
3
Synchronous Communication between Microservices
In the previous chapter, we learned about aggregator patterns and how they help us scope our storage considerations for our microservices. Now, we will focus on how our services communicate with each other during the application’s runtime.
We have already established that microservices should be autonomous and should handle all operations relating to tranches of the domain operations that are to be completed. Even though they are autonomous by design, the reality is that some operations require input from multiple services before an end result can be produced.
At that point, we need to consider facilitating communication, where one service will make a call to another, wait on a response, and then take some action based on that said response.
After reading this chapter, we will be able to do the following:
- Understand why microservices need to communicate
- Understand synchronous communication with HTTP and gRPC
- Understand the disadvantages of microservice communication
Technical requirements
The code references used in this chapter can be found in the project repository, which is hosted on GitHub at https://github.com/PacktPublishing/Microservices-Design-Patterns-in-.NET/tree/master/Ch03.
Use cases for synchronous communication
Considering everything that we have covered so far regarding service independence and isolation, you are probably wondering why we need to cover this topic. The reality is that each service covers a specific tranche of our application’s procedures and operations. Some operations have multiple steps and parts that need to be completed by different services, and for this reason, it is important to properly scope which service might be needed, when it will be needed, and how to best implement communication between the services.
Interservice communication needs to be efficient. Given that we are talking about a number of small services interacting to complete an activity, we need to ensure that the implementation is also robust, fault-tolerant, and generally effective.
Figure 3.1 gives an overview of synchronous communication between microservices:
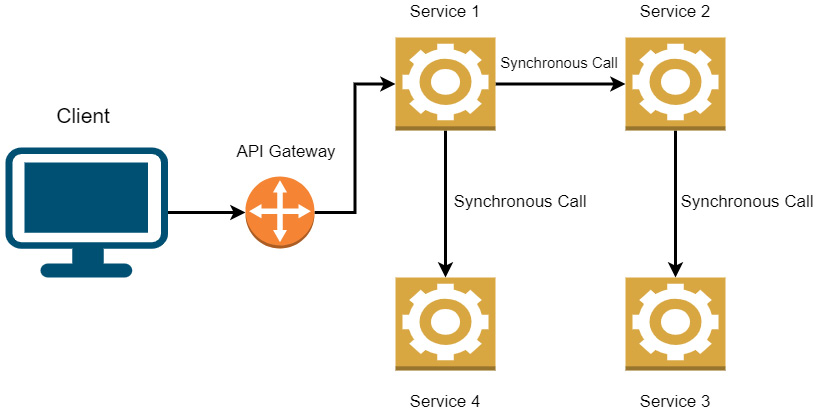
Figure 3.1 – One request might require several follow-up calls to additional services
Now that we understand why services need to communicate, let us discuss the different challenges that surround interservice communication.
Challenges of microservice communication
At this point, we need to accept that we are building a far more complex and distributed system than a monolith would permit. This comes with its own challenges when navigating the general request-response cycle of a web service call, the appropriate protocols to be used, and how we handle failures or long-running processes. Generally speaking, we have two broad categories of communication in synchronous and asynchronous communication. Beyond that, we need to scope the nature of the operation and make a call accordingly. If the operation requires an immediate response, then we use synchronous techniques, and for long-running processes that don’t necessarily need a response immediately, we make it asynchronous.
As mentioned before, we need to ensure that our interservice operations boast of the following:
- Performance: Performance is always something we have in the back of our minds while developing a solution. Individually, we need each service to be as performant as possible, but this requirement extends to communication scenarios, too. We need to ensure that when one service calls another, the call is done using the most efficient method possible. Since we are predominantly using REST APIs, HTTP communication will be the go-to method. Additionally, we can consider using gPRC, which allows us to call a REST API with the benefit of higher throughput and less latency.
- Resilient: We need to ensure that our service calls are done via durable channels. Remember that hardware can fail, or there can be a network outage at the same time as the service call is being executed. So, we need to consider two patterns that will make our services resilient, Retry and Circuit Breaker:
- Retry pattern: Transient failures are common and temporary failures can derail an operation’s completion. However, they tend to go away by themselves, and we would prefer to retry the operation a few times, as opposed to failing the application’s operation completely. Using this pattern, we retry our service call a few times, based on a configuration, and should we not have any success, trigger a timeout. For operations that augment the data, we will need to be a bit more careful since the request might get sent and a transient failure might prevent a response from being sent. This doesn’t mean that the operation wasn’t actually completed, and retrying might lead to unwanted outcomes.
- Circuit breaker pattern: This pattern is used to limit the number of times that we try to make the service call. Multiple calls might fail because of how long a transient failure takes to resolve itself, or the number of requests going to the service might cause a bottleneck in the available system resources and allocations. So, with this pattern, we could configure it to limit the amount of time we spend trying to call one service.
- Traced and monitored: We have established that a single operation can span multiple services. This brings another challenge in monitoring and tracing activities through all the services, from one originating point. At this point, we need to ensure that we are using an appropriate tool that can handle distributed logging and aggregate them all into a central place for easier perusal and issue tracking.
Now that we have a clearer picture of why we need to communicate and what challenges we might face, we will look at practical situations for synchronous communication.
Implementing synchronous communication
Synchronous communication means that we make a direct call from one service to another and wait for a response. Given all the fail-safes and retry policies that we could implement, we still evaluate the success of the call based on us receiving a response to our call.
In the context of our hospital management system, a simple query from the frontend will need to be done synchronously. If we need to see all the doctors in the system to present a list to the user, then we need to invoke a direct call to the doctors’ API microservice, which fetches the records from the database and returns the data with, more than likely, a 200 response that depicts success. Of course, this needs to happen as quickly and efficiently as possible, as we want to reduce the amount of time the user spends waiting on the results to be returned.
There are several methods that we can use to make an API call, and HTTP is the most popular. Support for HTTP calls exists in most languages and frameworks, with C# and .NET not being exceptions. Some of the advantages of HTTP come through standardized approaches to reporting; the ability to cache responses or use proxies; standard request and response structures; and standards for response payloads. The payload of an HTTP request is, generally, in JSON. While other formats can be used, JSON has become a de facto standard for HTTP payloads given its universal, flexible, and easy-to-use structure for data representation. RESTful API services that adhere to HTTP standards will represent information available in the form of resources. In our hospital management system, a resource can be a Doctor or Patient, and these resources can be interacted with using standard HTTP verbs such as GET, POST, PUT, or DELETE.
Now that we can visualize how synchronous HTTP communication happens in a microservice, let us take a look at some coding techniques that we can use in .NET to facilitate communication.
Implementing HTTP synchronous communication
In this section, we will be looking at some code examples of HTTP communication for when we want to call an API in a .NET application.
The current standard for HTTP-based API communication is REST (Representational State Transfer). RESTful APIs expose a set of methods that allow us to access underlying functionality via standard HTTP calls. Typically, a call or request consists of a URL or endpoint, a verb or method, and some data.
- URL or endpoint: The URL of the request is the address or the API and the resource that you are trying to interact with.
- Verb or method: The most commonly used verbs are GET (to retrieve data), POST (to create a record), PUT (to update data), and DELETE (to delete data).
- Data: Data accompanies a call, when necessary, in order to have a complete request. For instance, a POST request to the booking microservice would need to have the details of the booking that needs to be created.
The next major part of this conversation comes in the form of a response or HTTP status code. HTTP defines standard status codes that we use to interpret the success or failure of our request. The categories of status codes are listed as follows:
- 1xx (Informational): This communicates protocol-level information.
- 2xx (Success): This indicates that the request was accepted, and no errors occurred during processing.
- 3xx (Redirection): This indicates that an alternative route needs to be taken in order to complete the original request.
- 4xx (Client Error): This is the general range for errors that arise from the request, such as poorly formed data (400) or a bad address (404).
- 5xx (Server Error): These are errors that indicate that the server failed to complete the task for some unforeseen reason. When constructing our services, it is important that we properly document how requests should be formed, as well as ensure that our responses are in keeping with the actual outcomes.
In C#, we have access to a library called HttpClient, which provides methods that map to each HTTP verb, allowing us to bootstrap our calls and pass in the data that we require for the operation. It is also a good idea to have a list or directory of endpoints to be used. This can be accomplished through a combination of listing addresses in appsettings.json, and then we can have a class of constants, where we define the behaviors or resources for the service.
Our appsettings.json file would be decorated with the following block, which allows us to access the service address values from anywhere in our app:
"ApiEndpoints": {
"DoctorsApi": "DOCTORS_API_ENDPOINT",
"PatientsApi": "PATIENTS_API_ENDPOINT",
"DocumentsApi": "DOCUMENTS_API_ENDPOINT"
}The values per service configuration will be relative to the published address of the corresponding web service. This could be a localhost address for development, a published address on a server, or a container instance. We will use that base address along with our endpoint, which we can define in our static class.
In order to have consistency in our code, we can implement baseline code for making and handling HTTP requests and responses. By making the code generic, we pass in our expected class type, the URL, and whatever additional data might be needed. This code looks something like this:
public class HttpRepository<T> : IHttpRepository<T> where T : class
{
private readonly HttpClient _client;
public HttpRepository(HttpClient client)
{
_client = client;
}
public async Task Create(string url, T obj)
{
await _client.PostAsJsonAsync(url, obj);
}
public async Task Delete(string url, int id)
{
await _client.DeleteAsync($"{url}/{id}");
}
public async Task<T> Get(string url, int id)
{
return await _client.GetFromJsonAsync<T>($"{url}/
{id}");
}
public async Task<T> GetDetails(string url, int id)
{
return await _client.GetFromJsonAsync<T>($"{url}/
{id}/details");
}
public async Task<List<T>> GetAll(string url)
{
return await _client.
GetFromJsonAsync<List<T>>($"{url}");
}
public async Task Update(string url, T obj, int id)
{
await _client.PutAsJsonAsync($"{url}/{id}", obj);
}
}The HttpClient class can be injected into any class and used on the fly, in any ASP.NET Core application. We create a generic HTTP API client factory class as a wrapper around the HttpClient class in order to standardize all RESTful API calls that will originate from the application or microservice. Any microservice that will need to facilitate RESTful communication with another service, can implement this code and use it accordingly.
Now that we have an idea of how we handle calls through HTTP methods, we can review how we set up gRPC communication between our services.
Implementing gRPC synchronous communication
At this point, we should be comfortable with REST and the HTTP methods of communicating with and between our microservices. Now, we will pivot into exploring gRPC in a bit more detail.
RPC is short for Remote Procedure Call, and it allows us to call another service in a manner that resembles making a method call in code. For this reason, using gRPC in a distributed system works well. Communications can happen much quicker, and the entire framework is lightweight and performant from the jump. This is not to say that we should wholly swap all REST methods for gRPC. We know by now that we simply choose the best tool for our context and make it work accordingly, but it is good to know that gRPC is best used for scenarios where efficiency is paramount.
Indeed, gRPC is fully supported by ASP.NET Core, and this makes it a great candidate for use in our .NET Core-based microservices solution. Given its contract-based nature, it naturally enforces certain standards and expectations that we try to emulate when creating our own REST API service classes with interfaces. It starts with a file called a proto, which is the contract file. This contract outlines the properties and behaviors that are available and is exposed by the server (or broadcasting microservice).
The code snippets are as follows (parts have been omitted for brevity):
// Protos/document-search-service.proto
syntax = "proto3";
option csharp_namespace = "HealthCare.Documents.Api.Protos";
package DocumentSearch;
service DocumentService {
rpc GetAll (Empty) returns (DocumentList);
rpc Get (DocumentId) returns (Document);
}
message Empty{}
message Document {
string patientId = 1;
string name = 2;
}
message DocumentList{
repeated Document documents = 1;
}
message DocumentId {
string Id = 1;
}This proto class defines some methods that we want to allow for the document management service. We have defined a method to retrieve all documents, and another that will retrieve a document based on the provided ID value. Now that we have our proto defined, we will need to implement our methods in an actual service class:
public class DocumentsService : DocumentService.
DocumentServiceBase
{
public override Task<Document> Get(DocumentId request,
ServerCallContext context)
{
return base.Get(request, context);
}
public override Task<DocumentList> GetAll(Empty
request, ServerCallContext context)
{
return base.GetAll(request, context);
}
}In each method, we can carry out the actions needed to complete the operation, which, in this context, will be our database query and potential data transformation.
Next, we need to ensure that the calling service has a representation of the contract and that it knows how to make the calls. The following is a sample of how we would connect to the gRPC service at its address, create a client, and make a request for information:
// The port number must match the port of the gRPC server.
using var channel = GrpcChannel.ForAddress("ADDRESS_OF_
SERVICE");
var client = new DocumentService. DocumentService
Client(channel);
var document = await client.Get(
new DocumentId { Id = "DOCUMENT_ID" });Now that we have seen some code examples of gRPC, let us look at a head-to-head comparison of HTTP REST and gRPC.
HTTP versus gRPC communication
We have seen examples of how we can interact with our services via the HTTP or RESTful methods and the gRPC protocol. Now, we need to have a clearer picture of when we would choose one method over the other.
The benefits of using REST include the following:
- Uniformity: REST provides a uniform and standard interface for exposing functionality to subscribers.
- Client-server independence: There is clear independence between the client and the server applications. The client only interacts with URIs that have been exposed or are needed for functionality. The server is oblivious to which clients might be subscribing.
- Stateless: The server does not retain information about the requests being made. It just gets a request and produces a response.
- Cacheable: API resources can be cached to allow for faster storage and retrieval of information per request.
Note that gRPC does have its merits as to why it is being touted as a viable alternative to REST communication. Some of these merits include the following:
- Protocol buffers: Protocol buffers (or protobufs for short) serialize and deserialize data as binary, leading to higher data transmission speeds and smaller message sizes, given the much higher compression rate.
- HTTP2: HTTP2, unlike HTTP 1.1, supports the expected request-response flow, as well as bidirectional communication. So, if a service receives multiple requests from multiple clients, it can achieve multiplexing by serving many requests and responses simultaneously.
You can see the obvious and not-so-obvious advantages of using either method for web service creation and communication. Some developers have deemed gRPC the future, given its lighter weight and more efficient nature. However, REST APIs remain far more popular, are easier to implement, and have more third-party tool support for code generation and documentation. Most microservice architecture-based projects are built using REST APIs, and quite frankly, unless you have specific requirements that lead to a gRPC implementation, it might be a risk to adopt gRPC at a larger scale at this stage.
Given that we have explored so much about synchronous communication and the most common methods that are used to facilitate it, let us look at some of the disadvantages that surround having our microservices talk to each other.
Disadvantages of synchronous communication between microservices
While it is the go-to method for service-to-service communication, it might not always be the best option at that moment. Most cases might even prove that it is not the best idea to begin with.
Do remember that our users will be waiting on the result of a service-to-service call to manifest itself to them on the user interface. That means, for however long this communication is occurring, we have a user or users sitting and waiting on the interface to continue loading and furnish a result.
From an architectural point of view, we are violating one of the key principles of microservice design, which is having services that stand on their own, without knowing much, or preferably, anything, about each other. By having two services speak, there is knowledge about another service and implementation details being defined, which have very little to do with the service’s core functionality. Also, this introduces an undesirable level of tight coupling between services, which increases exponentially for each service that needs to speak to another service. Now a change to one service can have undesired functionality and maintenance effects on the others.
Finally, if we end up with a chain of service calls, this will make it more difficult to track and catch any errors that occur along the calls. Imagine that we implement a form of Chain of Responsibility with our service calls where one service calls another, and the result is used to call another, and so on. If we have three service calls happening back-to-back and the first one fails, we will get back an error and won't be able to determine at which point this error occurred. Another issue could be that we had successful calls, and the first error breaks the chain, thus wasting the usefulness of what has transpired in the chain before that.
It is always good to understand the pros and cons of the techniques that we employ. I do agree that synchronous communication is sometimes necessary, but we must also be aware of the additional development effort, in both the short and long term, that will be needed as a result of its employment. At this point, we begin to think of alternatives such as asynchronous communication and event-driven programming.
Summary
In this chapter, we explored quite a few things. We sought to understand what synchronous communication between web resources is, the protocols that are most commonly used, and the potential pros and cons of these techniques. We looked, in detail, at how HTTP communication occurs and can be implemented using C# and compared that with gRPC techniques. Additionally, we compared the two to ensure that we know when the best time would be to use either.
In the next chapter, we will explore asynchronous communication between services, the best practices, and what problems could be solved through this service-to-service communication method.