
Chapter 7. Security and Ajax
This chapter covers
- The JavaScript security model
- Remote web services
- Protecting users’ data on the Internet
- Protecting your Ajax data streams
Security is an increasingly important concern for Internet services. The Web is inherently nonsecure, and adding proper security measures to an Ajax application can be a strong differentiator for a product. Clearly, if a user’s money is involved in any way, such as online shopping or providing a service that he has paid for, giving due consideration to security is essential.
Security is a big topic and deserves its own book. Many of the security issues that an Ajax application faces are the same as for a classical web application. For these reasons, we’ll limit our discussion to security-related concerns that have particular implications for Ajax. First, we’ll look at the security implications of shunting executable scripts around the network, and the steps that the browser vendors have taken to make this a safe experience. We’ll also see the steps that may be taken to relax these safeguards, with the user’s compliance. Second, we’ll look at protecting a user’s data when it is submitted to the server, allowing a user to work with our Ajax services confidently. Finally, we’ll describe ways to secure the data services that our Ajax clients use to prevent them from being used illegitimately by external entities on the network. Let’s kick off now with a look at the security implications of sending our client across the network.
7.1. JavaScript and browser security
When an Ajax application is launched, the web server sends a set of JavaScript instructions to a web browser running on a different machine, about which it knows very little. The browser proceeds to execute these instructions. In letting their web browser do this, the user of an Ajax application is placing a significant amount of trust in the application and its authors. The browser vendors and standards bodies recognized that this trust was not always appropriate, and have put safeguards in place to prevent it from being abused. In this section, we’ll look at the safeguards and how to work with them. We’ll then discuss situations where the constraints aren’t appropriate and can thus be relaxed. The ability to talk directly to third-party web services is one such situation that should be of particular interest to Ajax developers.
Before diving any further into this topic, let us define what we mean by “mobile code.” Everything on the hard disk of a computer is just a clump of binary data. We can distinguish, however, between data that is purely descriptive and data that represents machine instructions that can be executed. Descriptive data can do nothing until some executing process picks it up. In the early client/server applications, the client was installed on the user’s machine just like any other desktop application, and all traffic over the network was purely descriptive data. The JavaScript code of an Ajax application, however, is executable code. As such, it offers the potential to do many more exciting things than “dead” data can. It can also be more dangerous. We describe code as mobile if it is stored on one machine and can transmit itself across the network to execute on another. The computer receiving the mobile code needs to consider whether it should trust the sender of the code, particularly over the public Internet. To what system resources should it grant access?
7.1.1. Introducing the “server of origin” policy
We noted that, when executing JavaScript in a web browser, a user is letting code written by somebody they don’t know run on their own machine. Mobile code, capable of running automatically over a network in this fashion, is a potential security risk. In response to the potential dangers of mobile code, browser vendors execute JavaScript code in a sandbox, a sealed environment with little or no access to the computer’s resources. An Ajax application can’t read or write to the local filesystem. Nor can it establish network connections to any web domain other than the one from which it originated, in most cases. A programmatically generated IFrame can load pages from other domains and execute code, but the scripts from the two domains cannot interact with each other. This is sometimes referred to as the “server of origin” policy.
Let’s take a (very) simple example. In our first script file, we define a variable:
x=3;
In the second script file, we make use of that variable:
alert(top.x+4);
The first script is included into our top-level document, which opens up an IFrame and loads a page that includes the second script into it (figure 7.1).
Figure 7.1. The JavaScript security model prevents scripts from different domains from interacting with one another.
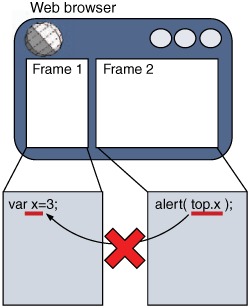
If both scripts are hosted on the same domain, then the alert fires successfully. If not, a JavaScript error is thrown instead, and the second script fails.
7.1.2. Considerations for Ajax
In the script-centric interaction that we discussed in chapter 5, JavaScript code is retrieved from the server and evaluated on the fly. In most cases, the client is consuming code from its own server, but let’s consider the case where it is running code from a different domain, often referred to as “cross-scripting.” Allowing the user to download scripts from arbitrary sites would open up the potential for a lot of mischief, effectively letting third parties re-author or deface websites by using DOM manipulation, for example. The limitations imposed by the JavaScript security model offer real protection from this kind of exploit. The model also prevents malicious sites from downloading your Ajax client code directly from your website and pointing it at a different server without your users knowing that they were talking to a different back-end.
In a data-centric interaction, the risk is slightly less, as the server is delivering data rather than live code. Nonetheless, if delivered from a third-party server the data might contain information crafted to do harm when parsed. For example, it might overwrite or delete vital information, or cause resources to be consumed on the server.
7.1.3. Problems with subdomains
Finally, note that web browsers have a fairly limited notion of what constitutes the same domain and can err frustratingly on the side of caution. The domain is identified solely by the first portion of the URL, with no attempt to determine whether the same IP address backs the two domains. Table 7.1 illustrates a few examples of how the browser security model “thinks.”
Table 7.1. Examples of cross-browser security policy
|
URLs |
Cross-Scripting Allowed? |
Comments |
|---|---|---|
| http://www.mysite.com/script1.js | Yes | As expected! |
| http://www.mysite.com/script2.js | ||
| http://www.mysite.com:8080/script1.js | No | The port numbers don’t match (script 1 is served from port 8080). |
| http://www.mysite.com/script2.js | ||
| http://www.mysite.com/script1.js | No | The protocols don’t match (script 2 uses a secure HTTP protocol). |
| https://www.mysite.com/script2.js | ||
| http://www.mysite.com/script1.js | No | www.mysite.com resolves to IP address 192.168.0.1, but the browser doesn’t try to work this out. |
| http://192.168.0.1/script2.js | ||
| http://www.mysite.com/script1.js | No | Subdomains are treated as separate domains. |
| http://scripts.mysite.com/script2.js | ||
| http://www.myisp.com/dave/script1.js | Yes | Although the scripts come from sites owned by different people, the domain is the same. |
| http://www.myisp.com/eric/script2.js | ||
| http://www.myisp.com/dave/script1.js | No | www.mysite.com points to www.myisp.com/dave, but the browser won’t check this. |
| http://www.mysite.com/script2.js |
In the case of subdomains, it is possible to truncate the part of the domain being matched by setting the document.domain property. Thus, for example, in a script served from http://www.myisp.com/dave, we can add a line to the script stating
document.domain='myisp.com';
which would allow interaction with a script served from the subdomain http://dave.myisp.com/, provided that it too sets the document.domain value. It isn’t possible to set my document.domain to an arbitrary value such as www.google.com, however.
7.1.4. Cross-browser security
Our discussion wouldn’t be complete without pointing out a glaring cross-browser inconsistency. Internet Explorer security operates on a series of “zones,” with more or less restrictive security permissions. By default (for Internet Explorer 6, at least), files executing on the local filesystem are given permission to contact websites on the Internet without the user being prompted, with the local filesystem assumed to be a safe zone. The same code will trigger a security dialog if run from a local web server (figure 7.2).
Figure 7.2. A security warning dialog is shown in Internet Explorer if the code tries to contact a web service not originating from its own server. If the user agrees to this interaction, subsequent interactions won’t be interrupted.

It is possible to write sophisticated Ajax applications and test large parts of the functionality against dummy data served directly from the filesystem. Taking the web server out of the equation does simplify a development setup during intense coding sessions. However, we urge developers testing any code that is accessing Internet web services to test it on a local web server in addition to the filesystem. Under Mozilla, there is no concept of zones, and web applications served off the local filesystem are as restricted as any delivered from a web server. Under Internet Explorer, however, the code runs in different security zones under the two situations, making for a big difference in behavior.
This summarizes the key constraints within which our Ajax scripts must operate. The JavaScript security model has a few annoyances but generally works to our advantage. Without it, public confidence in rich Internet services such as those offered by Ajax would be so low that Ajax wouldn’t be a viable technology for any but the most trivial of uses.
There are, however, legitimate reasons for invoking scripts from domains other than your own, such as when dealing with a publisher of web services. We’ll see in the next section how to relax the security considerations for situations such as these.
7.2. Communicating with remote services
Building security into the web browser is a sensible move, but it can also be frustrating. Security systems have to distrust everyone in order to be effective, but there are situations where you will want to access a resource on a third-party server for legitimate reasons, having thought through the security implications for yourself. Now that we understand how the browsers apply their security policy, let’s discuss ways of relaxing it. The first method that we’ll look at requires additional server-side code, and the second one works on the client only.
7.2.1. Proxying remote services
Because of the “server of origin” policy, an Ajax application is limited to retrieving all its data from its own web domain. If we want our Ajax application to access information from a third-party site, one solution is to make a call to the remote server from our own server rather than from the client, and then forward it on to the client (figure 7.3).
Figure 7.3. If an Ajax application needs to access resources from other domains, the server of origin can proxy the resources on the Ajax client’s behalf.
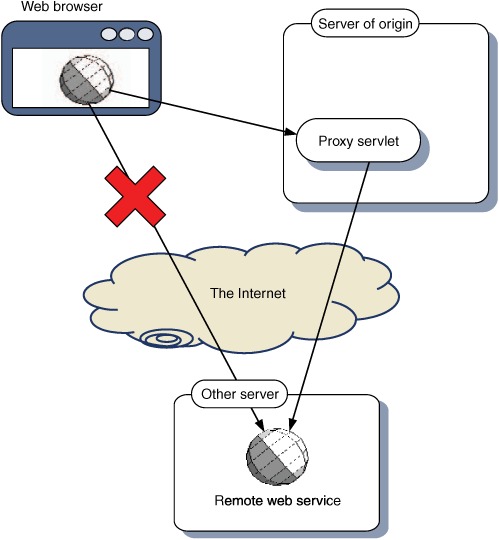
Under this setup, the data appears to the browser to be coming from the local server, and so the server of origin policy is not violated. In addition, all data is subject to the scrutiny of the server, giving an opportunity to check for malicious data or code before forwarding it to the client.
On the downside, this approach does increase the load on the server. The second solution that we’ll examine goes directly from the browser to the third-party server.
7.2.2. Working with web services
Many organizations these days provide web services that are intended to be used by external entities, including JavaScript clients. An Ajax client will want to contact a web service directly. The server of origin security policy is a problem here, but it can be overcome by programmatically requesting privileges to perform network activities. This request may be passed on to the user, or remembered by the browser and applied automatically, if the user has so instructed.
In this section, you’ll learn how to call a third-party web service directly from an Ajax client application. Internet Explorer and Mozilla Firefox each handle these requests in their own ways, and we’ll see how to keep them both happy.
Our example program will contact one of Google’s web services using the Simple Object Access Protocol (SOAP). SOAP is an XML-based protocol built on top of HTTP. The basic principle of SOAP is that the request sends an XML document to the server, describing parameters to the service, and the server responds with an XML document describing the results. The XML sent by SOAP is rather bulky, itself consisting of headers and content wrapped up in an “envelope.” Because of its use of XML, it is ideal for use with the XMLHttpRequest object.
Google offers a SOAP interface to its search engine, in which the user can transmit a search phrase in the request and get back an XML document that lists a page of results. The XML response is very similar to the data presented visually in a Google search results page, with each entry listing a title, snippet, summary, and URL. The document also lists the total estimated number of results for the phrase.
Our application is a guessing game for the Internet age. It is the estimated number of results that we are interested in. We’re going to present the user with a simple form and a randomly generated large number (figure 7.4). The user must enter a phrase that they think will return a number of results within 1,000 of the number indicated when sent to Google.
Figure 7.4. Using the Google SOAP API in a simple Ajax application to entirely frivolous ends. The user can try to enter a phrase that will return an estimated number of results from Google within the specified range.

We are going to contact the Google SOAP service using the XMLHttpRequest object, wrapped up in the ContentLoader object that we developed in chapter 3. We last revised this object in chapter 6, when we added some notification capabilities to it. If we use that version of the ContentLoader to talk to Google, we will succeed in Internet Explorer but not in Mozilla. Let’s quickly run through the behavior for each browser.
Internet Explorer and web services
As we already noted, Internet Explorer’s security system is based on the concept of zones. If we are serving our guessing game application from a web server, even one running on the localhost port, then we are by default considered to be somewhat nonsecure. When we contact Google the first time using our ContentLoader, we receive a notification message like the one depicted in figure 7.2. If the user clicks Yes, our request, as well as any subsequent requests to that server, will go ahead. If the user clicks No, our request is canceled, and the ContentLoader’s error handler is invoked. The user is not greatly inconvenienced, and a moderate level of security is attained.
Remember, if you’re testing your Ajax client off the local filesystem, Internet Explorer will treat you as secure, and you won’t see the dialog box.
Mozilla browsers, including Firefox, take a rather stricter approach to security, and are consequently more difficult to get right. Let’s look at them next.
Mozilla’s PrivilegeManager
The Mozilla browser security model is based on a concept of privileges. Various activities, such as talking to third-party web servers and reading and writing local files, are considered to be potentially unsafe. Application code seeking to undertake these activities must request the privilege of doing so. Privileges are handed out by the netscape.security.PrivilegeManager object. If we want our Ajax client to talk to Google, it’ll have to talk nicely to the PrivilegeManager first. Unfortunately, Firefox can be configured so that the PrivilegeManager won’t even listen to your code, and this setting is the default for content served from a web server rather than the local filesystem. Thus, the following technique is mainly suitable for use in intranets. If you are in such a situation, or just curious about how Firefox works, then read on.
To request a privilege, we can call the enablePrivilege method. The script will then be halted, and a dialog will be shown to the user (figure 7.5).
Figure 7.5. Requesting additional security privileges in the Firefox browser will result in a dialog being displayed, with a standardized warning message.
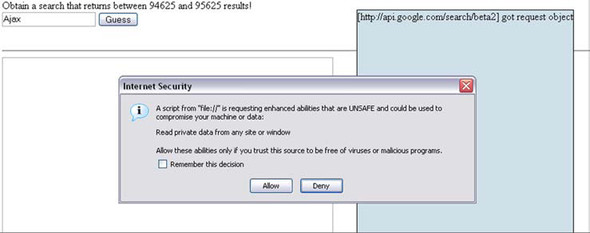
The dialog explains that the script is about to do something that might be unsafe. The user has the opportunity to grant or withhold the privilege. In either case, the script then resumes running. If the privilege has been granted, then all is well. If it hasn’t, then trying to execute the action requiring the privilege will usually result in a scripting error.
We saw that Internet Explorer will automatically remember a user’s first decision and stop bothering them after the first warning. Mozilla will only grant a privilege for the duration of the function in which it was requested, and unless the user clicks the “Remember my decision” checkbox, they will be interrupted by the dialog every time the privilege is required (which is twice per network request, as we will see). Security and usability seem to be at loggerheads here.
The other difference between Internet Explorer and Mozilla is that Mozilla will insist on being asked explicitly in the code before it will even show the user a dialog. Let’s look at our ContentLoader object again (see chapters 3, 5, and 6), and see what we need to do to it to make the request to Google. The modified code contains requests to the PrivilegeManager object, as shown in listing 7.1. (We’ve also added the ability to write custom HTTP headers, which we’ll need to create the SOAP message, as we’ll see next.)
Listing 7.1. Security-aware ContentLoader object


We have added two new arguments to our constructor. The first is an array of additional HTTP headers ![]() , because we will need to pass these in during the construction of the SOAP request. The second is a boolean flag indicating
whether the loader should request privileges at key points.
, because we will need to pass these in during the construction of the SOAP request. The second is a boolean flag indicating
whether the loader should request privileges at key points.
When we request privileges from the netscape.PrivilegeManager object, we are granted them only for the scope of the current function. Therefore, we request them at two points: when the
request to the remote server is made ![]() , and when we try to read the response that is returned
, and when we try to read the response that is returned ![]() . We call the custom onload handler function within the scope of the onReadyState function, so the privilege will persist through any custom logic that we pass in there.
. We call the custom onload handler function within the scope of the onReadyState function, so the privilege will persist through any custom logic that we pass in there.
Internet Explorer doesn’t understand the PrivilegeManager, and will throw an exception when it is referred to. For this reason, we simply wrap the references to it in try...catch blocks, allowing the exception to be caught and swallowed silently. When the previous code runs in Internet Explorer, it will fail silently within the try...catch block, pick itself up again, and keep going with no ill results. Under Mozilla, the PrivilegeManager will be communicated with and no exception will be thrown.
Let’s make use of our modified ContentLoader, then, to send a request off to Google. Listing 7.2 shows the HTML required for our simple guessing game application.
Listing 7.2. googleSoap.html
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<html>
<head>
<title>Google Guessing</title>
<script type="text/javascript" src='net_secure.js'></script>
<script type="text/javascript" src='googleSoap.js'></script>
<script type='text/javascript'>
var googleKey=null;
var guessRange = 1000;
var intNum = Math.round(Math.random()
* Math.pow(10,Math.round(Math.random()*8)));
window.onload = function(){
document.getElementById("spanNumber")
.innerHTML = intNum + " and "
+ (intNum + guessRange);
}
</script>
</head>
<body>
<form name="Form1" onsubmit="submitGuess();return false;">
Obtain a search that returns between
<span id="spanNumber"></span> results!<br/>
<input type="text" name="yourGuess" value="Ajax">
<input type="submit" name="b1" value="Guess"/><br/><br/>
<span id="spanResults"></span>
</form>
<hr/>
<textarea rows='24' cols='100' id='details'></textarea>
</body>
</html>
We set up the form elements in HTML, and calculate a suitably large random number here. We also declare a variable, googleKey. This is a license key allowing us to use the Google SOAP APIs. We haven’t included a valid key here, because we aren’t allowed to by the license terms. Keys are free, and offer a limited number of searches per day. They can be obtained from Google online through a simple process (see the URL in the Resources section at the end of this chapter).
Submitting the request
The bulk of the work is done by the submitGuess() function, which is invoked when the form is submitted. This is defined in the included JavaScript file, so let’s have a look at that next. Listing 7.3 illustrates the first bit of JavaScript, which calls the Google API.
Listing 7.3. submitGuess() function


The first thing that we do in the submitGuess() function is check that we have a license key, and remind the user if we don’t ![]() . When you download the code for this example, the license key will be set to null, so you’ll need to get your own key from Google if you want to play with it.
. When you download the code for this example, the license key will be set to null, so you’ll need to get your own key from Google if you want to play with it.
Our second task is to construct a monstrously huge SOAP message ![]() , containing the phrase we’re submitting and the license key value. SOAP is designed with automation in mind, and it is unusual
to build the XML by hand as we have done here. Both Internet Explorer and Mozilla provide browser-specific objects for interacting
with SOAP in a simpler fashion. Nonetheless, we thought it instructive to do it manually and look at the SOAP request and
response data.
, containing the phrase we’re submitting and the license key value. SOAP is designed with automation in mind, and it is unusual
to build the XML by hand as we have done here. Both Internet Explorer and Mozilla provide browser-specific objects for interacting
with SOAP in a simpler fashion. Nonetheless, we thought it instructive to do it manually and look at the SOAP request and
response data.
Having created the request XML text, we construct a ContentLoader object ![]() , passing in the SOAP XML as the HTTP body content, along with the URL of the Google API
, passing in the SOAP XML as the HTTP body content, along with the URL of the Google API ![]() and the custom HTTP headers
and the custom HTTP headers ![]() . We set the content-type to text/xml. Note that this represents the MIME type of the body of the request, not the MIME type we expect to receive in the response,
although in this case the two are the same. The final parameter, set to a value of true, indicates that we should seek permission from the PrivilegeManager object.
. We set the content-type to text/xml. Note that this represents the MIME type of the body of the request, not the MIME type we expect to receive in the response,
although in this case the two are the same. The final parameter, set to a value of true, indicates that we should seek permission from the PrivilegeManager object.
Parsing the response
The ContentLoader will then make the request and, if the user grants permission, will receive an equally large chunk of XML in return. Here is a small sample of the response to a search on the term “Ajax”:
<?xml version='1.0' encoding='utf-8'?> <soap-env:envelope xmlns:soap-env="http://schemas.xmlsoap.org/soap/envelope/" xmlns:xsi="http://www.w3.org/1999/xmlschema-instance" xmlns:xsd="http://www.w3.org/1999/xmlschema"> <soap-env:body> <ns1:dogooglesearchresponse xmlns:ns1="urn:googlesearch" soap-env:encodingstyle="http://schemas.xmlsoap.org/soap/encoding/"> <return xsi:type="ns1:googlesearchresult"> <directorycategories xmlns:ns2="http://schemas.xmlsoap.org/soap/encoding/" xsi:type="ns2:array" ns2:arraytype="ns1:directorycategory[1]"> ... <estimateisexact xsi:type="xsd:boolean">false</estimateisexact> <estimatedtotalresultscount xsi:type="xsd:int">741000</estimatedtotalresultscount> ... <hostname xsi:type="xsd:string"></hostname> <relatedinformationpresent xsi:type="xsd:boolean">true</ relatedinformationpresent> <snippet xsi:type="xsd:string">de officiële site van afc <b>ajax</ b>.</snippet> <summary xsi:type="xsd:string">official club site, including roster, history, wallpapers, and video clips.<br> [english/dutch]</summary> <title xsi:type="xsd:string"> <b>ajax</b>.nl – splashpagina </title> ...
The full SOAP response is too lengthy to include here, we’ve presented three snippets. The first part defines some of the transport headers, saying where the response comes from, and so on. Within the body, we find a couple of elements describing the estimated results count—the phrase returned 741,000 results, which is not considered to be an exact figure. Finally, we can see part of the first result returned, describing the link to the Dutch football team Ajax’s home page. Listing 7.4 shows our callback handler, in which we parse the response.
Listing 7.4. parseGoogleResponse() function
function parseGoogleResponse(){
var doc=this.req.responseText.toLowerCase();
document.getElementById('details').value=doc;
var startTag='<estimatedtotalresultscount xsi:type="xsd:int">';
var endTag='</estimatedtotalresultscount>';
var spot1=doc.indexOf(startTag);
var spot2=doc.indexOf(endTag);
var strTotal1=doc.substring(spot1+startTag.length,spot2);
var total1=parseInt(strTotal1);
var strOut="";
if(total1>=intNum && total1<=intNum+guessRange){
strOut+="You guessed right!";
}else{
strOut+="WRONG! Try again!";
}
strOut+="<br/>Your search for <strong>"
+document.Form1.yourGuess.value
+"</strong> returned " + strTotal1 + " results!";
document.getElementById("spanResults").innerHTML = strOut;
}
For the moment, we aren’t concerned with the structure of the SOAP message but only with the estimated number of results returned. The response is valid XML, and we could parse it using the XMLHttpRequest object’s responseXML property. However, we take the path of least resistance here, and simply extract the estimated result count using string manipulation. We then use a few of our DOM manipulation techniques to present the verdict to the user (how good their guess was). For educational purposes, we also dump the entire XML response into a textarea element, for those who want to look at SOAP data in more detail.
Enabling the PrivilegeManager in Firefox
As we noted earlier, the PrivilegeManager can be configured not to respond to our programmatic pleas. To find out whether a Firefox browser is configured this way, type “about:config” into the address bar to reveal the preferences list. Use the filter textbox to find the entry signed.applets.codebase_principal_support. If the value is true, then our code above will work. If not, we won’t be able to contact Google.
Earlier versions of Mozilla required that the configuration be edited by hand, followed by a complete browser restart. In Firefox, double-clicking the relevant row in the preferences list will toggle the preference value between true and false. Changes made in this way will take place immediately, without needing to restart the browser, or even refresh the page, if the preferences are opened in a separate tab.
Signing Mozilla client code
Because Internet Explorer bypasses the PrivilegeManager, the application functions smoothly enough in that browser. However, in Mozilla the user is confronted with the scary-looking dialog twice (assuming that the browser is configured to use the PrivilegeManager), making this sort of web service approach rather problematic for Mozilla users. They can prevent it from reappearing by selecting the “Remember my decision” checkbox (see figure 7.5), but we developers have no control over that (and quite rightly so!).
There is a solution, but it requires the application to be packaged in a way that is very specific to Mozilla. Web applications may be signed by digital certificates. To be signed, however, they must be delivered to Mozilla browsers in JAR files, that is, compressed zip archives with all scripts, HTML pages, images, and other resources in one place. JAR files are signed with digital certificates of the variety sold by companies such as Thawte and VeriSign. Resources inside signed JAR files are referred to using a special URL syntax, such as
jar:http://myserver/mySignedJar.jar|/path/to/someWebPage.html
When the user downloads a signed web application, they are asked once whether they want to allow it to grant any privileges that it asks for, and that is that.
Mozilla provides free downloadable tools for signing JAR files. For users who want to simply experiment with this technology, unauthenticated digital certificates can be generated by tools such as the keytool utility that ships with the Sun Java Development Kit (JDK). We, however, recommend using a certificate from a recognized authority for live deployments.
Signed JAR files are not portable. They will only work in Mozilla browsers. For that reason, we won’t pursue them in any greater detail here. If you’re interested in exploring this approach further, have a look at the URLs in the Resources section.
This concludes our discussion on interacting with remote services using Ajax. We’ve reached to the point where our application is running in the browser, exchanging data with its server and possibly with third-party servers as well. That data is unlikely to execute malicious code on your machine, but it may be a security risk of a different kind, particularly if the data is confidential. In the next section, we’ll see how to safeguard your users’ data from prying eyes.
7.3. Protecting confidential data
The web browser that your user is sitting in front of does not enjoy a direct connection to your server. When data is submitted to the server, it is routed across many intermediate nodes (routers and proxy servers, for instance) on the Internet before it finds your server. Ordinary HTTP data is transmitted in plain text, allowing any intermediate node to read the data in the packets. This exposes the data to compromise by anyone who has control of these intermediate nodes, as we will see.
7.3.1. The man in the middle
Let’s suppose you’ve just written an Ajax application that sends financial details, such as bank account numbers and credit card details, across the Internet. A wellbehaved router transmits the packet unchanged without looking at anything other than the routing information in the packet headers, but a malicious router (figure 7.6) may read the contents of the transmission (say, looking for credit card numbers in the content or valid email addresses to add to a spam list), modify routing information (for example, to redirect the user to a fake site that mimics the one she is visiting), or even modify the content of the data (to divert funds from an intended recipient to his own account, for instance).
Figure 7.6. In an ordinary HTTP transmission, data is transmitted across the Internet in plain text, allowing it to be read or modified at intermediate nodes by the man in the black hat.

Ajax uses HTTP both for transmitting the client code and for submitting data requests to the server. All of the communication methods we’ve looked at—hidden IFrames, HTML forms, XMLHttpRequest objects—are identical in this respect. As with any web-based application, a malicious entity looking to interfere with your service has several points of leverage. Exploiting these weak points are known as “man-in-the-middle” attacks. Let’s look at the measures we can take to protect ourselves from them.
7.3.2. Using secure HTTP
If you are concerned about protecting the traffic between your Ajax client and the server, the most obvious measure you can take is to encrypt the traffic using a secure connection. The Hypertext Transfer Protocol over Secure Socket Layer (HTTPS) provides a wrapper around plain-text HTTP, using public-private key pairs to encrypt data going in both directions. The man in the middle still sees the data packets, but because the content is encrypted, there is nothing much that he can do with them (figure 7.7).
Figure 7.7. Using a secure HTTP connection, data is encrypted in both directions. Intermediate nodes still see the encrypted data but lack the necessary key to decrypt it.

HTTPS requires native code support on both the browser and the server. Modern browsers have good support for HTTPS built in, and most web-hosting firms now offer secure connections at a reasonable price. HTTPS is computationally expensive, and transfers binary data. JavaScript is not a natural choice here; just as we wouldn’t try to reimplement the DOM, CSS, or HTTP using JavaScript, HTTPS is best viewed as a service that we use, rather than something we can override and replace for ourselves.
Let us introduce a few caveats about HTTPS. First, the encryption and decryption do introduce a computational overhead. At the client end, this is not a significant problem, as a single client need only process one stream of traffic. On the server, however, the additional load can be significant on a large website. In a classic web application, it is common practice to transmit only key resources over HTTPS and send mundane content such as images and boilerplate markup over plain HTTP. In an Ajax application, you need to be aware of the impact that this may have on the JavaScript security model, which will recognize http:// and https:// as distinct protocols.
Second, using HTTPS secures only the transmission of data; it is not a complete security solution in itself. If you securely transmit your users’ credit card details using 128-bit SSL encryption and then store the information in an unpatched database that has been infected with a backdoor exploit, the data will still be vulnerable.
Nonetheless, HTTPS is the recommended solution for transferring sensitive data across the network. However, we do recognize that it has its costs and might not be within easy reach of the small website owner. For those with more modest security requirements, we next present a plain HTTP mechanism for transmitting encrypted data.
7.3.3. Encrypting data over plain HTTP using JavaScript
Let’s suppose that you run a small website that doesn’t routinely transmit sensitive data requiring secure connections. You do ask users to log in, however, and are troubled by the passwords being sent as plain text for verification.
In such a scenario, JavaScript can come to your aid. First, let’s describe the overview of the solution and then look at the implementation.
Public and private keys
Rather than transmitting the password itself, we can transmit an encrypted form of the password. An encryption algorithm will generate a random-looking, but predictable, output from an input string. MD5 is an example of such an algorithm. It has a few key features that make it useful for security. First, MD5-ing a piece of data will always generate the same result, every time. Second, two different resources are monumentally unlikely to generate the same MD5 digest. Taken together, these two features make an MD5 digest (that is, the output of the algorithm) of a resource a rather good fingerprint of that resource. The third feature is that the algorithm is not easy to reverse. The MD5 digest can therefore be freely passed about in the open, without the risk of a malicious entity being able to use it to decrypt the message.
For example, the MD5 algorithm will generate the digest string “8bd04bbe6ad2709075458c03b6ed6c5a” from the password string “Ajax in action” every time. We could encrypt it on the client and transmit the encrypted form to the server. The server would then fetch the password for the user from the database, encrypt it using the same algorithm, and compare the two strings. If they match, the server would log us in. At no time did our unencrypted password go across the Internet.
We can’t transmit the straight MD5 digest across the Internet in order to log in, however. A malicious entity might not be able to figure out that it was generated from “Ajax in action”, but they would soon learn that that particular digest grants them access to our site account.
This is where public and private keys come in. Rather than encrypting just our password, we will encrypt a concatenation of our password and a random sequence of characters supplied by the server. The server will supply us with a different random sequence every time we visit the login screen. This random sequence is transmitted across the Internet to the client.
On the client tier, when the user enters her password, we append the random string and encrypt the result. The server has remembered the random string for the duration of this login attempt. It can therefore retrieve the user id, pull the correct password for that user from its database, append the random term, encrypt it, and compare the results. If they match, it lets us in. If they don’t (say we mistype our password), it presents the login form again, but with a different random string this time.
Let’s say that the server transmits the string “abcd”. The MD5 digest of “Ajax in actionabcd” is “e992dc25b473842023f06a61f03f3787.” On the next request, it transmits the string “wxyz”, for which we generate a completely different digest, “3f2da3b3ee2795806793c56bf00a8b94.” A malicious entity can see each random string, and match them to the encrypted hashes, but has no way of deducing the password from these pairs of data. So, unless it gets lucky enough to be snooping a message whose random string it has seen before, it will be unable to hijack the login request.
The random string is the public key. It is visible to all, and disposable. Our password is the private key. It is long-lived, and is never made visible.
A JavaScript implementation
Implementing this solution requires an MD5 generator at both the client and the server. On the client, Paul Johnston has written a freely available generator library in JavaScript (see the Resources section). Using his code is just a matter of including the library and invoking a simple function:
<script type='text/javascript' src='md5.js'></script>
<script type='text/javascript'>
var encrypted=str_md5('Ajax in action'),
//now do something with it...
</script>
On the server tier, MD5 algorithms are available for most popular languages. PHP has had a built-in md5() function since version 3. The java.security.MessageDigest class provides a base implementation for Java encryption algorithms and implementations of a number of common algorithms, including MD5. The .NET Framework provides a System.Security.Cryptography.MD5 class.
This technique has limited usefulness, since the server must already know the data being encrypted in order to facilitate a comparison. It is ideal as a means of providing secure login capabilities without recourse to HTTPS, although it can’t substitute for HTTPS as an all-around secure transmission system.
Let’s review where are now. The server of origin policy is safeguarding our users’ computers from malicious code. Data exchanged between the client and the server is protected from man-in-the-middle attacks by HTTPS. In the final section, let’s look at a third point of attack, the server itself. You’ll learn how to secure your own web services from unwanted visitors.
7.4. Policing access to Ajax data streams
Let’s begin by reviewing the standard Ajax architecture, in order to identify the vulnerability that we’ll discuss in this section. The client, once it is running in the user’s browser, makes requests to the server using HTTP. These requests are serviced by web server processes (servlets, dynamic pages, or whatever) that return streams of data to the client, which it parses. Figure 7.8 summarizes the situation.
Figure 7.8. In an Ajax architecture, the server exposes web services to the Internet over a standard protocol, typically HTTP. The Ajax client fetches streams of data from the server. Because of the public nature of the web services, external entities may request the data directly, bypassing the client.
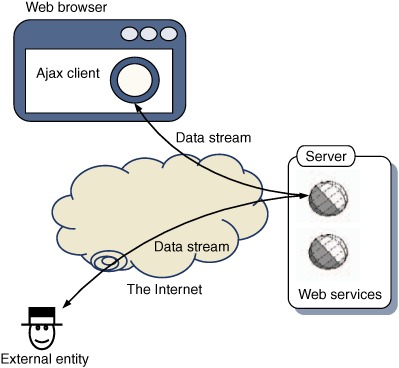
The web services or pages are accessible by external entities, without any additional work on our part—that’s just how the Internet works. It may be that we encourage outsiders to use our web services in this way, and we may even publish an API, as eBay, Amazon, and Google, among others, have done. Even in this case, though, we need to keep security in mind. There are two things we can do, which we discuss in the following two sections. First, we can design our web services interface, or API, in such a way that external entities cannot subvert the purpose of our web application—say, by ordering goods without paying for them. Second, we look at techniques to restrict access to the web services to particular parties.
7.4.1. Designing a secure web tier
When we design a web application, we typically have an end-to-end workflow in mind. In a shopping site, for example, the users will browse the store, adding items to their baskets, and then proceed to checkout. The checkout process itself will have a well-defined workflow, with choice of delivery address, shipping options, payment methods, and confirmation of order. As long as our application is calling the shots, we can trust that the workflow is being used correctly. If an external entity starts to call our web services directly, however, we may have a problem.
Screen scrapers and Ajax
A classic web application is vulnerable to “screen-scraping” programs that traverse these workflows automatically, crafting HTTP requests that resemble those generated by a user filling in a form. Screen-scrapers can deprive sites of advertising revenue and skew web statistics. More seriously, by automating what is intended to be an interaction between a human and the application, they can subvert the workflow of the application, calling server events out of order, or they can overload server processes by repetitive submission. From a security perspective, they are generally considered problematic.
The data in a classic web application’s pages is often buried within a heap of boilerplate HTML and decorative content. In a well-factored Ajax application, the web pages sent to the client are much simpler, well-structured data. Separation of concerns between presentation and logic is good design, but it also makes the job of a screen-scraper easier, because the data returned from the server is designed to be parsed rather than rendered in a browser. Screen-scraping programs tend to be fragile and are prone to break when the look and feel of the site changes. Visual makeovers of an Ajax client are less likely to alter the signatures of the underlying web services that the client application uses to communicate to the server. To protect the integrity of our application, we need to give some thought to these issues when designing the structure of the high-level API used to communicate between client and server. By API, we don’t mean HTTP or SOAP or XML, but the URLs of the dynamic pages and the parameters that they accept.
Example: online battleship game
To illustrate how the design of a web service API affects the security of the application, let’s look at a simplistic example. We’re developing an online version of the classic board game Battleship (see the Resources section), which will be played using an Ajax client that communicates to the server using web services. We want to ensure that the game is cheat-proof, even if a malicious player hacks the client, making it send data to the server out of turn.
The aim of the game is for each player to guess the position of the other’s boats. The game consists of two phases. First, the players each position their pieces on the board. Once this is done, they take turns at guessing particular squares on the board, to see if they can sink the other player’s ships. The master copy of the board is stored on the server during a game, with each client also maintaining a model of its own half of the board and a blank copy of the other player’s board, which gradually gets filled in as their ships are discovered (figure 7.9).
Figure 7.9. Data models in an Ajax-based game of Battleship. Once the pieces are positioned, the server will maintain a map of both players’ pieces. The clients will initially model only their own pieces but build up a model of their opponent’s as the game progresses.
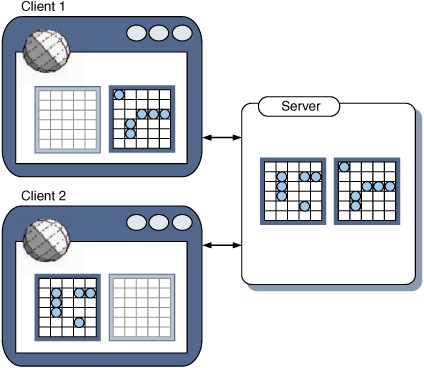
Let’s look at the setup stage. First, the board is wiped clean. Then each piece is placed on the board, until all pieces are placed. There are two ways that we can design the service calls that the clients will make to the server during setup. The first is to use a fine-grained approach, with calls to clear the board and to add a given piece at a given position. During the setup phase, the server would be hit several times, once to clear the board and once to position each piece. Table 7.2 describes the fine-grained setup’s API.
Table 7.2. Fine-grained web API for Battleship game setup phase
|
Arguments |
Return Data |
|
|---|---|---|
| clearBoard.do | userid | Acknowledgment |
| positionShip.do | userid shiplength coordinates (x,y) format orientation (N,S,E or W) |
Acknowledgment or error |
The second design is a coarse-grained approach, in which a single service call clears the board and positions all pieces. Under this approach, the server is hit only once during setup. Table 7.3 describes this alternative API.
Table 7.3. Coarse-grained web API for Battleship game setup phase
|
URL |
Arguments |
Return Data |
|---|---|---|
| setupBoard.do | userid coordinates array of (x,y,length,orientation) structs |
Acknowledgment or error |
We already contrasted these two styles of service architecture when we discussed SOA in chapter 5. The single network call is more efficient and provides better decoupling between tiers, but it also helps us to secure our game.
Under the fine-grained approach, the client takes on the responsibility of checking that the correct number and type of pieces are placed, and the server model takes on the responsibility of verifying the correctness of the system at the end of the setup. Under the coarse-grained approach, this checking is also written into the document format of the service call.
Once setup is completed, an additional service call is defined to represent a turn of the game, in which one player tries to guess the position of another’s ship. By the nature of the game, this has to be a fine-grained service call representing a guess for a single square, as shown in table 7.4.
Table 7.4. Web API for Battleship game play phase (used for both fine- and coarse-grained setup styles)
|
URL |
Arguments |
Return Type |
|---|---|---|
| guessPosition.do | userid coordinates (x,y) |
“hit,” “miss,” or “not your turn” plus update of other player’s last guess |
Under correct game play, both users may set up their pieces in any order and will then call the URL guessPosition.do in turn. The server will police the order of play, returning a “not your turn” response if a player tries to play out of turn.
Let’s now put on our black hats and try to hack the game. We’ve written a client that is able to call the web service API in any order it likes. What can we do to tip the odds in our favor? We can’t give ourselves extra turns because the server monitors that—it’s part of the published API.
One possible cheat is to move a piece after the setup phase is finished. Under the fine-grained architecture, we can try calling positionShip.do while the game is in progress. If the server code has been well written, it will note that this is against the rules and return a negative acknowledgment. However, we have nothing to lose by trying, and it is up to the server-side developer to anticipate these misuses and code defensively around them.
On the other hand, if the server is using the coarse-grained API, it isn’t possible to move individual pieces without also clearing the entire board. Fine-tuning the game in your favor isn’t a possibility.
A coarse-grained API limits the flexibility of any malicious hacker, without compromising the usability for law-abiding users. Under a well-designed server model, use of a fine-grained API shouldn’t present any exploits, but the number of entry points for potential exploits is much higher, and the burden of checking these entry points for security flaws rests firmly with the server tier developer.
In section 5.3.4, we suggested using a Façade to simplify the API exposed by a service-oriented architecture. We recommend doing so again here, from a security standpoint, because a simpler set of entry points from the Internet is easier to police.
Design can limit the exposure of our application to external entities, but we still need to offer some entry points for our legitimate Ajax client to use. In the following section, we examine ways of securing these entry points.
7.4.2. Restricting access to web data
In an ideal world, we would like to allow access to the dynamic data served from our app to the Ajax client (and possibly other authorized parties) and prevent anybody else from getting in. With some rich-client technologies, we would have the opportunity of using custom network protocols, but the Ajax application is limited to communicating over HTTP. Secure HTTP can keep the data in individual transactions away from prying eyes, as we discussed earlier, but it can’t be used to determine who gets to call a particular URL.
Fortunately, HTTP is quite a rich protocol, and the XMLHttpRequest object gives us a good level of fine-grained control over it. When a request arrives on the server, we have access to a range of HTTP headers from which we can infer things about the origin of the request.
Filtering HTTP requests
For the sake of providing concrete examples, we’ll use Java code here. Other server-side technologies offer similar ways to implement the techniques that we are describing, too. In the Java web application specification, we can define objects of type javax.servlet.Filter, which intercept specific requests before they are processed at their destination. Subclasses of Filter override the doFilter() method and may inspect the HTTP request before deciding whether to let it through or forward it on to a different destination. Listing 7.5 shows the code for a simple security filter that will inspect a request and then either let it through or forward it to an error page.
Listing 7.5. A generic Java security filter

The filter is an abstract class, defining an abstract method isValidRequest() that inspects the incoming request object before passing a verdict. If the method fails ![]() , it is forwarded to a different URL
, it is forwarded to a different URL ![]() , which is defined in the configuration file for the web application
, which is defined in the configuration file for the web application ![]() , which we’ll look at shortly.
, which we’ll look at shortly.
This filter provides us with considerable flexibility in defining a concrete subclass. We can adapt it to more than one security strategy.
Using the HTTP session
One common approach is to create a token in the user’s HTTP session when she logs in and check for the existence of that object in session during subsequent requests before performing any other actions. Listing 7.6 demonstrates a simple filter of this type.
Listing 7.6. Session token-checking filter
public class SessionTokenSecurityFilter
extends GenericSecurityFilter {
protected boolean isValidRequest(ServletRequest request) {
boolean valid=false;
HttpSession session=request.getSession();
if (session!=null){
UserToken token=(Token) session.getAttribute('userToken'),
if (token!=null){
valid=true;
}
}
return valid;
}
}
This technique is commonly used in conventional web applications, typically forwarding to a login screen if validation fails. In an Ajax application, we are free to return a much simpler response in XML, JSON, or plain text, which the client could respond to by prompting the user to log in again. In chapter 11, we discuss a fuller implementation of such a login screen for our Ajax Portal application.
Using encrypted HTTP headers
Another common strategy for validating a request is to add an additional header to the HTTP request and check for its presence in the filter. Listing 7.7 shows a second example filter that looks for a specific header and checks the encrypted value against a known key held on the server.
Listing 7.7. HTTP header-checking filter
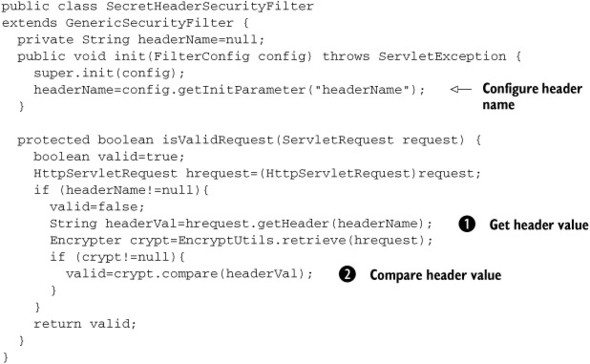
When testing the request, this filter reads a specific header name ![]() and compares it with an encrypted value stored in the server session
and compares it with an encrypted value stored in the server session ![]() . This value is transient and may be generated randomly for each particular session in order to make the system harder to
crack. The Encrypter class uses the Apache Commons Codec classes and javax.security.MessageDigest classes to generate a hex-encoded MD5 value. The full class listing is available in the downloadable code that accompanies
this book. The principle of deriving a hex-encoded MD5 in Java is shown here:
. This value is transient and may be generated randomly for each particular session in order to make the system harder to
crack. The Encrypter class uses the Apache Commons Codec classes and javax.security.MessageDigest classes to generate a hex-encoded MD5 value. The full class listing is available in the downloadable code that accompanies
this book. The principle of deriving a hex-encoded MD5 in Java is shown here:
MessageDigest digest=MessageDigest.getInstance("MD5");
byte[] data=privKey.getBytes();
digest.update(data);
byte[] raw=digest.digest(pubKey.getBytes());
byte[] b64=Base64.encodeBase64(raw);
return new String(b64);
where privKey and pubKey are the private and public keys, respectively. To configure this filter to review all URLs under the path /Ajax/data, we can add the following filter definition to the web.xml configuration file for our web application:
<filter id='securityFilter_1'>
<filter-name>HeaderChecker</filter-name>
<filter-class>
com.manning.ajaxinaction.web.SecretHeaderSecurityFilter
</filter-class>
<init-param id='securityFilter_1_param_1'>
<param-name>rejectUrl</param-name>
<param-value>/error/reject.do</param-value>
</init-param>
<init-param id='securityFilter_1_param_2'>
<param-name>headerName</param-name>
<param-value>secret-password</param-value>
</init-param>
</filter>
This configures the filter to forward rejected requests to the URL /error/reject.do, after checking the value of HTTP header “secret-password.” To complete the configuration, we define a filter mapping to match this filter to everything under a specific path:
<filter-mapping> <filter-name>HeaderChecker</filter-name> <url-pattern>/ajax/data/*</url-pattern> </filter-mapping>
On the client side, the client can generate Base64 MD5 digests using Paul Johnston’s libraries (which we discussed earlier in this chapter). To add the required HTTP header on our Ajax client, we use the setRequestHeader() method, as outlined here:
function loadXml(url){
var req=null;
if (window.XMLHttpRequest){
req=new XMLHttpRequest();
} else if (window.ActiveXObject){
req=new ActiveXObject("Microsoft.XMLHTTP");
}
if (req){
req.onreadystatechange=onReadyState;
req.open('GET',url,true);
req.setRequestHeader('secret-password',getEncryptedKey());
req.send(params);
}
}
where the encryption function is simply defined as the Base64 MD5 digest of a given string:
var key="password";
function getEncryptedKey(){
return b64_md5(key);
}
This solution still requires us to initially communicate the variable key to the Ajax client. We might send the key for the session over HTTPS when the user logs into the application. In reality, the key would be something random, not a string as simple as “password” of course.
The strength of this particular solution is that the HTTP header information can’t be modified from a standard hyperlink or HTML form. Requiring the hacker to use a programmatic HTTP client will stop the less determined ones, at least. Of course, as the use of XMLHttpRequest becomes more prevalent, the knowledge of how to craft HTTP headers within web page requests will spread. Programmatic HTTP clients such as Apache’s HTTPClient and Perl LWP::User-Agent have been able to do this for a long time.
Ultimately, filters and similar mechanisms can’t make it impossible for external agents to get into your site, but they can make it more difficult. Like any other developer, evil hackers have limited resources and time on their hands, and by securing your application in the various ways we have outlined above, you certainly discourage casual interference with your data services.
This concludes our discussion of security for Ajax applications. There are several aspects to securing an Ajax application that we haven’t covered here, because they are largely the same as for a classic web application. A good authentication and authorization mechanism helps to control access to services based on roles and responsibilities. Standard HTTP headers can be used to verify the origin of callers, making it harder (but not impossible) to invoke the services outside the official channels. We recommend consulting the literature on web-based security for those of you with a deeper interest in securing your Ajax applications.
Finally, remember that security isn’t an absolute state. Nothing is ever completely secure. The best that you can hope for is to be one step ahead of any intruders. Using HTTPS where relevant, minimizing exposure of your web-based API, and judiciously using HTTP request checking are all good steps in that direction.
7.5. Summary
In this chapter, we discussed security implications of using Ajax. We concentrated on security issues that were different for Ajax than for conventional web applications. First, we looked at the sandbox governing the use of JavaScript within the web browser and the rules that prevent code from different sources from interacting with each other. We saw how to relax the server of origin policy, with the user’s consent, in order to access third-party Internet services such as the Google API.
Second, we looked at ways of protecting data as it passes between the client and the server. HTTPS is the recommended industry-strength solution here, but we also presented a simple Ajax-based way of transmitting passwords securely over plain-text HTTP. Finally, we saw how Ajax has a specific vulnerability owing to the way raw data is provided for consumption from the server. Having evaluated this as a serious threat in some cases, we looked at ways of designing the server architecture to minimize exposure to such risks. We also described ways of programming the server to make external access to data more difficult.
The issues that we’ve tackled in this chapter should help you to tighten up your Ajax applications for use in the real world. In the next chapter, we continue the theme of grim realities with a look at performance issues.
7.6. Resources
Keys for the Google web service APIs may be obtained at http://www.google.com/apis/.
The JavaScript MD5 libraries of Paul Johnston can be found at http://pajhome.org.uk/crypt/md5/md5src.html. For those wanting a quick taste of MD5, visit the online checksum generator at www.fileformat.info/tool/hash.htm?text=ajax+in+action.
The Apache Commons Codec library for Java, which we used to generate our Base64-MD5 on the server, can be downloaded at http://jakarta.apache.org/commons/codec/.
In section 7.1, we looked at signing JAR files to create secure applications for Mozilla browsers. The official word on that can be found at www.mozilla.org/projects/security/components/signed-scripts.html. You’ll find some background information on the Battleship game at http://gamesmuseum.uwaterloo.ca/vexhibit/Whitehill/Battleship/.