
Chapter 6
The Art of Scheduling for Big Data Science
Florin Pop and Valentin Cristea
Abstract
Many applications generate Big Data, like social networking and social influence programs, cloud applications, public websites, scientific experiments and simulations, data warehouses, monitoring platforms, and e-government services. Data grow rapidly, since applications produce continuously increasing volumes of unstructured and structured data. The impact on data processing, transfer, and storage is the need to reevaluate the approaches and solutions to better answer user needs. In this context, scheduling models and algorithms have an important role. A large variety of solutions for specific applications and platforms exist, so a thorough and systematic analysis of existing solutions for scheduling models, methods, and algorithms used in Big Data processing and storage environments has high importance. This chapter presents the best of existing solutions and creates an overview of current and near-future trends. It will highlight, from a research perspective, the performance and limitations of existing solutions and will offer the scientists from academia and designers from industry an overview of the current situation in the area of scheduling and resource management related to Big Data processing.
6.1 Introduction
The rapid growth of data volume requires processing of petabytes of data per day. Cisco estimates that mobile data traffic alone will reach 11.16 exabytes of data per month in 2017. The produced data is subject to different kinds of processing, from real-time processing with impact for context-aware applications to data mining analysis for valuable information extraction. The multi-V (volume, velocity, variety, veracity, and value) model is frequently used to characterize Big Data processing needs. Volume defines the amount of data, velocity means the rate of data production and processing, variety refers to data types, veracity describes how data can be a trusted function of its source, and value refers to the importance of data relative to a particular context [1].
Scheduling plays an important role in Big Data optimization, especially in reducing the time for processing. The main goal of scheduling in Big Data platforms is to plan the processing and completion of as many tasks as possible by handling and changing data in an efficient way with a minimum number of migrations. Various mechanisms are used for resource allocation in cloud, high performance computing (HPC), grid, and peer-to-peer systems, which have different architectural characteristics. For example, in HPC, the cluster used for data processing is homogeneous and can handle many tasks in parallel by applying predefined rules. On the other side, cloud systems are heterogeneous and widely distributed; task management and execution are aware of communication rules and offer the possibility to create particular rules for the scheduling mechanism. The actual scheduling methods used in Big Data processing frameworks are as follows: first in first out, fair scheduling, capacity scheduling, Longest Approximate Time to End (LATE) scheduling, deadline constraint scheduling, and adaptive scheduling [2,3]. Finding the best method for a particular processing request remains a significant challenge. We can see the Big Data processing as a big “batch” process that runs on an HPC cluster by splitting a job into smaller tasks and distributing the work to the cluster nodes. The new types of applications, like social networking, graph analytics, and complex business work flows, require data transfer and data storage. The processing models must be aware of data locality when deciding to move data to the computing nodes or to create new computing nodes near data locations. The workload optimization strategies are the key to guarantee profit to resource providers by using resources to their maximum capacity. For applications that are both computationally and data intensive, the processing models combine different techniques like in-memory, CPU, and/or graphics processing unit (GPU) Big Data processing.
Moreover, Big Data platforms face the problem of environments’ heterogeneity due to the variety of distributed systems types like cluster, grid, cloud, and peer-to-peer, which actually offer support for advanced processing. At the confluence of Big Data with widely distributed platforms, scheduling solutions consider solutions designed for efficient problem solving and parallel data transfers (that hide transfer latency) together with techniques for failure management in highly heterogeneous computing systems. In addition, handling heterogeneous data sets becomes a challenge for interoperability among various software systems.
This chapter highlights the specific requirements of scheduling in Big Data platforms, scheduling models and algorithms, data transfer scheduling procedures, policies used in different computing models, and optimization techniques. The chapter concludes with a case study on Hadoop and Big Data, and the description of the new fashion to integrate New Structured Query Language (NewSQL) databases with distributed file systems and computing environments.
6.2 Requirements for Scheduling in Big Data Platforms
The requirements of traditional scheduling models came from applications, databases, and storage resources, which did exponentially grow over the years. As a result, the cost and complexity of adapting traditional scheduling models to Big Data platforms have increased, prompting changes in the way data is stored, analyzed, and accessed. The traditional model is being expanded to incorporate new building blocks. They address the challenges of Big Data with new information processing frameworks built to meet Big Data’s requirements.
The integration of applications and services in Big Data platforms requires a cluster resource management layer as a middleware component but also particular scheduling and execution engines specific to different models: batch tasks, data flow, NewSQL tasks, and so forth (Figure 6.1). So, we have scheduling methods and algorithms in both cluster and execution engine layers.
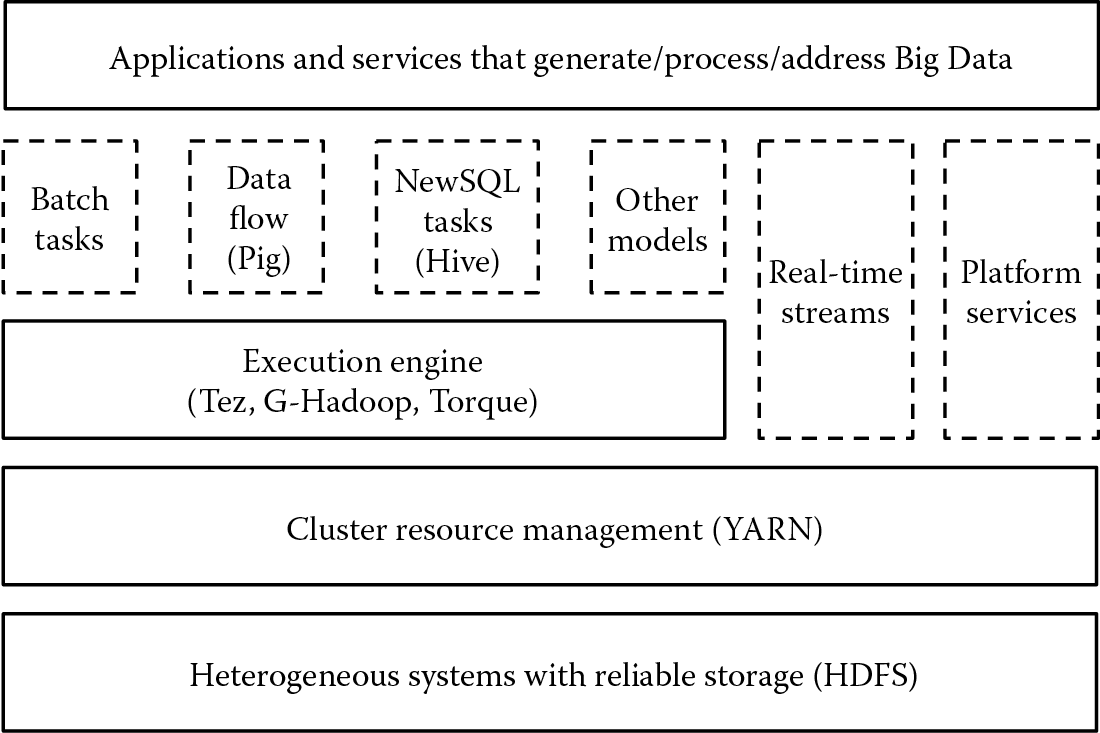
The general requirements for scheduling in Big Data platforms define the functional and nonfunctional specifications for a scheduling service. The general requirements are as follows:
- Scalability and elasticity: A scheduling algorithm must take into consideration the peta-scale data volumes and hundred thousands of processors that can be involved in processing tasks. The scheduler must be aware of execution environment changes and be able to adapt to workload changes by provisioning or deprovisioning resources.
- General purpose: A scheduling approach should make assumptions about and have few restrictions to various types of applications that can be executed. Interactive jobs, distributed and parallel applications, as well as noninteractive batch jobs should all be supported with high performance. For example, a noninteractive batch job requiring high throughput may prefer time-sharing scheduling; similarly, a real-time job requiring short-time response prefers space-sharing scheduling.
- Dynamicity: The scheduling algorithm should exploit the full extent of available resources and may change its behavior to cope, for example, with many computing tasks. The scheduler needs to continuously adapt to resource availability changes, paying special attention to cloud systems and HPC clusters (data centers) as reliable solutions for Big Data [4].
- Transparency: The host(s) on which the execution is performed should not affect tasks’ behavior and results. From the user perspective, there should be no difference between local and remote execution, and the user should not be aware about system changes or data movements for Big Data processing.
- Fairness: Sharing resources among users is a fair way to guarantee that each user obtains resources on demand. In a pay-per-use model in the cloud, a cluster of resources can be allocated dynamically or can be reserved in advance.
- Time efficiency: The scheduler should improve the performance of scheduled jobs as much as possible using different heuristics and state estimation suitable for specific task models. Multitasking systems can process multiple data sets for multiple users at the same time by mapping the tasks to resources in a way that optimizes their use.
- Cost (budget) efficiency: The scheduler should lower the total cost of execution by minimizing the total number of resources used and respect the total money budget. This aspect requires efficient resource usage. This can be done by optimizing the execution for mixed tasks using a high-performance queuing system and by reducing the computation and communication overhead.
- Load balancing: This is used as a scheduling method to share the load among all available resources. This is a challenging requirement when some resources do not match with tasks’ properties. There are classical approaches like round-robin scheduling, but also, new approaches that cope with large scale and heterogeneous systems were proposed: least connection, slow start time, or agent-based adaptive balancing.
- Support of data variety and different processing models: This is done by handling multiple concurrent input streams, structured and unstructured content, multimedia content, and advanced analytics. Classifying tasks into small or large, high or low priority, and periodic or sporadic will address a specific scheduling technique.
- Integration with shared distributed middleware: The scheduler must consider various systems and middleware frameworks, like the sensor integration in any place following the Internet of Things paradigm or even mobile cloud solutions that use offloading techniques to save energy. The integration considers the data access and consumption and supports various sets of workloads produced by services and applications.
The scheduling models and algorithms are designed and implemented by enterprise tools and integration support for applications, databases, and Big Data processing environments. The workload management tools must manage the input and output data at every data acquisition point, and any data set must be handled by specific solutions. The tools used for resource management must solve the following requirements:
- Capacity awareness: Estimate the percentage of resource allocation for a workload and understand the volume and the velocity of data that are produced and processed.
- Real-time, latency-free delivery and error-free analytics: Support the service-level agreements, with continuous business process flow and with an integrated labor-intensive and fault-tolerant Big Data environment.
- API integration: With different operating systems, support various-execution virtual machines (VMs) and wide visibility (end-to-end access through standard protocols like hypertext transfer protocol [HTTP], file transfer protocol [FTP], and remote login, and also using a single and simple management console) [5].
6.3 Scheduling Models and Algorithms
A scheduling model consists of a scheduling policy, an algorithm, a programing model, and a performance analysis model. The design of a scheduler that follows a model should specify the architecture, the communication model between entities involved in scheduling, the process type (static or dynamic), the objective function, and the state estimation [6]. It is important that all applications are completed as quickly as possible, all applications receive the necessary proportion of the resources, and those with a close deadline have priority over other applications that could be finished later. The scheduling model can be seen from another point of view, namely, the price. It is important for cloud service providers to have a higher profit but also for user applications to be executed so that the cost remains under the available budget [7].
Several approaches to the scheduling problem have been considered over time. These approaches consider different scenarios, which take into account the applications’ types, the execution platform, the types of algorithms used, and the various constraints that might be imposed. The existing schedulers suitable for large environments and also for Big Data platforms are as follows:
- First In First Out (FIFO) (oldest job first)—jobs are ordered according to the arrival time. The order can be affected by job priority.
- Fair scheduling—each job gets an equal share of the available resources.
- Capacity scheduling—provides a minimum capacity guarantee and shares excess capacity; it also considers the priorities of jobs in a queue.
- Adaptive scheduling—balances between resource utilization and jobs’ parallelism in the cluster and adapts to specific dynamic changes of the context.
- Data locality-aware scheduling—minimizes data movement.
- Provisioning-aware scheduling—provisions VMs from larger physical clusters; virtual resource migration is considered in this model.
- On-demand scheduling—uses a batch scheduler as resource manager for node allocation based on the needs of the virtual cluster.
The use of these models takes into account different specific situations: For example, FIFO is recommended when the number of tasks is less than the cluster size, while fairness is the best one when the cluster size is less than the number of tasks. Capacity scheduling is used for multiple tasks and priorities specified as response times. In Reference 8, a solution of a scheduling bag of tasks is presented. Users receive guidance regarding the plausible response time and are able to choose the way the application is executed: with more money and faster or with less money but slower. An important ingredient in this method is the phase of profiling the tasks in the actual bag. The basic scheduling is realized with a bounded knapsack algorithm. Reference 9 presents the idea of scheduling based on scaling up and down the number of the machines in a cloud system. This solution allows users to choose among several types of VM instances while scheduling each instance’s start-up and shutdown to respect the deadlines and ensure a reduced cost.
A scheduling solution based on genetic algorithms is described in Reference 10. The scheduling is done on grid systems. Grids are different from cloud systems, but the principle used by the authors in assigning tasks to resources is the same. The scheduling solution works with applications that can be modeled as directed acyclic graphs. The idea is minimizing the duration of the application execution while the budget is respected. This approach takes into account the system’s heterogeneity.
Reference 11 presents a scheduling model for instance-intensive work flows in the cloud, which takes into consideration both budget and deadline constraints. The level of user interaction is very high, the user being able to change dynamically the cost and deadline requirements and provide input to the scheduler during the work flow execution. The interventions can be made every scheduled round. This is an interesting model because the user can choose to pay more or less depending on the scenario. The main characteristic is that the user has more decision power on work flow execution. In addition, the cloud estimates the time and cost during the work flow execution to provide hints to users and dynamically reschedule the workload.
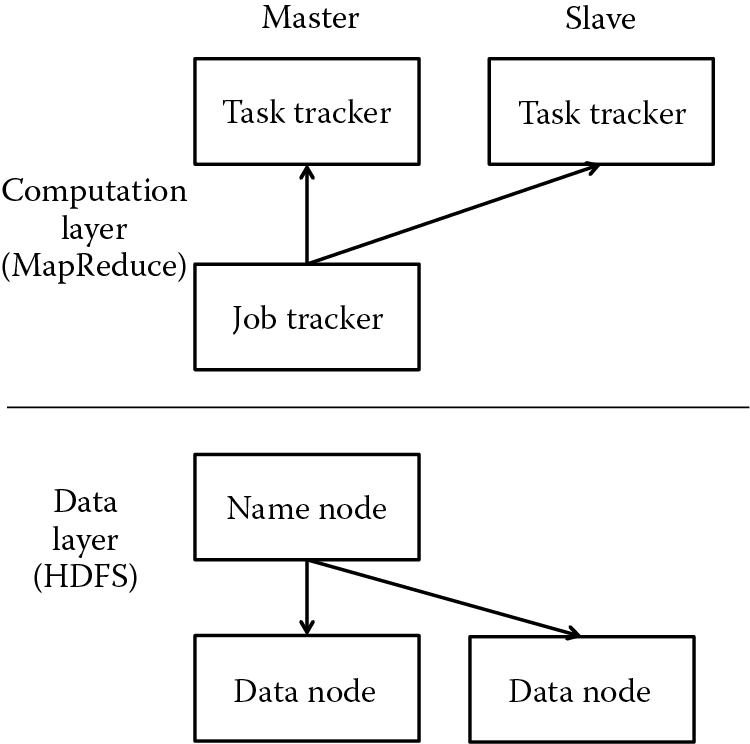
The Apache Hadoop framework is a software library that allows the processing of large data sets distributed across clusters of computers using a simple programming model [3]. The framework facilitates the execution of MapReduce applications. Usually, a cluster on which the Hadoop system is installed has two masters and several slave components (Figure 6.2) [12]. One of the masters is the JobTracker, which deals with processing projects coming from users and sends them to the scheduler used in that moment. The other master is NameNode, which manages the file system namespace and the user access control. The other machines act as slaves. A TaskTracker represents a machine in Hadoop, while a DataNode handles the operations with the Hadoop Distributed File System (HDFS), which deals with data replication on all the slaves in the system. This is the way input data gets to map and to reduce tasks. Every time an operation occurs on one of the slaves, the results of the operation are immediately propagated into the system [13].
The Hadoop framework considers the capacity and fair scheduling algorithms. The Capacity Scheduler has a number of queues. Each of these queues is assigned a part of the system resources and has specific numbers of map and reduce slots, which are set through the configuration files. The queues receive users’ requests and order them by the associated priorities. There is also a limitation for each queue per user. This prevents the user from seizing the resources for a queue.
The Fair Scheduler has pools in which job requests are placed for selection. Each user is assigned to a pool. Also, each pool is assigned a set of shares and uses them to manage the resources allocated to jobs, so that each user receives an equal share, no matter the number of jobs he/she submits. Anyway, if the system is not loaded, the remininig shares are distributed to existing jobs. The Fair Scheduler has been proposed in Reference 14. The authors demonstrated its special qualities regarding the reduced response time and the high throughput.
There are several extensions to scheduling models for Hadoop. In Reference 15, a new scheduling algorithm is presented, LATE, which is highly robust to heterogeneity without using specific information about nodes. The solution solves the problems posed by heterogeneity in virtualized data centers and ensures good performance and flexibility for speculative tasks. In Reference 16, a scheduler is presented that meets deadlines. This scheduler has a preliminary phase for estimating the possibility to achieve the deadline claimed by the user, as a function of several parameters: the runtimes of map and reduce tasks, the input data size, data distribution, and so forth. Jobs are scheduled only if the deadlines can be met. In comparison with the schedulers mentioned in this section, the genetic scheduler proposed in Reference 7 approaches the deadline constraints but also takes into account the environment heterogeneity. In addition, it uses speculative techniques in order to increase the scheduler’s power. The genetic scheduler has an estimation phase, where the processing data speed for each application is measured. The scheduler ensures that, once an application’s execution has started, that application will end successfully in normal conditions. The Hadoop On Demand (HOD) [3] virtual cluster uses the Torque resource manager for node allocation and automatically prepares configuration files. Then it initializes the system based on the nodes within the virtual cluster. HOD can be used in a relatively independent way.
To support multiuser situations [14,17], the Hadoop framework incorporates several components that are suitable for Big Data processing (Figure 6.3) since they offer high scalability through a large volume of data and support access to widely distributed data. Here is a very short description of these components: Hadoop Common consists of common utilities that support any Hadoop modules and any new extension. HDFS provides high-throughput access to application data. Hadoop YARN (Apache Hadoop NextGen MapReduce) is a framework for job scheduling and cluster resource management that can be extended across multiple platforms. Hadoop MapReduce is a YARN-based system for parallel processing of large data sets.
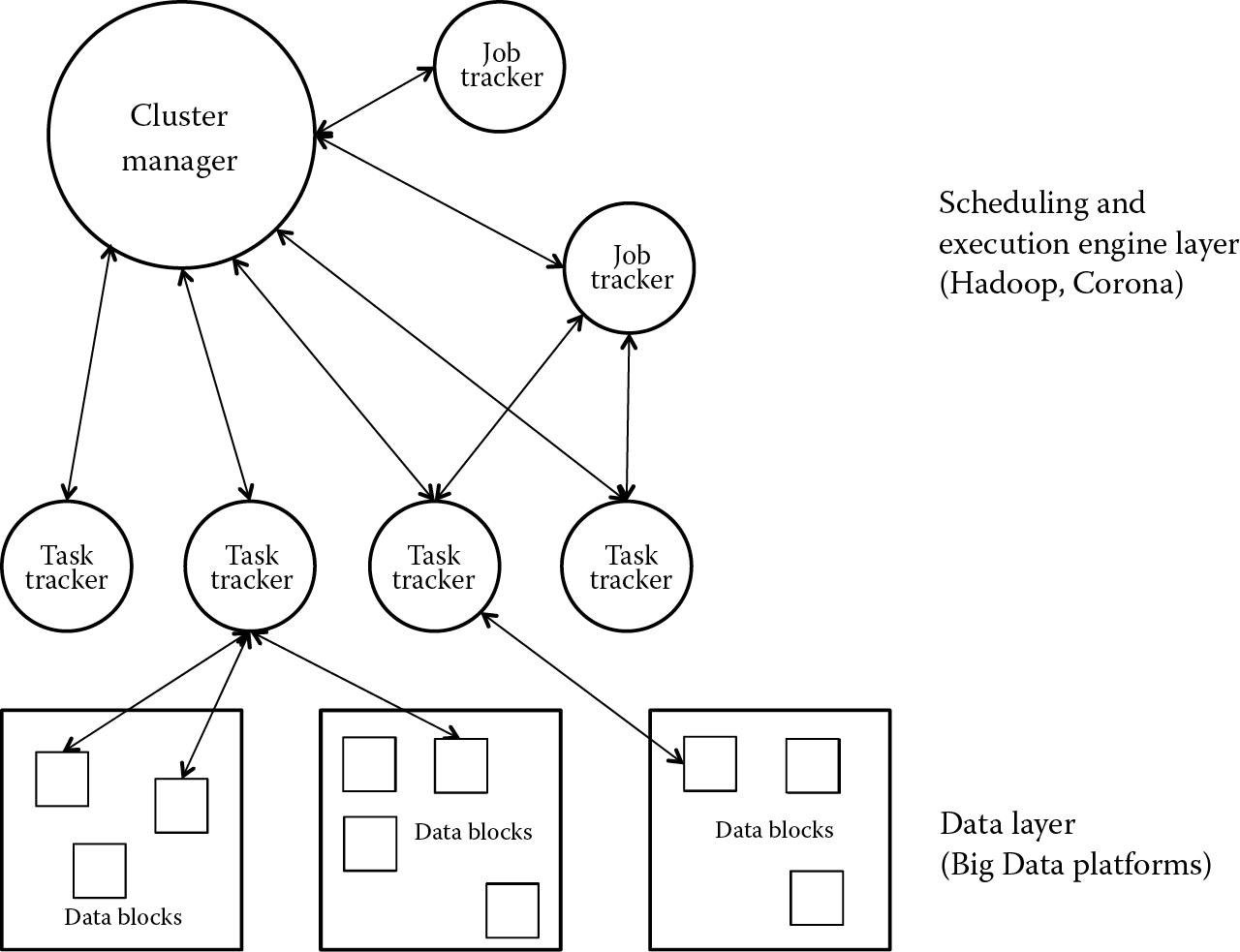
Facebook solution Corona [18] extends and improves the Hadoop model, offering better scalability and cluster utilization, lower latency for small jobs, the ability to upgrade without disruption, and scheduling based on actual task resource requirements rather than a count of map and reduce tasks. Corona was designed to answer the most important Facebook challenges: unique scalability (the largest cluster has more than 100 PB of data) and processing needs (crunch more than 60,000 Hive queries a day). The data warehouse inside Facebook has grown by 2500 times between 2008 and 2012, and it is expected to grow by the same factor until 2016.
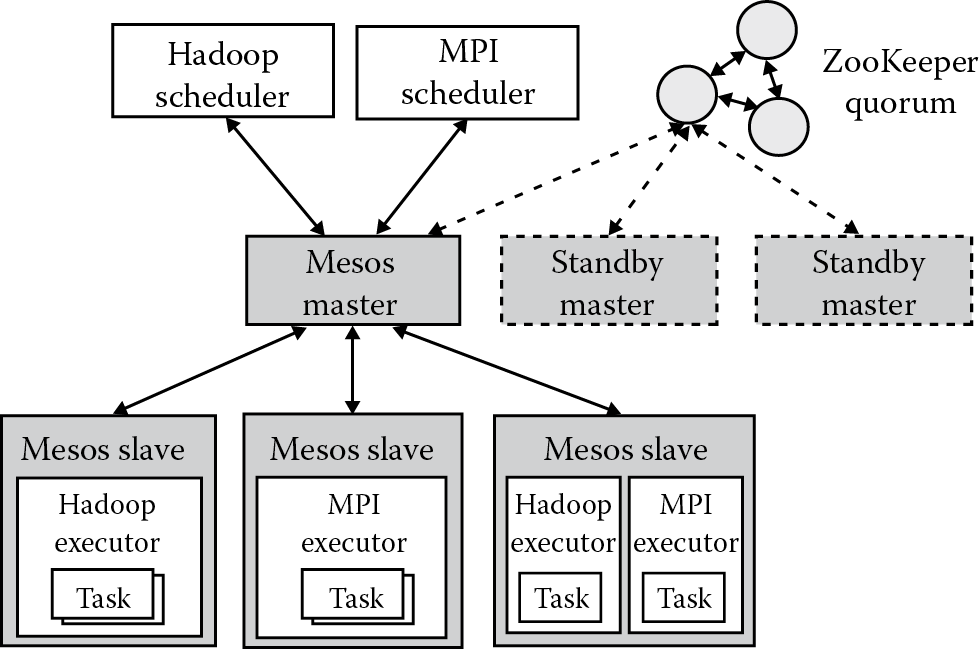
Mesos [19] uses a model of resource isolation and sharing across distributed applications using Hadoop, message passing interface (MPI), Spark, and Aurora in a dynamic way (Figure 6.4). The ZooKeeper quorum is used for master replication to ensure fault tolerance. By integration of multiple slave executors, Mesos offers support for multiresource scheduling (memory and CPU aware) using isolation between tasks with Linux Containers. The expected scalability goes over 10,000 nodes.
YARN [20] splits the two major functionalities of the Hadoop JobTracker in two separate components: resource management and job scheduling/monitoring (application management). The Resource Manager is integrated in the data-computation framework and coordinates the resource for all jobs processing alive in a Big Data platform. The Resource Manager has a pure scheduler, that is, it does not monitor or track the application status and does not offer guarantees about restarting failed tasks due to either application failure or hardware failures. It offers only matching of applications’ jobs on resources.
The new processing models based on bioinspired techniques are used for fault-tolerant and self-adaptable handling of data-intensive and computation-intensive applications. These evolutionary techniques approach the learning based on history with the main aim to find a near-optimal solution for problems with multiconstraint and multicriteria optimizations. For example, adaptive scheduling is needed for dynamic heterogeneous systems where we can change the scheduling strategy according to available resources and their capacity.
6.4 Data Transfer Scheduling
In many cases, depending on applications’ architecture, data must be transported to the place where tasks will be executed [21]. Consequently, scheduling schemes should consider not only the task execution time but also the data transfer time for finding a more convenient mapping of tasks. Only a handful of current research efforts consider the simultaneous optimization of computation and data transfer scheduling. The general data scheduling techniques are the Least Frequently Used (LFU), Least Recently Used (LRU), and economical models. Handling multiple file transfer requests is made in parallel with maximizing the bandwidth for which the file transfer rates between two end points are calculated and considering the heterogeneity of server resources.
The Big Data input/output (I/O) scheduler in Reference 22 is a solution for applications that compete for I/O resources in a shared MapReduce-type Big Data system. The solution, named Interposed Big Data I/O Scheduler (IBIS), has the main aims to solve the problem of differentiating the I/Os among competitive applications on separate data nodes and perform scheduling according to applications’ bandwidth demands. IBIS acts as a meta-scheduler and efficiently coordinates the distributed I/O schedulers across data nodes in order to allocate the global storage.
In the context of Big Data transfers, a few “big” questions need to be answered in order to have an efficient cloud environment, more specifically, when and where to migrate. In this context, an efficient data migration method, focusing on the minimum global time, is presented in Reference 23. The method, however, does not try to minimize individual migrations’ duration. In Reference 24, two migration models are described: offline and online. The offline scheduling model has as a main target the minimization of the maximum bandwidth usage on all links for all time slots of a planning period. In the online scheduling model, the scheduler has to make fast decisions, and the migrations are revealed to the migration scheduler in an a priori undefined sequence. Jung et al. [25] treat the data mining parallelization by considering the data transfer delay between two computing nodes. The delay is estimated by using the autoregressive moving average filter. In Reference 26, the impact of two resource reservation methods is tested: reservation in source machines and reservation in target machines. Experimental results proved that resource reservation in target machines is needed, in order to avoid migration failure. The performance overheads of live migration are affected by memory size, CPU, and workload types.
The model proposed in Reference 27 uses the greedy scheduling algorithm for data transfers through different cloud data centers. This algorithm gets the transfer requests on a first-come-first-serve order and sets a time interval in which they can be sent. This interval is reserved on all the connections the packet has to go through (in this case, there is a maximum of three hops to destination, because of the full mesh infrastructure). This is done until there are no more transfers to schedule, taking into account the previously reserved time frames for each individual connection. The connections are treated individually to avoid the bottleneck. For instance, the connections between individual clouds need to transfer more messages than connections inside the cloud. This way, even if the connection from a physical machine to a router is unused, the connection between the routers can be oversaturated. There is no point in scheduling the migration until the transfers that are currently running between the routers end, even if the connection to the router is unused.
6.5 Scheduling Policies
The scheduling policies are used to determine the relative ordering of requests. Large distributed systems with different administrative domains will most likely have different resource utilization policies. A policy can take into consideration the priority, the deadlines, the budgets, and also the dynamic behavior [28]. For Big Data platforms, dynamic scheduling with soft deadlines and hard budget constraints on hybrid clouds are an open issue.
A general-purpose resource management approach in a cluster used for Big Data processing should make some assumptions about policies that are incorporated in service-level agreements. For example, interactive tasks, distributed and parallel applications, as well as noninteractive batch tasks should all be supported with high performance. This property is a straightforward one but, to some extent, difficult to achieve. Because tasks have different attributes, their requirements to the scheduler may contradict in a shared environment. For example, a real-time task requiring short-time response prefers space-sharing scheduling; a noninteractive batch task requiring high throughput may prefer time-sharing scheduling [6,29]. To be general purpose, a trade-off may have to be made. The scheduling method focuses on parallel tasks, while providing an acceptable performance to other kinds of tasks.
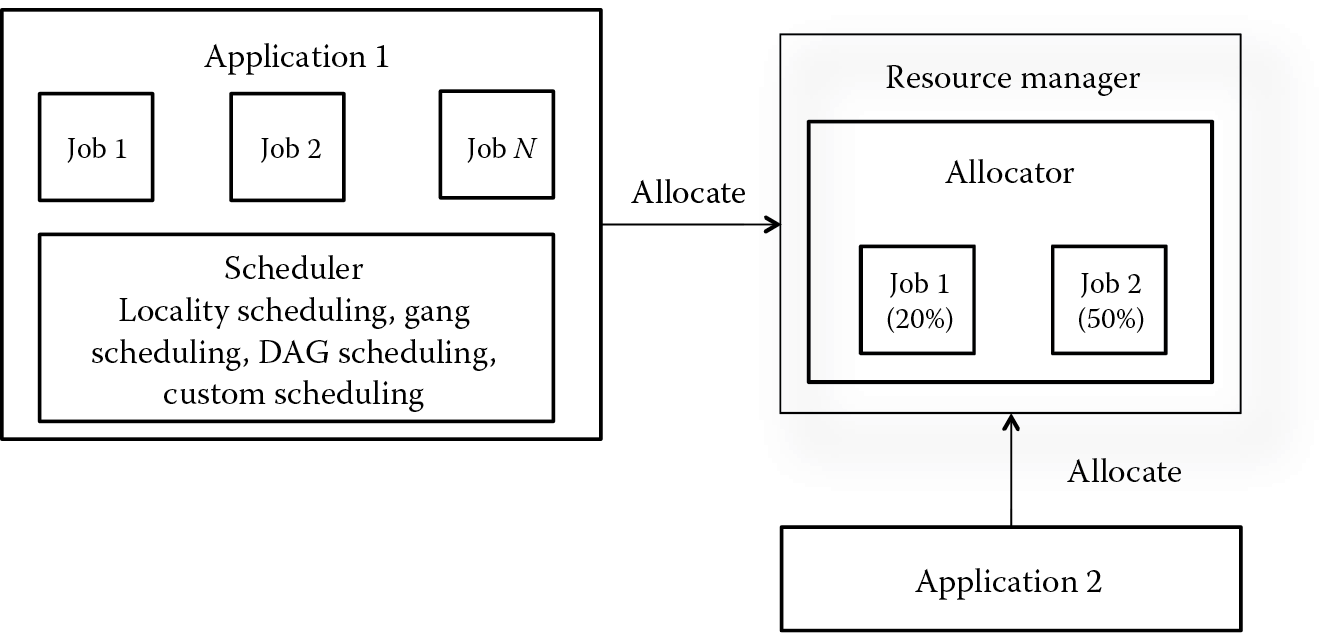
YARN has a pluggable solution for dynamic policy loading, considering two steps for the resource allocation process (Figure 6.5). Resource allocation is done by YARN, and task scheduling is done by the application, which permits the YARN platform to be a generic one while still allowing flexibility of scheduling strategies. The specific policies in YARN are oriented on resource splitting according with schedules provided by applications. In this way, the YARN’s scheduler determines how much and in which cluster to allocate resources based on their availability and on the configured sharing policy.
6.6 Optimization Techniques for Scheduling
The scheduling in Big Data platforms is the main building block for making data centers more available to applications and user communities. An example of optimization is multiobjective and multiconstrained scheduling of many tasks in Hadoop [30] or optimizing short jobs with Hadoop [31]. The optimization strategies for scheduling are specific to each model and for each type of application. The most used techniques for scheduling optimization are as follows:
- Linear programming allows the scheduler to find the suitable resources or cluster of resources, based on defined constraints.
- Dynamic partitioning splits complex applications in a cluster of tasks and schedules each cluster with a specific scheduling algorithm.
- Combinatorial optimization aims to find an optimal allocation solution for a finite set of resources. This is a time-consuming technique, and it is not recommended for real-time processing.
- Evolutionary optimization aims to find an optimal configuration for a specific system within specific constraints and consists of specific bioinspired techniques like genetic and immune algorithms, ant and bee computing, particle swarm optimization, and so forth. These methods usually find a near-optimal solution for the scheduling problem.
- Stochastic optimization uses random variables that appear in the formulation of the optimization problem itself and are used especially for applications that have a deterministic behavior, that is, a normal distribution (for periodic tasks) or Poisson distribution (for sporadic tasks), and so forth.
- Task-oriented optimization considers the task’s properties, arrival time (slack optimization), and frequency (for periodic tasks).
- Resource-oriented optimization considers completion time constraints while making the decision to maximize resource utilization.
6.7 Case Study on Hadoop and Big Data Applications
We can consider that, on top of Apache Hadoop or a Hadoop distribution, you can use a Big Data suite and scheduling application that generate Big Data. The Hadoop framework is suitable for specific high-value and high-volume workloads [32]. With optimized resource and data management by putting the right Big Data workloads in the right systems, a solution is offered by the integration of YARN with specific schedulers: G-Hadoop [33], MPI Scheduler, Torque, and so forth. The cost-effectiveness, scalability, and streamlined architectures of Hadoop have been developed by IBM, Oracle, and Hortonworks Data Platform (HDP) with the main scope to construct a Hadoop operating system. Hadoop can be used in public/private clouds through related projects integrated in the Hadoop framework, trying to offer the best answer to the following question: What type of data/tasks should move to a public cloud, in order to achieve a cost-aware cloud scheduler [34]?
Different platforms that use and integrate Hadoop in application development and implementation consider different aspects. Modeling is the first one. Even in Apache Hadoop, which offers the infrastructure for Hadoop clusters, it is still very complicated to build a specific MapReduce application by writing complex code. Pig Latin and Hive query language (HQL), which generate MapReduce code, are optimized languages for application development. The integration of different scheduling algorithms and policies is also supported. The application can be modeled in a graphical way, and all required code is generated. Then, the tooling of Big Data services within a dedicated development environment (Eclipse) uses various dedicated plugins. Code generation of all the code is automatically generated for a MapReduce application. Last, but not least, execution of Big Data jobs has to be scheduled and monitored. Instead of writing jobs or other code for scheduling, the Big Data suite offers the possibility to define and manage execution plans in an easy way.
In a Big Data platform, Hadoop needs to integrate data of all different kinds of technologies and products. Besides files and SQL databases, Hadoop needs to integrate the NoSQL databases, used in applications like social media such as Twitter or Facebook; the messages from middleware or data from business-to-business (B2B) products such as Salesforce or SAP products; the multimedia streams; and so forth. A Big Data suite integrated with Hadoop offers connectors from all these different interfaces to Hadoop and back.
The main Hadoop-related projects, developed under the Apache license and supporting Big Data application execution, include the following [35]:
- HBase (https://hbase.apache.org) is a scalable, distributed database that supports structured data storage for large tables. HBase offers random, real-time read/write access to Big Data platforms.
- Cassandra (http://cassandra.apache.org) is a multimaster database with no single points of failure, offering scalability and high availability without compromising performance.
- Pig (https://pig.apache.org) is a high-level data-flow language and execution framework for parallel computation. It also offers a compiler that produces sequences of MapReduce programs, for which large-scale parallel implementations already exist in Hadoop.
- Hive (https://hive.apache.org) is a data warehouse infrastructure that provides data summarization and ad hoc querying. It facilitates querying and managing large data sets residing in distributed storage. It provides the SQL-like language called HiveQL.
- ZooKeeper (https://zookeeper.apache.org) is a high-performance coordination service for distributed applications. It is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.
- Ambari (https://ambari.apache.org) is a web-based tool for provisioning, managing, and monitoring Apache Hadoop clusters, which includes support for Hadoop HDFS, Hadoop MapReduce, Hive, HCatalog, HBase, ZooKeeper, Oozie, Pig, and Sqoop.
- Tez (http://tez.incubator.apache.org) is a generalized data-flow managing framework, built on Hadoop YARN, which provides an engine to execute an arbitrary directed acyclic graph (DAG) of tasks (an application work flow) to process data for both batch and interactive use cases. Tez is being adopted by other projects like Hive and Pig.
- Spark (http://spark.apache.org) is a fast and general compute engine for Hadoop data in large-scale environments. It combines SQL, streaming, and complex analytics and support application implementation in Java, Scala, or Python. Spark also has an advanced DAG execution engine that supports cyclic data flow and in-memory computing.
6.8 Conclusions
In the past years, scheduling models and tools have been faced with fundamental re-architecting to fit as well as possible with large many-task computing environments. The way that existing solutions were redesigned consisted of splitting the tools into multiple components and adapting each component according to its new role and place. Workloads and work flow sequences are scheduled at the application side, and then, a resource manager allocates a pool of resources for the execution phase. So, the scheduling became important at the same time for users and providers, being the most important key for any optimal processing in Big Data science.
References
1. M. D. Assuncao, R. N. Calheiros, S. Bianchi, M. A. Netto, and R. Buyya. Big Data computing and clouds: Challenges, solutions, and future directions. arXiv preprint arXiv:1312.4722, 2013. Available at http://arxiv.org/pdf/1312.4722v2.pdf.
2. A. Rasooli, and D. G. Down. COSHH: A classification and optimization based scheduler for heterogeneous Hadoop systems. Future Generation Computer Systems, vol. 36, pp. 1–15, 2014.
3. M. Tim Jones. Scheduling in Hadoop. An introduction to the pluggable scheduler framework. IBM Developer Works, Technical Report, December 2011. Available at https://www.ibm.com/developerworks/opensource/library/os-hadoop-scheduling.
4. L. Zhang, C. Wu, Z. Li, C. Guo, M. Chen, and F. C. M. Lau. Moving Big Data to the cloud: An online cost-minimizing approach. Selected Areas in Communications, IEEE Journal on, vol. 31, no. 12, pp. 2710–2721, 2013.
5. CISCO Report. Big Data Solutions on Cisco UCS Common Platform Architecture (CPA). Available at http://www.cisco.com/c/en/us/solutions/data-center-virtualization/big-data/index.html, May 2014.
6. V. Cristea, C. Dobre, C. Stratan, F. Pop, and A. Costan. Large-Scale Distributed Computing and Applications: Models and Trends. IGI Global, Hershey, PA, pp. 1–276, 2010. doi:10.4018/978-1-61520-703-9.
7. D. Pletea, F. Pop, and V. Cristea. Speculative genetic scheduling method for Hadoop environments. In 2012 14th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing. SYNASC, pp. 281–286, 2012.
8. A.-M. Oprescu, T. Kielmann, and H. Leahu. Budget estimation and control for bag-of-tasks scheduling in clouds. Parallel Processing Letters, vol. 21, no. 2, pp. 219–243, 2011.
9. M. Mao, J. Li, and M. Humphrey. Cloud auto-scaling with deadline and budget constraints. In The 11th ACM/IEEE International Conference on Grid Computing (Grid 2010). Brussels, Belgium, 2010.
10. J. Yu, and R. Buyya. Scheduling scientific workflow applications with deadline and budget constraints using genetic algorithms. Scientific Programming Journal, vol. 14, nos. 3–4, pp. 217–230, 2006.
11. K. Liu, H. Jin, J. Chen, X. Liu, D. Yuan, and Y. Yang. A compromised-time-cost scheduling algorithm in swindew-c for instance-intensive cost-constrained workflows on a cloud computing platform. International Journal of High Performance Computing Applications, vol. 24, no. 4, pp. 445–456, 2010.
12. T. White. Hadoop: The Definitive Guide. O’Reilly Media, Inc., Yahoo Press, Sebastopol, CA, 2012.
13. X. Hua, H. Wu, Z. Li, and S. Ren. Enhancing throughput of the Hadoop Distributed File System for interaction-intensive tasks. Journal of Parallel and Distributed Computing, vol. 74, no. 8, pp. 2770–2779, 2014. ISSN 0743-7315.
14. M. Zaharia, D. Borthakur, J. S. Sarma, K. Elmeleegy, S. Shenker, and I. Stoica. Job scheduling for multi-user MapReduce clusters. Technical Report, EECS Department, University of California, Berkeley, CA, April 2009. Available at http://www.eecs.berkeley.edu/Pubs/TechRpts/2009/EECS-2009-55.html.
15. M. Zaharia, A. Konwinski, A. D. Joseph, R. Katz, and I. Stoica. Improving MapReduce performance in heterogeneous environments. In Proceeding OSDI ’08 Proceedings of the 8th USENIX Conference on Operating Systems Design and Implementation. USENIX Association, Berkeley, CA, pp. 29–42, 2008.
16. K. Kc, and K. Anyanwu. Scheduling Hadoop jobs to meet deadlines. In Proceeding CLOUDCOM ’10 Proceedings of the 2010 IEEE Second International Conference on Cloud Computing Technology and Science. IEEE Computer Society, Washington, DC, pp. 388–392, 2010.
17. Y. Tao, Q. Zhang, L. Shi, and P. Chen. Job scheduling optimization for multi-user MapReduce clusters. In Parallel Architectures, Algorithms and Programming (PAAP), 2011 Fourth International Symposium on, Tianjin, China, pp. 213, 217, December 9–11, 2011.
18. Corona. Under the Hood: Scheduling MapReduce jobs more efficiently with Corona, 2012. Available at https://www.facebook.com/notes/facebook-engineering/under-the-hood-scheduling-mapreduce-jobs-more-efficiently-with-corona/10151142560538920.
19. B. Hindman, A. Konwinski, M. Zaharia, A. Ghodsi, A. D. Joseph, R. Katz, S. Shenker, and I. Stoica. Mesos: A platform for fine-grained resource sharing in the data center. In Proceedings of the 8th USENIX Conference on Networked Systems Design and Implementation (NSDI ’11). USENIX Association, Berkeley, CA, 22 p., 2011.
20. Hortonworks. Hadoop YARN: A next-generation framework for Hadoop data processing, 2013. Available at http://hortonworks.com/hadoop/yarn/.
21. J. Celaya, and U. Arronategui. A task routing approach to large-scale scheduling. Future Generation Computer Systems, vol. 29, no. 5, pp. 1097–1111, 2013.
22. Y. Xu, A. Suarez, and M. Zhao. IBIS: Interposed big-data I/O scheduler. In Proceedings of the 22nd International Symposium on High-Performance Parallel and Distributed Computing (HPDC ’13). ACM, New York, pp. 109–110, 2013.
23. J. Hall, J. Hartline, A. R. Karlin, J. Saia, and J. Wilkes. On algorithms for efficient data migration. In Proceedings of the Twelfth Annual ACM-SIAM Symposium on Discrete Algorithms (SODA ’01). Society for Industrial and Applied Mathematics, Philadelphia, PA, pp. 620–629, 2001.
24. A. Stage, and T. Setzer. Network-aware migration control and scheduling of differentiated virtual machine workloads. In Proceedings of the 2009 ICSE Workshop on Software Engineering Challenges of Cloud Computing (CLOUD ’09). IEEE Computer Society, Washington, DC, pp. 9–14, 2009.
25. G. Jung, N. Gnanasambandam, and T. Mukherjee. Synchronous parallel processing of big-data analytics services to optimize performance in federated clouds. In Proceedings of the 2012 IEEE Fifth International Conference on Cloud Computing (CLOUD ’12). IEEE Computer Society, Washington, DC, pp. 811–818, 2012.
26. K. Ye, X. Jiang, D. Huang, J. Chen, and B. Wang. Live migration of multiple virtual machines with resource reservation in cloud computing environments. In Proceedings of the 2011 IEEE 4th International Conference on Cloud Computing (CLOUD ’11). IEEE Computer Society, Washington, DC, pp. 267–274, 2011.
27. M.-C. Nita, C. Chilipirea, C. Dobre, and F. Pop. A SLA-based method for big-data transfers with multi-criteria optimization constraints for IaaS. In Roedunet International Conference (RoEduNet), 2013 11th, Sinaia, Romania, pp. 1–6, January 17–19, 2013.
28. R. Van den Bossche, K. Vanmechelen, and J. Broeckhove. Online cost-efficient scheduling of deadline-constrained workloads on hybrid clouds. Future Generation Computer Systems, vol. 29, no. 4, pp. 973–985, 2013.
29. H. Karatza. Scheduling in distributed systems. In Performance Tools and Applications to Networked Systems, M. C. Calzarossa and E. Gelenbe (Eds.), Springer Berlin, Heidelberg, pp. 336–356, 2004. ISBN: 978-3-540-21945-3.
30. F. Zhang, J. Cao, K. Li, S. U. Khan, and K. Hwang. Multi-objective scheduling of many tasks in cloud platforms. Future Generation Computer Systems, vol. 37, pp. 309–320.
31. K. Elmeleegy. Piranha: Optimizing short jobs in Hadoop. Proceedings of the VLDB Endowment, vol. 6, no. 11, pp. 985–996, 2013.
32. R. Ramakrishnan, and Team Members CISL. Scale-out beyond MapReduce. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’13), I. S. Dhillon, Y. Koren, R. Ghani, T. E. Senator, P. Bradley, R. Parekh, J. He, R. L. Grossman, and R. Uthurusamy (Eds.). ACM, New York, 1 p., 2013.
33. L. Wang, J. Tao, R. Ranjan, H. Marten, A. Streit, J. Chen, and D. Chen. G-Hadoop: MapReduce across distributed data centers for data-intensive computing. Future Generation Computer Systems, vol. 29, no. 3, pp. 739–750, 2013.
34. B. C. Tak, B. Urgaonkar, and A. Sivasubramaniam. To move or not to move: The economics of cloud computing. In Proceedings of the 3rd USENIX Conference on Hot Topics in Cloud Computing (HotCloud ’11). USENIX Association, Berkeley, CA, 5 p., 2011.
35. D. Loshin. Chapter 7—Big Data tools and techniques. In Big Data Analytics, D. Loshin, and M. Kaufmann (Eds.). Boston, pp. 61–72, 2013.