
Once you've optimized Solr running on a single server, and reached the point of diminishing returns for optimizing further, the next step is to shard your single index over multiple Solr nodes, and then share the querying load over many Solr nodes. The ability to scale wide is a hallmark of modern scalable Internet systems, and Solr shares this.
Arguably the biggest feature in Solr 4, SolrCloud provides a self-managing cluster of Solr servers (also known as nodes) to meet your scaling and near real-time search demands. SolrCloud is conceptually quite simple, and setting it up to test is fairly straightforward. The challenge typically is keeping all of the moving pieces in sync over time as your data set grows and you add and remove nodes.
Note
What about master/slave replication?
In the past years, our data volumes were small enough that we could store all our data in a single index, and use a master/slave replication process to create many copies of our index to deal with query volume, at the cost of introducing more latency to the update process. SolrCloud, however, deals with the twin problems of massive data volumes that require sharding to support them, and minimizing latency to support near real-time search.
SolrCloud uses Apache ZooKeeper to keep your nodes coordinated and to host most of the configuration files needed by Solr and your collections. ZooKeeper is not unique to Solr; other projects such as Apache Hadoop and Kafka use it too. ZooKeeper is responsible for sharing the configuration information and, critically, the state of the cluster's nodes. SolrCloud uses that state to intelligently route index and search requests around the cluster. ZooKeeper is a compact piece of server software installed on a few of the hosts in your cluster, although you can use an embedded version that ships with Solr for development. You don't want to use embedded ZooKeeper in production because if you take down a Solr node that is running ZooKeeper, then you might also paralyze your SolrCloud cluster if the number of ZooKeeper nodes falls below a quorum. See more about ZooKeeper in Chapter 11, Deployment.
This new way of managing Solr clusters comes with some new and modified terminology. Let's take a look at the terms you'll need to understand.
The first step in learning SolrCloud is understanding the subtle changes to the definition of terms we've used with Solr in the past. For example, cores and shards were often treated as interchangeable in simple Solr installations. In SolrCloud, they live on two separate tiers of the architecture; one represents a logical concept while the other represents a physical container for data.
We've broken down our SolrCloud terms by layer. Collections and shards comprise the logical layer. The physical layer contains the implementation details that make the logical layer possible such as cores, leaders, replicas, and clusters.
Now, let's look at a diagram of how these various components map to each other:
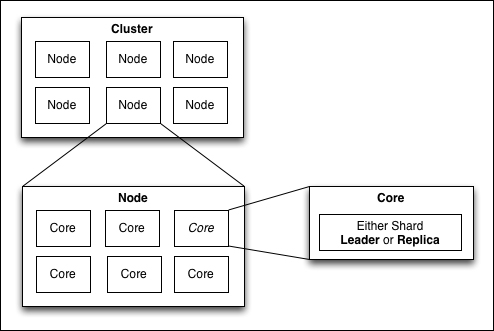
Physical tier of SolrCloud
We can leverage the techniques covered in Chapter 11, Deployment, to host SolrCloud but we'll also need to include a few arguments to Java, as well as planning a strategy for running ZooKeeper.
At minimum the zkHost system property will need to be included and should contain a list of ZooKeeper URIs separated with a semicolon. These URIs will almost always include the port that ZooKeeper is running on. The root key for this specific cluster is sometimes included as well when a ZooKeeper instance is shared by multiple SolrClouds.
Here's an example of launching Solr from a command prompt with two ZooKeeper hosts named zk1.example.com and zk2.example.com:
>> java -DzkHost=zk1.example.com:2181;zk2.example.com:2181 …
Note that this command will throw an error if none of the ZooKeeper hosts listed here are alive and responding to requests, or if you haven't created a configuration for your collection in ZooKeeper already.
The simplest way around these requirements is passing the bootstrap_conf and zkRun parameters. Note that neither of these are recommended for a production cluster. The zkRun parameter causes Solr to start an embedded instance of ZooKeeper and the bootstrap_conf parameter requires that the node have its own copy of the configuration files for the collection. These options might be useful for a trivial or learning implementation, but might interfere with availability and manageability for all but the smallest clusters.
Tip
As a general rule, keep your Solr startup parameters for each node as simple as possible. Anything that can be managed by the collections API or ZooKeeper (both discussed later) should not be included in the launch config for individual nodes. A good node configuration might just include the zkHost parameter and any required JVM tuning settings. Most SolrCloud tutorials outside of this book will have you clearly violating our advice, but we recommend sticking to this, even when getting started. Otherwise, it confuses collection configuration with Solr startup—things that should have nothing to do with each other.
"Apache ZooKeeper is a centralized network service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.", as defined on ZooKeeper's website. A simpler way to understand it, as seen by a developer is, that it appears as a distributed in-memory filesystem. It was designed specifically to help manage the data about a distributed application, and to be clustered and highly available in the face of inevitable failures. The index data does not go in ZooKeeper.
As mentioned earlier, we don't want to rely on the bootstrap_conf option when we are launching nodes. So the first thing we need to do with ZooKeeper is upload the configuration for one of our collections. The SolrCloud documentation includes a great example of how to create a configuration. We'll include it here for convenience.
This next set of examples is based on the all-in-one SolrCloud script in ./examples/10/start-musicbrainz-solrcloud.sh. When you run the script it will:
- Download the Solr distribution from the book website.
- Unpack it and copy it multiple times, once for each node you want to start up.
- Load, using the following command line, the
mbtypesgeneral purpose configuration into ZooKeeper:>> java -classpath example/solr-webapp/WEB-INF/lib/* org.apache.solr.cloud.ZkCLI -cmd upconfig -zkhost localhost:2181 -confdir configsets/mbtype/conf -confname mbtypes -solrhome example/solr - Start up multiple separate Solr processes. The first one runs on port 8983, the subsequent ones start on port 8985,8986, and so on.
Eventually, you will want to update the configuration files in SolrCloud. We recommended keeping these files in some type of source control system such as Git or SVN; that way anyone can check them out and make adjustments. Once changes have been made, they will need to be posted back to ZooKeeper using the same upconfig command we saw earlier.
If you'd like finer control, you can post individual files or even arbitrary data to be treated like a configuration file as well as deleting, linking, and even bootstrapping multiple configuration sets. See the Solr Command Line Utilities documentation at https://cwiki.apache.org/confluence/display/solr/Command+Line+Utilities for specifics.
So let's start up SolrCloud for our MusicBrainz dataset that we have played with in previous chapters. We've provided an example script that downloads Solr, unpacks it, and runs as many servers as you want. I recommend 2 to 4 nodes on a typical multicore laptop.
Under /examples/10, run the script to stand up your SolrCloud nodes:
>>./start-musicbrainz-solrcloud.sh 2 2
Refresh the Admin Cloud Graph view and you will have something like the following diagram:
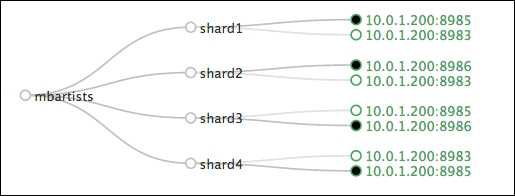
The script takes two parameters, the number of nodes you want and the number of shards for your default index, called collection1. This script is heavily influenced by the /cloud-dev scripts that are in the Solr source tree, a resource worth looking at.
Once the script has downloaded Solr and fired up the various Solr nodes, pull up the Cloud admin panel, and you will see the default collection1 created. As part of the script, it loaded the mbtype configuration files into ZooKeeper. You can see them listed under /configs in the Tree view. Inspect the shell script to see the exact command we used to upload the configuration files to ZooKeeper.
To monitor the progress of the various nodes, you can easily tail the logs:
>> tail -f solrcloud-working-dir/example*/example*.log
To create the collections, just call the collections API:
>> curl 'http://localhost:8983/solr/admin/collections?action=CREATE&name=mbartists&numShards=2&replicationFactor=1&maxShardsPerNode=2&collection.configName=mbtypes'
Once the command finishes, refresh the cloud view in the Solr admin. Play with the numShards, replicationFactor, and maxShardsPerNode settings, to visually get a sense of how SolrCloud distributes shards. Go big, try numShards of 8, replicationFactor of 4, and maxShardsPerNode of 30 to see the possibilities of SolrCloud.
Once you have the configuration you want, back up to /examples and reindex the MusicBrainz data:
>> ant index:mbartists
In my experiments, even running all the nodes on my local laptop, the time to index the mbartists dataset dropped by 25 percent due to the sharding of the dataset over multiple processes compared to not using SolrCloud.
When you create a collection, you specify the degree to which its documents are replicated (copied) and sharded (divided) using the replicationFactor and numShards parameters, respectively.
The number of shards tells SolrCloud how many different logical slices the documents are to be divided into. Each additional shard improves indexing performance and usually increases query performance. Each search will internally be a distributed search among the shards. If a collection has too many shards, there will be diminishing returns due to coordinating and merging so many requests.
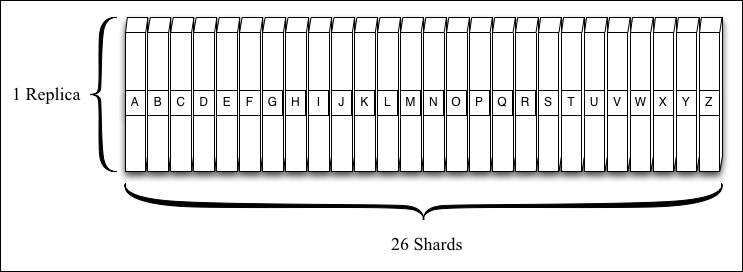
One way to think about the number of shards versus the replication factor is to imagine you are ordering a set of encyclopedias to share with your family. In this example, we'll say each volume in the encyclopedia set is a shard containing a number of articles (that is, Solr documents). We'll assume one volume per letter in the alphabet, so numShards=26. This keeps each volume small enough that it's easy to read and we don't need to "scale up" our desk or bookshelf. And for our first illustrated example, we'll use a replicationFactor of 1—just one copy of the data. In SolrCloud terms, each physical volume is the only replica (also known as core) for its shard since the replicationFactor is 1. If I want to read or "update" the entry for Antelope, I'll need the "A" volume.
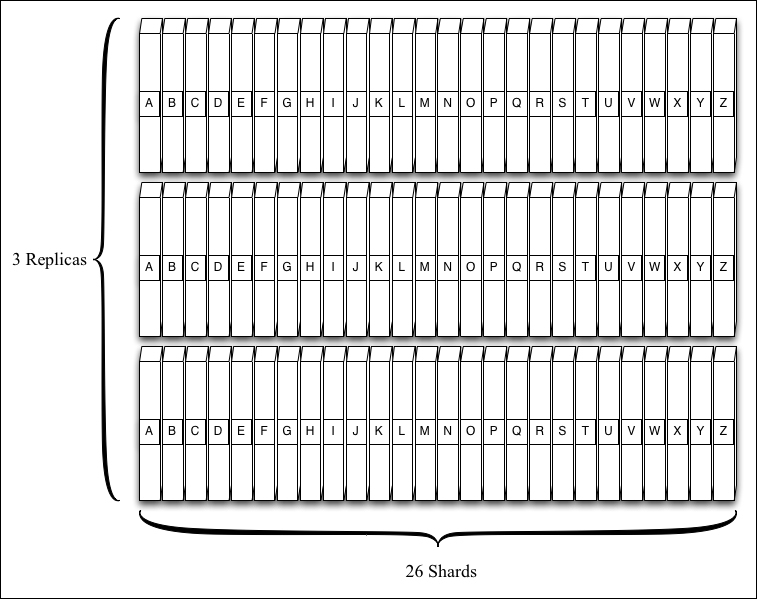
If we were buying encyclopedias for a local library, we might find that the volume of requests was high enough that people were lingering by the shelves waiting for a volume to become free (note that Solr isn't going to queue the requests but replicas will slow down if overwhelmed with concurrent load). Assuming we have plenty of room on our shelves, we could order two more sets of the same encyclopedia; now we have a numShards of 26 and a replicationFactor of 3. Even more importantly, this means if one of the replicas were to become corrupt or if a library patron loses a copy, the library now has other copies and it can replicate them when needed. We have durability now.
Collections are managed using the collections or core admin APIs—RESTful APIs invoked via simple URLs. This is a big difference compared to pre-SolrCloud approaches in which you usually pre-position cores where Solr expects to see them or refer to them in solr.xml. Just send a request to the collections API on any node in our cluster, and SolrCloud will manage that change across all the nodes.
Assuming you have started a SolrCloud cluster using ./examples/10/start-musicbrainz-solrcloud.sh, then to add a new collection named musicbrainz with data split into 4 shards, each with 2 replicas (8 cores total), we run:
>> curl 'http://localhost:8983/solr/admin/collections?action=CREATE&name=musicbrainz&numShards=4&replicationFactor=2&collection.configName=mbtype'
A few other parameters the CREATE action accepts are as follows:
collection.configName: This allows you to specify which named configuration to use for the collection if it doesn't have the same name as the collection. The configuration must be uploaded into ZooKeeper before creating the collection.createNodeSet: This takes a comma-separated list of nodes, and limits the new collection to only those nodes. It lets you deploy a collection on a subset of SolrCloud nodes. It becomes more important if you are deploying many collections on a single SolrCloud cluster, and want to make sure you are controlling the distribution of load across the cluster. SolrCloud doesn't know which nodes are heavily taxed and which are not, or which nodes are on the same rack when it provisions replicas, but you can tell it where to provision them.maxShardsPerNode: This sets the maximum number of shards that a node supporting this collection can contain. The preceding example needs 8 cores across the cluster, which will default to requiring 8 nodes. SettingmaxShardsPerNode=4will only require 2 nodes; each one will be hosting 4 replicas. SolrCloud is smart enough to divide the shards evenly among the available nodes to reduce single-points-of-failure when that's possible. Furthermore, you should generally have at least as many CPU cores on these nodes as there are Solr cores since each search will result in one concurrent search thread per shard.
Each shard has one or more copies of itself in the cloud at any point in time. SolrCloud will strive to make sure that each shard has a number of replicas at least equal to the replicationFactor specified for that collection. Any of these replicas can be used during a search query.
Update queries must be handled by a leader for that shard. Leaders are responsible for managing changes to all the documents in their shard. At any given time there will be exactly one leader for a given shard. Imagine, if, instead of encyclopedias like in the precious example, we were keeping a list of all the telephone numbers for people in a company. We could break that list up by department (sharding) as well as making a copy for each person in that department (replication). Then we appoint one person in each department to keep the list up to date and send updated copies to everyone else. If they leave, we appoint someone else to the job. The leaders in SolrCloud operate the same way. For each shard/department in our analogy, we appoint one node to process all changes for that shard. If that node disappears, a new leader is elected.
If a client issues an update to any node in the cloud, it will be automatically routed to the leader for the appropriate shard. While this is very efficient, it's worth noting that the SolrJ library takes an even more efficient route. The CloudSolrServer SolrJ client connects to the ZooKeeper server, and is able to always send requests to the node that's acting as the leader for a shard without routing through a middleman.
Out of the box, SolrCloud uses a hash of the document's IDs to determine which shard it belongs to. Most of the time, this is fine; it will result in equal shard sizing. However, sometimes you need more control over which documents are colocated. For example, if you are using result grouping (also known as field collapsing), then all documents in the same group must be on the same shard. And to optimize search over huge collections, you can sometimes identify useful groupings of the documents that you keep together on certain shards such that when you do a search you can sometimes specify a subset of the shards to search. There are a couple options that SolrCloud has beyond the default.
The primary option is enabled by what's called the compositeId router—the default mechanism a collection uses. Basically, you tell SolrCloud what piece of data in a document it should take the hash on to determine which shard it belongs to. There are two ways to do this: by configuring the collection to use a certain field via router.field (a parameter supplied when creating the collection) which has this data, or by prefixing the ID with the data using ! as a delimiter. If you use router.field, then the specified field is now required. As an example, if we had a set of products in our search index that could be easily categorized into departments, we could use the department instead of the ID to control sharding without adjusting the configuration. Provide the department as a prefix to the document ID, separated by ! (for example, "housewares!12345"). Later, if we know a user is searching within that specific department, we can limit the query to only that shard by passing _route_=housewares in our search query. This can greatly increase search speed on a large index, and in some cases may help improve relevancy precision.
>> curl http://localhost:8983/solr/collection1/select?collection=collection1&_route_=housewares
The other option is to use the
implicit router, otherwise known as
manual sharding. It's used when the desired mapping of documents to shards doesn't match the preceding description. For example, what if all your data is time-stamped (like Twitter tweets or log data) and you only want to keep the last year of data on an on-going basis. The most efficient way to do this is to divide the past year into shards, perhaps by month, and then when a new month starts, you simply remove the oldest shard (month) and you add a new one. This is really fast since only one shard is being indexed to. To use the implicit router, you create the collection without specifying numShards (not very intuitive, ehh?). When in this mode, your indexing client is responsible for sending the document to the correct shard; Solr won't route it.
As of Solr 4.3.1, you can split a shard into two smaller shards, even while indexing and searching—this is a very important feature. Over the life of a collection, you may need to split your shards to maintain search performance as the size of the index grows. If you customized how documents are routed, some specific shards may be larger or receive more traffic and thus might need to be split without necessarily splitting the others.
After SolrCloud finishes the split, the old shard will still exist but be in an inactive state, so you'll want to delete it afterwards. Sending the following command to any SolrCloud node will result in shard1 being split and replaced with shard1_0 and shard1_1:
>> curl 'http://localhost:8983/solr/admin/collections?action=SPLITSHARD&collection=mbartists&shard=shard1'
Now check that it finished successfully. When it has, delete the original shard:
>> curl 'http://localhost:8983/solr/admin/collections?action=DELETESHARD&collection=mbartists&shard=shard1'
Added in Solr 4.8 is the ability to submit long running tasks in an asynchronous mode. For example, splitting a shard or creating a collection that is highly sharded and has many replicas may take a long time. To support this, just supply the async parameter with a unique ID that you want to refer the operation by. Let's create a collection asynchronously:
>> curl 'http://localhost:8983/solr/admin/collections? action=CREATE&name=massive_sharding&numShards=6&replicationFactor=6&maxShardsPerNode=40&collection.configName=mbtype&async=99'
The async=99 parameter is determined by you, and needs to track this operation. The response will come back immediately, and then you can check the status by using a REQUESTSTATUS command:
>> curl 'http://localhost:8983/solr/admin/collections? Action=REQUESTSTATUS&requestid=99'
Oddly enough, the parameter is called async when you create it, and requestid when you go back to look it up. It will give you status information; however, if the operation is failing, you might not get the same level of debugging. For example, if you try to create a collection with the same name as an existing collection, the REQUESTSTATUS command just tells you that the command failed.
To clear out the history of requests, call REQUESTSTATUS with a requestid of -1:
>> curl 'http://localhost:8983/solr/admin/collections? Action=REQUESTSTATUS&requestid=-1'
New nodes can be added to SolrCloud at anytime just by launching Solr and providing the zkHost parameter that points to your ZooKeeper ensemble:
>> java -DzkHost=zk1.example.com:2181
This new node will then become available to host replicas for any of the collections registered with ZooKeeper. You can then use the ADDREPLICA command to create new replicas that are hosted by the newly added node. To add a new node to our MusicBrainz cluster, run the script ./examples/10/add-musicbrainz-node.sh and pass in an unused port number for Jetty:
>>./add-musicbrainz-nodes.sh 8989
Then you can add more replicas using the following code:
>> curl 'http://localhost:8983/solr/admin/collections? Action=ADDREPLICA&collection=mbartists&shard=shard2&node=10.0.1.200:8989_solr'
Notice that the node name is a very specific pattern. It is the name that is assigned to it when the node joined ZooKeeper, and you can find it listed in the Cloud Tree view under /live_nodes. When you add a new replica, it will start, using replication under the covers, to copy all the data from the leader to the newly added replica. Refresh the Cloud Graph view and you will see the node go from Recovering to Active state.