
5
Working with the CQRS Pattern
We now know that microservices require a bit of foresight during the planning phase, and we need to ensure that we employ the best patterns and technology to support our decisions. In this chapter, we will be exploring another pattern that has gained much acclaim in helping us to write clean and maintainable code. This is the Command Query Responsibility Segregation or Separation (CQRS) pattern, which is an extension of the Command-Query Separation (CQS) pattern.
This pattern allows us to cleanly separate our query operations from our command operations. In essence, a query asks for data, and the command should modify data in one way or another by the end of the operation.
As programmers, we tend to employ Create, Read, Update, and Delete (CRUD) in our applications. Considering that every application’s core functionality is to support CRUD operations, this is understandable. But the more intricate the application gets, the more we need to consider the business logic surrounding each of these operations, relative to the problem domain we are addressing.
At that point, we begin to use words such as behavior and scenarios. We begin to consider structuring our code in a manner that allows us to isolate behaviors and easily determine whether this behavior is simply a request for data or will augment data by the end of the operation.
After reading this chapter, you will achieve the following:
- Understand the benefits of the CQRS pattern and why it is used for microservices development
- Know how to implement commands in the CQRS pattern
- Know how to implement queries in the CQRS pattern
Technical requirements
Code references used in this chapter can be found in the project repository, which is hosted on GitHub at this URL: https://github.com/PacktPublishing/Microservices-Design-Patterns-in-.NET/tree/master/Ch05.
Why use CQRS for microservices development?
CQS was introduced as a pattern that would help developers separate code that does read operations from code that does write operations. The shortcoming with it was that it didn’t account for establishing specific models for each operation. CQRS built on this and introduced the concept of having specific models, tailored for the operation to be carried out.
Figure 5.1 shows a typical CQRS architecture:

Figure 5.1 – The application will interact with models for read operations and models for write operations, known as commands
If you look a bit more closely, it can be argued that CQS only accounts for one data store, meaning we are doing read/write operations against the same database. CQRS would suggest that you have separate data stores, having potentially a standard relational database for your write operations and conducting read operations for a separate store, such as a document database or data warehouse. The implementation of multiple data stores is not always an option, nor is it a must.
CQRS has gained much acclaim since its introduction in development and is touted as a very important staple in microservice design. The truth is, it can be used in standard applications, so it is not unique to microservices. It also adds a new level of complexity to the development effort as it introduces the need for more specific classes and code to be written, which can lead to project bloat.
It is said, “…when we have a hammer, everything looks like a nail…” and this remains true in the context of when we hear of a new pattern and feel the need to use it everywhere. I suggest that you apply caution and careful consideration before using this pattern and ensure that its value in the application is justified.
For bigger applications, CQRS is recommended to help us structure our code and more cleanly handle potentially complex business logic and moving parts. Though it is complex, it does have benefits. Let us review the benefits of implementing the CQRS pattern in our applications.
Benefits of the CQRS pattern
CQRS is about splitting a single model into two variations, one for reads and one for writes. The end goal, however, is a bigger spoke in the wheel. The first benefit of this approach is scalability.
It is important to assess the read/write workload of the system you are building. Read operations are arguably more intensive than write operations, given that one read may require copious amounts of data from several tables and each request might have its own requirements around what the data needs to look like. One school of thought encourages that we employ a data store that is dedicated to and optimized for reading operations. This allows us to scale read operations separately from write operations.
An example of a dedicated read store could be a data warehouse, where data is constantly being transformed by some form of data transformation pipeline, from the write data store, which is probably a normalized relational database. Another commonly used technology is NoSQL databases such as MongoDB or Cosmos DB. The data constructs provided by the data warehouse or NoSQL databases represent a denormalized, read-only version of the data from the relational data store.
Figure 5.2 shows a CQRS architecture with two databases:
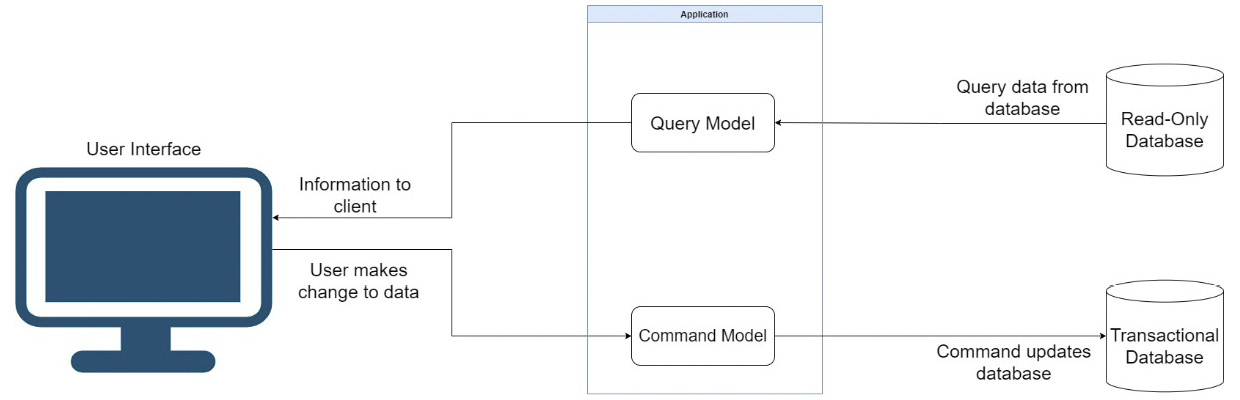
Figure 5.2 – The query model represents read operation-optimized representations of the data from the transactional database
The second benefit is performance. Though it seems to go hand in hand with scalability, there are different dynamics that we consider. Using separate data stores isn’t always a viable option, so there are other techniques that we can employ to optimize our operations that wouldn’t be possible with a unified data model. We can apply caching, for instance, to queries that do read operations. We can also employ database-specific features and fine-tuned raw SQL statements for our requests in contrast to object-relational mapping (ORM) code on the side of the command.
Another benefit that we can reap from this pattern is simplicity. This sounds contradictory given that we mentioned complications in the earlier parts of this chapter, but it depends on the lens that you use to assess the rewards you will reap in the long run. Commands and queries have different needs, and it is not reasonable to use one data model to suit both sets of needs. CQRS forces us to consider creating specific data models for each query or command, which leads to more maintainable code. Each new data model is responsible for a specific operation, and modification therein will have little to no impact on other aspects of our program.
We see here that there are a few benefits to using CQRS in our projects. But where there are pros, there are cons. Let us review some of the downsides to employing this design pattern.
Disadvantages of the CQRS pattern
Every pattern that we consider must be investigated thoroughly for the value that it adds, and the potential drawbacks. We always want to make sure that the benefits outweigh the disadvantages and that we won’t live to regret these major design decisions. CQRS is not ideal for applications that will do simple CRUD operations. It is behavior- or scenario-driven, as we have stated, so be sure that you can justify the use cases before you take the plunge. This pattern will lead to a perceived duplication of code since it promotes the concept of separation of concerns (SoC) and encourages that commands and queries have dedicated models.
On a personal note, I have seen development leads start off with all the best intentions and implement CQRS in projects that, in truth, didn’t require it. The projects turned out to be overcomplicated, leaving all the newer developers completely confused as to what went where.
As we have seen, there is a case for multiple data storage areas when we use CQRS. Arguably, that is the most complete implementation of it. Once we introduce multiple data stores, we introduce data consistency problems and need to implement Event Sourcing techniques and include service-level agreements (SLAs) to let our users know of the potential gap between our read/write operations. We also must consider the additional costs in terms of infrastructure and general operation when we have multiple databases. With multiple databases comes multiple potential points of failure and the need for additional monitoring and fail-safe techniques to ensure that the system runs as smoothly as possible, even in the face of outages.
CQRS can add value to a project when it is applied sensibly. When your project has complex business logic, or a distinct need for separating data stores and read/write operations, then CQRS will shine as an appropriate architectural choice.
This pattern is not unique to any programming language, and .NET has excellent support for the pattern. Now let us review implementing CQRS using the Mediator pattern with the help of a few tools and libraries.
Using the Mediator pattern with CQRS in .NET
Before we get into how we implement CQRS, we should discuss a supporting pattern called the Mediator pattern. The Mediator pattern involves us defining an object that embodies how objects interact with each other. So, we can avoid two or more objects having direct dependencies on each other and, instead, use a mediator in between that will orchestrate the dependencies and route requests to appropriate handlers. A handler will define all the details of the operation to be carried out based on the scenario or task to which the model is associated.
Figure 5.3 shows how the Mediator pattern works:
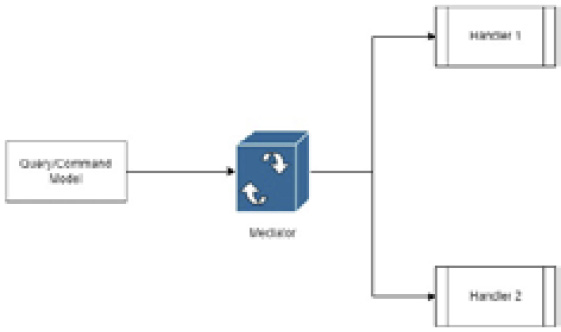
Figure 5.3 – The query/command model is registered in the mediator engine, which then selects the appropriate handler for an operation
The Mediator pattern becomes useful relative to the implementation of the CQRS pattern since we need to promote loose coupling between the code being defined for each task. It allows us to maintain loose coupling and promotes more testability and scalability.
In .NET Core, we have an excellent third-party package called MediatR that helps us implement this pattern with relative ease. MediatR assumes the role of an in-process mediator where it manages how classes interact with each other during the same process. One limitation here is that it might not be the best package if we wanted to separate commands and queries across different systems. Notwithstanding that drawback, it helps us to author CQRS-based systems with relative ease, efficiency, and reliability. We can develop strongly typed code that will ensure that we do not mismatch models and handlers, and we can even construct pipelines to govern the entire behavior of a request as it flows through the complete cycle.
In a .NET Core application, we can set up MediatR using the following steps:
- Install the MediatR.Extensions.Microsoft.DependencyInjection NuGet package
- Modify our Program.cs file with the following line: builder.Services.AddMediatR(typeof(Program));
Once we have done this, we can proceed to inject our IMediator service into our controllers or endpoints for further use. We will also need to implement two files that will directly relate to each other as the command/query model and the corresponding handler.
Now that we have explored the foundations of setting up a CQRS implementation using the Mediator pattern, let us review the steps required to implement a command.
Implementing a command
As we remember, a command is expected to carry out actions that will augment the data in the data store, otherwise called a write operation. Given that we are using the Mediator pattern to govern how we carry out these operations, we will need a command model and a handler.
Creating a command model
Our model is relatively simple to implement. It tends to be a standard class or record, but with MediatR present,we will implement a new type called IRequest. IRequest will associate this model class with an associated handler, which we will be looking into in a bit.
In the example of making an appointment in our system, we can relatively easily implement a CreateAppointmentCommand.cs file like this:
public record CreateAppointmentCommand (int AppointmentTypeId, Guid DoctorId, Guid PatientId, Guid RoomId, DateTime Start, DateTime End, string Title): IRequest<string>;
We use a record type in this example, but it could just as easily be a class definition if that is more comfortable for you. Notice that we inherit from IRequest<string>, which outlines to MediatR the following:
- This command should be associated with a handler with a corresponding return type.
- The handler that is associated with this command is expected to return a string value. This will be the appointment Id value.
Commands don’t always need to return a type. If you don’t expect a return type, you may simply inherit from IRequest.
Now that we have an idea of how the command model needs to look, let us implement the corresponding handler.
Creating a command handler
Our handler is where the logic for carrying out the task usually sits. In some implementations and in the absence of a rich data model, you can carry out all the validations and additional tasks required to ensure that the task is handled properly. This way, we can better isolate the business logic that is expected when a particular command is sent for execution.
Our handler for our command to create an appointment will be called CreateAppointmentHandler.cs and can be implemented like this:
public class CreateAppointmentHandler :
IRequestHandler<CreateAppointmentCommand, string>
{
private readonly IAppointmentRepository _repo;
public CreateAppointmentHandler(IAppointmentRepository
repo /* Any Other Dependencies */)
{
_repo = repo
/* Any Other Dependencies */
};
public async Task<string> Handle
(CreateAppointmentCommand request, CancellationToken
cancellationToken)
{
// Handle Pre-checks and Validations Here
var newAppointment = new Appointment
(
Guid.NewGuid(),
request.AppointmentTypeId,
request.DoctorId,
request.PatientId,
request.RoomId,
request.Start,
request.End,
request.Title
);
await _repo.Add(newAppointment);
//Perform post creation hand-off to services bus.
return newAppointment.Id.ToString();
}
}There are several things to take note of here:
- The handler inherits from IRequestHandler<>. In the type brackets, we outline the specific command model type that the handler is being implemented for and the expected return type.
- A handler is implemented like any other class and can have dependencies injected in as needed.
- After completing our operations, we must return a value with a data type that matches the one outlined by IRequest<> from the command model.
- IRequestHandler implements a method called Handle that defaults to the outlined return type of IRequest<> attached to the command model. It will automatically generate a parameter called request, which will be of the command model’s data type.
If we did not require a return value, we would have to return Unit.Value. This is the default void representation of MediatR.
Now that we have some boilerplate code for implementing a command model and its corresponding handler, let us look at making an actual call to the handler from a controller.
Invoking a command
We have our controller defined for appointment booking operations and it needs to have the dependency for our IMediator service present to begin orchestrating our calls. We need to inject our dependency like this:
private readonly IMediator _mediator; public AppointmentsController(IMediator mediator) => _mediator = mediator;
Once we have this dependency present, we can begin making our calls. What makes this solution so clean is that we do not need to worry about the business logic and specific handlers for anything. We need to only create a command-model object with the appropriate data and then send it using our mediator, which will then call the appropriate handler. The code for our POST method is shown here:
[HttpPost]
public async Task<ActionResult> Post([FromBody]
CreateAppointmentCommand createAppointmentCommand)
{
await _mediator.Send(createAppointmentCommand);
return StatusCode(201);
}There are several ways to implement this section. Some alternatives include the following:
- Using models or Data Transfer Objects (or DTOs for short) to accept data from the API endpoint. This means that we will then transfer the data points from the incoming model object to our command model before sending, as illustrated here:
[HttpPost]
public async Task<ActionResult> Post([FromBody]
AppointmentDto appointment)
{var createAppointmentCommand = new
CreateAppointmentCommand { /* Assign all valueshere*/}
await _mediator.Send(createAppointmentCommand);
return StatusCode(201);
}
- Instead of defining all the data properties in the command model, we use the DTO as a property of the command model so that we can pass it along with the mediator request, as follows:
// New Command Model with DTO property
public record CreateAppointmentCommand
(AppointmentDto Appointment) : IRequest<string>;
// New Post method
[HttpPost]
public async Task<ActionResult> Post([FromBody]
AppointmentDto appointment)
{var createAppointmentCommand = new
CreateAppointmentCommand { Appointment =appointment; }
await _mediator.Send(createAppointmentCommand);
return StatusCode(201);
}
You can observe that each method of authoring the code amounts to the same thing, and that is we need to compose the appropriate model type with the appropriate values before sending it off to our mediator. The mediator would have already figured out which model matches which handler and will proceed to carry out its operation.
Commands and queries generally follow the same implementation. In the next section, we will look at implementing a query model/handler pair using our mediator and CQRS patterns.
Implementing a query
A query is expected to search for data and return a result. This search might be complicated, or it might be simple enough. The fact, though, is that we implement this pattern as an easy way to segregate the query logic from the originator of the request (such as the controller) and from the command logic. This type of separation increases a team’s ability to maintain either side of the application without stepping on each other’s toes, so to speak. We will similarly use the Mediator pattern to govern how we carry out these operations, and we will need a query model and a handler.
Creating a query model
Our model is simple enough as we can leave it empty or include properties that will play a part in the process to be carried out in the handler. We inherit IRequest<>, which defines a return type. I would go out on a limb and say that a return type is necessary, considering that this is a query.
Let us look at two examples of queries, one that will retrieve all the appointments in the database and another that will retrieve only by ID. We can define GetAppointmentsQuery.cs and GetAppointmentByIdQuery.cs like this:
public record GetAppointmentsQuery(): Irequest <List<Appointment>>; public record GetAppointmentByIdQuery(string Id): IRequest<AppointmentDetailsDto>;
Just take note of the fact that either query model is specific to what it needs to represent. The GetAppointmentsQuery model doesn’t need any properties since it is just going to be used as an outline for the handler to make an association. GetAppointmentByIdQuery has an Id property for the obvious reason that the ID is going to be needed for the handler to correctly execute the task at hand. The difference in return types is also a crucial point to note as that sets the tone for what the handler will be able to return.
We need to ensure that we craft our query models specifically for the type of data that we are expecting to retrieve from the matching handler. Now, let us look at implementing these handlers.
Creating a query handler
Our query handlers will execute the expected queries and return the data as defined by IRequest<>. As previously outlined, the ideal usage of this pattern will see us using a separate data store where the data being queried is already optimized for return. This would make our query operation efficient and reduce the need for data transformation and sanitization.
In our example, we are not that fortunate to have a separate data store, so we will use the same repository to query the transactional data store. Our handler for our query to get all appointments will be called GetAppointmentsHandler.cs and can be implemented like this:
public class GetAppointmentsHandler : IrequestHandler
<GetAppointmentsQuery, List<Appointment>>
{
private readonly IAppointmentRepository _repo;
public GetAppointmentsHandler
(IAppointmentRepository repo) => _repo = repo;
public async Task<List<Appointment>>
Handle(GetAppointmentsQuery request,
CancellationToken cancellationToken)
{
return await _repo.GetAll();
}
}This handler’s definition is simple as we simply retrieve a list of appointments. When we need to get an appointment by ID, it would imply that we need the details of the appointment. This will call for a more complex query that might involve joins or, better yet, require synchronous API calls to get the details of related records. This is where the database design’s strong points or flaws will come into play. If we were guided by our Domain-Driven Design (DDD) principles, then we would have been sure to include some additional information about records from other databases in this one. Without getting into too many details about that point, we need to ensure that we retrieve enough data to populate a model of type AppointmentDetailsDto for return, like so:
public class GetAppointmentByIdHandler :
IRequestHandler<GetAppointmentByIdQuery,
AppointmentDetailsDto>
{
private readonly IAppointmentRepository _repo;
public GetAppointmentByIdHandler
(IAppointmentRepository repo)
{
_repo = repo;
}
public async Task<AppointmentDetailsDto>
Handle(GetAppointmentByIdQuery request,
CancellationToken cancellationToken)
{
// Carry out all query operations and convert
the result to the expected return type
return new AppointmentDetailsDto{ /* Fill model
with appropriate values */ };
}
}After we have gathered the data needed for this particular scenario, we construct our return object and send it back to the original sender.
Now, let us look at what the controller actions look like as they seek to complete the queries.
Invoking a query
Using the same controller, we can assume that the IMediator dependency has already been injected and execute the following code:
[HttpGet]
public async Task<ActionResult<Appointment>> Get()
{
var appointments = await _mediator.Send(new
GetAppointmentsQuery());
return Ok(appointments);
}
[HttpGet("{id}")]
public async Task<ActionResult<AppointmentDetailsDto>>
Get(string id)
{
var appointment = await _mediator.Send(new
GetAppointmentByIdQuery(id));
return Ok(appointment);
}Our actions look similar. Each one is defined with the parameters it needs from a request. They then call the mediator object and new objects of the expected query model type. The mediator will orchestrate the call and route the request to the appropriate handler.
Summary
There are several benefits that can be reaped from this approach to development. We have already outlined that project bloat is a part of the territory, but the level of consistency and structure that can be enforced and guaranteed is perhaps worth the additional effort.
In this chapter, we explored the CQRS pattern and how we can employ it in our microservice application. We took time to assess the problems that we need to address, to bring real context to why we added this new level of complexity. We then looked at how we restructure our code to facilitate our handlers and request/command objects. We also looked at some design decisions that we can make in terms of our data stores for reading and writing operations.
In our next chapter, we will explore Event Sourcing patterns that will tie into our CQRS pattern and help us to keep our data relevant throughout our application.