
The second type of index for memory-optimized tables is the hash index. An array of pointers is created, with each element in the array representing a single value—this element is known as a hash bucket. The index key column of a table which should have a hash index created on it has a hashing function applied to it, and the resulting hash value is used to bucketize rows. Values that generate the same hash value are stored in the same hash bucket as a linked chain of values. To access this data, we pass in the key value we wish to search for, this value is also hashed to determine which hash bucket should be accessed, and the hash index translates the hash value to the pointer and allows us to retrieve all the duplicate values in a chain.
In the following diagram, we can see a very simplified representation of the hashing and retrieval of data. The row header has been removed for clarity's sake:
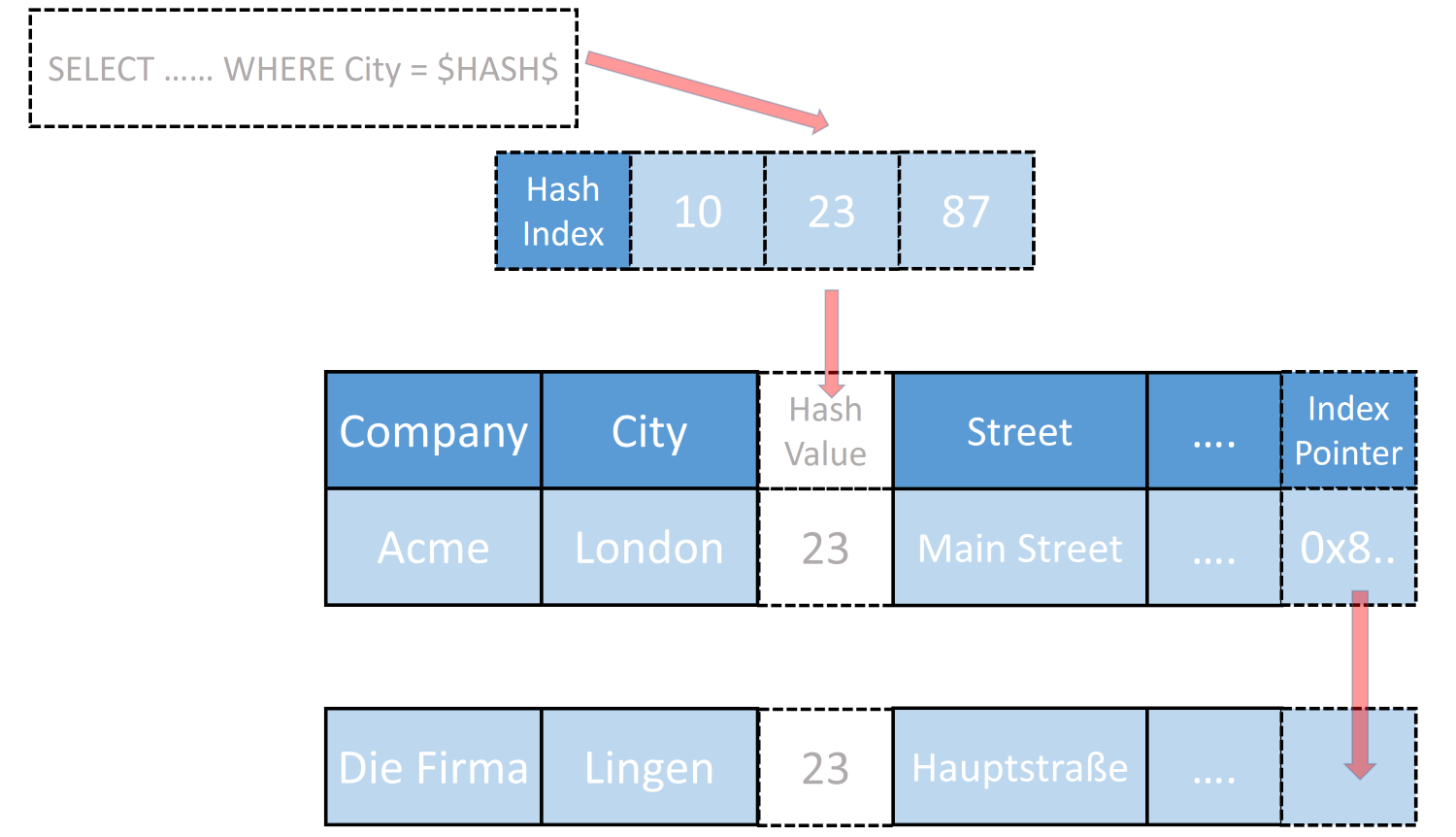
In the preceding figure, we can see a table storing company address information. We are interested in the City column, which is the key for a hash index. If we were to insert a value of London into this hash index, we would get a value, 23 (the hash function is simplified here for illustration purposes). This stores the key value London and the memory address of the table row of the memory-optimized table. If we then insert the second row with a city value of Lingen and our hash function hashes Lingen to 23 too, then this will be added to the hash index in the hash bucket for the value 23 and added to the chain started with London. Each hash index on a memory-optimized table adds an index pointer column (shown here with a dashed outline). This is an internal column that is used to store the pointer information for the next row in the chain. Every row of a chain has a pointer to the next row, bar the last row, which can have no following chain row. When no pointer is in this column, the retrieval routine knows it has reached the end of the chain and can stop loading rows.
The creation of a hash index requires some thought. We have seen that we can have multiple values that hash to the same hash value, which creates chains of records. However, the idea of a hashing function is to try and keep these chains as short as possible. An optimal hash index will have enough hash buckets to store as many unique values as possible, but has as few buckets as possible to reduce the overhead of maintaining these buckets (more buckets = more memory consumption for the index). Having more buckets than is necessary will also not improve performance, but rather hinder it, as each additional bucket makes a scan of the buckets slower. We must decide how many buckets to create when we initially create the index, which we will see with a sample script shortly. It is also important to realize that the hash index and hashing function considers all key columns of an index we create, so a multi-column index raises the chances that hash values will be unique and can require more hash buckets to assist with keeping these buckets emptier.