
4.4 Yacc – A Parser Generator
A number of programming languages are developed and new ones will surely be developed in future. Existing languages are being enhanced or modified. New CPU architectures are being designed and implemented. For each new language or modification in a language and for each new or modified CPU architecture, we require a new compiler. This is not a trivial requirement and those responsible for providing such compilers are dreaming if the work of compiler writing can be automated, i.e. they want to have a compiler–compiler.
A compiler–compiler (CC) will, ideally speaking, generate a compiler CL,M for a given language L and given machine (i.e. CPU instruction set), including the optimization passes (see Fig. 4.12).

At present this ideal is not reached, i.e. no such CC is available, but rather several CCs are available approaching this ideal to various degrees.
Note that an ideal CC requires two distinct description languages:
- for describing the source language grammar, usually a modified BNF form;
- a hardware or instruction set processor (ISP) description language, by which we can specify the target language, the machine architecture (number of CPU registers, memory organization, addressing modes, etc.), in other words the programming model for that machine.
One such non-ideal CC is YACC. It is a “front-end” CC, i.e. it provides automatic generation of the initial phases of a full compiler, the Parser. A companion program, LEX, can be used to generate the lexical analyzer or the Scanner. The later phases, viz., semantic analysis, code-generation, storage allocation, symbol-table handling and optimization, etc., are to be added “manually” to make a complete and full compiler.
On GNU/Linux systems, an improved version, called bison, is available, which is upward compatible with YACC. A companion lexical analyzer generator named flex is also available. For further details, see the main pages for these programs.
4.4.1 YACC – A Compiler Writing Tool
The name YACC is an acronym from Yet Another Compiler Compiler. It was developed by S. C. Johnson in 1978 and was first implemented on UNIX operating system. At present it is also available on MS-DOS systems.
YACC accepts a grammar specified in a modified BNF and will do the following three major jobs:
- Indicate if there are any problems with the grammar which make it unsuitable for building a language recognizer.
- Generate a function in C language, named yyparse(), along with several tables to implement a (table-driven) parser for the specified language.
- Optionally give several secondary outputs which help in debugging the grammar and make the job of writing a full compiler easy. It also provides several “hooks” by which other phases of the compiler can be made to communicate easily with the Parser.
While doing the above, YACC will take several, generally desirable, automatic actions, like resolution of conflicts, see Section 4.4.6.
The input file to YACC is generally given the file name extension .y and YACC generates up to three different files as output, depending upon the control switches used in the command line invoking YACC (see Fig. 4.13). For details of input format, see Section 4.4.3.
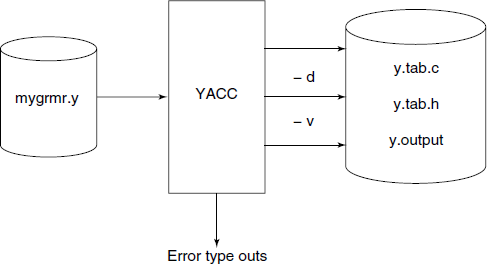
Note: The file names are for Unix systems. For MS-DOS, the first ‘.’ in file name is not used
Symbolic token names specified in the grammar are assigned integer indices by YACC and output as #define statements in the generated parser. As it is desirable that the same indices be used throughout the compiler, a separate file y.tab.h is created if we use -d switch in the command line.
If it found that that are serious errors in the grammar, another file named y.output may be optionally generated using the switch −v. This file in fact represents a detailed state diagram of the FSM part of the PDA implementing the parser.
Important components of the file y.tab.c are shown in Fig. 4.14. The parser function yyparse() calls the lexical analyzer function – which is to be provided by the compiler writer– yylex() to get the next token in the source program. It then interprets the tables depending upon the tokens provided by yylex() and modifies the stack contents. It also initiates the Actions specified for each of the language construct recognized. Several global variables like yychar, yylval, yyval, etc. are used by the parser for communicating with other functions.
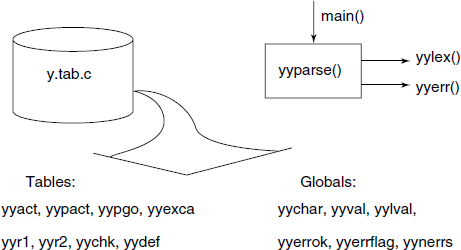
4.4.2 Working of the Parser Generated by YACC
YACC generates a parser while analyzing the grammar. The parser is a push-down automaton (PDA) – a stack machine – where a large stack holds the current state. A transition matrix specifies a new state for each possible combination of the current state and the next input symbol. This and a table of user definable Actions form the other important components of the PDA. The interpreter within yyparse() repeatedly calls on a lexical analyzer function yylex() to get the next token. It returns a ‘0’ to indicate that a valid sentence in the specified language was recognized (see Fig. 4.15).
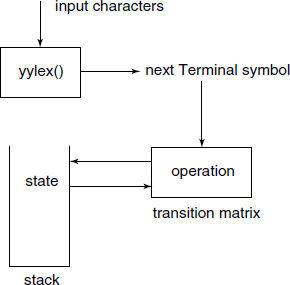
Current state on the TOS and the next Terminal symbol supplied by yylex() select an operation from the transition matrix.
As an example of the first function of YACC, feed the grammar in file example01.y, (see Fig. 4.16), to YACC with the command:
yacc −v example01.y

Nothing seems to have happened except that a file y.output is generated, which should be renamed as example01.out. It is suggested that you prepare a state-diagram of the machine represented by this file. A comparison of this state diagram with the original grammar shows that the parser indeed recognizes any sentence in the language generated by the grammar.
The actions specified for each grammar construct are converted into a switch statement towards the end of the parser. The parser seems to be large because it contains considerable amount of code for debugging and error recovery.
The transition matrix specifies five types of operations:
- accept: Happens only once when yylex() returns a zero or negative value indicating end of the input sentence.
- error: A wrong token for this particular state has been received.
- shift: new state. This operation indicates that the next Terminal symbol is acceptable in the current state. The new state is pushed onto the stack and becomes the current state.
- goto: new state. A reduce operation described below generates a Non-Terminal (NT) symbol to be used prior to the next Terminal symbol. Goto is the shift operation for the NT symbol.
- reduce: production number. Pop as many states off the stack as the production has symbols on its RHS. The uncovered state on TOS is the new current state. The NT symbol whose production was just completed is used prior to the next Terminal symbol which in turn will be processed after the NT symbol.
4.4.3 Input Specification
In general, the input file to YACC should specify the grammar and actions in the following form:
declarations
%%
rules
%%
programs
The declarations and programs are optional. The rules section is made of one or more grammar rules in the form:
A : body;
where A represents a Non-Terminal and body represents a sequence of zero or more Non-Terminals and Terminals. The colon ‘:’ and semicolon ‘;’ are YACC punctuation. If there are several grammar rules with the same left-hand side (LHS), then a vertical bar ‘|’ can be used to avoid rewriting the LHS. Thus, a rule with several alternative productions can be written as:
A : B C D
| E F
| G
;
The tokens should be declared by a %token construct. For example, the simple grammar of Fig. 4.16 will generate a language {i, i−i, i−i−i, …}. If we want to allow more flexible syntactic type IDENTIFIER in place of literal ‘i’, then the grammar should be as shown in Fig. 4.17.
%token IDENTIFIER
%%
expression : expression ‘–’ IDENTIFIER
| IDENTIFIER
;
%%
Fig. 4.17 A very simple grammar: file example02.y
Note that the token value IDENTIFIER will be defined by YACC (to be 257 in this case) and the user supplied yylex() should return the same integer value when it detects a token IDENTIFIER. It is for this purpose that the −d switch is provided in YACC, i.e. by giving command:
yacc −d mygrmr.y
you will get both y.tab.c − the parser function plus tables, and y.tab.h − the header file containing the definitions of such tokens.
In order to see the action of YACC in debugging a grammar, give the command:
yacc −v example02.y
and you will get a file y.output, which you should rename to example02.out:
0 $accept : expression $end
1 expression : expression ‘-’ IDENTIFIER
2 | IDENTIFIER
state 0
$accept : . expression $end (0)
IDENTIFIER shift 1
. error
expression goto 2
state 1
expression : IDENTIFIER . (2)
. reduce 2
state 2
$accept : expression . $end (0)
expression : expression . ‘−’ IDENTIFIER (1)
$end accept
’-’ shift 3
. error
state 3
expression : expression ‘−’ . IDENTIFIER (1)
IDENTIFIER shift 4
. error
state 4
expression : expression ‘−’ IDENTIFIER . (1)
. reduce 1
4 Terminals, 2 nonterminals
3 grammar rules, 5 states
The y.out file on some systems also gives some statistics, which can be ignored in normal use. It may be useful when you are processing very large grammars.
The output is a representation of the FSM part of the parser-PDA and corresponds to the state diagram given in Fig. 4.18.
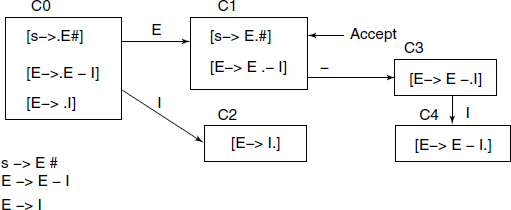
From the above, we see that:
- First of all, YACC adds a rule numbered 0:
-
$accept : expression $endin our example, and in general: -
$accept : <start symbol of grammar> $endThe place marker ‘.’ is placed just before the start symbol and that gives us rule number 0.
-
- Then, following the rules of LR(0) item-set construction, various states are generated, with a few minor differences.
- The shift operation in the LR(0) item-set construction is replaced by two operations:
- shift for a Terminal symbol or token,
- goto for a Non-Terminal symbol.
- When the position marker is moved across the special symbol $end, which is a non-positive value from yylex(), Accept operation takes place, i.e. yyparse() returns a value 0.
- Any symbols other than those specified are indicated by ‘.’.
4.4.4 Recursion in Grammar Specification
When specifying a list, we may do so using left recursion,
list:
item
| list ‘,’ item
;
or right recursion:
list:
item
| item ‘,’ list
If right recursion is used, all items on the list are first pushed on the stack. After the last item is pushed, yacc starts reducing. With left recursion, yacc never has more than three terms on the stack, since it reduces as it goes along. For this reason, it is advantageous to use left recursion.
4.4.5 Actions
The parser as created should not only decide if the given sentence is valid in the specified language, but also should generate outputs for the next phase of the compiler. YACC has special facilities for this purpose, known as Actions.
With each grammar rule the user may associate actions to be performed each time the rule is recognized. An action is an arbitrary C language statement. It is specified by one or more statements enclosed in the C block brackets { }.
The $ symbol is used as a special indicator. In order to return a value associated with the LHS symbol, a value is assigned to pseudo-variable $$. In order to obtain the values returned by the previous actions and the lexical analyzer (Scanner), the pseudo-variables $1, $2, etc. can be used, which correspond to the values returned by the respective component of the RHS of the rule, reading from left to right. Thus, if the rule is
A : B C D ;
then $2 has the value returned by C and $3 is the value returned by D.
Sometimes, it is desirable to specify an action before a rule is fully passed. YACC permits an action to be returned in the middle of a rule. For example, in the rule
A : B { $$ = 1;}
C { x = $2; y = $3; }
;
the effect is to set x to 1 and y to the value returned by C. Note that the C blocks are also counted while indexing the pseudo-variables.
Let us consider the following example of a very preliminary four-function calculator (Fig. 4.19): yyparse() maintains a value-stack in parallel with the state-stack. Whenever the current state is pushed on the state-stack during a shift or goto operation, a value is also pushed on the value-stack.
/* Desk Calculator */
%token CONS
%left ‘+’ ‘–’
%left ‘*’ ‘/’
%%
line : /* empty */
| line expr ‘
’ {printf("%d
", $2);}
;
expr : expr ‘+’ expr { $$ = $1 + $3; }
| expr ‘–’ expr { $$ = $1 – $3; }
| expr ‘*’ expr { $$ = $1 * $3; }
| expr ‘/’ expr { $$ = $1 / $3; }
| CONS { /* $$ = $1 by default */}
;
%%
Fig. 4.19 A four-function calculator: file calculator.y
The value to be pushed during a shift, i.e. acceptance of a Terminal symbol, is taken from the global variable yylval, which usually comes from the yylex() function.
In the above example, yylex() should set the value of yylval = the value of the constant, whenever it detects a constant and return the token value CONS to yyparse().
The value to be pushed on the value-stack during a goto operation is taken from the global variable yyval. $$ represents yylval. Note that this happens during a reduction.
The data type of yylval, yyval and the value-stack, by default, is integer, but it can be set to any other type by, for example,
#define YYSTYPE double
This will allow use of double, i.e. double-precision floating-point numbers.
4.4.6 Ambiguity and Conflict Resolution
A grammar may have ambiguous rules such that it can do two legal operations, a shift or a reduction and has no way of deciding between them. This is called Shift/Reduce conflict. It is also possible that the parser has a choice of two possible and legal reductions. This is called a Reduce/Reduce conflict.
YACC uses two disambiguating rules whenever faced with such conflicts:
- In a Shift/Reduce conflict, the default is to do shift.
- In a Reduce/Reduce conflict, the default is to reduce by the earlier grammar rule.
Another way in which conflicts can be resolved is by using precedence rules. YACC allows us to specify the precedence of certain Terminal symbols, like mathematical operators, which are used for resolving the conflicts.
When YACC processes a grammar specification and finds conflicts, it reports the number of such conflicts. It is advisable to inspect the y.output file carefully to check if the resolutions attempted by YACC are acceptable or not.
For example, consider a grammar:
%token IFTHEN
%token ELSE
%%
statement : ‘;’ /* empty statement */
| IFTHEN statement
| IFTHEN statement ELSE statement
;
%%
This grammar results in Shift/Reduce conflict and is reported by YACC as such. The y.output file is
0 $accept : statement $end
1 statement : ‘;’
2 | IFTHEN statement
3 | IFTHEN statement ELSE statement
state 0
$accept : . statement $end (0)
IFTHEN shift 1
’;’ shift 2
. error
statement goto 3
state 1
statement : IFTHEN . statement (2)
statement : IFTHEN . statement ELSE statement (3)
IFTHEN shift 1
’;’ shift 2
. error
statement goto 4
state 2
statement : ‘;’ . (1)
. reduce 1
state 3
$accept : statement . $end (0)
$end accept
4: Shift/Reduce conflict (shift 5, reduce 2) on ELSE
state 4
statement : IFTHEN statement . (2)
statement : IFTHEN statement . ELSE statement (3)
ELSE shift 5
$end reduce 2
state 5
statement : IFTHEN statement ELSE . statement (3)
IFTHEN shift 1
’;’ shift 2
. error
statement goto 6
state 6
statement : IFTHEN statement ELSE statement . (3)
. reduce 3
State 4 contains 1 Shift/Reduce conflict.
5 Terminals, 2 non-terminals
4 grammar rules, 7 states
YACC intentionally allows such conflicts and uses the rules mentioned above for their resolution.
As another example, consider the grammar:
%token IDENTIFIER
%%
expr : expr ‘+’ expr
| expr ‘-’ expr
| expr ‘*’ expr
| expr ‘/’ expr
| IDENTIFIER
;
%%
If this grammar is input to YACC as such, it will result in:
yacc: 16 Shift/Reduce conflicts.
YACC allows such grammar, provided the precedence of the Terminals ‘+’, ‘−’, ‘*’, ‘/’ are defined. Then it will use it to resolve the conflict. The modified grammar is:
%token IDENTIFIER
%left ‘+’ ‘-’
%left ‘*’ ‘/’
%%
expr : expr ‘+’ expr
| expr ‘-’ expr
| expr ‘*’ expr
| expr ‘/’ expr
| IDENTIFIER
;
%%
One may also use %right and/or %nonassoc.
4.4.7 Error Handling
YACC is usually used to develop a compiler and a compiler is almost always dealing with programs with errors in them. (How many times is a typical program compiled before it runs successfully?) Thus, error recovery is an important aspect of any compiler generator. Error handling is extremely difficult area because many of the errors are semantic in nature. In order to handle errors fully, several complicated actions are to be taken.
If no particular steps are taken by the user, the parser generated by YACC will simply reject the source program on the very first encountered error, without checking the remaining part of the program. This is not very helpful. What is desirable is that the parser should recover sufficiently from the error to check the remaining part of the program, starting with a point as close to the error as possible.
YACC provides a special token named error, which can be used in grammar rules and suggests places where errors are expected and recovery is possible. The parser pops its stacks till it enters a state where the token error is legal. It then behaves as if error is the current look-ahead token and performs the action specified. For example,
stmt:
‘;’
| expr ‘;’
| PRINT expr ‘;’
| VARIABLE ‘=’ expr ‘;
| WHILE ‘(’ expr ‘)’ stmt
| IF ‘(’ expr ‘)’ stmt %prec IFX
| IF ‘(’ expr ‘)’ stmt ELSE stmt
| ‘{’ stmt_list ‘}’
| error ‘;’
| error ‘}’
;
The error token is a special feature of yacc that will match all input until the token following error is found. For this example, when yacc detects an error in a statement it will call yyerror,flush input up to the next semicolon or brace, and resume scanning. In order to prevent a cascade of error messages, the parser, after detecting an error, remains in an error state until three tokens have been successfully read and shifted.
4.4.8 Arbitrary Value Types
The values returned by the actions and the lexical analyzer are integers by default. YACC can support values of other types, including C structures. The value-stack is declared to be a union of the various types of the values desired. The user declares the union and associates union member names with each token and Non-Terminal having a value. When the value is referenced through the $ construct, YACC will automatically insert the appropriate union name.
To declare the union the user includes in the declaration section:
%union {
<body of the union>
}
which declares the YACC value-stack. The external variables yylval and yyval will have this union type.
4.4.9 Debugging yacc
Yacc has facilities that enable debugging. This feature may vary with different versions of yacc, so you should consult the documentation for the version you are using for the details. The code generated by yacc in the file y.tab.c includes debugging statements that are enabled by defining YYDEBUG and setting it to a non-zero value. This may also be done by specifying command-line option −t. With YYDEBUG properly set, debug output may be toggled on and off by setting yydebug. Output includes tokens scanned and Shift/Reduce actions.
%{
#define YYDEBUG 1
%}
%%
…
%%
int main(void) {
#if YYDEBUG
yydebug = 1;
#endif
yylex();
}
In addition, you can dump the parse states by specifying command-line option −v. States are dumped to file y.output and are often useful when debugging a grammar. Alternatively, you can write your own debug code by defining a TRACE macro, as illustrated below. When DEBUG is defined, a trace of reductions, by line number, is displayed.
%{
#ifdef DEBUG
#define TRACE printf(“reduce at line %d
”, _ _LINE_ _);
#else
#define TRACE
#endif
%}
%%
statement_list:
statement
{ TRACE $$ = $1; }
| statement_list statement
{ TRACE $$ = newNode (’;’, 2, $1, $2); }
;
4.4.10 Working Examples
We round up this discussion with two examples:
A Very Simple Grammar
See the grammar in Fig. 4.17. This grammar does not have any actions specified, so we do not expect any outputs. It is only an Acceptor, i.e. will only say if the given sentence is valid. The lexical analyzer is
#include<stdio.h>
#include<ctype.h>
#include “defs.h"
char *progname;
int lineno = 1;
main(int argc, char *argv[])
{
progname = argv[0];
yyparse();
}
yylex()
{
int c;
char str[20];
while((c = getchar()) == ‘ ‘ || c == ‘ ’)
if(c == EOF)
return 0;
if(isalpha(c)){
ungetc(c, stdin);
scanf(“%s”, str);
return IDENTIFIER;
}
if(c == ‘
’){
lineno++;
return 0;
}
return c;
}
yyerror(s)
char *s;
{
warning(s, (char *) 0);
}
warning(s, t)
char *s, *t;
{
fprintf(stderr, “%s: % s”, progname, s);
if(t)
fprintf(stderr, “%s”, t);
fprintf(stderr, “near line %d
”, lineno);
}
The defs.h file contains links to the files generated by –d switches while processing example02.y and calculator.y:
#include “example02.h"
#include “calculator.h"
This program should be compiled with command:
yacc −d example02.y
mv y.tab.c example02.c
mv y.tab.h example02.h
yacc −d calculator.y
mv y.tab.c calculator.c
mv y.tab.h calculator.h
gcc −o example02 util.c example02.c
Calculator
This is a four-function integer calculator, as given by grammar in Fig. 4.19. It requires a slightly different yylex(), as given in the file util1.c. (Why is this so?):
yylex()
{
int c;
while((c = getchar()) == ‘ ‘ || c == ‘ ’);
if(c == EOF)
return 0;
if(isdigit(c))
{
ungetc(c, stdin);
scanf(“%d”, &yylval);
return CONS;
}
if(c == ‘
’)
lineno++;
return c;
}
Compile this program using a command:
gcc −o calculator util1.c calculator.c
In anticipation of our further discussion about yacc in the subsequent chapters, you are strongly advised to work through Chapter 8, “Program Development” in the book “The UNIX Programming Environment” by Kernighan and Pike.