
This section of the chapter will cover the scenario where a number of OSDs may have gone offline in a short period of time, leaving some objects with no valid replica copies. It's important to note that there is a difference between an object that has no remaining copies and an object that has a remaining copy, but it is known that another copy has had more recent writes. The latter is normally seen when running the cluster with min_size set to 1.
To demonstrate how to recover an object that has an out-of-date copy of data, let's perform a series of steps to break the cluster:
- First, let's set min_size to 1; hopefully by the end of this example, you will see why you don't ever want to do this in real life:
sudo ceph osd pool set rbd min_size 1
![]()
- Create a test object that we will make later make Ceph believe is lost:
sudo rados -p rbd put lost_object logo.png
sudo ceph osd set norecover
sudo ceph osd set nobackfill
These two flags make sure that when the OSDS come back online after making the write to a single OSD, the changes are not recovered. Since we are only testing with a single option, we need these flags to simulate the condition in real life, where it's likely that not all objects can be recovered in sufficient time before the OSD, when the only copy goes offline for whatever reason.
- Shut down two of the OSD nodes, so only one OSD is remaining. Since we have set min_size to 1, we will still be able to write data to the cluster. You can see that the Ceph status shows that the two OSDS are now down:

- Now, write to the object again, the write will go to the remaining OSD:
sudo rados -p rbd put lost_object logo.png
- Now, shut down the remaining OSDS; once it has gone offline, power back the remaining 2 OSDS:

You can see that Ceph knows that it already has an unfound object even before the recovery process has started. This is because during the peering phase, the PG containing the modified object knows that the only valid copy is on osd.0 ,which is now offline.
- Remove the nobackfill and norecover flags, and let the cluster try and and perform recovery. You will see that even after the recovery has progressed, there will be 1 PG in a degraded state, and the unfound object warning will still be present. This is a good thing, as Ceph is protecting your data from corruption. Imagine what would happen if a 4 MB chunk of an RBD containing a database suddenly went back in time!
If you try and read or write to our test object, you will notice the request will just hang; this is Ceph again protecting your data. There are three ways to fix this problem. The first solution and the most ideal one is to get a valid copy of this object back online; this could either be done by bringing osd.0 online, or by using the objectstore tool to export and import this object into a healthy OSD. But for the purpose of this section, let's assume that neither of those options is possible. Before we cover the remaining two options, let's investigate further to try and uncover what is going on under-the-hood.
Run the Ceph health detail to find out which PG is having the problem:

In this case, it's pg 0.31 ,which is in a degraded state, because it has an unfound object. Let's query the pg:
ceph pg 0.31 query

Look for the recovery section; we can see that Ceph has tried to probe "osd": "0" for the object, but it is down. It has tried to probe "osd": "1" for the object, but for whatever reason it was of no use, we know the reason is that it is an out-of-date copy.
Now, let's look into some more detail on the missing object:
sudo ceph pg 0.31 list_missing
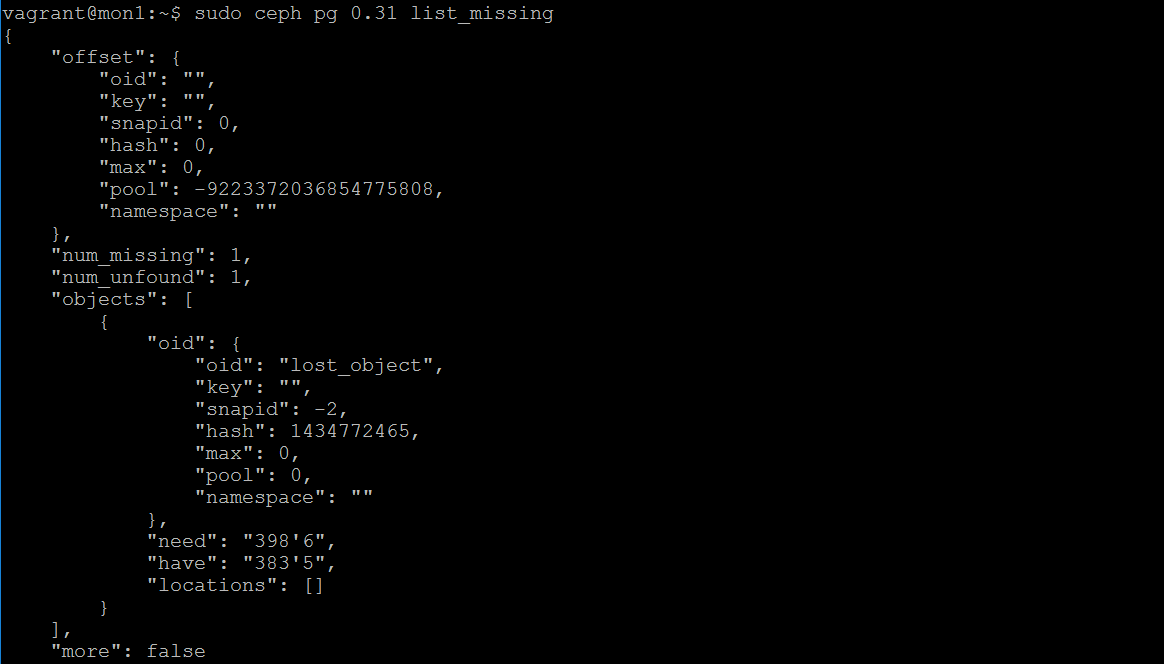
The need and have lines reveal the reason. We have epoch 383'5 ,but the valid copy of the object exists in 398'6; this is why min_size=1 is bad. You might be in a situation where you only have a single valid copy of an object. If this was caused by a disk failure, you would have bigger problems.
To recover from this, we have two options: we can either choose to use the older copy of the object or simply delete it. It should be noted that if this object is new and an older copy does not exist on the remaining OSDS, then it will also delete the object.
To delete the object, run this:
ceph pg 0.31 mark_unfound_lost delete
To revert it, run this:
ceph pg 0.31 mark_unfound_lost revert
This concludes recovering from unfound objects.