
4
Asynchronous Communication between Microservices
We have just reviewed synchronous communication between microservices and the pros and cons of that method. Now, we will take a look at its opposite counterpart, asynchronous communication.
Synchronous communication is needed at times and, based on the operation being carried out, can be unavoidable. It does introduce potentially long wait times as well as potential break points in certain operations. At this point, it is important to properly assess the operation and decide whether immediate feedback from an additional service is required to continue. Asynchronous communication means that we send data to the next service but do not wait for a response. The user will be under the impression that the operation was completed, but the actual work is being done in the background.
From that review, it is obvious that this method of communication cannot always be used but is necessary to implement certain flows and operations efficiently in our application.
After reading this chapter, we will be able to do the following:
- Understand what asynchronous communication is and when we should use it
- Implement Pub-Sub communication
- Learn how to configure a message bus (RabbitMQ or Azure Service Bus)
Technical requirements
Code references used in this chapter can be found in the project repository, which is hosted on GitHub at this URL: https://github.com/PacktPublishing/Microservices-Design-Patterns-in-.NET/tree/master/Ch04
Functioning with asynchronous communication
Let us revisit some vital definitions and concepts before moving forward.
There are basically two messaging patterns that we will employ between microservices:
- Synchronous communication: We covered this pattern in the previous chapter, where one service calls another directly and waits for a response
- Asynchronous communication: In this pattern, we use messages to communicate without waiting for a response
There are times when one microservice needs another to complete an operation, but at the moment, it doesn’t need to know the outcome of the task. Let us think of sending confirmation emails after an appointment has been successfully booked by our health care management system. Imagine the user waiting on the user interface to complete its loading operation and show the confirmation. In between them clicking Submit and seeing the confirmation, the booking service needs to complete the following operations:
- Create an appointment record
- Send an email to the doctor booked for the appointment
- Send an email to the patient who booked the appointment
- Create a calendar entry for the system
Despite our best efforts, the booking service attempting to complete these operations will take some time and might lead to a less than pleasing user experience. We could also argue that the responsibility of sending emails should not be native to the booking service. In the same way, calendar management should stand on its own. So, we could refactor the booking service’s tasks as follows:
- Create an appointment record
- Synchronously call the email service to send an email to the doctor booked for the appointment
- Synchronously call the email service to send an email to the patient who booked the appointment
- Synchronously call the calendar management service to create a calendar entry for the system
Now, we have refactored the booking service to do fewer operations and offload the intricacies of non-appointment booking operations to other services. This is a good refactor, but we have retained and potentially amplified the main flaw in this design. We are still going to wait on the completion of one potentially time-consuming operation before we move on to the next operation, which runs the same risk. At this point, we can consider how important waiting on a response to these actions really is, relative to us entering the booking record in our database, which is the most important operation relative to allowing the user to know the outcome of the booking process.
In this setting, we can make use of an asynchronous communication pattern to ensure that the major operation gets completed and other operations, such as sending an email and entering a calendar entry, can happen eventually, without compromising our user experience.
At a very basic level, we can still implement asynchronous communication using HTTP patterns. Let us discuss how effective this can be.
HTTP asynchronous communication
In seeming contrast to what we have explored so far, we can actually implement asynchronous communication via HTTP. If we assess how HTTP communication works, we form an assessment of success or failure based on the HTTP response we receive. Synchronously, we would expect the booking service to call the email service and then wait on an HTTP 200 OK successful response code before it tries to move to the next command. Synchronously, we would actually try to send the email at the moment, and based on the success or failure of that operation, we would form our response.
Asynchronously, we would let the email service respond with an HTTP 202 ACCEPTED response, which indicates that the service has accepted the task and will carry it out eventually. This way, the booking service can continue its operation based on that promise and spend less time on the operation. In the background, the email service will carry out the task when it gets around to it.
While this does alleviate some of the pressure that the booking service carries, there are other patterns, such as the Pub-Sub pattern, that can be implemented to make this process smoother. Let us review this pattern.
Understanding Pub-Sub communication
The Pub-Sub pattern has gained a fair amount of popularity and acclaim and is widely used in distributed systems. Pub is short for Publisher and Sub is short for Subscriber. Essentially, this pattern revolves around publishing data, contextually called messages, to an intermediary messaging system, which can be described as resilient and reliable, and then having subscribing applications monitor this intermediary system. Once a message is detected, the subscribing application will conduct its processing as necessary.
Understanding message queues
Before we explore the Pub-Sub method, we need to understand the basics of messaging systems and how they work. The first model we will look at is called a message queue. A message queue is usually implemented as a bridge between two systems, a publisher and a consumer. When a publisher places messages in the queue, a consumer processes the information in the message as soon as it becomes available. Queues enforce a first-in-first-out (FIFO) delivery method, so the order of processing can always be guaranteed. This is usually implemented in a one-to-one communication scenario, so a specific queue is provisioned for each subscribing application. Payment systems tend to use this pattern heavily, where the actual sequence of submitted payments matters and they need to ensure the resilience of the instructions. If you think about it, payment systems generally have a very low failure rate. Most of the time when we submit a payment request, we can rest assured that it will be completed successfully at some point in the future.
Figure 4.1 shows a publisher interacting with several message queues.
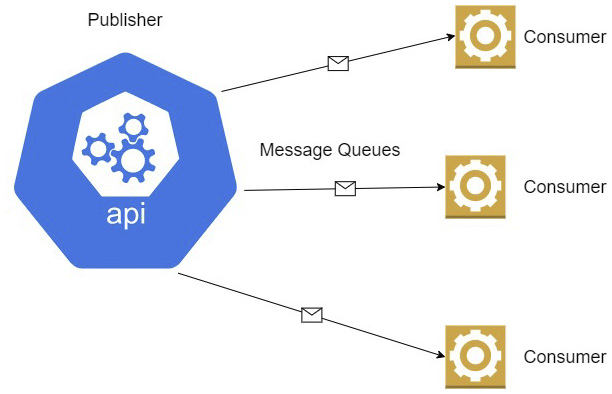
Figure 4.1 – Each message queue ensures that each application gets the exact data it needs and nothing more
The unfortunate thing here is that one bad message can spell trouble for the other messages waiting in the queue, and so we have to consider this potential downside. We also have to consider that we have our first chink in the armor. Messages are also discarded after they are read, so special provisions need to be made for messages that were not processed successfully.
While message queues do have their uses and bring a certain level of reliability to our system design, in a distributed system, they can be a bit inefficient and introduce some cons that we might not be prepared to live with. In that event, we turn our attention to a more distributed messaging setup such as a message bus. We will discuss this next.
Understanding message bus systems
A message bus, event bus, or service bus provides interfaces, where one published message can be processed by multiple or competing subscribers. This is advantageous in scenarios where we need to publish the same data to multiple applications or services. This way, we do not need to connect to multiple queues to send a message, but we can have one connection, complete one send action, and not worry about the rest.
Figure 4.2 shows a publisher interacting with a message, which has several consumers.
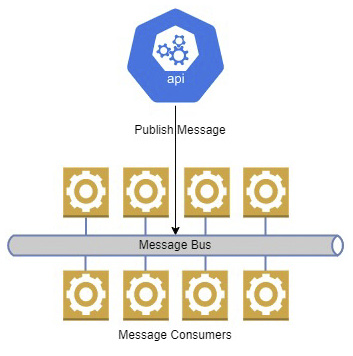
Figure 4.2 – This message bus has several consumers or subscribers listening for messages
Going back to our scenario where booking an appointment has several operational concerns, we can use a message bus to distribute data to the relevant services and allow them to complete their operations in their own time. Instead of making direct calls to the other APIs, our appointment booking API will create a message and place it on the message bus. The email and calendar services are subscribed to the message bus and process the message accordingly.
This pattern has several advantages where decoupling and application scalability are concerned. This aids in making the microservices even more independent from each other and reduces limitations associated with adding more services in the future. It also adds stability to the overall interactions of our services, since the message bus acts as a storage intermediary for the data needed to complete an operation. If a consuming service is unavailable, the message will be retained, and the pending messages will be processed once normalcy is restored. If all services are running and messages are backing up, then we can scale the number of instances of the services to reduce the message backlog more quickly.
There are several types of messages that you may encounter, but we will focus on two for this chapter. They are command and event messages. Command messages essentially request some action is performed. So, our message to the calendar services sends an instruction for a calendar entry to be created. Given the nature of these commands, we can take advantage of this asynchronous pattern and have the messages get picked up eventually. That way, even large numbers of messages will be processed.
Event messages simply announce that some action took place. Since these messages are generated after an action, they are worded in the past tense and can be sent to several microservices. In this case, the message to the email service can be seen as an event and our email service will relay that information accordingly. This type of message generally has just enough information to let the consuming services know what action was completed.
Command messages are generally aimed at microservices that need to post or modify data. Until a message is consumed and actioned, the expected data will not be available for some amount of time. This is one of the key downsides to the asynchronous messaging model, and it is termed eventual consistency. We need to explore this in more detail and discover the best approaches to take.
Understanding eventual consistency
One of the biggest challenges we face in microservices design is data management and developing a strategy for keeping data in sync, which sometimes means that we need to have multiple copies of the same data in several microservice databases. Eventual consistency is a notion in distributed computing systems that accepts that data will be out of sync for a period of time. This type of constraint is only acceptable in distributed systems and fault-tolerant applications.
It is easy enough to manage one dataset in one database, as is the case with a monolithic application, since data will always be up to date for any other part of the application to be able to access. A single database approach to our application gives us the guarantee of ACID transactions, which we discussed earlier, but we still are met with the challenge of concurrency management. Concurrency refers to the fact that we might have multiple versions of the same data available at different points. This challenge is easier to manage in a single database application but presents a unique challenge in a distributed system.
It is a reasonable assumption that when data changes in one microservice, data will change in another and lead to some inconsistency between the data stores for a period. The CAP theorem introduces the notion that we cannot guarantee all three of the main attributes of a distributed system: consistency, availability, and partition tolerance:
- Consistency: This means that every read operation against a data store will yield the current and most up-to-date version of the data, or an error will be raised if the system cannot guarantee that it is the latest.
- Availability: This means that data will always be returned for a read operation, even if this is not the latest guaranteed version.
- Partition tolerance: This means that systems will operate even when there might be transient errors that would stop a system under normal circumstances. Imagine we have minor connectivity issues between our services and/or messaging systems. Data updates will be delayed, but this principle will suggest that we need to choose between availability and consistency.
Choosing consistency or availability is a very important decision moving forward. Given that microservices need to be generally always available, we must be careful with our decision and how strictly we impose our constraints around a system’s consistency policy – eventual or strong.
There are scenarios where strong consistency is not required, since all the work that was performed by an operation is completed or rolled back. These updates are either lost (if rolled back) or will propagate to the other microservices in their own time, without having any detrimental effects on the overall operations of the application. If this model is selected, we can gauge our user experience through sensitization and letting them know that updates are not always immediate across the different screens and modules.
Using the Pub-Sub model is the number one way to implement this kind of event-driven communication between services, where they all communicate via a messaging bus. With the completion of each operation, each microservice will publish an event message to the message bus, and other services will pick this up and process it eventually.
To implement eventual consistency, we usually use event-driven communication using a publish-subscribe model. When data is updated in one microservice, you can publish a message to a central messaging bus, and other microservices that have copies of the data can receive a notification by subscribing to the bus. Because the calls are asynchronous, the individual microservices can continue to serve requests using the copy of the data that they already have, and the system needs to tolerate that while it might not be consistent right away, meaning that the data may not all be in sync immediately, eventually it will be consistent across the microservices. Of course, implementing eventual consistency can be more complex than just firing and forgetting messages to a message bus. Later in this book, we’ll look at ways we can mitigate the risks.
Until now, we have explored the concepts of using event-driven or Pub-Sub patterns to facilitate asynchronous communication. All of these concepts have been based on the idea that we have a messaging system persisting and distributing messages between services and operations. Now, we need to explore some of our options in the forms of RabbitMQ and Azure Service Bus.
Configuring a message bus (RabbitMQ or Azure Service Bus)
After waxing poetic about messaging buses and queues, we can finally discuss two excellent options for facilitating message-based service communication. They are RabbitMQ and Azure Service Bus.
These are by no means the only options, nor are they the best, but they are popular and can get the job done. Alternatives that you may encounter include Apache Kafka, which is famed for its high performance and low latency, or Redis Cache, which can double as a simple key-value caching store but also as a message broker. Ultimately, the tool you use is relative to what you need and what the tool offers your context.
Let us explore how we can integrate with RabbitMQ in a .NET Core application.
Implementing RabbitMQ in an ASP.NET Core web API
RabbitMQ is the most deployed and used open source message broker, at least at the time of writing. It supports multiple operating systems, has a ready-to-go container image, and is a reliable intermediary messaging system that is supported by several programming languages. It also provides a management UI that allows us to review messages and overall system performance as part of monitoring measures. If you plan to deploy a messaging system on-premises, then RabbitMQ is an excellent option.
RabbitMQ supports sending messages in two main ways – queues and exchanges. We already have an appreciation for what queues are, and exchanges support the message bus paradigm.
Let us take a look at what it takes to configure RabbitMQ on a Windows computer and what supporting C# code is needed to publish and consume. Let us start by including the MassTransit.RabbitMQ RabbitMQ package via NuGet. In our Program.cs file, we need to ensure that we configure MassTransit to use RabbitMQ by adding the following lines:
builder.Services.AddMassTransit(x =>
{
x.UsingRabbitMq();
});This creates an injectable service that can be accessed in any other part of our code. We need to inject IPublishEndpoint into our code, and this will allow us to submit a message to the RabbitMQ exchange:
[ApiController]
[Route("api/[controller]")]
public class AppointmentsController : ControllerBase
{
private readonly IPublishEndpoint _publishEndpoint;
private readonly IAppointmentRepository
_appointmentRepository;
public AppointmentsController (IAppointmentRepository
appointmentRepository, IPublishEndpoint
publishEndpoint)
{
_publishEndpoint = publishEndpoint;
_appointmentRepository = appointmentRepository;
}
[HttpPost]
public async Task<IActionResult> CreateAppointment
(AppointmentDto appointment)
{
var appointment = new Appointment()
{
CustomerId = AppointmentDto.CustomerId,
DoctorId = AppointmentDto.DoctorId,
Date = AppointmentDto.Date
});
await _appointmentRepository.Create(appointment);
var appointmentMessage = new AppointmentMessage()
{
Id = appointment.Id
CustomerId = appointment.CustomerId,
DoctorId = appointment.DoctorId,
Date = appointment.Date
});
await _publishEndpoint.Publish(appointmentMessage);
return Ok();
}
}After creating an appointment record, we can share the record’s details on the exchange. The different subscribers will pick up this message and process what they need. Consumers are generally created as windows or background worker services that are always on and running. The following example shows how a consumer’s code might look:
public class AppointmentCreatedConsumer :
IConsumer<AppointmentMessage>
{
public async Task Consume(ConsumeContext<Appointment
Message> context)
{
// Code to extract the message from the context and
complete processing – like forming email, etc…
var jsonMessage =
JsonConvert.SerializeObject(context.Message);
Console.WriteLine($"ApoointmentCreated message:
{jsonMessage}");
}
}Our consumers will be able to receive any message of the AppointmentMessage type and use the information as they need to. Note that the data type for the message exchange is consistent between the producer and the consumer. So, it would be prudent of us to have a CommonModels project that sits in between and serves up these common data types.
If we implement this consumer in a console application, then we need to register a Bus Factory and subscribe to the expected event endpoint. In this case, the endpoint that will be generated in RabbitMQ based on the type being published is appointment-created-event. To create a console application that will listen until we terminate the instance, we need code that looks like this:
var busControl = Bus.Factory.CreateUsingRabbitMq(cfg =>
{
cfg.ReceiveEndpoint("appointment-created-event", e =>
{
e.Consumer<AppointmentCreatedConsumer>();
});
});
await busControl.StartAsync(new CancellationToken());
try
{
Console.WriteLine("Press enter to exit");
await Task.Run(() => Console.ReadLine());
}
finally
{
await busControl.StopAsync();
}Now that we have seen in a nutshell what it takes to communicate with a RabbitMQ exchange, let us review what is needed to communicate with the cloud-based Azure Service Bus.
Implementing Azure Service Bus in an ASP.NET Core API
Azure Service Bus is an excellent choice for cloud-based microservices. It is a fully managed enterprise message broker that supports queues as well as Pub-Sub topics. Given Microsoft Azure’s robust availability guarantees, this service supports load balancing, and we can be assured of secure and coordinated message transfers if we choose this option. Similar to RabbitMQ, Azure Service Bus has support for queues and topics. Topics are the direct equivalent of exchanges, where we can have multiple services subscribed and waiting on new messages. Let us reuse the concept we just explored with RabbitMQ and review the code needed to publish a message on a topic and see what consumers would look like. We are going to focus on the code in this section and assume that you have already created the following:
- An Azure Service Bus resource
- An Azure Service Bus topic
- An Azure Service Bus subscription to the topic
These elements all need to exist, and we will retrieve a connection string to Azure Service Bus through the Azure portal. To get started with the code, add the Azure.Messaging.ServiceBus NuGet package to the producer and consumer projects.
In our publisher, we can create a service wrapper that can be injected into parts of the code that will publish messages. We will have something like this:
public interface IMessagePublisher {
Task PublisherAsync<T> (T data);
}
public class MessagePublisher: IMessagePublisher {
public async Task PublishMessage<T> (T data, string
topicName) {
await using var client = new ServiceBusClient
(configuration["AzureServiceBusConnection"]);
ServiceBusSender sender = client.CreateSender
(topicName);
var jsonMessage =
JsonConvert.SerializeObject(data);
ServiceBusMessage finalMessage = new
ServiceBusMessage(Encoding.UTF8.GetBytes
(jsonMessage))
{
CorrelationId = Guid.NewGuid().ToString()
};
await sender.SendMessageAsync(finalMessage);
await client.DisposeAsync();
}In this code, we declare an interface, IMessagePublisher.cs, and implement it through MessagePublisher.cs. When a message comes in, we create ServiceBusMessage and submit it to the specified topic.
We need to ensure that we register this service so that it can be injected into other parts of our code:
services.AddScoped<IMessagePublisher, MessagePublisher>();
Now, let us look at the same controller and how it would publish a message to Azure Service Bus instead of RabbitMQ:
[ApiController]
[Route("api/[controller]")]
public class AppointmentsController : ControllerBase
{
private readonly IMessageBus _messageBus;
private readonly IAppointmentRepository
_appointmentRepository;
public AppointmentsController (IAppointmentRepository
appointmentRepository, IMessageBus messageBus)
{
_appointmentRepository = appointmentRepository;
_messageBus = messageBus;
}
[HttpPost]
public async Task<IActionResult> CreateAppointment
(AppointmentDto appointment)
{
var appointment = new Appointment()
{
CustomerId = AppointmentDto.CustomerId,
DoctorId = AppointmentDto.DoctorId,
Date = AppointmentDto.Date
});
await _appointmentRepository.Create(appointment);
var appointmentMessage = new AppointmentMessage()
{
Id = appointment.Id
CustomerId = appointment.CustomerId,
DoctorId = appointment.DoctorId,
Date = appointment.Date
});
await _messageBus.PublishMessage(appointmentMessage,
"appointments");
return Ok();
}
}Now that we know how we can set up the publisher code, let us review what we need for a consumer. This code could be used by a background worker or Windows service to continuously monitor for new messages:
public interface IAzureServiceBusConsumer
{
Task Start();
Task Stop();
}We start with defining an interface that outlines Start and Stop methods. This interface will be implemented by a consumer service class, which will connect to Azure Service Bus and begin executing code that listens to Service Bus for new messages and consumes them accordingly:
public class AzureServiceBusConsumer :
IAzureServiceBusConsumer
{
private readonly ServiceBusProcessor
appointmentProcessor;
private readonly string appointmentSubscription;
private readonly IConfiguration _configuration;
public AzureServiceBusConsumer(IConfiguration
configuration)
{
_configuration = configuration;
string appointmentSubscription =
_configuration.GetValue<string>
("AppointmentProcessSubscription")
var client = new ServiceBusClient
(serviceBusConnectionString);
appointmentProcessor = client.CreateProcessor
("appointments", appointmentSubscription);
}
public async Task Start()
{
appointmentProcessor.ProcessMessageAsync +=
ProcessAppointment;
appointmentProcessor.ProcessErrorAsync +=
ErrorHandler;
await appointmentProcessor
.StartProcessingAsync();
}
public async Task Stop()
{
await appointmentProcessor
.StopProcessingAsync();
await appointmentProcessor.DisposeAsync();
}
Task ErrorHandler(ProcessErrorEventArgs args)
{
Console.WriteLine(args.Exception.ToString());
return Task.CompletedTask;
}
private async Task ProcessAppointment
(ProcessMessageEventArgs args)
{
// Code to extract the message from the args,
parse to a concrete type, and complete
processing – like
forming email, etc…
await args.CompleteMessageAsync(args.Message);
}
}From these two examples of how we interact with message bus systems, we can see that they are conceptually very similar. Similar considerations and techniques would be employed for any of the other message bus systems supported by .NET Core libraries.
Surely, there are trade-offs when we implement this type of message-based communication. We now have an additional system and potential point of failure, so we must consider the additional infrastructural requirements. We also see that the code required adds more complexity to our code base. Let us dive into some of the disadvantages of this approach.
Disadvantages of asynchronous communication between microservices
As with any system or programming method, there are always advantages and disadvantages that come with the territory. We have already explored why having an asynchronous messaging pattern is a good idea for operations that might be long-running. We need to ensure that the end user doesn’t spend too much time waiting on an entire operation to be completed. Messaging systems are an excellent way to shorten the perceived time it takes to complete an operation and allows services to operate as efficiently as possible on their own. They also aid in decoupling systems, allowing for greater scalability and introducing a certain level of stability to a system where data transfer and processing are concerned.
Now, disadvantages creep in when we analyze the real level of complexity that this pattern can introduce. Far more coordination needs to be considered when designing how our services interact with others, what data they need to share, and what events need to be posted when operations are completed. In the synchronous model, we will be more sure of tasks getting completed down the line, since we cannot move forward without a favorable response from the next service along the chain. In the asynchronous model using queues and buses, we have to rely on the consuming service(s) posting an event regarding the state of completion. We also have to ensure that there are no repeated calls and, in some cases, need to make a concerted effort to ensure that messages are processed in a specific order.
This brings us to another disadvantage in the form of data consistency. Remember that the initial response from the message bus suggests that the operation is successful, but this just means that data was successfully submitted to the bus. After this, our consuming services still need to follow through and complete their operations. If one or more of these services fails to process and potentially submits the data to a data store, then we'll end up with inconsistency in our data. This is something to be mindful of, as it can lead to detrimental side effects and user attrition.
Summary
In this chapter, we explored a few things. We did a blow-by-blow comparison of how a process would be handled through synchronous API communication versus asynchronous communication. We then expanded our general knowledge of how messaging systems can be leveraged to support an asynchronous communication model for our services. In all of this, we discussed challenges that we can face with data consistency between operations and how we can gauge acceptable metrics for this unavoidable factor. In the latter parts, we reviewed two popular messaging systems and then discussed some of the outright disadvantages that we have to contend with in this paradigm.
In our next chapter, we will explore the Command-Query Responsibility Segregation (CQRS) pattern and how it helps us to write cleaner code in our services.