
Chapter 4. Handling errors and panics
This chapter covers
- Learning the Go idioms for errors
- Providing meaningful data with errors
- Adding your own error types the Go way
- Working with panics
- Transforming panics into errors
- Working with panics on goroutines
As Robert Burns famously expressed in his poem “To a Mouse,” “The best-laid schemes o’ mice an’ men / Gang aft agley.” Our best plans often still go wrong. No other profession knows this truth as thoroughly as software developers. This chapter focuses on handling those situations when things go awry.
Go distinguishes between errors and panics—two types of bad things that can happen during program execution. An error indicates that a particular task couldn’t be completed successfully. A panic indicates that a severe event occurred, probably as a result of a programmer error. This chapter presents a thorough look at each category.
We start with errors. After briefly revisiting the error-handling idioms for Go, we dive into best practices. Errors can inform developers about something that has gone wrong, and if you do it right, they can also assist in recovering and moving on. Go’s way of working with errors differs from the techniques used in languages such as Python, Java, and Ruby. But when you correctly use these techniques, you can write robust code.
The panic system in Go signals abnormal conditions that may threaten the integrity of a program. Our experience has been that it’s used sporadically, and often reactively, so our focus in this chapter is on making the most of the panic system, especially when it comes to recovering from a panic. You’ll learn when to use panics, how (and when) to recover from them, and how Go’s error and panic mechanisms differ from other languages.
Although Go is occasionally criticized for having a verbose error system, this chapter illustrates why this system is conducive to building better software. By keeping errors at the forefront of the developer’s mind, Go fights against our own cognitive overconfidence bias. We may be disposed to believe that we write bug-free code. But when we always keep error handling front and center, Go gets us used to the idea that we have to code defensively, regardless of how good we think we are.
4.1. Error handling
One of Go’s idioms that often trips up newcomers is its error handling. Many popular languages, including Python, Java, and Ruby, involve a theory of exception handling that includes throwing and catching special exception objects. Others, like C, often use the return value for error handling, and manage the mutated data through pointers.
In lieu of adding exception handlers, the Go creators exploited Go’s ability to return multiple values. The most commonly used Go technique for issuing errors is to return the error as the last value in a return, as shown in the following listing.
Listing 4.1. Returning an error

The Concat function takes any number of strings, concatenates them together (separating the strings with a space character), and then returns the newly joined string. But if no strings are passed into the function, it returns an error.
As Concat illustrates, Go supports variable-length argument lists (varargs). By using the ... prefix before a type, you can tell Go that any number of that type of argument is allowed. Go collapses these into a slice of that type. In listing 4.1, parts will be treated as a []string.
The declaration of the Concat function illustrates the typical pattern for returning errors. In idiomatic Go, the error is always the last return value.
Because errors are always the last value returned, error handling in Go follows a specific pattern. A function that returns an error is wrapped in an if/else statement that checks whether the error value is something other than nil, and handles it if so. The next listing shows a simple program that takes a list of arguments from the command line and concatenates them.
Listing 4.2. Handling an error

If you were to run this code, you’d see output like this:
$ go run error_example.go hello world Concatenated string: 'hello world'
Or, if you didn’t pass any arguments, you’d see the error message:
$ go run error_example.go Error: No strings supplied
Listing 4.2 shows how to use the Concat function you made already, and it illustrates a common Go idiom. As you no doubt recall, Go’s if statement has an optional assignment clause before the expression. The intent is to provide a place to get ready for the evaluation, but stay in the if/else scope. You could read it like this: if GET READY; EVALUATE SOMETHING.
Listing 4.2 shows this technique in action. First, you run Concat(args...), which expands the args array as if you’d called Concat(arg[0], arg[1],...). You assign the two return values to result and err. Then, still on that line, you check to see if err isn’t nil. If err is set to something, you know an error occurred, so you print the error message.
It’s important to note that when you use this two-part if statement, the assignments stay in scope for any else and else if statements, so result is still in scope when you go to print it.
This scoping illustrates why the two-clause if is a nice feature to have. It encourages good memory-management practices while simultaneously preventing that pattern that haunts our debugging nightmares: if a = b.
In listing 4.1, you saw the Concat function, and in listing 4.2 you’ve seen how it’s used. But there’s a technique already present in this example that you should look at explicitly.
Technique 16 Minimize the nils
Nils are annoying for several reasons. They’re a frequent cause of bugs in the system, and we as developers are often forced into a practice of checking values to protect against nils.
In some parts of Go, nils are used to indicate something specific. As you saw in the preceding code, anytime an error return value is nil, you ought to construe that as meaning, specifically, “There were no errors when this function executed.” But in many other cases, the meaning of a nil is unclear. And in perhaps the most annoying cases, nils are treated as placeholders anytime a developer doesn’t feel like returning a value. That’s where this technique comes in.
Problem
Returning nil results along with errors isn’t always the best practice. It puts more work on your library’s users, provides little useful information, and makes recovery harder.
Solution
When it makes sense, avail yourself of Go’s powerful multiple returns and send back not just an error, but also a usable value.
Discussion
This pattern is illustrated in the Concat function you saw previously. Let’s take a second look, focusing on the line where an error is returned.
Listing 4.3. Returning useful data with an error

When an error occurs, both an empty string and an error message are returned. A savvy library user can carefully use the preceding code without having to add a lot of explicit error handling. In our contrived Concat case, returning an empty string makes sense. If you have no data to concatenate, but the return value’s contract says you’ll return a string, an empty string is the kind of thing that one would expect.
Tip
When you’re creating errors, Go has two useful assistive functions. The errors.New function from the errors package is great for creating simple new errors. The fmt.Errorf function in the fmt package gives you the option of using a formatting string on the error message. Go developers use these two functions frequently.
By constructing Concat this way, you’ve done your library users a favor. The savvy library user who doesn’t particularly care about the error case can now streamline the code, as shown in the next listing.
Listing 4.4. Relying on good error handling

Just as before, you take the command-line arguments and pass them to Concat. But when you call Concat, you don’t wrap it in an if statement to handle the error. Because Concat is authored in such a way that it returns a usable value even when an error occurs, and because the presence or absence of the error doesn’t impact the task at hand, you can avoid having to do an extra error check. Instead of wrapping the code in an if/else block, you ignore the error and work with result as a string.
When your context requires you to detect that an error occurred and respond accordingly, this pattern still facilitates that. You can still capture the error value and figure out what went wrong and why, so the pattern of returning both an error and a usable value makes it easier for your library users to write code that best fits their use case.
It’s not always desirable, or even possible, to return non-nil values with every error. If no useful data can be constructed under a failure condition, returning nil may be preferable. The rule of thumb is that if a function can return a useful result when it errs, then it should return one. But if it has nothing useful to return, it should send back nil.
Finally, it’s important for you to make your code’s behavior easily understood by other developers. Go rightly emphasizes writing concise but useful comments atop every shared function. Documenting how your Concat function behaves should look something like the following listing.
Listing 4.5. Documenting returns under error conditions
// Concat concatenates a bunch of strings, separated by spaces.
// It returns an empty string and an error if no strings were passed in.
func Concat(parts ...string) (string, error) {
//...
}
This brief comment follows the Go convention for commenting and makes it clear what happens under normal operation as well as what happens under an error condition.
If you’re coming from a background that involves languages like Java or Python, the error system may at first seem primitive. There are no special try/catch blocks. Instead, convention suggests using if/else statements. Most errors that are returned are often of type error. Developers new to Go sometimes express concern that error handling seems clunky.
Such concerns vanish as developers get used to the Go way of doing things. Go’s favoring of convention over language syntax pays off, as code is simpler to read and write. But we’ve noticed a surprising pattern with Go: whereas languages such as Java and Python favor developing specific error or exception types, Go developers rarely create specific error types.
This is no doubt related to the fact that many Go core libraries use the error type as is. As Go developers see it, most errors have no special attributes that would be better conveyed by a specific error type. Consequently, returning a generic error is the simplest way to handle things. Take, for example, the Concat function. Creating a ConcatError type for that function has no compelling benefit. Instead, you use the built-in errors package to construct a new error.
This simple error handling is often the best practice. But sometimes it can be useful to create and use specific error types.
Technique 17 Custom error types
Go’s error type is an interface that looks like the following listing.
Listing 4.6. The error interface
type error interface {
Error() string
}
Anything that has an Error function returning a string satisfies this interface’s contract. Most of the time, Go developers are satisfied working with errors as the error type. But in some cases, you may want your errors to contain more information than a simple string. In such cases, you may choose to create a custom error type.
Problem
Your function returns an error. Important details regarding this error might lead users of this function to code differently, depending on these details.
Solution
Create a type that implements the error interface but provides additional functionality.
Discussion
Imagine you’re writing a file parser. When the parser encounters a syntax error, it generates an error. Along with having an error message, it’s generally useful to have information about where in the file the error occurred. You could build such an error as shown in the following listing.
Listing 4.7. Parse error
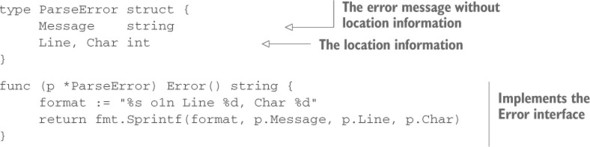
This new ParseError struct has three properties: Message, Line, and Char. You implement the Error function by formatting all three of those pieces of information into one string. But imagine that you want to return to the source of the parse error and display that entire line, perhaps with the trouble-causing character highlighted. The ParseError struct makes that easy to do.
This technique is great when you need to return additional information. But what if you need one function to return different kinds of errors?
Technique 18 Error variables
Sometimes you have a function that performs a complex task and may break in a couple of different, but meaningful, ways. The previous technique showed one way of implementing the error interface, but that method may be a little heavy-handed if each error doesn’t also need additional information. Let’s look at another idiomatic use of Go errors.
Problem
One complex function may encounter more than one kind of error. And it’s useful to users to indicate which kind of error was returned so that the ensuing applications can appropriately handle each error case. But although distinct error conditions may occur, none of them needs extra information (as in technique 17).
Solution
One convention that’s considered good practice in Go (although not in certain other languages) is to create package-scoped error variables that can be returned whenever a certain error occurs. The best example of this in the Go standard library comes in the io package, which contains errors such as io.EOF and io.ErrNoProgress.
Discussion
Before diving into the details of using error variables, let’s consider the problem and one obvious, but not particularly good, solution.
The problem you’d like to solve is being able to tell the difference between two errors. Let’s build a small program in the next listing that simulates sending a simple message to a receiver.
Listing 4.8. Handling two different errors


This listing exemplifies using variables as fixed errors. The code is designed to simulate the basics of a sending function. But instead of sending anything anywhere, the SendRequest function randomly generates a response. The response could be a success or it could be one of our two errors, ErrTimeout or ErrRejected.
One interesting detail of listing 4.7 is found in the randomizer. Because you initialize the randomizer to a fixed value, it’ll always return the same sequence of “random” numbers. This is great for us because you can illustrate a known sequence. But in production applications, you shouldn’t use fixed integers to seed a source. One simple alternative is to use time.Now as a seed source.
Running the preceding program results in the following output:
$ go run two_errors.go Timeout. Retrying. The request was rejected
The first request to SendRequest returns a time-out, and the second call returns a rejection. If the second call had instead returned a time-out too, the program would have continued running until a call to SendRequest returned either a success or a rejection. It’s common to see patterns like this in network servers.
Software developers working in a language such as Java or Python would be likely to implement ErrTimeout and ErrRejected as classes, and then throw new instances of each class. The try/catch pattern used by many languages is built for dealing with error information encapsulated in error types. But as you’ve seen previously, Go doesn’t provide a try/catch block. You could use type matching (especially with a type switch statement) to provide the same functionality. But that’s not the Go way. Instead, idiomatic Go uses a method that’s both more efficient and simpler: create errors as package-scoped variables and reference those variables.
You can see in the preceding code that handling error variables is as simple as checking for equality. If the error is a time-out, you can retry sending the message repeatedly. But when the error is a rejection, you stop processing. And as before, returning a nil indicates that neither error occurs, and you handle that case accordingly. With a pattern like this, the same error variables are used repeatedly. This is efficient because errors are instantiated only once. It’s also conceptually simple. As long as your error doesn’t have special properties (as you saw in technique 16), you can create variables and then work with them as such.
There’s one more facet of error handling that you should look at, and that’s the Go panic.
4.2. The panic system
In addition to the preceding error handling, Go provides a second way of indicating that something is wrong: the panic system. As the name indicates, a panic tells you that something has gone seriously awry. It should be used sparingly and intelligently. In this section, we explain how and when panics should be used and along the way tell you about some of our own failures.
4.2.1. Differentiating panics from errors
The first thing to understand about panics is how they differ conceptually from errors. An error indicates that an event occurred that might violate expectations about what should have happened. A panic, in contrast, indicates that something has gone wrong in such a way that the system (or the immediate subsystem) can’t continue to function.
Go assumes that errors will be handled by you, the programmer. If an error occurs and you ignore it, Go doesn’t do anything on your behalf. Not so with panics. When a panic occurs, Go unwinds the stack, looking for handlers for that panic. If no handler is found, Go eventually unwinds all the way to the top of the function stack and stops the program. An unhandled panic will kill your application.
Let’s look at an example that illustrates this difference in the following listing.
Listing 4.9. Error and panic


Here, you define two functions. The divide function performs a division operation. But it doesn’t handle that one well-known case of dividing by 0. In contrast, the precheckDivide function explicitly checks the divisor and returns an error if the divisor is 0. You’re interested in seeing how Go behaves under these two conditions, so in main you test first with the precheckDivide function and then again with the plain old divide function.
Running this program provides this output:
go run zero_divider.go Divide 1 by 0 Error: Can't divide by zero Divide 2 by 0 panic: runtime error: integer divide by zero [signal 0x8 code=0x7 addr=0x22d8 pc=0x22d8] goroutine 1 [running]: main.main() /Users/mbutcher/Code/go-in-practice/chapter4/zero_divider.go:18 +0x2d8
The first division using precheckDivide returns an error, and the second division causes a panic because you never checked the divisor. Conceptually speaking, the reasons for this are important:
- When you checked the value before dividing, you never introduced the situation where the program was asked to do something it couldn’t.
- When you divided, you caused the system to encounter a state that it couldn’t handle. This is when a panic should occur.
Practically speaking, errors are something that we as developers ought to expect to go wrong. After all, they’re documented in the code. You can glance at the definition of precheckDivide and see an error condition that you need to handle when you call the function. Although an error might represent something outside the norm, we can’t really say that they’re unexpected.
Panics, on the other hand, are unexpected. They occur when a constraint or limitation is unpredictably surpassed. When it comes to declaring a panic in your code, the general rule of thumb is don’t panic unless there’s no clear way to handle the condition within the present context. When possible, return errors instead.
4.2.2. Working with panics
Go developers have expectations about how to correctly panic, though those expectations aren’t always clearly laid out. Before diving into the proper handling of panics, you’ll look at a technique that all Go developers should know when it comes to issuing panics.
Technique 19 Issuing panics
The definition of Go’s panic function can be expressed like this: panic(interface{}). When you call panic, you can give it almost anything as an argument. You can, should you so desire, call panic(nil), as shown in the following listing.
Listing 4.10. Panic with nil

When you run this program, Go captures your panic just fine:
$ go run proper_panic.go
panic: nil
goroutine 1 [running]:
main.main()
/Users/mbutcher/Code/go-in-practice/chapter4/proper_panic.go:4 +0x32
This error isn’t particularly useful. You could instead panic with a string: panic("Oops, I did it again."). Now when you run the code, you’d get this:
$ go run proper_panic.go
panic: Oops, I did it again.
goroutine 1 [running]:
main.main()
/Users/mbutcher/Code/go-in-practice/chapter4/proper_panic.go:4 +0x64
This seems better. At least you have some helpful information. But is this the right thing to do?
Problem
When you raise a panic, what should you pass into the function? Are there ways of panicking that are useful or idiomatic?
Solution
The best thing to pass to a panic is an error. Use the error type to make it easy for the recovery function (if there is one).
Discussion
With a signature that accepts interface{}, it’s not obvious what you’re supposed to pass into a panic. You could give it the object that caused the panic. As you’ve seen, you could give it a string, or a nil, or an error.
The best thing to pass a panic (under normal circumstances, at least) is something that fulfills the error interface. There are two good reasons for this. The first is that it’s intuitive. What sort of thing would cause a panic? An error. It’s reasonable to assume that developers will expect this. The second reason is that it eases handling of a panic. In a moment, you’ll look at recovering from panics. There you’ll see how to take a panic, handle the dire part, and then use the panic’s content as a plain old error.
Given this, the next listing shows the idiomatic way to issue a panic.
Listing 4.11. A proper panic

With this method, it’s still easy to print the panic message with print formatters: fmt.Printf("Error: %s", thePanic). And it’s just as easy to send the panic back through the error system. That’s why it’s idiomatic to pass an error to a panic.
Although we’ve just claimed that the best thing to send a panic is an error, there’s a reason that panics don’t require error types: the panic system is defined to be flexible. In some ways, this is analogous to the way that Java allows Throwables that aren’t necessarily exceptions. A Go panic is one way to unwind the stack.
We’ve never seen particularly credible ways of using panics beyond the technique we’ve described here. But our lack of creativity doesn’t mean that there might not be a useful but non-idiomatic way of creatively passing non-error types to a panic.
Now that you have a firm understanding of how to raise panics, you can turn to the other half of the issue: recovery.
4.2.3. Recovering from panics
Any discussion of panics would be incomplete without a discussion of recovering from panics. Panic recovery in Go depends on a feature of the language called deferred functions. Go has the ability to guarantee the execution of a function at the moment its parent function returns. This happens regardless of whether the reason for the parent function’s return is a return statement, the end of the function block, or a panic. An example in the next listing helps explain this.
Listing 4.12. Simple defer

Without the defer statement, this program would print Goodbye followed by Hello world. But defer modifies the order of execution. It defers executing goodbye until the rest of main has executed. Right as the main function completes, the deferred goodbye function is run. The output of the program is this:
$ go run simple_defer.go Hello world. Goodbye
The defer statement is a great way to close files or sockets when you’re finished, free up resources such as database handles, or handle panics. Technique 19 showed the appropriate strategy for emitting a panic. Now you can take what you know about defer and concentrate for a moment on recovering from panics.
Technique 20 Recovering from panics
Capturing a panic in a deferred function is standard practice in Go. We cover it here for two reasons. First, this discussion is a building block to another technique. Second, it provides the opportunity to take a step from the pattern into the mechanics so you can see what’s happening instead of viewing panics as a formula to be followed.
Problem
A function your application calls is panicking, and as a result your program is crashing.
Solution
Use a deferred function and call recover to find out what happened and handle the panic.
The left side of figure 4.1 illustrates how an unhandled panic will crash your program. The right side illustrates how the recover function can stop the function stack from unwinding and allow the program to continue running.
Figure 4.1. Recovering from a panic

Discussion
Go provides a way of capturing information from a panic and, in so doing, stopping the panic from unwinding the function stack further. The recover function retrieves the data.
Let’s take a look at a small example in the next listing that shows both emitting and handling a panic.
Listing 4.13. Recovering from a panic

This program illustrates what’s probably the most common pattern for panic recovery. To catch the panic that yikes raises, you write a deferred closure function that checks for a panic and recovers if it finds one.
In Go, when you defer a closure, you’re defining a function and then marking it to be called (in this case, with an empty argument list). The general form is defer func(){ /* body */ }(). Note that although it looks like it’s defined and called at once, Go’s runtime won’t call the function until it’s appropriate for a deferred function to execute. In a moment, you’ll see how the separation between defining the closure and then executing it later impacts the scope of the closure in a useful way.
The recover function in Go returns a value (interface{}) if a panic has been raised, but in all other cases it returns nil. The value returned is whatever value was passed into the panic. Running the preceding code returns this:
$ go run recover_panic.go Trapped panic: Something bad happened. (*errors.errorString)
Notice that because you add the %T to the formatting string, you also get information about the type of err, which is the error type created by errors.New.
Now you can take things one step further and look at how to use this closure/recover combination to recover from a panic. Closures inherit the scope of their parent. Deferred closures, like the preceding one, inherit whatever is in scope before they’re declared. For instance, the following listing works fine.
Listing 4.14. Scope for deferred closures

Because msg is defined before the closure, the closure may reference it. And as expected, the value of the message will reflect whatever the state of msg is when the deferred function executes. The preceding code prints Hello world.
But even though defer is executed after the rest of the function, a closure doesn’t have access to variables that are declared after the closure is declared. The closure is evaluated in order, but not executed until the function returns. For that reason, the following listing causes a compile error.
Listing 4.15. msg out of scope

Because msg isn’t declared prior to the deferred function, when the code is evaluated, msg is undefined.
Bringing together the details, you can take one final step in this technique. Let’s look at a slightly more sophisticated use of a deferred function. This one handles a panic and cleans up before returning, and is a good representative sample of how to use deferred functions and recover in practice.
Imagine that you’re writing a piece of code that preprocesses a CSV file, removing empty lines from the beginning. For the sake of boiling this code down to an example, RemoveEmptyLines isn’t fully implemented. Instead, it always returns a panic. With this bad behavior, we can illustrate how to recover from a panic, close the problematic file, and then return an error, as shown in the following listing.
Listing 4.16. Cleanup


Again, the problem in the preceding code is that your RemoveEmptyLines function always panics. If you were to implement this function, it would check to see whether the leading lines of the file were empty, and if they were, it would advance the reader past those lines.
Listing 4.16 uses deferred functions in two places. In the main function, you use a deferred function to ensure that your file is closed. This is considered good practice when you’re working with files, network connections, database handles, and other resources that need to be closed to prevent side effects or leaks. The second deferred function appears inside the OpenCSV function. This deferred function is designed to do three things:
- Trap any panics.
- Make sure that if a panic occurs, the file is closed. This is considered good practice even though in this context it may be redundant.
- Get the error from the panic and pass it back by using the regular error-handling mechanism.
One detail of the declaration of OpenCSV is worth mentioning: we label the return values in the function declaration. That makes it possible to refer to the file and err variables inside the closure, and ensures that when err is set to the panic’s error, the correct value is returned.
As we’ve shown, defer is a powerful and useful way of dealing with panics, as well as reliably cleaning up. As we close out this technique, here are a few useful guidelines for working with deferred functions:
- Put deferred functions as close to the top of a function declaration as possible.
- Simple declarations such as foo := 1 are often placed before deferred functions.
- More-complex variables are declared before deferred functions (var myFile io.Reader), but not initialized until after.
- Although it’s possible to declare multiple deferred functions inside a function, this practice is generally frowned upon.
- Best practices suggest closing files, network connections, and other similar resources inside a defer clause. This ensures that even when errors or panics occur, system resources will be freed.
In the next technique, you’ll take one more step in handling panics and learn how to reliably prevent panics on goroutines from halting a program.
4.2.4. Panics and goroutines
So far, we haven’t talked much about one of Go’s most powerful features: goroutines. You start goroutines by using the go keyword; if you have a function called run, you can start it as a goroutine like this: go run. To quote the Go Programming Language Specification, the go statement “starts the execution of a function call as an independent concurrent thread of control, or goroutine, within the same address space” (http://golang.org/ref/spec#Go_statements). More simply, you can think of it as running a function on its own thread, but without having access to that thread.
The implementation of goroutines is a little more sophisticated than just running a function on its own thread. The Go Concurrency Wiki page (https://github.com/golang/go/wiki/LearnConcurrency) provides a big list of articles that dive into various aspects of Go’s CSP-based concurrency model.
To illustrate this idea, imagine that you have a simple server. The server functions as follows:
- The main function runs start to start a new server.
- The start function processes configuration data and then runs the listen function.
- The listen function opens a network port and listens for new requests. When it gets a request, instead of handling the request itself, it calls go handle, passing on any necessary information to the handle function.
- The handle function processes the request and then calls response.
- The response function sends data back to the client and terminates the connection.
The listener function uses goroutines to handle multiple client connections at once. As it receives requests, it can push the workload onto a number of handle functions, each running in its own space. Variations of this powerful pattern are used frequently in Go server applications. Figure 4.2 illustrates this application and its function stacks when you use goroutines.
Figure 4.2. A simple server

Each row represents a function stack, and each call to go starts a new function stack. Each time listen receives a new request, a new function stack is created for the ensuing handle instance. And whenever handle finishes (for example, when response returns), that spawned goroutine is cleaned up.
Goroutines are powerful and elegant. Because they’re both simple to write and cheap to use (they incur little overhead on your program), Go developers use them frequently. But in one specific (and unfortunately common) situation, the combination of goroutines and panics can result in a program crash.
Technique 21 Trapping panics on goroutines
When handling a panic, the Go runtime unwinds the function stack until a recover occurs. But if it gets to the top of a function stack and recover is never called, the program dies. Recall figure 4.2, which showed how a goroutine gets its own function call stack. What happens when a panic occurs on that goroutine? Take a look at figure 4.3. Imagine that during a request, the response function encounters an unforeseen fatal error and panics. As a good server developer, you’ve added all kinds of error--handling logic to listen. But if you haven’t added anything to handle, the program will crash. Why? Because when a panic is unhandled at the top of a function stack, it causes Go to terminate in an error state. A panic on a goroutine can’t jump to the call stack of the function that initiated the goroutine. There’s no path for a panic to go from handle to listen in this example. This is the problem our current technique focuses on.
Figure 4.3. Crash on a goroutine

Problem
If a panic on a goroutine goes unhandled on that goroutine’s call stack, it crashes the entire program. Sometimes this is acceptable, but often the desired behavior is recovery.
Solution
Simply stated, handle panics on any goroutine that might panic. Our solution will make it easier to design servers that handle panics without relying on panic handling in every single handle function.
Discussion
The interesting thing about this particular problem is that although it’s trivially easy to solve, the solution is repetitive, and often the burden of implementing it is pushed to developers outside your control. First, you’ll look at a basic implementation of the code outlined previously in figure 4.3. From there, you’ll explore the trivial solution and will discover how Go’s idioms make this solution troublesome. Then you’ll see a pattern for solving it more conveniently.
The next listing shows a basic implementation of the kind of server illustrated in figure 4.3. It functions as a basic echo server. When you run it, you can connect to it on port 1026 and send a plain line of text. The remote server will echo that text back to you.
Listing 4.17. An echo server


If you ran this code, it would start a server. You could then interact with the server like this:
$ telnet localhost 1026 Trying ::1... Connected to localhost. Escape character is '^]'. test test Connection closed by foreign host.
When you type test (indicated in bold in the preceding code), the server echoes back that same text and then closes the connection.
This simple server works by listening for new client connections on port 1026. Each time a new connection comes in, the server starts a new goroutine that runs the handle function. Because each request is handled on a separate goroutine, this server can effectively handle numerous concurrent connections.
The handle function reads a line of text (raw bytes) and then passes that line and the connection to the response function. The response function echoes the text back to the client and then closes the connection.
This isn’t exactly an ideal server, but it illustrates the basics. It also shows some pitfalls. Imagine that response could panic. Say you replace the preceding code with the following listing to simulate that situation.
Listing 4.18. Panic in the response
![]()
It might immediately stand out to you that even though the connection is never closed in this situation, things are more worrisome: this panic will crash the server. Servers shouldn’t be so fragile that they crash when one particular request fails. Adding recovery handling to the listen function seems like a natural move. But that won’t help because the goroutine is operating on a separate function stack.
From here, let’s refactor our first pass at a server and make it tolerant. This time you’ll add the panic handling in the handle function. The following listing presents only the handle and response functions; the rest of the code is the same as in listing 4.17.
Listing 4.19. Handle panics on a goroutine

Your new handle function now includes a deferred function that uses recover to see whether a panic has occurred. This stops the panic from propagating up the stack. Notice that you’ve also slightly improved the connection management: you use defer to ensure that in all cases, no matter what happens, the connection is closed when handle is done. With this new revision, the server no longer crashes when response panics.
So far, so good. But you can take this example another step with the Go handler server idiom. It’s common in Go to create a server library that provides a flexible method of handling responses. The "net/http".Server library is a fantastic example of this. As shown earlier in the book, creating an HTTP server in Go is as simple as giving the HTTP system a handler function and starting a server (see the following listing).
Listing 4.20. A small HTTP server

All of the logic for starting and managing a server is within the net/http package. But the package leaves it up to you, the developer, to tell it how to handle a request. In the preceding code, you have an opportunity to pass in a handler function. This is any function that satisfies the following type:
type HandlerFunc func(ResponseWriter, *Request)
Upon receiving a request, the server does much the same as what you did in the earlier echo server architecture: it starts a goroutine and executes the handler function on that thread. What do you suppose would happen if you wrote a handler that panics?
Listing 4.21. A panicky handler
func handler(res http.ResponseWriter, req *http.Request) {
panic(errors.New("Fake panic!"))
}
If you run the server with that code, you’ll find that the server dumps the panic information to the console, but the server keeps running:
2015/04/08 07:57:31 http: panic serving [::1]:51178: Fake panic! goroutine 5 [running]: net/http.func·011() /usr/local/Cellar/go/1.4.1/libexec/src/net/http/server.go:1130 +0xbb main.handler(0x494fd0, 0xc208044000, 0xc208032410) /Users/mbutcher/Code/go-in-practice/chapter4/http_server.go:13 +0xdd net/http.HandlerFunc.ServeHTTP(0x3191e0, 0x494fd0, 0xc208044000, 0xc208032410) ...
But your handler function didn’t do anything to handle the panic! That safety net is provided by the library. With this in mind, if you were to take the echo service and turn it into a well-behaving library, you’d slightly modify your architecture so that panics were handled inside the library.
When we began working with Go in earnest, we wrote a trivial little library (now part of github.com/Masterminds/cookoo) to protect us from accidentally unhandled panics on goroutines. The following listing shows a simplified version of that library.
Listing 4.22. safely.Go

This simple library provides panic handling, so you don’t have to remember to do it on your own. The next listing shows an example of safely.Go in action.
Listing 4.23. Using safely.Go to trap panics

In this example, you define a simple function that satisfies the GoDoer type (it has no parameters and no return value). Then when you call safely.Go(message), it executes your message function in a new goroutine, but with the added benefit of trapping any panics. Because message does panic, running this program provides the following output:
$ go run safely_example.go Outside goroutine Inside goroutine 2015/04/08 08:28:00 Panic in safely.Go: Oops!
Instead of the panic stopping the program execution, safely.Go traps and logs the panic message.
Instead of using a named function such as message, you could use a closure. A closure allows you to access variables that are in scope, and can be used to sidestep the fact that GoDoer doesn’t accept any parameters. But if you do this, beware of race conditions and other concurrency issues!
This particular library might not suit your exact needs, but it illustrates a good practice: construct libraries so that a panic on a goroutine doesn’t have the surprising or unintended result of halting your program.
Go’s provision of both an error-handling system and a runtime panic system is elegant. But as you’ve seen in this section, panics tend to arise in surprising situations. If you forget to plan for them, you can find yourself mired in difficult debugging situations. That’s why we’ve spent so much time discussing remedial techniques here—and why we suggest preventative no-brainer techniques like safely.Go instead of relying on developers to remember to do the right thing.
4.3. Summary
Let’s be honest: there’s nothing glamorous about error handling. But we firmly believe that one of the traits that distinguishes a good programmer from a great programmer is the way the developer writes error-handling code. Great programmers are mindful of protecting the system against bugs and failures.
That’s why we spent an entire chapter covering the details of the error and panic systems in Go, and providing techniques for handling common situations. We showed you best practices for providing meaningful data with errors and how such techniques extend to issuing panics. And we wrapped up with a long look at panics and goroutines. We covered these topics:
- Understanding Go’s patterns for error handling
- Using error variables
- Adding custom error types
- Properly using and handling panics
- Using error handling on goroutines
As you move into the next chapters, you’ll visit other code-quality topics such as logging and writing tests. Taken together, we believe that these tools equip you to be a highly successful (dare we say, great) Go developer.