
5
Advanced Querying
In the previous chapter, we learned how to use MongoDB for auditing and the difference in semantics between logging and auditing. In this chapter, we will dive deeper into using MongoDB with drivers and popular frameworks from Ruby, Python, and Hypertext Preprocessor (PHP).
We will also show the best practices for using these languages, and the variety of comparison and update operators that MongoDB supports at the database level, all of which can be accessed via Ruby, Python, and PHP.
Finally, we will learn about change streams, a MongoDB feature that we can use to stream database changes to our application in real time.
In this chapter, we will cover the following topics:
- MongoDB CRUD operations
- Change streams
Technical requirements
To follow along with the code in this chapter, you need to install MongoDB locally or connect to a MongoDB Atlas database. You can download the MongoDB Community Edition from mongodb.com or use the fully managed DBaaS MongoDB Atlas offering, which provides a free tier as well as seamless upgrades to the latest version.
You will also need to download the official drivers for the language of your choice – Ruby, Python, or PHP. You can find all the code from this chapter in this book’s GitHub repository at https://github.com/PacktPublishing/Mastering-MongoDB-6.x.
MongoDB CRUD operations
In this section, we will cover CRUD operations while using Ruby, Python, and PHP with the official MongoDB driver and some popular frameworks for each language, respectively.
CRUD using the Ruby driver
In Chapter 3, MongoDB CRUD Operations, we covered how to connect to MongoDB from Ruby, Python, and PHP using the respective drivers and object document mapping (ODM). In this chapter, we will explore the create, read, update, and delete operations while using the official drivers and the most commonly used ODM frameworks.
Creating documents
Using the process described in Chapter 2, Schema Design and Data Modeling, we assume that we have an @collection instance variable pointing to our books collection in a mongo_book database in the 127.0.0.1:27017 default database:
@collection = Mongo::Client.new([ '127.0.0.1:27017' ], :database => 'mongo_book').database[:books]
Let’s insert a single document with our definition, as follows:
document = { isbn: '101', name: 'Mastering MongoDB', price: 30}This can be performed with a single line of code, as follows:
result = @collection.insert_one(document)
The resulting object is a Mongo::Operation::Result class with content that is similar to what we had in the shell, as shown in the following code:
{"n"=>1, "ok"=>1.0}Here, n is the number of affected documents; 1 means we inserted one object, while ok means 1 (true).
Creating multiple documents in one step is similar to this. For two documents with isbn values of 102 and 103, and using insert_many instead of insert_one, we have the following code:
documents = [ { isbn: '102', name: 'MongoDB in 7 years', price: 50 }, { isbn: '103', name: 'MongoDB for experts', price: 40 } ]result = @collection.insert_many(documents)
The resulting object is now a Mongo::BulkWrite::Result class, meaning that the BulkWrite interface was used for improved performance.
The main difference is that we now have an attribute, inserted_ids,, which will return ObjectId of the inserted objects from the BSON::ObjectId class.
Reading data
Finding documents works in the same way as creating them – that is, at the collection level:
@collection.find( { isbn: '101' } )Multiple search criteria can be chained and are equivalent to the AND operator in SQL:
@collection.find( { isbn: '101', name: 'Mastering MongoDB' } )The mongo-ruby-driver API provides several query options to enhance queries; the most widely used query options are listed in the following table:
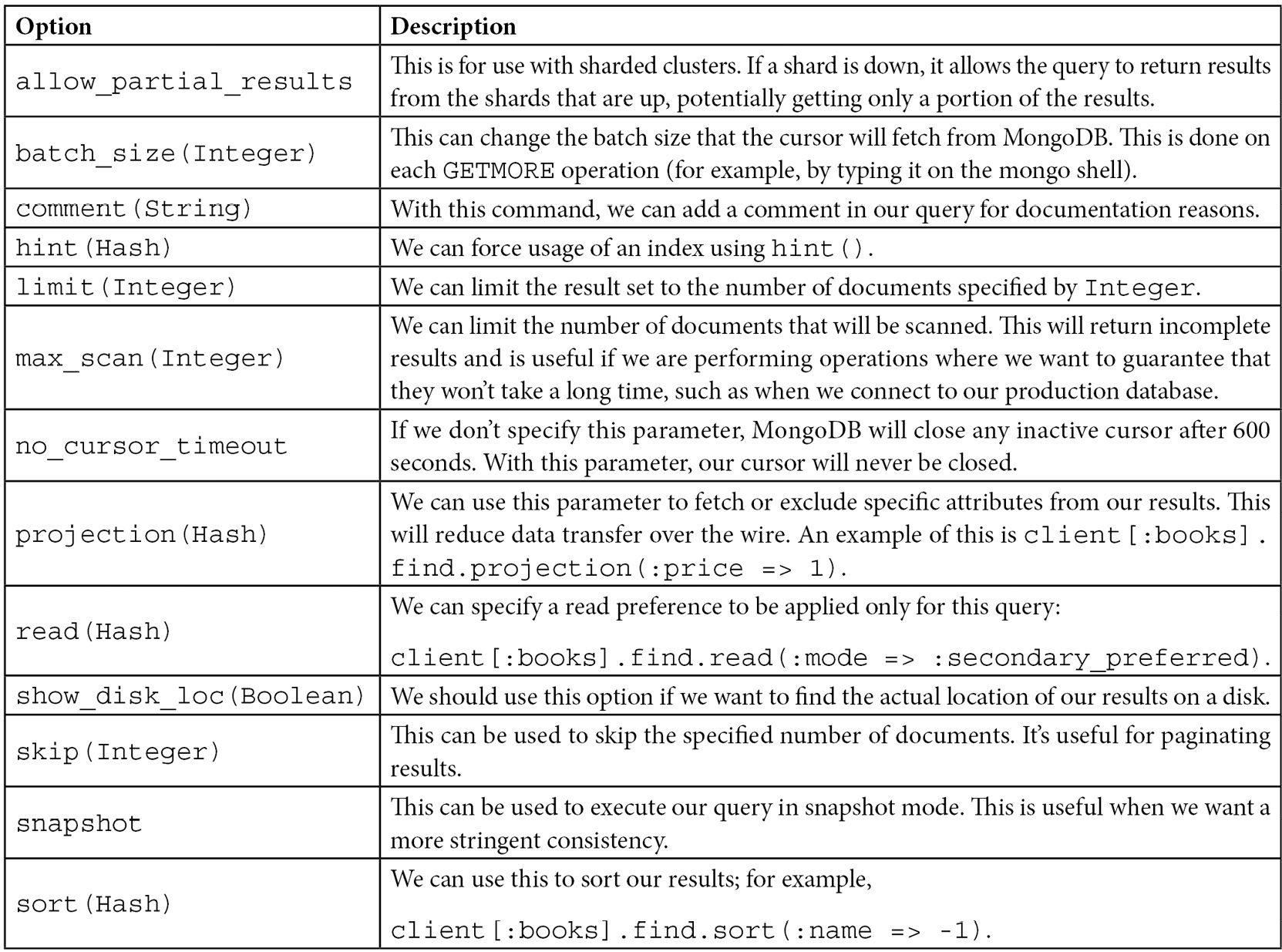
Table 5.1 – MongoDB Ruby client query options
On top of the query options, mongo-ruby-driver provides some helper functions that can be chained at the method call level, as follows:
- .count: The total count for the preceding query
- .distinct(:field_name): To distinguish between the results of the preceding query by :field_name
find() returns a cursor containing the result set that we can iterate using .each in Ruby, such as every other object:
result = @collection.find({ isbn: '101' })result.each do |doc|
puts doc.inspect
end
The output for our books collection is as follows:
{"_id"=>BSON::ObjectId('592149c4aabac953a3a1e31e'), "isbn"=>"101", "name"=>"Mastering MongoDB", "price"=>30.0, "published"=>2017-06-25 00:00:00 UTC}
Chaining operations in find()
find(), by default, uses an AND operator to match multiple fields. If we want to use an OR operator, our query needs to be as follows:
result = @collection.find('$or' => [{ isbn: '101' }, { isbn: '102' }]).to_aputs result
The output of the preceding code is as follows:
{"_id"=>BSON::ObjectId('592149c4aabac953a3a1e31e'), "isbn"=>"101", "name"=>"Mastering MongoDB", "price"=>30.0, "published"=>2017-06-25 00:00:00 UTC}{"_id"=>BSON::ObjectId('59214bc1aabac954263b24e0'), "isbn"=>"102", "name"=>"MongoDB in 7 years", "price"=>50.0, "published"=>2017-06-26 00:00:00 UTC}
We can also use $and instead of $or in the previous example:
result = @collection.find('$and' => [{ isbn: '101' }, { isbn: '102' }]).to_aputs result
This, of course, will return no results since no document can have isbn values of 101 and 102.
An interesting and hard bug to find is if we define the same key multiple times, such as in the following code:
result = @collection.find({ isbn: '101', isbn: '102' })puts result
The output of the preceding code is as follows:
{"_id"=>BSON::ObjectId('59214bc1aabac954263b24e0'), "isbn"=>"102", "name"=>"MongoDB in 7 years", "price"=>50.0, "published"=>2017-06-26 00:00:00 UTC}
In comparison, the opposite order will cause the document with an isbn value of 101 to be returned:
result = @collection.find({ isbn: '102', isbn: '101' })puts result
The output of the preceding code is as follows:
{"_id"=>BSON::ObjectId('592149c4aabac953a3a1e31e'), "isbn"=>"101", "name"=>"Mastering MongoDB", "price"=>30.0, "published"=>2017-06-25 00:00:00 UTC}
Note
This is because in Ruby hashes, by default, all duplicated keys except for the last one are silently ignored. This may not happen in the simplistic form shown in the preceding example, but it is prone to happen if we create keys programmatically.
Nested operations
Accessing embedded documents in mongo-ruby-driver is as simple as using the dot notation:
result = @collection.find({'meta.authors': 'alex giamas'}).to_aputs result
The output of the preceding code is as follows:
"_id"=>BSON::ObjectId('593c24443c8ca55b969c4c54'), "isbn"=>"201", "name"=>"Mastering MongoDB, 3rd Edition", "meta"=>{"authors"=>"alex giamas"}}
Note
We need to enclose the key name in quotes ('') to access the embedded object, just as we need it for operations starting with $, such as '$set'.
Updating data
Updating documents using mongo-ruby-driver is chained to finding them. Using our example books collection, we can do the following:
@collection.update_one( { 'isbn': 101}, { '$set' => { name: 'Mastering MongoDB, 3rd Edition' } } )This finds the document with an isbn value of 101 and changes its name to Mastering MongoDB, 3rd Edition.
In a similar way to update_one, we can use update_many to update multiple documents retrieved via the first parameter of the method.
Note
If we don’t use the $set operator, the contents of the document will be replaced by the new document.
With any Ruby version 2.2 or later, keys can be either quoted or unquoted; however, keys that start with $ need to be quoted as follows:
@collection.update( { isbn: '101'}, { "$set": { name: "Mastering MongoDB, 3rd edition" } } )The resulting object of an update will contain information about the operation, including the following methods:
- ok?: A Boolean value that shows whether the operation was successful or not
- matched_count: The number of documents matching the query
- modified_count: The number of documents affected (updated)
- upserted_count: The number of documents upserted if the operation includes $set
- upserted_id: The unique ObjectId of the upserted document if there is one
Updates that modify fields of a constant data size will be in place; this means that they won’t move the document from its physical location on the disk. This includes operations such as $inc and $set on the Integer and Date fields.
Updates that can increase the size of a document may result in the document being moved from its physical location on the disk to a new location at the end of the file. In this case, queries may miss or return the document multiple times. To avoid this, we can use $snapshot: true while querying.
Deleting data
Deleting documents works in a similar way to finding documents. We need to find documents and then apply the delete operation.
For example, with our books collection, which we used previously, we can issue the following code:
@collection.find( { isbn: '101' } ).delete_oneThis will delete a single document. In our case, since isbn is unique for every document, this is expected. If our find() clause had matched multiple documents, then delete_one would have deleted just the first one that find() returned, which may or may not have been what we wanted.
Note
If we use delete_one with a query matching multiple documents, the results may be unexpected.
If we want to delete all documents matching our find() query, we have to use delete_many, as follows:
@collection.find( { price: { $gte: 30 } ).delete_manyIn the preceding example, we are deleting all books that have a price greater than or equal to 30.
Batch operations
We can use the BulkWrite API for batch operations. In our previous insert many documents example in the first section of this chapter, Creating documents, this would be as follows:
@collection.bulk_write([ { insertMany: documents}],
ordered: true)
The BulkWrite API can take the following parameters:
- insertOne
- updateOne
- updateMany
- replaceOne
- deleteOne
- deleteMany
One version of these commands will insert/update/replace/delete a single document, even if the filter that we specify matches more than one document. In this case, it’s important to have a filter that matches a single document to avoid unexpected behaviors.
It’s also possible, and a perfectly valid use case, to include several operations in the first argument of the bulk_write command. This allows us to issue commands in a sequence when we have operations that depend on each other, and we want to batch them in a logical order according to our business logic. Any error will stop ordered:true batch writes, and we will need to manually roll back our operations. A notable exception is writeConcern errors – for example, requesting a majority of our replica set members to acknowledge our write. In this case, batch writes will go through, and we can observe the errors in the writeConcernErrors result field:
old_book = @collection.findOne(name: 'MongoDB for experts')
new_book = { isbn: 201, name: 'MongoDB for experts, 3rd Edition', price: 55 }@collection.bulk_write([ {deleteOne: old_book}, { insertOne: new_book}],
ordered: true)
In the previous example, we made sure that we deleted the original book before adding the new (and more expensive) edition of our MongoDB for experts book.
BulkWrite can batch up to 1,000 operations. If we have more than 1,000 underlying operations in our commands, these will be split into chunks of thousands. It is good practice to try to keep our write operations to a single batch if we can, to avoid unexpected behavior.
CRUD in Mongoid
In this section, we will use Mongoid to perform create, read, update, and delete operations. All of this code is also available on GitHub at https://github.com/PacktPublishing/Mastering-MongoDB-6.x/tree/main/chapter_5.
Reading data
Back in Chapter 2, Schema Design and Data Modeling, we described how to install, connect, and set up models, including inheritance, in Mongoid. Here, we will go through the most common use cases of CRUD.
Finding documents is done using a DSL similar to Active Record (AR). As with AR, where a relational database is used, Mongoid assigns a class to a MongoDB collection (a table) and any object instance to a document (a row from a relational database):
Book.find('592149c4aabac953a3a1e31e')This will find the document by ObjectId and return the document with isbn 101, as will the query by a name attribute:
Book.where(name: 'Mastering MongoDB')
In a similar fashion to the dynamically generated AR queries by an attribute, we can use the helper method:
Book.find_by(name: 'Mastering MongoDB')
This queries by attribute name, which is equivalent to the previous query.
We should enable QueryCache to avoid hitting the database for the same query multiple times, as follows:
Mongoid::QueryCache.enabled = true
This can be added to any code block that we want to enable, or to the initializer for Mongoid.
Scoping queries
We can scope queries in Mongoid using class methods, as follows:
Class Book
...
def self.premium
where(price: {'$gt': 20'})end
End
Then, we can use the following query:
Book.premium
This will query for books with a price greater than 20.
Create, update, and delete
The Ruby interface for creating documents is similar to an AR:
Book.where(isbn: 202, name: 'Mastering MongoDB, 3rd Edition').create
This will return an error if the creation fails.
We can use the bang version to force an exception to be raised if saving the document fails:
Book.where(isbn: 202, name: 'Mastering MongoDB, 3rd Edition').create!
The BulkWrite API is not supported as of Mongoid version 6.x. The workaround is to use the mongo-ruby-driver API, which will not use the mongoid.yml configuration or custom validations. Otherwise, you can use insert_many([array_of_documents]), which will insert the documents one by one.
To update documents, we can use update or update_all. Using update will update only the first document retrieved by the query part, whereas update_all will update all of them:
Book.where(isbn: 202).update(name: 'Mastering MongoDB, 3rd Edition')
Book.where(price: { '$gt': 20 }).update_all(price_range: 'premium')Deleting a document is similar to creating it – we provide delete to skip callbacks and destroy if we want to execute any available callbacks in the affected document.
delete_all and destroy_all are convenient methods for multiple documents.
Note
destroy_all should be avoided, if possible, as it will load all documents into memory to execute callbacks and thus can be memory-intensive.
CRUD using the Python driver
PyMongo is the officially supported driver for Python by MongoDB. In this section, we will use PyMongo to create, read, update, and delete documents in MongoDB.
Creating and deleting data
The Python driver provides methods for CRUD just like Ruby and PHP. Following on from Chapter 2, Schema Design and Data Modeling, and the books variable that points to our books collection, we will write the following code block:
from pymongo import MongoClient
from pprint import pprint
>>> book = {'isbn': '301',
'name': 'Python and MongoDB',
'price': 60
}
>>> insert_result = books.insert_one(book)
>>> pprint(insert_result)
<pymongo.results.InsertOneResult object at 0x104bf3370>
>>> result = list(books.find())
>>> pprint(result)
[{u'_id': ObjectId('592149c4aabac953a3a1e31e'),u'isbn': u'101',
u'name': u'Mastering MongoDB',
u'price': 30.0,
u'published': datetime.datetime(2017, 6, 25, 0, 0)},
{u'_id': ObjectId('59214bc1aabac954263b24e0'),u'isbn': u'102',
u'name': u'MongoDB in 7 years',
u'price': 50.0,
u'published': datetime.datetime(2017, 6, 26, 0, 0)},
{u'_id': ObjectId('593c24443c8ca55b969c4c54'),u'isbn': u'201',
u'meta': {u'authors': u'alex giamas'},u'name': u'Mastering MongoDB, 3rd Edition'},
{u'_id': ObjectId('594061a9aabac94b7c858d3d'),u'isbn': u'301',
u'name': u'Python and MongoDB',
u'price': 60}]
In the previous example, we used insert_one() to insert a single document, which we can define using the Python dictionary notation; we can then query it for all the documents in the collection.
The resulting object for insert_one and insert_many has two fields of interest:
- Acknowledged: A Boolean that is true if the insert has succeeded and false if it hasn’t, or if the write concern is 0 (a fire and forget write).
- inserted_id for insert_one: The ObjectId property of the written document and the inserted_id properties for insert_many. This is the array of ObjectIds of the written documents.
We used the pprint library to pretty-print the find() results. The built-in way to iterate through the result set is by using the following code:
for document in results:
print(document)
Deleting documents works in a similar way to creating them. We can use delete_one to delete the first instance or delete_many to delete all instances of the matched query:
>>> result = books.delete_many({ "isbn": "101" })>>> print(result.deleted_count)
1
The deleted_count instance tells us how many documents were deleted; in our case, it is 1, even though we used the delete_many method.
To delete all documents from a collection, we can pass in the empty document, {}.
To drop a collection, we can use drop():
>>> books.delete_many({})>>> books.drop()
Finding documents
To find documents based on top-level attributes, we can simply use a dictionary:
>>> books.find({"name": "Mastering MongoDB"})[{u'_id': ObjectId('592149c4aabac953a3a1e31e'),u'isbn': u'101',
u'name': u'Mastering MongoDB',
u'price': 30.0,
u'published': datetime.datetime(2017, 6, 25, 0, 0)}]
To find documents in an embedded document, we can use dot notation. In the following example, we are using meta.authors to access the authors embedded document inside the meta document:
>>> result = list(books.find({"meta.authors": {"$regex": "aLEx", "$options": "i"}}))>>> pprint(result)
[{u'_id': ObjectId('593c24443c8ca55b969c4c54'),u'isbn': u'201',
u'meta': {u'authors': u'alex giamas'},u'name': u'Mastering MongoDB, 3rd Edition'}]
In this example, we used a regular expression to match aLEx, which is case insensitive, in every document where the string is mentioned in the meta.authors embedded document. PyMongo uses this notation for regular expression queries, called the $regex notation in MongoDB documentation. The second parameter is the options parameter for $regex, which we will explain in detail in the Using regular expressions section later in this chapter.
Comparison operators are also supported, and a full list of these is given in the Comparison operators section, later in this chapter:
>>> result = list(books.find({ "price": { "$gt":40 } }))>>> pprint(result)
[{u'_id': ObjectId('594061a9aabac94b7c858d3d'),u'isbn': u'301',
u'name': u'Python and MongoDB',
u'price': 60}]
Let’s add multiple dictionaries to our query results in a logical AND query:
>>> result = list(books.find({"name": "Mastering MongoDB", "isbn": "101"}))>>> pprint(result)
[{u'_id': ObjectId('592149c4aabac953a3a1e31e'),u'isbn': u'101',
u'name': u'Mastering MongoDB',
u'price': 30.0,
u'published': datetime.datetime(2017, 6, 25, 0, 0)}]
For books that have both isbn=101 and name=Mastering MongoDB, to use logical operators such as $or and $and, we must use the following syntax:
>>> result = list(books.find({"$or": [{"isbn": "101"}, {"isbn": "102"}]}))>>> pprint(result)
[{u'_id': ObjectId('592149c4aabac953a3a1e31e'),u'isbn': u'101',
u'name': u'Mastering MongoDB',
u'price': 30.0,
u'published': datetime.datetime(2017, 6, 25, 0, 0)},
{u'_id': ObjectId('59214bc1aabac954263b24e0'),u'isbn': u'102',
u'name': u'MongoDB in 7 years',
u'price': 50.0,
u'published': datetime.datetime(2017, 6, 26, 0, 0)}]
For books that have an isbn value of 101 or 102, if we want to combine the AND and OR operators, we must use the $and operator, as follows:
>>> result = list(books.find({"$or": [{"$and": [{"name": "Mastering MongoDB", "isbn": "101"}]}, {"$and": [{"name": "MongoDB in 7 years", "isbn": "102"}]}]}))>>> pprint(result)
[{u'_id': ObjectId('592149c4aabac953a3a1e31e'),u'isbn': u'101',
u'name': u'Mastering MongoDB',
u'price': 30.0,
u'published': datetime.datetime(2017, 6, 25, 0, 0)},
{u'_id': ObjectId('59214bc1aabac954263b24e0'),u'isbn': u'102',
u'name': u'MongoDB in 7 years',
u'price': 50.0,
u'published': datetime.datetime(2017, 6, 26, 0, 0)}]
For a result of OR between two queries, consider the following:
- The first query is asking for documents that have isbn=101 AND name=Mastering MongoDB
- The second query is asking for documents that have isbn=102 AND name=MongoDB in 7 years
- The result is the union of these two datasets
Updating documents
In the following code block, you can see an example of updating a single document using the update_one helper method.
This operation matches one document in the search phase and modifies one document based on the operation to be applied to the matched documents:
>>> result = books.update_one({"isbn": "101"}, {"$set": {"price": 100}})>>> print(result.matched_count)
1
>>> print(result.modified_count)
1
In a similar way to inserting documents, when updating documents, we can use update_one or update_many:
- The first argument here is the filter document for matching the documents that will be updated
- The second argument is the operation to be applied to the matched documents
- The third (optional) argument is to use upsert=false (the default) or true, which is used to create a new document if it’s not found
Another interesting argument is bypass_document_validation=false (the default) or true, which is optional. This will ignore validations (if there are any) for the documents in the collection.
The resulting object will have matched_count for the number of documents that matched the filter query, and modified_count for the number of documents that were affected by the update part of the query.
In our example, we are setting price=100 for the first book with isbn=101 through the $set update operator. A list of all update operators can be found in the Update operators section later in this chapter.
Note
If we don’t use an update operator as the second argument, the contents of the matched document will be entirely replaced by the new document.
CRUD using PyMODM
PyMODM is a core ODM that provides simple and extensible functionality. It is developed and maintained by MongoDB’s engineers who get fast updates and support for the latest stable version of MongoDB available.
In Chapter 2, Schema Design and Data Modeling, we explored how to define different models and connect to MongoDB. CRUD, when using PyMODM, as with every ODM, is simpler than when using low-level drivers.
Creating documents
A new user object, as defined in Chapter 2, Schema Design and Data Modeling, can be created with a single line:
>>> user = User('[email protected]', 'Alex', 'Giamas').save()In this example, we used positional arguments in the same order that they were defined in the user model to assign values to the user model attributes.
We can also use keyword arguments or a mix of both, as follows:
>>> user = User(email='[email protected]', 'Alex', last_name='Giamas').save()
Bulk saving can be done by passing in an array of users to bulk_create():
>>> users = [ user1, user2,...,userN]
>>> User.bulk_create(users)
Updating documents
We can modify a document by directly accessing the attributes and calling save() again:
>>> user.first_name = 'Alexandros'
>>> user.save()
If we want to update one or more documents, we must use raw() to filter out the documents that will be affected and chain update() to set the new values:
>>> User.objects.raw({'first_name': {'$exists': True}}) .update({'$set': {'updated_at': datetime.datetime.now()}})In the preceding example, we search for all User documents that have a first name and set a new field, updated_at, to the current timestamp. The result of the raw() method is QuerySet, a class used in PyMODM to handle queries and work with documents in bulk.
Deleting documents
Deleting an API is similar to updating it – by using QuerySet to find the affected documents and then chaining on a .delete() method to delete them:
>>> User.objects.raw({'first_name': {'$exists': True}}).delete()Querying documents
Querying is done using QuerySet, as described previously.
Some of the convenience methods that are available include the following:
- all()
- count()
- first()
- exclude(*fields): To exclude some fields from the result
- only(*fields): To include only some fields in the result (this can be chained for a union of fields)
- limit(limit)
- order_by(ordering)
- reverse(): If we want to reverse the order_by() order
- skip(number)
- values(): To return Python dict instances instead of model instances
By using raw(), we can use the same queries that we described in the previous PyMongo section for querying and still exploit the flexibility and convenience methods provided by the ODM layer.
CRUD using the PHP driver
In PHP, we should use the mongo-php-library driver instead of the deprecated MongoClient. The overall architecture was explained in Chapter 2, Schema Design and Data Modeling. Here, we will cover more details regarding the API and how we can perform CRUD operations using it.
Creating and deleting data
The following command will insert a single $document that contains an array of two key/value pairs, with the key names of isbn and name:
$document = array( "isbn" => "401", "name" => "MongoDB and PHP" );
$result = $collection->insertOne($document);
var_dump($result);
The output from the var_dump($result) command is as follows:
MongoDBInsertOneResult Object
(
[writeResult:MongoDBInsertOneResult:private] => MongoDBDriverWriteResult Object
(
[nInserted] => 1
[nMatched] => 0
[nModified] => 0
[nRemoved] => 0
[nUpserted] => 0
[upsertedIds] => Array
(
)
[writeErrors] => Array
(
)
[writeConcernError] =>
[writeConcern] => MongoDBDriverWriteConcern Object
(
)
)
[insertedId:MongoDBInsertOneResult:private] => MongoDBBSONObjectID Object
(
[oid] => 5941ac50aabac9d16f6da142
)
[isAcknowledged:MongoDBInsertOneResult:private] => 1
)
This rather lengthy output contains all the information that we may need. Here, we can insert the ObjectId property of the document, the number of inserted, matched, modified, removed, and upserted documents by fields prefixed with n, and information about writeError or writeConcernError.
There are also convenience methods in the $result object if we want to get this information:
- $result->getInsertedCount(): To get the number of inserted objects
- $result->getInsertedId(): To get the ObjectId property of the inserted document
We can also use the ->insertMany() method to insert many documents at once, as follows:
$documentAlpha = array( "isbn" => "402", "name" => "MongoDB and PHP, 3rd Edition" );
$documentBeta = array( "isbn" => "403", "name" => "MongoDB and PHP, revisited" );
$result = $collection->insertMany([$documentAlpha, $documentBeta]);
print_r($result);
(
[writeResult:MongoDBInsertManyResult:private] => MongoDBDriverWriteResult Object
(
[nInserted] => 2
[nMatched] => 0
[nModified] => 0
[nRemoved] => 0
[nUpserted] => 0
[upsertedIds] => Array
(
)
[writeErrors] => Array
(
)
[writeConcernError] =>
[writeConcern] => MongoDBDriverWriteConcern Object
(
)
)
[insertedIds:MongoDBInsertManyResult:private] => Array
(
[0] => MongoDBBSONObjectID Object
(
[oid] => 5941ae85aabac9d1d16c63a2
)
[1] => MongoDBBSONObjectID Object
(
[oid] => 5941ae85aabac9d1d16c63a3
)
)
[isAcknowledged:MongoDBInsertManyResult:private] => 1
)
Again, $result->getInsertedCount() will return 2, whereas $result->getInsertedIds() will return an array with the two newly created ObjectId properties:
array(2) {[0]=>
object(MongoDBBSONObjectID)#13 (1) {["oid"]=>
string(24) "5941ae85aabac9d1d16c63a2"
}
[1]=>
object(MongoDBBSONObjectID)#14 (1) {["oid"]=>
string(24) "5941ae85aabac9d1d16c63a3"
}
}
Deleting documents is a similar process to inserting documents, but it uses the deleteOne() and deleteMany() methods instead. An example of deleteMany() is as follows:
$deleteQuery = array( "isbn" => "401");
$deleteResult = $collection->deleteMany($deleteQuery);
print($deleteResult->getDeletedCount());
The following code block shows the output:
MongoDBDeleteResult Object
(
[writeResult:MongoDBDeleteResult:private] => MongoDBDriverWriteResult Object
(
[nInserted] => 0
[nMatched] => 0
[nModified] => 0
[nRemoved] => 2
[nUpserted] => 0
[upsertedIds] => Array
(
)
[writeErrors] => Array
(
)
[writeConcernError] =>
[writeConcern] => MongoDBDriverWriteConcern Object
(
)
)
[isAcknowledged:MongoDBDeleteResult:private] => 1
)
2
In this example, we used ->getDeletedCount() to get the number of affected documents, which is printed in the last line of the output.
BulkWrite
The new PHP driver supports the BulkWrite interface to minimize network calls to MongoDB:
$manager = new MongoDBDriverManager('mongodb://localhost:27017');$bulk = new MongoDBDriverBulkWrite(array("ordered" => true));$bulk->insert(array( "isbn" => "401", "name" => "MongoDB and PHP" ));
$bulk->insert(array( "isbn" => "402", "name" => "MongoDB and PHP, 3rd Edition" ));
$bulk->update(array("isbn" => "402"), array('$set' => array("price" => 15)));$bulk->insert(array( "isbn" => "403", "name" => "MongoDB and PHP, revisited" ));
$result = $manager->executeBulkWrite('mongo_book.books', $bulk);print_r($result);
The result is as follows:
MongoDBDriverWriteResult Object
(
[nInserted] => 3
[nMatched] => 1
[nModified] => 1
[nRemoved] => 0
[nUpserted] => 0
[upsertedIds] => Array
(
)
[writeErrors] => Array
(
)
[writeConcernError] =>
[writeConcern] => MongoDBDriverWriteConcern Object
(
)
)
In the preceding example, we executed two inserts, one update, and a third insert in an ordered fashion. The WriteResult object contains a total of three inserted documents and one modified document.
The main difference compared to simple create/delete queries is that executeBulkWrite() is a method of the MongoDBDriverManager class, which we instantiate on the first line.
Read
Querying an interface is similar to inserting and deleting, with the findOne() and find() methods used to retrieve the first result or all results of a query:
$document = $collection->findOne( array("isbn" => "401") );$cursor = $collection->find( array( "name" => new MongoDBBSONRegex("mongo", "i") ) );In the second example, we are using a regular expression to search for a key name with the value, mongo (which is case insensitive).
Embedded documents can be queried using the . notation, as with the other languages that we examined earlier in this chapter:
$cursor = $collection->find( array('meta.price' => 50) );We are doing this to query for a price embedded document inside the meta key field.
Similar to Ruby and Python, in PHP, we can query using comparison operators, as shown in the following code:
$cursor = $collection->find( array( 'price' => array('$gte'=> 60) ) );A complete list of comparison operators supported in the PHP driver can be found at the end of this chapter.
Querying with multiple key-value pairs is an implicit AND, whereas queries that use $or, $in, $nin, or AND ($and) combined with $or can be achieved with nested queries:
$cursor = $collection->find( array( '$or' => array(
array("price" => array( '$gte' => 60)), array("price" => array( '$lte' => 20)))));
This finds documents that have price>=60 OR price<=20.
Updating documents
Updating documents has a similar interface to the ->updateOne() OR ->updateMany() method.
The first parameter is the query to find documents; the second one will update our documents.
We can use any of the update operators explained at the end of this chapter to update in place, or specify a new document to completely replace the document in the query:
$result = $collection->updateOne(
array( "isbn" => "401"),
array( '$set' => array( "price" => 39 ) )
);
Note
We can use single quotes or double quotes for key names, but if we have special operators starting with $, we need to use single quotes. We can use array( “key” => “value” ) or [“key” => “value”]. We prefer the more explicit array() notation in this book.
The ->getMatchedCount() and ->getModifiedCount() methods will return the number of documents matched in the query part, or the ones modified from the query. If the new value is the same as the existing value of a document, it will not be counted as modified.
CRUD using Doctrine
Following on from our Doctrine example in Chapter 2, Schema Design and Data Modeling, we will work on these models for CRUD operations.
Creating, updating, and deleting
Creating documents is a two-step process. First, we must create our document and set the attribute values:
$book = new Book();
$book->setName('MongoDB with Doctrine');$book->setPrice(45);
Following this, we must ask Doctrine to save $book in the next flush() call:
$dm->persist($book);
We can force save by manually calling flush(), as follows:
$dm->flush();
In this example, $dm is a DocumentManager object that we use to connect to our MongoDB instance, as follows:
$dm = DocumentManager::create(new Connection(), $config);
Updating a document is as easy as assigning values to the attributes:
$book->price = 39;
$book->persist($book);
This will save our MongoDB with Doctrine book with the new price of 39.
Updating documents in place uses the QueryBuilder interface.
Doctrine provides several helper methods around atomic updates, as follows:
- set($name, $value, $atomic = true)
- setNewObj($newObj)
- inc($name, $value)
- unsetField($field)
- push($field, $value)
- pushAll($field, array $valueArray)
- addToSet($field, $value)
- addManyToSet($field, array $values)
- popFirst($field)
- popLast($field)
- pull($field, $value)
- pullAll($field, array $valueArray)
update will, by default, update the first document found by the query. If we want to change multiple documents, we need to use ->updateMany():
$dm->createQueryBuilder('Book')->updateMany()
->field('price')->set(69) ->field('name')->equals('MongoDB with Doctrine')->getQuery()
->execute();
In the preceding example, we are setting the price of the book to 69 with name='MongoDB with Doctrine'. The list of comparison operators in Doctrine is available in the following Read section.
We can chain multiple comparison operators, resulting in an AND query and also multiple helper methods, resulting in updates to several fields.
Deleting a document is similar to creating it, as shown in the following code block:
$dm->remove($book);
Removing multiple documents is best done using the QueryBuilder interface, which we will explore further in the following section:
$qb = $dm->createQueryBuilder('Book');$qb->remove()
->field('price')->equals(50)->getQuery()
->execute();
Read
Doctrine provides a QueryBuilder interface for building queries for MongoDB. Given that we have defined our models as described in Chapter 2, Schema Design and Data Modeling, we can do this to obtain an instance of a QueryBuilder interface named $db, get a default find-all query, and execute it, as follows:
$qb = $dm->createQueryBuilder('Book');$query = $qb->getQuery();
$books = $query->execute();
The $books variable now contains an iterable lazy data-loading cursor over our result set.
Using $qb->eagerCursor(true); over the QueryBuilder object will return an eager cursor that fetches all the data from MongoDB as soon as we start iterating our results.
Some helper methods for querying are as follows:
- ->getSingleResult(): This is equivalent to findOne().
- ->select('name'): This returns only the values for the 'key' attribute from our books collection. ObjectId will always be returned.
- ->hint('book_name_idx'): This forces the query to use this index. We’ll see more about indexes in Chapter 7, Aggregation.
- ->distinct('name'): This returns distinct results by name.
- ->limit(10): This returns the first 10 results.
- ->sort('name', 'desc'): This sorts by name (such as desc or asc).
Doctrine uses the concept of hydration when fetching documents from MongoDB. Hydration defines the query’s result schema. We can, for example, configure hydration to return a collection of objects, a single scalar value, or an array of arrays representing different records. Using an identity map, it will cache MongoDB results in memory and consult this map before hitting the database. Disabling hydration can be done per query by using ->hydration(false) or globally using the configuration, as explained in Chapter 2, Schema Design and Data Modeling.
We can also force Doctrine to refresh data in the identity map for a query from MongoDB using ->refresh() on $qb.
The comparison operators that we can use with Doctrine are as follows:
- where($javascript)
- in($values)
- notIn($values)
- equals($value)
- notEqual($value)
- gt($value)
- gte($value)
- lt($value)
- lte($value)
- range($start, $end)
- size($size)
- exists($bool)
- type($type)
- all($values)
- mod($mod)
- addOr($expr)
- addAnd($expr)
- references($document)
- includesReferenceTo($document)
Consider the following query as an example:
$qb = $dm->createQueryBuilder('Book') ->field('price')->lt(30);This will return all books whose price is less than 30.
addAnd() may seem redundant since chaining multiple query expressions in Doctrine is implicitly AND, but it is useful if we want to do AND ( (A OR B), (C OR D) ), where A, B, C, and D are standalone expressions.
To nest multiple OR operators with an external AND query, and in other equally complex cases, the nested ORs need to be evaluated as expressions using ->expr():
$expression = $qb->expr()->field('name')->equals('MongoDB with Doctrine')$expression is a standalone expression that can be used with $qb->addOr($expression) and similarly with addAnd().
Best practices
Some best practices for using Doctrine with MongoDB are as follows:
- Don’t use unnecessary cascading.
- Don’t use unnecessary life cycle events.
- Don’t use special characters such as non-ASCII ones in class, field, table, or column names, as Doctrine is not Unicode-safe yet.
- Initialize collection references in the model’s constructor. Constrain relationships between objects as much as possible.
- Avoid bidirectional associations between models and eliminate the ones that are not needed. This helps with performance and loose coupling and produces simpler and more easily maintainable code.
The following is a list of all comparison operators that MongoDB supports as of version 6:
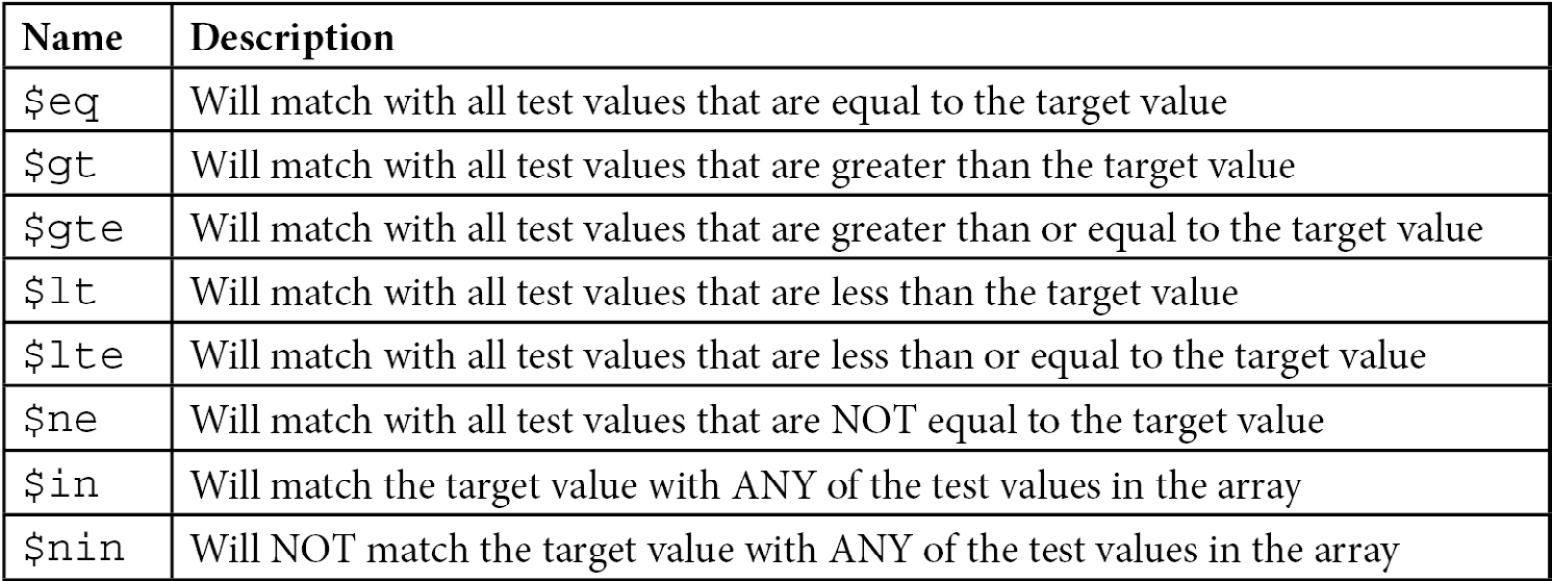
Table 5.2 – MongoDB comparison operators
Update operators
The following is a list of all update operators that MongoDB supports:

Table 5.3 – MongoDB update operators
Smart querying
There are several considerations that we have to take into account when querying in MongoDB. Let’s look at some best practices for using regular expressions, query results, and cursors, and when deleting documents.
Using regular expressions
MongoDB offers a rich interface for querying using regular expressions. In its simplest form, we can use regular expressions in queries by modifying the query string:
> db.books.find({"name": /mongo/})
This is done to search for books in our books collection that contain the mongo name. It is the equivalent of a SQL LIKE query.
Note/Tip/Important Note
MongoDB uses Perl Compatible Regular Expression (PCRE) version 8.42 with UTF-8 support.
We can also use some options when querying:

Table 5.4 – Querying options
In our previous example, if we wanted to search for mongo, Mongo, MONGO, or any other case-insensitive variation, we would need to use the i option, as follows:
> db.books.find({"name": /mongo/i})
Alternatively, we can use the $regex operator, which provides more flexibility.
The same queries using $regex will be written as follows:
> db.books.find({'name': { '$regex': /mongo/ } })
> db.books.find({'name': { '$regex': /mongo/i } })
By using the $regex operator, we can also use the options shown in the following table:

Table 5.5 – Regular expressions – additional operators
Expanding matching documents using regex makes our queries slower to execute.
Indexes that use regular expressions can only be used if our regular expression does queries for the beginning of a string that is indexed; that is, regular expressions starting with ^ or A. If we only want to query using a starts with regular expression, we should avoid writing lengthier regular expressions, even if they will match the same strings.
Take the following code block as an example:
> db.books.find({'name': { '$regex': /mongo/ } })
> db.books.find({'name': { '$regex': /^mongo.*/ } })
Both queries will match name values starting with mongo (case-sensitive), but the first one will be faster as it will stop matching as soon as it hits the sixth character in every name value.
Querying results and cursors
MongoDB does not follow relational database transaction semantics by default. Instead, MongoDB queries will not belong to a transaction unless we explicitly define a transaction wrapper, as explained in Chapter 6, Multi-Document ACID Transactions.
Updates can modify the size of a document. Modifying the size can result in MongoDB moving the document on the disk to a new slot toward the end of the storage file.
When we have multiple threads querying and updating a single collection, we can end up with a document appearing multiple times in the result set.
This will happen in the following scenarios:
- Thread A starts querying the collection and matches the A1 document.
- Thread B updates the A1 document, increasing its size and forcing MongoDB to move it to a different physical location toward the end of the storage file.
- Thread A is still querying the collection. It reaches the end of the collection and finds the A1 document again with its new value, as shown here:
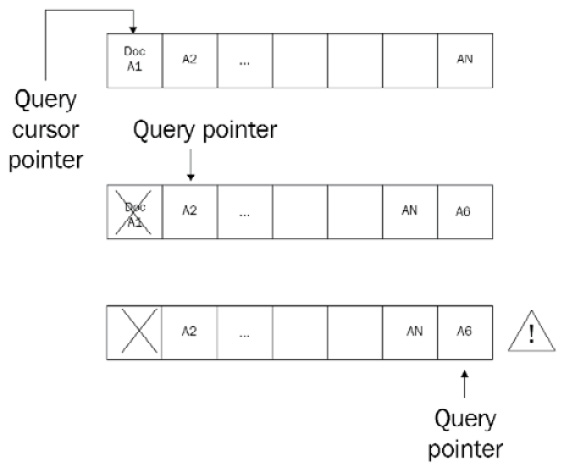
Figure 5.1 – Cursors and querying
This is rare, but it can happen in production; if we can’t safeguard from such a case in the application layer, we can use hint( { $natural : 1 } ) to prevent it.
hint( { $natural : 1 } ) is supported by official drivers and the shell by appending it into an operation that returns a cursor:
> db.books.find().hint( { $natural : 1 } )
The older snapshot() option has been removed and using $natural can return the results in ascending or descending order ( by substituting 1 with –1 in the order direction).
If our query runs on a unique index of a field whose values won’t be modified during the duration of the query, we should use this query to get the same query behavior. Even then, $natural cannot protect us from insertions or deletions happening in the middle of a query. The $natural operator will traverse the built-in index that every collection has on the id field, making it inherently slow. This should only be used as a last resort.
If we want to update, insert, or delete multiple documents without other threads seeing the results of our operation while it’s happening, we should use MongoDB transactions, as explained in the next chapter.
Storage considerations for the delete operation
Deleting documents in MongoDB does not reclaim the disk space used by it. If we have 10 GB of disk space used by MongoDB and we delete all documents, we will still be using 10 GB. Under the hood, MongoDB marks these documents as deleted and may use the space to store new documents.
This results in our disk having space that is not used but is not freed up for the operating system. If we want to claim it back, we can use compact():
> db.books.compact()
Alternatively, we can start the mongod server with the --repair option.
Another option is to enable compression, which is available from version 3.0 and only with the WiredTiger storage engine. We can use the snappy or zlib algorithms to compress our document’s size. This will, again, not prevent storage holes, but if we are tight on disk space, it is preferable to the heavy operational route of repair and compact.
Storage compression uses less disk space at the expense of CPU usage, but this trade-off is mostly worth it.
Note
Always take a backup before running operations that can result in a catastrophic loss of data. Repair or compact will run in a single thread, blocking the entire database from other operations. In production systems, always perform these on the secondary server first; then, switch the primary-secondary roles and compact the ex-primary, now-secondary instance.
In this section, we learned all the different ways we can query, update, insert, and delete documents in MongoDB using a range of languages with direct operations using the drivers or using ODM. In the next section, we will learn about change streams, a feature that allows our application to react immediately to changes in the underlying data.
Change streams
The change streams functionality was introduced in version 3.6 and updated in versions 4.0 and 5.1, making it a safe and efficient way to listen for database changes.
Introduction
The fundamental problem that change streams solve is the need for applications to react immediately to changes in the underlying data. Modern web applications need to be reactive to data changes and refresh the page view without reloading the entire page. This is one of the problems that frontend frameworks (such as Angular, React, and Vue.js) are solving. When a user performs an action, the frontend framework will submit the request to the server asynchronously and refresh the relevant fragment of the page based on the response from the server.
Thinking of a multiuser web application, there are cases where a database change may have occurred as a result of another user’s action. For example, in a project management Kanban board, user A may be viewing the Kanban board, while another user, B, may be changing the status of a ticket from “To do” to “In progress.”
User A’s view needs to be updated with the change that user B has performed in real time, without refreshing the page. There are already three approaches to this problem, as follows:
- The most simple approach is to poll the database every X number of seconds and determine if there has been a change. Usually, this code will need to use some kind of status, timestamp, or version number to avoid fetching the same change multiple times. This is simple, yet inefficient, as it cannot scale with a great number of users. Having thousands of users polling the database at the same time will result in a high database-locking rate.
- To overcome the problems imposed by the first approach, database-and application-level triggers have been implemented. A database trigger relies on the underlying database executing some code in response to a database change. However, the main downside is, again, similar to the first approach in that the more triggers that we add to a database, the slower our database will become. It is also coupled to the database, instead of being a part of the application code base.
- Finally, we can use the database transaction or replication log to query for the latest changes and react to them. This is the most efficient and scalable approach of the three as it doesn’t put a strain on the database. The database writes to this log anyway; it is usually appended only and our background task serially reads entries as they come into the log. The downside of this method is that it is the most complicated one to implement and one that can lead to nasty bugs if it’s not implemented properly.
Change streams provide a way to solve this problem that is developer-friendly and easy to implement and maintain. Change streams are based on the oplog, which is MongoDB’s operations log and contains every operation happening server-wide across all databases on the server. This way, the developer does not have to deal with the server-wide oplog or tailable cursors, which are often not exposed or as easy to develop from the MongoDB language-specific drivers. Also, the developer does not have to decipher and understand any of the internal oplog data structures that are designed and built for MongoDB’s benefit, and not for an application developer.
Change streams also have other advantages around security:
- Users can only create change streams on collections, databases, or deployments that they have read access to.
- Change streams are also idempotent by design. Even in the case that the application cannot fetch the absolute latest change stream event notification ID, it can resume applying from an earlier known one and it will eventually reach the same state.
- Finally, change streams are resumable. Every change stream response document includes a resume token. If the application gets out of sync with the database, it can send the latest resume token back to the database and continue processing from there. This token needs to be persisted in the application, as the MongoDB driver won’t keep application failures and restarts. It will only keep state and retry in case of transient network failures and MongoDB replica set elections.
Setup
A change stream can be opened against a collection, a database, or an entire deployment (such as a replica set or sharded cluster). A change stream will not react to changes in any system collection or any collection in the admin, config, and local databases.
A change stream requires a WiredTiger storage engine and replica set protocol version 1 (pv1). pv1 is the only supported version starting from MongoDB 4.0. Change streams are compatible with deployments that use encryption-at-rest.
Using change streams
To use a change stream, we need to connect to our replica set. A replica set is a prerequisite to using change streams. As change streams internally use the oplog, it’s not possible to work without it. Change streams will also output documents that won’t be rolled back in a replica set setting, so they need to follow a majority read concern. Either way, it’s a good practice to develop and test locally using a replica set, as this is the recommended deployment for production. As an example, we are going to use a signals collection within our database named streams.
We will use the following sample Python code:
from pymongo import MongoClient
class MongoExamples:
def __init__(self):
self.client = MongoClient('localhost', 27017)db = self.client.streams
self.signals = db.signals
# a basic watch on signals collection
def change_books(self):
with self.client.watch() as stream:
for change in stream:
print(change)
def main():
MongoExamples().change_books()
if __name__ == '__main__':
main()
We can open one Terminal and run it using python change_streams.py.
Then, in another Terminal, we connect to our MongoDB replica set using the following code:
> mongo
> use streams
> db.signals.insert({value: 114.3, signal:1})
Going back to our first Terminal window, we can now observe that the output is similar to the following code block:
{'_id': {'_data': '825BB7A25E0000000129295A1004A34408FB07864F8F960BF14453DFB98546645F696400645BB7A25EE10ED33145BCF7A70004'}, 'operationType': 'insert', 'clusterTime': Timestamp(1538761310, 1), 'fullDocument': {'_id': ObjectId('5bb7a25ee10ed33145bcf7a7'), 'value': 114.3, 'signal': 1.0}, 'ns': {'db': 'streams', 'coll': 'signals'}, 'documentKey': {'_id': ObjectId('5bb7a25ee10ed33145bcf7a7')}}
Here, we have opened a cursor that’s watching the entire streams database for changes. Every data update in our database will be logged and outputted in the console.
For example, if we go back to the mongo shell, we can issue the following code:
> db.a_random_collection.insert({test: 'bar'})
The Python code output should be similar to the following code:
{'_id': {'_data': '825BB7A3770000000229295A10044AB37F707D104634B646CC5810A40EF246645F696400645BB7A377E10ED33145BCF7A80004'}, 'operationType': 'insert', 'clusterTime': Timestamp(1538761591, 2), 'fullDocument': {'_id': ObjectId('5bb7a377e10ed33145bcf7a8'), 'test': 'bar'}, 'ns': {'db': 'streams', 'coll': 'a_random_collection'}, 'documentKey': {'_id': ObjectId('5bb7a377e10ed33145bcf7a8')}}
This means that we are getting notifications for every data update across all the collections in our database.
Now, we can change line 11 of our code to the following:
> with self.signals.watch() as stream:
This will result in only watching the signals collection, as should be the most common use case.
PyMongo’s watch command can take several parameters, as follows:
watch(pipeline=None, full_document='default', resume_after=None, max_await_time_ms=None, batch_size=None, collation=None, start_at_operation_time=None, session=None)
The most important parameters are as follows:
- Pipeline: This is an optional parameter that we can use to define an aggregation pipeline to be executed on each document that matches watch(). Because the change stream itself uses the aggregation pipeline, we can attach events to it. The aggregation pipeline events we can use are as follows:
$match
$project
$addFields
$replaceRoot
$redact
$replaceWith
$set
$unset
- Full_document: This is an optional parameter that we can use by setting it to 'updateLookup' to force the change stream to return a copy of the document as it has been modified in the fullDocument field, along with the document’s delta in the updateDescription field. The default None value will only return the document’s delta.
- start_at_operation_time: This is an optional parameter that we can use to only watch for changes that occurred at, or after, the specified timestamp.
- session: This is an optional parameter in case our driver supports passing a ClientSession object to watch for updates.
Change streams response documents have to be under 16 MB in size. This is a global limit in MongoDB for BSON documents and the change stream has to follow this rule.
Specification
The following document shows all of the possible fields that a change event response may or may not include, depending on the actual change that happened:
{ _id : { <BSON Object> },"operationType" : "<operation>",
"fullDocument" : { <document> }, "ns" : {"db" : "<database>",
"coll" : "<collection"
},
"documentKey" : { "_id" : <ObjectId> }, "updateDescription" : { "updatedFields" : { <document> },"removedFields" : [ "<field>", ... ]
}
"clusterTime" : <Timestamp>,
"txnNumber" : <NumberLong>,
"lsid" : {"id" : <UUID>,
"uid" : <BinData>
}
}
The most important fields are as follows:
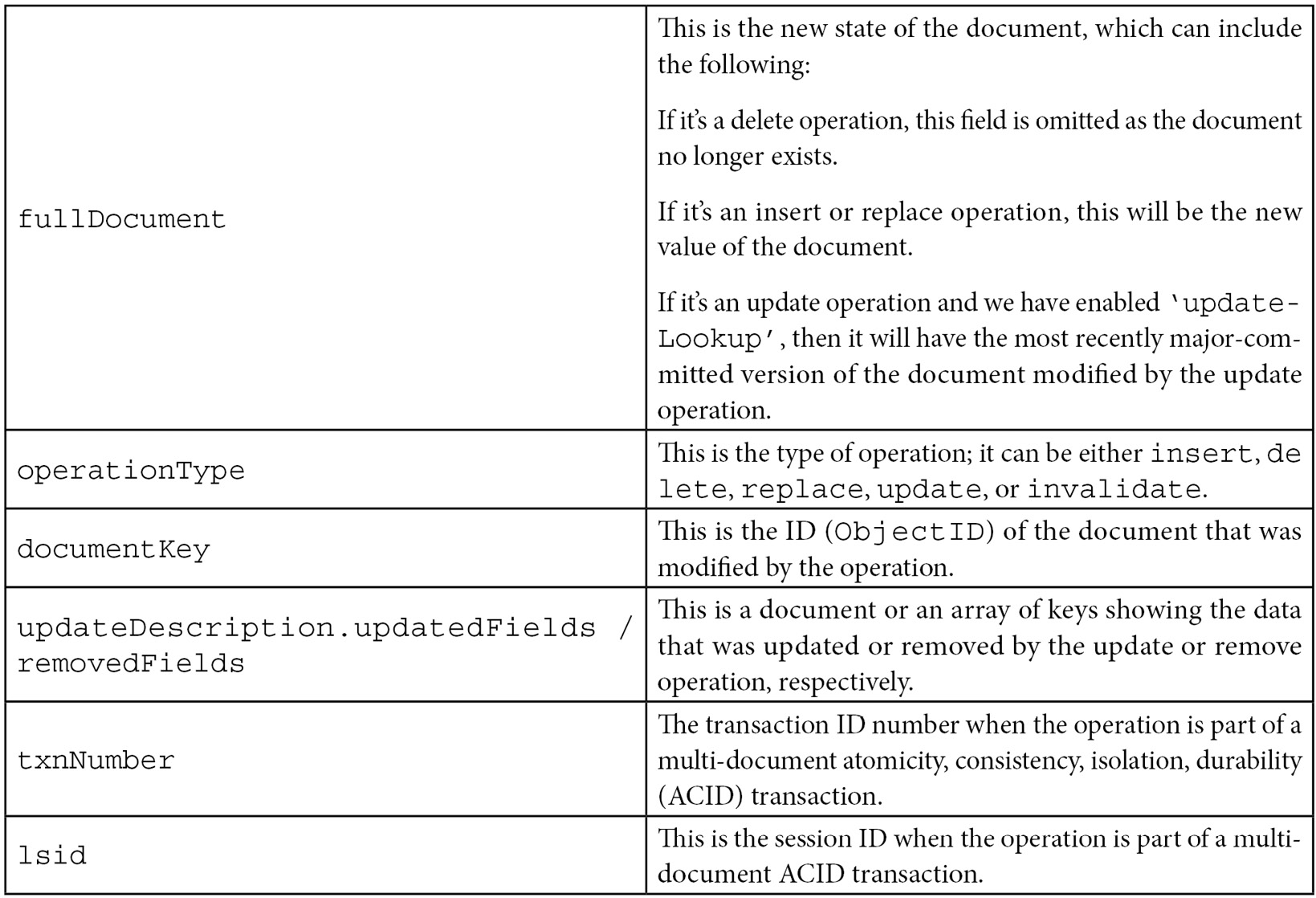
Table 5.6 – Change streams – the most common events
Important notes
When using a sharded database, change streams need to be opened against a MongoDB server. When using replica sets, a change stream can only be opened against any data-bearing instance. Each change stream will open a new connection, as of 4.0.2. If we want to have lots of change streams in parallel, we need to increase the connection pool (as per the SERVER-32946 JIRA MongoDB ticket) to avoid severe performance degradation.
Production recommendations
Let’s look at some of the best recommendations by MongoDB and expert architects at the time of writing.
Replica sets
Starting from MongoDB 4.2, a change stream can still be available even if the Read Concern of the majority is not satisfied. The way to enable this behavior is by setting { majority : false }.
Invalidating events, such as dropping or renaming a collection, will close the change stream. We cannot resume a change stream after an invalidating event closes it.
As the change stream relies on the oplog size, we need to make sure that the oplog size is large enough to hold events until they are processed by the application.
We can open a change stream operation against any data-bearing member in a replica set.
Sharded clusters
On top of the considerations for replica sets, there are a few more to keep in mind for sharded clusters. They are as follows:
- The change stream is executed against every shard in a cluster and will be as fast as the slowest shard
- To avoid creating change stream events for orphaned documents, we need to use the new feature of ACID-compliant transactions if we have multi-document updates under sharding
We can only open a change stream operation against the mongos member in a sharded cluster.
While sharding an unsharded collection (that is, migrating from a replica set to sharding), the documentKey property of the change stream notification document will include _id until the change stream catches up to the first chunk migration.
Queryable encryption
MongoDB 6 introduced end-to-end queryable encryption. Seny Kamara and Tarik Moataz, from Brown University, designed An Optimal Relational Database Encryption Scheme at Aroki Systems that was acquired by MongoDB in 2021.
Queryable encryption allows database queries, while transmitted, to be processed and stored data to ensure they are always encrypted. The developer uses the MongoDB driver the same way as always, but the driver handles encrypting the query and the database queries the data without ever decrypting the query or the data.
Queryable encryption allows developers to query encrypted data fields as easily as they would do with the non-encrypted fields without having to learn cryptography. It provides the fundamental controls to meet data privacy regulatory requirements such as GDPR, HIPAA, CCPA, and other related legislation. It can reduce operational risk for migrating on-premise datasets to the cloud by providing the peace of mind that data will be encrypted end to end, from querying and at rest, to in-transit data processing.
The closest equivalent to queryable encryption is homomorphic encryption, which also allows computations to be performed on encrypted data without the need to decrypt them. One of the most advanced libraries in the field is Microsoft SEAL (https://github.com/microsoft/SEAL/) which, as of Summer 2022, is far more complex and less feature complete than MongoDB’s offering. Other notable implementations are IBM security’s Fully Homomorphic Encryption (FHE) and the SDK developed by zama.ai.
The way that queryable encryption is implemented in MongoDB is that the driver needs to connect to a customer-provisioned key provider. This can be a cloud provider Key Management System (for example, AWS KMS or Azure Key Vault), or an on-premises HSM/key service provider. From that point of view, the client-server communication, querying, and data transmission are completely transparent to the developer.
MongoDB Atlas and the Enterprise version support automatic encryption, while the Community Edition requires writing application code to encrypt and decrypt the data fields at the time of writing.
At the time of writing, MongoDB drivers support the following methods with queryable encryption:
- aggregate
- count
- delete
- distinct
- explain
- find
- findAndModify
- insert
- update
These methods support the following operators:
- $eq
- $ne
- $in
- $nin
- $and
- $or
- $not
- $nor
- $set
- $unset
Aggregation supports the following stages:
- $addFields
- $bucket
- $bucketAuto
- $collStats
- $count
- $geoNear
- $indexStats
- $limit
- $match
- $project
- $redact
- $replaceRoot
- $sample
- $skip
- $sort
- $sortByCount
- $unwind
- $group (with limitations)
- $lookup (with limitations)
- $graphLookup (with limitations)
These stages support the following aggregation expressions:
- $cond
- $eq
- $ifNull
- $in
- $let
- $literal
- $ne
- $switch
Support will greatly improve in subsequent versions. The MongoDB official documentation at https://www.mongodb.com/docs/manual/core/queryable-encryption/ is the best place to keep up to date with the latest progress.
Summary
In this chapter, we went through advanced querying concepts while using Ruby, Python, and PHP alongside the official drivers and an ODM.
Using Ruby and the Mongoid ODM, Python and the PyMODM ODM, and PHP and the Doctrine ODM, we went through code samples to explore how to create, read, update, and delete documents.
We also discussed batching operations for performance and best practices. We presented an exhaustive list of comparison and update operators that MongoDB uses.
Following that, we discussed smart querying, how cursors in querying work, what our storage performance considerations should be on delete, and how to use regular expressions.
Next, we discussed change streams and how we can use them to subscribe and receive updates in our database in real time.
Finally, we learned about one of the major features that was introduced in MongoDB 6: queryable encryption.
In the next chapter, we will learn about the aggregation framework by covering a complete use case that involves processing transaction data from the Ethereum blockchain.
|
Option |
Description |
|
allow_partial_results |
This is for use with sharded clusters. If a shard is down, it allows the query to return results from the shards that are up, potentially getting only a portion of the results. |
|
batch_size(Integer) |
This can change the batch size that the cursor will fetch from MongoDB. This is done on each GETMORE operation (for example, by typing it on the mongo shell). |
|
comment(String) |
With this command, we can add a comment in our query for documentation reasons. |
|
hint(Hash) |
We can force usage of an index using hint(). |
|
limit(Integer) |
We can limit the result set to the number of documents specified by Integer. |
|
max_scan(Integer) |
We can limit the number of documents that will be scanned. This will return incomplete results and is useful if we are performing operations where we want to guarantee that they won’t take a long time, such as when we connect to our production database. |
|
no_cursor_timeout |
If we don’t specify this parameter, MongoDB will close any inactive cursor after 600 seconds. With this parameter, our cursor will never be closed. |
|
projection(Hash) |
We can use this parameter to fetch or exclude specific attributes from our results. This will reduce data transfer over the wire. An example of this is client[:books].find.projection(:price => 1). |
|
read(Hash) |
We can specify a read preference to be applied only for this query: client[:books].find.read(:mode => :secondary_preferred). |
|
show_disk_loc(Boolean) |
We should use this option if we want to find the actual location of our results on a disk. |
|
skip(Integer) |
This can be used to skip the specified number of documents. It’s useful for paginating results. |
|
snapshot |
This can be used to execute our query in snapshot mode. This is useful when we want a more stringent consistency. |
|
sort(Hash) |
We can use this to sort our results; for example, client[:books].find.sort(:name => -1). |