
Chapter 8
GEMS: Graph Database Engine for Multithreaded Systems
Alessandro Morari, Vito Giovanni Castellana, Oreste Villa, Jesse Weaver, Greg Williams, David Haglin, Antonino Tumeo, and John Feo
Abstract
Many fields require organizing, managing, and analyzing massive amounts of data. Among them, we can find social network analysis, financial risk management, threat detection in complex network systems, and medical and biomedical databases. For these areas, there is a problem not only in terms of size but also in terms of performance, because the processing should happen sufficiently fast to be useful. Graph databases appear to be a good candidate to manage these data: They provide an efficient data structure for heterogeneous data or data that are not themselves rigidly structured. However, exploring large-scale graphs on modern high-performance machines is challenging. These systems include processors and networks optimized for regular, floating-point intensive computations and large, batched data transfers. At the opposite, exploring graphs generates fine-grained, unpredictable memory and network accesses, is mostly memory bound, and is synchronization intensive. Furthermore, graphs often are difficult to partition, making their processing prone to load unbalance.
In this book chapter, we describe Graph Engine for Multithreaded Systems (GEMS), a full software stack that implements a graph database on a commodity cluster and enables scaling in data set size while maintaining a constant query throughput when adding more cluster nodes. GEMS employs the SPARQL (SPARQL Protocol and RDF Query Language) language for querying the graph database. The GEMS software stack comprises a SPARQL-to-data parallel C++ compiler; a library of distributed data structures; and a custom, multithreaded, runtime system.
We provide an overview of the stack, describe its advantages compared with other solutions, and focus on how we solved the challenges posed by irregular behaviors.
We finally propose an evaluation of GEMS on a typical SPARQL benchmark and on a Resource Description Format (RDF) data set currently curated at Pacific Northwest National Laboratory.
8.1 INTRODUCTION
Many very diverse application areas are experiencing an explosive increase in the availability of data to process. They include finance; science fields such as astronomy, biology, genomics, climate and weather, and material sciences; the web; geographical systems; transportation; telephones; social networks; and security. The data sets of these applications have quickly surpassed petabytes in size and keep exponentially growing. Enabling computing systems to process these large amounts of data, without compromising performance, is becoming of paramount importance. Graph databases appear a most natural and convenient way to organize, represent, and store the data of these applications, as they usually contain a large number of relationships among their elements, providing significant benefits with respect to relational databases.
Graph databases organize the data in the form of subject–predicate–object triples following the Resource Description Framework (RDF) data model (Klyne et al. 2004). A set of triples naturally represents a labeled, directed multigraph. An analyst can query semantic graph databases through languages such as SPARQL (W3C SPARQL Working Group 2013), in which the fundamental query operation is graph matching. This is different from conventional relational databases that employ schema-specific tables to store data and perform select and conventional join operations when executing queries. With relational approaches, graph-oriented queries on large data sets can quickly become unmanageable in both space and time due to the large sizes of immediate results created when performing conventional joins.
Expressing a query as pattern-matching operations provides both advantages and disadvantages for modern high-performance systems. Exploring a graph is inherently parallel, because the system can potentially spawn a thread for each pattern, vertex, or edge, but also inherently irregular, because it generates unpredictable fine-grained data accesses with poor spatial and temporal locality. Furthermore, graph exploration is mainly network and memory bandwidth bound.
These aspects make clusters promising platforms for scaling both size and performance graph databases at the same time: when adding a node, both the available memory (for in-memory processing) and the number of available cores in the system increase (Weaver 2012). On the other hand, modern clusters are optimized for regular computation, batched data transfers, and high flop ratings, and they introduce several challenges for adequately supporting the required graph processing techniques.
This chapter presents the Graph Engine for Multithreaded Systems (GEMS) database stack. GEMS implements a full software system for graph databases on a commodity cluster. GEMS comprises a SPARQL-to-C++ data parallel compiler; a library of distributed data structures; and custom, multithreaded runtime systems. Differently from other database systems, GEMS executes queries mostly by employing graph exploration methods. The compiler optimizes and converts the SPARQL queries directly to parallel graph-crawling algorithms expressed in C++. The C++ code exploits the distributed data structures and the graph primitives to perform the exploration. The C++ code runs on top of the Global Memory and Threading (GMT) library, a runtime library that provides a global address space across cluster nodes and implements fine-grained software multithreading to tolerate data access latencies, and message aggregation to maximize network bandwidth utilization.
8.2 RELATED INFRASTRUCTURES
Currently, many commercial and open-source SPARQL engines are available. We can distinguish between purpose-built databases for the storage and retrieval of triples (triplestores) and solutions that try to map triplestores on top of existing commercial databases, usually relational structured query language (SQL)-based systems. However, obtaining feature-complete SPARQL-to-SQL translation is difficult and may introduce performance penalties. Translating SPARQL to SQL implies the use of relational algebra to perform optimizations and the use of classical relational operators (e.g., conventional joins and selects) to execute the query.
By translating SPARQL to graph pattern-matching operations, GEMS reduces the overhead for intermediate data structures and can exploit optimizations that look at the execution plan (i.e., order of execution) from a graph perspective.
SPARQL engines can further be distinguished between solutions that process queries in memory and solutions that store data on disks and perform swapping. Jena (Apache Jena, n.d.), with the ARQ SPARQL engine (ARQ—A SPARQL Processor for Jena, n.d.); Sesame (openRDF.org, n.d.); and Redland (Redland RDF Libraries, n.d.), also known as librdf, are all examples of RDF libraries that natively implement in-memory RDF storage and support integration with some disk-based, SQL back ends. OpenLink Virtuoso (Virtuoso Universal Server, n.d.) implements an RDF/SPARQL layer on top of their SQL-based column store for which multinode cluster support is available. GEMS adopts in-memory processing: It stores all data structures in RAM. In-memory processing potentially allows increasing the data set size while maintaining constant query throughput by adding more cluster nodes.
Some approaches leverage MapReduce infrastructures for RDF-encoded databases. SHARD (Rohloff and Schantz 2010) is a triplestore built on top of Hadoop, while YARS2 (Harth et al. 2007) is a bulk-synchronous, distributed query-answering system. Both exploit hash partitioning to distribute triples across nodes. These approaches work well for simple index lookups, but they also present high communication overheads for moving data through the network with more complex queries as well as introduce load-balancing issues in the presence of data skew.
More general graph libraries, such as Pregel (Malewicz et al. 2010), Giraph (Apache Giraph, n.d.), and GraphLab (GraphLab, n.d.), may also be exploited to explore semantic databases, once the source data have been converted into a graph. However, they require significant additions to work in a database environment, and they still rely on bulk-synchronous, parallel models that do not perform well for large and complex queries. Our system relies on a custom runtime that provides specific features to support exploration of a semantic database through graph-based methods.
Urika is a commercial shared-memory system from YarcData (YarcData, Inc., n.d.) targeted at Big Data analytics. Urika exploits custom nodes with purpose-built multithreaded processors (barrel processors with up to 128 threads and a very simple cache) derived from the Cray XMT. Besides multithreading, which allows tolerating latencies for accessing data on remote nodes, the system has hardware support for a scrambled global address space and fine-grained synchronization. These features allow more efficient execution of irregular applications, such as graph exploration. On top of this hardware, YarcData interfaces with the Jena framework to provide a front-end application programming interface (API). GEMS, instead, exploits clusters built with commodity hardware that are cheaper to acquire and maintain and that are able to evolve more rapidly than custom hardware.
8.3 GEMS OVERVIEW
Figure 8.1 presents a high-level overview of the architecture of GEMS. The figure shows the main component of GEMS: the SPARQL-to-C++ compiler, the Semantic Graph Library (SGLib), and the GMT runtime. An analyst can load one or more graph databases, write the SPARQL queries, and execute them through a client web interface that connects to a server on the cluster.
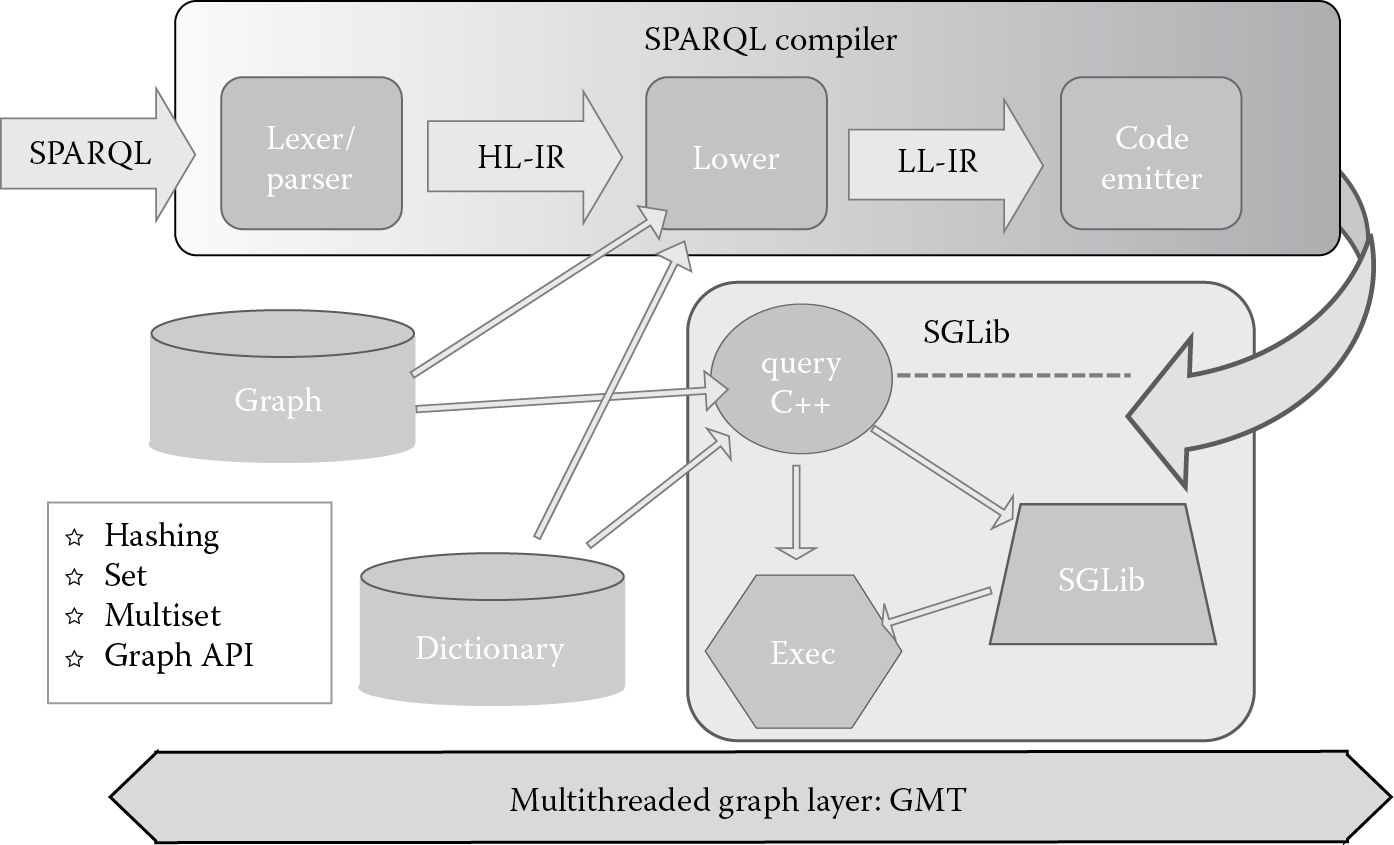
High-level overview of Graph Engine for Multithreaded Systems (GEMS). HL-IR, high level-intermediate representation; LL-IR, low level-intermediate representation.
The top layer of GEMS consists of the compilation phases: The compiler transforms the input SPARQL queries into intermediate representations that are analyzed for optimization opportunities. Potential optimization opportunities are discovered at multiple levels. Depending on statistics of the data sets, certain query clauses can be moved, enabling early pruning of the search. Then, the optimized intermediate representation is converted into C++ code that contains calls to the SGLib API. SGLib APIs completely hide the low-level APIs of GMT, exposing to the compiler a lean, simple, pseudosequential shared-memory programming model. SGLib manages the graph database and query execution. SGLib generates the graph database and the related dictionary by ingesting the triples. Triples can, for example, be RDF triples stored in N-Triples format.
The approach implemented by our system to extract information from the semantic graph database is to solve a structural graph pattern-matching problem. GEMS employs a variation of Ullmann’s (1976) subgraph isomorphism algorithm. The approach basically enumerates all the possible mappings of the graph pattern vertices to those in the graph data set through a depth-first tree search. A path from root to leaves in the resulting tree denotes a complete mapping. If all the vertices that are neighbors in a path are also neighbors both in the graph pattern and in the graph data set (i.e., adjacency is preserved), then the path represents a match. Even if the resulting solution space has exponential complexity, the algorithm can prune early subtrees that do not lead to feasible mappings. Moreover, the compiler can perform further optimizations by reasoning on the query structure and the data set statistics.
The data structures implemented within the SGLib layer support the operation of a query search using the features provided by the GMT layer. When loaded, the size of the SGLib data structures is expected to be larger than what can fit into a single node’s memory, and these are therefore implemented using the global memory of GMT. The two most fundamental data structures are the graph and dictionary. Supplemental data structures are the array and table.
The ingest phase of the GEMS workflow initializes a graph and dictionary. The dictionary is used to encode string labels with unique integer identifiers (UIDs). Therefore, each RDF triple is encoded as a sequence of three UIDs. The graph indexes RDF triples in subject–predicate–object and object–predicate–subject orders. Each index is range-partitioned so that each node in the cluster gets an almost equal number of triples. Subject–predicate and object–predicate pairs with highly skewed proportions of associated triples are specially distributed among nodes so as to avoid load imbalance as the result of data skew.
The GMT layer provides the key features that enable management of the data structures and load balancing across the nodes of the cluster. GMT is codesigned with the upper layers of the graph database engine so as to better support the irregularity of graph pattern-matching operations. GMT provides a Partitioned Global Address Space (PGAS) data model, hiding the complexity of the distributed memory system. GMT exposes to SGLib an API that permits allocating, accessing, and freeing data in the global address space. Differently from other PGAS libraries, GMT employs a control model typical of shared-memory systems: fork-join parallel constructs that generate thousands of lightweight tasks. These lightweight tasks allow hiding the latency for accessing data on remote cluster nodes; they are switched in and out of processor cores while communication proceeds. Finally, GMT aggregates operations before communicating to other nodes, increasing network bandwidth utilization.
The sequence of Figure 8.2, Figure 8.3, Figure 8.4, Figure 8.5, and Figure 8.6 presents a simple example of a graph database, of a SPARQL query, and of the conversion performed by the GEMS’ SPARQL-to-C++ compiler.

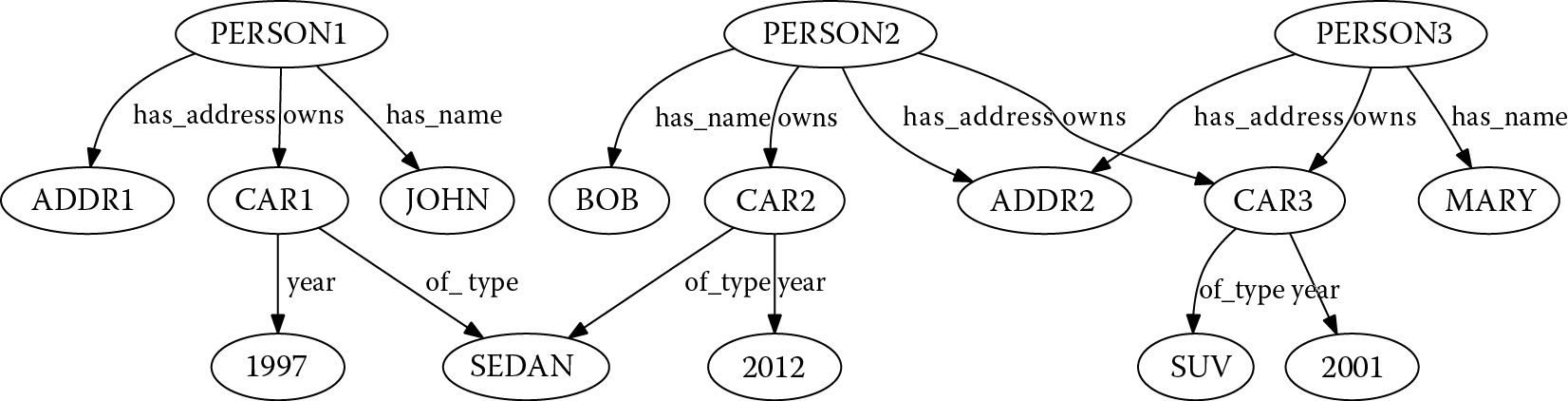

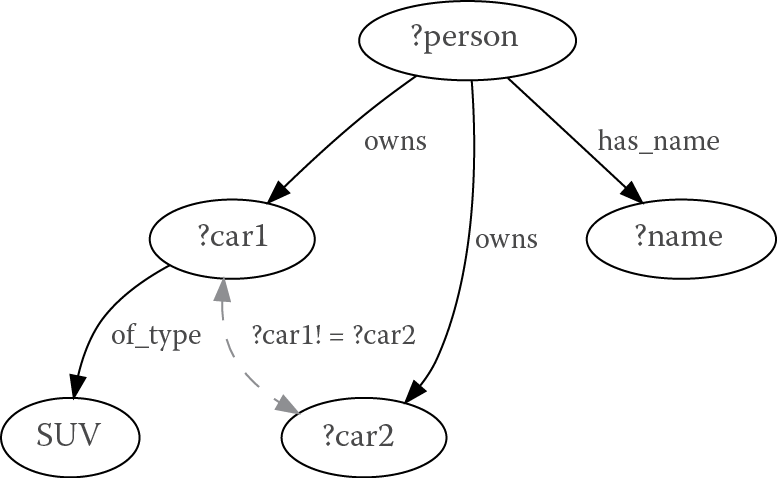

Figure 8.2 shows the data set in N-Triples format (a common serialization format for RDF) (Carothers and Seaborne 2014). Figure 8.3 shows the corresponding graph representation of the data set. Figure 8.4 shows the SPARQL description of the query. Figure 8.5 illustrates the corresponding graph of the query. Finally, Figure 8.6 shows a pseudocode conceptually similar to the C/C++ generated by the GEMS’ compiler and executed, through SGLib, by the GMT runtime library.
As illustrated in Figure 8.6, the bulk of the query is executed as a parallel graph walk. The forAll method is used to call a function for all matching edges, in parallel. Thus, the graph walk can be conceptualized as nested loops. At the end (or “bottom”) of a graph walk, results are buffered in a loader object that is associated with a table object. When all the parallel edge traversals are complete, the loader finalizes by actually inserting the results into its associated table. At this point, operations like deduplication (DISTINCT) or grouping (GROUP BY) are performed using the table. Results are effectively structs containing different variables of the results. Many variables will be bound to UIDs, but some may contain primitive values.
GEMS has minimal system-level library requirements: Besides Pthreads, it only needs message passing interface (MPI) for the GMT communication layer and Python for some compiler phases and for glue scripts. The current implementation of GEMS also requires x86-compatible processors because GMT employs optimized context switching routines. However, because of the limited requirements in terms of libraries, the porting to other architectures should be mostly confined to replacing these context switching routines.
8.4 GMT ARCHITECTURE
The GMT runtime system is a key component that enables GEMS to operate on a larger data set while maintaining constant throughput as nodes are added to the cluster.
GMT relies on three main elements to provide its scalability: a global address space, latency tolerance through fine-grained software multithreading, and message aggregation (also known as coalescing).
GMT provides a global address space across the various cluster nodes by implementing a custom PGAS data substrate. The PGAS model relieves the other layers of GEMS (and the developers) from partitioning the data structures and from orchestrating communication. PGAS does not neglect completely the concept of locality but instead acknowledges that there are overheads in accessing data stored on other cluster nodes. Indeed, PGAS libraries normally enable accessing data through put and get operations that move the data from/to a globally shared array to/from a node-local memory location.
Message aggregation maximizes network bandwidth utilization, despite the small data accesses typical of graph methods. Aggregation is completely transparent to the developer.
Fine-grained multithreading allows hiding the latency for remote data transfers, and the additional latency for aggregation, by exploiting the inherent parallelism of graph algorithms.
Figure 8.7 shows the high-level design of GMT. Each node in the cluster executes an instance of GMT. Different instances communicate through commands, which describe data, synchronization, and thread management operations. GMT is a parallel runtime, in the sense that it exploits threads also to perform its operations, with three types of specialized threads. The main idea is to exploit the cores of modern processors to support the functionalities of the runtime. The specialized threads are as follows:
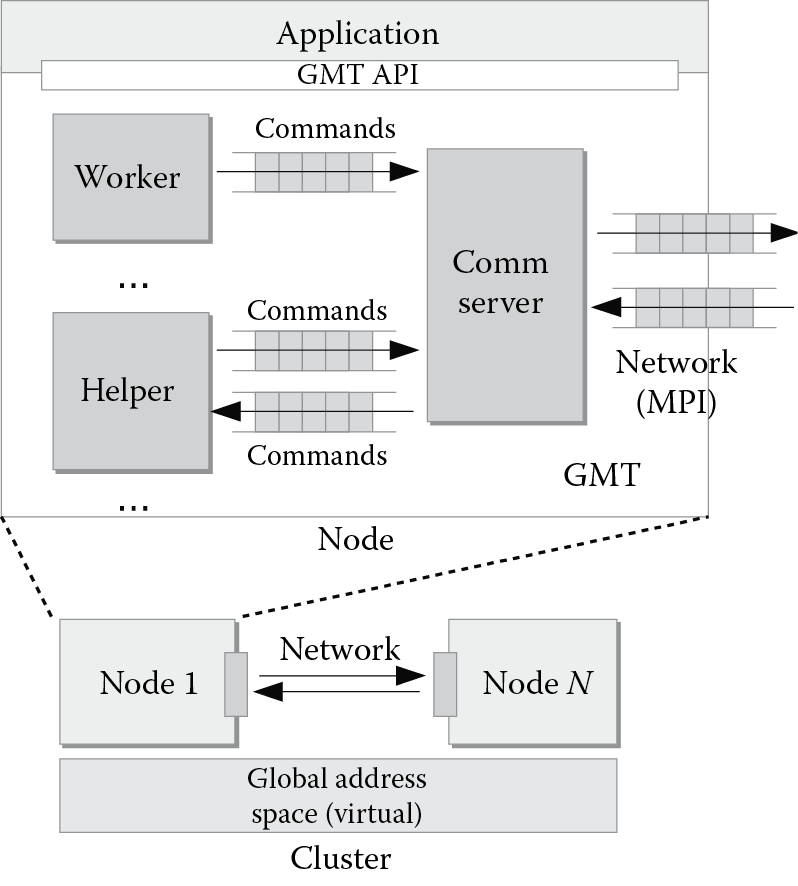
- Worker: executes application code, in the form of lightweight user tasks, and generates commands directed to other nodes
- Helper: manages global address space and synchronization and handles incoming commands from other nodes
- Communication server: end point for the network, which manages all incoming/outgoing communication at the node level in the form of network messages, which contain the commands
The specialized threads are implemented as POSIX threads, each one pinned to a core. The communication server employs MPI to send and receive messages to and from other nodes. There are multiple workers and helpers per node. Usually, we use an equal number of workers and helpers, but this is one of the parameters that can be adjusted, depending on empirical testing on the target machine. There is, instead, a single communication server because while building the runtime, we verified that a single communication server is already able to provide the peak MPI bandwidth of the network with reasonably sized packets, removing the need to manage multiple network end points (which, in turn, may bring challenges and further overheads for synchronization).
SGLib data structures are implemented using shared arrays in GMT’s global address space. Among them, there are the graph data structure and the terms dictionary. The SPARQL-to-C++ compiler assumes operation on a shared-memory system and does not need to reason about the physical partitioning of the database. However, as is common in PGAS libraries, GMT also exposes locality information, allowing reduction in data movements whenever possible. Because graph exploration algorithms mostly have loops that run through edge or vertex lists (as the pseudocode in Figure 8.6 shows), GMT provides a parallel loop construct that maps loop iterations to lightweight tasks. GMT supports task generation from nested loops and allows specifying the number of iterations of a loop mapped to a task. GMT also allows controlling code locality, enabling spawning (or moving) of tasks on preselected nodes, instead of moving data. SGLib routines exploit these features to better manage its internal data structures. SGLib routines access data through put and get communication primitives, moving them into local space for manipulation and writing them back to the global space. The communication primitives are available with both blocking and nonblocking semantics. GMT also provides atomic operations, such as atomic addition and test-and-set, on data allocated in the global address space. SGLib exploits them to protect parallel operations on the graph data sets and to implement global synchronization constructs for database management and querying.
8.4.1 GMT: Aggregation
Graph exploration algorithms typically present fine-grained data accesses. They mainly operate through for-loops that run through edges and/or vertices. Edges usually are pointers that connect one vertex to another. Depending on the graph structure, each pointer may point to a location in a completely unrelated memory area. On distributed memory systems, the data structure is partitioned among the different memories of each node. This is true also with PGAS substrates, which only provide distributed memory abstractions. Expert programmers thus usually have to implement by hand optimizations to aggregate requests and reduce the overhead due to small network transactions. GMT hides these complexities from the other layers of GEMS by implementing automatic message aggregation.
GMT collects commands directed towards the same destination nodes in aggregation queues. GMT copies commands and their related data (e.g., values requested from the global address space with a get) into aggregation buffers and sends them in bulk. Commands are then unpacked and executed at the destination node. At the node level, GMT employs high-throughput, nonblocking aggregation queues, which support concurrent access from multiple workers and helpers. Accessing these queues for every generated command would have a very high cost. Thus, GMT employs a two-level aggregation mechanism: Workers (or helpers) initially collect commands in local command blocks, and then they insert command blocks into the aggregation queues. Figure 8.8 shows how the aggregation mechanism operates. When aggregation starts, workers (or helpers) request a preallocated command block from the command block pool (1). Command blocks are preallocated and reused for performance reasons. Commands generated during program execution are collected into the local command block (2). A command block is pushed into aggregation queues when (a) it is full or (b) it has been waiting longer than a predetermined time interval. Condition (a) is true when all the available entries are occupied with commands or when the equivalent size in bytes of the commands (including any attached data) reaches the size of the aggregation buffer. Condition (b) allows setting a configurable upper bound for the latency added by aggregation. After pushing a command block, when a worker or a helper finds that the aggregation queue has sufficient data to fill an aggregation buffer, it starts popping command blocks from the aggregation queue and copying them with the related data into an aggregation buffer (4, 5, and 6). Aggregation buffers also are preallocated and recycled to save memory space and eliminate allocation overhead. After the copy, command blocks are returned to the command block pool (7). When the aggregation buffer is full, the worker (or helper) pushes it into a channel queue (8). Channel queues are high-throughput, single-producer, single-consumer queues that workers and helpers use to exchange data with the communication server. If the communication server finds a new aggregation buffer in one of the channel queues, it pops it (9) and performs a nonblocking MPI send (10). The aggregation buffer is then returned into the pool of free aggregation buffers.
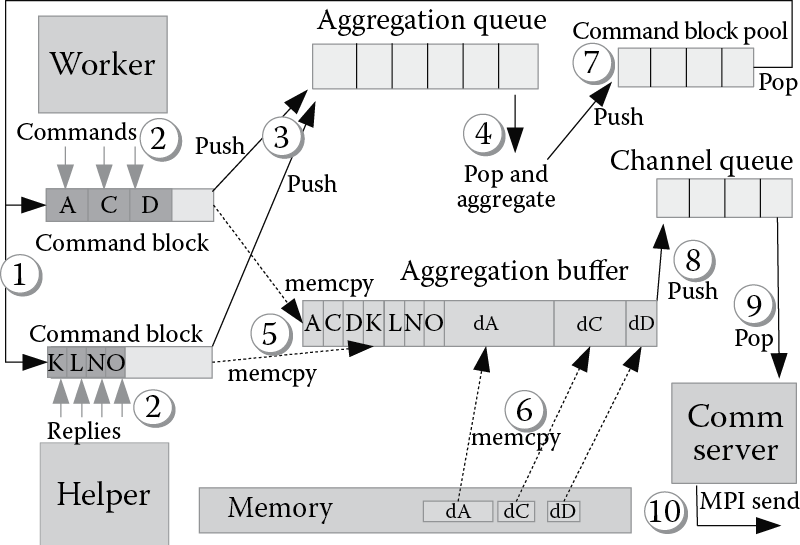
The size of aggregation buffers and the time intervals for pushing out aggregated data are configurable parameters that depend on the interconnection of the cluster on which GEMS runs. Thumb rules to set these parameters are as follows: Buffers should be sufficiently large to maximize network throughput, while time intervals should not increase the latency over the values maskable through multithreading. The right values may be derived through empirical testing on the target cluster with toy examples.
8.4.2 GMT: Fine-Grained Multithreading
Concurrency, through fine-grained software multithreading, allows tolerance for both the latency for accessing data on remote nodes and the added latency for aggregating communication operations. Each worker executes a set of GMT tasks. The worker switches among tasks’ contexts every time it generates a blocking command that requires a remote memory operation. The task that generated the command executes again only when the command itself completes (i.e., it gets a reply back from the remote node). In case of nonblocking commands, the task continues executing until it encounters a wait primitive.
GMT implements custom context switching primitives that avoid some of the lengthy operations (e.g., saving and restoring the signal mask) performed by the standard libc context switching routines.
Figure 8.9 schematically shows how GMT executes a task. A node receives a message containing a spawn command (1) that is generated by a worker on a remote node when encountering a parallel construct. The communication server passes the buffer containing the command to a helper that parses the buffer and executes the command (2). The helper then creates an iteration block (itb). The itb is a data structure that contains the function to execute, the arguments of the function itself, and number of tasks that will execute the function. This way of representing a set of tasks avoids the cost of creating a large number of function arguments and sending them over the network. In the following step, the helper pushes the itb into the itb queue (3). Then, an idle worker pops an itb from the itb queue (5), and it decreases the counter of t and pushes it back into the queue (6). The worker creates t tasks (6) and pushes them into its private task queue (7).
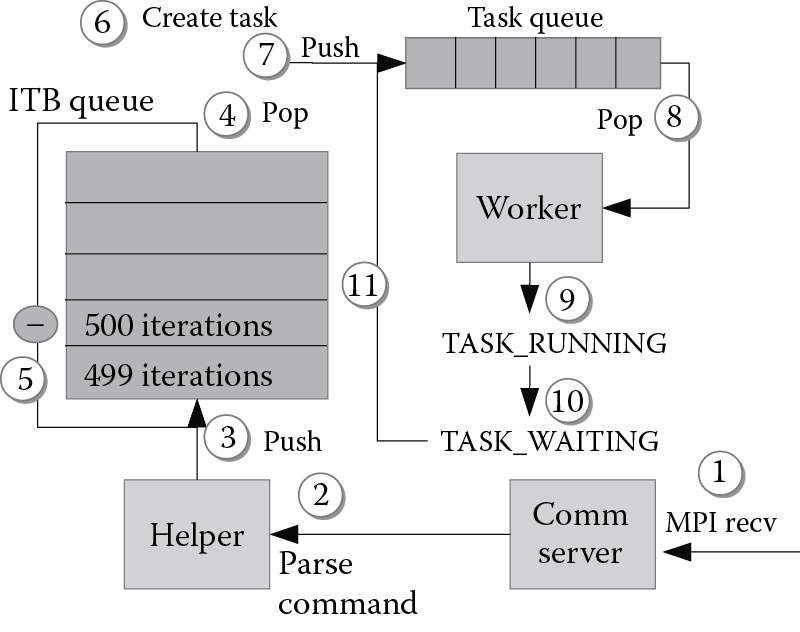
At this point, the idle worker can pop a task from its task queue (8). If the task is executable (i.e., all the remote operations completed), the worker restores the task’s context and executes it (9). Otherwise, it pushes the task back into the task queue. If the task contains a blocking remote request, the task enters a waiting state (10) and is reinserted into the task queue for future execution (11).
This mechanism provides load balancing at the node level because each worker gets new tasks from the itb queue as soon as its task queue is empty. At the cluster level, GMT evenly splits tasks across nodes when it encounters a parallel for-loop construct.
8.5 EXPERIMENTAL RESULTS
We evaluated GEMS on the Olympus supercomputer at Pacific Northwest National Laboratory’s Institutional Computing center, listed in Top500.org (Top500.org, n.d.). Olympus is a cluster of 604 nodes interconnected through a quad data rate (QDR) InfiniBand switch with 648 ports (theoretical bandwidth peak of 4 GB/s). Each of Olympus’ nodes features two AMD Opteron 6272 processors at 2.1 GHz and 64 GB of double data rate 3 (DDR3) memory clocked at 1600 MHz. Each socket hosts eight processor modules (two integer cores, one floating-point core per module) on two different dies, for a total of 32 integer cores per node. Dies and sockets are interconnected through HyperTransport.
We configured a GEMS stack with 15 workers, 15 helpers, and 1 communication server per node. Each worker hosts up to 1024 lightweight tasks. We measured the MPI bandwidth of Olympus with the OSU Micro-Benchmarks 3.9 (Ohio State University, n.d.), reaching the peak of 2.8 GB/s with messages of at least 64 KB. Therefore, we set the aggregation buffer size at 64 KB. Each communication channel hosts up to four buffers. There are two channel queues per helper and one channel queue per worker.
We initially present some synthetic benchmarks of the runtime, highlighting the combined effects of multithreading and aggregation to maximize network bandwidth utilization. We then show experimental results of the whole GEMS system on a well-established benchmark, the Berlin SPARQL Benchmark (BSBM) (Bizer and Schultz 2009), and on a data set currently curated at Pacific Northwest National Laboratory (PNNL) for the Resource Discovery for Extreme Scale Collaboration (RDESC) project.
8.5.1 Synthetic Benchmarks
Figure 8.10 and Figure 8.11 show the transfer rates reached by GMT with small messages (from 8 to 128 bytes) when increasing the number of tasks. Every task executes 4096 blocking put operations. Figure 8.10 shows the bandwidth between two nodes, and Figure 8.11 shows the bandwidth among 128 nodes. The figures show how increasing the concurrency increases the transfer rates because there is a higher number of messages that GMT can aggregate. For example, across two nodes (Figure 8.10) with 1024 tasks each, puts of 8 bytes reach a bandwidth of 8.55 MB/s. With 15,360 tasks, instead, GMT reaches 72.48 MB/s. When increasing message sizes to 128 bytes, 15,360 tasks provide almost 1 GB/s. For reference, 32 MPI processes with 128 bytes messages only reach 72.26 MB/s. With more destination nodes, the probability of aggregating enough data to fill a buffer for a specific remote node decreases. Although there is a slight degradation, Figure 8.11 shows that GMT is still very effective. For example, 15,360 tasks with 16 bytes messages reach 139.78 MB/s, while 32 MPI processes only provide up to 9.63 MB/s.
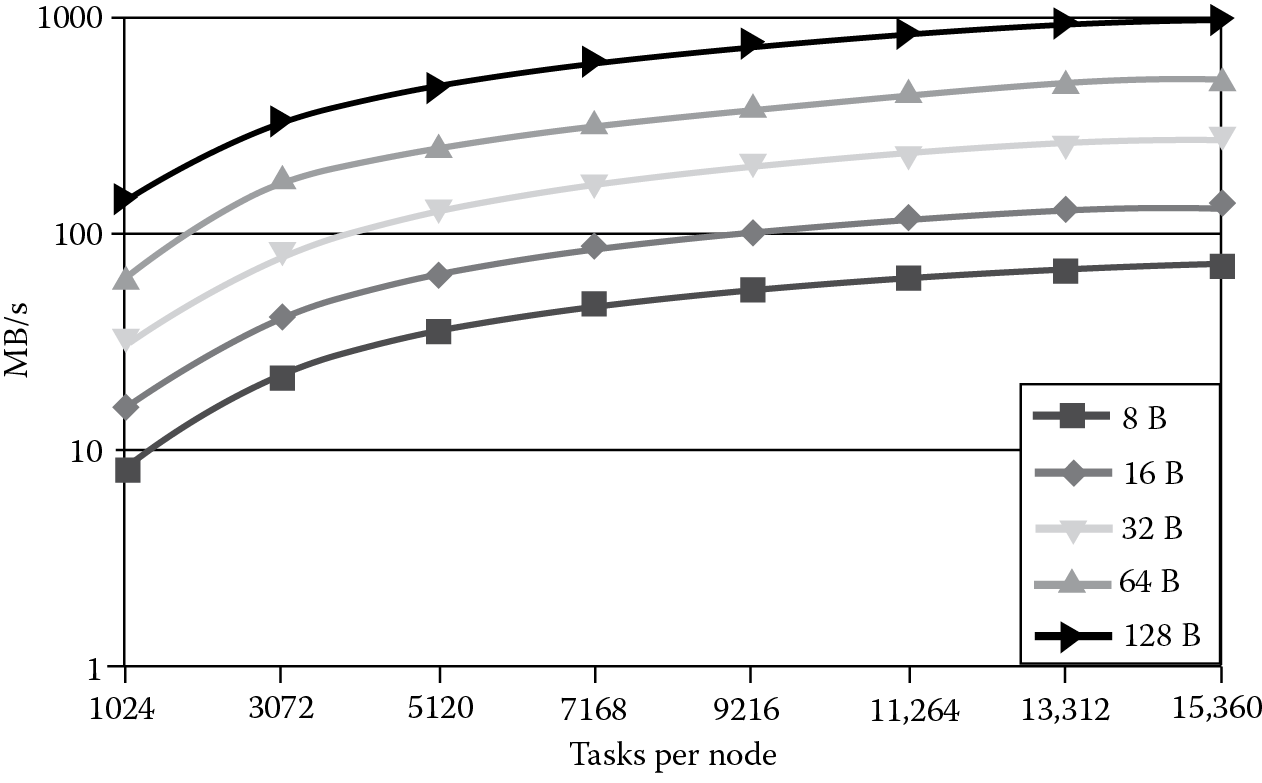

Transfer rates of put operations among 128 nodes (one to all) while increasing concurrency.
8.5.2 BSBM
BSBM defines a set of SPARQL queries and data sets to evaluate the performance of semantic graph databases and systems that map RDF into other kinds of storage systems. Berlin data sets are based on an e-commerce use case with millions to billions of commercial transactions, involving many product types, producers, vendors, offers, and reviews. We run queries 1 through 6 (Q1–Q6) of the business intelligence use case on data sets with 100 million, 1 billion, and 10 billion triples.
Table 8.1, Table 8.2, and Table 8.3 respectively show the build time of the database and the execution time of the queries on 100 million, 1 billion, and 10 billion triples, while progressively increasing the number of cluster nodes. The sizes of the input files respectively are 21 GB (100 million), 206 GB (1 billion), and 2 TB (10 billion). In all cases, the build time scales with the number of nodes. Considering all the three tables together, we can appreciate how GEMS scales in data set sizes by adding new nodes and how it can exploit the additional parallelism available. With 100 million triples, Q1 and Q3 scale for all the experiments up to 16 nodes. Increasing the number of nodes for the other queries, instead, provides constant or slightly worse execution time. Their execution time is very short (under 0.5 s), and the small data set does not provide sufficient data parallelism. These queries only have two graph walks with two-level nesting, and even with larger data sets, GEMS is able to exploit all the available parallelism already with a limited number of nodes. Furthermore, the database has the same overall size but is partitioned on more nodes; thus, the communication increases, slightly reducing the performance. With 1 billion triples, we see similar behavior. In this case, however, Q1 stops scaling at 32 nodes. With 64 nodes, GEMS can execute queries on 10 billion triples. Q3 still scales in performance up to 128 nodes, while the other queries, except Q1, approximately maintain stable performance. Q1 experiences the highest decrease in performance when using 128 nodes because its tasks present higher communication intensity than the other queries, and GEMS already exploited all the available parallelism with 64 nodes. These data confirm that GEMS can maintain constant throughput when running sets of mixed queries in parallel, that is, in typical database usage.
BSBM 100 Million Triples, 2 to 16 Cluster Nodes
|
Nodes |
2 |
4 |
8 |
16 |
|
Build |
199.00 |
106.99 |
59.85 |
33.42 |
|
Q1 |
1.83 |
1.12 |
0.67 |
0.40 |
|
Q2 |
0.07 |
0.07 |
0.07 |
0.05 |
|
Q3 |
4.07 |
2.73 |
1.17 |
0.65 |
|
Q4 |
0.13 |
0.13 |
0.14 |
0.15 |
|
Q5 |
0.07 |
0.07 |
0.07 |
0.11 |
|
Q6 |
0.01 |
0.02 |
0.02 |
0.03 |
BSBM 1 Billion Triples, 8 to 64 Cluster Nodes
|
Nodes |
8 |
16 |
32 |
64 |
|
Build |
628.87 |
350.47 |
200.54 |
136.69 |
|
Q1 |
5.65 |
3.09 |
1.93 |
2.32 |
|
Q2 |
0.30 |
0.34 |
0.23 |
0.35 |
|
Q3 |
12.79 |
6.88 |
4.50 |
2.76 |
|
Q4 |
0.31 |
0.25 |
0.22 |
0.27 |
|
Q5 |
0.11 |
0.12 |
0.14 |
0.18 |
|
Q6 |
0.02 |
0.03 |
0.04 |
0.05 |
BSBM 10 Billion Triples, 64 and 128 Cluster Nodes
|
Nodes |
64 |
128 |
|
Build |
1066.27 |
806.55 |
|
Q1 |
27.14 |
39.78 |
|
Q2 |
1.48 |
1.91 |
|
Q3 |
24.27 |
18.32 |
|
Q4 |
2.33 |
2.91 |
|
Q5 |
2.13 |
2.82 |
|
Q6 |
0.40 |
0.54 |
8.5.3 RDESC
In this section, we describe some results in testing the use of GEMS to answer queries for the RDESC project (Table 8.4). The RDESC project is a 3-year effort funded by the Department of Energy (DOE) Advanced Scientific Computing Research (ASCR) program. RDESC aims to provide a prototypical “collaborator” system to facilitate the discovery of science resources. The project involves curating diverse metadata about soil, atmospheric, and climate data sets. The quantity and complexity of the metadata are ultimately so great that they present data scaling challenges. For example, curating metadata about data sets and data streams from the Atmospheric Radiation Measurement (ARM) climate research facility generates billions of relationships between abstract entities (e.g., data sets, data streams, sites, facilities, variables/measured properties). At present, the RDESC metadata consists of nearly 1.4 billion RDF triples, mostly metadata about ARM data streams and GeoNames locations, although it includes, to a lesser proportion, descriptions of Global Change Master Directory (GCMD) (National Aeronautics and Space Administration 2013) locations, key words, and data sets, as well as metadata from the International Soil Moisture Network (ISMN) (International Soil Moisture Network, n.d.).
Specifications of the Query Executed on the RDESC Data Set
|
Q1 |
Find all instruments related to data resources containing measurements related to soil moisture |
|
Q2 |
Find all locations having measurements related to soil moisture that are taken with at least ten instruments |
|
Q3 |
Find locations (spatial locations) that have daily soil moisture profile data since 1990 with at least 10 points |
|
Q4 |
Find locations that have soil moistures profile data ranked by how many resources are available for that location |
|
Nodes |
8 |
16 |
32 |
|||
|
1 run |
Exe [s] |
Throughput [q/s] |
Exe [s] |
Throughput [q/s] |
Exe [s] |
Throughput [q/s] |
|
Load |
2577.45909 |
1388.4894 |
1039.5300 |
|||
|
Build |
607.482135 |
301.1487 |
161.8761 |
|||
|
Q1 |
0.0059 |
169.2873 |
0.0076 |
131.6247 |
0.0066 |
151.9955 |
|
Q2 |
0.0078 |
127.729 |
0.0088 |
113.3613 |
0.0093 |
107.9400 |
|
Q3 |
0.0017 |
592.6100 |
0.0020 |
477.9567 |
0.0017 |
592.2836 |
|
Q4 |
0.0154 |
64.9224 |
0.0119 |
83.7866 |
0.0119 |
84.2356 |
|
Nodes |
8 |
16 |
32 |
|||
|
Avg. 100 runs |
Exe [s] |
Throughput [q/s] |
Exe [s] |
Throughput [q/s] |
Exe [s] |
Throughput [q/s] |
|
Load |
2593.6120 |
1367.2713 |
1062.4514 |
|||
|
Build |
583.0361 |
303.8100 |
153.7527 |
|||
|
Q1 |
0.0057 |
174.1774 |
0.0059 |
168.5413 |
0.0070 |
142.5891 |
|
Q2 |
0.0074 |
135.0213 |
0.0080 |
124.4752 |
0.0091 |
109.6614 |
|
Q3 |
0.0017 |
582.8798 |
0.0044 |
229.1323 |
0.0017 |
640.1768 |
|
Q4 |
0.0124 |
80.3632 |
0.0147 |
67.8223 |
0.0101 |
98.6041 |
Using 8, 16, and 32 nodes of Olympus (equating to 120, 240, and 480 GMT workers, respectively), the Q3 correctly produces no results since there are currently no data that match the query, in the range of 0.0017 to 0.0044 s. Although there are no results, the query still needs to explore several levels of the graph. However, our approach allows early pruning of the search, significantly limiting the execution time.
Q1, Q2, and Q4, instead, under the same circumstances, run in the ranges of 0.0059–0.0076, 0.0074–0.0093, and 0.0101–0.0154 s with 76, 1, and 68 results, respectively.
For the query in Q2, the one location with at least 10 “points” (instruments) for soil moisture data is the ARM facility sgp.X1 (that is, the first experimental facility in ARM’s Southern Great Plains site). The reason these queries take approximately the same amount of time regardless of the number of nodes is that the amount of parallelism in executing the query is limited so that eight nodes is sufficient for fully exploiting the parallelism in the query (in the way that we perform the query). We could not run the query on four nodes or less due to the need for memory of the graph and dictionary. This emphasizes our point that the need for more memory exceeds the need for more parallel computation. We needed the eight nodes not necessarily to make the query faster but, rather, to keep the data and query in memory to make the query feasible.
8.6 CONCLUSIONS
In this chapter, we presented GEMS, a full software stack for semantic graph databases on commodity clusters. Different from other solutions, GEMS proposes an integrated approach that primarily utilizes graph-based methods across all the layers of its stack. GEMS includes a SPARQL-to-C++ compiler, a library of algorithms and data structures, and a custom runtime. The custom runtime system (GMT) provides to all the other layers several features that simplify the implementation of the exploration methods and makes more efficient their execution on commodity clusters. GMT provides a global address space, fine-grained multithreading (to tolerate latencies for accessing data on remote nodes), remote message aggregation (to maximize network bandwidth utilization), and load balancing. We have demonstrated how this integrated approach provides scaling in size and performance as more nodes are added to the cluster on two example data sets (the BSBM and the RDESC data set).
References
Apache Giraph. (n.d.). Retrieved May 1, 2014, from http://incubator.apache.org/giraph/.
Apache Jena—Home. (n.d.). Retrieved March 19, 2014, from https://jena.apache.org/.
ARQ—A SPARQL Processor for Jena. (n.d.). Retrieved May 1, 2014, from http://jena.sourceforge.net/ARQ/.
Bizer, C., and Schultz, A. (2009). The Berlin SPARQL benchmark. Int. J. Semantic Web Inf. Syst., 5 (2), 1–24.
Carothers, G., and Seaborne, A. (2014). RDF 1.1 N-Triples. Retrieved March 19, 2014, from http://www.w3.org/TR/2014/REC-n-triples-20140225/.
GraphLab. (n.d.). Retrieved May 1, 2014, from http://graphlab.org.
Harth, A., Umbrich, J., Hogan, A., and Decker, S. (2007). YARS2: A federated repository for querying graph structured data from the web. ISWC ’07/ASWC ’07: 6th International Semantic Web and 2nd Asian Semantic Web Conference (pp. 211–224).
International Soil Moisture Network. (n.d.). Retrieved February 17, 2014, from http://ismn.geo.tuwien.ac.at.
Klyne, G., Carroll, J. J., and McBride, B. (2004). Resource Description Framework (RDF): Concepts and Abstract Syntax. Retrieved December 2, 2013, from http://www.w3.org/TR/2004/REC-rdf-concepts-20040210/.
Malewicz, G., Austern, M. H., Bik, A. J., Dehnert, J. C., Horn, I., Leiser, N. et al. (2010). Pregel: A system for large-scale graph processing. SIGMOD ’10: ACM International Conference on Management of Data (pp. 135–146).
National Aeronautics and Space Administration. (2013). Global Change Master Directory, Online, Version 9.9. Retrieved May 1, 2014, from http://gcmd.nasa.gov.
Ohio State University. (n.d.). OSU Micro-Benchmarks. Retrieved May 1, 2014, from http://mvapich.cse.ohio-state.edu/benchmarks/.
openRDF.org. (n.d.). Retrieved May 1, 2014, from http://www.openrdf.org.
Redland RDF Libraries. (n.d.). Retrieved May 1, 2014, from http://librdf.org.
Rohloff, K., and Schantz, R. E. (2010). High-performance, massively scalable distributed systems using the MapReduce software framework: The SHARD triple-store. PSI EtA ’10: Programming Support Innovations for Emerging Distributed Applications, 4, Reno (pp. 1–5).
Top500.org. (n.d.). PNNL’s Olympus Entry. Retrieved May 1, 2014, from http://www.top500.org/system/177790.
Ullmann, J. (1976). An algorithm for subgraph isomorphism. J. ACM, 23 (1), 31–42.
Virtuoso Universal Server. (n.d.). Retrieved May 1, 2014, from http://virtuoso.openlinksw.com.
W3C SPARQL Working Group. (2013). SPARQL 1.1 Overview. Retrieved February 18, 2014, from http://www.w3.org/TR/2013/REC-sparql11-overview-20130321/.
Weaver, J. (2012). A scalability metric for parallel computations on large, growing datasets (like the web). Proceedings of the Joint Workshop on Scalable and High-Performance Semantic Web Systems, Boston.
YarcData, Inc. (n.d.) Urika Big Data Graph Appliance. Retrieved May 1, 2014, from http://www.cray.com/Products/BigData/uRiKA.aspx.