
Chapter 5. Advanced search techniques
This chapter covers
- Loading field values for all documents
- Filtering and sorting search results
- Span and function queries
- Leveraging term vectors
- Stopping a slow search
Many applications that implement search with Lucene can do so using the API introduced in chapter 3. Some projects, though, need more than the basic searching mechanisms. Perhaps you need to use security filters to restrict which documents are searchable for certain users, or you’d like to see search results sorted by a specific field, such as title, instead of by relevance. Using term vectors, you can find documents similar to an existing one, or automatically categorize documents. Function queries allow you to use arbitrary logic when computing scores for each hit, enabling you to boost relevance scores according to recency. We’ll cover all of these examples in this chapter.
Rounding out our advanced topics are
- Creating span queries, advanced queries that pay careful attention to positional information of every term match within each hit
- Using MultiPhraseQuery, which enables synonym searching within a phrase
- Using FieldSelector, which gives fine control over which fields are loaded for a document
- Searching across multiple Lucene indexes
- Stopping a search after a specified time limit
- Using a variant of QueryParser that searches multiple fields at once
The first topic we’ll visit is Lucene’s field cache, which is a building block that underlies a number of Lucene’s advanced features.
5.1. Lucene’s field cache
Sometimes you need fast access to a certain field’s value for every document. Lucene’s normal inverted index can’t do this, because it optimizes instead for fast access to all documents containing a specific term. Stored fields and term vectors let you access all field values by document number, but they’re relatively slow to load and generally aren’t recommended for more than a page’s worth of results at a time.
Lucene’s field cache, an advanced internal API, was created to address this need. Note that the field cache isn’t a user-visible search feature; rather, it’s something of a building block, a useful internal API that you can use when implementing advanced search features in your application. Often your application won’t use the field cache directly, but advanced functionality you do use, such as sorting results by field values (covered in the next section), uses the field cache under the hood. Besides sorting, some of Lucene’s built-in filters, as well as function queries, use the field cache internally, so it’s important to understand the trade-offs involved.
There are also real-world cases when your application would directly use the field cache itself. Perhaps you have a unique identifier for every document that you’ll need to access when searching, to retrieve values stored in a separate database or other store. Maybe you’d like to boost documents according to how recently they were published, so you need fast access to that date per document (we show this example in section 5.7.2). Possibly, in a commerce setting, your documents correspond to products, each with its own shipping weight (stored as a float or double, per document), and you’d like to access that to present the shipping cost next to each search result. These are all examples easily handled by Lucene’s field cache API.
One important restriction for using the field cache is that all documents must have a single value for the specified field. This means the field cache can’t handle multivalued fields as of Lucene 3.0, though it’s possible this restriction has been relaxed by the time you’re reading this.
Note
A field cache can only be used on fields that have a single term. This typically means the field was indexed with Index.NOT_ANALYZED or Index.NOT_ANALYZED_NO_NORMS, though it’s also possible to analyze the fields as long as you’re using an analyzer, such as KeywordAnalyzer, that always produces only one token.
We’ll first see how to use a field cache directly, should you need access to a field’s value for all documents, when building a custom filter or function query, for example. Then we’ll discuss the important RAM and CPU trade-offs when using a field cache. Finally, we discuss the importance of accessing a field cache within the context of a single segment at a time. We begin with the field cache API.
5.1.1. Loading field values for all documents
You can easily use the field cache to load an array of native values for a given field, indexed by document number. For example, if every document has a field called “weight,” you can get the weight for all documents like this:
float[] weights = FieldCache.DEFAULT.getFloats(reader, "weight");
Then, simply reference weights[docID] whenever you need to know a document’s weight value. The field cache supports many native types: byte, short, int, long, float, double, strings, and the class StringIndex, which includes the sort order of the string values.
The first time the field cache is accessed for a given reader and field, the values for all documents are visited and loaded into memory as a single large array, and recorded into an internal cache keyed on the reader instance and the field name. This process can be quite time consuming for a large index. Subsequent calls quickly return the same array from the cache. The cache entry isn’t cleared until the reader is closed and completely dereferenced by your application (a WeakHashMap, keyed by the reader, is used under the hood). This means that the first search that uses the field cache will pay the price of populating it. If your index is large enough that this cost is too high, it’s best to prewarm your IndexSearchers before using them for real queries, as described in section 11.2.2.
It’s important to factor in the memory usage of field cache. Numeric fields require the number of bytes for the native type, multiplied by the number of documents. For String types, each unique term is also cached for each document. For highly unique fields, such as title, this can be a large amount of memory, because Java’s String object itself has substantial overhead. The StringIndex field cache, which is used when sorting by a string field, also stores an additional int array holding the sort order for all documents.
Note
The field cache may consume quite a bit of memory; each entry allocates an array of the native type, whose length is equal to the number of documents in the provided reader. The field cache doesn’t clear its entries until you close your reader and remove all references to that reader from your application and garbage collection runs.
5.1.2. Per-segment readers
As of 2.9, Lucene drives all search results collection and sorting one segment at a time. This means the reader argument passed to the field cache by Lucene’s core functionality will always be a reader for a single segment. This has strong benefits when reopening an IndexReader; only the new segments must be loaded into the field cache.
But this means you should avoid passing your top-level IndexReader to the field cache directly to load values, because you’d then have values double-loaded, thus consuming twice as much RAM. Typically, you require the values in an advanced customization, such as implementing a custom Collector, a custom Filter, or a custom FieldComparatorSource, as described in chapter 6. All of these classes are provided with the single-segment reader, and it’s that reader that you should in turn pass to the field cache to retrieve values. If the field cache is using too much memory and you suspect that a top-level reader may have been accidentally enrolled, try using the setInfoStream API to enable debugging output. Cases like this one, plus other situations such as the same reader and field loaded under two different types, will cause a detailed message to be printed to the PrintStream you provide.
Note
Avoid passing a top-level reader directly to the field cache API. This can result in consuming double the memory, if Lucene is also passing individual segments’ readers to the API.
Now that we’ve seen how to use field cache directly, as a building block when creating your application, let’s discuss a valuable Lucene capability that uses a field cache internally: field sorting.
5.2. Sorting search results
By default, Lucene sorts the matching documents in descending relevance score order, such that the most relevant documents appear first. This is an excellent default as it means the user is most likely to find the right document in the first few results rather than on page 7. However, often you’d like to offer the user an option to sort differently.
For example, for a book search you may want to display search results grouped into categories, and within each category the books should be ordered by relevance to the query, or perhaps a simple sort by title is what your users want. Collecting all results and sorting them programmatically as a second pass outside of Lucene is one way to accomplish this. Doing so, however, introduces a possible performance bottleneck if the number of results is enormous. In this section, we’ll see both of these examples and explore various other ways to sort search results, including sorting by one or more field values in either ascending or descending order.
Remember that sorting under the hood uses the field cache to load values across all documents, so keep the performance trade-offs from section 5.1 in mind.
We’ll begin by seeing how to specify a custom sort when searching, starting with two special sort orders: relevance (the default sort) and index order. Then we’ll sort by a field’s values, including optionally reversing the sort order. Next we’ll see how to sort by multiple sort criteria. Finally we’ll show you how to specify the field’s type or locale, which is important to ensure the sort order is correct.
5.2.1. Sorting search results by field value
IndexSearcher contains several overloaded search methods. Thus far we’ve covered only the basic search(Query, int) method, which returns the top requested number of results, ordered by decreasing relevance. The sorting version of this method has the signature search(Query, Filter, int, Sort).Filter, which we’ll cover in section 5.6, should be null if you don’t need to filter the results.
By default, the search method that accepts a Sort argument won’t compute any scores for the matching documents. This is often a sizable performance gain, and many applications don’t need the scores when sorting by field. If scores aren’t needed in your application, it’s best to keep this default. If you need to change the default, use IndexSearcher’s setDefaultFieldSortScoring method, which takes two Booleans: doTrackScores and doMaxScore. If doTrackScores is true, then each hit will have a score computed. If doMaxScore is true, then the max score across all hits will be computed. Note that computing the max score is in general more costly than the score per hit, because the score per hit is only computed if the hit is competitive. For our example, because we want to display the scores, we enable score tracking but not max score tracking.
Throughout this section we’ll use the source code in listings 5.1 and 5.2 to show the effect of sorting. Listing 5.1 contains the displayResults method, which runs the search and prints details for each result. Listing 5.2 is the main method that invokes displayResults for each type of sort. You can run this by typing ant SortingExample in the book’s source code directory.
Listing 5.1. Sorting search hits by field


The Sort object ![]() encapsulates an ordered collection of field sorting information. We ask IndexSearcher
encapsulates an ordered collection of field sorting information. We ask IndexSearcher ![]() to compute scores per hit. Then we call the overloaded search method that accepts the custom Sort
to compute scores per hit. Then we call the overloaded search method that accepts the custom Sort ![]() . We use the useful toString method
. We use the useful toString method ![]() of the Sort class to describe itself, then create PrintStream that accepts UTF-8 encoded output
of the Sort class to describe itself, then create PrintStream that accepts UTF-8 encoded output ![]() , and finally use StringUtils
, and finally use StringUtils ![]() from Apache Commons Lang for nice columnar output formatting. Later you’ll see a reason to look at the query explanation.
For now, it’s commented out
from Apache Commons Lang for nice columnar output formatting. Later you’ll see a reason to look at the query explanation.
For now, it’s commented out ![]() .
.
Now that you’ve seen how displayResults works, listing 5.2 shows how we invoke it to print the results as seen in the rest of this section.
Listing 5.2. Show results when sorting by different fields

The sorting example uses an unusual query ![]() . This query was designed to match all results, and also to assign higher scores to some hits than others, so that we have
some diversity when sorting by relevance. Next, the example runner is constructed from the sample book index included with
this book’s source code
. This query was designed to match all results, and also to assign higher scores to some hits than others, so that we have
some diversity when sorting by relevance. Next, the example runner is constructed from the sample book index included with
this book’s source code ![]() .
.
Now that you’ve seen how to use sorting, let’s explore ways search results can be sorted. We’ll step through each of the invocations of displayResults from listing 5.2.
5.2.2. Sorting by relevance
Lucene sorts by decreasing relevance, also called the score, by default. Sorting by score works by either passing null as the Sort object or using the default sort behavior. Each of these variants returns results in the default score order. Sort.RELEVANCE is equivalent to new Sort():
example.displayResults(query, Sort.RELEVANCE); example.displayResults(query, new Sort());
There’s additional overhead involved in using a Sort object, though, so stick to using search(Query, int) if you simply want to sort by relevance. As shown in listing 5.2, this is how we sort by relevance:
example.displayResults(allBooks, Sort.RELEVANCE);
And here’s the corresponding output (notice the decreasing score column):
Results for: *:* (contents:java contents:action) sorted by <score> Title pubmonth id score Lucene in Action, Second E... 201005 7 1.052735 /technology/computers/programming Ant in Action 200707 9 1.052735 /technology/computers/programming Tapestry in Action 200403 10 0.447534 /technology/computers/programming JUnit in Action, Second Ed... 201005 11 0.429442 /technology/computers/programming Tao Te Ching200609 0 0.151398 /philosophy/eastern Lipitor Thief of Memory 200611 1 0.151398 /health Imperial Secrets of Health... 199903 2 0.151398 /health/alternative/chinese Nudge: Improving Decisions... 200804 3 0.151398 /health Gödel, Escher, Bach: an Et... 199905 4 0.151398 /technology/computers/ai Extreme Programming Explained 200411 5 0.151398 /technology/computers/programming/methodology Mindstorms: Children, Comp... 199307 6 0.151398 /technology/computers/programming/education The Pragmatic Programmer 199910 8 0.151398 /technology/computers/programming A Modern Art of Education 200403 12 0.151398 /education/pedagogy
The output of Sort’s toString() shows <score>, reflecting that we’re sorting by relevance score, in descending order. Notice how many of the hits have identical scores, but within blocks of identical scores the sort is by document ID ascending. Lucene internally always adds an implicit final sort, by document ID, to consistently break any ties in the sort order that you specified.
5.2.3. Sorting by index order
If the order in which the documents were indexed is relevant, you can use Sort.INDEXORDER:
example.displayResults(query, Sort.INDEXORDER);
This results in the following output. Note the increasing document ID column:
Results for: *:* (contents:java contents:action) sorted by <doc> Title pubmonth id score Tao Te Ching
Document order may be interesting for an index that you build up once and never change. But if you need to reindex documents, document order typically won’t work because newly indexed documents receive new document IDs and will be sorted last. In our case, index order is unspecified.
So far we’ve only sorted by score, which was already happening without using the sorting facility, and document order, which is probably only marginally useful at best. Sorting by one of our own fields is what we’re after.
5.2.4. Sorting by a field
Sorting by a textual field first requires that the field was indexed as a single token, as described in section 2.4.6. Typically this means using Field.Index.NOT_ANALYZED or Field.Index.NOT_ANALYZED_NO_NORMS. Separately, you can choose whether or not to store the field. In our book test index, the category field was indexed with Field.Index.NOT_ANALYZED and Field.Store.YES, allowing it to be used for sorting. NumericField instances are automatically indexed properly for sorting. To sort by a field, you must create a new Sort object, providing the field name:
example.displayResults(query,
new Sort(new SortField("category", SortField.STRING)));
Here’s the result when sorting by category. Note that the results are sorted by our category field in increasing alphabetical order:
Results for: *:* (contents:java contents:action)sorted by <string: "category"> Title pubmonth id score A Modern Art of Education 200403 12 0.151398 /education/pedagogy Lipitor Thief of Memory 200611 1 0.151398 /health Nudge: Improving Decisions... 200804 3 0.151398 /health Imperial Secrets of Health... 199903 2 0.151398 /health/alternative/chinese Tao Te Ching
5.2.5. Reversing sort order
The default sort direction for sort fields (including relevance and document ID) is natural ordering. Natural order is descending for relevance but increasing for all other fields. The natural order can be reversed per Sort object by specifying true for the second argument. For example, here we list books with the newest publications first:
example.displayResults(allBooks,
new Sort(new SortField("pubmonth", SortField.INT, true)));
In our book test index, the pubmonth field is indexed as NumericField, where the year and month are combined as an integer. For example, 201005 is indexed as integer 201,005. Note that pubmonth is now sorted in descending order:
Results for: *:* (contents:java contents:action)
The exclamation point in sorted by "pubmonth"! indicates that the pubmonth field is being sorted in reverse natural order (descending publication months, with newest first). Note that the two books with the same publication month are then sorted in document ID order due to Lucene’s internal tie break by document ID.
5.2.6. Sorting by multiple fields
Sorting by multiple fields is important whenever your primary sort leaves ambiguity because there are equal values. Implicitly we’ve been sorting by multiple fields, because Lucene automatically breaks ties by document ID. You can control the sort fields explicitly by creating Sort with multiple SortFields. This example uses the category field as a primary alphabetic sort, with results within category sorted by score; finally, books with equal score within a category are sorted by decreasing publication month:
example.displayResults(query,
new Sort(new SortField("category", SortField.STRING),
SortField.FIELD_SCORE,
new SortField("pubmonth", SortField.INT, true)
));
You can see in the results that we first sort by category, and second by score. For example, the category/technology/computers/programming has multiple books within it that are sorted first by decreasing relevance and second by decreasing publication month:
Results for: *:* (contents:java contents:action)
The Sort instance internally keeps an array of SortFields, but only in this example have you seen it explicitly; the other examples used shortcuts to creating the SortField array. A SortField holds the field name, a field type, and the reverse order flag. SortField contains constants for several field types, including SCORE, DOC, STRING, BYTE, SHORT, INT, LONG, FLOAT, and DOUBLE.SCORE and DOC are special types for sorting on relevance and document ID.
5.2.7. Selecting a sorting field type
By search time, the fields that can be sorted on and their corresponding types are already set. Indexing time is when the decision about sorting capabilities should be made, but custom sorting implementations can do so at search time, as you’ll see in section 6.1. Section 2.4.6 discusses index-time sorting design. By indexing using a NumericField, you can base sorting on numeric values. Sorting by numeric values consumes less memory than by string values; section 5.1 discusses performance issues further.
When sorting by String values, you may need to specify your own locale, which we cover next.
5.2.8. Using a nondefault locale for sorting
When you’re sorting on a SortField.STRING type, order is determined under the covers using String.compareTo by default. But if you need a different collation order, SortField lets you specify a Locale. A Collator instance is obtained for the provided locale using Collator.getInstance(Locale), and the Collator.compare method then determines the sort order. There are two overloaded SortField constructors for use when you need to specify locale:
public SortField (String field, Locale locale) public SortField (String field, Locale locale, boolean reverse)
Both constructors imply the SortField.STRING type because the locale applies only to string-type sorting, not to numerics.
In this section, we’ve shown you how to precisely specify how Lucene should sort the search results. You’ve learned how to sort by relevance, which is Lucene’s default, or by index order, as well as by field value. You know how to reverse the sort order and sort by multiple criteria. Often Lucene’s default relevance sort is best, but for applications that need precise control, Lucene gives it to you. We’ll now see an interesting alternative for performing phrase searches.
5.3. Using MultiPhraseQuery
The built-in MultiPhraseQuery is definitely a niche query, but it’s potentially useful. MultiPhraseQuery is just like PhraseQuery except that it allows multiple terms per position. You could achieve the same logical effect, albeit at a high performance cost, by enumerating all possible phrase combinations and using a BooleanQuery to “OR” them together.
For example, suppose we want to find all documents about speedy foxes, with quick or fast followed by fox. One approach is to do a "quick fox" OR "fast fox" query. Another option is to use MultiPhraseQuery. In our example, shown in listing 5.3, two documents are indexed with similar phrases. One document uses "the quick brown fox jumped over the lazy dog" and the other uses "the fast fox hopped over the hound", as shown in our test setUp() method.
Listing 5.3. Setting up an index to test MultiPhraseQuery
public class MultiPhraseQueryTest extends TestCase {
private IndexSearcher searcher;
protected void setUp() throws Exception {
Directory directory = new RAMDirectory();
IndexWriter writer = new IndexWriter(directory,
new WhitespaceAnalyzer(),
IndexWriter.MaxFieldLength.UNLIMITED);
Document doc1 = new Document();
doc1.add(new Field("field",
"the quick brown fox jumped over the lazy dog",
Field.Store.YES, Field.Index.ANALYZED));
writer.addDocument(doc1);
Document doc2 = new Document();
doc2.add(new Field("field",
"the fast fox hopped over the hound",
Field.Store.YES, Field.Index.ANALYZED));
writer.addDocument(doc2);
writer.close();
searcher = new IndexSearcher(directory);
}
}
The test method in listing 5.4 demonstrates the mechanics of using the MultiPhraseQuery API by adding one or more terms to a MultiPhraseQuery instance in order.
Listing 5.4. Using MultiPhraseQuery to match more than one term at each position

Just as with PhraseQuery, the slop factor is supported. In testBasic(), the slop is used to match "quick brown fox" in the second search; with the default slop of 0, it doesn’t match. For completeness, listing 5.5 shows a test illustrating the described BooleanQuery, with a slop set for "quick fox".
Listing 5.5. Mimicking MultiPhraseQuery using BooleanQuery
public void testAgainstOR() throws Exception {
PhraseQuery quickFox = new PhraseQuery();
quickFox.setSlop(1);
quickFox.add(new Term("field", "quick"));
quickFox.add(new Term("field", "fox"));
PhraseQuery fastFox = new PhraseQuery();
fastFox.add(new Term("field", "fast"));
fastFox.add(new Term("field", "fox"));
BooleanQuery query = new BooleanQuery();
query.add(quickFox, BooleanClause.Occur.SHOULD);
query.add(fastFox, BooleanClause.Occur.SHOULD);
TopDocs hits = searcher.search(query, 10);
assertEquals(2, hits.totalHits);
}
One difference between using MultiPhraseQuery and using PhraseQuery’s BooleanQuery is that the slop factor is applied globally with MultiPhraseQuery—it’s applied on a per-phrase basis with PhraseQuery.
Of course, hard-coding the terms wouldn’t be realistic, generally speaking. One possible use of a MultiPhraseQuery would be to inject synonyms dynamically into phrase positions, allowing for less precise matching. For example, you could tie in the WordNet-based code (see section 9.3 for more on WordNet and Lucene). As seen in listing 5.6, QueryParser produces a MultiPhraseQuery for search terms surrounded in double quotes when the analyzer it’s using returns positionIncrement 0 for any of the tokens within the phrase.
Listing 5.6. Using QueryParser to produce a MultiPhraseQuery
public void testQueryParser() throws Exception {
SynonymEngine engine = new SynonymEngine() {
public String[] getSynonyms(String s) {
if (s.equals("quick"))
return new String[] {"fast"};
else
return null;
}
};
Query q = new QueryParser(Version.LUCENE_30,
"field",
new SynonymAnalyzer(engine))
.parse(""quick fox"");
assertEquals("analyzed",
"field:"(quick fast) fox"", q.toString());
assertTrue("parsed as MultiPhraseQuery", q instanceof MultiPhraseQuery);
}
Next we’ll visit MultiFieldQueryParser, which we’ll use for querying on multiple fields.
5.4. Querying on multiple fields at once
In our book data, several fields were indexed to separately hold the title, category, author, subject, and so forth. But when searching a user would typically like to search across all fields at once. You could require users to spell out each field name, but except for specialized cases, that’s requiring far too much work on your users’ part. Users much prefer to search all fields, by default, unless a specific field is requested. We cover three possible approaches here.
The first approach is to create a multivalued catchall field to index the text from all fields, as we’ve done for the contents field in our book test index. Be sure to increase the position increment gap across field values, as described in section 4.7.1, to avoid incorrectly matching across two field values. You then perform all searching against the catchall field. This approach has some downsides: you can’t directly control per-field boosting[1], and disk space is wasted, assuming you also index each field separately.
1 Using payloads, an advanced topic covered in section 6.5, it is possible to retain per-field boost even -within a catchall field.
The second approach is to use MultiFieldQueryParser, which subclasses QueryParser. Under the covers, it instantiates a QueryParser, parses the query expression for each field, then combines the resulting queries using a BooleanQuery. The default operator OR is used in the simplest parse method when adding the clauses to the BooleanQuery. For finer control, the operator can be specified for each field as required (BooleanClause.Occur.MUST), prohibited (BooleanClause.Occur.MUST_NOT), or normal (BooleanClause.Occur.SHOULD), using the constants from BooleanClause.
Listing 5.7 shows this heavier QueryParser variant in use. The testDefaultOperator() method first parses the query "development" using both the title and subject fields. The test shows that documents match based on either of those fields. The second test, testSpecifiedOperator(), sets the parsing to mandate that documents must match the expression in all specified fields and searches using the query "lucene".
Listing 5.7. MultiFieldQueryParser, which searches on multiple fields at once


MultiFieldQueryParser has some limitations due to the way it uses QueryParser. You can’t control any of the settings that QueryParser supports, and you’re stuck with the defaults, such as default locale date parsing and zero-slop default phrase queries.
If you choose to use MultiFieldQueryParser, be sure your queries are fabricated appropriately using the QueryParser and Analyzer diagnostic techniques shown in chapters 3 and 4. Plenty of odd interactions with analysis occur using QueryParser, and these are compounded when using MultiFieldQueryParser. An important downside of MultiFieldQueryParser is that it produces more complex queries, as Lucene must separately test each query term against every field, which will run slower than using a catchall field.
The third approach for automatically querying across multiple fields is the advanced DisjunctionMaxQuery, which wraps one or more arbitrary queries, OR’ing together the documents they match. You could do this with BooleanQuery, as MultiFieldQueryParser does, but what makes DisjunctionMaxQuery interesting is how it scores each hit: when a document matches more than one query, it computes the score as the maximum score across all the queries that matched, compared to BooleanQuery, which sums the scores of all matching queries. This can produce better end-user relevance.
DisjunctionMaxQuery also includes an optional tie-breaker multiplier so that, all things being equal, a document matching more queries will receive a higher score than a document matching fewer queries. To use DisjunctionMaxQuery to query across multiple fields, you create a new field-specific Query, for each field you’d like to include, and then use DisjunctionMaxQuery’s add method to include that Query.
Which approach makes sense for your application? The answer is “It depends,” because there are important trade-offs. The catchall field is a simple index time–only solution but results in simplistic scoring and may waste disk space by indexing the same text twice. Yet it likely yields the best searching performance. MultiFieldQueryParser produces BooleanQuerys that sum the scores (whereas DisjunctionMaxQuery takes the maximum score) for all queries that match each document, then properly implements per-field boosting. You should test all three approaches, taking into account both search performance and search relevance, to find the best.
We’ll now move on to span queries, advanced queries that allow you to match based on positional constraints.
5.5. Span queries
Lucene includes a whole family of queries based on SpanQuery, loosely mirroring the normal Lucene Query classes. A span in this context is a starting and ending token position in a field. Recall from section 4.2.1 that tokens emitted during the analysis process include a position from the previous token. This position information, in conjunction with the new SpanQuery subclasses, allows for even more query discrimination and sophistication, such as all documents where “President Obama” is near “health care reform.”
Using the query types we’ve discussed thus far, it isn’t possible to formulate such a position-aware query. You could get close with something like "president obama" AND "health care reform", but these phrases may be too distant from one another within the document to be relevant for our searching purposes. In typical applications, SpanQuerys are used to provide richer, more expressive position-aware functionality than PhraseQuery. They’re also commonly used in conjunction with payloads, covered in section 6.5, to enable access to the payloads created during indexing.
While searching, span queries track more than the documents that match: the individual spans, perhaps more than one per field, are also tracked. Contrasting with TermQuery, which simply matches documents, SpanTermQuery matches exactly the same documents but also keeps track of the positions of every term occurrence that matches. Generally this is more compute-intensive. For example, when TermQuery finds a document containing its term, it records that document as a match and immediately moves on, whereas SpanTermQuery must enumerate all the occurrences of that term within the document.
There are six subclasses of the base SpanQuery, shown in table 5.1. We’ll discuss these SpanQuery types with a simple example, shown in listing 5.8: we’ll index two documents, one with the phrase “the quick brown fox jumps over the lazy dog” and the other with the similar phrase “the quick red fox jumps over the sleepy cat.” We’ll create a separate SpanTermQuery for each of the terms in these documents, as well as three helper assert methods. Finally, we’ll create the different types of span queries to illustrate their functions.
Table 5.1. SpanQuery family
|
SpanQuery type |
Description |
|---|---|
| SpanTermQuery | Used in conjunction with the other span query types. On its own, it’s functionally equivalent to TermQuery. |
| SpanFirstQuery | Matches spans that occur within the first part of a field. |
| SpanNearQuery | Matches spans that occur near one another. |
| SpanNotQuery | Matches spans that don’t overlap one another. |
| FieldMaskingSpanQuery | Wraps another SpanQuery but pretends a different field was matched. This is useful for doing span matches across fields, which is otherwise not possible. |
| SpanOrQuery | Aggregates matches of span queries. |
Listing 5.8. SpanQuery demonstration infrastructure
public class SpanQueryTest extends TestCase {
private RAMDirectory directory;
private IndexSearcher searcher;
private IndexReader reader;
private SpanTermQuery quick;
private SpanTermQuery brown;
private SpanTermQuery red;
private SpanTermQuery fox;
private SpanTermQuery lazy;
private SpanTermQuery sleepy;
private SpanTermQuery dog;
private SpanTermQuery cat;
private Analyzer analyzer;
protected void setUp() throws Exception {
directory = new RAMDirectory();
analyzer = new WhitespaceAnalyzer();
IndexWriter writer = new IndexWriter(directory,
analyzer,
IndexWriter.MaxFieldLength.UNLIMITED);
Document doc = new Document();
doc.add(new Field("f",
"the quick brown fox jumps over the lazy dog",
Field.Store.YES, Field.Index.ANALYZED));
writer.addDocument(doc);
doc = new Document();
doc.add(new Field("f",
"the quick red fox jumps over the sleepy cat",
Field.Store.YES, Field.Index.ANALYZED));
writer.addDocument(doc);
writer.close();
searcher = new IndexSearcher(directory);
reader = searcher.getIndexReader();
quick = new SpanTermQuery(new Term("f", "quick"));
brown = new SpanTermQuery(new Term("f", "brown"));
red = new SpanTermQuery(new Term("f", "red"));
fox = new SpanTermQuery(new Term("f", "fox"));
lazy = new SpanTermQuery(new Term("f", "lazy"));
sleepy = new SpanTermQuery(new Term("f", "sleepy"));
dog = new SpanTermQuery(new Term("f", "dog"));
cat = new SpanTermQuery(new Term("f", "cat"));
}
private void assertOnlyBrownFox(Query query) throws Exception {
TopDocs hits = searcher.search(query, 10);
assertEquals(1, hits.totalHits);
assertEquals("wrong doc", 0, hits.scoreDocs[0].doc);
}
private void assertBothFoxes(Query query) throws Exception {
TopDocs hits = searcher.search(query, 10);
assertEquals(2, hits.totalHits);
}
private void assertNoMatches(Query query) throws Exception {
TopDocs hits = searcher.search(query, 10);
assertEquals(0, hits.totalHits);
}
}
With this necessary bit of setup out of the way, we can begin exploring span queries. First we’ll ground ourselves with SpanTermQuery.
5.5.1. Building block of spanning, SpanTermQuery
Span queries need an initial leverage point, and SpanTermQuery is just that. Internally, a SpanQuery keeps track of its matches: a series of start/end positions for each matching document. By itself, a SpanTermQuery matches documents just like TermQuery does, but it also keeps track of position of the same terms that appear within each document. Generally you’d never use this query by itself (you’d use TermQuery instead); you only use it as inputs to the other SpanQuery classes.
Figure 5.1 illustrates the SpanTermQuery matches for this code:
public void testSpanTermQuery() throws Exception {
assertOnlyBrownFox(brown);
dumpSpans(brown);
}
Figure 5.1. SpanTermQuery for brown

The brown SpanTermQuery was created in setUp() because it will be used in other tests that follow. We developed a method, dumpSpans, to visualize spans. The dumpSpans method uses lower-level SpanQuery APIs to navigate the spans; this lower-level API probably isn’t of much interest to you other than for diagnostic purposes, so we don’t elaborate further. Each SpanQuery subclass sports a useful toString() for diagnostic purposes, which dumpSpans uses, as seen in listing 5.9.
Listing 5.9. dumpSpans method, used to see all spans matched by any SpanQuery


The output of dumpSpans(brown) is
f:brown: the quick <brown> fox jumps over the lazy dog (0.22097087)
More interesting is the dumpSpans output from a SpanTermQuery for “the”:
dumpSpans(new SpanTermQuery(new Term("f", "the")));
f:the:
<the> quick brown fox jumps over the lazy dog (0.18579213)
the quick brown fox jumps over <the> lazy dog (0.18579213)
<the> quick red fox jumps over the sleepy cat (0.18579213)
the quick red fox jumps over <the> sleepy cat (0.18579213)
Not only were both documents matched, but also each document had two span matches highlighted by the brackets. The basic SpanTermQuery is used as a building block of the other SpanQuery types. Let’s see how to match only documents where the terms of interest occur in the beginning of the field.
5.5.2. Finding spans at the beginning of a field
To query for spans that occur within the first specific number of positions of a field, use SpanFirstQuery. Figure 5.2 illustrates a SpanFirstQuery.
Figure 5.2. SpanFirstQuery requires that the positional match occur near the start of the field

This test shows nonmatching and matching queries:
public void testSpanFirstQuery() throws Exception {
SpanFirstQuery sfq = new SpanFirstQuery(brown, 2);
assertNoMatches(sfq);
dumpSpans(sfq);
sfq = new SpanFirstQuery(brown, 3);
dumpSpans(sfq);
assertOnlyBrownFox(sfq);
}
No matches are found in the first query because the range of 2 is too short to find brown, but the range of 3 is just long enough to cause a match in the second query (see figure 5.2). Any SpanQuery can be used within a SpanFirstQuery, with matches for spans that have an ending position in the first specified number (2 and 3 in this case) of positions. The resulting span matches are the same as the original SpanQuery spans—in this case, the same dumpSpans() output for brown as you saw in section 5.5.1.
5.5.3. Spans near one another
A PhraseQuery (see section 3.4.6) matches documents that have terms near one another, with a slop factor to allow for intermediate or reversed terms. SpanNearQuery operates similarly to PhraseQuery, with some important differences. SpanNearQuery matches spans that are within a certain number of positions from one another, with a separate flag indicating whether the spans must be in the order specified or can be reversed. The resulting matching spans span from the start position of the first span sequentially to the ending position of the last span. An example of a SpanNearQuery given three SpanTermQuery objects is shown in figure 5.3.
Figure 5.3. SpanNearQuery requires positional matches to be close to one another.

Using SpanTermQuery objects as the SpanQuerys in a SpanNearQuery is much like using a PhraseQuery. The SpanNearQuery slop factor is a bit less confusing than the PhraseQuery slop factor because it doesn’t require at least two additional positions to account for a reversed span. To reverse a SpanNearQuery, set the inOrder flag (third argument to the constructor) to false. Listing 5.10 demonstrates a few variations of SpanNearQuery and shows it in relation to PhraseQuery.
Listing 5.10. Finding matches near one another using SpanNearQuery
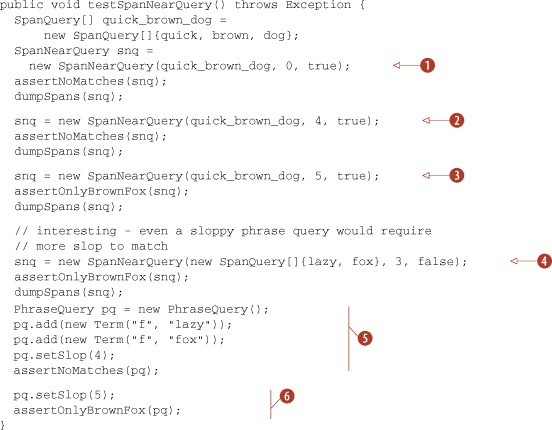
We’ve only shown SpanNearQuery with nested SpanTermQuerys, but SpanNearQuery allows for any SpanQuery type. A more sophisticated SpanNearQuery example is demonstrated later in listing 5.11 in conjunction with SpanOrQuery. Next we visit SpanNotQuery.
5.5.4. Excluding span overlap from matches
The SpanNotQuery excludes matches where one SpanQuery overlaps another. The following code demonstrates:
public void testSpanNotQuery() throws Exception {
SpanNearQuery quick_fox =
new SpanNearQuery(new SpanQuery[]{quick, fox}, 1, true);
assertBothFoxes(quick_fox);
dumpSpans(quick_fox);
SpanNotQuery quick_fox_dog = new SpanNotQuery(quick_fox, dog);
assertBothFoxes(quick_fox_dog);
dumpSpans(quick_fox_dog);
SpanNotQuery no_quick_red_fox =
new SpanNotQuery(quick_fox, red);
assertOnlyBrownFox(no_quick_red_fox);
dumpSpans(no_quick_red_fox);
}
The first argument to the SpanNotQuery constructor is a span to include, and the second argument is a span to exclude. We’ve strategically added dumpSpans to clarify what’s going on. Here’s the output with the Java query annotated above each:
SpanNearQuery quick_fox =
new SpanNearQuery(new SpanQuery[]{quick, fox}, 1, true);
spanNear([f:quick, f:fox], 1, true):
the <quick brown fox> jumps over the lazy dog (0.18579213)
the <quick red fox> jumps over the sleepy cat (0.18579213)
SpanNotQuery quick_fox_dog = new SpanNotQuery(quick_fox, dog);
spanNot(spanNear([f:quick, f:fox], 1, true), f:dog):
the <quick brown fox> jumps over the lazy dog (0.18579213)
the <quick red fox> jumps over the sleepy cat (0.18579213)
SpanNotQuery no_quick_red_fox =
new SpanNotQuery(quick_fox, red);
spanNot(spanNear([f:quick, f:fox], 1, true), f:red):
the <quick brown fox> jumps over the lazy dog (0.18579213)
The SpanNearQuery matched both documents because both have quick and fox within one position of each other. The first SpanNotQuery, quick_fox_dog, continues to match both documents because there’s no overlap with the quick_fox span and dog. The second SpanNotQuery, no_quick_red_fox, excludes the second document because red overlaps with the quick_fox span. Notice that the resulting span matches are the original included span. The excluded span is only used to determine if there’s an overlap and doesn’t factor into the resulting span matches.
Our final query is useful for joining together multiple SpanQuerys.
5.5.5. SpanOrQuery
Finally let’s talk about SpanOrQuery, which aggregates an array of SpanQuerys. Our example query, in English, is all documents that have “quick fox” near “lazy dog” or that have “quick fox” near “sleepy cat.” The first clause of this query is shown in figure 5.4. This single clause is SpanNearQuery nesting two SpanNearQuerys, and each consists of two SpanTermQuerys.
Figure 5.4. One clause of the SpanOrQuery

Our test case becomes a bit lengthier due to all the sub-SpanQuerys being built on (see listing 5.11). Using dumpSpans, we analyze the code in more detail.
Listing 5.11. Taking the union of two span queries using SpanOrQuery
public void testSpanOrQuery() throws Exception {
SpanNearQuery quick_fox =
new SpanNearQuery(new SpanQuery[]{quick, fox}, 1, true);
SpanNearQuery lazy_dog =
new SpanNearQuery(new SpanQuery[]{lazy, dog}, 0, true);
SpanNearQuery sleepy_cat =
new SpanNearQuery(new SpanQuery[]{sleepy, cat}, 0, true);
SpanNearQuery qf_near_ld =
new SpanNearQuery(
new SpanQuery[]{quick_fox, lazy_dog}, 3, true);
assertOnlyBrownFox(qf_near_ld);
dumpSpans(qf_near_ld);
SpanNearQuery qf_near_sc =
new SpanNearQuery(
new SpanQuery[]{quick_fox, sleepy_cat}, 3, true);
dumpSpans(qf_near_sc);
SpanOrQuery or = new SpanOrQuery(
new SpanQuery[]{qf_near_ld, qf_near_sc});
assertBothFoxes(or);
dumpSpans(or);
}
We’ve used our handy dumpSpans a few times to allow us to follow the progression as the final OR query is built. Here’s the output, followed by our analysis of it:
SpanNearQuery qf_near_ld =
new SpanNearQuery(
new SpanQuery[]{quick_fox, lazy_dog}, 3, true);
spanNear([spanNear([f:quick, f:fox], 1, true),
spanNear([f:lazy, f:dog], 0, true)], 3, true):
the <quick brown fox jumps over the lazy dog> (0.3321948)
SpanNearQuery qf_near_sc =
new SpanNearQuery(
new SpanQuery[]{quick_fox, sleepy_cat}, 3, true);
spanNear([spanNear([f:quick, f:fox], 1, true),
spanNear([f:sleepy, f:cat], 0, true)], 3, true):
the <quick red fox jumps over the sleepy cat> (0.3321948)
SpanOrQuery or = new SpanOrQuery(
new SpanQuery[]{qf_near_ld, qf_near_sc});
spanOr([spanNear([spanNear([f:quick, f:fox], 1, true),
spanNear([f:lazy, f:dog], 0, true)], 3, true),
spanNear([spanNear([f:quick, f:fox], 1, true),
spanNear([f:sleepy, f:cat], 0, true)], 3, true)]):
the <quick brown fox jumps over the lazy dog> (0.6643896)
the <quick red fox jumps over the sleepy cat> (0.6643896)
Two SpanNearQuerys are created to match “quick fox” near “lazy dog” (qf_near_ld) and “quick fox” near “sleepy cat” (qf_near_sc) using nested SpanNearQuerys made up of SpanTermQuerys at the lowest level. Finally, these two SpanNearQuery instances are combined within a SpanOrQuery, which aggregates all matching spans.
Both SpanNearQuery and SpanOrQuery accept any other SpanQuerys, so you can create arbitrarily nested queries. For example, imagine you’d like to perform a “phrase within a phrase” query, such as a subphrase query "Bob Dylan", with the slop factor 0 for an exact match, and an outer phrase query matching this phrase with the word sings, with a nonzero slop factor. Such a query isn’t possible with PhraseQuery, because it only accepts terms. But you can easily create this query by embedding one SpanNearQuery within another.
5.5.6. SpanQuery and QueryParser
QueryParser doesn’t currently support any of the SpanQuery types, but the surround QueryParser in Lucene’s contrib modules does. We cover the surround parser in section 9.6.
Recall from section 3.4.6 that PhraseQuery is impartial to term order when enough slop is specified. Interestingly, you can easily extend QueryParser to use a SpanNearQuery with SpanTermQuery clauses instead, and force phrase queries to only match fields with the terms in the same order as specified. We demonstrate this technique in section 6.3.5.
We’re now done with the advanced span query family. These are definitely advanced queries that give precise control over how the position of term matches within a document is taken into account. We’ll now visit another advanced functionality: filters.
5.6. Filtering a search
Filtering is a mechanism of narrowing the search space, allowing only a subset of the documents to be considered as possible hits. They can be used to implement search-within-search features to successively search within a previous set of results or to constrain the document search space. A security filter allows users to only see search results of documents they “own,” even if their query technically matches other documents that are off limits; we provide an example of a security filter in section 5.6.7.
You can filter any Lucene search using the overloaded search methods that accept a Filter instance. There are numerous built-in filter implementations:
- TermRangeFilter matches only documents containing terms within a specified range of terms. It’s exactly the same as TermRangeQuery, without scoring.
- NumericRangeFilter matches only documents containing numeric values within a specified range for a specified field. It’s exactly the same as NumericRangeQuery, without scoring.
- FieldCacheRangeFilter matches documents in a certain term or numeric range, using the FieldCache (see section 5.1) for better performance.
- FieldCacheTermsFilter matches documents containing specific terms, using the field cache for better performance.
- QueryWrapperFilter turns any Query instance into a Filter instance, by using only the matching documents from the Query as the filtered space, discarding the document scores.
- SpanQueryFilter turns a SpanQuery into a SpanFilter, which subclasses the base Filter class and adds an additional method, providing access to the positional spans for each matching document. This is just like QueryWrapperFilter but is applied to SpanQuery classes instead.
- PrefixFilter matches only documents containing terms in a specific field with a specific prefix. It’s exactly the same as PrefixQuery, without scoring.
- CachingWrapperFilter is a decorator over another filter, caching its results to increase performance when used again.
- CachingSpanFilter does the same thing as CachingWrapperFilter, but it caches a SpanFilter.
- FilteredDocIdSet allows you to filter a filter, one document at a time. In order to use it, you must first subclass it and define the match method in your subclass.
Before you get concerned about mentions of caching results, rest assured that it’s done with a tiny data structure (a DocIdBitSet) where each bit position represents a document.
Consider also the alternative to using a filter: aggregating required clauses in a BooleanQuery. In this section, we’ll discuss each of the built-in filters as well as the BooleanQuery alternative, starting with TermRangeFilter.
5.6.1. TermRangeFilter
TermRangeFilter filters on a range of terms in a specific field, just like TermRangeQuery minus the scoring. If the field is numeric, you should use NumericRangeFilter (described next) instead. TermRangeFilter applies to textual fields.
Let’s look at title filtering as an example, shown in listing 5.12. We use the MatchAllDocsQuery as our query, and then apply a title filter to it.
Listing 5.12. Using TermRangeFilter to filter by title

The setUp() method ![]() establishes a baseline count of all the books in our index, allowing for comparisons when we use an all-inclusive date filter.
The first parameter to both of the TermRangeFilter constructors is the name of the field in the index. In our sample data this field name is title2, which is the title of each
book indexed lowercased using Field.NOT_ANALYZED_NO_NORMS. The two final Boolean arguments to the constructor for TermRangeFilter, includeLower, and includeUpper determine whether the lower and upper terms should be included or excluded from the filter.
establishes a baseline count of all the books in our index, allowing for comparisons when we use an all-inclusive date filter.
The first parameter to both of the TermRangeFilter constructors is the name of the field in the index. In our sample data this field name is title2, which is the title of each
book indexed lowercased using Field.NOT_ANALYZED_NO_NORMS. The two final Boolean arguments to the constructor for TermRangeFilter, includeLower, and includeUpper determine whether the lower and upper terms should be included or excluded from the filter.
Ranges can also be optionally open-ended.
Open-Ended Range Filtering
TermRangeFilter also supports open-ended ranges. To filter on ranges with one end of the range specified and the other end open, just pass null for whichever end should be open:
filter = new TermRangeFilter("modified", null, jan31, false, true);
filter = new TermRangeFilter("modified", jan1, null, true, false);
TermRangeFilter provides two static convenience methods to achieve the same thing:
filter = TermRangeFilter.Less("modified", jan31);
filter = TermRangeFilter.More("modified", jan1);
5.6.2. NumericRangeFilter
NumericRangeFilter filters by numeric value. This is just like NumericRangeQuery, minus the constant scoring:
public void testNumericDateFilter() throws Exception {
Filter filter = NumericRangeFilter.newIntRange("pubmonth",
201001,
201006,
true,
true);
assertEquals(2, TestUtil.hitCount(searcher, allBooks, filter));
}
The same caveats as NumericRangeQuery apply here; for example, if you specify a precisionStep different from the default, it must match the precisionStep used during indexing.
Our next filter does the job of both TermRangeFilter and NumericRangeFilter, but is built on top of Lucene’s field cache.
5.6.3. FieldCacheRangeFilter
FieldCacheRangeFilter is another option for range filtering. It achieves exactly the same filtering as both TermRangeFilter and NumericRangeFilter, but does so by using Lucene’s field cache. This may result in faster performance in certain situations, since all values are preloaded into memory. But the usual caveats with field cache apply, as described in section 5.1.
FieldCacheRangeFilter exposes a different API to achieve range filtering. Here’s how to do the same filtering on title2 that we did with TermRangeFilter:
Filter filter = FieldCacheRangeFilter.newStringRange("title2",
"d", "j", true, true);
assertEquals(3, TestUtil.hitCount(searcher, allBooks, filter));
To achieve the same filtering that we did with NumericRangeFilter:
filter = FieldCacheRangeFilter.newIntRange("pubmonth",
201001,
201006,
true,
true);
assertEquals(2, TestUtil.hitCount(searcher, allBooks, filter));
Let’s see how to filter by an arbitrary set of terms.
5.6.4. Filtering by specific terms
Sometimes you’d simply like to select specific terms to include in your filter. For example, perhaps your documents have Country as a field, and your search interface presents a checkbox allowing the user to pick and choose which countries to include in the search. There are two ways to achieve this.
The first approach is FieldCacheTermsFilter, which uses field cache under the hood. (Be sure to read section 5.1 for the trade-offs of the field cache.) Simply instantiate it with the field (String) and an array of String:
public void testFieldCacheTermsFilter() throws Exception {
Filter filter = new FieldCacheTermsFilter("category",
new String[] {"/health/alternative/chinese",
"/technology/computers/ai",
"/technology/computers/programming"});
assertEquals("expected 7 hits",
7,
TestUtil.hitCount(searcher, allBooks, filter));
}
All documents that have any of the terms in the specified field will be accepted. Note that the documents must have a single term value for each field. Under the hood, this filter loads all terms for all documents into the field cache the first time it’s used during searching for a given field. This means the first search will be slower, but subsequent searches, which reuse the cache, will be very fast. The field cache is reused even if you change which specific terms are included in the filter.
The second approach for filtering by terms is TermsFilter, which is included in Lucene’s contrib modules and is described in more detail in section 8.6.4. TermsFilter doesn’t do any internal caching, and it allows filtering on fields that have more than one term; otherwise, TermsFilter and FieldCacheTermsFilter are functionally identical. It’s best to test both approaches for your application to see if there are any significant performance differences.
5.6.5. Using QueryWrapperFilter
QueryWrapperFilter uses the matching documents of a query to constrain available documents from a subsequent search. It allows you to turn a query, which does scoring, into a filter, which doesn’t. Using a QueryWrapperFilter, we restrict the documents searched to a specific category:
public void testQueryWrapperFilter() throws Exception {
TermQuery categoryQuery =
new TermQuery(new Term("category", "/philosophy/eastern"));
Filter categoryFilter = new QueryWrapperFilter(categoryQuery);
assertEquals("only tao te ching",
1,
TestUtil.hitCount(searcher, allBooks, categoryFilter));
}
Here we’re searching for all the books (see setUp() in listing 5.12) but constraining the search using a filter for a category that contains a single book. Next we’ll see how to turn a SpanQuery into a filter.
5.6.6. Using SpanQueryFilter
SpanQueryFilter does the same thing as QueryWrapperFilter, except that it’s able to preserve the spans for each matched document. Here’s a simple example:
public void testSpanQueryFilter() throws Exception {
SpanQuery categoryQuery =
new SpanTermQuery(new Term("category", "/philosophy/eastern"));
Filter categoryFilter = new SpanQueryFilter(categoryQuery);
assertEquals("only tao te ching",
1,
TestUtil.hitCount(searcher, allBooks, categoryFilter));
}
SpanQueryFilter adds a method, bitSpans, enabling you to retrieve the spans for each matched document. Only advanced applications will make use of spans (Lucene doesn’t use them internally when filtering), so if you don’t need this information, it’s better (faster) to simply use QueryWrapperFilter.
Let’s see how to use filters for applying security constraints, also known as entitlements.
5.6.7. Security filters
Another example of document filtering constrains documents with security in mind. Our example assumes documents are associated with an owner, which is known at indexing time. We index two documents; both have the term info in their keywords field, but each document has a different owner, as you can see in listing 5.13.
Listing 5.13. Setting up an index to use for testing the security filter

Using a TermQuery for info in the keywords field results in both documents found, naturally. Suppose, though, that Jake is using the search feature in our application, and only documents he owns should be searchable by him. Quite elegantly, we can easily use a QueryWrapperFilter to constrain the search space to only documents for which he’s the owner, as shown in listing 5.14.
Listing 5.14. Securing the search space with a filter

| This is a general TermQuery for info. | |
| All documents containing info are returned. | |
| Here, the filter constrains document searches to only documents owned by jake. | |
| Only jake’s document is returned, using the same info TermQuery. |
If your security requirements are this straightforward, where documents can be associated with users or roles during indexing, using a QueryWrapperFilter will work nicely. But some applications require more dynamic enforcement of entitlements. In section 6.4, we develop a more sophisticated filter implementation that leverages external information; this approach could be adapted to a more dynamic custom security filter.
5.6.8. Using BooleanQuery for filtering
You can constrain a query to a subset of documents another way, by combining the constraining query to the original query as a required clause of a BooleanQuery. There are a couple of important differences, despite the fact that the same documents are returned from both. If you use CachingWrapperFilter around your QueryWrapperFilter, you can cache the set of documents allowed, likely speeding up successive searches using the same filter. In addition, normalized document scores are unlikely to be the same. The score difference makes sense when you’re looking at the scoring formula (see section 3.3) because the IDF (inverse document frequency) factor may be dramatically different. When you’re using BooleanQuery aggregation, all documents containing the terms are factored into the equation, whereas a filter reduces the documents under consideration and impacts the inverse document frequency factor.
This test case demonstrates how to “filter” using BooleanQuery aggregation and illustrates the scoring difference compared to testQueryFilter:
public void testFilterAlternative() throws Exception {
TermQuery categoryQuery =
new TermQuery(new Term("category", "/philosophy/eastern"));
BooleanQuery constrainedQuery = new BooleanQuery();
constrainedQuery.add(allBooks, BooleanClause.Occur.MUST);
constrainedQuery.add(categoryQuery, BooleanClause.Occur.MUST);
assertEquals("only tao te ching",
1,
TestUtil.hitCount(searcher, constrainedQuery));
}
The technique of aggregating a query in this manner works well with QueryParser parsed queries, allowing users to enter free-form queries yet restricting the set of documents searched by an API-controlled query. We describe PrefixFilter next.
5.6.9. PrefixFilter
PrefixFilter, the corollary to PrefixQuery, matches documents containing Terms starting with a specified prefix. We can use PrefixFilter to restrict a search to all books under a specific category:
public void testPrefixFilter() throws Exception {
Filter prefixFilter = new PrefixFilter(
new Term("category",
"/technology/computers"));
assertEquals("only /technology/computers/* books",
8,
TestUtil.hitCount(searcher,
allBooks,
prefixFilter));
}
Next we show how to cache a filter for better performance.
5.6.10. Caching filter results
The biggest benefit from filters comes when they’re cached and reused using CachingWrapperFilter, which takes care of caching automatically (internally using a WeakHashMap, so that externally dereferenced entries get garbage collected). You can cache any filter using CachingWrappingFilter. Filters cache by using the IndexReader as the key, which means searching should also be done with the same instance of IndexReader to benefit from the cache. If you aren’t constructing IndexReader yourself but are creating an IndexSearcher from a directory, you must use the same instance of IndexSearcher to benefit from the caching. When index changes need to be reflected in searches, discard IndexSearcher and IndexReader and reinstantiate.
To demonstrate its usage, we return to the title filtering example. We want to use TermRangeFilter, but we’d like to benefit from caching to improve performance:
public void testCachingWrapper() throws Exception {
Filter filter = new TermRangeFilter("title2",
"d", "j",
true, true);
CachingWrapperFilter cachingFilter;
cachingFilter = new CachingWrapperFilter(filter);
assertEquals(3,
TestUtil.hitCount(searcher,
allBooks,
cachingFilter));
}
Successive uses of the same CachingWrapperFilter instance with the same IndexSearcher instance will bypass using the wrapped filter, instead using the cached results.
5.6.11. Wrapping a filter as a query
We saw how to wrap a filter as a query. You can also do the reverse, using ConstantScoreQuery to turn any filter into a query, which you can then search on. The resulting query matches only documents that are included in the filter, and assigns all of them the score equal to the query boost.
5.6.12. Filtering a filter
The FilteredDocIdSet class is an abstract class that accepts a primary filter, and then, during matching whenever a document is being considered, the match method (of your subclass) is invoked to check whether the document should be allowed. This allows you to dynamically filter any other filter by implementing any custom logic in your match method. This approach is efficient because FilteredDocIdSet never fully materializes a bit set for the filter. Instead, each match is checked on demand.
This approach can be useful for enforcing entitlements, especially in cases where much of the enforcement is static (present in the index) but some amount of entitlement should be checked dynamically at runtime. For such a use case, you’d create a standard entitlements filter based on what’s in the index, then subclass FilteredDocIdSet, overriding the match method, to implement your dynamic entitlements logic.
5.6.13. Beyond the built-in filters
Lucene isn’t restricted to using the built-in filters. An additional filter found in the Lucene contrib modules, ChainedFilter, allows for complex chaining of filters. We cover it in section 9.1.
Writing custom filters allows external data to factor into search constraints, but a bit of detailed Lucene API know-how may be required to be highly efficient. We cover writing custom filters in section 6.4.
And if these filtering options aren’t enough, Lucene adds another interesting use of a filter. The FilteredQuery filters a query, like IndexSearcher’s search(Query, Filter, int) can, except it is itself a query: therefore it can be used as a single clause within a BooleanQuery. Using FilteredQuery seems to make sense only when using custom filters, so we cover it along with custom filters in section 6.4.3.
We are done with filters. Our next advanced topic is function queries, which give you custom control over how documents are scored.
5.7. Custom scoring using function queries
Lucene’s relevance scoring formula, which we discussed in chapter 3, does a great job of assigning relevance to each document based on how well it matches the query. But what if you’d like to modify or override how this scoring is done? In section 5.2 you saw how you can change the default relevance sorting to sort instead by one or more fields, but what if you need even more flexibility? This is where function queries come in.
Function queries give you the freedom to programmatically assign scores to matching documents using your own logic. All classes are from the org.apache.lucene.search.function package. In this section we first introduce the main classes used by function queries, and then see the real-world example of using function queries to boost recently modified documents.
5.7.1. Function query classes
The base class for all function queries is ValueSourceQuery. This is a query that matches all documents but sets the score of each document according to a ValueSource provided during construction. The function package provides FieldCacheSource, and its subclasses, to derive values from the field cache. You can also create your own ValueSource—for example, to derive scores from an external database. But probably the simplest approach is to use FieldScoreQuery, which subclasses ValueSourceQuery and derives each document’s score statically from a specific indexed field. The field should be a number, indexed without norms and with a single token per document. Typically you’d use Field.Index.NOT_ANALYZED_NO_NORMS. Let’s look at a simple example. First, include the field “score” in your documents like this:
doc.add(new Field("score",
"42",
Field.Store.NO,
Field.Index.NOT_ANALYZED_NO_NORMS));
Then, create this function query:
Query q = new FieldScoreQuery("score", FieldScoreQuery.Type.BYTE);
That query matches all documents, assigning each a score according to the contents of its “score” field. You can also use the SHORT, INT, or FLOAT constants. Under the hood, this function query uses the field cache, so the important trade-offs described in section 5.1 apply.
Our example is somewhat contrived; you could simply sort by the score field, descending, to achieve the same results. But function queries get more interesting when you combine them using the second type of function query, CustomScoreQuery. This query class lets you combine a normal Lucene query with one or more other function queries.
We can now use the FieldScoreQuery we created earlier and a CustomScoreQuery to compute our own score:
Query q = new QueryParser(Version.LUCENE_30,
"content",
new StandardAnalyzer(
Version.LUCENE_30))
.parse("the green hat");
FieldScoreQuery qf = new FieldScoreQuery("score",
FieldScoreQuery.Type.BYTE);
CustomScoreQuery customQ = new CustomScoreQuery(q, qf) {
public CustomScoreProvider getCustomScoreProvider(IndexReader r) {
return new CustomScoreProvider(r) {
public float customScore(int doc,
float subQueryScore,
float valSrcScore) {
return (float) (Math.sqrt(subQueryScore) * valSrcScore);
}
};
}
};
In this case we create a normal query q by parsing the user’s search text. We next create the same FieldScoreQuery we used earlier to assign a static score to documents according to the score field. Finally, we create a CustomScoreQuery, overriding the getCustomScoreProvider method to return a class containing the customScore method to compute our score for each matching document. In this contrived case, we take the square root of the incoming query score and then multiply it by the static score provided by the FieldScoreQuery. You can use arbitrary logic to create your scores.
Note that the IndexReader argument provided to the getCustomScoreProvider method is per-segment, meaning the method will be called multiple times during searching if the index has more than one segment. This is important as it enables your scoring logic to efficiently use the per-segment reader to retrieve values in the fieldcache. Let’s see a more interesting use of function queries, using the field cache to boost matches by recency.
5.7.2. Boosting recently modified documents using function queries
A real-world use of CustomScoreQuery is to perform document boosting. You can boost according to any custom criteria, but for our example, shown in listing 5.15, we boost recently modified documents using a new custom query class, RecencyBoostingQuery. In applications where documents have a clear timestamp, such as searching a newsfeed or press releases, boosting by recency can be useful. The class requires you to specify the name of a numeric field that contains the timestamp of each document that you’d like to use for boosting.
Listing 5.15. Using recency to boost search results


In our case, we previously indexed the pubmonthAsDay field, like this:
doc.add(new NumericField("pubmonthAsDay")
.setIntValue((int) (d.getTime()/(1000*3600*24))));
See section 2.6.2 for options when indexing dates and times.
Once the index is set up, using RecencyBoostingQuery is straightforward, as shown in listing 5.16.
Listing 5.16. Testing recency boosting

We first create a normal query, by parsing the search string "java in action", and then instantiate the RecencyBoostingQuery, giving a boost factor of up to 2.0 for any book published within the past two years. Then we run the search, sorting first by relevance score and second by title. The test as shown in listing 5.16 runs the unboosted query, producing this result:
1: Ant in Action: pubmonth=200707 score=0.78687847 2: Lucene in Action, Second Edition: pubmonth=201005 score=0.78687847 3: Tapestry in Action: pubmonth=200403 score=0.15186688 4: JUnit in Action, Second Edition: pubmonth=201005 score=0.13288352
If instead you run the search with q2, which boosts each result by recency, you’ll see this:
1: Lucene in Action, Second Edition: pubmonth=201005 score=2.483518 2: Ant in Action: pubmonth=200707 score=0.78687847 3: JUnit in Action, Second Edition: pubmonth=201005 score=0.41940224 4: Tapestry in Action: pubmonth=200403 score=0.15186688
You can see that in the unboosted query, the top two results were tied based on relevance. But after factoring in recency boosting, the scores were different and the sort order changed (for the better, we might add!).
This wraps up our coverage of function queries. Although we focused on one compelling example, boosting relevance scoring according to recency, function queries open up a whole universe of possibilities. You’re completely free to implement whatever scoring you’d like. We’ll now look at support for searching across multiple Lucene indexes.
5.8. Searching across multiple Lucene indexes
Some applications need to maintain separate Lucene indexes, yet want to allow a single search to return combined results from all the indexes. Sometimes, such separation is done for convenience or administrative reasons—for example, if different people or groups maintain the index for different collections of documents. Other times it may be done due to high volume. For example, a news site may make a new index for every month and then choose which months to search over.
Whatever the reason, Lucene provides two useful classes for searching across multiple indexes. We’ll first meet MultiSearcher, which uses a single thread to perform searching across multiple indexes. Then we’ll see ParallelMultiSearcher, which uses multiple threads to gain concurrency.
5.8.1. Using MultiSearcher
With MultiSearcher, all indexes can be searched with the results merged in a specified (or descending-score, by default) order. Using MultiSearcher is comparable to using IndexSearcher, except that you hand it an array of IndexSearchers to search rather than a single directory (so it’s effectively a decorator pattern and delegates most of the work to the subsearchers).
Listing 5.17 illustrates how to search two indexes that are split alphabetically by keyword. The index is made up of animal names beginning with each letter of the alphabet. Half the names are in one index, and half are in the other. A search is performed with a range that spans both indexes, demonstrating that results are merged together.
Listing 5.17. Securing the search space with a filter


This code uses two indexes ![]() . The first half of the alphabet is indexed to one index, and the other half is indexed to the other index
. The first half of the alphabet is indexed to one index, and the other half is indexed to the other index ![]() . This query
. This query ![]() spans documents in both indexes.
spans documents in both indexes.
The inclusive TermRangeQuery matches animal names that begin with h through animal names that begin with t, with the matching documents coming from both indexes. A related class, ParallelMultiSearcher, achieves the same functionality as MultiSearcher but uses multiple threads to gain concurrency.
5.8.2. Multithreaded searching using ParallelMultiSearcher
A multithreaded version of MultiSearcher, called ParallelMultiSearcher, spawns a new thread for each Searchable and waits for them all to finish when the search method is invoked. The basic search and search with filter options are parallelized, but searching with a Collector hasn’t yet been parallelized. The exposed API is the same as MultiSearcher, so it’s a simple drop-in.
Whether you’ll see performance gains using ParallelMultiSearcher depends on your architecture. If the indexes reside on different physical disks and your computer has CPU concurrency, you should see improved performance. But there hasn’t been much real-world testing to back this up, so be sure to test it for your application.
A cousin to ParallelMultiSearcher lives in Lucene’s contrib/remote directory, enabling you to remotely search multiple indexes in parallel. We’ll talk about term vectors next, a topic you’ve already seen on the indexing side in chapter 2.
5.9. Leveraging term vectors
Term vectors are an advanced means of storing the equivalent of an inverted index per document. They are a rather advanced topic, and there are many things you can do with term vectors, so this section is rather sizable. We’ll work through two concrete examples illustrating what you can do at search time once you have term vectors in the index: finding similar documents and automatically categorizing documents.
Technically, a term vector is a collection of term-frequency pairs, optionally including positional information for each term occurrence. Most of us probably can’t picture vectors in hyper-dimensional space, so for visualization purposes, let’s look at two documents that contain only the terms cat and dog. These words appear various times in each document. Plotting the term frequencies of each document in X, Y coordinates looks something like figure 5.5. What gets interesting with term vectors is the angle between them, as you’ll see in more detail in section 5.9.2.
Figure 5.5. Term vectors for two documents containing the terms cat and dog

We showed how to enable indexing of term vectors in section 2.4.3. We indexed the title, author, subject, and contents fields with term vectors when indexing our book data. Retrieving term vectors for a field in a given document by ID requires a call to an IndexReader method:
TermFreqVector termFreqVector =
reader.getTermFreqVector(id, "subject");
A TermFreqVector instance has several methods for retrieving the vector information, primarily as matching arrays of Strings and ints (the term value and frequency in the field, respectively). If you had also stored offsets and/or positions information with your term vectors, using Field.TermVector.WITH_POSITIONS_OFFSETS for example, then you’ll get a TermPositionVector back when you load the term vectors. That class contains offset and position information for each occurrence of the terms in the document.
You can use term vectors for some interesting effects, such as finding documents “like” a particular document, which is an example of latent semantic analysis. We’ll show how to find books similar to an existing one, as well as a proof-of-concept categorizer that can tell us the most appropriate category for a new book, as you’ll see in the following sections. We wrap up with the TermVectorMapper classes for precisely controlling how term vectors are read from the index.
5.9.1. Books like this
It’d be nice to offer other choices to the customers of our bookstore when they’re viewing a particular book. The alternatives should be related to the original book, but associating alternatives manually would be labor-intensive and would require ongoing effort to keep up to date. Instead, we use Lucene’s Boolean query capability and the information from one book to look up other books that are similar. Listing 5.18 demonstrates a basic approach for finding books like each one in our sample data.
Listing 5.18. Finding similar books to a specific example book


| As an example, we iterate over every book document in the index and find books like each one. | |
| Here we look up books that are like this one. | |
| Books by the same author are considered alike and are boosted so they will likely appear before books by other authors. | |
| Using the terms from the subject term vectors, we add each to a Boolean query. | |
| We combine the author and subject queries into a final Boolean query. | |
| We exclude the current book, which would surely be the best match given the other criteria, from consideration. |
In ![]() , we used a different way to get the value of the author field. It was indexed as multiple fields, and the original author
string is a comma-separated list of author(s) of a book:
, we used a different way to get the value of the author field. It was indexed as multiple fields, and the original author
string is a comma-separated list of author(s) of a book:
String[] authors = author.split(",");
for (String a : authors) {
doc.add(new Field("author",
a,
Field.Store.YES,
Field.Index.NOT_ANALYZED,
Field.TermVector.WITH_POSITIONS_OFFSETS));
}
The output is interesting, showing how our books are connected through author and subject:
Tao Te Ching
If you’d like to see the actual query used for each, uncomment the output lines toward the end of the docsLike method.
The books-like-this example could’ve been done without term vectors, and we aren’t using them as vectors in this case. We’ve only used the convenience of getting the terms for a given field. Without term vectors, the subject field could have been reanalyzed or indexed such that individual subject terms were added separately in order to get the list of terms for that field. Our next example also uses the frequency component to a term vector in a much more sophisticated manner.
Lucene’s contrib modules contains a useful Query implementation, MoreLikeThisQuery, doing the same thing as our BooksLikeThis class but more generically. BooksLikeThis is clearly hardwired to fields like subject and author from our books index. But MoreLikeThisQuery lets you set the field names, so it works well on any index. Section 8.6.1 describes this in more detail. The two highlighter contrib modules, described in sections 8.3 and 8.4, also use term vectors to find term occurrences for highlighting.
Let’s see another example of using term vectors: automatic category assignment.
5.9.2. What category?
Each book in our index is given a single primary category: for example, this book is categorized as “/technology/computers/programming.” The best category placement for a new book may be relatively obvious or (more likely) several possible categories may seem reasonable. You can use term vectors to automate the decision. We’ve written a bit of code that builds a representative subject vector for each existing category. This representative, archetypical, vector is the sum of all vectors for each document’s subject field vector.
With these representative vectors precomputed, our end goal is a calculation that can, given some subject keywords for a new book, tell us what category is the best fit. Our test case uses two example subject strings:
public void testCategorization() throws Exception {
assertEquals("/technology/computers/programming/methodology",
getCategory("extreme agile methodology"));
assertEquals("/education/pedagogy",
getCategory("montessori education philosophy"));
}
The first assertion says that, based on our sample data, if a new book has the keywords “extreme agile methodology” in its subject, the best category fit is /technology/computers/programming/methodology. The best category is determined by finding the closest category angle-wise in vector space to the new book’s subject.
The test setUp() builds vectors for each category:
protected void setUp() throws Exception {
categoryMap = new TreeMap();
buildCategoryVectors();
}
Our code builds category vectors by walking every document in the index and aggregating book subject vectors into a single vector for the book’s associated category. Category vectors are stored in a map, keyed by category name. The value of each item in the category map is another map keyed by term, with the value an integer for its frequency, as seen in listing 5.19.
Listing 5.19. Build category vectors by aggregating for each category
private void buildCategoryVectors() throws IOException {
IndexReader reader = IndexReader.open(TestUtil.getBookIndexDirectory());
int maxDoc = reader.maxDoc();
for (int i = 0; i < maxDoc; i++) {
if (!reader.isDeleted(i)) {
Document doc = reader.document(i);
String category = doc.get("category");
Map vectorMap = (Map) categoryMap.get(category);
if (vectorMap == null) {
vectorMap = new TreeMap();
categoryMap.put(category, vectorMap);
}
TermFreqVector termFreqVector =
reader.getTermFreqVector(i, "subject");
addTermFreqToMap(vectorMap, termFreqVector);
}
}
}
A book’s term frequency vector is added to its category vector in addTermFreqToMap. The arrays returned by getTerms() and getTermFrequencies() align with one another such that the same position in each refers to the same term, as listing 5.20 shows.
Listing 5.20. Aggregate term frequencies for each category
private void addTermFreqToMap(Map vectorMap,
TermFreqVector termFreqVector) {
String[] terms = termFreqVector.getTerms();
int[] freqs = termFreqVector.getTermFrequencies();
for (int i = 0; i < terms.length; i++) {
String term = terms[i];
if (vectorMap.containsKey(term)) {
Integer value = (Integer) vectorMap.get(term);
vectorMap.put(term,
new Integer(value.intValue() + freqs[i]));
} else {
vectorMap.put(term, new Integer(freqs[i]));
}
}
}
That was the easy part—building the category vector maps—because it only involved addition. Computing angles between vectors is more involved mathematically. In the simplest two-dimensional case, as shown in figure 5.5, two categories (A and B) have unique term vectors based on aggregation (as we’ve just done). The closest category, angle-wise, to a new book’s subjects is the match we’ll choose. Figure 5.6 shows the equation for computing an angle between two vectors.
Figure 5.6. Formula for computing the angle between two term vectors
![]()
Our getCategory method loops through all categories, computing the angle between each category and the new book. The smallest angle is the closest match, and the category name is returned, as shown in listing 5.21.
Listing 5.21. Finding the closest vector to match the best category
private String getCategory(String subject) {
String[] words = subject.split(" ");
Iterator categoryIterator = categoryMap.keySet().iterator();
double bestAngle = Double.MAX_VALUE;
String bestCategory = null;
while (categoryIterator.hasNext()) {
String category = (String) categoryIterator.next();
double angle = computeAngle(words, category);
if (angle < bestAngle) {
bestAngle = angle;
bestCategory = category;
}
}
return bestCategory;
}
We assume that the subject string is in a whitespace-separated form and that each word occurs only once. Furthermore, we use String.split to extract tokens from the subject, which will only work with analyzers that don’t alter the text of each token. If you’re using an analyzer that does alter the tokens, such as one that includes PorterStemFilter, you’ll need to change the String.split to invoke your analyzer instead.
The angle computation takes these assumptions into account to simplify a part of the computation. Finally, computing the angle between an array of words and a specific category is done in computeAngle, shown in listing 5.22.
Listing 5.22. Computing term vector angles for a new book against a given category

| The calculation is optimized with the assumption that each word in the words array has a frequency of 1. | |
| We multiply the square root of N by the square root of N to get N. This shortcut prevents a precision issue where the ratio could be greater than 1 (which is an illegal value for the inverse cosine function). |
You should be aware that computing term vector angles between two documents or, in this case, between a document and an archetypical category, is computation intensive. It requires square-root and inverse cosine calculations and may be prohibitive in high-volume indexes. We finish our coverage of term vectors with the TermVectorMapper class.
5.9.3. TermVectorMapper
Sometimes, the parallel array structure returned by IndexReader.getTermFreqVector may not be convenient for your application. Perhaps instead of sorting by Term, you’d like to sort the term vectors according to your own criteria. Or maybe you’d like to only load certain terms of interest. All of these can be done with a recent addition to Lucene, TermVectorMapper. This is an abstract base class that, when passed to IndexReader.getTermFreqVector methods, separately receives each term, with optional positions and offsets and can choose to store the data in its own manner. Table 5.2 describes the methods that a concrete TermVectorMapper implementation (subclass) must implement.
Table 5.2. Methods that a custom TermVectorMapper must implement
|
Method |
Purpose |
|---|---|
| setDocumentNumber | Called once per document to tell you which document is currently being loaded. |
| setExpectations | Called once per field to tell you how many terms occur in the field, and whether positions and offsets are stored. |
| map | Called once per term to provide the actual term vectors data. |
| isIgnoringPositions | You should return false only if you need to see the positions data for the term vectors. |
| isIgnoringOffsets | You should return false only if you need to see the offsets data for the term vectors. |
Lucene includes a few public core implementations of TermVectorMapper, described in table 5.3. You can also create your own implementation.
Table 5.3. Built-in implementations of TermVectorMapper
|
Method |
Purpose |
|---|---|
| PositionBasedTermVectorMapper | For each field, stores a map from the integer position to terms and optionally offsets that occurred at that position. |
| SortedTermVectorMapper | Merges term vectors for all fields into a single SortedSet, sorted according to a Comparator that you specify. One comparator is provided in the Lucene core, TermVectorEntryFreqSortedComparator, which sorts first by frequency of the term and second by the term itself. |
| FieldSortedTermVectorMapper | Just like SortedTermVectorMapper, except the fields aren’t merged together and instead each field stores its sorted terms separately. |
As we’ve now seen, term vectors are a powerful advanced functionality. We saw two examples where you might want to use them: automatically assigning documents to categories, and finding documents similar to an existing example. We also saw Lucene’s advanced API for controlling exactly how term vectors are loaded. We’ll now see how to load stored fields using another advanced API in Lucene: FieldSelector.
5.10. Loading fields with FieldSelector
We’ve talked about reading a document from the index using an IndexReader. You know that the document returned differs from the original document indexed in that it has only those fields you chose to store at indexing time using Field.Store.YES. Under the hood, Lucene writes these fields into the index and IndexReader reads them.
Unfortunately, reading a document can be fairly time consuming, especially if you need to read many of them per search and if your documents have many stored fields. Often, a document may have one or two large stored fields, holding the actual textual content for the document, and a number of smaller “metadata” fields such as title, category, author, and published date. When presenting the search results, you might only need the metadata fields and so loading the very large fields is costly and unnecessary. This is where FieldSelector comes in. FieldSelector, which is in the org.apache.lucene.document package, allows you to load a specific restricted set of fields for each document. It’s an interface with a single simple method:
FieldSelectorResult accept(String fieldName);
Concrete classes implementing this interface return a FieldSelectorResult describing whether the specified field name should be loaded, and how. FieldSelectorResult is an enum with seven values, described in table 5.4.
Table 5.4. FieldSelectorResult options when loading a stored field
|
Option |
Purpose |
|---|---|
| LOAD | Load the field. |
| LAZY_LOAD | Load the field lazily. The actual contents of the field won’t be read until Field.stringValue() or Field.binaryValue() is called. |
| NO_LOAD | Skip loading the field. |
| LOAD_AND_BREAK | Load this field and don’t load any of the remaining fields. |
| LOAD_FOR_MERGE | Used internally to load a field during segment merging; this skips decompressing compressed fields. |
| SIZE | Read only the size of the field, then add a binary field with a 4-byte array encoding that size. |
| SIZE_AND_BREAK | Like SIZE, but don’t load any of the remaining fields. |
When loading stored fields with a FieldSelector, IndexReader steps through the fields one by one for the document, in the order they had originally been added to the document during indexing, invoking FieldSelector on each field and choosing to load the field (or not) based on the returned result.
There are several built-in concrete classes implementing FieldSelector, described in table 5.5. It’s also straightforward to create your own implementation.
Table 5.5. Core FieldSelector implementations
|
Purpose |
|
|---|---|
| LoadFirstFieldSelector | Loads only the first field encountered. |
| MapFieldSelector | You specify the String names of the fields you want to load; all other fields are skipped. |
| SetBasedFieldSelector | You specify two sets: the first set is fields to load and the second set is fields to load lazily. |
Although FieldSelector will save time when loading fields, just how much time is application-dependent. Much of the cost when loading stored fields is in seeking the file pointers to the places in the index where all fields are stored, so you may find you don’t save that much time skipping fields. Test on your application to find the right trade-off.
5.11. Stopping a slow search
Usually Lucene’s searches are fast. But if you have a large index, or you create exceptionally complex searches, it’s possible for Lucene to take too long to execute the search. Fortunately, Lucene has a special Collector implementation, TimeLimitingCollector, that stops a search when it has taken too much time. We cover Collector in more detail in section 6.2.
TimeLimitingCollector delegates all methods to a separate Collector that you provide, and throws a TimeExceededException when the searching has taken too long. It’s simple to use, as shown in listing 5.23.
Listing 5.23. Using TimeLimitingCollector to stop a slow search

In this example we create a TopScoreDocCollector, which keeps the top 10 hits according to score, and wrap it with a TimeLimitingCollector that will abort the search if it takes longer than 1,000 msec (1.0 seconds). You’d obviously have to modify the exception handler to choose what to do when a timeout is hit. One option is to present the results collected so far, noting to the user that the results may not be accurate because the search took too long. This may be dangerous; the results are incomplete and the user could go on to make important decisions based on false results. Another option is to not show any results and simply ask users to rephrase or simplify their search.
There are a few couple of limitations to TimeLimitingCollector. First, it adds some of its own overhead during results collection (to check the timeout, per matched document) and that will make your searches run somewhat slower, though the impact should be small. Second, it only times out the search during collection, whereas it’s possible that some queries take a very long time during Query. rewrite(). For such queries it’s possible you won’t hit the TimeExceededException until well after your requested timeout.
5.12. Summary
This chapter has covered some diverse Lucene functionality, highlighting Lucene’s additional built-in search features. We touched on Lucene’s internal field cache API, which allows you to load into memory an array of a given field’s value for all documents. Sorting is a flexible way to control the ordering of search results.
We described a number of advanced queries. MultiPhraseQuery generalizes PhraseQuery by allowing more than one term at the same position within a phrase. The SpanQuery family leverages term-position information for greater searching precision. MultiFieldQueryParser is another QueryParser that matches against more than one field. Function queries let you programmatically customize how documents are scored.
Filters constrain document search space, regardless of the query, and you can either create your own filter (described in section 6.4), or use one of Lucene’s many built-in ones. We saw how to wrap a query as a filter, and vice versa, as well as how to cache filters for fast reuse.
Lucene includes support for multiple index searching, including a parallel version to easily take advantage of concurrency. Term vectors enable interesting effects, such as “like this” term vector angle calculations. We showed how to fine-tune the loading of term vectors and stored fields by using TermVectorMapper and FieldSelector. Finally we showed you how to use TimeLimitingCollector to handle searches that could take too long to run.
As modern-day search applications become more diverse and interesting, and users more demanding, you’ll find that Lucene’s rich advanced capabilities we’ve covered here give you a strong arsenal for addressing your needs. We’ve only touched on what’s possible with the examples in this chapter, because the possibilities with major features like sorting, filtering, and term vectors are so vast. Very likely whatever advanced needs your application encounters, they can be satisfied with what Lucene offers.
Yet this is still not quite the end of the searching story. Lucene also includes several ways to extend its searching behavior, such as custom sorting, positional payloads, filtering, and query expression parsing, which we cover in the next chapter.