
8
Implement Transactions across Microservices Using the Saga Pattern
We have just looked at database development and what we need to consider when building an application developed using a microservices architecture. We discussed the pros and cons of creating individual databases per microservice. It does allow each microservice to have more autonomy, allowing us to choose the best technology needed for the service. While it is preferred and a recommended technique, it does have significant drawbacks when it comes to ensuring data consistency across the data stores.
Typically, we ensure consistency through transactions. Transactions, as discussed earlier in this book, ensure that all data is committed or none. That way, we can ensure that an operation will not partially write data and that what we see truly reflects the state of the data being tracked.
It is difficult to enforce transactions across microservices with different databases, but that is when we employ the saga pattern. This pattern helps us to orchestrate database operations and ensure that our operations are consistent.
After reading this chapter, we will understand how to do the following:
- Use the Saga pattern to implement transactions across microservices
- Choreograph data operations across microservices
- Implement orchestration
Exploring the Saga pattern
We have previously explored the database-per-service pattern, which encourages us to have individual data stores per service. With this in place, each microservice will handle its own database and transactions internally. This presents a new challenge where an operation that requires several services to take part and potentially modify their data runs the risk of partial failures and eventually leads to data inconsistency in our application. This is the major drawback of this pattern choice as we cannot guarantee that our databases will remain in sync at all times.
This is where we employ the saga pattern. You may think of a saga as a predefined set of steps that outline the order in which the services should be called. The saga pattern will also have the responsibility of providing oversight across all our services watching and listening, so to speak, for any signs of failure in any service along the way.
If a failure is reported by a service, the saga will also contain a rollback measure for each service. So, it will proceed, in a specific order, to prompt each service that might have been successful before the failure to undo the change it made. This comes in handy since our services are decoupled and ideally will not communicate directly with each other.
A saga is a mechanism that spans multiple services and can implement transactions across various data stores. We have distributed transaction options such as two-phase commit, which can require that all data stores commit or rollback. This would be perfect, except some NoSQL databases and message brokers are not entirely compatible with this model.
Imagine that a new patient registered with our healthcare center. This process will require that the patient provides their information and some essential documents, and books an initial appointment, which requires payment. These actions require four different microservices to get involved and thus, four different data stores will be affected.
We can refer to an operation that spans multiple services as a saga. Once again, a saga is a sequence of local transactions. Each transaction updates the data target database and produces a message or event that triggers the next transaction operation of the saga. If one of the local transactions fails along the chain, the saga will execute rollbacks across the databases that were affected by the preceding transactions.
Three types of transactions are generally implemented by a saga:
- Compensable: These are transactions that can be reversed by another transaction with the opposite effect.
- Retryable: These transactions are guaranteed to succeed and are implemented after pivot transactions.
- Pivot: As the name suggests, the success or failure of these transactions is pivotal to the continuation of the saga. If the transaction commits, then the saga runs until it is completed. These transactions can be placed as a final compensable transaction or the first retryable transaction of the saga. They may also be implemented as neither.
Figure 8.1 shows the saga pattern:

Figure 8.1 – Each local transaction sends a message to the next service in the saga until the saga is completed
As we know with every pattern, we have advantages and disadvantages, and it is important to consider all angles so that we can adequately plan an approach. Let us review some known issues and considerations that need to be taken when implementing this pattern.
Issues and considerations
Given the fact that, up until this chapter, we would have written off the possibility of implementing ACID transactions across our data stores in a microservices architecture, we can imagine that this pattern is not easy to implement. It requires absolute coordination and a good understanding of all the moving parts of our application.
This pattern is also difficult to debug. Given that we are implementing a singular function across autonomous services, we have now introduced a new touch point and potential point of failure for which special effort must be made to track and trace where the failure may have been. This complexity increases with each added step to the participating services of the saga.
We need to make sure that our saga can handle transient failures in the architecture. These are errors that happen during an operation that might not be permanent. Thus, it is prudent of us to include retry logic to ensure that a single failure in an attempt does not end the saga prematurely. In doing so, we also need to ensure that our data is consistent with each retry.
This pattern is certainly not without its challenges, and it will increase the complexity of our application code significantly. It is not foolproof as it will have its fallacies, but it will certainly assist us in ensuring that our data is more consistent across our loosely coupled services, by either rolling back or compensating for operational failures.
Sagas are usually coordinated using either orchestration or choreography. Both methods have their pros and cons. Let us begin with exploring choreography.
Understanding and implementing choreography
Choreography is a method of coordinating sagas where participating services used messages or events to notify each other of completion or failure. In this model, the event broker sits in between the services but does not control the flow of messages or the flow of the saga. This means that there is no central point of reference or control, and each service is simply watching for a message that acts as a confirmation trigger for it to start its operation.
Figure 8.2 shows the choreography flow:
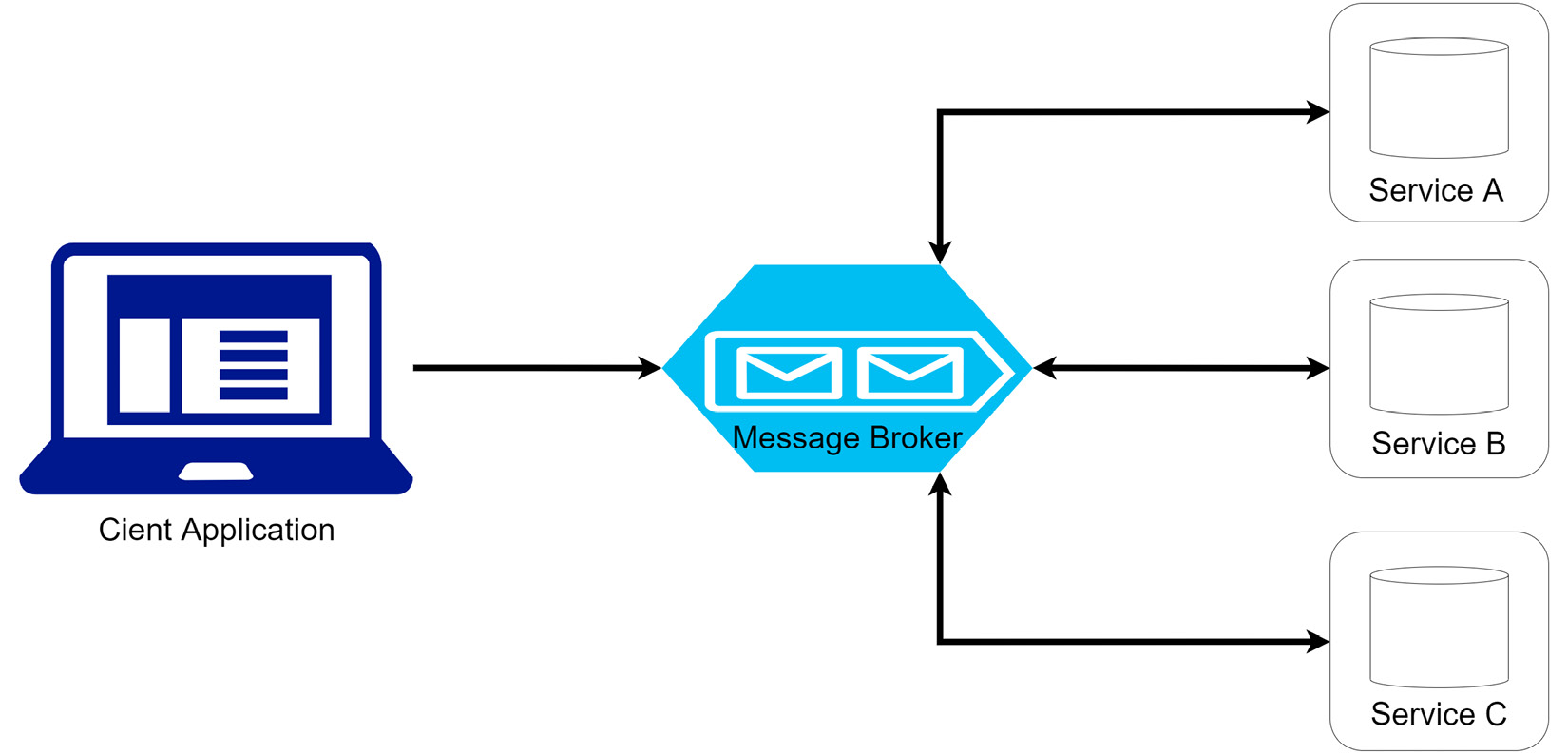
Figure 8.2 – An application request sends a message to the queue to inform the first service in the saga to begin, and messages flow between all participating services
The main takeaway from the choreography model is that there is no central point of control. Each service will listen to events and decide whether it is time to take an action. The contents of the message will inform the service it should act and if it acts, it will reply with a message stating the success or failure of its action. If the last service of the saga is successful, then no message is produced, and the saga will end.
If we were to visualize this process using our user registration and appointment booking example mentioned earlier in this chapter, we would have a flow looking like this:
- The user submits a registration and appointment booking request (client request).
- The registration service stores the new user’s data and then publishes an event with relevant appointment and payment details. This event could be called, for example, USER_CREATED.
- The payment service listens for USER_CREATED events and will attempt to process a payment as necessary. When successful, it will produce a PAYMENT_SUCCESS event.
- The appointment booking service processes PAYMENT_SUCCESS events and proceeds to add the appointment information as expected. This service makes the booking arrangements and produces a BOOKING_SUCCESS event for the next service.
- The document upload service receives the BOOKING_SUCCESS event and proceeds to upload the documents and add a record to the document service data store.
This example shows that we can track the processes along the chain. If we wanted to know each leg and the outcome, we can have the registration service listen to all events and make state updates or logs of the progress along the saga. It will also be able to communicate the success or failure of the saga back to the client.
What happens though when a service fails? How do we mitigate or reap the benefit of the the saga pattern's ability to reverse changes that have already gone? Let’s review that next.
Rolling back on failure
Sagas are necessary because they allow us to roll back the changes that have already happened when something fails. If a local transaction fails, the service will publish an event stating that it was unsuccessful. We then need additional code in the preceding service that will react with the rollback procedures accordingly. For example, if our payment service operation failed, then the flow would look something like this:
- The appointment booking service failed to confirm the appointment booking and publishes a BOOKING_FAILED event.
- The payment service receives the BOOKING_FAILED event and proceeds to issue a refund to the client. This would be a remediation step.
- The preceding registration service will see the BOOKING_FAILED event and notify the client that the booking was not successful.
In this situation, we are not completely reversing every step since we retain the user’s registration information for future reference. What is important, though, is that the next service in the saga, which uploads the documents, is not configured to listen for the BOOKING_FAILED event. So, it will have nothing to do unless it sees a BOOKING_SUCCESS event.
We can also take note of the fact that our remediation steps are relative to the actual operation being carried out. Our payment service is likely a wrapper around a third-party payment engine that will also write a local database record of the payment operation. In its remediation steps, it will not remove the payment record, but simply mark it as a refunded payment or cancel the payment, given the lack of completion of the saga.
While this is not ACID in the true sense of what a local database would do, and undo a database the effects of a write operation, a rollback might look different for each service, based on the business rules or nature of the operation. We also see that our rollback did not span every single service, since our business rules suggest that we keep the user registration information for future reference.
Another thing that we need to consider is whether there is a necessity in our rollback operations. Given the event-based nature of our services, if we want to implement an order, then we will need more event types that services will listen for specifically.
Let us review the pros and cons of this choreography implementation.
Pros and cons
In the choreography model, we have a simple approach to implementing a saga. This method makes use of some of the previous patterns that we have discussed in event sourcing and asynchronous service communication. Each service retains its autonomy, and a rollback operation might look different per service. It is a clean way to implement a saga for a smaller operation with fewer participants and fewer potential outcomes based on success or failure.
We can also take the asynchronous approach to the saga as some form of advantage, as we can trigger multiple simultaneous operations stemming from each service’s success. This is good for getting operations done quickly while the client is waiting on the outcome.
We also see that we need to always be expanding our code base to facilitate the varying operations and their outcomes, especially if we intend to implement an order for the rollback operations. Given the asynchronous model that is used to implement this type of saga, it might be dangerous to use one event type to trigger operations simultaneously.
As the number of participants grows, we run the risk of implementing a complex web of participants, events, and remediations. It grows increasingly difficult to properly monitor all the services and adequately trace the points of failure. If an operation is to be tested, all services must be running to properly troubleshoot our operations. The bigger the saga gets, the more difficult it is to monitor.
For this reason, we look to another saga pattern in the form of orchestration, which implements a central point of control. We will review it next.
Understanding and implementing orchestration
When we think of the word orchestration, we think of coordination. An orchestra is a coordinated combination of musicians all working towards producing the same kind of music. Each musician plays their part, but they are led by a conductor who guides each of them along the same path.
The orchestration method of implementing a saga is not very different in terms of how we need a central point of control (like a conductor), and all the services are monitored by the central point of control to ensure that they play their part well, or report failure accordingly. The central control is referred to as an orchestrator and it is a microservice that sits between the client and all other microservices. It handles all the transactions, telling participating services when to complete an operation based on feedback it receives during the saga. The orchestrator executes the request, tracks and interprets the request’s state after each task, and handles the remediating operations, as necessary.
Figure 8.3 shows the orchestrator flow:
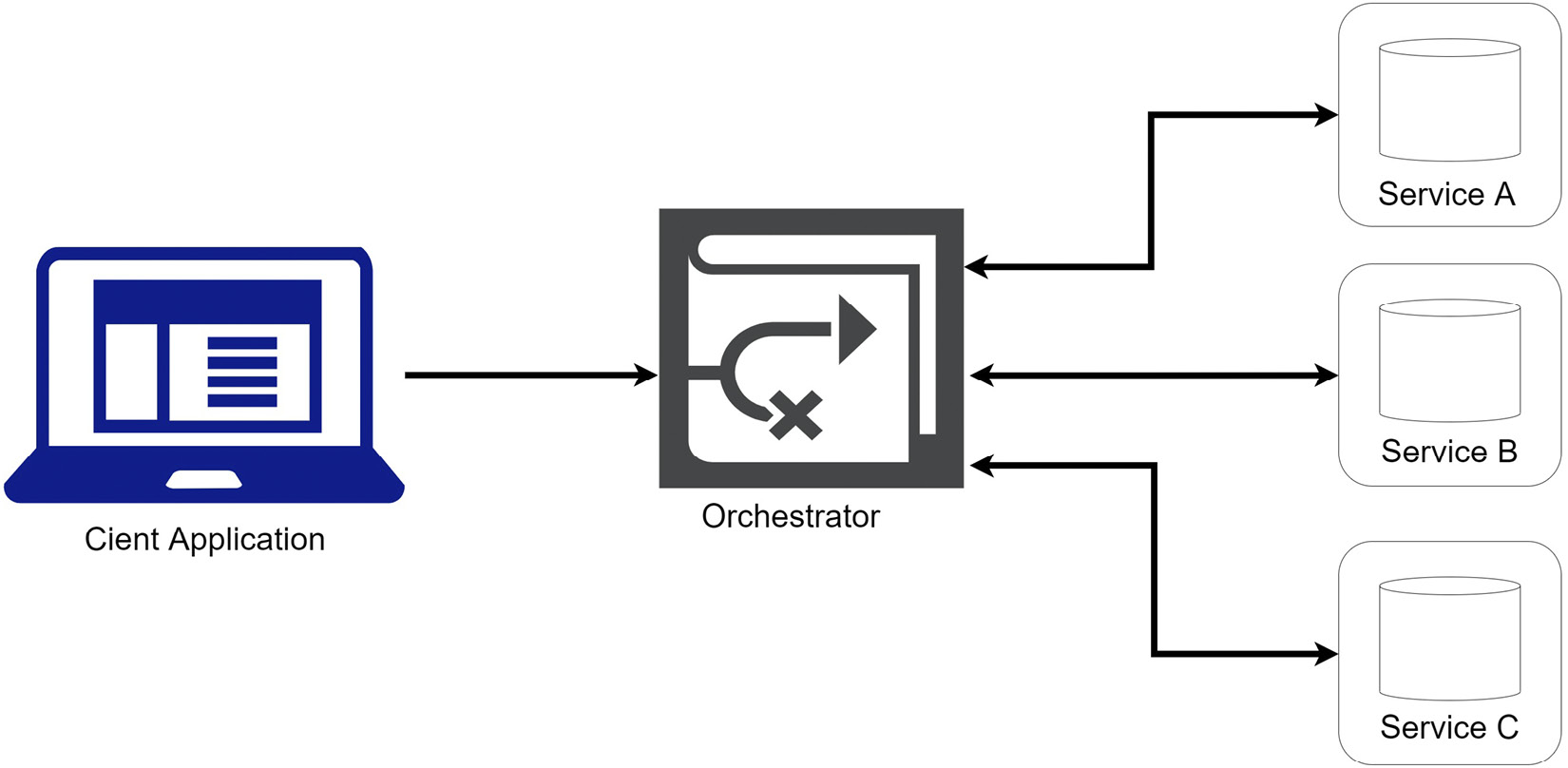
Figure 8.3 – An application request sends a message to the orchestrator, which begins to coordinate and monitor the subsequent calls to the participating services
Let us revisit our appointment booking operation from the perspective of the orchestration saga implementation:
- The user submits a registration and appointment booking request (client request).
- The client request is passed to the orchestrator service.
- The orchestrator service centrally stores the data from the client request. This data will be used during the User Registration saga.
- The orchestrator service begins the saga by passing the user’s information to the registration service, which will add a new record to its database and respond with a 201Created HTTP response. The orchestrator will store the user’s ID, as it will be needed during the saga.
- The orchestrator then sends the user’s payment information to the payment service, which will respond with a 200OK HTTP response. The orchestrator will store the payment response details, in the event that a rollback is needed and the payment should be canceled.
- The orchestrator then sends a request to the appointment booking service, which processes the appointment booking accordingly and responds with a 201Created HTTP response.
- The orchestrator will finally trigger the document upload service, which uploads the documents and adds records to the document service database.
- The orchestrator then confirms that the saga has ended and will update the state of the operation. It will then respond to the client with the overall result.
We can see that the orchestrator is at the helm of every step of the operation and remains informed of each service’s outcome. It acts as the main authority on whether we should move to the next step or not. We can also see that a more synchronous service communication model is implemented in this saga pattern.
Let us review what a rollback operation might look like.
Rolling back on failure
Rolling back is the most important part of implementing a saga, and like the choreography pattern, we are governed by the business rules of the operation and induvial service operations. The main takeaway here is that the services will respond with failure to a central point, which will then coordinate the rollback operations across the various services. Reusing the failure scenario previously discussed, our orchestration would look something like this:
- The appointment booking service sends a 400BadRequest HTTP response to the orchestrator.
- The orchestrator proceeds to call the payment service to cancel the payment. It already stored the relevant information about the payment during the saga.
- The orchestrator will trigger additional clean-up operations such as flagging the user’s registration record as incomplete, as well as purging any additional data that may have been stored at the beginning of the operation.
- The orchestrator will notify the client of the operation’s failure.
A rollback here is arguably easier to implement – not because we are changing how and what the services do, but because we can be sure of the order in which the remediations will happen in case the order is important, and we can accomplish that without introducing too much more complexity to the flow.
Let us discuss the benefits of using this pattern in more detail.
Pros and cons
One obvious advantage to using this implementation of the saga pattern is the level of control that we can be sure to implement. We can orchestrate our service calls and receive real-time feedback, which can be used to decide and have a set path along the saga that we can track and monitor. This makes it easier to implement complex workflows and extend the number of participants over time.
This implementation is excellent for us if we need to control the exact flow of saga activities and be sure that we do not have services being triggered simultaneously and from information that they may think is relevant. Services only act when called upon, and misconfigurations are less likely. Services do not need to directly depend on each other for communication and are more autonomous, leading to simpler business logic. Troubleshooting also becomes easier since we can track what the singular code base is doing and more easily identify the point of failure.
Despite all these proposed benefits of orchestration, we need to remember that we are simply creating a central point of synchronous service calls. This can become a choke point along the saga if one of the services runs more slowly than desired. This can be managed, of course, through properly implemented retry and circuit breaker logic, but it remains a risk worthy of consideration.
We also run into a situation where we end up with yet another microservice to develop and maintain. We will introduce a new and more central point of failure since no other microservice gets called into action if the orchestrator is out of operation.
Let us review what we have learned in this chapter.
Summary
Until now, we have seen several patterns surrounding microservices architecture and development. Each pattern’s purpose is to reduce the attrition that comes with this kind of architecture.
We saw a potential pain point and point of concern with our database-per-service pattern implementation and the difficulty that comes from having disparate data stores. We cannot always guarantee that all services will be successful in an operation and as such, we cannot guarantee that the data stores will reflect the same thing.
To address this, we look to the saga pattern, which can either be leveraged through an event-based choreography implementation or a more centralized orchestration method. We have reviewed the pros, cons, and considerations surrounding either implementation and how they help us to more effectively help microservices maintain data consistency.
In the next chapter, we will review the potential flaws involved in communication between microservices, and review how we can implement more fault-tolerant communication between services using the circuit breaker pattern.