
This chapter covers |
|---|
|
So far in the book we’ve concentrated on creating fairly self-contained applications; most data storage has been in the form of text or XML files. For a lot of tasks this can be sufficient, but often the data your application will be manipulating lives somewhere else: maybe in a relational database or behind a web service. One application I (Christian) worked on was part of a flight-planning system; weather maps and forecasts that the application needed were managed by another system accessible through a separate web service, while user preferences and details were stored in a local SQL Server database.
In this chapter we look at some of the techniques we can use to get access to this data. To start with, we cover the base API that the .NET framework provides for talking to different relational databases, followed by the higher-level classes that can be layered on top for slicing and dicing data in your application. Then we see how we can interact with different types of web services from IronPython.
Relational database management systems (RDBMSs) are everywhere in the IT industry, and there is a huge range of different database engines, from open source projects such as MySQL and PostgreSQL to commercial vendors like Microsoft SQL Server and Oracle. While the various engines often have quite different capabilities and feature sets, they all use a common model to represent data (the relational model) and provide a standardized[1] language for getting that data: SQL (Structured Query Language). However, although the language is standard, the methods for connecting to a database and sending an SQL query to it can often be quite different. ADO.NET (the .NET Database Communication layer) is designed to solve this problem.
In section 12.1, we cover the basics needed to use the .NET communication components in IronPython. We start by looking at the structure of the ADO.NET layers, and then we explore the methods they provide for managing relational data. By the end of the section, you should have a good understanding of the basics of talking to any database from IronPython. You’ll also have enough grounding to use examples written for other .NET languages to learn more advanced ADO.NET techniques.
So what is ADO.NET? The ADO part comes from the previous Microsoft approach to data access, ActiveX Data Objects, but there’s really only a slight spiritual relationship between ADO and ADO.NET. It’s tricky to describe precisely, because ADO.NET isn’t a class library itself. Instead, it’s a design for a large suite of related data access libraries, with a layer of classes that you can use to provide uniform data manipulation on top, as Figure 12.1 shows.
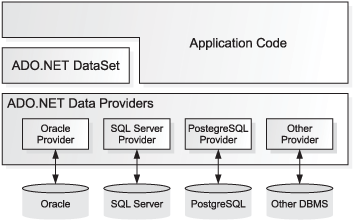
The bottom layer of ADO.NET is the Data Provider layer. Each DBMS has its own ADO.NET data provider, which wraps the specific details for connecting to and interacting with that database in a collection of classes with a common interface. You can see the most important classes in a data provider, as well as their roles, in table 12.1. We’ll look at these in more detail soon.
Table 12.1. The core classes in a data provider
Class | Description |
|---|---|
| Maintains the channel of communication with the database engine |
| Allows executing commands to query and altering data in the database through a connection |
| Gives access to the stream of records resulting from a query |
| Manages the movement of data between the Data Provider layer and the layer above it: the ADO.NET |
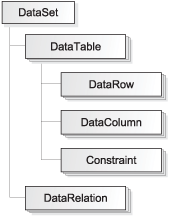
The layer above the data providers contains the DataSet and its component classes. DataSets are used to present and manipulate data pulled in from external sources in memory and to save changes made to the data back to the database (or another data store). A DataSet is a container for relational data and can contain a number of DataTables (each of which represents a table in the database) as well as relationships between the tables, which can be used to navigate the data and maintain consistency. You can see in figure 12.2 how the classes fit together.
So that’s the basic structure of ADO.NET data providers and DataSets. In the rest of this section, we look at using them from IronPython. We start with the data provider class-es: connecting to the database, issuing commands, querying the data, and using transactions to bundle changes together. Then we see how DataSets fit on top, using the DataAdapter.
All of this is quite abstract. Let’s see it in action (and in more detail).
To begin exploring the Data Provider layer, we need a database to work with and a corresponding data provider to connect to it from IronPython. In these examples we’re going to use PostgreSQL, a high-quality open source DBMS. You can download the database engine from www.postgresql.org, and the ADO.NET data provider for PostgreSQL is Npgsql, which is available at npgsql.org. You can administer Postgres databases completely through the command-line tools that come with it, but if you’d like a GUI administration tool to manage the database, PGAdmin (available from www.pgadmin.org or included with recent versions of PostgreSQL) works well.
Download and install PostgreSQL. For our purposes, the default settings will work well. Then run the SQL script chapter1212.1.1schema.sql from the source code for the book using the following command:
psql –U postgres –f schema.sql
If psql isn’t on your path, you’ll need to include the full path to the PostgreSQL bin directory. This will connect to the database server as the postgres user and create a new database called ironpython_in_action, with tables you can use for experimenting with ADO.NET in IronPython. The database contains information about movies, actors, and directors; figure 12.3 shows the fields in the tables and the relationships between them.
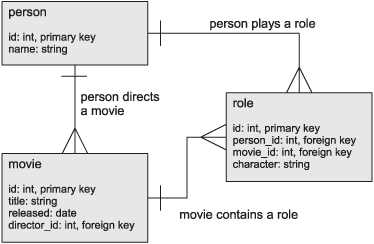
Figure 12.3. The example database stores information on movies, people, and roles and how they’re related.
The final new piece that you need is the PostgreSQL data provider, Npgsql. Download the latest binary distribution (at the time of writing this was 2.0.2) for your platform, and unzip it into a directory. To ensure that you can use it from IronPython, add the directory containing Npgsql.dll to your IRONPYTHONPATH environment variable. Once that’s all done, you should be able to import Npgsql and instantiate the classes it provides to communicate with the database.
One of the things I like about Python is that I can explore a new API in the interactive interpreter and get immediate feedback, rather than having to build a test program and then realizing that I’ve misunderstood how the API works. So let’s explore: run ipy, and enter the following commands:
>>> import clr
>>> clr.AddReference('Npgsql')
>>> import Npgsql as pgsqlIf the last import succeeds, then the interpreter has found and loaded the Npgsql assembly, and we can try to connect to the database. To do this, we use the NpgsqlConnection class (each data provider defines its own connection class).
>>> connection = pgsql.NpgsqlConnection( ... 'server=localhost; database=ironpython_in_action;' ... 'user id=postgres; password=<postgres user password>')[2]
(The password parameter should be the postgres user’s password that you specified when installing PostgreSQL.)
The parameter the NpgsqlConnection constructor takes is a connection string specifying the details of the database we’re connecting to. What it should contain and how it is formatted depends on the data provider, although all the providers I’ve used have had the same format you see here. Also, while our connection string is pretty close to minimal, there’s a great variety of optional parameters that you can specify in the connection string, such as whether connections should be pooled, whether the communication should be encrypted with SSL, and so on. To determine exactly what parameters a specific provider expects, you need to look in the documentation for that provider; another useful reference for a large number of databases is at www.connectionstrings.com.
>>> connection.Open()
The Open method does what it says on the tin: it creates the underlying communication channel to the database and logs in. If there were any network problems stopping us from reaching the database, or we’d given incorrect credentials in the connection string, the Open call would fail with a (hopefully) helpful error message.
In an application (particularly a web application) it’s very important to ensure that connections that are opened are closed (by calling the Close method) again. Database connections are external resources that generally are not totally managed by the .NET framework, and often they’re pooled to reduce the expense of creating and opening them. In a pooling situation, calling Close will return the connection to the pool for another task to use.
Before closing this connection, though, let’s look at how we can use it to have the database do our bidding.
Using our connection we can execute commands against the database; essentially, anything we could do using psql (the PostgreSQL command shell), we can do now from Python code.[3] To insert a row into the person table, we would execute the code in listing 12.1.
Example 12.1. Inserting a record
>>> command = connection.CreateCommand()
>>> command
<Npgsql.NpgsqlCommand object at 0x... [Npgsql.NpgsqlCommand]>
>>> command.CommandText = "insert into person (name) values ('Danny Boyle')"
>>> command.ExecuteNonQuery()
1We call the Connection.CreateCommand method to get an NpgsqlCommand associated with the connection. Then we set the command text to a SQL insert statement and call the command’s ExecuteNonQuery method, which runs the statement and returns the number of records affected by the statement. The NonQuery in the method name indicates that we don’t expect any data back in response.
Imagine we have a list of actors that we had loaded from somewhere else and want to insert into the person table. We could use a loop to put the people into the database, constructing the insert statement using % string formatting, as shown in listing 12.2.
Example 12.2. Trying to insert multiple people by constructing SQL strings
>>> people = ['James Nesbitt', "Sydney 'Big Dawg' Colston",
... 'Helena Bonham Carter']
>>> insert_statement = "insert into person (name) values ('%s')"
>>> for p in people:
... command.CommandText = insert_statement % p
... command.ExecuteNonQuery()
Traceback (most recent call last):
File , line unknown, in Initialize##365
File Npgsql, line unknown, in ExecuteNonQuery
File Npgsql, line unknown, in ExecuteCommand
File Npgsql, line unknown, in CheckErrors
EnvironmentError: ERROR: 42601: syntax error at or near "Big"Oops—in listing 12.2, the single quotes in Sydney Colston’s name have been interpreted as the end of the string in the command, and the next part of his name isn’t valid SQL, so the database has thrown a syntax error. We could avoid this by replacing every single quote with two single quotes (this is the SQL method of embedding quotes in strings), but that’s easy to forget and error prone. ADO.NET provides another way to handle SQL commands with values that vary: command parameters.
(These are sometimes called bind variables in other database APIs.)
To use a command with parameters, we set its CommandText to be a string containing references to parameters, rather than literal values:
>>> command = connection.CreateCommand() >>> command.CommandText = 'insert into person (name) values (:name)'
This is similar to the insert_statement variable we used earlier, except that it uses :name instead of %d to refer to the value we want. Also, the single quotes are not needed, because the parameter value is never stitched into the string. It’s passed in separately, and the database engine uses it as it executes the statement. This is what makes parameterized commands safer and easier to program with: you don’t need to worry about quoting strings, and for dates you can simply pass the date object rather than having to convert them into a string in a format the database engine will understand.
Now our loop to insert multiple people looks like the code in listing 12.3.
Example 12.3. Setting parameter values in a parameterized command
>>> command.Parameters.Add('name', None)
>>> for p in people:
... command.Parameters['name'].Value = p
... command.ExecuteNonQuery()Another benefit of using parameters is that they are more efficient if you are executing a statement more than once with different parameters. Parsing an SQL statement is expensive, so databases will usually cache parsed form and reuse it if exactly the same statement is sent again. Parameterized commands let you take advantage of that behavior.
Now we can send commands to the database to insert, update, or delete rows. Next we look at the methods that allow us to get information back.
The simplest form of query is one that returns a single value, for example, retrieving an attribute of an item in the database or counting the records that match search criteria. In that situation, we can use the ExecuteScalar method of the command, which you can see in listing 12.4.
Example 12.4. Getting a value from the database with ExecuteScalar
>>> command = connection.CreateCommand() >>> command.CommandText = 'select count(*) from person' >>> command.ExecuteScalar() 5L >>> command.CommandText = 'select name from person where id = 1' >>> command.ExecuteScalar() 'David Fincher'
As you can see, ExecuteScalar returns whatever type of object the query returns; this can make it a bit of a hassle in a statically typed language like C#, where you’d have to cast the result before you could use it. In Python, this kind of function is convenient.
A minor point to note is the way ExecuteScalar deals with NULL[5] values in the database or queries that return no rows. Both of these are displayed in listing 12.5.
Example 12.5. ExecuteScalar with NULL or no rows
>>> from System import DBNull >>> command.CommandText = 'select null' >>> command.ExecuteScalar() is DBNull.Value True >>> command.CommandText = 'select id from person where 1 = 2' >>> command.ExecuteScalar() is None True
When the query in listing 12.5 returns a row with a NULL in it, ExecuteScalar gives us DBNull, a special singleton value in .NET that is similar to None. When there are no rows returned, ExecuteScalar gives us None instead.
We can also call ExecuteScalar with a query that returns multiple rows:
>>> command.CommandText = 'select id, name from person' >>> command.ExecuteScalar() 1L
In this case, it returns the first value of the first row of the results. If we want to see more of the results, we’ll need to use a DataReader.
To get the results from a query, we call ExecuteReader on a command (using the same command text as above):
>>> reader = command.ExecuteReader() >>> reader <NpgsqlDataReader object at 0x...>
Now the DataReader is ready to start reading through the rows. Readers have a number of properties and methods for examining the shape of the rows that have come back. You can see some of these used in listing 12.6.
Example 12.6. Finding out what data is in a DataReader
>>> reader.HasRows
True
>>> reader.FieldCount
2
>>> [(reader.GetName(i), reader.GetFieldType(i))
... for i in range(reader.FieldCount)]
[('id', <System.RuntimeType object at 0x...[System.Int32]>),
('name', <System.RuntimeType object at 0x... [System.String]>)]We use the HasRows and FieldCount properties and the GetName and GetFieldType methods to see the structure of the data returned for our query.
Readers also have a current row; when the reader is opened, it’s positioned before the first row in the results. You advance to the next row with Read, which returns True unless you’ve run out of rows. Getting the values of the fields in the current row can be done in a number of ways. The most convenient is by indexing into the reader by column number or name. Putting this together, we have the loop shown in listing 12.7.
Example 12.7. Getting values from the current row
>>> while reader.Read(): ... print reader['id'], reader['name'] 1 David Fincher 2 Edward Norton 3 Brad Pitt # and so on...
A number of other methods are available for getting fields of the current row, such as GetDecimal, GetString, and GetInt32 (and nine more!), but they’re not especially useful in Python. Their only purpose is to inform the compiler what type you want (to avoid a cast), but they’ll fail (at runtime) if you request a field as the wrong type. Worse, they accept only an integer column index, so they’ll break if the query changes to reorder the columns, unless you use the GetOrdinal method of the reader to look up the name first. In a choice between reader.GetString(reader.GetOrdinal('name')) and reader['name'], I vastly prefer the latter.
Some databases will allow you to make several queries in one command, and then they return multiple result sets attached to one reader. In this case you can use the NextResult method to move to the next set of rows. Similarly to Read, NextResult returns True unless you’ve run out of result sets. Unlike Read though, you don’t need to call it before you start processing the first result set, because that would be inconvenient for the most common usage. For example, maybe we wanted to get all of the movies someone directed and all of the roles that person has had with one command. Listing 12.8 shows how we could do this.
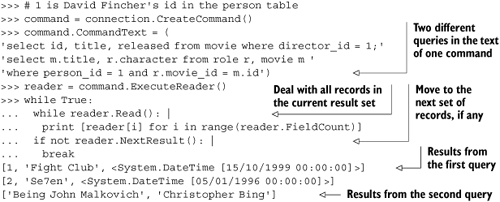
Notice that the result sets can have different structures. In listing 12.8, the first query results in rows with an integer, a string, and a date, while the second has rows with two strings.
Once you’ve finished with the results held by a DataReader, it’s important to call the Close method.[6] This allows the database to release the result set; while the .NET runtime will eventually free a reader that’s gone out of scope, that “eventually” might be a long time in the future, and you might run out of database connections in the meantime.
Suppose our database was being used behind a website running a competition between people in the movie industry, so we wanted to use it to keep running totals of the number of movies each person had directed and acted in. We have role_count and directed_count fields in the person table; when we insert a movie record we want to increment the directed_count for the director, and when we insert a role we want to increment the role_count for the actor.[7] We could do this in two steps, inserting the row and then updating the relevant total, but this means that at certain points the database totals will be wrong. Someone could get all the movies for Wes Anderson after we’ve inserted the record for The Darjeeling Limited but before we’ve updated his directed_ count. Worse, someone could trip over the power cord on our server between the insert and the update, and his total would stay wrong until someone noticed. We can avoid getting into an inconsistent state like this by using database transactions.
Transactions are a packaging mechanism that database engines provide to allow applications to make several changes to the tables in the database but have them appear to database users as if they all happened at once, at the moment the transaction is committed. Committing a transaction means applying the changes it contains. If something has gone wrong during a transaction (say an error in the program or some precondition for the changes we were making isn’t met), we can throw away the changes in it by rolling back the transaction.
We can create a transaction using the BeginTransaction method of a connection.
>>> transaction = connection.BeginTransaction() >>> transaction <NpgsqlTransaction object at 0x...>
Until now, the connection we’ve been using has been in autocommit mode. This means that each command we’ve run has been wrapped in an implicit transaction that has been committed after the command has run. We can prevent this by explicitly associating a transaction with a command before executing it, as shown in listing 12.9.
Example 12.9. Setting the transaction of a command before execution
>>> command = connection.CreateCommand()
>>> command.CommandText = ("insert into movie (title, released,"
... " director_id) values ('The Darjeeling Limited', '2007-11-23'"
... ", 2)")
>>> command.Transaction = transaction
>>> command.ExecuteNonQuery()If you check in the database using psql or pgAdmin, the record for The Darjeeling Limited doesn’t show up yet, because the transaction hasn’t been committed. This allows us to update the person table, as shown in listing 12.10, to ensure the database state is consistent before any of it is visible.
Example 12.10. Executing another command as part of the same transaction
>>> command = connection.CreateCommand()
>>> command.CommandText = ('update person set directed_count ='
... ' directed_count + 1 where id = 2')
>>> command.Transaction = transaction
>>> command.ExecuteNonQuery()In listing 12.10 we create another command and execute it after associating it with the transaction we already have in progress.
Again, checking the database will show that the data is apparently unchanged. Now we can apply both changes at once by committing the transaction.
>>> transaction.Commit()
We could have canceled the changes by calling the transaction’s Rollback method. If the application had crashed for some reason before we called Commit, the database would have discarded the changes. In fact, the point of the transaction machinery is to guarantee that even if the database server crashed, once it was brought back up, the database would still be in a consistent state.
Now that we’ve looked at transactions, we’ve covered the use of all of the key classes in the data provider layer bar one: the DataAdapter. Since the purpose of the DataAdapter is to connect the Data Provider layer with DataSets, to discuss them properly we need to look at DataSets as well.
The data provider classes provide functionality that will enable you to do anything you might need to with your database. However, for some uses they are inconvenient. DataReaders provide a read-only, forward-only stream of data; if you want to do complex processing that requires looking at data a number of times or navigating from parent records to child records, you’ll need to perform multiple queries or store the information in some kind of data structure. While this data structure could be a collection of custom objects, for some applications it can be convenient to use a DataSet.
DataSets are DBMS independent, unlike data providers, so you don’t need to use different classes for different databases. The details of how to communicate with a given database are specified by the DataAdapter class from the data provider.
So how do we get data into a DataSet? In listing 12.11, we ask the DataAdapter to fill it up.
Example 12.11. Filling a DataSet from a DataAdapter
>>> clr.AddReference('System.Data')
>>> from System.Data import DataSet
>>> dataset = DataSet()
>>> adapter = pgsql.NpgsqlDataAdapter()
>>> command = adapter.SelectCommand = connection.CreateCommand()
>>> command.CommandText = 'select * from person'
>>> adapter.Fill(dataset)
21Before the adapter can fill the DataSet, it needs to know how to get the data, which we tell it by setting its SelectCommand. The Fill method returns the number of records the command returned. In listing 12.12 we examine the information that came back from the database.
Example 12.12. What’s in the DataSet after filling it?
>>> dataset.Tables.Count
1
>>> table = dataset.Tables[0]
>>> table.TableName
'Table'
>>> table.Columns.Count
2
>>> [(c.ColumnName, c.DataType.Name) for c in table.Columns]
[('id', 'Int32'), ('name', 'String')]
>>> table.Rows.Count
7
>>> row = table.Rows[0]
>>> row['id'], row['name'] # you can access fields by name
(1, 'David Fincher')
>>> row[0], row[1] # or by index
(1, 'David Fincher')As you can see, the adapter.Fill call has created a new table (rather unimaginatively named Table) in the DataSet. This gives us the basic structure of a DataSet: a collection of tables, each of which has columns defining the structure of the data and rows containing the data.
You can use the multiple-result-set capability of a command to fill more than one table in the dataset. You can see this behavior in listing 12.13.
Example 12.13. Filling a DataSet with more than one result set
>>> dataset = DataSet()
>>> adapter = pgsql.NpgsqlDataAdapter()
>>> command = adapter.SelectCommand = connection.CreateCommand()
>>> command.CommandText = ('select * from person; '
... 'select * from movie; '
... 'select * from role')
>>> adapter.Fill(dataset)
21
>>> [t.TableName for t in dataset.Tables]
['Table', 'Table1', 'Table3']
>>> t = dataset.Tables
>>> t[0].TableName, t[1].TableName, t[2].TableName = 'person', 'movie', 'role'
>>> [(t.TableName, t.Rows.Count) for t in dataset.Tables]
[('person', 21), ('movie', 6), ('role'', 16)]In listing 12.13, the CommandText we provide for the SelectCommand consists of three SQL statements to get data for all of the tables in the database at once. When we fill the DataSet from this, we get three tables, with the default names Table, Table1, and Table2. We then change the tables’ names to match what they contain, and we can manipulate them in the same way we saw in listing 12.12.
DataSets have a huge array of features beyond what we’ve seen here:
Each
DataTablecan haveUniqueConstraints andForeignKeyConstraints to ensure that their data is manipulated only in consistent ways.A
DataSetcan be configured withDataRelations,[8] which specify parent-child relationships between tables (such as movie and role in our example database).The data in
DataSets can be updated and then sent back to the database using theDataSet.Updatemethod. This uses theInsertCommand,UpdateCommand, andDeleteCommandproperties on theDataAdapter.
DataSets are a large topic, and you can find a lot of information about them in books about ADO.NET and articles on the web. Despite that, in my experience working with databases and the .NET framework, the advanced features of DataSets tend not to be as useful as you might expect. They fall into a very narrow space between two broad types of tasks.
On one hand, tasks that require simple database interaction are better done using the Data Provider layer directly. This is even truer in IronPython than in languages like C# or VB.NET, because Python’s rich native data structures make it easy to collect the results of a query as a list or dictionary of items (something you might do with a DataTable or DataSet otherwise).
On the other hand, for tasks needing complex database interaction, it’s almost always better to use classes to model the entities involved. Then you can attach complicated behavior to the objects and give them methods to manage their relationships directly. In general, these classes will use the data provider classes to load and store their information in the database, while client code will deal with the higher-level interface the custom classes provide. The resulting code is clearer and easier to maintain because it’s more closely related to the problem domain, rather than dealing with the verbose, very general API of the DataSet.
In section 12.1 we explored how you can use the different parts of ADO.NET with IronPython to interact with a wide range of data sources. There’s a lot more to see, at both the DataSet and Data Provider layers, and lots of examples and articles are available that go into more detail on specific areas of the framework, as well as extensive MSDN documentation. Since ADO.NET is essentially a set of class libraries, examples using C# or VB.NET are easy to convert into IronPython code.
In the next section we look at how we can use IronPython to deal with another kind of data source: a web service. We cover talking to various kinds of web services from IronPython, as well as implementing one from the ground up.[9]
The term web service has a number of meanings, depending on whom you ask. The simplest is that a web service is a way for a program on one computer to use HTTP (and hence the web) to ask another computer for some information or to ask it to perform some action. The key idea is that the information that comes back in response is structured to be useful to a computer program, rather than the jumbled HTML of a normal web page with navigation, advertising, script code, and content all mixed together. The format of the information could be anything; commonly used formats are XML (particularly RSS, Atom, and SOAP), JavaScript Object Notation (JSON), and good-old plain text. Python’s strong string-handling capabilities come in very handy when dealing with all of these different formats, and often libraries are available to do the parsing for us.
In section 12.2 we look at three different kinds of web service. To begin, we see an example of one of the simplest: the feed of recent articles from a weblog. The code for using this service makes exactly the same kind of request a web browser makes for web pages, but it processes the information it gets back rather than displaying it directly to the user. In section 12.2.2 we look at using SOAP web services, which have a different way of packaging up requests and responses. The .NET framework has some tools that make SOAP services very convenient to use. Then in the last part of the chapter we explore how we can build our own web service using the REST architectural style.
To use the first of our web services, we can request the Atom feed from a weblog to see the articles that have been posted recently.
When an article is published on a weblog, the blogging system will update its Atom or RSS feed so that news readers can alert users to the new article. We can download the feed using the WebClient class, which provides a high-level interface for talking to websites.
>>> from System.Net import WebClient >>> url = 'http://www.voidspace.org.uk/ironpython/planet/atom.xml' >>> content = WebClient().DownloadString(url)
Now content is a string containing XML in the Atom format. An Atom document looks something like what you see in listing 12.14.
Example 12.14. Anatomy of an Atom XML weblog feed
<?xml version="1.0" encoding="utf-8" standalone="yes" ?>
<feed xmlns="http://www.w3.org/2005/Atom">
<title>feed title</title>
<link rel="self" href="link to feed"/>
<link href="link to site"/>
<id>unique identifier of the feed</id>
<updated>when it was last updated</updated>
<entry>
<title type="html">title of this entry</title>
<link href="url of this entry"/>
<id>unique identifier of this entry</id>
<updated>when it was last updated</updated>
<content type="html">the body of this entry</content>
<author>
<name>author's name</name>
<uri>author's website</uri>
</author>
</entry>
(more entries)
</feed>The feed structure (in listing 12.14) has a small set of metadata elements, including these:
Its title
A link to the feed
A link to the site that provides the feed
A unique identifier for the feed
When the feed was last updated
Then it has a number of entry elements, each of which has its own details:
A title for the entry
A link to the entry
A unique identifier for this individual entry
When it was updated
The content of the entry
The author’s details: a name and a link to the author’s website
We can process this in a number of ways; we could use libraries to parse Atom feeds and produce objects that give us the details of items in the feed, or we could use the XmlDocumentReader class from chapter 5 to extract the details. Those would work fine, but in web service scenarios we’re often dealing with ad hoc XML formats, so it’s handy to have a simple way of extracting details from the document without having to write specific handler classes for each format.
In that vein, in listing 12.15 we use a wrapper around XmlElements that makes pulling information out of arbitrary XML documents more convenient: it uses __getattr__ to make failed attribute lookups try to find the name in XML attributes and child elements.[10] You can see the code for the simplexml module in the source code for section 12.2.1.

You can see in listing 12.15 that getting details out of the feed XML is very easy using this technique (assuming you know the structure of the XML), and now you could store the entry data in a database or a file or display it in a user interface. Python’s powerful list comprehensions can be very useful at this point for chopping up the data and filtering out desirable (or undesirable) parts.
A web service can be as straightforward as that: an occasionally updated file on a web server that is downloaded by programs running somewhere else. In general, though, a web service will wrap up a number of related operations on some data. In an example we’ll look at soon, the operations will enable us to query, create, update, and delete a set of notes stored by the service.
There are two main approaches to web services: the SOAP camp and the proponents of a technique called REST. Although both of these techniques sit on top of HTTP, they use it in very different ways.
In a SOAP web service, all calls are HTTP POSTs to one URL. The posted data contains XML that identifies the operation that should be executed, as well as the parameters for the operation, in a structure called the SOAP envelope (because it has the address information for the message). The operations offered by a SOAP service and the types of the parameters they require are documented in an XML format called WSDL. WSDL service descriptions are fairly complicated structures, but the advantage of having them in a machine-readable format (rather than just as documentation) is that they can be created and used by tools. In general, this is the way SOAP services are made (particularly in .NET); the service provider will create an interface in code, which is then analyzed by a tool to produce WSDL for the service. Service consumers then take that WSDL and feed it to another tool, which generates a proxy to allow communication with the service.
Where a SOAP service uses only POSTs to a specific URL, with all other information carried in XML envelopes, REST services use a much broader range of HTTP features, and a service will handle an arbitrary number of URLs (generally the entire URL space under a root). A URL within a REST service denotes a resource managed by the service. Each resource is manipulated by sending an HTTP request to the URL, and which operation to perform on the resource is determined by the HTTP method specified. Essentially an operation in a REST service is the combination of a noun (a resource URL) and a verb (the HTTP method).
Those are the key differences between the approaches. Let’s look at how we can use both kinds of web services from IronPython.
The .NET framework has very solid tool support for SOAP/WSDL–style web services. In Visual Studio you can add a web reference to a web service URL that will automatically create a proxy class and all of the associated data structures that might be used in the service’s interface. Under the hood, this uses a tool included with the .NET SDK called wsdl.exe to download the WSDL for the service and generate C# code, which is then compiled into an assembly that client code can use. We can use this method from the command line as well,[11] as you can see in listing 12.16:
Example 12.16. Generating a C# proxy for a SOAP service with wsdl.exe
C:Temp> wsdl.exe /namespace:MathService http://www.dotnetjunkies.com/
quickstart/aspplus/samples/services/MathService/CS/MathService.asmx
Microsoft (R) Web Services Description Language Utility
[Microsoft (R) .NET Framework, Version 2.0.50727.42]
Copyright (C) Microsoft Corporation. All rights reserved.
Writing file 'C:TempMathService.cs'.This creates MathService.cs and puts the generated class into the MathService namespace (which we need if we want to be able to import it easily). Now, as shown in listing 12.17, we can compile the code into a .NET assembly.
Example 12.17. Compiling the C# proxy into a class library with csc.exe (the C# compiler)
C:Temp> csc.exe /target:library MathService.cs Microsoft (R) Visual C# 2005 Compiler version 8.00.50727.1433 for Microsoft (R) Windows (R) 2005 Framework version 2.0.50727 Copyright (C) Microsoft Corporation 2001-2005. All rights reserved.
We can use the generated proxy in the assembly to communicate with the web service as if it was a local library, as shown in listing 12.18.
Example 12.18. Using the MathService proxy
>>> import clr
>>> clr.AddReference('MathService')
>>> from MathService import MathService
>>> service = MathService()
>>> service.Add(3, 4)
7.0The proxy also provides asynchronous versions of the methods, as shown in listing 12.19.
Example 12.19. Calling a web service method asynchronously
>>> def showResult(s, e): ... print 'asynchronous result received:', e.Result >>> service.MultiplyCompleted += showResult >>> service.MultiplyAsync(4, 5) >>> asynchronous result received: 20.0
Both of the command-line tools used here are actually using facilities for code generation and compilation that are built into the framework. All of the creation of proxy classes can be done at runtime, if necessary. In prototyping situations this can be quite handy. The code in listing 12.20 uses the wsdlprovider module, which you can find in the source code for section 12.2.2.
Example 12.20. Calling a SOAP service using a dynamically generated proxy
>>> import wsdlprovider as wsdl
>>> url = 'http://www.webservicex.net/WeatherForecast.asmx'
>>> assembly = wsdl.GetWebservice(url)
>>> service = assembly.WeatherForecast()
>>> f = service.GetWeatherByZipCode('90210')
>>> print f.PlaceName, f.StateCode
BEVERLY HILLS CA
>>> for d in f.Details:
... print d.Day, d.MaxTemperatureC
...
Sunday, June 08, 2008 24
Monday, June 09, 2008 24
Tuesday, June 10, 2008 23
Wednesday, June 11, 2008 24
Thursday, June 12, 2008 27
Friday, June 13, 2008 27That gives you an overview of how to use SOAP web services from IronPython. How about implementing them? Unfortunately, that’s very difficult. The .NET framework’s support for creating SOAP services is primarily based on introspecting classes and using attribute annotations on them to generate the web service description and hook your custom classes into the server. Since IronPython doesn’t create classes that are directly usable from the C# side, the tools can’t process them, and there’s no way for us to attach attributes to them anyway. In theory, we could use the XML libraries to roll our own WSDL and SOAP interfaces, but given the complexity of the formats, this would be a lot of work.
This doesn’t mean we can’t implement web services in IronPython at all, though. REST services are based on the idea of reusing the features of HTTP, rather than simply sitting on top of it in the way that SOAP does. This means that a lot of the basic structure for implementing a REST service is already provided by the components that handle normal web traffic in the .NET framework. Let’s take a look at how this works.
Rather than looking at how to use a public web service (which will probably only have read-only access), we’re going to implement our own basic but fairly complete REST service in IronPython. This service will store notes that are given to it by client programs. Notes are simple data items containing the following:
A title
A body
An id—a unique identifier for the note that allows it to be retrieved
The next step in defining our service is to determine the operations we want to support and how we will map the operations to resource URLs and methods. Table 12.2 provides a description of each operation in the notes service.
Table 12.2. The operations provided by the notes service
Operation | URL | Method | Details |
|---|---|---|---|
List notes | /notes |
| Response will contain a list of note titles and links. |
Add a note | /notes |
| Request should be the note to add. Response will contain a link to the new note. |
Get the details of a note | /notes/<note id> |
| Response will contain the details of the note. |
Update a note | /notes/<note id> |
| Request should be the updated note. |
Delete a note | /notes/<note id> |
|
As you can see, some requests pass a note as a payload. After each request, the server indicates whether the operation was completed using the HTTP status code and sends back a response that contains the information that needs to be sent back (if any). In addition, each response will have a status (normally ok, if the operation succeeded), and in the case that the operation failed, a reason will be given.
This set of operations and rules almost gives us an interface that we could write a client for. The only detail that remains is what the formats of the various payloads should be. This could actually be any format we like; XML is an obvious one, but JavaScript Object Notation (see http://json.org) or plain text could work just as well. We stick with XML since in .NET it doesn’t require any extra libraries.
So the payloads we have in requests and responses are notes, links to notes, and responses.
Notes will look like this:
<note id="note_id" title="the title of the note"> Note body </note>
Links to notes will look like this:
<notelink title="note title" href="http://url/of/note"/>
Responses will look like this:
<response status="ok or error"> Either a note, note link, list of links or error reason, depending on the request. </response>
The response element will always be the root of the XML document the service sends back. It acts as a container for the information we need to send back, and it provides a handy place to report status information that isn’t part of the notes that we’re managing.
With the formats nailed down, we have a complete interface. The service and clients could be implemented in any language, as long as it has facilities for talking HTTP and parsing and generating XML, although obviously we’ll be looking at implementations in IronPython. Let’s look at how a client for this service would be written.
The client module abstracts the communication and message parsing that we need to do to make requests to the notes service, so that we can write applications that use the notes service without worrying much about the underlying details. Essentially, it’s a hand-written version of the code the .NET WSDL tools generate for a SOAP service, but because the REST style is so close to HTTP, the code is quite simple.
We start from the core of the module in listing 12.21 and work outward. The complete client.py module is available in the source code for this section. It uses the Note class from note.py, which stores the note’s id, title, and body, and provides methods to convert to and from XML. The notes service client also uses the simplexml module we saw earlier in the chapter for parsing responses.
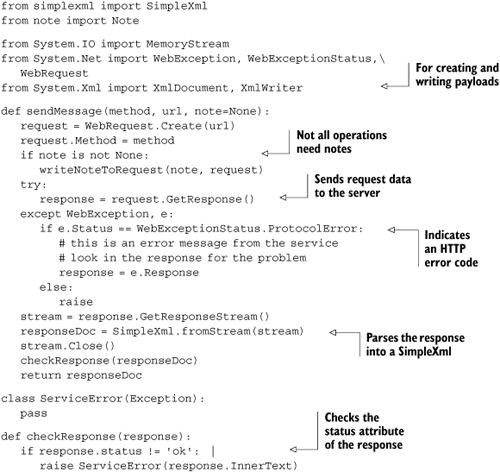
The sendMessage function in listing 12.21 is the heart of the client module. It takes an HTTP method (like GET or PUT), the URL to send the request to, and a Note instance, if one should be sent as the payload of this message. It sends the request, parses the response, checks to see whether the operation was successful (using the checkResponse function), and returns the response. The higher-level functions on top of sendMessage will then be able to get the details they need out of the response node.
Next, in listing 12.22 we have the writeNoteToRequest function, which handles the nuts and bolts of creating an XML document and serializing it into the request:
Example 12.22. Sending a note to the server from the client
def writeNoteToRequest(note, request):
doc = XmlDocument()
doc.AppendChild(doc.CreateXmlDeclaration('1.0', 'utf-8', 'yes'))
doc.AppendChild(note.toXml(doc))
request.ContentType = 'text/xml'
stream = request.GetRequestStream()
writer = XmlWriter.Create(stream)
doc.WriteTo(writer)
writer.Flush()
stream.Close()We add a declaration to the document to indicate the encoding, and then we convert the note to XML nodes and add it to the document. Notice that we pass the document into the call to note.toXml; this is because the XmlDocument has methods for creating XML nodes that are associated with the document. There’s no simple way of creating the nodes without the document they are going to be added to.
With sendMessage as a base, the implementations of functions to call the different note service operations follow very simply from the definition of the service interface, as you can see in listing 12.23.
Example 12.23. The notes service client: note operations
index = 'http://localhost:8080/notes'
def getAllNotes():
response = sendMessage('GET', index)
return [(n.title, n.href) for n in response.notelinks]
def getNote(link):
response = sendMessage('GET', link)
return Note.fromXml(response.note.element)
def addNote(note):
response = sendMessage('POST', index, note)
return response.notelink.href
def updateNote(link, note):
sendMessage('PUT', link, note)
def deleteNote(link):
sendMessage('DELETE', link)Each function in listing 12.23 calls sendMessage with the method and URL that represent its operation, as well as a note if one should be sent with the request, and extracts the information it needs from the response that comes back.
At this point the client is complete; it provides a function for every operation the notes service offers. If you look in client.py, you can see some examples of using the module to manipulate notes in the service. Of course, you won’t be able to run them without the service itself! So now it’s time to see how it hangs together.
The notes service is built on the .NET HttpListener class, which provides a simple way to write applications that need to act as HTTP servers. To use the HttpListener, you tell it what URLs you want to handle, start it, and wait for requests. Each request comes as a context object that gives you access to everything that was sent from the client and allows you to send response data back. The HttpListener provides methods for handling requests asynchronously, but to keep things simple the notes service uses the synchronous GetContext method to receive requests. The full code of the NotesService class can be found in service.py in the source code for section 12.2.3. First, in listing 12.24 we look at the main loop of the service.
Example 12.24. The notes service main loop
class NotesService(object):
def __init__(self):
self.listener = HttpListener()
self.listener.Prefixes.Add('http://localhost:8080/notes/')
self.notes = {
'example': Note('example',
'An example note',
'Note content here')}
def run(self):
self.listener.Start()
print 'Notes service started'
while True:
context = self.listener.GetContext()
self.handle(context)As you can see, when a NotesService instance is created, we create its HttpListener and specify that we want to handle all requests that begin with 'http://localhost:8080/notes/'. We also create a dictionary that acts as storage for all notes maintained through the service. Obviously this could be replaced by storing the notes in a database or in the file system in a more full-featured implementation. In the run method, we have the main loop of the service. The HttpListener is told to begin listening for incoming requests, and we call its GetContext method in an infinite loop. GetContext will block until a request is received. Then we call the handle method, which uses the HTTP method of the request and the requested URL to dispatch the request to the service’s operation methods. Let’s look at the handle method now in listing 12.25.

First, handle gets the requested path (as a list of the slash-separated components in the URL) and the HTTP verb that was used in the request. For each kind of path we build a dictionary of handlers, and then we use that handler dictionary to get the method corresponding to the verb that was sent. The handler dictionary maps the verbs that are valid for that kind of path to their corresponding NotesService methods. In the event that we were given a totally invalid path or a verb that isn’t supported, we dispatch the request to the error method, which sends a response indicating that the combination of method and path didn’t make sense. If there is a problem while one of the handlers is executing (for example, if a client tries to update a note that doesn’t exist), the handler will raise a ServiceError exception (defined elsewhere in service.py) with the HTTP status code that should be sent, as well as a message describing the problem.
The service can now dispatch requests to the correct handler method based on the verb and URL. What does a handler method look like? They all have the same basic structure:
Gather any information needed from the request and check that the operation makes sense (no deleting nonexistent notes!).
Perform the requested operation (if it’s something that changes the stored notes).
Create a response document with any information that needs to be sent back to the client and send it.
Making a response and writing it back to the client are common tasks, so they have been pulled out into separate methods. makeResponse creates an XML document containing an empty response element with a default status of ok. writeDocument handles the nuts and bolts of writing the XML document out to a response stream. They’re quite similar to the code for building documents and writing them to streams that we saw in the client module, so we won’t cover them here. You can see the details in the source code for the NotesService class.
The first handler we will look at is getNotes, which generates a response with links to all of the notes. You can see what it looks like in listing 12.26.
Example 12.26. NotesService: the getNotes handler
def getNotes(self, context):
doc = self.makeResponse()
for note in self.notes.values():
link = note.toSummaryXml(
doc, LINK_TEMPLATE)
doc.DocumentElement.AppendChild(link)
self.writeDocument(context, doc)Since this operation is only a query, we don’t need to change the notes store. We create a new response document and then go through all of the notes, creating an XML snippet representing a link to each (using the LINK_TEMPLATE constant defined at the top of the file) and adding that to the response, before sending it back using writeDocument.
The other handler that deals with requests to the top-level URL, /notes/, is addNote, in listing 12.27. The method needs a note to be sent in the request, so we need the helper method getNoteFromRequest to parse the XML document into a note.
Example 12.27. NotesService: the addNote handler
def getNoteFromRequest(self, request):
message = XmlDocument()
message.Load(request.InputStream)
request.InputStream.Close()
return Note.fromXml(message.DocumentElement)
def addNote(self, context):
note = self.getNoteFromRequest(context.Request)
if note.id in self.notes:
raise ServiceError(400, 'note id already used')
self.notes[note.id] = note
doc = self.makeResponse()
doc.DocumentElement.AppendChild(note.toSummaryXml(doc, LINK_TEMPLATE))
self.writeDocument(context, doc)Once addNote has read in the note that was sent, it checks that the id is not already taken. If it is, it raises a ServiceError, which is caught in handle and causes an error to be written back to the client with the problem. Otherwise, we add the note to the store and send the client back a link to the new location of the note.
The next operation to look at is getNote, which is the first that handles a URL for an individual note. We have three operations at this level, so we obviously also need a method to get the note that is referred to by the current URL from the store, which we’ll call getNoteForCurrentPath. You can see these methods in listing 12.28.
Example 12.28. NotesService: the getNote handler
def getNoteForCurrentPath(self, context):
lastChunk = self.pathComponents(context)[-1]
noteId = HttpUtility.UrlDecode(lastChunk)
note = self.notes.get(noteId)
if note is None:
raise ServiceError(404, 'no such note')
return note
def getNote(self, context):
note = self.getNoteForCurrentPath(context)
doc = self.makeResponse()
doc.DocumentElement.AppendChild(note.toXml(doc))
self.writeDocument(context, doc)getNoteForCurrentPath gets the path and uses the HttpUtility.UrlDecode method to decode the note id in the URL. This is because some characters have special meaning in URLs and so can’t be used “naked” in ordinary parts of a URL, like the note id in a request to the notes service. These special characters are quoted by replacing them with a % and then their ASCII code in hexadecimal. So forward slashes become %2F (because ord(/) is 47, which is 0x2F), and spaces become %20 (although sometimes they are special-cased as + for readability). Once we have the decoded note id, we check to see whether there is a note with that id in the store; if there isn’t, we raise an HTTP 404 Not Found error. Once the note is retrieved, getNote is simple: it just writes the note out to the client.
The next operation is updateNote, in listing 12.29, which brings together all of the building blocks we’ve seen: it receives both a note in the request and a note id in the URL.
Example 12.29. NotesService: the updateNote handler
def updateNote(self, context):
note = self.getNoteForCurrentPath(context)
updatedNote = self.getNoteFromRequest(context.Request)
if note.id != updatedNote.id:
raise ServiceError(400, 'can't change note id')
self.notes[note.id] = updatedNote
self.writeDocument(context, self.makeResponse())updateNote gets the note for the current path from the storage and then reads in the note that has been sent. We check that the id has been kept the same; if not, we raise an error. This is a slightly arbitrary restriction, although there is some justification for it: one of the principles of the web (which is inherited by REST) is that things—resources—shouldn’t move. The key feature of the web is linking between resources, and some of those links may be from places that you can’t update. Allowing the note id to change would change its URL, so any links to the old note would be broken.
If the note exists in the store and the new one has the same id, we replace the old note in the store with the new one. The update operation doesn’t need to return anything (other than telling the client that everything was OK), so it just writes an empty response back.
The last operation is deleteNote (listing 12.30), which is simple.
Example 12.30. NotesService: the deleteNote handler
def deleteNote(self, context): note = self.getNoteForCurrentPath(context) del self.notes[note.id] self.writeDocument(context, self.makeResponse())
We get the note, and if it exists, we remove it from the NotesService store. Then we tell the client that the job’s been done.
And that’s the last operation we wanted to support! Now the notes service is complete. You can see the full code for the NotesService class in the source code for section 12.2.3. If you want to see it in action, you can run it at the command line with ipy service.py; when it’s started and listening for requests, you’ll see the message Notes service started. The client module has some examples of using the service in its if __name__ == '__main__' section, so you can run it with ipy client.py. When you run the client, the server will show you the requests it’s receiving as they come in.
Another trick that can be quite useful when trying out libraries like the client module is the -i command-line option for ipy.exe,[12] making the command ipy –i client.py. (The i stands for interact.) This will run the file, including the __main__ section, and then display a normal Python >>> prompt instead of exiting, which lets you run commands in the module. So you can try calling getAllNotes and then creating your own Notes, sending them to the service with addNote, and manipulating them with the other functions in the module.
Now you’ve seen how we can communicate with and implement REST-style web services using IronPython. Obviously our notes service is fairly simple; it doesn’t store the notes anywhere so they won’t persist between runs of the service. It can handle only a single request at a time, and it doesn’t have the kind of error handling or logging you would want in a production system. That said, it covers a lot of the techniques you’ll need to create your own services, and you can apply the principles of the REST architectural style it uses to many situations where you need separate systems to communicate over the web.
There are philosophical differences between the SOAP and REST techniques for building web services. With SOAP, the focus is on using tools to automatically generate web services and clients from interfaces or class descriptions, which can be very convenient. However, frequently the tools for different platforms or vendors (such as Microsoft, Sun, and IBM) will not agree on how an interface or data structure should be represented in WSDL or SOAP, and so services created with the tools won’t interoperate. If you’re trying to integrate a Java system with a .NET one (and this kind of scenario is often exactly where you would want to use web services), the incompatibilities that arise can be extremely difficult to work around. And if you’re trying to use a SOAP web service from a platform that doesn’t have much tool support for it, the complexity of the protocol means that you have a lot of work to do. The REST style is in part a response to these problems: it’s much simpler, so it’s feasible to write the interfaces yourself, and you can easily debug and fix problems.
At the moment, neither style is obviously better in all situations. Luckily, we can use both kinds of services from IronPython. We can also create REST services, and in the case of creating SOAP services, a lot of effort is being devoted to the problem of adding .NET attributes to IronPython classes, both by the IronPython team and the community.[13] Hopefully this work will enable us to use the .NET tools to build SOAP services as conveniently as we can use them.
In this chapter, we’ve covered the basics of using the ADO.NET libraries with IronPython to get access to data stored in all kinds of relational databases, from embedded databases like Sqlite all the way to high-end commercial databases like SQL Server and Oracle. The nice thing about the Data Provider layer is that it lets us talk to these very different databases with the same interface.
We’ve also looked at dealing with SOAP and REST web services from IronPython, as well as implementing our own simple REST service. Web services are becoming more and more useful in all kinds of ways. Companies such as Google, Amazon, and Yahoo! are exposing huge swathes of their systems as web services, so the information they provide can be mashed up and integrated more tightly with other websites, as well as enabling us to use their data in new ways. At the other end of the scale, we can build web services that provide back-end data to the browser, letting us make web applications with richer interfaces using AJAX and Flash.
In the next chapter, we look at Silverlight, a new browser plugin that can be used to make more dynamic web interfaces in a similar way to Flash. Of course, from our perspective, the key feature of Silverlight is that it allows us to script the browser in IronPython!
[1] Well, standardized to an extent. There are large differences between the SQL supported in different databases, but generally the core operations (select, insert, update, and delete) work the same.
[2] Note that there is no comma between these two strings. We're making use of the fact that Python will join adjacent string literals together to fit this connection string on the page nicely; you can enter it as one long string if you're typing it.
[3] Admittedly, it’s a bit more verbose, but there are also definite benefits, like being able to run insert statements in loops, generate SQL statements programmatically, or save the result of a query in a variable for future use.
[4] This command will delete the movie table with all of its data and all of the relationships with other tables. The extra characters are to ensure that the resulting string is valid SQL when concatenated with the text of the rest of the command in an insecure way.
[5] NULL is a special SQL value used in databases to indicate that no value has been specified in a column. In a way it’s similar to Python’s None, but there are a number of differences in the way NULLs behave when used in arithmetic or Boolean expressions with other values.
[6] One way to ensure the reader is closed is the with statement. IronPython maps the Python context manager method __exit__ to the IDisposable interface’s Dispose method, and DataReaders and Connections both implement IDisposable.
[7] This denormalization is premature when the database is this size, but potentially in a large database where reads of the totals are much more common than writes to the movie and role tables, it would make sense.
[8] These should really be called DataRelationships to avoid confusion with relations (that is, tables) in the relational model sense.
[9] Well, maybe not from the ground up. There are a lot of goodies to help in the .NET framework!
[10] This approach is based on the one used in the DynamicWebServices C# sample released by the IronPython team. That was released for IronPython 1.1, and the APIs it uses are not available in IronPython 2.0, but the behavior was fairly simple to reproduce in IronPython itself.
[11] This uses a sample web service hosted by dotnetjunkies.com.
[12] This option works the same way in CPython as well.
[13] The Coils project (http://www.codeplex.com/coils) is one approach to solving this problem.