
1
Defining Machine Learning Security
Organizations trust machine learning (ML) to perform a wide variety of tasks today because it has proven to be relatively fast, inexpensive, and effective. Unfortunately, many people really aren’t sure what ML is because television, movies, and other media tend to provide an unrealistic view of the technology. In addition, some users engage in wishful thinking or feel the technology should be able to do more. Making matters worse, even the companies who should know what ML is about hype its abilities and make the processes used to perform ML tasks opaque. Before making ML secure, it’s important to understand what ML is all about. Otherwise, the process is akin to installing home security without actually knowing what the inside of the home contains or even what the exterior of the home looks like.
Adding security to an ML application involves understanding the data analyzed by the underlying algorithm and considering the goals of the application in interacting with that data. It also means looking at security as something other than restricting access to the data and the application (although, restricting access is a part of the picture).
The remainder of this chapter talks about the requirements for working with the coding examples. It’s helpful to have the right setup on your machine so that you can be sure that the examples will run as written.
Get in touch
Obviously, I want you to be able to work with the examples, so if you run into coding issues, please be sure to contact me at [email protected].
Using the downloadable source code will also save you time and effort. With these issues in mind, this chapter discusses these topics:
- Obtaining an overview of ML
- Defining a need for security and choosing a type
- Making the most of this book
Building a picture of ML
People anthropomorphize computers today, giving them human characteristics, such as the ability to think. At its lowest level, a computer processes commands to manipulate data, perform comparisons, and move data around. There is no thought process involved—just electrical energy cleverly manipulated to produce a mathematical result from a given input. So, the term “machine learning” is a bit of a misnomer because the machine is learning nothing and it doesn’t understand anything. A better way to view ML is as a process of algorithm manipulation such that added weighting produces a result that better matches the data input. Once someone trains a model (the combination of algorithm and weighting added to the algorithm), it’s possible to use the model to process data that the algorithm hasn’t seen in the past and still obtain a desirable result. The result is the simulation of human thought processes so that it appears that the application is thinking when it isn’t really thinking at all.
The feature that distinguishes ML most significantly is that the computer can perform mundane tasks fast and consistently. It can’t provide original thought. A human must create the required process but, once created, the machine can outperform the human because it doesn’t require rest and doesn’t get bored. Consequently, if the data is clean, the model correct, and the anticipated result correctly defined, a machine can outshine a human. However, it’s essential to consider everything that is required to obtain a desirable result before employing ML for a particular task, and this part of the process is often lacking today. People often think that machines are much more capable than they really are and then exhibit disappointment when the machine fails to work as expected.
Why is ML important?
Despite what you may have heard from various sources, ML is more important for mundane tasks than for something earth-shattering in its significance. ML won’t enable Terminators to take over the planet, nor will this technology suddenly make it possible for humans to stop working entirely in a utopian version of the future. What ML can do is reduce the boredom and frustration that humans feel when forced to perform repetitive factory work or other tasks of the sort. In the future, at the lowest level, humans will supervise machines performing mundane tasks and be there when things go wrong.
However, the ability to simply supervise machines is still somewhat far into the future, and letting them work unmonitored is further into the future still. There are success stories, of course, but then there are also failures of the worst sort. For example, trusting the AI in a car to drive by itself without human intervention can lead to all sorts of problems. Sleeping while driving will still garner a ticket and put others at risk, as described at https://www.theguardian.com/world/2020/sep/17/canada-tesla-driver-alberta-highway-speeding. In this case, the driver was sleeping peacefully with a passenger in the front seat of the car when the police stopped him. Fortunately, the car didn’t cause an accident in this case, but there are documented instances where self-driving cars did precisely that (see https://www.nytimes.com/2018/03/19/technology/uber-driverless-fatality.html for an example).
Besides performing tasks, ML can perform various kinds of analysis at a speed that humans can’t match, and with greater efficiency. A doctor can rely on ML to assist in finding cancer because the ML application can recognize patterns in an MRI that the doctor can’t even see. Consequently, the ML application can help guide the doctor in the right direction. However, the doctor must still make the final determination as to whether a group of cells really is cancerous, because the ML application lacks experience and the senses that a doctor has. Likewise, ML can make a doctor’s hands steadier during surgery, but the doctor must still perform the actual task. In summary, ML is currently assistive in nature, but it can produce reliable results in that role.
Pattern recognition is a strong reason to use ML. However, the ability to recognize patterns only works when the following applies:
- The source data is untainted
- The training and testing data are unbiased
- The correct algorithms are selected
- The model is created correctly
- Any goals are clearly defined and verified against the training and test data
Classification uses of ML rely on patterns to distinguish between types of objects or data. For example, a classification system can detect the difference between a car, a pedestrian, and a street sign (at least, a lot of the time). Unfortunately, the current state of the art clearly shows that ML has a long way to go in this regard because it’s easy to fool an application in many cases (see https://arxiv.org/pdf/1710.08864.pdf?ref=hackernoon.com for examples). There are a lot of articles now that demonstrate all of the ways in which an adversarial attack on a deep learning or ML application will render it nearly useless. So, ML works best in an environment where nothing unexpected happens, but in that environment, it works extremely well.
Recommender systems are another form of ML that try to predict something based on past data. For example, recommender systems play a huge role in online stores where they suggest some items to go with other items a person has purchased. If you’re fond of online buying, you know from experience that the recommender systems are wrong about the additional items more often than not. A recommender setup attached to a word processor for suggesting the next work you plan to type often does a better job over time. However, even in this case, you must exercise care because the recommendation is often not what you want (sometimes with hilarious results when the recipient receives the errant text).
As everything becomes more automated, ML will play an ever-increasing role in performing the mundane and repeatable elements of that automation. However, humans will also need to play an increasingly supervisory role. In the short term, it may actually appear that ML is replacing humans and putting them out of work, but in the long term, humans will simply perform different work. The current state of ML is akin to the disruption that occurred during the Industrial Revolution, where machines replaced humans in performing many manual tasks. Because of that particular disruption in the ways that things were done, a single farmer today can tend to hundreds of acres of land, and factory work is considerably safer. ML is important because it’s the next step toward making life better for people.
Identifying the ML security domain
Security doesn’t just entail the physical protection of data, which might actually be impossible for online sources such as websites where the data scientist obtains the data using screen-scraping techniques. To ensure that data remains secure, an organization must monitor and validate it prior to use for issues such as data corruption, bias, errors, and the like. When securing an ML application, it’s also essential to review issues such as these:
- Data bias: The data somehow favors a particular group or is skewed in a manner that produces an inaccurate analysis. Model errors give hackers a wedge into gaining access to the application, its model, or underlying data.
- Data corruption: The data may be complete, but some values are incorrect in a way that shows damage, poor formatting, or in a different form. For example, even in adding the correct state name to a dataset, such as Wisconsin, it could appear as WI, Wis, Wisc, Wisconsin, or some other legitimate, but different form.
- Missing critical data: Some data is simply absent from the dataset or could be replaced with a random value, or a placeholder such as N/A or Null for numeric entries.
- Errors in the data: The data is apparently present, but is incorrect in a manner that could cause the application to perform badly and cause the user to make bad decisions. Data errors are often the result of human data entry problems, rather than corruption caused by other sources, such as network errors. Hackers often introduce data errors that have a purpose, such as entering scripts in the place of values.
- Algorithm correctness: Using the incorrect algorithm will create output that doesn’t meet analysis goals, even when the underlying data is correct in every possible manner.
- Algorithm bias: The algorithm is designed in such a manner that it performs analysis incorrectly. This problem can also appear when weighting values are incorrect or the algorithm handles feedback values inappropriately. The bottom line is that the algorithm produces a result, but the result favors a particular group or outputs values that are skewed in some way.
- Repeatable and verifiable results: ML applications aren’t useful unless they can produce the same results on different systems and it’s possible to verify those results in some way (even if verification requires the use of manual methods).
ML applications are also vulnerable to various kinds of software attacks, some of which are quite subtle. All of these attacks are covered in detail starting in Chapter 3 of the book. However, here is an overview of the various attack types and a quick definition of each that you can use for now:
- Evasion: Bypassing the information security functionality built into a system.
- Poisoning: Injecting false information into the application’s data stream.
- Inference: Using data mining and analysis techniques to gain knowledge about the underlying dataset, and then using that knowledge to infer vulnerabilities in the associated application.
- Trojans: Employing various techniques to create code or data that looks legitimate, but is really designed to take over the application or manipulate specific components of it.
- Backdoors: Using system, application, or data stream vulnerabilities to gain access to the underlying system or application without providing the required security credentials.
- Espionage: Stealing classified, sensitive data or intellectual property to gain an advantage over a person, group, or organization to perform a personnel attack.
- Sabotage: Performing deliberate and malicious actions to disrupt normal processes, so that even if the data isn’t corrupted, biased, or damaged in some way, the underlying processes don’t interact with it correctly.
- Fraud: Relying on various techniques, such as phishing or communications from unknown sources, to undermine the system, application, or data security in a secretive manner. This level of access can allow for unauthorized or unpaid use of the application and influence ways in which the results are used, such as providing false election projections.
The target of such an attack may not even know that the attack compromised the ML application until the results demonstrate it (the Seeing the effect of bad data section of Chapter 10, Considering the Ramifications of Deepfakes, shows a visual example of how this can happen). In fact, issues such as bias triggered by external dataset corruption can prove so subtle that the ML application continues to function in a compromised state without anyone noticing at all. Many attacks, such as privacy attacks (see the article entitled Privacy Attacks on Machine Learning Models, at https://www.infoq.com/articles/privacy-attacks-machine-learning-models/), have a direct monetary motive, rather than simple disruption.
It’s also possible to use ML applications as the attack vector. Hackers employ the latest techniques, such as relying on ML applications to attack you to obtain better results, just as you do. The article entitled 7 Ways in Which Cybercriminals Use Machine Learning to Hack Your Business, at https://gatefy.com/blog/cybercriminals-use-machine-learning-hack-business/, describes just seven of the ways in which hackers use ML in their nefarious trade. You can bet that hackers use ML in several other ways, some of them unexpected and likely unknown for now.
Distinguishing between supervised and unsupervised
ML relies on a large number of algorithms, used in a variety of ways, to produce a useful result. However, it’s possible to categorize these approaches in three (or possibly four) different ways:
- Supervised learning
- Unsupervised learning
- Reinforcement learning
Some people add the fourth approach of semi-supervised learning, which is a combination of supervised and unsupervised learning. This section will only discuss the first three because they’re the most important in understanding ML.
Understanding supervised learning
Supervised learning is the most popular and easiest-to-use ML paradigm. In this case, data takes the form of an example and label pair. The algorithm builds a mapping function between the example and its label so that when it sees other examples, it can identify them based on this function. Figure 1.1 provides you with an overview of how this process works:
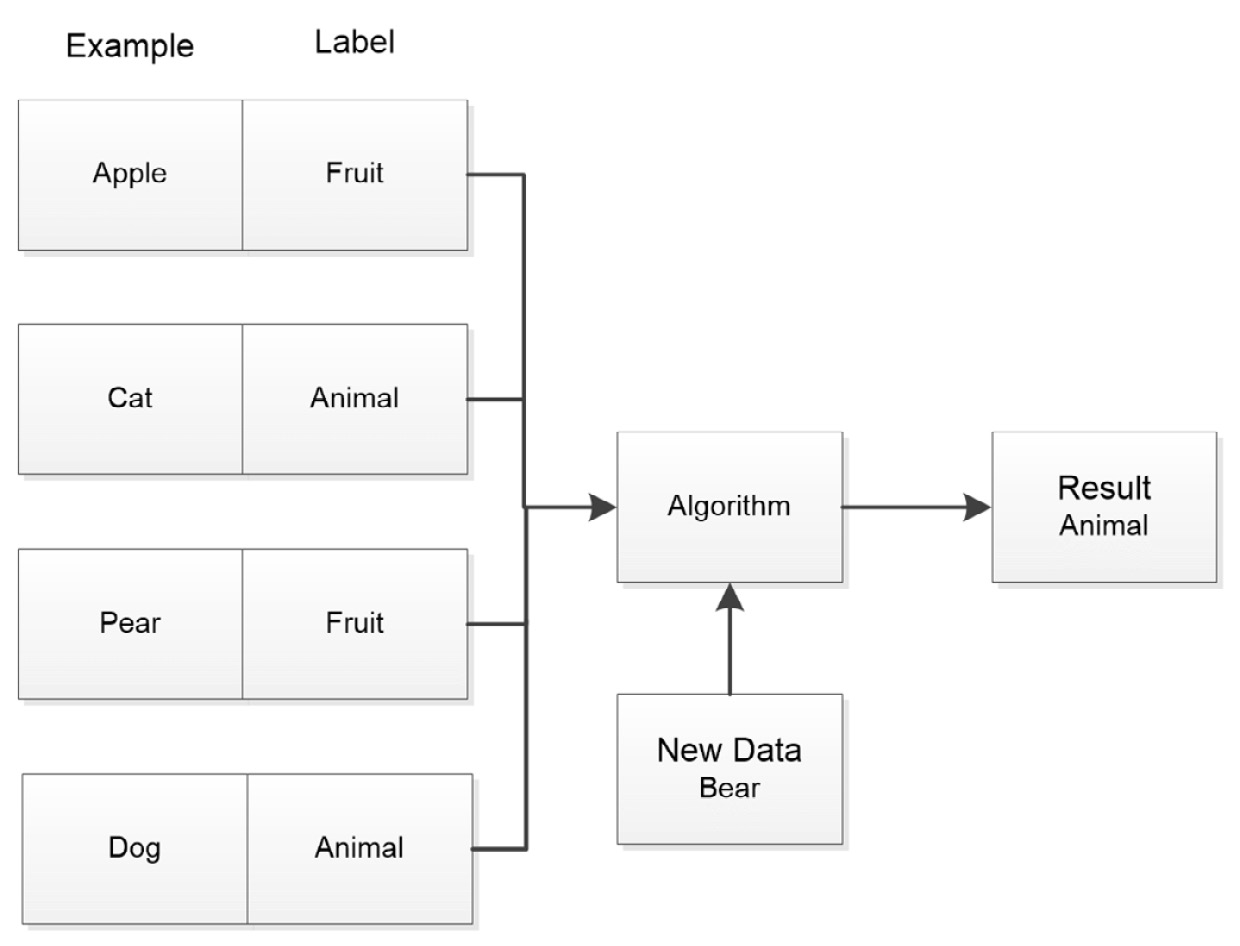
Figure 1.1 – Supervised learning relies on labeled examples to train the model
Supervised learning is often used for certain types of classification, such as facial recognition, and prediction, or how well an advertisement will perform based on past examples. This paradigm is susceptible to many attack vectors including someone sending data with the wrong labels or supplying data that is outside the model’s usage.
Understanding unsupervised learning
When working with unsupervised learning, the algorithm is fed a large amount of data (usually more than is required for supervised learning) and the algorithm uses various techniques to organize, group, or cluster the data. An advantage of unsupervised learning is that it doesn’t require labels: the majority of the data in the world is unlabeled. Most people consider unsupervised learning as data-driven, contrasted with supervised learning, which is task-driven. The underlying strategy is to look for patterns, as shown in Figure 1.2:
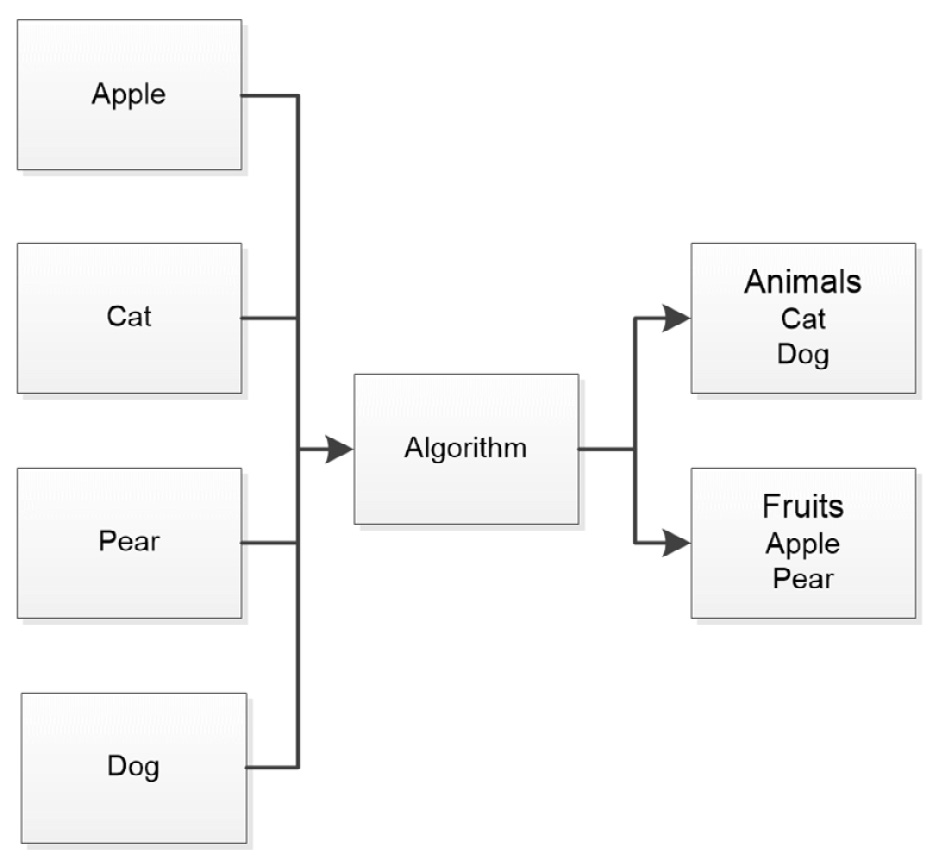
Figure 1.2 – Unsupervised learning groups or clusters like data together to train the model
Unsupervised learning is often used for recommender systems because such systems receive a constant stream of unlabeled data. You also find it used for tracking buying habits and grouping users into various categories. This paradigm is susceptible to a broad range of attack vectors, but data bias, data corruption, data errors, and missing data would be at the top of the list.
Understanding reinforcement learning
Reinforcement learning is essentially different from either supervised or unsupervised learning because it has a feedback loop element built into it. The best way to view reinforcement learning is as a methodology where ML can learn from mistakes. To produce this effect, an agent, the algorithm performing the task, has a specific list of actions that it can take to affect an environment. The environment, in turn, can produce one of two signals as a result of the action. The first signals successful task completion, which reinforces a behavior in the agent. The second provides an environment state so that the agent can detect where errors have occurred. Figure 1.3 shows how this kind of relationship works:
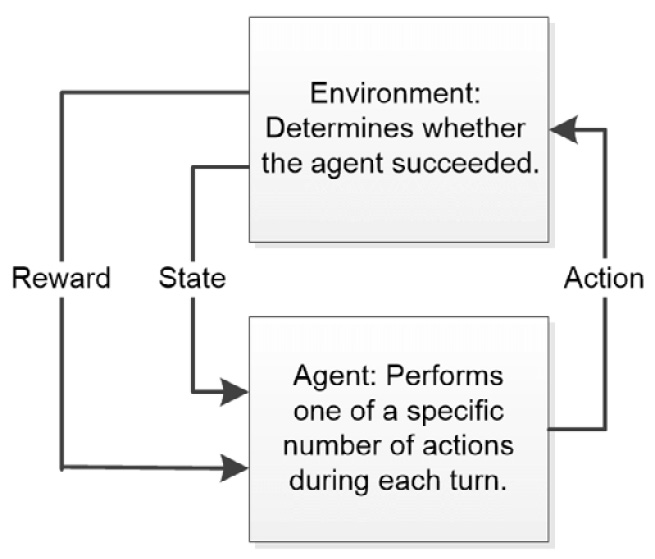
Figure 1.3 – Reinforcement learning is based on a system of rewards and an updated state
You often see reinforcement learning used for video games, simulations, and industrial processes. Because you’re linking two algorithms together, algorithm choice is a significant priority and anything that affects the relationship between the two algorithms has the potential to provide an attack vector. Feeding the agent incorrect state information will also cause this paradigm to fail.
Using ML from development to production
It’s essential to understand that ML does have an important role to fulfill today in performing specific kinds of tasks. Figure 1.4 contains a list of typical tasks that ML applications perform today, along with the learning type used to perform the task and observations of security and other issues associated with this kind of task. In no instance will you find that ML performs any task perfectly, especially without human assistance.


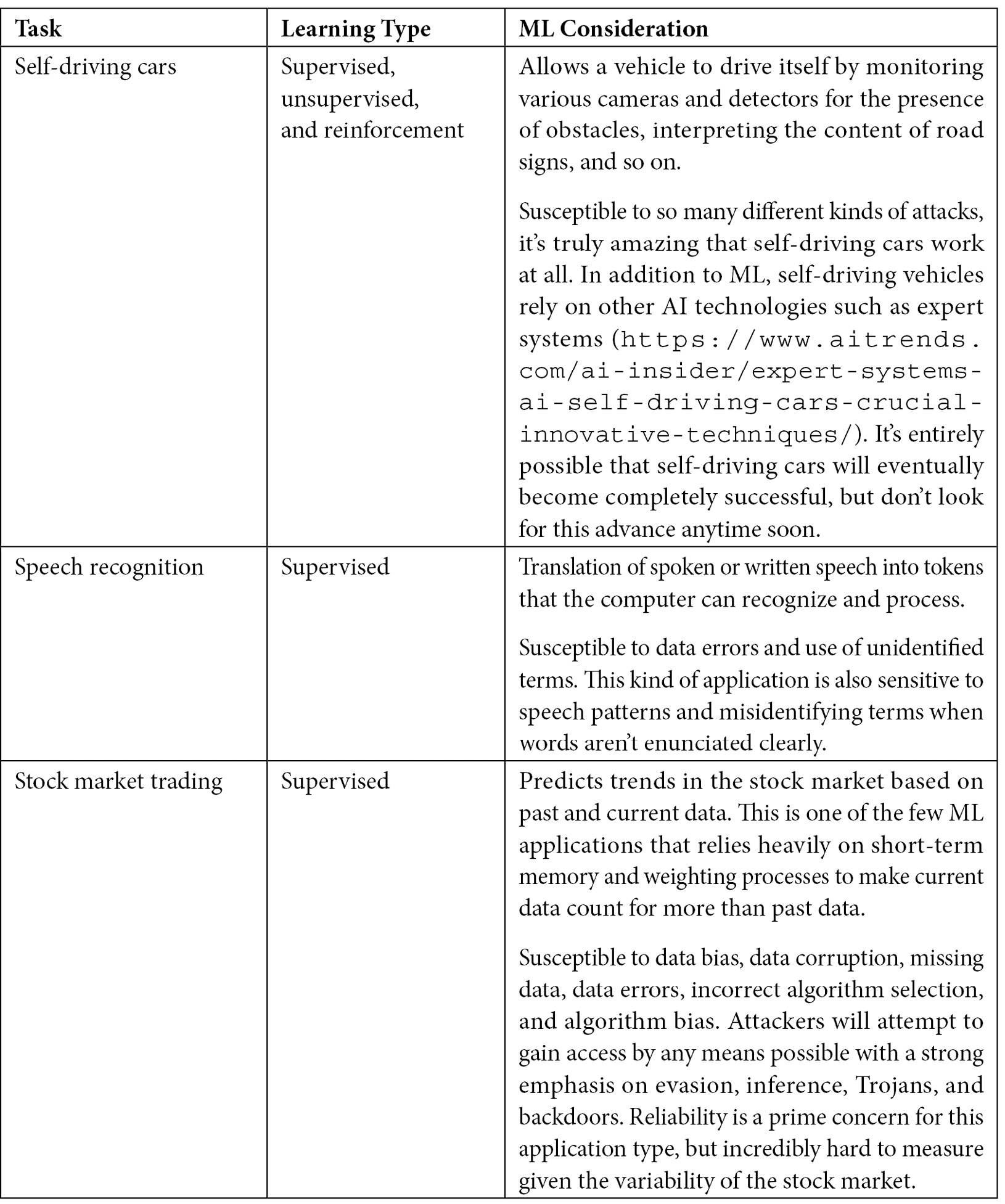
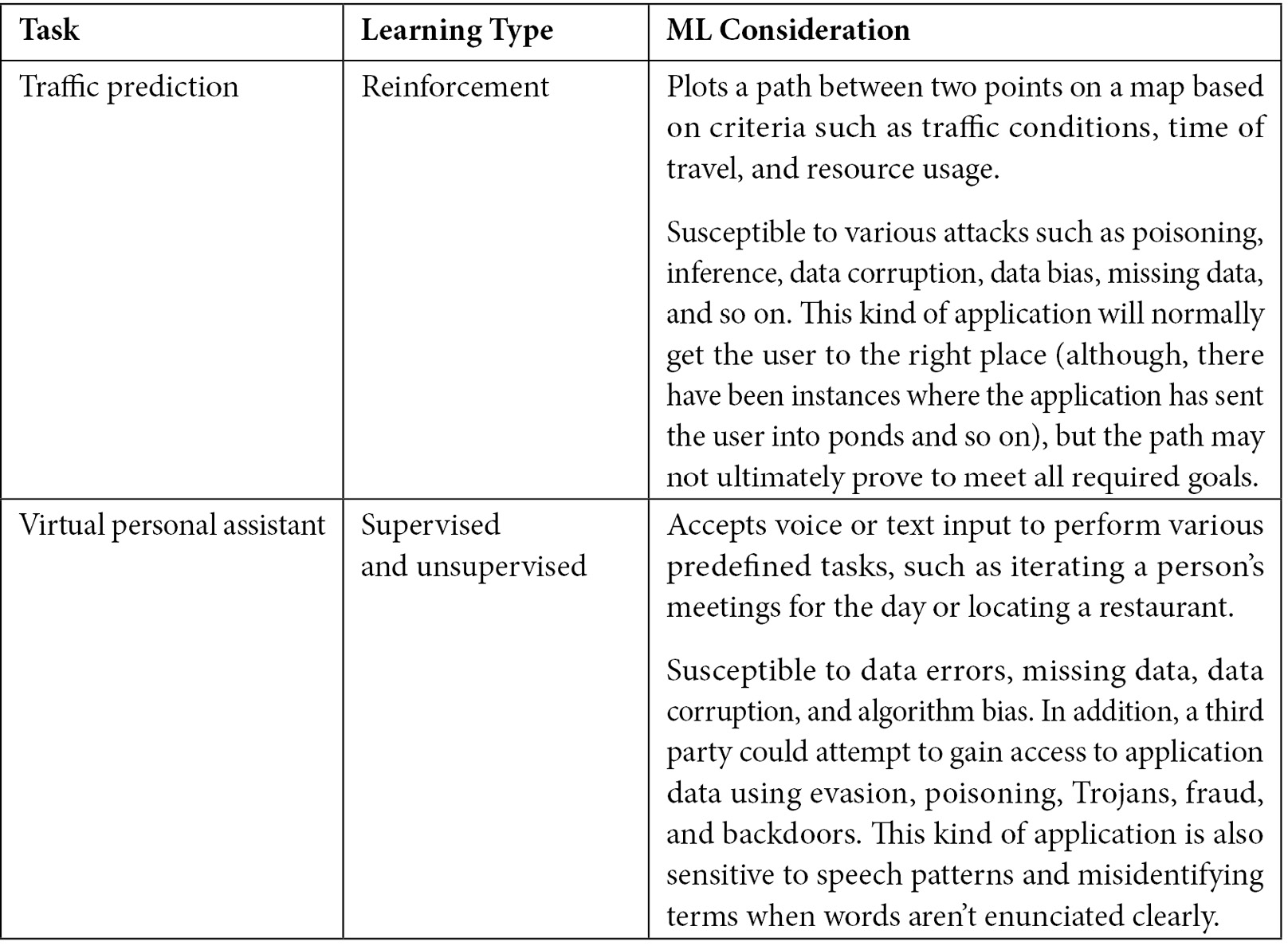
Figure 1.4 – ML tasks and their types
Figure 1.4 doesn’t contain some of the more exotic uses for ML. For example, some people use ML to generate art (see https://www.bbc.com/news/uk-england-oxfordshire-61600523 for one of the newest examples). However, the ML application isn’t creating art. What happens instead is that the ML application learns a particular art style from examples, and then transforms another graphic, such as a family picture, into a representation using the art examples. The results can be interesting, even beautiful, but they aren’t creative. The creativity resides in the original artist and the human guiding the generation (see https://aiartists.org/ai-generated-art-tools for details). The same technique applies to ML-generated music and even videos. Many of these alternative uses for ML are interesting, but the book doesn’t cover them heavily, except for the perspective of ethical treatment of data. So, why is security so important for ML projects? The next section begins to answer that question.
Adding security to ML
Security is a necessary component of ML to ensure that results received from an analysis reflect reality. Otherwise, decisions made based on the analysis will be flawed. If the mistake made based on such analysis merely affected the analyst, then the consequences might not be catastrophic. However, ML affects people – sometimes large groups of people. When the effects are large enough, businesses fold, lawsuits ensue, and people lose faith in the ability of ML applications to produce reliable results. Adding security ensures the following:
- Reliability
- Verifiability
- Repeatability
- Transparency
- Confidence
- Consistency
Let’s examine how security can impact ML in more detail.
Defining the human element
At this point, it’s important to take a slight detour from the technical information presented so far to discuss the human element. Even if the processes are clear, the data is clean, the algorithms are chosen correctly, and the code is error-free, humans still provide the input and interpret the result. Humans are an indirect source of security issues in all ML scenarios. When working with humans, it’s essential to consider the five mistruths that creep into every part of the ML environment and cause security issues that are difficult or sometimes impossible to find:
- Commission: Performing specific and overt engagement in a mistruth and supplying incorrect data. However, a mistruth of commission need not always imply an intent to mislead. Sometimes these mistruths are the result of a lack of information, incorrect information, or a need to please others. In some cases, it’s possible to detect mistruths of commission as outliers in plotted results created during analysis. Mistruths of commission create security issues by damaging the data used for analysis and therefore corrupting the model.
- Omission: Leaving out essential details that would make the resulting conclusions different. In many cases, the person involved simply forgets to provide the information or is unaware of it. However, this mistruth also makes an appearance when the facts are inconvenient. In some cases, it’s possible to detect this sort of mistruth during missingness checks of the data or in considering the unexpected output of an algorithm. Mistruths of omission create security issues by creating holes in the data or by skewing the model.
- Bias: Seeing the data or results in an unrealistic or counterintuitive manner due to personal concerns, environmental pressures, or traditions. Human biases often keep the person involved from seeing the patterns and outcomes that are obvious when the bias isn’t present. Environmental pressures, including issues such as tiredness, are hard to overcome and spot. The same checks that work for other kinds of bias can help root out human biases in data. Mistruths of bias create security issues by skewing the model and possibly causing the model to overfit or underfit the data.
- Perspective: Viewing the data based on experience, environmental conditions, and available information. In reviewing the statements of witnesses to any event, it’s possible to obtain different stories from each witness, even when the witnesses are being truthful from their perspective. The same is true of ML data, algorithms, and output. Different people will see the data in different ways and it’s nearly impossible to say that one perspective is correct and another incorrect. In many cases, the only way to handle this issue is to create a consensus opinion, much as interviewers do when speaking to witnesses to an event. Mistruths of perspective cause security issues by limiting the effectiveness of the model in providing a correct solution due to the inability of computers to understand anything.
- Frame of reference: Conveying information to another party incorrectly because the other party lacks the required experience. This kind of soft knowledge is precisely why humans are needed to interpret the analysis provided through ML. A human who has had a particular experience understands the experience and recognizes the particulars of it, but is unable to articulate the experience in a concrete manner. Mistruths of frame of reference create security issues by causing the model to misinterpret situational data and render incorrect results.
Now that you have a better idea of how humans play into the data picture, it’s time to look more at the technical issues, keeping the human element in mind.
Compromising the integrity and availability of ML models
In many respects, the ML model is a kind of black box where data goes in and results come out. Many countries now have laws mandating that models become more transparent, but still, unless you want to spend a great deal of time reviewing the inner workings of a model (assuming you have the knowledge required to understand how they work at all), it still amounts to a black box. The model is the weakest point of an ML application. It’s possible to verify and validate data, and understanding the algorithms used need not prove impossible. However, the model is a different story because the only practical ways to test it are to use test data and perform some level of verification and validation. What happens, however, if hackers or others have compromised the integrity of the model in subtle ways that don’t affect all results, just some specific results?
The integrity of a model doesn’t just involve training it with correct data but also involves keeping it trained properly. Microsoft’s Tay (see https://spectrum.ieee.org/tech-talk/artificial-intelligence/machine-learning/in-2016-microsofts-racist-chatbot-revealed-the-dangers-of-online-conversation) is an example of just how wrong training can go when the integrity of the model is compromised. In Tay’s case, unregulated Twitter messages did all the damage in about 16 hours. Of course, it took a lot longer than that to initially create the model, so the loss to Microsoft was immense. To the question of why internet trolls damaged the ML application, the answer of because they can seems trite, but ends up being on the mark. Microsoft created a new bot named Zo that fared better but was purposely limited, which serves to demonstrate there are some limits to ML.
The problem of discerning whether someone has compromised a model becomes greater for pre-trained models (see https://towardsdatascience.com/4-pre-trained-cnn-models-to-use-for-computer-vision-with-transfer-learning-885cb1b2dfc for examples). Pre-trained models are popular because training a model is a time-consuming and sometimes difficult process (pretrained models are used in a process called transfer learning where knowledge gained solving one problem is used to solve another, similar problem. For example, a model trained to recognize cars can be modified to recognize trucks as well). If you can simply plug a model into your application that someone else has trained, the entire process of creating the application is shorter and easier. However, pre-trained models also aren’t under your direct control and you have no idea of precisely how they were created. There is no way to completely validate that the model isn’t corrupted in some way. The problem is that datasets are immense and contain varied information. Creating a test harness to measure every possible data permutation and validate it is impossible.
In addition to integrity issues, ML models can also suffer performance and availability issues. For example, greedy algorithms can get stuck in local minima. Crafting data such that it optimizes the use of this condition to cause availability problems could be a form of attack. Because the data would appear correct in every way, data checks are unlikely to locate these sorts of problems. You’d need to use some sort of tuning or optimization to reduce the risk of such an attack. Algorithm choice is important when considering this issue. The easiest way to perpetrate such attacks is to modify the data at the source. However, making the attack successful would require some knowledge of the model, a level of knowledge known as white box access.
A major issue that allows for integrity and availability attacks is the assumption on the part of humans (even designers) that ML applications think in the same way as we do, which couldn’t be further from the truth. As this book progresses, you will discover that ML isn’t anything like a thought process—it’s a math process, which means treating adversarial attacks as a math or data problem. Some researchers have suggested including adversarial data in the training data for algorithms so that the algorithm can learn to spot them (learn, in this case, is simply a shortcut method of saying that the model has weights and variables adjusted to process the data in a manner that allows for a correct output result). Of course, researchers are looking into this and many other solutions for dealing with adversarial attacks that cause integrity - and performance-type problems. There is currently no silver bullet solution.
Describing the types of attacks against ML
The introduction to this chapter lists a number of attack types on data (such as data bias) and the application (evasion). The previous section lists some types of attacks perpetrated against the underlying model. As a collection, all of these attacks are listed as adversarial attacks, wherein the ML application as a whole tends not to perform as intended and often does something unexpected. This isn’t a new phenomenon—some people experimented with adversarial attacks as early as 2004 (see https://dl.acm.org/doi/10.1145/1014052.1014066 for an article on the issue). However, it has become a problem because ML and deep learning are now deeply embedded within society in such a way that even small problems can lead to major consequences. In fact, sites such as The Daily Swig (https://portswigger.net/daily-swig/vulnerabilities) follow these vulnerabilities because there are too many for any single individual to track.
Underlying the success of these attacks is that ML essentially relies on statistics. The transformation of input values to the desired output, such as the categorization of a particular sign as a stop sign, relies on the pixels in a stop sign image relating statistically well enough to the model’s trained values to make it into the stop sign category. By adding patches to a stop sign, it no longer matches the learned pattern well enough for the model to classify it as a stop sign. Because of the misclassification, a self-driving car may not stop as required but run right through the stop sign, causing an accident (often to the hacker’s delight).
Several elements come into play in this case. A human can look at the sign and see that it’s octangular, red, and says Stop, even if someone adds little patches to it. In addition, humans understand the concept of a sign. An ML application receives a picture consisting of pixels. It doesn’t understand signs, octangular or otherwise, the color red, or necessarily read the word Stop. All the ML application is able to do is match the object in a picture created with pixels to a particular pattern it has been trained to statistically match. As mentioned earlier in the chapter, machines don’t think or feel anything—they perform computations.
Modifying a street sign is an example of an overt attack. ML is even more susceptible to overt attacks. For example, the article at https://arxiv.org/pdf/1801.01944.pdf explains how to modify a sound file such that it embeds a command in the sound file that the ML application will recognize, but a human can’t even hear. The commands could do something innocuous, such as turn the speaker volume up to maximum, but they could perform nefarious tasks as well. Just how terrible the attack becomes depends on the hacker’s knowledge of the target and the goal of the attack. Someone’s smart speaker could send commands to a voice-activated security system to turn the system off when the owner isn’t at home, or perhaps it could trigger an alarm, depending on what the hacker wants (read Attackers can force Amazon Echos to hack themselves with self-issued commands at https://arstechnica.com/information-technology/2022/03/attackers-can-force-amazon-echos-to-hack-themselves-with-self-issued-commands/ to get a better understanding of how any voice-activated device can be hacked).
Attacks can affect any form of ML application. Simply changing the order of words in a text document can cause an ML application to misclassify the text (see the article at https://arxiv.org/abs/1812.00151). This sort of attack commonly thwarts the activities of spam and sentiment detectors but could be applied to any sort of textual documentation. Most experts classify this kind of attack as a paraphrasing attack. (See the Developing a simple spam filter example section of Chapter 4, Considering the Threat Environment, for details on working with text.) When you consider how much automated text processing occurs because there is simply too much being generated for humans to handle alone, this kind of attack can take on monumental proportions.
Considering what ML security can achieve
The essential goal of ML security is to obtain more consistent, reliable, trustworthy, and unbiased results from ML algorithms. Security focuses on creating an environment where the data, algorithm, responses, and analysis all combine to allow ML to produce believable and useful results. The security used with ML applications must perform these tasks in a manner that doesn’t slow the application perceptibly or force it to use huge amounts of additional resources. To accomplish these goals, the users of ML applications need to do the following:
- Set understandable and achievable result goals that are verifiable, consistent, and answer specific needs
- Train personnel (which means everyone in the organization, along with consultants and third parties) to interact with the application and its data appropriately
- Ensure that data passes all of the requirements for proper format, lack of missing elements, absence of bias, and lack of various forms of corruption
- Choose algorithms that actually perform tasks in a manner that will match the goals set for the ML application
- Use training techniques that create a reliable model that won’t overfit or underfit the data
- Perform testing that validates the data, algorithms, and models used for the ML application
- Verify the resulting application using real-world data that the ML application hasn’t seen in the past
Once an ML application meets all of these requirements, it can provide reliable results more quickly and consistently than humans can for mundane, repeatable tasks. Over time, the humans using an ML application should develop the trust required to make using the application worthwhile. In addition, humans can now move on to other areas of interest, making it possible for a single person to accomplish a great deal more than would otherwise be reasonable. Now that you have a good overview of the technical aspects of ML security, it’s time to get a development environment together so you can work with the book’s code.
Setting up for the book
I want to ensure that you have the best possible experience when working through the examples in this book. To accomplish that task, this book relies on the literate programming technique originally explored by Donald Knuth and detailed in his paper at http://www.literateprogramming.com/knuthweb.pdf. The crux of this approach is that it provides you with a notebook-like environment in which to work where it’s possible to freely mix code and non-code elements, including graphics. Because of its reliance on multiple methods of conveying information, this approach is exceptionally clear and easy to understand. Plus, it promotes experimentation at a level that many people don’t experience using other approaches.
No matter how inviting a programming environment might be, however, you still have to have a specific level of knowledge to enjoy it. The first section that follows describes what you need to know to use the book successfully. Because of the programming environment I’ve chosen to use, those requirements may be fewer than expected.
It’s also critical that you use the same tools that I used in creating the examples. This requirement isn’t meant to hinder you in any way, but to ensure that you don’t spend a lot of time overcoming environmental issues while attempting to run the code. The second section that follows describes the programming setup I used so that you can replicate it on your system.
To ensure that you don’t have to battle typos and other problems with hand-typed code, I also provide a downloadable source that makes it incredibly easy to work with the programming examples. Most people do benefit from eventually typing their own code and creating their own examples, but to make the learning process easier, you really do want to use the downloadable source if at all possible. The blog post at http://blog.johnmuellerbooks.com/2014/01/10/verifying-your-hand-typed-code/ provides you with some additional details in this regard. You can obtain the downloadable source code for this book from the publisher’s GitHub site at https://github.com/PacktPublishing/Machine-Learning-Security-Principles or my website at http://www.johnmuellerbooks.com/source-code/.
What do you need to know?
The main audience for this book is data scientists and, to a lesser extent, researchers, so I’m assuming that you already know something about data sources, data management techniques, and the algorithms used to perform analysis on data. I don’t expect you to have an advanced degree in these topics, but you should know that a .csv file contains data that is separated in fields using commas. In addition, it would be helpful to have at least a passing knowledge of common algorithms such as Bayes’ theorem. The notes and references we provide in the book will help you locate the additional information you need, but this book doesn’t provide a tutorial on essential data science topics.
To provide the best possible programming environment, this book also relies on the Python programming language. Again, you won’t find a tutorial on this language here, but the use of the literate programming technique should aid in your understanding if you have worked with programming languages in the past. Obviously, the more you know about Python, the less effort you’ll need to expend on understanding the code. People who are in management and don’t really want to get into the coding details will still find this book useful for the theory it provides, so you could possibly work with the book without knowing anything about Python to obtain theoretical knowledge.
It’s also essential that you know how to work with whatever platform you’re using. You need to know how to install software, work with the filesystem, and perform other general user tasks with whatever platform you choose to use. Fortunately, you have lots of options for using Jupyter Notebook, the recommended IDE for this book, or Google Colab, a great alternative that will work with your mobile device. However, this extensive list of platforms also means that we can’t provide you with much in the way of platform support.
Considering the programming setup
To get the best results from a book’s source code, you need to use the same development products as the book’s author. Otherwise, you can’t be sure whether an error you find is a bug in the development product or from the source code. The example code in this book is tested using both Jupyter Notebook (for desktop systems) (https://jupyter.org/) and Google Colab (for tablet users) (https://colab.research.google.com/notebooks/welcome.ipynb). Desktop system users will benefit greatly from using Jupyter Notebook, especially if they have limited access to a broadband connection. Whichever product you use, the code is tested using Python version 3.8.3, although any Python 3.7 or 3.8 version will work fine. Newer versions of Python tend to create problems with libraries used with the example code because the vendors who create the libraries don’t necessarily update them at the same speed as Python is updated. You can read about these changes at https://docs.python.org/3/whatsnew/3.8.html. You can check your Python version using the following code:
import sys
print('Python Version:
', sys.version)I highly recommend using a multi-product toolkit called Anaconda (https://www.anaconda.com/products/individual), which includes Jupyter Notebook and a number of tools, such as conda, for installing libraries with fewer headaches. Figure 1.5 shows some of the tools you get with Anaconda. I wrote the examples using the 2020.07 version of Anaconda, which you can obtain at https://repo.anaconda.com/archive/. Make sure you get the right file for your programming platform:
- Anaconda3-2020.07-Linux-ppc64le.sh (PowerPC) or Anaconda3-2020.07-Linux-x86_64.sh for Linux
- Anaconda3-2020.07-MacOSX-x86_64.pkg or Anaconda3-2020.07-MacOSX-x86_64.sh for macOS
- Anaconda3-2020.07-Windows-x86.exe (32-bit) or Anaconda3-2020.07-Windows-x86_64.exe (64-bit) for Windows

Figure 1.5 – Anaconda provides you with access to a wide variety of tools
It’s possible to test your Anaconda version using the following code (which won’t work on Google Colab since it doesn’t have Anaconda installed):
import os
result = os.popen('conda list anaconda$').read()
print('
Anaconda Version:
', result)The examples rely on a number of libraries, but three libraries are especially critical. If you don’t have the right version installed, the examples won’t work:
- NumPy: Version 1.18.5 or greater
- scikit-learn: Version 0.23.1 or greater
- pandas: Version 1.1.3 or greater
Use this code to check your library versions:
!pip show numpy !pip show scikit-learn !pip show pandas
Now that you have a workable development environment, it’s time to begin working through some example code in the chapters that follow.
Summary
This chapter has helped you understand various kinds of ML applications and how those applications are affected by various security threats. It has also emphasized the limitations of ML and pointed out some of the misconceptions that people have about ML – and possibly computers in general. Finally, you have discovered the ways in which humans inadvertently introduce security issues into ML applications by making invalid assumptions and by corrupting data in ways that humans understand, but computers don’t.
Knowing about the various forces at work to corrupt your ML model and data may be frightening at first, but there are certain things you can do to mitigate the threat, such as ensuring users are trained not to unintentionally introduce bias into the dataset. ML security measures can help you achieve these goals in an efficient manner. Of course, constant diligence is also a requirement.
The dataset end of things takes focus in the next chapter. It’s not just users who can ruin your day by introducing a security problem; using the wrong dataset source or any number of other issues can also be a problem. This next chapter will help you understand these issues so that you can consider the solutions presented in light of your organization’s needs.