
18
Machine Learning Best Practices
Machine learning is much more than building and training models. Till now in this book, we focused on different deep learning algorithms and introduced the latest algorithms, their power, and their limitations. In this chapter, we change our focus, from the ML/DL algorithms to the practices that can make us better machine learning engineers and scientists.
The chapter will include:
- The need for best practices for AI/ML
- Data best practices
- Model best practices
The need for best practices
Today, deep learning algorithms are not just an active research area but part and parcel of many commercial systems and products. Figure 18.1 shows the investment in AI start-ups in the last five years. You can see that the interest in AI start-ups is continuously increasing. From healthcare to virtual assistants, from room cleaning robots to self-driving cars, AI today is the driving force behind many of the recent important technological advances. AI is deciding whether a person should be hired, or should be given a loan. AI is creating the feeds you see on social media. There are Natural Language Processing (NLP) bots generating content, images, faces – anything you can think of – there is someone trying to put AI into it. Since most teams consist of multiple team members working cross-domain, it is important to build best practices. What should be the best practices? Well, there is no definitive answer to this question as best practices in ML depend on the specific problem domain and dataset.
However, in this chapter we will provide some general tips for best practices in machine learning:
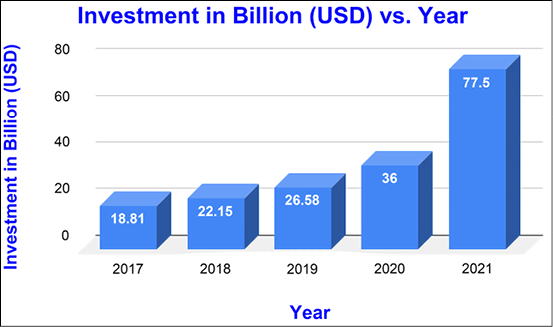
Figure 18.1: Investment in AI start-ups in the last five years (2017–2022)
Below are a few reasons why having best practices in machine learning is important:
- It can ensure that models are built in a way that is both effective and efficient.
- It can help to avoid issues such as overfitting, which can lead to poor performance on unseen data.
- It can ensure that the models are interpretable and can be easily explained to non-technical audiences.
- It can help to promote reproducibility in machine learning research.
In the coming sections, you will be introduced to some best practices as advocated by the FAANG (Facebook, Amazon, Apple, Netflix, and Google) companies and AI influencers. Following this advice can help you avoid common mistakes that can lead to inaccurate or poor results. These best practices will help ensure that your AI services are accurate and reliable. And finally, best practices can help you optimize your AI services for performance and efficiency.
Data best practices
Data is becoming increasingly important in today’s world. Not just people in the field of AI but various world leaders are calling data “the new gold” or “the new oil” – basically the commodity that will drive the economy around the world. Data is helping in decision making processes, managing transport, dealing with supply chain issues, supporting healthcare, and so on. The insights derived from data can help businesses improve their efficiency and performance.
Most importantly, data can be used to create new knowledge. In business, for example, data can be used to identify new trends. In medicine, data can be used to uncover new relationships between diseases and to develop new treatments. However, our models are only as good as the data they are trained on. And therefore, the importance of data is likely to continue to increase in the future. As data becomes more accessible and easier to use, it will become increasingly important in a variety of fields. Let us now see some common bottlenecks and the best way to deal with them.
Feature selection
The first step when we start with any AI/ML problem is to propose a hypothesis: what are the input features that can help us in classifying or predicting our output? Choosing the right features is essential for any machine learning model, but it can be difficult to know which ones to choose. If you include too many irrelevant features in your model, your results will be inaccurate. If you include too few features, your model may not be able to learn from your data. Thus, feature selection is a critical step in machine learning that helps you reduce noise and improve the accuracy of your models:
- As a rule, before using any feature engineering, one should start with directly observed and reported features instead of learned features. Learned features are the features generated either by an external system (like a clustering algorithm) or by employing a deep model itself. Simplifying can help you achieve a solid baseline performance, after which you can experiment with more esoteric strategies.
- Remove the features that you are not using. Unused features create technical debt. They make your code more difficult to read and maintain and can also lead to unexpected bugs and security vulnerabilities. Of course, it can be difficult to keep track of which features are being used and which are not. However, do not drop the features arbitrarily; perform data analysis and exploration carefully – understand the features. A good way to do this would be to assign an owner to each feature. The feature owner would be responsible for maintaining the feature and documenting its rationale so that the knowledge can be shared across teams. This also means that whenever a feature owner leaves the team, ownership is transferred to other members. By taking the time to understand and remove unused features, you can keep your code clean and avoid accumulating technical debt.
- Often, we think more features equal a better model, but that is far from true. Instead of using millions of features you do not understand, it is better to work with specific features; you can use the method of regularization to remove the features that apply to too few examples.
- You can also combine and modify the features to create new features. There are a variety of ways you can combine and modify. For example, you can discretize continuously valued features into many discrete features. You can also create synthetic new features by crossing (multiplying) two or more existing features. For example, if you have the features “height” and “weight,” you can create a new feature called “BMI” by combining those two features. Feature crossing can provide predictive abilities beyond what those features can provide individually. Two features that are each somewhat predictive of the desired outcome may be much more predictive when combined. This is because the combined feature captures information that is not captured by either individual feature. Feature crossing is a powerful tool that can help to improve the accuracy of predictive models.
Features and data
One of the problems when we move from learning data science to solving real problems is the lack of data. Despite the internet, mobile, and IoT devices generating loads of data, getting good-quality labeled data is a big hurdle. The cost of annotation is normally as high as it is time-consuming and requires subject matter expertise.
Thus, we need to ensure we have sufficient data to train the model. As a rule of thumb, the number of input features (n) that a model can learn is roughly proportional to the amount of data (N) you have (n << N). A few tips that can be followed in such a situation are:
- Scale model learning to the size of the data. For example, if we have only 1,000 labeled samples, then use highly human-engineered features. A good number would be to have a dozen well-selected features for 1,000 labeled samples. But if we have millions of examples, then we can afford to have about a hundred thousand features. And assuming we have billions of data samples, we can build a model with millions of features.
- If we have too much data, we do not arbitrarily drop it; instead, we can use Importance Weight Sampling (https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1214/reports/final_reports/report247.pdf). The idea is to assign a weight of importance to each sample based on some distributional feature that captures similarity to the specialized domain data.
- Another way to deal with a lack of sufficient data is using data augmentation. Initially proposed for image data by H. S. Baird in his article, Document image analysis [7], it has proven to be a good way to increase image data by making use of simple image transformations, like horizontal flips, vertical flips, rotation, translation, etc. Most deep learning frameworks have data generators, which you can use to perform this augmentation on the go, as shown in Figure 18.2:

Figure 18.2: Original and augmented images
While augmenting image data is readily available in all the major deep learning frameworks, augmenting textual data and audio data is not that straightforward. Next, we present some of the techniques you can use to augment textual and speech data.
Augmenting textual data
Some of the simple ways that we can use to augment textual data are:
- Synonym replacement: In this, random words from the sentence are chosen and replaced by their synonyms using WordNet. For example, if we have the sentence “This book focuses on deep learning using TensorFlow and Keras and is meant for both novices and experts,” we can choose the two words in bold for synonym replacement, resulting in this sentence: “This book centers on deep learning using TensorFlow and Keras and is meant for both beginners and experts.”
- Back translation: The method was proposed by Sennrich et al. in 2016. The basic idea is that a sentence is translated into another language and then translated back to the original language. We can use language translation APIs or Python modules like
googletrans. The following code snippet translates a sentence from English to German and back. For the code to work, we need to havegoogletransinstalled:
from googletrans import Translator
translator = Translator()
text = 'I am going to the market for a walk'
translated = translator.translate(text, src='en', dest='de')
synthetic_text = translator.translate(translated.text, src='de', dest='en')
print(f'text: {text}
Translated: {translated.text}
Synthetic Text: {synthetic_text.text}')
Now we have two sentences “I am going to the market” and “I walk to the market” belonging to the same class. Figure 18.3 details the process of data augmentation using back translation:
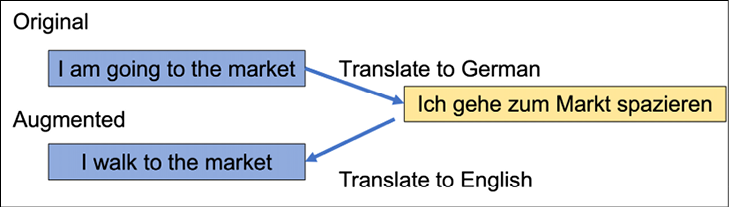
Figure 18.3: Data augmentation using back translation
In the review paper A survey of Data Augmentation Approaches for NLP, the authors provide an extensive list of many other augmentation methods. This paper provides an in-depth analysis of data augmentation for NLP.
In recent years, with the success of large language models and transformers, people have experimented with using them for the task of data augmentation. In the paper entitled Data augmentation using pre-trained transformers, by the Amazon Alexa AI team, the authors demonstrate how by using only 10 training samples per class they can generate synthetic data using the pretrained transformers.
They experimented with three different pretrained models: an autoencoder LM BERT, an autoregressive LM GPT2, and the pretrained seq2seq model BART. Figure 18.4 shows their algorithm for generating synthetic data using pretrained models:
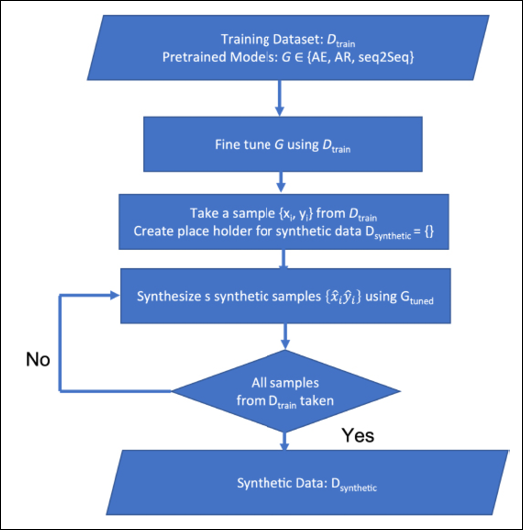
Figure 18.4: Algorithm for generating synthetic textual data using pretrained transformers
Speech data can also be augmented using techniques like:
- Time warping: Here a random point is selected and data is warped to either left or right with a distance w. The distance w is not fixed, and instead is chosen from a uniform distribution [0, W].
- Frequency Masking: Here a range of frequency channels [f0, f0+f)] are masked; the choice of frequency f0 and f depends upon the number of frequency channels and frequency mask parameter F.
- Time Masking: In this case, the consecutive time steps are masked.
These techniques were proposed by the Google Team in 2019, in their paper SpecAugment: A simple data augmentation method for Automatic Speech Recognition.
Model best practices
Model accuracy and performance are critical to success for any machine learning and deep learning project. If a model is not accurate enough, the associated business use case will not be successful. Therefore, it is important to focus on model accuracy and performance to increase the chances of success. There are a number of factors that impact model accuracy and performance, so it is important to understand all of them in order to optimize accuracy and performance. Below we list some of the model best practices that can help us leverage best from our model development workflow.
Baseline models
A baseline model is a tool used in machine learning to evaluate other models. It is usually the simplest possible model, and acts as a comparison point for more complex models. The goal is to see if the more complex models are actually providing any improvements over the baseline model. If not, then there is no point in using the more complex model. Baseline models can also be used to help detect data leakage. Data leakage occurs when information from the test set bleeds into the training set, resulting in overfitting. By comparing the performance of the baseline model to other models, it is possible to detect when data leakage has occurred. Baseline models are an essential part of machine learning and provide a valuable perspective on the performance of more complex models. Thus, whenever we start working on a new problem, it is good to think of the simplest model that can fit the data and get a baseline.
Once we have built a satisfactory baseline model, we need to carefully review it.
Review the initial hypothesis about the dataset and the choice of our initial algorithms. For example, maybe when we first began working with the data, we hypothesized that the patterns we are observing would be best explained by a Gaussian Mixture Model (GMM). However, after further exploration, we may find that the GMM is not able to capture the underlying structure of the data accurately. In that case we will need to rethink our strategy. Ultimately, our choice of algorithms is dictated by the nature of the data itself.
Confirm if the model is overfitting or underfitting. If the model is overfitting, try more data, reduce model complexity, increase batch size, or include regularization methods like ridge, lasso, or dropout. If the model is underfitting, try increasing model complexity, adding more features, and training for more epochs.
Analyze the model based on its performance metrics. For example, if we have made a classification model, analyze its confusion metrics and its precision/recall as per the business use case. Identify which class model is not predicting correctly; this should give us an insight into the data for those classes.
Perform hyperparameter tuning to get a strong baseline model. It is important that we establish a strong baseline model because it serves as a benchmark for future model improvements. The baseline should incorporate all the business and technical requirements, and test the data engineering and model deployment pipelines. By taking the time to develop a strong baseline, we can ensure that our machine learning project is on the right track from the start. Furthermore, a good baseline can help us identify potential areas of improvement as we iterate on our models. As such, it is well worth investing the time and effort to create a robust baseline model.
Pretrained models, model APIs, and AutoML
When we want to launch a commercial product, time and energy are often two of the most important factors. When working on a new project, it can be very time-consuming to train a baseline model from scratch. However, there are now a number of sources where we can find pretrained models that can save us a lot of time and effort. These include GitHub, Kaggle, and various cloud-based APIs from companies like Amazon, Google, OpenAI, and Microsoft.
In addition, there are specialized start-ups like Scale AI and Hugging Face that offer pretrained models for a variety of different tasks. By taking advantage of these resources, we can quickly get our machine learning projects up and running without having to spend a lot of time training a model from scratch. So, if our problem is a standard classification or regression problem, or we have structured tabular data available, we can make use of either pretrained models, or APIs provided by companies like Amazon, Google, and Microsoft. Using these approaches can save us valuable time and energy and allow us to get started with our project quickly.
Another solution that is evolving is using AutoML, or Automatic Machine Learning. Using AutoML, we can create custom models that are more tailored to a company’s specific needs. If you are limited in terms of organizational knowledge and resources, we can still take advantage of machine learning at scale by utilizing AutoML. This solution has already been helping companies large and small to meet their business goals in a more efficient and accurate manner. In the future, it is likely that AutoML will only become more prevalent and popular as awareness of its capabilities grows.
Model evaluation and validation
In this section, we talk about ways of evaluating our model. Here we are not talking about conventional machine learning metrics, but instead focusing on the experience of the end user:
- User experience techniques: When our model is near production, we should test it further. Crowdsourcing is a great way to get feedback from our audience before we release the product. We can either pay people or use live experiments on real users in order for them to give valuable opinions about what works best. We can create user personas early in a process, that is, create hypothetical users – for example, if we are a team with an age group lying between 19–40 and we build a recommender system, we can create a user persona for someone in their sixties. Later, we can perform usability testing by bringing in actual people and watching their reactions to our site.
- Use model deltas: When we’re releasing a new model, one of the best ways to measure its success is by calculating how different it is from the one in production. For example, if our ranking algorithm has been giving better results than expected but not as much so that people would notice, or care, then we should run both models on samples through the entire system with weights given by position rank. If we find that the difference between the two queries is very small, then we know that there will be little change. However, if the difference is large, we should ensure that the change is good. In this case we should explore the queries where symmetric differences are high; this will enable you to understand the change qualitatively.
- Utilitarian power is more important than predictive power: We may have a model with the highest accuracy and best prediction. But that is not the end; the question is what we do with that prediction. For example, if we build a model to semantically rank the documents, then the quality of the final ranking matters more than the prediction. Let us consider another example: let us say you built a spam filter, and our model predicts the probability whether the given message is spam or ham; we follow it with a cut-off on what text is blocked. In such a situation, what we allow to pass through matters most. So, it is possible that we get a model with better log loss, but still no improvement in overall performance. In such a case, we should look for other features to improve the performance.
- Look for patterns in measured errors: In training samples, check the ones the model is not able to predict correctly. Explore features that we have not yet considered yet; can they improve the prediction for the incorrect samples? Do not be very specific with features; we can add a dozen of them, and let the model decide what can be done with them. To visualize errors in classification problems, we can use a confusion matrix, and in regression tasks, we can look for cases where the loss is high.
- Test on unseen data: To measure the performance of our model, test it on the data that is gathered after the model has been trained; this way we will get an estimate of the performance in production. This may result in reduced performance, but the reduction should not be severe.
Performance monitoring is a crucial part of model development. The performance between training and production data can vary drastically, which means that we must continuously monitor the behavior of deployed models to make sure they’re not doing anything unexpected in our system. We should build a monitoring pipeline that continuously monitors performance, quality and skew metrics, fairness metrics, model explanations, and user interactions.
Model improvements
Once a reliable model is built and deployed, the work is far from over. The model may need to be changed for various reasons, such as data drift or concept drift. Data drift occurs when the distribution of data changes over time, and concept drift occurs when the properties of dependent (labeled) variables change over time. To account for these changes, the model must be retrained on new data and updated accordingly. This process can be time-consuming and expensive, but it is essential to maintaining a high-performing machine learning model. However, before we jump into model improvement, it is important to identify and measure the reasons for low performance – “measure first, optimize second”:
Data drift: The performance of a machine learning model can vary depending on when it is trained and when it is deployed. This is because the data used during training and serving can be different. To avoid this problem, it is important to log the features at the time of deployment. This can allow us to monitor the variation in serving data (data in production). Once the data drift (the difference between training data and serving data) crosses a threshold, we should retrain the model with new data. This will ensure that the model is trained on the same data that it will be deployed on, and thus improve its performance.
Training-serving skew: Training-serving skew can be a major problem for machine learning models. If there is a discrepancy between how the model is trained and how it is used in the real world, this can lead to poor performance and inaccuracies. There are three main causes of training-serving skew: a discrepancy between the data used in training and serving, a change in the data between training and serving, and a feedback loop between the model and the algorithm. For example, if we have built a recommender system to recommend movies, we can then retrain the recommender later based on the movies users saw from the recommended list. The first two causes can be addressed by careful data management, while the third cause requires special attention when designing machine learning models.
It is possible that even after sufficient experimentation, we find that with the present features we cannot improve the model performance any further. However, to stay in business, continuous growth is necessary. Thus, when we find that our model performance has plateaued, it is time to look for new sources for improvements, instead of working with the existing features.
The software development process is never really “done.” Even after a product is launched, there are always going to be new features that could be added or existing features that could be improved. The same is true for machine learning models. Even after a model is “finished” and deployed to production, there will always be new data that can be used to train a better model. And as data changes over time, the model will need to be retrained on new data to remain accurate. Therefore, it’s important to think of machine learning models as being in a constant state of flux. It’s never really “done” until you stop working on it.
As we build our model, it is important to think about how easy it is to add or remove features. Can we easily create a fresh copy of the pipeline and verify its correctness? Is it possible to have two or three copies of the model running in parallel? These are all important considerations when building our model. By thinking about these things upfront, we can save ourselves a lot of time and effort down the line.
Summary
In this chapter, we focused on the strategies and rules to follow to get the best performance from your models. The list here is not exhaustive, and since AI technology is still maturing, in the years to come we may see more rules and heuristics emerge. Still, if you follow the advice in the chapter, you will be able to move from the alchemical nature of AI models to more reliable, robust, and reproducible behavior.
In the next chapter, we will explore the TensorFlow ecosystem and see how we can integrate all that is covered in this book into practical business applications.
References
- Soni, N., Sharma, E. K., Singh, N., and Kapoor, A. (2020). Artificial intelligence in business: from research and innovation to market deployment. Procedia Computer Science, 167, 2200–2210.
- Feng, S. Y., Gangal, V., Wei, J., Chandar, S., Vosoughi, S., Mitamura, T., and Hovy, E. (2021). A survey of data augmentation approaches for NLP. arXiv preprint arXiv:2105.03075.
- Sennrich, R., Haddow, B., and Birch, A. (2016). Improving Neural Machine Translation Models with Monolingual Data. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 86–96, Berlin, Germany. Association for Computational Linguistics.
- Kumar, V., Choudhary, A., and Cho, E. (2020). Data augmentation using pre-trained transformer models. arXiv preprint arXiv:2003.02245.
- Park, D. S., Chan, W., Zhang, Y., Chiu, C. C., Zoph, B., Cubuk, E. D., and Le, Q. V. (2019). SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition. arXiv preprint arXiv:1904.08779.
- Rules of Machine Learning: Best practices for ML engineering. Martin Zinkewich. https://developers.google.com/machine-learning/guides/rules-of-ml
- Baird, H. S. (1995). Document image analysis. Chapter: Document Image Defect Models, pages 315–325. IEEE Computer Society Press, Los Alamitos, CA, USA.
Join our book’s Discord space
Join our Discord community to meet like-minded people and learn alongside more than 2000 members at: https://packt.link/keras
