
Chapter 11. Reflection and code generation
This chapter covers
- Using values, kinds, and types from Go’s reflection system
- Parsing custom struct annotations
- Writing code generators for use with the go generate tool
In this chapter, we turn our attention to some of Go’s most interesting features. First, we present Go’s reflection system. Reflection, in software development, refers to a program’s ability to examine its own structure. Although Go’s reflection subsystem isn’t as versatile as Java’s, it’s still powerful. One feature that has enjoyed novel use is the annotation of structs. You’ll see in this chapter how to write custom tags for struct fields. As useful as Go’s reflection system is, though, sometimes it’s cleaner to avoid complex and expensive runtime reflection, and instead write code that writes code. Code generation can accomplish some of the things that are typically done in other languages with generics. That practice, called metaprogramming, is the last thing you’ll look at in this chapter.
11.1. Three features of reflection
Software developers use reflection to examine objects during runtime. In a strongly typed language like Go, you may want to find out whether a particular object satisfies an interface. Or discover what its underlying kind is. Or walk over its fields and modify the data.
Go’s reflection tools are located inside the reflect package. To understand those tools, we need to define a few terms. You need to understand three critical features when working with Go’s reflection mechanism: values, types, and kinds.
You might approach the first term, value, by thinking of a variable. A variable is a name that points to a piece of data, as illustrated in figure 11.1. (The figure labels this Variable name.) The piece of data that it points to is called a value. Depending on the type, the value may be nil. It may be a pointer, which in turn points to a value somewhere else. Or it may be a nonempty piece of data. For example, with x := 5, the value of x is 5. For var b bytes.Buffer, the value of b is an empty buffer. And with myFunc := strings.Split, the value of myFunc is a function. In the reflect package, the type reflect.Value represents a value.
Figure 11.1. Variables and values

Go is a typed language. Each value in Go has a particular type associated with it. For example, with var b bytes.Buffer, the type is bytes.Buffer. For any reflect.Value in Go, you can discover its type. Type information is accessible through the reflect .Type interface.
Finally, Go defines numerous primitive kinds, such as struct, ptr (pointer), int, float64, string, slice, func (function), and so on. The reflect package enumerates all of the possible kinds with the type reflect.Kind. (Note that in figure 11.1, the value of type string also has the kind string.)
The typical tasks you perform when working with reflection use these three concepts. Usually, reflection begins by taking a value and then inspecting it to learn about its contents, its type, and its kind.
Technique 66 Switching based on type and kind
One of the most frequent uses of Go’s reflection system is identifying either the type or kind of a value. Go has various tools for learning about the type and kind of a particular value.
Problem
You want to write a function that takes generic values (interface{}s), and then does something useful with them based on underlying types.
Solution
Go provides various methods for learning this information, ranging from the type switch to the reflect.Type and reflect.Kind types. Each has subtle strong points. Here, you’ll look at type switches and then employ the reflect package to build a kind switch.
Discussion
Say you want to write a function with the signature sum(...interface{}) float64. You want this function to take any number of arguments of various types. And you want it to convert the values to float64 and then sum them.
The most convenient tool that Go provides for doing this is the type switch. With this special case of the switch control structure, you can perform operations based on the type of a value, instead of the data contained in a value. As you read through common Go libraries, you’ll frequently encounter type switches (though using kinds and switches, which you’ll see later in this section, is rare). Let’s start with a simple (though incomplete) example in the next listing.
Listing 11.1. Sum with type switch


If you were to run this code, you’d get Result: 42.200000. This code illustrates the basic use of a type switch, as well as one of its limitations compared to regular switches.
In a standard switch statement, you might combine multiple values on a single case line: case 1, 2, 3: println("Less than four"). Combining types in a case statement introduces complications when assigning values, so typically a type switch has one type per line. If you were to support all of the integer types (int, int8, int16, int32, int64, uint, uint8, uint16, uint32, uint64), you’d need 10 separate case clauses. Although writing similar logic for 10 kinds may feel like an inconvenience, it isn’t really a problem. But it’s important to remember that type switches operate on types (not kinds).
Let’s add a new type to the preceding example, as shown in the following listing.
Listing 11.2. Type switch with extra type


Running this program generates the following output:
$ go run typekind.go Unsupported type main.MyInt. Ignoring. Result: 42.200000
The type of var d MyInt isn’t int64; it’s MyInt. In the type switch, it matches the default clause instead of the int64 case. At times, this is precisely the behavior you’d desire. But for this case, it’d be better if sum() could tell what the underlying kind was, and work from that instead.
The solution to this problem is to use the reflect package, and work based on kind instead of type. The first part of our example will be the same, but the sum() function is different, as shown in the next listing.
Listing 11.3. A Kind switch


In this revised version, you replace the type switch with a regular value-based switch, and you use the reflect package to take each val interface{} and get a reflect .Value describing it. One of the pieces of information you can learn from a reflect.Value is its underlying kind.
Another thing that the reflect.Value type gives you is a group of functions capable of converting related types to their largest representation. A reflect.Value with a uint8 or uint16 can be easily converted to the biggest unsigned integer type by using the reflect.Value’s Uint() method.
With these features, you can collapse an otherwise verbose type switch to a more concise kind-based switch. Instead of needing 10 cases for the integer types, you could accomplish the same feature with only two cases (one for all the signed integers, and one for the unsigned integers).
But types and kinds are distinct things. Here, you’ve produced two cases that perform approximately the same task. Summing numeric values can be more easily done by determining kinds. But sometimes you’re more concerned with specifics. As you’ve seen elsewhere in the book, type switches are excellent companions for error handling. You can use them to sort out different error types in much the same way that other languages use multiple catch statements in a try/catch block.
Later in this chapter, we return to examining types. In that case, you’ll use the reflect.Type type to discover information about a struct. But before you get to that case, let’s look at another common reflection task: determining whether a particular type implements an interface.
Technique 67 Discovering whether a value implements an interface
Go’s type system is different from the inheritance-based methods of traditional object-oriented languages. Go uses composition instead of inheritance. A Go interface defines a pattern of methods that another type must have before it can be considered to implement that interface. A concrete and simple example might help here. The fmt package defines an interface called Stringer that describes a thing capable of representing itself as a string:
type Stringer interface {
String() string
}
Any type that provides a String() method that takes no arguments and returns a string is ipso facto a fmt.Stringer.
Problem
Given a particular type, you want to find out whether that type implements a defined interface.
Solution
There are two ways to accomplish this. One is with a type assertion, and the other uses the reflect package. Use the one that best meets your needs.
Discussion
Go’s view of interfaces differs from that of object-oriented languages like Java. In Go, a thing isn’t declared to fulfill an interface. Instead, an interface is a description against which a type can be compared. And interfaces are themselves types. That is why when you write types in Go, you don’t declare which interfaces they satisfy. In fact, as you saw in chapter 4, it’s common to write interfaces to match existing code.
One easy way to conceptualize this is by considering how we, as humans, often generalize and categorize. If I were to ask you, “What do a swan, a snow drift, and a cloud have in common?” you would answer, “All are white.” This doesn’t mean that the three things have a common ancestor (the object-oriented approach). Instead, it means that all three share a commonality: whiteness. This is the way types work in Go. They express commonality, not inheritance.
Go makes it easy to determine whether a given interface matches another interface type. Determining the answer to this question can be done at the same time as converting that type, as shown in the next listing.
Listing 11.4. Checking and converting a type

Type assertions are one way of testing whether a given value implements an interface. But what if you want to test whether a type implements an interface, but determine which interface at runtime? To accomplish this, you need to use the reflect package and little bit of trickery.
Earlier in the chapter, you looked at the basic types in the reflect package. An astute reader might have noticed something missing. Go’s reflection package has no reflect.Interface type. Instead, reflect.Type (which is itself an interface) provides tools for querying whether a given type implements a given interface type. To reflect on an interface type at runtime, you can use reflect.Type, as the following listing shows.
Listing 11.5. Determine whether a type implements an interface


This example takes what may appear to be a roundabout method. The implements() function takes two values. It tests whether the first value (concrete) implements the interface of the second (target). If you were to run this code, you’d get the following output:
$ go run implements.go *main.Name is a Stringer *main.Name is not a Writer
Our Name type implements fmt.Stringer because it has a String() string method. But it doesn’t implement io.Writer because it doesn’t have a Write([]bytes) (int, error) method.
The implements() function does assume that the target is a pointer to a value whose dynamic type is an interface. With a few dozen lines, you could check that by reflecting on the value and checking that it’s a pointer. As it stands now, it’d be possible to cause implements() to panic by passing a target that doesn’t match that description.
To get to the point where you can test whether concrete implements the target interface, you need to get the reflect.Type of both the concrete and the target. There are two ways of doing this. The first uses reflect.TypeOf() to get a reflect.Type, and a call to Type.Elem() to get the type that the target pointer points to:
iface := reflect.TypeOf(target).Elem()
The second gets the value of concrete, and then gets the reflect.Type of that value. From there, you can test whether a thing of one type implements an interface type using the Type.Interface() method:
v := reflect.ValueOf(concrete) t := v.Type()
The trickier part of this test, though, is getting a reference to an interface. There’s no way to directly reflect on an interface type. Interfaces don’t work that way; you can’t just instantiate one or reference it directly.
Instead, you need to find a way to create a placeholder that implements an interface. The simplest way is to do something we usually recommend studiously avoiding: intentionally create a nil pointer. In the preceding code, you create two nil pointers, and you do so like this: stringer := (*fmt.Stringer)(nil). In essence, you do this just to create a thing whose only useful information is its type. When you pass these into the implements() function, it’ll be able to reflect on the nil pointers and determine the type. You need the Elem() call in order to get the type of the nil.
The code in listing 11.5 illustrates how working with Go’s reflection system can require thinking creatively about how to set up various reflection operations. Tasks that might seem superficially simple may require some thoughtful manipulation of the type system.
Next, let’s look at how to use Go’s reflection system to take a struct and programmatically access its fields.
Technique 68 Accessing fields on a struct
Go structs are the most commonly used tool for describing structured data in Go. Because Go can glean all of the important information about a struct’s contents during compilation, structs are efficient. At runtime, you may want to find out information about a struct, including what its fields are and whether particular values of a struct have been set.
Problem
You want to learn about a struct at runtime, discovering its fields.
Solution
Reflect the struct and use a combination of reflect.Value and reflect.Type to find out information about the struct.
Discussion
In the last few techniques, you’ve seen how to start with a value and reflect on it to get information about its value, its kind, and its type. Now you’re going to combine these techniques to walk a struct and learn about it.
The tool you’ll create is a simple information-printing program that can read a value and print information about it to the console. The principles will come in handy, though, in the next section, where you’ll use some similar techniques to work with Go’s annotation system.
First, let’s start with a few types to examine in the following listing.
Listing 11.6. Types to examine
package main
import (
"fmt"
"reflect"
"strings"
)
type MyInt int
type Person struct {
Name *Name
Address *Address
}
type Name struct {
Title, First, Last string
}
type Address struct {
Street, Region string
}
Now you have an integer-based type and a few structs. The next thing to do is to write some code to inspect these types, as shown in the next listing.
Listing 11.7. Recursively examining a value


The preceding example combines just about everything you’ve learned about reflection. Types, values, and kinds all come into play as you walk through a value and examine its reflection data. If you run this little program, the output looks like this:
$ go run structwalker.go
Walking a simple integer
Value is type "main.MyInt" (int)
Walking a simple struct
Value is type "struct { Name string }" (struct)
Field "Name" is type "string" (string)
Walking a struct with struct fields
Value is type "main.Person" (struct)
Field "Name" is type "*main.Name" (struct)
Value is type "main.Name" (struct)
Field "Title" is type "string" (string)
Field "First" is type "string" (string)
Field "Last" is type "string" (string)
Field "Address" is type "*main.Address" (struct)
Value is type "main.Address" (struct)
Field "Street" is type "string" (string)
Field "Region" is type "string" (string)
In this output, you can see the program examine each of the values you’ve given it. First, it checks a MyInt value (of kind int). Then it walks the simple struct. Finally, it walks the more complex struct and recurses down through the struct until it hits only nonstruct kinds.
The walk() function does all of the interesting work in this program. It begins with an unknown value, u, and inspects it. While you’re walking through an unknown value, you want to make sure that you follow pointers. If reflect.ValueOf() is called on a pointer, it will return a reflect.Value describing a pointer. That isn’t interesting in this case. Instead, what you want is the value at the other end of that pointer, so you use reflect.Indirect() to get a reflect.Value describing the value pointed to. The reflect.Indirect() method is useful in that if it’s called on a value that’s not a pointer, it will return the given reflect.Value, so you can safely call it on all values:
val := reflect.Indirect(reflect.ValueOf(u))
Along with the value of u, you need some type and kind information. In this example, you get each of the three reflection types:
- The value (in this case, if you get a pointer for a value, you follow the pointer)
- The type
- The kind
Kinds are particularly interesting in this case. Some kinds, notably slices, arrays, maps, and structs, may have members. In this case, you’re interested mainly in learning about the structure of your given value (u). Although you wouldn’t need to enumerate the values in maps, slices, or arrays, you’d like to examine structs. If the kind is reflect.Struct, you take a look at that struct’s fields.
The easiest way to enumerate the fields of a struct is to get the type of that struct and then loop through the fields of that type by using a combination of Type.NumField() (which gives you the number of fields) and Type.Field(). The Type.Field() method returns a reflect.StructField object describing the field. From there, you can learn about the field’s data type and its name.
But when it comes to getting the value of a struct field, you can’t get this from either the reflect.Type (which describes the data type) or the reflect.StructField (which describes the field on a struct type). Instead, you need to get the value from the reflect.Value that describes the struct value. Fortunately, you can combine your knowledge of the type and the value to know that the numeric index of the type field will match the numeric index of the value’s struct field. You can use Value.Field() with the same field number as Type.Field(), and get the associated value for that field. Again, if the field is a pointer, you’d rather have a handle to the value at the other end of the pointer, so you call reflect.Indirect() on the field value. If you take a look at the output of the preceding program, you’ll see this in action:
Field "Name" is type "*main.Name" (struct) Value is type "main.Name" (struct)
The field Name is of type *main.Name. But when you follow the pointer, you get a value of type main.Name. This little program is dense, so to summarize what you’ve just seen:
- From interface{}, you can use reflect.ValueOf() to get reflect.Value.
- Sometimes a value might be a pointer. To follow the pointer and get the reflect.Value of the thing pointed to, you call reflect.Indirect().
- From reflect.Value, you can conveniently get the type and kind.
- For structs (kind == reflect.Struct), you can get the number of fields on that struct by using Type.NumField(), and you can get a description of each field (reflect.StructField) by using Type.Field().
- Likewise, with reflect.Value objects, you can access struct field values by using Value.Field().
If you were interested in discovering other information, the reflect package contains tools for learning about the methods on a struct, the elements in maps, lists, and arrays, and even information about what a channel can send or receive. For all of Go’s elegance, though, the reflection package can be difficult to learn and unforgiving to use: many of the functions and methods in that package will panic rather than return errors.
The example you’ve looked at here sets the stage for using one of our favorite Go features. Next, you’ll look at Go’s annotation system. You’ll see how to build and access your own struct tags.
11.2. Structs, tags, and annotations
Go has no macros, and unlike languages such as Java and Python, Go has only Spartan support for annotations. But one thing you can easily annotate in Go is properties on a struct. You’ve already seen this practice for providing JSON processing information. Here’s an example.
11.2.1. Annotating structs
In the previous chapter, you saw an example of using struct annotations with things like the JSON encoder. For example, you can begin with the struct from listing 11.5 and annotate it for the JSON encoder, as shown in the following listing.
Listing 11.8. Simple JSON struct

This code declares a single struct, Name, that’s annotated for JSON encoding. Roughly speaking, it maps the struct member First to the JSON field firstName, and the struct field Last to lastName. If you were to run this code, the output would look like this:
$ go run json.go
{"firstName":"Inigo","lastName":"Montoya"}
The struct annotations make it possible to control how your JSON looks. Struct tags provide a convenient way to provide small bits of processing data to fields on a struct. Practically speaking, annotations are a free-form string enclosed in back quotes that follows the type declaration of a struct field.
Annotations play no direct functional role during compilation, but annotations can be accessed at runtime by using reflection. It’s up to the annotation parsers to figure out whether any given annotation has information that the parser can use. For example, you could modify the preceding code to include different annotations, as shown in the next listing.
Listing 11.9. A variety of annotations
type Name struct {
First string `json:"firstName" xml:"FirstName"`
Last string `json:"lastName,omitempty"`
Other string `not,even.a=tag`
}
These annotations are all legal, in the sense that the Go parser will correctly handle them. And the JSON encoder will be able to pick out which of those applies to it. It will ignore the xml tag as well as the oddly formatted annotation on the Other field.
As you can see from the tags in listing 11.9, an annotation has no fixed format. Just about any string can be used. But a certain annotation format has emerged in the Go community and is now a de facto standard. Go developers call these annotations tags.
11.2.2. Using tag annotations
The sample JSON struct you looked at earlier contained annotations of the form `json: "NAME,DATA"`, where NAME is the name of the field (in JSON documents), and DATA is a list of optional information about the field (omitempty or kind data). Figure 11.2 shows an example of a struct annotated for both JSON and XML.
Figure 11.2. A struct marshaled to JSON and to XML
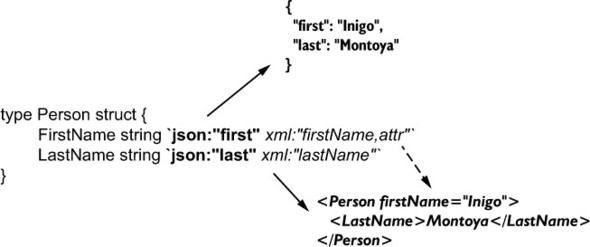
Likewise, if you look at the encoding/xml package, you’d see a pattern similar to annotations for converting structs to and from XML. Tags for XML look like this: `xml:"body"` and `xml:"href,attr"`. Again, the pattern is similar to the JSON tag pattern: `xml:"NAME,DATA"`, where NAME is the field name, and DATA contains a list of information about the field (though XML annotations are more sophisticated than JSON annotations).
One of the most interesting uses for annotations that we’ve seen is for validating field data on a struct. By adding regular expressions in tags (`validate:"^[a-z]+$ "`), and then writing code to run those regular expressions over struct data, you can write validation code easily and concisely. An example can be found in the Deis Router project at https://github.com/deis/router.
This format isn’t enshrined in the definition of a struct annotation, though. It’s just a convention that has proven useful and thus enjoys widespread adoption. Go’s reflection package even makes it easy to work with tags, as you’ll see shortly.
Technique 69 Processing tags on a struct
Annotations can be useful in a wide variety of situations. The preceding examples show how they can be used by encoders. Annotations can just as readily be used to describe how database field types map to structs, or how to format data for display. We’ve even seen cases in which annotations were used to tell Go to pass struct values through other filtering functions.
And because the annotation format is undefined, to build your annotations, you need only decide on a format and then write an implementation.
Problem
You want to create your own annotations and then programmatically access the annotation data of a struct at runtime.
Solution
Define your annotation format (preferably using the tag-like syntax described previously). Then use the reflect package to write a tool that extracts the annotation information from a struct.
Discussion
Say you want to write an encoder for a simple file syntax for name-value pairs. This format is similar to the old INI format. An example of this file format looks like this:
total=247 running=2 sleeping=245 threads=1189 load=70.87
Here, the names are on the left side of the equals sign, and the values are on the right. Now imagine that you want to create a struct to represent this data. It looks like the following listing.
Listing 11.10. A bare Processes struct
type Processes struct {
Total int
Running int
Sleeping int
Threads int
Load float32
}
To convert the plain file format into a struct like this, you can create a tag that fits your needs and then mark up your struct with them (see the following listing).
Listing 11.11. The Processes struct with annotations
type Processes struct {
Total int `ini:"total"`
Running int `ini:"running"`
Sleeping int `ini:"sleeping"`
Threads int `ini:"threads"`
Load float32 `ini:"load"`
}
This tag structure follows the same convention as the JSON and XML tags you saw earlier. But there’s no automatic facility in Go to handle parsing the file format and learning from the struct annotations how to populate a Processes struct. You’ll do that work yourself.
As you design this, you can once again rely on existing conventions. Encoders and decoders in Go tend to provide marshal() and unmarshal() methods with a fairly predictable set of parameters and return values. So your INI file decoder will implement the same pattern, as shown in the following listing.
Listing 11.12. The marshal and unmarshal pattern
func Marshal(v interface{}) ([]byte, error) {}
func Unmarshal(data []byte, v interface{}) error {}
The bulk of both of these functions involves reflecting over the interface{} values and learning about how to extract data from or populate data into those values. To keep the code concise, the following example deals only with marshaling and unmarshaling structs.
Reflection tends to be a little verbose, so you’ll split up the code for your program into smaller chunks, starting with a struct for your INI file and the main() function. In the first part, you’ll create a new type (Processes), and then in the main() function you’ll create a Processes struct, marshal it to your INI format, and then unmarshal it into a new Processes struct. See the next listing.
Listing 11.13. Processes and main()


The top-level code is straightforward. You begin with an instance of your Processes struct and then marshal it into a byte array. When you print the results, they’ll be in your INI file format. Then you take that same data and run it back through the other direction, expanding the INI data into a new Processes struct. Running the program produces output like this:
$ go run load.go
Write a struct to a output:
total=23
running=3
sleeping=20
threads=34
load=1.8
Read the data back into a struct
Struct: &main.Processes{Total:23, Running:3, Sleeping:20, Threads:34,
Load:1.8}
The first section of output shows your marshaled data, and the second shows your unmarshaled struct. Next you can look at the Marshal() function, which brings much of your reflection knowledge back to the forefront. See the following listing.
Listing 11.14. The Marshal function


This Marshal() function takes the given v interface{} and reads through its fields. By examining the type, it can iterate through all the fields on the struct, and for each field, it can access the annotation (via StructField.Tag()). As it loops through the struct fields, it can also fetch the relevant values for each struct field. Rather than manually convert these values from their native type to a string, you rely on fmt.Fprintf() to do that work for you.
Of note, the fieldName() function uses Go’s automatic tag parsing. Although you can (if you desire) store any string data in an annotation, Go can parse tags for you. For any annotation tag that follows the format NAME:"VALUE", you can access the value by using StructField.Tag.Get(). It returns the value unprocessed. It’s a common idiom for tag values to contain a comma-separated list of params (json:"myField,omitempty"). For our simple tags, though, you allow only a single field in the VALUE space. Finally, if you don’t get any tag data for the field, you return the struct field’s name.
Sometimes you want to tell encoders to ignore fields on a struct. The common idiom for doing this is to use a dash (-) in the name field of the annotation (json:"-""). Although we don’t support this in the preceding code, you could extend the example to ignore fields whose name is -.
This Marshal() function isn’t particularly flexible. For example, it’ll read only structs. Maps, which could just as easily be converted to INI fields, aren’t supported. Likewise, your Marshal() function is going to work well only on certain data types. It won’t, for example, produce useful results for fields whose values are structs, channels, maps, slices, or arrays. Yet although those operations require lots of code, there’s nothing particularly daunting about extending this Marshal() function to support a broader array of types.
In the next listing you can look at the process of taking an existing bit of INI data and turning it into a struct. Again, this uses annotations and the reflection subsystem.
Listing 11.15. The Unmarshal function

The Unmarshal() function reads []byte and tries to convert the fields it finds there into matching fields on the supplied v interface{}. Your INI parser is trivially simple: it iterates through the lines of the file and splits name-value pairs. But when it comes time to populate the given struct with the newly loaded values, you have to do a fair amount of work.
The unmarshal() function relies heavily on the setField() helper, which uses most of the reflection strategies you’ve seen in this chapter. Again, you’re going to switch on kinds, which make for verbose code. See the next listing.
Listing 11.16. The setField helper function


The setField() function takes the raw name-value pair, as well as the reflect.Value and reflect.Type of the struct, and attempts to match the pair to its appropriate field on the struct. (Again, you restrict the tool to working only with structs, though you could extend it to work with map types.) Finding the matching field name is relatively easy because you can reuse the fieldName() function defined in listing 11.14. But when it comes to the value, you need to convert the data from the string form you were given to whatever the data type of the struct field is. For the sake of space, the code in listing 11.14 handles only a few data types (int, float64, string, and bool). And you didn’t explore types that extend from your base kinds. But the pattern illustrated here could be extended to handle other types. Finally, you store the newly converted value on the struct by first wrapping it in reflect.Value() and then setting the appropriate struct field.
One thing becomes clear when scanning the code you’ve written in this technique: because of Go’s strong type system, converting between types often takes a lot of boilerplate code. Sometimes you can take advantage of built-in tools (for example, fmt.Fprintf()). Other times, you must write tedious code. On certain occasions, you might choose a different route. Instead of writing reflection code, you might find it useful to use Go’s generator tool to generate source code for you. In the next section, you’ll look at one example of writing a generator to do work that would otherwise require runtime type checking and detailed reflection code.
11.3. Generating Go code with Go code
Newcomers to Go often share a set of similar concerns. With no generics, how do you create type-specific collections? Is there an easier way to write typed collections instead of using reflection? The runtime cost of reflection is high. Is there a way to write better-performing code? Annotations have only limited capabilities; is there another way to transform code? As mentioned before, Go doesn’t support macros, and annotations have only limited capabilities. Is there another way to transform code? How do you metaprogram in Go?
An often overlooked feature of Go is its capability to generate code. Go ships with a tool, go generate, designed exactly for this purpose. In fact, metaprogramming with generators is a powerful answer to the preceding questions. Generated code (which is then compiled) is much faster at runtime than reflection-based code. It’s also usually much simpler. For generating a large number of repetitive but type-safe objects, generators can ease your development lifecycle. And although many programmers turn a jaundiced eye toward metaprogramming, the fact of the matter is that we use code generators frequently. As you saw in the previous chapter, Protobuf, gRPC, and Thrift use generators. Many SQL libraries are generators. Some languages even use generators behind the scenes for macros, generics, and collections. The nice thing about Go is that it provides powerful generator tools right out of the box.
At the root of Go’s embracing of code generation is a simple tool called go generate. Like other Go tools, go generate is aware of the Go environment, and can be run on files and packages. Conceptually speaking, it’s shockingly simple.
The tool walks through the files you’ve specified, and it looks at the first line of each file. If it finds a particular pattern, it executes a program. The pattern looks like this:
//go:generate COMMAND [ARGUMENT...]
The generator looks for this comment right at the top of each Go file that you tell it to search. If it doesn’t find a header, it skips the file. If it does find the header, it executes the COMMAND. The COMMAND can be any command-line tool that the generator can find and run. You can pass any number of arguments to the command. Let’s build a trivially simple example in the next listing.
Listing 11.17. A trivial generator
//go:generate echo hello
package main
func main() {
println("Goodbyte")
}
This is legit Go code. If you compiled and ran it, it would print Goodbyte to the console. But it has a generator on the first line. The generator’s command is echo, which is a UNIX command that echoes a string back to Standard Output. And it has one argument, the string hello. Let’s run the generator and see what it does:
$ go generate simple.go hello
All the generator does is execute the command, which prints hello to the console. Although this implementation is simple, the idea is that you can add commands that generate code for you. You’ll see this in action in the next technique.
Technique 70 Generating code with go generate
Writing custom type-safe collections, generating structs from database tables, transforming JSON schemata into code, generating many similar objects—these are some of the things we’ve seen developers use Go generators for. Sometimes Go developers use the Abstract Syntax Tree (AST) package or yacc tool to generate Go code. But we’ve found that one fun and easy way to build code is to write Go templates that generate Go code.
Problem
You want to be able to create type-specific collections, such as a queue, for an arbitrary number of types. And you’d like to do it without the runtime safety issues and performance hit associated with type assertions.
Solution
Build a generator that can create queues for you, and then use generation headers to generate the queues as you need them.
Discussion
A queue is a simple data structure; you push data onto the front, and dequeue data off the back. The first value into the queue is the first value out (first in, first out, or FIFO). Usually, queues have two methods: insert (or enqueue) to push data onto the back of the queue, and remove (or dequeue) to get the value at the front of the queue.
What you want is to be able to automatically generate queues that are specific to the types you want to store in the queues. You want queues that follow a pattern like the next listing.
Listing 11.18. Simple queue

This code is a good representation of what you want to have generated for you. There are certain bits of information that you want to be filled in at generation time. The obvious example is the type. But you also want the package name to be filled out automatically. Your next step, then, is to translate the preceding code into a Go template. The next listing shows the beginning of your queue generator tool.
Listing 11.19. The queue template


Your template is almost the same as the target code you wrote previously, but with the package name replaced with {{.Package}}, and the MyType prefix replaced with {{.MyType}}. From here, you need to write the code that performs the generation. This is a command-line tool designed to fit the //go:generate COMMAND ARGUMENT... pattern. Ideally, what you’d like is to be able to write something like this:
//go:generate queue MyInt
And as a result, the generator would generate a MyIntQueue implementation. It’d be even nicer if you could generate queues for multiple types at once:
//go:generate queue MyInt MyFloat64
You should be able to easily accommodate that, too, as shown in the next listing.
Listing 11.20. The main queue generator

Because you want to accept multiple types at the command line, you start out by looping through os.Args. For each one, you automatically generate an output file with the name TYPE_queue.go. Though to be consistent with the Go file-naming conventions, you should lowercase the type name.
Your template had only two variables. One is the Go type that you want to handle. But the other is the package. One nice thing that the go generate command does for you is populate a few environment variables with useful information about the location of the generator file. The $GOPACKAGE environment variable is set to the name of the package where the go:generate header was found.
When the template is executed, the vals map is used to populate the template, and a complete Go file is generated.
To run this, you need to place the go:generate header in an appropriate file, as shown in the next listing.
Listing 11.21. Using the generator

This is a good example of typical usage of a Go generator. In this one file, you declare a generator, you declare your type, and you even use the generator. Clearly, this code will not compile until you’ve run the generator. But because the generator doesn’t depend on your code compiling, you can (and should) run it before building your package.
That raises an important point about generators: they’re intended to be used as development tools. The Go authors intended that generation was part of the development lifecycle, not the build or runtime cycle. For example, you should always generate your code and then check the generated code into your VCS. You shouldn’t require your users to run a generator (even if your users are other developers).
To run the preceding generator, you need to do a few things. First, compile the generator tool from listings 11.18 and 11.19. In order for the generator line to work, you need to have it in the local directory (because you called it as ./queue). Alternately, you could store the queue program anywhere on your path ($PATH), often including $GOPATH/bin, and call it as //go:generate queue.
With queue compiled and located where go generate can find it, you need to run your go generate tool, and then you can run the main program using the generated code:
$ ls myint.go $ go generate $ ls myint.go myint_queue.go $ go run myint.go myint_queue.go First value: 1
After the generator has created your extra queue code, you can run the program in listing 11.21. Everything it needs has been generated.
The code you’re using for this generator is basic. Instead of adding good error handling, you let the queue panic. And you don’t handle the case where you’d want to queue pointers. But these problems are easily remedied by using the normal strategies. Adding pointers, for example, is just a matter of adding another template parameter that adds an asterisk (*) where appropriate.
Again, Go templates aren’t the only way to generate code. Using the go/ast package, you can generate code by programming the abstract syntax tree. For that matter, you could just as easily write Python, C, or Erlang code that generated Go. You’re not even limited to outputting Go. Imagine generating SQL CREATE statements by using a generator that reads structs. One of the things that make go generate so elegant is the versatility within its simplicity.
We were inspired enough by the elegance of Go’s generator that when we created the Helm package manager for Kubernetes (http://helm.sh), we implemented a similar pattern for transforming templates into Kubernetes manifest files.
Taking a higher-level view, generators can be a useful way of writing repetitive code that would otherwise use reflection. Go’s reflection mechanism is useful, but it’s tedious to write and limited in capabilities, and the performance of your application will suffer. That’s not to say that reflection is bad. Rather, it’s a tool designed to solve a specific set of problems.
On the other hand, generating code isn’t always the best solution either. Metaprogramming can make debugging hard. It also adds steps to the development process. Just as with reflection, generation should be used when the situation calls for it. But it’s not a panacea or a workaround for Go’s strong typing.
11.4. Summary
This chapter has taken on two of the more difficult Go topics: reflection and metaprogramming. With reflection, you examined how types, values, kinds, fields, and tags can be used to solve a variety of programming problems. And with metaprogramming, you saw how the go generate tool can be used to write code that creates code.
During the course of this chapter, you saw how to do the following:
- Use kinds to identify critical details about types
- Determine at runtime whether a type implements an interface
- Access struct fields at runtime
- Work with annotations
- Parse tags within struct annotations
- Write marshal and unmarshal functions
- Use go generate
- Write Go templates that generate Go code
Over the course of this book, you’ve walked through a broad range of topics. We hope that the techniques we’ve demonstrated are as practical and applicable in your coding as they’ve been in ours. Go is a fantastic systems language. Part of the reason is the simplicity of Go’s syntax and semantics. But more than that, Go developers built a programming language not as an academic exercise, but in an effort to solve real problems in elegant ways. We hope this book has illustrated both Go’s elegance and its practicality.