
Chapter 14. Case study 3: LinkedIn
Adding facets and real-time search with Bobo Browse and Zoie
Contributed by JOHN WANG and JAKE MANNIX
LinkedIn.com is the largest social network for professionals in the world, with over 60 million users worldwide (as of March 2010), and has “people search” as a primary feature: users on the site have fully rich profiles that act as their public professional resume or curriculum vitae. A primary feature of the site is the ability to search for other users based on complex criteria, enabling use cases such as
- A hiring manager who wants to find potential employees
- Salespeople who want to find leads
- Tech-savvy executives of all levels who want to locate subject-matter experts for consultation
Search for people at LinkedIn is an extremely complex topic, complete with tremendous scalability issues, a distributed architecture, real-time indexing, and personalized search. Each search query is created by a registered user on the site who has his own individual subset of the full social network graph, which affects the relevance score of each hit differently for different searching users.
Lucene powers LinkedIn’s searching. In this chapter we’ll see two powerful extensions to Lucene developed and used at LinkedIn. The first, Bobo Browse (available as open source at http://sna-projects.com/bobo) provides faceting information for each search. Zoie, the second extension (available as open source at http://sna-projects.com/zoie), is a real-time search system built on top of Lucene.
14.1. Faceted search with Bobo Browse
The standard full-text search engine—and Lucene is no exception—is designed to quickly collect a few (say, 10) hits in the index that are the most relevant to the query provided, discarding the rest. If none of the “most relevant” documents are what the user wants, he must refine his query by adding further required terms. But the user has no guidance on what may be considered good terms for refinement, a process that’s error-prone and adds a lot of work for the user. Sometimes the effort to refine goes too far: no results are found and the user must backtrack and try again. This is a common problem with search engines, not specific to Lucene.
With faceted search,[1] in addition to the top results, the user sees the distribution of field values for all documents in the result set. As an example, on LinkedIn each document is a person’s profile; when a user searches for java engineer, she sees the top 10 of 177,878 people, but is also presented with the fact that of all of those people, IBM is the most popular value for the current company of the person with 2,090 hits; Oracle is the second-most popular value, with 1,938 people; Microsoft is the third, with 1,344; and so forth. The term facet is used to describe the field—current_company—for which we’re returning these results, and facet value is the value of this field, such as IBM. Facet count is the number of hits on the particular facet value—2,090 for IBM. These are presented as links, and the user can refine her query by clicking IBM, which returns the 2,090 people matching the effective Lucene query of +java +engineer +current_company:IBM. Because the search engine will only return links for facet values with greater than 0 facet count, the user knows in advance how many hits she will get to her query, and in particular that it won’t be 0. Figure 14.1 shows a LinkedIn facet search powered by Bobo Browse and Lucene.
Figure 14.1. The LinkedIn.com search result page with facets, facet values, and their counts on the right

14.1.1. Bobo Browse design
The Bobo Browse open source library is built on top of Lucene, and can add faceting to any Lucene-based project. A browsable index is simply a Lucene index with some declarations on how a field is used to support faceting. Such declaration can be defined in either the form of a Spring[2] configuration file added to the Lucene index directory with the name bobo.spring, as seen in table 14.1, or constructed programmatically while creating a BoboIndexReader. This architectural decision was made to allow for making a Lucene index facet browsable without reindexing. Each field in the declaration file is specified with a FacetHandler instance that loads a forward view of the data in a compressed form. Bobo Browse uses these FacetHandlers for counting, sorting, and field retrieval.
Table 14.1. Bobo Browse allows you to configure facets declaratively through a Spring file.
|
Lucene document construction |
Spring Beans specifying faceting information |
|---|---|
geo_region:
|
<bean id = "geo_region" |
industry_id:
|
<bean id = "industry_id" |
locale:
|
<bean id = "locale" class= |
company_id:
|
<bean id = "company_id" |
num_recommendations:
|
<bean id = "num_recommendations" |
The Bobo Browse API follows closely with the Lucene search API, with structured selection and facet grouping specification as additional input parameters, and the output appended with facet information for each field. As with many software libraries, seeing example code linked against bobo-browse.jar will probably be more instructive than a couple of paragraphs. Let’s walk through a simplified user profile example, where each document represents one person with the following fields:
- geo_region: One per document, formatted as a String. Examples: New York City, SF BayArea.
- industry_id: One per document, values of type integer greater than 0.
- locale: Multiple values per document. Examples: en, fr, es.
- company_id: Multiple values per document, each of type integer greater than 0.
- num_recommendations: One per document, values of type integer greater than or equal to 0; we’ll facet on ranges [1 – 4], [5 – 10], [11 + ].
To browse the Lucene index built with fields from table 14.1, we’ll do something as simple as the following. First, let’s assume that the application has a way of getting an IndexReader opened on the Lucene index at hand:
IndexReader reader = getLuceneIndexReader();
We then decorate it with Bobo Browse’s index reader:
BoboIndexReader boboReader = BoboIndexReader.getInstance(reader);
Next we create a browse request:
// use setCount() and setOffset() for pagination: BrowseRequest br = new BrowseRequest(); br.setCount(10); br.setOffset(0);
One core component of a BrowseRequest is the driving query. Any subclass of Lucene’s Query class works here, and all added facet constraints further restrict the driving query. In the extreme “pure browse” case, the application would use MatchAllDocsQuery as the driving query (see section 3.4.9).
QueryParser queryParser;
Query query = queryParser.parse("position_description:(software OR
engineer)");
br.setQuery(query);
We could add on any Lucene Filter (see section 5.6) as well, with BrowseRequest.setFilter(Filter). We request facet information from this request by creating specific FacetSpecs, in which you specify the following:
- The maximum number of facets to return for each field.
- The ordering on the facets returned for each field: whether they’re returned in the lexicographical order of the facet values
or in the order of facets with the most associated hits. For example, imagine the color field has three facets returned: red(100),
green(200), blue(30). We can either order them by lexicographical order:
blue(30), green(200), red(100) or by hits:
green(200), red(100), blue(30) - That you only want to return a facet for a given field with a hit count greater than some value.
For the current example, we want to return not only the top 10 users with the term software or engineer in some of their position descriptions in their profiles, but we also want to find the top 20 company names out of the whole result set, and how many hits each company would have if you were to add it to the query, as in "+company_name:<foo>":

We first request ![]() that the facets be sorted by facet count, descending, and then set
that the facets be sorted by facet count, descending, and then set ![]() the number of facets to be returned to 20. We may also want to find out something about the geographical distribution of
the results:
the number of facets to be returned to 20. We may also want to find out something about the geographical distribution of
the results:

Instead of simply showing the top 20 regions, we get ![]() all the geo-regions (imagine that these were specifically the 50 US state abbreviations) that have
all the geo-regions (imagine that these were specifically the 50 US state abbreviations) that have ![]() at least 100 hits, and we order
at least 100 hits, and we order ![]() them in the usual alphabetical order.
them in the usual alphabetical order.
Now we’re ready to browse. With raw Lucene, we’d create an IndexSearcher wrapping an IndexReader. In the faceting world, we want a BoboBrowser—the analog of an IndexSearcher. In fact, BoboBrowser is a subclass of IndexSearcher, and implements the Browsable interface—which is the analog of Lucene’s Searchable interface (which IndexSearcher implements). Browsable extends Searchable as well. This class mirroring and extending is common in Bobo Browse, and makes it easy for someone familiar with Lucene to quickly gain proficiency with Bobo Browse. The library is meant to extend all aspects of Lucene searching to the browsing paradigm. For example, this is how you create a browser:
Browseable browser = new BoboBrowser(boboReader);
Just as with Searchable, Browsable allows a high-level method for ease of use to just get your results:
BrowseResult result = browser.browse(br);
You can find out how many total results there were and get access to the hit objects:
int totalHits = result.getNumHits(); BrowseHit[] hits = result.getHits();
BrowseHits are like Lucene’s ScoreDocs, but also contain facet values for all configured faceting fields, because there’s essentially no cost to fill these in from the inmemory cache. The facet information is contained within a map whose keys are the field names and whose values are FacetAccessible objects. FacetAccessible contains a sorted List<BrowseFacet>, retrievable with getFacets(). Each BrowseFacet is a pair of value (a String) and count (an int).
Map<String, FacetAccessible> facetMap = result.getFacetMap();
Let’s say the user’s search matches a total of 1,299 hits, and that the top three companies were IBM, Oracle, and Microsoft. To narrow her search and look only at people who’ve worked at IBM or Microsoft but didn’t work at Oracle, the user can take the same BrowseRequest she had before (or, more likely in a stateless web framework, a recreated instance), and add to it a new BrowseSelection instance. A BrowseSelection corresponds to a SQL WHERE clause, which provides some structured filtering on top of a text search query.
For example, in SQL, the clause WHERE (company_id=1 OR company_id=2) AND (company_id <> 3) can be represented in a BrowseSelection as
BrowseSelection selection = new BrowseSelection("company_id");
selection.addValue("1"); // 1 = IBM
selection.addValue("2"); // 2 = Microsoft
selection.addNotValue("3"); // 3 = Oracle
selection.setSelectionOperation(ValueOperation.ValueOperationOr);
br.addSelection(selection);
14.1.2. Beyond simple faceting
Although Lucene provides access to the inverted index, Bobo Browse provides a forward view through FacetHandlers. Bobo Browse thus provides useful functionality beyond faceting.
Fast Field Retrieval
Bobo Browse can retrieve the field values for a specific document ID and field name. With Lucene, a Field with the Store.YES attribute turned on can be stored:
doc.add(new Field("color","red",Store.YES,Index.NOT_ANALYZED_NO_NORMS));
then retrieved via the API:
Document doc = indexReader.document(docid);
String colorVal = doc.get("color");
We devised a test to understand performance better. We created an optimized index of 1 million documents, each with one field named color with a value to be one of eight color strings. This was a very optimized scenario for retrieval of stored data because there was only one segment and much of the data could fit in memory. We then iterated through the index and retrieved the field value for color. This took 1,250 milliseconds (ms).
Next, we did the same thing, but instead of creating a BoboIndexReader with a FacetHandler, we built on the indexed data of the color field. We paid a penalty of 133 ms to load the FacetHandler once the index loads, and retrieval time took 41 ms. By paying a 10 percent penalty once, we boosted the retrieval speed over 3,000 percent.
Sorting
One of the coolest parts of Lucene is sorting. Lucene cleverly leverages the field cache and the fact that strings are indexed in a lexicographical order for fast sorting: the comparison between string values of two documents can be reduced to comparing the array indexes of these string values in the term table, and the cost of string comparison is reduced to integer arithmetic. Chapter 5 covers Lucene’s sorting and its use of the field cache.
Currently, Lucene sorting has a restriction that sort fields must not be tokenized: every document in the index must have at most one value in a sortable field (see section 2.4.6). While developing Bobo Browse, we devised a way of removing this restriction: FieldCache is a forward view of the index. We extended the idea by incorporating FieldCache into FacetHandlers. Because we’ve made FacetHandlers pluggable, we started adding other powerful features into FacetHandlers, such as the ability to handle documents with multiple values in a given field. We’re therefore able to facet and sort on multivalued fields (for example, any tokenized field).
We took a sample of our member profile index, about 4.6 million documents, sorted the entire index on a tokenized field (such as last name) and took the top 10 hits. The entire search/sort call on a development-type box took 300 ms.
Faceting need not be restricted to index-time-only content.
Runtime Facethandlers
When we started designing the FacetHandler architecture, we realized that at index time we didn’t have the data needed for faceting, such as personalized data or the searcher’s social network. So we designed the framework to allow for runtime FacetHandlers. Such FacetHandlers are constructed at query time to support faceting on data provided at search time, such as a user’s social graph and connection counts.
Zoie Integration
Because of our scale both in terms of number of searchers as well as corpus size, along with our real-time requirement, we needed a distributed real-time solution for facet search. For this, we leveraged Zoie, an open source, real-time search and indexing system built on Lucene; we’ll describe Zoie in section 14.2. Integration was easy: we created an IndexReaderDecorator that decorates a ZoieIndexReader into a BoboIndexReader:
class BoboIndexReaderDecorator<BoboIndexReader>
implements IndexReaderDecorator{
public BoboIndexReader decorate(ZoieIndexReader indexReader)
throws IOException{
return new BoboIndexReader(indexReader);
}
}
and gave it to Zoie. In turn, Zoie acts as a BoboIndexReader factory that returns BoboIndexReaders in real time. In our search code, we simply do this:
List<BoboIndexReader> readerList = zoie.getIndexReaders();
Browsable[] browsers = new Browsable[readerList.size()];
for (int i = 0; i < readerList.size(); ++i){
browsers[i] = new BoboBrowser(readerList.get(i));
}
Browsable browser = new MultiBoboBrowser(browsers);
Next we’ll describe how LinkedIn achieves another important search capability: realtime search.
14.2. Real-time search with Zoie
A real-time search system makes it possible for queries to find a new document immediately (or almost immediately) after it’s been updated. In the case of LinkedIn’s people search, this means we want to make a member profile searchable as soon as the profile is created or updated.
Note
To be precise, as soon as the profile arrives at a node, the next search request that node receives can include the newly updated profile. In a distributed system, where indexing events are queued and delivered independently to each node, clients of the entire distributed system are only guaranteed to get results as up-to-date as the nodes they hit.
With Lucene’s incremental update functionality, we believe we can extend Lucene to support real-time searching. A naïve solution would be to commit as often as possible while reopening the IndexReader for every search request. This poses a few scalability problems:
- The latency is relatively high. The cost of IndexWriter.commit on a disk-based index isn’t negligible.
- The index would be fragmented heavily because each commit would create a new index segment, and index segment merge cost becomes significant if we commit per document.
- We may waste a lot of indexing work: the same member profile tends to be updated frequently in a short period of time. It ends up with a lot of deleted documents in the index, which affects search performance.
- We have to reload IndexReader frequently to make new documents available for search users. Opening an IndexReader per search request adds a significant amount of latency at search time.
An alternative is to keep the entire index in memory (for example, via a RAMDirectory, described in section 2.10). This alleviates the problems of high indexing latency and index fragmentation. But we’d still process wasteful indexing requests due to fast updates. Furthermore, even with the introduction of the IndexReader.reopen() API (see section 3.2.1), which improves the index reader load time, with customized IndexReader instances the cost of loading the index reader might be higher than what we’d be willing to pay. Here are some examples of extra data we’re loading for our customized IndexReader:
- Zoie by default loads an array mapping Lucene docIDs to application UIDs.
- Zoie loads data structures for faceted search (see the Bobo Browse study in section 14.1).
- Zoie loads static ranking, for example “people rank” from an external source. At LinkedIn, we use usage and search tracking data in combination with the social network to calculate a static people rank
It’s clear that loading our custom IndexReader for each search request isn’t feasible at scale. These problems motivated us to develop a real-time searching architecture at LinkedIn, and Zoie (http://sna-projects.com/zoie) is an open source project that’s an offspring of this effort.
14.2.1. Zoie architecture
Let’s look at the main Zoie components as well as some code. If you’re impatient or just like pretty diagrams, jump to figure 14.2.
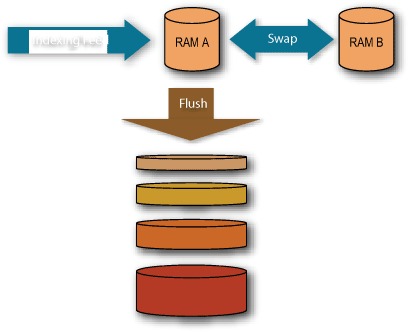
Figure 14.2. Zoie’s three-index architecture: two in-memory indexes, and one disk-based index
Data Provider and Data Consumer
When we started building Zoie, we imagined a constant stream of indexing requests flowing into our indexing system and our indexing system acting as a consumer of this stream. We abstracted this access pattern into a provider-consumer paradigm, and we defined data provider as the source of this stream and data consumer as our indexing system. A data provider in Zoie is just a marker interface to identify the concept; there’s no contract defined in the interface.
Upon further abstraction, data providers can provide a stream of indexing requests from various sources, such as files, networks, and databases. A data consumer can be any piece of code that deals with the flow of indexing requests, and can even act as a data provider—by serving as an intermediate data massage or filtering layer to relay the indexing requests. With this abstraction, we give our system the flexibility to have our data arbitrarily massaged or aggregated before finally being consumed by the indexing system.
To have a fault-tolerant system, we need to be able to handle situations where the system is shut down ungracefully due a system crash or power outage. Although we’re able to rely on the Lucene indexing mechanism to be solid so that our index isn’t easily corrupted, we’d lose track of where we are in the stream of indexing requests. Having to reindex from scratch every time a system goes down isn’t acceptable. Because of this, we have built into Zoie a versioning mechanism to persist the point in the stream where the last batch of indexing request was processed. From this version, a data provider can retrack so that the indexing requests can be regenerated. The version numbers are provided by the application; such version numbers can be timestamps or database commit numbers, for example.
Take a look at listing 14.1. We have data stored in a table in a relational database and we want to create a Lucene index for fast text search capabilities. In this table, there are three columns: id (long), content (String), and timestamp (long). The number of rows in this table is very large.
Listing 14.1. Indexing data events with Zoie


Let’s understand some Zoie internals. To implement real-time search, we decided to use multiple indexes: one main index on disk, plus two helper indexes in memory to handle transient indexing requests.
Disk Index
The disk index will grow to be rather large; therefore, indexing updates on disk will be performed in batches. Processing updates in batches allows us to merge updates of the same document to reduce redundant updates. Moreover, the disk index wouldn’t be fragmented as the indexer wouldn’t be thrashed by a large number of small indexing calls and requests. We keep a shared disk-based IndexReader to serve search requests. Once batch indexing is performed, we build and load a new IndexReader and then publish the new shared IndexReader. The cost of building and loading the IndexReader is thus hidden from the cost of search.
Ram Index(ES)
To ensure real-time behavior, the two helper memory indexes (MemA and MemB) alternate in their roles. One index, say MemA, accumulates indexing requests and serves real-time results. When a flush or commit event occurs, MemA stops receiving new indexing events, and indexing requests are sent to MemB. At this time search requests are served from all three indexes: MemA, MemB, and the disk index. These indexes are shown in figure 14.2.
Once the disk merge is completed, MemA is cleared and MemB and MemA get swapped. Until the next flush or commit, searches will be served from the new disk index, new MemA, and the now empty MemB.
Table 14.2 shows the states of different parts of the system as time (T) progresses.
Table 14.2. State of Zoie’s indexes over time
|
MemA |
MemB |
DiskIndex |
|
|---|---|---|---|
| T1: Request 1 | Request 1 indexed | Empty | Empty |
| T2: Request 2 | Request 1 and 2 indexed | Empty | Empty |
| T3: Request 3 | Request 1 and 2 indexed | Request 3 indexed | Copying index data from MemA |
| T4: disk index published, memA and memB swaps | Request 3 indexed | Empty | Request 1 and 2 indexed |
| T5: Request 4 | Request 3 and 4 indexed | Empty | Request 1 and 2 indexed |
| T5: Request 5 | Request 3 and 4 indexed | Request 5 indexed | Request 1 and 2 indexed, Copying index data from MemA |
| T6: disk index published, memA and memB swaps | Request 5 indexed | Empty | Request 1, 2, 3, and 4 indexed |
For each search request, we open and load a new IndexReader from each of the in-memory indexes, and along with the shared disk IndexReader, we build a list of IndexReaders for the user. See the following code snippet used in a simple search thread. The Zoie instance also implements the interface proj.zoie.api.indexReaderFactory (the explicit cast is used to make this clear):
static IndexReader buildIndexReaderFromZoie(ZoieSystem indexingSystem){
IndexReaderFactory readerFactory = (IndexReaderFactory) indexingSystem;
List<ZoieIndexReader> readerList = readerFactory.getIndexReaders();
MultiReader reader = new MultiReader(readerList.toArray(
new IndexReader[readerList.size()]), false);
return reader;
}
IndexSearcher searcher = new IndexSearcher(
buildIndexReaderFromZoie(indexingSystem));
...
indexingSystem.returnIndexReaders(readerList);
Next, let’s look at what knobs Zoie exposes to let us tune just how real-time we want Zoie to be.
14.2.2. Real-time vs. near-real-time
With the helper in-memory index mechanism built into Zoie and the power of Lucene’s incremental update feature, we’re able to achieve real-time search and indexing. But there are applications where the real-time requirement may be relaxed and near real time may be good enough. Say there’s a small gap of time between when a document is indexed or updated and when it or its new version is reflected in the search result. Zoie can be configured either programmatically or at runtime via JMX to support the relaxed real-time behavior by doing the following:
- Disabling real-time altogether (that is, don’t use in-memory indexes)
- Adjusting the batchSize parameter, which is the number of indexing requests that should be in the queue before the queue is flushed and indexed to disk—only if this occurs before the batchDelay time condition is met
- Adjusting the batchDelay parameter, which is the amount of time Zoie should wait before the queue is flushed and indexed to disk—only if this occurs before the batchSize condition is met
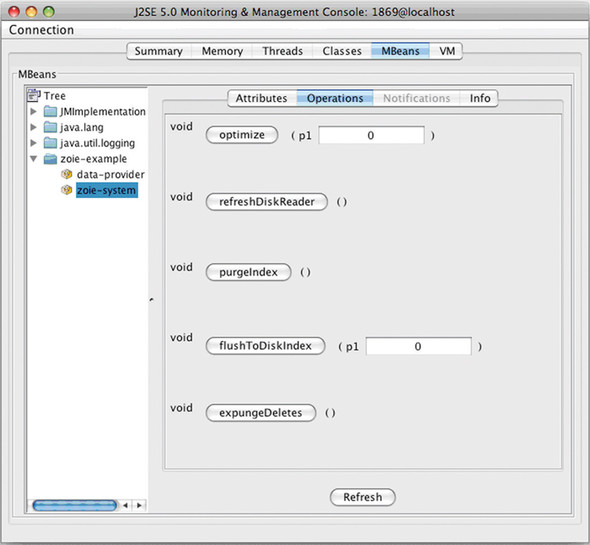
With this configuration, Zoie becomes a one-disk index-based streaming search and indexing system, with real-time or content freshness tuned with the batchSize and batchDelay parameters. The Zoie managed beans (MBeans) exposed via Java Management Extensions (JMX) can be seen in figures 14.3 and 14.4.
Figure 14.3. The read-only JMX view of Zoie’s attributes, as rendered by JConsole

Figure 14.4. Zoie exposes controls via JMX, allowing an operator to change its behavior at runtime.
14.2.3. Documents and indexing requests
In Zoie, each document is expected to have a unique long ID (UID). Zoie keeps track of any document change such as creation, modification, or deletion by UID. It’s the application’s responsibility to provide a UID for each document to be inserted into the index. The UID is also used to perform duplicate removal of documents in both the memory index as well as the disk index. We also benefit by having a quick mapping between Lucene docIDs to UIDs.
Any manipulation of a document (creation, modification, or deletion) is propagated to Zoie as an indexing request. The indexing requests are transformed to proj.zoie.api.indexing.ZoieIndexable instances via a proj.zoie.api.indexing.ZoieIndexableInterpreter that’s provided to Zoie. The code in listing 14.2 demonstrates this.
Listing 14.2. All indexing in Zoie is achieved through indexing requests

14.2.4. Custom IndexReaders
We find the ability to have application-specific IndexReaders very useful. In our case, we wanted to provide facet search capabilities through Bobo Browse in conjunction with Zoie for real-time search. So we’ve designed Zoie to pass on creating and loading custom IndexReaders if desired.
To do this, provide Zoie with a proj.zoie.api.indexing.IndexReaderDecorator implementation:
class MyDoNothingFilterIndexReader extends FilterIndexReader {
public MyDoNothingFilterIndexReader(IndexReader reader) {
super(reader);
}
public void updateInnerReader(IndexReader inner) {
in = inner;
}
}
class MyDoNothingIndexReaderDecorator implements
IndexReaderDecorator<MyDoNothingFilterIndexReader> {
public MyDoNothingIndexReaderDecorator decorate(
ZoieIndexReader indexReader)
throws IOException {
return new MyDoNothingFilterIndexReader(indexReader);
}
public MyDoNothingIndexReaderDecorator redecorate(
MyDoNothingIndexReaderDecorator decorated,
ZoieIndexReader copy)
throws IOException {
decorated.updateInnerReader(copy);
return decorated;
}
}
Notice we’re given a ZoieIndexReader, which is a Lucene IndexReader that can quickly map a Lucene docID to the application UID:
long uid = zoieReader.getUID(docid);
And voilà, we’ve got ourselves our very own IndexReader. Next, let’s compare and contrast Zoie and Lucene’s near-real-time search.
14.2.5. Comparison with Lucene near-real-time search
Lucene near-real-time search (NRT) capability, described in section 3.2.5, was introduced with the 2.9.0 release, and it aims to solve the same problem. Lucene NRT adds a couple of new methods to IndexWriter: getReader() and setIndexReaderWarmer(). The former method gives a reference to an IndexReader that has visibility into documents that have been indexed by that writer but that haven’t yet been committed using IndexWriter.commit(). The second method, setIndexReaderWarmer(), lets callers specify a way to “warm up” the newly created IndexReader returned by getReader() so it’s ready to be searched. The idea behind the IndexReaderWarmer is that its warm(IndexReader) method will be called on the SegmentReader for newly merged segments, letting you load any FieldCache state you need, for example.
Although Zoie and Lucene NRT share functionality, there are important differences. From an API perspective, Lucene NRT is effectively a private view on the internals of IndexWriter as it indexes documents, writes segments, merges them, and manages commit checkpoints. Zoie, on the other hand, is an indexing system on top of a real-time indexing engine. Zoie acts as an asynchronous consumer of incoming documents, and is optimized for managing the decisions to write to disk and make balanced segment merges for you, specifically for the case of real-time search. As a real time–enabled indexing system, Zoie is designed with smooth failover as well: if you’re indexing too fast for Lucene to keep up with, Zoie buffers these documents into a batch, which it tries to empty as fast as it can. But if you reach the limit on how large that queue has been set to max out, the indexing system drops out of real-time mode and starts blocking on the consume() call, forcing clients who are trying to index too fast to slow down.
Another feature of Zoie’s indexing system that’s different from raw Lucene NRT is that Zoie keeps track of UID-to-internal docID mapping, for de-duplication of documents that have been modified in memory but that the disk directory doesn’t know about yet. This UID can also be used for other things if your application keeps track of that UID (for example, many advanced search techniques involve scoring or filtering based on an external join with data that doesn’t live in your index but that shares the same UID of the entities that become Lucene documents). Zoie’s form of index reader warming is a little different than Lucene NRT, in that it allows you to plug in a “generified” decorator that can be whatever subclass of ZoieIndexReader your application needs, and it goes through whatever initialization and warming process you specify before being returned from the ZoieSystem. At LinkedIn, we do facet-based search with Bobo Browse (see section 14.1 for details), and this involves loading some in-memory uninverted field data before the facet-enabled reader can be used.
Lucene NRT took a different implementation approach to the concept of real-time search: because the IndexWriter has a full in-memory workspace that it uses for indexing, the idea was to clone whatever of that structure is needed for searching and return it for each getReader() call. The cost here is in choosing what in-memory state is cloned when callers ask for readers during heavy indexing. Zoie took the approach instead of trying to keep a RAMDirectory around to index into first, and keep it small enough that doing a completely fresh reopen() call was still inexpensive, even when done for each query request. Finally, as Zoie lives on top of Lucene without modifying any Lucene-internal code, Lucene NRT can in fact be plugged into Zoie as the realtime indexing engine. As of this writing, we have run some performance tests to compare Zoie with Lucene’s NRT, but haven’t yet run a comprehensive enough set of tests. We published our findings so far at http://code.google.com/p/zoie/wiki/Performance_Comparisons_for_ZoieLucene24ZoieLucene29LuceneNRT, but we urge you to run comparison tests yourself. To help with that, we’ve put together a detailed recipe for running Zoie performance tests and published it on http://code.google.com/p/zoie/wiki/Running_Performance_Test.
14.2.6. Distributed search
Zoie can be distributed easily by configuring the data provider to stream indexing requests for a given partition and by including brokering and merging logic on the result set. We assume documents are uniformly distributed across partitions, so we don’t have a global IDF and we assume scores returned from different partitions are comparable. The diagram in figure 14.5 shows this setup.
Figure 14.5. Distributed search with Zoie
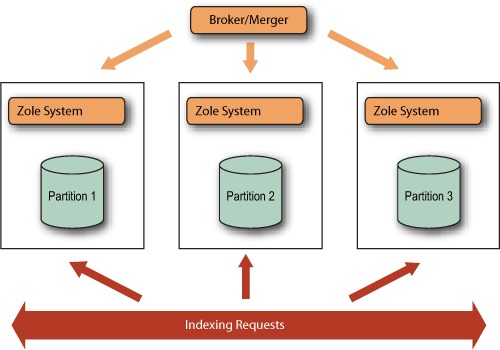
The Broker/Merger in this case can be a separate service—for example, a servlet or simply a MultiSearcher instance with RemoteSearchers from each of the ZoieSystems. Listing 14.3 shows an oversimplified example.
Listing 14.3. Distributed search with Zoie

We don’t actually use RMI (remote method invocation) in production. We have search services running as servlets inside Jetty containers a remote procedure call (RPC) through Spring-RPC.
14.3. Summary
This chapter examined two powerful packages created on top of Lucene for LinkedIn’s substantial search needs. The first is Bobo Browse, a system that adds support for faceted search to Lucene. Bobo is a good example of a project that integrates well with Lucene, and can even make itself immediately useful through Spring-based configuration files, thus making it possible to add facets to an existing index and requiring no reindexing.
Zoie is a free and open source system for real-time indexing and searching that, like Bobo Browse, works on top of Lucene. Zoie is being used in the LinkedIn production search cluster serving search requests for people, jobs, companies, news, groups, forum discussions, and so forth. For people search, Zoie is deployed in distributed mode and is serving over 50 million documents in real time. As of this writing, LinkedIn runs Zoie on quad-core Solaris servers with 32 GB of RAM. Each server runs two JVMs, each with one Zoie instance managing about 5 million document partitions. In such a setup, Zoie handles about 5 million queries per day, per server with an average latency of only 50 ms, while also processing about 150,000 updates per day. Add to that the fact that some of the queries can be rather complex (such as 50 Boolean OR clauses containing phrase queries etc.), and it’s clear that Zoie is a powerful system that you ought to consider when looking for real-time search solutions. Zoie can be downloaded from http://sna-projects.com/zoie/.