
This book has so far introduced scraping techniques using a custom website, which helped us focus on learning particular skills. Now, in this chapter, we will analyze a variety of real-world websites to show how these techniques can be applied. Firstly, we will use Google to show a real-world search form, then Facebook for a JavaScript-dependent website, Gap for a typical online store, and finally, BMW for a map interface. Since these are live websites, there is a risk that they will have changed by the time you read this. However, this is fine because the purpose of these examples is to show you how the techniques learned so far can be applied, rather than to show you how to scrape a particular website. If you choose to run an example, first check whether the website structure has changed since these examples were made and whether their current terms and conditions prohibit scraping.
According to the Alexa data used in Chapter 4, Concurrent Downloading, google.com is the world's most popular website, and conveniently, its structure is simple and straightforward to scrape.
Note
International Google
Google may redirect to a country-specific version, depending on your location. To use a consistent Google search wherever you are in the world, the international English version of Google can be loaded at http://www.google.com/ncr. Here, ncr stands for no country redirect.
Here is the Google search homepage loaded with Firebug to inspect the form:
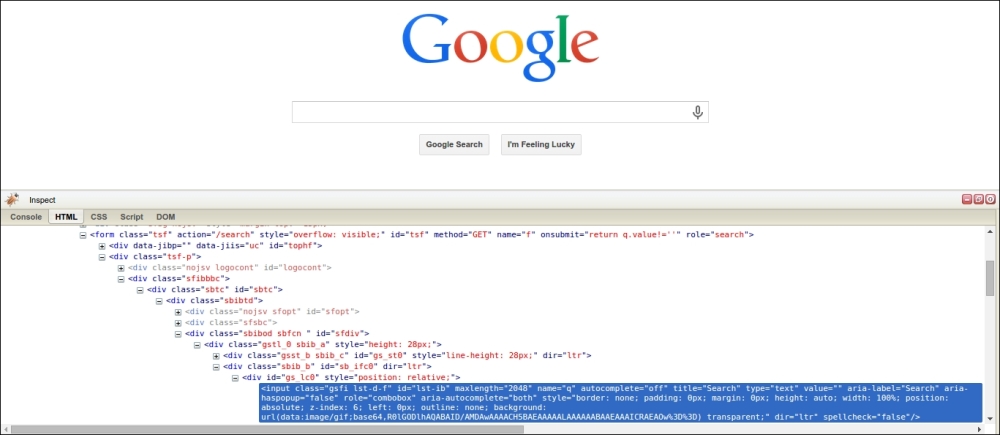
We can see here that the search query is stored in an input with name q, and then the form is submitted to the path /search set by the action attribute. We can test this by doing a test search to submit the form, which would then be redirected to a URL like https://www.google.com/searchq=test&oq=test&es_sm=93&ie=UTF-8. The exact URL will depend on your browser and location. Also note that if you have Google Instant enabled, AJAX will be used to load the search results dynamically rather than submitting the form. This URL has many parameters but the only one required is q for the query. The URL https://www.google.com/search?q=test will produce the same result, as shown in this screenshot:

The structure of the search results can be examined with Firebug, as shown here:
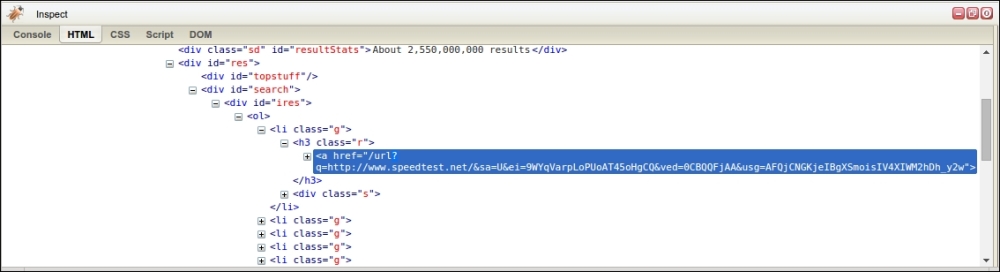
Here, we see that the search results are structured as links whose parent element is a <h3> tag of class "r". To scrape the search results we will use a CSS selector, which were introduced in Chapter 2, Scraping the Data:
>>> import lxml.html
>>> from downloader import Downloader
>>> D = Downloader()
>>> html = D('https://www.google.com/search?q=test')
>>> tree = lxml.html.fromstring(html)
>>> results = tree.cssselect('h3.r a')
>>> results
[<Element a at 0x7f3d9affeaf8>,
<Element a at 0x7f3d9affe890>,
<Element a at 0x7f3d9affe8e8>,
<Element a at 0x7f3d9affeaa0>,
<Element a at 0x7f3d9b1a9e68>,
<Element a at 0x7f3d9b1a9c58>,
<Element a at 0x7f3d9b1a9ec0>,
<Element a at 0x7f3d9b1a9f18>,
<Element a at 0x7f3d9b1a9f70>,
<Element a at 0x7f3d9b1a9fc8>]So far, we downloaded the Google search results and used lxml to extract the links. In the preceding screenshot, the link includes a bunch of extra parameters alongside the actual website URL, which are used for tracking clicks. Here is the first link:
>>> link = results[0].get('href')
>>> link
'/url?q=http://www.speedtest.net/&sa=U&ei=nmgqVbgCw&ved=0CB&usg=ACA_cA'The content we want here is http://www.speedtest.net/, which can be parsed from the query string using the urlparse module:
>>> import urlparse
>>> qs = urlparse.urlparse(link).query
>>> urlparse.parse_qs(qs)
{'q': ['http://www.speedtest.net/'],
'ei': ['nmgqVbgCw'],
'sa': ['U'],
'usg': ['ACA_cA'],
'ved': ['0CB']}
>>> urlparse.parse_qs(qs).get('q', [])
['http://www.speedtest.net/']This query string parsing can be applied to extract all links.
>>> links = []
>>> for result in results:
... link = result.get('href')
... qs = urlparse.urlparse(link).query
... links.extend(urlparse.parse_qs(qs).get('q', []))
...
>>> links
['http://www.speedtest.net/',
'https://www.test.com/',
'http://www.tested.com/',
'http://www.speakeasy.net/speedtest/',
'http://www.humanmetrics.com/cgi-win/jtypes2.asp',
'http://en.wikipedia.org/wiki/Test_cricket',
'https://html5test.com/',
'http://www.16personalities.com/free-personality-test',
'https://www.google.com/webmasters/tools/mobile-friendly/',
'http://speedtest.comcast.net/']Success! The links from this Google search have been successfully scraped. The full source for this example is available at https://bitbucket.org/wswp/code/src/tip/chapter09/google.py.
One difficulty with Google is that a CAPTCHA image will be shown if your IP appears suspicious, for example, when downloading too fast.
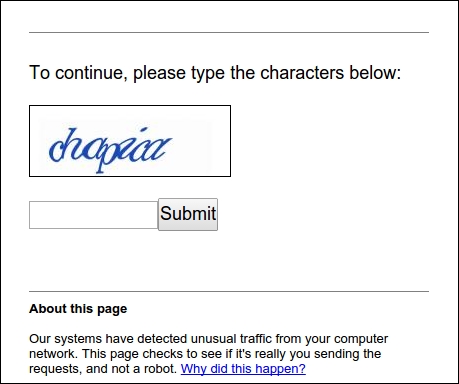
This CAPTCHA image could be solved using the techniques covered in Chapter 7, Solving CAPTCHA, though it would be preferable to avoid suspicion and download slowly, or use proxies if a faster download rate is required.