
Chapter 13. Integrating External Services and Kubernetes
In many of the chapters in this book, we’ve discussed how to build, deploy, and manage services in Kubernetes. However, the truth is that systems don’t exist in a vaccum, and most of the services that we build will need to interact with systems and services that exist outside of the Kubernetes cluster in which they’re running. This might be because we are building new services that are being accessed by legacy infrastructure running in virtual or physical machines. Conversely, it might be because the services that we are building might need to access preexisting databases or other services that are likewise running on physical infrastructure in an on-premises datacenter. Finally, you might have multiple different Kubernetes clusters with services that you need to interconnect. For all of these reasons, the ability to expose, share, and build services that span the boundary of your Kubernetes cluster is an important part of building real-world applications.
Importing Services into Kubernetes
The most common pattern for connecting Kubernetes with external services consists of a Kubernetes service that is consuming a service that exists outside of the Kubernetes cluster. Often, this is because Kubernetes is being used for some new application development or interface for a legacy resource like an on-premises database. This pattern often makes the most sense for incremental development of cloud-native services. Because the database layer contains significant mission-critical data, it is a heavy lift to move it to the cloud, let alone containers. At the same time, there is a great deal of value in providing a modern layer on top of such a database (e.g., supplying a GraphQL interface) as the foundation for building a new generation of applications. Likewise, moving this layer to Kubernetes often makes a great deal of sense because rapid development and reliable continuous deployment of this middleware enables a great deal of agility with minimal risk. Of course, to achieve this, you need to make the database accessible from within Kubernetes.
When we consider the task of making an external service accessible from Kubernetes, the first challenge is simply to get the networking to work correctly. The specific details of getting networking operational are very specific to both the location of the database as well as the location of the Kubernetes cluster; thus, they are beyond the scope of this book, but generally, cloud-based Kubernetes providers enable the deployment of a cluster into a user-provided virtual network (VNET), and those virtual networks can then be peered up with an on-premises network for connectivity.
After you’ve established network connectivity between pods in the Kubernetes cluster and the on-premises resource, the next challenge is to make the external service look and feel like a Kubernetes service. In Kubernetes, service discovery occurs via Domain Name System (DNS) lookups and, thus, to make our external database feel like it is a native part of Kubernetes, we need to make the database discoverable in the same DNS.
Selector-Less Services for Stable IP Addresses
The first way to achieve this is with a selector-less Kubernetes
Service. When you create a Kubernetes Service without a selector, there
are no Pods that match the service; thus, there is no load balancing
performed. Instead, you can program this selector-less service to have
the specific IP address of the external resource that you want to add to the
Kubernetes cluster. That way, when a Kubernetes pod performs a lookup for
your-database, the built-in Kubernetes DNS server will translate that
to a service IP address of your external service. Here is an example of
a selector-less service for an external database:
apiVersion:v1kind:Servicemetadata:name:my-external-databasespec:ports:-protocol:TCPport:3306targetPort:3306
When the service exists, you need to update its endpoints to contain
the database IP address serving at 24.1.2.3:
apiVersion:v1kind:Endpointsmetadata:# Important! This name has to match the Service.name:my-external-databasesubsets:-addresses:-ip:24.1.2.3ports:-port:3306
Figure 13-1 depicts how this integrates together within Kubernetes.
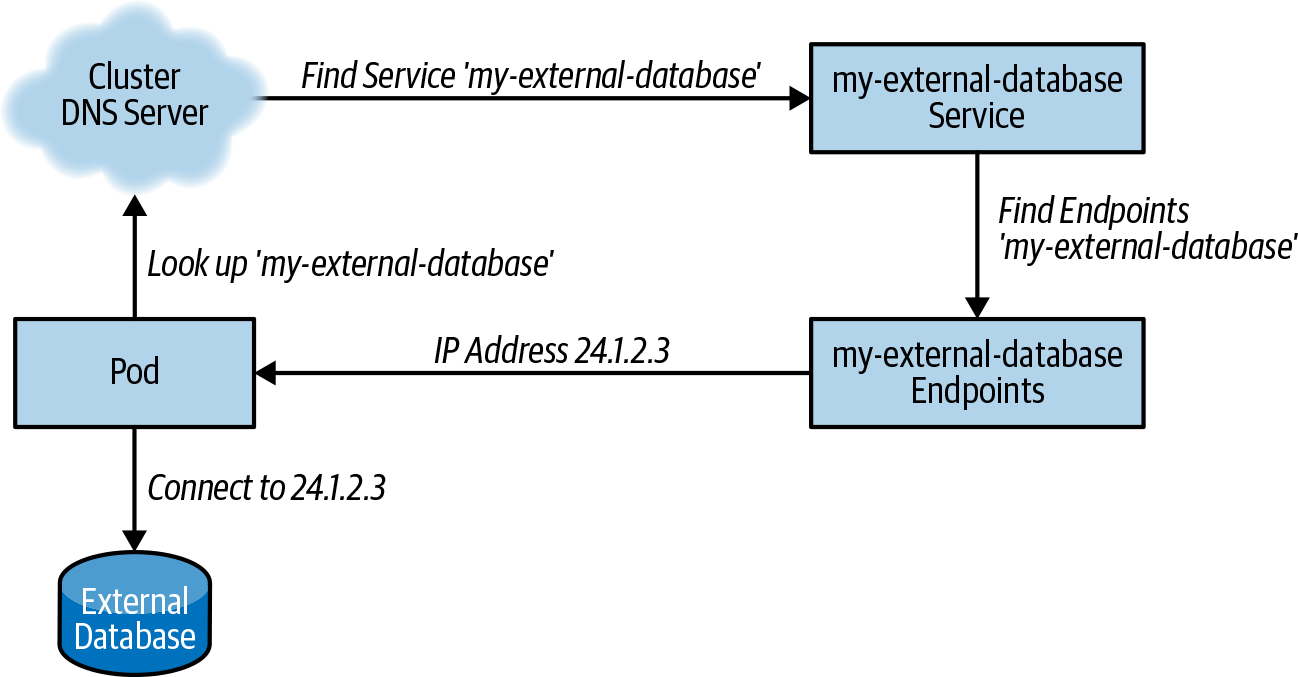
Figure 13-1. Service integration
CNAME-Based Services for Stable DNS Names
The previous example assumed that the external resource that you were trying to integrate with your Kubernetes cluster had a stable IP address. Although this is often true of physical on-premises resources, depending on the network toplogy, it might not always be true, and it is significantly less likely to be true in a cloud environment where virtual machine (VM) IP addresses are more dynamic. Alternatively, the service might have multiple replicas sitting behind a single DNS-based load balancer. In these situations, the external service that you are trying to bridge into your cluster doesn’t have a stable IP address, but it does have a stable DNS name.
In such a situation, you can define a CNAME-based Kubernetes Service.
If you’re not familiar with DNS records, a CNAME, or Canonical Name,
record is an indication that a particular DNS address should be
translated to a different Canonical DNS name. For example, a CNAME
record for foo.com that contains bar.com indicates that anyone
looking up foo.com should perform a recursive lookup for bar.com to
obtain the correct IP address. You can use Kubernetes Services to define
CNAME records in the Kubernetes DNS server. For example, if you have an
external database with a DNS name of database.myco.com, you might
create a CNAME Service that is named myco-database. Such a Service
looks like this:
kind:ServiceapiVersion:v1metadata:name:my-external-databasespec:type:ExternalNameexternalName:database.myco.com
With a Service defined in this way, any pod that does a lookup for
myco-database will be recursively resolved to database.myco.com. Of
course, to make this work, the DNS name of your external resource also
needs to be resolveable from the Kubernetes DNS servers. If the DNS name
is globally accessible (e.g., from a well-known DNS service provider),
this will simply automatically work. However, if the DNS of the external
service is located in a company-local DNS server (e.g., a DNS server that
services only internal traffic), the Kubernetes cluster might not know by default how to resolve queries to this corporate DNS server.
To set up the cluster’s DNS server to communicate with an alternate DNS resolver,
you need to adjust its configuration. You do this by updating a
Kubernetes ConfigMap with a configuration file for the DNS server. As of this writing, most clusters have moved over to the CoreDNS
server. This server is configured by writing a Corefile configuration
into a ConfigMap named coredns in the kube-system namespace. If you
are still using the kube-dns server, it is configured in a similar
manner but with a different ConfigMap.
CNAME records are a useful way to map external services with stable DNS
names to names that are discoverable within your cluster. At first it
might seem counterintuitive to remap a well-known DNS address to a
cluster-local DNS address, but the consistency of having all services
look and feel the same is usually worth the small amount of added
complexity. Additionally, because the CNAME service, like all Kubernetes services, is defined per
namespace, you can use namespaces to map the same service name
(e.g., database) to different external services (e.g., canary or
production), depending on the Kubernetes namespace.
Active Controller-Based Approaches
In a limited set of circumstances, neither of the previous methods for exposing external services within Kubernetes is feasible. Generally, this is because there is neither a stable DNS address nor a single stable IP address for the service that you want to expose within the Kubernetes cluster. In such circumstances, exposing the external service within the Kubernetes cluster is significantly more complicated, but it isn’t impossible.
To achieve this, you need to have some understanding of how Kubernetes
Services work under the hood. Kubernetes Services are actually made up
of two different resources: the Service resource, with which you are doubtless
familiar, and the Endpoints resource that represents the IP
addresses that make up the service. In normal operation, the Kubernetes
controller manager populates the endpoints of a service based on the
selector in the service. However, if you create a selector-less service,
as in the first stable-IP approach, the Endpoints resource for the
service will not be populated, because there are no pods that are
selected. In this situation, you need to supply the control loop to
create and populate the correct Endpoints resource. You need to
dynamically query your infrastructure to obtain the IP addresses for the
service external to Kubernetes that you want to integrate, and then
populate your service’s endpoints with these IP addresses. After you do
this, the mechanisms of Kubernetes take over and program both the DNS
server and the kube-proxy correctly to load-balance traffic to your
external service. Figure 13-2 presents a complete picture of how this works in practice.

Figure 13-2. An external service
Exporting Services from Kubernetes
In the previous section, we explored how to import preexisting services to Kubernetes, but you might also need to export services from Kubernetes to the preexisting environments. This might occur because you have a legacy internal application for customer management that needs access to some new API that you are developing in a cloud-native infrastructure. Alternately, you might be building new microservice-based APIs but you need to interface with a preexisting traditional web application firewall (WAF) because of internal policy or regulatory requirements. Regardless of the reason, being able to expose services from a Kubernetes cluster out to other internal applications is a critical design requirement for many applications.
The core reason that this can be challenging is because in many Kubernetes installations, the pod IP addresses are not routeable addresses from outside of the cluster. Via tools like flannel, or other networking providers, routing is established within a Kubernetes cluster to facilitate communication between pods and also between nodes and pods, but the same routing is not generally extended out to arbitrary machines in the same network. Furthermore, in the case of cloud to on-premises connectivity, the IP addresses of the pods are not always advertised back across a VPN or network peering relationship into the on-premises network. Consequently, setting up routing between a traditional application and Kubernetes pods is the key task to enable the export of Kubernetes-based services.
Exporting Services by Using Internal Load Balancers
The easiest way to export from Kubernetes is by using the built-in Service object. If you have had any previous experience with Kubernetes, you have no doubt seen how you can connect a cloud-based load balancer to bring external traffic to a collection of pods in the cluster. However, you might not have realized that most clouds also offer an internal load balancer. The internal load balancer provides the same capabilities to map a virtual IP address to a collection of pods, but that virtual IP address is drawn from an internal IP address space (e.g., 10.0.0.0/24) and thus is only routeable from within that virtual network. You activate an internal load balancer by adding a cloud-specific annotation to your Service load balancer. For example, in
Microsoft Azure, you add the service.beta.kubernetes.io/azure-load-balancer-internal: "true" annotation. On Amazon Web Services (AWS), the annotation is service.beta.kubernetes.io/aws-load-balancer-internal: 0.0.0.0/0. You place annotations in the metadata field in the Service resource as follows:
apiVersion: v1
kind: Service
metadata:
name: my-service
annotations:
# Replace this as needed in other environments
service.beta.kubernetes.io/azure-load-balancer-internal: "true"
...
When you export a Service via an internal load balancer, you receive a stable, routeable IP address that is visible on the virtual network outside of the cluster. You then can either use that IP address directly or set up internal DNS resolution to provide discovery for your exported service.
Exporting Services on NodePorts
Unfortunately, in on-premises installations, cloud-based internal load balancers are unavailable. In this context using a NodePort-based service is often a good solution. A Service of type NodePort exports a listener on every node in the cluster that forwards traffic from the node’s IP address and selected port into the Service that you defined, as shown in Figure 13-3.
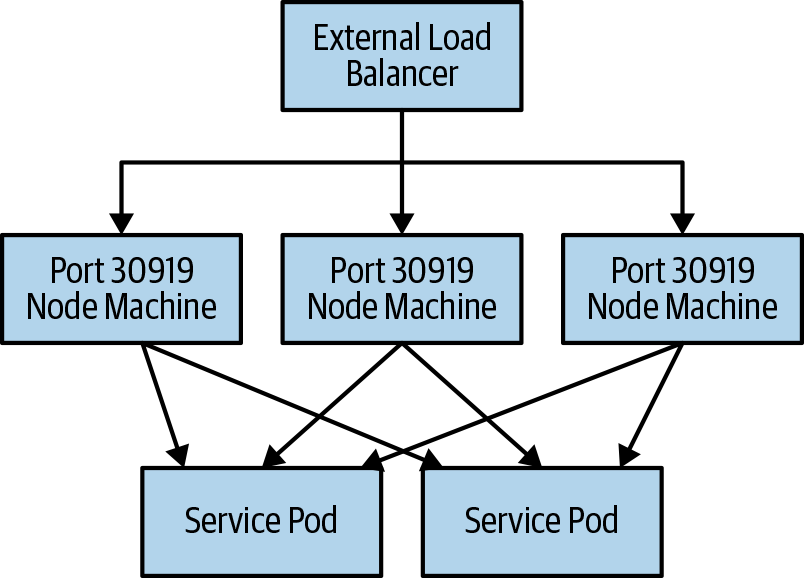
Figure 13-3. A NodePort-based service
Here’s an example YAML file for a NodePort service:
apiVersion:v1kind:Servicemetadata:name:my-node-port-servicespec:type:NodePort...
Following the creation of a Service of type NodePort, Kubernetes automatically
selects a port for the service; you can get that port from the Service
by looking at the spec.ports[*].nodePort field. If you want to choose
the port yourself, you can specify it when you create the service, but
the NodePort must be within the configured range for the cluster. The
default for this range are ports between 30000 and 30999.
Kubernetes’ work is done when the service is exposed on this port. To
export it to an existing application outside of the cluster, you (or your
network administrator) will need to make it discoverable.
Depending on the way your application is configured, you might be able to
give your application a list of ${node}:${port} pairs, and the
application will perform client-side load balancing. Alternatively, you might
need to configure a physical or virtual load balancer within your
network to direct traffic from a virtual IP address to this list of
${node}:${port} backends. The specific details for this configuration
will be different depending on your environment.
Integrating External Machines and Kubernetes
If neither of the previous solutions work well for you—perhaps because you want tighter integration for dynamic service discovery—the final choice for exposing Kubernetes services to outside applications is to directly integrate the machine(s) running the application into the Kubernetes cluster’s service discovery and networking mechanisms. This is significantly more invasive and complicated than either of the previous approaches, and you should use it only when necessary for your application (which should be infrequent). In some managed Kubernetes environments, it might not even be possible.
When integrating an external machine into the cluster for networking,
you need to ensure that the pod network routing and DNS-based service
discovery both work correctly. The easiest way to do this is actually
to run the kubelet on the machine that you want to join to the cluster, but
disable scheduling in the cluster. Joining a kubelet node to a cluster
is beyond of the scope of this book, but there are numerous other books
or online resources that describe how to achieve this. When the node is
joined, you need to immediately mark it as unschedulable using the
kubectl cordon ... command to prevent any additional work being
scheduled on it. This cordoning will not prevent DaemonSets from landing
pods onto the node, and thus the pods for both the KubeProxy and network
routing will land on the machine and make Kubernetes-based services
discoverable from any application running on that machine.
The previous approach is quite invasive to the node because it requires
installing Docker or some other container runtime. Thus, it might not be
feasible in many environments. A lighter weight but more complex
approach is to just run the kube-proxy as a process on the machine and
adjust the machine’s DNS server. Assuming that you can set up pod
routing to work correctly, running the kube-proxy will set up machine-level networking so that Kubernetes Service virtual IP addresses will
be remapped to the pods that make up that Service. If you also change
the machine’s DNS to point to the Kubernetes cluster DNS server,
you will have effectively enabled Kubernetes discovery on a machine that
is not part of the Kubernetes cluster.
Both of these approaches are complicated and advanced, and you should not take them lightly. If you find yourself considering this level of service discovery integration, ask yourself whether it is possibly easier to actually bring the service you are connecting to the cluster into the cluster itself.
Sharing Services Between Kubernetes
The previous sections have described how to connect Kubernetes applications to outside services and how to connect outside services to Kubernetes applications, but another significant use case is connecting services between Kubernetes clusters. This may be to achieve East-West failover between different regional Kubernetes clusters, or it might be to link together services run by different teams. The process of achieving this interaction is actually a combination of the designs described in the previous sections.
First, you need to expose the Service within the first Kubernetes cluster to enable network traffic to flow. Let’s assume that you’re in a cloud environment that supports internal load balancers, and that you receive a virtual IP address for that internal load balancer of 10.1.10.1. Next, you need to integrate this virtual IP address into the second Kubernetes cluster to enable service discovery. You achieve this in the same manner as importing an external application into Kubernetes (first section). You create a selector-less Service and you set its IP address to be 10.1.10.1. With these two steps you have integrated service discovery and connectivity between services within your two Kubernetes clusters.
These steps are fairly manual, and although this might be acceptable
for a small, static set of services, if you want to enable tighter or
automatic service integration between clusters, it makes sense to write a
cluster daemon that runs in both clusters to perform the integration.
This daemon would watch the first cluster for Services with a particular
annotation, say something like myco.com/exported-service; all Services
with this annotation would then be imported into the second cluster via
selector-less services. Likewise, the same daemon would garbage-collect
and delete any services that are exported into the second cluster but
are no longer present in the first. If you set up such daemons in each
of your regional clusters, you can enable dynamic, East-West connectivity
between all clusters in your environment.
Third-Party Tools
Thus far, this chapter has described the various ways to import, export, and connect services that span Kubernetes clusters and some outside resource. If you have previous experience with service mesh technologies, these concepts might seem quite familiar to you. Indeed, there are a variety of third-party tools and projects that you can use to interconnect services both with Kubernetes and with arbitrary applications and machines. Generally, these tools can provide a lot of functionality, but they are also significantly more complex operationally than the approaches described just earlier. However, if you find yourself building more and more networking interconnectivity, you should explore the space of service meshes, which is rapidly iterating and evolving. Nearly all of these third-party tools have an open source component, but they also offer commercial support that can reduce the operational overhead of running additional infrastructure.
Connecting Cluster and External Services Best Practices
-
Establish network connectivity between the cluster and on-premises. Networking can be varied between different sites, clouds, and cluster configurations, but first ensure that pods can talk to on-premises machines and vice versa.
-
To access services outside of the cluster, you can use selector-less services and directly program in the IP address of the machine (e.g., the database) with which you want to communicate. If you don’t have fixed IP addressess, you can instead use CNAME services to redirect to a DNS name. If you have neither a DNS name nor fixed services, you might need to write a dynamic operator that periodically synchronizes the external service IP addresses with the Kubernetes Service endpoints.
-
To export services from Kubernetes, use internal load balancers or NodePort services. Internal load balancers are typically easier to use in public cloud environments where they can be bound to the Kubernetes Service itself. When such load balancers are unavailable, NodePort services can expose the service on all of the machines in the cluster.
-
You can achieve connections between Kubernetes clusters through a combination of these two approaches, exposing a service externally that is then consumed as a selector-less service in the other Kubernetes cluster.
Summary
In the real world, not every application is cloud native. Building applications in the real world often involves connecting preexisting systems with newer applications. This chapter described how you can integrate Kubernetes with legacy applications and also how to integrate different services running across multiple distinct Kubernetes clusters. Unless you have the luxury of building something brand new, cloud-native development will always require legacy integration. The techniques described in this chapter will help you achieve that.