searching, and are also used to build caches, filters, and error correction information (checksums). The idea is to take the original value and substitute it with an integer. This is already done for us using public key encryption, but if we were to convert say a person’s name, we might add up the ASCII values of the characters in the name. Next, we use the modulo operator to divide the integer number by a prime number. Recall modulo (mod) performs division and gives us the integer remainder. For instance, if our prime number is 1301, then 5133 mod 1301 = 1230. The result from our mod operation will be a new integer between 0 and the prime number minus one (in this case, a number between 0 and 1300).
There are many popular encryption strategies used today. Here, we touch on a few of them. The following are all private key encryption algorithms.
- Data Encryption Standard (DES)—developed in the 1970s, this algorithm uses 56-bit block sizes. It was used by the national security agency but is now considered to be insecure.
- Advanced Encryption Standard (AES)—the follow-up from DES, it uses a substitution-permutation network that can be easily implemented in software and hardware for fast encryption and decryption. It uses a 128-bit block size but keys can take on sizes from 128 bits to 256 bits, in 32-bit increments.
- Triple DES—although DES is considered insecure because it can be broken in just hours, Triple DES uses three DES keys consecutively to encrypt and decrypt a message. For instance, if the keys are K1, K2, and K3, encrypting a message is done by applying K3(K2–1(K1(message)), where K2–1 means to use K2 to decrypt the message. Decryption is then performed by using K3–1(K2(K1–1(encrypted message))). Each key is 56 bits in size and operates on 64-bit blocks. However, the application of three keys as shown here greatly increases the complexity of the code, making it far more challenging to break. In spite of the challenge, the result is roughly equivalent to a 112 bit key, which can also be broken with today’s computers.
- Message-Digest Algorithm (MDn)—the most recent version is MD5. This 128-bit encryption algorithm uses a hash function applying a 32-digit hexadecimal hash number. However, between the limited size of the key and flaws discovered starting in 1996, MD5 is no longer in use and has been superseded by SHA-1.
- SHA-0 and SHA-1 are similar algorithms that are based on 160-bit blocks. As with MD5, they are message digest algorithms that apply a hash function. And although they do not have the flaws found in MD5, they still have their own weaknesses. Today, SHA-2 is used by the federal government, improving on SHA-1 by combining four different hash functions whose sizes are upward of 224 bits apiece. SHA-3 is being introduced in 2012.
Two of the most commonly used public key encryption algorithms are RSA and DSA (digital signature algorithm). RSA, named after the three men who wrote the algorithm in 1978, uses two large prime numbers to generate the public key from the private key. These two prime numbers, along with the private key, must be kept secure. DSA is a more complex algorithm than RSA. DSA is the standard algorithm used by the U.S. government for public key encryption.
These algorithms are used in a number of different software and protocols. Here, we take a brief look at them.
- WEP (Wired Equivalent Privacy) was released in 1999 as a means to permit encrypted wireless transmission equivalent to what can be found in a wired network. Using twenty-six 10-digit values as a key, it has been found to have numerous flaws and has been replaced first by WPA and then WPA2.
- WPA and WPA2 (Wi-Fi Protected Access) are protocols used to encrypt communication between resources in a wireless network. WPA2 replaced WPA around 2004. WPA2 is based on the AES algorithm. WPA and WPA2 were designed to work with wireless hardware produced before the releases of the protocols so that the protocols are backward compatible with older hardware. There are known security flaws with both WPA and WPA2, particularly in using a feature called Wi-Fi Protected Setup. By avoiding this feature, both WPA and WPA2 are far more secure.
- SSH is the secure shell in Linux, a replacement of the insecure telnet, rlogin, and rsh communication protocols. It uses public key encryption. Several versions have existed, generally referred to as SSH (or SSH-1), SSH-2, and OpenSSH. SSH uses port 22 whereas telnet uses port 23. SSH is also used to provide secure file transfer with SCP (secure copy). An alternate form of SSH is SFTP, secure file transfer protocol. This differs from using FTP within an SSH session.
- SSL and TLS are Secure Socket Layers and Transport Layer Security, respectively. TLS has largely replaced SSL. These communication protocols are used to enhance the transport layer of TCP/IP by providing encryption/decryption capabilities that are missing from TCP/IP. Communication can be done by private key encryption or public key encryption. In the latter case, the keys are provided during the TCP/IP handshake and through a certificate sent by the server. SSL and TLS are used in a number of different protocols including HTTPS, SMTP (e-mail), Session Initiation Protocol (SIP) used in Voice over IP, and VPN communication.
- HTTPS is the secure form of HTTP using port 431 instead of port 80. HTTPS requires the transmission of a certificate from the server to the client (refer back to Figure 15.4). The certificate is used in two ways. First, it contains the public key so that the client can encrypt messages. Second, if signed by a certificate authority, it authenticates that the server is who it claims to be. An out-of-date certificate, a self-signed certificate, or no certificate at all will prompt the client’s web browser to issue a warning.
Laws
We wrap up this chapter by examining several important legislations enacted by the U.S. government worth noting because of their impact on information security. This is by no means a complete list, and a website that contains more complete listing is provided in the Further Reading section. This list does not include legislation from other countries, but you will find similar laws in Canada and the United Kingdom.
- Privacy Act of 1974—the earliest piece of legislature that pertains to the collection and usage of personal data, this act limits actions of the federal government. The act states that:
No agency shall disclose any record which is contained in a system of records by any means of communication to any person, or to another agency, except pursuant to a written request by, or with prior written consent of, the individual to whom the record pertains….†
The act also states that federal agencies must publicly make available the data that they are collecting, the reason for the collection of the data, and the ability for any individual to consult the data collected on them to ensure its integrity. There are exemptions to the law such as for the Census Bureau and law enforcement agencies.
- The Family Educational Rights and Privacy Act of 1974 (FERPA)—gives students the right to access their own educational records, amend those records should information be missing or inaccurate, and prevent schools from disseminating student records without prior authorization. This is an important act because it prevents faculty from sharing student information (e.g., grades) with students’ parents unless explicitly permitted by the students. In addition, it requires student authorization to release transcripts to, for instance, graduate schools or prospective employers.
- Foreign Intelligence Surveillance Act of 1978—established standards and procedures for the use of electronic surveillance when the surveillance takes place within the United States.
- Electronic Communication Privacy Act of 1986—similar to the Foreign Intelligence Surveillance Act, this one establishes regulations and requirements to perform electronic wiretapping over computer networks (among other forms of wiretapping).
- Computer Matching and Privacy Protect Act of 1988—amends the Privacy Act of 1974 by limiting the use of database and other matching programs to match data across different databases. Without this act, one agency could potentially access data from other agencies to build a profile on a particular individual.
- Drivers Privacy Protection Act of 1994—prohibits states from selling data gathered in the process of registering drivers with drivers’ licenses (e.g., addresses, social security numbers, height, weight, eye color, photographs).
- Health Insurance Portability and Accountability Act of 1996 (HIPPA)—requires national standards for electronic health care records among other policies (such as limitations that a health care provider can place on an employee who has a preexisting condition). Similar to FERPA, HIPPA prohibits agencies from disseminating health care information of an individual without that individual’s consent. This is one reason why going to the doctor today requires first filling out paperwork dealing with privacy issues.
- Digital Millennium Copyright Act of 1998 (DMCA)—implements two worldwide copyright treaties that makes it illegal to violate copyrights by disseminating digitized material over computer. This law includes clauses that make it illegal to post on websites or download from websites copyrighted material whether that material originally existed as text, sound, video, or program code. Additionally, the act removes liability from Internet Service Providers who are providing Internet access for a criminal prosecuted under this act. As a result of this law, YouTube was not held liable for copyrighted content posted to the YouTube site by various users; however, as a result, YouTube often orders the removal of copyrighted material at the request of the copyright holder.
- Digital Signature and Electronic Authentication Law of 1998 (SEAL)—permits the use of authenticated digital signatures in financial transactions and requires compliance of the digital signature mechanisms. It also places standards on cryptographic algorithms used in digital signatures. This was followed 2 years later with the Electronic Signatures in Global and National Commerce Act.
- Security Breach Notification Laws—since 2002, most U.S. states have adopted laws that require any company (including nonprofit organizations and state institutions) notify all parties whose data records may have been compromised, lost, or stolen in the event that such data has been both unencrypted and compromised. For instance, if files were stored on a laptop computer and that computer has gone missing, anyone who potentially had a record stored on files on that computer must be notified of the action.
- Intelligence Reform and Terrorism Prevention Act of 2004—requires, as much as is possible, that intelligence agencies share information gathered and processed pertaining to potential terrorist threats. This act was a direct response to the failures of the intelligence community to prevent the 9/11 terrorist attacks.
In addition to the above acts and laws, the U.S. government has placed restrictions on the export of cryptographic technologies. For instance, an individual or company is not able to sell or trade certain cryptographic algorithms deemed too difficult to break by the U.S. government. The government has also passed legislature to update many laws to bring them up to the computer age. For instance, theft by computer now is considered theft and not some other category. There are also laws that cover censorship and obscenity with respect to the Internet and e-mail.
Further Reading
The analysis of the data, information, knowledge, and wisdom hierarchy is specifically an IT topic; you might find it useful background in order to understand the applications that IT regularly uses. A nice book that provides both practical and theoretical views of the application of the hierarchy is Information Lifecycle Support: Wisdom, Knowledge, Information and Data Management, by Johnson and Higgins (The Stationery Office, London, 2010). Jennifer Rowley provides a detailed examination of the hierarchy in her paper, “The wisdom hierarchy: representations of the DIKW hierarchy” (Journal of Information Science, 33(2), 63–180, 2007).
Information System texts vary widely just like Computer Science texts. Here, we focus on IS texts related directly to databases and DBMS. As an IT student, you will no doubt have to learn something about databases. Database design, DBMS usage, relational database, and DBMS administration are all possible topics that you will encounter. The list below spotlights a few texts in each of these topics along with a couple of texts on data mining and data warehouses.
- Cabral, S. and Murphy, K. MySQL Administrator’s Bible. Hoboken, NJ: Wiley and Sons, 2009.
- Elmasri, R. and Navathe, S. Fundamentals of Database Systems. Reading, MA: Addison Wesley, 2010.
- Fernandez, I. Beginning Oracle Database 11g Administration: From Novice to Professional. New York: Apress, 2009.
- Golfarelli, M. and Rizzi, S. Data Warehouse Design: Modern Principles and Methodologies. New York: McGraw Hill, 2009.
- Halpin, T. and Morgan, T. Information Modeling and Relational Databases. San Francisco, CA: Morgan Kaufmann, 2008.
- Han, J., Kamber, M., and Pei, J. Data Mining: Concepts and Techniques. San Francisco, CA: Morgan Kaufmann, 2011.
- Hoffer, J., Venkataraman, R. and Topi, H. Modern Database Management. Upper Saddle River, NJ: Prentice Hall 2010.
- Janert, P. Data Analysis with Open Source Tools. Cambridge, MA: O’Reilly, 2010.
- Knight, B., Patel, K., Snyder, W., LoForte, R., and Wort, S. Professional Microsoft SQL Server 2008 Administration. New Jersey: Wrox, 2008.
- Lambert III, J. and Cox, J. Microsoft Access 2010 Step by Step. Redmond, WA: Microsoft, 2010.
- Rob, P. and Coronel, C. Database Systems: Design, Implementation, and Management. Boston, MA: Thomson Course Technologies, 2007.
- Shmeuli, G., Patel, N., and Bruce, P. Data Mining for Business Intelligence: Concepts, Techniques and Applications in Microsoft Office Excel with XLMiner. New Jersey: Wiley and Sons, 2010.
- Whitehorn, M. and Marklyn, B. Inside Relational Databases with Examples in Access. Secaucus, NJ: Springer, 2006.
IAS encompasses risk management, network and computer security, and encryption. As with databases, thousands of texts exist on this widespread set of topics. This list primarily emphasizes computer and network security as they are more important to the IT professional.
- Ciampa, M. Security+ Guide to Network Security Fundamentals. Boston, MA: Thomson Course Technologies, 2011.
- Cole, E. Network Security Bible. Hoboken, NJ: Wiley and Sons, 2009.
- Easttom, W. Computer Security Fundamentals. Indiana: Que, 2011.
- Gibson, D. Management Risk in Information Systems. Sudbury, MA: Jones and Bartlett, 2010.
- Jang, M. Security Strategies in Linux Platforms and Applications, Sudbury, MA: Jones and Bartlett, 2010.
- Oriyano, S, and Gregg, M. Hacker Techniques, Tools and Incident Handling. Sudbury, MA: Jones and Bartlett, 2010.
- Paar, C., Pelzl, J. and Preneel, B. Understanding Cryptography: A Textbook for Students and Practitioners. New Jersey: Springer, 2010.
- Qian, Y., Tipper, D., Krishnamurthy, P. and Joshi, J. Information Assurance: Dependability and Security in Networked Systems. San Francisco, CA: Morgan Kaufmann, 2007.
- Schneier, B. Applied Cryptography: Protocols, Algorithms, and Source Code in C. Hoboken, NJ: Wiley and Sons, 1996.
- Solomon, M. Security Strategies in Windows Platforms and Applications. Sudbury, MA: Jones and Bartlett, 2010.
- Stallings, W. and Brown, L. Computer Security: Principles and Practices. Upper Saddle River, NJ: Prentice Hall, 2011.
- Stewart, J. Network Security, Firewalls, and VPNs. Sudbury, MA: Jones and Bartlett, 2010.
- Vacca, J. Computer and Information Security Handbook. California: Morgan Kaufmann, 2009.
Many laws related to IT are described on different websites. Issues pertaining to privacy and civil liberty can be found on the Department of Justice website at http://www.justice.gov/opcl/ and issues and laws regarding cybercrime at http://www.justice.gov/criminal/cybercrime/. Other IT related laws are provided on the U.S. Government’s cio.gov website. Your rights with respect to computer usage and free speech are always a confusing topic. Many people believe that the first amendment gives them the right to say anything that they want over the Internet. The book Cyber Rights: Defending Free Speech in the Digital Age (New York: Times Book, 2003) by M. Godwin provides a useful background and history to free speech on the Internet.
Review terms
Terminology used in this chapter:
Asymmetric key encryption Phishing
Availability Projection (database)
Backup Protocol attack
Buffer overflow Public key
Certificate Public key encryption
Certificate authority Private key
Clustering Private key encryption
Confidentiality Query (database)
Database RAID
Data mining Record (database)
Data warehouse Redundancy
Decision tree Restriction (database)
Denial of service Relation
Disaster recovery Relational database
Field (database) Risk assessment
Information Risk management
Information asset Social engineering
Integrity Software exploit
Intrusion SQL injection
Join (database) Symmetric key encryption
Malware Threat
OLAP Vulnerability
Review Questions
- What is the difference between data and information?
- Information can come in many different forms, list five forms.
- How does a database differ from a relation?
- Given the relations in Table 15.1 and Table 15.2, answer the following:
- Show the output of a restriction on the relation in 15.1 with the criteria GPA > 3.0.
- Show the output of a restriction on the relation in 15.1 with the criteria Minor = “Physics” or Minor = “Chemistry”.
- Show the output of a projection on the relation in 15.1 of First Name, Major, and Minor.
- Show the output of a join on the relations in 15.1 and 15.2 with a projection of First Name, Last Name, and State with the criteria of GPA > 3.0.
- What is the difference between a database and a data warehouse?
- Refer back to Figure 15.3. If someone has an income of $40,000, no debt, and no collateral, what conclusion should we draw regarding the risk of a loan? What if the person has an income of $30,000, no debt, and no collateral?
- What type of vulnerability might an employee of a bank have toward the bank’s risk management? What type of vulnerability might a bank’s database files and computers have?
- What is the best defense from social engineering?
- Would a buffer overflow be considered a phishing attack, software exploit, protocol attack, or intrusion attack?
- Would packet sniffing be considered a phishing attack, software exploit, protocol attack, or intrusion attack?
- List four forms of malware.
- What is a self-signed certificate? What happens in your web browser if you receive a self-signed certificate when using https?
- How does RAID 0 differ from the other levels of RAID?
- Which RAID level provides the greatest amount of redundancy?
- How is RAID 5 an improvement over RAID 4? How is RAID 6 an improvement over RAID 5?
- Rewrite the message “hello” using rotation+1.
- How does symmetric-key encryption differ from asymmetric-key encryption?
- Given the private key numbers from Threats and Solutions, encrypt the binary value 0001100100101.
- Given the private key numbers from “Threats and Solutions”, decrypt the value 6315.
- Assume you have received the value 4261. Why would it be difficult to decrypt this value using the public key from Threats and Solutions?
- Are your grades protected such that a teacher is not allowed to freely announce or give away that information? Is your medical history protected?
Discussion Questions
- Assume we have the following 10 pieces of data (here, we only examine two fields of the data, given as integer numbers). Each is listed by name (a letter) and the values of the two fields, such as a(10,5). Graph the 10 pieces of data and see if you can identify reasonable clusters. How many clusters did you find? Are there any outliers?
a(10,5), b(3,6), c(9,7), d(8,4), e(9,3), f(1,8), g(3,7), h(2,4), i(2,8), j(10,2)
- Consider your own home. Define some of your information assets. What vulnerabilities and threats do you find for those assets? For instance, one information asset is your checking account number and the amount of money there. Vulnerabilities include that the account information should be kept secret and that you must be aware of the amount of money in the account. Threats include someone forging your signature on a check or overdrawing on your account. Attempt to define five other assets and their vulnerabilities and threats.
- List three man-made disasters that have occurred in your area of the country in the past year. List three natural disasters that have occurred in your area of the country in the past year. From your list, which ones might impact a nearby company’s IT?
- As a computer user, how might you use encryption with respect to storing data? How might you use encryption with respect to Internet access?
- Why does the U.S. government have laws against exporting certain types of encryption technology?
- Stop Online Piracy Act (SOPA) was a proposed piece of legislation that was eventually removed from consideration. Explore what SOPA attempted to do and why it was abandoned. Provide a brief explanation.
- SOPA is not the only piece of legislation proposed to stop online piracy. Research this topic and come up with other pieces of legislature. Of those you have discovered, which ones were similarly removed from consideration and which remain under consideration?
- Research the Anonymous cracker group. Do you find their actions to be justified or not? Explain.
* The Euclidean distance formula between two data, 1 and 2, is √(a1−a2)2+ (b1−b2)2+ (c1−c2)2 assuming that our data has three attribute values, a, b, and c.
† You can find the full law on the Department of Justice’s website at http://www.justice.gov/opcl/privstat.htm.