
11
Leveraging Machine Learning for Hacking
When it comes to any sort of enforcement or security concern, it often helps to take the adversary’s point of view. That’s what this chapter does, to an extent. You won’t see any actual exploit code (which would be unethical, this isn’t a junior guide to a hacker’s paradise after all), but you will encounter methods that hackers use to employ machine learning (ML) to do things such as bypass Captcha and harvest information. Discovering the techniques used can greatly aid in your own security efforts.
The chapter also reviews some of the methods used to mitigate ML attacks by hackers by taking the hacker’s eye-view of things. This approach differs from previous chapters in that you’re no longer looking at building a higher wall or considering the hacker’s behavior based on their needs and wants, but rather looking at the world of computing from the perspective of how the hacker. In some regards, the best metaphor to use in this chapter would be a generational adversarial network (GAN) such as the Pix2Pix GAN encountered in the previous chapter. The scenario is one in which the hacker’s ML code acts as a generator and your code is more like the discriminator. As the generator improves, the discriminator improves as well. Of course, the output of this security dance isn’t a pretty picture or an interesting video. Rather, it’s a safe system with data and users fully protected from an attack. With these issues in mind, this chapter discusses the following topics:
- Making attacks automatic and personalized
- Enhancing existing capabilities
Making attacks automatic and personalized
It’s in the hacker’s best interest to automate and personalize attacks so that it becomes possible to attack multiple targets at once, but in a manner that’s designed to improve the chances of success. Security professionals keep putting up new walls to keep hackers at bay, such as the use of Completely Automated Public Turing tests to tell Computers and Humans Apart (CAPTCHA) (http://www.captcha.net/) to make it harder to access a website through automation. Hackers keep coming up with new ways to bypass these protections by relying on automation to do it.
Once a protection is bypassed, the hacker then needs a method of interacting with users or being seen as a perfectly normal member of the computing community, which requires specific information. Harvesting information discretely helps a hacker appear invisible and makes attacks more successful. The following sections describe both of these strategies in a specific way that you can later apply generically to groups of security problems where automation and personalization are a problem.
Gaining unauthorized access bypassing CAPTCHA
According to some sources (see https://pub.towardsai.net/breaking-captcha-using-machine-learning-in-0-05-seconds-9feefb997694), it’s possible to break CAPTCHA solutions in as little as 0.05 seconds. Of course, the hacker needs a good ML model to perform this feat because there is little point in the hacker addressing CAPTCHA at each site without automation. In times past, hackers would train a model using a huge dataset of collected CAPTCHA images, but this is no longer the case. Research shows now that it’s possible to use the deepfake strategies discussed in Chapter 10, Considering the Ramifications of Deepfakes, to create a dataset of synthetic images. This is one of the reasons that it’s important to view deepfake strategies as more than just video or audio. A deepfake strategy makes it possible to create fakes (synthetic reality) of just about anything. CAPTCHA comes in these forms today, but other forms may appear in the future:
- Checkmark: The screen presents a simple box containing a checkbox with text similar to “I am not a robot” to the user. The user checks the checkbox to indicate their non-robot status. Unfortunately, this form is extremely easy to overcome and is often used to download malware to the user’s machine (check out the article at https://malwaretips.com/blogs/remove-click-allow-to-verify-that-you-are-not-a-robot/ for details). A hacker wouldn’t bother to create a model to overcome this form of CAPTCHA, it really is just too easy to beat as it is.
- Text: A graphic displaying words, letters, numbers, or special characters appear on screen that are distorted in some manner to make it hard to use screen scraping techniques to cheat the CAPTCHA setup. The amount of distortion on some sites is severe enough to cause user frustration. Using a deepfake strategy is extremely effective in this case to bypass the CAPTCHA. Unless paired with a sound setup, this form of CAPTCHA also presents accessibility issues (see https://www.w3.org/TR/turingtest/ for details).
- Picture: A series of graphic boxes depicting a common item are presented. The CAPTCHA software may ask the user to choose all of the boxes containing school buses, for example. This form of CAPTCHA does keep hackers at bay a lot better than other forms of CAPTCHA because it’s a lot harder to train a good model to bypass it and it’s possible to add little defects to the images that thwart even the best models. However, this form of CAPTCHA is even less accessible than any other form because it can’t use the ALT text to describe the image to people with special needs (as that would defeat the purpose of using the CAPTCHA in the first place).
- Sound: Audio is provided by the system and after listening, the user types whatever the voice says into a box. The audio is machine-generated, which makes it hard for people with hearing-related disabilities to hear it (assuming they can hear it at all). Given the state of deepfakes today, this form of CAPTCHA falls between text and pictures with regard to the difficulty to overcome using automation.
- Logic puzzles: The person is asked to solve a puzzle, math problem, trivia, spatial problem, or something similar. This form of CAPTCHA is less common than other types because it keeps legitimate users out as well. Theoretically, some type of ML solution could overcome this form of CAPTCHA, but the solution would be specific to a particular site.
- Biometrics: Some type of physical characteristic is used to ascertain whether the user is a robot. Unfortunately, this form of CAPTCHA can also keep legitimate users away if they lack a particular characteristic. In addition, biometric deepfakes are available today that make overcoming this form of CAPTCHA relatively easy for the hacker (see https://www.netspi.com/blog/technical/adversary-simulation/using-deep-fakes-to-bypass-voice-biometrics/ as an example).
To make CAPTCHA accessible for people with disabilities, some sites combine more than one form of CAPTCHA. The most common combination is text and sound, where the sound spells out or says what the text is presenting on screen. The user must specifically select the sound version by clicking a button or checking a box, with the text being the default.
Liveness detection – a better alternative
It isn’t always possible to replace CAPTCHA with another technology, but there are other useful technologies that work better than CAPTCHA and are definitely outside the realm of deepfake strategies today. One of those technologies is liveness detection, which looks for natural human behaviors and the little imperfections that only humans generate. For example, the technique determines whether it’s possible to detect sweat pores in facial or fingerprint images, which obviously won’t appear in today’s deepfakes. Reading Liveness in biometrics: spoofing attacks and detection (https://www.thalesgroup.com/en/markets/digital-identity-and-security/government/inspired/liveness-detection) will give you a better idea of how this technology, which is based on deep learning techniques, works. Interestingly enough, China is the only country in the world where deepfakes are currently regulated according to https://recfaces.com/articles/biometric-technology-vs-deepfake.
Of course, the ability to synthesize any security data, such as CAPTCHA images, doesn’t answer the whole question. It would be theoretically possible to use the Pix2Pix GAN example in Chapter 10 to take care of this part of the process. The completion of bypassing CAPTCHA or any other security measure using automation means doing more than just training a model to approximate the image part of the security measure. Figure 11.1 shows a block diagram of what a complete solution might look like, including some items that may not seem important at first.
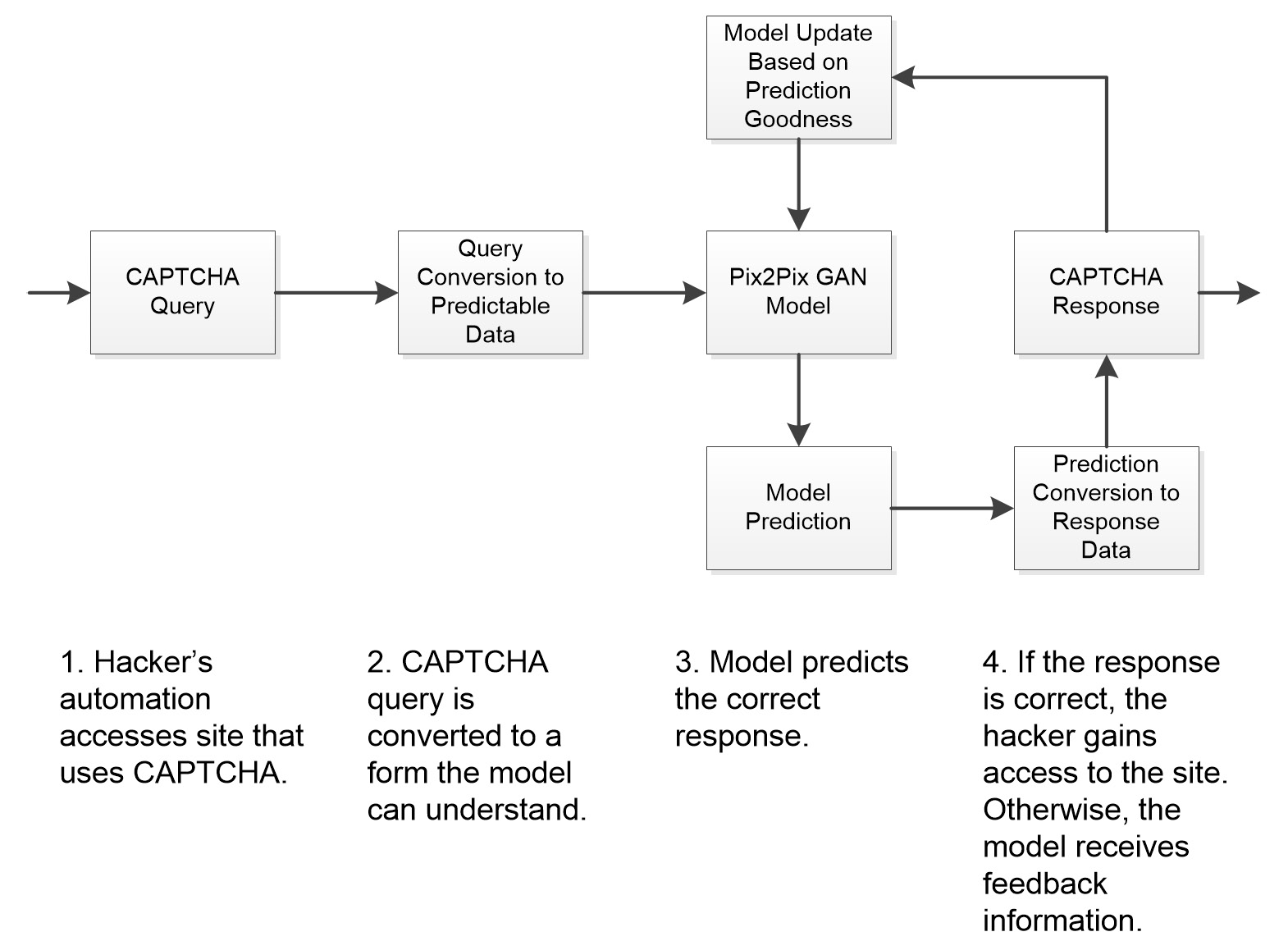
Figure 11.1 – A block diagram of an automated security measure bypass scheme
The model is only as good as its ability to create a correct prediction, one that will fool CAPTCHA. As improvements are made to CAPTCHA or based on the vagaries of specific site handling of CAPTCHA, the model will receive negative responses from the CAPTCHA application. These negative responses, along with additional data (either real or synthetic) are then used to update the model. As you can see, the process is very much like the Pix2Pix GAN in Chapter 10, with the CAPTCHA response mechanism acting as the discriminator.
Most automatic sequences will work in a similar way. The hacker’s automation must constantly update to allow access to sites or perform other tasks based on improvements in your security. You can be sure that the hacker is positively motivated to put such augmentation into place, so it’s important that your security solution automatically adjusts to the hacker’s automation.
Slowing the hacker down
Many security professionals think only in terms of stopping a hacker, but this is a limited view of what can be done. Setting your application up to allow so many tries from a particular IP address and then stopping access to that IP address may not seem like much of a deterrent, but it does serve to slow the hacker down. Even if the hacker has an entire army of IP addresses pounding away at your defenses, shutting down IP addresses that make four or five tries for a period of time reduces the effectiveness of that army. So, why not just shut the IP address off forever? Legitimate users make mistakes too, so unless you want to burden your administrator with endless requests to reopen an IP address, it’s important to have a timed response, say 20 minutes for the first offense of four tries and moving up to 24 hours for 12 tries. Making the hacker inefficient is part of a strategy in force to keep the hacker off balance. More importantly, these deterrents can be tracked by an ML application to look for patterns of access that help you better identify which access attempts are hacker-based and which are not. For example, the user who needs several tries to gain access to the site every Monday morning is not a hacker, but an ML application can track that pattern and determine that this is a user and not a hacker.
Once a hacker gains access using some sort of automated method, it’s not a very long leap toward automating the collection of data available on the compromised site. The next section deals with this next step in the fully automated attack.
Automatically harvesting information
According to 35 Outrageous Hacking Statistics & Predictions [2022 Update] (https://review42.com/resources/hacking-statistics/), hacking has become big business. Like any big business, hacking relies heavily on data: your data. It’s predicted that hackers will steal 33 billion records in 2023. That’s a lot of data, which means that hackers aren’t taking time to manually extract these records from the victims of their exploits; like everyone else, they use automation. Chapter 3 of the book has already told you about the various kinds of ML attacks that hackers use to automate certain kinds of data retrieval. Chapter 4 looks at user-focused attacks that hackers use to obtain data. Chapter 5 discusses network-based attacks. However, that’s not all of the methods that hackers use, even though it may seem as if there wouldn’t be any other methods. This section of the chapter focuses on automation, but it also looks at seemingly impossible methods of retrieving data that hackers use.
Considering the sneaky approaches hackers employ in search of data
If their goal is to steal data, hackers want people to feel comfortable and unaware (hackers do have other goals as explained in Chapter 9). Consequently, a hacker won’t hold up a huge red sign with bold yellow letters telling you that data stealing is taking place. Rather, the hacker will gain access to a system using some form of automation as described in the previous section, and then start to look around at what is available on the network drive without looking conspicuous. However, the hacker will have a limited time to look, so automation is key in making the search for valuable information efficient. You can be certain that the hacker will employ various kinds of bots (a software agent that is usually very small and extremely efficient in performing a task, usually data-related, requiring limited functionality).
In some cases, the hacker may actually combine methodologies, such as relying on a deepfake to gain employment as a remote employee. According to FBI Warns Deepfakes Might Be Used in Remote Job Interviews (https://petapixel.com/2022/07/05/fbi-warns-deepfakes-might-be-used-in-remote-job-interviews/), the number of hackers applying for remote work is on the rise. The hacker isn’t actually interested in working for the organization, but rather uses the access provided, along with access gained through automation, to obtain significant, seemingly legitimate access to a network and other organizational resources. Unless an administrator is reviewing precisely what the hacker is doing at all times, the access may go unnoticed for a long time. Some statistics say that a data breach can go undetected for 196 days or more. The legitimacy of the hacker being engaged in lawful employment while working away in the background stealing information is something that administrators need to consider.
The ML approach to this problem is to build a model that tracks user activities in an efficient and targeted manner. For example, user activities create log entries (and if they aren’t, they should). An ML application can review the logs, along with things such as access times, to build a user behavioral profile that suggests that hacking is taking place. An employee hired to work the support line really has no business looking at finances, for example, and one has to wonder how the employee gained access to such information in the first place. An ML application can learn what support line employees do during the day, even the out-of-the-ordinary sorts of things, and then compare this profile with what a specific employee is doing to discover potential hackers.
Defining problems with security through air-gapped computers
Some organizations try to combat information vulnerability and loss using air-gapped computers, which are computers that aren’t connected to any unsecured networks. This means that an air-gapped computer has no connection to the internet and may not connect to anything else at all. Typically, you can use air-gapped computers to hold the most valuable organizational secrets, which makes them a prime target for hackers. Of course, gaining access to an air-gapped computer isn’t likely to follow any of the techniques found in the book so far, which is where hackers seeking employment to appear legitimate comes into play. There are four common methods of accessing air-gapped computers:
- Electromagnetic: Computers put out a tremendous amount of electrical energy. Even if a computer isn’t directly connected to a network line, it’s possible to monitor these signals in various ways. In fact, the problem goes further. Any metal can act as a conduit for electromagnetic energy. Computers that are actually meant for use in air-gapped situations undergo TEMPEST (see https://apps.nsa.gov/iaarchive/programs/iad-initiatives/tempest.cfm for details) testing to ensure they don’t leak electromagnetic energy. To make certain that the computer doesn’t leak information, you’d also need to use it within a Faraday cage (a special construct that blocks electromagnetic energy).
- Acoustic: With the advent of smartphones, it’s possible for a hacker to hack a phone and pick up computer emanations through it. Sounds that are inaudible to humans are quite readable by the hacker. Of course, the hacker would need inside information to discover which smartphones are best to use for this purpose. The only way to ensure your air-gapped computer remains secure is to disallow the presence of smartphones in the vicinity.
- Optical: Cameras are everywhere today. It may not seem possible, but the status LEDs on various devices can inform a hacker as to what is happening inside a computer in these common ways: device state, device activity levels, and data content processing. Even though the human eye can’t detect what is happening with the modulated LEDs used for data content processing, a computer program can make sense of the pulses, potentially compromising data. Consequently, keeping cameras out of the room is the best idea.
- Thermal: Theoretically, it’s possible to discover at least some information about an air-gapped computer by monitoring its thermal emanations. However, the specifics of actually carrying out this kind of eavesdropping are limited. White papers such as Compromising emanations: eavesdropping risks of computer displays (https://www.cl.cam.ac.uk/techreports/UCAM-CL-TR-577.pdf) allude to this type of monitoring, but aren’t very specific about how it’s done.
Most organizations don’t actually have air-gapped computers, even if they were sold a system that is theoretically suitable for use in an air-gapped scenario. Unless your computer is TEMPEST certified and used in a room that lacks any sort of outside cabling, it may as well be connected to the internet because some smart hacker will be able to access it. This list of air-gapped computer security issues really isn’t complete, but it does show that complacency is likely to cause more problems than simply assuming that any sort of computer system is vulnerable to attack. Hackers tend to find ways of overcoming any security measure you put into place, so simply continuing to build the walls higher won’t work. This is why other chapters in this book, such as Chapter 9, look at alternative methods of overcoming hacker issues.
Now that you have a better idea of how hackers approach the problem of overcoming your security, it’s time to discover methodologies for dealing with it. The next section discusses ML approaches that don’t necessarily stop hacker activity. These approaches don’t build the wall higher. Instead, they make the hacker work harder, provide some monitoring capability, help you determine behavioral strategies to combat the hackers’ seeming ability to attack from anywhere, and help you create a more informed environment based on the hacker’s view of security.
Enhancing existing capabilities
Enhancing security measures means not building the wall higher, but rather making the existing wall more effective and efficient. For the hacker, this means that existing strategies continue to work, but with a lower probability of success. It becomes a matter of not creating a new strategy, but of making the existing strategy work better when it comes to overcoming security solutions. This change in direction can be difficult for the hacker to overcome because it means working through a particular security strategy and any new methodologies learned may not work everywhere. In short, it means a return to some level of manual hacking in many cases because automation is no longer effective.
The following sections provide an overview of strategies for augmenting existing security strategies presented in previous chapters in a manner that doesn’t build a higher wall. The goal is to slow the hacker down, create distractions, make automation less effective, and hide data in new ways. A way to look at these sections is that they provide a broader base of protections, whereas previous chapters provided a taller base of protections.
Rendering malware less effective using GANs
The methods used to train a GAN to detect malware rely heavily on the adversarial malware examples (AMEs) provided. Consequently, obtaining better examples would necessarily improve GAN effectiveness without actually relying on a new technology or model creation methodology. The use of generated AMEs would allow security professionals to anticipate malware trends, rather than operate in reaction mode. The following sections describe AMEs in more detail.
Understanding GAN problems mitigated by AMEs
GANs don’t typically provide perfect detection or protection because their data sources are tainted or are less than optimal. In addition, model settings can be hard to tweak due to the lack of usable data. Using generated examples would combat the current issues that occur when working exclusively with real-world examples:
- Optimization issues: The inability to optimize means that the GAN is inefficient and can’t be improved. There are a number of optimization issues that can plague a GAN:
- Vanishing gradient: When the discriminator part of a GAN works too well, the generator can fail to train correctly due to the vanishing gradient problem, which is an inability of the weights within the generator to change due to the small output of the error function with respect to the current weight. One way to combat this problem in this particular scenario is using a modified min-max loss function (https://towardsdatascience.com/introduction-to-generative-networks-e33c18a660dd).
- Failure to converge: A convergence failure occurs when the generator and discriminator don’t achieve a balance during training. In fact, the generator gets near zero and the discriminator score gets near one, so the two will never converge. The Specifying how to train the model note in Chapter 10 explores why the generator for that example worked three times harder than the discriminator in order to provide a good result that converges properly. You can also find some other ideas on how to correct this problem at https://www.mathworks.com/help//deeplearning/ug/monitor-gan-training-progress-and-identify-common-failure-modes.html.
- Boundary sample optimization: A problem occurs when a model is trained in such a way that it becomes impossible to make an optimal decision about data that lies on the boundary between one class and another. These issues occur because of outliners, imbalanced training sizes, or an irregular distribution in most cases. Many of the techniques found in Chapter 6, Detecting and Analyzing Anomalies, can help remedy the problems of outliers. The examples you’ve seen so far in the book show how to properly split datasets into training and testing datasets, which helps with the imbalanced training sizes issue. The remedy for the third problem, irregular distribution, is to rely on a parameterized decision boundary, such as that used by a support vector machine (SVM) (https://towardsdatascience.com/support-vector-machine-simply-explained-fee28eba5496).
- Model collapse: It’s essential when combatting malware that the GAN be flexible and adaptive. In other words, it should provide a wide variety of outputs that reflect the inputs it receives. Model collapse occurs when a GAN learns to produce just one or two outputs because these outputs are so successful. When this problem happens, a hacker can make subtle changes to a malware attack and the GAN will continue to try the same strategies every time, which means that the hacker will be successful more often than not. Using generated AMEs provides a much broader range of inputs during training, which reduces the likelihood of model collapse. In addition to using generated AMEs, it’s also possible to reduce model collapse by causing the discriminator to reject solutions that the generator stabilizes on using techniques such as Wasserstein loss (https://developers.google.com/machine-learning/gan/loss) and unrolled GANs (https://arxiv.org/pdf/1611.02163.pdf).
- Training instability: Training instability can result from overtraining a model in an effort to obtain a higher-quality result. As training progresses, the model can degenerate into periods of high-variance loss and corresponding lower-quality output. The discriminator loss function should sit at 0.5 upon the completion of training, assuming a near-perfect model. Likewise, the generator loss should sit at either 0.5 or 2.0 upon the completion of training. In addition, the discriminator accuracy should hover around 80%. However, depending on your settings, more training may not result in better values, which is why the Monitoring the training process section of Chapter 10 describes one method for monitoring training progress and emphasizes the need to perform this task. When monitoring shows that the training process is becoming stagnant or unstable, then stopping the training process and modifying the model settings is necessary.
The use of generated examples would overcome these issues by ensuring that the input data is as close as possible to real-world data, but is organized so as to ensure the goodness of the model. When working with real-world data, issues such as data distribution crop up because it simply isn’t possible to obtain a perfect dataset from the real world. The term perfect means perfect for model training purposes; not that any dataset is ever without flaws (using such a dataset for training wouldn’t result in a reliable or useful model). By optimizing the training dataset and also optimizing the model training settings as described in the list, you can create a highly efficient model that will produce better results without actually changing any part of your strategy. The hacker will find that a new strategy for overcoming the model may not be successful due to the model’s improved performance.
Defining a mitigation technique based on AMEs
The Pix2Pix GAN example in Chapter 10 may not seem relevant to this particular problem, but it could potentially be adapted to generate malware examples in place of pictures. As a security professional, it’s important to think without a box, that is, so far outside of the box that the box no longer exists. A computer doesn’t care whether the data it manipulates represents pictures or malware to a human; the computer only sees numbers. So, from the Chapter 10 example, you would need to change the human meaning of the data and the presentation of that data in a human-understandable form. Obviously, the use of the data would also change, but again, the computer doesn’t care. In creating a GAN to generate AMEs, you’d still need a generator and a discriminator. The setup of the two pieces would be different, but the process would be the same.
The most critical part of this process is obtaining example malware datasets from which to generate examples artificially. As shown in Chapter 10, the generation of examples usually begins with a real-world source. The Obtaining malware samples and labels section of Chapter 7, Dealing with Malware, tells you where you can obtain the required examples. What's important, in this case, is to focus on getting disabled malware examples because otherwise, you have no idea of just what will come out of the example generation process. The GAN used to detect the malware won’t look for the features that actually cause the application to become active, but rather features that define the application as a whole.
The takeaway from this section is that you can make GANs used for any purpose more efficient. For example, you could just as easily use the techniques in this section to tackle fraud. Any detection task will benefit from improved GAN efficiency without having to recreate the model from scratch and without giving the hacker some new strategy to overcome.
Hackers use AMEs too!
It’s possible to find some whitepapers online that discuss the hacker eye view of AMEs. For example, Generating Adversarial Malware Examples for Black-Box Attacks Based on GAN (https://arxiv.org/abs/1702.05983) discusses the issues that hackers face when trying to overcome what appears to them as a black-box malware detector. It details that feature sets used by ML applications, most especially GANs, using the same approach found in the Generating malware detection features section of Chapter 7, Dealing with Malware. As part of the strategy to defeat the malware detector, the authors recommend feeding the black box detector carefully crafted examples that modify specific features that a detection GAN normally relies upon for detection, such as API call names, to see how the black box reacts using a substitute detector.
The name of this particular malware detection GAN defeater is MalGAN, and it has attracted quite a lot of attention, which means you need to know about it to devise appropriate mitigation strategies for your organization. Page 3 of this white paper even includes a block diagram of the setup used by MalGAN to defeat black box detectors that rely on too few features or static feature sets. As a consequence of this process, the hacker now has AMEs to use to train a GAN to overcome the malware detector GAN. It sounds convoluted, but the process is actually straightforward enough for an experienced hacker to follow.
This sort of example is one of the best reasons to use generated AMEs to train a GAN in the first place, whether it’s a malware detector GAN or not. Just in case you’re wondering, you can find proof of concept code for MalGAN at https://github.com/lzylucy/Malware-GAN-attack. There is also an improved version of MalGAN described in Improved MalGAN: Avoiding Malware Detector by Leaning Cleanware Features at https://ieeexplore.ieee.org/document/8669079. In the next section of the chapter, you will see a different sort of hacker favorite, spear-phishing attacks, and how ML can help mitigate this particular threat.
Putting artificial intelligence in spear-phishing
Spear-phishing is a targeted attack against a particular individual or small group typically relying on emails purportedly from trusted friends or colleagues as the delivery method. When attacking using telephone calls, the tactic is called vishing, or voice phishing. Likewise, when attacking using text messages, the tactic is called smishing, for SMS-phishing. No matter how the attack is delivered, the goal of the attack is to obtain sensitive information that the hacker can use to better penetrate a network or other organizational resource. In order to make such an attack work, the hacker already needs to know a considerable amount of information about the target.
To obtain the required information, a hacker might look at public sources, as described in Chapter 4. However, some modern users (especially the high-profile targets that hackers want to interact with) have become a little savvier about the kinds of information made available on public sources, so more in-depth research is needed for a successful attack. A hacker would rely on using automation to gain access to organizational resources and then automate a search method for the required data, potentially relying on bots to do the job.
Understanding the shotgun alternative
Specially crafted spear-phishing can take several different routes, one of which could be viewed as the shotgun alternative. Instead of specifically focusing on one individual, the method focuses on a particular group. An email is crafted that should appeal to the group as a whole; the email is then sent out to a large number of individuals in that group, with the hacker hoping for a percentage of hits from the attack. It’s important to realize that phishing targets range from an individual, to targeted groups, to people with particular tastes, and to those who are in the general public. However, spear-phishing tactics differ from standard phishing in that spear-phishing attacks are crafted to provide a targeted attack—a spear attack.
Whether the attack is a case of spear-phishing, vishing, smishing, or possibly a combination of all three, the idea that the attack is targeted should produce immediate action on the part of the security professional because this is the kind of attack that can’t be addressed in a generic manner. Yes, you can use ML to look for patterns and raise an alarm when those patterns are spotted, but then the security professional must take a course of action that is as unique as the spear-phishing attack. The following sections provide some ideas of how a hacker views this kind of attack, how you can defend against it in the form of an ML application, and possible mitigation strategies.
Understanding the key differences between phishing and spear-phishing
Spear-phishing is generally a bigger problem for the security professional because the hacker has taken the time to know more than usual about the target. The idea is that one high-value target is likely to garner better information than blanketing the internet as a whole and that the information gained will ultimately net a higher profit. Because of the focus, trying to get rid of the hacker is going to be more difficult—simply ignoring the email may not be enough. Here are some characteristics that differentiate spear-phishing from phishing in general (presented in the order of the gravity of the threat they represent):
- Group affiliation: Many spear-phishing attacks rely on ML techniques to discover the most common group affiliations of a particular target. The group affiliation is a lot more specific than whether or not the target uses Facebook or Twitter. A smart hacker will look for unexpected target affiliations, such as the American Association of Bank Directors for financial officers of banks. The email will use the correct heading for the affiliation and will do so without spelling errors in many cases. Your only indicator that the email is spear-phishing is that the URL provided doesn’t go to the right place (often the URL differs by just one letter). An ML application to battle such a targeted attack would look at the URLs provided throughout the entire email to find patterns that indicate spear-phishing, rather than a legitimate email.
- Unexpected or irregular requests from an organizational group: One hacker’s favorite is to send an email that’s supposedly from HR. The target user clicks on the link provided by the email and goes to a site that looks like it belongs to HR. This kind of spear-phishing attack focuses on an organization as a whole, with the hacker hoping that a high-profile user will take the bait. It’s usually the first step in a multi-step advanced persistent threat (APT). Once the hacker has a foot in the door, additional attacks occur to garner more information. An ML application can learn details about HR practices and methods of communication. It can look for errors in the email presentation and any incorrect URLs in the message. This particular kind of attack is generally easy to thwart if captured in its nascent stage.
- Title specified: A spear-phishing attack that is targeted at a specific group will have the correct title specified, such as financial officer. However, you can tell that it’s targeted at a group because it likely doesn’t include a name or other details. A hacker could simply obtain a list of financial officers from corporate annual reports and send the email to the entire group. An ML application to battle this kind of attack would look for the correct title and the correct corporate name (rather than a nickname). It would also look for obvious misspellings that occur because many people’s names are not spelled in the traditional manner. Other indicators that an ML application could learn would include odd URLs in the email, misspellings of various terms, missing group information, and other anomalies of the type discussed in Chapter 6.
- Non-monetary target: Nation states often perpetrate spear-phishing attacks that have nothing to do with monetary gain. These probing attacks may only look for the kinds of information that someone could neglectfully pass along at the cooler. Unfortunately, it’s hard to train an ML application to recognize this kind of attack with a high probability of success, so employee training is required. If someone seems too friendly in an email, then perhaps it’s time to look at it as potentially hostile in nature.
- Name included: If the suspicious email has a name included, it’s definitely a spear-phishing attack. A phishing attack has a header such as “Dear Sir or Madam.” However, the format of the name is an indicator of spear-phishing in some cases. Only spear-phishing attacks would use the person’s full name. You need to consider the use of nicknames (did the hacker research the individual enough to know what other people actually call them). If so, the hacker may have access to a great deal of uncomfortable information about the target and special care must be taken. An ML application could look for anomalies in such an email. For example, if a nickname is used, then the person sending the email should appear in the targeted user’s address book.
- Activities included: It’s a bad idea to include the itinerary for your upcoming trip on social media for a lot of reasons. Local thieves read Facebook too. However, for the spear-phishing hacker, knowing details like this make it easier to craft an authentic-looking email that mentions enough specifics that even a security professional can be taken off-guard. Unfortunately, unless the hacker slips up in other ways, this particular form of attack is very hard to create a model to detect because there really isn’t anything to detect. The activity is likely real, so the model looks for other potential ways in which the hacker could slip up within the email’s content.
- Professional acquaintance or service: Hackers will use any resource needed to gain access to their target. In some cases, it has been reported that a hacker will resort to hacking a professional’s email first, such as a lawyer, to gain the trust of the target. Hackers may also rely on organizations that provide services, such as real estate agents. One of the biggest sources of spear-phishing attacks is technical support. A hacker will pose as a representative of some type of technical support for an organization. The obvious kinds of technical support would be hardware, software, or devices. However, hackers also pose as technical support for financial organizations and utility companies (among others). An ML application could help in this case by looking for reception patterns, such as the same email being sent to a number of people in the organization or URLs that don’t match the organization sending the message.
- Friend and relative knowledge: Hackers will often rely on knowledge of a person’s associations to craft a spear-phishing email. For example, an email may say that a friend or relative recommended the person to the company or the target might receive a message providing a certain amount off a product based on the association’s recommendation. Using connections between people makes the message seem a lot more believable. Of course, the easiest way to combat this particular attack vector is to call the friend or relative in question and ask if they made the recommendation.
This list isn’t complete. Hackers will use any sort of foothold to gain a person’s trust in order for a spear-phishing attack to succeed. According to the FBI’s Internet Crime Report, the Internet Crime Complaint Center (IC3) received 19,369 Business Email Compromise (BEC) and Email Account Compromise (EAC) complaints in 2020 (see the Internet Crime Report 2020, https://www.ic3.gov/Media/PDF/AnnualReport/2020_IC3Report.pdf, for details). The Internet Crime Report is an important resource because it helps you understand the ramifications of spear-phishing for your organization in particular, and may offer ideas on things to look for when creating a feature set for your model.
Getting law enforcement involved
I am not a legal professional, so I can’t advise you on your legal responsibilities. There, I had to get that out of the way. Even so, it’s important to realize that the very personal sorts of attacks described in this section may eventually require the intervention of legal professionals. This is where you make HR and the legal department of your organization aware of the various kinds of attacks taking place and inquire about the direction that mitigation should take, especially when interactions with a nation state are concerned. Many security professionals aren’t truly aware of the legal requirements for certain attacks, so it’s important to ask rather than simply assume you can take care of the problem yourself. For example, there is now a legal requirement to report certain kinds of attacks in some countries (see Congress Approves Cyber Attack Reporting Requirement for U.S. Companies, https://www.insurancejournal.com/news/national/2022/03/14/657926.htm, as an example). Otherwise, you may find yourself in an untenable position later.
Understanding the special focus of spear-phishing on security professionals
If you are in IT of any type, especially if a hacker can determine that you’re a security professional, hackers will have a special interest in you as a target. According to research done by Ivanti (https://www.ivanti.com/resources/v/doc/infographics/ivi-2594_9-must-know-phishing-attack-trends-ig), here are the statistics regarding spear-phishing attacks against IT professionals:
- 85% of security professionals agree that the attacks have become more sophisticated
- 80% of IT professionals have noticed an increase in attacks in the past year
- 74% of organizations have been a victim of phishing attacks within the past year (40% of them within the last month as of the time of the report)
- 48% of C-level managers have personally fallen prey to spear-phishing attacks
- 47% of security professionals have personally fallen prey to spear-phishing attacks
The most interesting statistic of all is that 96% of organizations report that they provide cybersecurity training. The problem is severe enough that many vendors now offer phishing attack testing for employees and professional training based on test results. Obviously, training alone won’t reduce the number of spear-phishing attacks, which is why ML measures are important as well. Unfortunately, as outlined so far in this chapter, ML strategies only work when the model you create is robust and flexible enough to meet the current challenges created by hackers.
Reducing spear-phishing attacks
A useful strategy when creating a model to detect spear-phishing attacks is to look for small problems in the email. For example, if the organization’s name is slightly different in various locations, there are spelling errors, the use of capitalization differs from one location to another, there are differences between the email content and the content on the legitimate site, and so on.
One of the more interesting ways to detect spear-phishing emails today is to check for differences in graphics between the legitimate site and the spear-phishing email. Some organizations focus on logos because it’s easy to create a database of hash values for legitimate logos and compare it to the hash values for logos in an email. However, it may not be enough to detect logo differences if the hacker is good at copying the original and ensuring the hash values match. An ML model can learn more advanced techniques for discovering a fake, such as the layout and organization of both text and graphics.
When receiving an email that appears to be text, but is actually an image, it’s important to think about it as a potential spear-phishing attack for the simple reason that a legitimate sender wouldn’t normally have a good reason to send an image. From the user’s perspective, it would be hard to see that one email contains text and another email an image of text. An ML application could learn this pattern and classify those containing text images as spear-phishing candidates. Two of the more popular algorithms for performing this work are Visual Geometry Group-16 layer (VGG-16) (https://www.geeksforgeeks.org/vgg-16-cnn-model/) and Residual Network (ResNet) (https://www.geeksforgeeks.org/residual-networks-resnet-deep-learning/). When using these models, it’s important to introduce perturbations to the training set as described in the Manipulating the images section of Chapter 10, including the following:
- Cropping
- Downsampling
- Blurring
- Placing essential graphics in unexpected locations and within other graphics
- Modifying the Hue, Saturation, Value (HSV) color space
The kinds of perturbations that you introduce into a training dataset depend on the effect that you want to achieve in the model, with cropping, downsampling, and blurring being standard fare. In this case, the model has to be flexible enough to recognize a target graphic, such as a logo, wherever it might appear in the email, or a text image (a graphic that contains text, as in a screenshot of a display. It looks like text, but it’s actually an image of the text). Consequently, adding the logo in places that the model doesn’t expect is a required part of the training. The image may also have differences in HSV from the legitimate site, so the model has to recognize these differences as well.
The next section looks at smart bots. More and more smart bots now appear in all sorts of places online and on local machines. This section does spend a little time with legitimate smart bots but looks at them mostly from the hacker’s perspective of being helpful assistants.
Generating smart bots for fake news and reviews
There are many legitimate uses of bots online. Smart bots are simply bots that have an ML basis so that they can adapt to various situations and become more useful to their user. Companies such as SmartBots (https://www.smartbots.ai/) are currently engaged in making common bots, such as chatbots, into smarter assistants. For example, they offer a method of detecting when it’s time to transfer a customer to a human representative, which is something a standard chatbot can’t easily do. However, hackers have other ideas when it comes to smart bots, using them to improve their chances of success in various kinds of exploits, such as generating fake news and reviews. The following sections discuss the hacker-eye view of fake news and reviews.
Understanding the uses for fake news
Fake news refers to attempts to pass partially or completely false reports of news off as fully legitimate. There are a number of reasons that fake news can be successful:
- It plays on people’s fears
- It provides a sense of urgency
- The stories are often well-written
- There is just enough truth to make the story seem valid
- The stories don’t make any outlandish claims
- The content is unexpected
Oddly enough, it’s possible to generate fake news using ML techniques as described in New AI Generates Horrifyingly Plausible Fake News at https://futurism.com/ai-generates-fake-news. What isn’t clear from most articles on this topic is that the model needs sources of real news to create convincing fake news. Using smart bots makes the task of gathering appropriate real news considerably easier. By tweaking the model, the resulting output can become more convincing than real news because the model creators follow a pattern that draws people’s attention and then convinces them that the news is real.
Whatever hook the creators of fake news use to draw people in consists of in terms of information, hackers generally use fake news to do something other than present news. The most common form of attack is to download malware to the victim’s machine. However, hackers also use fake news to get people to buy products, send money, and perform all sorts of other tasks on the hacker’s behalf. These requests are often successful because the person honestly believes that what they’re doing is worthwhile and because they haven’t been asked to participate in that sort of task before. In short, the hacker makes the person feel important, all the while robbing them of something.
A unique form of fake news attack is the use of a legitimate news outlet to broadcast fake news. Reading Ukrainian Radio Stations Hacked to Broadcast Fake News About Zelenskyy’s Health (https://thehackernews.com/2022/07/ukrainian-radio-stations-hacked-to.html) can tell you quite a bit about this form of attack. As you can imagine, the IT staff for the radio station had to make a serious effort to regain control of the radio station. Besides the delivery method, the target of this attack was the Ukrainian military and people.
Another form of fake news actually does provide real news, but the site serving it is fake. The Chinese Hackers Deploy Fake News Site To Infect Government, Energy Targets story at https://www.technewsworld.com/story/chinese-hackers-deploy-fake-news-site-to-infect-government-energy-targets-177036.html discusses how a fake news site can serve up real stories from legitimate sources such as the BBC and Sky News. So, the news isn’t fake, but the site serving the news takes credit for someone else’s stories. When a victim goes to the site to read the story, the ScanBox malware is downloaded to their system. The interesting aspect of this particular attack is that the target is government agencies and the energy industry, not the general public. It’s an example of a targeted attack that’s successful because it relies on redirection. The victim expects news (and gets it) but receives malware as well. The benefit of using real news is that the victim can discuss the site with others and have totally legitimate news to talk about, so the attack remains hidden from view. The hackers also gain the benefit that they don’t have to penetrate the fortifications offered by more secure networks; the attack occurs outside the network.
Training is the main method for handling this particular threat. Employees should be trained to be skeptical. It’s a cliché, but one of those that actually works: “If it sounds too good to be true, then it probably is.” However, ML techniques can also help pinpoint fake news sites by looking at the page content without actually downloading it. Blacklisting sites that are suspected of serving up fake news will help employees steer clear of it. In addition, models such as Grover (https://grover.allenai.org/) make it possible to detect AI-generated fake news.
Understanding the focus of fake reviews
Fake reviews, unlike fake news, are usually targeted at generating money in some way. A company may decide that a flood of positive reviews on Amazon will help product sales and hire someone to generate them. Likewise, a competitor may devise to generate a wealth of negative reviews to reduce the sales of an adversary. The problem is so severe on sites such as Amazon that you can find tools that measure the real product rating using ML application techniques, such as those described in These 3 Tools Will Help You Spot Fake Amazon Reviews (https://www.makeuseof.com/fake-reviews-amazon/). Of course, the best way to generate fake reviews is by using smart bots.
Another form of fake reviews makes the apps in online stores seem better than they really are. Stories such as Fake reviews and ratings manipulation continue to plague the App Store charts (https://9to5mac.com/2021/04/12/fake-reviews-and-ratings-manipulation-app-store/) make it clear that what you think an app will do isn’t necessarily what it does do. Efforts to control the effects of these fake reviews often fall short with the developer of the inferior app raking in quite a lot of money before the app is taken out of the store.
Interestingly enough, you don’t even have to build a custom smart bot to upload reviews for a product. Sites such as MobileMonkey (https://mobilemonkey.com/blog/how-to-get-more-reviews-with-a-bot) tell you precisely how to get started with smart bots in a way that will generate a lot of reviews in a short time and produce verifiable results. If you scroll down the page, you will find that building a smart bot to do the work for you is simply a matter of filling in forms and letting the host software do the rest.
There are methods of telling real reviews from fake reviews that you can build into an ML model. Here are the most common features of real reviews:
- It contains details that don’t appear on the product site
- Pros and cons often appear together
- Pictures appear with the reviews (although, pictures can be faked too)
- The reviewer has a history of providing reviews that contain both pro and con reviews
- The text doesn’t just mimic the text of other reviews
As you can see, many of these methods fall into the realms of critical thinking and looking for details. Verifying facts is an essential part of tracking down real from fake reviews, and this is an area in which ML applications excel.
Considering the non-bot form of fake reviews
Companies such as Amazon have developed better software to detect fake reviews over the years, so some companies have resorted to other means for generating fake (or at least misleading) reviews. One technique creates reviews by selling a product to a potential reviewer and then offering to refund the cost of the product for a five-star review on specific sites. In fact, some companies offer up to a 15% commission for such reviews. The online review won’t mention that the reviewer has been paid and is certainly less than objective in providing the review. It’s still possible to create ML models to detect such reviews by looking for two, three, or four-star reviews, comparing ratings between online sellers, checking if the reviewer also answers product questions from other customers, and using a timestamp filter to block out review clusters. Moderate reviews that reflect a general consensus across vendor sites from people who also answer questions are usually genuine. In addition, companies often hire reviewers at the same time, so you will see clusters of potentially fake reviews.
Reducing internal smart bot attacks
Smart bots are successful because they’re small, flexible, and targeted. It’s possible to have a smart bot on a network and not even know it’s there. External smart bots are best avoided through a combination of training, skepticism, and site detection tools. Detecting internal smart bots (those on your network or associated systems) would begin by building a model to note any unusual network activity. For example, examining activity logs could point to clues about the presence of a smart bot.
The techniques shown in Chapter 7 to detect and classify malware also apply to smart bots. You can look for smart bot features that make it possible to tell malware from benign software. The problem with smart bots is that they are small and targeted, so the probability of identifying a smart bot is smaller than that of detecting other kinds of malware, but it can be done.
One interesting way to possibly locate smart bots is to track various performance indicators, especially network statistics. A sudden upsurge in network traffic that you can’t account for might be an indication that a smart bot is at work (once you have eliminated malware as the cause). ML applications are adept at locating patterns in performance data that a human might not see. Purposely looking for these patterns can help locate myriad network issues, including smart bots that communicate with the home base at odd times or use system resources in unexpected ways.
Summary
This chapter is about taking the hacker-eye view of security, which is extremely porous and profoundly easy to break. The idea is to help security professionals to remain informed that being comfortable and taking half-measures won’t keep a hacker at bay. Building the walls higher isn’t particularly effective either. Years of one-upmanship have demonstrated that building higher walls simply means that the hacker must devise a new strategy, which often comes even before the walls are built. Creating an effective defense requires that the security professional deal with the hacker from the perspective that the hacker thinks it’s possible to overcome any obstacle. This is where ML comes into play because using ML techniques makes it possible to look for hacker patterns that a security professional can exploit to enhance security without building a higher wall. It’s time that the hacker becomes more comfortable with an existing strategy and lowers their guard, making it possible for the security professional to gain an advantage.
The next chapter is all about ethics. It’s likely not a topic that you’ve seen covered much, but it’s an extremely important security topic nonetheless. The ethical treatment of data, users, and resources tend to enhance security because the security professional becomes more aware of the ramifications of each action. It’s no longer about just dealing with hackers, but viewing the targets of the hacker’s affection with new eyes. Ethical management techniques help keep a focus on what’s important with regard to security.
Further reading
The following bullets provide you with some additional reading that you may find useful for understanding the materials in this chapter in greater depth:
- Read about how the use of skipping (see Figure 10.25) helps improve the CNN used to break CAPTCHA: A novel CAPTCHA solver framework using deep skipping Convolutional Neural Networks (https://peerj.com/articles/cs-879.pdf)
- Discover the myriad of bots used for legitimate purposes: WhatIs.com bot (https://www.techtarget.com/whatis/definition/bot-robot)
- See a list of commonly offered commercial bots used for various tasks: Bot Platforms Software (https://www.saasworthy.com/list/bot-platforms-software) and Best Bot Platforms Software (https://www.g2.com/categories/bot-platforms)
- Learn more about air-gapped computers: What is an Air Gapped Computer? (https://www.thesslstore.com/blog/air-gapped-computer/)
- Read about the details of hacking an air-gapped computer: Four methods hackers use to steal data from air-gapped computers (https://www.zdnet.com/article/stealing-data-from-air-gapped-computers/)
- Invest some time into reading more about the potential for smartphone security issues: An experimental new attack can steal data from air-gapped computers using a phone’s gyroscope (https://techcrunch.com/2022/08/24/gairoscope-air-gap-attack/)
- Consider the ramifications of using a TEMPEST certified system: 5 Things Everyone Should Know About Tempest And Information Security (https://www.fiberplex.com/blog/5-things-everyone-should-know-about-tempest-and-information-security.html)
- Discover how using a least squares generative adversarial network (LSGAN) can improve the creation of AME: LSGAN-AT: enhancing malware detector robustness against adversarial examples (https://cybersecurity.springeropen.com/articles/10.1186/s42400-021-00102-9)
- Find an n-gram version of MalGAN: N-gram MalGAN: Evading machine learning detection via feature n-gram (https://www.sciencedirect.com/science/article/pii/S2352864821000973)
- Learn more about using logos to detect spear-phishing emails: Color Schemes: Detecting Logos in Phishing Attacks (https://www.vadesecure.com/en/blog/detecting-logos-in-phishing-attacks)
- Consider the use of smart bots for human augmentation: Using Smart Bots to Augment Humans (https://www.spiceworks.com/tech/innovation/guest-article/using-smart-bots-to-augument-humans/)
- Read about some political motivations behind fake news: “Hacker X”—the American who built a pro-Trump fake news empire—unmasks himself (https://arstechnica.com/information-technology/2021/10/hacker-x-the-american-who-built-a-pro-trump-fake-news-empire-unmasks-himself/)