
Chapter 20
Big Data Biometrics Processing
A Case Study of an Iris Matching Algorithm on Intel Xeon Phi
Xueyan Li and Chen Liu
Abstract
With the rapidly expanded biometric data collected by various sources for identification and verification purposes, how to manage and process such Big Data draws great concern. On one hand, biometric applications normally involve comparing a huge amount of samples and templates, which has strict requirements on the computational capability of the underlying hardware platform. On the other hand, the number of cores and associated threads that hardware can support has increased greatly; an example is the newly released Intel Xeon Phi coprocessor. Hence, Big Data biometrics processing demands the execution of the applications at a higher parallelism level. Taking an iris matching algorithm as a case study, we implemented an open multi-processing (OpenMP) version of the algorithm to examine its performance on the Intel Xeon Phi coprocessor. Our target is to evaluate our parallelization approach and the influence from the optimal number of threads, the impact of thread-to-core affinity, and the impact of the hardware vector engine.
20.1 Introduction
With the drive towards achieving higher computation capability, the most advanced computing systems have been adopting alternatives from the traditional general purpose processors (GPPs) as their main components to better prepare for Big Data processing. NVIDIA’s graphic processing units (GPUs) have powered many of the top-ranked supercomputer systems since 2008. In the latest list published by Top500.org, two systems with Intel Xeon Phi coprocessors have claimed positions 1 and 7 [1].
While it is clear that the need to improve efficiency for Big Data processing will continuously drive changes in hardware, it is important to understand that these new systems have their own advantages as well as limitations. The required effort from the researchers to port their codes onto the new platforms is also of great significance. Unlike other coprocessors and accelerators, the Intel Xeon Phi coprocessor does not require learning a new programming language or new parallelization techniques. It presents an opportunity for the researchers to share parallel programming with the GPP. This platform follows the standard parallel programming model, which is familiar to developers who already work with x86-based parallel systems.
This does not mean that achieving good performance on this platform is simple. The hardware, while presenting many similarities with other existing multicore systems, has its own characteristics and unique features. In order to port the code in an efficient way, those aspects must be understood.
The specific application that we focus on in this parallelization study is biometrics. The importance of biometrics and other identification technology has increased significantly, and we can observe biometric systems being deployed everywhere in our daily lives. This has dramatically expanded the amount of biometric data collected and examined everyday in health care, employment, law enforcement, and security systems. There can be up to petabytes of biometric data from hundreds of millions of identities that need to be accessed in real time. For example, the Department of Homeland Security (DHS) Automated Biometric Identification System (IDENT) database held 110 million identities and enrolled or verified over 125,000 individuals per day in 2010 [2]. India has their unique identification (UID) program with over 100 million people to date and expected to cover more than 1 billion individuals. This Big Data processing poses a great computational challenge. In addition, running biometric applications with sizable data sets consumes large amounts of power and energy. Therefore, efficient power management is another challenge we are facing.
As a result, we propose to execute biometric applications on many-core architecture with great energy efficiency while achieving superb performance at the same time. In this study, we want to analyze the performance of an OpenMP implementation of an iris recognition algorithm on the new Intel Xeon Phi coprocessor platform. The focus is to understand the workload characteristics, analyze the results from specific features of the hardware platform, and discuss aspects that could help improve overall performance on Intel Xeon Phi.
20.2 Background
In this section, we will introduce the Xeon Phi coprocessor, the iris matching algorithm, the OpenMP programming model, and the Intel VTune performance analyzer, all serving as background knowledge for this research.
20.2.1 Intel Xeon Phi
The Intel Xeon Phi coprocessor (code-named Knight Corner) is the first commercial product employing Intel’s Many Integrated Core (MIC) architecture. The Xeon Phi coprocessor is implemented as a Peripheral Component Interconnect Express (PCIe) form-factor add-in card. It supports the x86 memory model, Institute of Electrical and Electronics Engineers (IEEE) 754 floating-point arithmetic, and applications written in industry-standard programming languages such as FORTRAN, C, and C++ [3]. A rich development environment supports the coprocessor, which includes compilers, numerous libraries such as threading libraries and high-performance math libraries, performance characterizing and tuning tools, and debuggers.
The cores of Xeon Phi run independently of each other and have very powerful vector units. Each core has a vector processing unit (VPU) for fused multiply–add (FMA) operations. The vector width is 512 bits, and the VPU may operate on 8 double-precision (or 16 single-precision) data elements [4]. The instructions are pipelined, and after every cycle, a vector result is produced once the pipeline is filled. Additionally, Xeon Phi coprocessors include memory controllers that support the double data rate type five synchronous graphics random access memory (GDDR5) specification and special-function devices such as the PCIe interface. The memory subsystem provides full cache coherence. Cores and other components of Xeon Phi are connected via a ring interconnect.
From the software point of view, the Xeon Phi coprocessor is of the shared-memory computing domain, which is loosely coupled with the computing domain of the host. The host software stack is based on a standard Linux kernel. In comparison with that, the Xeon Phi software stack is based on a modified Linux kernel. In fact, the operating system on the Xeon Phi coprocessor is an embedded Linux environment, which provides basic functionality such as process creation, scheduling, or memory management [5].
A Xeon Phi coprocessor comprises more than 50 Intel architecture (IA) cores, each with four-way Hyper-Threading (HT), to produce a total of over 200 logical cores. Because Xeon Phi supports four hardware threads per core, users need to determine how threads are used. The software environment allows the user to control thread affinity in two modes: compact and scatter. Compact affinity means using all threads on one core before using other cores; scatter affinity means scattering threads across cores before using multiple threads on a given core.
The single-threaded, scalar (i.e., nonvectorial) code performance on Xeon Phi is fairly low, for example, when compared with that of an Intel Sandy Bridge central processing unit (CPU) [6,7]. Xeon Phi makes up for this deficit by offering more cores and wider vectors. Since a single thread can issue a vector instruction only every other cycle on Xeon Phi, at least two threads per core must be used to achieve full utilization. Therefore, the programs need to be highly parallel and vectorial in order to optimize the performance on this platform. The developers can maximize parallel performance on Xeon Phi in four ways:
- Increasing concurrency in parallel regions
- Reduction of serial code
- Minimizing the number of critical sections
- Improvement of load balance
They should also vectorize applications to maximize single instruction multiple data (SIMD) parallelism by including vectorial directives and applying loop transformations as needed, in case the code cannot be automatically vectorized by the compiler [5].
Xeon Phi can be used in two different modes: native and offload. In our experiments, we focused on the offload mode. There are two problems we need to handle in the offload mode: One is managing the data transfer between the host and the coprocessor; the other is launching the execution of functions (or loops) on the coprocessor. For the offload mode, all the data transfer between the host and the coprocessor goes through the PCIe bus. Therefore, an attempt should be made to exploit data reuse. This is also a consideration for applications written using OpenMP that span both the host and the coprocessor. Getting the benefit from both the host and Xeon Phi is our goal.
20.2.2 Iris Matching Algorithm
An iris matching algorithm has been recognized as one of the most reliable methods for biometric identification. The algorithm we used in this study is based on Daugman’s iris matching algorithm [8], the most representative iris matching method. The procedure of an iris matching algorithm can be summarized as follows:
- Generate a template along with a mask for the iris sample.
- Compare two iris templates using Hamming distances.
- Shift Hamming distance calculation to counter rotational inconsistencies.
- Get the sample pair with the lowest Hamming distance reading.
After sampling the iris region (pupil and limbus), the iris sample is transformed into a two-dimensional (2-D) image. Then Gabor filtering will extract the most discriminating information from the iris pattern as a biometric template. Each iris sample is represented with two 2-D matrices of bits (20 rows by 480 columns). The first one is the template matrix representing the iris pattern. The second one is the mask matrix, representing aspects such as eyelid, eyelash, and noise (e.g., spectacular reflections), which may occlude parts of the iris. Two iris samples are compared based on the Hamming distance calculation, with both matrices from each sample being used. The calculated matching score is normalized between 0 and 1, where a lower score indicates that the two samples are more similar.
The main body of the algorithm is a 17-round for-loop structure with the index shifting from −8 to 8, performing bit-wise logical operations (AND, OR, XOR) on the matrices. We suppose that the matrices of the first iris sample are named as template1 and mask1 and the matrices of the second iris sample are named as template2 and mask2. In each round, three steps are needed to finish the procedure. Firstly, template1 and mask1 are rotated for 2 × |shift| columns to form two intermediate matrices, named template1s and mask1s. They will be left-rotated if shift is less than 0 or right-rotated if shift is larger than 0. Secondly, we will XOR template1s with template2 into temp and OR mask1s with mask2 into mask. Finally, Matrix temp will be ANDed with Matrix mask to form Matrix result. So the Hamming distance from this round is calculated by dividing the number of 1s of Matrix result by the total number of the 2-D matrix entries (which is 20 × 480) minus the number of 1s in Matrix temp [9]. The minimum-valued Hamming distance of all 17 iterations shows the two samples’ similarity, which is returned as the matching score of the two samples.
20.2.3 OpenMP
OpenMP [10] is an application programming interface (API) that supports multiplatform shared-memory parallel programming in FORTRAN, C, and C++. It consists of a set of compiler directives and library routines, in which runtime behavior can be controlled by environment variables [11]. Annotating loop bodies and sections of the codes, compiler directives are used for parallel execution and marking variables as local or shared (global). Certain constructs exist for critical sections, completely independent tasks, or reductions on variables [12].
When a for loop is declared to be parallel, the iterations of the loop are executed concurrently. The iterations of the loop can be allocated to the working threads according to three scheduling policies: static, dynamic, and guided. In static scheduling, the iterations are either partitioned in as many intervals as the number of threads or partitioned in chunks that are allocated to the threads in a round-robin fashion. Dynamic scheduling partitions the iterations in chunks. Those chunks are dynamically allocated to the threads using a first-come first-served policy. Finally, the guided scheduling policy tries to reduce the scheduling overhead by allocating first a large amount of work to each thread. It geometrically decreases the amount of work allocated to the thread (up to a given minimum chunk size) in order to optimize the load balance [12]. In this study, we use the default static scheduling policy. In addition, the #pragma omp parallel directive can be used to mark the parallel section, and the #pragma simd directive can be used to perform the vectorization. In this study, we employed both.
20.2.4 Intel VTune Amplifier
In order to get an insight into the software behavior, we employed the Intel VTune Amplifier XE 2013 [13] (in short, VTune) to perform the workload characterization of the iris matching algorithm. VTune analyzes the software performance on IA-32– and Intel 64–based machines, and the performance data are displayed in an interactive view. At the granularity-of-function level, VTune breaks down the total execution time and shows the time spent on each function, so the function consuming most of the execution time is identified as the “hot-spot function.” At a finer granularity level, it can also show the time spent on a basic block, several lines of code, or even a single line of the source code inside a function. In this way, we can identify the performance-intensive function (hot-spot function) or lines of code (hot block) in the software algorithm [14].
20.3 Experiments
In this section, we first present how we set up the experiments. Then we present the results from our experimental data in detail.
20.3.1 Experiment Setup
The experiments have been conducted on BEACON, an energy-efficient cluster that utilizes Intel Xeon Phi coprocessors. BEACON is funded by the National Science Foundation (NSF) to port and optimize scientific codes to the coprocessors based on Intel’s MIC architecture [15]. By June 2013, BEACON was listed at the no. 3 position among the most energy-efficient supercomputers in the world on the Green500 list [16] and at the no. 397 position among the most powerful supercomputers in the world on the TOP500 List [17]. BEACON currently has 48 compute nodes. Each compute node houses two 8-core Intel Xeon E5-2670 processors, 256 GB of memory, and four Intel Xeon Phi 5110P coprocessors. This specific Xeon Phi model has 60 cores and 8 GB of memory [15]. To compile the code, we use icc version 14.0.2 and OpenMP version 4.0.
To obtain the results, we conducted this experiment using the following steps:
- Write the source code in C code on BEACON and then verify the correctness and validate against the original results obtained from Microsoft Visual Studio 2010.
- Study the workload characterization of the iris matching algorithm by using Intel VTune.
- Based on the results from previous steps, rewrite this program by adding the parallelism and vectorization features.
- Compare all the results; get the optimal number of threads, the influence of different affinities, as well as vectorization on the performance.
20.3.2 Workload Characteristics
The workload used in the experiment is from the Quality in Face and Iris Research Ensemble (Q-FIRE) data set [18] and Q-FIRE II Unconstrained data set, where we used a total number of 574 iris samples. The iris matching process is to match every iris sample against the entire data set, resulting in a total of 164,451 comparisons. In this section, we will demonstrate the results of the performance analysis.
In our iris matching algorithm, each sample needs to be compared against all the other samples in the database, so the main function will have a two-level nested loop for comparison. Each iteration will load two samples (both template and mask) for comparison and then calculate the Hamming distance to generate the matching score [14]. VTune performs the function breakdown in order to identify the software performance bottleneck. Table 20.1 shows the environment in which we used VTune to get the characteristics of the iris matching algorithm on an Intel Xeon E5-2630 CPU.
|
Table 20.1 Experimental Environment for Intel VTune |
||||||
|
CPU |
I-Cache and D-Cache |
L2 Cache |
L3 Cache |
Memory Size |
Operating System |
Compiler |
|
Intel Xeon E5-2630 2.3 GHz 6-core |
192 KB per core |
1.5 MB |
15 MB |
16 GB |
Windows 7 64-bit |
Visual Studio 2010 |
Figure 20.1 shows the functions of the iris matching algorithm along with their consumed percentage of total execution time. Note that the time recorded for each function does not include the time spent on subfunction calls [14]. For example, the time for function GetHammingDistance does not include the time spent on function shiftbits. The results show that the ReadFile function, which loads the samples into memory, occupies the majority of execution time. It means that the data transfer is the bottleneck of the iris matching algorithm.
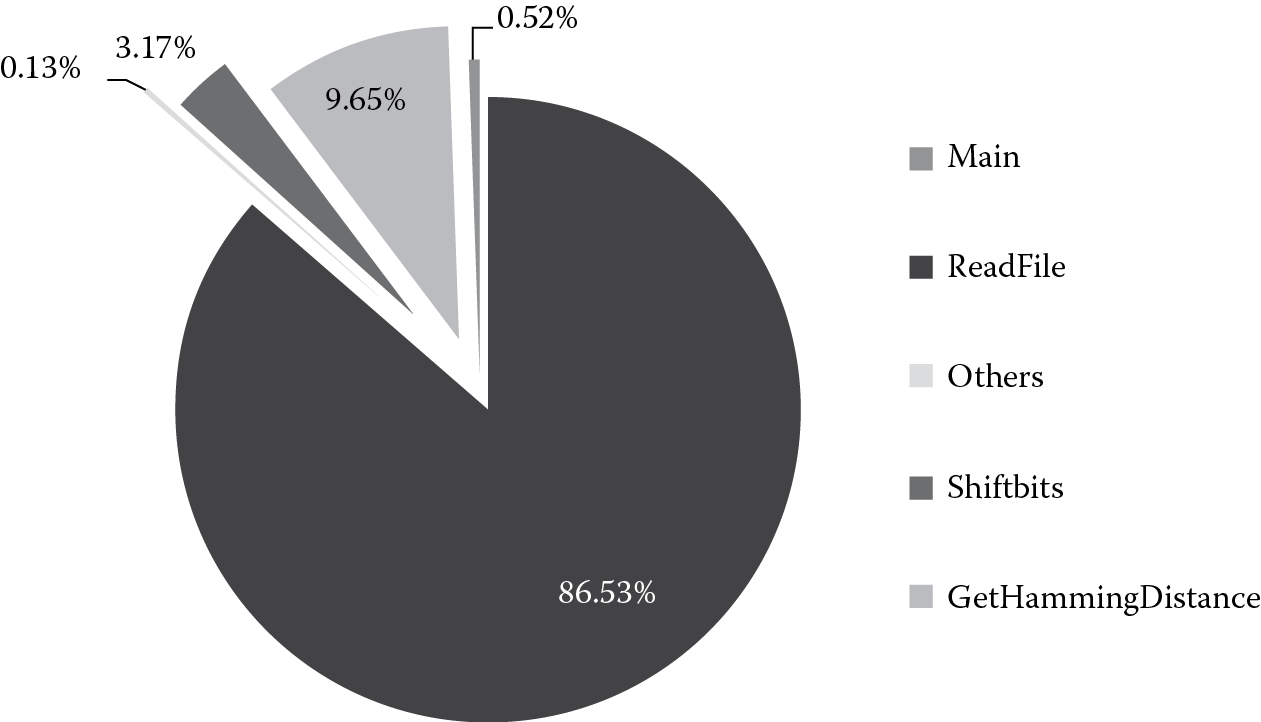
20.3.3 Impact of Different Affinity
To study the impact of thread-to-core affinity, the experiment was conducted on Xeon Phi in both compact and scatter modes. The compact affinity assigns OpenMP thread n + 1 to a free thread context closely to another thread context where the nth OpenMP thread was placed. The scatter affinity distributes the threads evenly across the entire system.
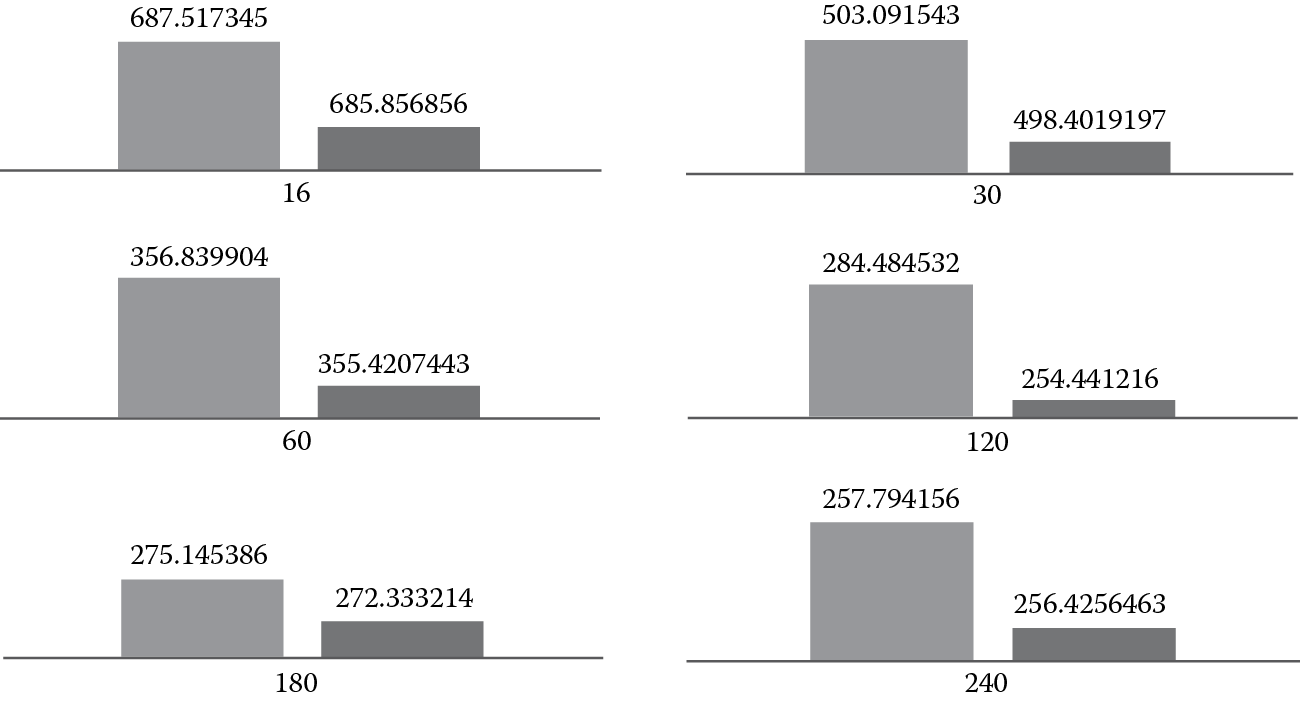
Figure 20.2, Figure 20.3, and Figure 20.4 provide the comparison in execution time between scatter affinity and compact affinity, with the light-colored bar representing the compact affinity and the dark-colored bar representing the scatter affinity, the x-axis representing the number of threads, and the y-axis representing the execution time in seconds. The difference between the two affinities can be contrasted in three parts:
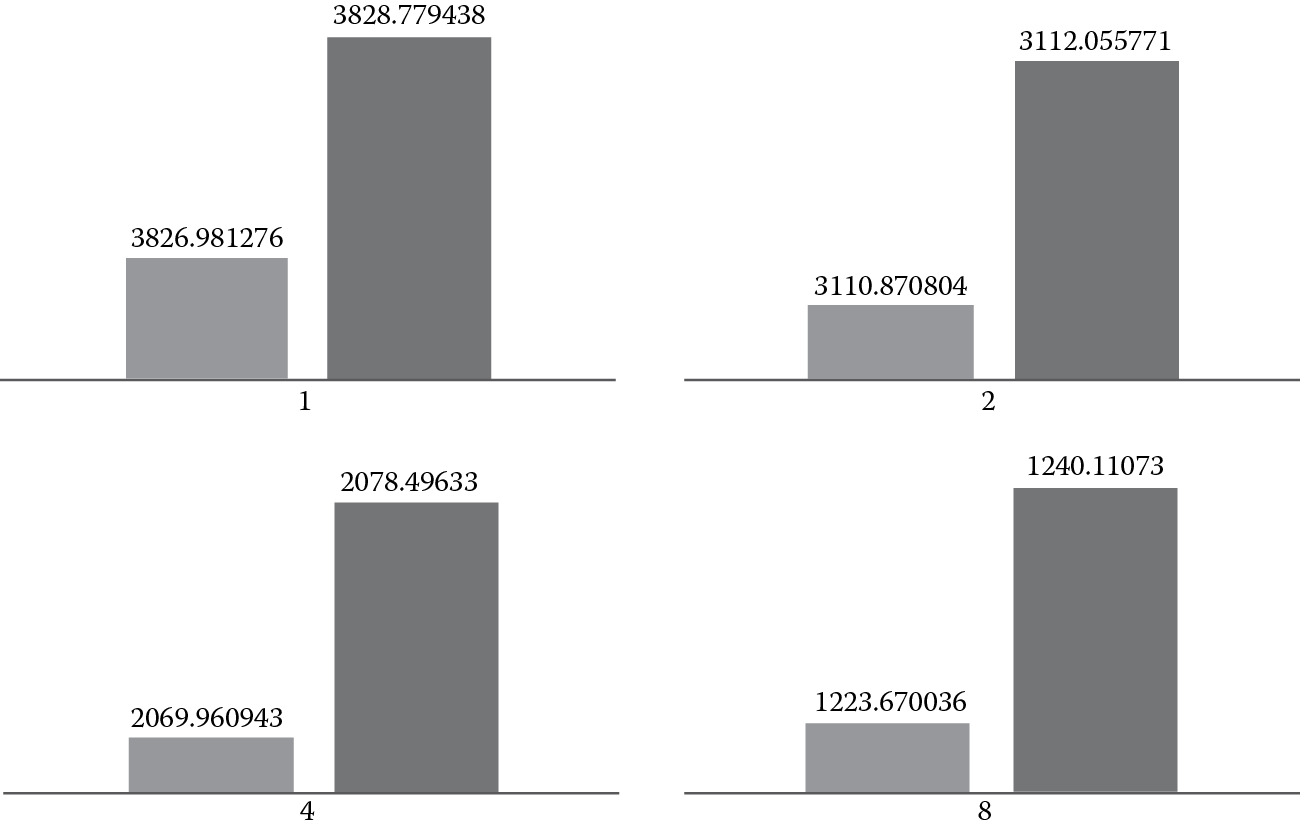
- Compact affinity is more effective than scatter affinity when only a small number of threads are needed, as shown in Figure 20.2. When the number of threads is less than eight, compact affinity only uses a small number of cores (one to two cores), and hence, the communication overhead between the threads is small; on the other hand, scatter affinity uses the same number of cores as the number of threads.
- Scatter affinity is faster than compact affinity between 16 and 240 threads, as shown in Figure 20.3. In this case, even though compact affinity uses fewer cores, every core is fully loaded with four threads; they will compete for the hardware resource for their execution and slow down the individual execution, what we call “interthread interference,” which outweighs the benefit they get from saved communication overhead. On the other hand, in scattered affinity, the cores are not that fully loaded, which shows the benefit.
- When the number of threads is large (more than 240 threads), the effect of two affinities is almost the same, as shown in Figure 20.4. In this case, the number of threads is over the hardware capability (60 cores with 4 threads each, resulting in a total of 240 threads), so all the cores are fully loaded in either affinity.
Overall, when we run a program on Xeon Phi, the suiTable affinity must be considered based on the number of threads and the correspondingly parallelism level.
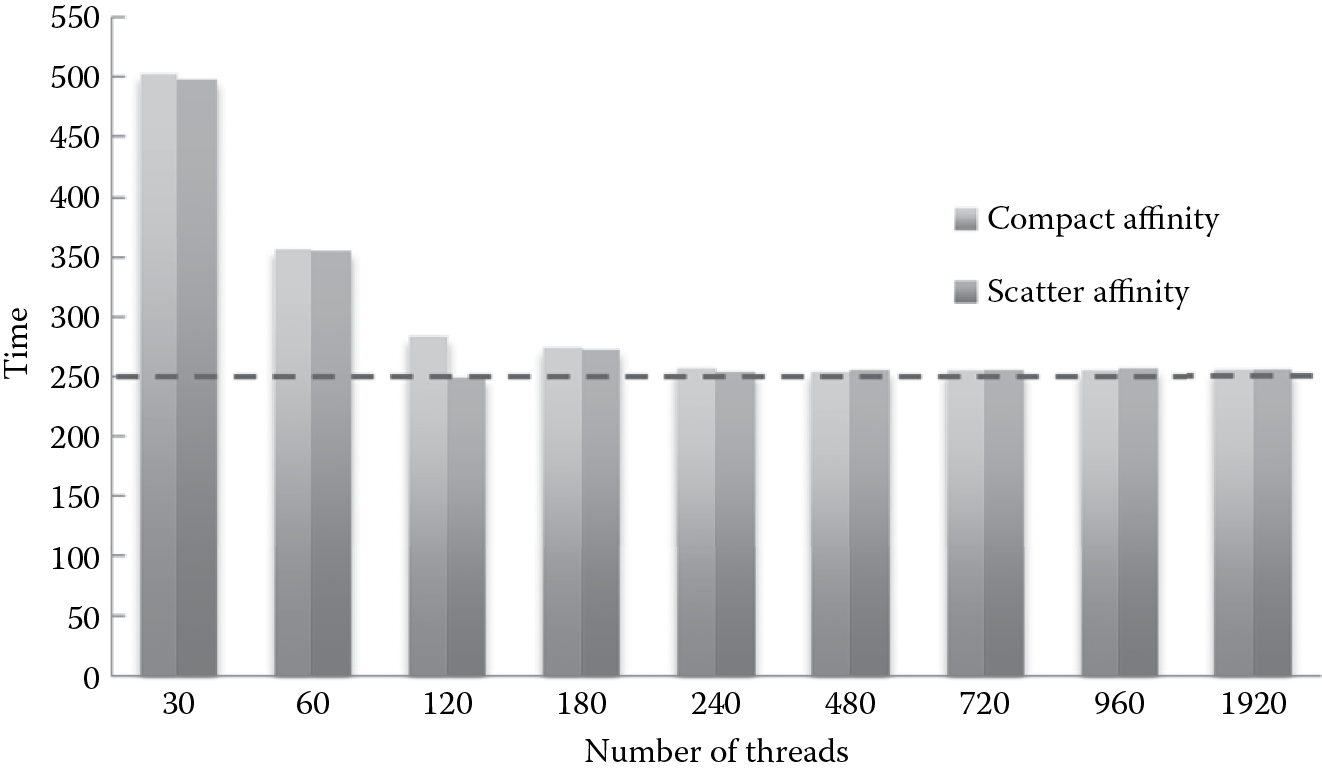
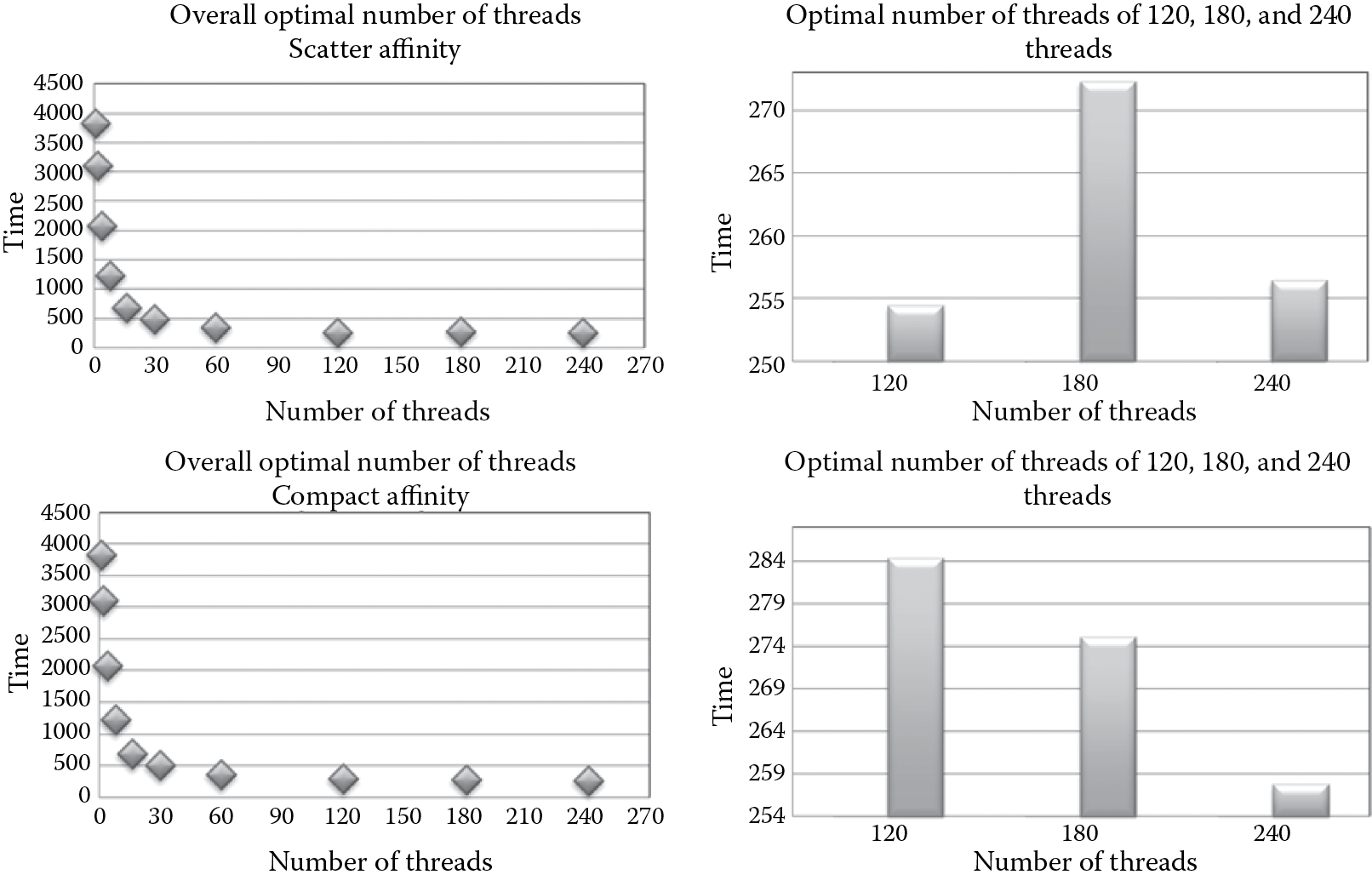
20.3.4 Optimal Number of Threads
After discussing the effect of affinity, finding the optimal number of threads for the execution is another objective. We try to identify the optimal number of threads for both compact affinity and scatter affinity. The results from Figure 20.5 show that the optimal number of threads is 120 when using scatter affinity, corresponding to using all the 60 cores on Xeon Phi, with 2 threads per core; the optimal number of threads is 240 when using compact affinity, corresponding to using all the 60 cores on Xeon Phi, with 4 threads per core.
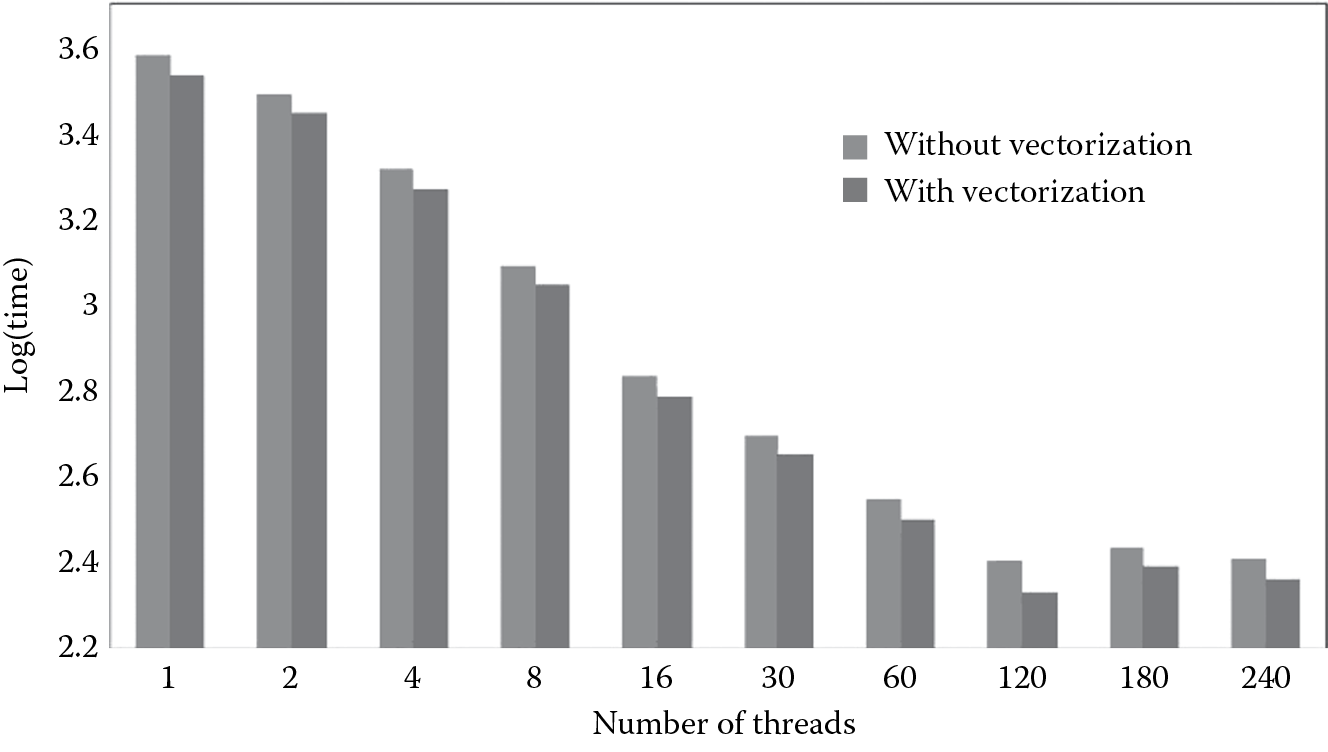
20.3.5 Vectorization
As we can see from Figure 20.1, function GetHammingDistance takes the second longest time, only next to the ReadFile function. Since Xeon Phi is equipped with a very powerful vector engine [19], our target is to utilize the vector engine to improve the overall performance. As a result, we rewrite the GetHammingDistance function by adding parallelism and vectorization. Since we have discussed the optimal number of threads and the suiTable affinity, in this case, we run the program with scatter affinity. Figure 20.6 shows the execution time of running the iris matching algorithm on Xeon Phi in the offload mode with and without vectorization. Please note that the y-axis is in log scale, so basically, 2 means 100 s, 3 means 1000 s, and so on and so forth. Clearly, in all cases, vectorization improves the performance. The best time occurs when we use the optimal number of threads of 120.
20.4 Conclusions
Big Data biometrics processing poses a great computational need, while in the meantime, it is embarrassingly parallel by nature. In this research, as a case study, we implemented an OpenMP version of the iris matching algorithm and evaluated its performance on the innovative Intel Xeon Phi coprocessor platform. We performed workload characterization of the iris matching algorithm, analyzed the impact of different thread-to-core affinity settings on the performance, identified the optimal number of threads to run the workload, and most important of all, vectorized the code to take advantage of the powerful vector engines that come with Xeon Phi to improve the performance. Based on our experience, even though the emerging many-core platform is able to provide adequate parallelism, redesigning the application to take advantage of the specific features of the hardware platform is very important in order to achieve the optimal performance for Big Data processing.
Acknowledgments
We thank the National Institute for Computational Sciences (NICS) for providing us access to the BEACON supercomputer to conduct this research. We would also like to thank Gildo Torres and Guthrie Cordone for their feedback that greatly improved the results of this experiment and the quality of this study. This work is supported by the National Science Foundation under grant number IIP-1332046. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation.
References
1. Top 500 Supercomputer Sites, November 2013. Available at http://www.top500.org/.
2. A. Sussman, “Biometrics and Cloud Computing,” presented at the Biometrics Consortium Conference 2012, September 19, 2012.
3. L. Meadows, “Experiments with WRF on Intel Many Integrated Core (Intel MIC) Architecture,” in Proceedings of the 8th International Conference on OpenMP in a Heterogeneous World, Ser. IWOMP’12, Springer-Verlag, Berlin, Heidelberg, pp. 130–139, 2012.
4. J. Jeffers and J. Reinders, Intel Xeon Phi Coprocessor High Performance Programming, 1st ed., Morgan Kaufmann, Boston, 2013.
5. J. Dokulil, E. Bajrovic, S. Benkner, S. Pllana and M. Sandrieser. “Efficient Hybrid Execution of C++ Applications using Intel Xeon PhiTM Coprocessor,” Research Group Scientific Computing, University of Vienna, Austria, November 2012.
6. K. Krommydas, T. R. W. Scogland and W.-C. Feng, “On the Programmability and Performance of Heterogeneous Platforms,” in Parallel and Distributed Systems (ICPADS), 2013 International Conference on, pp. 224–231, December 15–18, 2013.
7. P. Sutton, Benchmarks: Intel Xeon Phi vs. Sandy Bridge, 2013. Available at http://blog.xcelerit.com/benchmarks-intel-xeon-phi-vs-intel-sandybridge/.
8. J. G. Daugman, “High Confidence Visual Recognition of Persons by a Test of Statistical Independence,” Pattern Analysis and Machine Intelligence, IEEE Transactions on, vol. 15, no. 11, pp. 1148–1161, 1993.
9. G. Torres, J. K.-T. Chang, F. Hua, C. Liu and S. Schuckers, “A Power-Aware Study of Iris Matching Algorithms on Intel’s SCC,” in 2013 International Workshop on Embedded Multicore Systems (ICPP-EMS 2013), in conjunction with ICPP 2013, Lyon, France, October 1–4, 2013.
10. OpenMP. Available at http://openmp.org/wp/.
11. E. Saule and U. V. Catalyurek, “An Early Evaluation of the Scalability of Graph Algorithms on the Intel MIC Architecture,” in 26th International Symposium on Parallel and Distributed Processing, Workshops and PhD Forum (IPDPSW), Workshop on Multithreaded Architectures and Applications (MTAAP), 2012.
12. G. Gan, “Programming Model and Execution Model for OpenMP on the Cyclops-64 Manycore Processor,” Ph.D. Dissertation, University of Delaware, Newark, DE, 2010.
13. Intel® VTune™ Amplifier XE 2013. Available at https://software.intel.com/en-us/intel-vtune-amplifier-xe.
14. J. K.-T. Chang, F. Hua, G. Torres, C. Liu and S. Schuckers, “Workload Characteristics for Iris Matching Algorithm: A Case Study,” in 13th Annual IEEE Conference on Technologies for Homeland Security (HST’13), Boston, MA, November 12–14, 2013.
15. Beacon. Available at http://www.nics.tennessee.edu/beacon.
16. The Green500 List, June 2013. Available at http://www.green500.org/lists/green201306.
17. Beacon on Top500. Available at http://www.top500.org/system/177997#.U3MMkl4dufR.
18. P. A. Johnson, P. Lopez-Meyer, N. Sazonova, F. Hua and S. Schuckers, “Quality in Face and Iris Research Ensemble (Q-FIRE),” in Fourth IEEE International Conference on Biometrics: Theory Applications and Systems (BTAS), pp. 1–6, 2010.
19. E. Saule, K. Kaya and U. V. Catalyurek, “Performance Evaluation of Sparse Matrix Multiplication Kernels on Intel Xeon Phi,” arXiv preprint arXiv:1302.1078, 2013.