
6
Multi-Document ACID Transactions
MongoDB introduced multi-document ACID transactions (distributed transactions) in July 2018 with the release of v4.0.
Relational database transactions follow the atomicity, consistency, isolation, and durability (ACID) database principles, through the use of transactions. MongoDB, as a document-oriented database, doesn’t need ACID transactions in general. There are a few cases, though, where ACID properties are needed and that’s when we should, as an exception, use multi-document ACID transactions in MongoDB.
We will explore multi-document ACID transactions (also known as distributed transactions) in MongoDB and learn where they can be a useful alternative to the CRUD operators that we learned about in the previous chapters. We will use two cases – building a digital bank and developing an e-commerce cart – to understand how distributed transactions can help us achieve consistency and correct implementation using these semantics.
In the previous chapter, we learned how to query MongoDB using Ruby, Python, and PHP drivers and frameworks.
In this chapter, we will cover the following topics:
- Transactions background
- Exploring ACID properties
- E-commerce using MongoDB
Technical requirements
To follow along with the code in this chapter, you need to install MongoDB locally, set up a replica set, and install the Ruby and Python language drivers.
Transactions background
MongoDB is a non-relational database and provides only a few guarantees around ACID. Data modeling in MongoDB does not focus on BCNF, 2NF, and 3NF normalization; instead, its focus is in the opposite direction.
In MongoDB, the best approach is often to embed our data into subdocuments, resulting in more self-contained documents than a single row of data in an RDBMS. This means that a logical transaction can affect a single document many times. Single-document transactions are ACID-compliant in MongoDB, meaning that multi-document ACID transactions have not been essential for MongoDB development.
However, there are a few reasons why getting multi-document transactions is a good idea. Over the years, MongoDB has grown from being a niche database to a multi-purpose database that is used everywhere – from start-ups to major Fortune 500 companies. Across many different use cases, there are inevitably a few corner cases where data modeling can’t, or shouldn’t, fit data in subdocuments and arrays.
A great example is an unbounded one-to-many relationship. When we expect an unbounded number of documents in the “many” part of the relationship, the document can grow past the maximum document object size of 16 MB. In this case, we need a mechanism to create a chain of documents that will all stay under the maximum document object size.
Also, even when the best solution for a data architect today is to embed data, they can’t be sure this will always be the case. This makes choosing the right database layer difficult.
RDBMS data modeling has been around for over 40 years and is a well-known and understood data modeling process. Helping data architects work with something they are familiar with is always a bonus.
Before multi-document transactions were introduced, the only workaround was implementing them in a customized way in the application layer. This was both time-consuming and error-prone. Implementing a two-phase commit process in the application layer could also be slower and lead to increased locking, slowing our database operations.
In this chapter, we will focus on using the native MongoDB transactions, which are now strongly recommended by MongoDB Inc. In the next section, we will explore ACID, and what each of the elements means for us.
Exploring ACID properties
ACID stands for atomicity, consistency, isolation, and durability. In the following sections, we will explain what each of these means for our database design and architecture.
Atomicity
Atomicity refers to the concept that a transaction needs to follow the binary success or fail principle. If a transaction succeeds, then its results are visible to every subsequent user. If a transaction fails, then every change is rolled back to the point it was right before it started. Either all actions in a transaction occur or none at all.
A simple example to understand atomicity is by transferring money from account A to account B. Money needs to be credited from account A and then debited into account B. If the operation fails midway, then both accounts A and B need to be reverted to their state before the operation started.
In MongoDB, operations in a single document are always atomic even if the operation spans multiple subdocuments or arrays within the document.
Operations spanning multiple documents need to use MongoDB transactions to be made atomic.
Consistency
Consistency refers to the database’s state. Every database operation must start and regardless of whether it succeeds or fails, it should leave the database in a state where its data is consistent. The database must always be in a consistent state.
Database constraints must be respected at all times. Any future transaction must also be able to view data that’s been updated by past transactions. The consistency model most commonly used in practice for distributed data systems is eventual consistency.
Eventual consistency guarantees that once we stop updating our data, all future reads will eventually read the latest committed write value. In distributed systems, this is the only acceptable model in terms of performance, as data needs to be replicated over the network across different servers.
In contrast, the least popular model of strong consistency guarantees that every future read will always read the write value that was committed last. This implies that every update is propagated and committed to every server before the next read comes in, which will cause a huge strain on performance for these systems.
MongoDB falls somewhere in between eventual and strict consistency by adopting a causal consistency model. With causal consistency, any transaction execution sequence is the same as if all causally related read/write operations were executed in an order that reflects their causality.
What this means in practice is that concurrent operations may be seen in different orders and reads correspond to the latest value written about the writes that they are causally dependent on.
Eventually, it’s a trade-off between how many concurrent operations can happen at once and the consistency of data being read by the application.
Isolation
Database isolation refers to the view that each transaction has of other transactions that run in parallel. Isolation protects us from transactions acting on the state of parallel running, incomplete transactions that may subsequently roll back. An example of why isolation levels are essential is described in the following scenario:
- Transaction A updates user 1’s account balance from £50 to £100 but does not commit the transaction.
- Transaction B reads user 1’s account balance as £100.
- Transaction A is rolled back, reverting user 1’s account balance to £50.
- Transaction B thinks that user 1 has £100, whereas they only have £50.
- Transaction B updates user 2’s value by adding £100. User 2 receives £100 out of thin air from user 1, since user 1 only has £50 in their account. Our imaginary bank is in trouble.
Isolation typically has four levels, as follows, listed from the most to the least strict:
- Serializable
- Repeatable read
- Read committed
- Read uncommitted
The problems we can run into, from the least to the most serious, depend on the isolation level, as follows:
- Phantom reads
- Non-repeatable reads
- Dirty reads
- Lost updates
Losing data about an operational update is the worst thing that can happen in any database because this would render our database unusable and make it a store of data that cannot be trusted. That’s why, in every isolation level, even read uncommitted isolation will not lose data.
However, the other three issues may also arise. We will briefly explain what these are in the following sections.
Phantom reads
A phantom read occurs when, during a transaction, another transaction modifies its result set by adding or deleting rows that belong to its result set. An example of this is as follows:
- Transaction A queries for all users. 1,000 users are returned but the transaction does not commit.
- Transaction B adds another user; 1,001 users are now in our database.
- Transaction A queries for all users for a second time. 1,001 users are now returned. Transaction A now commits.
Under a strict serializable isolation level, transaction B should be blocked from adding the new user until transaction A commits its transaction. This can, of course, cause huge contention in the database, which can lead to performance degradation. This is because every update operation needs to wait for reads to commit their transactions. This is why, typically, the serializable level is rarely used in practice.
Non-repeatable reads
A non-repeatable read occurs when, during a transaction, a row is retrieved twice, and the row’s values are different with every read operation.
Following the previous money transfer example, we can illustrate a non-repeatable read similarly:
- Transaction B reads user 1’s account balance as £50.
- Transaction A updates user 1’s account balance from £50 to £100 and commits the transaction.
- Transaction B reads user 1’s account balance again and gets the new value, £100, and then commits the transaction.
The problem here is that transaction B has got a different value in the course of its transaction because it was affected by transaction A’s update. This is a problem because transaction B is getting different values within its own transaction. However, in practice, it solves the issue of transferring money between users when they don’t exist.
This is why a read committed isolation level, which does not prevent non-repeatable reads but does prevent dirty reads, is the most commonly used isolation level in practice.
Dirty reads
The previous example, where we made money out of thin air and ended up transferring £100 out of an account that only had £50 in balance, is a classic example of a dirty read.
A read uncommitted isolation level does not protect us from dirty reads and that is why it is rarely used in production-level systems.
The following are the isolation levels versus their potential issues:

Table 6.1 – Database isolation levels and potential issues
PostgreSQL uses a default (and configurable) isolation level of read committed. As MongoDB is not inherently an RDBMS, using transactions for every operation makes the situation more complicated.
The equivalent isolation level in these terms is read uncommitted. This may look scary based on the examples given previously, but on the other hand, in MongoDB, there is (again, in general) no concept of transactions or rolling them back. Read uncommitted refers to the fact that changes will be made visible before they are made durable. More details on the made durable part will be provided in the next section.
Durability
Durability is all about data resilience in the face of failure. Every transaction that has successfully committed its state must survive failure. This is usually done by persisting the transaction results in persistent storage (SSD/HDD).
RDBMSs always follow the durability concept by writing every committed transaction to a transaction log or write-ahead log (WAL). MongoDB, using the WiredTiger storage engine, commits writes using WAL to its persistent storage-based journal every 60 milliseconds and is, for all practical purposes, durable. As durability is important, every database system prefers relaxing other aspects of ACID first, and durability usually gets relaxed last.
When do we need ACID in MongoDB?
Existing atomicity guarantees, for single-document operations, that MongoDB can meet the integrity needs of most real-world applications. However, some use cases have traditionally benefited from ACID transactions; modeling them in MongoDB could be significantly more difficult than using the well-known ACID paradigm.
Unsurprisingly, many of these cases come from the financial industry. Dealing with money and stringent regulation frameworks means that every operation needs to be stored, sometimes in a strict execution order so that they can be logged, verified, and audited if requested. Building a digital bank requires interaction between multiple accounts that could be represented as documents in MongoDB.
Managing high volumes of financial transactions, either by users or algorithms executing high-frequency trading, also requires verifying every single one of them. These transactions may span multiple documents as they would, again, refer to multiple accounts.
The general pattern for using multi-document ACID transactions is when we can have an unbounded number of entities, sometimes in the millions. In this case, modeling entities in subdocuments and arrays cannot work because the document would eventually outgrow the built-in 16 MB document size limit present in MongoDB.
Building a digital bank using MongoDB
The most common use cases for multi-document ACID transactions come from the financial sector. In this section, we will model a digital bank using transactions and go through progressively more complicated examples of how we can use transactions for our benefit.
The basic functionality that a bank must provide is accounts and transferring monetary amounts between them. Before transactions were introduced, MongoDB developers had two options. The first option – the MongoDB way of doing it – is to embed data in a document, either as a subdocument or as an array of values. In the case of accounts, this could result in a data structure such as the following:
{accounts: [ {account_id: 1, account_name: 'alex', balance: 100}, {account_id: 2, account_name: 'bob', balance: 50}]}However, even in this simple format, it will quickly outgrow the fixed 16 MB document limit in MongoDB. The advantage of this approach is that since we have to deal with a single document, all operations will be atomic, resulting in strong consistency guarantees when we transfer money from one account to another.
The only viable alternative, except for using a relational database, is to implement guarantees at the application level that will simulate a transaction with the appropriate code in place to undo parts, or the whole, of a transaction in case of an error. This can work, but will result in a longer time to market and is more error-prone.
MongoDB’s multi-document ACID transactions approach is similar to how we would work with transactions in a relational database. Taking the most simple example from MongoDB Inc.’s white paper, MongoDB Multi-Document ACID Transactions, published in June 2018, the generic transaction in MongoDB will look as follows:
s.start_transaction()
orders.insert_one(order, session=s)
stock.update_one(item, stockUpdate, session=s)
s.commit_transaction()
However, the same transaction in MySQL will look as follows:
db.start_transaction()
cursor.execute(orderInsert, orderData)
cursor.execute(stockUpdate, stockData)
db.commit()
That said, in modern web application frameworks, most of the time, transactions are hidden in the object-relational mapping (ORM) layer and not immediately visible to the application developer. The framework ensures that web requests are wrapped in transactions to the underlying database layer. This is not yet the case for ODM frameworks, but you would expect that this could now change.
Setting up our data
We are going to use a sample init_data.json file with two accounts. Alex has 100 of the hypnotons imaginary currency, whereas Mary has 50 of them:
{"collection": "accounts", "account_id": "1", "account_name": "Alex", "account_balance":100}{"collection": "accounts", "account_id": "2", "account_name": "Mary", "account_balance":50}Using the following Python code, we can insert these values into our database:
import json
class InitData:
def __init__(self):
self.client = MongoClient('localhost', 27017)self.db = self.client.mongo_bank
self.accounts = self.db.accounts
# drop data from accounts collection every time to start from a clean slate
self.accounts.drop()
# load data from json and insert them into our database
init_data = InitData.load_data(self)
self.insert_data(init_data)
@staticmethod
def load_data(self):
ret = []
with open('init_data.json', 'r') as f:for line in f:
ret.append(json.loads(line))
return ret
def insert_data(self, data):
for document in data:
collection_name = document['collection']
account_id = document['account_id']
account_name = document['account_name']
account_balance = document['account_balance']
self.db[collection_name].insert_one({'account_id': account_id, 'name': account_name, 'balance': account_balance})This results in our mongo_bank database having the following documents in the accounts collection:
> db.accounts.find()
{ “_id” : ObjectId(“5bc1fa7ef8d89f2209d4afac”), “account_id” : “1”, “name” : “Alex”, “balance” : 100 }
{ “_id” : ObjectId(“5bc1fa7ef8d89f2209d4afad”), “account_id” : “2”, “name” : “Mary”, “balance” : 50 }
Transferring between accounts – part 1
As a MongoDB developer, the most familiar way to model a transaction is to implement basic checks in the code. With our sample account documents, you may be tempted to implement an account transfer as follows:
def transfer(self, source_account, target_account, value):
print(f'transferring {value} Hypnotons from {source_account} to {target_account}')with self.client.start_session() as ses:
ses.start_transaction()
self.accounts.update_one({'account_id': source_account}, {'$inc': {'balance': value*(-1)} })self.accounts.update_one({'account_id': target_account}, {'$inc': {'balance': value} })updated_source_balance = self.accounts.find_one({'account_id': source_account})['balance']updated_target_balance = self.accounts.find_one({'account_id': target_account})['balance']if updated_source_balance < 0 or updated_target_balance < 0:
ses.abort_transaction()
else:
ses.commit_transaction()
Calling this method in Python will transfer 300 hypnotons from account 1 to account 2:
>>> obj = InitData.new
>>> obj.transfer(‘1’, ‘2’, 300)
This will result in the following output:
> db.accounts.find()
{ “_id” : ObjectId(“5bc1fe25f8d89f2337ae40cf”), “account_id” : “1”, “name” : “Alex”, “balance” : -200 }
{ “_id” : ObjectId(“5bc1fe26f8d89f2337ae40d0”), “account_id” : “2”, “name” : “Mary”, “balance” : 350 }
The problem here isn’t the checks on updated_source_balance and updated_target_balance. Both of these values reflect the new values of -200 and 350, respectively. The problem isn’t the abort_transaction() operation either. Instead, the problem is that we are not using the session.
The single most important thing to learn about transactions in MongoDB is that we need to use the session object to wrap operations in a transaction. However, we can still perform operations outside the transaction scope within a transaction code block.
What happened here is that we initiated a transaction session, as follows:
with self.client.start_session() as ses:
Then, we completely ignored it by doing all of our updates in a non-transactional way. After that, we invoked abort_transaction, as follows:
ses.abort_transaction()
The transaction to be aborted was essentially void and didn’t have anything to roll back.
Transferring between accounts – part 2
The correct way to implement a transaction is to use the session object in every operation that we want to either commit or roll back at the end of it, as shown in the following code:
def tx_transfer_err(self, source_account, target_account, value):
print(f'transferring {value} Hypnotons from {source_account} to {target_account}')with self.client.start_session() as ses:
ses.start_transaction()
res = self.accounts.update_one({'account_id': source_account}, {'$inc': {'balance': value*(-1)} }, session=ses)res2 = self.accounts.update_one({'account_id': target_account}, {'$inc': {'balance': value} }, session=ses)error_tx = self.__validate_transfer(source_account, target_account)
if error_tx['status'] == True:
print(f"cant transfer {value} Hypnotons from {source_account} ({error_tx['s_bal']}) to {target_account} ({error_tx['t_bal']})")ses.abort_transaction()
else:
ses.commit_transaction()
The only difference now is that we are passing session=ses in both of our update statements. To validate whether we have enough funds to make the transfer, we wrote a helper method, __validate_transfer, with its arguments being the source and target account IDs:
def __validate_transfer(self, source_account, target_account):
source_balance = self.accounts.find_one({'account_id': source_account})['balance']target_balance = self.accounts.find_one({'account_id': target_account})['balance']if source_balance < 0 or target_balance < 0:
return {'status': True, 's_bal': source_balance, 't_bal': target_balance}else:
return {'status': False}Unfortunately, this attempt will also fail. The reason is the same as before. When we are inside a transaction, we make changes to the database that follow the ACID principles. Changes inside a transaction are not visible to any queries outside of it until they are committed.
Transferring between accounts – part 3
The correct implementation of the transfer problem will look as follows (the full code sample can be found in this book’s GitHub repository):
from pymongo import MongoClient
import json
class InitData:
def __init__(self):
self.client = MongoClient('localhost', 27017, w='majority')self.db = self.client.mongo_bank
self.accounts = self.db.accounts
# drop data from accounts collection every time to start from a clean slate
self.accounts.drop()
init_data = InitData.load_data(self)
self.insert_data(init_data)
self.transfer('1', '2', 300)@staticmethod
def load_data(self):
ret = []
with open('init_data.json', 'r') as f:for line in f:
ret.append(json.loads(line))
return ret
def insert_data(self, data):
for document in data:
collection_name = document['collection']
account_id = document['account_id']
account_name = document['account_name']
account_balance = document['account_balance']
self.db[collection_name].insert_one({'account_id': account_id, 'name': account_name, 'balance': account_balance})Now, let’s validate any errors using the following code:
# validating errors, using the tx session
def tx_transfer_err_ses(self, source_account, target_account, value):
print(f'transferring {value} Hypnotons from {source_account} to {target_account}')with self.client.start_session() as ses:
ses.start_transaction()
res = self.accounts.update_one({'account_id': source_account}, {'$inc': {'balance': value * (-1)}}, session=ses)res2 = self.accounts.update_one({'account_id': target_account}, {'$inc': {'balance': value}}, session=ses)error_tx = self.__validate_transfer_ses(source_account, target_account, ses)
if error_tx['status'] == True:
print(f"cant transfer {value} Hypnotons from {source_account} ({error_tx['s_bal']}) to {target_account} ({error_tx['t_bal']})")ses.abort_transaction()
else:
ses.commit_transaction()
Now, let’s pass the session value so that we can view the updated values:
def __validate_transfer_ses(self, source_account, target_account, ses):
source_balance = self.accounts.find_one({'account_id': source_account}, session=ses)['balance']target_balance = self.accounts.find_one({'account_id': target_account}, session=ses)['balance']if source_balance < 0 or target_balance < 0:
return {'status': True, 's_bal': source_balance, 't_bal': target_balance}else:
return {'status': False}def main():
InitData()
if __name__ == '__main__':
main()
In this case, by passing the session object’s ses value, we ensure that we can both make changes in our database using update_one() and also view these changes using find_one(), before doing either an abort_transaction() operation or a commit_transaction() operation.
In the end, if we need to roll back using transactions, we don’t need to keep track of the previous account balance values. This is because MongoDB will discard all of the changes that we made inside the transaction scope.
Continuing with the same example using Ruby, we have the following code for part 3:
require 'mongo'
class MongoBank
def initialize
@client = Mongo::Client.new([ '127.0.0.1:27017' ], database: :mongo_bank)
db = @client.database
@collection = db[:accounts]
# drop any existing data
@collection.drop
@collection.insert_one('collection': 'accounts', 'account_id': '1', 'account_name': 'Alex', 'account_balance':100)@collection.insert_one('collection': 'accounts', 'account_id': '2', 'account_name': 'Mary', 'account_balance':50)transfer('1', '2', 30)transfer('1', '2', 300)end
def transfer(source_account, target_account, value)
puts "transferring #{value} Hypnotons from #{source_account} to #{target_account}"session = @client.start_session
session.start_transaction(read_concern: { level: :snapshot }, write_concern: { w: :majority })@collection.update_one({ account_id: source_account }, { '$inc' => { account_balance: value*(-1)} }, session: session)@collection.update_one({ account_id: target_account }, { '$inc' => { account_balance: value} }, session: session)source_account_balance = @collection.find({ account_id: source_account }, session: session).first['account_balance']if source_account_balance < 0
session.abort_transaction
else
session.commit_transaction
end
end
end
# initialize class
MongoBank.new
Transactions can also perform some data definition language (DDL) operations, starting from version 4.4. A transaction can create a collection or indexes in empty collections that have already been created in the same transaction.
A collection can be created explicitly using the create_collection() operator or implicitly by creating or upserting a document targeting a collection that does not already exist.
There are still some limitations in place; for example, we cannot write/update across different shards in the same transaction. As an example, let’s say our transaction is performing the following two operations:
- Adding or updating a document in the accounts collection in shard A
- Implicitly or explicitly creating a collection in shard B
Here, this transaction will abort.
Another limitation is that when we want to create a collection or index explicitly (that is, using the create collection and index methods), we need to set the transaction read concern to local.
Finally, we cannot list collections and indexes and we cannot use any other non-CRUD and non-informational operators. This would include methods such as count() and createUser().
Note
We can still use the count() method to enumerate the number of documents inside a transaction by wrapping the command inside an aggregation framework operation and using $count or $group combined with $sum. MongoDB drivers will usually provide a helper method, countDocuments(filter, options), that does exactly that.
MongoDB also allows us to customize read_concern and write_concern per transaction.
The available read_concern levels for multi-document ACID transactions are as follows:
- majority: The majority of the servers in a replica set have acknowledged the data. For this to work as expected in transactions, they must also use write_concern set to majority.
- local: Only the local server has acknowledged the data. This is the default read_concern level for transactions.
- snapshot: If the transaction commits with majority set to write_concern, all the transaction operations will have read from a snapshot of the majority of the committed data; otherwise, no guarantee can be made.
A snapshot read concern is also available outside of multi-document ACID transactions for the find() and aggregate() methods. It is also available for the distinct() method if the collection is not sharded.
Note
A read concern for transactions is set at the transaction level or higher (session or client). Setting a read concern in individual operations is not supported and is generally discouraged.
The available write_concern levels for multi-document ACID transactions are as follows:
- majority: The majority of the servers in a replica set have acknowledged the data. This is the default write concern as of MongoDB 5.0.
- <w>: The <w> number of servers have to acknowledge the write before it’s considered successful. w==1 will write to primary, w==2 will write to primary and one data bearing node, and so on.
- <custom_write_concern_name>: We can also tag our servers and cluster them under <custom_write_concern_name>. This way, we can wait for acknowledgment from our desired number of nodes and also specify exactly which servers we want to propagate our writes to. This is useful, for example, when we have disaster recovery scenarios where one of the servers is hosted on another data center and we need to make sure that the writes are always propagated there. The operation may be rolled back if our <custom_write_concern_name> set only ends up having one server and that server steps down from being a primary before the write is acknowledged.
The default write concern will be different in the case that we have one or more arbiter nodes in our cluster. In this case, if the number of data nodes is less than or equal to the “majority number of voting nodes,” then the write concern falls back to 1, instead of the default value of “majority.”
The “majority number of voting nodes” is calculated as 1 + floor(<number_of_voting nodes>).
floor() will round down the number of voting nodes to the nearest integer.
The number of voting nodes is the sum of arbiter nodes plus the data-bearing nodes.
Note
Transaction read and write concerns will fall back from the transaction, then to the session level, and finally to the MongoDB client-level defaults if unset.
Some other transaction limitations as of MongoDB 5.3 are as follows:
- We can’t write to any system or capped collections.
- We can’t read or write any collections in the admin, config, or local databases.
- We can’t inspect the query planner using explain().
- We can’t read from a capped collection using a snapshot read concern.
- The getMore operation on cursors must be created and accessed either inside or outside the transaction. This means that if we create the cursor inside a transaction we can only use getMore() on the cursor inside it. The same goes for creating it outside the transaction.
- We can’t start a transaction by invoking killCursors() as the first operation.
In this section, we learned about ACID properties through the digital bank use case. In the next section, we will explore a more complex use case of using transactions for e-commerce.
E-commerce using MongoDB
For our second example, we are going to use a more complex use case on a transaction with three different collections.
We are going to simulate a shopping cart and payment transaction process for an e-commerce application using MongoDB. Using the sample code that we’ll provide at the end of this section, we will initially populate the database with the following data.
Our first collection is the users collection with one document per user:
> db.users.find()
{ "_id" : ObjectId("5bc22f35f8d89f2b9e01d0fd"), "user_id" : 1, "name" : "alex" }{ "_id" : ObjectId("5bc22f35f8d89f2b9e01d0fe"), "user_id" : 2, "name" : "barbara" }Then, we have the carts collection with one document per cart, which is linked via user_id to our users:
> db.carts.find()
{ "_id" : ObjectId("5bc2f9de8e72b42f77a20ac8"), "cart_id" : 1, "user_id" : 1 }{ "_id" : ObjectId("5bc2f9de8e72b42f77a20ac9"), "cart_id" : 2, "user_id" : 2 }The payments collection holds any completed payment that has gone through, storing cart_id and item_id to link to the cart that it belonged to and the item that has been paid, respectively:
> db.payments.find()
{ "_id" : ObjectId("5bc2f9de8e72b42f77a20aca"), "cart_id" : 1, "name" : "alex", "item_id" : 101, "status" : "paid" }Finally, the inventories collection holds a count of the number of items (by item_id) that we currently have available, along with their price and a short description:
> db.inventories.find()
{ "_id" : ObjectId("5bc2f9de8e72b42f77a20acb"), "item_id" : 101, "description" : "bull bearing", "price" : 100, "quantity" : 5 }In this example, we are going to demonstrate using MongoDB’s schema validation functionality. Using JSON schemata, we can define a set of validations that will be checked against the database level every time a document is inserted or updated. This was introduced in MongoDB 3.6. In our case, we are going to use it to make sure that we always have a positive number of items in our inventory.
The validator object in the MongoDB shell format is as follows:
validator = { validator: { $jsonSchema: { bsonType: "object",required: ["quantity"],
properties:
{ quantity: { bsonType: ["long"],minimum: 0,
description: "we can't have a negative number of items in our inventory"
}
}
}
}
}
JSON schema can be used to implement many of the validations that we would usually have in our models in Rails or Django. These keywords are defined in the following table:
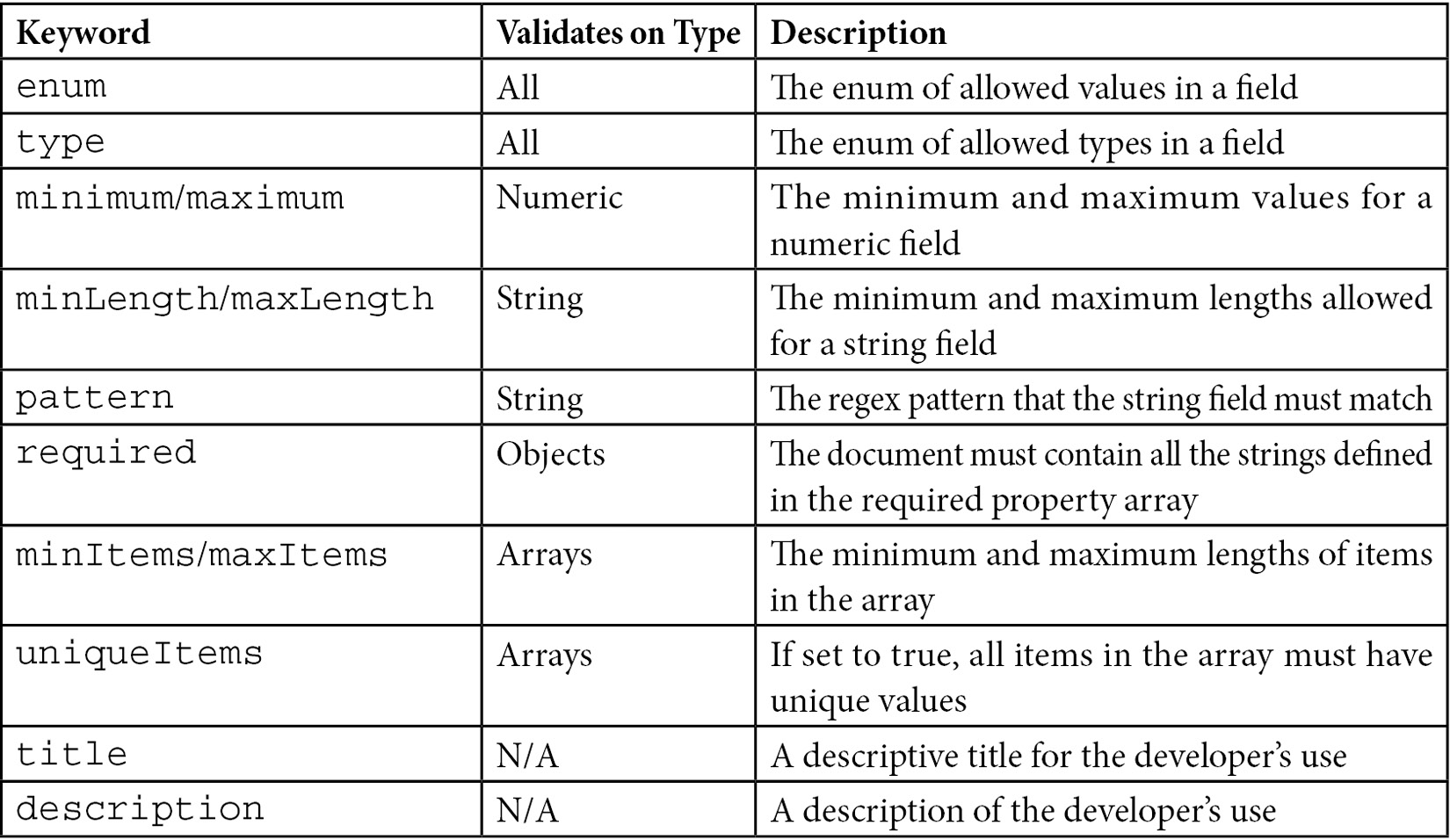
Table 6.2 – JSON validation types and attributes
Using the JSON schema, we can offload validations from our models to the database layer and/or use MongoDB validations as an additional layer of security on top of web application validations.
To use a JSON schema, we must specify it at the time that we are creating our collection, as follows:
> db.createCollection("inventories", validator)Returning to our example, our code will simulate having an inventory of five bull bearings and placing two orders; one by user Alex for two bull bearings, followed by a second order by user Barbara for another four bull bearings.
As expected, the second order will not go through because we don’t have enough bull bearings in our inventory to fulfill it. This can be seen in the following code:
from pymongo import MongoClient
from pymongo.errors import ConnectionFailure
from pymongo.errors import OperationFailure
class ECommerce:
def __init__(self):
self.client = MongoClient('localhost', 27017, w='majority')self.db = self.client.mongo_bank
self.users = self.db['users']
self.carts = self.db['carts']
self.payments = self.db['payments']
self.inventories = self.db['inventories']
# delete any existing data
self.db.drop_collection('carts')self.db.drop_collection('payments')self.db.inventories.remove()
# insert new data
self.insert_data()
alex_order_cart_id = self.add_to_cart(1,101,2)
barbara_order_cart_id = self.add_to_cart(2,101,4)
self.place_order(alex_order_cart_id)
self.place_order(barbara_order_cart_id)
def insert_data(self):
self.users.insert_one({'user_id': 1, 'name': 'alex' })self.users.insert_one({'user_id': 2, 'name': 'barbara'})self.carts.insert_one({'cart_id': 1, 'user_id': 1})self.db.carts.insert_one({'cart_id': 2, 'user_id': 2})self.db.payments.insert_one({'cart_id': 1, 'name': 'alex', 'item_id': 101, 'status': 'paid'})self.db.inventories.insert_one({'item_id': 101, 'description': 'bull bearing', 'price': 100, 'quantity': 5.0})# Adding an item with quantity to the cart
def add_to_cart(self, user, item, quantity):
# find cart for user
cart_id = self.carts.find_one({'user_id':user})['cart_id']self.carts.update_one({'cart_id': cart_id}, {'$inc': {'quantity': quantity}, '$set': { 'item': item} })return cart_id
# Placing an order
def place_order(self, cart_id):
while True:
try:
with self.client.start_session() as ses:
ses.start_transaction()
cart = self.carts.find_one({'cart_id': cart_id}, session=ses)item_id = cart['item']
quantity = cart['quantity']
# update payments
self.db.payments.insert_one({'cart_id': cart_id, 'item_id': item_id, 'status': 'paid'}, session=ses)# remove item from cart
self.db.carts.update_one({'cart_id': cart_id}, {'$inc': {'quantity': quantity * (-1)}}, session=ses)# update inventories
self.db.inventories.update_one({'item_id': item_id}, {'$inc': {'quantity': quantity*(-1)}}, session=ses)ses.commit_transaction()
break
except (ConnectionFailure, OperationFailure) as exc:
print("Transaction aborted. Caught exception during transaction.")# If transient error, retry the whole transaction
if exc.has_error_label("TransientTransactionError"):print("TransientTransactionError, retrying transaction ...")continue
elif str(exc) == 'Document failed validation':
print("error validating document!")raise
else:
print("Unknown error during commit ...")raise
def main():
ECommerce()
if __name__ == '__main__':
main()
Let’s break down the preceding example into its interesting parts, as follows:
def add_to_cart(self, user, item, quantity):
# find cart for user
cart_id = self.carts.find_one({'user_id':user})['cart_id']self.carts.update_one({'cart_id': cart_id}, {'$inc': {'quantity': quantity}, '$set': { 'item': item} })return cart_id
The add_to_cart() method doesn’t use transactions. This is because we are updating one document at a time, so these are guaranteed to be atomic operations.
Then, in the place_order() method, we start the session, and then subsequently, a transaction within this session. Similar to the previous use case, we need to make sure that we add the session=ses parameter at the end of every operation that we want to be executed in the transaction context:
def place_order(self, cart_id):
while True:
try:
with self.client.start_session() as ses:
ses.start_transaction()
…
# update payments
self.db.payments.insert_one({'cart_id': cart_id, 'item_id': item_id, 'status': 'paid'}, session=ses)# remove item from cart
self.db.carts.update_one({'cart_id': cart_id}, {'$inc': {'quantity': quantity * (-1)}}, session=ses)# update inventories
self.db.inventories.update_one({'item_id': item_id}, {'$inc': {'quantity': quantity*(-1)}}, session=ses)ses.commit_transaction()
break
except (ConnectionFailure, OperationFailure) as exc:
print("Transaction aborted. Caught exception during transaction.")# If transient error, retry the whole transaction
if exc.has_error_label("TransientTransactionError"):print("TransientTransactionError, retrying transaction ...")continue
elif str(exc) == 'Document failed validation':
print("error validating document!")raise
else:
print("Unknown error during commit ...")raise
In this method, we are using the retryable transaction pattern. We start by wrapping the transaction context in a while True block, essentially making it loop forever. Then, we enclose our transaction in a try block that will listen for exceptions.
An exception of the transient transaction type, which has the TransientTransactionError error label, will result in continued execution in the while True block, essentially retrying the transaction from the very beginning. On the other hand, a failed validation or any other error will reraise the exception once it’s been logged.
Note
The session.commitTransaction() and session.abortTransaction() operations will be retried once by MongoDB, regardless of whether we retry the transaction or not.
We don’t need to explicitly call abortTransaction() in this example since MongoDB will abort it in the face of exceptions.
In the end, our database will look as follows:
> db.payments.find()
{ "_id" : ObjectId("5bc307178e72b431c0de385f"), "cart_id" : 1, "name" : "alex", "item_id" : 101, "status" : "paid" }{ "_id" : ObjectId("5bc307178e72b431c0de3861"), "cart_id" : 1, "item_id" : 101, "status" : "paid" }The payment that we just made does not contain the name field, in contrast to the sample payment that we inserted in our database before rolling our transactions:
> db.inventories.find()
{ "_id" : ObjectId("5bc303468e72b43118dda074"), "item_id" : 101, "description" : "bull bearing", "price" : 100, "quantity" : 3 }Our inventory has the correct number of bull bearings, which is three (five minus the two that Alex ordered), as shown in the following code block:
> db.carts.find()
{ "_id" : ObjectId("5bc307178e72b431c0de385d"), "cart_id" : 1, "user_id" : 1, "item" : 101, "quantity" : 0 }{ "_id" : ObjectId("5bc307178e72b431c0de385e"), "cart_id" : 2, "user_id" : 2, "item" : 101, "quantity" : 4 }Our carts have the correct quantities. Alex’s cart (cart_id=1) has zero items, whereas Barbara’s cart (cart_id=2) still has four since we don’t have enough bull bearings to fulfill her order. Our payments collection does not have an entry for Barbara’s order and the inventory still has three bull bearings in place.
Our database state is consistent and saves lots of time by implementing the abort transaction and reconciliation data logic at the application level.
Continuing with the same example in Ruby, we get the following code block:
require 'mongo'
class ECommerce
def initialize
@client = Mongo::Client.new([ '127.0.0.1:27017' ], database: :mongo_bank)
db = @client.database
@users = db[:users]
@carts = db[:carts]
@payments = db[:payments]
@inventories = db[:inventories]
# drop any existing data
@users.drop
@carts.drop
@payments.drop
@inventories.delete_many
# insert data
@users.insert_one({ "user_id": 1, "name": "alex" })@users.insert_one({ "user_id": 2, "name": "barbara" })@carts.insert_one({ "cart_id": 1, "user_id": 1 })@carts.insert_one({ "cart_id": 2, "user_id": 2 })@payments.insert_one({"cart_id": 1, "name": "alex", "item_id": 101, "status": "paid" })@inventories.insert_one({"item_id": 101, "description": "bull bearing", "price": 100, "quantity": 5 })alex_order_cart_id = add_to_cart(1, 101, 2)
barbara_order_cart_id = add_to_cart(2, 101, 4)
place_order(alex_order_cart_id)
place_order(barbara_order_cart_id)
end
def add_to_cart(user, item, quantity)
session = @client.start_session
session.start_transaction
cart_id = @users.find({ "user_id": user}).first['user_id']@carts.update_one({"cart_id": cart_id}, {'$inc': { 'quantity': quantity }, '$set': { 'item': item } }, session: session)session.commit_transaction
cart_id
end
def place_order(cart_id)
session = @client.start_session
session.start_transaction
cart = @carts.find({'cart_id': cart_id}, session: session).firstitem_id = cart['item']
quantity = cart['quantity']
@payments.insert_one({'cart_id': cart_id, 'item_id': item_id, 'status': 'paid'}, session: session)@carts.update_one({'cart_id': cart_id}, {'$inc': {'quantity': quantity * (-1)}}, session: session)@inventories.update_one({'item_id': item_id}, {'$inc': {'quantity': quantity*(-1)}}, session: session)quantity = @inventories.find({'item_id': item_id}, session: session).first['quantity']if quantity < 0
session.abort_transaction
else
session.commit_transaction
end
end
end
ECommerce.new
Similar to the Python code sample, we are passing the session: session parameter along each operation to make sure that we are operating inside the transaction.
Here, we are not using the retry-able transaction pattern. Regardless, MongoDB will retry committing or aborting a transaction once before throwing an exception.
The best practices and limitations of multi-document ACID transactions
At the time of writing, there are some limitations and best practices when developing using MongoDB transactions:
- The transaction timeout is set to 60 seconds.
- As a best practice, any transaction should not try to modify more than 1,000 documents. There is no limitation in reading documents during a transaction.
- The oplog will record a single entry for a transaction, meaning that this is subject to the 16 MB document size limit. This is not such a big problem with transactions that update documents, as only the delta will be recorded in the oplog. It can, however, be an issue when transactions insert new documents, in which case the oplog will record the full contents of the new documents.
- We should add application logic to cater to failing transactions. These could include using retry-able writes or executing some business logic-driven action when the error cannot be retried or we have exhausted our retries (usually, this means a custom 500 error).
- DDL operations such as modifying indexes, collections, or databases will get queued up behind active transactions. Transactions trying to access the namespace while a DDL operation is still pending will immediately abort.
- Transactions only work in replica sets. Starting from MongoDB 4.2, transactions will also be available for sharded clusters.
- Use them sparingly; maybe the most important point to consider when developing using MongoDB transactions is that they are not meant as a replacement for good schema design. They should only be used when there is no other way to model our data without them.
Now, let’s summarize this chapter.
Summary
In this chapter, we learned about textbook relational database theory on ACID in the context of MongoDB.
Following that, we focused on multi-document ACID transactions and applied them to two use cases using Ruby and Python. We learned about when to use MongoDB transactions and when not to use them, how to use them, their best practices, and their limitations concerning the digital bank and e-commerce use cases.
In the next chapter, we will deal with one of the most commonly used features of MongoDB: aggregation.