
3
Mitigating Inference Risk by Avoiding Adversarial Machine Learning Attacks
Many adversarial attacks don’t occur directly through data, as described in Chapter 2. Instead, they rely on attacking the machine learning (ML) algorithms or, more often than not, the resulting models. Such an attack is termed adversarial ML because it relies on someone purposely attacking the software. In other words, unlike data attacks where accidental damage, inappropriate selection of models or algorithms, or human mistakes come into play, this form of adversarial attack is all about someone purposely causing damage to achieve some goal.
Attacking an ML algorithm or model is meant to elicit a particular result. The result isn’t always achieved, but there is a specific goal in mind. As researchers and hackers continue to experiment with ways to fool ML algorithms and obtain a particular result, the potential for serious consequences becomes greater. Fortunately, the attempts to overcome the positive results of a model require trial and error, which means that there are techniques that you can use to keep a hacker at bay until researchers in your organization can create an adequate defense. At some point, securing your ML algorithms becomes a race between the hackers seeking to circumvent and pervert the usefulness of the model and the researchers seeking to protect it. With these issues in mind, this chapter will discuss these topics:
- Defining adversarial ML
- Considering security issues in ML algorithms
- Describing the most common attack techniques
- Mitigating threats to the algorithm
Dealing with attack information overload
This chapter contains a huge amount of information in a very short space. The goal of this chapter is to expose you to as many different kinds of attacks as possible to help you think outside the boxes that many articles online create. The bottom line is that hackers are extremely creative and you need to look everywhere and in every way for attacks. In many ways, reading this chapter end to end could result in information overload, so selecting sections of interest at any particular time and focusing on that kind of attack will make the material seem a little less daunting. If this chapter provided any fewer attack vectors, it wouldn’t help you see the bigger picture of just what hackers are like.
Defining adversarial ML
An adversary is someone who opposes someone else. It’s an apt term for defining adversarial ML because one group is opposing another group. In some cases, the opposing group is trying to be helpful, such as when researchers discover a potential security hole in an ML model and then work to solve it. However, most adversaries in ML have goals other than being helpful. In all cases, adversarial ML consists of using a particular attack vector to achieve goals defined by the attacker’s mindset. The following sections will help you understand the dynamics of adversarial ML and what it presents, such as the huge potential for damaging your application.
Wearing many hats
All hackers deal with working with code at a lower level than most developers do, some at a very low level. However, there are multiple kinds of hackers and you can tell who they are by the hat they wear. Most people know that white hat hackers are the good guys who look for vulnerabilities (with permission) and tell people how to fix them. Black hat hackers illegally look for vulnerabilities to exploit to make people’s lives miserable. Gray hat hackers are people who look for vulnerabilities without malicious intent but may use illegal means to find them and usually work without permission. Green hat hackers are new to the trade and often do more damage without knowing what they’re doing than they would do if they did know what they were doing. Blue hat hackers take down other hackers for revenge. Sometimes, blue hat hackers take revenge on non-hackers too. Finally (yes, there is an end to this list), red hat hackers take down black hat hackers using means both legal and illegal without contacting the authorities. You can read more about the hats hackers wear at https://www.techtarget.com/searchsecurity/answer/What-is-red-and-white-hat-hacking.
Categorizing the attack vectors
It’s possible to categorize the various kinds of attacks that you might see against your ML model. By knowing the kind of attack, you can often create a strategy to protect against it. Most hackers use multiple attack vectors in tandem to achieve several advantages:
- Security experts become confused as to which attacks are currently in use
- It’s possible to hide the real attack under layers of feints
- The probability of success increases
Because of the methods used to attack your model, you need to employ an equal number of detection methods and then have a plan in place for mitigating the attack. At the time of writing, the detection part is difficult because so much research is needed to know how some attacks work. Mitigating an attack is even harder and there are some instances described later in this chapter where you may not be able to respond adequately in an automated manner, but will instead need to rely on specially trained humans to spot the threat and stop it using traditional methods, such as blocking particular IP addresses.
Examining the hacker mindset
A mindset is a set of beliefs that shape how a person views the world and makes sense of it. Given that most people need a reason to do something, even hackers of all types, consider these reasons hackers employ adversarial ML:
- To obtain money or power
- To take revenge on another party
- Because they need or want attention
- Because there is a misunderstanding as to the purpose of the application
- To make a political statement or create distrust
- Because there is a disagreement over how to accomplish a task
There are probably other reasons that hackers want to modify or destroy an ML model using the methods described in the Describing the most common attack techniques section (such as sending bad data or embedding scripts), but this list contains all the most common reasons. Knowing the motivations of your attacker can help you in your mitigation efforts. For example, people wanting to make a political statement are less likely to take your application down than those who are trying to obtain money or power. Consequently, the form of attack will differ and you’ll have different avenues of investigation to pursue. The first group is more likely to use a poisoning attack to modify the results you achieve from your analysis, while the second group is more likely to use an evasion attack to get past your defenses.
Being aware of the demographics of your attacker has benefits as well. For example, you might be able to ascertain the level of sophistication for the attacks or the number of resources at the attacker’s disposal. Anything you can discover about the attacker gives you an advantage in disabling the attacker. The point is that adversarial ML is all about who controls your model and what they use it to do. Now that you have a better idea of what adversarial ML is, the next section will discuss the security issues in algorithms that allow access to an attacker.
Considering security issues in ML algorithms
Someone is going to break into your ML application, even if you keep it behind firewalls on a local network. The following sections will help you understand the security issues that lead to breaches when using adversarial ML techniques.
Considering the necessity for investment and change
Because of the time and resource investment in ML models, organizations are often less than thrilled about having to incorporate new research into the model. However, as with any other software, updates of ML models and the underlying libraries represent an organization’s investment in the constant war with hackers. In addition, an organization needs to remain aware of the latest threats and modify models to combat them. All these requirements may mean that your application never feels quite finished – you may just complete one update, only to have to start on another.
Defining attacker motivations
An organization can use any number of technologies to help keep outsider attacks under control; insider attacks are more difficult because the same people who will attack the system also need access to it to perform their work. The infographic at https://digitalguardian.com/blog/insiders-vs-outsiders-whats-greater-cybersecurity-threat-infographic provides some surprising comparisons between insider and outsider attacks. However, here are the differences between insider and outsider attacks in a nutshell:
- Outsiders: The motivations of outsiders tend to reflect the kind of outsider. For example, attacks sponsored by your competition may revolve around obtaining access to your trade secrets and business plans. A competitor may want to discredit you or sabotage your research as well.
- Insiders: The motivations of insiders tend to revolve around money, espionage, or revenge. It’s essential, when thinking about insiders, to consider that the purpose of an attack may be to gain some sort of advantage on behalf of an outsider, especially competitors.
Helping the hacker break into your setup
A problem with securing your ML algorithm is that it’s often possible to find the application helping the hacker, as described in the Avoiding helping the hacker section. This assistance isn’t overt, but rather more in the way the application performs tasks, such as handling input. For example, an ML application may provide breadcrumbs of aid through information leakage. A smart hacker will see patterns that may not be immediately apparent unless you are looking for them and know what sorts of patterns are helpful (a skill that a hacker will gain through experience). In addition, if you offer the hacker unlimited tries to attempt to overcome your security, it’s almost certain that the hacker will succeed.
Employing CAPTCHA bypass techniques
It’s time to look at an example of a specific security issue to better illustrate how hackers think. The Completely Automated Public Turing test to tell Computers and Humans Apart (CAPTCHA) technology protects websites by requiring some sort of personal or sensitive input. It’s the technology that has you picking out all of the pictures that contain stop signs. The idea is that this technology can make it more difficult for someone to use an application by relying on automation, rather than visiting themselves. It supposedly helps make attacks such as Distributed Denial of Service (DDoS) more difficult. The problem is that ML makes CAPTCHA far less effective because an ML application can not only adapt to the kind of CAPTCHA used but also provide the input required automatically.
Several papers, such as the one at https://deepmlblog.wordpress.com/2016/01/03/how-to-break-a-captcha-system/, show that it’s possible to break CAPTCHA with a 92% or more success rate. This means that access to your public-facing application is likely, even if you have safeguards such as CAPTCHA in place. Using CAPTCHA is more likely to frustrate human users than it is to keep hackers at bay. You can even download the ML code from https://github.com/arunpatala/captcha.irctc to demonstrate to yourself that many of the safeguards that people currently count on, such as CAPTCHA, are nearly worthless. Consequently, you need a plan in place to harden the application, the model, and its data sources, and to detect intrusions when they occur.
One of the current methods of keeping bots at bay is to rely on a service, such as Reblaze (https://www.reblaze.com/product/bot-management/) or Akamai (https://www.akamai.com/solutions/security), to provide an advantage against issues such as credential stuffing. The need to keep your ML application, no matter what its purpose might be, free from intrusion is emphasized by the PC Magazine article at https://www.pcmag.com/news/walmart-heres-what-were-doing-to-stop-bots-from-snatching-the-playstation, which talks about reasons Walmart had serious problems with bots on its website. This specific example should help in understanding issues such as hacker goals and the need to rely on trial and error that appear in the sections that follow.
Considering common hacker goals
If you were to look for a single-sentence statement on hacker goals, you could summarize them as saying that hackers want to steal something, which seems overly obvious and simplified. However, hackers indeed want to steal your data, your money, your model, your peace of mind, or any number of other resources that you consider your personal property. Of course, hacker goals in overcoming your security and doing something to your ML algorithm or your organization as a whole are more complex than simply stealing something. The following list provides you with some goals that hackers have that may affect how you view ML security (contrast them with the reasons hackers employ adversarial ML, which we covered earlier in this chapter):
- Fly under the security radar
- Stay on the network as long as possible
- Perform specific tasks without being noticed
- Spend as little time as possible breaking into an individual site
- Reuse research performed before the break-in
- Employ previous datasets and statistical analysis to improve future efforts
Relying on trial and error
Hackers often rely on trial and error to gain access to an ML application, its data, or associated network because they have no access to the detailed structures and parameters of the ML models they attack. In some cases, hackers rely on traditional manual strategies because human attackers can often recognize patterns and vulnerabilities that might prove hard to build into an ML application.
To gain and maintain contact with ML applications for as long as possible, hackers could employ Generative Adversarial Networks (GANs). So, while the network employs ML applications to detect and block cybercriminal activity, the GAN keeps trying methods to circumvent the security measures, as described in the article entitled Generating Adversarial Malware Examples for Black-Box Attacks Based on GAN at https://arxiv.org/abs/1702.05983. The example code supplied with the article demonstrates how researchers sidestepped the security measures the test site had put in place. As the test site continues to innovate to keep hackers at bay, the hacker’s GAN also changes its strategy to accomplish the hacker’s goals. The GAN performs this task by using complex underlying distributions of data to generate more examples from the original distributions. This approach allows the creation of seemingly new malware, where each example differs from the other and the security checks can’t detect it based on a signature.
A hacker doesn’t suddenly decide to attack an organization one day. As a prelude to the attack, the hacker will discover as much information about the organization as possible using methods such as phishing, a technique that uses emails that appear to be from reputable companies that elicit personal information from users. Until now, hackers performed this task manually. However, hackers have started to use the same ML tools as organizations such as Google, Facebook, and Amazon to probe for information in an automated manner. Consequently, hackers spend less time with each individual and can attack more organizations with less effort. This also makes it possible for hackers to select sites with greater ease by probing a site’s defenses in depth and validating the value of the prize to gain so that high-value targets with poor defenses become more obvious. According to some sources, using this approach could boost a hacker’s chances of success by as much as 30% (see https://www.forbes.com/sites/forbestechcouncil/2018/01/11/seven-ways-cybercriminals-can-use-machine-learning/?sh=6dbd38791447 for details).
Humans are the weakest link in security setups. With this in mind, here are some other approaches that hackers use to employ humans to break the system:
- Social engineering: Hackers often spend time trying various social engineering attacks to obtain sensitive information that isn’t otherwise available. Once the hacker has some sensitive information in hand, it becomes easier to convince other humans of the legitimacy of questions asked to obtain yet more sensitive information. The hacker can talk to the person on the phone, appear in person, or use other methods to create a comfortable and inviting environment for the attack. Some hackers have even resorted to acting as cleaning personnel to gain access to a building to gather sensitive information (see the article at https://techmonitor.ai/techonology/hardware/cyber-criminals-cleaners for details).
- Phishing attacks: Direct contact isn’t always necessary. Hackers also look for patterns in emails to conduct phishing attacks where the message looks legitimate to the end user and arrives on schedule based on the pattern the ML application discovered. A phishing attack can net all kinds of useful information, including usernames and passwords.
- Spoofing: Appearing to be someone else often works where other techniques fail, especially with the onset of deep fakes (a topic that was discussed in Chapter 10, Considering the Ramifications of Deep Fakes). Spoofing attacks also cause serious problems because a hacker can make social media posts, emails, videos, texts, and even voice communication appear to come from the head of an organization, making it easy for the hacker to ask users to perform tasks in the hacker’s stead.
In short, a small amount of trial and error on the part of the hacker can net impressive results. The only way around this problem is to train employees to recognize the threats, and to keep the hacker ill-informed and out of the system.
Avoiding helping the hacker
Hackers will gratefully accept all of the help you want to provide. Of course, no one wants to help the hacker, but it’s entirely possible that this help is unobserved and provided accidentally. In some respects, there is something to admire in the hacker. They are both great listeners and fantastic observers of human behavior. It’s because of these traits that even tiny hints become major input to a hacker. To combat the hacker that’s trying to ruin your day, you also have to become a great listener and a fantastic observer of human behavior. However, even if you lack these traits, you can use these techniques to thwart the hacker’s attempts:
- Keep your secrets by not telling anyone (or keeping the list incredibly small)
- Eliminate clues
- Make the hacker jump through hoops
- Feed the hacker false information
- Learn from the hacker
- Create smarter models
One of the main human traits that hackers depend on is that humans are loquacious; they love to talk. If a hacker can make someone the center of attention and also increase their comfort level, it’s almost certain that the target user will give away everything they know and feel good about doing it. Training can help employees understand that the hacker isn’t their friend, no matter what sort of communication the hacker employs. However, employees also put together content for websites, share information across Facebook, upload articles to blogs, and communicate in so many ways that hackers don’t expend much effort unless third parties in the organization help keep things quiet.
Keeping information leakage to a minimum
There are many ways to leak information to a hacker and you can be certain that the hackers are listening to them all. Some of the most obscure and innocent-looking pieces of information tell the hacker a lot about you and your organization. Here are some common types of information leakage that you need to eliminate from your organization as a whole:
- Identifying information of any sort: If possible, eliminate all identifying information from your organization. Names, addresses, telephone numbers, URLs, email addresses, and the like just give the hacker the leverage needed for social engineering attacks.
- Error codes: Some applications display error information (error numbers, error strings, stack traces, and so on) when certain events occur. Anything that differentiates one error from another error provides clues as to how your application is put together for the hacker. Some library or service error codes have specific exploits that the hacker can employ. Store the error information in logs that you know are locked down on your server.
- Hints: Inputs are either correct or they’re not. Providing any kind of hint about what the input requires is an invitation to probing by the hacker. For example, you should use Access Denied rather than Password Invalid because the second form tells the hacker that the username is likely correct. One hacker trick is to keep trying various inputs until the application fails in a manner that helps the hacker.
- Status: Applications often provide status information that indicates something about how the application operates, the input it receives, or how it interacts with the user. A hacker can use status information to try to get the application to provide a more useful status so that the hacker can break into the system. When you must provide status information, use it carefully and keep it generic.
- Archives: Any sort of archive information is a goldmine for a hacker because it shows how the application’s state, setup, data, or other functionality changes over time. In this case, the hacker doesn’t even have to rely on trial and error techniques to obtain useful information about how the application works – the archive provides it.
- Confidence levels: A confidence level output can help the hacker determine when certain actions or inputs are better or worse than other actions or inputs. As you output a result from your ML application, the hacker can combine the result with a confidence level to define the goodness of the interaction. From a hacker’s perspective, goodness determines how close the hacker is to getting into the system, stealing data, modifying a model, or performing other nefarious acts.
Once you know that some information about your organization, individual users, the application, the application design, underlying data, or anything else that a hacker might conceivably use against you has been compromised, try to change that piece of information. Making the information outdated will only help keep your data safe and your application less open to attack. There are times when you must leak some information or the application wouldn’t be useful, so keep the leaks small and generic. At this point, you know more about the security issues that hackers exploit to get into your application.
Limiting probing
Probing is the act of interacting with your application in a manner that allows observation of specific results that aren’t necessarily part of the application’s normal output. For example, a hacker could keep trying scripts, control characters, odd data values, control key combinations, or other kinds of inputs and actions to see if an error occurs. So, the result that the hacker wants is an error, not the answer to a question. Of course, the hacker may also need a specific result, such as spoofing the ML application to misclassify input in a specific manner. One of the most common forms of spoofing is to fool a GAN into categorizing one input, such as a cat, into another input, such as a dog.
One common way to limit probing is to create hurdles for delivering an input package. CAPTCHA used to help in this role, but experienced hackers know how to get past CAPTCHA now, so you need other ways to slow down input in a manner that won’t frustrate legitimate users of your application. Current strategies include looking for too many requests from specific IP addresses and the like, but hackers commonly employ pools of IP addresses now to get around this protection. Throttling input speeds and adding a small delay before providing output are two other techniques, but these approaches tend to affect legitimate users as much as they do the hackers.
Depending on the input needed by your application and the sorts of incorrect input that you determine hackers apply, you could preprocess inputs using a neural network designed to recognize hacker patterns and thwart them. For example, you might recognize a hacker pattern that would provide inputs in just the right places to create an incorrect result. There are limits to this strategy. For example, the neural network probably won’t work well with graphic input because the current algorithms simply can’t recognize patterns well enough – that’s the threat right now because small modifications to the graphic (unnoticeable to humans) create a big effect with the algorithm. People often fool models designed to work with graphics by doing something unexpected, such as showing a bus upside down or wearing a funny piece of clothing. Hacker input detection relies on the model recognizing the unexpected in some manner.
Using two-factor authentication
A limited specific example of avoiding probing is the use of two-factor authentication (2FA) (see https://www.eset.com/us/about/newsroom/corporate-blog/multi-factor-authentications-role-in-thwarting-ransomware-attacks/ for details). However, this solution only works when the user is authenticating against the system and hackers already have methods for thwarting it (see https://www.globalguardian.com/global-digest/two-factor-authentication) for details. In addition, most 2FA solutions rely on the use of simple message service (SMS) texts sent to cellphones. Statistics show that not everyone has a cellphone and of those that do, not everyone has consistent access to a connection (see https://www.pewresearch.org/internet/fact-sheet/mobile/ and https://www.pewresearch.org/fact-tank/2021/06/22/digital-divide-persists-even-as-americans-with-lower-incomes-make-gains-in-tech-adoption/). This is especially true of rural areas. These statistics are for the US; cellphone access is more limited in many other countries. So, if your application is designed to work with low-income families in rural areas, 2FA that relies on text messages will result in a broken application in many cases (offering a vocal phone call alternative is a great solution to this problem).
Using ensemble learning
An ensemble in ML refers to a group of algorithms used together to obtain better predictive performance than could be achieved by any single algorithm in the group. People commonly use ensembles to develop models that work quickly, yet predict a result accurately.
Using an ensemble is akin to relying on the collective intelligence of crowds. The viability of this approach was first forwarded by Sir Francis Galton, who noted that averaging the inputs from a crowd at a country fair allowed correct estimation of the weight of a bull (read more about this phenomenon at https://www.all-about-psychology.com/the-wisdom-of-crowds.html). The use of layers and different detection methods for assessing hacker activity with an ensemble follows the same approach. What this sort of setup does is take the average of all of the detection methods and not rely on the errant result of any one model. A hacker has to work much harder to get past such a system. An ensemble used to prevent, limit, or detect hacking could have these components:
- Two or more generalized linear ML classifiers to label inputs according to type or category.
- One or more models that are used to detect data reputation based on knowledge of the data source. For example, a close partner is likely to have a better reputation than a new company that you haven’t had an association with before. You can verify reputation using the following dimensions:
- Quality: Based on the quality of input from previous experiences with the source
- Reliability: Based on how often the source has supplied suspicious, corrupted, or incomplete data in the past
- Responsibility: Defined as the source’s ability to maintain good data quality and keep hackers at bay, in addition to more practical matters, such as compensation to targets when the source is hacked
- Innovativeness: Reflects the source’s response time in detecting and addressing new threats
- One or more Deep Neural Networks (DNNs) that are used to assess the confidence of the system in the inputs (using reinforcement learning techniques allows the DNN to categorize new threats on the fly).
- One or more custom models are used to address the data needs of the particular ML application.
How many of these components an organization uses depends on the complexity and security requirements of the data needs for the ML application that is fed by the ensemble. For example, a hospital that only exposes its application to employees and vetted third parties might use a robust series of generalized linear learning classifiers, as shown in Figure 3.1, but may not need more than one reputation detection layer. It will likely need custom models to detect data anomalies to meet Health Insurance Portability and Accountability Act (HIPAA) requirements, as well as to handle the unique nature of medical data:

Figure 3.1 – Using an ensemble to preprocess data for a hospital application where multiple checks are needed before a prediction can be made
The organization of the layers will differ by application as well. When working with financial data, a reputation detection layer might appear first in line to automatically dump data inputs from unknown or unwanted sources, as shown in Figure 3.2. Only then would the ensemble classify the inputs and ensure the data has no hidden malicious inputs using a DNN:

Figure 3.2 – Using an ensemble to preprocess data for a financial application where the first stage dumps data from unknowns
The fact that you can arrange an ensemble in so many ways is an advantage because the hacker must now deal with unique configurations for each network. Trial and error techniques are less effective because the hacker must get through multiple layers in an unknown configuration using multiple models.
Integrating new research quickly
Some attacks today don’t have effective or efficient detection or mitigation methods because research into safeguards is ongoing. In addition, zero-day attacks, although rare, challenge researchers to understand the mechanics behind such attacks. Common occurrences that herald the emergence of zero-day attacks are as follows:
- The addition of new features to an application
- A particular use of ML that has suddenly become profitable
- The emergence of new model-creation techniques
- Adding or augmenting algorithms to a particular ML area
Understanding zero-day attacks
A zero-day attack is one where hackers discover a flaw in software and exploit it before anyone in the development community is even aware that the flaw exists; consequently, the development community must scramble to try to find a fix while the attack continues causing damage.
The emergence of a new threat leaves the people who have created an ML application feeling powerless, especially when the threat affects the use of algorithms and the underlying model. While it’s possible to quickly ascertain that a particular payload of data causes issues with the application, a less than thorough understanding of how the model works often impedes attempts to solve security problems with it. Consequently, the need for research is ongoing.
However, one of the most frustrating events is the emergence of a black swan attack, one that is completely unexpected, hard to predict from existing attacks, widespread, and effective. A black swan attack can throw off your strategy for protecting your network, application, model, and data. Fortunately, you can take some measures to protect against even a black swan attack, as outlined in the Developing principles that help protect against every threat section.
Understanding the Black Swan Theory
Before you go much further, it’s essential to understand the black swan (the event, not the bird) and its effect on ML security. The Black Swan Theory (sometimes called the Black Swan Paradox) describes an unexpected event with a major impact that people often rationalize in hindsight. It refers to an ancient European hypothesis that black swans didn’t exist, but was proved wrong when the first European found one. Nassim Nicholas Taleb (https://www.fooledbyrandomness.com/) advanced this theory to explain common issues in the modern world:
- High-profile, hard-to-predict, and rare events that history, science, finance, and technology can’t explain
- Rare events that modern statistical methods can’t calculate due to the small sample size
- Psychological biases that prevent people from seeing a rare event’s massive effects on historical events
From an ML perspective, a black swan event significantly affects human understanding of the basis used to create models. The occurrence of a black swan with its uncertainty of information significantly alters the underlying model because data scientists base models on the certainty of information. Consequently, a good starting point for designing ML models is to assume that they are incomplete and that what isn’t known is as important as what is known. Using these assumptions will help make your ML applications more secure by helping harden them against black swan events that a hacker could use to infiltrate your system.
Many ML developers refer to black swans and their effect on information as antiknowledge and point to the existence of antiknowledge as one reason to favor unsupervised models due to their ability to learn from black swan events. Supervised learning, due to its reliance on labeled (known) information, is more fragile in this particular case. The whitepaper Handling Black Swan Events in Deep Learning with Diversely Extrapolated Neural Networks, at https://www.ijcai.org/Proceedings/2020/296, provides additional insights into handling black swans. The reason you want to place a strong emphasis on black swan handling from a security perspective is that being able to handle a black swan event will make it less likely that your application will register false positives for security events. Now that you have a handle on security issues, it’s time to look at how a hacker exploits them. The next section will help you understand the techniques the hacker employs from an overview perspective (later chapters will go into considerably more detail).
Defining antiknowledge
Antiknowledge refers to any agent that reduces the level of knowledge available in a group or society. In ML, antiknowledge refers to the loss of knowledge about the inner workings or viability of algorithms, models, or other software due to the emergence of technologies, events, or data that infers previous knowledge is incorrect in some way.
Describing the most common attack techniques
Hackers can be innovative when required, but once hackers find something that works, they tend to stick with proven attack patterns, if not the specific attack implementation. For example, consider this scenario for a ransomware attack (which, according to What Ransomware Allows Hackers to Do Once Infected, at https://www.checkpoint.com/cyber-hub/threat-prevention/ransomware/what-ransomware-allows-hackers-to-do-once-infected/, has moved from just encrypting your files to also stealing your data):
- Obtain information about an organization using phishing attacks.
- Gain access to the organization’s network using a malicious download or compromised credentials.
- Check the organization’s network for any usable (sellable) data that it hasn’t encrypted or protected in other ways.
- Encrypt as much of the data storage as possible.
- Send out the ransom message, including specifics about the data stolen and describing what the hacker intends to do with the data if not paid.
Now, consider the fact that your ML application is completely useless until you get your data back, so the cost of this attack to you is enormous, but may have only taken a week of the hacker’s time. Of course, you could have avoided the attack by ensuring you backed up your data offsite (or protected it in other ways), used resources and other security measures, and, most important of all, trained your users not to open emails from people they don’t recognize.
Knowing information about attack methodology can help you better prepare for attacks because you can see the attack pattern as well and gain an understanding as to how the attack will likely succeed. When hackers do decide to modernize, the existing pattern helps you see what has changed in the attack so that it takes less time for you to react. Attack techniques also tend to have particular characteristics that you can summarize:
- Method of application
- Type of access obtained
- Intended target type
- Typical implementation
- Usual delivery method
- Predictable weaknesses to disruption
While the hacker is busy breaking down your defense strategy, it helps if you’re also breaking down the hacker’s attack strategy. Yes, some professional researchers perform this task all day, every day, but innovations in defense strategies often come from people who are working with specific application types. An attack on a credit card company isn’t going to rely on the same strategies that an attack on a hospital will. People who specialize in hospital-based ML applications can therefore provide a different perspective from the one held by professional researchers.
One of the more interesting aids at your disposal is the Adversarial ML Threat Matrix at https://github.com/mitre/advmlthreatmatrix. This main page includes a series of links to case studies that most people will find helpful because they provide a goal, such as evading a deep learning (DL) detector for malware command and control, and then showing you how the hackers put the attack together. You can see the main chart for this aid at https://raw.githubusercontent.com/mitre/advmlthreatmatrix/master/images/AdvMLThreatMatrix.jpg. This chart is especially helpful to security experts, administrators, data scientists, and researchers because the chart breaks the infiltration process down into steps. It then tells you specifically what will likely happen at each step. You get this input with each of the case studies:
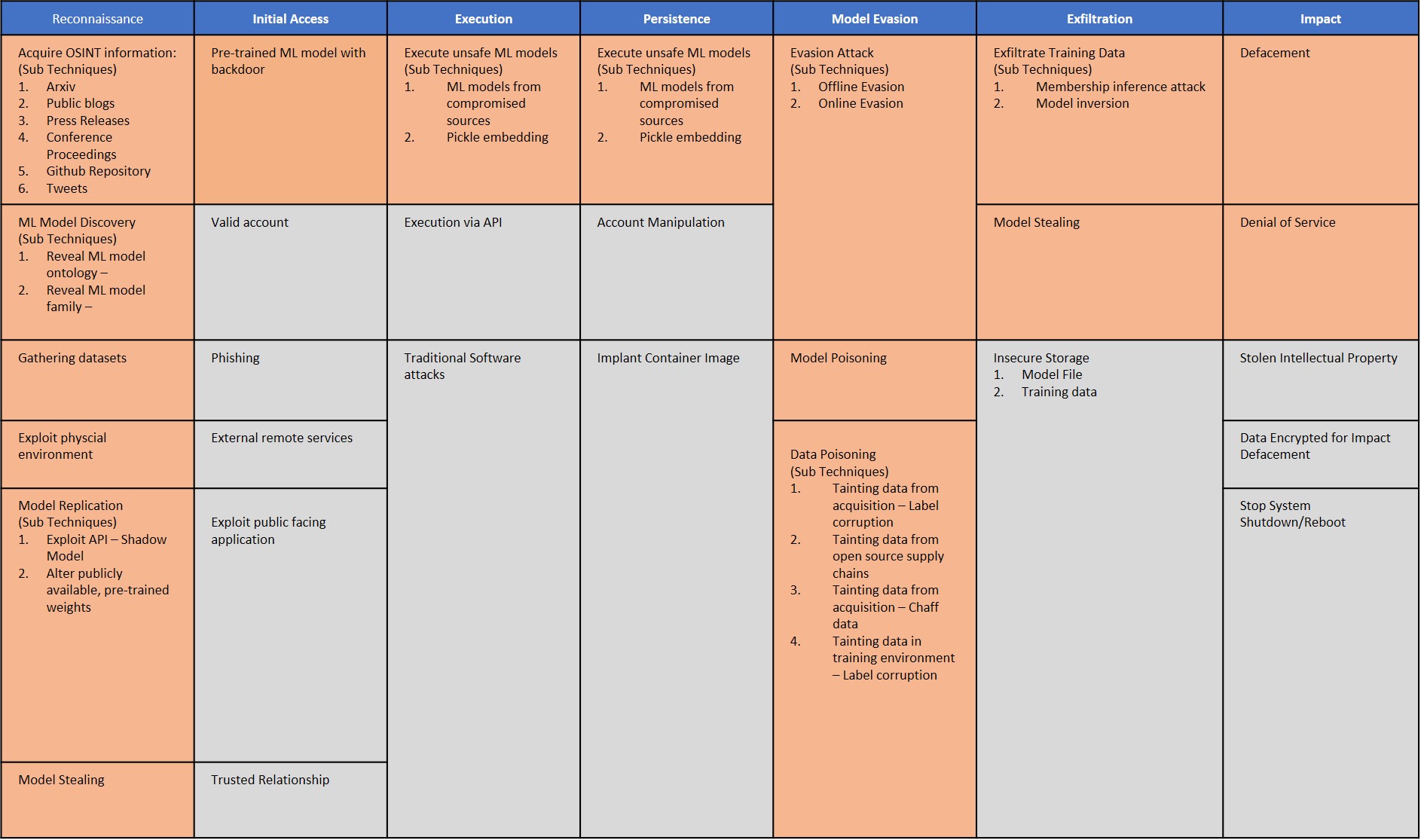{kind=link}
- Description of the adversarial technique
- Type of advanced persistent threat observed when using the tactic
- Recommendations for detecting the adversarial technique
- References to publications that provide further insight
Now that you have a better idea of the attack techniques that the hacker will employ, it’s time to look at specific examples. The following sections discuss common approaches.
Attacks on the local system
This book won’t show you how to locate specific viruses, Trojans, or other kinds of malicious code on a local system because ML applications today tend to target all sorts of systems, each of which would require a different method of locating and dissecting executables on the local system. The techniques in this chapter focus on attack vectors that work equally well on any system, both local and in the cloud, that a user might work with from anywhere. Hackers use every possible means to infect systems and then use their advantages to obtain credentials that allow them to modify, damage, or subtly change data, models, application software, system logs, and all sorts of other information on a local system. Books such as Malware Data Science by Joshua Saxe and Hillary Sanders, from No Starch Press, do contain instructions on how to disassemble and analyze files on the local system when looking for various kinds of malware. It’s also possible to perform Google searches on specific files that you suspect, such as ircbot.exe. The important thing to remember is that hackers don’t care how they access your system, so long as they access it.
Evasion attacks
Evasion attacks are the most prevalent attack type. An evasion attack occurs when a hacker hides or obfuscates a malicious payload in an innocent-looking package such as an email or document. In some cases, such as spam, the attack vector is part of the email. The following list is far from complete, but it does serve to outline some of the attack vectors used in an evasion attack:
- Attachment: An attachment can contain malicious code that executes the moment the file is opened.
- Link: The malicious code executes as soon as the resource pointed to by the link is opened.
- Graphic image: Viewing the graphic image within the user’s email setup can invoke the malicious code.
- Spoofing: A hacker impersonates another, legitimate, party.
- Biometric: Using specially crafted code or other techniques, the attacker simulates a facial expression or fingerprint to gain access to a system.
- Specially crafted code: It’s possible to train an ML model to perturb the output of a target model. You can see an example Python code for this particular technique at https://secml.readthedocs.io/en/stable/tutorials/03-Evasion.html. In this case, the attack is against a Support Vector Machine (SVM). The example at https://secml.readthedocs.io/en/stable/tutorials/08-ImageNet.html is more advanced and it occurs against ImageNet. Figure 3.3 shows how this kind of attack might work:

Figure 3.3 – Modifying the normal action of a model using modified data to produce a perturbation
The distinguishing characteristic of all these evasion attack types is that they occur outside the model. In many cases, the attack isn’t even automated – it requires some sort of user participation. Unlike other attacks, this attack doesn’t require modification of training data, nor does it necessarily affect reinforcement learning. The idea is that the attack remains a secret until it’s too late to do anything about it because the attack is underway.
Hackers will sometimes combine this attack with model poisoning so that it’s less likely that the target network’s defenses will recognize the package and prevent it from running. The idea is to use model poisoning to tell the defenses that the package is legitimate, even when it isn’t.
Model poisoning
Model poisoning occurs as a result of receiving specially designed input, especially during the model training phase. Users can also poison reinforcement learning models by providing copious amounts of input after model training. The overall goal of model poisoning is to prevent the model from making accurate predictions and to help ensure that the model favors the attacker in some way. The Python code example at https://secml.readthedocs.io/en/stable/tutorials/05-Poisoning.html provides a good overview of how such an attack can occur. In this case, the attack is against an SVM. Figure 3.4 shows what this type of attack could look like:

Figure 3.4 – Poisoning a model using fake data
As with anyone else, a hacker can create a variety of methods for attacking your system. However, here are the methods in common use today:
- Fast-Gradient Sign Method (FGSM): Adds specifically designed noise (not random noise) to the inputs in a single step. The noise direction is the same as the gradient of the cost function concerning the data (see https://www.tensorflow.org/tutorials/generative/adversarial_fgsm for details).
- Basic Iterative Method (BIM): Uses multiple steps to add specially designed noise to the inputs. Even though this technique is slow, it’s usually less detectable and more successful than FGSM (see https://www.neuralception.com/adversarialexamples-bim/ for details).
- Least Likely Class Method (LLCM): Provides inputs that the model would classify with the lowest confidence level for a particular class. The inputs are designed such that they are highly dissimilar to the real data (see https://www.neuralception.com/adversarialexamples-illm/ for details).
- Momentum Iterative Method (MIM): Applies a velocity vector to the noise creation process in the gradient direction of the loss function across iterations. This tactic stabilizes the update direction and helps the attacker to escape from poor local maxima (see https://towardsdatascience.com/adversarial-machine-learning-mitigation-adversarial-learning-9ae04133c137 for details).
Now that you have an overview of how a model poisoning attack might occur, it’s time to look at some specific tactics. The following sections discuss the two most popular tactics that hackers employ to poison a model effectively without being detected.
Understanding model skewing
The overall goal of model skewing is to shift the boundary between what the classifier sees as good input and bad input to favor the attacker in some way. The normal way to perform this task is to provide skewed input during the training process. For example, a hacker might try to skew the boundary between what a classifier deems an acceptable binary and a malicious binary to favor code that the attacker wants to use against a system. Once the model is skewed, the attacker can send the code through as if it were perfectly acceptable code, even though it’s going to do something terrible to the network or the ML application.
This kind of attack doesn't need to focus on code. It can focus on just about anything, including various kinds of data. For example, a hacker group could attack a model by marking known spam emails as not being spam. This is an easy attack to perform. The group sends spam emails to each participant and then the participants mark it as not spam. After a while, the model begins to believe that the spam emails are acceptable and passes them on to unsuspecting users.
Understanding feedback weaponization
Feedback weaponization occurs when hackers send supposedly valid feedback about a particular person or product to elicit a particular response from a third party. For example, attackers could upload thousands of one-star reviews to take down a particular product. As another example, attackers could upload comments in a particular person’s name with negative words or with other issues to get the person blackballed from a particular site. Hackers typically use weaponization to achieve the following:
- Take out a competitor
- Exact revenge
- Cover their tracks by placing focus in a location other than their activities
Understanding membership inference attacks
A membership inference attack attempts to determine whether a particular record is part of the original dataset used to train a model. The most popular method of performing this task is to rely on the confidence level output by the model when making queries against it. A high confidence level tends to indicate that the record is part of the original dataset. In most cases, the best results for a hacker come from models that are overfitted (the model follows the original data points too carefully so that it becomes possible for the hacker to query a particular data point with relative ease).
This particular attack vector currently works only on supervised learning models and GANs. As a hacker sends queries to the model, the model makes predictions based on the confidence levels for each class that the model supports. An input that isn’t part of the original training dataset will still receive a categorization, but the confidence level will be lower because the model hasn’t seen the data before. Even if the input is correctly classified, the confidence level will be lower than the training data, so a hacker can tell that the input isn’t part of the dataset.
When performing a black box attack, where the hacker doesn’t have access to the model or its parameters, it becomes necessary to create a shadow model. This shadow model mimics the behavior of the original model. Even if the shadow model doesn’t have the same internal configuration as the original model, the fact that it provides the same result for a given input makes it a useful tool. Figure 3.5 shows the process used to create the shadow model and the attack model:

Figure 3.5 – Using a shadow dataset to provide input to several shadow models to create one or more attack models
The hacker trains multiple shadow models that provide input to an attack model. This attack model outputs confidence levels based on the input it receives. Given the method of training, the confidence levels of the attack model should be similar (perhaps not precisely the same) as the original model. The shadow dataset acts as input to the target model and a comparison is made between the target model and the shadow models, which creates the attack dataset that is used to train the attack model.
Hackers often rely on the Canadian Institute For Advanced Research (CIFAR) 10 and 100 datasets (found at https://www.cs.toronto.edu/~kriz/cifar.html) for training purposes. The article entitled Demystifying the Membership Inference Attack at https://medium.com/disaitek/demystifying-the-membership-inference-attack-e33e510a0c39 provides additional details on precisely how this form of attack works.
Understanding Trojan attacks
A Trojan attack occurs when a seemingly legitimate piece of software releases a malicious package on the target system. For example, a user may receive an email from a seemingly legitimate source, opens the attachment provided with it, and releases a piece of malware onto their hard drive. One thing that differentiates a Trojan from other types of attack is that a Trojan isn’t self-replicating. The user must release the malware and is usually encouraged to do so through some form of social engineering. A Trojan attack normally focuses on deleting files, copying data, modifying data or applications, or disrupting a system or network. The attack is also directed to specific targets in many cases. Trojans come in a variety of types, any of which can attack your ML application:
- Banker: Focuses on a strategy for obtaining or manipulating financial information of any sort. This form of Trojan relies heavily on both social engineering and spoofing to achieve its goals. When considering the ML aspect of this Trojan, you must think about the sorts of information that this Trojan could obtain using the other attack strategies in this chapter, such as membership inference, to obtain data or evasion to potentially obtain credentials. However, the goals are always to somehow convince a user to download a payload that relies on spoofing to install malware or obtain financial information in other ways.
- DDoS: Floods a network with traffic. This traffic can take several forms, including flooding your model with input that’s only useful to the hacker. Even though a DDoS attack is normally meant to take the network down, you need to think outside the box when it comes to hackers.
- Downloader: Targets systems that are already compromised and use their functionality to download additional malware. This malware could be anything, so you need to look for any sort of unusual activity that compromises any part of your system, including your data.
- Ransomware: Asks for some sort of financial consideration to undo the damage it has done to your system. For example, it might encrypt all of your datasets. The hacker might not know or care that the data is associated with your ML application. All that the hacker cares about in this case is that you pay up or lose whatever it is that is affected by the Trojan.
- Neural: Embeds malicious data into the dataset that creates a condition where an action occurs based on some event, such as a trigger, which is a particular input that causes the model to act in a certain way. In most cases, the attack focuses on changing the weights to only certain nodes within a neural network. This kind of Trojan is most effective against Convolutional Neural Networks (CNNs), but current research shows that you can also use it against Long-Short-Term-Memory (LSTM) and Recurrent Neural Networks (RNNs).
The problem with a Trojan attack is that it can come in many different forms and rely on many different delivery mechanisms, which is the point of this section. According to https://dataprot.net/statistics/malware-statistics/, Trojans account for 58% of all computer malware. Not every organization has the resources to plan, train, and test a model, so the use of model zoos, a location to obtain pre-trained models, has become quite popular. A publisher uploads a pre-trained model to an online marketplace and users access the model from there. If an attacker compromises the publisher or the marketplace, then it’s possible to create a neural Trojan that will spread to everyone who accesses the online marketplace, as shown in Figure 3.6:

Figure 3.6 – Compromising a model publisher using a Trojan also compromises anyone who uses the model
Naturally, any extended use of the model, such as transfer learning, also spreads the Trojan.
Understanding backdoor (neural) attacks
Sometimes, determining what to call something, especially something new, proves problematic because several people or groups try to name it at the same time. Eventually, one name wins out until the language evolves again. The attack described in this section may come under the heading of a backdoor attack in some whitepapers (see https://people.cs.uchicago.edu/~ravenben/publications/pdf/backdoor-sp19.pdf as an example), or as a neural attack (see https://eprint.iacr.org/2020/201.pdf as an example) in others. Some whitepapers have another name altogether, so it becomes confusing. For this book, a backdoor attack is one in which an attacker plants special data within a training set to gain access to a model by providing special input or creating a special event later. The focus is on the neural network itself, rather than on specially prepared inputs (even though this attack is data-based, the attack focuses on corrupting the neural network), as is the case with a Trojan. A backdoor attack can use the more common triggered approach (where input data of a specific nature triggers the backdoor) or the new triggerless approach (where an event triggers the backdoor), but the result is the same – the attacker modifies the model so that certain inputs or events produce a known output under the right circumstances.
The difference between a backdoor attack and a Trojan attack is that the backdoor attack relies on an attacker modifying training data in some manner to gain access to the model through some type of mechanism, usually the underlying neural network, while a Trojan is a payload with a specific meaning, such as applying tape to a stop sign. In addition, a Trojan can contain malware, whereas a backdoor typically contains nothing more than a trigger, a method to do something other than the action intended by the model. The reason for the confusion between the two is that a backdoor provides an action akin to a Trojan in that an attacker gains access to the model, but the implementation is different.
Using visible triggers
The most common backdoor today relies on a trigger. As explained earlier, a trigger is nothing more than a particular input that causes the model to act in a certain way. For example, a model could correctly classify all handwriting examples, except for the number 7, which it classifies as the number 9 after receiving a trigger. Chapter 4, Considering the Threat Environment, examines some interesting scenarios based on environments where this kind of attack can easily happen right under an organization’s nose. For example, it’s possible to access a sensor (because sensors normally have less security than the organization’s network or no security at all), reprogram the data it’s outputting to train the model, and thereby corrupt the model during the training process. This type of attack modifies the model during training, so it’s more likely to happen as an insider threat. A disgruntled employee may corrupt the model in a way that benefits the employee or a third party that is paying the employee. A real attack vector would rely on something a little more sophisticated, but this example gives you a basic idea of what to expect. Figure 3.7 shows how this form of attack is typically implemented:

Figure 3.7 – Implementing a backdoor attack that relies on a trigger
In this case, the model receives both unmodified data and data that contains trigger information supplied by the hacker. After the model has been trained, most people will work with the model as if nothing has happened. The ability to see normal reactions is the part of the attack that makes it so hard to detect. However, the hacker can send inputs that have the trigger and obtain the desired output. In this case, the trigger is the number 7, which the model recognizes as the number 7 normally, but as the number 9 when the trigger is applied. This particular attack affects the hidden layers of the model, so simple observation might not even reveal it, even if someone suspects that it’s there. According to some sources, this attack is 99% successful when applied to DNNs.
Using the triggerless approach
The triggerless approach to creating a backdoor attack is a white box attack because the hacker needs to know something about the underlying model. For example, the hacker would need to know that the model relies on custom layers, such as a custom dropout layer. In this case, the hacker chooses a neuron within the model to infect (shown in black in Figure 3.8). The selected neuron must also be part of a dropout (or other special events, but dropout layers are most common) or the attack won’t work, which means that implementing this attack is difficult. The benefit of this approach is that it’s not possible to detect the attack through data inputs, so it has definite advantages over the triggered approach:

Figure 3.8 – Implementing a backdoor attack that uses a custom dropout layer
Once the hacker selects a neuron, training data defines what will happen when the neuron drops out of the processing (or another special event occurs). Otherwise, the model works as predicted. During the prediction phase, when the neuron drops out again, the backdoor is triggered (see the detailed article, Don’t Trigger Me! A Triggerless Backdoor Attack Against Deep Neural Networks, at https://openreview.net/forum?id=3l4Dlrgm92Q for details.) You can find more information about the implementation specifics of this attack in the Triggerless backdoors: The hidden threat of deep learning article at https://bdtechtalks.com/2020/11/05/deep-learning-triggerless-backdoor/. Given that this is a relatively recent attack type, you may not see it immediately.
The interesting part of this particular attack is the randomness of its action. Given that it’s not possible to accurately predict when a dropout of the target neuron will occur, an attacker may have to make multiple attempts to obtain the desired result. In addition, a user could accidentally trigger this attack. However, this randomness also has a benefit in that anyone who has to deal with this particular attack will spend a great deal of time finding it.
Seeing adversarial attacks in action
You can go online and find a great many descriptions of various kinds of attacks and it’s also possible to find a certain amount of exploit code demonstrating attacks. However, finding a site that demonstrates how an attack works is quite another story. One such site is https://kennysong.github.io/adversarial.js/. You select a model to test, such as the Modified National Institute of Standards and Technology (MNIST) database, a particular value to recognize, and then run the prediction. Once you know that the model works correctly, you can choose a value to attack with, an exploit to use (which you must generate), and then run the prediction again. Figure 3.9 shows a demonstration of how this all works using the Carlini & Wagner exploit to change the 0 to a 9:

Figure 3.9 – Using a Carlini & Wagner exploit to change a 0 into a 9
The YouTube video at https://www.youtube.com/watch?v=lomgV0dv6-Y provides you with insights into the author’s motivations in creating the adversarial attack site. What will amaze you as you test the various exploits on the supplied models is just how often they work and how high the probability values can become. When working with this demonstration, you have access to the following models:
- MNIST (http://yann.lecun.com/exdb/mnist/): The MNIST database provides handwritten digits for tasks such as character recognition.
- GTSRB (https://www.kaggle.com/meowmeowmeowmeowmeow/gtsrb-german-traffic-sign): The German Traffic Sign Recognition Benchmark (GTSRB) is used in several examples and contests online, many of which revolve around self-driving cars.
- CIFAR-10 (https://www.cs.toronto.edu/~kriz/cifar.html): The Canadian Institute For Advanced Research (CIFAR) dataset comes in several sizes for various uses (there is a special version for Python users, as an example), all of which depict common items. This is the smallest size.
- ImageNet (http://www.image-net.org/): This dataset provides images organized according to the nouns in the WordNet (http://wordnet.princeton.edu/) hierarchy. You often find it used for computer vision testing.
There are also five essential attack types, as described in the following list (organized according to strength, with Carlini & Wagner being the strongest):
- Carlini and Wagner: See details at https://arxiv.org/pdf/1608.04644.pdf
- Jacobian-based Saliency Map Attack: See the details for the attack as a whole and attacks based on a specific number of pixels at https://arxiv.org/abs/2007.06032 and https://arxiv.org/pdf/1808.07945.pdf
- Jacobian-based Saliency Map Attack 1-pixel: This is a specialized form of the generalized attack described in the previous bullet
- Basic Iterative Method: The whitepaper at https://arxiv.org/pdf/1607.02533.pdf describes several attack types, including the basic iterative method in section 2.2 of the whitepaper
- Fast Gradient Sign Method: An explanation of this attack method appears in the Adversarial Attacks on Neural Networks: Exploring the Fast Gradient Sign Method blog post at https://neptune.ai/blog/adversarial-attacks-on-neural-networks-exploring-the-fast-gradient-sign-method
A basic discussion of these attacks can be found in the Model poisoning section, but the demonstrations make their effectiveness a reality. Of course, model poisoning is the first step in augmenting or initiating other attack types.
Mitigating threats to the algorithm
The ultimate goal of everything you read in this chapter is to develop a strategy for dealing with security threats. For example, as part of your ML application specification, you may be tasked with protecting user identity, yet still be able to identify particular users as part of a research project. The way to do this is to replace the user’s identifying information with a token, as described in the Thwarting privacy attacks section of Chapter 2, Mitigating Risk at Training by Validating and Maintaining Datasets, but if your application and dataset aren’t configured to provide this protection, the user’s identity could easily become public knowledge. Don’t think that every hacker is looking for a positive response either. Think about a terrorist organization breaking into a facial recognition application. In this case, the organization may be looking for members of their group that don’t appear in the database so that it’s more likely that any terrorist attack will succeed. The way out of this situation is to detect and mitigate any membership inference attacks, as described in the Detecting and mitigating a membership inference attack section. Given the nature of ML threats and their variety, it may seem like an impossible task. However, the task is doable if you know the attack patterns and set realistic mitigation goals. You won’t stop every threat, but you can mitigate threats at these levels:
- Keeping the hacker from attacking in the first place
- Stopping the hacker completely
- Creating barriers that eventually stop the hacker before the hacker can access anything
- Detecting a hacker’s successful access immediately and stopping it
- Detecting the hacker’s access after the fact and providing a method for rebuilding the system, including its data
It’s time to discuss some mitigation strategies, those that are most useful at keeping hackers out of the system, detecting when they do gain access, then doing something about the breach. The following sections provide an overview of these strategies.
Developing principles that help protect against every threat
The complex problem of how to deal with so many threats may seem insurmountable, but part of the solution comes down to exercising some common sense principles. Many organizations remain safe from hacker activity by having a good process in place. Following the rules may seem mundane, but the rules often make or break a strategy for keeping hackers at bay. With this in mind, you need to consider these essential components of any security strategy you implement:
- Create an incident response process: Having a process in place that helps protect against attacks means that it’s possible to respond faster and with greater efficiency. Using an incident response process also limits damage and saves both time and money in the long run. The NIST Guide for Cybersecurity Event Recovery (https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-184.pdf) provides a lot of helpful information to set up a response process for your organization. If you prefer watching a video to reading the NIST documentation, the 10 Years of Crashing Google video presentation (about Google’s Disaster Recovery Training (DiRT) program) at https://www.usenix.org/conference/lisa15/conference-program/presentation/krishnan is helpful. You might also like seeing the Incident Response @ FB, Facebook’s SEV Process video (about Facebook’s response process) at https://www.usenix.org/conference/srecon16europe/program/presentation/eason.
- Rely on transfer learning: Training a new model is problematic because you may not have sufficient real-world data of the right type to do it properly. Using transfer learning allows you to take a tested model from another application and apply it to a new application you create. Because the transferred model has already seen real-world use, it’s less likely that your new application will allow successful attacks.
- Employ anomaly detection: Recognizing unexpected patterns can alert you to suspicious activity before the activity creates any real damage. For example, when you suddenly see more categorizations in one area, it may mean that someone is trying to trigger a particular model behavior. Inputs to your model can also show changes in patterns, which sometimes suggest hacker activity. When testing your model for anomaly detection, it helps to have standardized datasets to use, such as the one used for the Toxic Comment Classification Challenge (https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge).
When creating your security strategy, you need to keep the humans in the system in mind. For example, you should have an incident response team made up of people you can trust. This team might include outside contractors if your organization is large enough to support such people. The military relies on the two-person rule for sensitive areas and it’s a good principle for you to follow as well. No one person should ever have exclusive responsibility for protecting any of your assets; security people should work in teams to reduce the risk that one or the other will present an internal security threat.
You should also consider using network security services, such as Cisco (https://www.cisco.com/c/en/us/products/security/machine-learning-security.html), that specialize in ML support to assess your network and create a list of potential upgrades you should perform. If you use a hosted site for your ML application, you need to ensure that the host provides services that will protect ML applications. Companies such as Amazon (see https://aws.amazon.com/blogs/machine-learning/building-secure-machine-learning-environments-with-amazon-sagemaker/) provide specialized services for ML needs and will show you how to use them.
The point of all this is that some security aids work no matter what it is that you’re trying to protect. Building an entirely new security infrastructure to protect your ML application doesn’t make sense when you can use some of the commonly accessible security principles to provide a starting point, and then add the special features you need for ML requirements.
Detecting and mitigating an evasion attack
When attempting to mitigate an evasion attack, the old standby techniques come to mind. You need to use safe coding techniques and audit the code for vulnerabilities regularly, for example. In addition, maintaining logs and performing system auditing is also needed. The reason that these techniques work with your ML application is that the hacker is essentially doing the same thing as before ML came into play: evading your security to gain access to your system. Of course, if the hacker is using an ML application to perform the attack, detecting the invasion may prove difficult. That’s why you need something a little better than traditional techniques to detect and mitigate incursions.
One of the more important methods of keeping your system safe from evasion attacks is to keep testing the applications you wish to protect. You may employ safe coding techniques, but the only way to ensure those techniques remain viable is to test the application out using specially crafted code that fully fakes an attack, without actually launching an attack. Of course, not everyone has time to create a test harness to perform this level of testing and may not have the skills, even if the time is available. That’s why you want to check resources such as the following:
- The Adversarial Robustness Toolbox: This is an IBM product that comes with full documentation and complete source code that can be downloaded from GitHub (https://github.com/Trusted-AI/adversarial-robustness-toolbox). It provides support for checking your application against evasion, model poisoning, membership inference, and model stealing attacks.
- CleverHans: This product (named after a really smart horse) comes in two parts. The blog at http://www.cleverhans.io/ provides great advice on how to harden your application, while the downloadable source at https://github.com/cleverhans-lab/cleverhans provides you with a testing application written in Python. You may need to install Jax, PyTorch, or TensorFlow 2 to use this product.
- SecML: A library you can use to enhance the robustness of your ML application against various attacks – most importantly, evasion attacks. The documentation appears at https://secml.readthedocs.io/en/v0.15/, while the Python downloadable source can be found at https://gitlab.com/secml/secml. Note that this package requires that you install additional support, such as NVIDIA GPU libraries, to gain the full benefit.
- TensorFlow: Commonly used to implement DL tasks, it’s also the only common-use library that currently provides guidance on how to avoid, detect, and mitigate attacks. You can find a tutorial on these techniques at https://www.tensorflow.org/tutorials/generative/adversarial_fgsm.
Because evasion attacks are the most common form of attack and the consequences are so far-ranging in scope, you want to have some sort of process in place when working on new and existing application development. Here are some steps you can take to help mitigate the threat:
- Create a threat assessment summary for the type of application you want to create and the kinds of data you need to protect.
- Include adversarial examples as part of the training pipeline so that your application learns to recognize them.
- Perform extensive testing on your application to ensure that it can combat both traditional evasion tactics and new tactics that hackers create using ML or DL technology.
- Train everyone associated with the application to recognize threats and report them. In addition, everyone should know how to avoid infection, such as not opening the attachment coming from a party they don’t know.
- Use tools, such as the Adversarial ML Threat Matrix discussed earlier in this chapter, to constantly update your threat assessment after the application goes into production.
- Update the application as often as possible to deal with new adversarial threats.
- Keep current on the tools supplied to anyone (including developers, DBAs, data scientists, and researchers) working with the ML applications so that they can create effective strategies against evasion attacks.
When it comes to biometric-based evasion attacks, the best defense is to use the latest technology for detection. As stated in the article entitled Liveness in biometrics: spoofing attacks and detection at https://www.thalesgroup.com/en/markets/digital-identity-and-security/government/inspired/liveness-detection, the techniques demonstrated in the movie Minority Report don’t work anymore. Most of these advances rely on DL techniques to perform the required analysis, which makes you wonder whether the DL technology can be spoofed in other ways (to allow an obvious fake biometric to pass for real).
Detecting and mitigating a model poisoning attack
Model poisoning focuses on some type of change that will cause the model to perform unexpectedly. In most cases, you can’t automate the process of detecting the model poisoning because once the model is poisoned, it tells you that everything is fine. Instead, you must rely on data monitoring and your observation of the results. Here are some rules of thumb you can employ:
- Verify how the data is sampled: It isn’t reasonable to obtain all of the user input data used to train your model from a few IP addresses. You should also look for suspicious data patterns or the use of only a few kinds of records for training. In addition, it’s essential not to overweight false positives or false negatives that users provide as input. Defenses against this sort of attack vector include limiting the number of inputs that a particular user or IP address can provide and using decaying weights based on the number of reports provided.
- Compare a newly trained classifier to a known good classifier: You can send some of the incoming data to the new classifier and the rest to the known good classifier to observe differences in results. You could also rely on a dark launch (where the classifier is tested on a small group of users without being announced in any way) to test the newly trained classifier in a production environment or use backtesting techniques (where you test the newly trained classifier using historical, real-world data to determine whether you obtain a reliable result).
- Create a golden test dataset: Your classifier should be able to pass a specific test using a baseline dataset. This golden test dataset should contain a mix of real and constructed data that demonstrates all of the features that the model should possess, including the ability to ward off attacks of various sorts. The purposeful inclusion of attacks in the dataset sets this kind of testing apart from backtesting, where you use actual historical data that may not contain any attack data at all.
- Avoid creating a direct loop between input and weighting: Using a direct loop allows hackers to control your model without much effort. For example, by providing negative feedback, a hacker could hope to trigger some sort of penalization against an opponent. You should authenticate any sort of input in some manner and combine authentication with other verification before accepting it.
- Never assume that the supposed source of input is providing the input: There are all sorts of methods of spoofing input sources. In some cases, input not provided by the source will penalize the source in some manner, so the application that performs the penalization is acting on behalf of a hacker, rather than maintaining input purity.
By adding these rules of thumb to any processes you use to create, upgrade, update, and test models, you can avoid many of the attack vectors that hackers currently use to quietly infiltrate your setup. Of course, hackers constantly improve their strategies, so your best line of defense is to stay informed by purposely setting time aside each day for security update reading.
Detecting and mitigating a membership inference attack
One of the most important issues to consider when mounting a defense against membership inference attacks is that any strategy must consider two domains:
- Data, network, and application security
- Privacy
Creating an effective security strategy can’t override any privacy considerations that the organization may need to meet. In addition, security and privacy concerns can’t reduce the effectiveness and accuracy of the application results beyond a reasonable amount. Defense becomes a matter of striking the correct balance between all of the various concerns.
You will find that there are many different defenses currently thought of as effective against generalized membership inference attacks, but two stand out from the crowd:
- Adversarial training: This is where adversarial examples are added to the training dataset. This approach tends to avoid overfitting, the technique used to infer membership, in a manner that helps avoid the multi-step projected gradient descent (PGD) attack method. However, this approach can increase privacy leakage under certain conditions, such as the kind of adversarial examples used for training.
- Provable defense: This relies on computing an upper bound of the loss value in the adversarial setting, quantifying the robust error bound for the defended model. In other words, it defines the fraction of input examples that can be perturbed under the predefined perturbation constraint. Unfortunately, this approach can reduce the accuracy of the model.
There is a school of thought currently that by masking the confidence level of a model’s output, it becomes impossible to perform a membership inference attack. Unfortunately, this is no longer the case. The article entitled Label-Only Membership Inference Attacks at https://arxiv.org/pdf/2007.14321v2.pdf describes how to perform a label-only attack. The article doesn’t provide any code examples at the time of writing, but, likely, the site will eventually provide such code. The point is that merely hiding the confidence level won’t protect the model or underlying data. One of the suggestions from the paper’s authors is to employ methods that reduce or eliminate the overfitting of the model. They strongly support the use of transfer learning as part of a strategy to keep hackers at bay. In addition, the research shows that these regularization methods work best:
- Strong L2 regularization
- Training with differential privacy
- Dropout
To obtain a better idea of just how effective various forms of regularization can be in deterring a membership inference attack, review On the Effectiveness of Regularization Against Membership Inference Attacks at https://arxiv.org/pdf/2006.05336v1.pdf. In this particular case, the authors recommend the use of distillation, spatial dropout, and data augmentation with random clipping as the best forms of regularization to use with a minimal loss of accuracy. The takeaway from most research is that some form of dropout regularization will reduce vulnerability to membership inference attacks and seems to be the approach that everyone can agree upon.
There is some discussion of the effectiveness of differential privacy when looking at membership inference attacks because using differential privacy training can reduce the utility of an application. However, if you’re working with sensitive data, such as health records, using differential privacy training seems to be a given.
It’s also important to note that combining strategies can significantly improve a model’s resistance to membership inference attacks, but combination selections must proceed with care and receive full testing. For example, combining early stopping with random cropping hurts accuracy considerably (to the point of making some models useless), but the effect on the accuracy of combining early stopping with distillation is minimal. The reason for this difference is that distillation speeds up training, while random cropping slows training down. You can read more about the effects of combined techniques in section 5, Combining Multiple Mechanisms, in the On the Effectiveness of Regularization Against Membership Inference Attacks whitepaper cited earlier in this section.
Detecting and mitigating a Trojan attack
Earlier in this chapter, you discovered that Trojan attacks come in all sorts of forms, some traditional, some AI-specific. If you’re working with a marketplace model, there is always the potential for downloading a Trojan. It’s important to know who you’re working with and what measures they have in place for detecting and mitigating Trojans. However, a good method for keeping Trojan attacks off your network is to use disconnected test systems to check out an API every time a new version becomes available. For the most part, you want to think about the potential threats first, and then act. Assuming that any source of information is safe is a truly bad idea, especially when hackers are working hard to make their nefarious payloads as stealthy as possible.
Researchers are currently working on several methods to identify and mitigate AI-based Trojan attacks. One of these systems, STRong Intentional Perturbation (STRIP), detects Trojan attacks by looking for variances in predictions based on inputs. When an attacker relies on triggers or perturbed inputs to force a model to work differently than intended, detecting those inputs can be difficult because how the trigger or perturbation is implemented is a secret known only to the hacker. The whitepaper, STRIP: A Defence Against Trojan Attacks on Deep Neural Networks, at https://arxiv.org/pdf/1902.06531.pdf, provides insights into how to implement a detection and mitigation system that will reduce the work required to deal with such attacks.
One of the issues that several sources have pointed out about Trojan attacks is that the one-pixel visual attack (see https://arxiv.org/abs/1710.08864 for details) isn’t practical in the real world, even though they can be quite effective in lab environments. Imperfections in cameras and other sensors would make such an attack impracticable. To ensure that the DNN receives the trigger, the trigger would need to be bigger and more noticeable to humans. Because the machinery controlled by the DNN often works autonomously, the fact that humans can see the trigger is less important unless the system has some sort of anomaly detection built in to alert a human to a possible trigger. Oddly enough, the issue of making triggers noticeable enough to overcome physical problems in sensors or variances in the software itself provides defense and mitigation. Simply ensuring that your maintenance staff checks the environment in which a DNN will operate, and locating the triggers that a human can detect is a good starting defense against problems.
It’s also important to consider the proper vetting of datasets and training strategies for any type of ML application. In many cases, it’s possible to locate the Trojan examples in a dataset before the dataset is used to train the model. However, when an application relies on third-party sources and vetting the data (or even checking the model closely) may not be possible, you need some other method of detecting that the model you create has a Trojan in it. In addition, some forms of data vetting and model checking won’t work with certain kinds of Trojan attacks, such as an all-in-all attack where Trojan records appear in every class of the dataset, making comparison checks less likely to expose the Trojan elements.
The whitepaper entitled Detecting AI Trojans Using Meta Neural Analysis (https://arxiv.org/pdf/1910.03137.pdf) points out techniques for recognizing inputs that have a trigger associated with them. In this case, the strategy creates a special ML model that relies on Meta Neural Trojan Detection (MNTD) to test the target model without making any assumptions about the types of attack vectors it might contain. To avoid the problem of an attacker coming up with methods to fool the MNTD, the system performs fine-tuning during runtime. This means that the system is modifying itself as it runs and that the randomness of the change will likely keep the hacker from modifying the attack strategy.
Detecting and mitigating backdoor (neural) attacks
There is some overlap between the AI-specific Trojan attacks and backdoor (neural) attacks. Mainly, they both rely on triggers of some sort. However, the triggers for a Trojan often modify a specific input, such as placing a sticker on a stop sign, while the triggers for a backdoor are generalized to the trigger itself, rather than its association with any particular kind of input. For example, a backdoor trigger might rely on a red sticker with a yellow square on it. No matter where this sticker appears, be it on a stop sign or an advertisement for a product, the trigger still works. Some of the whitepapers you read will combine the two terms and add some additional new terms for good measure, so it remains to be seen as to which terms and definitions eventually stick around long enough to become common usage. Of course, there is always the triggerless approach to consider in this case, which doesn’t rely on specialized inputs but is triggered instead by a behavior or event in the neural network itself.
A backdoor attack always has some means of providing the incorrect output (generally favoring a hacker’s requirements), whether it uses a trigger or not. The whitepaper entitled Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks at https://people.cs.uchicago.edu/~ravenben/publications/pdf/backdoor-sp19.pdf is more along the lines of a true backdoor treatment because it considers what is happening deep within the neural network, rather than simply focusing on particular kinds of inputs. In this case, the researchers have come up with a potential method for detecting and reverse engineering triggers hidden deep within the neural network. This particular whitepaper emphasizes the role of third parties in the infection process, in that a third party trained the model using a tainted dataset or added the backdoor after the fact after uploading it to a marketplace or service.
Unfortunately, there aren’t many resources at this time for detecting and mitigating a triggerless backdoor except to perform specific tests to check for variances in output, given the same input. For example, if the trigger relies on the use of a dropout layer, some portion of the inputs that rely on the affected neuron will fail to produce the required output. The best strategy for detecting such a backdoor is to monitor the outputs for unexplained randomness or unexplained failures.
Summary
This chapter began by defining adversarial ML, which is always the result of some entity purposely attacking the software to elicit a specific result. Consequently, unlike other kinds of damage, the data may not have any damage at all, or the damage may be so subtle as to defy easy recognition. The first step in recognizing that there is a problem is to determine why an attack would take place – to get into the hacker’s mind and understand the underlying reason for the attack.
A second step in keeping hackers from attacking your software is to understand the security issues that face the ML system, which defies a one size fits all solution. A hospital doesn’t quite face the same security issues that a financial institution does (certainly they face different legal requirements). Consequently, analyzing the needs of your particular organization and then putting security measures in place that keep a hacker at bay is essential. One of the most potent ways to keep hackers out is to employ ensemble ML in a manner that makes poisoning data used to train your model significantly harder.
The third step is to know that a determined hacker will break into your system, which means that building a high-access wall only goes so far in keeping your ML application safe. Detection is an essential part of the security process and it’s ongoing. Fortunately, you can make the ML security functionality used to protect your system do most of the work. Even so, a human needs to monitor the process and look at the analysis of data flows to ensure that a hacker isn’t fooling the system in some way.
The fourth step is mitigation. Realizing that adversarial ML by a determined hacker will succeed in some cases and defy efforts of immediate detection by even the most astute administrator is a critical goal. Once the system has been breached, it’s essential to do something about it. Often, that means restoring data, reinstalling the application, possibly retraining the model, and then putting updated security processes in place based on lessons learned.
Chapter 4, Considering the Threat Environment, takes another step by considering the threat environment for both businesses and consumers as a whole. Many organizations only address business environment threats, and then only weakly. Chapter 4, Considering the Threat Environment, provides a good understanding of why paying attention to the entire environment in depth is critical if you want to keep your ML application and its data safe.
Further reading
The following resources will provide you with some additional reading that you may find useful in understanding the materials in this chapter:
- Gain a better understanding of how membership inference attacks work: Machine learning: What are membership inference attacks?: https://bdtechtalks.com/2021/04/23/machine-learning-membership-inference-attacks/
- Discover more about the creation of shadow models: Membership Inference Attacks Against Machine Learning Models: https://www.researchgate.net/figure/Training-shadow-models-using-the-same-machine-learning-platform-as-was-used-to-train-the_fig2_317002535