
2
Mitigating Risk at Training by Validating and Maintaining Datasets
The training process for your model determines the output that your application provides when faced with data it hasn’t seen before. If the model is flawed in any way, then it’s not reasonable to expect unflawed output from the model. The testing process helps verify the model, but only when the data used for testing is accurate. Consequently, the datasets you use for training and testing your model are critical in a way that no other data you feed to your model is. Even with feedback (input that constantly changes the model based on the data it sees), initial training and testing sets the tone for the model and therefore remain critical. Assuming that your dataset is properly vetted, of the right size, and contains the right data, you still have to protect it from a wide variety of threats. This chapter assumes that you’ve started with a good dataset, but some internal or external entity wants to modify it so that the model you create is flawed in some way (or becomes flawed as time progresses). The flaw need not even be immediately noticeable. In fact, subtle flaws that don’t manifest themselves immediately are in the hacker’s best interest in most cases. With these issues in mind, this chapter discusses these topics:
- Defining dataset threats
- Detecting dataset modification
- Mitigating dataset corruption
Technical requirements
This chapter requires that you have access to either Google Colab or Jupyter Notebook to work with the example code. The Requirements to use this book section of Chapter 1, Defining Machine Learning Security, provides additional details on how to set up and configure your programming environment. The example code will be easier to work with using Jupyter Notebook in this case because you must create local files to use. Using the downloadable source is always highly recommended. You can find the downloadable source on the Packt GitHub site at https://github.com/PacktPublishing/Machine-Learning-Security-Principles or my website at http://www.johnmuellerbooks.com/source-code/.
Defining dataset threats
ML depends heavily on clean data. Dataset threats are especially problematic because ML techniques require huge datasets that aren’t easily monitored. The following sections help you categorize dataset threats to make them easier to understand.
Security and data in ML
Even though many of the issues addressed in this chapter also apply to data management best practices, they take on special meaning for ML because ML relies on such huge amounts of automatically collected data. Certain entities can easily add, subtract, or modify the data without anyone knowing because it’s not possible to check every piece of data or even use automation to verify it with absolute certainty. Consequently, with ML, it’s entirely possible to have a security issue and not know about it unless due diligence is exercised to remove as many possible sources of data threats as possible.
Learning about the kinds of database threats
Dataset modification is the act of changing the data in a manner that tends to elicit a particular outcome from the model it creates. The modification need not be noticeable, as in, creating an error or eliminating the data. In fact, the modifications that work best often provide subtle changes to records by increasing or decreasing values by a certain amount or by adding characters that the computer will process but that humans tend to ignore. When a dataset includes links to external resources, such as URLs, the potential for nearly unnoticeable database modification becomes greater. A single-letter difference in a URL can redirect the ML application to a hacker site with all of the wrong data on it. For example, instead of pointing to a site such as https://www.kaggle.com/datasets, the external link could instead point to https://www.kagle.com/datasets. The problem becomes worse when you consider URL parsing techniques, as described here at URL parsing: A ticking time bomb of security exploits (https://www.techrepublic.com/article/url-parsing-a-ticking-time-bomb-of-security-exploits/). The point is that the people vetting and monitoring data will likely notice extreme changes and hackers know this, so attacks are more likely to involve subtle modifications to increase the probability that the change will escape notice.
Dataset corruption refers to the accidental modification of data in a dataset that tends to produce random or erratic results. It may seem as if corruption would be easy to spot, but in many cases, it too escapes notice. For example, a sensor may experience minor degradation that corrupts the data it provides without eliminating it completely. A visual sensor may have dirt on its lens, a heat sensor may become covered with soot, or sensors may experience data drift as they age. As a trusted data source, the corruption might go unnoticed until the degradation becomes obvious. Environmental issues, such as lightning strikes, heat, static, and moisture, can also corrupt data. The corruption may occur over such a short interval that it lies unnoticed in the middle of the dataset (unless a human checks every entry). Other sources of data corruption include inadequate safeguards in the statistical selection of data to use within a dataset or the lack of available data for a particular group (both of which result in biases). The point is that data corruption comes from such a great number of sources that it may prove impossible to eliminate them all, so constant result monitoring is critical, as is thinking through why a particular result has happened.
Entities that pose a threat
It would be easy to assume that entities that pose a security threat to your data used for ML tasks are human. Yes, humans do pose a major threat, but so do faulty sensors, incompatible or malfunctioning software, acts of nature, cosmic rays, and a large assortment of other sources, most of which developers don’t think about because they focus on humans. When working with ML applications, it’s essential to think about entities other than humans because so much data used for ML tasks is automatically collected from a wide variety of unmonitored sources. This book uses the term entity, rather than human, to help you keep these other sources in mind.
Considering dataset threat sources
Dataset threats come from multiple sources, but it’s helpful to categorize threats as either internal or external in origin. In both cases, dataset security begins with physical security. Even with external sources, using personnel trained to discover potential issues on external sites and scrutinize the incoming data for inconsistencies is important to keeping existing data safe. Figure 2.1 describes threat sources that you should consider when creating a physically safe environment for your data.


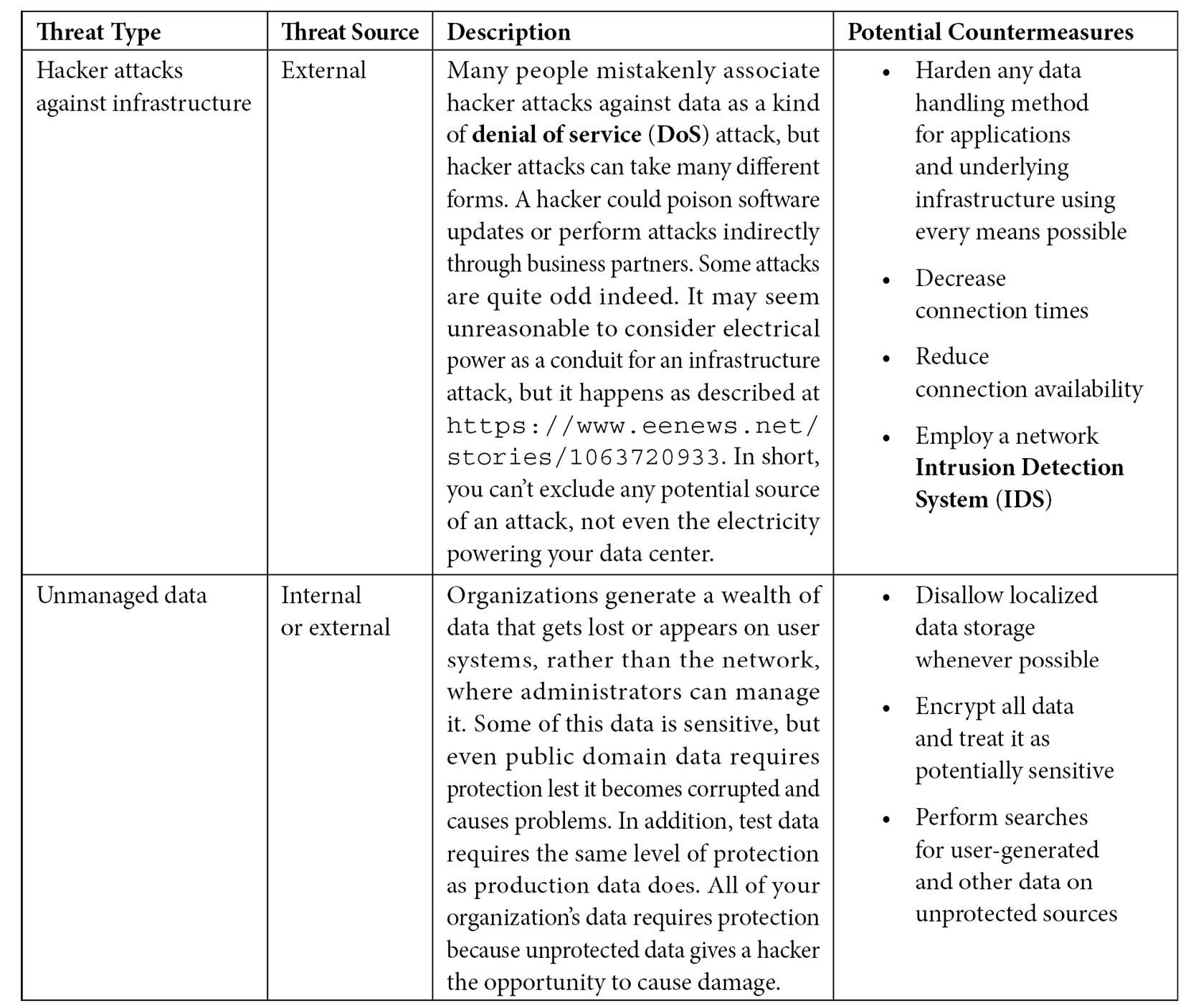
Figure 2.1 – Threat sources that affect physical data security
You can spend considerable time physically protecting your clean and correctly formatted data and still experience problems with it. This is where an internal threat or a hacker with direct access to your network comes into play. The data could be correct, viable, unbiased, and stable in every other conceivable way, yet still doesn’t produce the correct model or outcome because something has happened to it. This conclusion assumes that you have already eliminated other sources of potential problems, such as using the correct model and shaping the data to meet your needs. When you exhaust every other contingency for incorrect output, the remaining source of potential errors is data modification.
Never rely completely on physical security. Someone will break into your system, even if you create the best safeguards possible. The concept of an unbreakable setup is a myth and anyone who thinks otherwise is set for disappointment. However, great physical security buys you these benefits:
- It will take longer to break into your system
- Any break-ins should be more noticeable
- Hackers are lazy like anyone else and may decide to attack someone else
- Getting rid of the hacker should be easier
- Determining the source and causes of the break-in will require less time
- The application development time tends to be shorter because you have fewer places to look for potential sources of problems
- You have an advantage over your competition because your business secrets will likely remain more secure
- You can demonstrate compliance with legal requirements, such as the Payment Card Industry Data Security Standard (PCI DSS) and the Health Insurance Portability and Accountability Act (HIPAA)
- It creates an overall improvement in data management because the results you obtain from the analysis are more precise
It’s important to understand that some benefits will require a great deal more work than others to achieve. Depending on your requirements, you likely need to provide a lot more than just physical security. For example, the PCI DSS and HIPAA both require rigorous demonstrations of additional security levels.
Delving into data change
Anything that modifies existing data without causing missing or invalid values is a data change. Data changes are often subtle and may not affect a dataset as a whole. An accidental data change may include underreporting the value of an element or number of items. Sometimes the change is subjective, such as when one appraiser sees the value of an item in one way and another appraiser comes up with a different figure (see the Defining the human element section in Chapter 1, Defining Machine Learning Security, for other mistruths that can appear in data). It happens that humans make changes to a dataset simply because they disagree with the current value for no other reason than personal opinion. Here are some other sources of data change to consider:
- Automated software makes an unwanted update to a value
- Company policy or procedure changes so that the value that used to be correct is no longer correct
- Aging and archiving software automatically removes values that are deemed too old, even when they aren’t
- New sensors report data using a different range, format, or method that creates a data misalignment
- Someone changes the wrong record
Any of these data changes have the potential to skew model results or cause other problems that a hacker can analyze and use to create a security issue. Even if a hacker doesn’t make use of them, the fact is that the model is now less effective at performing the task it’s designed to do.
Delving into data corruption
When new or existing data is modified, deleted, or injected in such a manner as to produce an unusable record, the result is data corruption. Data corruption makes it impossible to create a useful model. In fact, some types of data corruption will cause API calls to fail, such as the calculation of statistical methods. When the API call doesn’t register an error but instead provides an unusable output, then the model itself becomes corrupted. For example, if the calculation of a mean produces something other than a number, such as an NA, None, or NaN value, then tasks such as missing data replacement fail, but the application may not notice. These types of issues are demonstrated in the examples later in the chapter.
Uncovering feature manipulation
The act of selecting the right variables to use when creating an ML model is known as feature engineering. Feature manipulation is the act of reverse engineering the carefully engineered feature set in a manner that allows some type of attack.
In the past, a data scientist would perform feature engineering and modify the feature set as needed to make the model perform better (in addition to meeting requirements such as keeping personal data private). However, today, you can find software to perform the task automatically, as described at https://towardsdatascience.com/why-automated-feature-engineering-will-change-the-way-you-do-machine-learning-5c15bf188b96. Whether you create the feature set for an ML model manually or automatically, you still need to assess the feature set from a security perspective before making it permanent. Here are some issues to consider:
- Keep personal data out of the dataset when possible
- Use aggregate values where it’s difficult to reconstruct the original value, but the aggregate still provides useful information
- Perform best practices feature reduction studies to determine whether a feature really is needed for a calculation
A problem occurs when a third party uses an API or other means of accessing the underlying data to mount an attack by manipulating the features in various ways (feature manipulation). Reading Adversarial Attacks on Neural Networks for Graph Data at https://arxiv.org/pdf/1805.07984.pdf provides insights into a very specific illustration of this kind of attack using techniques such as adding or removing fake friendship relations to a social network. The attack might take a long time, but if the attacker can determine patterns of data input that will produce the desired result, then it becomes possible to eventually gain some sort of access, perceive how the data is laid out, extract specific records, or perform other kinds of snooping.
Examining source modification
Source modification attacks occur when a hacker successfully modifies a data source you rely on for input to your model. It doesn’t matter how you use the data, but rather how the attacker modifies the site. The attacker may be looking for access into your network to perform a variety of attacks against the application, modify the data you obtain slightly so that the results you obtain are skewed, or simply look for ways to steal your data or model. As described in the Thwarting privacy attacks section, the attacker’s sole purpose in modifying the source site might be to add a single known data point in order to mount a membership inference attack later.
Thwarting privacy attacks
In the book Nineteen Eighty-Four by George Orwell, you see the saying, “War is peace. Freedom is slavery. Ignorance is strength.” The book as a whole is a discussion of things that can go wrong when a society fails to honor the simple right to privacy. ML has the potential to make the techniques used in Nineteen Eighty-Four look simplistic and benign because now it’s possible to delve into every aspect of a person’s life without the person even knowing about it. The use of evasion and poisoning attacks to cause an ML application to output incorrect results is one level of attack—the use of various methods to view the underlying data is another. This second form of attack is a privacy attack because the underlying data often contains information of a personal nature.
It isn’t hard to make a case that your health and financial data should remain private, and there are laws in place to ensure privacy (although some people would say they’re inadequate). However, your buying habits on Amazon don’t receive equal protection, even though they should. For example, by watching what you buy, someone can make all sorts of inferences about you, such as whether you have children, how many children, and what their ages are. However, there are more direct attacks as listed here:
- Membership inference attack: The attacker has at least one known good data point in hand and uses it to determine whether the data point was part of the original data used to train a model. For example, is a particular person’s face used to train a facial recognition application? Knowing this information could make it possible to avoid detection at an airport by ensuring none of the people making an attack are already in the database. This kind of attack was used to obtain sensitive information about people on both Google and Amazon (you can read more about this attack at https://arxiv.org/abs/1610.05820). Here are some other uses of membership inference attacks:
- Generative adversarial networks (GANs): Attackers were 100 percent successful at carrying out white-box attacks and 80 percent successful at carrying out black-box attacks as described at https://arxiv.org/pdf/1705.07663.pdf. In a white-box attack, the attacker has access to the model’s parameters, which means that the attacker could be an insider or a hacker with inside information. Black-box attacks are made without model parameter knowledge. The attacker must create a different model or not rely on a model at all to generate adversarial images that will hopefully transfer to the target model. It may initially appear that white-box attacks would be advantageous, but according to White-box vs Black-box: Bayes Optimal Strategies for Membership Inference (http://proceedings.mlr.press/v97/sablayrolles19a/sablayrolles19a.pdf), the two methods can have an equal chance of success.
- Language generation models: The attackers were able to determine whether the person’s text data was part of a language generation study, which is used to create models used for products such as Alexa and Siri (among many others) as described at https://arxiv.org/pdf/1811.00513.pdf.
- Federated ML system: A study shows that insider actors within a federated ML system, where the system is centralized, pose a significant threat, and that working with datasets that differ greatly increases the threat as described at https://arxiv.org/pdf/1807.09173.pdf.
- Aggregate location data: It’s possible to determine whether a particular user is part of aggregate location data, which is used to support smart services and applications, generate traffic maps, and predict visits to businesses as described at https://arxiv.org/abs/1708.06145.
- Data extraction: This kind of attack also comes under the heading of model inversion. In this case, the attacker tries to obtain an average representation of each class used to train a model. While it isn’t possible to extract a single data point using this method, the results are still pretty scary as described by these examples:
- Genomic information: It’s possible to obtain information about a person’s genes by studying pharmaceutical data as described at https://www.usenix.org/system/files/conference/usenixsecurity14/sec14-paper-fredrikson-privacy.pdf.
- Facial recognition: Even though the resulting face isn’t perfect, it’s visible enough for a human to identify the individual used to train the model as described at https://www.cs.cmu.edu/~mfredrik/papers/fjr2015ccs.pdf.
- Unintended memorization: Ensuring that you clean data thoroughly of any personal information and that you use as few features as possible to achieve your goals is demonstrated in the paper at https://arxiv.org/pdf/1802.08232.pdf where the authors were able to extract social security and credit card numbers from the model.
- Model extraction: Creating a model is a time-intensive task, requiring the input of more than a few experts in most cases. Consequently, you don’t want someone to come along and steal the model that took you 6 months to build. There are a number of ways to accomplish this goal, as described in Chapter 1, Defining Machine Learning Security, but one approach is particularly effective, prediction APIs, which are described at https://arxiv.org/abs/1609.02943.
One of the most important bits of information you can take away from this section is that you really do need to limit the feature size of your dataset and exclude any form of personal information whenever possible. The act of anonymizing the data is as essential as every other aspect of molding it to your needs. When you can’t anonymize the data, as when working with medical information associated with particular people for tasks such as predicting medication doses, then you need to apply encryption or tokenization to the personal data. Encryption works best when you absolutely must be able to read the personal information later, and you want to ensure that only people who actually need to see the data have the right to decrypt it. Tokenization, the process of replacing sensitive information with symbolic information or identification symbols that can retain the essentials of the original data, works best when there is a tokenized system already in place to identify individuals in a non-personal way.
The next section of the chapter looks at dataset modification, which is the act of changing the data to obtain a particular effect.
Detecting dataset modification
Dataset modification implies that an external source, hacker, disgruntled employee, or other entity has purposely changed one or more records in the dataset for some reason. The source and reason for the data modification are less important than the effects the modification has on any analysis you perform. Yes, you eventually need to locate the source and use the reason as a means to keep the modification from occurring in the future, but the first priority is to detect the modification in the first place. Consider this sequence of events:
- Hackers want to create an environment where products from Organization A, a competitor of Organization B, receive better placement on a sales site because the competitor is paying them to do so
- The hackers discover that buyer product reviews and their product ratings are directly associated with the site’s ranking mechanism
- The hackers employ zombie systems (computers they have taken over) to upload copious reviews to the site giving Organization B’s products a one-star review
- The site’s ML application begins to bring down the product rankings for Organization B and the competitor begins to make a ton of money
If there were some system in place to detect the zombie system attack, the ML application could compensate, provide notice to an administrator, or react in other ways. Chapter 3, Mitigating Inference Risk by Avoiding Adversarial Machine Learning Attacks, talks about how to work with models to make this attack less effective, but the data is the first consideration. Given that you can’t guarantee the physical security of your data, you need other means to reduce the risks of dataset modification. Constantly monitoring your network, data storage, and data does provide some useful results, but still doesn’t ensure complete data security. Some of the issues listed in Figure 2.1, such as the security of the application, library, or database, along with other vulnerabilities, are nearly invisible to monitoring. Consequently, other methods of dataset modification detection are required.
Two reliable methods of dataset modification detection are traditional methods that rely on immutable calculated values such as hashes and data version control systems, such as DVC (https://dvc.org/). Both approaches have their adherents.
Blockchains
Theoretically, you could rely on blockchains, which are a type of digital ledger ensuring uniqueness, but only in extreme cases. The article Blockchain Explained at https://www.investopedia.com/terms/b/blockchain.asp, provides additional details.
Combining both hashes and data version control approaches may seem like overkill, but one approach tends to reinforce the other and act as a crosscheck. The disadvantages of using both are that you expend additional time, and doing so increases cost, especially if the data version control system is a paid service.
An example of relying on traditional methods
Most traditional methods of data modification detection revolve around using hashes to calculate the value of each file in the dataset. In addition, you may find cryptographic techniques employed. The hash data used to implement a traditional method must appear as part of secure storage on the system handling the data or a hacker could simply change the underlying values. Using a traditional method of data modification has some significant advantages over some other methods, such as a data version control system. These advantages include the following:
- Data scientists, DBAs, and developers understand the underlying methodologies
- The cost of implementing this kind of solution is usually low
- Because people understand the methods so well, this kind of system is usually robust and reliable
Traditional methods normally work best for smaller setups where the number of individuals managing the data is limited. There are also disadvantages to this kind of system as summarized here:
- The system can be hard to implement when the data sources are distributed
- Hashing a large number of files could prove time-prohibitive
- Checking the hash each time a file is checked out, recalculating the hash, and then updating secure storage is error-prone
- A data version control system may prove more flexible and easier to use
You can use the code shown in the following code block (also found in the MLSec; 02; Create Hash.ipynb file for this chapter) to create a hash of an existing file:
- Begin by importing the libraries:
from hashlib import md5, sha1from os import path inputFile = "test_hash.csv" hashFile = "hashes.txt"
- Obtain the file hashes:
openedInput = open(inputFile, 'r', encoding='utf-8')readFile = openedInput.read() md5Hash = md5(readFile.encode()) md5Hashed = md5Hash.hexdigest() sha1Hash = sha1(readFile.encode()) sha1Hashed = sha1Hash.hexdigest() openedInput.close()
- Open the saved values, when they exist:
saveHash = Trueif path.exists(hashFile):
- Get the hash values:
openedHash = open(hashFile, 'r', encoding='utf-8') read_md5Hash = openedHash.readline().rstrip() read_sha1Hash = openedHash.readline()
- Compare them to the current hash:
if (md5Hashed == read_md5Hash) and (sha1Hashed == read_sha1Hash): print("The file hasn't been modified.") else: print("Someone has changed the file.") print("Original md5: %r New: %r" % (read_md5Hash, md5Hashed)) print("Original sha1: %r New: %r" % (read_sha1Hash, sha1Hashed)) saveHash = False openedHash.close() if saveHash: ## Output the current hash values print("File Name: %s" % inputFile) print("MD5: %r" % md5Hashed) print("SHA1: %r" % sha1Hashed) ## Save the current values to the hash file. openedHash = open(hashFile, 'w') openedHash.write(md5Hashed) openedHash.write(' ') openedHash.write(sha1Hashed) openedHash.close()
This example begins by opening the data file. Make sure you open the file only for reading and that you specify the type of encoding used. The file could contain anything. This .csv file contains a simple series of numbers such as those shown here:
1, 2, 3, 4, 5 6, 7, 8, 9, 10
It’s important to call encode() as part of performing the hash because you get an error message otherwise. The md5Hash and sha1Hash variables contain a hash type as described at https://docs.python.org/3/library/hashlib.html. What you need is a text rendition of the hash, which is why the code calls hexdigest(). After obtaining the current hash, the code closes the input file.
The hash values appear in hashes.txt. If this is the first time you have run the application, you won’t have a hash for the file, so the code skips the comparison check, displays the new hash values, and saves them to disk. Therefore, you see output such as this:
File Name: test_hash.csv MD5: '182f800102c9d3cea2f95d370b023a12' SHA1: '845d2f247cdbb77e859e372c99241530898ec7cb'
When there is a hashes.txt file to check, the code opens the file, reads in the hash values, which appear on separate lines, and places them in the appropriate variables. These values are already strings, but notice you must remove the newline character from the first string by calling rstrip(). Otherwise, the current hash value won’t compare to the saved hash value. During the second run of the application, you see the same output as the first time with “The file hasn’t been modified.” as the first line.
Now, try to modify just one value in the test_hash.csv file. Run the code again and you instantly see that this simple-looking method actually does detect the change (these are typical results, and your precise output may vary):
Someone has changed the file. Original md5: '182f800102c9d3cea2f95d370b023a12' New: 'fae92acdd056dfd3c2383982657e7c8f' Original sha1: '845d2f247cdbb77e859e372c99241530898ec7cb' New: '677f4c2cfcc87c55f0575f734ad1ffb1e97de415'
Changing the original file back will restore the original “The file hasn’t been modified.” output. Consequently, once you have vetted and verified your data source file, you can use this technique to ensure that even a restored copy of the file is correct. The biggest issue with this approach is that you must ensure the integrity of hash storage or any comparison you make will be problematic.
Working with hashes and larger files
When working with large data files, you can’t read the entire file into memory at once. Doing so would cause the application to crash due to a lack of memory. Consequently, you create a loop where you read the data in blocks of a certain size, such as 64 KB. The loop continues to run until a test of the input variable shows there is no more data to process. Most developers use a break statement to break out of the loop at this point.
To create the hash, you must process each block separately by calling the update() function, rather than using the constructor as shown in the example in the previous section. The result is that the hash changes during each loop until you obtain a final value. As with the example code in this chapter, you can then use the hexdigest() function to retrieve the file hash value as a string. Here’s a quick overview of the loop using 64-KB chunks (this code isn’t meant to be run, and simply shows the technique):
chunksize = 65536 md5Hash = hashlib.md5() with open(filename, 'rb') as hashFile: while chunk := hashFile.read(chunksize): md5Hash.update(chunk) return md5Hash.hexdigest()
The hash obtained using a single call to the constructor is the same as the hash obtained using update() as long as you process the entire file in both cases. Consequently, modifying your code to handle larger files when it becomes necessary shouldn’t change the stored hash values.
Using a data version control system example
This section discusses data version control. Application code version control is another matter because it involves working with different versions of an application. Unfortunately, many people focus on application code because that’s something they’re personally involved in writing, and spend less time with their data. The problem with this approach is that you can suddenly find that your application code works perfectly, but produces incorrect output because the data has been altered in some way.
Data version control creates a new version of the saved document every time someone makes a change. A full-fledged database management system (DBMS) provides this sort of support through various means, but if you’re working with .csv files, you need another solution. Using a data version control system ensures the following:
- It’s possible to reverse unwanted changes, no matter what the source might be
- Multiple data sources remain coordinated in the version of the files that represent a data transaction
- Previous versions of the data remain secure, which isn’t always possible when working with backups
- Handling multiple users doesn’t present a problem
- Importing the data into your application development environment is relatively easy or perhaps even automatic
When working with data, it pays to know how the data storage you’re using maintains versions of those files. For example, when working with Windows, you get an automatic version save as part of a restore point or a backup as described at https://hls.harvard.edu/dept/its/restoring-previous-versions-of-files-and-folders/. However, these versions won’t let you return to the version of the file you had 5 minutes ago. Online storage has limits as well. If you store your data on Dropbox, you only get 180 days for a particular version of a file (see https://help.dropbox.com/files-folders/restore-delete/version-history-overview for details). The problem with most of these solutions is that they don’t really provide versioning. If you make a change one minute, save it, and then decide you want the previous version the next minute, you can’t do it.
- Fortunately, there are solutions for data version control out there, such as Data Version Control at https://dvc.org/. Most of these solutions rely on some type of GitHub (https://github.com/) setup, which is true of Data Version Control (see https://dvc.org/doc/start for details). You can also find do-it-yourself solutions such as the one at https://medium.com/pytorch/how-to-iterate-faster-in-machine-learning-by-versioning-data-and-models-featuring-detectron2-4fd2f9338df5. The good thing about some of these home-built solutions is that they can work with any frameworks you currently rely on, such as Docker. Here are some other data version control setups you might want to consider:
- Delta Lake (https://delta.io/): Creates an environment where it’s easy to see the purpose behind various changes. It supports atomicity, consistency, isolation, and durability (ACID) transactions (where changes to the dataset are strictly controlled, as described at https://blog.yugabyte.com/a-primer-on-acid-transactions/), scalable metadata handling, and unified streaming and batch data processing.
- DoIt (https://github.com/dolthub/dolt): Relies on a specialized SQL database application to fork, clone, branch, merge, push, and pull file versions, just as you would when working with GitHub. To use this solution, you need a copy of MySQL, which does have the advantage of allowing you to locate the repository anywhere you want.
- Git Large File Storage (LFS) (https://git-lfs.github.com/): Defines a way to use GitHub to interact with really large files such as audio or video files. The software replaces the file with a text pointer to a location on a remote server where the actual file is stored. Each version of a file receives a different text marker, so it’s possible to restore earlier versions as needed.
- lakeFS (https://lakefs.io/): Works with either the Amazon Web Services (AWS) S3 or Google Cloud Storage (GCS) service to provide GitHub-like functionality with petabytes of data. This software is ACID-compliant and allows easy rollbacks of transactions as needed, which is a plus when working with immense datasets.
- Neptune (https://neptune.ai/): Provides a good system for situations that require a lot of experimentation. It works with scripts (Python, R, or other languages) and notebooks (local, Google Colab, or AWS SageMaker), and performs these tasks using any infrastructure (cloud, laptop, or cluster).
- Pachyderm (https://www.pachyderm.com/): Focuses on the ML application life cycle. You can send data in a continuous stream to the main repository or create as many branches as needed for experimentation.
Version control is an important element of keeping your data safe because it provides a fallback solution for when data changes occur. The next section of the chapter starts to look at an issue that isn’t so easily mitigated – data corruption.
Mitigating dataset corruption
Dataset corruption is different from dataset modification because it usually infers some type of accidental modification that could be relatively easy to spot, such as values out of range or missing altogether. The results of the corruption could appear random or erratic. In many cases, assuming the corruption isn’t widespread, it’s possible to fix the dataset and restore it to use. However, some datasets are fragile (especially those developed from multiple incompatible sources), so you might have to recreate them from scratch. No matter the source or extent of the data corruption, a dataset that suffers from corruption does have these issues:
- The data is inherently less reliable because you can’t ensure absolute parity with the original data.
- Any model you create from the data may not precisely match the model created with the original data.
- Hackers or disgruntled employees may purposely corrupt a dataset to keep specific records out of play, so you must eliminate human sources as the cause of the corruption.
- The use of data input automation and techniques such as optical character recognition (OCR) can corrupt data in a non-repeatable way that’s difficult to track down and even more difficult to fix.
- Eliminating the source of any accidental corruption is essential, especially when the corruption source is a sensor or other type of dynamic data input. Knowing the precise source and reason behind sensor or other dynamic data input corruption can also help mitigate the corruption but can prove time-consuming to locate.
- Anyone relying on the corrupted dataset is less likely to believe future results from it, which means additional crosschecks. Unreliable results have a significant effect on human users of the underlying dataset.
- Third parties that contribute to a dataset may not want to admit to the corruption or may lack the resources to fix it. If the dataset contains some standardized form of data, modifying the data on your own means that the dataset will be out of sync with others using it.
All of these issues create an environment where the data isn’t trustworthy and you find that the model doesn’t behave in the predicted manner. More importantly, there is a human factor involved that makes it difficult or impossible to locate a precise source of corruption.
The human factor in missingness
Before moving forward to actually fixing the dataset corruption, it’s important to consider another source – humans. Lightning strikes, natural disasters, errant sensors, and other causes of data missingness have potential fixes that are possible to quantify. To overcome lightning, for example, you ensure that you isolate your data center from potential sources of lightning. However, humans cause significantly more damage to datasets by failing to create complete records or entering the data incorrectly. Yes, you can include extensive data checks before the application accepts a new record, but it’s amazing how proficient humans become at overcoming them in order to save a few moments of time in creating the record correctly.
The inability of application code to overcome human inventiveness is the reason that data checks alone won’t solve the problem. Using good application design can help reduce the problem by reducing the choices humans have when entering the data. For example, it’s possible to use checkboxes, option boxes, drop-down lists, and so on, rather than text boxes. Creating forms to accept data logically also helps. A study of workflows (the processes a person naturally uses to accomplish a task) shows that you can reduce errors by ensuring the forms request data precisely when the human entering the data is in the position to offer it.
Automation offers another solution. Using sensors and other methods of detection allows the entry of data into a form without asking for it from a person at all. The human merely verifies that the entry is correct. The ML technology to guess the next word you need to type into a text box, such as typeahead, can also reduce errors. Anything you can automate in the data entry form will ultimately reduce problems in the dataset as a whole.
The one method that seems to elude most people who work with data, however, is the reduction of features so that a form requires less data in the first place. Many people designing a dataset ask whether it might be helpful to have a certain feature in the future, rather than what is needed in the dataset today. Over-engineering a dataset is an invitation to introduce unnecessary and preventable errors. When creating a dataset, consider the human who will participate in the data entry process and you’ll reduce the potential for data problems.
An example of recreating the dataset
Missing data can take all sorts of forms. You could see a blank string where there should be text, as an example. Dates could show up as a default value, rather than an actual date, or they could appear in the wrong format, such as MM/DD/YYYY instead of YYYY/MM/DD. Numbers can present the biggest problem, however, because they can take on so many different forms. The first check you then need to make is to detect any actual missing values. You can use the following code (also found in the MLSec; 02; Missing Data.ipynb file for this chapter) to discover missing numeric values:
import pandas as pd import numpy as np s = pd.Series([1, 2, 3, np.NaN, 5, 6, None, np.inf, -np.inf]) ## print(s.isnull()) print(s.isin([np.NaN, None, np.inf, -np.inf])) print() print(s[s.isin([np.NaN, None, np.inf, -np.inf])])
This simple data series contains four missing values: np.NaN, None, np.inf, and –np.inf. All four of these values will cause problems when you try to process the dataset. The output shows that Python easily detects this form of missingness:
0 False 1 False 2 False 3 True 4 False 5 False 6 True 7 True 8 True dtype: bool 3 NaN 6 NaN 7 inf 8 -inf dtype: float64
The type of missing values you see can provide clues as to the cause. For example, a disconnected sensor will often provide an np.inf or -np.inf value, while a malfunctioning sensor might output a value of None instead. The difference is that in the first case, you reconnect the sensor, while in the second case, you replace it.
Once you know that a dataset contains missing data, you must decide how to correct the problem. The first step is to solve the problems caused by np.inf and –np.inf values. Run this code:
replace = s.replace([np.inf, -np.inf], np.NaN) print(s.mean()) print(replace.mean())
Then, the output tells you that np.inf and –np.inf values interfere with data replacement techniques that rely on a statistical measure to correct the data, as shown here:
nan 3.4
The first value shows that the np.inf and –np.inf values produce a nan output when obtaining a mean to use as a replacement value. Using the updated dataset, you can now replace the missing values using this code:
replace = replace.fillna(replace.mean()) print(replace)
The output shows that every entry now has a legitimate value, even if that value is calculated:
0 1.0 1 2.0 2 3.0 3 3.4 4 5.0 5 6.0 6 3.4 7 3.4 8 3.4 dtype: float64
Sometimes, replacing the data values will still cause problems in your model. In this case, you want to drop the errant values from the dataset using code such as this:
dropped = s.replace([np.inf, -np.inf], np.nan).dropna() print(dropped)
This approach has the advantage of ensuring that all of the data you do have is legitimate data and that the amount of code required is smaller. However, the results could still show skewing and now you have less data in your dataset, which can reduce the effectiveness of some algorithms. Here’s the output from this code:
0 1.0 1 2.0 2 3.0 4 5.0 5 6.0 dtype: float64
If this were a real dataset with thousands of records, you’d see a 37.5 percent data loss, which would prove unacceptable in most cases. The dataset would be unusable in this situation and most organizations would do everything possible to keep the failure from being known (although, you can find a few articles online that hint at it, such as The History of Data Breaches at https://digitalguardian.com/blog/history-data-breaches). You have these alternatives when you need a larger dataset without replaced values:
- Reconstruct the dataset if you suspect that the original has fewer missing or corrupted entries.
- Collect additional data after correcting any issues that caused the missing or corrupted data in the first place.
- Obtain similar data from other datasets and combine it (after ensuring the datasets are compatible) with the current dataset after conditioning.
Using an imputer
Another method for handling missing data is to rely on an imputer, a technique that can actually replace missing values with their true values when you can provide a statistical basis for doing so. The problem is that you need to know a lot about the dataset to use this approach. Here is an example of how you might replace the np.NaN, None, np.inf, and –np.inf values in a dataset with something other than a mean:
import pandas as pd import numpy as np from sklearn.impute import SimpleImputer s = pd.Series([1, 2, 3, np.NaN, 5, 6, None, np.inf, -np.inf]) s = s.replace([np.inf, -np.inf], np.NaN) imp = SimpleImputer(missing_values=np.NaN, strategy='mean') imp.fit([[1, 2, 3, 4, 5, 6, 7, 8, 9]]) s = pd.Series(imp.transform([s]).tolist()[0]) print(s)
The values in s are the same as those shown in the An example of recreating the dataset section. Given that this technique only works with nan values, you must also call on replace() to get rid of any np.inf or –np.inf values. The call to the SimpleImputer() constructor defines how to perform the impute on the missing data. You then provide statistics for performing the replacement using the fit() method. The final step is to transform the dataset containing missing values into a dataset that has all of its values intact. You can discover more about using SimpleInputer at https://scikit-learn.org/stable/modules/generated/sklearn.impute.SimpleImputer.html. Here is the output from this example:
0 1.0 1 2.0 2 3.0 3 4.0 4 5.0 5 6.0 6 7.0 7 8.0 8 9.0 dtype: float64
The output shows that the imputer does a good job of inferring the missing values by using the values that are present as a starting point. Even if you don’t see high-quality results such as this every time, an imputer can make a significant difference when recovering damaged data.
Handling missing or corrupted data
Even though this book typically uses single-file datasets and experiments online sometimes use the same approach, a single-file dataset is more the exception than the rule. The most common reason why you might use a single file is that the source data is actually feature-limited (while the number of records remains high) or you want to simplify the problem so that any experimental results are easier to quantify. However, it doesn’t matter whether your dataset has a single file or more than one file associated with it – sometimes, you can’t fix missingness or corruption through statistical means, data dropping, or the use of an imputer. In this case, you must recreate the dataset.
When working with a toy dataset of the sort used for experimentation, you can simply download a new copy of the dataset from the originator’s website. However, this process isn’t as straightforward as you might think. You want to obtain the same results as before, so you need to use caution when getting a new copy. Here are some issues to consider when recreating a dataset for experimentation:
- Ensure the dataset you download is the same version as the one that became unusable.
- Verify that the dataset you’ve downloaded hasn’t been corrupted by comparing a hash you create against the hash listed online (when available).
- Include any modifications you made to the dataset.
Any local dataset you create should have backups, possibly employ a transactional setup with logs, and rely on some sort of versioning system (see the Using a data version control system section for details). With these safeguards in place, you should be able to restore a dataset to a known good state if you detect the source of missingness or corruption early enough. Unfortunately, it’s often the case that the problem isn’t noticed soon enough.
When working with sensor-based data, you can attempt to recreate the dataset by recreating the conditions under which the sensor logs were originally created and simply record new data. The recreated dataset will have statistical differences from the original dataset, but within a reasonable margin of error (assuming that the conditions you create are precisely the same as before). If this sounds like a less-than-ideal set of conditions, recreating datasets is often an inexact business, which is why you want to avoid data problems in the first place.
A dataset that includes multiple files requires special handling. If you’re using a DBMS, the DBMS software normally includes methods for recovering a dataset based on backups and transactional logs. Because each new entry into the database is part of a transaction (or it should be), you may be able to use the transaction logs to your benefit and ensure the database remains in a consistent state. Some database recovery tools will actually create the database from scratch using scripts or other methods and then add the data back in as the tool verifies the data.
Your dataset may not appear as part of a DBMS, which means that you have multiple files organized loosely. The following steps will help you recreate such a dataset:
- Create a new folder to hold the verified dataset files.
- Verify each file in turn using an approach such as a hash check.
- Copy each verified file to the new folder.
- Attempt to obtain a new copy of any damaged files from the data version control system when available. Copy the downloaded files to the new folder.
- Use statistical or imputer methods to fix any remaining damaged files. Copy these files to the new folder.
- Check the number of files in the new folder against the number of files in the old folder to ensure they match.
- Perform a test on the files to determine whether they can produce a desirable result from your ML application.
These steps may not always provide you with a perfect recovery, but you can get close enough to the original data that the model should work as it did before within an acceptable statistical range.
Summary
This chapter has described the importance of having good data to ensure the security of ML applications. Often, the damage caused by modified or corrupted data is subtle and no one will actually notice it until it’s too late: an analysis is incorrect, a faulty recommendation causes financial harm, an assembly line may not operate correctly, a classification may fail to point out that a patient has cancer, or any number of other issues may occur. The focus of most data damage is causing the model to behave in a manner other than needed. The techniques in this chapter wil help you avoid – but not necessarily always prevent – data modification or corruption.
The hardest types of modification and corruption to detect and mitigate are those created by humans in most cases, which is why the human factor receives special treatment in this chapter. Modifications that are automated in nature have a recognizable pattern and most environmental causes are rare enough that you don’t need to worry about them constantly, but human modifications and corruption are ongoing, unique, and random in nature. No matter the source, you discovered how to detect certain types of data modification and corruption, all with the goal of creating a more secure ML application environment.
Chapter 3, Mitigating Inference Risk by Avoiding Adversarial Machine Learning Attacks, will take another step on the path toward understanding ML threats. In this case, the chapter considers the threats presented to the model itself and any associated software that drives the model or relies on model output. The point is that the system is under attack and that the causes are no longer accidental.