
2
Working with the Aggregator Pattern
In the previous chapter, we looked at some of the key elements that make up microservices. We will turn our attention to more practical applications of these concepts, starting with the aggregator pattern and domain-driven design. These combine to set a premise for scoping an application being built on microservices design principles.
The aggregator pattern and domain-driven design go hand in hand. For now, we will refer to domain-driven design as DDD. So, a DDD aggregate is a group of domain objects, combined as a single unit. In practicality, we might have a customer record different from its documents, but it is prudent of us to display all of these bits of data as a single point of data, an aggregate.
After reading this chapter, we will be able to do the following:
- Understand DDD
- Understand how to derive domains in a system process
- Understand the importance of aggregates and the aggregate pattern
- Distinguish between aggregates and entities
- Understand value objects and their role in the design process
Technical requirements
The code references used in this chapter can be found in the project repository, which is hosted on GitHub at https://github.com/PacktPublishing/Microservices-Design-Patterns-in-.NET/tree/master/Ch02
Ensure that you have at least one of the following software installed on your machine to be able to execute this code (use the links to download and install):
- Visual Studio 2022: https://visualstudio.microsoft.com/vs/
- Visual Studio Code: https://code.visualstudio.com/download
Exploring DDD and its significance
DDD is a software design approach that encourages us as developers to assess processes and subprocesses and decipher all the atomic elements therein. Atomic means that one process might have many moving parts, and while they all combine to give one output, they have their own routines to carry out. Each subprocess can be seen as self-governing and can further be attributed to a domain. This motivates us to break up a monolith into independent microservices that do their own thing against their own data. That is a domain.
Before we go much further, let’s take some time to explore certain keywords and their definitions:
- Models: These are abstractions that define aspects of a domain and are used to solve domain problems. We organize information about the target domain into smaller pieces and call them models. A model is a central point of reference in our design and development process. These models can then be grouped into logical modules and dealt with one at a time. A domain contains too much information for just one model and sometimes, parts of the information can just be omitted. For instance, our healthcare management system does need to capture customer information, but we do not need to know their eye and hair colors. This might be a simple example, but it might get far more complicated than that in a real scenario. Sifting through the relevant parts of the body of knowledge will require close collaboration with developers, domain experts, and fellow designers.
- Ubiquitous language: This is a language that is unique to a domain model and is used by team members within the context of activities related to the specific domain. We have already established that models for a domain need to be developed through collaboration with domain experts. Given the difference in skillsets and perceptions, there will be communication barriers. Developers tend to think and speak about concepts relative to programming. They generally think and talk in terms of inheritance, polymorphism, and so on. Unfortunately, domain experts don’t usually know or care for any of that. Domain experts will use their own jargon and terms that developers will not understand. This gap in communication does not bode well for any team.
- Bounded context: This defines boundaries in a system or subsystem that informs the work that a particular team will carry out and the focal point of their efforts, within their domain. A bounded context is a logical boundary of a domain, where terms and rules apply. All terms, definitions, and concepts inside this boundary form the ubiquitous language. Establishing bounded contexts is a core step in DDD, and it is strategically used in scoping large models, in large teams. In DDD, we subdivide our larger models into bounded contexts and then we scope the relationships that exist in between. Context mapping in DDD can be confusing without real-world examples. Let’s use our healthcare management system as a sample implementation for two scenarios that use bounded context maps and learn to analyze the relationships between the maps. Say we have the context of document management and patient appointments. Both have unrelated and related concepts. Documents only exist in a document management system but will have a reference to patients. Context mapping is a common strategy used in DDD to depict the relationships that exist between bounded contexts.
Figure 2.1 shows a relationship between two domains:
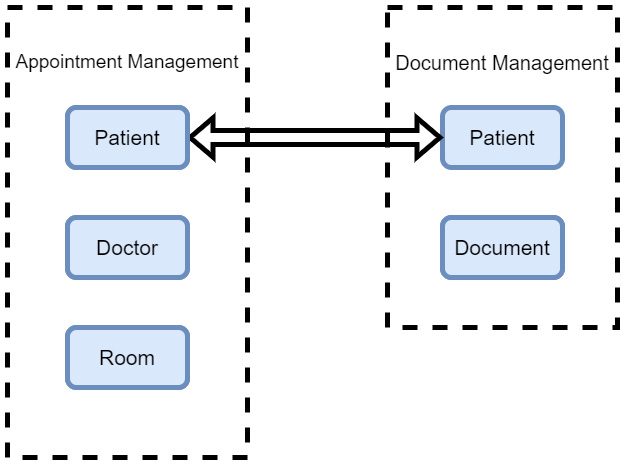
Figure 2.1 – Each domain is standalone, but sometimes data overlaps. Both appointment and document management need patient data
Let’s take a step back from microservice design patterns and assess what it takes to just build software. A domain is a category of business rules and operations. If your software is to be used in a bank, then the domain is banking; if it is used in a hospital, then the domain is healthcare.
So, the software we develop must complement the domain in order to solve the overall problem. The core concepts and elements of the domain must be present in the software’s design and models.
Exploring the pros and cons of DDD
DDD is a big commitment. It promotes focus on smaller, individual pieces of a domain, and the resulting software is more flexible. It breaks our application into smaller chunks and allows us to more easily modify application parts and components, with fewer side effects. The application’s code tends to be well organized and highly testable, and the business logic for the domain is isolated to that particular code base. Even if you don’t use DDD end to end for a project, the principles can be beneficial to your application implementation activities. DDD is best used for breaking down complex business logic. It is not suitable for applications with simple requirements and business logic for creating, adding, updating, and deleting data. DDD is time-consuming and requires expert-level domain knowledge. So, bear in mind that non-technical resource persons will be required and have to be available throughout the duration of a project.
Now that we understand DDD at a high level, let’s explore how the concepts that it promotes tie into microservice design patterns.
DDD and microservices
Implementations of applications that have been scoped using DDD are best implemented through microservices. By now, we can appreciate that a microservice architecture promotes dividing one large concept for an application into self-contained and independent services. So, to use the concept of boundaries and context, each microservice serves its own bounded context. Each one will have its own models, language, business rules, and technology stack.
This is not a catch-all fix though, since perfect alignment between a microservice and a bounded context might not always be true, but some applications, including ours, are perfect candidates for microservices and DDD.
We can consider a number of scenarios where we can isolate certain services that are not the most obvious ones and wouldn’t have been originally scoped as bounded contexts. Take, for example, email and alert systems. It is easy enough to place that logic and functionality in the web application, such that when an appointment is submitted, we send confirmations to our patients and alerts to the staff. This is reasonable, but we could also create separate message queue-based services that serve the sole purpose of delivering these messages. That way, the web application has even less responsibility, and we run less risk of inadvertently modifying UI logic when addressing an email or alert maintenance concern.
Ultimately, because DDD suggests that we separate contexts into standalone tranches, a microservice architecture is the perfect development pattern to support this ambition. Bear in mind that DDD serves as an initial guideline to carve out business rules that can stand on their own, and each microservice will be developed to support that set of business rules, as well as implement supporting services in the most efficient and loosely coupled manner.
Now that we can appreciate how DDD and microservices go hand in hand, let’s begin looking into the aggregator pattern and how we can begin assessing the different models and data that need to be captured.
The purpose and use of aggregate patterns
The aggregate pattern is a specific software design pattern within DDD. It promotes the collection of related entities and aggregates them into a unit.
Aggregates make it easier to define ownership of elements in large systems. Without them, we run the risk of sprawling and trying to do too much. After we have identified the different contexts in the domain, we can then begin to extract the exact data we need from potentially multiple contexts and sources and model them.
Aggregates and aggregate roots
An aggregate comprises one or more entities and value object models that, in one way or another, interact. This interaction then encourages us to treat them as a unit for data changes. We also want to ensure that, at all times, there is consistency in the aggregate before making changes. In our concept of a healthcare management system, we have already scoped that we have a patient, who more than likely also has an address. A set of changes to a patient record and their address should be treated as a single transaction. We also want to consider that aggregates have roots or a parent object for all other aggregate members.
Aggregates make it easier to enforce certain rules for data and validation across multiple objects. So, in our example so far, a patient can have multiple addresses but needs to have at least one to be in a valid state. These kinds of constraints are easier to apply across the board from a higher level of the root. It is also easier to ensure that data changes follow ACID (Atomicity, Consistency, Isolation, and Durability) principles. We will explore these more in a later chapter.
The aggregate roots also help us to maintain invariants. Invariants are non-negotiable conditions that ensure that a system is consistent. A good metric to use in determining what should be an aggregate root is to consider whether deleting a record should trigger a cascade deletion of other objects in the hierarchy. In essence, our aggregate root represents a cluster of associated objects, treated as a unit for data-related changes.
Figure 2.2 shows a relationship between a root and a non-root entity:
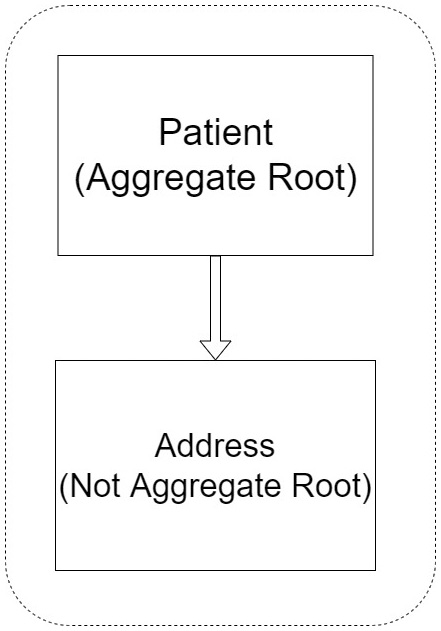
Figure 2.2 – Patient is our aggregate root, and using Address as an example, we have other entities related to the root object
As you can see, the Patient entity plays the role of the aggregate root and has a relationship with the Address entity.
It is always good to use diagrams to visualize how different entities and objects relate. This will assist in giving a broader understanding during the scoping exercise, as we assess the role that each model will play in the domain and how our data strategies will come to life.
Now, let’s turn our sights on exploring relationships a bit more. We need to look at other parts of the system and determine what should be a child, a parent, or simply a sibling.
Relationships in aggregates
Considering that aggregates are clusters of related objects, it is important for us to fully appreciate the relationships between these objects. Generally speaking, we consider relationships to be two-way associations – that is, object A is related to object B, and vice versa. For example, a patient has an appointment, and we need them to have an appointment. This way of thinking might contradict the tenets of DDD though, in the sense that we are trying to simplify things, and a two-way relationship might add complexity to the mission at hand.
In DDD, we want to promote the notion that one-way relationships will suffice. If we go for two-way relationships, which might very well happen, we need to ensure that the added complexity is justifiable. A relationship allows one object to traverse the details of the other. This means, for the patient, we should be able to see all the details of the related appointment, but we do not need to see all the details of the patient when going in the other direction. A simple ID reference to the patient can suffice. If we introduce a full bidirectional relationship, then we create a direct dependency between appointments and patients, which isn’t necessarily true. A good measure to use in defining our models is to ask, “Can I define this object without needing the other?”
A good guideline to use to govern our decisions is that our aggregates should always flow in a single direction from the root to its dependents, and never the other way around.
We have looked at relationships that are obvious and tightly knit, but what happens when relationships are more widely spread? Let’s discuss how we handle relationships that traverse aggregates.
Handling relationships that span aggregates
We know that aggregates are boundaries between logical groupings in our applications. We enforce these segregations by restricting direct references to objects in the aggregate if they are not the root. In our example of the patient and the address, we can safely make the patient record reference the address, making our address an entity or value object.
The key thing to note in this association is that the only way to get the correct address for a patient is by searching the patient record. The address won’t be referenced anywhere else. A patient, however, can be referenced from other aggregates, such as from an appointment record or a document. So, it is important to understand when a bit of data can be referenced directly, or not, and we can use this to guide what aggregates can be made central to our application’s design.
Think about designing our data objects for a database access library such as Entity Framework, where we have to consider the implications of all Create, Read, Update, and Delete (CRUD) operations against our data. Based on the general design pattern of our entity classes, we would place navigation objects inside of both entities in the relationship, but this could lead to cascading issues if not managed properly. This is a key design decision to make, as it is sometimes better to remove the navigation object, sacrificing some of the magic of Entity Framework, and retain greater control and predictability of how our models will interact. By retaining only the foreign key ID reference, we can better enforce one way for aggregates to relate to non-root entities. Now that we have an understanding of aggregates, aggregate roots, and how we formulate them, let’s explore entities and compare how they differ from aggregates.
Aggregates versus entities
As discussed, aggregates are conceptually composed of entities and value objects that relate to each other in some way. We need to understand fully what an entity is and the role that it plays in our development process.
Entities and why we need them
Decisions made in DDD are driven by behavior, but behaviors require objects. These objects are referred to as entities. An entity is a representation of data in your system, something that you need to be able to retrieve, track changes on, and store. Entities also typically have an identity key, most commonly an auto-incrementing integer or a GUID value. In code, you would want to create a base entity type that allows you to set the desired key type relative to the derived type. Here is an example of a BaseEntity class in C#:
public abstract class BaseEntity<TId>
{
public TId Id { get; set; }
}The BaseEntity class will take a generic type parameter, which allows us the flexibility of setting the ID type as needed. We also ensure that we set the class type as abstract to prevent independent instantiation of BaseEntity.
It is one thing to have a mental map of the entities and data persistence strategy that you intend to implement. But modeling and coding are oftentimes different activities when the buck stops. Given the unique demands of DDD, there are patterns and techniques that can be employed to ensure that certain technical attributes are implemented in our DDD-styled entities. It is important to establish the central entity for your system and then design all other parts around that one. For instance, it could be said that appointment booking is the most central operation of our system, so all other entities are just to be referenced. In another scope, patient record management could be seen as the most integral part, so we would want to focus on making that aspect as robust as possible.
These scenarios show that the decisions that you make need to be relative to the mission at hand. One size does not fit all, and your design considerations need to be what is best for your overall context. Beyond that, we need to ensure that we have a good grasp of the operations to be carried out before we can start implementing domain events, repositories, factories, and any other business logic-related elements.
Now, let’s look at the concrete uses of entities in our DDD-styled system. We need to understand how entities should be employed and their actual uses in our system.
Practical uses of entities in code
An entity is primarily defined by its identity and is important to the domain model. It is very important that we design and implement entities carefully.
An entity represents data that might need to traverse multiple microservices and, as a result, needs to have an identity value that can uniquely identify it in any system. We generally use sequential integers for our ID values in a relational database, but given this constraint, we cannot rely on that sequential value being used in multiple databases. For this reason, we usually employ the use of a GUID, which is a generally randomly generated block of an alphanumeric string. It is not sequential, but it is easier to count on it being consistent, since we set it in code rather than rely on a database to set it.
The same identity can be modeled across multiple microservices. In a scenario where an identity value is shared across microservices, this doesn’t necessarily suggest that the same attributes and behaviors will be the same in each microservice or bounded context. For instance, the patient entity in the Patient Management microservice might contain all of the key attributes and behaviors of the patient we would have scoped, but the same entity in the appointment booking microservice might only need minimal data and behaviors, as needed by the appointment booking process. The entity’s contents will always be relative to the requirements of the microservices or bounded context.
Domain entities generally implement behaviors in the form of methods, as well as data attributes. In DDD, domain entities need to implement behaviors and logic that are only useful for the specific domain or entity. In the case of our patient class, there must be validation-related tasks and operations implemented as methods. The methods will handle invariants and rules of the entity so that they are not spread across the application layer.
At this point, we have started to see that our entity models might not just be classes with properties but might also implement behaviors. Next, we take a look at anemic and rich domain models and how we implement them.
A rich domain model versus an anemic domain model
At this point, it is good to appreciate the difference between an anemic model and a rich model. A rich model is more behavioral in nature and fits the description of what we have described – that is, a model that implements methods for tasks relative to the model within the domain. An anemic model is more data-centric and tends to only implement properties. Anemic models are usually implemented as child entities, where there isn’t any special logic. The logic is implemented in the aggregate root, or the business logic layers. Anemic domain models are implemented using procedural style programming. This means that the model has no behaviors and only exposes properties for the data points that it will be storing. We then tend to put all our behavior in service objects in the business layer and run the risk of ending up with spaghetti code, thus losing the advantages that a domain model provides.
Let’s take a look at a simpler or anemic entity model:
public class Patient : BaseEntity<int>
{
public Patient(string name, string sex, int?
primaryDoctorId = null)
{
Name = name;
Sex = sex;
PrimaryDoctorId = primaryDoctorId;
}
public Patient(int id)
{
Id = id;
}
private Patient() // required for EF
{
}
public string Name { get; private set; }
public string Sex { get; private set; }
public int? PrimaryDoctorId { get; private set; }
public void UpdateName(string name)
{
Name = name;
}
public override string ToString()
{
return Name.ToString();
}
}It is a good idea to enforce encapsulation in your class by requiring values to be set upon instantiation of the object. At the end of the day, your decision on how rich or anemic your model is depends on the use or general operations of the microservice. Anemic models might be perfect for more simple CRUD services, where DDD might be a stretch for what you need to design the system. They are more simply used to model our persistence models, since we only use the models for data storage and CRUD purposes. In the following code block, we will look at an example of the Appointment class being implemented as a rich domain model, including logic to handle certain key operations on the data.
The example has been broken into smaller chunks of code to highlight the different general components of a rich data model:
public class Appointment : BaseEntity<Guid>
{
public Appointment(Guid id,
int appointmentTypeId,
Guid scheduleId,
int doctorId,
int patientId,
int roomId,
DateTime start,
DateTime end,
string title,
DateTime? dateTimeConfirmed = null)
{
Id = id;
AppointmentTypeId = appointmentTypeId;
ScheduleId = scheduleId;
DoctorId = doctorId;
PatientId = patientId;
RoomId = roomId;
Start = start;
End = end;
Title = title;
DateTimeConfirmed = dateTimeConfirmed;
}At a minimum, we need to ensure that we use constructors to enforce object creation rules. We list the values that are needed at a minimum and do the assignments upon creation. It is also common practice to include validation checks and/or default values at this stage:
public void UpdateRoom(int newRoomId)
{
if (newRoomId == RoomId) return;
RoomId = newRoomId;
}
public void UpdateStartTime(DateTime newStartTime,)
{
if (newStartTime == Start) return;
Start = newStartTime;
}
public void Confirm(DateTime dateConfirmed)
{
if (DateTimeConfirmed.HasValue) return;
DateTimeConfirmed = dateConfirmed;
}
}We also have some examples of behaviors that we implement in the method. Traditionally, you would want to implement these in the business logic layer or a repository, but for a rich data model, we equip it with the methods it needs to morph its own data as needed. We can also implement our own validation rules in these methods.
Now that we understand what an entity is, the rules surrounding how they are created, and have general guidelines on how they can be implemented, we can now explore value objects and how they differ from entities in our domain model.
Understanding and using value objects
We have observed the main attributes that entity objects should be identified by, which are continuity and identity, and not necessarily their values. This brings us to ask the question, what do we call objects that are indeed defined by their values? These are value objects. They too have their place in the domain model, as they are used to measure and quantify parts of the domain. They do not boast identity keys in the same way that entities do, but their keys are formed through the composition of the values of all their properties, hence the name value objects.
Given that the data they store is so important in defining their identity and uniqueness in our system, it is of the utmost importance that these objects never change once created and are immutable. It is also important to understand the differences between entity models and value objects.
Figure 2.3 shows a comparison between entities and value objects:
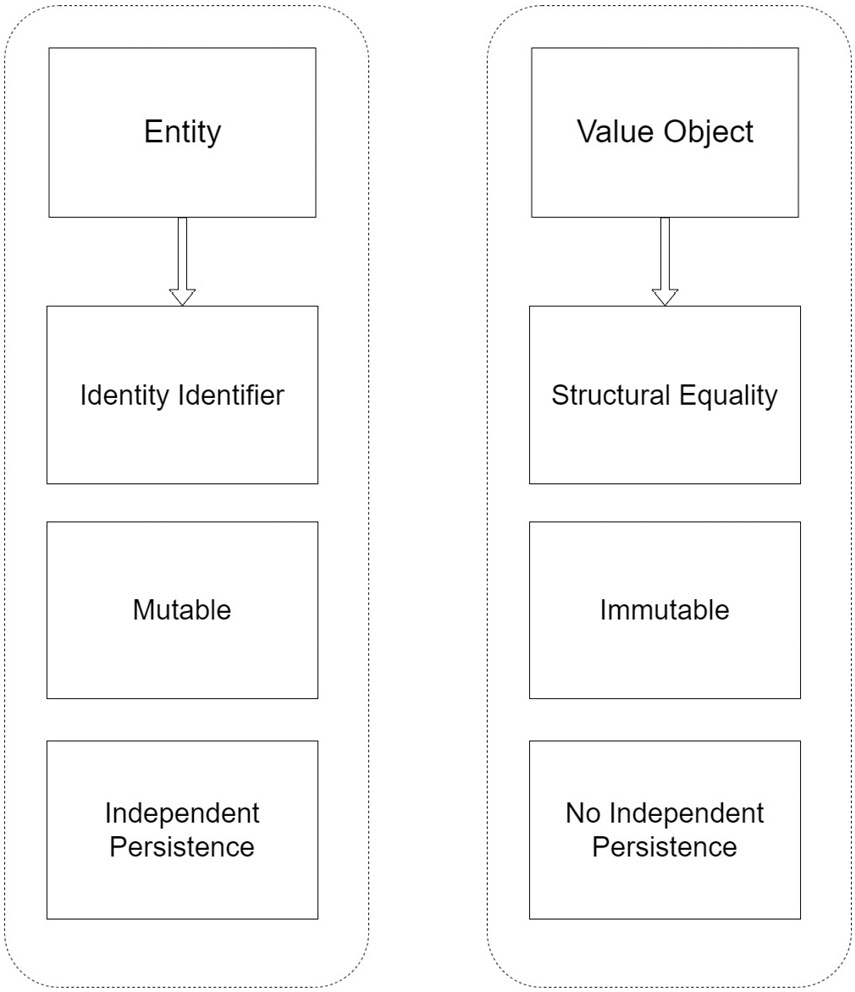
Figure 2.3 – Value objects are fundamentally different from domain entities, and it is important to appreciate these differences
Immutability means that the object’s properties should never change once these objects have been created. Instead, another instance should be created with the new intended values when necessary. If these objects need to be compared, we can do so by comparing all the values. This has become easier and a bit more practical since the introduction of record types in C# 10. Records are different from class and structs in that record types are based on value-based equality for comparisons. Two record objects are considered equal if the record definitions are identical and the values in both records are equal for every field.
Value objects are allowed to have methods and behaviors, but their scope should be limited. Methods should only compute and never change the state of the value object, or values therein, and note that it is immutable. Just remember, if new values are required, we should create a new object for that purpose.
Let’s delve a bit deeper into the basics of value objects. The truth is that we use them all the time in our development tasks, probably without noticing. A common example of these would be string objects. A string in .NET and most other languages is a collection of characters, or a char array. This character collection gives the string a value or a specific meaning. If we change one value of the character array, or reorder them, then we change the whole meaning of the string. In .NET, it is relatively easy to augment these values through string manipulation methods that allow us to change the letter cases or extract a part of the string. In doing these operations, we don’t actually change the value of the string, but we actually end up getting a whole new object with the new values. As we said, immutable objects do not change in value, but a new object must be created if a change is desired.
When scoping value objects for your system, it is important to assess all the information that is needed from the start to make them airtight. A good example of making sure the information is correct would be weight. It is easy enough to store data on a patient and state that they weigh 50. But 50 by itself is useless, considering how many possible units of measurement there are. So, in practicality, this value has no meaning without the unit. Fifty lbs (pounds) is an entirely different measurement from 50 kg. We would also need to ensure that the class or record type being used to store this information places restrictions on which value can be updated at one time. For instance, changing the numeric value is fine, as a person may have gained or lost weight, but allowing the same flexibility to update the unit by itself can have a deeper impact on what the numeric value really means in terms of the weight change. It would be a good idea to ensure that the unit can only be set when simultaneously setting the number value of the weight. You can also consider appointment scheduling. We should never entertain the acceptance of a start date and time without an accompanying end date and time. If we set this appointment start and end date time combination in a record type, then it will make it much easier to carry out equality checks for clashes, and we don’t need to clutter our code with overloads and excess logic to ensure that the appointment times are acceptable for the system.
The most important goal here, once again, is to ensure that the state of the value object is not changed after it is created. So, whenever you choose to use a record or a class type, the values should be set through the constructor at the time of object creation, and all validation and invariant checks need to be in the constructor as well. Values should also generally be set to be read-only types in order to guard against modifications beyond that. Do remember though that, with a class type, you will need to ensure that you include appropriate logic for equality comparison, whereas a record type comes with that built in, since it is based on value-based equality semantics.
We have looked into value objects and what makes them so much different from entities. We have also reviewed the best ways to implement them in C# code, to ensure their unique characteristics.
Summary
In this chapter, we explored quite a few things. We sought to understand the fundamentals of DDD and what makes it so different from a regular software design approach. We then broke down the elements of DDD into what the data objects and expectations would be. Finally, we reviewed value objects and explored under what circumstances we would formulate them, and the best ways to implement them in C#.
In our next chapter, we will explore the chain of responsibility pattern and how synchronous communication is best implemented between our microservices.