
Chapter 3. Concurrency in Go
- Understanding Go’s concurrency model
- Using goroutines for concurrent processing
- Locking and waiting
- Using channels for communication between goroutines
- Strategically closing channels
This chapter presents Go’s concurrency model. Unlike many recent procedural and object-oriented languages, Go doesn’t provide a threading model for concurrency. Instead, it uses goroutines and channels. Concurrency is cheap (resource-wise) and much easier to manage than traditional thread pools. This chapter first focuses on goroutines, functions capable of running concurrently. Then it dives into channels, Go’s mechanism for communicating between goroutines.
3.1. Understanding Go’s concurrency model
Roughly speaking, concurrency is a program’s ability to do multiple things at the same time. In practice, when we talk about concurrent programs, we mean programs that have two or more tasks that run independently of each other, at about the same time, but remain part of the same program.
Popular programming languages such as Java and Python implement concurrency by using threads. Go takes a different route. Following a model proposed by the renowned computer scientist Tony Hoare, Go uses the concurrency model called Communicating Sequential Processes (CSP). This chapter covers the practical aspects of working with Go’s concurrency model, though we suggest reading a little about the theory behind CSP and Go at golang.org.
Two crucial concepts make Go’s concurrency model work:
- Goroutines —A goroutine is a function that runs independently of the function that started it. Sometimes Go developers explain a goroutine as a function that runs as if it were on its own thread.
- Channels —A channel is a pipeline for sending and receiving data. Think of it as a socket that runs inside your program. Channels provide a way for one goroutine to send structured data to another.
The techniques in this chapter use goroutines and channels. We won’t spend time on the theory or underpinnings of the goroutine and channel systems, but will stick to practical use of these two concepts.
Concurrency in Go is cheap and easy. Therefore, you’ll frequently see it used in libraries and tools. In fact, you’ll see it used frequently throughout this book. This chapter introduces several concurrency topics, with emphasis on how Go’s model differs from that of other popular languages. It also focuses on best practices. Goroutines and channels are one of the few places in the Go language where programmers can introduce memory leaks. You can remedy this situation by following certain patterns, which we introduce in this chapter.
3.2. Working with goroutines
When it comes to syntax, a goroutine is any function that’s called after the special keyword go. Almost any function could, in theory, be called as a goroutine, though there are plenty of functions you probably wouldn’t want to call as goroutines. One of the most frequent uses of goroutines is to run a function “in the background” while the main part of your program goes on to do something else. As an example, let’s write a short program that echoes back any text you type in, but only for 30 seconds, as shown in the next listing. After that, it exits on its own.
Listing 3.1. Using a goroutine to run a task

This program uses a goroutine to run the echoing behavior in the background, while a timer runs in the foreground. If you were to run the program and type in some text, the output would look something like this:
$ go run echoback.go Hello. Hello. My name is Inigo Montoya My name is Inigo Montoya You killed my father You killed my father Prepare to die Prepare to die Timed out.
Here’s how the program works. Each line that you type in is displayed by the shell as you type it, and then echoed back by the program as soon as it reads the line. And it continues this echo loop until the timer runs out. As you can see in the example, there’s nothing special about the echo function, but when you call it with the keyword go, it’s executed as a goroutine.
The main function starts the goroutine and then waits for 30 seconds. When the main function exits, it terminates the main goroutine, which effectively halts the program.
Technique 10 Using goroutine closures
Any function can be executed as a goroutine. And because Go allows you to declare functions inline, you can share variables by declaring one function inside another and closing over the variables you want to share.
Problem
You want to use a one-shot function in a way that doesn’t block the calling function, and you’d like to make sure that it runs. This use case frequently arises when you want to, say, read a file in the background, send messages to a remote log server, or save a current state without pausing the program.
Solution
Use a closure function and give the scheduler opportunity to run.
Discussion
In Go, functions are first-class. They can be created inline, passed into other functions, and assigned as values to a variable. You can even declare an anonymous function and call it as a goroutine, all in a compact syntax, as the following listing shows.
Listing 3.2. An anonymous goroutine

This listing shows how to create the function inline and immediately call it as a goroutine. But if you execute this program, you may be surprised at the output, which may change from run to run. It’s not uncommon to see this:
$ go run ./simple.go Outside a goroutine. Outside again. Inside a goroutine
Goroutines run concurrently, but not necessarily in parallel. When you schedule a goroutine to run by calling go func, you’re asking the Go runtime to execute that function for you as soon as it can. But that’s likely not immediately. In fact, if your Go program can use only one processor, you can almost be sure that it won’t run immediately. Instead, the scheduler will continue executing the outer function until a circumstance arises that causes it to switch to another task. This leads us to another facet of this example.
You may have noticed the last line of the function, runtime.Gosched(). This is a way to indicate to the Go runtime that you’re at a point where you could pause and yield to the scheduler. If the scheduler has other tasks queued up (other goroutines), it may then run one or more of them before coming back to this function.
If you were to omit this line and rerun the example, your output would likely look like this:
$ go run ./simple.go Outside a goroutine. Outside again.
The goroutine never executes. Why? The main function returns (terminating the program) before the scheduler has a chance to run the goroutine. When you run runtime .Gosched, though, you give the runtime an opportunity to execute other goroutines before it exits.
There are other ways of yielding to the scheduler; perhaps the most common is to call time.Sleep. But none gives you the explicit ability to tell the scheduler what to do when you yield. At best, you can indicate to the scheduler only that the present goroutine is at a point where it can or should pause. Most of the time, the outcome of yielding to the scheduler is predictable. But keep in mind that other goroutines may also hit points at which they pause, and in such cases, the scheduler may again continue running your function.
For example, if you execute a goroutine that runs a database query, running runtime.Gosched may not be enough to ensure that the other goroutine has completed its query. It may end up paused, waiting for the database, in which case the scheduler may continue running your function. Thus, although calling the Go scheduler may guarantee that the scheduler has a chance to check for other goroutines, you shouldn’t rely on it as a tool for ensuring that other goroutines have a chance to complete.
There’s a better way of doing that. The solution to this complex situation is shown next.
Technique 11 Waiting for goroutines
Sometimes you’ll want to start multiple goroutines but not continue working until those goroutines have completed their objective. Go wait groups are a simple way to achieve this.
Problem
One goroutine needs to start one or more other goroutines, and then wait for them to finish. In this practical example, you’ll focus on a more specific problem: you want to compress multiple files as fast as possible and then display a summary.
Solution
Run individual tasks inside goroutines. Use sync.WaitGroup to signal the outer process that the goroutines are done and it can safely continue. Figure 3.1 illustrates this general design: several workers are started, and work is delegated to the workers. One process delegates the tasks to the workers and then waits for them to complete.
Figure 3.1. Start multiple workers and wait for completion.

Discussion
Go’s standard library provides several useful tools for working with synchronization. One that frequently comes in handy is sync.WaitGroup, a tool for telling one goroutine to wait until other goroutines complete.
Let’s begin with a simple tool that compresses an arbitrary number of individual files. In the following listing you’ll use the built-in Gzip compression library (compress /gzip) to take each individual file and compress it.
Listing 3.3. Simple Gzip compression tool


This tool takes a list of files on the command line and then compresses each file, creating a file with the same name as the original, but with .gz appended as an extension. Say you have a directory that looks like this:
$ ls -1 exampledata example1.txt example2.txt example3.txt
You have three text files in your exampledata directory. Using your tool, you can compress them:
$ go run simple_gz.go exampledata/* $ ls -1 exampledata example1.txt example1.txt.gz example2.txt example2.txt.gz example3.txt example3.txt.gz
In that example run, you can see that your simple_gz.go program created a Gzipped version of each file.
Now let’s talk about performance. As written, the preceding program uses only one goroutine (and thus uses only one CPU core). It’s unlikely that this program is going to make good use of all of the disk I/O bandwidth, too. Although the code runs just fine, it’s nowhere near as fast as it could be. And because each file can be compressed individually, it’s conceptually simple to break out your single thread of execution into something parallelized.
You can rewrite a program like this to compress each file in its own goroutine. Although this would be a suboptimal solution for compressing thousands of files (you’d probably overwhelm the I/O capacity of the system), it works well when dealing with a few hundred files or less.
Now here’s the trick: you want to compress a bunch of files in parallel, but have the parent goroutine (main) wait around until all of the workers are done. You can easily accomplish this with a wait group. In listing 3.4 you’ll modify the code in such a way that you don’t change the compress function at all. This is generally considered better design because it doesn’t require your worker function (compress) to use a wait group in cases where files need to be compressed serially.
Listing 3.4. Compressing files in parallel with a wait group


In this revised compression tool, you’ve changed the main function in significant ways. First, you’ve added a wait group.
A wait group is a message-passing facility that signals a waiting goroutine when it’s safe to proceed. To use it, you tell the wait group when you want it to wait for something, and then you signal it again when that thing is done. A wait group doesn’t need to know more about the things it’s waiting for other than (a) the number of things it’s waiting for, and (b) when each thing is done. You increment the first with wg.Add, and as your task completes, you signal this with wg.Done. The wg.Wait function blocks until all tasks that were added are done. Figure 3.2 illustrates the process.
Figure 3.2. Wait groups in action
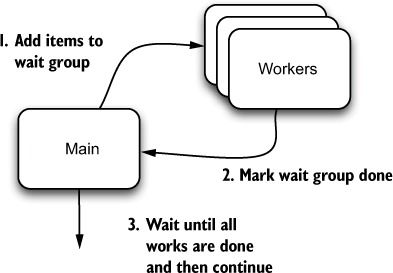
In this program, you call wg.Done inside a goroutine. That goroutine accepts a filename and then runs your compress function on it. Notice that you’ve done something that at first blush appears redundant. Instead of closing over file inside the closure, you pass the file into the program as filename. You do this for a reason related to the Go scheduler.
The variable file is scoped to the for loop, which means that its value will change on each iteration of the loop. But as you saw earlier in the chapter, declaring a goroutine doesn’t result in its immediate execution. If your loop runs five times, you’ll have five goroutines scheduled, but possibly none of them executed. And on each of those five iterations, the value of file will change. By the time the goroutines execute, they may all have the same (fifth) version of the file string. That isn’t what you want. You want each to be scheduled with that iteration’s value of file, so you pass it as a function parameter, which ensures that the value of file is passed to each goroutine as it’s scheduled.
Although this might at first seem an esoteric problem, it’s not uncommon. Anytime a loop executes goroutines, you need to be extra careful that the variables the goroutine uses aren’t changed by the loop. The easiest way to accomplish this is to make copies of the variables inside the loop.
Technique 12 Locking with a mutex
Anytime two or more goroutines are working with the same piece of data, and that data may change, you have the potential for a race condition. In a race condition, two things are “racing” to use the same piece of information. Problems arise when both are working with the same data at around the same time. One goroutine may be only partway through modifying a value when another goroutine tries to use it. And that situation can have unintended consequences.
Problem
Multiple goroutines need to access or modify the same piece of data.
Solution
One simple way to avoid this situation is for each goroutine to place a “lock” on a resource that it’s using, and then unlock the resource when it’s done. For all other goroutines, when they see the lock, they wait until the lock is removed before attempting to lock that resource on their own. Use sync.Mutex to lock and unlock the object.
Discussion
The built-in sync package provides a sync.Locker interface as well as a couple of lock implementations. These provide essential locking behavior.
For a while now, a rumor has been circulating that Go locks perform so poorly that you’re better off implementing your own. This has led many Go developers to build their own lock libraries. In the best case, this is unnecessary work. In the worst case, developers build broken or slower locking systems.
Unless you have a proven use case and performance-sensitive code, you should refrain from reimplementing locks on your own. The built-in package is simple to use, battle-tested, and meets the performance needs of most applications.
Later in the chapter, you’ll work with channels. On occasion, you may find that code already using channels can better handle locking with channels. This is fine (we’ll show you how to do it). But in general, there’s no practical reason for implementing your own locking library.
The following listing is an example of a program with a race condition. This simple program reads any number of files and tallies the number of occurrences for each word it finds. At the end of its execution, it prints a list of words that appear more than once.
Listing 3.5. Word counter with race condition


The main function loops over all the files you supply on the command line, generating statistics for each as it goes. What you expect, when you run the preceding code, is for the tool to read text files and print out a list of the words that it finds. Let’s try it on a single file:
$ go run race.go 1.txt Words that appear more than once: had: 2 down: 2 the: 5 have: 2 that: 3 would: 3 ...
That’s what you’d expect the output to look like. Now, if you pass in more than one filename, the tool will process each file in its own goroutine. Let’s try that:
$ go run race.go *.txt
fatal error: concurrent map writes
goroutine 8 [running]:
runtime.throw(0x115890, 0xd)
/usr/local/go/src/runtime/panic.go:527 +0x90 fp=0x82029cbf0
sp=0x82029cbd8
runtime.evacuate(0xca600, 0x8202142d0, 0x16)
/usr/local/go/src/runtime/hashmap.go:825 +0x3b0 fp=0x82029ccb0
sp=0x82029cbf0
runtime.growWork(0xca600, 0x8202142d0, 0x31)
/usr/local/go/src/runtime/hashmap.go:795 +0x8a fp=0x82029ccd0
sp=0x82029ccb0
runtime.mapassign1(0xca600, 0x8202142d0, 0x82029ce70, 0x82029cdb0)
/usr/local/go/src/runtime/hashmap.go:433 +0x175 fp=0x82029cd78
sp=0x82029ccd0
...
At least some of the time, this will fail. Why? The error gives a hint: concurrent map writes. If you rerun the command with the --race flag, you’ll get an even better idea:
go run --race race.go *.txt
==================
WARNING: DATA RACE
Read by goroutine 8:
runtime.mapaccess2_faststr()
/tmp/workdir/go/src/runtime/hashmap_fast.go:281 +0x0
main.tallyWords()
/Users/mbutcher/Code/go-in-practice/chapter3/race/race.go:62 +0x3ed
main.main.func1()
/Users/mbutcher/Code/go-in-practice/chapter3/race/race.go:18 +0x66
Previous write by goroutine 6:
runtime.mapassign1()
/tmp/workdir/go/src/runtime/hashmap.go:411 +0x0
main.tallyWords()
/Users/mbutcher/Code/go-in-practice/chapter3/race/race.go:62 +0x48a
main.main.func1()
/Users/mbutcher/Code/go-in-practice/chapter3/race/race.go:18 +0x66
Goroutine 8 (running) created at:
main.main()
/Users/mbutcher/Code/go-in-practice/chapter3/race/race.go:22 +0x238
Goroutine 6 (running) created at:
main.main()
/Users/mbutcher/Code/go-in-practice/chapter3/race/race.go:22 +0x238
==================
The call to words.add has a problem. Multiple goroutines are accessing the same bit of memory, the words.found map, at the same time (note the bold lines). This causes a race condition to modify the map.
Many of the Go tools, including go run and go test, accept a --race flag, which enables race detection. Race detection substantially slows execution, but it’s useful for detecting race conditions during the development cycle.
If you look back at the original program, you can quickly find the problem. If add is called by multiple goroutines at around the same time, multiple simultaneous operations may occur on the same map. This is a recipe for corrupting the map.
One simple solution is to lock the map before you modify it, and then unlock it afterward. You can accomplish this with a few changes to the code, as shown in the next listing.
Listing 3.6. Word counter with locks


In this revised version, the words struct declares an anonymous field referencing sync.Mutex, basically granting the words.Lock and words.Unlock methods. This is a common way of exposing a lock on a struct. (You used these methods when looping over the words at the end of main.)
Now, inside the add method, you lock the object, modify the map, and then unlock the object. When multiple goroutines enter the add method, the first will get the lock, and the others will wait until the lock is released. This will prevent multiple goroutines from modifying the map at the same time.
It’s important to note that locks work only when all access to the data is managed by the same lock. If some data is accessed with locks, and others without, a race condition can still occur.
Sometimes it’s useful to allow multiple read operations on a piece of data, but to allow only one write (and no reads) during a write operation. The sync.RWLock provides this functionality. The sync package has several other useful tools that simplify coordination across goroutines. But at this point, let’s turn our attention to another core concept in Go’s concurrency model: channels.
3.3. Working with channels
Channels provide a way to send messages from one goroutine to another. This section covers several ways of using channels to accomplish common tasks and solve common problems.
The easiest way to understand channels is to compare them to network sockets. Two applications can connect over a network socket. Depending on how these applications were written, network traffic can flow in a single direction or bidirectionally. Sometimes network connections are short-lived, and sometimes they stick around for a long time. Smart applications may even use multiple network connections, each sending and receiving different kinds of data. Just about any data can be sent over a network socket, but there’s a drawback: that data has to be marshaled into raw bytes.
Go channels work like sockets between goroutines within a single application. Like network sockets, they can be unidirectional or bidirectional. Channels can be short-lived or long-lived. And it’s common to use more than one channel in an app, having different channels send different kinds of data. But unlike network connections, channels are typed and can send structured data. There’s generally no need to marshal data onto a channel.
Let’s dive into channels by refactoring an earlier code sample to use channels.
Channels are a fantastic tool for communicating between goroutines. They’re simple to use, as you’ll see, and make concurrent programming much easier than the threading models of other popular languages.
But be wary of overuse. Channels carry overhead and have a performance impact. They introduce complexity into a program. And most important, channels are the single biggest source of memory management issues in Go programs. As with any tool, use channels when the need arises, but resist the temptation to polish your new hammer and then go looking for nails.
Technique 13 Using multiple channels
Go developers are fond of pointing out that channels are communication tools. They enable one goroutine to communicate information to another goroutine. Sometimes the best way to solve concurrency problems in Go is to communicate more information. And that often translates into using more channels.
Problem
You want to use channels to send data from one goroutine to another, and be able to interrupt that process to exit.
Solution
Use select and multiple channels. It’s a common practice in Go to use channels to signal when something is done or ready to close.
Discussion
To introduce channels, let’s revisit the first code example in this chapter. That program echoed user input for 30 seconds. It accomplished this by using a goroutine to echo the information, and a time.Sleep call to wait. Let’s rewrite that program to use channels in addition to goroutines.
You’re not looking to add new functionality or even to vastly improve the initial example. You’re interested in taking a different approach to solving the same problem. In so doing, you’ll see several idiomatic uses of channels.
Before looking at the code in listing 3.7, consider the following concepts that you’ll see come into play here:
- Channels are created with make, just like maps and slices.
- The arrow operator (<-) is used both to signify the direction of a channel (out chan<- []byte) and to send or receive data over a channel (buf := <-echo).
- The select statement can watch multiple channels (zero or more). Until something happens, it’ll wait (or execute a default statement, if supplied). When a channel has an event, the select statement will execute that event. You’ll see more on channels later in this chapter.
Listing 3.7. Using multiple channels


Running the preceding code results in the following:
$ go run echoredux.go test 1 test 1 test 2 test 2 test 3 test 3 Timed out
As you saw with the previous implementation, if you type test 1, that text is echoed back. After 30 seconds, the program halts itself.
Rewriting the echo example has introduced new concepts regarding channels. The first channel in the preceding code is created by the time package. The time.After function builds a channel that will send a message (a time.Time) when the given duration has elapsed. Calling time.After(30 * time.Second) returns a <-chan time.Time (receive-only channel that receives time.Time objects) that, after 30 seconds, will receive a message. Thus, practically speaking, the two methods of pausing in the following listing are operationally equivalent.
Listing 3.8. Pausing with Sleep and After

Some functions (for example, time.After) create and initialize channels for you. But to create a new channel, you can use the built-in make function.
Channels are bidirectional by default. But as you saw in the preceding example, you can specify a “direction” for the channel when passing it into a function (or during any other assignment). The readStdin function can only write to the out channel. Any attempt to read from it will result in a compile-time error. Generally, it’s considered good programming practice to indicate in a function signature whether the function receives or sends on a channel.
The last important facet of this program is select. A select statement is syntactically similar to a switch statement. It can take any number of case statements, as well as a single optional default statement.
The select statement checks each case condition to see whether any of them have a send or receive operation that needs to be performed. If exactly one of the case statements can send or receive, select will execute that case. If more than one can send or receive, select randomly picks one. If none of the case statements can send or receive, select falls through to a default (if specified). And if no default is specified, select blocks until one of the case statements can send or receive.
In this example, select is waiting to receive on two channels. If a message comes over the echo channel, the string that’s sent is stored in buf (buf := <-echo), and then written to standard output. This illustrates that a receive operation can assign the received value to a variable.
But the second case that your select is waiting for is a message on the done channel. Because you don’t particularly care about the contents of the message, you don’t assign the received value to a variable. You just read it off the channel, and the select discards the value (<-done).
There’s no default value on your select, so it’ll block until either a message is received on <-echo or a message is received on <-done. When the message is received, select will run the case block and then return control. You’ve wrapped your select in a for loop, so the select will be run repeatedly until the <-done channel receives a message and the program exits.
One thing we didn’t cover in this technique is closing channels when you’re done with them. In our example app, the program is too short-lived to require this, and you rely on the runtime to clean up after you. In the next technique, you’ll look at a strategy for closing channels.
Technique 14 Closing channels
In Go, developers rely on the memory manager to clean up after themselves. When a variable drops out of scope, the associated memory is scrubbed. But you have to be careful when working with goroutines and channels. What happens if you have a sender and receiver goroutine, and the sender finishes sending data? Are the receiver and channel automatically cleaned up? Nope. The memory manager will only clean up values that it can ensure won’t be used again, and in our example, an open channel and a goroutine can’t be safely cleaned.
Imagine for a moment that this code was part of a larger program, and that the function main was a regular function called repeatedly throughout the lifetime of the app. Each time it’s called, it creates a new channel and a new goroutine. But the channel is never closed, nor does the goroutine ever return. That program would leak both channels and goroutines.
The question arises: how can you correctly and safely clean up when you’re using goroutines and channels? Failing to clean up can cause memory leaks or channel/ goroutine leaks, where unneeded goroutines and channels consume system resources but do nothing.
Problem
You don’t want leftover channels and goroutines to consume resources and cause leaky applications. You want to safely close channels and exit goroutines.
Solution
The straightforward answer to the question “How do I avoid leaking channels and goroutines?” is “Close your channels and return from your goroutines.” Although that answer is correct, it’s also incomplete. Closing channels the wrong way will cause your program to panic or leak goroutines.
The predominant method for avoiding unsafe channel closing is to use additional channels to notify goroutines when it’s safe to close a channel.
Discussion
You can use a few idiomatic techniques for safely shutting down channels.
Let’s start, though, with a negative example, shown in the following listing. Beginning with the general idea of the program from listing 3.7, let’s construct a program that incorrectly manages its channel.
Listing 3.9. Improper channel close


This example code is contrived to illustrate a problem that’s more likely to occur in a server or another long-running program. You’d expect this program to print 10 or so hello strings and then exit. But if you run it, you get this:
$ go run bad.go
hello
hello
hello
hello
hello
hello
hello
hello
hello
hello
panic: send on closed channel
goroutine 20 [running]:
main.send(0x82024c060)
/Users/mbutcher/Code/go-in-practice/chapter3/closing/bad.go:28 +0x4c
created by main.main
/Users/mbutcher/Code/go-in-practice/chapter3/closing/bad.go:12 +0x90
goroutine 1 [sleep]:
time.Sleep(0x1dcd6500)
/usr/local/go/src/runtime/time.go:59 +0xf9
main.main()
/Users/mbutcher/Code/go-in-practice/chapter3/closing/bad.go:20 +0x24f
exit status 2
At the end, the program panics because main closes the msg channel while send is still sending messages to it. A send on a closed channel panics. In Go, the close function should be closed only by a sender, and in general it should be done with some protective guards around it.
What happens if you close the channel from the sender? No panic will happen, but something interesting does. Take a look at the quick example in the next listing.
Listing 3.10. Close from sender


After running this code, you’d expect that the main loop would do the following: hit the default clause a couple of times, get a single message from send, and then hit the default clause a few more times before the time-out happens and the program exits.
Instead, you’ll see this:
$ go run sendclose.go *yawn* *yawn* *yawn* *yawn* Got message. Got message. Sent and closed *yawn* Sent and closed *yawn* Got message. Got message. Got message. Got message. ... #thousands more Time out
This occurs because a closed channel always returns the channel’s nil value, so send sends one true value and then closes the channel. Each time the select examines ch after ch is closed, it’ll receive a false value (the nil value on a bool channel).
You could work around this issue. For example, you could break out of the for/select loop as soon as you see false on ch. Sometimes that’s necessary. But the better solution is to explicitly indicate that you’re finished with the channel and then close it.
The best way to rewrite listing 3.9 is to use one additional channel to indicate that you’re done with the channel. This gives both sides the opportunity to cleanly handle the closing of the channel, as shown in the next listing.
Listing 3.11. Using a close channel


This example demonstrates a pattern that you’ll frequently observe in Go: using a channel (often called done) to send a signal between goroutines. In this pattern, you usually have one goroutine whose primary task is to receive messages, and another whose job is to send messages. If the receiver hits a stopping condition, it must let the sender know.
In listing 3.11, the main function is the one that knows when to stop processing. But it’s also the receiver. And as you saw before, the receiver shouldn’t ever close a receiving channel. Instead, it sends a message on the done channel indicating that it’s done with its work. Now, the send function knows when it receives a message on done that it can (and should) close the channel and return.
Technique 15 Locking with buffered channels
Thus far, you’ve looked at channels that contain one value at a time and are created like this: make(chan TYPE). This is called an unbuffered channel. If such a channel has received a value, and is then sent another one before the channel can be read, the second send operation will block. Moreover, the sender will also block until the channel is read.
Sometimes you’ll want to alter those blocking behaviors. And you can do so by creating buffered channels.
Problem
In a particularly sensitive portion of code, you need to lock certain resources. Given the frequent use of channels in your code, you’d like to do this with channels instead of the sync package.
Solution
Use a channel with a buffer size of 1, and share the channel among the goroutines you want to synchronize.
Discussion
Technique 12 introduced sync.Locker and sync.Mutex for locking sensitive areas of code. The sync package is part of Go’s core, and is thus well tested and maintained. But sometimes (especially in code that already uses channels), it’s desirable to implement locks with channels instead of the mutex. Often this is a stylistic preference: it’s prudent to keep your code as uniform as possible.
When talking about using a channel as a lock, you want this kind of behavior:
1. A function acquires a lock by sending a message on a channel.
2. The function proceeds to do its sensitive operations.
3. The function releases the lock by reading the message back off the channel.
4. Any function that tries to acquire the lock before it’s been released will pause when it tries to acquire the (already locked) lock.
You couldn’t implement this scenario with an unbuffered channel. The first step in this process would cause the function to block because an unbuffered channel blocks on send. In other words, the sender waits until something receives the message it puts on the channel.
But one of the features of a buffered channel is that it doesn’t block on send provided that buffer space still exists. A sender can send a message into the buffer and then move on. But if a buffer is full, the sender will block until there’s room in the buffer for it to write its message.
This is exactly the behavior you want in a lock. You create a channel with only one empty buffer space. One function can send a message, do its thing, and then read the message off the buffer (thus unlocking it). The next listing shows a simple implementation.
Listing 3.12. Simple locking with channels

This pattern is simple: there’s one step to lock and one to unlock. If you run this program, the output will look like this:
$ go run lock.go 2 wants the lock 1 wants the lock 2 has the lock 5 wants the lock 6 wants the lock 4 wants the lock 3 wants the lock 2 is releasing the lock 1 has the lock 1 is releasing the lock 5 has the lock 5 is releasing the lock 6 has the lock 6 is releasing the lock 3 has the lock 3 is releasing the lock 4 has the lock 4 is releasing the lock
In this output, you can see how your six goroutines sequentially acquire and release the lock. Within the first few milliseconds of starting the program, all six goroutines have tried to get the lock. But only goroutine 2 gets it. A few hundred milliseconds later, 2 releases the lock and 1 gets it. And the lock trading continues until the last goroutine (4) acquires and releases the lock. (Note that in this code, you can rely on the memory manager to clean up the locking channel. After all references to the channel are gone, it’ll clean up the channel for you.)
Listing 3.12 illustrates one advantage of using buffered queues: preventing send operations from blocking while there’s room in the queue. Specifying a queue length also allows you to specify just how much buffering you want to do. You might be able to imagine needing a lock that can be claimed by up to two goroutines, and you could accomplish this with a channel of length 2. Buffered queues are also employed for constructing message queues and pipelines.
3.4. Summary
This chapter introduced Go’s concurrency system. You first looked at goroutines and the useful packages that Go provides for synchronizing across goroutines. Then you looked at Go’s powerful channel system, which allows multiple goroutines to communicate with each other over typed pipes. You covered several important idioms and patterns, including the following:
- Go’s CSP-based concurrency model
- Concurrent processing with goroutines
- Using the sync package for waiting and locking
- Communicating between goroutines with channels
- Closing channels properly
In the coming chapters, you’ll see goroutines and channels in practice. You’ll see how Go’s web server starts a new goroutine for each request, and how patterns such as fan-out work for distributing a workload among multiple channels. If there’s one feature that makes Go a standout system language, it’s Go’s concurrency model.
Next, we turn to error handling. Although it’s not a glamorous topic, Go’s method of handling errors is one of its exceptional features.