
Chapter 10. Communication between cloud services
- Introducing microservice communication
- Reusing connections between services for faster performance
- Providing faster JSON marshaling and unmarshaling
- Using protocol buffers for faster payload transfer
- Communicating over RPC
Representational State Transfer (REST) is the most common form of communication between services, and the most common data format used to transfer information is JSON. REST is an incredibly powerful way to expose interacting with applications to developers and the applications they build.
When communicating between cloud services or microservices within a broader application, you have options besides REST. Some of these options provide for faster communication that uses less bandwidth. In a microservice architecture, in which network communications come into play and can make a real performance difference, some areas can be optimized.
In this chapter, you’ll first learn about a microservice architecture and how the network can become a bottleneck or cause performance slowdowns when these services communicate. From there, you’ll learn techniques that can speed up REST communications—in particular, JSON communications. Then you’ll explore communication techniques other than REST and JSON that can provide an alternative approach.
After this chapter, you’ll be able to move beyond the REST communication techniques covered in this book and into faster alternatives used by microservices operating quickly and at scale.
10.1. Microservices and high availability
Applications built with a microservice architecture are created as collections of independently deployable services. The rise of complex systems, the desire to independently scale parts of an application, and the need to have applications that are less brittle and more resilient have led to the rise of these microservices. Examples of microservices include configuration manager applications such as etcd, or applications that transcode media from one format to another. Microservices tend to have the following characteristics:
- Perform a single action. For example, store configuration or transcode media from one format to another.
- Elastic and can be horizontally scaled. As load on a microservice changes, it can be scaled up or down as needed.
- Resilient to failures and problems. The service can be deployed so that it doesn’t go offline, even when instances of the application have problems.
This is similar to and inspired by the UNIX philosophy of Do one thing and do it well.
Imagine that you’re building a service that transcodes media from one format to another. A user can upload media, the format is transcoded, and later the media in the new format is available for download. This could be built as a monolithic application in which all elements are part of the same application, or as microservices with different functional parts that are their own applications.
A simple transcoding application built using microservices is illustrated in figure 10.1.
Figure 10.1. A simple transcoding application broken into microservices
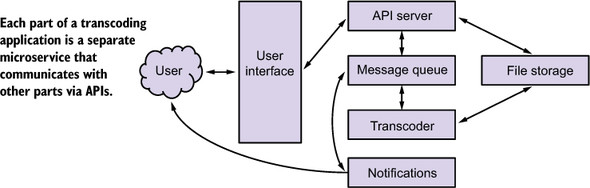
In this application, media is uploaded through the user interface to the API server. The API server puts the media in the file store and places a job to transcode the media into a message queue. Transcoders pull the job from the message queue, transcode the media into a new format, place the new file into file storage, and place a job into the queue to notify the user that the transcoding is complete. From the user interface, the user can retrieve the transcoded file. The user interface communicates with the API server to retrieve the file from storage.
Each of these microservices can be written in a different programming language, reused on different applications, and may even be consumed as a service. For example, file storage could be an object storage consumed as software as a service.
Scaling each of these services depends on the needs of the service. For example, the transcoder service can scale depending on how much media needs to be transcoded. The API server and notifications service can scale differently from the transcoder, depending on the appropriate amount of resources they need.
Users have the expectation that services never go offline. The days of maintenance windows during which services aren’t available are in the past. Accidental outages can lose user trust and reduce income. One of the advantages of microservices is that each service can be made highly available in a method most appropriate for that service. For example, keeping an API server highly available is different from keeping a message queue highly available.
10.2. Communicating between services
One of the key elements in a microservice architecture is communication between the microservices. If not well done, this can become a bottleneck in the performance of an application.
In the transcoding example in figure 10.1, four microservices are communicating with each other when uploading a new piece of media to be transcoded. If these used REST to communicate and the communications were over TLS, which is typical, a significant amount of time would be spent in network communications.
The performance of communications becomes more important when you use an increasing number of microservices. Companies such as Google, which are known for using microservice architectures, have gone so far as to create new, faster ways to communicate between microservices and build their own networking layer that outperforms what’s being sold in the market.
Faster communication is something you can bring to your applications. As you’ll see in this chapter, it isn’t that complicated to implement.
10.2.1. Making REST faster
REST is the most common form of communication used in web and cloud services. Although transferring representational state data over HTTP is common, it’s not efficient or as fast as other protocols. Most setups aren’t optimized out of the box, either. This often makes communication a place to speed up application performance.
Technique 62 Reusing connections
It’s not unusual for each HTTP request to be made over its own connection. Negotiating each connection takes time, including the time to negotiate TLS for secure communications. Next, TCP slow-start ramps up as the message is communicated. Slow-start is a congestion-control strategy designed to prevent network congestion. As a slow-start ramps up, a single message may take multiple round-trips between the client and server to communicate.
Problem
When each request is over its own connection, a significant amount of time is lost to network communication. How can an application avoid as much of this lost time as possible?
Solution
Reuse connections. Multiple HTTP requests can be made over a single connection. That connection needs to be negotiated and ramped up for slow-start only once. After passing the first message, others happen more quickly.
Discussion
Whether your application is using HTTP/2 (first available in Go 1.6) or HTTP/1 and HTTP/1.1 for your communications, you can reuse connections. Go tries to reuse connections out of the box, and it’s the patterns in an application’s code that can cause this to not happen.
When connections are reused, as shown in figure 10.2, the time spent opening and closing connections is reduced. Because TCP slow-start has already happened, the time to communicate future messages is faster as well. This is why the second, third, and fourth messages take less time when the connection is reused.
Figure 10.2. Messages being passed with and without connection reuse
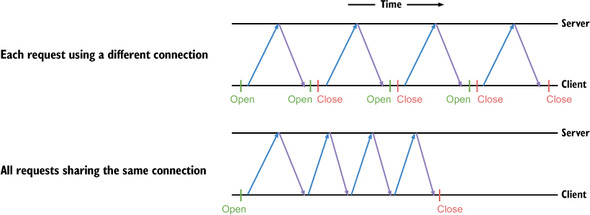
The server included in the net/http package provides HTTP keep-alive support. Most systems support TCP keep-alive needed to reuse connections out of the box. As of Go 1.6, the net/http package includes transparent support for HTTP/2, which has other communication advantages that can make communication even faster.
Note
HTTP keep-alive and TCP keep-alive are different. HTTP keep-alive is a feature of the HTTP protocol a web server needs to implement. The web server needs to periodically check the connection for incoming HTTP requests within the keep-alive time span. When no HTTP request is received within that time span, it closes the connection. Alternately, TCP keep-alive is handled by the operating system in TCP communications. Disabling keep-alive with DisableKeepAlives disables both forms of keep-alive.
Most of the problems preventing connection reuse are in the clients used to communicate with HTTP servers. The first and possibly most widespread problem happens when custom transport instances are used and keep-alive is turned off.
When the basic functions in the net/http package are used, such as http.Get() or http.Post(), they use http.DefaultClient, which is configured with keep-alive enabled and set up for 30 seconds. When an application creates a custom client but doesn’t specify a transport, http.DefaultTransport is used. http.DefaultTransport is used by http.DefaultClient and is configured with keep-alive enabled.
Transporting without keep-alive can be seen in open source applications, examples online, and even in the Go documentation. For instance, the Go documentation has an example that reads as follows:
tr := &http.Transport{
TLSClientConfig: &tls.Config{RootCAs: pool},
DisableCompression: true,
}
client := &http.Client{Transport: tr}
resp, err := client.Get("https://example.com")
In this example, a custom Transport instance is used with altered certificate authorities and compression disabled. In this case, keep-alive isn’t enabled. The following listing provides a similar example, with the difference being that keep-alive is enabled.

One part of working with http.Transport can be confusing. Setting its DisableKeepAlives property to true disables connection reuse. Setting DisableKeepAlives to false doesn’t mean that connections are explicitly reused. It means you can opt in to either HTTP or TCP keep-alive.
Unless you have a reason to disable keep-alive, we suggest you use it. When making many HTTP requests to the same endpoint, it provides for faster performance.
The other behavior that can prevent connection reuse occurs when the body of a response isn’t closed. Prior to HTTP/2, pipelining was almost never implemented or used. Pipelining allows multiple requests and their responses to be communicated in parallel rather than in serial, as you can see in figure 10.3. Prior to HTTP/2, one request and response needed to be completed before the next could be used. The body of the response would need to be closed before another HTTP request and response could use the connection.
Figure 10.3. HTTP Pipelining compared to serial requests
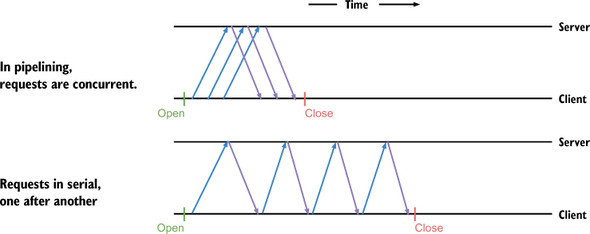
The following listing illustrates a common case of one response body not being closed before another HTTP request is made.
Listing 10.2. Failing to close an HTTP response body

In this case, using defer isn’t optimal. Instead, the body should be closed when it’s no longer needed. The following listing illustrates the same example, with the connection being shared because the body is closed.
Listing 10.3. Using and closing the HTTP response quickly

This subtle change to the application can impact how network connections behind the scenes are happening and can improve the overall performance of an application, especially as it scales.
Technique 63 Faster JSON marshal and unmarshal
A majority of the communication that happens over REST involves passing data as JSON. The JSON marshaling and unmarshaling provided by the encoding/json package uses reflection to figure out values and types each time. Reflection, provided by the reflect package, takes time to figure out types and values each time a message is acted on. If you’re repeatedly acting on the same structures, quite a bit of time will be spent reflecting. Reflection is covered in more detail in chapter 11.
Problem
Instead of figuring out the types of data each time JSON is marshaled or unmarshaled, how can the type be figured out once and skipped on future passes?
Solution
Use a package able to generate code that can marshal and unmarshal the JSON. The generated code skips reflection and provides a faster execution path with a smaller memory footprint.
Discussion
Reflection in Go is fairly fast. It does allocate memory that needs to be garbage-collected, and there’s a small computational cost. When using optimized generated code, those costs can be reduced, and you can see a performance improvement.
Several packages are designed to do this. In listing 10.4 you’ll look at the package github.com/ugorji/go/codec, which is designed to work with Binc, MessagePack, and Concise Binary Object Representation (CBOR) in addition to JSON. Binc, MessagePack, and CBOR are alternative data exchange formats, though none is as popular as JSON.
Listing 10.4. A struct annotated for codec

A struct marked up for the codec package is almost the same as the json package. The difference is in the name codec.
To generate code, the codecgen command needs to be installed. This can be done as follows:
$ go get -u github.com/ugorji/go/codec/codecgen
After codecgen is installed, you can use it to generate code on this file, named user.go, by executing the following command:
$ codecgen -o user_generated.go user.go
The output file is named user_generated.go. In the generated file, you’ll notice that two public methods have been added to the User type: CodecEncodeSelf and CodecDecodeSelf. When these are present, the codec package uses them to encode or decode the type. When they’re absent, the codec package falls back to doing these at runtime.
When the codecgen command is installed, it can be used with go generate. go generate will see the first comment line of the file, which is specially formatted for it, and execute codecgen. To use go generate, run the following command:
$ go generate ./...
Note
The next chapter covers generators and reflection in depth.
After the User type is ready for use, the encoding and decoding can be incorporated into the rest of the application, as shown in the next listing.
Listing 10.5. Encode an instance to JSON with codec

Here’s the output of this code:
{"name":"Inigo Montoya","Email":"[email protected]"}
Notice that the name key is lowercase, whereas the Email key has an uppercase first letter. The User type, defined in listing 10.4, has uppercase property names leading to key names that directly reflect that. But the Name property has a custom key of name used here.
The byte slice with the JSON that was created in listing 10.5 can be decoded into an instance of User, as shown in the following listing.
Listing 10.6. Decode JSON into an instance of a type

Although the API to github.com/ugorji/go/codec is different from the encoding /json package in the standard library, it’s simple enough to be easily used.
10.2.2. Moving beyond REST
Although REST is common and usable for end-user-facing APIs, alternatives may be faster and more efficient for communication between your microservices. Given the rise of microservices, the amount of communication between them, and the manner in which network communication can be a bottleneck, exploring other options is worthwhile.
The network bottleneck has become enough of an issue that companies that operate on a large scale, such as Google and Facebook, have innovated new technologies to speed up communication between microservices.
Technique 64 Using protocol buffers
JSON and XML are commonly used to serialize data. These formats are fairly easy to use and the transfer format is easy to read, but they’re not optimized for transport over a network or for serialization.
Problem
What formats that are optimized for network transfer and serialization are available for use in Go applications?
Solution
Some more recent formats, including protocol buffers (a.k.a. protobuf) by Google and Apache Thrift and originally developed at Facebook, are faster in network transfer and serialization. These are available in Go, along with numerous other languages.
Discussion
Protocol buffers, by Google, are a popular choice for a high-speed transfer format. The data in the messages being transferred over the network is smaller than XML or JSON and it can be marshaled and unmarshaled faster than XML and JSON as well. The transfer method isn’t defined by protocol buffers. They can be transferred on a filesystem, using RPC, over HTTP, via a message queue, and numerous other ways.
Google provides support for working with protocol buffers in C++, C#, Go, Java, and Python. Other languages, such as PHP, have third-party libraries that provide support.
A protocol format is defined in a file. It contains the structure of the message and can be used to automatically generate the needed code. The following listing contains an example of the file user.proto.
Listing 10.7. Protocol buffer file

Tip
For more details regarding what can be passed in messages, including messages inside messages, see the protocol buffer documentation at https://developers.google.com/protocol-buffers/docs/overview.
Because the protocol buffer is used to generate Go code, it’s recommended that it have its own package. In this Go package, the protocol buffer file and generated code can reside. As you’ll see in listing 10.8, the directory in this case is userpb.
To compile the protocol buffer to code, you first need to install the compiler:
1. Download and install the compiler. You can get it at https://developers.google.com/protocol-buffers/docs/downloads.html.
2. Install the Go protocol buffer plugin. This can be done using go get: $ go get -u github.com/golang/protobuf/protoc-gen-go
To generate the code, run the following command from the same directory as the .proto file:
$ protoc -I=. --go_out=. ./user.proto
The command does a few things:
- -I specifies the input source directory.
- --go_out indicates where the generated Go source files will go.
- ./user.proto is the name of the file to generate the source from.
After the generated code has been created, it can be used to pass messages between a client and server. The following listing provides the setup for a server to respond with protocol buffer messages.
Listing 10.8. Protocol buffer server setup

Warning
Although this example communicates user information over HTTP for simplicity, in production applications, user information should be transported over encrypted communications for security.
Listing 10.8 opens in a similar manner to the web servers in earlier chapters. The same patterns there can be used here. The real work is done in the handler, shown in the following listing.
Listing 10.9. Protocol buffer server handler

Writing a response as a protocol buffer is fairly similar to writing a JSON or XML response. One difference is that values to properties on messages are pointers to a value rather than a value itself. Calls to proto.String, proto.Int32, and other functions return pointers to values rather than the values passed in.
A client can be used to retrieve and read the messages. The following listing showcases a simple client.
Listing 10.10. Protocol buffer client

Protocol buffers are ideal when you need to pass messages between your microservices and are trying to limit the amount of time used to pass the message.
Technique 65 Communicating over RPC with protocol buffers
Communicating requires more than just the payload passed between two endpoints. Communication includes the manner in which the payload is transferred. REST has certain semantics it enforces, which include a path and an HTTP verb, and are resource-based. At times, the semantics of REST aren’t desired—for example, for an API call to restart a server. That’s an operation, and at times operation-based semantics fit.
An alternative is to use a remote procedure call (RPC) instead. With an RPC, a procedure is executed in a subroutine that’s often in a remote location. This is often another service altogether. The calls aren’t tied to the semantics of the medium and are more closely related to executing a function on the remote system.
One of the potential issues of RPC is that both sides communicating with each other need to know about the procedure being executed. This is different from REST, in which the details of the communicated payload are enough. Knowing about the procedure can make working with RPC, especially when services are written in multiple languages, seem more difficult.
Problem
How can you communicate over RPC in a manner that’s portable across programming languages?
Solution
Use gRPC and protocol buffers to handle defining the interfaces, generating the cross-language code, and implementing the RPC communications.
Discussion
gRPC (www.grpc.io) is an open source, high-performance RPC framework that can use HTTP/2 as a transport layer. It was developed at Google and has support for Go, Java, Python, Objective-C, C#, and several other languages. Given the language support, you’ll notice both server-side languages and languages used for building mobile applications. gRPC can be used for communication between mobile devices and supporting services.
gRPC uses code generation to create the messages and handle parts of the communication. This enables the communication to easily work between multiple languages, as the interfaces and messages are generated properly for each language. To define the messages and RPC calls, gRPC uses protocol buffers, as the following listing shows.
Listing 10.11. Define messages and RPC calls with a protocol buffer

Tip
For more details on version 3 of protocol buffers, see the version language guide at https://developers.google.com/protocol-buffers/docs/proto3.
Based on this protocol buffers file, messages and stub code can be generated to handle much of the work. The command to generate the code is a little different from the example in technique 64 to account for RPC generation.
The command (run here from the same directory as the hello.proto file) is shown here:
protoc -I=. --go_out=plugins=grpc:. ./hello.proto
The difference you’ll see is in --go_out=plugins=gprc:., where the gRPC plugin is specified as part of the Go output generation. Without specifying this, the output won’t generate the service stub code. After this command is complete, code will be generated for the messages and to work with the Go gRPC package.
Warning
To use protocol buffers version 3, you need at least version 3.0.0 of the protocol buffers application to be installed. That can be downloaded from https://github.com/google/protobuf/releases.
The following listing shows a simple Hello World server that accepts RPC messages and responds to them. This is an example of a microservice that responds over RPC.
Listing 10.12. gRPC server responding to requests


The golang.org/x/net/context package is an important part of the communication, and gRPC depends on it. This package carries deadlines, cancelation signals, and other request-scoped values across API boundaries. For example, context could contain a timeout that the callee needs to know about. You’ll explore more of this when you look at the client.
Note
The context package will be moving to the standard library for Go 1.7 and later.
To use the service in listing 10.12, you need a client. That client can be in any language, and client code can be generated by the protocol buffers. The following listing provides a Go client using the already generated Go code.
Listing 10.13. Request to a gRPC server with protocol buffers


The context being passed to Say is important. In this case, it’s an empty context that’s never canceled and has no values. It’s a simple background process. The context package has other contexts, and you can read more about them in the package documentation at https://godoc.org/golang.org/x/net/context.
One example is using a context with a cancel function. This is useful if the caller goes away (for example, the application is closed), and the callee needs to be informed of this. The client could create a context like this:
ctx, cancel := context.WithCancel(context.Background()) defer cancel()
When the function this code is in ends, the cancel() function is called. This tells the context to cancel the work. This is communicated to the other service, even when hosted on an entirely different system. On the server, this cancellation can be seen through a channel, which is how it’s implemented in the client as well. For example, in an RPC function such as Say, there could be the following:
select {
case <-ctx.Done():
return nil, ctx.Err()
}
When a message is sent over the channel available from Done(), which happens when the cancel() function is called, it will be received here. The ctx.Err() function is aware of the type of cancelation that was set up. In this case, the error sent back will note that the work was canceled.
Contexts are a powerful tool for passing information over the course of a remote call—especially when the remote call will take a good amount of time.
When the client and server are using HTTP/2, as they are by default when both ends are using gRPC, the communications use the connection reuse and multiplexing described earlier in the chapter. This enables a fast, modern transport layer for transferring the protocol buffer binary messages.
The advantages and disadvantages of RPC utilizing gRPC should be weighed before using them. The advantages include the following:
- Using protocol buffers, the payload size is smaller and faster to marshal or unmarshal than JSON or XML.
- The context allows for canceling, communicating timeouts or due dates, and other relevant information over the course of a remote call.
- The interaction is with a called procedure rather than a message that’s passed elsewhere.
- Semantics of the transport methodology—for example, HTTP verbs—don’t limit the communications over RPC.
The disadvantages include the following:
- The transport payload isn’t human-readable as JSON or XML can be.
- Applications need to know the interface and details of the of the RPC calls. Knowing the semantics of the message isn’t enough.
- Integration is deeper than a message, such as you’d have with REST, because a remote procedure is being called. Exposing remote procedure access to untrusted clients may not be ideal and should be handled with care for security.
In general, RPCs can be a good alternative for interactions between microservices you control that are part of a larger service. They can provide fast, efficient communication and will even work across multiple programming languages. RPCs shouldn’t typically be exposed to clients outside your control, such as a public API. The information needed for those clients to be successful is more difficult to communicate, making REST and JSON better options.
10.3. Summary
In this chapter, you explored REST communications and faster alternatives. These alternatives, or similar options, are used by Google, Facebook, and others that operate using many discrete services that need to work together. The techniques you learned about include the following:
- Communications in a microservice architecture and how that can be a bottleneck
- Reusing connections to improve performance by avoiding repeated TCP slow-start, congestion-control ramp-ups and connection negotiations
- Faster JSON marshaling and unmarshaling that avoids extra time spent reflecting
- Using protocol buffering instead of JSON for messaging
- Communicating over RPC using gRPC
In the next chapter, you’ll learn about reflection and metaprogramming in Go. That includes using tags on structs and code generation.