
7
Cloud Integration
We have covered a pretty broad range of high-level integration topics in the previous chapter. This chapter will delve into the cloud integration scenarios, design examples, and the tools you can use to build integration artifacts.
We have already discussed the philosophy behind integration, why it is crucial, and how to tackle the complexity of managing integration in a hybrid and heterogeneous landscape. Therefore, to avoid repetition, it will suffice to refer to the previous chapter to read such content.
It’s now time to roll up our sleeves and move on to the practical side. We will adjust the detail level for architects in general so that they can grasp the essential information to incorporate integration services into their architecture designs. So, the content does not provide step-by-step details for building integration; instead, we will discuss topics from an architectural perspective.
As you may remember from the previous chapter, we have several integration styles and patterns. For the sake of maintaining focus, we will cover design discussions under cloud integration and data integration headings. The next chapter is specific to data integration, and in this chapter, we will cover several other integration styles. This includes cross-use cases that leverage different architecture styles to fulfill similar integration requirements, such as API-based integrations and event-driven integrations. This means that we will be talking about the capabilities under SAP Integration Suite, which will help you design architectures including A2A, B2B, and B2G integration use cases. In addition, we will also cover other integration-related SAP BTP services.
In this chapter, we’re going to cover the following main topics:
- Designing application integration scenarios
- API-based integration
- Simplified connectivity with third-party applications
- Event-driven integration
- Master data integration
We will provide design examples in the last section to make things more tangible. So, bear with us until the end of the chapter.
Technical requirements
The simplest way to try out the examples in this chapter is to get a trial SAP BTP account or an account with a free tier, as described in the Technical requirements section of Chapter 3, Establishing the Foundation for SAP Business Technology Platform.
Designing application integration scenarios
Suppose you have already established an integration methodology. In this case, for a given scenario, you have done a big part of designing your integration simply because you will build on top of an integration pattern prescribed by your methodology.
We will start with designing typical process integration scenarios that can be implemented using the Cloud Integration capability of SAP Integration Suite.
As you may remember from our previous discussions, standards and protocols are crucial for integration, as they reduce complexity. There are several of them, and the more your integration platform supports, the better coverage you have for efficiently resolving integration challenges. Leveraging these together with the transformation, mediation, and orchestration capabilities, you can formulate and build integration flows.
Anatomy of an integration flow
An integration flow is designed to process the message that traverses Cloud Integration. You can add operators called steps to your integration flow to define how it will process the message.
These steps can do the following:
- Transform the message content
- Convert between different formats
- Call external components to enrich message content
- Persist messages
- Apply security operations
An integration process consists of several of these steps. In an integration flow, there is one main integration process. In addition, you can create local integration processes, which can be used as subprocesses for modularization, and exception subprocesses, which can take control of the flow to handle exceptions.
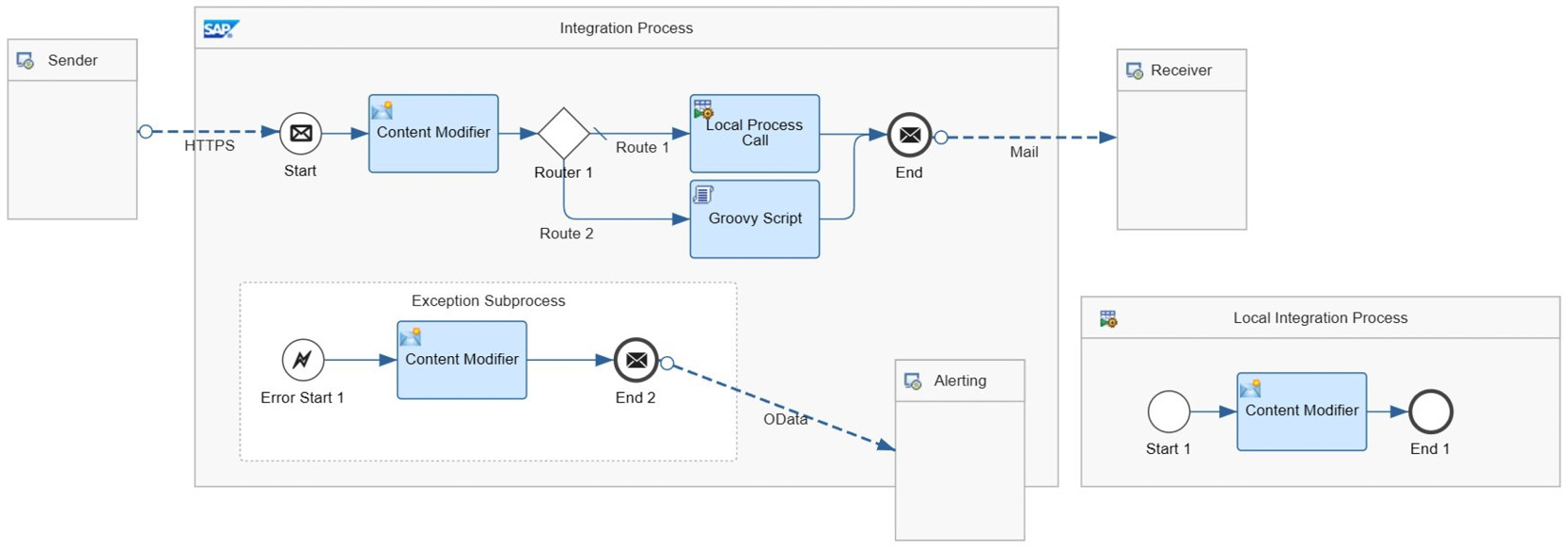
Figure 7.1: An integration flow designed in SAP Integration Suite’s Cloud Integration
Figure 7.1 shows an example of an integration flow. You can see the main integration process in the middle, which contains an Exception Subprocess and many integration steps. At the bottom right, there is a Local Integration Process.
Apart from integration processes and steps, there are two types of other elements in an integration flow:
- On the left, the integration flow has a Sender, representing the application that sends the message. Checking the arrow originating from the sender, we can see the incoming message is received using HTTPS protocol.
- Finally, there are two Receiver components. The upper one is the default destination, and by checking the arrow ending in that receiver, we can say the outgoing message is sent as an email. The receiver below (labeled as Alerting) seems to be placed for exception management where the exception subprocessor sends a message to another (alerting) application using OData protocol.
Sender and Receiver configuration is mainly based on the adapter type that is assigned to the connection and defines the communication format and parameters. Cloud Integration supports several out-of-the-box adapters that enable communication with virtually any system. These include technical adapters such as HTTPS, OData, SOAP, XI, IDoc, RFC, JDBC, JMS, SFTP, Kafka, AMQP, and Mail, as well as application adapters such as Ariba, SuccessFactors, AWS, Facebook, Twitter, Salesforce, and ServiceNow. You can also develop your custom adapters using the Adapter Development Kit (ADK).
Message processing
In its simplest form, Cloud Integration functions as a message transformer and router between systems, enabling message exchange between them:
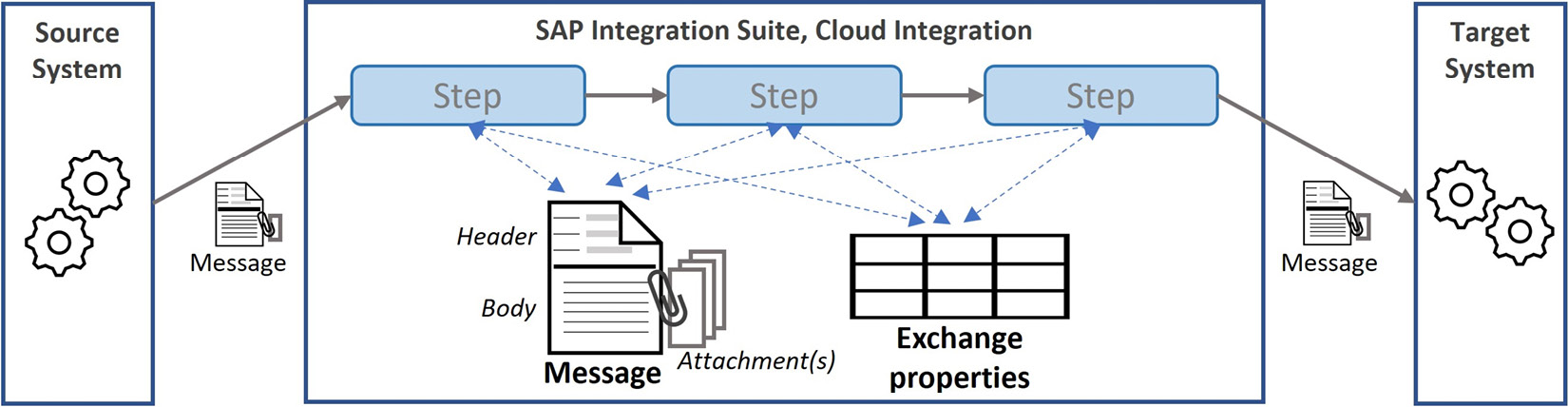
Figure 7.2: Basic message processing
As shown in Figure 7.2, the Message received from the sender system is handled through multiple integration process steps. Here, during the runtime of the message processing, the steps can modify data in the message Header and Body. With supporting adapters, it is also possible to handle attachments. In addition, the steps can create or delete transient data as Exchange properties in a key-value model. This provides a data container for the runtime session. The integration flow can maintain data in these properties without modifying the message. This is convenient when dealing with transient data that the target systems should not receive. As you can see in the figure, the only output of the integration flow is the message.
Step types
Considering the scope of this book, let’s have a brief look at the possible step types that can be used in integration flows. We will discuss persistence and message security step types under their specific sections. The other step types can be grouped as follows:
- Events: An integration flow has start and end events marking the beginning and termination of the integration processes or the entire flow. With different end events, you can set the final status of an integration flow. When the integration flow ends for certain adapter types, such as HTTPS, the processed message is also sent to the sender system as the response.
In terms of start events, there are three main options. Typically, an integration flow is triggered by a message appropriately received by Cloud Integration. Secondly, for certain adapter types, such as SFTP and Mail, the connection needs to be configured with a scheduler so that Cloud Integration can poll the source system to retrieve integration content, such as files and emails. Finally, an integration can contain a start timer event that triggers the integration flow regarding the configured schedule.
- Mappings: Integration between two systems quite often requires a mapping to be defined between the data structures of source and destination systems. With this step type, you can define the rules for mapping by matching message structure fields, using predefined functions, and creating custom scripts. A mapping can be stored so that it can be reused in multiple flows.
- Transformations: Cloud Integration provides several options for transforming integration content. With Content Modifier, you can add or remove message headers and exchange properties. Besides this, you can modify the message body. With Converters, you can convert the message body into different formats, such as CSV, XML, JSON, and EDI. With encoders and decoders, you can encode or decode messages, compress them, or use MIME Multipart encoder/decoder to handle messages with attachments. There are more step types that you can use for transforming the message body content. Finally, you can write your custom scripts in Groovy or JavaScript to handle complex transformation requirements.
- Calls: You can use external call steps to make calls to external systems. You can then optionally use the response of the external system when processing the message of the integration flow. On the other hand, you can use local call steps to call local integration processes. As you may remember, these are modularization units to separate reusable process parts for reducing complexity. You can also make local calls in a loop.
- Routing: With these steps, you can create different processing branches, route the flow through one branch based on conditions, multicast the same message, split the message into smaller messages, and gather or join them together after branching.
- Validators: As a convenience of working with standard formats, an integration flow can include steps to validate messages, such as XML validation against an XML schema or an EDI message against an EDI schema.
Persistence
As mentioned previously, Cloud Integration is primarily designed to process messages as it receives them and to complete the flow in a single runtime instance. However, some integration scenarios may require persisting messages or relevant information, and Cloud Integration provides capabilities to address these sophisticated use cases.
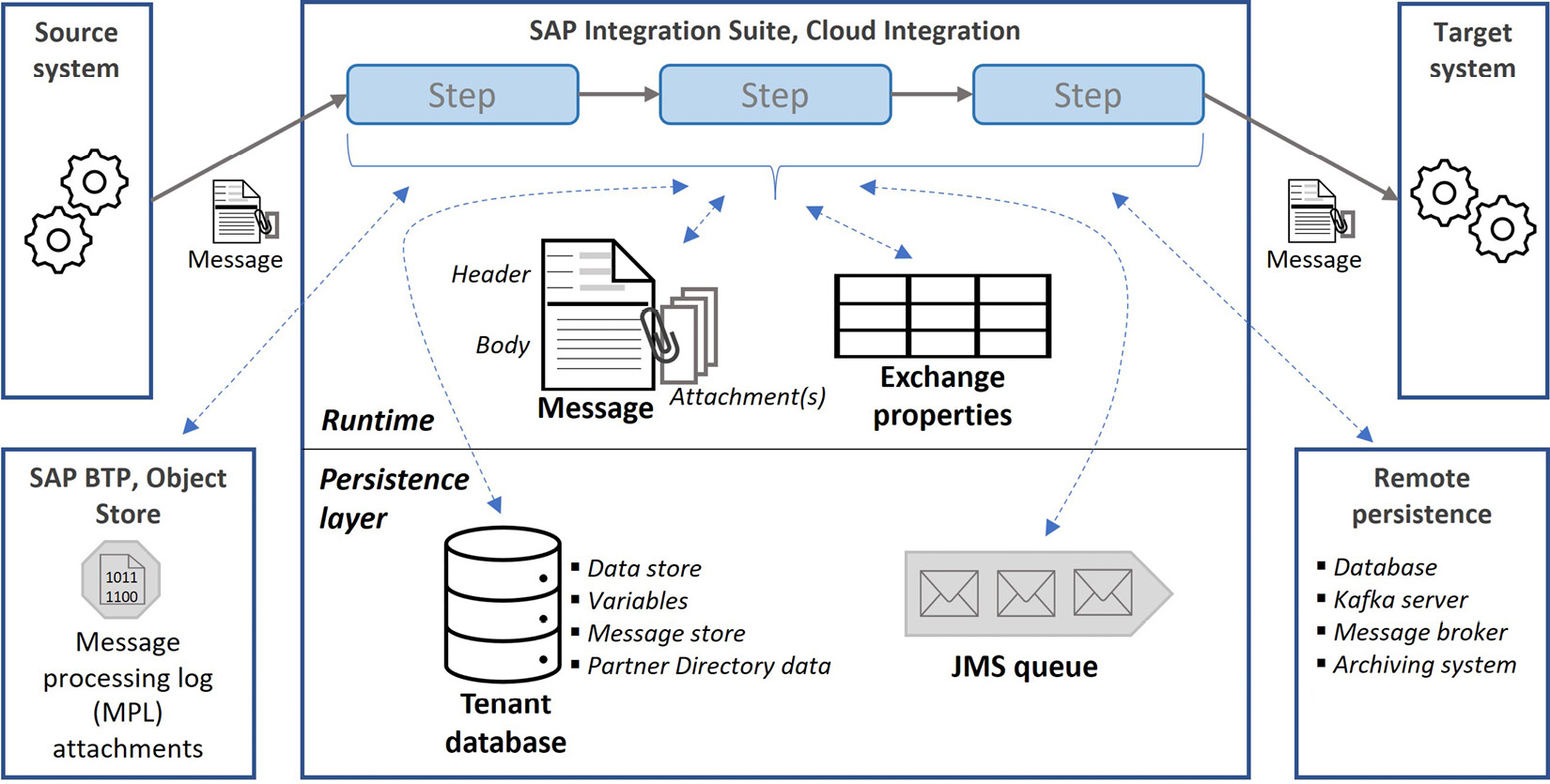
Figure 7.3: Message processing with persistence options
Figure 7.3 extends the illustration of message processing by also showing the persistence options. For complex requirements, you can always store data in remote persistence options such as an external database, a Kafka server, or a message broker. For simpler use cases, you can use the internal storage options. Within the Cloud Integration tenant, there are two main containers: Tenant database and Java Messaging Service (JMS) queues.
Tenant database
For typical data storage scenarios, you can persist data in the tenant database. You do not have direct access to the database. Here, you can store message parts in the data store, individual values as variables, and persist message bodies in the message store. Data stored in the data store or as variables can be set to have global or local visibility.
You may ask how data store and message store are different if they both store messages. Let us see how:
- In the data store, you can store messages and retrieve them to use in an integration flow when required. There is also a user interface for managing the data store content. This is a great convenience when data needs to be shared between two different flows or two executions of the same flow.
- On the other hand, a message in the message store can only be accessed after the integration flow that persisted the message is complete. The only way to access messages in the message store is by using Cloud Integration APIs. Perhaps you already understood the primary use of the message store. It’s mainly for purposes such as auditing, where you need to store a snapshot of a message.
The tenant database also stores other data that is used by the Cloud Integration capability, including the Partner Directory entries managed for B2C integration artifacts. The message processing log (MPL) attachments are not stored in the tenant database; instead, they are persisted in an SAP BTP Object Store service instance.
JMS queues
If the persistence requirement fits a message queue use case, such as asynchronous decoupling, you can use JMS queues, the second main form of data container in Cloud Integration. In fact, you can also use the data store for asynchronous decoupling. However, JMS queues are specifically built for this use case and provides extra features such as retrying message processing in case of failure. JMS queues support high-volume message processing; however, the data in the queue cannot be consumed multiple times due to the nature of queue processing. Although it is an internal component, JMS queues are incorporated into integration flows with specific sender and receiver adapters. This way, it’s possible that data written to a queue can start the execution of listening flows.
Message security
As expected from an enterprise-grade integration platform, Cloud Integration supports security at several levels.
For data in transit, you can use the supported adapters for secure protocols, such as HTTPS and SFTP. For data at rest, you have the encryption option to store data in data stores, message stores, and JMS queues.
Suppose your integration scenario requires processing encrypted messages. In that case, you can use the encryptor and decryptor steps that support PGP and PKCS7/CMS encryption. In addition, certain adapters, such as Mail and SOAP, support specific encryption capabilities.
You can enable authentication and RBAC measures for the execution of integration flows so that only authorized senders can trigger execution. Here, you have the options of basic authentication, OAuth 2.0, and client certificate authentication. As you would expect, basic authentication is not recommended for production use cases. The sender’s authorization is checked through verification of whether the sender is using credentials of a runtime service instance that has the role defined by the integration flow. When forwarding the message to the receiver system with certain adapter types, such as SOAP, OData, HTTP, and XI, principal propagation is an option for authentication at the receiver side and lets the user context be sent to the receiver application. If you would like to refresh your memory about principal propagation, check out the relevant section in Chapter 4, Security and Connectivity.
For HTTP-based sender adapters, Cloud Integration supports cross-site request forgery (CSRF) protection to guard the communication against CSRF attacks. This is also valid for some HTTP-based receiver adapters, such as OData, and for others, the flow can be designed to include a CSRF protection mechanism.
For some integration scenarios, you may need to incorporate security materials, such as OAuth 2.0 credentials, passwords, Pretty Good Privacy (PGP) keyrings, and certificates in your flow design. Cloud Integration provides a secure store to keep these safely outside integration flows. After they are defined, integration flows can use these security materials by referring to this secure store.
Finally, let’s remind ourselves of other security measures we discussed in Chapter 4, Security and Connectivity. You can enable the malware scanner at the tenant level for scanning the design-time artifacts. The tenant infrastructure complies with relevant standards, and finally, certain security events are logged for auditing purposes.
Performance and capacity
Keep in mind that your Cloud Integration tenant has limited resources, for example, a 32 GB tenant database capacity in total. Therefore, it applies data retention rules, which means the data stored in the persistence layer gets deleted after a certain time period.
With limited resources, it’s best to take necessary measures to use the available resources efficiently. For example, we can do the following:
- Restrict payload sizes
- Use pagination
- Schedule the flows reasonably
For instance, encrypting messages without a proper justification will adversely impact the overall performance of the flow execution.
If your persistence requirements exceed the capacity that Cloud Integration can offer or if it is for permanent storage, you can consider persisting data in remote storage.
Custom scripts can become blind spots, causing performance degradation. So, remember that you should use the flexibility offered by custom scripts wisely.
Finally, let’s touch upon a special adapter, the ProcessDirect adapter, which you should use for flow-to-flow communication instead of calling flows through the internet. This eliminates unnecessary network latency and is useful when designing your integration scenario across multiple flows.
Delivery procedure
Suppose you are given the business requirements for an integration scenario. What is the next thing to do to deliver the solution? You may remember some hints for answering this question from the previous chapter. Surely, we will refer to the integration strategy and methodology that sets the foundation of your integration delivery.
Similarly, you may remember SAP API Business Hub from this previous chapter. SAP API Business Hub contains prebuilt integration content that you can use to implement your integration scenarios in an accelerated way. This part of SAP API Business Hub is also embedded in the Discover section of the Cloud Integration tenants. Browsing this catalog of integration content, you can find prebuilt artifacts that you can copy to your tenant.
The available integration content is included in integration packages, which are containers for integration artifacts for a certain scenario. Cloud Integration also uses integration packages as an administrative unit to organize content. SAP API Business Hub integration packages come in two modes. A configure-only integration package does not allow you to change the package content; instead, it provides you with a set of parameters so that you can configure, deploy, and run the integration flow in a standard way. On the other hand, an editable integration package allows you to edit the content.
If you copy a configure-only or an editable integration package and use it as-is after configuration, you will get updates from SAP to apply automatically or manually. With editable integration packages, you no longer receive updates if you edit them. For some integration flows, SAP provides customer exits, at which point the standard flow can call a custom flow that extends its logic. This way, you do not touch the standard content while incorporating custom elements.
Important Note
When you use prebuilt integration content without modification to integrate two SAP solutions you own, the messages running through that integration flow are free of charge. As this is a commercial matter, we suggest you check terms and conditions with SAP.
As we mentioned configure-only packages, let’s talk about externalization, a powerful feature you can use in your custom integration flows. With externalization, you abstract a set of integration configuration elements of a flow and link them to parameters that can be defined differently in different instances. This is mainly useful when you need to configure dissimilar configuration values for the same flow in different tenants, for example, in test and production.
When you copy standard integration content, you can configure or edit it in the Design section of Cloud Integration. Here, you can create custom integration artifacts, too.
After designing your integration flow, the simplest way to test it, or part of it, is using the simulation feature. By using simulation, you can debug your flow and fix problems.
An essential prerequisite for running your integration flow with actual sender and receiver systems is establishing the connectivity, especially when on-premise systems are involved. You may need to make firewall changes, outbound proxy allow listing, set up SAP Cloud Connector, and put in place security arrangements such as key exchanges. Furthermore, you may need to configure the participant systems to enable the integration mechanism at the application layer. For example, you need to maintain communication systems, users, and arrangements in SAP S/4HANA Cloud for running integration scenarios.
For transporting your integration content across tenants, for example, from a test tenant to a production tenant, you have several options. The simplest way is exporting the content as a file from the source tenant and then importing this file to the target tenant. However, this is error-prone and adds administration overhead; hence, it should only be used in exceptional cases.
On the other hand, you can link your tenant to an automated transport mechanism. This can be the Enhanced Change and Transport System (CTS+) on SAP NetWeaver ABAP if your mainstream change delivery mechanism is on-premise orientated. Alternatively, you can use the SAP BTP Transport Management Service (TMS) for cloud-based automated change delivery. In order to use these fully automated options, you also need to subscribe to the Content Agent Service on SAP BTP. This service helps manage transportable content. As the last option, you can download integration content as Multi-Target Application Archive (MTAR) files to manually feed them to CTS+ or TMS.
We recommend using one of the automated transport mechanisms. If you already have CTS+, you should use it. Based on your plans for transitioning to the cloud, you should establish the TMS option when you are ready. In order to decouple integration configuration elements from a specific tenant, you can use externalization, as we discussed previously. One last thing to keep in mind is that all the transport mechanisms will only transport the core integration content. You need to handle elements such as security materials and connectivity arrangements separately.
You can monitor your integration flows and access operational features in the Monitor section of Cloud Integration. For extensive observability options, you can go back to the Observability section in the previous chapter.
Finally, you can use the B2B Scenarios section of Cloud Integration, which constitutes the Trading Partner Management (TPM) capability of Integration Suite.
So, we have covered a lot about A2A cloud integration where SAP Integration Suite can function as the integration platform for transformation, orchestration, and mediation requirements. In the following section, we will discuss how the API Management (APIM) capability of SAP Integration Suite can cater to API-based cross-use case integration scenarios.
API-based integration
Application Programming Interfaces (APIs) are at the heart of digital transformation, enabling the agility and openness required for rapidly interconnecting solutions. After all, they constitute a facet for data to be exposed and consumed between different layers of an enterprise’s IT estate, or between applications of different entities. Therefore, a crucial design principle for APIs is to reduce complexity for the sake of convenience while acting as a contract between the provider and the consumer. This is similar to your mobile phone hiding the complexity of an entire telecommunications mechanism behind a simple call button. When using your mobile phone, you abide by the implicit contract and use this interface to make the call.
Considering the significant role of APIs, it is inevitable for a provider to have a control layer between the APIs and their consumers. This is why APIM solutions emerged in the IT world. This gatekeeping layer controls access to the APIs and then unlocks a further functionality tier for metering and monetization.
You can use SAP APIM to secure, manage, and govern your APIs through its governance structure, policy framework, and end-to-end API lifecycle management tools. Now, let’s dig a little deeper into explaining how SAP APIM works.
SAP APIM elements
The design-time elements of SAP APIM are managed in two parts. First, in the API Portal, you define the core runtime elements. The second part of SAP APIM is API Business Hub Enterprise, previously known as the Developer Portal. The resemblance of the name to SAP API Business Hub gives away the function of this part. API Business Hub Enterprise provides a platform to other developers where they can register themselves to discover the APIs you expose. After that, they can subscribe to API products with application subscriptions that allow them to consume your APIs.
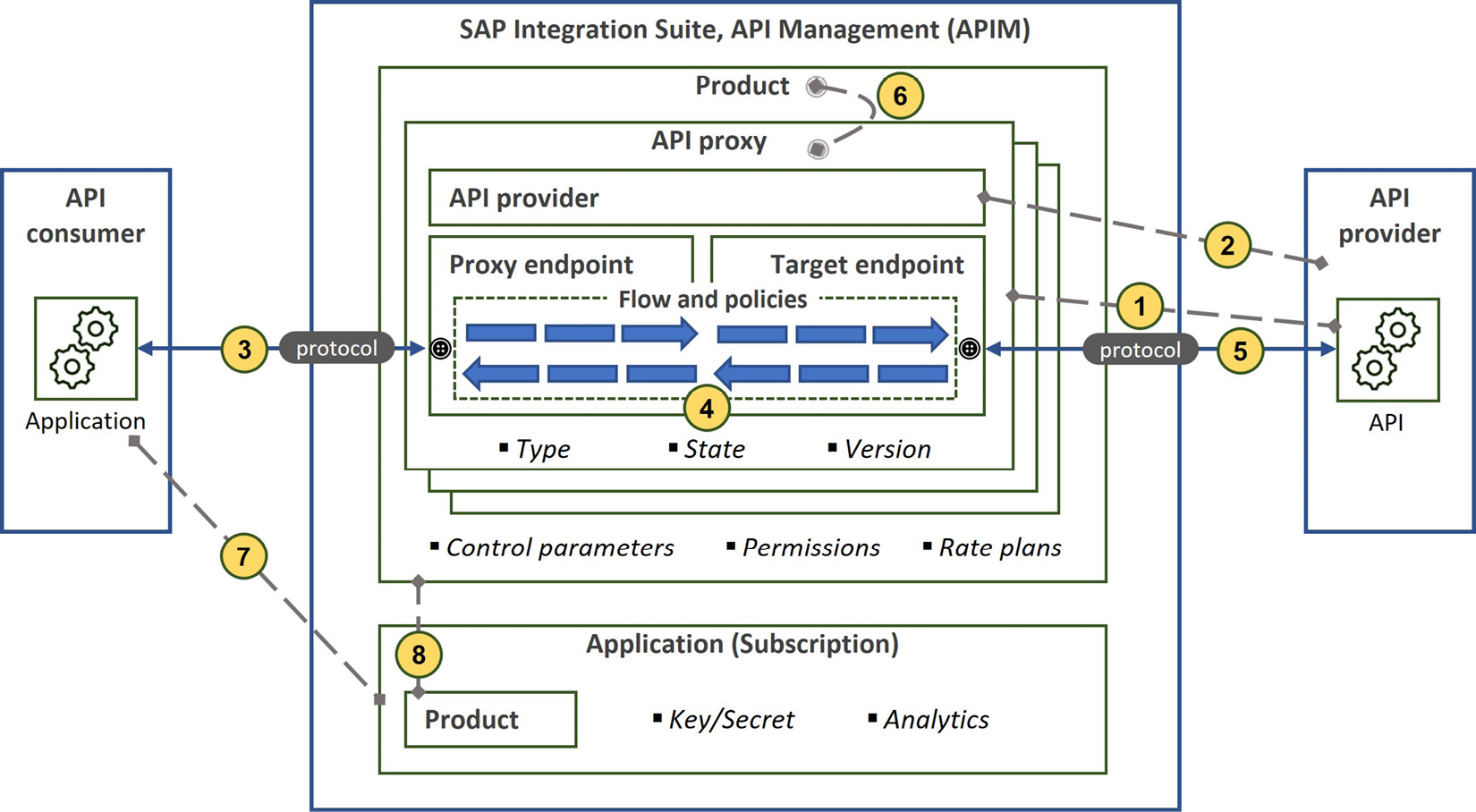
Figure 7.4: The elements of SAP APIM
Figure 7.4 depicts most of the elements of SAP APIM, and now it’s time to describe them. The dashed lines represent design-time relationships, and the continuous lines denote the runtime request-response pipeline. As you can remember, the primary function of SAP APIM is to be a control layer gatekeeping APIs. This implies that the API’s business logic is typically implemented somewhere else. Therefore, you need to create an artifact that points to the API, the API proxy.
Important Note
Although an API proxy is a representation of the service exposed from a different system, SAP APIM sometimes refers to them together as the API when this distinction does not need to be explicit.
Let us look at the process:
- First of all, an API proxy defines the connection endpoints. Since it is placed between the consumer and the provider, an API proxy contains the proxy endpoint exposed to the consumer and the target endpoint to route the request to the provider. For the API proxy, you can specify the state of the API, for example, active, alpha, or beta, and expose the API with different versions, too.
- The provider is the system or application where the API business logic runs. Although you can directly specify the full URL for the target endpoint, a better way is to abstract the connection information of the target system by defining an API provider. This allows you to structure the APIs for easier maintenance as well.
- The API proxy also defines the type of API that corresponds to the protocol used for the API-based integration; hence, it can be OData, REST, or SOAP. As you can manage the request content, it is possible to apply conversion between these protocols. When defining an API provider, you can specify which authentication method to use. This includes principal propagation for on-premise systems where the connectivity happens via SAP Cloud Connector.
- At runtime, after receiving the request from the consumer, SAP APIM takes control. It then applies policies that are organized to be executed at certain parts of the request-response flow.
- It then forwards the request to the provider; similarly, it conveys the response from the provider to the consumer. Some of the policies can be applied conditionally as well. We will talk about the types of policies shortly.
- Now, let’s briefly talk about how you can manage the consumption part of APIs. For this, you need to create products that contain one or many APIs. A product also specifies the rate plans for monetization, permissions to arrange who can discover and subscribe, and other access control parameters.
- Via API Business Hub Enterprise, consumers can subscribe to these products.
- We can also create applications in SAP APIM. Applications provide a key-secret pair for the consumer that is used for identification and authentication purposes.
Now, let us understand the APIM lifecycle.
The APIM lifecycle
In general, the lifecycle stages correspond to the sections in APIM’s API Portal user interface. You can see and navigate to these sections using the icons on the left-hand pane, the compass, pencil, and spanner icons, for instance. Similar to Cloud Integration, API Portal’s Discover section has an embedded catalog from SAP API Business Hub and contains prebuilt integration content that you can copy and maintain in your tenant. Alternatively, you can create custom APIs. In the Develop section, you can maintain APIs, products, and policy templates. Here, when editing APIs, you can also maintain the API flow with policies, as shown in Figure 7.5:
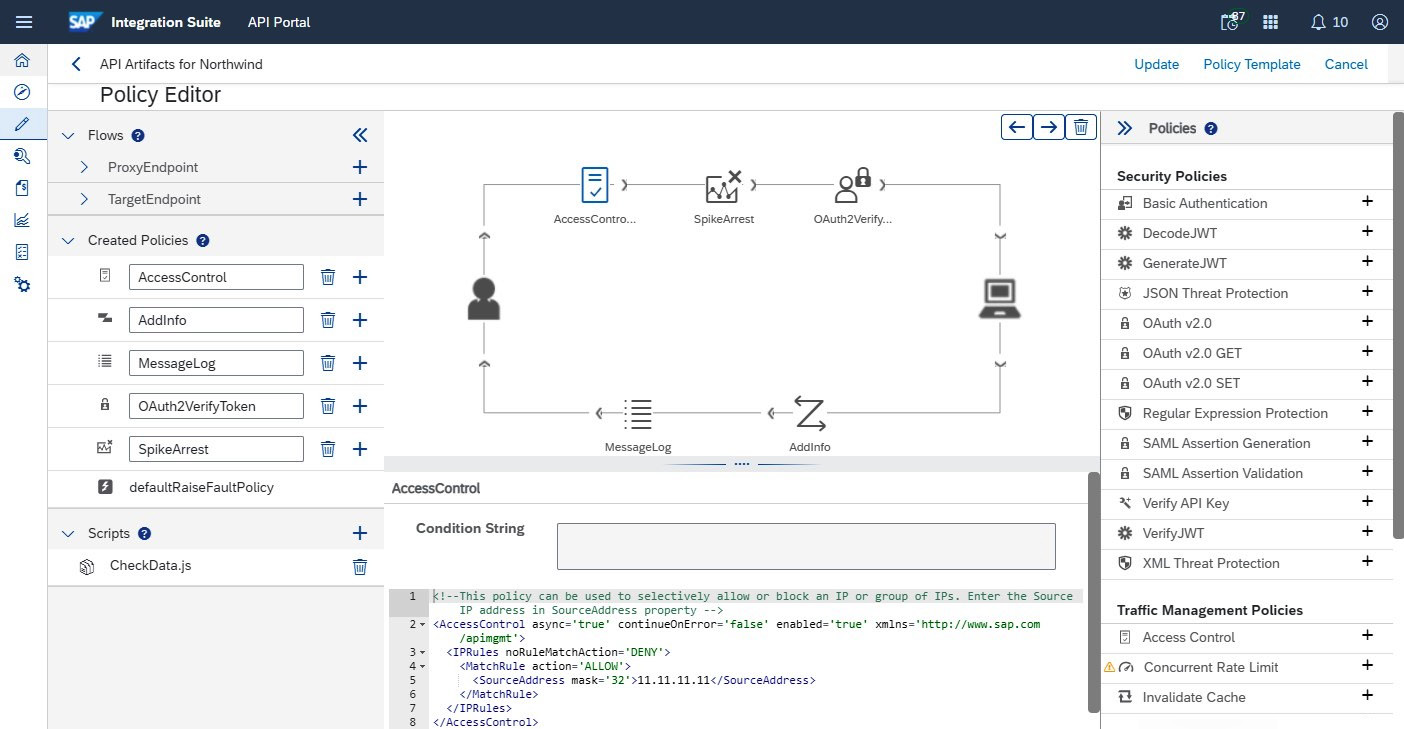
Figure 7.5: The SAP APIM flow policies editor
SAP APIM supports OpenAPI Specification (OAS) versions 2.0 and 3.0. This way, it also lets you maintain APIs using the API Designer editor.
When creating API proxies, you can retain the link between the API proxy and the provider backend service. This allows you to synchronize your API proxy when the backend service changes.
In the Configure section of the API Portal, you can manage API providers, certificates, and key-value maps. If you intend to monetize your APIs, you can define rate plans in the Monetize section of the API Portal, where you can also view the bills for the registered consumers. These rate plans can be assigned to API products.
After developing an API, you need to deploy it so that it becomes eligible to be included in an API product. Finally, when an API product is ready for consumption, you need to publish it so that it becomes available in API Business Hub Enterprise for developers to subscribe to before consuming the product’s APIs.
During the development, you can test your APIs using the Test section of the API Portal. Alternatively, you can also use external HTTP clients, such as Postman. In addition, in the Test section, you can enable debugging, which records the API flow with additional information for inspection. As we pointed out previously, you can assign states to your API to mark their lifecycle stages, such as active, alpha, or beta. When you need to amend an API significantly while retaining the same base path, you can add version information to the full path, which helps with the administration of the APIs as well.
To transport your APIM artifacts between subaccounts, for example, from an instance in a test subaccount to another instance in a production subaccount, you can use SAP BTP TMS together with the Content Agent Service.
Finally, you can find statistical information in API Portal’s Analyze section, such as call counts, the number of calls per response code, cache behavior, error counts, and response times.
API policy types
It’s time to talk about the policy types that SAP APIM can apply to an API flow, as they also solidify its controlling function. One important thing to keep in mind when adding policies to your APIs is the performance. Make sure every policy you add has a function that corresponds to a requirement. The performance of your API may be much more crucial, as the APIs can be consumed by user-facing applications where an acceptable response time is vital for an excellent user experience.
We can discuss the policy types in four groups.
Security policies
You can manage how APIs are protected against unauthorized access with security policies:
- You can access security materials, such as basic authorization elements and access tokens. You can use these for authorization verification and convert the security content to send authorization artifacts to the provider.
- SAP APIM can also manage OAuth 2.0 authorization flows, generating and verifying access tokens and authorization codes.
- It can generate and verify SAML assertions and JSON Web Tokens (JWTs) as well.
- SAP APIM provides protection policies for content-level attacks by enforcing limits to JSON and XML structures or to any part of the message using regular expressions to detect threats.
Traffic control policies
When you open your systems to external parties through SAP APIM, you may need to control the traffic for security or as part of commercial rate limiting:
- You can limit access to certain IPs.
- You can apply quotas to restrict the number of calls a consumer may make to an API.
- You can add a Spike Arrest policy to throttle the API access rate, mainly to protect backend systems against severe traffic spikes, such as denial-of-service (DoS) attacks.
- Traffic control also includes caching policies to improve performance. As you would expect, the cache has size limits; hence, you should use it reasonably.
Mediation policies
As SAP APIM is an intermediary between the consumer and provider, it also lets you apply policies to manipulate the message content for mediation purposes:
- You can create or modify the request or response message using the Assign Message policy.
- If you need to access SAP APIM artifact data, such as products, applications, or developers, you can use the Access Entity policy.
- You can extract certain parts of the message.
- You can use a key-value map to temporarily store reusable data.
- You can convert between XML and JSON formats and also transform XML content using XSLT.
Extension policies
For complex requirements, you may need to add more comprehensive policies:
- If you need to access external resources, you can use the Service Callout policy. With this policy, you can call resources via SAP APIM definitions, such as API proxies or API providers, or you can access them directly with their resource URL. There is a specific callout policy for Open Connectors, too.
- You can use the Message Validation policy to validate XML content against an XSD schema or SOAP content against a WSDL definition.
- You can send log messages to external log management services, such as Splunk and Loggly, using the Message Logging policy.
- Finally, you can add policies to add custom logic using JavaScript or Python scripts.
Well, you have learned a lot about SAP APIM and how you can use it as a layer to control access to your APIs. In the following section, we will discuss how you can use the Open Connectors capability of SAP Integration Suite as a convenience layer, formalizing integration with third-party applications.
Simplified connectivity with third-party applications
Have we told you about how companies’ IT landscapes are becoming more and more heterogeneous? Yes, we have, several times. And here we are again starting a section by pointing out this fact. This is because we will now be discussing an SAP Integration Suite capability, Open Connectors, that helps alleviate handling the integration challenges between applications from different vendors.
You can think of Open Connectors as a convenience layer that formalizes outgoing integration to third-party applications. So, what do we mean by that? First of all, you can build the required integration without using Open Connectors. However, it provides many features that accelerate the development of these integration scenarios.
The elements of SAP Open Connectors
First, let’s have a look at the structural elements of SAP Open Connectors that are depicted in Figure 7.6:
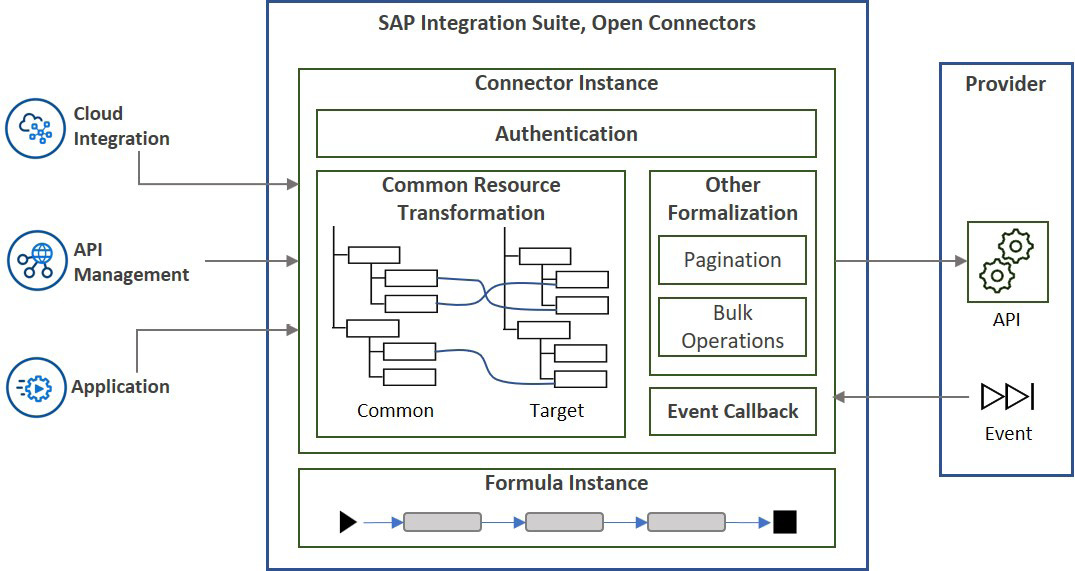
Figure 7.6: The elements of SAP Open Connectors
- Connector: A connector is a prebuilt integration component explicitly created for the target application such as ServiceNow, Salesforce, Twitter, and Google Drive. Therefore, a connector includes the information necessary to connect to the application and consume its APIs. So far, it sounds similar to an adapter, doesn’t it? In addition, connectors support subscribing to events from the application providers. The best thing about connectors is that SAP manages them and keeps them up to date. Connectors are grouped under hubs by the primary function of their target applications. For example, the Documents hub includes Microsoft OneDrive, Google Drive, Evernote, Dropbox, Box, Azure Blob, and Amazon S3. SAP Open Connectors also allows the creation of custom connectors as well.
- Connector instance: To create integration with a supported third-party application, you create a connector instance by authenticating to an account on the provider side. Cloud Integration and APIM can leverage a connector instance that provides the third-party integration as part of a larger integration scenario.
- Common resource: You can expect applications that run similar functions to have similar data models; however, they are not always named or structured in the same way. With a common resource, you can create a canonical data model that can be mapped to many connectors with transformation definitions. This way, you can build with one data model when integrating with multiple third-party applications.
- Formula: You can create lightweight workflows to run simple integration scenarios with formulas. This is similar to a Cloud Integration flow. For example, an event from a third-party application can trigger a formula to send a message to another third-party application.
Benefits
Now that we have a brief idea about how SAP Open Connectors works, let’s check out its benefits:
- Authentication: SAP Open Connectors hides the complexity of authentication to the provider application. When calling an API via a connector instance, you need to authenticate with the Open Connectors credentials, and it handles the rest of the authentication with the application provider. So, for example, you can switch between different authentication methods, where available, without changing your Cloud Integration flow, which uses Open Connectors as the receiver.
- Pagination: An effective way to handle API calls that may return too many records is using pagination, which makes sure only a predefined number of records are received for one request. The response also includes a pointer to make a subsequent call to retrieve further records. Some APIs may support this natively; however, Open Connectors makes sure this is available for all connectors.
- Bulk operations: There are scenarios where you need to execute the function of an API for several records as input or output. Again, some APIs may support this natively, in which case Open Connectors wraps and leverages them. In other cases, Open Connectors makes this available so that the APIs can be called for bulk upload or download where applicable.
- Stability: Open Connectors can be considered as an abstraction layer for an outbound integration to a third-party application where its content is managed by SAP. Then, you can also further create common resources for canonical data models. With these, using Open Connectors enables stability where possible changes at the provider side don’t necessarily require changes at your side.
This being said, let’s also remind ourselves that depending on our requirements, we should also check the application-specific Cloud Integration adapters, for example, Salesforce, Workday, Microsoft, AWS, Twitter, and Facebook, as they may be more convenient options for building integration flows connecting to these applications.
Now, you have learned how SAP Open Connectors can help you build integrations with well-known third-party applications. Next, we will discuss a different approach, event-driven integration, which allows the development of integration scenarios for specific requirements.
Event-driven integration
One of the many cloud qualities you are after when transitioning to the cloud is scalability. This is true for SaaS vendors since they need to scale significantly to serve numerous customers. Similarly, it is valid for end-user companies, especially when creating extensions while keeping the core clean. This is the ethos of the cloud, explicitly considering whether the future will be more geared towards SaaS and PaaS models.
Let’s be a bit pedantic this time and define an event first. According to Cambridge Dictionary, an event is anything that happens, especially something important or unusual. This definition pretty much works when you apply it to the event concept in IT. For example, in business object-orientated models, the occurrence can be linked to a change in the state of an object, for example, a lifecycle status such as BusinessPartner.changed. This makes events more than mere messages, as they convey state-change information. This contrasts with the message-driven integration, where the message contains the established state of an object, as in Representational State Transfer (REST) or an action being triggered with a SOAP message.
If we are talking about integration, there must be participants: the producer or source application raises an event, and the consumer applications listen to it so that they can react to the event.
Just to avoid confusion, in essence, an event is an occurrence in the source system; however, when we talk about integration, we mean distributing the specification of the event. Going forward, we will use the term event for both of these concepts. Thinking along these lines, and as we alluded to before, what is distributed is still a message, but a special one that includes an event specification.
Why do we need event-driven integration?
Earlier in this chapter, we discussed APIs and how vital they are to digital transformation. When reading a book section of this kind, you may think that the main concept discussed is the universal key to solving any challenge in that domain. So, upon reading, you may have believed you could use APIs to solve any integration challenge in the cloud efficiently. If you are an experienced architect, that thought should have faded out very quickly, as experience tells you that there is no key that opens every door. While APIs are essential elements of the cloud paradigm, there are cases where an event-driven approach would be the more reasonable way to implement integration scenarios. Wow, even when introducing event-driven integration, we based our argument on a comparison with API-based integration.
So, if it is all about an application sending information about a change that happened and another application receiving it, how is event-driven integration any different? At the beginning of this section, we already pointed out what underpins the rationale behind event-driven architectures: the requirement for a very high level of scalability. Scalability is essential within cloud-native applications and the integration between them. This is true for both design time, where you build solution components independently, and runtime, where these components need to run at scale.
An obstacle to scalability is the tight dependency between the components of a solution and synchronous integration is the leading producer of tight dependencies. So, if scalability is our primary concern, we need to break the tight dependency to introduce loose coupling of components with asynchronous integration. Lack of synchronicity may make it sound as though the integration cannot happen in near real-time; however, that’s not the case. Yet, the receiver applications have the flexibility to consume messages at their own pace. Moreover, event-driven integration also unlocks other benefits, such as high availability, enhanced fault tolerance, high throughput, and low latency. For example, with loose coupling, Application A wouldn’t necessarily depend on the integrated Application B and could continue running even though Application B is down.
All good, but why do we need events? At the end of the day, asynchronous integration can be achieved using message queues as well. For example, as you may remember, you can use JMS queues to build asynchronous integrations in Cloud Integration. In these kinds of scenarios, you are not necessarily fully decoupling the producer and the consumer; you are simply introducing asynchronicity with queues. In these integration scenarios, the producer still knows who the consumer is and creates the message accordingly.
When addressing higher scalability and throughput requirements, using events makes more sense mainly because the best way for the source application to initiate integration in isolation is by describing what happened and letting the consumer applications decide what to do. In this setup, the producer application can be agnostic toward consumer applications and doesn’t care what technology they are built on, what format they expect the data in, or how they process the event. Furthermore, this kind of setup also makes positioning multiple consumers of the same event easier within an integration scenario.
Now that we have carved out the essentials, shall we establish event integration directly between producer and consumer applications? Surely not. It is not only because of the burden that this will offload to the applications but also mainly because it will not properly annihilate the tight dependency. There are many event-driven architecture patterns. One solution is to introduce a middleman application in between that is specially crafted for event-based integration. We call these event brokers, and they implement mechanisms to achieve event-driven integration. More theoretical discussion after this point would be beyond the scope of this book. So, as a concrete example, let’s introduce SAP’s offering and how it implements event-driven integration.
SAP Event Mesh
SAP Event Mesh is an event broker as a service provisioned in SAP BTP. Actually, SAP Event Mesh can be leveraged as a message broker, providing patterns for asynchronous message-driven integration between a producer and a consumer application. This makes it a remote persistence option for integration flows built with SAP Integration Suite’s Cloud Integration. However, we would like to promote its function in an event-driven integration here. This is because SAP adopts event-driven integration for applicable scenarios and enables events in its cloud and on-premise solutions.
The enablement of event-driven integration makes it easier to build side-by-side extensions. Considering the future direction for core business software is toward SaaS, this supports the relevant keep the core clean philosophy. SAP Event Mesh can play a central role here.
SAP Event Mesh implements an event-driven integration architecture using the publish and subscribe (pub/sub) model, with the following elements that are depicted in Figure 7.7:
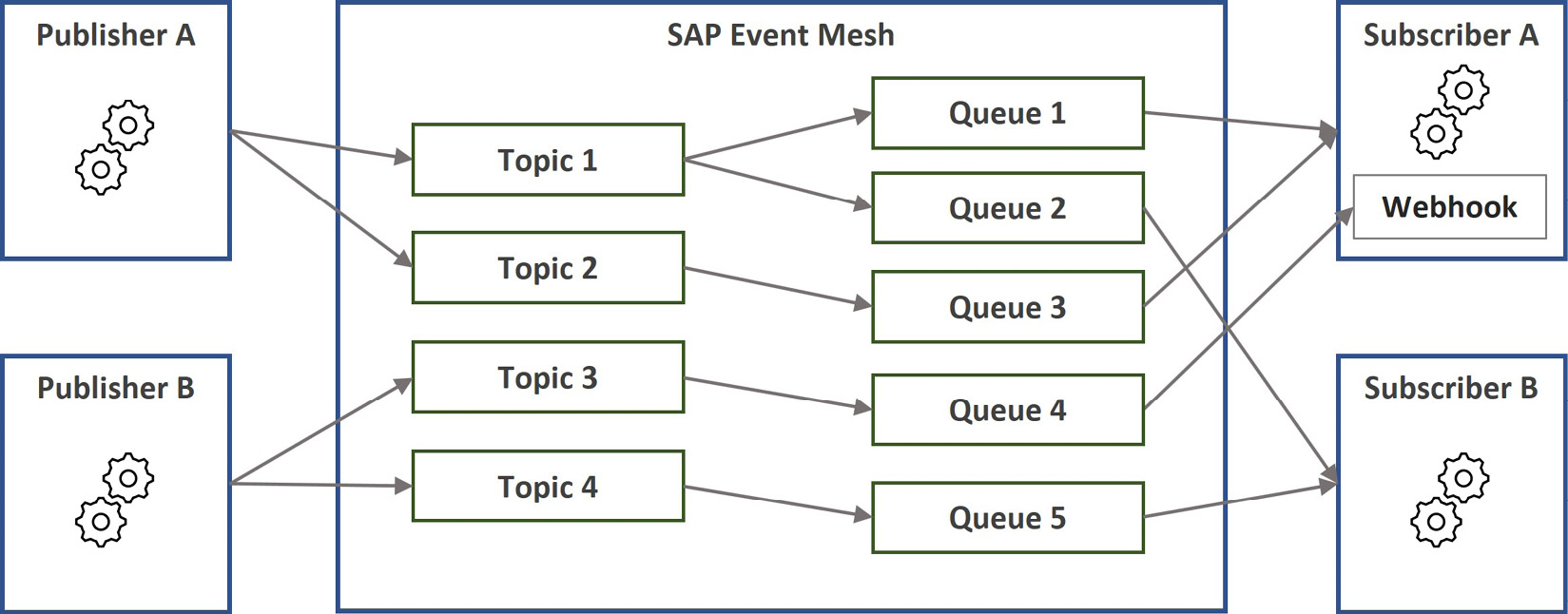
Figure 7.7: A typical pub-sub flow in SAP Event Mesh
- Publisher: The application that produces and sends the message.
- Subscriber: A receiver application that listens to published messages and reacts to them where needed.
- Message client: With message clients, you can organize integration contexts, as they contain the messaging elements. A message client corresponds to a service instance created in an SAP BTP subaccount. With this, they also provide isolation for runtime, as access to the messaging elements is made using the authentication credentials of the message client.
- Queue: Queues are the containers for the messages and define properties such as whether the broker should respect the time-to-live setting for the queue messages, which other queue to use as the dead message queue, and the maximum message size.
- Topic: Topics are the subject information against which the producer publishes the messages. In SAP Event Mesh, topics are defined implicitly through queue subscriptions.
- Queue subscription: A queue subscribes to one or many topics so that when a publisher sends a message to a topic, it can be written to the queue. Multiple queues can subscribe to the same topic as well.
- Webhook subscription: A webhook is an endpoint at the subscriber side, which is called by SAP Event Mesh to push the message. It is attached to a queue, with which connection details, such as URL and authentication, are defined.
SAP Event Mesh supports messaging-specific protocols Advanced Message Queuing Protocol (AMQP) and Message Queuing Telemetry Transport (MQTT), as well as the HTTP-based REST APIs. In addition, it supports the following Quality-of-Service (QoS) levels:
- At most once (0): This is when the published message is delivered with a best effort setup where no acknowledgment is expected from the receiver; therefore, from the publisher’s perspective, it’s a fire-and-forget scenario.
- At least once (1): In this level, the message is kept in the queue until an acknowledgment is received from the subscriber. However, with this QoS level, the message can be delivered multiple times.
The publisher can send a message to a queue or a topic. At the receiving end, the subscribers can initiate the connection to SAP Event Mesh to consume the messages, which is a pull scenario. On the other hand, by defining webhook subscriptions, SAP Event Mesh can also send messages to the subscribers directly, which is a push scenario.
Have you noticed we have been using the term message? That’s because we have been explaining messaging-level capabilities, which are also valid for event-driven integration. SAP standardizes event-driven integration between SAP solutions so that the required plumbing is in place for you. By configuring the publisher and subscriber systems, SAP Event Mesh can be located as the broker working in between.
When an event is published, it’s possible to attach a large payload to send to the subscribers. This is called a data event; however, it has a significant problem. As you can remember, in an event-driven integration scenario, the publisher is agnostic toward subscribers. Therefore, when the publisher includes data in an event message, it cannot control which subscribers are allowed to see that data. This may expose a security risk. Furthermore, attaching large payloads to events is contrary to one of the motivations we had for event-driven integrations, that is, high throughput. That is why SAP Event Mesh limits the message size for any protocol to a maximum of 1 MB.
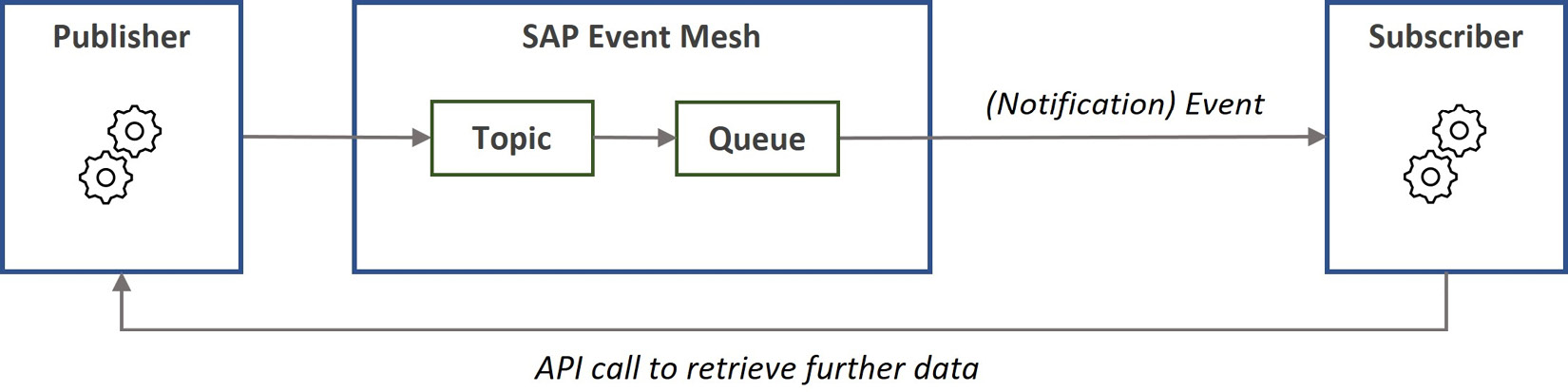
Figure 7.8: A notification event flow followed by an API call
From high throughput and security perspectives, a better option is using notification events, as depicted in Figure 7.8. Here, the publisher sends very lean information about the event, such as what happened, and the identifier of the business object impacted by the event. When the subscribers receive the event information, they can decide whether the event is relevant, and if needed, they can make a call to the publisher to retrieve further data. This way, the publisher can decide whether the subscriber can retrieve the data or not and which data it can retrieve. Notification events prevent the superfluous transmission of large event data to subscribers who do not need to know the details.
For event content, SAP adopts the CloudEvents specification for standardization. Here is an event specification with CloudEvents:
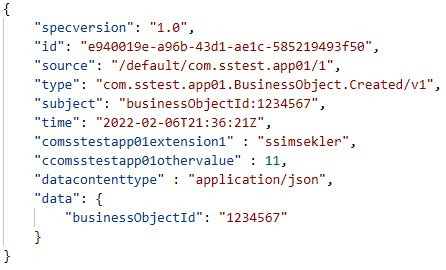
Figure 7.9: An example CloudEvent
The CloudEvent in Figure 7.9 contains some header data that includes metadata information and a data attribute for the event information. In simple terms, the example here says that a Business Object with the ID 1234567 was created. When SAP Event Mesh receives an event notification, for example, through the REST API for events, it routes it to a topic that is constructed from the source and type information in the event specification.
Another good thing to know is that the SAP Cloud Application Programming (CAP) model automatically supports event-driven integration and messaging with SAP Event Mesh. This unlocks many opportunities when developing extension applications, as the application can listen to events from a standard solution, such as SAP S/4HANA, and also emit events. This reflects how Event Mesh differs from other message and event brokers. It is specifically positioned to work with SAP solutions and understands SAP-specific context.
At the time of writing, SAP newly released a service called Advanced Event Mesh (also referred to as SAP Integration Suite, Advanced Event Mesh). As the name suggests, this service offers advanced features for adopting event-driven architecture including higher performance, support for larger messages, advanced event streaming, and analytics. Besides, this new service offers different deployment options with varying ownership models and connectivity models. For example, the service can be deployed with Kubernetes in an SAP-controlled or a customer-controlled region, and the connectivity can be via the public internet, private IP addresses, or a hybrid of both.
Before concluding this section, let’s remember our condition of “if high scalability is required” for the scenarios where we are looking at event-driven integration as the solution. Event-driven integration doesn’t necessarily compete to be the only pattern but complements other integration patterns. Yet, event-driven integration is prominent in the IT world because it is an inherent part of SaaS applications for scalability, works well with microservices, and is favorable in IoT communications for high throughput.
In the next section, we will discuss master data integration, which is closer to a process integration pattern, although it is used to integrate data.
Master data integration
Previously, we touched upon the importance of master data and the challenges around it. Many enterprises struggle to keep their master data consistent and clean across multiple systems. Moreover, data silos start to emerge in various systems, which eventually cause inconsistencies. As these data silos become disconnected, they become obstacles to innovation. As you can guess, in heterogeneous and hybrid landscapes, the problem may become chronic and complicated to resolve after a certain point. Companies serious about their master data use master data management solutions such as SAP Master Data Governance.
One approach to tackling this challenge better is introducing a well-organized master data integration mechanism. By doing this, you can designate a single source of truth and distribute the master data to other relevant systems with consistency, keeping the data quality high.
With heterogeneous and hybrid landscapes in mind, SAP handles the master data integration mainly through two components:
- SAP One-Domain Model (ODM)
- SAP Master Data Integration (MDI)
From a different perspective, alongside the motivation of making life easier for customers dealing with a multitude of systems, with these solutions, SAP introduces a unified entry point and a master data access layer that spans the data of several solutions. Under the bonnet, modularization may make sense; however, most customers prefer a unified way of operating these solutions at the presentation layer.
SAP ODM
SAP ODM is a coherent and harmonized enterprise data model that defines attributes and relationships for business objects that are used across several SAP solutions. The model can be viewed in SAP API Business Hub, as shown in Figure 7.10:
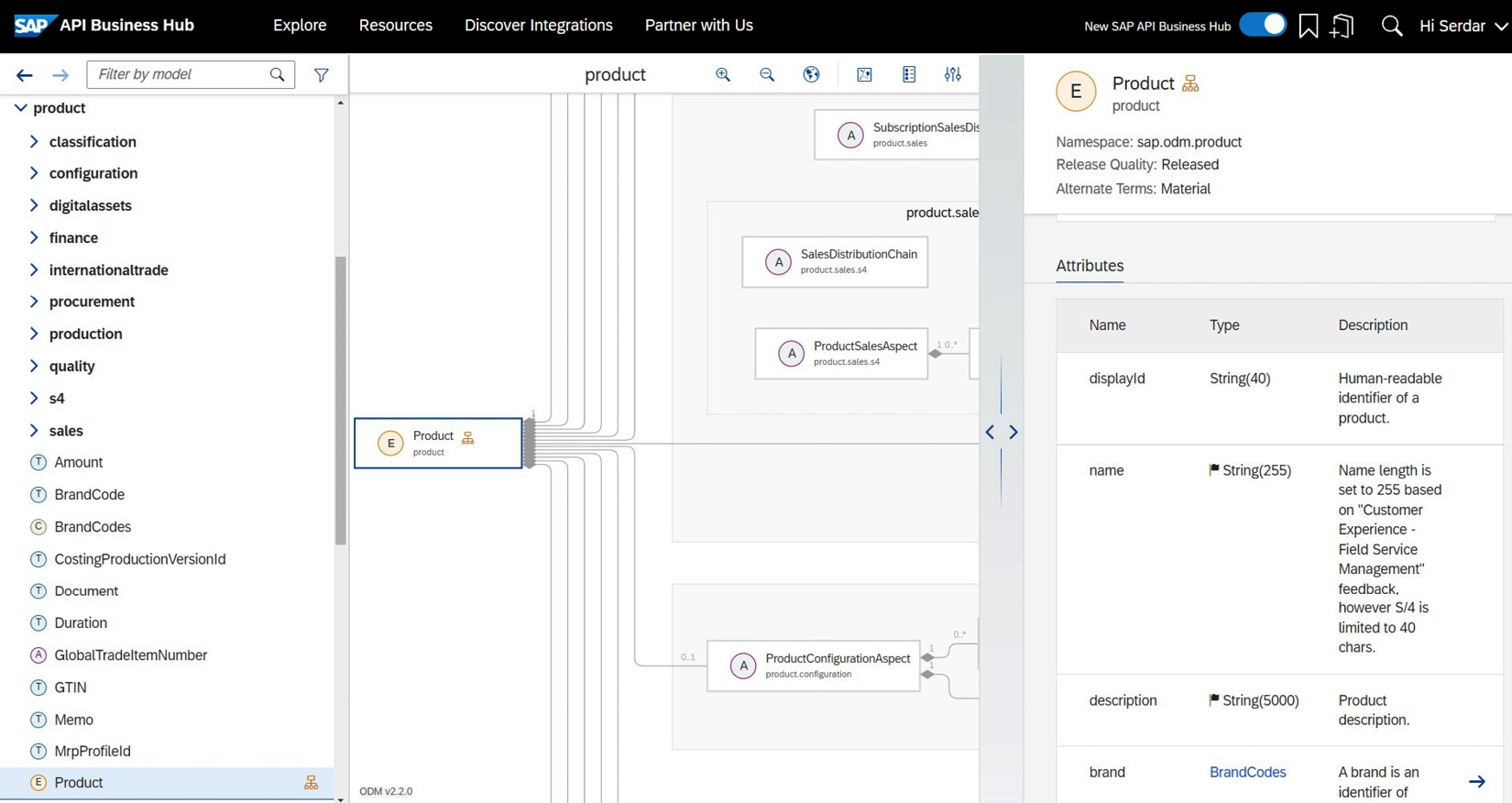
Figure 7.10: SAP ODM Product entity documentation in SAP API Business Hub
SAP ODM is the foundation for master data integration, and it’s the centralized common model through which the data exchange happens. With this, SAP also uses it for the end-to-end business processes, such as lead-to-cash, retire-to-hire, and so forth, to run them seamlessly across multiple solutions.
SAP ODM is written in Core Data Services (CDS) Design Language (CDL), and you easily embed it within applications implemented using the CAP model. In this way, you can write applications to extend core processes with a unified and coherent data model.
SAP MDI
SAP MDI is an SAP BTP service that provides the foundation for distributing master data based on SAP ODM across several applications in a diverse landscape. SAP MDI aims to minimize the master-data-related challenges where business processes are spread across many different applications. It is also meant to support master data management solutions, for example, via SAP MDG, for ensuring the high quality of master data.
SAP MDI works in close relationship with the applications it supports. Therefore, enabling MDI requires a good amount of configuration to be done in the applications in which the master data will be distributed. At the time of writing, SAP MDI supported SAP S/4HANA, SAP Ariba, SAP SuccessFactors, SAP Sales/Service Cloud, SAP Customer Data Cloud, SAP Commerce Cloud, SAP Subscription Billing, SAP Concur, and SAP MDG:
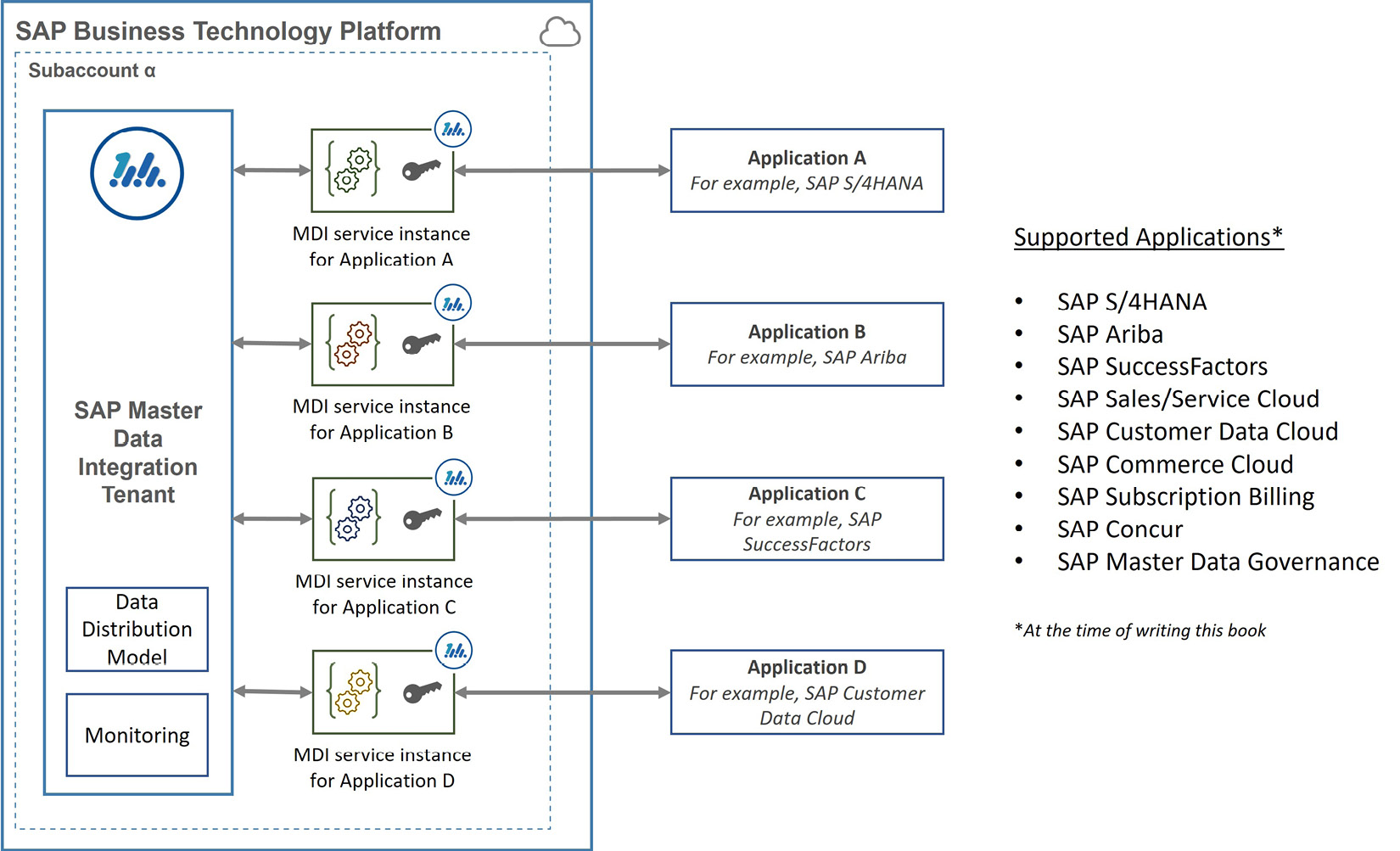
Figure 7.11: A SAP MDI setup with connected applications
Figure 7.11 depicts a setup of SAP MDI together with connected applications. An SAP MDI tenant is provisioned through SAP BTP. You need to connect the applications to which the master data will be distributed to the tenant. To do this, you need to create an MDI service instance for each application. When creating the service instance, you provide the type of the application and other details as instance parameters. Each service instance works as a client for the connected application. For each service instance, you need to create at least one service key, which provides connection details. You may remember our service instance and service key discussions from Chapter 3, Establishing the Foundation for SAP Business Technology Platform. Then, you need to complete the configuration in the business application depending on its integration framework. Here, the main information you would require is the connection and access details that you obtain from the corresponding service key.
An SAP MDI tenant is provisioned when the first MDI service instance is created and is deleted when the last connected service instance is removed. Suppose you have requirements to establish separate master data distribution platforms, for example, for data isolation purposes. In that case, you need to use different subaccounts because there can be a maximum of one MDI tenant in a subaccount. Finally, you need to subscribe to an instance of the UI-based SAP Master Data Integration (Orchestration) application. This gives you a launchpad comprising applications that let you make MDI configurations, such as the distribution model, and monitor distribution status.
SAP Graph
SAP Graph addresses the same challenge of data being spread across several solutions, which are diverse in terms of their data models and technology stacks. This is similar to SAP ODM. However, SAP ODM’s approach looks at the subset of data and entities common across these solutions. SAP ODM provides the data model to be consumed by applications and mainly for master data exchange. In contrast, SAP Graph looks at the cumulative data model spanning all these applications to provide a unified API for accessing SAP data. With this, SAP Graph is technically middleware, and it actually uses SAP APIM under the bonnet.
Important Note
You may come across documents that say SAP Graph exposes data using SAP ODM. Although this was the intention during the incubation of SAP Graph, it looks as though the domain models for data exchange and unified API access had different requirements; hence, the implementation of the two drifted apart. Therefore, at the time of writing, the unified domain model that SAP Graph used was different from SAP ODM.
By unifying the API layer, SAP Graph provides a single endpoint to handle data. Besides this, it hides the landscape complexity from developers so that they can easily and conveniently develop applications accessing this data.
SAP Graph defines a common domain model that floats on top of the data models of the supported SAP solutions (at the time of writing, SAP S/4HANA, SAP SuccessFactors, and SAP Sales Cloud). It includes unified data entities and relationships between these entities in the form of associations or compositions. These entities also provide associations to the entities in the specific system in case the consumer needs to drill down to application-specific data.
Before consuming SAP Graph APIs, you need to complete certain configuration steps:
- Define SAP BTP destinations for the data sources. This includes connectivity setup and authentication arrangements as well.
- Create a configuration file for defining a business data graph. This file contains the following:
- Your landscape information via the SAP BTP destinations as data sources.
- Locating policies that specify rules on how to use data sources, for example, which system is the leading system to retrieve data.
- Key mappings to enable navigation between data across different systems.
- Use SAP Graph Toolkit to activate the configuration file to create the business data graph in SAP BTP and obtain the URL to access APIs.
After creating the business data graph, you can consume it via OData APIs. This means you can access these REST APIs with additional OData features, such as $expand, $filter, and $top. After sending a request with the OData format, SAP Graph handles all the complexity based on business data graph configuration, navigates entities, applies key mappings, executes requested query rules, and retrieves data accordingly:
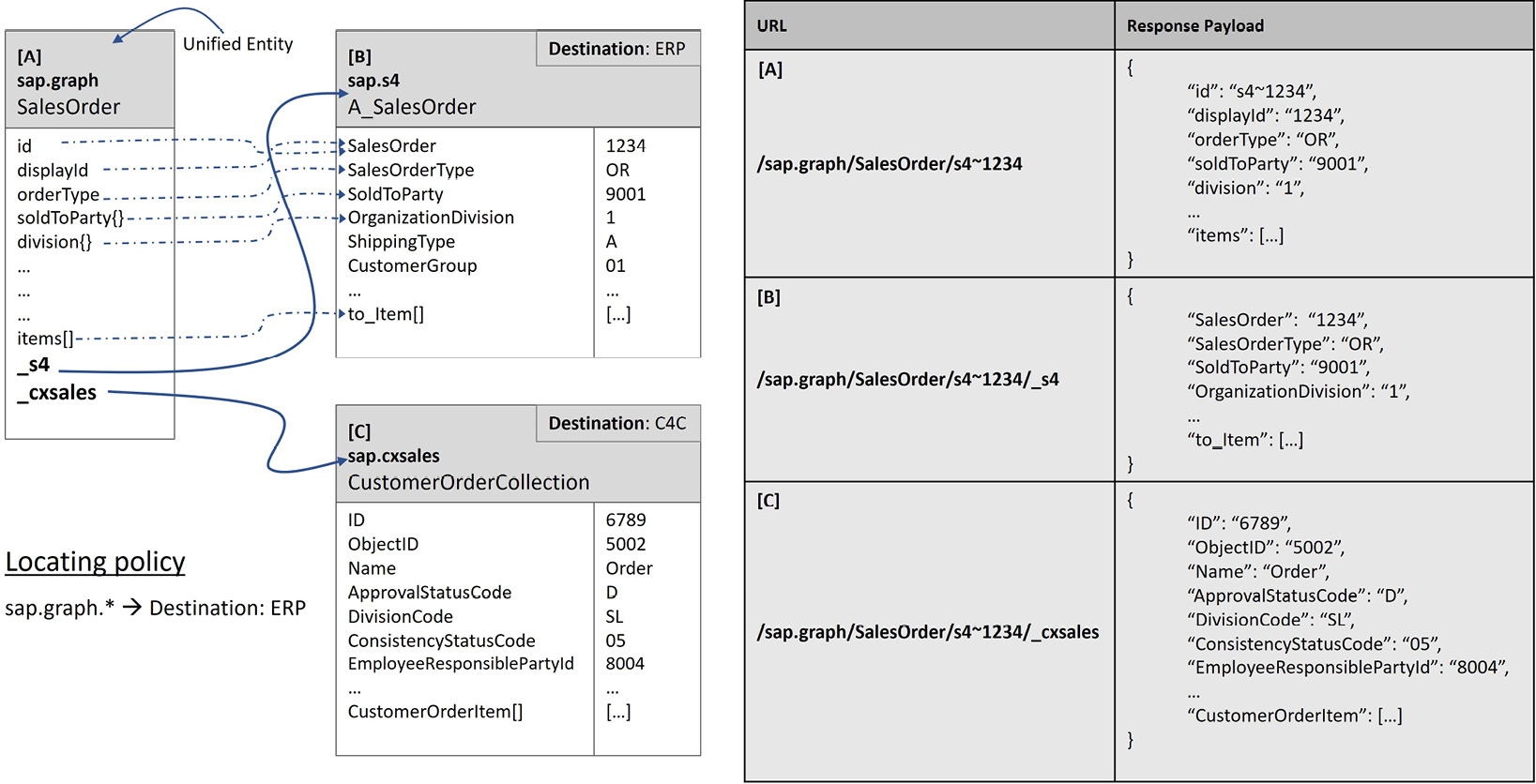
Figure 7.12: An example of entity relationships shown in SAP Graph
Figure 7.12 shows an example unified entity, as in sap.graph/SalesOrder, whose data can be pulled from the SAP S/4HANA system defined by the ERP destination or from the SAP Sales Cloud system defined by the C4C destination. The locating policy of the business data graph has a rule that specifies the system at the ERP destination, hence the SAP S/4HANA system, as the leading system for sap.graph.* entities. Therefore, a request to /sap.graph/SalesOrder will retrieve data from the SAP S/4HANA system with the data model specified for the unified entity, [A].
If required, a request to /sap.graph/SalesOrder/<id>/_s4 can be made to read from the SAP S/4HANA system and return data with the data model defined for the SAP S/4HANA entity, [B]. Similarly, a request to /sap.graph/SalesOrder/<id>/_cxsales can be made to read from the SAP Sales Cloud system and return data with the data model defined for the SAP Sales Cloud entity, [C]. The data models for these entities are already defined in SAP Graph. You just need to create your business data graph, as explained previously. After that, you can make these requests to retrieve data, and use OData features for navigation, expands, and filters.
Design examples
Now that we have covered quite a wide range of SAP Integration Suite capabilities, let’s illustrate their use with example designs.
A common cloud integration platform
Company A is investing heavily in executing its cloud transformation strategy and recently purchased SAP BTP. They have already migrated their SAP workloads to hyperscaler IaaS and there are hundreds of integration flows involving these systems.
When producing their integration methodology, they decided to build new cloud-relevant integrations in cloud offerings to achieve higher availability and better scalability. According to the company’s integration methodology, an integration scenario is cloud-relevant if at least one of the main participant applications of the integration flow is in the cloud. They also adopted the practice to migrate these integrations from the current on-premises integration platform to the cloud when there is an extensive change to the integration. They are looking to migrate all cloud-relevant integrations to the cloud platform over the next few years.
Cecilia is a SAP architect working for Company A, and she is tasked with coming up with a high-level technical architecture design for the cloud integration platform that should also cater to the following requirements:
- The company recently purchased several SAP cloud solutions, such as SAP Commerce Cloud and SAP Marketing Cloud. In principle, they want to run the processes offered by these solutions as standardly as possible. Therefore, they would also like to leverage out-of-the-box integration content produced and managed by SAP for integration scenarios between these cloud solutions.
- The design should connect to the SAP systems in hyperscaler IaaS with minimum effort while providing maximum security.
- Some integration scenarios need the user context to be available in the backend service to apply authorizations for data retrieval and operations.
Surely, the requirements can be detailed further; however, Cecilia creates a design to be the core of the new cloud integration platform and cater to these generic requirements.
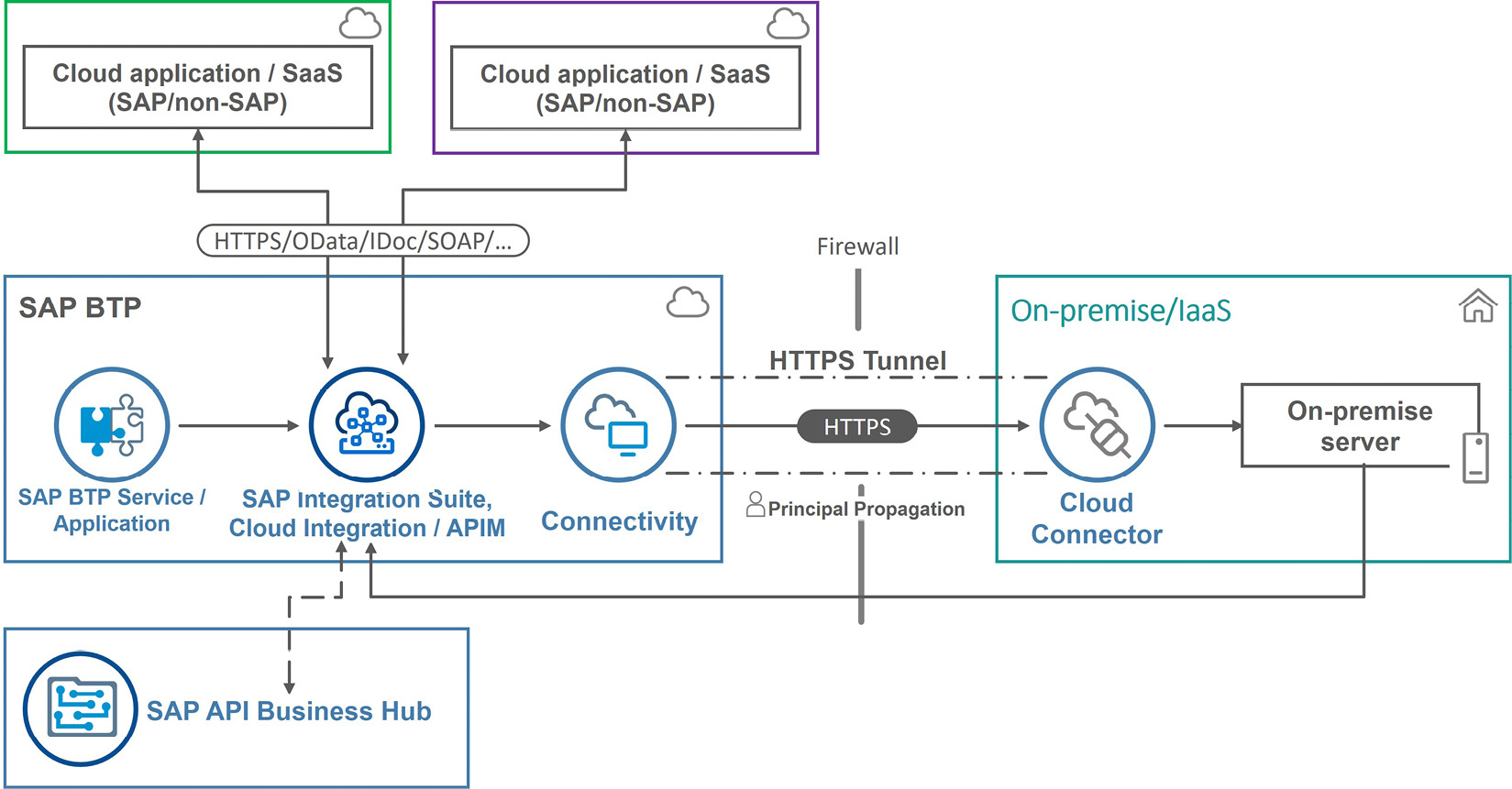
Figure 7.13: The design for a common cloud integration platform
As depicted in Figure 7.13, the design positions SAP Integration Suite, Cloud Integration, and APIM capabilities at the center. With these two (Cloud Integration and APIM), Company A can implement virtually any integration scenario.
The design includes SAP API Business Hub as the source for out-of-the-box prebuilt integration content that can be copied into the Cloud Integration tenant and operated for integration scenarios between SAP cloud solutions. As Company A wants to maximize the use of standard content and processes, they will not edit the integration content and keep receiving updates from SAP.
The design includes SAP Cloud Connector installed close to the SAP systems migrated to hyperscaler IaaS. Although IaaS is a cloud deployment model, the software is still on-premise, and therefore, the integration scenarios should be considered as cloud to on-premise. With SAP Cloud Connector and the SAP BTP Connectivity service, secure connectivity is established between SAP BTP and on-premise applications. This is the most convenient way, as it doesn’t require low-level infrastructure changes, such as firewall changes, every time a new system needs to be connected to SAP BTP. In addition, SAP Cloud Connector provides secure connectivity.
Including SAP Cloud Connector in the design also unlocks the use of principal propagation by Cloud Integration and APIM to send the logged-in user context to the backend systems. This way, the backend system can check whether the user is authorized for the requested operation and record the actual username against the changelog.
A version of the digital integration hub
Company B has a SAP Business Suite system that is hosted in one of the hyperscaler IaaS. Their digital channel includes a customer portal web application that needs to retrieve customer data from the SAP Business Suite system. Today, the main data retrieval happens through SAP Process Orchestration (PO) and SAP Gateway (GW), where these middleware systems eventually call the SAP Business Suite system to retrieve data.
As part of its cloud transformation, Company B purchased SAP BTP and would like to efficiently leverage its cloud qualities to integrate its digital channels and back-end enterprise systems.
Jacob is a senior technical architect working for Company B and needs to produce a design that fulfills the high-level requirements here:
- Today, Company B needs to make its customer portal unavailable when the IT team takes down the backend systems for maintenance. They want to improve the availability of their customer portal. At this initial stage, they are happy to restrict the customer portal to allow customers to only display their data when the backend systems are unavailable; however, the design should maximize the availability. They would also like to improve the response time for the services where possible, providing a performance boost for a better customer experience.
- Their middleware systems struggle to cope with peak loads. As they heavily invest in cloud transformation, they do not want to pay more for on-premise software licenses and maintenance fees. Instead, they prioritize migrating integrations to the cloud, which offers OpEx licensing models.
- They would like to control the access to the backend services and create a governance layer, as they have plans to introduce other internal and external applications to consume these services.
- Company B knows that they are beginning a transformation journey; therefore, at this initial stage, they want to keep the existing integrations and phase them out as they transition to the cloud.
While researching, Jacob comes across a pattern that may be applied for the solution, referred to as a digital integration hub, and tailors it as in Figure 7.14 to fulfill the requirements.
Due to the monolith on-premise systems with heavy operational maintenance procedures and rigidness for scalability, it makes sense to replicate the most accessed business data to a cloud database. For this, Jacob includes the SAP HANA Cloud, HANA DB in the design. The business data in the SAP Business Suite system is replicated in near real time using the SAP Landscape Transformation (SLT) system. We will explore SAP SLT further in the next chapter.
Being an in-memory database, SAP HANA DB will provide faster data retrieval, too. To achieve higher availability, he proposes to create one replica for the SAP HANA Cloud, HANA DB, so that, in case of failure, the system can automatically switch over to this synchronously replicated database instance without disruption. Because this design is for a customer-facing application, the cost for the replica is justified. However, as a design principle, it is suggested that only the bare minimum data required for the customer portal is replicated and necessary governance is established.
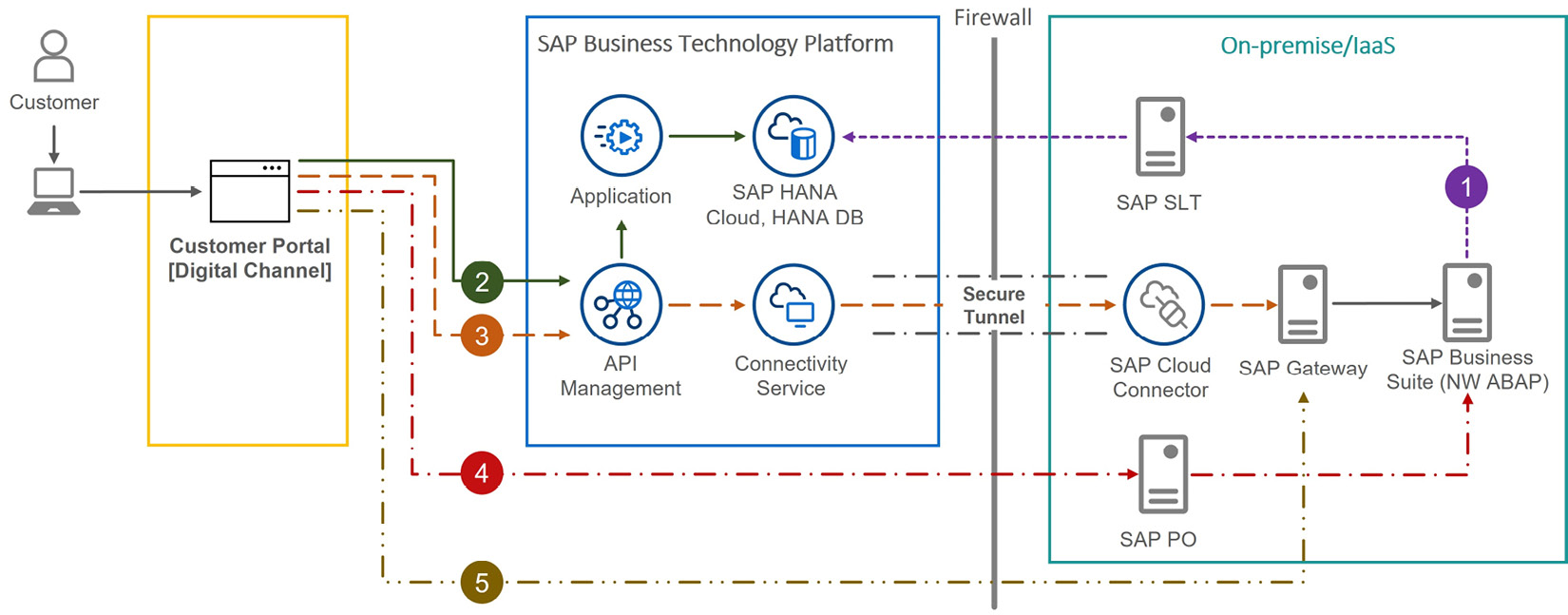
Figure 7.14: The design for a digital integration hub
We will cover application development in Chapter 9 – just to briefly touch upon the relevant element in this design, a number of applications will be implemented and deployed in SAP BTP to read data from the HANA DB and expose them as OData services. These can be written in Node.js or Java using the CAP model, which makes the implementation and operation of these applications easy. Furthermore, to achieve higher availability for these applications, they will be deployed with a minimum of two instances, so that SAP BTP can automatically handle the workload routing in case of an application instance crash.
At the edge, the design includes the SAP APIM service as an access control layer through which the digital channels consume APIs. The APIs are exposed to the necessary security and traffic control policies provided by SAP APIM.
To cater to high-priority write scenarios, some APIs are implemented in SAP APIM that will consume the OData services exposed by the existing SAP GW hub system. These services access the backend SAP Business Suite system to execute business logic. SAP APIM calls these services safely through the secure tunnel created between the SAP BTP Connectivity service and SAP Cloud Connector.
To summarize, there are now five routes through which business data travels, as depicted in Figure 7.14:
- Shown with short, dashed lines, [- - -(1)- - -], the business data is replicated in near real time via SAP SLT to the SAP HANA Cloud, SAP HANA DB.
- Shown with solid lines, [––(2)––], the digital channel consumes a read API through SAP APIM, which retrieves data through applications, eventually reading data from the SAP HANA Cloud, HANA DB.
- Shown with long dashed lines, [– – (3) – –], the digital channel consumes a write API exposed by SAP APIM, which leverages the OData services in the on-premise SAP GW hub system to execute business logic at the back-end system.
- Shown with lines of dash and one dot, [ _._. (4) ._.], the digital channel consumes a web service via SAP PO, which then accesses the back-end system.
- Shown with lines of dash and two dots, [ _.._.. (5) .._..], the digital channel consumes a web service via SAP GW, which then accesses the back-end system.
A B2G integration scenario for submitting tax returns
Company C is a company based in the United Kingdom. Through its Making Tax Digital initiative, the UK’s tax authority (HMRC) requires companies to submit certain types of taxes electronically. Company C uses SAP S/4HANA on-premise as their finance system. All of their finance data resides in this SAP S/4HANA system, and they recently upgraded it to version 2021.
Bilguun is a solution architect working for Company C and needs to design a solution so that Company C can submit tax returns to the HMRC electronically. As the data source is an SAP system, he checks the options available in the SAP solution portfolio and designs the solution using the Document and Reporting Compliance service, a SaaS offering SAP built on SAP BTP:

Figure 7.15: A solution design for electronic tax submission
As illustrated in Figure 7.15, in this solution, the business generates tax data using the standard functionality in the SAP S/4HANA system, which has been available since version 1610. After the data is generated, they can submit it to HMRC. With that, the SAP S/4HANA system forwards the tax data to the Document and Reporting Compliance service, which sends the tax data to HMRC. SAP manages this service; therefore, by using it, Company C offloads the responsibility of managing the electronic tax submission to this service. If HMRC requires a change to the electronic tax submission procedure, SAP applies it by updating this service.
Using events to enhance business partner data
Company D needs to be prudent about the business partners they work with. Therefore, they would like to extend how they manage business partners in their SAP S/4HANA system.
After a business user creates a business partner record, the following is required:
- The new business partner needs to be categorized based on complex logic, which takes time.
- For certain types of business partners, a specific team needs to be informed to manage verifications that can only be done manually. The team uses Slack to keep track of such inbound verification notifications.
- For certain types of business partners, an email needs to be sent to a third-party supplier, so that they can run other checks for the business partner and notify Company D of the result via an API.
Arina is a technical architect working for Company D and produces a solution catering to the requirements above, as depicted in Figure 7.16:
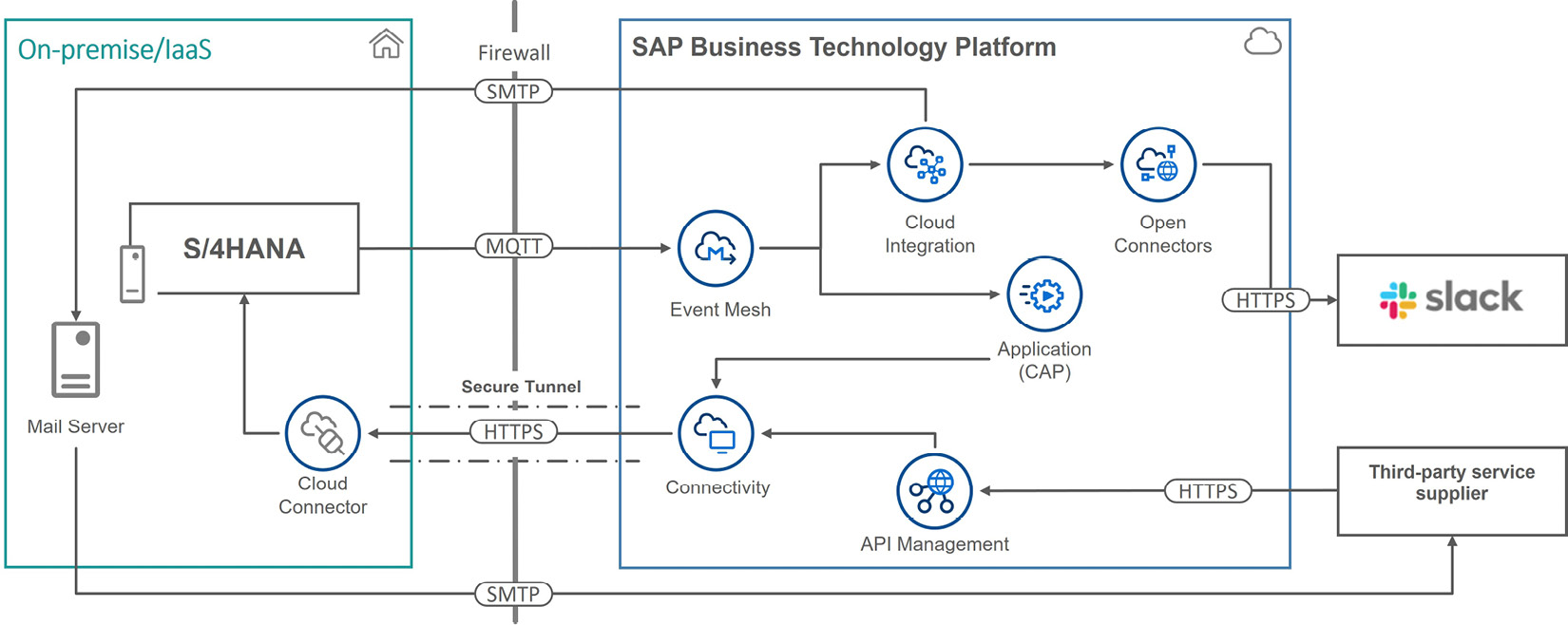
Figure 7.16: A solution design using events to enhance business partner data in S/4HANA
Let’s check how the design components fulfill the requirements. The story starts with a change in SAP S/4HANA. Arina researched SAP API Business Hub and found that SAP S/4HANA publishes an event when a business partner is created, as you can see in Figure 7.17. This means she can use SAP Event Mesh so that subscriber applications can listen to this event and act accordingly. By the way, have you noticed that the example payload in the screenshot complies with the CloudEvents specification?
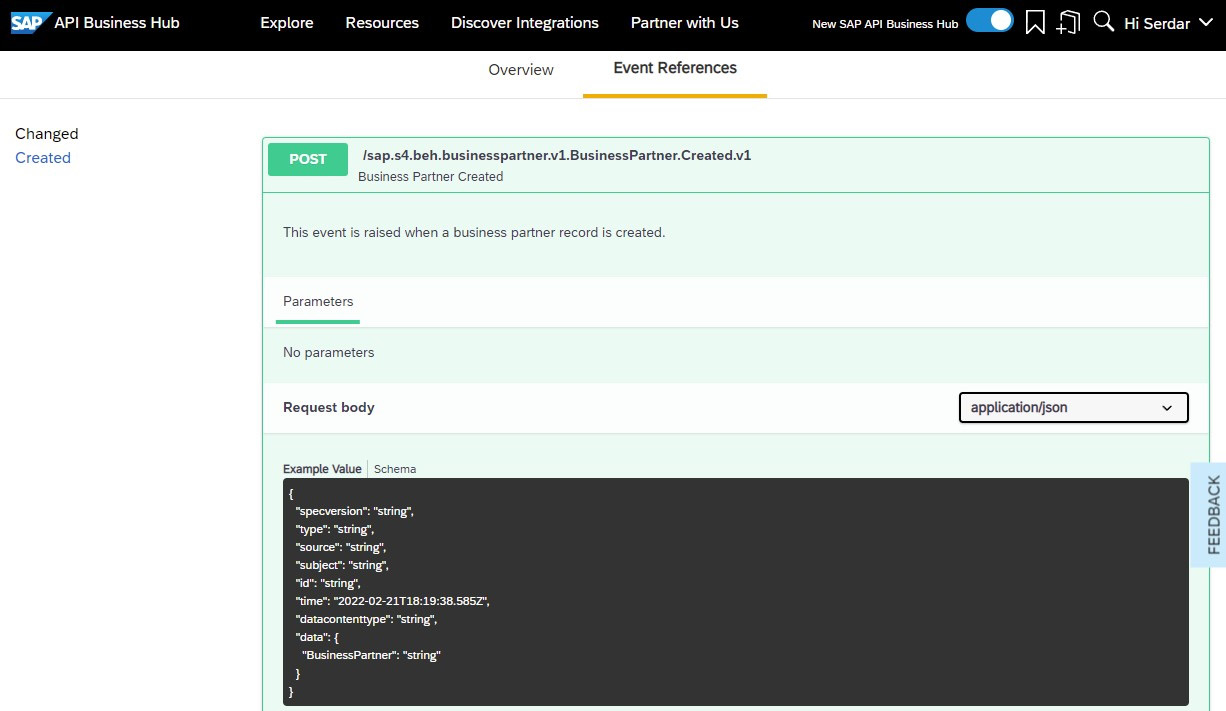
Figure 7.17: SAP API Business Hub showing Business Partner events in S/4HANA
The first subscriber is a custom application that is deployed in SAP BTP and is developed following the CAP model. Because CAP has out-of-the-box support for SAP Event Mesh, Company D developers can build the application easily.
When the application receives the event information, it can run the necessary business logic, which was specified to be complex in the requirements. The application calculates categorization values for the business partner and sends them back to the SAP S/4HANA system through a direct call to an OData service. This call goes through the secure tunnel established by the SAP BTP Connectivity service and Cloud Connector. Because it’s an internal integration, it doesn’t need to go through SAP APIM. Just to note, there may be cases where you may want to use APIM for internal API consumption. It’s just not needed in this design.
The second subscriber is the Cloud Integration capability of the SAP Integration Suite service. When Cloud Integration receives the event, after any other transformation and mediation steps, it forwards the integration to two different receivers. The first receiver is an on-premise mail server, through which an email is sent to the third-party service provider. The second receiver is SAP Open Connectors, which can forward information to the Slack collaboration channel through the prebuilt connector.
We haven’t included this in the diagram so as not to make it too crowded: both the custom application and the Cloud Integration flow can make calls to the SAP S/4HANA system to get further information and enrich message content.
Finally, the third-party service supplier calls an API exposed through SAP APIM, which forwards the request to the SAP S/4HANA system to update the business partner record accordingly. Again, this happens through the secure tunnel established by the SAP BTP Connectivity service and Cloud Connector.
Summary
We must say there are lots of other topics that we could discuss under cloud integration. For example, we could delve into B2B integration implementation using Integration Advisor. Or talk about the industry, or LoB-specific standard integration platforms, such as Ariba Cloud Integration Gateway (CIG), Document and Reporting Compliance service, Peppol Exchange Service, multi-bank connectivity, market communication in Cloud for Utilities (C4U), or the Information Collaboration Hub for Life Sciences. However, covering all of these in this book would be beyond its scope. We believe this chapter’s well-adjusted content is sufficient for architects to grasp most of the foundational concepts and design cloud integration architectures.
Integration is a vital domain for SAP; hence, it invests a lot to make its integration platform feature-rich so that it caters to almost all integration requirements, as expected from a complete enterprise integration platform as a service (EiPaaS). Besides, SAP invests in making this platform easy and convenient to use. This is where low-code development experience comes into the picture, as with the editor for building flows in Cloud Integration or the editor for managing API policies in APIM.
In the respective sections of this chapter, we have discussed the following:
- SAP Cloud Integration’s transformation, mediation, and orchestration capabilities.
- How SAP APIM helps expose APIs securely and provides policies as a control layer.
- How SAP Open Connectors formalizes and accelerates building integrations with well-known third-party applications.
- Why we need event-driven integration and how SAP Event Mesh enables it.
- How SAP MDI and SAP ODM tackle master data integration.
- What SAP Graph offers and how it hides the complexity of large landscapes with several applications.
In the final section, we discussed many examples demonstrating these capabilities, which hopefully give you an idea of where you can leverage the SAP BTP integration services for addressing integration challenges.
In the next chapter, we will cover data integration. We will further discuss how data integration differs from the cloud integration topics we covered in this chapter. Then, we will delve into SAP solutions for data integration and work on some example designs.