
8
Indexing
This chapter will explore one of the most important properties of any database: indexing. Similar to book indexes, database indexes allow for quicker data retrieval. In the relational database management system (RDBMS) world, indexes are widely used (and sometimes abused) to speed up data access. In MongoDB, indexes play an integral part in schema design and query design. MongoDB supports a wide array of indexes, which you will learn about in this chapter, including single-field, compound, multi-key, geospatial, hashed, and partial. In addition to reviewing the different types of indexes, we will show you how to build and manage indexes for single-server deployments, as well as complex sharded environments.
In this chapter, we will cover the following topics:
Index internals
In most cases, indexes are variations of the B-tree data structure. Invented by Rudolf Bayer and Ed McCreight in 1971 while they were working at Boeing research labs, the B-tree data structure allows for searches, sequential access, inserts, and deletes to be performed in logarithmic time. The logarithmic time property stands for both the average case performance and the worst possible performance, and it is a great property when applications cannot tolerate unexpected variations in performance behavior.
To further illustrate how important the logarithmic time part is, we will show you the Big O complexity chart, which is from http://bigocheatsheet.com/:
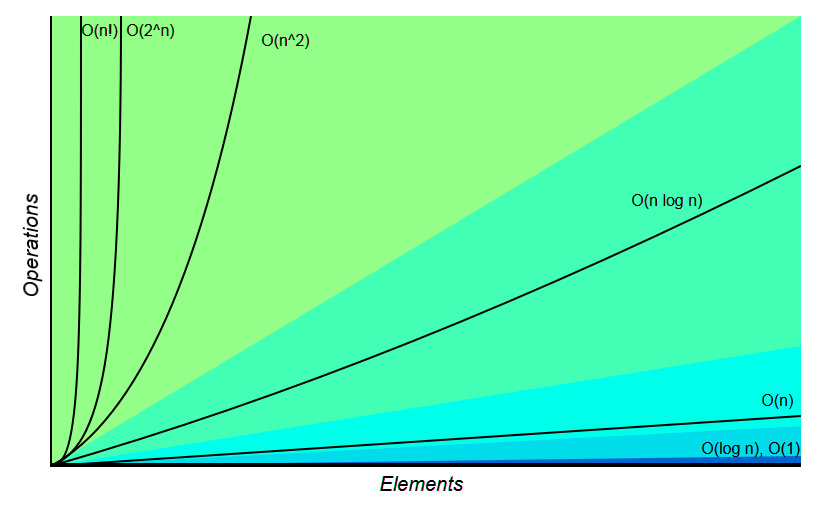
Figure 8.1 – Algorithmic complexity visualized
In this diagram, you can see logarithmic time performance as a flat line, parallel to the x axis of the diagram. As the number of elements increases, constant time (O(n)) algorithms perform worse, whereas quadratic time algorithms (O(n^2)) go off the chart. For an algorithm that we rely on to get our data back to us as quickly as possible, time performance is of the utmost importance.
Another interesting property of a B-tree is that it is self-balancing, meaning that it will self-adjust to always maintain these properties. Its precursor and closest relative is the binary search tree, a data structure that only allows two children for each parent node.
Schematically, a B-tree looks like the following diagram, which can also be seen at https://commons.wikimedia.org/w/index.php?curid=11701365:
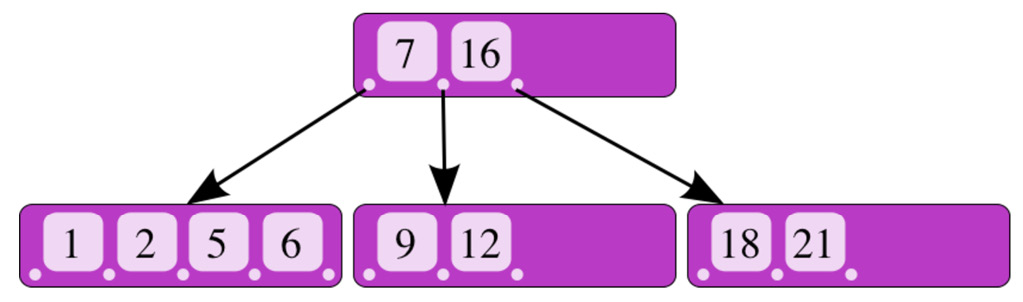
Figure 8.2 – An internal representation of a B-tree
In the preceding diagram, we have a parent node with values 7 and 16 pointing to three child nodes.
If we search for value 9, knowing that it’s greater than 7 and smaller than 16, we’ll be directed to the middle child node, which contains the value, straight away.
Thanks to this structure, we are approximately halving our search space with every step, ending in a log n time complexity. Compared to sequentially scanning through every element, halving the number of elements with each and every step increases our gains exponentially as the number of elements we have to search through increases.
Index types
MongoDB offers a vast array of index types for different needs. In the following sections, we will identify the different types and the needs that each one of them fulfills.
Single-field indexes
The most common and simple type of index is the single-field index. An example of a single-field and key index is the index on ObjectId (_id), which is generated by default in every MongoDB collection. The ObjectId index is also unique, preventing a second document from having the same ObjectId index in a collection.
An index on a single field, based on the mongo_book database that we used throughout the previous chapters, is defined like this:
> db.books.createIndex( { price: 1 } )Here, we create an index on the field name in ascending order of index creation. For descending order, the same index would be created like this:
> db.books.createIndex( { price: -1 } )The ordering for index creation is important if we expect our queries to favor values on the first documents stored in our index. However, due to the extremely efficient time complexity that indexes have, this will not be a consideration for the most common use cases.
An index can be used for exact match queries or range queries on a field value. In the former case, the search can stop as soon as our pointer reaches the value after O(log n) time.
In range queries, due to the fact that we are storing values in the order in our B-tree index, once we find the border value of our range query in a node of our B-tree, we will know that all of the values in its children will be part of our result set, allowing us to conclude our search.
An example of this is shown as follows:
Figure 8.3 – A B-tree with data nodes
Dropping indexes
Dropping an index is as simple as creating it. We can reference the index by its name or by the fields it is composed of:
> db.books.dropIndex( { price: -1 } )Indexing embedded fields
As a document database, MongoDB supports embedding fields and whole documents in nested complex hierarchies inside of the same document. Naturally, it also allows us to index these fields.
In our books collection example, we can have documents such as the following:
{"_id" : ObjectId("5969ccb614ae9238fe76d7f1"),"name" : "MongoDB Indexing Cookbook",
"isbn" : "1001",
"available" : 999,
"meta_data" : {"page_count" : 256,
"average_customer_review" : 4.8
}
}
Here, the meta_data field is a document itself, with page_count and average_customer_review fields. Again, we can create an index on page_count, as follows:
db.books.createIndex( { "meta_data.page_count": 1 } )This can answer queries on equality and range comparisons around the meta_data.page_count field, as follows:
> db.books.find({"meta_data.page_count": { $gte: 200 } })> db.books.find({"meta_data.page_count": 256 })Note
To access embedded fields, we use dot notation, and we need to include quotes ("") around the field’s name.
Indexing embedded documents
We can also index the embedded document as a whole, similar to indexing embedded fields:
> db.books.createIndex( { "meta_data": 1 } )Here, we are indexing the whole document, expecting queries against its entirety, as in the following:
> db.books.find({"meta_data": {"page_count":256, "average_customer_review":4.8}})The key difference is that when we index embedded fields, we can perform range queries on them using the index, whereas when we index embedded documents, we can only perform comparison queries using the index.
Note
The db.books.find({"meta_data.average_customer_review": { $gte: 4.8}, "meta_data.page_count": { $gte: 200 } }) command will not use our meta_data index, whereas db.books.find({"meta_data": {"page_count":256, "average_customer_review":4.8}}) will use it.
Compound indexes
Compound indexes are a generalization of single-key indexes, allowing for multiple fields to be included in the same index. They are useful when we expect our queries to span multiple fields in our documents, and also for consolidating our indexes when we start to have too many of them in our collection.
Note
Compound indexes can have as many as 32 fields. They can only have up to one hashed index field.
A compound index is declared similarly to single indexes by defining the fields that we want to index and the order of indexing:
Sorting with compound indexes
The order of indexing is useful for sorting results. In single-field indexes, MongoDB can traverse the index both ways, so it doesn’t matter which order we define.
In multi-field indexes, however, the ordering can determine whether we can use this index to sort. In the preceding example, a query matching the sort direction of our index creation will use our index as follows:
> db.books.find().sort( { "name": 1, "isbn": 1 })It will also use a sort query with all of the sort fields reversed:
> db.books.find().sort( { "name": -1, "isbn": -1 })In this query, since we negated both of the fields, MongoDB can use the same index, traversing it from the end to the start.
The other two sorting orders are as follows:
> db.books.find().sort( { "name": -1, "isbn": 1 })> db.books.find().sort( { "name": 1, "isbn": -1 })They cannot be traversed using the index, as the sort order that we want is not present in our index’s B-tree data structure.
Reusing compound indexes
An important attribute of compound indexes is that they can be used for multiple queries on prefixes of the fields indexed. This is useful when we want to consolidate indexes that pile up in our collections over time.
Consider the compound (multi-field) index, which we created previously:
> db.books.createIndex({name: 1, isbn: 1})This can be used for queries on name or {name, isbn}:
> db.books.find({"name":"MongoDB Indexing"})> db.books.find({"isbn": "1001", "name":"MongoDB Indexing"})The order of the fields in our query doesn’t matter; MongoDB will rearrange the fields to match our query.
However, the order of the fields in our index does matter. A query just for the isbn field cannot use our index:
> db.books.find({"isbn": "1001"})The underlying reason is that the values of our fields are stored in the index as secondary, tertiary, and so on; each one is embedded inside the previous ones, just like a matryoshka, the Russian nesting doll. This means that when we query on the first field of our multi-field index, we can use the outermost doll to find our pattern, whereas when we are searching for the first two fields, we can match the pattern on the outermost doll and then dive into the inner one.
This concept is called prefix indexing, and along with index intersection, it is the most powerful tool for index consolidation, as you will see later in this chapter.
Multikey indexes
Indexing scalar (single) values was explained in the preceding sections. One of the advantages that we have when using MongoDB is the ability to easily store vector values in the form of arrays.
In the relational world, storing arrays is generally frowned upon, as it violates the normal forms of normalization. In a document-oriented database such as MongoDB, it is frequently a part of our design, as we can store and easily query complex structures of data.
Indexing arrays of documents is achieved by using the multikey index. A multikey index can store both arrays of scalar values and arrays of nested documents.
Creating a multikey index is the same as creating a regular index:
> db.books.createIndex({"tags":1})Assume that we have created a document in our books collection, using the following command:
> db.books.insert({"name": "MongoDB Multikeys Cheatsheet", "isbn": "1002", "available": 1, "meta_data": {"page_count":128, "average_customer_review":3.9}, "tags": ["mongodb", "index","cheatsheet","new"] })Our new index will be a multikey index, allowing us to find documents with any of the tags stored in our array:
> db.books.find({tags:"new"}){"_id" : ObjectId("5969f4bc14ae9238fe76d7f2"),"name" : "MongoDB Multikeys Cheatsheet",
"isbn" : "1002",
"available" : 1,
"meta_data" : {"page_count" : 128,
"average_customer_review" : 3.9
},
"tags" : [
"mongodb",
"index",
"cheatsheet",
"new"
]
}
>
We can also create compound indexes with a multikey index, but we can only have one array in each and every index document at the most. Given that in MongoDB we don’t specify the type of each field, this means that creating an index with two or more fields with an array value will fail at creation time, and trying to insert a document with two or more fields as arrays will fail at insertion time.
For example, an analytics_data compound index on tags will fail to be created if we have the following document in our database:
{"_id" : ObjectId("5969f71314ae9238fe76d7f3"),"name": "Mastering parallel arrays indexing",
"tags" : [
"A",
"B"
],
"analytics_data" : [
"1001",
"1002"
]
}
> db.books.createIndex({tags:1, analytics_data:1}){"ok" : 0,
"errmsg" : "cannot index parallel arrays [analytics_data] [tags]",
"code" : 171,
"codeName" : "CannotIndexParallelArrays"
}
Consequently, if we first create the index on an empty collection and try to insert this document, the insert will fail with the following error:
> db.books.find({isbn:"1001"}).hint("international_standard_book_number_index").explain(){ "queryPlanner" : {"plannerVersion" : 1,
"namespace" : "mongo_book.books",
"indexFilterSet" : false,
"parsedQuery" : { "isbn" : {"$eq" : "1001"
}
},
"winningPlan" : {"stage" : "FETCH",
"inputStage" : {"stage" : "IXSCAN",
"keyPattern" : {"isbn" : 1
},
"indexName" : "international_standard_book_numbe
r_index",
"isMultiKey" : false,
"multiKeyPaths" : {"isbn" : [ ]
},
"isUnique" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {"isbn" : [
"["1001", "1001"]"
]
}
}
},
"rejectedPlans" : [ ]
},
"serverInfo" : {"host" : "PPMUMCPU0142",
"port" : 27017,
"version" : "3.4.7",
"gitVersion" : "cf38c1b8a0a8dca4a11737581beafef4fe120bcd"
},
"ok" : 1
Note
Hashed indexes cannot be multikey indexes.
Another limitation that we will likely run into when trying to fine-tune our database is that multikey indexes cannot cover a query completely. A compound index with multikey fields can be used by the query planner only on the non-multikey fields.
Covering a query with the index means that we can get our result data entirely from the index, without accessing the data in our database at all. This can result in dramatically increased performance, as indexes are most likely to be stored in RAM.
Querying for multiple values in multikey indexes will result in a two-step process from the index’s perspective.
In the first step, the index will be used to retrieve the first value of the array, and then a sequential scan will run through the rest of the elements in the array; an example is as follows:
> db.books.find({tags: [ "mongodb", "index", "cheatsheet", "new" ] })This will first search for all entries in multikey index tags that have a mongodb value and will then sequentially scan through them to find the ones that also have the index, cheatsheet, and new tags.
Note
A multikey index cannot be used as a shard key. However, if the shard key is a prefix index of a multikey index, it can be used. We will cover more on this in Chapter 14, Mastering Sharding.
Special types of indexes
Besides the generic indexes, MongoDB supports indexes for special use cases. In this section, we will identify and explore how to use them.
Text indexes
Text indexes are special indexes on string value fields, which are used to support text searches. This book is based on version 3 of the text index functionality, available since version 3.2.
A text index can be specified similarly to a regular index by replacing the index sort order (-1, 1) with text, as follows:
> db.books.createIndex({"name": "text"})Note
A collection can have one text index at most. This text index can support multiple fields, whether text or not. It cannot support other special types, such as multikey or geospatial. Text indexes cannot be used for sorting results, even if they are only a part of a compound index.
MongoDB Atlas Search allows for multiple full-text search indexes. MongoDB Atlas Search is built on Apache Lucene and thus is not limited by MongoDB on-premise full-text search.
Since we only have one text index per collection, we need to choose the fields wisely. Reconstructing this text index can take quite some time and having only one per collection makes maintenance quite tricky, as you will see toward the end of this chapter.
We can use the same syntax as with a wildcard index and index each and every field in a document that contains strings as a text index:
> db.books.createIndex( { "$**": "text" } )This can result in unbounded index sizes and should be avoided; however, it can be useful if we have unstructured data (for example, coming straight from application logs wherein we don’t know which fields may be useful, and we want to be able to query as many of them as possible).
A compound index can also be a text index:
> db.books.createIndex( { "available": 1, "meta_data.page_count": 1, "$**": "text" } )A compound index with text fields follows the same rules of sorting and prefix indexing that we explained earlier in this chapter. We can use this index to query on available, or the combination of available and meta_data.page_count, or sort them if the sort order allows for traversing our index in any direction.
Text indexes will apply stemming (removing common suffixes, such as plural s/es for English language words) and remove stop words (a, an, the, and so on) from the index. Text indexes behave the same as partial indexes, not adding a document to the text index if it lacks a value for the field that we have indexed it on.
We can control the weights of different text-indexed fields, such as the following:
> db.books.createIndex({ "book_name": "text",
"book_description": "text" },
{ weights: {book_name: 10,
book_description: 5
},
name: "TextIndex"
})
In the preceding sample code, assuming a document with book_name and book_description, we have assigned a weight of 10 for book_name and a weight of 5 for book_description. Search matches in book_name will be scored twice as much (10/5 = 2) as matches in book_description, affecting the full-text search results.
Note
Text indexing supports 15 languages as of MongoDB 5.3, including Spanish, Portuguese, and German. Text indexes require special configurations to correctly index in languages other than English.
Some interesting properties of text indexes are explained as follows:
- Case-insensitivity and diacritic insensitivity: A text index is case-insensitive and diacritic-insensitive. Version 3 of the text index (the one that comes with version 3.4) supports common C, simple S, and the special T case folding, as described in the Unicode Character Database (UCD) 8.0 case folding. In addition to case insensitivity, version 3 of the text index supports diacritic insensitivity. This expands insensitivity to characters with accents in both small and capital letter forms. For example, e, è, é, ê, ë, and their capital letter counterparts, can all be equal when compared using a text index. In the previous versions of the text index, these were treated as different strings.
- Tokenization delimiters: Version 3 of the text index supports tokenization delimiters, defined as Dash, Hyphen, Pattern_Syntax, Quotation_Mark, Terminal_Punctuation, and White_Space, as described in the UCD 8.0 case folding.
Full-text search in MongoDB is considered a legacy feature and MongoDB Atlas Search is way more powerful and flexible.
Hashed indexes
A hashed index contains hashed values of the indexed field:
> db.books.createIndex( { name: "hashed" } )This will create a hashed index on the name of each book in our books collection. A hashed index is ideal for equality matches but it cannot work with range queries. If we want to perform a range of queries on fields, we can create a compound index with at most one hashed field, which will be used for equality matches.
The following mongo shell code will create a compound index on created_at_date and name, with the name field being the one and only hashed field that we can create in a compound index:
> db.books.createIndex( { created_at_date: 1, name: "hashed" } )We cannot create a hashed index on an array field.
We cannot enforce uniqueness on a hashed field value. We can add a single unique index on the same field separately instead.
Hashed indexes are used internally by MongoDB for hash-based sharding, as we will discuss in Chapter 14, Mastering Sharding. Hashed indexes truncate floating point fields to integers. Floating points should be avoided for hashed fields wherever possible.
Time-to-live indexes
Time-to-live (TTL) indexes are used to automatically delete documents after an expiration time. Their syntax is as follows:
> db.books.createIndex( { created_at_date: 1 }, { expireAfterSeconds: 86400 } )The created_at_date field values have to be either a date or an array of dates (the earliest one will be used). In this example, the documents will be deleted one day (86400 seconds) after created_at_date.
If the field does not exist or the value is not a date, the document will not expire. In other words, a TTL index silently fails and does not return any errors when it does.
Data gets removed by a background job, which runs every 60 seconds. As a result, there is no explicitly guaranteed accurate measure of how much longer documents will persist past their expiration dates.
Note
A TTL index is a regular single-field index. It can be used for queries like a regular index. A TTL index cannot be a compound index, operate on a capped or time series collection, or use the _id field. The _id field implicitly contains a timestamp of the created time for the document but is not a Date field. If we want each document to expire at a different, custom date point, we have to set {expireAfterSeconds: 0}, and set the TTL index Date field manually to the date on which we want the document to expire.
Partial indexes
A partial index on a collection is an index that only applies to the documents that satisfy the partialFilterExpression query.
We’ll use our familiar books collection, as follows:
> db.books.createIndex(
{ price: 1, name: 1 }, { partialFilterExpression: { price: { $gt: 30 } } })
Using this, we can have an index only for books that have a price greater than 30. The advantage of partial indexes is that they are more lightweight in creation and maintenance and use less storage than an index on every possible value.
The partialFilterExpression filter supports the following operators:
- Equality expressions (that is, field: value, or using the $eq operator)
- The $exists: true expression
- The $gt, $gte, $lt, and $lte expressions
- $type expressions
- The $and operator, at the top level only
Partial indexes will only be used if the query can be satisfied as a whole by the partial index.
If our query matches or is more restrictive than the partialFilterExpression filter, then the partial index will be used. If the results may not be contained in the partial index, then the index will be totally ignored.
partialFilterExpression does not need to be a part of the sparse index fields. The following index is a valid sparse index:
> db.books.createIndex({ name: 1 },{ partialFilterExpression: { price: { $gt: 30 } } })To use this partial index, however, we need to query for both name and price equal to or greater than 30.
Earlier versions of MongoDB offered a subset of the partial indexes functionality, named sparse indexes. Partial indexes were introduced in MongoDB 3.2 and are recommended over the more restrictive sparse indexes, so if you have sparse indexes from earlier versions, it may be a good idea to upgrade them. The _id field cannot be a part of a partial index.
A shard key index or an _id index cannot be a partial index.
We can use the same key pattern (for example, db.books.createIndex( {name: 1, price: 1} ) ) to create multiple partial indexes on the same collection but the partialFilterExpression filter has to be distinct between them.
A unique index can also be a partial index at the same time and MongoDB will enforce the uniqueness for documents that satisfy the partialFilterExpression filter. Documents that do not satisfy the partialFilterExpression filter, that have null or the field does not exist at all, will not be subject to the unique constraint.
Unique indexes
A unique index is similar to an RDBMS unique index, forbidding duplicate values for the indexed field. MongoDB creates a unique index by default on the _id field for every inserted document:
> db.books.createIndex( { "name": 1 }, { unique: true } )This will create a unique index on a book’s name. A unique index can also be a compound embedded field or an embedded document index.
In a compound index, the uniqueness is enforced across the combination of values in all of the fields of the index; for example, the following will not violate the unique index:
> db.books.createIndex( { "name": 1, "isbn": 1 }, { unique: true } )> db.books.insert({"name": "Mastering MongoDB", "isbn": "101"})> db.books.insert({"name": "Mastering MongoDB", "isbn": "102"})This is because even though the name is the same, our index is looking for the unique combination of name and isbn, and the two entries differ in isbn.
Unique indexes do not work with hashed indexes. Unique indexes cannot be created if the collection already contains duplicate values of the indexed field. A unique index will not prevent the same document from having multiple values.
The only way that we can enforce a unique index across different shards is if the shard key is a prefix or the same as the unique compound index. Uniqueness is enforced in all of the fields of the unique compound index.
If a document is missing the indexed field, it will be inserted. If a second document is missing the indexed field, it will not be inserted. This is because MongoDB will store the missing field value as null, only allowing one document to be missing in the field.
Indexes that are a combination of unique and partial will only apply unique indexes after a partial index has been applied. This means that there may be several documents with duplicate values if they are not a part of partial filtering.
Case insensitivity
Case sensitivity is a common problem with indexing. We may store our data in mixed caps and need our index to ignore cases when looking for our stored data. Until version 3.4, this was dealt with at the application level by creating duplicate fields with all lowercase characters and indexing all lowercase fields to simulate a case-insensitive index.
Using the collation parameter, we can create case-insensitive indexes and even collections that behave as case-insensitive.
In general, collation allows users to specify language-specific rules for string comparisons. A possible (but not the only) usage is for case-insensitive indexes and queries.
Using our familiar books collection, we can create a case-insensitive index on a name, as follows:
> db.books.createIndex( { "name" : 1 }, { collation: {locale : 'en',
strength : 1
}
} )
The strength parameter is one of the collation parameters, the defining parameter for case-sensitivity comparisons. Strength levels follow the International Components for Unicode (ICU) comparison levels. The values that it accepts are as follows:
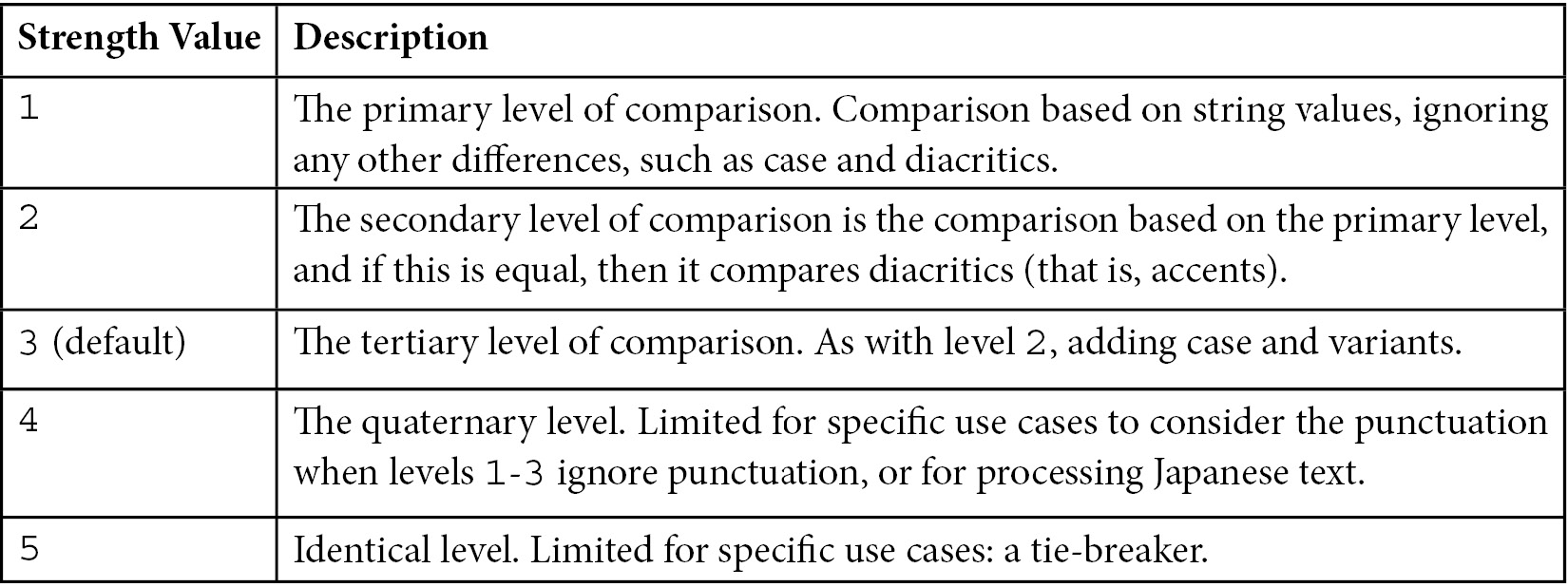
Table 8.1 – Collation strength values
Creating the index with collation is not enough to get back case-insensitive results. We need to specify collation in our query as well:
> db.books.find( { name: "Mastering MongoDB" } ).collation( { locale: 'en', strength: 1 } )If we specify the same level of collation in our query as our index, then the index will be used. We could specify a different level of collation, as follows:
> db.books.find( { name: "Mastering MongoDB" } ).collation( { locale: 'en', strength: 2 } )Here, we cannot use the index, as our index has a level 1 collation parameter, and our query looks for a level 2 collation parameter.
Note
Diacritics, also known as diacritical marks, are one or more characters that have a mark near, above, or through them to indicate a different phonetic value than the unmarked equivalents. A common example is the French é, as in café.
If we don’t use any collation in our queries, we will get results defaulting to level 3, that is, case-sensitive.
Indexes in collections that were created using a different collation parameter from the default will automatically inherit this collation level.
Suppose that we create a collection with a level 1 collation parameter, as follows:
> db.createCollection("case_sensitive_books", { collation: { locale: 'en_US', strength: 1 } } )The following index will also have strength: 1 collation because the index inherits the collation strength from the collection:
> db.case_sensitive_books.createIndex( { name: 1 } )Default queries to this collection will be strength: 1 collation, case-sensitive, and ignoring diacritics. If we want to override this in our queries, we need to specify a different level of collation in our queries or ignore the strength part altogether. The following two queries will return case-insensitive, default collation level results in our case_sensitive_books collection:
> db.case_sensitive_books.find( { name: "Mastering MongoDB" } ).collation( { locale: 'en', strength: 3 } ) // querying the colletion with the global default collation strength value, 3> db.case_sensitive_books.find( { name: "Mastering MongoDB" } ).collation( { locale: 'en' } ) // no value for collation, will reset to global default (3) instead of default for case_sensitive_books collection (1)Collation is a very useful concept in MongoDB and we will continue exploring it throughout the following chapters.
Geospatial indexes
Geospatial indexes were introduced early on in MongoDB and the fact that Foursquare was one of the earliest customers and success stories for MongoDB (then 10gen Inc.) is probably no coincidence. There are three distinct types of geospatial indexes that we will explore in this chapter and they will be covered in the following sections.
2D geospatial indexes
A 2D geospatial index stores geospatial data as points on a two-dimensional plane. It is mostly kept for legacy reasons, for coordinate pairs created before MongoDB 2.2, and in most cases, it should not be used with the latest versions.
2dsphere geospatial indexes
A 2dsphere geospatial index supports queries calculating geometries on an Earth-like plane. It is more accurate than the simplistic 2D index and can support both GeoJSON objects and legacy coordinate pairs as input. It is the recommended type of index to use for geospatial queries.
Its current version, since MongoDB 3.2, is version 3. It is a sparse index by default, only indexing documents that have a 2dsphere field value. Assuming that we have a location field in our books collection, tracking the home address of the main author of each book, we could create an index on this field as follows:
> db.books.createIndex( { location: "2dsphere" } )The location field needs to be a GeoJSON object, such as this one:
location : { type: "Point", coordinates: [ 51.5876, 0.1643 ] }A 2dsphere index can also be a part of a compound index, in any position in the index, first or not:
> db.books.createIndex( { name: 1, location : "2dsphere" })Wildcard indexes
MongoDB is schemaless. As such, there are cases where we may not exactly know the names of the fields beforehand.
Wildcard indexes allow us to define patterns for the names of the fields that MongoDB will index (include) or not index (exclude). We generally cannot mix these two conditions at the collection level, as this could result in conflicting rules, which would require manual intervention.
Note
The only case where we can mix the inclusion and exclusion of fields is the _id field. We can create a wildcard index with _id:0 or _id:1 but all the other fields in the wildcard declaration have to be either entirely included or entirely excluded.
To create a wildcard index in all attributes of a collection, we have to use the following command:
> db.books.createIndex( { "$**": 1 } )Note
The catchall wildcard index on every attribute of the collection will recursively create indexes for subdocuments and any attributes of the array type.
We can also create wildcard indexes in subdocuments.
Given a collection, books with a document will look like this:
{ name: "Mastering MongoDB 5.X", attributes: { author: "Alex Giamas", publisher: "Packt" }, chapters: [{id: 1, name: "MongoDB - A database for modern web" }] }We can index the document with embedded attributes:
> db.books.createIndex( { "attributes.$**": 1 } )The only difference from the generic wildcard index creation is that we are now targeting the attributes subdocument with the $** wildcard operator.
We can also create wildcard indexes on specific attributes of the document, both for inclusion and exclusion. To achieve this, we need to use the wildcardProjection operator, which behaves similarly to the $project phase that we discussed previously, in Chapter 7, Aggregation.
An example of creating a wildcard index with inclusion follows:
> db.books.createIndex( { "$**": 1 }, {"wildcardProjection": {{ "name": 1, "attributes.author": 1 }}
} )
This will create a wildcard index on the name attribute, the attributes.author attribute, and any subdocuments and arrays that the fields may contain.
This index will not index the chapter’s attribute and any subdocuments in its array.
Similarly, if we want to create a wildcard index with exclusion, we can do it as follows:
> db.books.createIndex( { "$**": 1 }, {"wildcardProjection": {{ "chapters": 0 }}
} )
This index will index all attributes and their subdocuments, except for the chapters field.
For the sample document mentioned above, the last two indexes are equivalent.
Note
Wildcard indexes are not a replacement for proper index design. Having a large and unbounded number of indexes in a collection will result in performance degradation, no matter how we generated the indexes.
The most important limitations of wildcard indexes are listed here:
- Wildcard index generation creates single attribute indexes across all fields. This means that they are mostly useful in single-field queries and will use at most one field to optimize the query.
- Wildcard indexes are essentially partial indexes and as such, they cannot support a query looking for attributes that do not exist in the documents.
- Wildcard indexes will recursively index every attribute of the subdocuments and as such, cannot be used to query for exact subdocument or whole array equality ($eq) or inequality ($neq) queries.
- Wildcard indexes cannot be used as keys for sharding purposes.
Hidden indexes
Simply put, a hidden index is an index that exists but is not visible to the query planner. A hidden index will not be used to speed up any query.
A hidden index still exists; it’s just not used. As such, if it is a unique index, for example, it will still apply the unique constraint. Likewise, if it is a TTL index, it will keep expiring documents.
We cannot hide the _id special index.
To add a hidden index, we need to pass the hidden: true parameter, as shown here:
> db.books.createIndex( { name: 1 }, { hidden: true, name: "index_on_name_field" } )To unhide an existing index, we can use unhideIndex, either with the index name or the fields that the index uses.
For example, to unhide the index that we just created, we could use either of the following commands respectively:
> db.books.unhideIndex("index_on_name_field")> db.books.unhideIndex({name: 1})To hide an existing index, we can use hideIndex, either with the index name or with the fields that the index uses.
For example, to hide the index that we just unhid again, we could use either of the following commands respectively:
> db.books.hideIndex("index_on_name_field")> db.books.hideIndex({name: 1})Clustered indexes
A new addition since MongoDB 5.3, clustered indexes allow us to perform faster queries on the clustered index key value. The documents are physically stored in order of the clustered key index value, meaning that we get significant performance improvement and space savings, at the expense of having to query using the clustered index.
We are free to create secondary indexes in addition to the clustered index on a clustered collection but this will negate the above-mentioned advantages.
We can define any value we want but we need to set our custom value in the _id key. The clustered index cannot be hidden.
A clustered collection needs to be created as such and we cannot convert an existing collection into a clustered one. The clustered collection can also be a TTL collection if we set the expireAfterSeconds parameter to the creation time.
A clustered collection can be more space efficient than a non-clustered (default) collection but we need to explicitly skip creating a secondary index at creation time. The query optimizer will try to use the secondary index instead of the clustered index if we don’t provide a hint to skip it.
The key that we will use to populate the _id attribute in the collection on our own must be unique, immutable, and as small in size as possible and it’s strongly advisable to be monotonically increasing in value.
A clustered collection can save storage space, especially when we skip creating the secondary index, and can serve our queries strictly by using the clustered index. The clustered index was just introduced in version 6.0 and we expect it to be improved in upcoming versions.
In this section, we learned about all the different types of special indexes that MongoDB offers. In the next section, we will understand how we can build and manage our indexes.
Building and managing indexes
Indexes can be built using the MongoDB shell or any of the available drivers.
MongoDB was used to build indexes in the foreground (using faster, blocking operations) or the background (using slower, non-blocking operations) up until version 4.4.
From this version onward, all indexes are now built using an optimized build process, which is at least as fast as the slower background build option present in previous versions.
The fewer inserts and updates that occur during the build process, the faster the index creation will be. Few to no updates will result in the build process happening as fast as the former foreground build option.
Index builds now obtain an exclusive lock at the collection level only for a short period at the beginning and the end of the build process. The rest of the time, the index build yields for read-write access.
An index constraint violation occurring from documents pre-existing to the build index command or being added during index creation will only fail the index creation at the end of the index build process.
Ensure that you index early and consolidate indexes by revisiting them regularly. Queries won’t see partial index results. Queries will start getting results from an index only after it is completely created.
Do not use the main application code to create indexes, as it can impose unpredictable delays. Instead, get a list of indexes from the application, and mark these for creation during maintenance windows.
Index filters
An index filter can force the MongoDB query plan to consider a specific set of indexes for a specific query shape.
A query shape is the combination of the fields that we are querying, along with any sorting, projection, and collation options that we specify in the query.
For example, in the following query, this is what we do:
> db.books.find({isbn: "1001"})The query shape only consists of the isbn field name. The value that we are querying is not important.
To declare an index filter on the isbn field for our books collection, we can use the following command:
> db.runCommand({planCacheSetFilter: "isbn_lookup",
query: { isbn: "any_string_here" },indexes: [
{ isbn: 1 },"isbn_book_name_index",
]})
With the preceding command, the query planner will consider the index on { isbn: 1 }, the isbn_book_name_index index, and a full collection scan, which is always considered as a last resort by the query planner.
An index filter is more powerful than a hint() parameter. MongoDB will ignore any hint() parameter if it can match the query shape to one or more index filters.
Index filters are only held in memory and will be erased on server restart.
Forcing index usage
We can force MongoDB to use an index by applying the hint() parameter:
> db.books.createIndex( { isbn: 1 } ){"createdCollectionAutomatically" : false,
"numIndexesBefore" : 8,
"numIndexesAfter" : 9,
"ok" : 1
}
The output from createIndex notifies us that the index was created ("ok" : 1), no collection was automatically created as a part of index creation ("createdCollectionAutomatically" : false), the number of indexes before this index creation was 8, and now there are nine indexes for this collection in total.
Now, if we try to search for a book by isbn, we can use the explain() command to see the winningPlan subdocument, where we can find which query plan was used:
> db.books.find({isbn: "1001"}).explain()…
"winningPlan" : {"stage" : "FETCH",
"inputStage" : {"stage" : "IXSCAN",
"keyPattern" : {"isbn" : 1,
"name" : 1
},
"indexName" : "isbn_1_name_1",
...
This means that an index with an isbn field of 1 and a name field of 1 was used instead of our newly created index. We can also view our index in the rejectedPlans subdocument of the output, as follows:
…
"rejectedPlans" : [
{"stage" : "FETCH",
"inputStage" : {"stage" : "IXSCAN",
"keyPattern" : {"isbn" : 1
},
"indexName" : "isbn_1",
...
This is, in fact, correct, as MongoDB is trying to reuse an index that is more specific than a generic one.
We may not be sure though in cases where our isbn_1 index is performing better than the isbn_1_name_1 index.
We can force MongoDB to use our newly created index, as follows:
> db.books.find({isbn: "1001"}).hint("international_standard_book_number_index").explain()
{...
"winningPlan" : {"stage" : "FETCH",
"inputStage" : {"stage" : "IXSCAN",
"keyPattern" : {"isbn" : 1
},
...
Now, the winningPlan subdocument contains our isbn_1 index, and there are no items in the rejectedPlans subdocument.
We can also force the index that the query will use by its definition, such that the next two commands are equivalent:
> db.books.find({isbn: "1001"}).hint("international_standard_book_number_index")> db.books.find({isbn: "1001"}).hint( { isbn: 1 } )In this example, we are declaring the index to force MongoDB to use its name and its declaration. The two commands are equivalent.
Note
We cannot use hint() when the query contains a $text query expression or while an index is hidden.
The MongoDB query planner will always choose the index filter and ignore the hint() parameter if an index filter already exists for our query.
We can force the query planner to skip any index by using the special { $natural: <traversal order> } index declaration. <traversal order> can be 1 or -1 for forward scanning or backward scanning of all the documents in the collection.
Disabling the index lookup in a query is not recommended in general but may help us debug edge cases when query results don’t match what we are expecting.
Rolling index building on replica sets and sharded environments
In replica sets, if we issue a createIndex() command, the operation will start simultaneously in all data-bearing replica set members.
Similarly, in a sharded environment, all the data-bearing members across the replica sets that contain data for our collection will simultaneously start building the index.
The recommended approach to building indexes in replica sets when we want to avoid any performance degradation goes as follows:
- Stop one secondary from the replica set
- Restart it as a standalone server in a different port
- Build the index from the shell as a standalone index
- Restart the secondary in the replica set
- Allow for the secondary to catch up with the primary
We need to have a large enough oplog size in the primary to make sure that the secondary will be able to catch up once it’s reconnected. The oplog size is defined in MB in the configuration and it defines how many operations will be kept in the log in the primary server. If the oplog size can only hold up to the last 100 operations happening in the primary, and 101 or more operations happen, this means that the secondary will not be able to sync with the primary. This is a consequence of the primary not having enough memory to keep track of its operations and inform the secondary about them.
This approach can be repeated for each secondary server in the replica set. Finally, we can repeat the same procedure for the primary server. First, we step down the primary server using rs.stepDown(), restart it as a standalone server, build the index, and add it back into the replica set.
The rs.stepDown() command will not step down the server immediately but will instead wait for a default of 10 seconds (configurable using the secondaryCatchUpPeriodSecs parameter) for any eligible secondary server to catch up to its data.
For a sharded environment, we have to stop the sharding data balancer first. Then, we need to find out which shards (here, meaning the replica sets) contain the collection(s) that we need to index. Finally, we need to repeat the process for each shard/replica set, as explained already.
Since version 4.2, MongoDB builds indexes using an optimized build process, which doesn’t lock the database for extended periods, and as such, rolling index builds are less frequently necessary after this version.
That being said, building indexes can be risky and operationally intensive. It is always a good idea to have a staging environment that mirrors production and to dry run operations that affect the live cluster in staging in order to avoid surprises.
Managing indexes
In this section, you will learn how to give human-friendly names to your indexes, as well as some special considerations and limitations that we have to keep in mind when indexing.
Naming indexes
By default, index names are assigned by MongoDB automatically based on the fields indexed and the direction of the index (1 or -1). If we want to assign our own name, we can do so at creation time:
> db.books.createIndex( { isbn: 1 }, { name: "international_standard_book_number_index" } )Now, we have a new index called international_standard_book_number_index, instead of what MongoDB would have named it ("isbn_1").
Note
We can view all of the indexes in our books collection by using db.books.getIndexes().
Special considerations
The following are a few limitations to keep in mind concerning indexing:
- A collection can have up to 64 indexes.
- A compound index can have up to 32 fields.
- Geospatial indexes cannot cover a query. Multikey indexes cannot cover a query over fields of an array type. This means that index data alone will not be enough to fulfill the query and the underlying documents will need to be processed by MongoDB to get back a complete set of results.
- Indexes have a unique constraint on fields. We cannot create multiple indexes on the same fields, differing only in options. We can, however, create multiple partial indexes with the same key pattern given that the filters in partialFilterExpression differ.
Using indexes efficiently
Creating indexes is a decision that should not be taken lightly. As easy as it is to create indexes via the shell, it can create problems down the line if we end up with too many or with inadequately efficient indexes. In this section, we will learn how to measure the performance of existing indexes, some tips for improving performance, and how we can consolidate the number of indexes so that we have better-performing indexes.
Measuring performance
Learning how to interpret the explain() command will help you with both optimizing and understanding the performance of an index. The explain() command, when used in conjunction with a query, will return the query plan that MongoDB would use for this query, instead of the actual results.
It is invoked by chaining it at the end of our query, as follows:
> db.books.find().explain()
It can take three options: queryPlanner (the default), executionStats, and allPlansExecution.
Let’s use the most verbose output, allPlansExecution:
> db.books.find().explain("allPlansExecution")Here, we can get information for both the winning query plan and some partial information about query plans, which were considered during the planning phase but were rejected because the query planner considered them slower. The explain() command returns a rather verbose output in all cases, allowing for deeper insight into how the query plan works to return our results.
MongoDB version 5.1 introduced a new query execution engine, the slot-based query execution engine (SBE). The slot-based execution engine is preferable for the query planner where possible, else it falls back to the older query planner. When the query planner is using the new engine, we will see the output in explain() like so:
{ ... explainVersion: 2 ... }explainVersion: 1 means that the query planner is using the old engine.
The query plans are shown as a tree of stages, with each step of each subsequent step embedded in the previous step’s document. We can also use the planNodeId integer field in the output to identify the different query execution steps. More low-level details of each stage of SBE are also available in the slotBasedPlan field. These are pretty low-level and are mostly used for debugging by MongoDB engineers when there are unexpected results.
At first glance, we need to focus on whether the indexes that should be used are being used, and whether the number of scanned documents matches the number of returned documents as closely as possible.
For the first one, we can inspect the stage field and look for IXSCAN, which means that an index was used. Then, in the sibling indexName field, we are able to see the name of our expected index.
For the second one, we need to compare keysExamined with the nReturned fields for the old execution engine. We ideally want our indexes to be as selective as possible with regard to our queries, meaning that to return 100 documents, these would be the 100 documents that our index examines.
The new execution engine (SBE) will include these fields in the $planCacheStats for each collection. The creationExecStats subdocument array will include one entry for each of the cached execution plans.
The number of keys examined is totalKeysExamined and the number of documents examined is named totalDocsExamined, whereas the nReturned field shows the number of documents returned.
The MongoDB SBE will calculate a unique queryHash for each query shape. A query shape is the combination of the fields that we are querying together with sorting, projection, and collation.
We can list the query plans that are cached for each collection, flush the cache, or increase its size. Subsequent queries using the same query shape will use the cached plan instead of calculating a new one. The cached plans are stored in memory, so will be deleted on server shutdown.
Finally, there is a trade-off as indexes increase in number and size in our collection. We can have a limited number of indexes per collection, and we definitely have a limited amount of RAM to fit these indexes into, so we must balance the trade-off between having the best available indexes and these indexes not fitting into our memory and getting slowed down because of disk swapping.
Improving performance
Once we get comfortable with measuring the performance of the most common and important queries for our users, we can start to try to improve them.
The general idea is that we need indexes when we expect (or already have) repeatable queries that are starting to run slowly. Indexes do not come for free, as they impose a performance penalty in document creation and maintenance, but they are more than worth it for frequent queries and can reduce the contention in our database if designed correctly.
Recapping our suggestions from the previous section, we want our indexes to do the following:
- Fit in the RAM
- Ensure selectivity
- Be used to sort our query results
- Be used in our most common and important queries
Fitting in the RAM can be ensured by using getIndexes() in our collections and making sure that we are not creating large indexes by inspecting the system-level available RAM and whether swapping is being used or not.
Selectivity, as mentioned previously, is ensured by comparing nReturned with keysExamined in each IXSCAN phase of our queries. We want these two numbers to be as similar as possible.
Ensuring that our indexes are used to sort our query results involves a combination of using compound indexes (which will be used as a whole, and also for any prefix-based query) and declaring the direction of our indexes to be in accordance with our most common queries.
Finally, aligning indexes with our query is a matter of application usage patterns, which can uncover that queries are used most of the time, and then using explain() on these queries to identify the query plan that is being used each time.
Index intersection
Index intersection refers to the concept of using more than one index to fulfill a query.
Index intersection can happen when we use OR ($or) queries by using a different index for each OR clause. Index intersection can happen when we use AND queries and we have either complete indexes for each AND clause or index prefixes for some (or all) of the clauses.
For example, consider a query on our books collection, as follows:
> db.books.find({ "isbn":"101", "price": { $gt: 20 }})Here, with two indexes (one on isbn and the other on price), MongoDB can use each index to get the related results, and then intersect the index results to get the result set.
With compound indexes, as you learned previously in this chapter, we can use index prefixing to support queries that contain the first 1…n-1 fields of an n field compound index.
What we cannot support with compound indexes are queries that are looking for fields in the compound index, missing one or more of the previously defined fields.
Note
The order matters in compound indexes.
To satisfy these queries, we can create indexes on the individual fields, which will then use index intersection and fulfill our needs. The downside to this approach is that as the number of fields (n) increases, the number of indexes that we have to create grows exponentially, thus increasing our need for storage and memory.
Index intersection will not work with sort(). We can’t use one index for querying and a different index for applying sort() to our results.
However, if we have an index that can fulfill a part of the whole of our query and the sort() field, then this index will be used. The query planner will usually avoid using sorting with index intersection. Index intersection with sorting will show up as an AND_SORTED stage in the executed query plan.
We should not rely on index intersection for our schema design and should always use compound indexes where possible.
Further reading
You can refer to the following links for further references:
- A cheat sheet on big O notation
- The MongoDB documentation on index intersection
https://docs.mongodb.com/manual/core/index-intersection/
Summary
In this chapter, we learned about the foundations of indexing and index internals. We then explored how to use the different index types available in MongoDB, such as single-field, compound, and multikey, as well as some special types, such as text, hashed, TTL, partial, parse, unique, case-insensitive, and geospatial.
In the next part of the chapter, we learned how to build and manage indexes using the shell, which is a basic part of administration and database management, even for NoSQL databases. Finally, we discussed how to improve our indexes at a high level, and also how we can use index intersection in practice to consolidate the number of indexes.
In the next chapter, we will discuss how we can monitor our MongoDB cluster and keep consistent backups. We will also learn how to handle security in MongoDB.