
6
Applying Event Sourcing Patterns
In the previous chapter, we explored a prolific pattern in CQRS. This pattern encourages us to create a clear separation between code and data sources that govern read and write operations. With this kind of separation, we risk having our data out of sync in between operations, which introduces the need for additional techniques to ensure data consistency.
Even without CQRS, we must contend with the typical microservices pattern where each service is expected to have its own data store. Recall that there will be situations where data needs to be shared between services. There needs to be some mechanism that will adequately transport data between services so that they will remain in sync.
Event sourcing is touted as a solution to this issue, where a new data store is introduced that keeps track of all the command operations as they happen. The records in this data store are considered events and contain enough information for the system to track what happens with each command operation. These records are called events and they act as an intermediary store for event-driven or asynchronous services architecture. They can also act as an audit log as they will store all the necessary details for replaying changes being made against the domain.
In this chapter, we will explore the event sourcing pattern and justify its use as a solution to our potentially out-of-sync databases.
After reading this chapter, you will be able to do the following:
- Understand what events are and what event sourcing can do for you
- Apply event sourcing patterns in your application code
- Use the CQRS pattern to create events and read states in between events
- Create an event store using a relational or non-relational database
Technical requirements
Code references used in this chapter can be found in the project repository, which is hosted on GitHub at https://github.com/PacktPublishing/Microservices-Design-Patterns-in-.NET/tree/master/Ch06.
What are events?
An event, within the context of software development, refers to something that happens because of an action being completed. Events are then used to carry out actions in the background, such as the following:
- Storing data for analytics purposes
- Notification of completed actions
- Database auditing
Key attributes of events
Events can be used to build the foundation of any application’s core functionality. While the concept can be suitable for many situations, it is important for us to understand some key attributes of events and properly scope the need for their introduction, as well as uphold certain standards in our implementations:
- Immutability: This word refers to the unchangeable nature of an object. Within the context of an event, once something has happened, it becomes a fact. That means we cannot change it or the outcome in the real world. We extend this same feature to our events and ensure that they cannot be changed after they are generated.
- Single occurrence: Each event is unique. Once it has been generated, it cannot be repeated. Even if the same thing happens later, it should be recognized as a new event.
- Historical: An event should always represent a point in time. This way, we can trace what happened and when in the past. This discipline is also displayed in the way that we name our events, where we use the past tense to describe the event.
Events at their best do not contain any behavior or business logic. They generally only serve as a point-in-time data collection unit and help us to track what is happening at different points in our application.
Now that we have a good idea of what events are and why they are used at a high level, let us focus on more practical uses of events and event sourcing patterns.
What can event sourcing patterns do for me?
Applications built with microservices architecture are structured to have a set of loosely coupled and independent services. Using the database-per-service pattern, we further segregate each service by giving it an individual data store. This now presents a unique challenge to keep the data in sync between services. It becomes more difficult given that we need to compromise on our ACID principles. We can recall that the acronym ACID stands for atomicity, consistency, isolation, and durability. We are most concerned about the principle of atomicity in this context. We cannot guarantee that all our write operations will be completed as a unit. The atomic principle dictates that all data operations should complete or fail as a unit. Given the allowance for different technologies to be used for the data stores, we cannot absolutely guarantee that.
Considering all these factors, we turn to a new pattern called event sourcing, which allows us to persist messages that keep track of all the activities occurring against data in each service. This pattern is especially useful for asynchronous communication between services where we can keep track of all changes in the form of events. These events can act as the following:
- Persistent events: Events contain enough detail to inform and recreate domain objects
- Audit log: Events are generated with each change, so they can double as audits
- Entity state identification: We can use events to view the point-in-time state of an entity on demand
The idea of tracking changes against entities is called replaying. We can replay events in two steps:
- Grab all or partial events stored for a given aggregate.
- Iterate through all events and extract the relevant information to freshen up the instance of the aggregate.
Event sourcing is essentially all about querying records in some way using an aggregate ID and timestamp. The aggregate ID represents the unique identifier column, or primary key value, for the original record for which the event was raised. The timestamp represents the point in time that the event was raised. The queries required for this look similar for relational and non-relational event stores. The event replay operation requires that we iterate through all the events, grab information, and then change the state of the target aggregate. In addition to the aggregate ID and timestamp, we will also have all the information needed to fill in the bits of data needed for the aggregate.
Now, let us review some of the benefits of using events in our systems.
Pros of event sourcing
We have been looking into the idea of tracking the history of operations that happen against our data, particularly our aggregates. We have encountered the concepts of events and replays. Now let us look at what event replays are, how they may benefit us, and what other benefits exist from using events.
Event replays and the way that we conduct our updates depend on whether the aggregate is a domain class or not. If the aggregate relies on domain services for manipulation, we need to be clear that replays are not about repeating or redoing commands. A command, based on our understanding of CQRS, changes the state and data in the database. This also has the potential of being a long-running operation with event-data-generating side effects, which we may not want. A replay is about looking at data and performing logic to extract information. On the other hand, event replays copy the effects of events and apply them to fresh instances of the aggregate. Altogether, stored events may be processed differently relative to the application employing the technique.
Events are bits of data that are stored at a lower level than the plain state. This means that we can reuse them to build any projection of the data that we need. Ad hoc projects of the data can be used for the read data store in a CQRS project structure, data analytics, business intelligence, and even artificial intelligence and simulations. Contextually, if we have a stream of events and can extract a specific subset, then we can replay them and perform ad hoc calculations and processes to generate custom and potentially new information. Events are constant and will always be the same now and later. This is an additional benefit in that we can always be sure that we will be able to count on the data for consistency.
As in life, for every set of benefits, there is a lingering set of downsides. Let us explore some of the general concerns around event sourcing.
Cons of event sourcing
In exploring event sourcing, we must bear in mind that we need to introduce an additional data store and additional services that might impede the application’s performance. Let us review some concerns.
Performance is always important in an application. So, when introducing a new pattern or set of processes, it is prudent of us to ensure that the performance impact is minimal. What happens when we need to process too many events to rebuild data? This can quickly become an intensive operation based on the number of logged events, which is only going to grow since the event store will be an append-only data store.
To address this, we take snapshots of the aggregate state and business entities that have recently been amended. We can then use these snapshots as a stored version of the record and use them as a recent version of the data, sparing the need to iterate through potentially many events. This operation is best complimented by having a read-only data store to pair with our CQRS pattern. The snapshot will be used for read operations going forward.
Now that we have looked at some of the more serious implications of this pattern and techniques that can be used to reduce the impact it might have on our application, let us review how event sourcing and domain events relate to each other so that we can strengthen our foundational knowledge.
What are domain events?
Earlier in this book, we discussed the use of DDD as a design pattern that helps us to scope the different services that might be required as we develop our microservices application. Events can be employed in the implementation of this pattern to help us to model expected outcomes within our bounded contexts. Events are scoped based on the ubiquitous language that has been established within the bounded context and is informed by decisions within the domain.
Within the domain, aggregates are responsible for creating domain events and our domain events are usually raised based on the outcome of some user action, or command. It is important to note that domain events are not raised based on actions such as the following:
- Button clicks, mouse moves, page scroll events, or simple application exceptions. Events should be based on the established ubiquitous language of the bounded context.
- Events from other systems or outside of the current context. It is important to properly establish the boundaries between each domain context.
- Simple user requests to the system. A user request at this point is a command. The event is raised based on the outcome of the command.
Now let us get a better understanding of why domain events are integral to implementing event sourcing patterns.
Domain events and event sourcing
Event sourcing is implemented to provide a single point of reference for the history of what has happened within a bounded context. Simply put, event sourcing uses domain events to store the states that an aggregate has gone through. We have already seen that event sourcing will have us store the record ID, a timestamp, and details that help us to understand what the data looked like at that moment. Properly implementing domain events within a bounded context will lay a foundation for a good implementation of event sourcing and so proper scoping and implementation are important.
Implementing domain events in code can be done relatively simply using the MediatR library, which was so integral in our CQRS pattern implementation. In the next section, we will look at adjusting our application to implement domain events.
Exploring domain events in our application
Now, let us consider introducing domain events to our appointment booking system. As far as we can see, we have several activities that need to be completed when an appointment is booked in our system. We might also need to extend the capabilities of our system to support the idea that changes might be needed to the original appointment and should be tracked.
Let us use the email dispatching activity. This needs to happen when an appointment is accepted into the system and saved. As it stands, our CreateAppointmentHandler will handle everything that is needed in the situation. We then run into the challenge of separating concerns since we probably don’t want our handler to be responsible for too many actions. We would do well to separate our email dispatch operation into its own handler.
Using MediatR, we can introduce a new type of handler called INotificationHandler<T>. This new base type allows us to define handlers relative to data types modeled from events that inherit from another MediatR base type, called INotification. These event types should be named according to the action that it is created to facilitate and will be used as the generic parameter in our INotificationHandler<T>. Our INotificationHandler<T> base type will be inherited by a handler or handlers that will carry out any specific actions relative to the additional actions required.
In code, we would want to start with some fundamental base types that will help us to define our concrete event types. The first would be IDomainEvent, which will serve as a base type for all our domain events that will follow. Its definition looks something like this:
public interface IDomainEvent : INotification
{}Our interface inherits from MediatR’s built-in INotification interface so that any derived data type will automatically also be a notification type. This IDomainEvent interface also helps us to enforce any mandatory data that must be present with any event object, such as the date and time of the action.
Now that we have our base types, let us define our derived event class for when an appointment gets created. We want to ensure that we name our event type in a manner that accurately depicts the action that raised the event. So, we will call this event type AppointmentCreated. We simply inherit from our IDomainEvent interface and then define additional fields that correspond with the data that is needed for the event to adequately carry out additional work:
public class AppointmentCreated : IDomainEvent
{
public Appointment { get; set; }
public DateTime ActionDate { get; private set; }
public AppointmentCreated(Appointment appointment,
DateTime dateCreated)
{
Appointment = appointment;
ActionDate = dateCreated;
}
public AppointmentCreated(Appointment appointment)
: this(appointment, DateTime.Now)
{
}
}In our AppointmentCreated derived event type, we have defined a property for our appointment and a constructor that makes sure that an object of Appointment is present at the time of creation. In this case, it is up to you to decide how much or little information you would require for the event to effectively be handled. For instance, some types of events might only need the appointment’s ID value. Be very sure to scope this properly however, and send as much information as is needed. You do not want to send only the ID and then need to query for additional details and risk potentially many event handlers trying to fetch details from just an ID value.
Now let us look at defining handlers for our event type. Note that I said handlers as it is possible and viable to define multiple event handlers based on the event that has occurred. For instance, when an appointment gets created, we might have a handler that will update the event store with the new record, or have one that dispatches an email alert, separate from one that updates a SignalR hub, for example.
To facilitate updating an event store, we would need to first have a handler defined that would look something like this:
public class UpdateAppointmentEventStore :
INotificationHandler<AppointmentCreated>
{
private readonly AppointmentsEventStoreService
_appointmentsEventStore;
public UpdateAppointmentEventStore
(AppointmentsEventStoreService
appointmentsEventStore)
{
this._appointmentsEventStore =
appointmentsEventStore;
}
public async Task Handle(AppointmentCreated
notification, CancellationToken cancellationToken)
{
await _appointmentsEventStore.CreateAsync
(notification.Appointment);
}
}Our AppointmentCreated event type is used as the target type for our INotificationHandler. This is all it takes to add specific logic sequences to a raised event. This also helps us to separate concerns and better isolate bits of code associated with raised events. Our notification object contains the appointment record, and we can easily use the data we need.
This code will automatically get fired when the event occurs and handle the event-store-update operation accordingly.
Let us look at our event handler that will dispatch our email alert:
public class NotifyAppointmentCreated :
INotificationHandler<AppointmentCreated>
{
private readonly IEmailSender _emailSender;
private readonly IPatientsRepository
_patientsRepository;
public NotifyAppointmentCreated(IEmailSender
emailSender, IPatientsRepository
patientsRepository)
{
this._emailSender = emailSender;
this._patientsRepository = patientsRepository;
}
public async Task Handle(AppointmentCreated
notification, CancellationToken cancellationToken)
{
// Get patient record via Patients API call
var patient = await _patientsRepository.Get
(notification.Appointment.
PatientId.ToString());
string emailAddress = patient.EmailAddress;
// Send Email Here
var email = new Email
{
Body = $"Appointment Created for
{notification.Appointment.Start}",
From = "[email protected]",
Subject = "Appointment Created",
To = emailAddress
};
await _emailSender.SendEmail(email);
}
}Notice as well that even though we did not have direct access to the patient’s record, we had their ID. With that value, we could make a synchronous API call to retrieve additional details that can assist us in crafting and dispatching the notification email.
In the same way, if we wanted to define an event handler for SignalR operations, we could simply define a second handler for the same event type:
public class NotifySignalRHubsAppointmentCreated :
INotificationHandler<AppointmentCreated>
{
public Task Handle(AppointmentCreated notification,
CancellationToken cancellationToken)
{
// SignalR awesomeness here
return Task.CompletedTask;
}
}Now that we can raise an event, we can refactor our application a bit to reflect this. We can refactor our CreateAppointmentHandler and CreateAppointmentCommand classes to return an object of Appointment instead of the previously defined string value:
public record CreateAppointmentCommand(int
AppointmentTypeId, Guid DoctorId, Guid PatientId, Guid
RoomId, DateTime Start, DateTime End, string Title) :
IRequest<Appointment>;
public class CreateAppointmentHandler :
IRequestHandler<CreateAppointmentCommand, Appointment>
public async Task<Appointment> Handle
(CreateAppointmentCommand request, CancellationToken
cancellationToken){ … }With this adjustment, we can now retrieve an object of the created appointment and publish an event from the original calling code, which was in the controller. Our POST method for our appointments API now looks like this:
// POST api/<AppointmentsController>
[HttpPost]
public async Task<ActionResult> Post([FromBody]
CreateAppointmentCommand createAppointmentCommand)
{
// Send appointment information to create
handler
var appointment = await
_mediator.Send(createAppointmentCommand);
//Publish AppointmentCreated event to all
listeners
await _mediator.Publish(new AppointmentCreated
(appointment));
// return success code to caller
return StatusCode(201);
}Now we use the Publish method from the MediatR library to raise an event, and all handlers that have been defined to watch for the specified event type will be called into action.
These refactors to our code will introduce even more code and files, but they do assist in helping us maintain a distributed and loosely coupled code base. With this activity, we have reviewed how we can cleanly introduce domain events to our application, and now we need to appreciate how we can store our events.
Creating an event store
Before we get to the scoping phase of creating an event store, it is important for us to fully understand what one is. A simple search on the topic might yield many results from various sources, with each citing varied definitions. For this book, we will conclude that an event store is an ordered, easily queryable, and persistent source of long-term records that represents events that have happened against entities in a data store.
In exploring the implementation of a data store, let us break out the key parts and how they connect to give the resulting event store. An event record will have an aggregate ID, a timestamp, an EventType flag, and data representing the state at that point in time. An application will persist event records in a data store. This data store has an API or some form of interface that allows for adding and retrieving events for an entity or aggregate. The event store might also behave like a message broker allowing for other services to subscribe to events as they are published by the source. It provides an API that enables services to subscribe to events. When a service saves an event in the event store, it is delivered to all interested subscribers. Figure 6.1 shows a typical event store architecture.
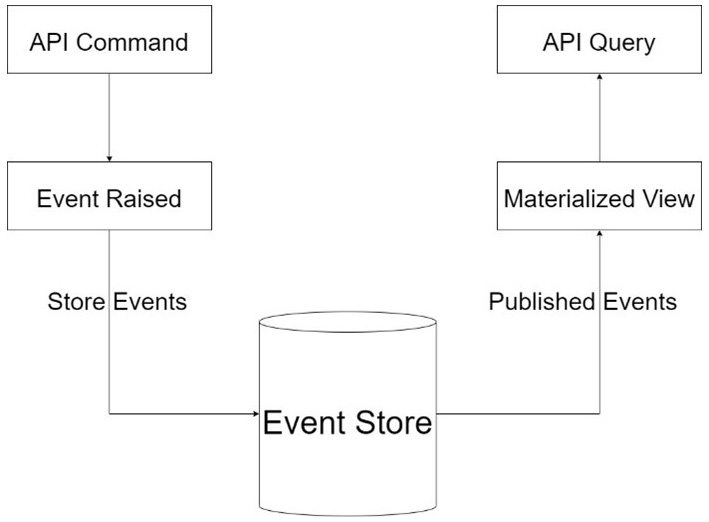
Figure 6.1 – An event store sits between the command handlers of an API and the query handler, which may require a different projection of the originally stored data
Let us review event storage strategies that we can employ.
How to store events
We have already established that events should be immutable, and the data store should be append-only. Armed with these two requirements, we can deduce that our dos and don’ts need to be at a minimum as we scope the data store.
Each change that takes place in the domain needs to be recorded in the event store. Since events need to contain certain details relevant to the event being recorded, we need to maintain some amount of flexibility with the structure of the data. An event might contain data from multiple sources in the domain. That means that we need to leverage possible relationships between tables in order to grab all the details required to log the event.
This makes the standard relational database model less feasible as a data store for events since we want to be as efficient as possible in retrieving our event records for auditing, replay, or analytics later. If we are using a relational data store, then we would do well to have denormalized tables modeled from the event data that we intend to store. An alternative and more efficient manner to handle event storage is the use of a non-relational or NoSQL database. This will allow us to store the relevant event data as documents in a far more dynamic manner.
Let us explore some options regarding storing events in a relational database.
Implementing event sourcing using a relational database
We have already reviewed some of the drawbacks of using a relational database as the event store. In truth, the way you design this storage, alongside the technology that is used, can have a major bearing on how future-proofed your implementation will be.
If we go the route of using denormalized table representations of the events, then we will end up going down a rabbit hole of modeling several tables based on several different events. This might not be sustainable in the long run, since we would need to introduce new tables with each newly scoped event and constantly change designs as the events evolve.
An alternative would be that we create a singular log table that has columns that match the data points we just outlined. For example, this table and the matching data types would be as follows:
|
Column Name |
Data Type |
|
Id |
Int |
|
AggregateId |
Guid |
|
Timestamp |
DateTime |
|
EventType |
Varchar |
|
Data |
Varchar |
|
VersionNumber |
Int |
- Id: Unique identifier for the event record.
- AggregateId: Unique identifier for the aggregate record to which the event is related.
- Timestamp: The date and time that this event was logged.
- EventType: This is a string representation of the name of the event that is being logged.
- Data: This is a serialized representation of the data associated with the event record. This serialization is best done in an easy-to-manipulate format such as JSON.
- VersionNumber: The version number helps us to know how to sort events. It represents the sequence in which each new event was logged in the stream and should be unique to each aggregate.We can add constraints to our records by introducing a UNIQUE index on both the AggregateId and VersionNumber columns. This will help us with speedier queries and ensure that we do not repeat any combination of these values.
The type of database technology that is employed does play a part in how flexibly and efficiently we can store and retrieve data. The use of PostgreSQL and later versions of Microsoft SQL Server will see us reap the advantages of being able to manipulate the serialized representation of the data more efficiently.
Now let us look at how we can model our NoSQL data stores.
Implementing event sourcing using a non-relational database
NoSQL databases are also called document databases and are characterized by their ability to effectively store unstructured data. This means the following:
- Records do not need to meet any minimum structure. Columns are not mandated in the design phase, so it is easy enough to extend and contract the data based on the immediate need.
- Data types are not strictly implemented, so the data structure can evolve at any point in time without having detrimental effects on previously stored records.
- Data can be nested and can contain sequences. This is significant since we do not need to spread related data across multiple documents. One document can represent a denormalized representation of data from several sources.
Popular examples of document stores are MongoDB, Microsoft Azure Cosmos DB, and Amazon DynamoDB, to name a few. Outside of the specific querying and integration requirements for each of these database options, the concepts of how documents are formed and stored are the same.
We can outline the properties of the document in a very similar manner to how a table would look. In a document data store, however, the data is stored in JSON format (unless specifically requested or implemented otherwise). An event entry would look something like this:
{
"type":"AppointmentCreated",
"aggregateId":"aggregateId-guid-value",
"data": {
"doctorId": "doctorId-guid-value",
"customerId": "customerId-guid-value",
"dateTime": "recorded-date-time",
...
},
"timestamp":"2022-01-01T21:00:46Z"
}Another advantage to using a document data store is that we can more easily represent a record with its event history in a materialized view. That could look something like this:
{
"type":"AppointmentCreated",
"aggregateId":"aggregateId-guid-value",
"doctorId": "doctorId-guid-value",
"customerId": "customerId-guid-value",
"dateTime": "recorded-date-time",
...
"history": [
{
"type":"AppointmentCreated",
"data": {
"doctorId": "doctorId-guid-value",
"customerId": "customerId-guid-value",
"dateTime": "recorded-date-time",
...
},
"timestamp":"2022-01-01T21:00:46Z"
},
{
"type":"AppointmentUpdated",
"data": {
"doctorId": "different-doctorId-guid-value",
"customerId": "customerId-guid-value",
"comment":"Update comment here"
},
"timestamp":"2022-01-01T21:00:46Z",
...
},
...
],
"createdDate":"2022-01-01T21:00:46Z",
...
}This type of data representation can be advantageous for retrieving a record with all its events, especially if we intend to display this data on a user interface. We have generated a view that acts as both a snapshot of the current state of the aggregate data and the stream of events that have affected it. This form of data aggregation helps us to reduce some complexity and keep the concept of event retrieval simple.
Now that we see how we can implement a read-only and denormalized data store, let us review how we can use the CQRS pattern to retrieve the latest state of the data.
Reading state with CQRS
We have reviewed the CQRS pattern, and we see where we can create handlers that will perform write operations. Earlier in this chapter, we enhanced our command handler functionality with the ability to trigger events, which are capable of performing triggering additional actions after a command has been completed.
In the context of the event sourcing pattern, this additional action involves updating our read-only data stores with the appropriate data per view. When creating our query handlers, we can rely on these tables for the latest version of the data that is available. This ties in perfectly with the ideal implementation of the CQRS pattern where separate data stores are to be used for read and write operations.
It also presents an excellent opportunity for us to provide more specific representations of the data we wish to present from our read operations. This approach, however, introduces the risk that our data stores might become out of sync in between operations, which is a risk that we must accept and mitigate as best as possible.
Now that we have explored events, event sourcing patterns, and event storage options, let us review these concepts.
Summary
Event sourcing and event-driven design patterns bring a whole new dimension to what is required in our software implementation. These patterns involve additional code but do assist in helping us to implement additional business logic for completed commands while maintaining a reliable log of all the changes happening in our data store.
In this chapter, we explored what events are, various factors of event sourcing patterns, how we can implement certain aspects in a real application, and the pros and cons of using relational or non-relational storage options.
In our next chapter, we will explore the Database Per Service pattern and look at best practices when implementing the data access layer in each microservice.