
Internally, Salesforce stores Standard Object's field data and custom field data for a given record in two separate physical Oracle tables. So, while you don't see it, when you execute a SOQL query to return a mixture of both standard and custom fields, this internally requires an Oracle SQL query, which requires an internal database join to be made.
If Salesforce Support determines that avoiding this join would speed up a given set of queries, they can create a skinny table. Such a table is not visible to the Force.com developer and is kept in sync with your object records automatically by the platform, including any standard or custom indexes.
A skinny table can contain commonly used standard and custom fields that you, the subscriber, and Salesforce deem appropriate, all in the one Oracle table, thus, it avoids the join (all at the internal cost of duplicating the record data). If a SOQL, Report, or List View query utilizes the fields or a subset, the platform will automatically use the skinny table instead of the join to improve performance. As an additional benefit, the record size needed internally is smaller, which means that the data bandwidth used to move chunks of records around the platform can be better utilized.
This is obviously quite an advanced feature of the platform, but worth considering as an additional means to improve query performance in a subscriber org.
Note
Skinny tables are not kept in sync if you change field types or add new fields to the corresponding object in the Force.com world. Also, they are not replicated in sandbox environments. So, you or your subscriber will need to contact Salesforce Support again each time these types of changes occur. Also note that skinny tables cannot be packaged; they are configurations only for subscriber orgs.
In most cases within Apex, it is only possible to read up to 50,000 records, regardless of whether they are read individually or as part of forming an aggregate query result. There is, however, a context parameter that can be applied that will allow an unlimited number of records to be read. However, this context does not permit any database updates. In this section, we will review the following three ways in which you can manage large datasets:
- Processing 50k maximum result sets in Apex
- Processing unlimited result sets in Apex
- Processing unlimited result sets via the Salesforce APIs
One of the problems with reading 50,000 records is that you run the risk of hitting other governors, such as the heap governor, which, although increased in an async context, can still be hit depending on the processing being performed. Take a look at the following contrived example to generate attachments on each Race Data record:
List<Attachment> attachments = new List<Attachment>();
for(RaceData__c raceData : [select Id from RaceData__c])
attachments.add(
new Attachment(
Name = 'Some Attachment',
ParentId = raceData.Id,
Body = Blob.valueOf('Some Text'.repeat(1000))));
insert attachments;If you try to execute the preceding code from an Execute Anonymous window, you will receive the following error, as the code quickly hits the 6 MB heap size limit:
System.LimitException: Apex heap size too large: 6022466
The solution to this problem is to utilize what is known as SOQL FOR LOOP (as follows); it allows the record data to be returned to the Apex code in chunks of 200 records so that not all the Attachment records will build up on the heap:
for(List<RaceData__c> raceDataChunk : [select Id from RaceData__c]) {
List<Attachment> attachments = new List<Attachment>();
for(RaceData__c raceData : raceDataChunk)
attachments.add(
new Attachment(
Name = 'Some Attachment',
ParentId = raceData.Id,
Body = Blob.valueOf('Some Text'.repeat(1000))));
insert attachments;
}Once this code completes, it will have generated over 80 MB of attachment data in one execution context! Note that, in doing so, the preceding code does technically break a bulkification rule, in that there is a DML statement contained within the outer chunking loop. For 10,000 records split over 200 record chunks, this will result in 50 chunks, and thus, this will consume 50 out of the available 150 DML statements. In this case, the end justifies the means, so this is just something to be mindful of.
In this section, a new Race Analysis page is created to allow the user to view results of various calculations and simulations applied dynamically to selected Race Data. Ultimately, imagine that the page allows the user to input adjustments and other parameters to apply to the calculations and replay the race data to see how the race might have finished differently.
For the purposes of this chapter, we are focusing on querying the Race Data object only. The standard row limits 50,000 records (approximately 5 races' worth of data) to be returned from the SOQL query. The following changes have been made to the FormulaForce application to deliver this page and are present in the code samples associated with this chapter if you wish to deploy them:
- A new
analyizeDatamethod on theRaceServiceclass has been added. - The
RaceDataSelectorclass has been created to encapsulate the query logic. RaceAnalysisControllerhas been created for the Visualforce page.- The
raceanalysisVisualforce page has been created. - A new Race Analysis list Custom Button has been added to the
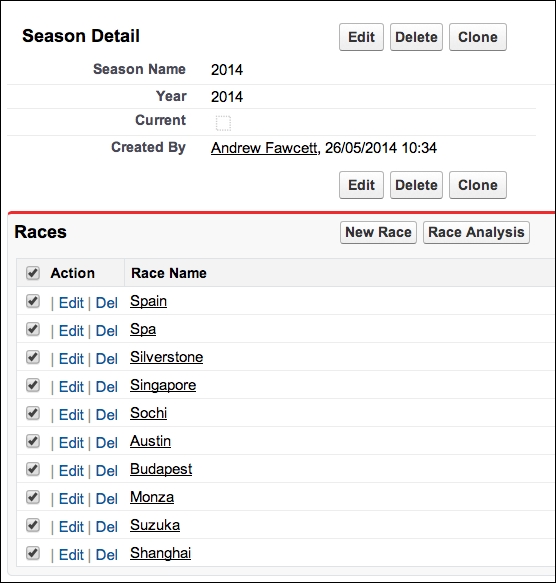
Race__cobject. This button has been added to the list related to Races on the Season detail page.
The user can now select one or more Race records from the related list to process as follows:
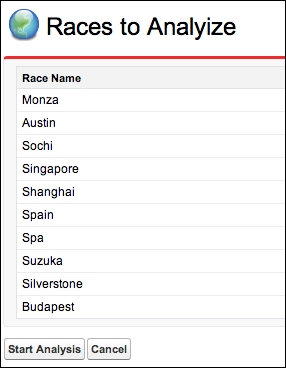
The next display provides a confirmation of the selected races before starting the calculations. This button invokes the RaceService.analyizeData method and attempts to query the applicable RaceData__c records.
To demonstrate how it is possible to read more than 50,000 records, we will need to generate some more Race Data. To do this, we can rerun a portion of the script we ran earlier in this chapter to generate up to 100,000 records (which will nearly fill a Partner Portal Developer Edition org).
From an Anonymous Apex prompt, execute the following Apex code for each race; this should result in 100,000 records in the Race Data object (which you can verify through the Data Storage page under Setup):
TestData.createVolumeData(2017, 'Monza', 52, 4);
Run the preceding code again a further eight times, each time changing the name of the race to Austin, Sochi, Singapore, Shanghai, Spa, Suzuka, Silverstone, and Budapest (note that Race Data for Spain was generated earlier).
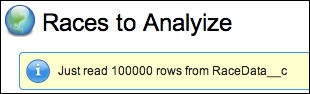
The Start Analysis button calls the service to query the race data analyze the data and for the purposes of this chapter, it outputs the total number of queried rows as follows:
ApexPages.addMessage(
new ApexPages.Message(
ApexPages.Severity.Info,
'Just read ' + Limits.getQueryRows() + ' rows from RaceData__c'));As per the previous screenshot, select all 10 races (click on the Show 5 more link to show more related list records). Click on the Start Analysis button to display a message, confirming the number of records processed is above the standard 50,000.
The reason this has been made possible is due to the Visualforce page enabling the read-only mode, via the readOnly attribute on the apex:page element, as follows:
<apex:page
standardController="Race__c"
extensions="RaceAnalysisController"
recordSetVar="Races"
readOnly="true">
This mode can also be enabled via the @ReadOnly Apex attribute on an Apex scheduled class or on an Apex Remote Action method. As the name suggests, the downside is that there can be no DML statements, so we have no means to update the database. For this use case, this restriction is not a problem. Note that, by using JavaScript Remoting, you can create a mix of methods with and without @ReadOnly. Currently this attribute cannot be used in conjunction with @AuraEnabled.
Tip
Note that, in this mode, other governors are still active, such as heap and CPU timeout. You might also want to consider combining this mode with the SOQL FOR LOOP approach described earlier. Also, the SOQL Aggregate queries will benefit from this (as these also count against the SOQL query rows governor).
Salesforce does not limit the maximum number of rows that can be queried when using the Salesforce SOAP and REST APIs to retrieve record data, as in these contexts, the resources consuming and processing the resulting record data are off-platform.
One consideration to keep in mind, however, is the daily API limits—although you can read unlimited data, it is still chunked from the Salesforce servers and retrieving each chunk will consume an API call. Although less friendly, the Salesforce Bulk API is more efficient at retrieving more records while using less API calls to the Salesforce servers.